URL 筛选小工具 提取网页中的链接地址
- 格式:doc
- 大小:13.50 KB
- 文档页数:1

urlfinder使用方法【最新版3篇】目录(篇1)1.urlfinder 简介2.urlfinder 使用方法2.1 查询网址2.2 提取链接2.3 查询网站信息2.4 查询关键词排名正文(篇1)【urlfinder 简介】Urlfinder 是一款功能强大的网址查询工具,可以帮助用户快速查询各种网站信息,如网站权重、关键词排名等。
使用 Urlfinder 可以提高用户的工作效率,让用户更方便地了解和分析网站。
【urlfinder 使用方法】Urlfinder 的使用方法非常简单,主要包括以下几个步骤:1.查询网址用户可以直接在 Urlfinder 的搜索框中输入网址,然后点击“查询”按钮,系统就会自动获取该网址的相关信息,包括网站权重、关键词排名等。
2.提取链接如果用户需要提取某个网页中的所有链接,可以使用 Urlfinder 的“提取链接”功能。
只需将需要提取链接的网页网址输入到 Urlfinder 中,系统就会自动提取出该网页的所有链接。
3.查询网站信息Urlfinder 可以查询网站的各种信息,包括网站权重、域名年龄、服务器地址等。
用户只需输入网址,就能获取到该网站的详细信息。
4.查询关键词排名Urlfinder 还可以查询关键词在搜索引擎中的排名。
用户只需输入关键词和网址,系统就会显示出该关键词在搜索引擎中的排名情况。
目录(篇2)1.urlfinder 简介2.urlfinder 使用方法3.使用 urlfinder 的优点4.使用 urlfinder 的注意事项正文(篇2)一、urlfinder 简介Urlfinder 是一款功能强大的网络爬虫工具,它可以帮助用户在互联网上找到和抓取所需的数据。
Urlfinder 具有简单易用的界面,用户无需具备编程基础,只需输入目标网址,即可获取到网页中的数据。
它广泛应用于数据分析、网站数据抓取、网络数据采集等领域。
二、urlfinder 使用方法1.打开 Urlfinder 官方网站,点击“开始使用”按钮,进入使用界面。

url使用方法
URL(统一资源定位符)在万维网上用于定位每一个信息和资源,具有统一且唯一的地址。
以下是URL的使用方法:
1. 创建一个URL类的对象。
例如,使用字符串“网址”来创建一个URL对象。
2. 通过对象url打开网络连接,并获取一个网络连接对象con。
3. 通过网络连接对象con获取到读取网页内容的输入流is。
4. 将字节流装饰成字符流,可以使用InputStreamReader类来实现。
5. 再将字符流装饰成可以读取一行的字符流,可以使用BufferedReader类来实现。
6. 通过字符流br读取一行信息,将其存储到变量str里。
以上是使用URL的基本步骤,请注意,这只是一个简单的示例,实际使用中可能需要根据具体情况进行适当的修改和调整。

URL获取方法范文在网络中,URL(Uniform Resource Locator)是一种用来唯一标识网络资源的字符串。
它可以用来定位和访问网络上的各种资源,如网页、图片、文件等。
获取URL是指通过其中一种方式获取和解析URL地址的操作。
本文将介绍几种获取URL的方法。
一、从浏览器地址栏获取URL最常见的获取URL的方法就是从浏览器的地址栏中复制URL地址。
当我们访问网页时,浏览器会将网页的URL显示在地址栏中,我们只需要复制地址栏中的URL即可。
二、从网页源代码获取URL有时我们想获取网页中一些资源的URL,可以通过查看网页源代码来获取。
在浏览器中,我们可以通过右键点击网页,选择“查看页面源代码”或者“检查元素”选项来打开开发者工具,然后在源代码中查找相应资源的URL。
三、使用网络抓包工具获取URL网络抓包工具可以用来监控和捕获网络数据包,并可以提取其中的URL地址。
常用的网络抓包工具包括Fiddler、Wireshark等。
这些工具可以在电脑上安装并运行,当我们访问网络资源时,它们会捕获到相应的数据包,然后可以在工具中查看和提取其中的URL地址。
四、使用编程语言获取URL我们可以使用编程语言来编写程序,通过程序来获取URL地址。
不同的编程语言提供了不同的方法和库来进行URL的获取和解析。
下面以Python语言为例,介绍如何使用编程语言获取URL。
Python提供了urllib库来处理URL相关的操作。
