
利用回归分析对金属的含量在矿脉中的分布的研究
摘要
本文主要采用先利用Spss16.0分别画出x 关于y 的散点图,判断两者的线性关系,我们将采用回归分析和方差分析,用统计分析决定其拟合程度并作出修正。 通过观察散点图我们可以得出两者具有很明显的线性关系,因此作出假设模型
01y x ββ=+,利用Matlab7.6编写程序(见附录一)得出模型合理的结果,紧接着通过观察残差分布图(见附录二)发现第一组数据不合理,因此我们对其进行剔除,并对剔除后的数据进行重新统计分析,得出剔除第一组数据后的模型更合理的结果。
关键词:回归分析 残差分析
一、 问题重述
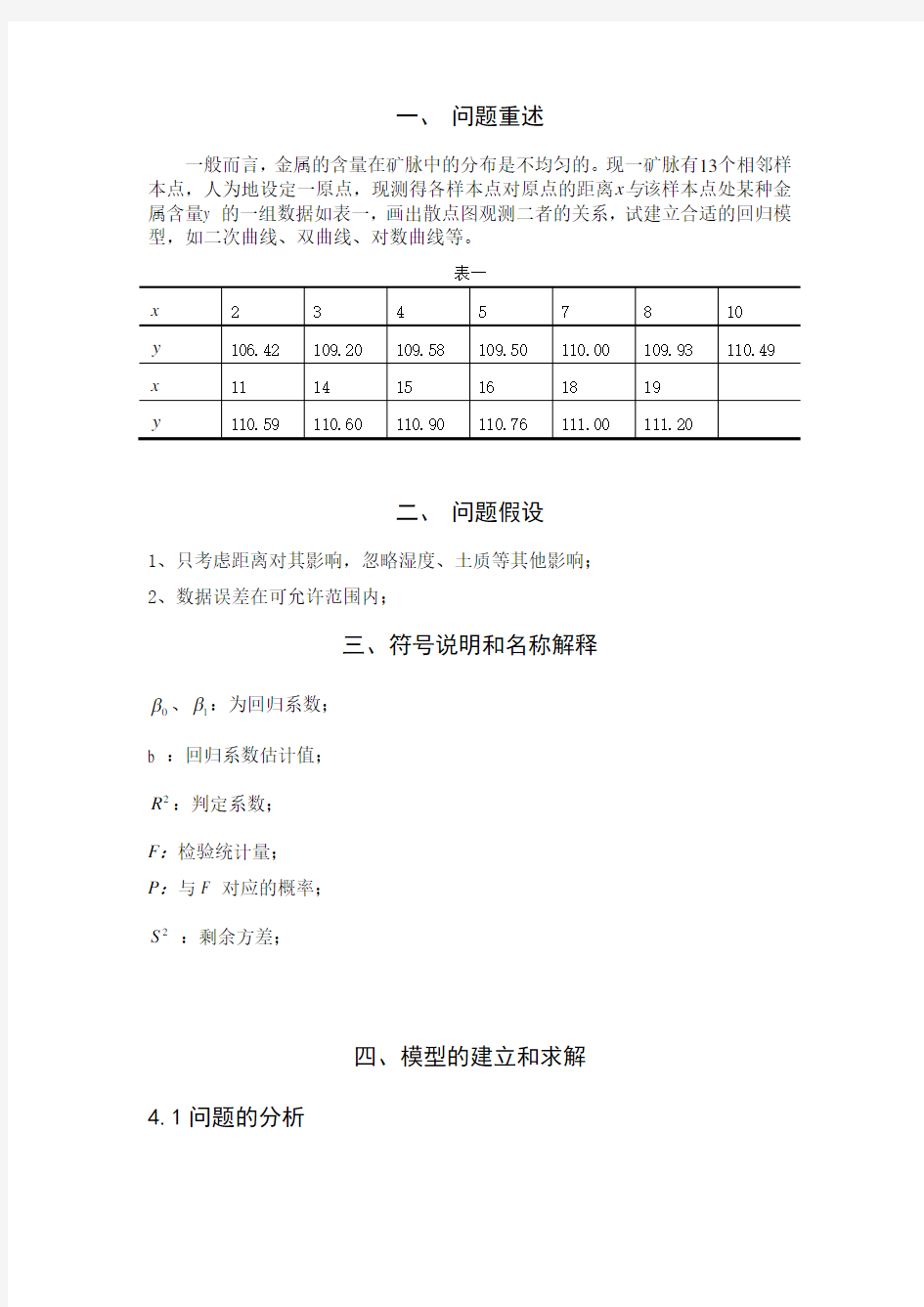
一般而言,金属的含量在矿脉中的分布是不均匀的。现一矿脉有13个相邻样本点,人为地设定一原点,现测得各样本点对原点的距离x 与该样本点处某种金属含量y 的一组数据如表一,画出散点图观测二者的关系,试建立合适的回归模型,如二次曲线、双曲线、对数曲线等。
表一
二、 问题假设
1、只考虑距离对其影响,忽略湿度、土质等其他影响;
2、数据误差在可允许范围内;
三、符号说明和名称解释
0β、1β:为回归系数;
b :回归系数估计值;
2R :判定系数;
F :检验统计量; P :与F 对应的概率;
2S :剩余方差;
四、模型的建立和求解
4.1问题的分析
题目中已经给出了各样本点对原点的距离x 与该样本点处某金属含量y 的数据表,画出散点图便可以直接明了的观察出两者是否具有线性关系。并通过观察拟合确定其回归模型。 4.2问题的求解
利用Spss16.0绘制各样本点对原点的距离x 与该样本点处某金属含量y 的散点图,结果如下:
可以看出两者具有很明显的线性关系,因此,我们建立线性回归模型: 01y x ββ=+ (1) 利用Matlab7.6编写程序(程序见附录一)可得:
b = 108.2726 0.1714
bint =107.2936 109.2517 0.0870 0.2558
stats =0.6450 19.9873 0.0009 0.602 即:0β=108.2726,
1β=0.1714, :0β的置信区间为[107.2936,109.2517],1β的置信区间
为[0.0870,0.2558], 2
R =0.6450 , F =19.9873, p =0.0009, 2
S =0.602。
4.2.1模型的检验
当2R较大时原数据的总变异基本可以由拟合值的变异来解释,并且残差较小,即拟合点与原数据吻合程度高。p =0.0009较小拒绝原假设模型不成立。因此模型(1)成立。
观察命令rcoplot(r,rint)所画的残差分布(见附录二),除第1个数据外其余残差的置信区间均包含零点,第1个点应视为异常点,将其剔除后重新计算,可得
b =109.0778
0.1140
bint =108.8292 109.3264
0.0934 0.1346
stats = 0.9382 151.7945 0.0000 0.0289
对剔除第一组后数据编写程序(程序见附录三)的观察重新计算后的残差分布图(见附录四)可以得出剔除后的数据更合理
应该用修改后的这个结果:
表二
所以模型应该为:y=109.0778+0.1140x
五、模型的分析、评价与推广
该模型简单并且拟合程度较好,可以解决一般的线性问题。只要采用的模型和数据相同,通过标准的统计方法可以计算出唯一的结果。除此之外还可以准确地计量各个因素之间的相关程度与回归拟合程度的高低,提高预测方程式的效果。
不足之处是但在图和表的形式中,数据之间关系的解释往往因人而异,不同分析者画出的拟合曲线很可能是不一样的,而且有时候在回归分析中,选用何种因子和该因子采用何种表达式只是一种推测,这影响了因子的多样性和某些因子的不可测性,使得回归分析在某些情况下受到限制[1]。
参考文献
[1]回归分析优缺点https://www.doczj.com/doc/f86450764.html,/view/b472747a168884868762d66a.html 20140824
附录
附录一、
x1=[2 3 4 5 7 8 10 11 14 15 16 18 19]';
y=[106.42 109.20 109.58 109.50 110.00 109.93 110.49 110.59 110.60 110.90 110.76 111.00 111.20]';
x=[ones(13,1),x1];
[b,bint,r,rint,stats]=regress(y,x);
b,bint,stats,rcoplot(r,rint)
附录二、
附录三、
x1=[3 4 5 7 8 10 11 14 15 16 18 19]';
y=[109.20 109.58 109.50 110.00 109.93 110.49 110.59 110.60 110.90 110.76 111.00 111.20]';
x=[ones(13,1),x1];
[b,bint,r,rint,stats]=regress(y,x);
b,bint,stats,rcoplot(r,rint)
附录四、
(数学建模B题) 数学建模竞赛阅卷中的问题 参赛队员:梁俊元(10044124,信息工程学院) 张育榕(10044139,信息工程学院) 余景荣(11044127,信息工程学院)参赛时间:2012年8月25 - 28日
承诺书 我们仔细阅读了中国大学生数学建模竞赛的竞赛规则. 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们将受到严肃处理。 我们参赛选择的题号是(从A/B/C/D 中选择一项填写):B 所属学校(请填写完整的全名):南昌航空大学 参赛队员:1、梁俊源 2、张育榕 3、余景荣 日期:2012 年8月25日-28日
