HACMP第一部分_规划篇
- 格式:pdf
- 大小:445.67 KB
- 文档页数:9


PowerHA完全手册(一)前言自2008 年4 月02 日笔者在IBM DevelopWork网站首次发表《HACMP 5.X 完全手册》以来,加上各网站的转载,应该已过了10万的阅读量,在此非常感谢大家的认可和支持。
转眼已经5年过去了,期间非常感谢不少同仁指出了该文的各种不足,并且HACMP已经改名为HACMP了,由于软件版本的更新和本人当时的技术水准有限,同时也存储不少同仁的希望,在原文基础上进行了补充和修订完善,也就有了本文。
正是由于AIX专家俱乐部的兴起,对AIX和HACMP的技术感兴趣的技术人员又更多了。
因此选择本杂志作为原创发表,就是希望能对更多的同仁日常工作有所帮助。
此外,虽然本文号称“完全手册”,一是为了吸引眼球,二也只是相对于其他只谈安装配置的文档而言。
由于HACMP现在已相当复杂,本文范围也主要关注于最常用的双节点,还望大家谅解。
即便如此,本文篇幅可能仍然较长,虽然也建议大家先通读一下,但实际使用使用时可根据具体目的按章节直接查阅操作。
这是因为一方面本文所述操作笔者都加以验证过;一方面也是全中文,省得大家去查一大堆原版资料。
希望能帮助大家在集成和运维HACMP的过程中节省精力、降低实施风险,这也是本文编写的初衷。
同时还望那些被部分摘抄文章的同仁也能理解,你们都是笔者的老师,这里也一一谢过。
虽笔者端正态度,尽力认真编写,但由于能力有限,恐仍有错漏之处,还望众多同仁多多指正海涵,在此先行谢过。
1. 为什么需要PowerHA/HACMP随着业务需求日益增加,IT的系统架构中核心应用必须一直可用,系统必须对故障必须有容忍能力,已经是现代IT高可用系统架构的基本要求。
10 年前各厂商现有的UNIX服务器就已拥有很高的可靠性,在这一点上IBM的Power系列服务器表现尤为突出。
但所有UNIX服务器均无法达到如原来IBM大型主机S/390那样的可靠性级别,这是开放平台服务器的体系结构和应用环境所决定的,这一点,即使科技发展到云计算的今天仍然如此。




HACMP认证知识:资源组规划HACMP认证知识:资源组规划资源组是一个逻辑实体,其中包含HACMP 要使其高度可用的资源。
资源可以是:存储空间(应用程序代码和数据)文件系统网络文件系统原始逻辑卷原始物理磁盘服务 IP 地址/标签(由客户端用于访问应用程序数据)应用程序服务器应用程序启动脚本应用程序停止脚本要让HACMP 使资源高度可用,必须将每个资源包括在资源组中。
每当发生集群事件和集群中的条件发生改变,HACMP 就将资源组从一个节点移动到另一个节点,从而确保集群资源的可用性。
HACMP 控制资源组在以下情况下的行为:集群启动节点故障节点重新集成集群关闭在这其中的每个集群阶段,HACMP 中的资源组行为由以下条件确定:哪个或哪些节点在集群启动时获取该资源组。
哪个节点在所有者节点发生故障时接管该资源组。
资源组是要退回刚从先前发生的故障中恢复的节点,还是保留在当前拥有它的.节点上。
集群节点之间的优先级关系决定了哪个集群节点最初控制某个资源组,以及原始节点在发生故障后重新加入集群时,哪个节点将接管该资源组的控制权。
资源组接管关系可定义为:级联(Cascading)循环(Rotating)并发(Concurrent)自定义(Custom)级联、循环和并发资源组是 HACMP V5.1 以前的“传统”类型。
由于这些类型的定义可能难于理解,HACMP V5.1 中引入了新的“自定义”类型的资源组。
这只是规范化 HACMP 术语并使得 HACMP 概念更容易理解的第一步。
从 HACMP V5.2 开始,“传统”资源组类型已被唯一的自定义资源组所取代。
【HACMP认证知识:资源组规划】。
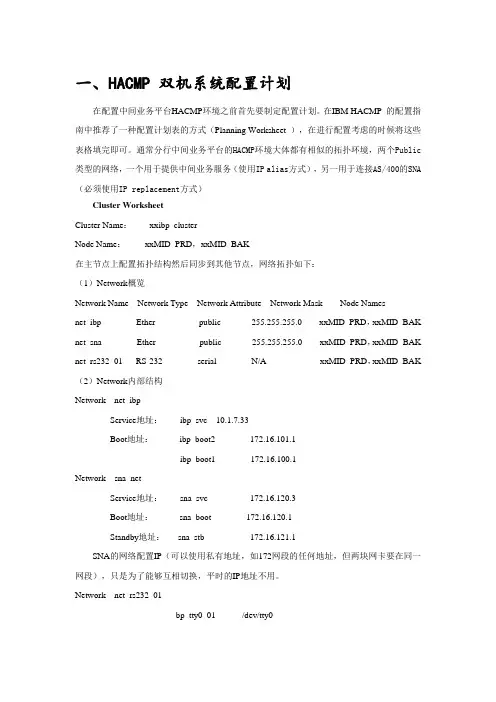
一、HACMP 双机系统配置计划在配置中间业务平台HACMP环境之前首先要制定配置计划。
在IBM HACMP 的配置指南中推荐了一种配置计划表的方式(Planning Worksheet ),在进行配置考虑的时候将这些表格填完即可。
通常分行中间业务平台的HACMP环境大体都有相似的拓扑环境,两个Public 类型的网络,一个用于提供中间业务服务(使用IP alias方式),另一用于连接AS/400的SNA (必须使用IP replacement方式)Cluster WorksheetCluster Name:xxibp_clusterNode Name:xxMID_PRD,xxMID_BAK在主节点上配置拓扑结构然后同步到其他节点,网络拓扑如下:(1)Network概览Network Name Network Type Network Attribute Network Mask Node Namesnet_ibp Ether public 255.255.255.0 xxMID_PRD,xxMID_BAK net_sna Ether public 255.255.255.0 xxMID_PRD,xxMID_BAK net_rs232_01 RS-232 serial N/A xxMID_PRD,xxMID_BAK (2)Network内部结构Network net_ibpService地址:ibp_svc 10.1.7.33Boot地址:ibp_boot2 172.16.101.1ibp_boot1 172.16.100.1Network sna_netService地址:sna_svc 172.16.120.3Boot地址:sna_boot 172.16.120.1Standby地址:sna_stb 172.16.121.1SNA的网络配置IP(可以使用私有地址,如172网段的任何地址,但两块网卡要在同一网段),只是为了能够互相切换,平时的IP地址不用。

