多元统计分析考试重点
- 格式:doc
- 大小:65.50 KB
- 文档页数:3
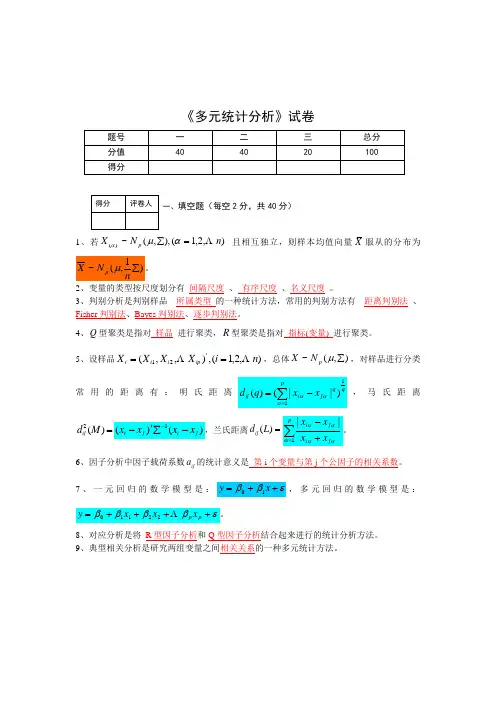
《多元统计分析》试卷1、若),2,1(),,(~)(n N X p =∑αμα 且相互独立,则样本均值向量X 服从的分布为2、变量的类型按尺度划分有_间隔尺度_、_有序尺度_、名义尺度_。
3、判别分析是判别样品 所属类型 的一种统计方法,常用的判别方法有__距离判别法_、Fisher 判别法、Bayes 判别法、逐步判别法。
4、Q 型聚类是指对_样品_进行聚类,R 型聚类是指对_指标(变量)_进行聚类。
5、设样品),2,1(,),,('21n i X X X X ip i i i ==,总体),(~∑μp N X ,对样品进行分类常用的距离有:明氏距离,马氏距离2()ijd M =)()(1j i j i x x x x -∑'--,兰氏距离()ij d L =6、因子分析中因子载荷系数ij a 的统计意义是_第i 个变量与第j 个公因子的相关系数。
7、一元回归的数学模型是:εββ++=x y 10,多元回归的数学模型是:εββββ++++=p p x x x y 22110。
8、对应分析是将 R 型因子分析和Q 型因子分析结合起来进行的统计分析方法。
9、典型相关分析是研究两组变量之间相关关系的一种多元统计方法。
一、填空题(每空2分,共40分)1、设三维随机向量),(~3∑μN X ,其中⎪⎪⎪⎭⎫ ⎝⎛=∑200031014,问1X 与2X 是否独立?),(21'X X 和3X 是否独立?为什么?解: 因为1),cov(21=X X ,所以1X 与2X 不独立。
把协差矩阵写成分块矩阵⎪⎪⎭⎫⎝⎛∑∑∑∑=∑22211211,),(21'X X 的协差矩阵为11∑因为12321),),cov((∑='X X X ,而012=∑,所以),(21'X X 和3X 是不相关的,而正态分布不相关与相互独立是等价的,所以),(21'X X 和3X 是独立的。

多元统计分析简答题1、简述多元统计分析中协差阵检验的步骤第⼀,提出待检验的假设H0和H1;第⼆,给出检验的统计量及其服从的分布;第三,给定检验⽔平,查统计量的分布表,确定相应的临界值,从⽽得到否定域;第四,根据样本观测值计算出统计量的值,看是否落⼊否定域中,以便对待判假设做出决策(拒绝或接受)。
协差阵的检验检验0=ΣΣ0p H =ΣI : /2/21exp 2np n e tr n λ=-?? ?S S00p H =≠ΣΣI : /2/2**1exp 2np n e tr n λ=-?? ?S S 检验12k ===ΣΣΣ 012k H ===ΣΣΣ:统计量/2/2/2/211i i k k n n pn np k i i i i nn λ===∏∏S S2. 针对⼀个总体均值向量的检验⽽⾔,在协差阵已知和未知的两种情形下,如何分别构造的统计量?3. 作多元线性回归分析时,⾃变量与因变量之间的影响关系⼀定是线性形式的吗?多元线性回归分析中的线性关系是指什么变量之间存在线性关系?答:作多元线性回归分析时,⾃变量与因变量之间的影响关系不⼀定是线性形式。
当⾃变量与因变量是⾮线性关系时可以通过某种变量代换,将其变为线性关系,然后再做回归分析。
多元线性回归分析的线性关系指的是随机变量间的关系,因变量y 与回归系数βi 间存在线性关系。
多元线性回归的条件是:(1)各⾃变量间不存在多重共线性;(2)各⾃变量与残差独⽴;(3)各残差间相互独⽴并服从正态分布;(4)Y 与每⼀⾃变量X 有线性关系。
4.回归分析的基本思想与步骤基本思想:所谓回归分析,是在掌握⼤量观察数据的基础上,利⽤数理统计⽅法建⽴因变量与⾃变量之间的回归关系函数表达式(称回归⽅程式)。
回归分析中,当研究的因果关系只涉及因变量和⼀个⾃变量时,叫做⼀元回归分析;当研究的因果关系涉及因变量和两个或两个以上⾃变量时,叫做多元回归分析。
此外,回归分析中,⼜依据描述⾃变量与因变量之间因果关系的函数表达式是线性的还是⾮线性的,分为线性回归分析和⾮线性回归分析。

二名词解释1、多元统计分析:多元统计分析是运用数理统计的方法来研究多变量(多指标)问题的理论和方法,是一元统计学的推广2、聚类分析:是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。
将个体或对象分类,使得同一类中的对象之间的相似性比与其他类的对象的相似性更强。
使类内对象的同质性最大化和类间对象的异质性最大化3、随机变量:是指变量的值无法预先确定仅以一定的可能性(概率)取值的量。
它是由于随机而获得的非确定值,是概率中的一个基本概念。
即每个分量都是随机变量的向量为随机向量。
类似地,所有元素都是随机变量的矩阵称为随机矩阵。
