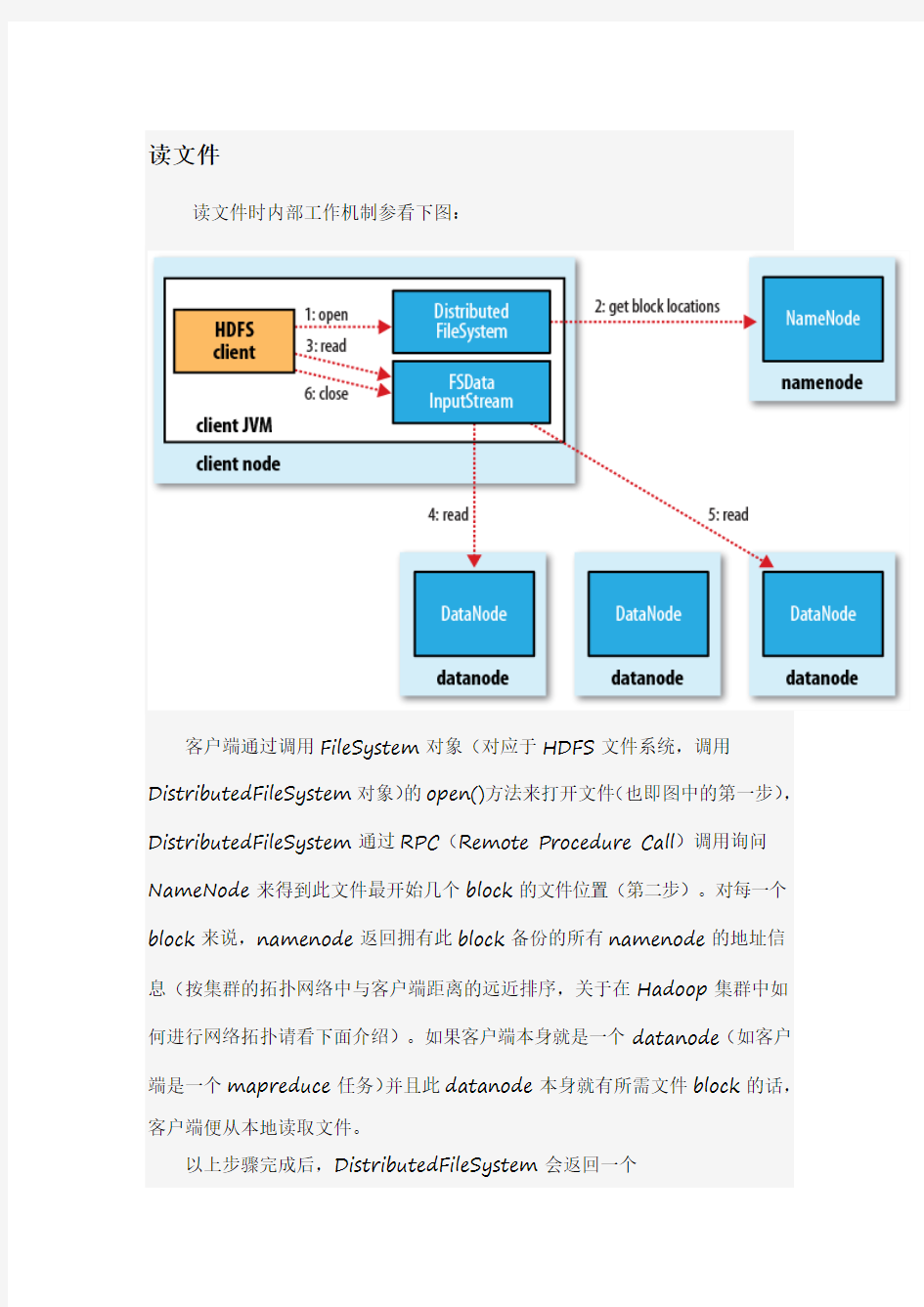

读文件
读文件时内部工作机制参看下图:
客户端通过调用FileSystem对象(对应于HDFS文件系统,调用DistributedFileSystem对象)的open()方法来打开文件(也即图中的第一步),DistributedFileSystem通过RPC(Remote Procedure Call)调用询问NameNode来得到此文件最开始几个block的文件位置(第二步)。对每一个block来说,namenode返回拥有此block备份的所有namenode的地址信息(按集群的拓扑网络中与客户端距离的远近排序,关于在Hadoop集群中如何进行网络拓扑请看下面介绍)。如果客户端本身就是一个datanode(如客户端是一个mapreduce任务)并且此datanode本身就有所需文件block的话,客户端便从本地读取文件。
以上步骤完成后,DistributedFileSystem会返回一个
FSDataInputStream(支持文件seek),客户端可以从FSDataInputStream 中读取数据。FSDataInputStream包装了一个DFSInputSteam类,用来处理namenode和datanode的I/O操作。
客户端然后执行read()方法(第三步),DFSInputStream(已经存储了欲读取文件的开始几个block的位置信息)连接到第一个datanode(也即最近的datanode)来获取数据。通过重复调用read()方法(第四、第五步),文件内的数据就被流式的送到了客户端。当读到该block的末尾时,DFSInputStream就会关闭指向该block的流,转而找到下一个block的位置信息然后重复调用read()方法继续对该block的流式读取。这些过程对于用户来说都是透明的,在用户看来这就是不间断的流式读取整个文件。
当真个文件读取完毕时,客户端调用FSDataInputSteam中的close()方法关闭文件输入流(第六步)。
如果在读某个block是DFSInputStream检测到错误,DFSInputSteam 就会连接下一个datanode以获取此block的其他备份,同时他会记录下以前检测到的坏掉的datanode以免以后再无用的重复读取该datanode。DFSInputSteam也会检查从datanode读取来的数据的校验和,如果发现有数据损坏,它会把坏掉的block报告给namenode同时重新读取其他datanode上的其他block备份。
这种设计模式的一个好处是,文件读取是遍布这个集群的datanode的,namenode只是提供文件block的位置信息,这些信息所需的带宽是很少的,这样便有效的避免了单点瓶颈问题从而可以更大的扩充集群的规模。Hadoop中的网络拓扑
在Hadoop集群中如何衡量两个节点的远近呢?要知道,在高速处理数据时,数据处理速率的唯一
限制因素就是数据在不同节点间的传输速度:这是由带宽的可怕匮乏引起的。所以我们把带宽作为衡量两个节点距离大小的标准。
但是计算两个节点之间的带宽是比较复杂的,而且它需要在一个静态的集群下才能衡量,但Hadoop
集群一般是随着数据处理的规模动态变化的(且两两节点直接相连的连接数是节点数的平方)。于是Hadoop使用了一个简单的方法来衡量距离,它把集群内的网络表示成一个树结构,两个节点之间的
距离就是他们离共同祖先节点的距离之和。树一般按数据中心(datacenter),机架(rack),计算节点(datanode)的结构组织。计算节点上的本地运算速度最快,跨数据中心的计算速度最慢(现在跨数据中心的Hadoop集群用的还很少,一般都是在一个数据中心内做运算的)。
假如有个计算节点n1处在数据中心c1的机架r1上,它可以表示为/c1/r1/n1,下面是不同情况
下两个节点的距离:
? distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node)
? distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the same rack)
? distance(/d1/r1/n1, /d1/r2/n3) = 4 (nodes on different racks in the same data
center)
? distance(/d1/r1/n1, /d2/r3/n4) = 6 (nodes in different data centers)
如下图所示:
写文件
现在我们来看一下Hadoop中的写文件机制解析,通过写文件机制我们可以更好的了解一下Hadoop中的一致性模型。
上图为我们展示了一个创建一个新文件并向其中写数据的例子。
首先客户端通过DistributedFileSystem上的create()方法指明一个欲创建的文件的文件名(第一步),DistributedFileSystem再通过RPC调用向NameNode申请创建一个新文件(第二步,这时该文件还没有分配相应的block)。namenode检查是否有同名文件存在以及用户是否有相应的创建权限,如果检查通过,namenode会为该文件创建一个新的记录,否则的话文件创建失败,客户端得到一个IOException异常。DistributedFileSystem返回一个FSDataOutputStream以供客户端写入数据,与FSDataInputStream类似,FSDataOutputStream封装了一个DFSOutputStream用于处理namenode与datanode之间的通信。
当客户端开始写数据时(第三步),DFSOutputStream把写入的数据分成包(packet), 放入一个中间队列——数据队列(data queue)中去。DataStreamer从数据队列中取数据,同时向namenode申请一个新的block 来存放它已经取得的数据。namenode选择一系列合适的datanode(个数由文件的replica数决定)构成一个管道线(pipeline),这里我们假设replica 为3,所以管道线中就有三个datanode。DataSteamer把数据流式的写入到管道线中的第一个datanode中(第四步),第一个datanode再把接收到的数据转到第二个datanode中(第四步),以此类推。
DFSOutputStream同时也维护着另一个中间队列——确认队列(ack queue),确认队列中的包只有在得到管道线中所有的datanode的确认以后才会被移出确认队列(第五步)。