HACMP配置环境:OS:Aix 6.1P740两台,每台机器两个物理网卡.共享存储:IBM V7000操作系统:AIX 6.1HACMP版本:HACMP 5.3一.IP地址规划1.节点nodeA启动ip地址(nodeA_boot): en0 192.168.10.11 netmask:255.255.255.0 备用ip地址(nodeA_sta): en1 192.168.20.11 netmask:255.255.255.0 服务ip地址(nodeA_svc): 192.168.30.11永久ip地址(nodeA_per): 192.168.40.112.节点nodeB启动ip地址(nodeB_boot): en0 192.168.10.12 netmask:255.255.255.0 备用ip地址(nodeB_sta): en1 192.168.20.12 netmask:255.255.255.0 服务ip地址(nodeB_svc): 192.168.30.12永久ip地址(nodeB_per): 192.168.40.12二.安装HACMP5.3文件集1.安装HACMP5.3要求的操作系统文件集:bos.databos.adt.libbos.adt.libmbos.adt.syscalls.tcp.client.tcp.serverbos.rte.SRCbos.rte.libcbos.rte.libcfgbos.rte.libpthreadsbos.rte.odmbos.rte.lvmbos.clvm.enh(IBM aix5.3系统默认没有安装)2.要求的RSCT文件集pat.basic.hacmp 2.4.2.0pat.clients.hacmp 2.4.2.0rsct.core.sec 2.4.2.1rsct.basic.sp.2.4.2.0三.安装HACMP5.31.插入hacmp5.3光盘,除以下文件集外全部安装:cluster.es.pluginscluster.hativolicluster.haviewrsct.exp2.安装完成后重启AIX系统,并查看相关进程#lssrc -g cluster#ps -ef|grep cl*四、网络配置nodeA地址配置:#ifconfig en0 192.168.10.11 netmask 255.255.255.0#ifconfig en1 192.168.20.11 netmask 255.255.255.0nodeB地址配置:#ifconfig en0 192.168.10.12 netmask 255.255.255.0#ifconfig en1 192.168.20.12 netmask 255.255.255.0五.编写/etc/hosts文件(nodeA 和nodeB上都需要做相同添加)192.168.10.11 nodeA_boot nodeA192.168.20.11 nodeA_sta192.168.30.11 nodeA_svc192.168.40.11 nodeA_per192.168.10.12 nodeB_boot nodeB192.168.20.12 nodeB_sta192.168.30.12 nodeB_svc192.168.40.12 nodeB_per注:nodeA 和nodeB上配置完ip地址并且修改完hosts文件后,两台主机可以互相ping下,检测两边是否连通.六.修改网络参数#no -p -o nonlocsrcroute=1#no -p -o ipsrcrouterec=1#no -p -o routerevalidate=1七.编写/usr/es/sbin/cluster/etc/rhosts 文件(nodeA和nodeB上都需要相同修改),建立信任关系.192.168.10.11 //(nodeA的启动ip)192.168.20.11 //(nodeA的备用ip)192.168.10.12 //(nodeB的启动ip)192.168.20.12 //(nodeB的备用ip)八.编写/usr/es/sbin/cluster/netmon.cf文件(nodeA 和nodeB上各添加自己的启动ip和备用ip)nodeA上添加:192.168.10.11192.168.20.11nodeB上添加:192.168.10.12192.168.20.12九.创建程序服务的脚本启动文件(nodeA 和nodeB 上都做相同操作)#touch /etc/hastart1.sh#touch /etc/hastop1.sh#chmod -R /etc/hast*.sh十.验证串口设备的通信,以便于串口设置做HACMP心跳线nodeA上:#lsdev -c tty#cat < /dev/tty0nodeB上:#lsdev -c tty#cat /etc/hosts >/dev/tty0反之,将nodeA上查看的hosts文件信息重定向输出到nodeB的终端上.十一.共享存储配置SSA在节点nodeA上,配置SSA存储的raid#smiity ssaraid----> add an ssa raid array选择要创建的raid的类型添加创建raid所需要的磁盘查看命令:#lsdev -c disk 查看SSA logical disk drive#lspv 查看是否出现一个新的磁盘在nodeB上使用cfgmgr命令扫描硬件然后使用lspv命令查看是否能看到与nodeA上一样的一块新磁盘,如果nodeA和nodeB上都出现一块相同的的物理磁盘则证明共享存储SSA配置成功十二.共享卷组配置在节点nodeA上,使用共享磁盘创建卷组,并指定卷组的major号(主设备号),使用lspv查看共享磁盘为hdisk2.