目录 1.摘要 -----------------------------------------4 2.关键词 ---------------------------------------4 3.问题重述 ---------------------------------------5 4.模型的条件和假设 ------------------------------5 5.符号说明 --------------------------------------5 6.问题的分析及模型的建立 ------------------------6 6.1问题一的分析与求解 -----------------------6 6.2问题二的分析与求解 -----------------------10 6.3问题三的分析与求解 -----------------------18 6.4问题死的求解 -----------------------------21 7.模型的评价 ------------------------------------23 8.参考文献 --------------------------------------23 9.附录 ------------------------------------------23
数学模型按照不同的分类标准有许多种类: 1。按照模型的数学方法分,有几何模型,图论模型,微分方程模型.概率模型,最优控制模型,规划论模型,马氏链模型. 2。按模型的特征分,有静态模型和动态模型,确定性模型和随机模型,离散模型和连续性模型,线性模型和非线性模型. 3.按模型的应用领域分,有人口模型,交通模型,经济模型,生态模型,资源模型。环境模型。 4.按建模的目的分,有预测模型,优化模型,决策模型,控制模型等。 5.按对模型结构的了解程度分,有白箱模型,灰箱模型,黑箱模型。 数学建模的十大算法: 1.蒙特卡洛算法(该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟可以来检验自己模型的正确性,比较好用的算法。) 2.数据拟合、参数估计、插值等数据处理算法(比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用matlab作为工具。) 3.线性规划、整数规划、多元规划、二次规划等规划类问题(建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用lingo、lingdo软件实现) 4.图论算法(这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。) 5.动态规划、回溯搜索、分治算法、分支定界等计算机算法(这些算法是算法设计中比较常用的方法,很多场合可以用到竞赛中) 6.最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法(这些问题时用来解决一些较困难的最优化问题的算法,对于有些问题非常有帮助,但是算法的实现比较困难,需谨慎使用) 7.网格算法和穷举法(当重点讨论模型本身而情史算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具) 8.一些连续离散化方法(很多问题都是从实际来的,数据可以是连续的,而计算机只认得是离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。
数学建模中的图论方法 一、引言 我们知道,数学建模竞赛中有问题A和问题B。一般而言,问题A是连续系统中的问题,问题B是离散系统中的问题。由于我们在大学数学教育内容中,连续系统方面的知识的比例较大,而离散数学比例较小。因此很多人有这样的感觉,A题入手快,而B题不好下手。 另外,在有限元素的离散系统中,相应的数学模型又可以划分为两类,一类是存在有效算法的所谓P类问题,即多项式时间内可以解决的问题。但是这类问题在MCM中非常少见,事实上,由于竞赛是开卷的,参考相关文献,使用现成的算法解决一个P类问题,不能显示参赛者的建模及解决实际问题能力之大小;还有一类所谓的NP问题,这种问题每一个都尚未建立有效的算法,也许真的就不可能有有效算法来解决。命题往往以这种NPC问题为数学背景,找一个具体的实际模型来考验参赛者。这样增加了建立数学模型的难度。但是这也并不是说无法求解。一般来说,由于问题是具体的实例,我们可以找到特殊的解法,或者可以给出一个近似解。 图论作为离散数学的一个重要分支,在工程技术、自然科学和经济管理中的许多方面都能提供有力的数学模型来解决实际问题,所以吸引了很多研究人员去研究图论中的方法和算法。应该说,我们对图论中的经典例子或多或少还是有一些了解的,比如,哥尼斯堡七桥问题、中国邮递员问题、四色定理等等。图论方法已经成为数学模型中的重要方法。许多难题由于归结为图论问题被巧妙地解决。而且,从历年的数学建模竞赛看,出现图论模型的频率极大,比如: AMCM90B-扫雪问题; AMCM91B-寻找最优Steiner树; AMCM92B-紧急修复系统的研制(最小生成树) AMCM94B-计算机传输数据的最小时间(边染色问题) CMCM93B-足球队排名(特征向量法) CMCM94B-锁具装箱问题(最大独立顶点集、最小覆盖等用来证明最优性) CMCM98B-灾情巡视路线(最优回路) 等等。这里面都直接或是间接用到图论方面的知识。要说明的是,这里图论只是解决问题的一种方法,而不是唯一的方法。 本文将从图论的角度来说明如何将一个工程问题转化为合理而且可求解的数学模型,着重介绍图论中的典型算法。这里只是一些基础、简单的介绍,目的在于了解这方面的知识和应用,拓宽大家的思路,希望起到抛砖引玉的作用,要掌握更多还需要我们进一步的学习和实践。