如果某个datanode在写数据的时候当掉了,下面这些对用户透明的步骤会被执行:
1)管道线关闭,所有确认队列上的数据会被挪到数据队列的首部重新发送,这样可以确保管道线中当掉的datanode下流的datanode不会因为当掉的datanode而丢失数据包。
2)在还在正常运行的datanode上的当前block上做一个标志,这样当当掉的datanode重新启动以后namenode就会知道该datanode上哪个block是刚才当机时残留下的局部损坏block,从而可以把它删掉。
3)已经当掉的datanode从管道线中被移除,未写完的block的其他数据继续被写入到其他两个还在正常运行的datanode中去,namenode知道这个block还处在under-replicated状态(也即备份数不足的状态)下,然后他会安排一个新的replica从而达到要求的备份数,后续的block写入方法同前面正常时候一样。
有可能管道线中的多个datanode当掉(虽然不太经常发生),但只要dfs.replication.min(默认为1)个replica被创建,我们就认为该创建成功了。剩余的replica会在以后异步创建以达到指定的replica数。
当客户端完成写数据后,它会调用close()方法(第六步)。这个操作会冲洗(flush)所有剩下的package到pipeline中,等待这些package确认成功,然后通知namenode写入文件成功(第七步)。这时候namenode就知道该文件由哪些block组成(因为DataStreamer向namenode请求分配新block,namenode当然会知道它分配过哪些blcok给给定文件),它会等待最少的replica数被创建,然后成功返回。
replica是如何分布的
Hadoop在创建新文件时是如何选择block的位置的呢,综合来说,要考虑以下因素:带宽(包括写带宽和读带宽)和数据安全性。如果我们把三个备份全部放在一个datanode上,虽然可以避免了写带宽的消耗,但几乎没有提供数据冗余带来的安全性,因为如果这个datanode当机,那么这个文件的所有数据就全部丢失了。另一个极端情况是,如果把三个冗余备份全部放在不同的机架,甚至数据中心里面,虽然这样数据会安全,但写数据会消耗很多的带宽。Hadoop 0.17.0给我们提供了一个默认replica分配策略(Hadoop 1.X以后允许replica策略是可插拔的,也就是你可以自己制定自己需要的replica分配策略)。replica的默认分配策略是把第一个备份放在与客户端相同的datanode上(如果客户端在集群外运行,就随机选取一个datanode来存放第一个replica),第二个replica放在与第一个replica不同机架的一个随机datanode上,第三个replica放在与第二个replica相同机架的随机datanode上。如果replica数大于三,则随后的replica在集群中随机存放,Hadoop会尽量避免过多的replica存放在同一个机架上。选取replica的放置位置后,管道线的网络拓扑结构如下所示:
总体来说,上述默认的replica分配策略给了我们很好的可用性(blocks放置在两个rack上,较为安全),写带宽优化(写数据只需要跨越一个rack),读带宽优化(你可以从两个机架中选择较近
的一个读取)。
一致性模型
HDFS某些地方为了性能可能会不符合POSIX(是的,你没有看错,POSIX 不仅仅只适用于linux/unix,Hadoop 使用了POSIX的设计来实现对文件系统文件流的读取),所以它看起来可能与你所期望的不同,要注意。
创建了一个文件以后,它是可以在命名空间(namespace)中可以看到的:Path p = new Path("p");
fs.create(p);
assertThat(fs.exists(p), is(true));
但是任何向此文件中写入的数据并不能保证是可见的,即使你flush了已经写入的数据,此文件的长度可能仍然为零:
Path p = new Path("p");
OutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.flush();
assertThat(fs.getFileStatus(p).getLen(), is(0L));
这是因为,在Hadoop中,只有满一个block数据量的数据被写入文件后,此文件中的内容才是可见的(即这些数据会被写入到硬盘中去),所以当前正在写的block中的内容总是不可见的。
Hadoop提供了一种强制使buffer中的内容冲洗到datanode的方法,那就是FSDataOutputStream的sync()方法。调用了sync()方法后,Hadoop 保证所有已经被写入的数据都被冲洗到了管道线中的datanode中,并且对所有读者都可见了:
Path p = new Path("p");
FSDataOutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.flush();
out.sync();
assertThat(fs.getFileStatus(p).getLen(), is(((long) "content".length())));
这个方法就像POSIX中的fsync系统调用(它冲洗给定文件描述符中的所有缓冲数据到磁盘中)。例如,使用java API写一个本地文件,我们可以保证在调用flush()和同步化后可以看到已写入的内容:
FileOutputStream out = new FileOutputStream(localFile);
out.write("content".getBytes("UTF-8"));
out.flush(); // flush to operating system
out.getFD().sync(); // sync to disk(getFD()返回与该流所对应的文件描述符)
assertThat(localFile.length(), is(((long) "content".length())));
在HDFS中关闭一个流隐式的调用了sync()方法:
Path p = new Path("p");
OutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.close();