#mkvg -V 60 -y oravg hdisk2#lsvg -orootvgoravg修改卷组oravg属性,开机不自动启动#chvg -an oravg在新的卷组oravg上创建逻辑卷#mklv -t jfs2 -y halv oravg 5G在新的逻辑卷halv上创建文件系统 /hafs#crfs -v jfs2 -d halv -m /hafs在节点nodeA 上varyoffvg卷组#varyoffvg oravg在节点nodeB上为扫描出来的新共享磁盘hdisk2添加PVID#chdev -l hdisk2 -a pv=yes在几点nodeB上导入卷组,同时指定卷组的major号与节点nodeA上卷组的major 号相同#importvg -y oravg -V 60 hdisk2#lsvg -l oravg在节点nodeB上修改卷组的属性,使开机不自动激活并关闭卷组#chvg -an oravg#varyoffvg oravg#lspv十三.添加集群(以下操作需要在卷组所在的主机上操作,本篇中为nodeB)添加集群cluster1#smittyhacmp——>initialization and standard configuration ——>add nodes to an HACMP cluster指定cluster名:cluster1:选择nodeA和nodeB的启动ip地址十四.添加服务ip地址标签添加节点nodeA上的服务ip地址nodeA_svc#smitty hacmp——>initialization andstandard configuration——>configure resources to make highly available——>configure service ip labels/addresses——>add a service ip label/address选择nodeA的服务ip地址(该位置指定以后真正使用的服务ip地址)十五.添加应用服务#smitty hacmp——>initialization and standardconfiguration——>configure resources to make highlyavailable——>configure application servers——>add an application server添加如下:server name:appserverstart script: /etc/hastart1.shstop script: /etc/hastop1.sh十六.添加资源组添加新的资源组rsg1,参与的节点为nodeA和nodeB,且nodeA在前,表示节点nodeA的优先级最高#smitty hacmp——>initialization and standardconfiguration——>configure HACMP resource Groups——>add a resource group指定资源组名:rsg1;选择节点nodeA nodeB(备注:nodeA在前优先级高)十七.更改资源组更改资源组rsg1,将资源(服务ip,应用服务,卷组)加入资源组中#smitty hacmp——>initialization and standardconfiguration——>configure hacmp resource groups——>change/show resources for a resource group选择nodeA_svc,appserver1,oravg等资源十八.添加永久IP地址添加节点nodeA的永久ip地址(节点NodeA)#smitty hacmp——>extended configuration——>extended topologyconfiguration——>configure hacmp persistent node iplabel/address——>add a persistent node ip label/address选择节点nodeA上的永久ip地址:nodeA_per添加节点nodeB的永久ip地址(节点NodeB)#smitty hacmp——>extended configuration——>extended topology configuration——>configure hacmp persistent node iplabel/address——>add a persistent node ip label/address选择节点nodeB上的永久ip地址:nodeB_per十九.添加串口心跳网络和网络设备添加串口网络和设备#smitty hacmp——>extended configuration——>extended topology configuration——>configure hacmp communicationinterfaces/devices——>add communication interface/devices按F7键选中nodeA nodeB的串口心跳网络设备:>nodeA tty0 /dev/tty0>nodeB tty0 /dev/tty0二十.显示HACMP配置显示HACMP配置#smittyhacmp——>initialization and standard configuration——>display HACMP configuration二十一.验证并同步HACMP配置(将在nodeA上做的集群配置同步到nodeB上) smitty hacmp——>initialization and standard configuration——>verify and synchronize HACMP configuration同步成功表示集群配置成功!