题目:
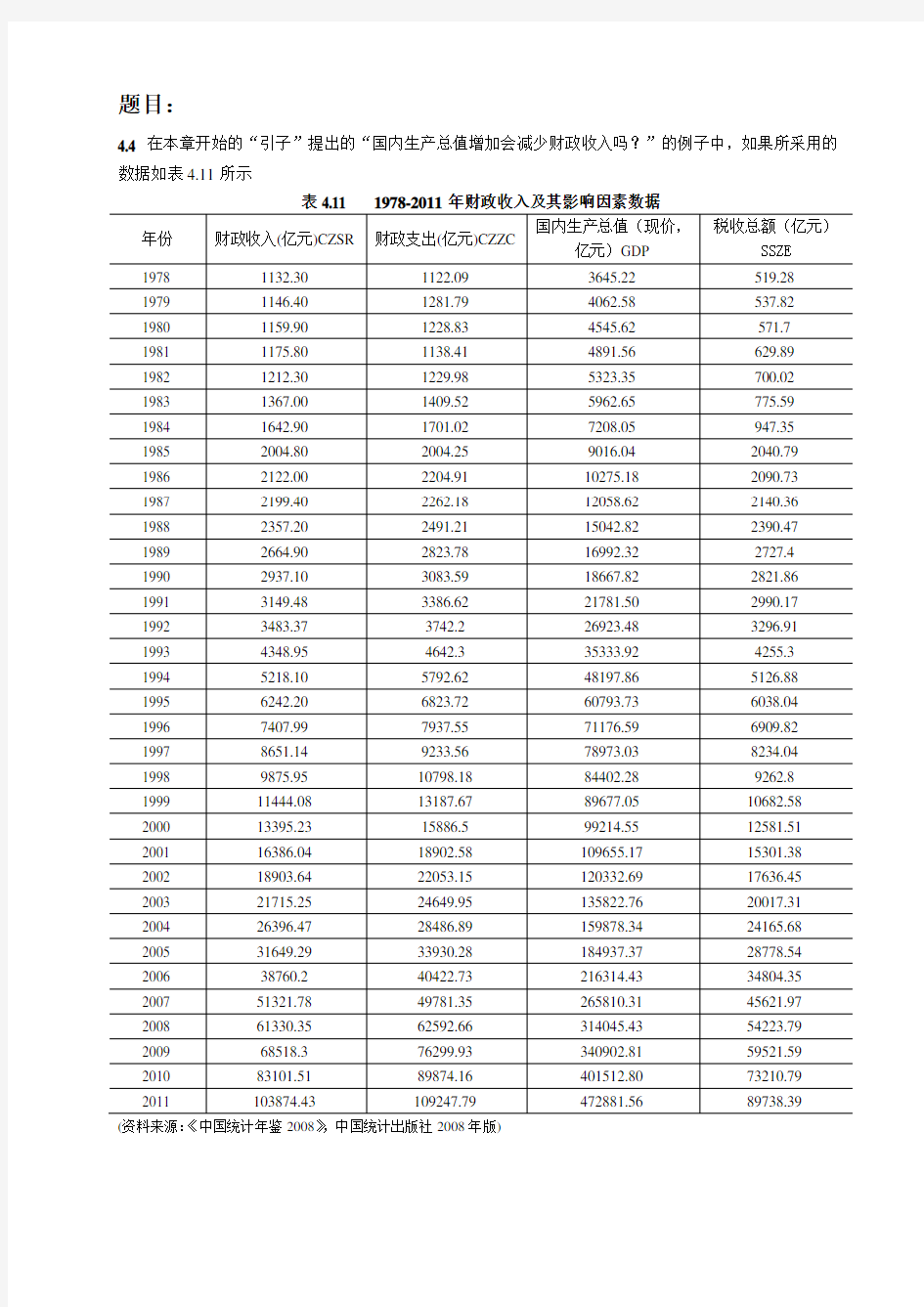
4.4 在本章开始的“引子”提出的“国内生产总值增加会减少财政收入吗?”的例子中,如果所采用的数据如表4.11所示
表4.11 1978-2011年财政收入及其影响因素数据
(资料来源:《中国统计年鉴2008》,中国统计出版社2008年版)
一、 模型设定及其估计
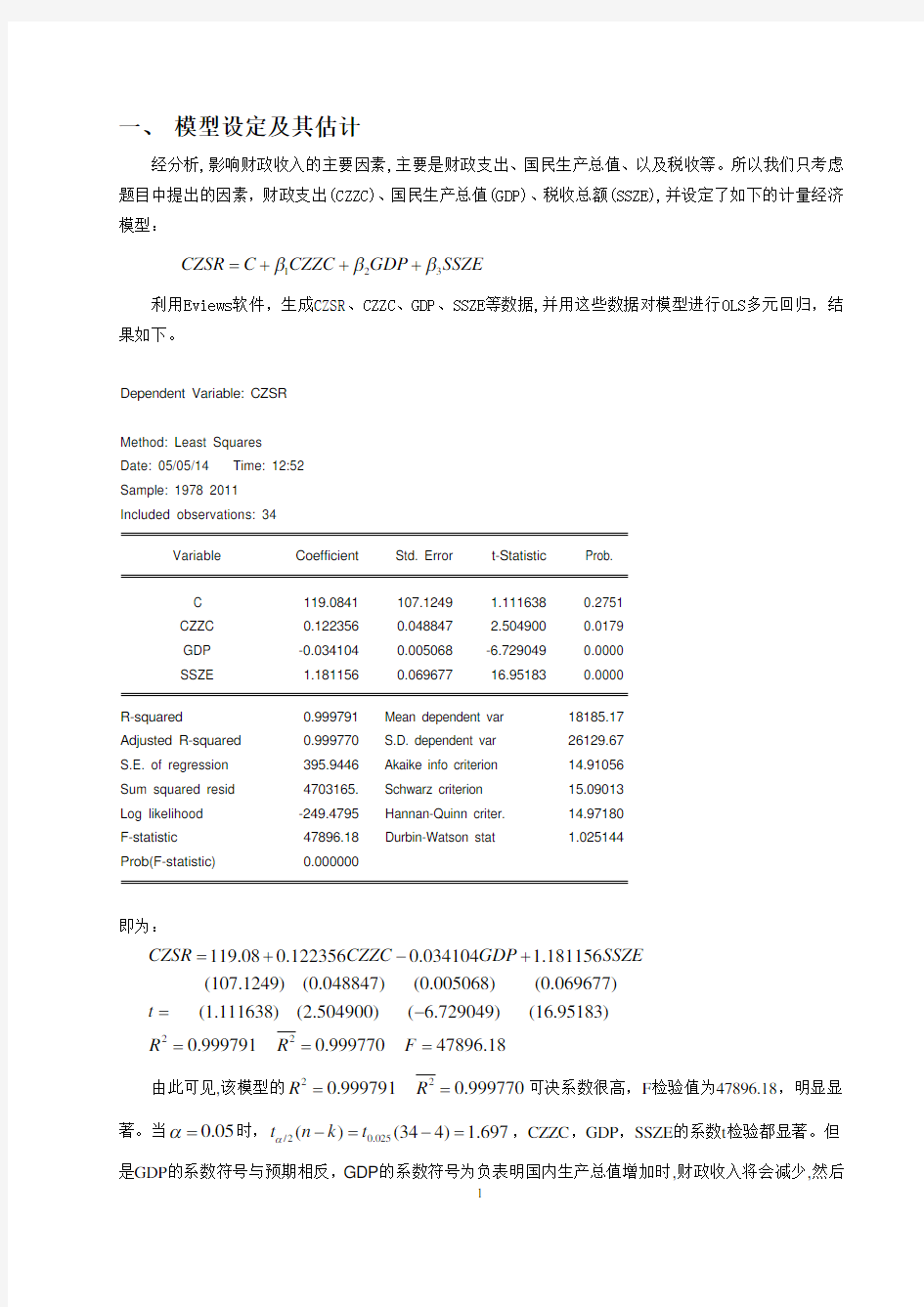
经分析,影响财政收入的主要因素,主要是财政支出、国民生产总值、以及税收等。所以我们只考虑题目中提出的因素,财政支出(CZZC)、国民生产总值(GDP)、税收总额(SSZE),并设定了如下的计量经济模型:
123CZSR C CZZC GDP SSZE βββ=+++
利用Eviews 软件,生成CZSR 、CZZC 、GDP 、SSZE 等数据,并用这些数据对模型进行OLS 多元回归,结果如下。
Dependent Variable: CZSR
Method: Least Squares Date: 05/05/14 Time: 12:52 Sample: 1978 2011 Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob.