4、统计量:多元统计研究的是多指标问题,为了了解总体的特征,通过对总体抽样得到代表总体的样本,但因为信息是分散在每个样本上的,就需要对样本进行加工,把样本的信息浓缩到不包含未知量的样本函数中,这个函数称为统计量三、计算题解:答:答:题型三解答题1、简述多元统计分析中协差阵检验的步骤答:第一,提出待检验的假设和H1;第二,给出检验的统计量及其服从的分布;第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域;第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。
2、简述一下聚类分析的思想答:聚类分析的基本思想,是根据一批样品的多个观测指标,具体地找出一些能够度量样品或指标之间相似程度的统计量,然后利用统计量将样品或指标进行归类。
把相似的样品或指标归为一类,把不相似的归为其他类。
直到把所有的样品(或指标)聚合完毕.3、多元统计分析的内容和方法答:1、简化数据结构,将具有错综复杂关系的多个变量综合成数量较少且互不相关的变量,使研究问题得到简化但损失的信息又不太多。
(1)主成分分析(2)因子分析(3)对应分析等2、分类与判别,对所考察的变量按相似程度进行分类。
(1)聚类分析:根据分析样本的各研究变量,将性质相似的样本归为一类的方法。

1、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设H0和H1; 第二,给出检验的统计量及其服从的分布;第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。
协差阵的检验检验0=ΣΣ0p H =ΣI : /2/21exp 2np n e tr n λ⎧⎫⎛⎫=-⎨⎬ ⎪⎩⎭⎝⎭S S00p H =≠ΣΣI : /2/2**1exp 2np n e tr n λ⎧⎫⎛⎫=-⎨⎬ ⎪⎩⎭⎝⎭S S检验12k ===ΣΣΣ012k H ===ΣΣΣ:统计量/2/2/2/211i i kkn n pn np k ii i i n n λ===∏∏S S2. 针对一个总体均值向量的检验而言,在协差阵已知和未知的两种情形下,如何分别构造的统计量?3. 作多元线性回归分析时,自变量与因变量之间的影响关系一定是线性形式的吗?多元线性回归分析中的线性关系是指什么变量之间存在线性关系? 答:作多元线性回归分析时,自变量与因变量之间的影响关系不一定是线性形式。
当自变量与因变量是非线性关系时可以通过某种变量代换,将其变为线性关系,然后再做回归分析。
多元线性回归分析的线性关系指的是随机变量间的关系,因变量y 与回归系数βi 间存在线性关系。
多元线性回归的条件是:(1)各自变量间不存在多重共线性; (2)各自变量与残差独立;(3)各残差间相互独立并服从正态分布; (4)Y 与每一自变量X 有线性关系。
4.回归分析的基本思想与步骤 基本思想:所谓回归分析,是在掌握大量观察数据的基础上,利用数理统计方法建立因变量与自变量之间的回归关系函数表达式(称回归方程式)。
回归分析中,当研究的因果关系只涉及因变量和一个自变量时,叫做一元回归分析;当研究的因果关系涉及因变量和两个或两个以上自变量时,叫做多元回归分析。

多元统计分析期末考试考点The following text is amended on 12 November 2020.二名词解释1、多元统计分析:多元统计分析是运用数理统计的方法来研究多变量(多指标)问题的理论和方法,是一元统计学的推广2、聚类分析:是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。
将个体或对象分类,使得同一类中的对象之间的相似性比与其他类的对象的相似性更强。
使类内对象的同质性最大化和类间对象的异质性最大化3、随机变量:是指的值无法预先确定仅以一定的可能性(概率)取值的量。
它是由于随机而获得的非确定值,是概率中的一个基本概念。
即每个分量都是随机变量的向量为随机向量。
类似地,所有元素都是随机变量的矩阵称为随机矩阵。
4、统计量:多元统计研究的是多指标问题,为了了解总体的特征,通过对总体抽样得到代表总体的样本,但因为信息是分散在每个样本上的,就需要对样本进行加工,把样本的信息浓缩到不包含未知量的样本函数中,这个函数称为统计量三、计算题解:答:答:题型三解答题1、简述多元统计分析中协差阵检验的步骤答:第一,提出待检验的假设和H1;第二,给出检验的统计量及其服从的分布;第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域;第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。
2、简述一下聚类分析的思想答:聚类分析的基本思想,是根据一批样品的多个观测指标,具体地找出一些能够度量样品或指标之间相似程度的统计量,然后利用统计量将样品或指标进行归类。
把相似的样品或指标归为一类,把不相似的归为其他类。