我们可以使用urllib库中的urlopen(函数来打开一个URL链接,并获取相应的内容。
以下是一个使用Python获取URL的示例代码:```pythonimport urllib.requestresponse = urllib.request.urlopen(url)#获取URL的内容content = response.read(.decodeprint(content)```以上代码中,首先我们导入了urllib.request库,然后指定需要获取的URL地址,并使用urlopen(函数打开URL链接,得到一个response 对象。

从url获取参数并超链接的方法在Web开发中,获取URL中的参数并在页面中创建超链接是一项常见的需求。
以下将详细介绍如何从URL中获取参数,并利用这些参数创建超链接的方法。
### 从URL获取参数在网页中获取URL的参数通常可以通过JavaScript来实现,以下是几种常用的方法:1.**使用JavaScript自带的URL对象**```javascript// 假设当前URL为:?name=JohnDoe&age=30const urlParams = newURLSearchParams(window.location.search);const name = urlParams.get("name"); // 返回"JohnDoe"const age = urlParams.get("age"); // 返回"30"```2.**传统方式解析查询字符串**```javascriptfunction getQueryVariable(variable) {var query = window.location.search.substring(1);var vars = query.split("&");for (var i=0;i<vars.length;i++) {var pair = vars[i].split("=");if(pair[0] == variable){return pair[1];}}return(false);}// 使用方法const name = getQueryVariable("name"); // 返回"JohnDoe"const age = getQueryVariable("age"); // 返回"30"```### 创建超链接一旦获取了URL中的参数,我们就可以使用这些参数来动态创建超链接。

website extractor使用方法1. 引言1.1 什么是website extractorWebsite Extractor是一种用于提取网站数据的工具,它能够自动化地从网页中抓取所需的信息,并将其转化为结构化数据。
通过使用Website Extractor,用户可以快速准确地收集大量网站上的数据,而无需手动复制粘贴或者浏览多个页面。
这个工具通常使用在数据挖掘、市场调研、竞争分析等领域,能够帮助用户节省大量时间和精力。
Website Extractor利用网络爬虫技术,可以访问并解析网页上的各种信息,如文本、图片、链接等。
用户可以通过设定特定的规则和筛选条件,来提取他们感兴趣的数据,并将其保存或导出到本地文件或数据库中。
这种工具通常具有界面友好,操作简单的特点,让用户可以快速上手并开始进行数据提取工作。
Website Extractor是一种强大的数据采集工具,能够帮助用户轻松获取网站上的信息,提高工作效率。
通过合理的配置和使用,用户可以满足各种网站数据提取需求,从而得到更多有用的信息和见解。
1.2 website extractor的作用1. 网站内容获取:Website extractor可以帮助用户快速准确地从网站中抓取所需的信息,无需手动复制粘贴,大大提高了工作效率。
2. 数据分析:通过使用website extractor,用户可以轻松地对提取的数据进行分析和处理,从而获取更多有用的信息和洞察。
4. 市场研究:对于市场研究人员来说,使用website extractor可以快速获取市场上的信息,帮助他们更好地制定营销策略和决策。
website extractor的作用在于帮助用户快速准确地从网站中提取数据,进行数据分析和处理,帮助用户更好地了解市场和竞争情况,从而帮助他们做出更明智的决策。
2. 正文2.1 website extractor的安装步骤1. 下载安装程序:需要从官方网站或其他可信任的来源下载website extractor的安装程序。