数学建模常用的十大算法==转 (2011-07-24 16:13:14) 转载▼ 1. 蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。 2. 数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MA TLAB 作为工具。 3. 线性规划、整数规划、多元规划、二次规划等规划类算法。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。 4. 图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。 5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。 6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。 7. 网格算法和穷举法。两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。 8. 一些连续数据离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。 9. 数值分析算法。如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。 10. 图象处理算法。赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MA TLAB 进行处理。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 2 十类算法的详细说明 2.1 蒙特卡罗算法 大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。 举个例子就是97 年的A 题,每个零件都有自己的标定值,也都有自己的容差等级,而求解最优的组合方案将要面对着的是一个极其复杂的公式和108 种容差选取方案,根本不可能去求解析解,那如何去找到最优的方案呢?随机性模拟搜索最优方案就是其中的一种方法,在每个零件可行的区间中按照正态分布随机的选取一个标定值和选取一个容差值作为一种方案,然后通过蒙特卡罗算法仿真出大量的方案,从中选取一个最佳的。另一个例子就是去年的彩票第二问,要求设计一种更好的方案,首先方案的优劣取决于很多复杂的因素,同样不可能刻画出一个模型进行求解,只能靠随机仿真模拟。 2.2 数据拟合、参数估计、插值等算法 数据拟合在很多赛题中有应用,与图形处理有关的问题很多与拟合有关系,一个例子就是98 年美国赛A 题,生物组织切片的三维插值处理,94 年A 题逢山开路,山体海拔高度的插值计算,还有吵的沸沸扬扬可能会考的“非典”问题也要用到数据拟合算法,观察数据的
第11章第2题 摘要 本题分析4 种化肥和3 个小麦品种对小麦产量的影响,以及二者交互作用对小麦产量的影响,可视为两因素方差分析,即化肥和小麦品种两个因素,4种化肥可看作是化肥的四个不同水平,3个小麦品种也可以看作是小麦品种的三个不同水平。 试验的目的是分析化肥的四个不同水平以及小麦品种的三个不同水平对小麦产量有无显着性影响。 关键词:方差分析显着性化肥种类小麦品种
一.问题重述 为了分析4 种化肥和3 个小麦品种对小麦产量的影响,把一块试验田等分成36个小块,分别对3种种子和四种化肥的每一种组合种植3 小块田,产量如表1所示(单位公斤),问不同品种、不同种类的化肥及二者的交互作用对小麦产量有无显着影响。 二.问题分析 本题意在分析四种化肥和三种小麦品种对小麦产量的影响,以及二者交互作用对小麦产量的影响,为两因素方差分析问题,即化肥和小麦品种两个因素,4种化肥可看作是化肥的四个不同水平,3个小麦品种也可以看作是小麦品种的三个不同水平。通过对这两种因素的不同水平及交互作用的分析,从而分析 4 种化肥和3 个小麦品种对小麦产量的影响。 三.模型假设 1.假设只有化肥种类和小麦品种两个因素,其他因素对试验结果不构成影响。 2.假设不存在数据记录错误。 3.假设每一块试验田本身各项指标相同,不会影响结果。 四.符号说明 数字1,2,3,4——不同的化肥种类 数字1,2,3——不同的小麦品种 五.模型建立 将化肥种类和小麦品种视为两个因素,四种化肥种类看作是化肥种类的四个不同水平,三个小麦品种看作是小麦品种的三个不同水平,将表1的数据进行整理,如表2所示。
六.模型求解 将表2数据导入到spss软件中,进行两因素方差检验,得到结果如下:表3
1 预测模块:灰色预测、时间序列预测、神经网络预测、曲线拟合(线性回归); 2 归类判别:欧氏距离判别、fisher判别等; 3 图论:最短路径求法; 4 最优化:列方程组用lindo 或lingo软件解; 5 其他方法:层次分析法马尔可夫链主成分析法等; 6 用到软件:matlab lindo (lingo)excel ; 7 比赛前写几篇数模论文。 这是每年参赛的赛提以及获奖作品的解法,你自己估量着吧…… 赛题解法 93A非线性交调的频率设计拟合、规划 93B足球队排名图论、层次分析、整数规划 94A逢山开路图论、插值、动态规划 94B锁具装箱问题图论、组合数学 95A飞行管理问题非线性规划、线性规划 95B天车与冶炼炉的作业调度动态规划、排队论、图论 96A最优捕鱼策略微分方程、优化 96B节水洗衣机非线性规划 97A零件的参数设计非线性规划 97B截断切割的最优排列随机模拟、图论 98A一类投资组合问题多目标优化、非线性规划 98B灾情巡视的最佳路线图论、组合优化 99A自动化车床管理随机优化、计算机模拟 99B钻井布局0-1规划、图论 00A DNA序列分类模式识别、Fisher判别、人工神经网络 00B钢管订购和运输组合优化、运输问题 01A血管三维重建曲线拟合、曲面重建 01B 工交车调度问题多目标规划 02A车灯线光源的优化非线性规划 02B彩票问题单目标决策 03A SARS的传播微分方程、差分方程 03B 露天矿生产的车辆安排整数规划、运输问题 04A奥运会临时超市网点设计统计分析、数据处理、优化 04B电力市场的输电阻塞管理数据拟合、优化 05A长江水质的评价和预测预测评价、数据处理 05B DVD在线租赁随机规划、整数规划