C 119.0841 107.1249 1.111638 0.2751 CZZC 0.122356 0.048847 2.504900 0.0179 GDP -0.034104 0.005068 -6.729049 0.0000 SSZE
1.181156
0.069677
16.95183
0.0000
R-squared 0.999791 Mean dependent var 18185.17 Adjusted R-squared 0.999770 S.D. dependent var 26129.67 S.E. of regression 395.9446 Akaike info criterion 14.91056 Sum squared resid 4703165. Schwarz criterion 15.09013 Log likelihood -249.4795 Hannan-Quinn criter. 14.97180 F-statistic 47896.18 Durbin-Watson stat 1.025144
Prob(F-statistic) 0.000000
即为:
22119.080.1223560.034104 1.181156(107.1249)(0.048847)(0.005068)(0.069677)
(1.111638)(2.504900)( 6.729049)(16.95183)0.9997910.99977047896.18
CZSR CZZC GDP SSZE t R R F =+-+=-===
由此可见,该模型的2
2
0.9997910.999770R R == 可决系数很高,F 检验值为47896.18,明显显著。当0.05α=时,/20.025()(344) 1.697t n k t α-=-=,CZZC ,GDP ,SSZE 的系数t 检验都显著。但是GDP 的系数符号与预期相反,GDP 的系数符号为负表明国内生产总值增加时,财政收入将会减少,然后
与实际定性结果相违背,所以该模型有一定的缺陷,很有可能存在严重的多重共线性,为此做进一步分析。
二、多重共线性的检测
三个解释变量CZZC 、GDP 、SSZE 的相关系数
表 1 CZZC 、GDP 、SSZE 的相关系数
由相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实确实存在一定的多重共线性。 为进一步了解多重共线性的性质,我们做辅助回归,即将每个变量分别作被解释变量对其余的变量进行回归。
结果如下:
czzc1czzc2czzc CZZC C GDP SSZE ββ=++的参数估计结果:
Dependent Variable: CZZC Method: Least Squares Date: 05/05/14 Time: 12:57 Sample: 1978 2011 Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob. C 96.70225 393.5066 0.245745 0.8075 GDP -0.018851 0.018325 -1.028685 0.3116 SSZE
1.312407
0.100377
13.07482
0.0000
R-squared 0.997400 Mean dependent var 19460.41 Adjusted R-squared 0.997232 S.D. dependent var 27672.44 S.E. of regression 1455.857 Akaike info criterion 17.48867 Sum squared resid 65705105 Schwarz criterion 17.62335 Log likelihood -294.3075 Hannan-Quinn criter. 17.53460 F-statistic 5945.806 Durbin-Watson stat 1.368239
Prob(F-statistic) 0.000000
gdp 1gdp2gdp GDP C CZZC SSZE ββ=++的参数估计
Dependent Variable: GDP Method: Least Squares Date: 05/05/14 Time: 12:59 Sample: 1978 2011 Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob. C 13110.88 2977.712 4.403006 0.0001 CZZC -1.751043 1.702216 -1.028685 0.3116 SSZE
7.562376
2.062088
3.667339
0.0009
R-squared 0.988187 Mean dependent var 101654.7 Adjusted R-squared 0.987425 S.D. dependent var 125124.3 S.E. of regression 14031.46 Akaike info criterion 22.02009 Sum squared resid 6.10E+09 Schwarz criterion 22.15477 Log likelihood -371.3415 Hannan-Quinn criter. 22.06602 F-statistic 1296.583 Durbin-Watson stat 0.233153
Prob(F-statistic) 0.000000
12ssze ssze ssze SSZE C CZZC GDP ββ=++的参数估计
Dependent Variable: SSZE Method: Least Squares Date: 05/05/14 Time: 13:04 Sample: 1978 2011 Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob. C -404.7214 266.3939 -1.519259 0.1388 CZZC 0.644996 0.049331 13.07482 0.0000 GDP
0.040011
0.010910
3.667339
0.0009
R-squared 0.998125 Mean dependent var 16214.46 Adjusted R-squared 0.998004 S.D. dependent var 22843.09 S.E. of regression 1020.617 Akaike info criterion 16.77830 Sum squared resid 32291435 Schwarz criterion 16.91298 Log likelihood -282.2311 Hannan-Quinn criter. 16.82423 F-statistic 8249.980 Durbin-Watson stat 1.291261
Prob(F-statistic) 0.000000
表2 辅助回归的2
R 值
由于辅助回归的可决系数很高,经验表明扩大因子vif>10时,通常说明该被解释变量与其他解释变量之间有严重的多重共线性,上表中czzc 、gdp 、ssze 方差扩大因子都远大于10,表明存在严重的多重共线性。同时解释变量GDP 的回归系数带有负号,与定性分析的结果相违背,则可能存在多重共线性。
三、修正多重共线性
采用逐步回归的办法,去解决多重共线性问题。分别做czsr 对czzc 、gdp 、ssze 的一元回归。
CZSR C CZZC β=+?
Dependent Variable: CZSR Method: Least Squares Date: 05/09/15 Time: 11:35 Sample: 1978 2011 Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob. C -169.3819 266.7056 -0.635089 0.5299 CZZC
0.943174
0.007962
118.4530
0.0000
R-squared 0.997725 Mean dependent var 18185.17 Adjusted R-squared 0.997653 S.D. dependent var 26129.67 S.E. of regression 1265.756 Akaike info criterion 17.18175 Sum squared resid 51268423 Schwarz criterion 17.27154 Log likelihood -290.0897 Hannan-Quinn criter. 17.21237 F-statistic 14031.12 Durbin-Watson stat 1.250442
Prob(F-statistic)
0.000000
CZSR C GDP β=+?
