
Netview Without RP1 Manua l
This manual is aimed for using netview function without rp1. The operator should make the setting both on the bf1 machine and on the bfeditor machine. This manual explains the procedure of setting netview.
1. The setting on the bf1 machine
The procedure of setting netview on bf1 machine is shown in the steps below.
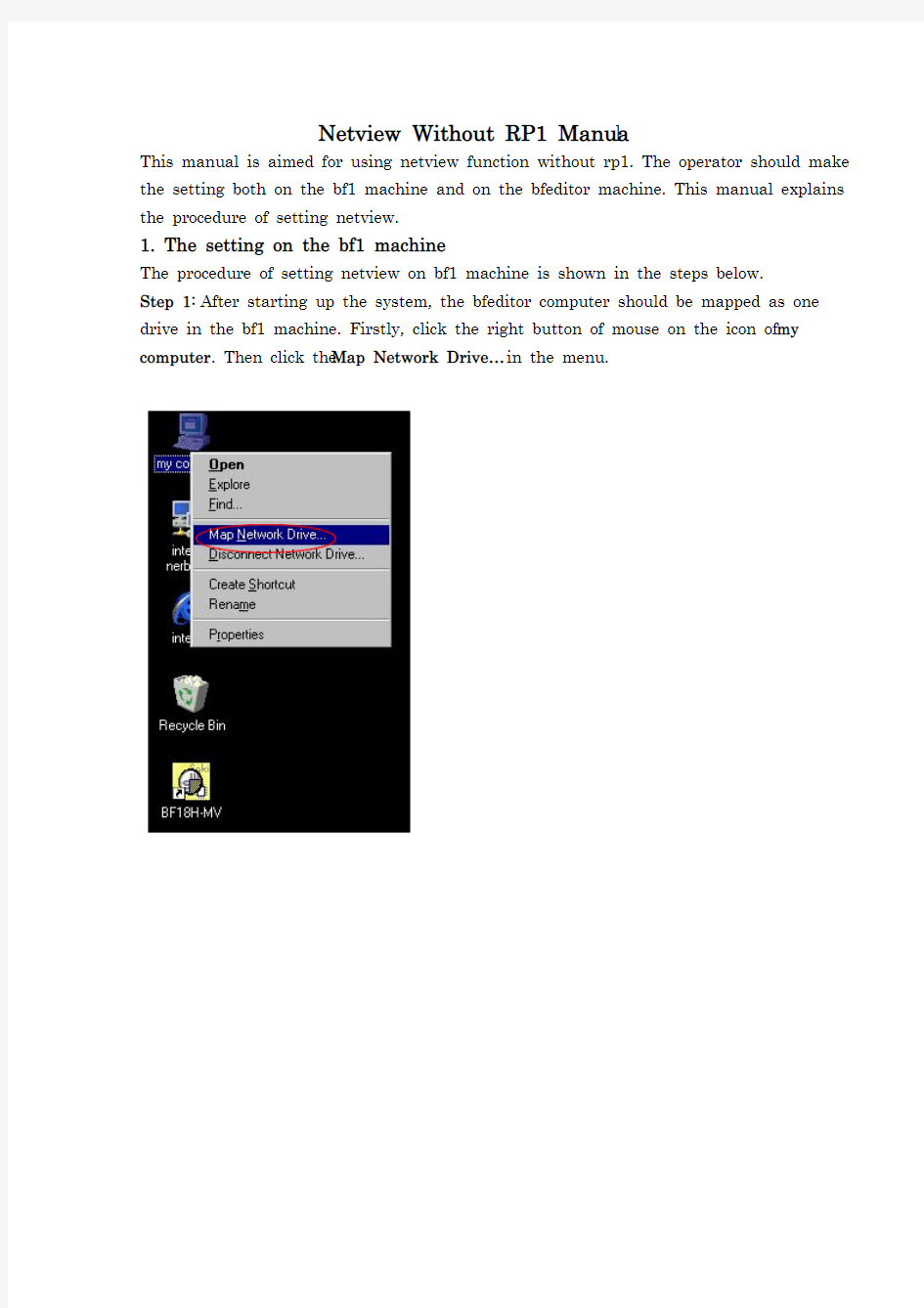
Step 1: After starting up the system, the bfeditor computer should be mapped as one drive in the bf1 machine. Firstly, click the right button of mouse on the icon of my computer. Then click the Map Network Drive… in the menu.
Step 2: The Map Network Drive dialog box appears. Click the bfeditor computer name you want to map.
Step 3: Choose the path in the bfeditor computer you want to save data to. Then the path will show in the combo box. Choose the drive name. DEVELOP is the name of bfeditor computer. So DEVELOP¥SPC is mapped to G: drive in the bf1 computer. Attention: SPC file folder in the bfeditor computer should be set as share before mapping.
Step 4: In my computer in the bf1 computer, the mapped drive will appear.
Step 5: Then boot the application software, BF1.exe. After starting up the application software, click Edit on the menu bar, and then click System setup.
Step 6: The Select System Setup dialog box appears. Click System button.
Step 7: The System Setup dialog box appears. Enter the line number in the edit box. For example, enter Line 5. Then click OK.
Attention: In the Line Number edit box, “ : , ; , ¥ ” shouldn’t be involved.
Step 8: Then it will return to the Select System Setup dialog box, select Output Files.
Step 9: The Output File dialog box appears. Select the check box Output log file for Netview. Enter the mapped drive name (G:) to the edit box. Enter the image number that you want to save in the bfeditor machine, (for example 40 as the following window). This number is the maximum number of the images in one board that are saved in the bfeditor machine. If the Not output False Call Images check box is checked, the False Call images will not appear, only the NG images appear. Then click OK.