一.关于参赛时间分配,竞赛共72个小时完成。 下题:今年是9月11日早上8:00在https://www.doczj.com/doc/f86450764.html,下载,9月14日早8:00交试题。 选题:这三天的时间按排基本如下:11日8:00-15:00左右选题,选题分为粗选,细选。粗选就是直观的看这两道题是否平时练习相关问题或方法的,选题要对每试题的每一问都要认真分析,大至看看基本能用哪些方法,做到心中有数,对两道题都分析后在选择自已能够容易完成的一题去做。选题的过程中要去查资料、找数据、看论文,通过这些工作,你可以发现找到的东西能否够解决你选的题。 做题:11日15点-13日22点左右。从第一天下午开始去做题,做题的过程分为问题分析,数据处理,模型建立,模型求解等,一会在下边要专门讨论。 换题:如果选题后做一些后其它问题不好处理,或者没有办法处理,有人就会想到换题,当然尽可能的不要换题,要是换题一定不能晚于11日20:00,否则就有做不完题的可能。当然也因人而宜。 写论文:最迟要在13日22:00开始,到14日凌晨5:00写完,尽可能让指导教师帮着修改。7:00打印,打印好后要仔细看一遍,有问题在修改。8:00交论文。写论文的过程贯穿于选题做题过程之中,我们在选题做题时就把做的一些东西分别处理好,只是这说的写论文就是把所做的题目的不同问题,不同部分都贯穿在一起,形成一篇有血有肉的论文。论文写作应该专门有一人在做题的过程中进行。 二、关于写论文 1.正确的论文格式: 论文属于科学性的文章,它有严格的书写格式规范,因此一篇好的论文一定要有正确的格式,就拿摘要来说吧,它要包括6 要素(问题,方法,模型,算法,结论,特色),它是一篇论文的概括,摘要的好坏将决定你的论文是否吸引评委的目光,但听阅卷老师说,有些论文的摘要里出现了大量的图表和程序,这都是不符合论文格式的,这种论文也不会取得好成绩,因此我们写论文时要端正态度,注意书写格式。 2、论文的写作: 论文的写作是至关重要的,其实大家最后的模型和结果都差不多,为什么有些队可以送全国,有些队可以拿省奖,而有些队却什么都拿不到,这关键在于论文的写作上面。一篇好的论文首先读上去便使人感到逻辑清晰,有条例性,能打动评委;其次,论文在语言上的表述也很重要,要注意用词的准确性;另外,一篇好的论文应有闪光点,有自己的特色,有自己的想法和思考在里面,总之,论文写作的好坏将直接影响到成绩的优劣。
数据建模目前有两种比较通用的方式1983年,数学建模作为一门独立的课程进入我国高等学校,在清华大学首次开设。1987年高等教育出版社出版了国内第一本《数学模型》教材。20多年来,数学建模工作发展的非常快,许多高校相继开设了数学建模课程,我国从1989年起参加美国数学建模竞赛,1992年国家教委高教司提出在全国普通高等学校开展数学建模竞赛,旨在“培养学生解决实际问题的能力和创新精神,全面提高学生的综合素质”。近年来,数学模型和数学建模这两个术语使用的频率越来越高,而数学模型和数学建模也被广泛地应用于其他学科和社会的各个领域。本文主要介绍了数学建模中常用的方法。 一、数学建模的相关概念 原型就是人们在社会实践中所关心和研究的现实世界中的事物或对象。模型是指为了某个特定目的将原型所具有的本质属性的某一部分信息经过简化、提炼而构造的原型替代物。一个原型,为了不同的目的可以有多种不同的模型。数学模型是指对于现实世界的某一特定对象,为了某个特定目的,进行一些必要的抽象、简化和假设,借助数学语言,运用数学工具建立起来的一个数学结构。 数学建模是指对特定的客观对象建立数学模型的过程,是现实的现象通过心智活动构造出能抓住其重要且有用的特征的表示,常常是形象化的或符号的表示,是构造刻画客观事物原型的数学模型并用以分析、研究和解决实际问题的一种科学方法。 二、教学模型的分类 数学模型从不同的角度可以分成不同的类型,从数学的角度,按建立模型的数学方法主要分为以下几种模型:几何模型、代数模型、规划模型、优化模型、微分方程模型、统计模型、概率模型、图论模型、决策模型等。 三、数学建模的常用方法 1.类比法 数学建模的过程就是把实际问题经过分析、抽象、概括后,用数学语言、数学概念和数学符号表述成数学问题,而表述成什么样的问题取决于思考者解决问题的意图。类比法建模一般在具体分析该实际问题的各个因素的基础上,通过联想、归纳对各因素进行分析,并且与已知模型比较,把未知关系化为已知关系,
数学建模中竞赛阅读中的问题 摘要 本文主要研究的是数学建模竞赛中试卷的优化配发,评分的标准化处理及对教师的评阅效果定量评价的问题. 问题一:针对试卷的随机分发问题,先利用MATLAB软件自带的randperm 函数产生一个1至500的随机矩阵,再用reshape函数对其进行重新排列成25行20列的矩阵,对矩阵y进行列列交换的变化成两个新矩阵y1与y2,构成75行20列的新矩阵z=[]2 ,1 y y,从而实现对试卷的随机分发;针对均匀性问题, ,y 以交叉数的方差作为评价任务单均匀性的评定指标,从多个随机分配方案中,选取交叉数方差最小的任务单供组委会使用. 问题二:评分的预处理需要对评阅教师的分数进行标准化,评分预处理方法是将不同的评分者变换到同一个尺度下,就是以某一位评分者的均值作为参照点,以其标准差表示距离转化为以零为参照点的标准分;然后采用均值为70标准差为10将标准分转化为百分制的标准,分这样使得标准分与原始分相差不大;最后将同一份试卷的三个标准评分的几何平均值作为该份试卷的最终标准分.将附录中的200份试卷的数据根据用Excel软件的统计与函数功能最终得到各份试卷的标准分值. 问题三:针对教师评阅效果的评价问题,本文给出两个评价标准:分别是评阅的原始成绩的可信度和评阅的原始成绩与成绩标准化合成后的最终成绩的偏差值的稳定性.对于可信度,结合评分分制,对评阅的原始成绩与成绩标准化合成后的最终成绩的差分值做百分化处理,建立可信度数学模型,得出可信度最高的有10,11,15,19,20号教师,高达96%;对于偏差值的稳定性,采用偏差值的方差来反映,得出稳定性最好的是第3号教师,稳定性较好的还有第1,7,10,11,19号教师.最后,综合可信度和偏差值的稳定性两项指标,得出评阅效果较好的教师有第1,3,10,11,15,19,20号教师,在下一次阅卷后合成成绩的时候可以考虑给他们以更大的权重. 关键词:随机数矩阵标准化参照点可信度偏差值