xpath提取链接写法XPath是一种在XML文档中查找信息的语言,它可以在XML文档中定位到特定的元素,并提取出其中的链接。
XPath在网页抓取、数据提取等领域有着广泛的应用。
下面将介绍一些常用的XPath提取链接的写法。
一、提取所有链接如果要提取一个XML文档中所有的链接,可以使用以下XPath表达式:```//a/@href|//link/@href```这个表达式会匹配所有的`<a>`和`<link>`元素,并提取其中的`href`属性值,即链接地址。
需要注意的是,如果文档中有其他类型的链接元素,例如`<img>`元素的`src`属性,也可以使用同样的XPath 表达式来提取。
二、提取指定元素的链接如果要提取XML文档中某个特定元素的链接,可以使用以下XPath表达式:```python//element_name[@attribute='value']/@href```这个表达式会匹配所有符合指定元素名和属性的链接元素,并提取其中的`href`属性值。
例如,如果要提取所有名为`<div>`的元素的链接地址,可以使用以下XPath表达式:```css//div[@id='div_id']/@href```三、提取HTML页面中链接如果要提取HTML页面中的链接,可以使用以下XPath表达式:```css//a/@href|//link/@href|//img[@src='']/@src```这个表达式会匹配所有的`<a>`,`<link>`和`<img>`元素,并提取其中的`href`和`src`属性值。
需要注意的是,如果要提取其他类型的链接元素,例如`<area>`元素的`href`属性,也可以使用同样的XPath 表达式来提取。
四、提取特定标签内部的链接如果要提取HTML页面中某个特定标签内部的链接,可以使用以下XPath表达式:```css//tag_name[text()='search_string']/@href```这个表达式会匹配所有符合指定标签名和文本内容的链接元素,并提取其中的`href`属性值。

网页内容抓取工具哪个好用互联网上目前包含大约几百亿页的数据,这应该是目前世界上最大的可公开访问数据库。
利用好这些内容,是相当有意思的。
而网页内容抓取工具则是一种可以将网页上内容,按照自己的需要,导出到本地文件或者网络数据库中的软件。
合理有效的利用,将能大大提高自己的竞争力。
网页内容抓取工具有哪些1. 八爪鱼八爪鱼是一款免费且功能强大的网站爬虫,用于从网站上提取你需要的几乎所有类型的数据。
你可以使用八爪鱼来采集市面上几乎所有的网站。
八爪鱼提供两种采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。
下载免费软件后,其可视化界面允许你从网站上获取所有文本,因此你可以下载几乎所有网站内容并将其保存为结构化格式,如EXCEL,TXT,HTML或你的数据库。
2、ParseHubParsehub是一个很棒的网络爬虫,支持从使用AJAX技术,JavaScript,cookie 等的网站收集数据。
它的机器学习技术可以读取,分析然后将Web文档转换为相关数据。
Parsehub的桌面应用程序支持Windows,Mac OS X和Linux等系统,或者你可以使用浏览器中内置的Web应用程序。
作为免费软件,你可以在Parsehub中设置不超过五个publice项目。
付费版本允许你创建至少20private项目来抓取网站。
3、ScrapinghubScrapinghub是一种基于云的数据提取工具,可帮助数千名开发人员获取有价值的数据。
它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub使用Crawlera,一家代理IP第三方平台,支持绕过防采集对策。
它使用户能够从多个IP和位置进行网页抓取,而无需通过简单的HTTP API进行代理管理。
Scrapinghub将整个网页转换为有组织的内容。
如果其爬虫工具无法满足你的要求,其专家团队可以提供帮助。
4、Dexi.io作为基于浏览器的网络爬虫,Dexi.io允许你从任何网站基于浏览器抓取数据,并提供三种类型的爬虫来创建采集任务。
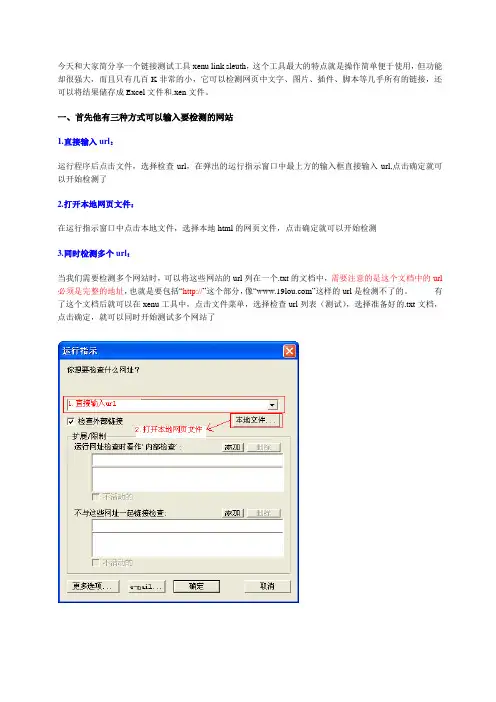
