第11章聚类分析
聚类分析(CLUSTER)是将样本或变量进行分类的一种方法。
通常用相似性指标“距离”和“相似系数”来衡量研究对象的联系紧密程度,从而进行合理分类。“距离”常用来对样本分类,即把每一个样本看作是m维空间(若样本被m个变量所描述)的一个点,把距离较近的点归为一类,距离较远的点归为不同的类。“相似系数”用来对变量分类,将变量间相似系数较大的归为一类,较小的归为不同类。
第一节距离和相似系数
一、距离
1、“欧几里得”距离
A和B两点由m个变量所描述,其坐标分别是(x
1,x
2
,…,x
m
)和(y
1
,y
2
,…,y
m
),
那么d(A,B)=
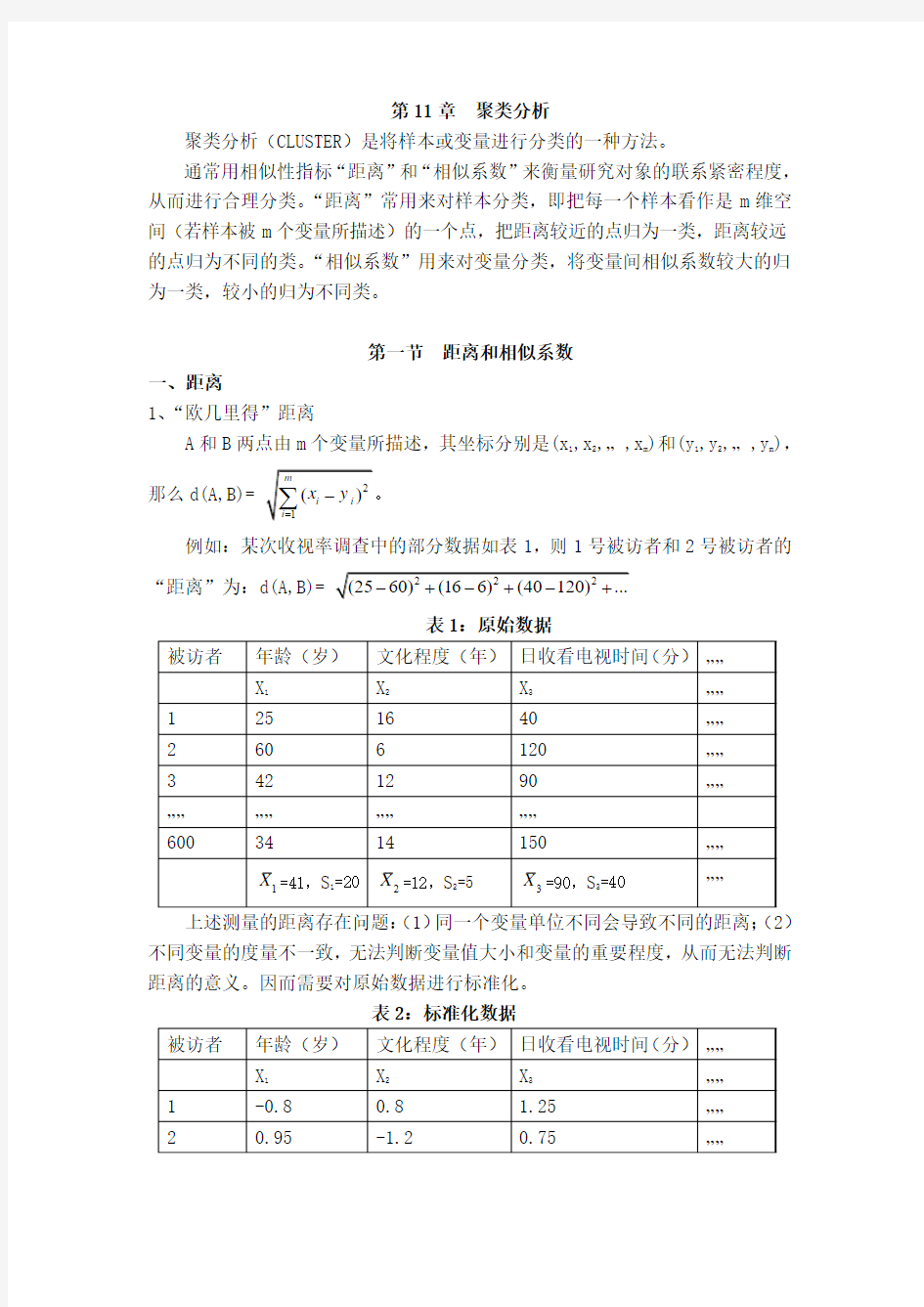
例如:某次收视率调查中的部分数据如表1,则1号被访者和2号被访者的
“距离”为:d(A,B)=
表1:原始数据
上述测量的距离存在问题:(1)同一个变量单位不同会导致不同的距离;(2)不同变量的度量不一致,无法判断变量值大小和变量的重要程度,从而无法判断距离的意义。因而需要对原始数据进行标准化。
表2:标准化数据
2、SPSS 聚类分析中提供的距离
(1)欧式距离(EUCLID ) (2)欧式距离的平方(SEUCLID ),等于变量差2+变量差2+…… (3)曼哈顿距离(BLOCK ),等于变量差的绝对值之和
(4)切比雪夫距离(CHEBYCHEV ),等于变量差中绝对值最大者
(5)幂距离POWER(p,r),等于变量差的绝对值的p 次方之和,再求r 方根。 2、相似系数
(1)变量间的相关系数即皮尔逊相关系数;
(2)变量间的夹角余弦,即将两变量分别看成n 维空间的向量时的夹角余弦值。
相关系数一般针对定距变量,对于定类变量特别是二项变量也可引入虚拟变量后计算相关系数。
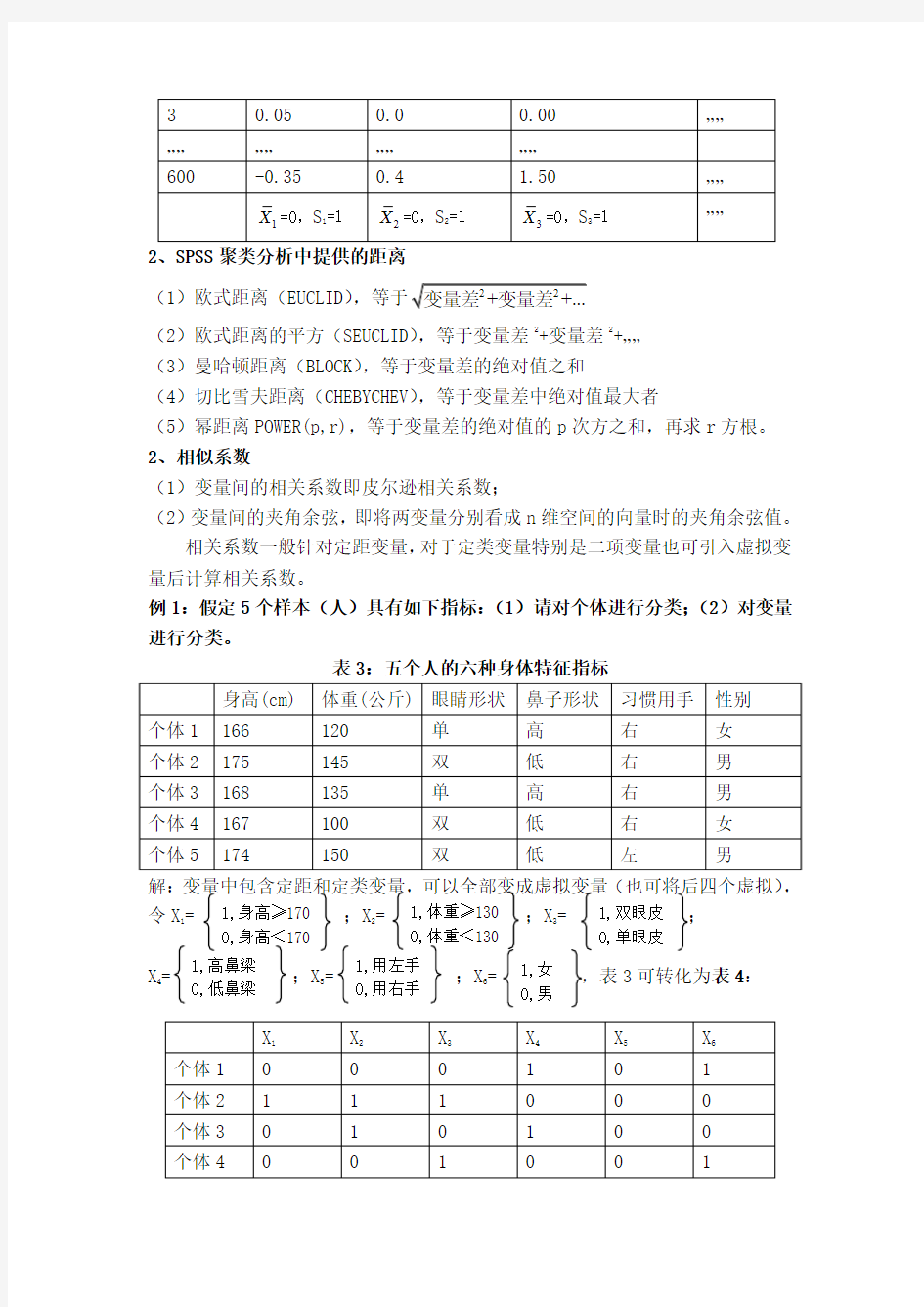
例1:假定5个样本(人)具有如下指标:(1)请对个体进行分类;(2)对变量进行分类。
表3:五个人的六种身体特征指标
解:变量中包含定距和定类变量,可以全部变成虚拟变量(也可将后四个虚拟),
令X 1=
;X 2= ;X 3= X 4= ;X 5= ;X 6=
,表3可转化为表4: 1,身高≥170 0,身高<170 1,体重≥130 0,体重<130
1,双眼皮 0,单眼皮
1,高鼻梁
0,低鼻梁
1,用左手 0,用右手
1,女 0,男
(1)根据两个个体共同特征的多少来对个体分类,以欧式距离的平方来进行聚类,个体之间的距离越小越相似,可求得:
d 2(1,2)=(0-1)2+(0-1)2+(0-1)2+(1-0)2+(0-0)2+(1-0)2=5; d 2(1,3)=(0-0)2+(0-1)2+(0-0)2+(1-1)2+(0-0)2+(1-0)2=2; d 2(1,4)=(0-0)2+(0-0)2+(0-1)2+(1-0)2+(0-0)2+(1-1)2=2;
d 2(1,5)=(0-1)2+(0-1)2+(0-1)2+(1-0)2+(0-1)2+(1-0)2=6;同理计算其他距离,得到下表:
表5:5个体间距离
根据距离大小,判断相似程度。个体2和5距离最小,最相似。1和3,1和4距离较小,较相似。如果分两类,则可分为{1,5}和{ 1,3,4}。 (2)对特征变量进行分类,先计算两个变量间的相似系数: r 12=
()()
X X X X --(0.4)(0.6)
X X --=0.6667
同理计算其它相关系数:
表6:六个变量间的相关系数
表6中出现负相关系数,不予考虑符号,仅以绝对值来表示相关程度。X 2
与X 6,X 3与X 4两对变量最相似,同时X 2和X 3、X 4,X 6和X 3、X 4之间相关系数很小,所以{ X 2,X 6}和{ X 3,X 4}是几乎不相交的两类。X 1、X 5和其它5个变量的相关关系都适中,所以二者都不宜于其它变量合并,将X 1和X 5单独归为一类。
几个注意问题:(1)对个体进行聚类时,1-1匹配和0-0匹配是完全同等看待,实际上不太合理。如两个左撇子比两个同用右手的人更相似一些。因此有时
对1-1匹配和0-0匹配区别处理,或给予不同权数。(2)此法聚类较为主观,对X 1和X 2处理较粗糙。
第二节 谱系聚类法
谱系聚类法中常用的聚集法是先将所有研究对象都各自视为一类,将最靠近的首先聚类,再将这个类和其它类中最靠近的对象结合,一直合并到所有对象都综合成一类。谱系聚类法的聚集或分割过程可以用“谱系图”直观表示出来。 一、最短距离法
两个类之间的距离定义为:两类中两两元素之间距离最小者,并依此逐次选择最靠近的类聚集的方法。例如
d{1,2,3,4}{5,6,7}= min{d 15, d 16, d 17, d 25, d 26, d 27, d 35, d 36, d 37, d 45, d 46, d 47 }= d 37
例2:假定5个对象间的距离如表9所示,用最短距离法聚类,并画出谱系图。
表7:5个对象间距离
解:将5个对象分别视为1类,最靠近的两类是2和5,因为它们间具有最小类间距离d 25=min{ 6,2,3,7,4,1,5}=1,将2和5合并为一个新类{2,5}。
其次再求出{2,5}和1,3,4的距离: d {2,5}1=min{ d 21, d 51 }= min{ 6, 7}=6 d {2,5}3=min{ d 23, d 53 }= min{ 4,5}=4 d {2,5}4=min{ d 24, d 54 }= min{ 4,5}=4
于是可以将{2,5},1,3,4这四类的距离重新做出表10(1):
表8(1):4个类间的距离
在这4类中,1和3最靠近,它们具有最小类间距离d
13
=min{ 6, 4,2,3,5}=2。将1和3合并成新类{ 1,3},再求出{ 1,3}和{ 2,5},4的距离:
d
{ 1,3}{2,5}=min{ d
1{2,5}
, d
3{2,5}
}= min{ 6, 4}=4
d
{ 1,3}4=min{ d
14
, d
34
}= min{ 3,5}=3
将{ 1,3},{ 2,5},4这三类的距离作出表10(2):