直到把所有的样品(或指标)聚合完毕.3、多元统计分析的内容和方法答:1、简化数据结构,将具有错综复杂关系的多个变量综合成数量较少且互不相关的变量,使研究问题得到简化但损失的信息又不太多。
(1)主成分分析(2)因子分析(3)对应分析等2、分类与判别,对所考察的变量按相似程度进行分类。

天津市考研统计学复习资料多元统计分析重点知识点梳理多元统计分析是统计学的一个重要分支,主要研究多个变量之间的关系。
在天津市考研统计学考试中,多元统计分析是一个重要的考点。
本文将为大家梳理多元统计分析的重点知识点,帮助大家更好地复习。
一、多元统计分析的基本概念多元统计分析是指研究多个变量之间关系的一种统计方法。
基本概念包括变量、样本、总体以及数据矩阵等。
变量是研究对象的属性或特征,可以分为自变量和因变量。
样本是从总体中抽取出来的一部分观察对象。
总体是包含所有观察对象的集合,数据矩阵则是由多个变量构成的数据表格。
二、多元统计分析的基本假设多元统计分析中,基本的假设包括正态性、方差齐性、线性关系和独立性。
正态性假设要求变量呈正态分布;方差齐性假设要求不同组之间的方差相等;线性关系假设要求变量之间存在线性关系;独立性假设要求各个样本之间是相互独立的。
三、多元统计分析的方法多元统计分析的方法包括主成分分析、因子分析、聚类分析、判别分析以及多元方差分析等。
主成分分析是一种降维技术,可以将多个变量转化为少数几个主成分;因子分析是一种变量提取技术,用于研究隐藏在观测变量背后的潜在因素;聚类分析是一种将样本按照某种相似性划分为不同群体的方法;判别分析是一种用于分类的方法,可以根据已知类别的样本训练分类模型,然后对未知类别的样本进行分类;多元方差分析是用于研究多个因素对多个变量的影响的方法。
四、多元统计分析的应用领域多元统计分析在实际应用中有广泛的应用领域。
比如,在金融风险管理领域,可以利用因子分析来识别和度量风险因子;在市场调研和消费者行为研究中,可以利用聚类分析来对消费者进行划分和分类;在医学研究中,可以利用判别分析来辅助诊断疾病。
五、多元统计分析的局限性多元统计分析也存在一定的局限性。
首先,多元统计分析的结果可能受到数据质量和样本分布的影响。
其次,多元统计分析的结果只是对样本的推断,不能直接推广到整个总体。
此外,多元统计分析的结果需要结合实际情况进行解释和分析,不能仅仅依赖统计指标。

多元统计期末考试试题一、选择题(每题2分,共20分)1. 以下哪项不是多元统计分析中常用的数据预处理方法?- A. 标准化- B. 归一化- C. 特征选择- D. 数据清洗2. 多元回归分析中,当自变量之间存在高度相关性时,我们通常称之为:- A. 多重共线性- B. 正态性- C. 同方差性- D. 独立性3. 以下哪项不是主成分分析(PCA)的目的?- A. 降维- B. 特征选择- C. 变量解释- D. 增加数据的维度4. 聚类分析中,若要衡量聚类效果,常用的指标不包括:- A. 轮廓系数- B. 熵- C. 戴维斯-库尔丁指数- D. 距离方差5. 因子分析中,因子载荷矩阵的元素表示:- A. 观测变量的均值- B. 因子的方差- C. 观测变量与因子之间的关系- D. 因子之间的相关性二、简答题(每题10分,共30分)1. 请简述多元线性回归分析的基本假设,并说明违反这些假设可能带来的问题。
2. 描述主成分分析(PCA)的基本步骤,并说明其在数据降维中的应用。
3. 聚类分析与分类分析有何不同?请举例说明。
三、计算题(每题25分,共50分)1. 假设有一组数据,包含三个变量X1、X2和Y,数据如下:| X1 | X2 | Y ||-|-|-|| 1 | 2 | 3 || 2 | 4 | 6 || 3 | 6 | 9 || 4 | 8 | 12 |请计算多元线性回归模型的参数,并检验模型的显著性。
2. 给定以下数据集,进行K-means聚类分析,选择K=3,并计算聚类中心。
| 变量1 | 变量2 | 变量3 ||--|-|-|| 1.2 | 2.3 | 3.4 || 1.5 | 2.5 | 3.6 || 4.1 | 5.2 | 6.3 || 4.4 | 5.6 | 6.8 || 7.1 | 8.2 | 9.3 || 7.4 | 8.6 | 9.9 |四、论述题(每题30分,共30分)1. 论述因子分析与主成分分析的异同,并讨论它们在实际应用中可能遇到的问题及解决方案。

多元统计期末考试题及答案一、选择题(每题2分,共20分)1. 在多元线性回归中,如果一个变量的系数为0,这意味着什么?A. 该变量对因变量没有影响B. 该变量与因变量完全相关C. 该变量与因变量无关D. 该变量是多余的2. 主成分分析(PCA)的主要目的是什么?A. 减少数据的维度B. 增加数据的维度C. 找到数据的均值D. 找到数据的中位数3. 以下哪个不是聚类分析的优点?A. 可以揭示数据的内在结构B. 可以用于分类C. 可以减少数据的维度D. 可以找到数据的异常值4. 在因子分析中,如果一个因子的方差贡献率很低,这通常意味着什么?A. 该因子对数据的解释能力很强B. 该因子对数据的解释能力很弱C. 该因子是多余的D. 该因子是重要的5. 以下哪个是多元统计分析中常用的距离度量?A. 欧氏距离B. 曼哈顿距离C. 切比雪夫距离D. 所有以上选项二、简答题(每题10分,共30分)6. 解释什么是多元线性回归,并简述其在实际问题中的应用。