数学模型的分类 按模型的数学方法分: 几何模型、图论模型、微分方程模型、概率模型、最优控制模型、规划论模型、马氏链模型等 按模型的特征分: 静态模型和动态模型,确定性模型和随机模型,离散模型和连续性模型,线性模型和非线性模型等 按模型的应用领域分: 人口模型、交通模型、经济模型、生态模型、资源模型、环境模型等。 按建模的目的分: 预测模型、优化模型、决策模型、控制模型等 一般研究数学建模论文的时候,是按照建模的目的去分类的,并且是算法往往也和建模的目的对应 按对模型结构的了解程度分: 有白箱模型、灰箱模型、黑箱模型等 比赛尽量避免使用,黑箱模型、灰箱模型,以及一些主观性模型。 按比赛命题方向分: 国赛一般是离散模型和连续模型各一个,2016美赛六个题目(离散、连续、运筹学/复杂网络、大数据、环境科学、政策) 数学建模十大算法 1、蒙特卡罗算法 (该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟可以来检验自己模型的正确性,比较好用的算法) 2、数据拟合、参数估计、插值等数据处理算法 (比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用Matlab作为工具) 3、线性规划、整数规划、多元规划、二次规划等规划类问题 (建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo软件实现) 4、图论算法 (这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备)
5、动态规划、回溯搜索、分治算法、分支定界等计算机算法 (这些算法是算法设计中比较常用的方法,很多场合可以用到竞赛中) 6、最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法 (这些问题是用来解决一些较困难的最优化问题的算法,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用) 7、网格算法和穷举法 (当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具) 8、一些连续离散化方法 (很多问题都是从实际来的,数据可以是连续的,而计算机只认的是离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的) 9、数值分析算法 (如果在比赛中采用高级语言进行编程的话,那一些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用) 10、图象处理算法 (赛题中有一类问题与图形有关,即使与图形无关,论文中也应该要不乏图片的这些图形如何展示,以及如何处理就是需要解决的问题,通常使用Matlab进行处理) 算法简介 1、灰色预测模型(必掌握) 解决预测类型题目。由于属于灰箱模型,一般比赛期间不优先使用。 满足两个条件可用: ①数据样本点个数少,6-15个 ②数据呈现指数或曲线的形式 2、微分方程预测(高大上、备用) 微分方程预测是方程类模型中最常见的一种算法。近几年比赛都有体现,但其中的要求,不言而喻。学习过程中 无法直接找到原始数据之间的关系,但可以找到原始数据变化速度之间的关系,通过公式推导转化为原始数据的关系。 3、回归分析预测(必掌握) 求一个因变量与若干自变量之间的关系,若自变量变化后,求因变量如何变化; 样本点的个数有要求: ①自变量之间协方差比较小,最好趋近于0,自变量间的相关性小; ②样本点的个数n>3k+1,k为自变量的个数;
关于数学建模竞赛的一点思考、总结和建议 关于数学建模竞赛的一点思考、总结和建议 宋一凡 环境保护与安全工程学院核安全工程专业 大学生活即将结束,回顾几年的经历,数学建模竞赛留给我太多的回忆。虽然数模竞赛已经远去,但至今看到听到“三天三夜72小时”时,精神还会为之一振。在要告别数模竞赛的时候,想写一点自己零零碎碎的思考和总结,并给以后参赛的学弟学妹一点建议。 1. 关于我的数模之路 大一从学长口中知道了数模竞赛,就想参加,自学了姜启源的《数学模型》,但校赛时,队友不给力使第一次校赛不了了之,至今仍然遗憾大一时校赛未能入围;大二时,和本院的两个同学组队,比我高一级的闯哥给了不少经验和资料,经过暑假的培训和多次模拟赛训练,12年国赛拿到了湖南赛区的三等奖。 13年寒假,留在学校参加美赛,偌大的宿舍楼空无一人,好不凄凉,南方湿冷的冬天让我这个北方人冻得难以忍受,搞完比赛回到家时已经是腊月二十七夜里,美赛S奖使我很失落,也从中找到了自己的很多不足之处。 因今年考研,本不愿参加国赛,但两位新队友的盛情邀请让我不忍拒绝,于是重新组队,再战国赛,一雪前耻,最后拿到国家一等奖,为大学的数模之路画上一个圆满的句号。 从大一到现在,关于数模的比赛,热身赛、校赛、模拟赛、国赛、美赛,大大小小不记得参加过多少次,也不知道熬过了多少个“72小时”。建模、程序员、写手,三个角色的工作我都认认真真做过,饱尝里面的酸甜苦辣,一步一个脚印走来,最后得到一个不错的成绩,收获颇多,感触颇深。 数模给我打开了一扇窗,窗外的世界带给我不一样的精彩,而不仅仅是拿几张证书,加几分综测。外人看来,数模痛苦、费人,而我感觉数模自由、快乐。尤其是竞赛结束,早上八点交卷的时刻,经过三天三夜的努力,队友通力合作,从第一天的一筹莫展,到最后一天的顺利解决,疲惫、兴奋、满足、急切、不安,很多的感受一时涌上心头,那是只有真正参加比赛的人才能体会到的快乐! 2. 关于数学建模竞赛的作用 在做一件事情之前总会去思考做成这件事情有什么好处,这样的心里再正常不过了。而数模竞赛这种需要投入很多时间和精力的事情,更需要好好决定下是否要参加。指导老师说:数模“费时间,强意志,提能力”,我以自己的经历来讲下数模竞赛的作用。 2.1 对自身能力的提高 参加数模竞赛可以提高自身能力,这一点是毋庸置疑的,全国数模竞赛组委会的网站上都有写“一次参赛,终生受益”。可能一两次的比赛看不出来,经过多次竞赛的锻炼,与没有经过