表8(2):3个类间的距离
在这三类中,最靠近的类是{ 1,3}和4,d
{ 1,3}4
=min{ 4, 3 }=3。因此可将{ 1,3}和4合并成为一个新类{ 1,3,4},这时只有两个不同的类{ 2,5}和{ 1,3,4},它
们的距离为d
{2,5}{ 1,3,4}= min{ d
{2,5}{ 1,3}
, d
{2,5}4
}= min{ 4, 4}=4。最后再将{ 2,5}
和{ 1,3,4}合并为一类,由此完成整个聚类过程。相应谱系图如图1:
图1:最短距离法谱系图
1 2 3 4 距离
2
5
1
3
4
对象
2、最长距离法
与最短距离法聚类方式相同,不同的是类与类之间的距离定义为两类中元素之间距离最大者。例如:
15161725262735, d
36
, d
37
, d
45
, d
46
, d
47
}=
d
16
例3:对例3中的相同数据用最长距离法聚类并画处谱系图:
解:首先将最靠近的2和5合并为一类,并计算{2,5}和1,3,4的距离:
d
{2,5}1= max { d
21
, d
51
}= max { 6, 7}=7
d {2,5}3= max { d 23, d 53 }= max { 4,5}=5 d {2,5}4= max { d 24, d 54 }= max { 4,5}=5
由此可以写出新的四个类间的距离如表9(1)所示。其中最靠近的是1和3,将其合并为新类{ 1,3},并计算{ 1,3}和{ 2,5},4的距离:
d { 1,3}{2,5}= max { d 1{2,5}, d 3{2,5} }= max {7,5}=7 d { 1,3}4= max { d 14, d 34 }= max { 3,5}=5
新的三类间的距离如表9(2)所示,由于两个距离都是5,因此可以合并{ 1,3}和4为一个新类,也可以合并{2,5}和4为一个新类。不管何种合并,最后新的两类间的距离都是7,如表9(3)和表9(4)。 表9(1):4个类间的距离 表9(2):3个类间的距离
表9(3):两个类间的距离 表9(4):两个类间的距离
两种聚类过程的谱系图如图3,第一种聚类结果和图1的结果一致。
图3:最长距离法谱系图(两种可能聚类结果)
1 2 3 4 5 6 7 距离 1 2 3 4 5 6 7 距离 2 2 5 5 1 4 3 1 4 3
3、中间距离法
类与类之间的距离即不取最短距离也不取最长距离,而是取某个中间的距离,即中间距离法。
G 3N
12N 3d 的平
方:33132122222211
()22
N G G G G G G G G d d d d d ==+-。采用中间距离法进行聚类时一般使
用欧式距离的平方。
最短距离法和最长距离法的优点:聚类过程是单调的,即每一步聚类时的距离都大于前一步,所以谱系图一目了然。
中间距离法的优点:空间守恒,即两个类之间的距离基本上都取中间的,即不取最短(空间收缩),也不取最长(空间扩张)。
最短距离法和最长距离法的缺点:空间不守恒。
中间距离法的缺点:非单调,有时聚类的距离小于前一步聚类时的距离,所以谱系图有时不易理解。
共同的缺点:没有考虑各类中研究对象的数量以及各样本的信息。 4、重心法——两个类之间的距离定义为两类的重心间的距离,聚类过程同前。 5、类平均法——两个类之间的距离(平方)定义为两类中的元素两两之间的平均(平方)距离。
6、变差平方和法——分类思想类似方差分析,使类内元素间的变差平方和尽可能小,类与类之间的变差平方和尽可能大。
表10:六种谱系聚类法的比较
谱系聚类法在距离的选择以及各种聚类法的选择仍带有一定主观性,因而在聚类时,可多用几种距离和方法,最后根据实际问题性质确定合适的聚类结果。除谱系聚类法外,还有非谱系聚类法和模糊聚类法等。
如果对变量进行聚类,一般先求出变量间的相似系数,按照相似系数越大变量越相似的原则,聚类过程类似样本聚类。也可将相似系数转化为距离,然后再
聚类,2,c表示两个变量间的某种相似系数,d为某种距离。
例5:24名优秀运动员的七项全能项目得分间的相关系数如表14,对这七项指标进行聚类分析。
表11:七个体育项目的相关系数
解:变量X
1和X
4
(简称1和4)的相关系数最大,先将1和4聚成一个新类{ 1,4},
然后计算{ 1,4}和变量2、3、5、6、7的相关系数:
r
2{1,4}= max { r
21
, r
24
}= max { 0.4498,0.3298}=0.4498
r
3{1,4}= max { r
31
, r
34
}= max { 0.6838,0.5675}=0.6838……
这些相关系数绘成新表12(1),其中最大的相关系数是0.8113,所以将变量5归入{ 1,4}中形成{ 1,4,5},然后求出{ 1,4,5}与变量2、3、6、7的相关系数。继续下去直到全部变量都并为一类为止(见表14(1)至14(5))。最后的谱系图(图5)说明,7个变量可分为四类:{ 1,4,5},{ 3,6},{ 7}和{ 2},即速度型项目{ 100米栏,200米,跳远},投掷型项目{铅球,标枪},耐力型项目{ 800米}和弹跳型项目{ 跳高}。表12(1)
表12(2)
表12(3)
表12(4)
表12(5)
1.0 0.9 0.8 0.7 0.6 0.5 相关系数
100米栏1
200米 4
跳远 5
铅球 3
标枪 6
800米 7
跳高 2
对象图5:7个变量的谱系图
用谱系聚类法对变量的聚类也叫做R型聚类,对样本的聚类也叫Q型聚类。