今天和大家简分享一个链接测试工具xenu link sleuth,这个工具最大的特点就是操作简单便于使用,但功能却很强大,而且只有几百K非常的小,它可以检测网页中文字、图片、插件、脚本等几乎所有的链接,还可以将结果储存成Excel文件和.xen文件。
一、首先他有三种方式可以输入要检测的网站1.直接输入url:运行程序后点击文件,选择检查url,在弹出的运行指示窗口中最上方的输入框直接输入url,点击确定就可以开始检测了2.打开本地网页文件:在运行指示窗口中点击本地文件,选择本地html的网页文件,点击确定就可以开始检测3.同时检测多个url:当我们需要检测多个网站时,可以将这些网站的url列在一个.txt的文档中,需要注意的是这个文档中的url 必须是完整的地址,也就是要包括“http://”这个部分,像“”这样的url是检测不了的。
有了这个文档后就可以在xenu工具中,点击文件菜单,选择检查url列表(测试),选择准备好的.txt文档,点击确定,就可以同时开始测试多个网站了设置检查的链接层次:我们可以通过点击运行指示窗口的“更多选项”按钮来设置检测链接的层次,也就是链接深度,这里的默认值是999,其实是不需要这么大的,一般2、3层就可以了设置并列线程数:默认情况下,会并行启动30个线程来对站点进行爬网检测,我们也可以根据实际情况将并行的线程数调整成1至100之间检查外部链接:选中则检测页面中的所有链接,不区分域名。
不选择就只是检测当前域名下的链接,其他链接会自动跳过二、检测结果分析在检测结果中最重要的属性就是“状态”,通过状态值我们可以判断出链接是活链接、死链接或者暂时性无效链接。
检测结果是以彩色字体来显示,其中:∙绿色字体:状态是OK,这类的链接表示是正常的活链接∙灰褐色字体:状态是skip type,这类一般是JS脚本,也没有什么问题∙红色字体:状态是timeout、not found、invalid response(无响应)、no connection(没有链接)等等,这类就是有问题的链接了,是需要我们发现的,问题的原因也比较多,其中一部分可能是因为链接超时或临时性的错误导致,这就需要重新检测以排除这些暂时性无效的链接。

js 获取url的方法JavaScript是一种常用的编程语言,用于实现网页的交互和动态效果。
在网页开发中,经常需要获取URL,也就是当前网页的地址。
以下是几种常见的获取URL的方法。
方法一:使用window.location对象window.location对象包含了当前网页的URL信息,可以通过它来获取URL的各部分。
获取完整URL:```javascriptvar url = window.location.href;```获取主机名(域名):```javascriptvar hostname = window.location.hostname;```获取路径名:```javascriptvar pathname = window.location.pathname;```获取查询字符串(参数)部分:```javascriptvar search = window.location.search;```获取哈希值(锚点)部分:```javascriptvar hash = window.location.hash;```方法二:使用document.URL属性document.URL属性返回当前网页的完整URL,可以直接使用它来获取URL。
```javascriptvar url = document.URL;```方法三:使用location.href属性location.href属性返回当前网页的完整URL,也可以直接使用它来获取URL。
```javascriptvar url = location.href;```以上是几种常见的获取URL的方法。
根据具体需求选择合适的方法即可。
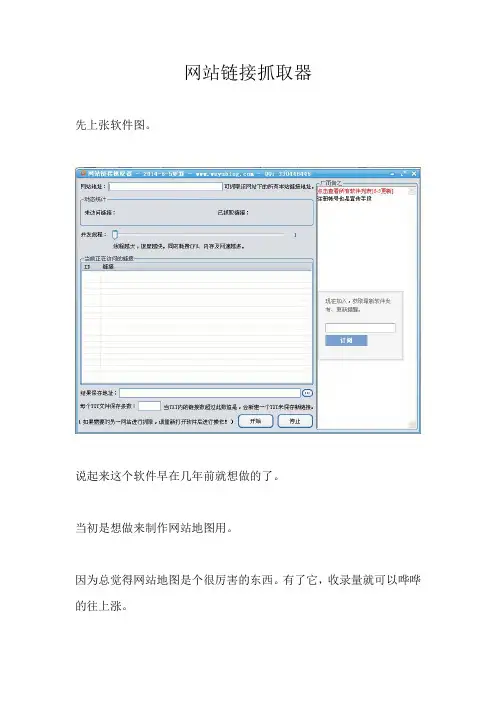
网站链接抓取器
先上张软件图。
说起来这个软件早在几年前就想做的了。
当初是想做来制作网站地图用。
因为总觉得网站地图是个很厉害的东西。
有了它,收录量就可以哗哗的往上涨。
忘记当时是为啥没做了。
现在这个是4月份时候做的。
当时正在测试百度提交URL。
就想着用这么一个软件,把自己网站上的所有网页链接都给抓取下来。
然后一条一条的提交到百度URL上去。
这样网站的收录量应该会涨许多。
但是当时还正在测试URL提交中,所以这个软件也就没有发布。
到后来百度改验证码,提交URL的没啥用了,纯粹一苦力活。