Dependent Variable: CZSR Method: Least Squares Date: 05/09/15 Time: 11:35 Sample: 1978 2011 Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob. C -2861.490 770.4344 -3.714126 0.0008 GDP
0.207041
0.004822
42.93776
0.0000
R-squared 0.982939 Mean dependent var 18185.17 Adjusted R-squared 0.982406 S.D. dependent var 26129.67 S.E. of regression 3465.891 Akaike info criterion 19.19635 Sum squared resid 3.84E+08 Schwarz criterion 19.28614 Log likelihood -324.3379 Hannan-Quinn criter. 19.22697 F-statistic 1843.651 Durbin-Watson stat 0.151983
Prob(F-statistic)
0.000000
CZSR C SSZE β=+?
Dependent Variable: CZSR Method: Least Squares Date: 05/09/15 Time: 11:36 Sample: 1978 2011 Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob. C -356.3761 140.0831 -2.544034 0.0160 SSZE
1.143519
0.005050
226.4253
0.0000
R-squared 0.999376 Mean dependent var 18185.17 Adjusted R-squared 0.999357 S.D. dependent var 26129.67 S.E. of regression 662.7204 Akaike info criterion 15.88761 Sum squared resid 14054348 Schwarz criterion 15.97739 Log likelihood -268.0893 Hannan-Quinn criter. 15.91823 F-statistic 51268.43 Durbin-Watson stat 0.511014 Prob(F-statistic)
0.000000
结果如下表:
表 3 一元回归估计结果
其中,加入ssze 的方程2
R 最大,多以以ssze 为基础,顺次加入其它解释变量做逐步回归。
Dependent Variable: CZSR
Method: Least Squares
Date: 05/09/15 Time: 13:55
Sample: 1978 2011
Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob.
C -356.3761 140.0831 -2.544034 0.0160
SSZE 1.143519 0.005050 226.4253 0.0000
R-squared 0.999376 Mean dependent var 18185.17 Adjusted R-squared 0.999357 S.D. dependent var 26129.67 S.E. of regression 662.7204 Akaike info criterion 15.88761 Sum squared resid 14054348 Schwarz criterion 15.97739 Log likelihood -268.0893 Hannan-Quinn criter. 15.91823 F-statistic 51268.43 Durbin-Watson stat 0.511014 Prob(F-statistic) 0.000000
情况1:加入解释变量czzc,再加入gdp的结果如下:
Dependent Variable: CZSR
Method: Least Squares
Date: 05/09/15 Time: 11:44
Sample: 1978 2011
Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob.
C -328.0485 130.9403 -2.505328 0.0177
SSZE 0.923250 0.090677 10.18172 0.0000
CZZC 0.182073 0.074852 2.432434 0.0210
R-squared 0.999476 Mean dependent var 18185.17 Adjusted R-squared 0.999442 S.D. dependent var 26129.67 S.E. of regression 617.0121 Akaike info criterion 15.77175 Sum squared resid 11801822 Schwarz criterion 15.90643 Log likelihood -265.1198 Hannan-Quinn criter. 15.81768 F-statistic 29575.82 Durbin-Watson stat 0.517163 Prob(F-statistic) 0.000000
Dependent Variable: CZSR
Method: Least Squares
Date: 05/09/15 Time: 11:49
Sample: 1978 2011
Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob.
C 119.0841 107.1249 1.111638 0.2751
SSZE 1.181157 0.069677 16.95183 0.0000
CZZC 0.122356 0.048847 2.504900 0.0179
GDP -0.034104 0.005068 -6.729049 0.0000
R-squared 0.999791 Mean dependent var 18185.17 Adjusted R-squared 0.999770 S.D. dependent var 26129.67 S.E. of regression 395.9446 Akaike info criterion 14.91056 Sum squared resid 4703164. Schwarz criterion 15.09013 Log likelihood -249.4795 Hannan-Quinn criter. 14.97180 F-statistic 47896.19 Durbin-Watson stat 1.025144 Prob(F-statistic) 0.000000
情况2:加入解释变量gdp,再加入czzc的结果如下:
Dependent Variable: CZSR
Method: Least Squares
Date: 05/09/15 Time: 11:46
Sample: 1978 2011
Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob.
C 130.9162 115.7678 1.130852 0.2668
SSZE 1.341737 0.029530 45.43588 0.0000
GDP -0.036410 0.005391 -6.753731 0.0000
R-squared 0.999748 Mean dependent var 18185.17 Adjusted R-squared 0.999731 S.D. dependent var 26129.67 S.E. of regression 428.3063 Akaike info criterion 15.04165 Sum squared resid 5686834. Schwarz criterion 15.17633 Log likelihood -252.7081 Hannan-Quinn criter. 15.08758 F-statistic 61395.04 Durbin-Watson stat 1.210574 Prob(F-statistic) 0.000000
Dependent Variable: CZSR
Method: Least Squares
Date: 05/09/15 Time: 11:50
Sample: 1978 2011
Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob.
C 119.0841 107.1249 1.111638 0.2751
SSZE 1.181157 0.069677 16.95183 0.0000
GDP -0.034104 0.005068 -6.729049 0.0000
CZZC 0.122356 0.048847 2.504900 0.0179
R-squared 0.999791 Mean dependent var 18185.17
Adjusted R-squared 0.999770 S.D. dependent var 26129.67
S.E. of regression 395.9446 Akaike info criterion 14.91056
Sum squared resid 4703164. Schwarz criterion 15.09013
Log likelihood -249.4795 Hannan-Quinn criter. 14.97180
F-statistic 47896.19 Durbin-Watson stat 1.025144
Prob(F-statistic) 0.000000
R都在增大,且各个参数的t检验也我们发现上诉两种情况下,随着新的解释变量加入,模型的2
是显著的。为此无法判断,于是将CZZC做为基础,再进行一次逐步回归。
Dependent Variable: CZSR
Method: Least Squares
Date: 05/09/15 Time: 11:16
Sample: 1978 2011
Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob.
C -169.3819 266.7056 -0.635089 0.5299
CZZC 0.943174 0.007962 118.4530 0.0000
R-squared 0.997725 Mean dependent var 18185.17
Adjusted R-squared 0.997653 S.D. dependent var 26129.67
S.E. of regression 1265.756 Akaike info criterion 17.18175
Sum squared resid 51268423 Schwarz criterion 17.27154
Log likelihood -290.0897 Hannan-Quinn criter. 17.21237
F-statistic 14031.12 Durbin-Watson stat 1.250442
Prob(F-statistic) 0.000000
Dependent Variable: CZSR
Method: Least Squares
Date: 05/09/15 Time: 11:16
Sample: 1978 2011
Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob.
C -358.9552 330.6697 -1.085540 0.2861
CZZC 0.884197 0.061234 14.43969 0.0000
GDP 0.013155 0.013542 0.971404 0.3389
R-squared 0.997792 Mean dependent var 18185.17
Adjusted R-squared 0.997649 S.D. dependent var 26129.67
S.E. of regression 1266.872 Akaike info criterion 17.21059
Sum squared resid 49753935 Schwarz criterion 17.34527
Log likelihood -289.5800 Hannan-Quinn criter. 17.25652
F-statistic 7003.674 Durbin-Watson stat 1.176735
Prob(F-statistic) 0.000000
其中解释变量GDP进行t检验时,发现并不显著。说明主要是GDP引起的多重共线性,予以剔除。
Dependent Variable: CZSR
Method: Least Squares
Date: 05/09/15 Time: 11:18
Sample: 1978 2011
Included observations: 34
Variable Coefficient Std. Error t-Statistic Prob.