《统计分析与S P S S的应用(第五版)》(薛薇) 课后练习答案 第10章SPSS的聚类分析 1、根据“高校科研研究.sav”数据,利用层次聚类分析对各省市的高校科研情况进行层次聚类分析。要求: 1)根据凝聚状态表利用碎石图对聚类类数进行研究。 2)绘制聚类树形图,说明哪些省市聚在一起。 3)绘制各类的科研指标的均值对比图。 4)利用方差分析方法分析各类在哪些科研指标上存在显著差异。 采用欧氏距离,组间平均链锁法 利用凝聚状态表中的组间距离和对应的组数,回归散点图,得到碎石图。大约聚成4类。 步骤:分析→分类→系统聚类→按如下方式设置…… 结果: 凝聚计划 阶段 组合的集群 系数 首次出现阶段集群 下一个阶段集群 1 集群 2 集群 1 集群 2 1 26 30 328.189 0 0 2 2 26 29 638.295 1 0 7 3 20 25 1053.423 0 0 5 4 4 12 1209.922 0 0 15 5 8 20 1505.035 0 3 6 6 8 16 1760.170 5 0 9 7 24 26 1831.926 0 2 10 8 7 11 1929.891 0 0 11 9 5 8 2302.024 0 6 22 10 24 31 2487.209 7 0 22 11 2 7 2709.887 0 8 16 12 22 28 2897.106 0 0 19 13 6 23 2916.551 0 0 17 14 10 19 3280.752 0 0 25 15 4 21 3491.585 4 0 21 16 2 3 4229.375 11 0 21 17 6 13 4612.423 13 0 20 18 9 18 5377.253 0 0 25 19 14 22 5622.415 0 12 24 20 6 15 5933.518 17 0 23 21 2 4 6827.276 16 15 26 22 5 24 7930.765 9 10 24 23 6 27 9475.498 20 0 26 24 5 14 14959.704 22 19 28 25 9 10 19623.050 18 14 27 26 2 6 24042.669 21 23 28 27 9 17 32829.466 25 0 29 28 2 5 48360.854 26 24 29 29 2 9 91313.530 28 27 30 30 1 2 293834.503 0 29 0 将系数复制下来后,在EXCEL中建立工作表。 选中数据列,点击“插入”菜单→拆线图……
第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第10章SPSS的聚类分析 1、根据“高校科研研究.sav”数据,利用层次聚类分析对各省市的高校科研情况进行层次聚类分析。要求: 1)根据凝聚状态表利用碎石图对聚类类数进行研究。 2)绘制聚类树形图,说明哪些省市聚在一起。 3)绘制各类的科研指标的均值对比图。 4)利用方差分析方法分析各类在哪些科研指标上存在显著差异。 采用欧氏距离,组间平均链锁法 利用凝聚状态表中的组间距离和对应的组数,回归散点图,得到碎石图。大约聚成4类。步骤:分析分类系统聚类按如下方式设置……
结果: 凝聚计划 阶段 组合的集群 系数 首次出现阶段集群 下一个阶段集群1集群2集群1集群2 12630002 22629107 32025005 44120015 5820036 6816509 724260210 87110011 9580622 1024317022 11270816 1222280019 136230017 1410190025 154214021 162311021 1761313020 189180025 19142201224 2061517023 2124161526 2252491024 2362720026 24514221928 25910181427 2626212328 2791725029 2825262429 2929282730 30120290
将系数复制下来后,在EXCEL中建立工作表。选中数据列,点击“插入”菜单拆线图……
碎石图: 由图可知,北京自成一类,江苏、广东、上海、湖南、湖北聚成一类。其他略。 接下来,添加一个变量CLU4_1,其值为类别值。(1、2、3、4),再数据汇总设置……确定。
第三章 聚类分析 一、填空题 1.在进行聚类分析时,根据变量取值的不同,变量特性的测量尺度有以下三种类型: 间隔尺度 、 顺序尺度 和 名义尺度 。 2.Q 型聚类法是按___样品___进行聚类,R 型聚类法是按_变量___进行聚类。 3.Q 型聚类统计量是____距离_,而R 型聚类统计量通常采用_相似系数____。 4.在聚类分析中,为了使不同量纲、不同取值范围的数据能够放在一起进行比较,通常需要对原始数据进行变换处理。常用的变换方法有以下几种:__中心化变换_____、__标准化变换____、____规格化变换__、__ 对数变换 _。 5.距离ij d 一般应满足以下四个条件:对于一切的i,j ,有0≥ij d 、 j i =时,有 0=ij d 、对于一切的i,j ,有ji ij d d =、对于一切的i,j,k ,有kj ik ij d d d +≤。 6.相似系数一般应满足的条件为: 若变量i x 与 j x 成比例,则1±=ij C 、 对一 1≤ij 和 对一切的i,j ,有ji ij C C =。 7.常用的相似系数有 夹角余弦 和 相关系数 两种。 8.常用的系统聚类方法主要有以下八种: 最短距离法 、最长距离法、中间距离法、重心法、类平均法、可变类平均法、可变法、离差平方和法。 @ 9.快速聚类在SPSS 中由__K-mean_____________过程实现。 10.常用的明氏距离公式为:()q p k q jk ik ij x x q d 11?? ????-=∑=,当1=q 时,它表示 绝 对距离 ;当2=q 时,它表示 欧氏距离 ;当q 趋于无穷时,它表示 切比雪夫距离 。 11.聚类分析是将一批 样品 或 变量 ,按照它们在性质上 的 亲疏、相似程度 进行分类。 12.明氏距离的缺点主要表现在两个方面:第一 明氏距离的值与各指标的量纲有关 ,第二 明氏距离没有考虑到各个指标(变量)之间的相关性 。 13.马氏距离又称为广义的 欧氏距离 。 14,设总体G 为p 维总体,均值向量为()' p μμμμ,, ,= 21,协差阵为∑,则样品()' =p X X X X ,,,21 与总体G 的马氏距离定义为 ()()()μμ-∑' -=-X X G X d 12,。 15.使用离差平方和法聚类时,计算样品间的距离必须采用 欧氏距离 。 16.在SPSS 中,系统默认定系统聚类方法是 类平均法 。 17.在系统聚类方法中, 中间距离法和 重心法 不具有单调性。 18.离差平方和法的基本思想来源于 方差分析 。 , 19.最优分割法的基本步骤主要有三个:第一,定义类的直径 ;第二, 定义目标函数 ;第三, 求最优分割 。 20.最优分割法的基本思想是基于 方差分析的思想 。 二、判断题 1.在对数据行进中心化变换之后,数据的均值为0,而协差阵不变,且变换后后的数据与变量的量纲无关。 ( )