查看永久ip地址,可以看到没有启动hacmp服务时永久nodeA和nodeB的永久ip已经存在.nodeA#ifconfig -anodeB#ifconfig -a二十二.启动HACMP服务启动节点nodeA和节点nodeB的集群服务#smitty hacmp——>system management(C-SPOC)——>manage hacmp services——>start cluster services二十三.查看集群当前状态启动完成后,查看集群当前状态#smitty hacmp——>problem determination tools——>view current state 二十四.测试集群的高可用性1.服务ip地址在网卡间的漂移(服务ip地址nodeA_svc在nodeA的en0网卡上) nodeA#ifconfig en0 down 模拟en0网卡宕掉nodeA#ifconfig -dl 查看关闭的网卡nodeA#ifconfig -a 查看服务ip地址是否转移漂移到en1上nodeA#ifconfig en1 down 模拟en1网卡也宕掉了看服务ip地址是否漂移到nodeB主机上面2.服务ip地址主机间漂移#假设服务ip地址当前在nodeB主机上,通过reboot命令重启nodeB主机服务ip会自动漂移到nodeA主机上,当nodeA主机重启时服务ip地址会自动漂移到nodeB主机上;nodeB主机正常的关机,开机操作服务ip地址不会发生漂移,资源组中默认的是级联的漂移方式优先级高的优先获得服务ip地址.。

IBM认证知识:HACMP集群规划IBM认证知识:HACMP集群规划集群规划也许是实现成功的配置过程中最重要的步骤。
HACMP 规划应该包括以下方面:硬件规划节点网络存储软件规划操作系统版本HACMP 版本应用程序兼容性测试和维护规划测试过程变更管理管理操作硬件规划实现高可用性配置的目标是通过消除单点故障(硬件、软件和网络),以及通过屏蔽服务中断(无论是计划内还是计划外的中断),从而提供高度可用的服务。
节点规划的决策因素包括:支持的.节点:计算机类型、功能、支持的适配器、电源(AC、DC、双电源与单电源等等)。
连接和电缆:电缆类型、长度、接头、型号、导线管布线、电缆槽容量需求,以及可用性。
节点配置HACMP V5.1 支持在一个集群中使用 IBM Eserver pSeries(独立和 LPAR 模式)、IBM SP 节点以及现有的 RS/6000 服务器的任何节点组合。
节点必须满足内部内存、内部磁盘、可用I/O 插槽数量和操作系统兼容性(AIX 版本)的最低要求。
要考虑的项包括:内部磁盘(磁盘数量、容量以及是否使用LVM 镜像)共享磁盘容量和存储数据保护方法(RAID 和 LVM 镜像)I/O 插槽限制及其对导致单点故障(SPOF) 的影响对集群的客户端访问(网络适配器)其他LAN 设备(交换机、路由器和网桥)I/O 适配器和子系统冗余电源冗余网络配置规划群集网络时的主要目标是评估所需的冗余程度,以消除网络组件成为单点故障的可能性。
应该考虑以下方面:网络:连接到多个物理网络的节点对于 TCP/IP 子系统故障:使用非 IP 网络以帮助决策过程网络接口:每个网络上的冗余网络适配器(以防止在单个网络接口发生故障情况下的资源组故障转移)在规划集群网络配置时,必须为节点连接选择正确的组合:集群网络拓扑(交换机、路由器等等)。
连接集群节点的IP 和非IP(点到点)网络组合和每个节点到所有网络的连接数量。


HACMP for AIX 原理、设计及实现联想集成系统有限公司目录前言__________________________________________________________________ 3 第一章HACMP的概念和原理 ______________________________________________ 4 §1.1 HACMP简介_____________________________________________________________ 5 §1.2 HACMP中术语的定义______________________________________________________ 6 §1.3 HACMP群集的硬件组成____________________________________________________ 7 §1.4 AIX与HACMP __________________________________________________________ 10 §1.5 HACMP群集的软件结构____________________________________________________ 11 §1.6 HACMP群集资源________________________________________________________ 12 §1.7 建立高可用系统――避免单点故障 __________________________________________ 15 第二章HACMP群集的设计 _______________________________________________ 21 §2.1 高可用性设计要点 ________________________________________________________ 21 §2.2 存储系统设计 ____________________________________________________________ 21 §2.3 LVM组件设计____________________________________________________________ 30 §2.4 HACMP for AIX的网络设计________________________________________________ 