这个软件又被遗忘了。
昨天好不容易才看到它。
就给发布出来了。
使用admin5的网站测试了一下。
设置的50线程,8M联通的网。
一共抓取了28W+的链接。
共花时间1
小时55分钟。
保存格式是一行一个的保存到TXT里。
不过现在这上软件鸡肋的地方在于,有啥用呢?把链接当网站地图提交到搜索引擎?
无语博客,希望能和大家多多交流。

涨姿势:教你一键复制所有已打开的网页标签的链接!
小编因为工作需要,经常需要大量的复制网页链接整理成表格,因此每每都是开着一堆标签页,然后一个个CTRL+C——CTRL+V,累个半死效率还低!
终于小编爆发了去外面的世界看了看,然后找到了最快捷的一个方法。
带个大家,拿走不谢!
首先,需要确保你用的是Chrome或者Chrome内核的浏览器。
然后我们这里需要用到一款插件。
名字嘛,先卖个关子~后面会告诉大家!
安装好后,进行设置,右键单击插件图标,点击选项
这时候我们能看到一个长长的参数输入框,上面还有各种参数的功能提示。
而我们的目的是只把链接复制下来,所以就把参数修改为【%url%】不带中括号,然后点击右侧的SAVE保存。
然后试试多打开一些标签后,然后点击CP图标,看到没!所有的已打开网页的链接都已经显示在框内,而且是选中状态,一个链接一行,这时候只需要CTRL+C ——CTRL+V,直接到手罗!是不是解脱了?
当然这个插件还有其他的格式:
比如我参数修改为【%text%%url%】不带中括号,那么就是现实网页标签的名称和网址链接。
里面还可以自己输入字符来设置适合自己的格式!自己去常识吧!
插件的名字叫“Copy All Urls”,这个大家自行问度妹,很容易找到!OK!姿势学会了吗?下次以给大家讲如何让chrome合并标签,让你每天都要用的网页标签不占用标签栏和内存。
免责声明:文档转载自网络,版权归原作者所有。
url scheme跳转的提取方式
URL Scheme(统一资源定位符)是一种在应用程序之间进行跳转的方式,它允许开发者指定一个URL,用户点击这个URL后,设备会打开特定的应用程序并执行特定操作。
URL Scheme的提取方式如下:
1. 查阅相关文档:首先,你需要查阅目标应用程序的官方文档或相关资料,了解其提供的URL Scheme。
例如,对于微信支付,你可以查阅其官方文档以了解如何获取其URL Scheme。
2. 分析应用程序:在一些情况下,开发者可能会在应用程序的代码或配置文件中透露URL Scheme。
你可以通过分析应用程序的代码或配置文件来提取URL Scheme。
3. 使用调试工具:对于iOS平台,你可以使用Xcode或其他调试工具来查看应用程序的URL Scheme。
在运行应用程序时,调试工具会显示应用程序接收到的URL,从而帮助你提取URL Scheme。
4. 网络请求分析:如果你无法直接获取应用程序的代码或配置文件,你可以尝试分析应用程序与服务器之间的网络请求。
通过分析网络请求,你可能会发现URL Scheme。
5. 询问开发者:最后,如果你无法通过以上方法提取URL Scheme,可以尝试联系应用程序的开发者或官方客服,询问他们提供的URL Scheme。
请注意,提取URL Scheme可能涉及侵犯应用程序的隐私和安全。
在提取URL Scheme时,请确保遵循相关法律法规和开发者许可协议。
未经授权地公开或使用他人的URL Scheme可能会引发法律问题。
提取 url 正则
正则表达式是一种强大的工具,可以帮助我们快速而准确地匹配和提取字符串中的特定部分。
在提取 URL 地址时,也可以使用正则表达式来简化操作。
以下是一些常用的提取 URL 的正则表达式:
1. 提取 http 或 https 开头的 URL:
^(http|https)://[^s]+
2. 提取 www 开头的 URL:
^www.[^s]+
3. 提取带有端口号的 URL:
^(http|https)://[^s]+:[0-9]+
4. 提取带有参数的 URL:
^[^?]+?[^s]+
5. 提取带有锚点的 URL:
^[^#]+#[^s]+
注意:在使用正则表达式时,一定要考虑到可能存在的特殊情况,例如 URL 中可能包含特殊字符、空格等,需要进行特殊处理。
同时,也要注意正则表达式的效率和可读性,不要过于复杂和冗长。
- 1 -。
url helper使用方法URL助手是一种在Web开发中经常使用的工具,它通常用于生成URL链接,以便在网页中导航到其他页面或执行特定的操作。