第三章 聚类分析 一、填空题 1.在进行聚类分析时,根据变量取值的不同,变量特性的测量尺度有以下三种类型: 间隔尺度 、 顺序尺度 和 名义尺度 。 2.Q 型聚类法是按___样品___进行聚类,R 型聚类法是按_变量___进行聚类。 3.Q 型聚类统计量是____距离_,而R 型聚类统计量通常采用_相似系数____。 4.在聚类分析中,为了使不同量纲、不同取值范围的数据能够放在一起进行比较,通常需要对原始数据进行变换处理。常用的变换方法有以下几种:__中心化变换_____、__标准化变换____、____规格化变换__、__ 对数变换 _。 5.距离ij d 一般应满足以下四个条件:对于一切的i,j ,有0≥ij d 、 j i =时,有0=ij d 、对于一切的i,j ,有ji ij d d =、对于一切的i,j,k ,有kj ik ij d d d +≤。 6.相似系数一般应满足的条件为: 若变量i x 与 j x 成比例,则1±=ij C 、 对一 1≤ij 和 对一切的i,j ,有ji ij C C =。 7.常用的相似系数有 夹角余弦 和 相关系数 两种。 8.常用的系统聚类方法主要有以下八种: 最短距离法 、最长距离法、中间距离法、重心法、类平均法、可变类平均法、可变法、离差平方和法。 9.快速聚类在SPSS 中由__K-mean_____________过程实现。 10.常用的明氏距离公式为:()q p k q jk ik ij x x q d 11?? ????-=∑=,当1=q 时,它表示 绝 对距离 ;当2=q 时,它表示 欧氏距离 ;当q 趋于无穷时,它表示 切比雪夫距离 。 11.聚类分析是将一批 样品 或 变量 ,按照它们在性质上 的 亲疏、相似程度 进行分类。 12.明氏距离的缺点主要表现在两个方面:第一 明氏距离的值与各指标的量纲有关 ,第二 明氏距离没有考虑到各个指标(变量)之间的相关性 。 13.马氏距离又称为广义的 欧氏距离 。 14,设总体G 为p 维总体,均值向量为()'p μμμμ,, ,= 21,协差阵为∑,则样品()'=p X X X X ,,,21 与总体G 的马氏距离定义为 ()()()μμ-∑'-=-X X G X d 12,。 15.使用离差平方和法聚类时,计算样品间的距离必须采用 欧氏距离 。 16.在SPSS 中,系统默认定系统聚类方法是 类平均法 。 17.在系统聚类方法中, 中间距离法和 重心法 不具有单调性。 18.离差平方和法的基本思想来源于 方差分析 。 19.最优分割法的基本步骤主要有三个:第一,定义类的直径 ;第二, 定义目标函数 ;第三, 求最优分割 。 20.最优分割法的基本思想是基于 方差分析的思想 。 二、判断题 1.在对数据行进中心化变换之后,数据的均值为0,而协差阵不变,且变换后后的数据与变量的量纲无关。 ( ) 2.根据分类的原理,我们可以把聚类分为样品聚类和变量聚类。 ( )
第五章 聚类分析 5.1 判别分析和聚类分析有何区别? 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 5.2 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造? 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1) p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2) () p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-= +∑
第九章 聚类分析与判别分析 在实际工作中,我们经常遇到分类问题.若事先已经建立类别,则使用判别分析,若事先没有建立类别,则使用聚类分析. 聚类分析主要是研究在事先没有分类的情况下,如何将样本归类的方法. 聚类分析的内容包含十分广泛,有系统聚类法、动态聚类法、分裂法、最优分割法、模糊聚类法、图论聚类法、聚类预报等多种方法. §9.1 聚类分析基本知识介绍 在MA TLAB 软件包中,主要使用的是系统聚类法. 系统聚类法是聚类分析中应用最为广泛的一种方法.它的基本原理是:首先将一定数量的样品(或指标)各自看成一类,然后根据样品(或指标)的亲疏程度,将亲疏程度最高的两类合并,然后重复进行,直到所有的样品都合成一类.衡量亲疏程度的指标有两类:距离、相似系数. 一、常用距离 1)欧氏距离 假设有两个n 维样本和),,,(112111n x x x x =),,,(222212n x x x x =,则它们的欧氏距离为 ∑=-= n j j j x x x x d 1 22121)(),( 2)标准化欧氏距离 假设有两个n 维样本),,,(112111n x x x x =和),,,(222212n x x x x =,则它们的标准化欧氏距离为 12(,)sd x x == 其中:D 表示n 个样本的方差矩阵,),,,(22221n diag D σσσ =,2 j σ表示第j 列的方差,即每个指标的方差。若每个指标的均值相等,方差相同,则有 12(,)sd x x == 3)马氏距离 假设共有n 个指标,第i 个指标共测得m 个数据(要求n m >): ?????? ? ??=im i i i x x x x M 21 于是,我们得到n m ?阶的数据矩阵),,,(21n x x x X =,每一行是一个样本数据.n m ?阶数据矩阵X 的n n ?阶协方差矩阵记做)(X Cov .