7. 描述主成分分析(PCA)的基本原理,并举例说明其在数据分析中的作用。
8. 简述聚类分析的过程,并讨论其在商业数据分析中的应用。
三、计算题(每题25分,共50分)9. 假设有以下数据集,包含两个变量X和Y,以及它们的观测值:| 观测 | X | Y |||||| 1 | 2 | 3 || 2 | 3 | 4 || 3 | 4 | 5 || 4 | 5 | 6 |请计算X和Y的协方差,并解释其意义。
10. 给定以下数据集,进行聚类分析,并解释聚类结果:| 观测 | 变量1 | 变量2 |||-|-|| 1 | 1.5 | 2.5 || 2 | 2.0 | 3.0 || 3 | 3.5 | 4.5 || 4 | 4.0 | 5.0 |多元统计期末考试题答案一、选择题1. A2. A3. C4. B5. D二、简答题6. 多元线性回归是一种统计方法,用于分析两个或两个以上的自变量(解释变量)与一个因变量之间的关系。

1.多元分析研究的是多个随机变量及其相互关系的统计总体。
2.多元统计中常用的统计量有:样本均值、样本方差、样本协方差和样本相关系数。
3.协方差和相关系数仅仅是变量间离散程度的一种度量,并不能刻画变量间可能存在的关联程度。
4.人们通过各种实践,发现变量之间的相互关系可以分成相关和不相关两种类型。
5.总离差平方和可以分解为回归离差平方和和剩余离差平方和两个部分,各自的自由度为p 和n-p-1,其中回归离差平方和在总离差平方和中所占比重越大,则线性回归效果越显著。
7.偏相关系数是指多元回归分析中,当其他变量固定后,给定的两个变量之间的的相关系数。
8.Spss中回归方程的建模方法有一元线形回归、多元线形回归、岭回归、多对多线形回归等。
9.主成分分析是通过适当的变量替换,使新变量成为原变量的综合变量,并寻求相关性的一种方法。
10.主成分分析的基本思想是:设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。
11.主成分的协方差矩阵为对角矩阵。
12.主成分表达式的系数向量是相关系数矩阵的特征向量。
13.原始变量协方差矩阵的特征根的统计含义是原始数据的相关系数。
14.原始数据经过标准化处理,转化为均值为0 ,方差为1 的标准值,且其协方差矩阵与相关系数矩阵相等。
15.样本主成分的总方差等于1 。
16.变量按相关程度为,在相关性很强程度下,主成分分析的效果较好。
17.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为方差贡献度。
19.因子分析是把每个原始变量分解为两部分因素,一部分是公共因子,另一部分为特殊因子。
20.变量共同度是指因子载荷矩阵中第i行元素的平方和。
21.公共因子方差与特殊因子方差之和为 1 。
22.聚类分析是建立一种分类方法,它将一批样哂或变量按照它们在性质上的亲疏程度进行科学的分类。
23.Q型聚类法是按样品进行聚类,R型聚类法是按变量进行聚类。

多元统计分析期末考试考点标准化管理处编码[BBX968T-XBB8968-NNJ668-MM9N]多元统计分析题型一定义、名词解释题型二计算(协方差阵、模糊矩阵)题型三解答题一、定义二名词解释1、多元统计分析:多元统计分析是运用数理统计的方法来研究多变量(多指标)问题的理论和方法,是一元统计学的推广2、聚类分析:是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。
将个体或对象分类,使得同一类中的对象之间的相似性比与其他类的对象的相似性更强。
使类内对象的同质性最大化和类间对象的异质性最大化3、随机变量:是指的值无法预先确定仅以一定的可能性(概率)取值的量。
它是由于随机而获得的非确定值,是概率中的一个基本概念。
即每个分量都是随机变量的向量为随机向量。
类似地,所有元素都是随机变量的矩阵称为随机矩阵。
4、统计量:多元统计研究的是多指标问题,为了了解总体的特征,通过对总体抽样得到代表总体的样本,但因为信息是分散在每个样本上的,就需要对样本进行加工,把样本的信息浓缩到不包含未知量的样本函数中,这个函数称为统计量三、计算题解:答:答:题型三解答题1、简述多元统计分析中协差阵检验的步骤答:第一,提出待检验的假设和H1;第二,给出检验的统计量及其服从的分布;第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域;第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。