31 §2.5 群集结构的设计 __________________________________________________________ 36 §2.6 应用的设计 ______________________________________________________________ 42 第三章HACMP群集的实现 _______________________________________________ 43 §3.1 准备AIX ________________________________________________________________ 44 §3.2 安装HACMP ____________________________________________________________ 51 §3.3 配置HACMP ____________________________________________________________ 52 第四章HACMP群集的管理 _______________________________________________ 57 §4.1 群集的启动 ______________________________________________________________ 57 §4.2 群集的停止 ______________________________________________________________ 58 §4.3 群集的监视 ______________________________________________________________ 59 §4.4 群集的测试 ______________________________________________________________ 60 附录A HACMP和数据库 _________________________________________________ 61 附录B HACMP与同类产品的比较 _________________________________________ 64前言传统概念里,关键性任务的计算一直是大型主机的专有领域。
高可靠性集群系统软件HACMP高可用性群集多处理(HACMP)是一种可以将RS/6000 服务器连接起来的高可用的群集的应用。
群集服务器支持并行数据访问,能够帮助提供冗余和容错恢复能力,完全满足关键性商务应用的需求。
HACMP 包含基于图形用户界面的工具,可以帮助您以一种极为高效的方式对群集进行安装、配置和管理。
HACMP 的配置和使用十分灵活。
单处理器和对称多处理器(SMP)都可以加入到具有高可用性的群集之中。
您可以将不同规模、性能水平、网络结构和磁盘阵列的系统混合在一起,以满足各种应用、网络和磁盘性能的需求。
HACMP 群集可以配置为多种模式,以满足不同类型的处理需求。
并发访问模式比较适合的环境是所有的处理器必须工作于同一工作负荷并共享数据;互为备份模式是处理器共享工作负荷并相互备份;热备份模式允许一个节点备份群集中任何其它的节点。
无论您选择哪种模式,HACMP 都将提供数据访问和备份计划,以帮助您优化应用程序的执行和扩展性,同时帮助您避免代价高昂的系统故障和停机时间。
HACMP 同样支持服务器针对应用恢复/重启进行配置,以便为关键性的商务应用提供保护。
HACMP/ES 和RS/6000 群集技术总体系统故障时间中有很大一部分是由计划内的故障时间引起的。
HACMP 可以通过以并行方式执行硬件、软件和其它维护活动,使计划内的故障时间最小化,与此同时应用程序依然持续运作于其它节点上。
服务可能会从某一群集节点上转移至另一个节点,当维护活动完成后再转回该节点。
计划外的故障时间可能是由如下两方面原因之一造成的:硬件或软件。
结合由AIX 操作系统提供的各种实用工具,HACMP 可以通过将服务从一个故障节点自动转移到另一个群集节点,来保护您的系统运作不受硬件故障的影响。
引起节点故障的软件故障可检测到。
但是对于那些中断系统运作、但不引起系统故障或挂起的软件故障而言,则需要使用RS/6000 群集技术(RSCT)所代表的更进一步的可用性技术,该项技术由HACMP/ES 特性提供。
H A C M PHigh Availability Cluster Multi – Processing前言现代企业的应用和数据都储存在计算机中,由计算机来处理,一旦计算机系统发生意外故障,而引起应用停止甚至重要数据丢失,必将造成巨大损失,因此企业计算对高可用性和可靠性的要求非常高。
IBM RS / 6000 系列通过AIX操作系统的支持,利用HACMP 实现了多种功能的高可用群集多处理方案。
为高可用性计算提供了一个完美的解决方案。
目录一: HACMP 的基本概念二: HACMP 的规划1 :群集节点2 :群集网络3 :群集磁盘4 :资源规划5 :应用规划6 :用户 ID 规划三: HACMP 的安装与配置1 :HACMP 的安装2 :群集的配置( 1 )定义群集拓扑结构( 2 )定义群集资源四: HACMP 的测试五: HACMP 的管理一:HACMP的基本概念 :IBM的高可靠性群集系统软件HACMP-- High Availability Cluster Multi-Processing提供了RS/6000平台上关键应用的高可靠性解决方案,该软件能使一个群集内的所有的RS/6000系统不存在单点失效( 在群集中单独某一部分出现故障而引起对用户端的服务失效 ) 。
HACMP系统能自动地检测系统硬件失效,重新配置群集系统,使得所有的资源完全不受系统硬件失效的影响 ,从而提供了可靠的应用平台。