在不同的编程语言和框架中,URL助手的使用方法可能会有所不同。
我将以常见的PHP框架Laravel为例来介绍URL助手的使用方法。
在Laravel中,URL助手通常是通过全局辅助函数来调用的。
要生成一个链接,你可以使用`url`辅助函数。
例如,要生成到特定控制器动作的链接,你可以这样使用:php.$url = url('controller/action');这将生成一个指向指定控制器动作的URL链接。
另外,你也可以使用`route`辅助函数来生成具有命名路由的链接。
例如:php.$url = route('');这将生成一个指向指定命名路由的URL链接。
除了这些基本的用法之外,URL助手还可以用于生成包含查询参数或片段的URL链接。
你可以使用`URL`类的`to`方法来实现这一点。
例如:php.$url = URL::to('user/profile', ['id' => 1]);这将生成一个指向用户配置文件页面的URL链接,并带有ID查询参数。
此外,URL助手还可以用于生成HTTPS链接、asset链接(用于引用应用程序中的资源文件,如CSS、JavaScript和图片等)、以及生成带有签名的URL链接以确保链接的完整性等。
总的来说,URL助手是Web开发中非常有用的工具,它能够帮助开发人员轻松地生成各种类型的URL链接,从而实现网页导航和操作的需求。
在实际应用中,开发人员可以根据具体的需求和框架的要求来灵活地运用URL助手,以实现网站的功能和交互效果。
Python中的`geturl`方法是用于获取URL位置区域的方法,它常用于处理网络请求和爬取网页数据。
本文将从以下几个方面来介绍`geturl`方法的用法和相关知识。
一、`geturl`方法的作用在Python中,`geturl`方法通常是用于获取HTTP请求返回的URL位置区域。
在使用Python进行网络编程或者进行网页数据爬取的过程中,我们经常会发送HTTP请求来获取网页内容,而`geturl`方法就可以用来获取请求的最终URL位置区域,这在一些需要跟踪重定向信息的情况下非常有用。
二、`geturl`方法的使用在Python中,`geturl`方法通常是通过urllib或者requests等库来使用的。
下面以urllib库为例,介绍一下`geturl`方法的使用。
```pythonimport urllib.requestresponse = urllib.request.urlopen('final_url = response.geturl()print(final_url)```以上代码中,我们首先使用urllib库的`urlopen`方法发送了一个请求,然后通过`geturl`方法获取了最终的URL位置区域,并将其打印出来。
这样就可以很方便地获取到HTTP请求的最终URL位置区域了。
三、`geturl`方法的参数`geturl`方法通常不需要传入额外的参数,它是在发送HTTP请求后,通过访问响应对象的`geturl`属性来获取最终的URL位置区域的。
四、`geturl`方法的注意事项在使用`geturl`方法时,需要注意以下几点:1. `geturl`方法只能用于HTTP请求的最终URL获取,对于其他协议的请求可能无法正常工作。
2. 在实际使用中,要考虑到可能出现的异常情况,比如网络连接超时、URL不存在等情况,需要适当处理异常。
五、`geturl`方法的应用场景`geturl`方法通常用于以下几个场景:1. 网络编程中,需要获取HTTP请求的最终URL位置区域。
url命令的使用方法
URL(统一资源定位符)是用于定位互联网上资源的地址。
在命
令行中,可以使用一些命令来处理URL。
1. 在Linux或者Mac系统中,可以使用curl命令来获取URL
的内容。
例如,要获取一个网页的内容,可以使用以下命令:
curl [URL]
这将返回URL指定的网页内容。
2. 另一个常见的命令是wget,它也可以用来从URL下载内容。
例如:
wget [URL]
这将下载URL指定的内容到当前目录。
3. 在Windows系统中,可以使用类似的命令来获取URL内容。
使用Invoke-WebRequest命令可以获取URL的内容,例如:
Invoke-WebRequest -Uri [URL]
这将返回URL指定的内容。
4. 除了获取URL内容,还可以使用一些命令来测试URL的连接状态。