Step 10: After making the setting on the bfeditor machine, operate the AOI machine in the Auto mode.
2. The setting on the bfeditor machine
The procedure of setting netview on bf1 machine is shown in the steps below.
Step 1: Start up the system, and boots the application software, BFeditor.exe.
Step 2: After starting up the application software, click Net view on the menu bar, and then click RP1-monitor.
Step 3: The RP1-Monitor window appears. Select File on the menu bar, and then click setting.
Step 4: The Line Setting dialog box appears. Click Without Bfrp1 checkbox. In the File path, please enter the saving path, and then click OK. This saving path is the path in the bfeditor computer you want to save the data to. C:¥ SPC is the path that has been mapped in the bf1 computer, Line 5 is the line number that has been set in the bf1 computer.
Attention: SPC file folder should be set as share.
Step 5: Then some colored bars will appear in the RP1-Monitor window. Click the right button of the mouse in the area of one bar.
Step 6: The E:¥Line 5 dialog box appears. Select one log file you want to see. Click OK.
Step 7: Some pie and bar pictures and some curves will appear in the RP1-Monitor window. If you double click the window area, the window will switch to previous window.
Step 8: If you click the right button of the mouse in the area of one colored bar, some images will appear in the RP1-Monitor window. If you double click the window area, it will switch to the previous window.
Step 9: If you click the right button of the mouse on one image, this image will be enlarged separately in the RP1-Monitor window. If you double click the window area, it will switch to the previous window.
Step 10: In the step 6, if you click Day Filters or Hour Filters checkbox, please enter the time you want to see in the report. Then click the button Make Report.
Step 11: The aoi_history file will appear in the web way.
第二节文字处理的基本操作——文本编辑 一、教学目标 知识与技能: 1.学习文本的编辑方法,掌握文字的设置与修饰。 2.掌握文本框和图片的插入与修饰的方法 3.段落的设置方法 过程与方法: 通过动手操作,加深所学知识的印象,巩固学习成果。 情感态度与价值观: 培养良好的学习态度和学习风气,感受Word在生活的实际应用。 二、教学的重点和难点: 重点:文本编辑的方法;文字的设置与修饰; 难点:段落设置 三、教学准备:多媒体网络控制系统、足量的电脑、练习 四、教学方法:讲授法提问法讨论法练习法 五、教学安排:1课时 六、教学过程: (一)引言 上节课我们学习了Word中窗口的基本操作及汉字的输入方法。谁能说一说。 简单提问:(如文件在哪保存?女字用智能ABC如何输入?) (二)讲授新课 学生看一段已经排版好文稿,复习输入法的操作。 如果我们要对其中的一部分文字做修改,该怎么操作呢? 1.文本编辑的方法 1)插入文字:①用键盘移光标到插入文字处;②在插入文字处单击鼠标光标。 2)输入特殊符号:①插入→符号;②右键—>快捷菜单中“符号” 3)删除不需要的文字:按DELETE键删除光标后面的字符;按退格键删除光标前面的字符。4)选定一段文字:单击段首选取中当前行;双击段首选中当前段;三击段落任意处选中当前段。 5)移动或复制一段文字 移动:选定文字—>剪切→选定目标位置→粘贴(或用鼠标选定直接拖动到目标位置)复制:选定文字—>复制→选定目标位置→粘贴(或用鼠标选定按Ctrl键直接拖动到目标位置) 6)查找或替换某些文字 查找:编辑→查找→查找内容→查找下一处 替换:编辑→替换→查找内容、替换为→查找下一处→替换(全部替换) 2.文字的美化 1)改变字号、字体和颜色:单击工具栏上的字号、字体和颜色按钮。 2)改变文字的格式:加粗、倾斜、下划线、字符边框、字符底纹、字符缩放。 3)使文字产生特殊效果:格式→字体(字体、字型、字号、着重号、效果)→动态效果 4)改变字间距:格式→字体→字符间距 5)改变文档中文字的方向:常用工具栏→更改文字方向(格式→文字方向)