HACMP可用来最多将32部RS/6000服务器或SP的节点连结成高可用性的群集结构。
对于企业关键性的应用程序而言,群集式的服务器或节点提供代理式的数据访问,具备复制性(redundancy),使得系统应用程序具有灵活的容错能力。
HACMP所具有灵活的结构和简单的使用。
从单一处理机(SMP)主机到SP节点皆可结构成高可用性之群集,您可混用,且跨越系统大小及性能等级,将各种网络适配卡和磁盘子系统融合在一起确 ,来满足您的应用程序、网络等方面的需求。
HACMP双机配置指导书本文介绍HA CMP双机的配置。
1.1 概述在启动短消息系统之前,需要对双机系统进行配置,IBM-pSeries的双机控制软件称之为HACMP。
HACMP双机软件的配置过程分为两部分,分别为HA CMP基本配置(Cluster配置)和HACMP应用定制配置。
配置过程如下:在启动双机系统HA CMP之前,需要对两个独立的主机进行配置,以构成一个完整的双机系统,这些配置工作都将通过IBM的HACMP双机软件工具来完成,称为Cluster配置。
在Cluster配置正确完成之后,就可以结合具体的短消息系统对HACMP进行定制配置,也就是进行应用的监管配置,将短消息系统置于HACMP双机系统的监控管理之下。
说明:以下配置操作以root用户进行,每个步骤完成,可使用Esc+3 / F3 回退到上一步,使用Esc+4/F4进行配置项值列表选择,使用Esc+0/F10退出smitty 配置环境,Enter确认配置参数。
1.2 双机规划方案1.2.1以下为中山短消息系统的双机规划实例,供参考!表1-1Network Adapter Worksheet表1-2Share IP Address用户/组规划1.2.2 修改配置文件根据以上网络规划,修改相应的配置文件:1、以root用户修改主备小型机上/etc/security/limits文件:# cd /etc/security;切换到目录:/etc/security.# vi limits ;修改配置文件limits。
在文件中增加或修改root用户的参数如下:smc:fsize = -1core = 409600cpu = -1data = -1rss = -1stack =-1nofiles = 20002、修改hosts文件127.0.0.1 loopback localhost # loopback (lo0) name/address# zs_smc_smc1172.10.14.31 zs_smc_smc1_boot zs_smc_smc1192.168.14.31 zs_smc_smc1_stb zs_smc_smc1# zs_smc_smc2172.10.14.33 zs_smc_smc2_boot zs_smc_smc2192.168.14.33 zs_smc_smc2_stb zs_smc_smc2# service_ip172.10.14.30 service_ip#fix ip172.10.114.31 zs_smc_smc1172.10.114.33 zs_smc_smc2.rhosts文件zs_smc_smc1zs_smc_smc1_bootzs_smc_smc1_stbzs_smc_smc2zs_smc_smc2_bootzs_smc_smc2_stbservice_ip1.3 配置前提1.3.1 检查双机上正确安装了HACMP软件检查双机两台机器上是否都安装了HA CMP软件,详细安装步骤见附录二。
3.1.网络配置群集之间节点通过群集通讯网络进行通讯。
如果一个网络上的一个节点的一块网卡失效,群集会通过该节点的另一块网卡进行通讯。
如果节点连接失败,HACMP会将该节点拥有的资源传送给其他可用节点。
附加的,HACMP(通过RSCT拓扑服务的)在节点之间使用心跳信息来检查群集节点的可用性和群集节点通讯接口的可用性。
如果HACMP检测到一个节点没有心跳,该节点就被认为已经失效,它的资源就会自动传送至其他可用节点。
推荐配置群集节点之间的多条通讯路径,这样能防止群集分割。
在分割的群集中的危险在于,不同分割区的群集节点会不经过协调同时访问一个数据,这会造成数据破坏。
3.1.1.网络类型这里我们讨论下列网络类型:物理的和逻辑的网络一个物理的网络连接两个或更多的物理网络接口。
有很多种物理网络,HACMP将其分为两种:➢基于IP的网络,如以太网、令牌环➢基于设备的网络,如RS-232、SSA标记模式在HACMP中,一组逻辑网络中的接口可以直接和其他网络接口通讯,HACMP给每个逻辑网络一个名称(如net_ether_01)。
HACMP中的一个逻辑网络可以包含一或多个子网,RSCT管理每个逻辑子网中的心跳包。
全局网络多个HACMP网络组成一个全局网络。
HACMP网络是一些不同物理网络和/或逻辑网络的集合,这些网络共享一个冲突域,例如,以太网。
HACMP将这种组合的全局网络视为网络一个网络。
RSCT处理全局网络内部路由。
3.1.2.TCP/IP网络HACMP支持的基于IP的网络有:➢ether(以太网)➢atm(异步传输模式-ATM)➢fddi(光纤分布式数据接口-FDDI)➢hps(SP交换)➢token(令牌环)HACMP通过RSCT拓扑服务监视这些网络。
通过IP别名的心跳在HACMP中,你可以配置通过IP别名控制心跳。
在以前的HACMP版本中心跳只能通过服务/非服务IP地址/标签(基本或引导IP地址/标签)来进行交换。
IBM HACMP 系列-- 安装和配置一规划是成功的实现的一半,就 HACMP 而言,如何强调正确规划的重要性都不过分。
如果规划做得不正确,您可能会在以后某个时候发现自己陷入种种限制之中,而要摆脱这些限制可能是非常痛苦的经历。
因此,请保持镇定从容,并使用产品附带的规划工作表;这些工作表对于任何迁移或问题确定情形或者对于为规划做文档记录都是非常有价值的。