C -328.0485 130.9403 -2.505328 0.0177
CZZC 0.182073 0.074852 2.432434 0.0210
SSZE 0.923250 0.090677 10.18172 0.0000
R-squared 0.999476 Mean dependent var 18185.17
Adjusted R-squared 0.999442 S.D. dependent var 26129.67
S.E. of regression 617.0121 Akaike info criterion 15.77175
Sum squared resid 11801822 Schwarz criterion 15.90643
Log likelihood -265.1198 Hannan-Quinn criter. 15.81768
F-statistic 29575.82 Durbin-Watson stat 0.517163
Prob(F-statistic) 0.000000
所以其最终修正多重共线性影响后的回归结果为:
22-328.04850.1820730.923250(130.9403)(0.074852)(0.090677)
(-2.505328)(2.432434)(10.18172)0.9994760.99944229575.82
CZSR CZZC SSZE t R R F =+?+?====
这说明,在其他因素不变的情况下,当财政支出(CZZC)每增加1亿元,财政收入(CZSR)增加0.182073亿元,当税收总额(SSZE)每增加1亿元,财政收入(CZSR)增加0.923250亿元。
简答 计量经济学与经济理论、统计学、数学的联系是什么? (主要体现在计量经济学对经济理论、统计学、数学的应用方面)1)计量经济学对经济理论的利用主要体现在: (1)计量经济模型的选择和确定 (2)对经济模型的修改和调整C (3)对计量经济分析结果的解读和应用 2)计量经济学对统计学的应用 (1)数据的收集、处理、 (2)参数估计 (3)参数估计值、模型和预测结果的可靠性的判断 3)计量经济学对数学的应用 (1)关于函数性质、特征等方面的知识 (2)对函数进行对数变换、求导以及级数展开 (3)参数估计 (4)计量经济理论和方法的研究L 模型的检验包括那几个方面?具体含义是什么? ①经济意义检验:检验模型是否符合经济意义,检验求得的参数估计值的符号、 大小、参数之间的关系是否与根据人们的经验和经济理论所拟订的期望值相符合; ②统计检验: 检验模型参数估计值的可靠性,即检验模型的统计学性质,有拟合 优度检验、变量显著检验、方程显著性检验等; ③计量经济学检验: 检验模型的计量经济学性质,包括随机扰动项的序列相关检 验、异方差性检验、解释变量的多重共线性检验等; ④预测检验: 检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以 确定所建立的模型是否可以用于样本观测值以外的范围。 @为什么计量经济学模型的理论方程中必需包括含随机干扰项? 模型考察的是具有因果关系的随机变量间的具体联系方式。由于是随机变量,意味着影响被解释变量的因素是复杂的,除了解释变量的影响外,还有其他无法在模型中独立列出的各种因素的影响。所以,理论模型中就必须使用一个称为随机干扰项的变量来代表所有这些无法在模型中独立表示出来的影响因素,以保证模型在理论上的科学性。 总体回归函数和样本回归函数之间有那些区别和联系? 将总体被解释变量的条件期望表示为解释变量的某种函数,这个函数就称为总体回归函数,其一般表达式为:()() i i E Y X f X =,一元线性总体回归函数为01 () i i E Y X X ββ =+;样本回归函数:将被解释变量Y的样本观测值的拟和值 表示为解释变量的某种函数?() i i Y f X =,一元线性样本回归函数为01 ?? ? i i Y X ββ =+。 样本回归函数是总体回归函数的一个近似。总体回归函数具有理论上的意义,但其具体的参数不可能真正知道,只能通过样本估计。样本回归函数就是总体回归函数 的参数用其估计值替代之后的形式,即 01 ?? ββ ,为 01 ββ ,的估计值。 为什么用可决系数R2评价拟合优度,而不是用残差平方和作为评价标准? 可决系数R2=ESS/TSS=1-RSS/TSS,含义为由解释变量引起的被解释变量的变化占被解释变量总变化的比重,用来判定回归直线拟合的优劣,该值越大说明拟合的越好;而残差平方和与样本容量关系密切,当样本容量比较小时,残差平方和的值也比较小,尤其是不同样本得到的残差平方和是不能做比较的。此外,作为检验统计量的一般应是相对量而不能用绝对量,因而不能使用残差平方和判断模型的拟合优度。O 根据最小二乘原理,所估计的模型已经使得拟合误差达到最小,为什么还要讨论模型的拟合优度问题?
计量经济学模拟考试题第5套 一、单项选择题 1、下列说法正确的有( C ) A.时序数据和横截面数据没有差异 B.对总体回归模型的显著性检验没有必要 C.总体回归方程与样本回归方程是有区别的 D.判定系数2R 不可以用于衡量拟合优度 2、所谓异方差是指( A ) 3、在给定的显著性水平之下,若DW 统计量的下和上临界值分别为dL 和du,则当dL 06A卷 一、判断说明题(每小题1分,共10分) 1.在实际中,一元回归没什么用,因为因变量 的行为不可能仅由一个解释变量来解释。(×) 4.在线性回归模型中,解释变量是原因,被解 释变量是结果。(×) 7. 给定显著性水平 及自由度,若计算得到 的t 值超过t的临界值,我们将拒绝零假设。 (√) 8.为了避免陷入虚拟变量陷阱,如果一个定性 变量有 m类,则要引入m个虚拟变量。(×) 二、名词解释(每小题2分,共10分) 1.计量经济学:融合数学、统计学及经济理论,结合研究经济行为和现象的理论和实务。 2.最小二乘法:使全部观测值的残差平方和为最小的方法就是最小二乘法。 3.虚拟变量:在经济生活研究中,有一些暂时起作用的因素。如战争、天灾、人祸等,这些因素在经济中不经常发生,但又带有相同特性,经济学家把这些不经常发生的、又起暂时影响作用的称为虚拟变量。 4.滞后变量:用来作为解释变量的内生变量的前期值称为滞后内生变量,简称为滞后变量。 5.自回归模型:包含有被解释变量滞后值的模型,称为自回归模型。 三、简答题(每小题5分,共20分) 1.应用最小二乘法应满足的古典假定有哪些?(1)随机项的均值为零; (2)随机项无序列相关和等方差性; (3)解释变量是非随机的,如果是随机的则与随机项不相关; (4)解释变量之间不存在多重共线性。 2.运用计量经济学方法解决经济问题的步骤一般是什么? (1)建立模型; (2)估计参数; (3)验证理论; (4)使用模型。 3.你能分别举出三个时间序列数据、截面数据、混合数据、虚拟变量数据的实际例子吗? (1)时间序列数据如:每年的国民生产总值、 各年商品的零售总额、各年的年均人口增长 数、年出口额、年进口额等等; (2)截面数据如:西南财大2002年各位教师年收入、2002年各省总产值、2002年5月成都市 各区罪案发生率等等; (3)混合数据如:1990年~2000年各省的人均收入、消费支出、教育投入等等; (4)虚拟变量数据如:婚否,身高是否大于170厘米,受教育年数是否达到10年等等。 4.随机扰动项μ的一些特性有哪些? (1)众多因素对被解释变量Y的影响代表的综合体; (2)对Y的影响方向应该是各异的,有正有负;(3)由于是次要因素的代表,对Y的总平均影响可能为零; (4)对Y的影响是非趋势性的,是随机扰动的。 四、分析、计算题(每小题15分,共45分) 1. 根据下面Eviews回归结果回答问题。