网络社区划分算法 目录 ? 1 简介 ? 2 构建一个点击流网络 ? 3 网络社区划分的两种主要思路:拓扑分析和流分析 ? 4 拓扑分析 o 4.1 计算网络的模块化程度Q-Modularity o 4.2 计算网络的连边紧密度Edge betweenness o 4.3 计算网络拉普拉斯矩阵的特征向量Leading eigenvector o 4.4 通过fast greedy方法搜索网络模块化程度Q-Modularity的最大值 o 4.5 通过multi level方法搜索网络模块化程度Q-Modularity的最大值 ? 5 流分析 o 5.1 随机游走算法Walk Trap o 5.2 标签扩散算法label propagation o 5.3 流编码算法 the Map Equation o 5.4 流层级算法 Role-based Similarity ? 6 总结 使用许多互联网数据,我们都可以构建出这样的网络,其节点为某一种信息资源,如图片,视频,帖子,新闻等,连边为用户在资源之间的流动。对于这样的网络,使用社区划分算法可以揭示信息资源之间的相关性,这种相关性的发现利用了用户对信息资源的处理信息,因此比起单纯使用资源本身携带的信息来聚类(例如,使用新闻包含的关键词对新闻资源进行聚类),是一种更深刻的知识发现。 假设我们手头有一批用户在一段期间访问某类资源的数据。为了减少数据数理规模,我们一般只考虑最经常被访问的一批资源。因此在数据处理中,我们考虑UV(user visit)排名前V的资源,得到节点集合|V|,然后对于一个用户i在一段时间(例如一天)访问的资源,选择属于|V|的子集vi。如果我们有用户访问资源的时间,就可以按照时间上的先后顺序,从vi中产生vi-1条有向边。如果我们没有时间的数据,可以vi两两间建立联系,形成vi(vi-1)/2条无向边。因为后者对数据的要求比较低,下文中,暂时先考虑后者的情况。对于一天的n个用户做这个操作,最后将得到的总数为的连边里相同的边合并,得到|M|个不同的边,每条边上都带有权重信息。这样,我们就得到了V个节点,M条边的一个加权无向网络,反应的是在一天之用户在主要的信息资源间的流动情况。在这个网络上,我们可以通过社区划分的算法对信息资源进行分类。
基于协同过滤的推荐算法与代码实现 什么是协同过滤? 协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤(Collaborative Filtering, 简称CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。 协同过滤一般是在海量的用户中发掘出一小部分和你品位比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成一个排序的目录作为推荐给你。当然其中有一个核心的问题: 如何确定一个用户是不是和你有相似的品位? 如何将邻居们的喜好组织成一个排序的目录? 简单来说: 1. 和你兴趣合得来的朋友喜欢的,你也很有可能喜欢; 2. 喜欢一件东西A,而另一件东西B 与这件十分相似,就很有可能喜欢B; 3. 大家都比较满意的,人人都追着抢的,我也就很有可能喜欢。 三者均反映在协同过滤的评级(rating)或者群体过滤(social filtering)这种行为特性上。 深入协同过滤的核心 首先,要实现协同过滤,需要一下几个步骤: 1. 收集用户偏好 2. 找到相似的用户或物品 3. 计算推荐 (1)收集用户偏好 要从用户的行为和偏好中发现规律,并基于此给予推荐,如何收集用户的偏好信息成为系统推荐效果最基础的决定因素。用户有很多方式向系统提供自己的偏好信息,而且不同的应用也可能大不相同,下面举例进行介绍:
以上列举的用户行为都是比较通用的,推荐引擎设计人员可以根据自己应用的特点添加特殊的用户行为,并用他们表示用户对物品的喜好。 在一般应用中,我们提取的用户行为一般都多于一种,关于如何组合这些不同的用户行为,基本上有以下两种方式: 将不同的行为分组:一般可以分为“查看”和“购买”等等,然后基于不同的行为,计算不同的用户/物品相似度。类似于当当网或者Amazon 给出的“购买了该图书的人还购买了...”,“查看了图书的人还查看了...”
文字处理常用操作及素材 1.字符查找替换。将素材1中的换行符替换成回车符;将素材1中所有的黄龙溪替换成蓝 色、加粗的黄龙溪。 2.字体格式设置。将素材1中的标题段文字的字体格式设置成:水平居中、宋体、二号字、 加粗、蓝色;其余段落的文字字体格式设置为:宋体、小四号字。 3.段落格式设置。将素材1中的标题段设置成段前1.5行,段后1.5行;其他段落设置成 首行缩进2字符,段前0.5行,段后0.5行,段落文字之间的行距为固定值20磅。 4.段落分栏。将素材1中的第二、三自然段分成两栏显示,栏宽相等。 素材1: 黄龙溪古镇 出成都东门沿成仁公路(成都—仁寿)向东南方向行进约40千米处,便是近几年被影视界人士和旅游者看好的新辟旅游景点——黄龙溪。 黄龙溪东临府河(锦江)、北靠牧马山,是成都通往乐山的水路要冲,也是成都历史上最南边的江防据点、屯兵要地。据载,诸葛亮南征时,曾在这里驻有重兵。明末农民军首领张献忠也在此与官军苦战过。当年镇上曾有7座庙宇和仁(寿)、彭(山)、华(阳)总府衙门。码头上舟楫如林,商旅云集,一派繁荣景象。 黄龙溪古镇之所以引起影视界人士关注,是因为这里清代风格的街肆建筑仍然保存完好。 青石板铺就的街面,木柱青瓦的楼阁房舍,镂刻精美的栏杆窗棂,无不给人以古朴宁静的感受。镇内还有6棵树龄在300年以上的黄桷树,枝繁叶茂,遮天蔽日,给古镇更增添了许多灵气。镇内现还保存有镇江寺、潮音寺和古龙寺三座古庙,每年农历六月初九和九月初九的庙会,还能再现昔日古镇的喧闹场面。 古镇黄龙溪之所以为游人所青睐,是因为这里不仅山清水秀,没有大城市的喧嚣与嘈杂; 更因这里弯弯曲曲的石径古道、河边飞檐翘角的木质吊脚楼,街道上的茶楼店铺,古庙内的缭绕青烟等,展现出一幅四川乡镇的民俗风情图,给人一种古朴而又新奇的感受。 很多少年宫的老师喜欢带着学画画的同学到黄龙溪写生。因为黄龙溪不仅风景优美,有很多古树和古建筑,非常适合写生。如果到河对面看风景,更是别有一番风味。 5.首字下沉。将素材2中的第一自然段设置成首字下沉,下沉行数为两行。 6.边框和底纹。将素材2中的第二自然段加上段落边框;第三自然段加上段落底纹;第四 自然段的文字加边框;第五自然段的文字加上底纹。所有的框线和颜色任选。 素材2:
——————————————— 收稿日期:年-月-日*投稿时不填写此项*;最终修改稿收到日期:年-月-日 *投稿时不填写此项*. 基金项目:中国农业大学研究生科研创新专项基金(2013YJ008) 基于数据位图的滑动分块算法 邓雪峰,孙瑞志,张永瀚,聂娟 (中国农业大学农业部农业信息获取技术重点实验室 北京100083) (北京农学院计算机与信息工程学院 北京 100083) (dxf75@https://www.doczj.com/doc/eb16142807.html,) Sliding blocking algorithm based on data bitmap Deng Xuefeng, Sun Ruizhi, Zhang Yonghan, Nie Juan (Key laboratory of Agricultural information acquisition technology (Beijing ),Ministry of Agriculture P.R.China, China Agricultural University, Beijing, 100083) (College of Computer and Information Engineering in Beijing University of Agriculture, Beijing, 102206 China) Abstract During similar data synchronization and storage, data blocking is an important step to detect duplication of data. Only after effective data blocking can you find difference between data accurately. This paper first summarizes and analyzes the methods of data blocking, then re-organize data files in the form similar to bitmap based on the sliding blocking algorithm. After that we read data bitmap by column to form a new data chunk and compute fingerprint information of the column. To improve its ability to locate difference in data, fingerprint of column serve as supplement for sliding bolcking algorithm to acquire more accurate information of data difference. Experimental results show that this method is better than sliding blocking algorithm in data duplication detection under the same conditions. Key words Sliding blocking algorithm; Duplicate data detection; data bitmap; data difference; data synchronization 摘 要 网络中相似的数据文件进行同步与存储的过程中,对数据进行分块,是检测数据重复的重要步骤之一,在有效的对数据分块的基础上才能更准确的定位数据间的差异部分。本文就数据分块方法予以分析总结,在滑动分块算法的基础上,重新将数据文件组织成类似位图的排列形式,对数据位图以列向读取数据信息,形成新的数据分块,并计算列向读取数据的分块指纹信息,以列向数据指纹为补充校正滑动分块算法定位差异数据的能力的不足之处,从而获得更精确的数据差异信息。经实验证明,本方法在同源文件的数据重复检测中效果好于相同条件下的滑动分块方法。 关键词 滑动分块算法;重复数据检测;数据位图;数据差异;数据同步 中图法分类号 TP31;TP39 随着大数据时代的到来,大量的数据将通过网络进行更新与存储。在这些数据文件中存在着大量的同源或类似文件。对同源的数据文件进行同步更新的过程中如何降低网络的占用;对内容大部分相同的文件如何利用更少的存储空间进行存储一直是计算机领域研究的热点问题之一。 同源或内容相近的数据文件进行网络同 步过程中,经常采用基于差异的数据传输方法。这种方法是低带宽网络中文件同步的高效方案之一,利用这个技术可以减少网络流量的开销,同时也能提升数据同步更新的速度。利用这种技术为核心定制了相当多的应用系统[1]。该技术在文件的传输过程中,非常重要的一个处理过程就是将数据分块,数据分块的方法是提升查找差异数据精确度的
Hans Journal of Data Mining 数据挖掘, 2019, 9(3), 81-87 Published Online July 2019 in Hans. https://www.doczj.com/doc/eb16142807.html,/journal/hjdm https://https://www.doczj.com/doc/eb16142807.html,/10.12677/hjdm.2019.93010 Overview and Prospect of Personalized Recommendation Algorithm Xinxin Li Dalian University of Foreign Languages, Dalian Liaoning Received: Jun. 19th, 2019; accepted: Jul. 2nd, 2019; published: Jul. 9th, 2019 Abstract In recent years, the word “information overload” frequently appears in people’s vision, it has be-come a hot word in the field