一. HACMP 软件安装HACMP 软件提供了一系列可用于使应用程序高度可用的功能。
务必记住,并非所有的系统或应用程序组件都受到 HACMP 的保护。
例如,如果某个关键应用程序的所有数据都驻留在单个磁盘上,并且该磁盘发生了故障,则该磁盘就成了整个集群的单点故障,并且未受到 HACMP 的保护。
在此情况下,必须使用 AIX 逻辑卷管理器或存储子系统保护功能。
HACMP 仅在备份节点上提供磁盘接管,以使数据可继续使用。
这就是 HACMP 规划是如此重要的原因,因为整个规划过程中的主要目标是消除单点故障。
当关键集群功能由单个组件提供时,就存在单点故障。
如果该组件发生故障,集群没有提供该功能的其他途径,依赖该组件的应用程序或服务就会变得不可用。
还要记住,规划良好的集群非常容易安装,可提供更高的应用程序可用性,能够按预期执行,并且比规划不当的集群需要更少的维护。
1.1 检查先决条件在完成规划工作表以后,请验证您的系统是否满足 HACMP 所必需的要求;执行这项额外的工作可以消除许多潜在的错误。
HACMP V5.1 需要下列操作系统组件之一:(1)带 RSCT V2.2.1.30 或更高版本的 AIX 5L V5.1 ML5。
(2)带 RSCT V2.3.1.0 或更高版本(建议使用 2.3.1.1)的 AIX 5L V5.2 ML2。
(3)C-SPOC vpath 支持(需要 SDD 1.3.1.3 或更高版本)。
有关先决条件和 APAR 的最新信息,请参考产品附带的自述文件和以下 IBM 网站:/server/cluster/1.2 全新安装HACMP 支持网络安装管理(Network Installation Management,NIM)程序,包括“备选磁盘迁移”(Alternate Disk Migration) 选项。
第一部分--规划篇万事开头难,对于一个有经验的HACMP工程师来说,会深知规划的重要性,一个错误或混乱的规划将直接导致实施的失败和不可维护性。
HACMP实施的根本目的不是安装测试通过,而是在今后运行的某个时刻突然故障中,能顺利的发生自动切换或处理,使得服务只是短暂中断即可自动恢复,使高可用性成为现实。
2.1.规划前的需求调研在做规划之前,或者说一个准备实施HACMP来保证高可用性的系统初步设计之前,至少需要调查了解系统的以下相关情况,这些都可能影响到HACMP的配置。
应用特点1)对负荷的需求,如CPU、内存、网络等特别是I/O的负载的侧重。
2)对起停的要求,如数据库重起可能需要应用重起等等。
3)对于自动化的限制,如重起需要人工判断或得到命令,需要在控制台执行。
网络状况和规划包括网段的划分、路由、网络设备的冗余等等在系统上线前的状况和可提供条件,以及实施运行过程中可能出现的变更。
操作系统情况目前IBM的HACMP除了AIX,还支持Linux。
目前新装机器都是AIX5.3,即使安装HA5.4也没有问题。
但如果安装可能是在老机器上进行升级,需要仔细了解操作系统版本及补丁情况。
主机设计1)可能实施的机器网卡的数量,网卡是否只能是双口或更多。
2)是否有槽位增加异步卡3)主机之间的距离,这影响到串口线的长度。
预计实施高可用性的情况1)希望实施HACMP的机器数量2)希望方式,如一备一,双机互备,一备多,环形互备等等。
2.2.PowerHA/HACMP版本确定IBM HACMP 自从出了5.2 版本后,到了5.205后比较稳定,并经过我们自己充分的测试(见测试篇)和实践证明(已有多个系统成功自动切换)。
之前个人觉得HACMP5.3后变化较快快,功能增加多,稳定性不够,相当长时间还是一直推荐HA5.209。
这也是本文出了第一版完全手册之后一直没有修订的原因之一。
随着Power主机和AIX的更新换代,名称也在变化,虽然目前最新版为PowerHA SystemMirror7.1, 又增加了不少绚丽夺目的功能,但个人以为作为高可用性软件,其成熟度为第一要素,其稳定性有待进一步验证。
而经过我们这2年来的充分实施经验,目前可以放心推荐版本为PowerHA 6.1的6.1.10及以上。
2.3.IP地址设计IP地址切换(IPAT)方式有3种方式:图1a,1b,和1c中描述了三个主要的IPAT配置场景。
◆第一个拓扑模式:IPAT via Replacement在分开的子网中包含boot 和standby网卡。
当集群服务启动的时候boot 地址被换成service 地址。
尽管这种方式有效性强,但是在需要实现多服务IP地址的环境下这种方式是不可取的。
集群的管理员不得不利用pre-和post-events 定制其环境建立额外的别名,并且需要确认这些别名在下一次接管发生前被删除。
IPAT via Replacement示意图◆第二个拓扑模式:IPAT via AliasingHACMP 4.5 开始引入了IPAT via Aliasing 作为缺省的拓扑模式。
在这种新的模式中,standby网卡的功能被另外一个boot网卡替换。
子网需求的不同点是还需要一个另外的子网,每一个boot 网卡需要它自己的子网,并且任何service 或persistent 的IP 将在其本身的子网上操作,所以一共三个子网。
当集群服务启动并且需要service IP 的时候,boot IP 并不消失。
这个设计和第一种是不同的,在同一个HACMP网络中有多个service IP存在并且通过别名来控制。
IPAT via Aliasing示意图第三种模式:EthernetChannel(EC)这种模式把底层的以太网卡藏到一个单一的“ent”接口之后。
该模式不是对前述任何一种方式的替换,而是可以和前述的任一种模式共同存在。
因为在每一个节点EC 都被配置成冗余方式,可以在HACMP中使用IP别名定义它们每一个作为单一网卡网络。