2、简述一下聚类分析的思想答:聚类分析的基本思想,是根据一批样品的多个观测指标,具体地找出一些能够度量样品或指标之间相似程度的统计量,然后利用统计量将样品或指标进行归类。
把相似的样品或指标归为一类,把不相似的归为其他类。
直到把所有的样品(或指标)聚合完毕.3、多元统计分析的内容和方法答:1、简化数据结构,将具有错综复杂关系的多个变量综合成数量较少且互不相关的变量,使研究问题得到简化但损失的信息又不太多。

22121212121~(,),(,),(,),,1X N X x x x x x x ρμμμμσρ⎛⎫∑==∑=⎪⎝⎭+-1、设其中则Cov(,)=____.10312~(,),1,,10,()()_________i i i i X N i W X X μμμ='∑=--∑L 、设则=服从。
()1234433,492,3216___________________X x x x R -⎛⎫ ⎪'==-- ⎪⎪-⎝⎭=∑、设随机向量且协方差矩阵则它的相关矩阵4、__________, __________,________________。
215,1,,16(,),(,)15[4()][4()]~___________i p p X i N X A N T X A X μμμμ-=∑∑'=--L 、设是来自多元正态总体和分别为正态总体的样本均值和样本离差矩阵,则。
(),123设X=x xx 的相关系数矩阵通过因子分析分解为211X h =的共性方差111X σ=的方差21X g =1公因子f 对的贡献121330.93400.1280.9340.4170.8351100.4170.8940.02700.8940.44730.8350.4470.1032013R⎛⎫- ⎪⎛⎫⎛⎫⎪-⎛⎫ ⎪ ⎪⎪=-=-+ ⎪ ⎪ ⎪ ⎪⎝⎭ ⎪ ⎪ ⎪⎝⎭⎝⎭ ⎪⎪⎝⎭12332313116421(,,)~(,),(1,0,2),441,2142X x x x N x x x x x μμ-⎛⎫⎪'=∑=-∑=-- ⎪ ⎪-⎝⎭-⎛⎫+ ⎪⎝⎭、设其中试判断与是否独立?11262(90,58,16),82.0 4.310714.62108.946460.2,(5)( 115.6924)14.6210 3.17237.14.5X S μ--'=-⎛⎫ ⎪==-- ⎪ ⎪⎝⎭0、对某地区农村的名周岁男婴的身高、胸围、上半臂围进行测量,得相关数据如下,根据以往资料,该地区城市2周岁男婴的这三个指标的均值现欲在多元正态性的假定下检验该地区农村男婴是否与城市男婴有相同的均值。
一、填空题:1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法.2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著.3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。
通常聚类分析分为 Q型聚类和R型聚类。
4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。
5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。
6、若()(,), Px N αμα∑=1,2,3….n且相互独立,则样本均值向量x服从的分布为_x~N(μ,Σ/n)_。
二、简答1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。
在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。
选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。
被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。
2、简述相应分析的基本思想。
相应分析,是指对两个定性变量的多种水平进行分析。
设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。
对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。
要寻求列联表列因素A和行因素B 的基本分析特征和最优列联表示。
相应分析即是通过列联表的转换,使得因素A 和因素B具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。
把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。