of computer, and it is also an important problem that researchers ur-gently need to solve. In order to solve the problem of information overload, researchers in the field of computer constantly optimize the personalized recommendation algorithm, strive to re-duce the difficulty of information retrieval for users, to provide users with the best personalized recommendation results. This paper gives a brief overview of the personalized recommendation methods which are widely used and common. Combined with the experience of using personalized recommendation algorithm to generate results in daily life, the author puts forward expectations for the development of personalized recommendation algorithm in the future. Keywords Personalized Recommendation, Collaborative Filtering, Hybrid Recommendation 个性化推荐算法概述与展望 李鑫欣 大连外国语大学,辽宁大连 收稿日期:2019年6月19日;录用日期:2019年7月2日;发布日期:2019年7月9日 摘要 近年来,“信息过载”一词频繁出现在人们的视野中,它成为了计算机相关领域中的热门词汇,同时它也是研究人员急待解决的重要问题。为解决信息超载的问题,计算机领域研究人员不断优化个性化推荐
系统重装、备份、恢复步骤 一、系统安装和备份 1、安装系统前的准备 在电脑正常运行状态下,将桌面文件或我的文档以及存放在C盘的重要文 件拷贝到D盘或除C盘以外的磁盘,因为重装系统或还原后C盘会被格式化。 如果平时就养成不在桌面或C盘摆放文件的习惯则不需要有此操作。因为C盘 是电脑默认系统盘,不在C盘存放东西将会有以下好处:(1)文件的安全性得到 保障;(2)加快电脑的运行速度;(3)方便重装系统和系统还原。 2、驱动备份 有的电脑硬件驱动盘已丢失或损坏,所以在重装之前最好将驱动备份一下,以免重装系统后难装驱动,Driver Genius是一个不错的工具。把Driver Genius 复制到C盘以外的磁盘盘,打开Driver Genius选择备份,在下拉列表里找到搜 索第三方驱动,在所有复选框中打钩,然后修改备份保存位置,如在E盘建一个“驱动备份”文件夹。备份开始后请耐心等待,可能需要几分钟。 3、安装系统 以winxp系统为例,在光驱中装入winxp系统盘后,重启电脑,进入BIOS 将第一启动设备设置为CD/DVD-ROM,或使用快捷键F11或F12。对于台式机,把光碟放入光驱后没必要关闭光驱,因为重启计算机一般会自动关闭光驱(节 约时间)。 重启计算机后,在第一界面按Pause暂停(以便你寻找按哪个键可以进入BIOS界面,不同的电脑按键不同,大部分台式机都按DELETE,较多的笔记本电脑按F2,但有一些特殊的会是F10、F11、ESC等),找到按键后不间断地按,直至进入BIOS界面。 进入BIOS界面后,台式机一般需要进入Advanced Bios Features进行设置, 一般是用page dn/up进行设置;而对于笔记本电脑,一般需要找到BOOT选项,按照右面的提示和最下面的提示栏进行操作,把CD/DVD-ROM设置成First Boot(第一启动设备)。至于按哪个键进行顺序更改,则需要看英文提示。如图: 许多笔记本可以在开机界面按提示操作后单次更改启动顺序,例如有的品牌 是按ESC键会弹出启动顺序选择,此时选择DVD即可。以后重启过程则按BIOS设置的顺序,对于有该快捷功能的计算机则没必要进入BIOS设置启动顺序。 设置完毕保存并退出后便自动进入系统盘操作界面,按提示选择欲安装的WindowsXP版本,开始安装。 3、之后按提示一步一步操作。
word文字处理基本操作 1. 新建/ 打开文档 当直接启动Word 时,Word 自动新建一个标题为“文档1”的空白文档,用 户也可使用“文件”|“新建”新建文档。当新建文档时,“新建文档”任务窗格会提供多种文档模板来新建所需文档,如“报告”、“备忘录”、“信函和传真”等。用户可通过双击Word 文档启动Word 并打开该文档,也可使用“文件”| “打开”打开文档。 2. 输入文档内容 新建/打开文档后,在文档编辑区中可输入文档内容。 ·输入中英文 当关闭中文输入法时,可通过键盘输入英文;当打开中文输入法时,可输入 中文。用户可通过语言栏或Ctrl+空格键,切换中英文输入法。 ·输入数字 打开Num Lock,可使用数字小键盘输入数字。 ·输入符号 当输入某些键盘上没有的字符时,可使用“插入”|“特殊符号”或“符号”, 如特殊字符§和?(字体wingdings3)。 ·输入日期和时间 使用“插入”|“日期和时间”,可输入日期和时间。如选择了“日期和时间” 对话框中的“自动更新”,则每次打开文档时,日期和时间都自动更新为当前系统时间。 ·制作超链接 使用“插入”| “超级链接”,可在文档中制作某个Web 站点或文档的超链接。 ·自动替换 选择“工具”|“自动更正选项”|“自动更正”,并选中“键入时自动替换”, 就可使用自动替换简化文本输入。例如,在文档中经常输入“Microsoft Office 2003”,可在“替换”框中输入“M3”,在“替换为”框中输入“Microsoft Office 2003”,单击“添加”将此条目添加到自动更正条目中。此后,在文档中输入“M3”并回车,Word 就会自动更正为“Microsoft Office 2003”。 ·插入/改写模式 在插入模式下,输入的文本插入到光标位置。在改写模式下,输入的文本替 换光标后边的文本。 如状态栏中的“改写”为深色,表示当前处于改写模式,否则处于插入模式。 通常,Word 处于插入模式,可使用“Insert”或双击状态栏上的“改写”切换插入/改写模式。 ·回车换行 文本输入中可用Enter 产生一个“? ”符号,称为段落标记符或硬回车, 标志段落结束进行换行。如需在一个段落中换行,可用Shift+Enter 产生一个“?”符号,称为分行符或软回车。