Dependent Variable: DEBT Method: Least Squares Date: 05/31/06 Time: 08:35 Sample: 1980 1995 Included observations: 16 Variable Coefficie nt Std. Erro r t-Statist ic Prob . C() INCOME() COST() R-squared Mean dependent var Adjusted R-squared () . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic()Durbin-Wats on stat Prob(F-statisti c) INCOME——个人收入,单位亿美元; COST——抵押贷款费用,单位%。 1. 完成Eviews回归结果中空白处内容。 2. 说明总体回归模型和样本回归模型的区别。 1、已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X (45.2)(1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题: (1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 答:(1)系数的符号是正确的,政府债券的价格与利率是负相关关系,利率的上升会引起政府债券价格的下降。 (2)i Y 代表的是样本值,而i ?Y 代表的是给定i X 的条件下i Y 的期望值,即?(/)i i i Y E Y X 。此模型是根据样本数据得出的回归结果,左边应当是i Y 的期望值,因此是i ?Y 而不是i Y 。 (3)没有遗漏,因为这是根据样本做出的回归结果,并不是理论模型。 (4)截距项101.4表示在X 取0时Y 的水平,本例中它没有实际意义;斜率项-4.78表明利率X 每上升一个百分点,引起政府债券价格Y 降低478美元。 2、有10户家庭的收入(X ,元)和消费(Y ,百元)数据如下表: 10户家庭的收入(X )与消费(Y )的资料 X 20 30 33 40 15 13 26 38 35 43 Y 7 9 8 11 5 4 8 10 9 10 若建立的消费Y 对收入X 的回归直线的Eviews 输出结果如下: Dependent Variable: Y Variable Coefficient Std. Error X 0.202298 0.023273 C 2.172664 0.720217 R-squared 0.904259 S.D. dependent var 2.233582 Adjusted R-squared 0.892292 F-statistic 75.55898 Durbin-Watson stat 2.077648 Prob(F-statistic) 0.000024 (1)说明回归直线的代表性及解释能力。 (2)在95%的置信度下检验参数的显著性。(0.025(10) 2.2281t =,0.05(10) 1.8125t =,0.025(8) 2.3060t =,0.05(8) 1.8595t =) (3)在95%的置信度下,预测当X =45(百元)时,消费(Y )的置信区间。(其中29.3x =,2()992.1x x -=∑) 答:(1)回归模型的R 2=0.9042,表明在消费Y 的总变差中,由回归直线解释的部分占到90%以上,回归直线的代表性及解释能力较好。 (2)对于斜率项,11 ? 0.20238.6824?0.0233 ()b t s b ===>0.05(8) 1.8595t =,即表明斜率项 显著不为0,家庭收入对消费有显著影响。对于截距项, 00? 2.1727 3.0167?0.7202 ()b t s b ===>0.05(8) 1.8595t =, 即表明截距项也显著不为0,通过了显著性检验。 (3)Y f =2.17+0.2023×45=11.2735 0.025(8) 1.8595 2.2336 4.823t ?=?= 95%置信区间为(11.2735-4.823,11.2735+4.823),即(6.4505,16.0965)。 计量经济学分章练习题 第一章习题 一、判断题 1.投入产出模型和数学规划模型都是计量经济模型。(×) 2.弗里希因创立了计量经济学从而获得了诺贝尔经济学奖。(√) 3.丁伯根因创立了建立了第1个计量经济学应用模型从而获得了诺贝尔经济学奖。(√) 4.格兰杰因在协整理论上的贡献而获得了诺贝尔经济学奖。(√) 5.赫克曼因在选择性样本理论上的贡献而获得了诺贝尔经济学奖。(√) 二、名词解释 1.计量经济学,经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论。 2.计量经济学模型,是一个或一组方程表示的经济变量关系以及相关条件或假设,是经济问题相关方面之间数量联系和制约关系的基本描述。 3.计量经济检验,由计量经济学理论决定的,目的在于检验模型的计量经济学性质。通常最主要的检验准则有随机误差项的序列相关检验和异方差性检验,解释变量的多重共线性检验等。 4.截面数据,指在同一个时点上,对不同观测单位观测得到的多个数据构成的数据集。 5.面板数据,是由对许多个体组成的同一个横截面,在不同时点的观测数据构成的数据。 三、单项选择题 1.把反映某一单位特征的同一指标的数据,按一定的时间顺序和时间间隔排列起来,这样的数据称为( B ) A. 横截面数据 B. 时间序列数据 C. 面板数据 D. 原始数据 2.同一时间、不同单位按同一统计指标排列的观测数据称为( C ) A.原始数据 B.时间序列数据 C.截面数据 D.面板数据 3.不同时间、不同单位按同一统计指标排列的观测数据称为( D ) A.原始数据 B.时间序列数据 C.截面数据 D.面板数据 4.对计量经济模型进行的结构分析不包括( D ) A.乘数分析 B.弹性分析 C.比较静态分析 D.随机分析 5.一个普通家庭的每月所消费的水费和电费是( B ) 计量经济学题库 、单项选择题(每小题1分) 1?计量经济学是下列哪门学科的分支学科(C)O A.统计学 B.数学 C.经济学 D.数理统计学 2?计量经济学成为一门独立学科的标志是(B)。 A. 1930年世界计量经济学会成立 B. 1933年《计量经济学》会刊出版 C. 1969年诺贝尔经济学奖设立 D. 1926年计量经济学(EConOIniCS) —词构造出来 3.外生变量和滞后变量统称为(D)O A.控制变量B?解释变量 C.被解释变量 D.前定变量 4.横截面数据是指(A)O A.同一时点上不同统计单位相同统计指标组成的数据 B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据 D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)O A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据 6.在计量经济模型中,由模型系统部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是(B )o A.生变量 B.外生变量 C.滞后变量 D.前定变量 7.描述微观主体经济活动中的变量关系的计量经济模型是(A )o A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量 经济模型 &经济计量模型的被解释变量一定是(C )o A.控制变量 B.政策变量 C.生变量 D.外生变量 9.下面属于横截面数据的是(D )o A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )0 A.