3、简述费希尔判别法的基本思想。
从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数:确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。
将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。
(完整版)多元统计分析试题及答案试题:1. 试解释多元统计分析的含义及其与单变量和双变量统计分析的区别。
2. 简述卡方检验方法及适用场景。
3. 请解释回归分析中的回归系数及其p值的含义及作用,简单说明如何进行回归模型的选择和评估。
4. 试解释主成分分析的原理及目的,如何进行主成分分析及如何解释因子载荷矩阵。
5. 请列举和简要解释聚类分析和判别分析的适用场景,并说明两种方法的区别。
答案:1. 多元统计分析是一种将多个变量进行综合分析的方法。
与单变量和双变量统计分析不同的是,多元统计分析可以处理多个自变量和因变量的组合关系,从而探究它们之间的综合关系。
该方法通常适用于探究多种变量在某个问题中的关系、探究影响某一结果变量的因素、探究各个变量相互作用的影响等。
2. 卡方检验是根据样本数据与期望值的差异来判断观察值与理论预期是否相符,以此来验证假设是否成立的方法。
它通常用于对某个现象进行分类的相关度检验。
适用场景包括:样本的数量大于等于40,且至少有一个期望值小于5;变量为分类变量,且分类类别数不超过10个。
卡方检验的原理是将观察值和期望值进行比较,并计算卡方值,然后根据卡方值与自由度的乘积查找p值,从而得出结论。
3. 回归系数是回归方程中自变量与因变量之间的关系,在线性回归中,回归系数表示每一个自变量单位变化与因变量单位变化的关系。
p值是评估回归系数是否具有显著性的指标。
回归模型的选择有两种方法:一种是逐步回归分析,根据不同的准则进行多个回归模型的比较,选择最优的模型;另一种是正则化回归,通过加入惩罚项来保证回归模型具有良好的泛化性能。
回归模型的评估有多种方法,包括:残差分析、R方值、方差齐性检验、变量的共线性检验等。
4. 主成分分析是一种将多维数据降维处理的方法,它的目的是通过数据的变换,将多个变量转化为一些综合指标,这些指标是原始变量的线性组合。
主成分分析的步骤包括:数据标准化、计算协方差矩阵或相关系数矩阵、计算特征值和特征向量、选取主成分。
第一章:多元统计分析研究的内容(5点)1、简化数据结构(主成分分析)2、分类与判别(聚类分析、判别分析)3、变量间的相互关系)(典型相关分析、多元回归分析)4、多维数据的统计推断5、多元统计分析的理论基础第二三章:二、多维随机变量的数字特征1、随机向量的数字特征随机向量X均值向量:随机向量X与Y的协方差矩阵:当X=Y时Cov(X,Y) =D(X);当Cov( X,Y)=0,称X,Y不相关。
随机向量X与Y的相关系数矩阵:2、均值向量协方差矩阵的性质(1) .设X,Y为随机向量,A,B为常数矩阵E ( AX)二AE( X);E ( AXB =AE (X)B;D(AX)=AD(X)A ';Cov(AX,B Y)二ACov(X, Y)EX ' ( EX^EX?, , EX p) ( 2,…,P )'cov( X ,Y ) E ( X EX )( YEY )' (2) .若X,Y独立,则Cov(X,Y) =0,反之不成立.(X,Y) (r j)pq(3) .X的协方差阵D(X)是对称非负定矩阵。
例2.见黑板三、多元正态分布的参数估计2、多元正态分布的性质特别地,当为对角阵时,相互独立。
(2) .若,、为sxp阶常数矩阵,d为s阶向量,AX+ d〜即正态分布的线性函数仍是正态分布.(3) .多元正态分布的边缘分布是正态分布,反之不成立.(4) .多元正态分布的不相关与独立■等价.,X pX ~ N p(,) '例3 .见黑板.N s( A d , A A )三、多元正态分布的参数估计⑴“为来自p兀总体X的(简单)样本”的理解---独立同截面.X(1),,X(n)(2)多兀分布样本的数字特征- —常见多兀统计量X n(X i,X2,,X p)' 1(X (i)X )( X (i) X )' —样本均值向量i 1X样本离差阵S = 样本协方差阵V = S ;样本相X X X ~ N p(,-)关阵R W p(n1,)X n(3) , V分别是和的最大似然估计;⑷估计的性质是的无偏估计;,V分别是和的有效和一致估计;S〜,与S相互独立;第五章聚类分析:一、什么是聚类分析:聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。
@什么是多元统计分析多元统计分析是运用数理统计的方法来研究多变量(多指标)问题的理论和方法,是一元统计学的推广@多元统计分析的内容和方法1、简化数据结构,将具有错综复杂关系的多个变量综合成数量较少且互不相关的变量,使研究问题得到简化但损失的信息又不太多。