第十章聚类分析 教学目的:掌握快速聚类和层次聚类的操作,了解各种距离,掌握其结果的阅读。 教学重点:重点考察K-means cluster、hierarchial cluster过程 教学时数:讲授2学时,操作2学时 教学方法:讲授与演示结合 聚类分析(Cluster Analysis)是研究将个体或变量进行分类的一种多元统计方法。是直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。 属于一种探索性分析,不同研究者对于同一组数据进行聚类分析,由于所使用的方法不同,常会得出不同的结论。 聚类分析方法根据统计方法的不同分为层次聚类和快速聚类 根据分类对象的不同分为两类:一类是对样本所作的分类,即Q-型聚类,一类是对变量所作的分类,即R-型聚类。聚类分析的基本思想是,据已知数据,计算各观察个体或变量之间亲疏关系的统计量(距离或相关系数)。根据某种准则(最短距离法、最长距离法、中间距离法),使同一类内的差别较小,而类与类之间的差别较大,最终将观察个体或变量分为若干类。分类过程是一个逐步减少类别的过程,在每一个聚类层次,必须满足“类内差异小,类间差异大”原则,直至归为一类。 例: 不同地区城镇居民收入和消费状况的分类研究 区域经济及社会发展水平的分析及全国区域经济综合评价 在儿童生长发育研究中,把以形态学为主的指标归于一类,以机能为主的指标归于另一类 研究样品间的关系常用距离,研究指标间的关系常用相似系数。 1、距离 (1)欧式(Euclidian )距离 假使每个样品有p个变量,则每个样品都可以看成p维空间中的一个点,n个样品就是p维空间中的n 个点,则第i样品与第j样品之间的距离记为dij (2)欧式距离平方(系统默认) 2、相似系数 相似系数常用的有:夹角余弦与相关系数 3、类间距离 最近距离、最远距离、类间平均法等 10.1 层次聚类分析(系统聚类) 10.1.1基本概念与方法 其原理是将n个变量(观察量)看成不同的n类,然后将性质最接近的两类合并为一类,再从这n-1类中找到最接近的两类加以合并,依此类推,直到所有的变量(观察量)被合为一类。得到该结果后,使用者再根据具体的问题和聚类结果来决定应当分为几类。 其优点:可以对变量进行聚类(R型聚类),也可对观察量进行聚类(Q型聚类);变量可以是连续性变量,也可是分类变量。计算距离的方法也较丰富。 其缺点:需反复计算距离,观察量太大或变量较多时,速度较慢。 10.1.2实例1 一、例题与数据E10-1a.sav(将北京地区18区县按中等职业教育发展水平的9个指标进行聚类,)
第 10 章 聚类分析 “物以类聚,人以群分”。对事物进行分类,是人们认识事物的出发点,也是人们认识世界的一种重要方法。因此,分类学已成为人们认识世界的一门基础科学。 在生物、经济、社会、人口等领域的研究中,存在着大量量化分类研究。例如:在生物学中,为了研究生物的演变,生物学家需要根据各种生物不同的特征对生物进行分类。在经济研究中,为了研究不同地区城镇居民生活中的收入和消费情况,往往需要划分不同的类型去研究。在地质学中,为了研究矿物勘探,需要根据各种矿石的化学和物理性质和所含化学成分把它们归于不同的矿石类。在人口学研究中,需要构造人口生育分类模式、人口死亡分类状况,以此来研究人口的生育和死亡规律。但历史上这些分类方法多半是人们主要依靠经验作定性分类,致使许多分类带有主观性和任意性,不能很好地揭示客观事物内在的本质差别与联系;特别是对于多因素、多指标的分类问题,定性分类的准确性不好把握。为了克服定性分类存在的不足,人们把数学方法引入分类中,形成了数值分类学。后来随着多元统计分析的发展,从数值分类学中逐渐分离出了聚类分析方法。随着计算机技术的不断发展,利用数学方法研究分类不仅非常必要而且完全可能,因此近年来,聚类分析的理论和应用得到了迅速的发展。 聚类分析就是分析如何对样品(或变量)进行量化分类的问题。根据聚类对象的不同,聚类分析分为Q 型聚类和R 型聚类。Q 型聚类是对样品进行分类处理,R 型聚类是对变量进行分类处理。根据聚类方法的不同,聚类分析又可以分为系统聚类法、K -均值聚类法、有序样品聚类法、模糊聚类法等。本书将仅针对系统聚类法和K -均值聚类法进行介绍。 10.1 系统聚类法的理论与方法 10.1.1 系统聚类的基本思想 系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。系统聚类过程是:假设总共有个样品(或变量),第一步将每个样品(或变量)独自聚成一类,共有类;第二步根据所确定的样品(或变量)“距离”公式,把距离较近的两个样品(或变量)聚合为一类,其它的样品(或变量)仍各自聚为一类,这样,形成1n n n ?类;第三步1? 个类中“距离”最近的两个类进一步聚成一类,这样,形2n 将n 成?类;……。 以上步骤一直进行下去,最后将所有的样品(或变量)全聚成一类。为了直观地反映以上的系统聚类过程,可以把整个分类系统画成一张谱系图,所以,系统聚类有时也称为谱系分析。 10.1.2 个体之间距离的度量方法 进行聚类分析首先要建立在各个样品(或变量)之间“距离”的精确度量的基础之上。根据变量类型的不同,“距离”的度量方式也不相同,下面分别叙述: 1. 针对连续变量的距离测度 欧氏距离(Euclidean distance ): 两个体p 个变量值之差平方和的平方根
第11章聚类分析 摘要:聚类分析(cluster analysis)是物以类聚的一种统计分析方法。用于对事物类别的面貌尚不清楚,甚至在事前连总共有几类都不能确定的情况下进行分类的场合。 §11.1 聚类分析概述 聚类分析是用于对个体进行分类的方法。根据分析对象的不同可将其分为样品聚类和变量聚类。 1.样品聚类 俗话说:“物以类聚,人以群分”,对研究对象可根据不同的特征进行分类。这里所说的特征就是反映研究对象特点的各种变量的值。用SAS中的术语来说,样品聚类就是对观测值进行分类。样品聚类是进行判别分析之前的必要工作。根据样品聚类的结果进行判别分析,得出判别函数.进而可对其他研究对象属于何类作出判断。 2.变量聚类 一般来说,可以反映研究对象特点的变量有许多,而且由于对客观事物的认识有限,往往难以找出彼此独立且有代表性的变量,而影响对问题进一步的认识和研究。例如在回归分析中,由于自变量间的共线性而导致偏回归系数不能真正反映自变量对因变量的影响,等等。因此往往需要先进行变量聚类,找出相互独立的、有代表性的自变量,而又不丢失大部分信息。 无论哪种聚类分析所得出的结果都是为了某种目的所做的工作,并不是去寻找自然真实的类。 聚类方法大致可归纳如下: ①系统聚类法:先将n个元素(样品或变量)看成n类,然后将性质最接近(或相似程度最大)的2类合并为一个新类,得到n-1类,再从中找出最接近的2类加以合并变成了n-2类,如此下去,最后所有的元素全聚在一类之中。 ②分解法:其程序与系统聚类相反,首先所有的元素均在一类,然后用某种最优准则将它分成2类,再用同样准则将这2类各自试图分裂为2类,从中选1个使目标函数较好者,这样由2类变成了3类。如此下去,一直分裂到每类中只有1个元素为止,有时即使是同一种聚类方法,因聚类形式(即距离的定义方法)不同而有不同的停止规则。 ③动态聚类法:开始将n个元素粗糙地分成若干类,然后用某种最优准则进行调整,一次又一次地调整,直至不能调整时为止。