机器视觉中常用图像处理算法 机器视觉就是用机器代替人眼来做测量和判断。机器视觉系统是指通过机器视觉产品(即图像摄取装置,分CMOS 和CCD 两种)将被摄取目标转换成图像信号,传送给专用的图像处理系统,得到被摄目标的形态信息,根据像素分布和亮度、颜色等信息,转变成数字化信号;图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作。机器视觉是使用计算机(也许是可移动式的)来模拟人的视觉,因此模拟才是计算机视觉领域的最终目标,而真正意义上的图像处理侧重在“处理”图像:如增强,还原,去噪,分割,等等,如常见的Photoshop就是功能强大的图像处理软件。大部分的机器视觉,都包含了图像处理的过程,只有图像处理过后,才能找到图像中需要的特征,从而更进一步的执行其它的指令动作。在我们实际工程应用中研究的一些图像算法,实际上是属于机器视觉,而不是纯粹的图像处理。总的来说,图像处理技术包括图像压缩,增强和复原,匹配、描述和识别3个部分,在实际工程中,这几块不是独立的,往往是环环相扣、相互辅助来达到实际效果。接下来简单介绍一下机器视觉中常用的图像处理算法。 一、滤波 滤波一般在图像预处理阶段中使用,改善图像信息,便于后续处理,当然,这不是绝对的,在图像算法过程中如果有需要,随时可以进行滤波操作。比较常用的滤波方法有以下三种: 1、均值滤波 均值滤波也称为线性滤波,其采用的主要方法为邻域平均法。线性滤波的基本原理是用均值代替原图像中的各个像素值,即对待处理的当前像素点(,) x y,选择一个模板,该模板由其近邻的若干像素组成,求模板中所有像素的均值,再把该均值赋予当前像素点(,) g x y,即 x y,作为处理后图像在该点上的灰度值(,) 波方法可以平滑图像,速度快,算法简单。但是无法去掉噪声,只能减弱噪声。 2、中值滤波
基于内容的推荐算法(Content-Based Recommendation)1.基本思想 基本思想就是给用户推荐与他们曾经喜欢的项目内容相匹配的新项目。 基于内容的推荐的基本思想是:对每个项目的内容进行特征提取(FeatureExtraction),形成特征向量(Feature Vector);对每个用户都用一个称作用户的兴趣模型(User Profile)的文件构成数据结构来描述其喜好;当需要对某个用户进行推荐时,把该用户的用户兴趣模型同所有项目的特征矩阵进行比较得到二者的相似度,系统通过相似度推荐文档。 (基于内容的推荐算法不用用户对项目的评分,它通过特定的特征提取方法得到项目特征用来表示项目,根据用户所偏好的项目的特征来训练学习用户的兴趣模型,然后计算一个新项目的内容特征和用户兴趣模型的匹配程度,进而把匹配程度高的项目推荐给用户。) 2.基于内容的推荐层次结构图:
CB的过程一般包括以下三步: (1)Item Representation:为每个item抽取出一些特征(也就是item的content 了)来表示此item;对应着上图中的Content Analyzer。 (2)Profile Learning:利用一个用户过去喜欢(及不喜欢)的item的特征数据,来学习出此用户的喜好特征(profile);对应着上图中的Profile Learner。 (3)Recommendation Generation:通过比较上一步得到的用户profile与候选item 的特征,为此用户推荐一组相关性最大的item。对应着上图中的Filtering Component。 3.详细介绍上面的三个步骤: 3.1 Item Representation 项目表示:对项目进行特征提取,比如最著名的特征向量空间模型,它首先将一份文本(项目)以词袋形式来表示,然后对每一个词用词频-逆向文档频率(TF-IDF)来计算权重,找出若干权重较大的词作为关键词(特征)。每个文本(项目)都可以表示成相同维度的一个向量 TF-IDF词频-逆文档频率计算: TF 词项t在文档d中出现的次数,df 表示词项t在所有文档出现的次数,idf 为反向文档频率,N为文档集中所有文档的数目。 TF-IDF公式同时引入词频和反向文档频率,词频TF表示词项在单个文档中的局部权重,某一词项在文档中出现的频率越高,说明它区分文档内容的属性越强,权重越大。IDF表示词项在整个文档集中的全局权重,某一词项在各大文档都有出现,说明它区分文档类别属性的能力越低,权值越小。
重装系统c盘数据恢复重装系统后恢复c盘的东西的方法 各位读友大家好,此文档由网络收集而来,欢迎您下载,谢谢 系统重装就是将原来系统盘的系统删除后重新植入新的系统的过程。这也意味着原来系统盘的内容全部删除。那么重装系统后c盘的东西如何恢复呢?下面是学习小编给大家整理的有关介绍,希望对大家有帮助! 重装系统后恢复c盘的东西的方法 首先,系统盘电脑一般默认的是C 盘,如果没有备份的话,几乎不可能恢复重装前的系统盘的内容了。除非找电脑维修店,他们有收费的硬盘数据恢复软件。不如东西不是很重要,建议不要恢复了。因为收费也是很高的。 其次,如果是恢复出厂设置或者一键还原式的重装系统,那么系统恢复前
会提示你是否备份个人文件,一定要选择备份。当新系统重装后会保留个人文件。 再者,如果是用优盘或者光盘重新装系统,一定要手动备份C盘的内容。你可以选择用软件备份你的应用、桌面文件等。百度一下备份软件很多。 另外,也可以自己将C盘的东西拷贝出来,拷贝到D、E、F盘都可以。重装系统,出了C盘之外其他盘的内容是不受影响的。其实,应用都可以重装以后再下载安装,主要是C盘里面的个人重要的数据文件,比如工作文件、下载软件下载的东西等。有些人安装的是网上下载的GHOST系统,可能自带的驱动不全,你可以用驱动备份软件将驱动提前备份到其他盘。到时候以免安装的系统没有驱动。 5最后,回到恢复数据的问题上。其实系统重装之后,硬盘上的数据已经被擦除改写了。所以单纯的想通过简单操作恢复之前的数据是不可能的。但是硬
盘擦除和修改也是有一定规律的,擦除的部分物理存储区可能并没有被完全改写。所以,从道理上来说这部分未被改写的区域还是可以恢复的。不过跟我说的第一条类似,代价比较高。个人建议,对于一般用户来说,还是提前做好备份比较划算。 各位读友大家好,此文档由网络收集而来,欢迎您下载,谢谢