设定理论模型一收集样本资料一估计模型参数一检验模型 B.设定模型一估计参数一检验模型一应用模型 C:个体设计f总体估计f估计模型f应用模型D.确定模型导向一确定变量及方程式一估计模型一应用模型 11.将生变量的前期值作解释变量,这样的变量称为( A.虚拟变量 B.控制变量 12.( B )是具有一定概率分布的随机变量, A.外生变量 B.生变量 13.同一统计指标按时间顺序记录的数据列称为( A.横截面数据 B.时间序列数据据 14?计量经济模型的基本应用领域有( A.结构分析、经济预测、政策评价 C.消费需求分析、生产技术分析、 15.变量之间的关系可以分为两大类, A.函数关系与相关关系 C.正相关关系和负相关关系 D )0 C.政策变量 它的数值由模型本身决定。 C.前定变量 B )0 C.修匀数据 A )0 B.弹性分析、D.季度分析、它们是(A 乘数分析、政策模拟年度分析、中长期分析 )o B.线性相关关系和非线性相关关系D.简单相关关系和复杂相关关系 D ?滞后变量D.滞后变量D.原始数 计量经济学简答题及答案 1、比较普通最小二乘法、加权最小二乘法和广义最小二乘法的异同。 答:普通最小二乘法的思想是使样本回归函数尽可能好的拟合样本数据,反映在 图上就是是样本点偏离样本回归线的距离总体上最小,即残差平方和最小 ∑=n i i e 12min 。 只有在满足了线性回归模型的古典假设时候,采用OLS 才能保证参数估计结果的可靠性。 在不满足基本假设时,如出现异方差,就不能采用OLS 。加权最小二乘法是对原 模型加权,对较小残差平方和2i e 赋予较大的权重,对较大2i e 赋予较小的权重,消除异方差,然后在采用OLS 估计其参数。 在出现序列相关时,可以采用广义最小二乘法,这是最具有普遍意义的最小二乘 法。 最小二乘法是加权最小二乘法的特例,普通最小二乘法和加权最小二乘法是广义 最小二乘法的特列。 6、虚拟变量有哪几种基本的引入方式? 它们各适用于什么情况? 答: 在模型中引入虚拟变量的主要方式有加法方式与乘法方式,前者主要适用于 定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。 7、联立方程计量经济学模型中结构式方程的结构参数为什么不能直接应用OLS 估计? 答:主要的原因有三:第一,结构方程解释变量中的内生解释变量是随机解释变 量,不能直接用OLS 来估计;第二,在估计联立方程系统中某一个随机方程参数时,需要考虑没有包含在该方程中的变量的数据信息,而单方程的OLS 估计做不到这一点;第三,联立方程计量经济学模型系统中每个随机方程之间往往存在某种相关性,表现于不同方程随机干扰项之间,如果采用单方程方法估计某一个方程,是不可能考虑这种相关性的,造成信息的损失。 2、计量经济模型有哪些应用。 答:①结构分析,即是利用模型对经济变量之间的相互关系做出研究,分析当其 他条件不变时,模型中的解释变量发生一定的变动对被解释变量的影响程度。②经济预测,即是利用建立起来的计量经济模型对被解释变量的未来值做出预测估计或推算。③政策评价,对不同的政策方案可能产生的后果进行评价对比,从中做出选择的过程。④检验和发展经济理论,计量经济模型可用来检验经济理论的正确性,并揭示经济活动所遵循的经济规律。 6、简述建立与应用计量经济模型的主要步骤。 答:一般分为5个步骤:①根据经济理论建立计量经济模型;②样本数据的收集; ③估计参数;④模型的检验;⑤计量经济模型的应用。 7、对计量经济模型的检验应从几个方面入手。 答:①经济意义检验;②统计准则检验;③计量经济学准则检验;④模型预测检 验。 计量经济学课后习题答 案汇总 标准化工作室编码[XX968T-XX89628-XJ668-XT689N] 计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【 A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【 D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据 D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列 分析三大支柱。 ⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系 和恒等关系。 三、简答题 ⒈什么是计量经济学它与统计学的关系是怎样的 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常不一定需要特定的经济理论或模型作为基础和出发点,常常是通过对经济数据的统计处理直接得出结论,统计学侧重的工作是经济数据的采集、筛选和处理。 此外,计量经济学不仅是通过数据处理和分析获得经济问题的一些数字特征,而且是借助于经济思想和数学工具对经济问题作深刻剖析。经过计量经济分析实证检验的经济理论和模型,能够对分析、研究和预测更广泛的经济问题起重要作用。计量经济学从 计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【 A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【 D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据 D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分 析三大支柱。 ⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒 等关系。 三、简答题 ⒈什么是计量经济学它与统计学的关系是怎样的 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常 第一套 一、单项选择题 1、双对数模型 μββ++=X Y ln ln ln 10中,参数1β的含义是 ( ) A. Y 关于X 的增长率 B .Y 关于X 的发展速度 C. Y 关于X 的边际变化 D. Y 关于X 的弹性 2、设k 为回归模型中的参数个数,n 为样本容量。则对多元线性回归方 程进行显著性检验时,所用的F 统计量可表示为( ) A. )1() (--k RSS k n ESS B .) ()1()1(2 2k n R k R --- C .) 1()1()(2 2---k R k n R D .)()1/(k n TSS k ESS -- 3、回归分析中使用的距离是点到直线的垂直坐标距离。最小二乘准则 是指( ) A. 使() ∑=-n t t t Y Y 1 ?达到最小值 B. 使() 2 1 ?∑=-n t t t Y Y 达到最小值 C. 使t t Y Y ?max -达到最小值 D. 使?min i i Y Y -达到最小值 4、 对于一个含有截距项的计量经济模型,若某定性因素有m 个互斥的类型, 为将其引入模型中,则需要引入虚拟变量个数为( ) A. m B. m+1 C. m-1 D. m-k 5、 回归模型中具有异方差性时,仍用OLS 估计模型,则以下说法正确的是( ) A. 参数估计值是无偏非有效的 B. 参数估计量仍具有最小方差性 C. 常用F 检验失效 D. 参数估计量是有偏的 6、 在一元线性回归模型中,样本回归方程可表示为( ) A. t t t u X Y ++=10ββ B. i t t X Y E Y μ+=)/( C. t t X Y 10???ββ+= D. ()t t t X X Y E 10/ββ+= 7、 在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。 