聚类分析 在实际工作中,我们经常遇到分类问题。若事先已经建立类别,则使用判别分析,若事先没有建立类别,则使用聚类分析。 聚类分析主要是研究在事先没有分类的情况下,如何将样本归类的方法。 聚类分析的内容包含十分广泛,有系统聚类法、动态聚类法、分裂法、最优分割法、模糊聚类法、图论聚类法、聚类预报等多种方法。 在Matlab 软件包中,主要使用系统聚类法。 系统聚类法是聚类分析中应用最为广泛的一种方法。它的基本原理是:首先将一定数量的样品(或指标)各自看成一类,然后根据样品(或指标)的亲疏程度,将亲疏程度最高的两类合并,如此重复进行,直到所有的样品都合成一类。衡量亲疏程度的指标有两类:距离、相似系数。 (1)常用距离 ①欧氏距离 假设有两个n 维样本()n x x x x 112111,,,???=和()n x x x x 222212,,,???=,则它们的欧氏距离为:()()∑=-=n j j j x x x x d 1 2 2121, ②标准化欧氏距离 假设有两个n 维样本()n x x x x 112111,,,???=和()n x x x x 222212,,,???=,则它们的标准化欧氏距离为: ()()()T x x D x x x x sd 2112121,--=- 其中,D 表示m 个样本的方差矩阵:( ) 2 2221,,,m diagonal D σσσ???=,其中2j σ表 示第j 个样本的方差。 ③马氏距离 假设共有n 个指标,第i 个指标共测得m 个数据(要求n m >): ?????? ? ?????=im i i i x x x x 21 于是,我们得到n m ?阶的数据矩阵()n x x x X ,,,21???=,每一行是一个样本数据。 n m ?阶数据矩阵X 的n n ?阶协方差矩阵记作()X Cov 。 两个n 维样本()n x x x x 112111,,,???=和()n x x x x 222212,,,???=的马氏距离如下:
Abbo无私奉献,只收1个金币,BS收5个金币的… 何老师考简单点啊……
第五章 聚类分析 5.1 判别分析和聚类分析有何区别? 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 5.2 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造? 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
§3系统聚类法 层次聚类法(Hierarchical Clustering)的计算步骤: ①计算n个样本两两间的距离{d ij},记D ②构造n个类,每个类只包含一个样本; ③合并距离最近的两类为一新类; ④计算新类与当前各类的距离;若类的个数等于1,转到5);否则回3); ⑤画聚类图; ⑥决定类的个数和类; Matlab软件对系统聚类法的实现(调用函数说明): cluster 从连接输出(linkage)中创建聚类 clusterdata 从数据集合(x)中创建聚类 dendrogram 画系统树状图 linkage 连接数据集中的目标为二元群的层次树 pdist计算数据集合中两两元素间的距离(向量) squareform 将距离的输出向量形式定格为矩阵形式 zscore 对数据矩阵X 进行标准化处理 各种命令解释 ⑴T = clusterdata(X, cutoff)
其中X为数据矩阵,cutoff是创建聚类的临界值。即表示欲分成几类。 以上语句等价与以下几句命令: Y=pdist(X,’euclid’) Z=linkage(Y,’single’) T=cluster(Z,cutoff) 以上三组命令调用灵活,可以自由选择组合方法! ⑵T = cluster(Z, cutoff) 从逐级聚类树中构造聚类,其中Z是由语句likage产生的(n-1)×3阶矩阵,cutoff是创建聚类的临界值。 ⑶Z = linkage(Y) Z = linkage(Y, 'method') 创建逐级聚类树,其中Y是由语句pdist产生的n(n-1)/2 阶向量,’method’表示用何方法,默认值是欧氏距离(single)。有’complete’——最长距离法;‘average’——类平均距离;‘centroid’——重心法;‘ward‘——递增平方和等。 ⑷Y = pdist(X) Y = pdist(X, 'metric') 计算数据集X中两两元素间的距离,‘metric’表示使用特定的方法,有欧氏距离‘euclid’(缺失值) 、标准欧氏距离‘SEuclid’ 、马氏距离‘mahal’、明可夫斯基距离‘Minkowski‘等。 ⑸H = dendrogram(Z) H = dendrogram(Z, p) 由likage产生的数据矩阵z画聚类树状图。P是结点数,默认值是30。
第12章 聚类分析
12.1 聚类分析简介 12.2 聚类分析中的数据类型 12.3 主要聚类分析方法 聚类分析是数据分析中的一种重要技术,它 的应用极为广泛。许多领域中都会涉及聚类 分析方法的应用与研究工作,如数据挖掘、 统计学、机器学习、模式识别、生物学、空 间数据库技术、电子商务等。
《数据仓库与数据挖掘》 P2
12.1 聚类(Clustering)分析简介
聚类(Clustering)分析是对物理的或抽象的对象集合分 组的过程。 聚类是将数据对象分组成多个簇(Cluster),同一个簇内 部的任意两个对象之间具有较高的相似度,而属于不同簇 的两个对象间具有较高的相异度。相异度可以根据描述对 象的属性值计算,对象间的距离是最常采用的度量指标。
? 聚类就是把整个数据分成不同的组,并使组与组之间的差距尽可能