assertThat(fs.getFileStatus(p).getLen(), is(((long) "content".length())));
由于Hadoop中的一致性模型限制,如果我们不调用sync()方法的话,我们很可能会丢失多大一个block的数据。这是难以接受的,所以我们应该使用
sync()方法来确保数据已经写入磁盘。但频繁调用sync()方法也是不好的,因为会造成很多额外开销。我们可以再写入一定量数据后调用sync()方法一次,
至于这个具体的数据量大小就要根据你的应用程序而定了,在不影响你的应用程序的性能的情况下,这个数据量应越大越好。
转载请注明出处:
https://www.doczj.com/doc/fa15907532.html,/beanmoon/archive/2012/12/17/28215
48.html
基于Hadoop的研究及性能分析 摘要 在大数据到来的今天,本文首先介绍了Hadoop及其核心技术MapReduce的工作原理。详细讨论了Hadoop推测执行算法和SALS 推测执行算法并对它们的性能进行分析。最后,分析了MapReduce 框架的通用二路连接算法 RSJ。为了提高性能,提出了一种基于DistributedCache 的改进算法,通过减少 mapper 输出的数据来达到优化的目的。 关键字:Hadoop MapReduce 性能算法
Abstract:In the era of big data, this paper introduces Hadoop, MapReduce and its core technology works.I have discussed the Hadoop speculative execution algorithms and SALS speculative execution algorithm and analyzed their performance.Finally, I analyzed the Common Road Join Algorithm in MapReduce framework.To improve performance, I propose an improved algorithm based DistributedCache by reducing the mapper output data to achieve optimization purposes. Key words:Hadoop; MapReduce; Performance;Algorithm
https://www.doczj.com/doc/fa15907532.html, 大数据培训学习心得体会_光环大数据 来光环大数据学习大数据已经有一段时间了,这段时间感触颇多,下面我就我在大数据培训学习心得体会做个简单的分享。大数据(big data)也成为海量数据、海量资料。在面对海量数据资料时,我们无法透过主流的软件工具在合理的时间内进行管理、处理并整理成为对需求者有价值的信息时,就涉及到了我们现在所学的大数据技术。大数据的特点目前已经从之前的4V升级到了5V,即Volume(大量)、Velocity (速率)、Variety(多样性)、Veracity (真实)、Value(价值)。进一步可以理解为大数据具有数据体量巨大、处理速度快、数据种类繁多、数据来源真实可靠、价值巨大等特性。目前大数据所用的数据记录单位为PB(2的50次方)和EB(2的60次方),甚至到了ZB(2的70次方)。数据正在爆炸式的增长,急需一批大数据人才进行处理、挖掘、分析。大数据的一个重大价值就在于大数据的预测价值。如经济指数预测、经典预测、疾病预测、城市预测、赛事预测、高考预测、电影票房预测等。在光环大数据培训班学习期间,我感受到了光环大数据良好的学习氛围和先进的教学方式。几乎是零基础入学的我,从Java编程开始学起,目前已经进入了大数据的入门课程阶段。光环大数据的课程安排十分合理,不同科目的讲师风格各异,授课方式十分有趣,教学内容都可以轻松记下来。光环大数据还安排了充足的自习时间,让我们充分消化知识点,全程都有讲师、助教陪同,有疑问随时就可以得到解答,让我的学习特别高效。阶段性的测试让我能够充分认识到自己的学习漏洞,讲师也会根据我们测试反映的情况对课程进行调整。光环大数据还专门设置了大数据实验室,我们每天学习时均使用了真实的大数据环境,让我们真正体会到了大数据之美。在光环大数据的大数据学习时间还要持续3个月左右,我会及时分享我在光环大数据的大数据培训学习心得体会,为想要学习大数据的同学提供帮助。 为什么大家选择光环大数据! 大数据培训、人工智能培训、培训、大数据培训机构、大数据培训班、数据
基于hadoop的大规模文本处理技术实验专业班级:软件1102 学生姓名:张国宇 学号: Setup Hadoop on Ubuntu 11.04 64-bit 提示:前面的putty软件安装省略;直接进入JDK的安装。 1. Install Sun JDK<安装JDK> 由于Sun JDK在ubuntu的软件中心中无法找到,我们必须使用外部的PPA。打开终端并且运行以下命令: sudo add-apt-repository ppa:ferramroberto/java sudo apt-get update sudo apt-get install sun-java6-bin sudo apt-get install sun-java6-jdk Add JAVA_HOME variable<配置环境变量>: 先输入粘贴下面文字: sudo vi /etc/environment 再将下面的文字输入进去:按i键添加,esc键退出,X保存退出;如下图: export JAVA_HOME="/usr/lib/jvm/java-6-sun-1.6.0.26" Test the success of installation in Terminal<在终端测试安装是否成功>: sudo . /etc/environment