(1)主成分分析(2)因子分析(3)对应分析等2、分类与判别,对所考察的变量按相似程度进行分类。
(1)聚类分析:根据分析样本的各研究变量,将性质相似的样本归为一类的方法。
(2)判别分析:判别样本应属何种类型的统计方法。
@方差分析的基本思想:方差分析又称变异数分析或F检验,其目的是推断两组或多组资料的总体均数是否相同,检验两个或多个样本均数的差异是否有统计学意义。
应用条件: (1)可比性,若资料中各组均数本身不具可比性则不适用方差分析。
(2)正态性,各组的观察数据,是从服从正态分布的总体中随机抽取的样本。
(3)方差齐性,各组的观察数据,是从具有相同方差的相互独立的总体中抽取得到的。
@聚类分析:是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。
将个体或对象分类,使得同一类中的对象之间的相似性比与其他类的对象的相似性更强。
使类内对象的同质性最大化和类间对象的异质性最大化@聚类分析的基本思想:是根据一批样品的多个观测指标,具体地找出一些能够度量样品或指标之间相似程度的统计量,然后利用统计量将样品或指标进行归类。
把相似的样品或指标归为一类,把不相似的归为其他类。
直到把所有的样品(或指标)聚合完毕. @判别分析的特点(基本思想)1、是根据已掌握的、历史上若干样本的p个指标数据及所属类别的信息,总结出该事物分类的规律性,建立判别公式和判别准则。
2、根据总结出来的判别公式和判别准则,判别未知类别的样本点所属的类别。
@聚类分析的类型有:(1)对样本分类,称为Q型聚类分析(2)对变量分类,称为R型聚类分析 # Q型聚类是对样本进行聚类,它使具有相似性特征的样本聚集在一起,使差异性大的样本分离开来。
@什么是多元统计分析
多元统计分析是运用数理统计的方法来研究多变量(多指标)问题的理论和方法,是一元统计学的推广
@多元统计分析的内容和方法
1、简化数据结构,将具有错综复杂关系的多个变量综合成数量较少且互不相关的变量,使研究问题得到简化但损失的信息又不太多。
(1)主成分分析(2)因子分析(3)对应分析等
2、分类与判别,对所考察的变量按相似程度进行分类。
(1)聚类分析:根据分析样本的各研究变量,将性质相似的样本归为一类的方法。
(2)判别分析:判别样本应属何种类型的统计方法。
@方差分析的基本思想:方差分析又称变异数分析或F检验,其目的是推断两组或多组资料的总体均数是否相同,检验两个或多个样本均数的差异是否有统计学意义。
应用条件: (1)可比性,若资料中各组均数本身不具可比性则不适用方差分析。
(2)正态性,各组的观察数据,是从服从正态分布的总体中随机抽取的样本。
(3)方差齐性,各组的观察数据,是从具有相同方差的相互独立的总体中抽取得到的。
@聚类分析:是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。
将个体或对象分类,使得同一类中的对象之间的相似性比与其他类的对象的相似性更强。
使类内对象的同质性最大化和类间对象的异质性最大化
@聚类分析的基本思想:是根据一批样品的多个观测指标,具体地找出一些能够度量样品或指标之间相似程度的统计量,然后利用统计量将样品或指标进行归类。
把相似的样品或指标归为一类,把不相似的归为其他类。
直到把所有的样品(或指标)聚合完毕. @判别分析的特点(基本思想)1、是根据已掌握的、历史上若干样本的p个指标数据及所属类别的信息,总结出该事物分类的规律性,建立判别公式和判别准则。
2、根据总结出来的判别公式和判别准则,判别未知类别的样本点所属的类别。
@聚类分析的类型有:(1)对样本分类,称为Q型聚类分析(2)对变量分类,称为R型聚类分析 # Q型聚类是对样本进行聚类,它使具有相似性特征的样本聚集在一起,使差异性大的样本分离开来。
# R型聚类是对变量进行聚类,它使具有相似性的变量聚集在一起,差异性大的变量分离开来,可在相似变量中选择少数具有代表性的变量参与其他分析,实现减少变量个数,达到变量降维的目的。
@判别分析根据已知对象的某些观测指标和所属类别来判断未知对象所属类别的一种统计学方法。
@判别分析类型及方法(1)按判别的组数来分,有两组判别分析和多组判别分析(2)按区分不同总体所用的数学模型来分,有线性判别和非线性判别(3)按判别对所处理的变量方法不同有逐步判别、序贯判别。
(4)按判别准则来分,有费歇尔判别准则、贝叶斯判别准则
@因子分析:因子分析是主成分分析的推广,也是利用降维的思想,由研究原始变量相关矩阵或协方差矩阵的内部依赖关系出发,把一些具有错综复杂关系的多个变量归结为少数几个综合因子的一种多元统计分析方法。
@主成分分析与因子分析的联系和差异:因子分析是主成分分析的推广,是主成分分析的逆问题。
主成分分析是将原始变量加以综合、归纳;因子分析是将原始变量加以分解、演绎。
(1)主成分分析仅仅是变量变换,而因子分析需要构造因子模型。