大,组内数据的差异尽可能小。
? 在许多应用中,可以将一个簇中的对象作为一个整体来对待。
典型应用
? 作为一个独立的分析工具,用于了解数据的分布; ? 作为其它算法的一个数据预处理步骤。
《数据仓库与数据挖掘》
P3
聚类问题的数学描述
给定数据集合V,根据数据对象间的相似程度将数 据集合分成组,并满足: {Ci| 1,2,..., k} Ci?V Ci∩ Cj=φ ∪Ci=V (i=1…k) 则该过程称为聚类。Ci称为簇。 一个好的聚类方法要能产生高质量的聚类结果—簇 ,这些簇要具备以下两个特点:
? 高的簇内相似性 ? 低的簇间相异性
《数据仓库与数据挖掘》 P4
统计学的观点-聚类分析
从统计学的观点看,聚类分析是通过数据建 模简化数据的一种方法。 传统的统计聚类分析方法包括系统聚类法、 分解法、加入法、动态聚类法、有序样品聚 类、有重叠聚类和模糊聚类等。 采用k-均值、k-中心点等算法的聚类分析工 具已被加入到许多著名的统计分析软件包中 ,如SPSS、SAS等。
《数据仓库与数据挖掘》
P5
机器学习的角度-聚类分析
从机器学习的角度讲,簇相当于隐藏模式,聚类是搜索簇 的无监督学习过程。
? 没有预先指定的类别
应用角度-聚类分析
从实际应用的角度看,聚类分析是数据挖掘的主要 任务之一。 就数据挖掘功能而言,聚类能够作为一个独立的工 具获得数据的分布状况,观察每一簇数据的特征, 集中对特定的聚簇集合作进一步地分析。 聚类分析还可以作为其他数据挖掘任务(如分类、 关联规则)的预处理步骤。 数据挖掘领域主要研究面向大型数据库、数据仓库 的高效实用的聚类分析算法。
聚类与分类区别:
? 与分类不同,在开始聚集之前用户并不知道要把数据分成几组,也
不知分组的具体标准,聚类分析时数据集合的特征是未知的。
? 聚类根据一定的聚类规则,将具有某种相同特征的数据聚在一起,
是典型无监督学习;它不需要依赖预先定义的类或带类标记的训练 实例,需要由聚类学习算法自动确定样本标记。
? 分类用户则知道数据可分为几类,将要处理的数据按照分类器分入
不同的类别,是典型有监督学习;分类学习的实例或数据对象有类 别标记。
聚类是观察式学习,而不是示例式的学习。
《数据仓库与数据挖掘》
P6
《数据仓库与数据挖掘》
P7
1
第8章聚类分析与判别分析 分类学是人类认识世界的基础科学。聚类分析和判别分析是研究事物分类的基本方法。 聚类分析 聚类分析(Cluster Analysis)是根据事物本身的特性研究个体分类的方法。聚类分析的原则是同一类中的个体有较大的相似性,不同类中的个体差异很大。 根据分类对象的不同分为样品聚类和变量聚类。 1.样品聚类 样品聚类在统计学中又称为Q型聚类。用SPSS的术语来说就是对事件(Cases)进行聚类,或是说对观测量进行聚类。是根据被观测的对象的各种特征,即反映被观测对象的特征的各变量值进行分类。 样品聚类是进行判别分析之前的必要工作。根据样品聚类的结果进行判别分析,得出判别函数,进而对其他研究对象属于哪一类作出判断。例如在选拔少年运动员时首先要根据少年的身体形态、身体素质、心理素质、生理功能的各种指标(变量)进行测试,得到各种指标的测试值(变量值),据此对少年进行分类。根据分类结果再求得出选材的判别函数,作为选材的依据。 2.变量聚类 变量聚类在统计学中又称为R型聚类。反映同一事物特点的变量有很多,我们往往根据所研究的问题选择部分变量对事物的某一方面进行研究。由于人类对客观事物的认识是有限的,往往难以找出彼此独立的有代表性的变量,而影响对问题的进一步认识和研究。例如在回归分析中,由于自变量的共线性导致偏回归系数不能真正反映自变量对因变量的影响等。因此往往先要进行变量聚类,找出彼此独立且有代表性的自变量,而又不丢失大部分信息。 判别分析 判别分析是根据表明事物特点的变量值和它们所属的类求出判别函数,根据判别函数对未知所属类别的事物进行分类的一种分析方法。 在自然科学和社会科学的各个领域经常遇到需要对某个个体属于哪一类进行判断。 判别分析与聚类分析的不同在于判别分析要求已知一系列反映事物特征的数值变量值及其分类变量值。 分类命令的功能 其中包括: (1)K-Means Cluster进行快速聚类的过程。(略) (2)Hierarchical Cluster进行样本聚类和变量聚类的过程。 (3)Discriminate进行判别分析的过程。 快速样本聚类过程 快速聚类的基本概念 当要聚成的类数已知时,使用QUICK CLUSTER过程可以很快将观测量分到各类中去。其特点是处理速度快,占用内存少。适用于大样本的聚类分析。 分层聚类 分层聚类的概念与聚类分析过程 1.分层聚类的概念 聚类的方法有多种,除了前面介绍的快速聚类法外,最常用的是分层聚类法。根据聚类过程不同又分为凝聚法和分解法。 (1)分解法:聚类开始把所有个体(观测量或变量)都视为属于一大类,然后根据距离和相似性逐层分解,直到参与聚类的每个个体自成一类为止。 (2)凝聚法:聚类开始把参与聚类的每个个体(观测量或变量)视为一类,根据两类之间的距离或相似性逐步合并,直到合并为一个大类为止。
第5章 聚类分析 上一章针对确定性的模式分类方法进行了讨论,所谓确定性的模式是指:如果试验对象和测量条件相同,所有的测量具有重复性,即在多次的测量中,它们的结果不变,这样获得的模式,简称确定性的模式。与之相对应的,测量结果是随机的,这样的模式称为随机模式。随机模式可以采用基于Bayes 理论的分类方法进行分类,其前提是各类别总体的概率分布已知,要决策的分类的类别数一定。对于确定性的模式,如果类别已知(训练样本属性也已知),则可以通过第4章介绍的方法进行分类。 当预先不知道类型数目,或者用参数估计和非参数估计难以确定不同类型的类概率密度函数时,为了确定分类器的性能,可以利用聚类分析的方法。聚类分析无训练过程,训练与识别混合在一起。 5.1 相似性准则(相似性度量) 设有样本集},....,,{21n x x x X ,要求按某种相似性把X 分类,怎样实现? 利用参数估计或非参数估计的方法,在混合密度的局部极大值区域对应着一个类型,但是这个方法需要大量的样本。况且,有时混合训练样本集X 的数据结构具有相同的统计特征,它们都包含着不同数目的类型。 如下图所示,表示具有相同的试验平均值和样本协方差矩阵的三个数据集。 在上述图中,(a)具有一个类型,(b)、(c)各有两个类型。此时,无论是参数估计,还是非参数估计,都无法取得合理的结果,必须采用聚类分析的方法进行分类。 聚类分析符合“物以类聚,人以群分“的原则,它把相似性大的样本聚集为一个类型,在特征空间里占据着一个局部区域。每个局部区域都形成一个聚合中心,聚合中心代表相应类型。如上图中,(a)有一个聚合中心,(b)、(c)有两个。 聚类分析避免了估计类概率密度的困难,对每个聚合中心来说都是局部密度极大值位置,其附近密度高,距离越远密度越小。因此,聚类分析方法与估计密度函数的方法还是一致的,只是采用了不同的技术途径。 聚类分析的关键问题:如何在聚类过程中自动地确定类型数目c 。 实际工作中,也可以给定c 值作为算法终止的条件。 聚类分析的结果与特征的选取有很大的关系。不同的特征,分类的结果不同。