按模型的数学方法分: 几何模型、图论模型、微分方程模型、概率模型、最优控制模型、规划论模型、马氏链模型等 按模型的特征分: 静态模型和动态模型,确定性模型和随机模型,离散模型和连续性模型,线性模型和非线性模型等 按模型的应用领域分: 人口模型、交通模型、经济模型、生态模型、资源模型、环境模型等。 按建模的目的分: 预测模型、优化模型、决策模型、控制模型等 一般研究数学建模论文的时候,是按照建模的目的去分类的,并且是算法往往也和建模的目的对应 按对模型结构的了解程度分: 有白箱模型、灰箱模型、黑箱模型等 比赛尽量避免使用,黑箱模型、灰箱模型,以及一些主观性模型。 按比赛命题方向分: 国赛一般是离散模型和连续模型各一个,2016美赛六个题目(离散、连续、运筹学/复杂网络、大数据、环境科学、政策) 数学建模十大算法 1、蒙特卡罗算法 (该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟可以来检验自己模型的正确性,比较好用的算法) 2、数据拟合、参数估计、插值等数据处理算法 (比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用Matlab作为工具)
3、线性规划、整数规划、多元规划、二次规划等规划类问题 (建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo软件实现) 4、图论算法 (这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备) 5、动态规划、回溯搜索、分治算法、分支定界等计算机算法 (这些算法是算法设计中比较常用的方法,很多场合可以用到竞赛中) 6、最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法 (这些问题是用来解决一些较困难的最优化问题的算法,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用) 7、网格算法和穷举法 (当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具) 8、一些连续离散化方法 (很多问题都是从实际来的,数据可以是连续的,而计算机只认的是离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的) 9、数值分析算法 (如果在比赛中采用高级语言进行编程的话,那一些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用)10、图象处理算法 (赛题中有一类问题与图形有关,即使与图形无关,论文中也应该要不乏图片的这些图形如何展示,以及如何处理就是需要解决的问题,通常使用Matlab进行处理) 算法简介 1、灰色预测模型(必掌握)
在数学建模中常用的方法:类比法、二分法、量纲分析法、差分法、变分法、图论法、层次分析法、数据拟合法、回归分析法、数学规划(线性规划,非线性规划,整数规划,动态规划,目标规划)、机理分析、排队方法、对策方法、决策方法、模糊评判方法、时间序列方法、灰色理论方法、现代优化算法(禁忌搜索算法,模拟退火算法,遗传算法,神经网络)。 用这些方法可以解下列一些模型:优化模型、微分方程模型、统计模型、概率模型、图论模型、决策模型。拟合与插值方法(给出一批数据点,确定满足特定要求的曲线或者曲面,从而反映对象整体的变化趋势):matlab可以实现一元函数,包括多项式和非线性函数的拟合以及多元函数的拟合,即回归分析,从而确定函数;同时也可以用matlab实现分段线性、多项式、样条以及多维插值。 在优化方法中,决策变量、目标函数(尽量简单、光滑)、约束条件、求解方法是四个关键因素。其中包括无约束规则(用fminserch、fminbnd实现)线性规则(用linprog实现)非线性规则、(用fmincon实现)多目标规划(有目标加权、效用函数)动态规划(倒向和正向)整数规划。 回归分析:对具有相关关系的现象,根据其关系形态,选择一个合适的数学模型,用来近似地表示变量间的平均变化关系的一种统计方法(一元线性回归、多元线性回归、非线性回归),回归分析在一组数据的基础上研究这样几个问题:建立因变量与自变量之间的回归模型(经验公式);对回归模型的可信度进行检验;判断每个自变量对因变量的影响是否显著;判断回归模型是否适合这组数据;利用回归模型对进行预报或控制。相对应的有线性回归、多元二项式回归、非线性回归。 逐步回归分析:从一个自变量开始,视自变量作用的显著程度,从大到地依次逐个引入回归方程:当引入的自变量由于后面变量的引入而变得不显著时,要将其剔除掉;引入一个自变量或从回归方程中剔除一个自变量,为逐步回归的一步;对于每一步都要进行值检验,以确保每次引入新的显著性变量前回归方程中只包含对作用显著的变量;这个过程反复进行,直至既无不显著的变量从回归方程中剔除,又无显著变量可引入回归方程时为止。(主要用SAS来实现,也可以用matlab软件来实现)。 聚类分析:所研究的样本或者变量之间存在程度不同的相似性,要求设法找出一些能够度量它们之间相似程度的统计量作为分类的依据,再利用这些量将样本或者变量进行分类。 系统聚类分析—将n个样本或者n个指标看成n类,一类包括一个样本或者指标,然后将性质最接近的两类合并成为一个新类,依此类推。最终可以按照需要来决定分多少类,每类有多少样本(指标)。 系统聚类方法步骤: 1.计算n个样本两两之间的距离 2.