java –version 2. Check SSH Setting<检查ssh的设置> ssh localhost 如果出现“connection refused”,你最好重新安装 ssh(如下命令可以安装): sudo apt-get install openssh-server openssh-client 如果你没有通行证ssh到主机,执行下面的命令: ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 3. Setup Hadoop<安装hadoop> 安装 apache2 sudo apt-get install apache2 下载hadoop: 1.0.4 解压hadoop所下载的文件包: tar xvfz hadoop-1.0.4.tar.gz 下载最近的一个稳定版本,解压。编辑/ hadoop-env.sh定义java_home “use/library/java-6-sun-1.6.0.26”作为hadoop的根目录: Sudo vi conf/hadoop-env.sh 将以下内容加到文件最后: # The java implementation to use. Required. export JAVA_HOME=/usr/lib/jvm/java-6-sun-1.6.0.26
HADOOP表操作 1、hadoop简单说明 hadoop 数据库中的数据是以文件方式存存储。一个数据表即是一个数据文件。hadoop目前仅在LINUX 的环境下面运行。使用hadoop数据库的语法即hive语法。(可百度hive语法学习) 通过s_crt连接到主机。 使用SCRT连接到主机,输入hive命令,进行hadoop数据库操作。 2、使用hive 进行HADOOP数据库操作
3、hadoop数据库几个基本命令 show datebases; 查看数据库内容; 注意:hadoop用的hive语法用“;”结束,代表一个命令输入完成。 usezb_dim; show tables;
4、在hadoop数据库上面建表; a1: 了解hadoop的数据类型 int 整型; bigint 整型,与int 的区别是长度在于int; int,bigint 相当于oralce的number型,但是不带小数点。 doubble 相当于oracle的numbe型,可带小数点; string 相当于oralce的varchar2(),但是不用带长度; a2: 建表,由于hadoop的数据是以文件有形式存放,所以需要指定分隔符。 create table zb_dim.dim_bi_test_yu3(id bigint,test1 string,test2 string)
row format delimited fields terminated by '\t' stored as textfile; --这里指定'\t'为分隔符 a2.1 查看建表结构: describe A2.2 往表里面插入数据。 由于hadoop的数据是以文件存在,所以插入数据要先生成一个数据文件,然后使用SFTP将数据文件导入表中。
Hadoop云计算实验报告
Hadoop云计算实验报告 1实验目的 在虚拟机Ubuntu上安装Hadoop单机模式和集群; 编写一个用Hadoop处理数据的程序,在单机和集群上运行程序。 2实验环境 虚拟机:VMware 9 操作系统:ubuntu-12.04-server-x64(服务器版),ubuntu-14.10-desktop-amd64(桌面版)Hadoop版本:hadoop 1.2.1 Jdk版本:jdk-7u80-linux-x64 Eclipse版本:eclipse-jee-luna-SR2-linux-gtk-x86_64 Hadoop集群:一台namenode主机master,一台datanode主机salve, master主机IP为10.5.110.223,slave主机IP为10.5.110.207。 3实验设计说明 3.1主要设计思路 在ubuntu操作系统下,安装必要软件和环境搭建,使用eclipse编写程序代码。实现大数据的统计。本次实验是统计软件代理系统操作人员处理的信息量,即每个操作人员出现的次数。程序设计完成后,在集成环境下运行该程序并查看结果。 3.2算法设计 该算法首先将输入文件都包含进来,然后交由map程序处理,map程序将输入读入后切出其中的用户名,并标记它的数目为1,形成
学习云计算的心得体会 说实话,刚接触这门课,我对《云计算》的认识比较狭隘,只是知道它是一种商业服务计算技术和存储技术,对其他不甚了解。但是通过十几周的不断深入学习,我从跟班上改变对《云计算》的认识。可能作为一名非计算机网络专业学员,我还没有能力在短短十几周内学会弄懂教员所传授的Vmware云计算和Hadoop使用,并进行编程计算。但是我深刻认识到这不仅是一门高科技技术知识课程,更是我军在未来军事战场上的杀手锏。 一、云计算的正确理解。 通过学习,我知道云计算是在xx年诞生的新词。虽然它产生的较晚。但并不能掩盖它的火热程度。仅仅过了半年多,受到关注程度就超过网格计算,而且关注度至今一直高居不下。 云计算普遍认为是一种商业计算模型。它将计算任务分布在大量计算机构成的资源池上,使用能够按需获取计算存储空间和信息服务。 这里所说的“云”不是我们通常所理解的云。它 是一些可以自我维护和管理的虚拟计算资源。通常是一些大型服务器集群,包括计算服务器、存储服务器和宽带资源等。 从研究现状上看,云计算有以下特点。 1、超大规模。“云”具有相当的规模。它需要有几十万台服务器同时工作。因此它能赋予用户前所未有的计算能力。
2、虚拟化。云计算支持用户在任意位置使用各种终端获取服务。随着我国信息技术产业突飞猛进,3G技术不断发展,越来越多人通过各种通信电子产品使用云计算服务。例如我们平时使用3G手机上网淘宝或用云存储将自己手机上的资源备份到网盘上等等。 3、高可靠性。“云”使用了数据多副本容错。计算节点同构可互换等措施来保障服务的高可靠性,使用云计算比使用本地计算机更加可靠。 4、通用性。云计算不针对特定的应用。云计算应用非常广泛,可以涵盖整个网络计算,它并不拘泥于某一项功能而是围绕3G、4G 等新型高速运算网络展开的多功能多领域的应用。 5、高可伸缩性。“云”的规模可以动态伸缩。这一点与传统固态存储有本质区别。因为传统存储介质有存储容量限制而“云计算”它的边界是模糊的。它 能满足应用和用户规模增长的需要,使用户不必因为空间不够而烦恼。 6、按需服务。“云”是一个庞大的资源池,用户按需购买。例如有人喜欢听歌、看电影,有人喜欢看财经消息,我们都能按自己的意愿去获取相关消息资源。 7、极其廉价。云计算有更低的硬件和网络成本,更低的管理成本和电力成本,以及更高的资源利用率,两个乘起来就能够将成本节省30倍以上,因此云计算是划时代的技术。作为我国经济发展现状来说,既要保持GDP增长速度有必须最大限度节约能源消耗。解决好