(2)主成分分析:原始变量的线性组合表示新的综合变量,即主成分;因子分析:用潜在的假想变量(公共因子)和随机影响变量(特殊因子)的线性组合表示原始变量。
用假设的公因子来“解释”相关矩阵内部的依赖关系。
(3)主成分分析中主成分个数和变量个数相同,它是将一组具有相关关系的变量变换为一组互不相关的变量,在解决实际问题时,一般取前m个主成分;因子分析的目的是用尽可能少的公因子,以便构造一个结构简单的因子模型。
@因子分析的基本思想:把每个研究变量分解为几个影响因素变量,将每个原始变量分解成两部分因素,一部分是由所有变量共同具有的少数几个公共因子组成的,另一部分是每个变量独自具有的因素,即特殊因子。
@主成分分析:将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法。
@共同度----又称共性方差或公因子方差就是变量与每个公共因子之负荷量的平方总和(一行中所有因素负荷量的平方和)。
@简述两个变量之间的相关分析
相关分析是研究随机变量之间的相关关系的一种统计方法。
相关关系是一种非确定性的关系。
相关性探讨的是两变量间相关情况的的大致趋势。
相关分析涉及两个变量:应变量和自变量。
应变量是度量研究结果的变量;自变量是解释或影响反应变量的变量。
两变量数据相关检验的步骤:一、图示两变量数据以及各个统计数字;二、查看整体状态及数据的离散情况;三、如果有较稳定的关系,就用简单的数学模式描述该关系。
对连续型变量常用相关系数刻画两个变量之间的相关性,而对离散型变量则用质相关系数。
@系统聚类法基本原理和步骤为
先计算
n
个样本两两间的距离n
个类,每
个类只包含一个样本
类为一新类
类的个数是否等于1,如果不等于回到
3
在做
@聚类和判别分析的异同
聚类分析是把研究目标分割成为具有
相同属性的小的群体。
对变量的聚类称为R 型聚类,而对观测值聚类称为Q型聚类。
它们在数学上是无区别的。
聚类的基本想法:根据某种距离,把最近的聚在一起。
这里的距离含义很广,如欧氏距离、马氏距离等距离,相似系数也可看作为距离。
判别分析的基本思路是:设有G1、
G2、…GK个总体,从不同的总体中抽出不同的样本,根据样本→建立判别法则→判别新的样品属于哪一个总体。
当然,根据不同的方法,建立的判别法则也是不同的。
常用的判别方法有:距离判别、Fisher判别、Bayes判别。
判别分析和聚类分析都是分类。
其主要不同点就是,在聚类分析中一般人们事先并不知道或一定要明确应该分成几类,完全根据数据来确定。
而在判别分析中,至少有一个已经明确知道类别的“训练样本”,利用这个数据,就可以建立判别准则,并通过预测变量来为未知类别的观测值进行判别
了。
@Fisher判别和贝叶斯判别的基本原理Fisher判别法是一种先投影的方法。
使多维问题简化为一维问题来处理。
选择一个适当的投影轴,使所有的样品点都投影到这个轴上得到一个投影值。
对这个投影轴的方向的要求是:使每一类内的投影值所形成的类内离差尽可能小,而不同类间的投影值所形成的类间离差尽可能大。
进行投影后,再根据距离判别思想由距离的远近得到判别准则,从而进行判别分析。
贝叶斯(BAYES)判别思想是根据先验概率求出后验概率,并依据后验概率分布作出统计推断。
所谓先验概率,就是用概率来描述人们事先对所研究的对象的认识的程度;所谓后验概率,就是根据具体资料、先验概率、特定的判别规则所计算出来的概率。
它是对先验概率修正后的结果。
jk
ik p k ij x x d -=∞≤≤1max )(
@简述两个类别的判别及判别准则
用距离判别法的基本思想是,先根据已知分类的数据,分别计算各类的重心,然后计算待判样本与各类的距离,与哪一类距离最近,就判待判样本x 属于哪一类。
计算距离时常用的是马氏距离D(x,G 1)、D(x,G 2),根据基本思想,可得距离判别法的判别函数为:W(x)=D(x,G 2)-D(x,G 1)
判别准则
)( 0)(,0
)(,21=<∈>∈x W x W G x x W G x 当待判,当当 @主成分分析基本步骤
(1)对原变量的样本数据矩阵进行标准化变换(2)求标准化数据矩阵的相关系数矩阵R (3)求R 的特征根及相应的特征向量和贡献率等(4)确定主成分的个数(5)解释主成分的实际意义和作用
@明考夫斯基距离三种特殊形式:
绝对距离
欧氏距离
切比雪夫距离
@主成分分析的基本步骤
1:将原始数据X 进行标准化,得*X ; 2:计算*X 的相关系数矩阵R ;
3:求相关系数矩阵R 的特征根120p λλλ≥≥≥>及相应的单位正交特征
向量12,,,p U U U ;
4:计算方差累积贡献率,确定主成分的个数q ;
5:写出主成分*F X U =,解释其实际经济意义并指导实践。
()
∑
=-=p k jk
ik ij x x d 11()2
1
12
)(2⎥
⎦
⎤
⎢⎣⎡-=∑=p k jk ik ij x x d。