例如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出Y 对实际可支配收入X 的回归关系明显不同。现以1991年为转折时期,设虚拟变 量?? ?=年以前 , 年以后 , 1991019911t D ,数据散点图显示消费函数发生了结构性变化:基本 消费部分下降了,边际消费倾向变大了。则城镇居民线性消费函数的理论方程可 简答: 1、时间序列数据和横截面数据有何不同? 时间序列数据是一批按照时间先后排列的统计数据。截面数据是一批发生在同一时间截面上的调查数据。这两类数据都是反映经济规律的经济现象的数量信息,不同点:时间序列数据是含义、口径相同的同一指标按时间先后排列的统计数据列;而横截面数据是一批发生在同一时间截面上不同统计单元的相同统计指标组成的数据列。 2、建立计量经济模型赖以成功的三要素。P16(课本) 成功的要素有三:理论、方法和数据。理论:即经济理论,所研究的经济现象的行为理论,是计量经济学研究的基础;方法:主要包括模型方法和计算方法,是计量经济学研究的工具与手段,是计量经济学不同于其他经济学分支科学的主要特征;数据:反映研究对象的活动水平、相互间以及外部环境的数据,更广义讲是信息,是计量经济学研究的原料。三者缺一不可。 3、什么是相关关系、因果关系;相关关系与因果关系的区别与联系。 相关关系是指两个以上的变量的样本观测值序列之间表现出来的随机数学关系,用相关系数来衡量。 因果关系是指两个或两个以上变量在行为机制上的依赖性,作为结果的变量是由作为原因的变量所决定的,原因变量的变化引起结果变量的变化。因果关系有单向因果关系和互为因果关系之分。 具有因果关系的变量之间一定具有数学上的相关关系。而具有相关关系的变量之间并不一定具有因果关系。 4、回归分析与相关分析的区别与关系。P23-P24(课本) 相关分析与回归分析既有联系又有区别。首先,两者都是研究非确定性变量间的统计依赖关系,并能测度线性依赖程度的大小。其次,两者间又有明显的区别。相关分析仅仅是从统计数据上测度变量间的相关程度,而无需考察两者间是否有因果关系,因此,变量的地位在相关分析中饰对称的,而且都是随机变量;回归分析则更关注具有统计相关关系的变量间的因果关系分析,变量的地位是不对称的,有解释变量与被解释变量之分,而且解释变量也往往被假设为非随机变量。再次,相关分析只关注变量间的具体依赖关系,因此可以进一步通过解释变量的变化来估计或预测被解释变量的变化,达到深入分析变量间依存关系,掌握其运动规律的目的。 5、数理经济模型和计量经济模型的区别。 答:数理经济模型揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。计量经济模型揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述。 6、从哪几方面看,计量经济学是一门经济学科?P6(课本) 1. 请问自回归模型的估计存在什么困难?如何来解决这些苦难? 答:主要存在两个问题: (1) 出现了随机解释变量Y ,而可能与随机扰动项相关; (2) 随机扰动项可能存在自相关,库伊克模型和自适应预期模型的随机扰动项都会导致自相关,只有局部调整模型的随机扰动项无自相关。 对于第一个问题的解决可以使用工具变量法;对于第二个问题的检验可以用德宾h 检验法,目前还没有很好的解决办法,唯一能做的就是模型尽可能的设定正确。 2. 为什么要进行广义差分变换?写出其过程。 答:进行广义差分变换是为了处理自相关,写出其过程如下: 以一元模型为例:Y t = b 0 + b 1 X t +u t 假设误差项服从AR(1)过程:u t =ρu t-1 +v t -1 ≤ρ≤1 其中,v 满足OLS 假定,并且是已知的。 为了弄清楚如何使变换后模型的误差项不具有自相关性,我们将回归方程中的变量滞后一期,写为: Y t-1 = b 0 + b 1 X t-1 +u t-1 方程的两边同时乘以ρ,得到:ρY t-1 = ρb 0 + ρb 1 X t-1 +ρu t-1 现在将两方程相减,得到:(Y t -ρY t-1 ) = b 0 ( 1 -ρ) + b 1 (X t -ρX t-1 ) + v t 由于方程中的误差项v t 满足标准OLS 假定,方程就是一种变换形式,使得变换后的模型无序列相关。如果我们将方程写成:Y t * = b 0* + b 1 X t * +v t ,其中,Y t * = (Y t -ρY t-1 ) ,X t * = (X t -ρX t-1 ) ,b 0* = b 0 ( 1 -ρ)。 3. 什么是递归模型? 答:递归模型是指在该模型中,第一个方程的内生变量Y 1仅由前定变量表示,而无其它内生变量;第二个方程内生变量Y 2表示成前定变量和一个内生变量Y 1的函数;第三个方程内生变量Y 3表示成前定变量和两个内生变量Y 1与Y 2的函数;按此规律下去,最后一个方程内生变量Y m 可表示成前定变量和m -1个Y 1,Y 2、,Y 3,…、Y m-1的函数。 4. 为什么要进行同方差变换?写出其过程,并证实之。 答:进行同方差变换是为了处理异方差,写出其过程如下: 我们考虑一元总体回归函数Y i = b 0 + b 1 X i + u i 假设误差σi 2 是已知的,也就是说,每个观察值的误差是已知的。对模型作如下“变换”: Y i /σi = b 0 /σi + b 1 X i /σi + u i /σi 这里将回归等式的两边都除以“已知”的σi 。σi 是方差σi 2 的平方根。 令 v i = u i /σi 我们将v i 称作是“变换”后的误差项。v i 满足同方差吗?如果是,则变换后的回归方程就不存在异方差问题了。假设古典线性回归模型中的其他假设均能满足,则方程中各参数的OLS 估计量将是最优线性无偏估计量,我们就可以按常规的方法进行统计分析了。 证明误差项v i 同方差性并不困难。根据方程有:E (v i 2 ) = E (u i 2 /σi 2 ) = E (u i 2 ) /σi 2 =σi 2 /σi 2 = 1 显然它是一个常量。简言之,变换后的误差项v i 是同方差的。因此,变换后的模型不存在异方差问题,我们可以用常规的OLS 方法加以估计。 5. 简述逐步回归法的基本步骤。 答:先用被解释变量对每一个解释变量做简单回归,然后以对被解释变量贡献最大的解释变量所对应的回归方程为基础,再逐个引入其余的解释变量。这个过程会出现3种情形:①若新变量的引入改进了R 2 和F 检验,且其它回归系数的t 检验在统计上仍是显著的,则可考 《计量经济学》综合练习题 1、 单项选择题 1.对联立方程模型进行参数估计的方法可以分两类,即:( ) A.间接最小二乘法和系统估计法 B.单方程估计法和系统估计法 C.单方程估计法和二阶段最小二乘法 D.工具变量法和间接最小二乘法 2.当模型中第i个方程是不可识别的,则该模型是( ) A.可识别的 B.不可识别的 C.过度识别 D.恰好识别 3.结构式模型中的每一个方程都称为结构式方程,在结构方程中,解释变量可以是前定变量,也可以是( ) A.外生变量 B.滞后变量 C.内生变量 D.外生变量和内生变量 4.已知样本回归模型残差的一阶自相关系数接近于-1,则DW统计量近似等于( ) A.0 B.1 C.2 D.4 5.假设回归模型为 其中Xi为随机变量,Xi与Ui相关则 的普通最小二乘估计量( ) A.无偏且一致 B.无偏但不一致 C.有偏但一致 D.有偏且不一致 6.对于误差变量模型,模型参数的普通最小二乘法估计量是( ) A.无偏且一致的 B.无偏但不一致 C.有偏但一致 D.有偏且不一致 7.戈德菲尔德-匡特检验法可用于检验( ) A.异方差性 B.多重共线性 C.序列相关 D.