Hadoop 集群基本操作命令 列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help (注:一般手动安装hadoop大数据平台,只需要创建一个用户即可,所有的操作命令就可以在这个用户下执行;现在是使用ambari安装的dadoop大数据平台,安装过程中会自动创建hadoop生态系统组件的用户,那么就可以到相应的用户下操作了,当然也可以在root用户下执行。下面的图就是执行的结果,只是hadoop shell 支持的所有命令,详细命令解说在下面,因为太多,我没有粘贴。) 显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name (注:可能有些命令,不知道什么意思,那么可以通过上面的命令查看该命令的详细使用信息。例子: 这里我用的是hdfs用户。) 注:上面的两个命令就可以帮助查找所有的haodoop命令和该命令的详细使用资料。
创建一个名为 /daxiong 的目录 $ bin/hadoop dfs -mkdir /daxiong 查看名为 /daxiong/myfile.txt 的文件内容$ bin/hadoop dfs -cat /hadoop dfs -cat /user/haha/part-m-00000 上图看到的是我上传上去的一张表,我只截了一部分图。 注:hadoop fs <..> 命令等同于hadoop dfs <..> 命令(hdfs fs/dfs)显示Datanode列表 $ bin/hadoop dfsadmin -report
$ bin/hadoop dfsadmin -help 命令能列出所有当前支持的命令。比如: -report:报告HDFS的基本统计信息。 注:有些信息也可以在NameNode Web服务首页看到 运行HDFS文件系统检查工具(fsck tools) 用法:hadoop fsck [GENERIC_OPTIONS]
大数据心得体会 早在2007年,人类制造的信息量有史以来第一次在理论上超过可用存储空间总量,近几年两者的剪刀差越来越大。2010年,全球数字规模首次达到了“ZB”(1ZB=1024TB)级别。2012年,淘宝网每天在线商品数超过8亿件。2013年底,中国手机网民超过6亿户。随着互联网、移动互联网、传感器、物联网、社交网站、云计算等的兴起,我们这个社会的几乎所有方面都已数字化,产生了大量新型、实时的数据。无疑,我们已身处在大数据的海洋。 有两个重要的趋势使得目前的这个时代(大数据时代)与之前有显著的差别:其一,社会生活的广泛数字化,其产生数据的规模、复杂性及速度都已远远超过此前的任何时代;其二,人类的数据分析技术和工艺使得各机构、组织和企业能够以从前无法达到的复杂度、速度和精准度从庞杂的数据中获得史无前例的洞察力和预见性。 大数据是技术进步的产物,而其中的关键是云技术的进步。在云技术中,虚拟化技术乃最基本、最核心的组成部份。计算虚拟化、存储虚拟化和网络虚拟化技术,使得大数据在数据存储、挖掘、分析和应用分享等方面不仅在技术上可行,在经济上也可接受。 在人类文明史上,人类一直执着探索我们处的世界以及人类自身,一直试图测量、计量这个世界以及人类自身,试图找到隐藏其中的深刻关联、运行规律及终极答案。大数据以其人类史上从未有过的庞大容量、极大的复杂性、快速的生产及经济可得性,使人类第一次试图从总体而非样本,从混杂性而非精确性,从相关关系而非因果关系来测量、计量我们这个世界。人类的思维方式、行为方式及社会生活的诸多形态(当然包括商业活动)正在开始发生新的变化。或许是一场革命性、颠覆性的变化。从这个意义上讲,大数据不仅是一场技术运动,更是一次哲学创新。 1 大数据的概述 1.1 大数据的概念 大数据(Big Data)是指那些超过传统数据库系统处理能力的数据。它的数据规模和转输速度要求很高,或者其结构不适合原本的数据库系统。为了获取大数据中的价值,我们必须选择另一种方式来处理它。
Hadoop命令大全 Hadoop配置: Hadoop配置文件core-site.xml应增加如下配置,否则可能重启后发生Hadoop 命名节点文件丢失问题:
1、列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help 2、显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name 3、用户可使用以下命令在指定路径下查看历史日志汇总 $ bin/hadoop job -history output-dir 这条命令会显示作业的细节信息,失败和终止的任务细节。 4、关于作业的更多细节,比如成功的任务,以及对每个任务的所做的尝试次数等可以用下面的命令查看 $ bin/hadoop job -history all output-dir 5、格式化一个新的分布式文件系统: $ bin/hadoop namenode -format 6、在分配的NameNode上,运行下面的命令启动HDFS: $ bin/start-dfs.sh bin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。 7、在分配的JobTracker上,运行下面的命令启动Map/Reduce: $ bin/start-mapred.sh bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves 文件的内容,在所有列出的slave上启动TaskTracker守护进程。 8、在分配的NameNode上,执行下面的命令停止HDFS: $ bin/stop-dfs.sh bin/stop-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止DataNode守护进程。 9、在分配的JobTracker上,运行下面的命令停止Map/Reduce: $ bin/stop-mapred.sh bin/stop-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止TaskTracker守护进程。 10、启动所有 $ bin/start-all.sh 11、关闭所有 $ bin/stop-all.sh DFSShell 10、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 11、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 12、查看名为 /foodir/myfile.txt 的文件内容 $ bin/hadoop dfs -cat /foodir/myfile.txt