[文字处理的基本方法(Word)] 一、初识Word2003 1、Word2003的特点:集成化、智能化、网络化。 2、Word2003的启动/退出:①启动:方法一:单击“开始菜单”→程序→Microsoft Office→Microsoft Word2003;方法二:双击桌面上的图标; ②退出:方法一:“文件”→“退出”;方法二:单击关闭按钮;方法三:“Alt+F4”。 二、文章的输入、修改与保存 1、保存:“文件”→保存(或)→选择保存位置和文件名→保存 2、另存为:“文件”→另存为→选择保存位置和文件名→保存 注1:第一次保存时会弹出对话框,提示输入保存位置和文件名,以后则不会,只把最新的内容按原位置和原名保存起来。 注2:如果需要更改保存位置或文件名,则需使用“另存为”,会弹出对话框,要求输入更改后的位置和文件名。注3:Word2003 文件的类型为.DOC文件,即扩展名为.DOC。 3、文档的编辑 a、打开:“文件”→“打开” b、选定文字 选定指定内容:拖动左键。 ㈡、选定一句:双击左键。 ㈢、选定一行:鼠标移到左侧空白处,单击左键。
㈣、选定一段:①鼠标移到左侧空白处,双击左键;②在段落中三击左键。 ㈤、选定全文:①Ctrl+A或“编辑”→“选择全文”②鼠标移到左侧空白处,三击左键。 ㈥、撤销选定:在文本区任何位置单击左键。 4、Word2003有两种编辑方式:插入(增加内容时原文不减少)和改写(光标后的原文被新增内容所替代)用Insert键切换。 5、文字的移动 ①用鼠标:选定,拖放到目标位置。 ②用菜单或工具栏:选定→“剪切”→移动光标到目标位置→“粘贴” 6、文字的复制 ①用鼠标:选定,按住Ctrl键拖放到目标位置。 ②用菜单或工具栏:选定→“复制”→移动光标到目标位置→“粘贴” 7、查找/替换:“编辑”→“查找”/“替换” 8、插入图像:“插入”→“图像”→通过“搜寻”找到要插入的图象→“打开”。 ①、改变图像的位置:拖动图像 ②、改变图像的大小:选中(单击)图像,拖动边框 ③、改变绕排方式:选中图像,单击右键,选择“绕排方式”→两边绕排/只绕排一边/两边不绕排……… ④、删除图像:选中图像,单击右键→“删除” 9、插入表格:“插入”→“表格”→绘制表格
Delaunay 三角网是Voronoi(或称thiessen多边形,V 图)图的伴生图形 ◆Delaunay 三角网的定义: 由一系列相连的但不重叠的三角形的集合, 而且这些 三角形的外接圆不包含这个面域的其他任何点。 ◆Voronoi图的定义: Voronoi图把平面分成N 个区,每一个区包括一个点, 该点所在的区域是距离该点最近的点的集合。 ◆Delaunay三角网的特性: ◆不存在四点共圆; ◆每个三角形对应于一个Voronoi图顶点; ◆每个三角形边对应于一个Voronoi图边; ◆每个结点对应于一个Voronoi图区域; ◆Delaunay图的边界是一个凸壳; ◆三角网中三角形的最小角最大。 空外接圆准则最大最小角准则最短距离和准则 在TIN中,过每个三角形的外接圆均不包含点集的其余任何点在TIN中的两相邻三角形形成 的凸四边形中,这两三角形 中的最小内角一定大于交换 凸四边形对角线后所形成的 两三角形的最小内角 一点到基边的两端的距离 和为最小 Delaunay三角剖分的重要的准则
张角最大准则面积比准则对角线准则 一点到基边的张角为最大三角形内切圆面积与三角形 面积或三角形面积与周长平 方之比最小 两三角形组成的凸四边形 的两条对角线之比。这一 准则的比值限定值,须给 定,即当计算值超过限定 值才进行优化 Delaunay三角剖分的重要的准则 不规则三角网(TIN)的建立 ●三角网生长算法就是从一个“源”开始,逐步形成覆盖整个数据区域的三角网。 ●从生长过程角度,三角网生长算法分为收缩生长算法和扩张生长算法两类。 方法说明方法实例 收缩生长算法先形成整个数据域的数据边界(凸壳), 并以此作为源头,逐步缩小以形成整个三 角网 分割合并算法 逐点插入算法 扩张生长算法从一个三角形开始向外层层扩展,形成覆 盖整个区域的三角网 递归生长算法
文字处理的基本操作——文本编辑 一、概述 ·七年级下册第一单元《文字处理及其应用》中第一节《文字处理的基本操作》的有关内容。本节课需要1课时,主要学习word文本编辑的方法、文字的美化、简单排版、文本框的插入与修饰、图片的插入与设置,并指导学生提供获取扩展知识,完成基本操作。 二、教学目标分析 知识与技能: 1.学习文本的编辑方法,掌握文字的设置与修饰。 2.掌握文本框和图片的插入与修饰的方法 3.段落的设置方法 过程与方法: 通过动手操作,加深所学知识的印象,巩固学习成果。 情感态度与价值观: 培养良好的学习态度和学习风气,感受Word在生活的实际应用。 三、学习者特征分析 我校七年级学生在信息技术学科中有20%左右的学生是“零起点”,根本没有开设过信息技术课。有50%的学生虽然是“非零起点”,但对以前学过的知识掌握的较差。Word这一部分的内容,非零起点的学生基本都已学过。但只局限在文字的录入方面。美化文章、图文混排都没有学过。因此,从学生的认知特点和学生已有的知识经验及能力水平出发,通过教师讲解、示范,学生模仿、练习,这样更符合学生的认识特点,从而使学生能熟练掌握文字格式的设置操作技能。 四、教学策略选择与设计 《文字处理及其应用》中指出,主要是要让学生“完成一份电子板报作品来,引导学生学习文字处理基本操作,并能自主的学习和创作”在日常生活中,文字处理及其应用是非常广泛,本单元就是在学生的生活经验和已有知识的基础上,进一步提高信息处理能力,并通过实践活动进行简单的电子板报排版,培养学生的创新思维能力。 五、教学资源与工具设计 本节课的教学在多媒体机房进行,需要多媒体广播系统,投影等设备,学生机应装有Office软件,另外还有教师为教学设计的课件及教材配套的教学素材等资源。六、教学过程 (一)引言 上节课我们学习了Word中窗口的基本操作及汉字的输入方法。谁能说一说。 简单提问:(如文件在哪保存?女字用智能ABC如何输入?) (二)讲授新课 学生看一段已经排版好文稿,复习输入法的操作。 如果我们要对其中的一部分文字做修改,该怎么操作呢? 1.文本编辑的方法 1)插入文字:①用键盘移光标到插入文字处;②在插入文字处单击鼠标光标。2)输入特殊符号:①插入 符号;②右键—>快捷菜单中“符号” 3)删除不需要的文字:按DELETE键删除光标后面的字符;按退格键删除光标前面的字符。 4)选定一段文字:单击段首选取中当前行;双击段首选中当前段;三击段落