设定误差 8.对于误差变量模型,估计模型参数应采用( ) A.普通最小二乘法 B.加权最小二乘法 C.广义差分法 D.工具变量法 9.系统变参数模型分为( ) A.截距变动模型和斜率变动模型 B.季节变动模型和斜率变动模型 C.季节变动模型和截距变动模型 D.截距变动模型和截距、斜率同时变动模型 10.虚拟变量( ) A.主要来代表质的因素,但在有些情况下可以用来代表数量因素 B.只能代表质的因素 C.只能代表数量因素 D.只能代表季节影响因素 11.单方程经济计量模型必然是( ) A.行为方程 B.政策方程 C.制度方程 D.定义方程 12.用于检验序列相关的DW统计量的取值范围是( ) 练习题一 一、单选题(15小题,每题2分,共30分) 1.有关经济计量模型的描述正确的为( ) A.经济计量模型揭示经济活动中各个因素之间的定性关系 B.经济计量模型揭示经济活动中各个因素之间的定量关系,用确定性的数学方程加以描述 C.经济计量模型揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述 D.经济计量模型揭示经济活动中各个因素之间的定性关系,用随机性的数学方程加以描述 2.在X 与Y 的相关分析中( ) A.X 是随机变量,Y 是非随机变量 B.Y 是随机变量,X 是非随机变量 C.X 和Y 都是随机变量 D.X 和Y 均为非随机变量 3.对于利用普通最小二乘法得到的样本回归直线,下面说法中错误的是( ) A. 0i e =∑ B.0i i e X =∑ C. 0i i eY ≠∑ D.?i i Y Y =∑∑ 4.在一元回归模型中,回归系数2β通过了显著性t 检验,表示( ) A.20β= B.2?0β≠ C.20β=,2?0β≠ D.22 ?0,0ββ≠= 5.如果X 为随机解释变量,X i 与随机误差项u i 相关,即有Cov(X i ,u i )≠0,则普通最小二乘估计β?是( ) A .有偏的、一致的 B .有偏的、非一致的 C .无偏的、一致的 D .无偏的、非一致的 6.有关调整后的判定系数2 R 与判定系数2 R 之间的关系叙述正确的是( ) A.2 R 与2 R 均非负 B.模型中包含的解释个数越多,2 R 与2 R 就相差越小 C.只要模型中包括截距项在内的参数的个数大于1,则2 2 R R < D.2 R 有可能大于2 R 7.如果回归模型中解释变量之间存在完全的多重共线性,则最小二乘估计量( ) A .不确定,方差无限大 B.确定,方差无限大 C .不确定,方差最小 D.确定,方差最小 8.逐步回归法既检验又修正了( ) A .异方差性 B.自相关性 C .随机解释变量 D.多重共线性 9.如果线性回归模型的随机误差项存在异方差,则参数的普通最小二乘估计量是( ) A .无偏的,但方差不是最小的 B .有偏的,且方差不是最小的 C .无偏的,且方差最小 D .有偏的,但方差仍为最小 10.如果dL 简答题:1.选择工具变量的原则是什么:(1)工具变量必须与所替代的随机解释变量高度相关;(2)工具变量与随机误差项不相关(3)工具变量与其它解释变量不相关,避免出现多重共线性。 2.实际经济问题中的多重共线性 (1)经济变量的趋同性(2)滞后变量的引入(3)样本资料的限制 3.序列相关性产生的原因: (1)惯性;(2)模型设定误差;(3)蛛网现象;(4)数据加工。 4、随机解释变量问题及其解决方法。如果存在一个或多个随机变量作为解释变量,则称原模型出现随机解释变量问题。第一、随机解释变量与误差项相互独立;第二、随机解释变量与误差项同期无关,而异期相关;第三、随机解释变量与误差项同期相关;第四、解决方法为工具变量法。 5.随机解释变量产生的后果 1.若相互独立,则参数估计量仍然无偏一致。2 若同期相关,异期不相关,得到的参数估计有偏,但却是一致的3 若同期相关,则估计量有偏且非一致。 6.简述最小二乘估计量的性质:(1)线性性,即它是否是另一随机变量的线性函数;(2)无偏性,即它的均值或期望值是否等于总体的真实值;(3)有效性,即它是否在所有线性无偏估计量中具有最小方差。(4)渐近无偏性,即样本容量趋于无穷大时,是否它的均值序列趋于总体真值;(5)一致性,即样本容量趋于无穷大时,它是否依概率收敛于总体的真值;(6)渐近有效性,即样本容量趋于无穷大时,是否它在所有的一致估计量中具有最小的渐近方差。 7、虚拟变量的作用:(1)表现定性因素对被解释变量的影响(2)提高模型的说明能力与水平(3)季节变动分析。(4)方程差异性检验。 8、虚拟变量设置的原则:如果有定性因素共有个结果需要区别,那么至多引入m-1 个虚拟变量 9、实际经济问题中的多重共线性:(1)经济变量的趋同性(2)滞后变量的引入(3)样本资料的限制 10.引入随机误差形式为了:(1)代表未知的影响因素(2)代表残缺数据(3)代表众多细小的影响因素(4)代表数据观测误差(5)代表模型设定误差(6)变量的随机存在性 11. 12.回归分析的主要内容有:(1)根据样本观测值对经济计量模型参数进行估计,求得回归方程(2)对回归方程、参数估计值进行显著性检验(3)利用回归方程进行分析、评价及预测。 13.叙述原理:最小二乘法:当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得模型能最好的的拟合样本数据:最大似然法:当从模型的总体随机抽取n组样本观测值后,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大。在满足一系列基本假设的情况下,模型结构参数的最大或然估计量与普通最小二乘估计量是相同的。 《计量经济学》综合练习题 一、单项选择题 1.对联立方程模型进行参数估计的方法可以分两类,即:( ) A.间接最小二乘法和系统估计法 B.单方程估计法和系统估计法 C.单方程估计法和二阶段最小二乘法 D.工具变量法和间接最小二乘法 2.当模型中第i个方程是不可识别的,则该模型是( ) A.可识别的 B.不可识别的 C.过度识别 D.恰好识别 3.结构式模型中的每一个方程都称为结构式方程,在结构方程中,解释变量可以是前定变量,也可以是( ) A.外生变量 B.滞后变量 C.内生变量 D.外生变量和内生变量 4.已知样本回归模型残差的一阶自相关系数接近于-1,则DW统计量近似等于 ( ) A.0 B.1 C.2 D.4 5.假设回归模型为其中Xi为随机变量,Xi与Ui相关则的普通最小二乘估计量( ) A.无偏且一致 B.无偏但不一致 C.有偏但一致 D.有偏且不一致 6.对于误差变量模型,模型参数的普通最小二乘法估计量是( ) A.无偏且一致的 B.无偏但不一致 C.有偏但一致 D.有偏且不一致 7.戈德菲尔德-匡特检验法可用于检验( ) A.异方差性 B.多重共线性 C.序列相关 D.设定误差 8.对于误差变量模型,估计模型参数应采用( ) A.普通最小二乘法 B.加权最小二乘法 C.广义差分法 D.工具变量法 9.系统变参数模型分为( ) A.截距变动模型和斜率变动模型 B.季节变动模型和斜率变动模型 C.季节变动模型和截距变动模型 D.截距变动模型和截距、斜率同时变动模型 10.虚拟变量( ) A.主要来代表质的因素,但在有些情况下可以用来代表数量因素 B.只能代表质的因素 C.只能代表数量因素 D.只能代表季节影响因素计量经济学试题
计量经济学练习题答案完整
《计量经济学》-谢识予-分章练习题
计量经济学期末考试题库(完整版)及答案
计量经济学简答题及答案
计量经济学课后习题答案汇总
计量经济学课后习题答案
计量经济学 模拟考试题(第1套)
计量经济学简答题及答案43378
计量经济学简答题整理版
《计量经济学》综合练习题
计量经济学期末考试试题-是模拟试卷
计量经济学简答
《计量经济学》综合练习题
相关主题
文本预览