学习《云计算》心得体会 说实话,刚接触这门课,我对《云计算》的认识比较狭隘,只是知道它是一种商业服务计算技术和存储技术,对其他不甚了解。但是通过十几周的不断深入学习,我从跟班上改变对《云计算》的认识。可能作为一名非计算机网络专业学员,我还没有能力在短短十几周内学会弄懂教员所传授的Vmware云计算和Hadoop使用,并进行编程计算。但是我深刻认识到这不仅是一门高科技技术知识课程,更是我军在未来军事战场上的杀手锏。 一、云计算的正确理解。 通过学习,我知道云计算是在2007年诞生的新词。虽然它产生的较晚。但并不能掩盖它的火热程度。仅仅过了半年多,受到关注程度就超过网格计算,而且关注度至今一直高居不下。 云计算普遍认为是一种商业计算模型。它将计算任务分布在大量计算机构成的资源池上,使用能够按需获取计算存储空间和信息服务。 这里所说的“云”不是我们通常所理解的云。它
是一些可以自我维护和管理的虚拟计算资源。通常是一些大型服务器集群,包括计算服务器、存储服务器和宽带资源等。 从研究现状上看,云计算有以下特点。 1、超大规模。“云”具有相当的规模。它需要有几十万台服务器同时工作。因此它能赋予用户前所未有的计算能力。 2、虚拟化。云计算支持用户在任意位置使用各种终端获取服务。随着我国信息技术产业突飞猛进,3G 技术不断发展,越来越多人通过各种通信电子产品使用云计算服务。例如我们平时使用3G手机上网淘宝或用云存储将自己手机上的资源备份到网盘上等等。 3、高可靠性。“云”使用了数据多副本容错。计算节点同构可互换等措施来保障服务的高可靠性,使用云计算比使用本地计算机更加可靠。 4、通用性。云计算不针对特定的应用。云计算应用非常广泛,可以涵盖整个网络计算,它并不拘泥于某一项功能而是围绕3G、4G等新型高速运算网络展开的多功能多领域的应用。 5、高可伸缩性。“云”的规模可以动态伸缩。这一点与传统固态存储有本质区别。因为传统存储介质有存储容量限制而“云计算”它的边界是模糊的。它
Hadoop测试题 一.填空题,1分(41空),2分(42空)共125分 1.(每空1分) datanode 负责HDFS数据存储。 2.(每空1分)HDFS中的block默认保存 3 份。 3.(每空1分)ResourceManager 程序通常与NameNode 在一个节点启动。 4.(每空1分)hadoop运行的模式有:单机模式、伪分布模式、完全分布式。 5.(每空1分)Hadoop集群搭建中常用的4个配置文件为:core-site.xml 、hdfs-site.xml 、mapred-site.xml 、yarn-site.xml 。 6.(每空2分)HDFS将要存储的大文件进行分割,分割后存放在既定的存储块 中,并通过预先设定的优化处理,模式对存储的数据进行预处理,从而解决了大文件储存与计算的需求。 7.(每空2分)一个HDFS集群包括两大部分,即namenode 与datanode 。一般来说,一 个集群中会有一个namenode 和多个datanode 共同工作。 8.(每空2分) namenode 是集群的主服务器,主要是用于对HDFS中所有的文件及内容 数据进行维护,并不断读取记录集群中datanode 主机情况与工作状态,并通过读取与写入镜像日志文件的方式进行存储。 9.(每空2分) datanode 在HDFS集群中担任任务具体执行角色,是集群的工作节点。文 件被分成若干个相同大小的数据块,分别存储在若干个datanode 上,datanode 会定期向集群内namenode 发送自己的运行状态与存储内容,并根据namnode 发送的指令进行工作。 10.(每空2分) namenode 负责接受客户端发送过来的信息,然后将文件存储位置信息发 送给client ,由client 直接与datanode 进行联系,从而进行部分文件的运算与操作。 11.(每空1分) block 是HDFS的基本存储单元,默认大小是128M 。 12.(每空1分)HDFS还可以对已经存储的Block进行多副本备份,将每个Block至少复制到 3 个相互独立的硬件上,这样可以快速恢复损坏的数据。 13.(每空2分)当客户端的读取操作发生错误的时候,客户端会向namenode 报告错误,并 请求namenode 排除错误的datanode 后,重新根据距离排序,从而获得一个新的的读取路径。如果所有的datanode 都报告读取失败,那么整个任务就读取失败。14.(每空2分)对于写出操作过程中出现的问题,FSDataOutputStream 并不会立即关闭。 客户端向Namenode报告错误信息,并直接向提供备份的datanode 中写入数据。备份datanode 被升级为首选datanode ,并在其余2个datanode 中备份复制数据。 NameNode对错误的DataNode进行标记以便后续对其进行处理。 15.(每空1分)格式化HDFS系统的命令为:hdfs namenode –format 。 16.(每空1分)启动hdfs的shell脚本为:start-dfs.sh 。 17.(每空1分)启动yarn的shell脚本为:start-yarn.sh 。 18.(每空1分)停止hdfs的shell脚本为:stop-dfs.sh 。 19.(每空1分)hadoop创建多级目录(如:/a/b/c)的命令为:hadoop fs –mkdir –p /a/b/c 。 20.(每空1分)hadoop显示根目录命令为:hadoop fs –lsr 。 21.(每空1分)hadoop包含的四大模块分别是:Hadoop common 、HDFS 、
学习云计算的心得体会 【篇一:学习心得-云计算】 学习心得 云计算是分布式处理、并行处理、和网格计算的发展,可以或许说 是这些计算机科学观念的贸易实现。即把存储于个人电脑、移动电 话和此外装备上的多量动静和处理器本钱齐集在一起,协同工作。 在极大范畴上可扩展的动静妙技才干向外部客户作为任事来供应的 一种计算法子。云计算分为广义云计算和广义云计算。广义云计算 是指 it 基础装备的寄予和使用模式,经过网络以按需、易扩展的法 子失去所需的本钱。 广义云计算是指任事的寄予和使用模式,指通过网络以按需、易扩 展的法子失去所需的任事。这种任事可以是 it 和软件、互联网关连的,也能够使任意此外的任事。云有三种类型:公有云、公有云和 异化云。(1)公有云是指云计算任事供应商经过过自己的基础装 备直接向多个内部用户供应任事,内部用户经过互联网访问任事, 并不领有云计算本钱。本色是成本高贵,存在范畴经济效益。数据 安然问题,任事品质易受内部网络品质影响。