在Linux系统中,可以使用curl命令来测试URL的连接,例如:
curl -I [URL]
这将返回URL的头信息,包括状态码和其他相关信息。
总之,URL命令的使用方法取决于你想要对URL做什么操作,包括获取内容、下载文件或者测试连接状态等。
不同的命令和参数可以帮助你完成不同的任务。
希望这些信息能够帮助你理解URL命令的使用方法。
URL筛选⼩⼯具提取⽹页中的超链接地址使⽤⽅法:将下⾯的代码保存为jb51.vbs然后拖动你保存在本地的htm页⾯,拖放在这个vbs即可'备注:URL筛选⼩⼯具'防⽌出现错误On Error Resume Next'vbs代码开始----------------------------------------------Dim p,s,reIf Wscript.Arguments.Count=0 ThenMsgbox "请把⽹页拖到本程序的图标上!",,"提⽰"Wscript.QuitEnd IfFor i= 0 to Wscript.Arguments.Count - 1p=Wscript.Arguments(i)With CreateObject("Adodb.Stream").Type=2.Charset="GB2312".Open.LoadFromFile=ps=.ReadTextSet re =New RegExpre.Pattern= "[A-z]+://[^""<>()\s']+"re.Global = TrueIf Not re.Test(s) ThenMsgbox "该⽹页⽂件中未出现⽹址!",,"提⽰"Wscript.QuitEnd IfSet Matches = re.Execute(s)s=""For Each Match In Matchess=s & "<a href=""" & Match.Value & """>" & Match.Value & "<p>"Nextre.Pattern= "&\w+;?|\W{5,}"s=re.Replace(s,"").Position=0.setEOS.WriteText s.SaveToFile p & "'s URLs.html",2.CloseEnd WithNextMsgbox "⽹址列表已经⽣成!",,"成功"'vbs代码结束----------------------------------------------到此这篇关于URL 筛选⼩⼯具提取⽹页中的链接地址的⽂章就介绍到这了,更多相关提取⽹页中的链接地址内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
这个VBS是用来将一个本地网页中的URL筛选出来并保存在新的网页文件中。
当然,只要改变里面的正则表达式,就可以作其他用途了。
使用方法:将下面的代码保存为jb51.vbs 然后拖动你保存在本地的htm页面,拖放在这个vbs即可
代码如下:
'备注:URL筛选小工具
'防止出现错误
On Error Resume Next
'vbs代码开始----------------------------------------------
Dim p,s,re
If Wscript.Arguments.Count=0 Then
Msgbox "请把网页拖到本程序的图标上!",,"提示"
Wscript.Quit
End If
For i= 0 to Wscript.Arguments.Count - 1
p=Wscript.Arguments(i)
With CreateObject("Adodb.Stream")
.Type=2
.Charset="GB2312"s)
s=""
For Each Match In Matches
s=s & "<a href=""" & Match.Value & """>" & Match.Value & "<p>"
Next
re.Pattern= "&\w+;?|\W{5,}"
s=re.Replace(s,"")
.Position=0
.setEOS
.WriteText s
.SaveToFile p & "'s URLs.html",2
.Close
End With
Next
Msgbox "网址列表已经生成!",,"成功"
'vbs代码结束----------------------------------------------。