构成n个类,每类只包含一个样品 3.合并距离最近的两类为一个新类 4.计算新类与当前各类的距离(新类与当前类的距离等于当前类与组合类中包含的类的距离最小值), 若类的个数等于1,转5,否则转3 5.画聚类图 6.决定类的个数和类。 判别分析:在已知研究对象分成若干类型,并已取得各种类型的一批已知样品的观测数据,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类。 距离判别法—首先根据已知分类的数据,分别计算各类的重心,计算新个体到每类的距离,确定最短的距离(欧氏距离、马氏距离) Fisher判别法—利用已知类别个体的指标构造判别式(同类差别较小、不同类差别较大),按照判别式的值判断新个体的类别 Bayes判别法—计算新给样品属于各总体的条件概率,比较概率的大小,然后将新样品判归为来自概率最大的总体 模糊数学:研究和处理模糊性现象的数学(概念与其对立面之间没有一条明确的分界线)与模糊数学相关的问题:模糊分类问题—已知若干个相互之间不分明的模糊概念,需要判断某个确定事物用哪一个模糊概念来反映更合理准确;模糊相似选择—按某种性质对一组事物或对象排序是一类常见的问题,但是用来比
数学竞赛中的图论问题
分类号密级 U D C 编号 本科毕业论文(设计) 题目数学竞赛中的图论问题 所在院系数学与数量经济学院 专业名称数学与应用数学 年级 08级 学生姓名李曼 学号 0850410013 指导教师孙静
二 0一二年三月 学位论文原创性声明 本人郑重声明:所呈交的论文是本人在孙静老师的指导下独立进行研究所取得的研究成果. 除了文中特别加以标注引用的内容外,本论文不包含任何其他个人或集体已经发表或撰写的成果作品.本人完全意识到本声明的法律后果由本人承担. 作者:
日期:2012年3月29日 文献综述 一综述 在18世纪30年代,一个非常有趣的问题引起了欧洲数学家的浓厚兴趣,这个问题就是著名的哥尼斯堡七桥问题,即要求遍历哥尼斯堡七桥中的每一座桥恰好一次后回到出发点. 欧拉证明这是不可能完成的. 此后,欧拉发表了著名的论文《依据集合位置的阶梯方法》,这是图论领域的第一篇论文,标志着图论的诞生. 图论的真正发展始于20世纪五六十年代之间,是一门既古老又年轻的学科. 图论极有趣味性,严格来讲,它是组合数学的一个重要分支. 虽然图论只是研究点和线的学科,但是它的应用领域十分广泛,不仅局限于数学和计算机学科,还涵盖了社会学、交通管理等. 总的来说,图论这门科学具有以下特点:(1)图论蕴含了丰富的思想、漂亮的图形和巧妙的证明; (2)涉及的问题多且广泛,问题表明上简单朴素,本质上却十分深刻复杂; (3)解决问题的方法千变万化,非常灵活,常常是一种问题一种解法. 由以上三个特点可以看出,图论与其他的数学分支不同,它不像群论、拓扑等学科那样有一套完整的体系和解决问题的系统. 而且图论所研究的内容非常广泛,如图的连通性、遍历性、图的着色、图的可平面性等等. 二内容 由于图论具有蕴含了丰富的思想、漂亮的图形和巧妙的证明,涉及的问题多且广泛,问题表面上简单朴素,本质上却十分深刻复杂,解决问题的方法千变万化,非常灵活,常常是一种问题一种解法的特点. 随着数学竞赛越来越规范化,并且越来越考察考生的灵活运用知识的能力. 因此近年来,图论问题频繁的出现在数学竞赛中,如典型的一笔画问题、中国邮递员问题、旅游推销员问题、排课表问题等.
§1 最小生成树 1.1 生成树的概念 设图G=(V,E)是一个连通图,当从图中任一顶点出发遍历图G时,将边集E(G)分成两个集合A(G)和B(G)。其中A(G)是遍历图时所经过的边的集合,B(G)是遍历图时未经过的边的集合。显然,G1=(V,A)是图G的子图,则称子图G1是连通图G的生成树。图的生成树不是惟一的。如对图1(a),当按深度和广度优先搜索法进行遍历就可以得到图1中(b)和(c)的两棵不同的生成树,并分别称之为深度优先生成树和广度优先生成树。 对于有n个顶点的连通图,至少有n-1条边,而生成树中恰好有n-1条边,所以连通图的生成树是该图的极小连通子图。若图G的生成树中任意加一条边属于边集B(G)中的边,则必然形成回路。 求解生成树在许多领域有实际意义。例如,对于供电线路或煤气管道的铺设问题,即假设要把n个城市联成一个供电或煤气管道网络,则需要铺设n-1条线路。任意两城市间可铺设一条线路,n个城市间最多可能铺设n(n-1)/2条线路,各条线路的造价一般是不同的。一个很实际的问题就是如何在这些可能的线路中选择n-1条使该网络的建造费用最少,这就是下面要讨论的最小生成树问题。 1.2 网的最小生成树 在前面我们已经给出图的生成树的概念。这里来讨论生成树的应用。 假设,要在n个居民点之间敷设煤气管道。由于,在每一个居民点与其余n-1个居民点之间都可能敷设煤气管道。因此,在n个居民点之间,最多可能敷设n(n-1)/2条煤气管道。然而,连通n个居民点之间的管道网络,最少需要n-1条管道。也就是说,只需要n-1条管道线路就可以把n个居民点间的煤气管道连通。另外,还需进一步考虑敷设每一条管道要付出的经济代价。这就提出了一个优选问题。即如何在n(n-1)/2条可能的线路中优选n-1条线路,构成一个煤气管道网络,从而既能连通n个居民点,又能使总的花费代价最小。 解决上述问题的数学模型就是求图中网的最小生成树问题。把居民点看作图的顶点,把居民点之间的煤气管道看作边,而把敷设各条线路的代价当作权赋给相应的边。这样,便构成一个带权的图,即网。对于一个有n个顶点的网可以生成许多互不相同的生成树,每一棵生成树都是一个可行的敷设方案。现在的问题是应寻求一棵所有边的权总和为最小的生成树。