(2)公有云是企业 内部创建的专有云计算机细碎,仅为企业内部使用,安排在企业数 据焦点的防火墙内或安然的主机托管场合,并能对其数据、安然性 和任事品质发展无效地管制。本色是数据安然,任事品质高不受内 部网络影响,进步基础装备垄断率,初始创建成本较高,管理成本高。(3)异化云则是同时供应公有和公有任事的云计算细碎,它是介于公有云和公有云之间的一种折中管理。比如企业的关头贸易 数据动静寄存在公有云中,垄断公有云来发展数据运算处理。云存 储就比方是一个机器的硬盘存储空间有限,而所重要存储的数据较多,我们可以决意将多个机器的硬盘连在一起,重要添加存储空间 时再添加机器就可。为了防范由于某台机器装备阻碍而导致数据丧失,我们可以将一份文件拷贝到多台机器上备份。具体应用如:网 络硬盘、网络视频监控、网络游戏、搜索引擎、邮件存储等。与古 板的存储装备对比,云存储不仅仅是一个硬件,而是一个网络装备、存储装备、任事器、应用软件、公用访问接口、接中计、和客户端 步调等多个一部分形成的烦复细碎。 云主机是新一代的主机租用任事,它整合了高效率任事器与优良网 络带宽,无效规画了古板主机租用代价偏高、任事品错落不齐等害
基于Hadoop平台的并行数据挖掘算法工具 箱与数据挖掘云 来源:南京大学计算机科学与技术系作者:高阳,杨育彬,商琳时间:2011-06-27 浏览次数:60 一基于云计算的海量数据挖掘 2008年7 月,《Communications of the ACM》杂志发表了关于云计算的专辑,云计算因其清晰的商业模式而受到广泛关注,并得到工业和学术界的普遍认可。目前工业界推出的云计算平台有Amazon公司的EC2和S3,Google公司的Google Apps Engine, IBM公司的Blue Cloud,Microsoft公司的Windows Azure, Salesforce公司的Sales Force, VMware公司的vCloud,Apache软件开源组织的Hadoop等。在国内,IBM与无锡市共建了云计算中心,中石化集团成功应用IBM的云计算方案建立起一个企业云计算平台。阿里巴巴集团于2009年初在南京建立电子商务云计算中心。 严格的讲,云计算是一种新颖的商业计算模型,它可以将计算任务分布在大量互连的计算机上,使各种应用系统能够根据需要获取计算资源、存储资源和其他服务资源。Google公司的云平台是最具代表性的云计算技术之一,包括四个方面的主要技术:Google文件系统GFS、并行计算模型MapReduce、结构化数据表BigTable和分布式的锁管理Chubby。基于以上技术,云计算可以为海量数据处理和分析提供一种高效的计算平台。简单来说,将海量数据分解为相同大小、分布存储,然后采用MapReduce模型进行并行化编程,这种技术使Google公司在搜索引擎应用中得到了极大的成功。 然而MapReduce计算模型适合结构一致的海量数据,且要求计算简单。对于大量的数据密集型应用(如数据挖掘任务),往往涉及到数据降维、程序迭代、
Hadoop面试题目及答案(附目录) 选择题 1.下面哪个程序负责HDFS 数据存储。 a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker 答案C datanode 2. HDfS 中的block 默认保存几份? a)3 份b)2 份c)1 份d)不确定 答案A 默认3 份 3.下列哪个程序通常与NameNode 在一个节点启动? a)SecondaryNameNode b)DataNode c)TaskTracker d)Jobtracker 答案D 分析:hadoop 的集群是基于master/slave 模式,namenode 和jobtracker 属于master,datanode 和tasktracker 属于slave,master 只有一个,而slave 有多个SecondaryNameNode 内存需求和NameNode 在一个数量级上,所以通常secondaryNameNode(运行在单独的物理机器上)和NameNode 运行在不同的机器上。 JobTracker 和TaskTracker JobTracker 对应于NameNode,TaskTracker 对应于DataNode,DataNode 和NameNode 是针对数据存放来而言的,JobTracker 和TaskTracker 是对于MapReduce 执行而言的。mapreduce 中几个主要概念,mapreduce 整体上可以分为这么几条执行线索:jobclient,JobTracker 与TaskTracker。 1、JobClient 会在用户端通过JobClient 类将应用已经配置参数打包成jar 文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker 创建每一个Task(即MapTask 和ReduceTask)并将它们分发到各个TaskTracker 服务中去执行。 2、JobTracker 是一个master 服务,软件启动之后JobTracker 接收Job,负责调度Job 的每一个子任务task 运行于TaskTracker 上,并监控它们,如果发现有失败的task 就重新运行它。一般情况应该把JobTracker 部署在单独的机器上。 3、TaskTracker 是运行在多个节点上的slaver 服务。TaskTracker 主动与JobTracker 通信,接收作业,并负责直接执行每一个任务。TaskTracker 都需要运行在HDFS 的DataNode 上。 4. Hadoop 作者 a)Martin Fowler b)Kent Beck c)Doug cutting 答案C Doug cutting 5. HDFS 默认Block Size a)32MB b)64MB c)128MB 答案:B 6. 下列哪项通常是集群的最主要瓶颈 a)CPU b)网络c)磁盘IO d)内存 答案:C 磁盘 首先集群的目的是为了节省成本,用廉价的pc 机,取代小型机及大型机。小型机和大型机