第十二章聚类分析 聚类分析(CLUSTER)是将样本或变量进行分类的一种方法。 通常用相似性指标“距离”和“相似系数”来衡量研究对象的联系紧密程度,从而进行合理分类。“距离”常用来对样本分类,即把每一个样本看作是m维空间(若样本被m个变量所描述)的一个点,把距离较近的点归为一类,距离较远的点归为不同的类。“相似系数”用来对变量分类,将变量间相似系数较大的归为一类,较小的归为不同类。 第一节距离和相似系数 一、距离 1、“欧几里得”距离 A和B两点由m个变量所描述,其坐标分别是(x 1,x 2 ,…,x m )和(y 1 ,y 2 ,…,y m ), 那么d(A,B)= 例如:某次收视率调查中的部分数据如表1,则1号被访者和2号被访者的 “距离”为:d(A,B)= 表1:原始数据 上述测量的距离存在问题:(1)同一个变量单位不同会导致不同的距离;(2)不同变量的度量不一致,无法判断变量值大小和变量的重要程度,从而无法判断
距离的意义。因而需要对原始数据进行标准化。 表2:标准化数据 2、SPSS聚类分析中提供的距离 (1)欧式距离(EUCLID) (2)欧式距离的平方(SEUCLID),等于变量差2+变量差2+…… (3)曼哈顿距离(BLOCK),等于变量差的绝对值之和 (4)切比雪夫距离(CHEBYCHEV),等于变量差中绝对值最大者 (5)幂距离POWER(p,r),等于变量差的绝对值的p次方之和,再求r方根。2、相似系数 (1)变量间的相关系数即皮尔逊相关系数; (2)变量间的夹角余弦,即将两变量分别看成n维空间的向量时的夹角余弦值。 相关系数一般针对定距变量,对于定类变量特别是二项变量也可引入虚拟变量后计算相关系数。 例1:假定5个样本(人)具有如下指标:(1)请对个体进行分类;(2)对变量进行分类。 表3:五个人的六种身体特征指标
5.2 聚类准则函数 在样本相似性度量的基础上,聚类分析还需要一定的准则函数,才能把真正属于同一类的样本聚合成一个类型的子集,而把不同类的样本分离开来。如果聚类准则函数选得好,聚类质量就会高。同时,聚类准则函数还可以用来评价一种聚类结果的质量,如果聚类质量不满足要求,就要重复执行聚类过程,以优化结果。在重复优化中,可以改变相似性度量,也可以选用新的聚类准则。 1.误差平方和准则(最常用的) 假定有混合样本} ,......, , { 2 1n x x x X=,采用某种相似性度量,X被聚合成c个分离开的子集c X X X,....., , 2 1 ,每个子集是一个类型,它们分别包含 c n n n,......, , 2 1 个样本。 为了衡量聚类的质量,采用误差平方和 c J聚类准则函数,定义为: ∑∑ == - = c j n k j k c j m x J 11 2 || || 式中 j m为类型 j w中样本的均值:∑ = = j n j j j j x n m 1 1 ,c j,...., 2,1 =。 j m是c个集合的中心,可以用来代表c个类型。 c J是样本和集合中心的函数。在样本集X给定的情况下, c J的取值取决于c个集合中心。 c J描述n个 试验样本聚合成c个类型时,所产生的总误差平方和。 c J越小越好。 最小方差划分:寻找 c J最小的聚类结果,也就是在误差平方和准则下的最优结果。 误差平方和准则适用于各类样本比较密集且样本数目悬殊不大的样本分布。例如: 上图的样本分布,共有3个类型,各个类型的样本数目相差不多(10个左右)。类内较密集,误差平方和很小,类别之间距离远。 注意:如果不同类型的样本数目相差很大,采用误差平方和准则,有可能把样本数目多的类型分开, 以便达到总的 c J最小。如下图所示: 下面进一步说明上述问题:
第11章聚类分析 聚类分析(CLUSTER)是将样本或变量进行分类的一种方法。 通常用相似性指标“距离”和“相似系数”来衡量研究对象的联系紧密程度,从而进行合理分类。“距离”常用来对样本分类,即把每一个样本看作是m维空间(若样本被m个变量所描述)的一个点,把距离较近的点归为一类,距离较远的点归为不同的类。“相似系数”用来对变量分类,将变量间相似系数较大的归为一类,较小的归为不同类。 第一节距离和相似系数 一、距离 1、“欧几里得”距离 A和B两点由m个变量所描述,其坐标分别是(x 1,x 2 ,…,x m )和(y 1 ,y 2 ,…,y m ), 那么d(A,B)= 例如:某次收视率调查中的部分数据如表1,则1号被访者和2号被访者的 “距离”为:d(A,B)= 表1:原始数据 上述测量的距离存在问题:(1)同一个变量单位不同会导致不同的距离;(2)不同变量的度量不一致,无法判断变量值大小和变量的重要程度,从而无法判断距离的意义。因而需要对原始数据进行标准化。 表2:标准化数据
2、SPSS 聚类分析中提供的距离 (1)欧式距离(EUCLID ) (2)欧式距离的平方(SEUCLID ),等于变量差2+变量差2+…… (3)曼哈顿距离(BLOCK ),等于变量差的绝对值之和 (4)切比雪夫距离(CHEBYCHEV ),等于变量差中绝对值最大者 (5)幂距离POWER(p,r),等于变量差的绝对值的p 次方之和,再求r 方根。 2、相似系数 (1)变量间的相关系数即皮尔逊相关系数; (2)变量间的夹角余弦,即将两变量分别看成n 维空间的向量时的夹角余弦值。 相关系数一般针对定距变量,对于定类变量特别是二项变量也可引入虚拟变量后计算相关系数。 例1:假定5个样本(人)具有如下指标:(1)请对个体进行分类;(2)对变量进行分类。 表3:五个人的六种身体特征指标 解:变量中包含定距和定类变量,可以全部变成虚拟变量(也可将后四个虚拟), 令X 1= ;X 2= ;X 3= X 4= ;X 5= ;X 6= ,表3可转化为表4: 1,身高≥170 0,身高<170 1,体重≥130 0,体重<130 1,双眼皮 0,单眼皮 1,高鼻梁 0,低鼻梁 1,用左手 0,用右手 1,女 0,男