数学建模应该注意的一些事项 一、序 数学建模比赛已经成为当今各个高校每年必参加的活动。要想在比赛中取得比较好的成绩,尤其是在全国赛中取得好成绩经验第一,运气第二,实力第三,这种说法是功利了点,但是在现在中国这种科研浮躁的大环境中要在全国赛中取得好成绩经验是首要的。全国赛注重“稳”,与参考答案越接近,文章通顺就可以有好成绩了,在数模竞赛中经验会告诉我们该怎么选题,怎么安排时间,怎么控制进度,知道什么是最重要的,该怎么写论文......,或许有人会认为选题也需要经验吗?选题是有技巧的,选个好题成功的机会就大的多,选题不能一味的根据自己的兴趣或能力去选,还要和全体参赛队互动下,不大容易做到,只能是在极小的范围内做到,分析下选这个题的利弊后决定选哪个题,这里面学问也不少。希望自己总结的一些经验能帮助大家能尽快的成长,尽快的发挥自己的能力,体验数学在应用中的作用,爱上数学,甚至和数学打一辈子交道。 二、组队和分工 数学建模竞赛是三个人的活动,参加竞赛首要是要组队,而怎么样组队是有讲究的。此外还需要分工等等一般的组队情况是和同学组队,很多情况是三个人都是同一系,同一专业以及一个班的,这样的组队是不合理的。让三人一组参赛一是为了培养合作精神,其实更为重要的原因是这项工作需要多人合作,因为人不是万能的,掌握知识不是全面的,当然不排除有这样的牛人存在,事实上也是存在的,什么都会,竞赛可以一个人独立搞定。但既然允许三个人组队,有人帮忙总是好的,至少不会太累。而三个人同系同专业甚至同班的话大家的专业知识一样,如果碰上专业知识以外的背景那会比较麻烦的。所以如果是不同专业组队则有利的多。众所周知,数学建模特别需要数学和计算机的能力,所以在组队的时候需要优先考虑队中有这方面才能的人,根据现在的大学专业培养信息与计算科学,应用数学专业的较为有利,尤其是信息与计算科学可以说是数学和计算机专业的结合,两方面都有兼顾,虽然说这个专业的出路不是很好,数学和计算机都涉及点但是都没有真正的学通这两门专业的,但对于弄数学建模来说是再合适不过了。应用数学则偏重于数,但是一般来讲玩计算机的时
图论 一.最短路问题 问题描述:寻找最短路径就是在指定网络中两结点间找一条距离最小的路。最短路不仅仅指一般地理意义上的距离最短,还可以引申到其它的度量,如时间、费用、线路容量等。 将问题抽象为赋权有向图或无向图G ,边上的权均非负 对每个顶点定义两个标记(()l v ,()z v ),其中: ()l v :表示从顶点到v 的一条路的权 ()z v :v 的父亲点,用以确定最短路的路线 S :具有永久标号的顶点集 1.1Dijkstra 算法:即在每一步改进这两个标记,使最终()l v 为最短路的权 输入:G 的带权邻接矩阵(,)w u v 步骤: (1) 赋初值:令0()0l u =,对0v u ≠,令 ()l v =∞,0={u }S ,0i = 。 (2) 对每个(\)i i i v S S V S ∈= (即不属于上 面S 集合的点),用min{(),()()}i u S l v l u w uv ∈+ 代替()l v ,这里()w uv 表示顶点u 和v 之间边的权值。计算min{()}i u S l v ∈,把达到这个最小值的一个顶点记为1i u +,令11{}i i i S S u ++=?。 (3) 若1i V =-,则停止;若1i V <-,则 用1i +代替i ,转(2) 算法结束时,从0u 到各顶点v 的距离由v 的最后一次编号()l v 给出。在v 进入i S 之前的编号()l v 叫T 标号,v 进入i S 之后的编号()l v 叫P 标号。算法就是不断修改各顶点的T 标号,直至获得P 标号。若在算法运行过程中,将每一顶点获得P 标号所由来的边在图上标明,则算法结束时,0u 至各顶点的最短路也在图上标示出来了。 理解:贪心算法。选定初始点放在一个集合里,此时权值为0初始点搜索下一个相连接点,将所有相连接的点中离初始点最近的点纳入初始点所在的集合,并更新权值。然后以新纳入的点为起点继续搜索,直到所有的点遍历。
数学建模图论问题 B题灾情巡视路线 下图为某县的乡(镇)、村公路网示意图,公路边的数字为该路段的公里数。 今年夏天该县遭受水灾。为考察灾情、组织自救,县领导决定,带领有关部门负责人到全县各乡(镇)、村巡视。巡视路线指从县政府所在地出发,走遍各乡(镇)、村,又回到县政府所在地的路线。 1.若分三组(路)巡视,试设计总路程最短且各组尽可能均衡的巡视路线。 2.假定巡视人员在各乡(镇)停留时间T=2小时,在各村停留时间t=1小时,汽车行 驶速度V=35公里/小时。要在24小时内完成巡视,至少应分几组;给出这种分组下你认为最佳的巡视路线。 3.在上述关于T , t和V的假定下,如果巡视人员足够多,完成巡视的最短时间是多少; 给出在这种最短时间完成巡视的要求下,你认为最佳的巡视路线。 4.若巡视组数已定(如三组),要求尽快完成巡视,讨论T,t和V改变对最佳巡视路线 的影响。 B题:乘公交,看奥运 我国人民翘首企盼的第29届奥运会明年8月将在北京举行,届时有大量观众到现场观看奥运比赛,其中大部分人将会乘坐公共交通工具(简称公交,包括公汽、地铁等)出行。这些年来,城市的公交系统有了很大发展,北京市的公交线路已达800条以上,使得公众的出行更加通畅、便利,但同时也面临多条线路的选择问题。针对市场需求,某公司准备研制开发一个解决公交线路选择问题的自主查询计算机系统。 为了设计这样一个系统,其核心是线路选择的模型与算法,应该从实际情况出发考虑,满足查询者的各种不同需求。请你们解决如下问题: 1、仅考虑公汽线路,给出任意两公汽站点之间线路选择问题的一般数学模型与算法。并根据附录数据,利用你们的模型与算法,求出以下6对起始站→终到站之间的最佳路线(要有清晰的评价说明)。 (1)、S3359→S1828 (2)、S1557→S0481 (3)、S0971→S0485 (4)、S0008→S0073 (5)、S0148→S0485 (6)、S0087→S3676 2、同时考虑公汽与地铁线路,解决以上问题。 3、假设又知道所有站点之间的步行时间,请你给出任意两站点之间线路选择问题的数学模型。 【附录1】基本参数设定 相邻公汽站平均行驶时间(包括停站时间):3分钟 相邻地铁站平均行驶时间(包括停站时间): 2.5分钟 公汽换乘公汽平均耗时:5分钟(其中步行时间2分钟) 地铁换乘地铁平均耗时:4分钟(其中步行时间2分钟)