对大数据的心得体会 早在XX 年,人类制造的信息量有史以来第一次在理论上超过可用存储空间总量,近几年两者的剪刀差越来越大。 XX年,全球数字规模首次达到了“ ZB”级别。XX年,淘宝网每天在线商品数超过8亿件。XX年底,中国手机网民超过6 亿户。随着互联网、移动互联网、传感器、物联网、社交网站、云计算等的兴起,我们这个社会的几乎所有方面都已数字化,产生了大量新型、实时的数据。无疑,我们已身处在大数据的海洋。有两个重要的趋势使得目前的这个时代与之前有显著的差别:其一,社会生活的广泛数字化,其产生数据的规模、复杂性及速度都已远远超过此前的任何时代;其二,人类的数据分析技术和工艺使得各机构、组织和企业能够以从前无法达到的复杂度、速度和精准度从庞杂的数据中获得史无前例的洞察力和预见性。 大数据是技术进步的产物,而其中的关键是云技术的进步。在云技术中,虚拟化技术乃最基本、最核心的组成部份。计算虚拟化、存储虚拟化和网络虚拟化技术,使得大数据在数据存储、挖掘、分析和应用分享等方面不仅在技术上可行,在经济上也可接受。 在人类文明史上,人类一直执着探索我们处的世界以及人类自身,一直试图测量、计量这个世界以及人类自身,试图找到隐藏其中的深刻关联、运行规律及终极答案。大数据以其人类史上从未有过的庞大容量、极大的复杂性、快速的生产及经济可得性,使人类第一次试图从总体而非样本,从混杂性而非精确性,从相关关系而非因果关系来测
量、计量我们这个世界。人类的思维方式、行为方式及社会生活的诸多形态正在开始发生新的变化。或许是一场革命性、颠覆性的变化。从这个意义上讲,大数据不仅是一场技术运动,更是一次哲学创新。 1 大数据的概述 大数据的概念 大数据是指那些超过传统数据库系统处理能力的数据。它的数据规模和转输速度要求很高,或者其结构不适合原本的数据库系统。为了获取大数据中的价值,我们必须选择另一种方式来处理它。 数据中隐藏着有价值的模式和信息,在以往需要相当的时间和成本才能提取这些信息。如沃尔玛或谷歌这类领先企业都要付高昂的代价才能从大数据中挖掘信息。而当今的各种资源,如硬件、云架构和开源软件使得大数据的处理更为方便和廉价。即使是在车库中创业的公司也可以用较低的价格租用云服务时间了。 对于企业组织来讲,大数据的价值体现在两个方面:分析使用和二次开发。对大数据进行分析能揭示隐藏其中的信息,例如零售业中对门店销售、地理和社会信息的分析能提升对客户的理解。对大数据的二次开发则是那些成功的网络公司的长项。例如Facebook 通过结合大量用户信息,定制出高度个性化的用户体验,并创造出一种新的广告模式。这种通过大数据创造出新产品和服务的商业行为并非巧合,谷歌、雅虎、亚马逊和Facebook,它们都是大数据时代的创新者。 大数据的三层关系
基于Hadoop 平台的海量数据高效抽取方法及应用 徐金玲1,金 璐1,李昆明2,熊 政2,仲春林2,方 超2 (1.江苏省南京供电公司,江苏南京,210008;2.江苏方天电力技术有限公司,江苏南京,211102) 摘要:本文从数据抽取过程的本质出发,论述了传统数据抽取过程与大数据平台数据抽取过程的异同,以基于Hadoop 的大数据平台为例,结合传统的关系型数据库和非关系型数据库(NoSQL)的特点,提出了一种从关系型数据库到大数据平台的高效数据抽取方法,实现了对数据源系统资源占用的最小化,并在电力公司用电大数据抽取中得到广泛应用。关键词:海量数据;数据抽取;NoSQL;大数据平台 Method and application of efficient extraction of mass data based on Hadoop platform Xu Jinling 1,Jin Lu 1,Li Kunming 2,Xiong Zheng 2,Zhong Chunlin 2,Fang Chao 2 (1.Jiangsu Nanjing power supply company,Jiangsu Nanjing,210008;2.Jiangsu Fangtian Power Technology Co. Ltd.,Jiangsu Nanjing,211102) Abstract :This article from the essence of data extraction process,discusses the similarities and differences between traditional data extraction process and the data platform,data extraction process, the data platform based on Hadoop as an example,combining the traditional relational database and non relational database(NoSQL)characteristics,proposes a from relational database to efficient data extraction method of data platform,thereby minimizing the occupancy of the data source of the system resources, and the power companies in large data extraction has been widely applied in. Keywords :data;data extraction;NoSQL;data platform 0 引言 对于大数据的抽取,一般通过使用Sqoop 来实现。但是Sqoop 组件自身的局限性导致其对于特定的场景并不适用(例如,进行TB 级大数据量数据抽取时效率较低,进行增量数据抽取需改变源数据库表结构,对源数据库性能也有较大影响)。因此,本文提出了基于大数据平台的一种海量数据抽取的高效方法,该方法可以快速、高效、可靠地将海量数据从关系型数据库抽取到大数据平台中。同时,由于通过对数据源日志文件的分析实现对增量数据的抽取,因此该方法在抽取数据时对源数据库的影响非常小。 1 系统开发环境 系统开发环境采用CentOS 6.5操作系统,以Cloudera CDH 5.0为大数据平台框架,并结合Tomcat 作为Web Server。集群由20台服务器组成,划分为2个机架,每台服务器配置32核CPU、64GB 内存和10块磁盘。Cloudera 是全球领先的Hadoop 服务提供商,其CDH 5.0是最新的Hadoop 发行版,提供了高度的稳 定性和使用便捷性。数据源采用Oracle 数据库,抽取工具采用Golden Gate。 2 系统结构和处理流程 2.1 技术架构 系统以Oracle 为数据源,以CDH 5.0为大数据平台框架,结合Tomcat 作为Web Server 提供Web 层的访问服务。在大数据平台中,以MapReduce 作为大数据的计算引擎,以HDFS 分布式文件系统存储非结构化和半结构化的数据,以HBase 分布式数据库存 图1. 系统技术架构