因为在每个节点只有一个网卡被定义,所以只有两个子网,一个是用作boot(每个节点的基本IP地址),另一个是用于提供高可用服务。
IPAT via EthernetChannel示意图本文讨论实际工作中使用最多的为第2种:别名方式(IPAT via Aliasing),即使到今天,其使用仍然最为广泛,对交换机要求也最低。
对于新型核心交换机和网络人员可紧密配合的,则推荐第3种,由于第3种更为简单,切换时间更短。
但本文这里以第2种为主加以讨论。
这样设计时就需要注意以下事情:1.网段设计:一个服务地址需要3个网段对应,boot地址网段不能和服务地址一致。
避免网络变更造成的系统不可用,boot地址的网段不要和实际其他系统的网段一致。
在网段比较紧张的地方,建议设计时询问网络人员。
举例来说,下面的地址将会由于网络变更后打通合一后可能造成冲突:设计人机器名服务地址boot1地址boot2地址张三app1_db10.66.1.110.10.1.110.10.1.1张三app1_app1李四app2_db10.66.2.110.66.3.110.66.1.1李四app2_app1王五app3_db10.66.3.110.66.1.110.66.2.1王五app3_app12.boot地址的设计:不要和实际其他同网段机器的boot地址冲突,最好不同网段。
即这个规划不能只考虑系统本身,还需要从同网段的高度考虑。
举例来说,下面的地址由于2个系统分开设计,同时开启将直接导致2个系统不可用。
boot地址的设计表1设计人机器名服务地址boot1地址boot2地址张三app1_db10.66.3.110.10.1.110.10.1.1张三app1_app1李四app2_db10.66.3.111李四app2_app11所以在设计时,我们建议boot地址的IP地址最后一段参照服务地址,这样虽然可记忆性不是很好,但即使设计在同一网段,也可以避免上述错误发生。
更改设计如下:boot地址的设计表2设计人机器名服务地址boot1地址boot2地址张三app1_db10.66.3.110.10.1.110.10.1.1张三app1_app1李四app2_db10.66.3.111李四app2_app11此外,如果是每个网卡多个网口,记得设计时必须注意同一网络的boot地址要分开到2块网卡,以保证真正的冗余。
2.4.心跳设计配置HACMP的过程中,除了TCP/IP网络之外,您也可以在其它形式的网络上,如串行网络和磁盘总线上配置心跳网络。
1.TCP/IP网络优点:要求低,不需要任何额外硬件或软件,即可实现。
缺点:占用IP地址,不能避免由于TCP/IP的软件问题导致HACMP崩溃,系统不可用。
2.串口网络优点:真正实现高可用性,不占用IP地址。
缺点:需要硬件支持,需要新增异步卡,而中低端的机器的插槽有限。
3.磁盘心跳优点:不占用插槽,磁盘总线上的心跳网络能够在TCP/IP网络资源有限的情况下提供额外的HACMP节点间的通信手段,并且能够防止HACMP节点之间由于TCP/IP软件出现问题而无法相互通信。
缺点:需要操作系统和存储支持,如使用增强型卷组,此外对于I/O读写负荷高的应用,也需要慎用。
正如IBM红皮书所说,条件许可的情况下,强烈推荐使用串口网络,其次是磁盘心跳。
不过我们也注意到HACMP7.1将不再支持串口心跳,而改为其他如SAN方式,效果有待进一步观察。
2.5.资源组设计对于HACMP来讲,服务IP地址和磁盘VG、文件系统、应用服务器都是资源,如何规划需要根据实际情况来,包括以下内容:资源组的数量即资源:一般情况下每台机器只要建立一个资源组即可,包括服务IP地址、应用服务器及VG。
现在不推荐具体确定VG里的文件系统,这是因为确定后,有可能造成有些新增文件系统不在HACMP的控制范围,结果是HACMP切换时由于这些文件系统没有unmount掉而导致切换失败。
资源组的策略:分failover(故障切换)和fallback(回切)等。
一般选缺省,当然你可以根据具体情况修正,如oracle 10g RAC的并发VG资源组的选择就不一样。
2.5.1.磁盘及VG设计虽然实际上HACMP是靠PVID来认磁盘的,但集群的机器上磁盘顺序不一,磁盘对应不一致会造成某种混乱。
以致于安装配置和维护时很容易产生各种人为错误,所以我们强烈建议机器上看到的磁盘和VG名称都一一对应,此外VG 的MajorNumber也需要预先设计规划,以免不一致。
同时新的AIX6.1已很好提供了修改hdisk号的rendev 命令,以前这样的烦恼也就迎刃而解了。
2.5.2.用户及组设计HA要求所有切换需要用到的用户必须所有节点对应,ID完全相同,用户运行的环境变量完全相同,即当系统切换时,对使用该用户的程序用户即组设置没有区别的。
如某系统的host2上oracle用户为orarun,host1上的orarun必须为切换保留,ID均为209,host1上平时用的oracle用户就设为orarunc。
2.5.3.逻辑卷和文件系统设计HACMP要求切换相关的文件系统和lv不能重名,如host2上oracle软件目录为/ora11run,host1上的/ora11run必须为切换保留,改为/ora11runc。
此外,集群下相关的文件系统和lv,在各个节点主机的定义也需要一致,如/etc/filesystems里是一致的,这个通过importvg或HACMP的C-SPOC 来保证。
2.5.4.路由设计对于有通信需求的主机,很可能对路由有一定要求,如本次实验环境,就有2个网段走的不是缺省路由,需要设计清楚,最后在起停脚本实现。
2.5.5.应用脚本设计我们这里说的应用,是包括数据库在内除OS和HACMP之外的所有程序,对于应用程序的起停顺序和各种要求,都需要预先和应用人员加以沟通,并预先设计伪码,最终编写脚本实现。