分块写HDF示例源码 算法原理,该图片是从IDL的jpeg2000help中截取,原理基本类似,依次分块写入 程序运行效果如下,将一6000*6000的数据按照tileSize = [1024, 1024]的大小写入一hdf文件中
看看最终结果文件(HDF Explorer查看)
下载 (142.06 KB) 2010/5/9 02:47 运行源码 ;+ ;+ ;:Description: PRO CENTERTLB, tlb, x, y, NoCenter=nocenter COMPILE_OPT StrictArr geom = WIDGET_INFO(tlb, /Geometry)
IF N_ELEMENTS(x) EQ 0 THEN xc = 0.5 ELSE xc = FLOAT(x[0]) IF N_ELEMENTS(y) EQ 0 THEN yc = 0.5 ELSE yc = 1.0 - FLOAT(y[0]) center = 1 - KEYWORD_SET(nocenter) ; oMonInfo = OBJ_NEW('IDLsysMonitorInfo') rects = oMonInfo -> GetRectangles(Exclude_Taskbar=exclude_Taskbar) pmi = oMonInfo -> GetPrimaryMonitorIndex() OBJ_DESTROY, oMonInfo screenSize =rects[[2, 3], pmi] ; Get_Screen_Size() IF screenSize[0] GT 2000 THEN screenSize[0] = screenSize[0]/2 ; Dual monitors. xCenter = screenSize[0] * xc yCenter = screenSize[1] * yc xHalfSize = geom.Scr_XSize / 2 * center yHalfSize = geom.Scr_YSize / 2 * center XOffset = 0 > (xCenter - xHalfSize) < (screenSize[0] - geom.Scr_Xsize) YOffset = 0 > (yCenter - yHalfSize) < (screenSize[1] - geom.Scr_Ysize) WIDGET_CONTROL, tlb, XOffset=XOffset, YOffset=YOffset END ; ; 测试分块写如HDF文件 ; 读取请参考 C:\Program Files\ITT\IDL71\examples\doc\sdf\hdf_info.pro ; Author: DYQ 2010-5-9; ; ; Blog: https://www.doczj.com/doc/eb16142807.html,/dyqwrp ;- PRO WRITEREADHDF ;创建隐藏tlb,目的为了显示进度条 wtlb = WIDGET_BASE(map = 0) WIDGET_CONTROL,wtlb,/realize ;tlb居中显示 CENTERTLB,wtlb ;创建进度条 process = IDLITWDPROGRESSBAR( TIME=0,$ GROUP_LEADER=wtlb, $ TITLE='测试分块保存HDF... 请等待') IDLITWDPROGRESSBAR_SETVALUE, process, 0
推荐系统的出现 推荐系统的任务就是解决,当用户无法准确描述自己的需求时,搜索引擎的筛选效果不佳的问题。联系用户和信息,一方面帮助用户发现对自己有价值的信息,另一方面让信息能够展现在对他感兴趣的人群中,从而实现信息提供商与用户的双赢。 推荐算法介绍 基于人口统计学的推荐 这是最为简单的一种推荐算法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。 系统首先会根据用户的属性建模,比如用户的年龄,性别,兴趣等信息。根据这些特征计算用户间的相似度。比如系统通过计算发现用户A和C比较相似。就会把A喜欢的物品推荐给C。 优缺点: ?不需要历史数据,没有冷启动问题 ?不依赖于物品的属性,因此其他领域的问题都可无缝接入。 ?算法比较粗糙,效果很难令人满意,只适合简单的推荐 基于内容的推荐 与上面的方法相类似,只不过这次的中心转到了物品本身。使用物品本身的相似度而不是用户的相似度。
系统首先对物品(图中举电影的例子)的属性进行建模,图中用类型作为属性。 在实际应用中,只根据类型显然过于粗糙,还需要考虑演员,导演等更多信息。 通过相似度计算,发现电影A和C相似度较高,因为他们都属于爱情类。系统还会发现用户A喜欢电影A,由此得出结论,用户A很可能对电影C也感兴趣。 于是将电影C推荐给A。 优缺点: ?对用户兴趣可以很好的建模,并通过对物品属性维度的增加,获得更好的推荐精度 ?物品的属性有限,很难有效的得到更多数据 ?物品相似度的衡量标准只考虑到了物品本身,有一定的片面性 ?需要用户的物品的历史数据,有冷启动的问题 协同过滤 协同过滤是推荐算法中最经典最常用的,分为基于用户的协同过滤和基于物品的协同过滤。那么他们和基于人口学统计的推荐和基于内容的推荐有什么区别和联系呢? 基于用户的协同过滤——基于人口统计学的推荐 基于用户的协同过滤推荐机制和基于人口统计学的推荐机制都是计算用户的相似度,并基于“邻居”用户群计算推荐,但它们所不同的是如何计算用户的相似度,基于人口统计学的机制只考虑用户本身的特征,而基于用户的协同过滤机制可是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户可能有相同或者相似的口味和偏好。 基于物品的协同过滤——基于内容的推荐
系统帮助 我的电脑重装了操作系统,计费系统用不了了,怎么办? 1、请在重装电脑操作系统之前,先把您软件安装目录下面的文件拷贝到您的U盘上。安装 目录在哪儿呢?请您鼠标右键点击电脑桌面上的“中科计费系统主控台”快捷图标 ,会出现右键菜单,选择“属性”,弹出属性界面,如下图所示,点击 “查找目标”按钮,,即可达到软件的安装目录。如
2、找到了安装目录,请您将安装目录下面的所有文件拷贝到您的U盘上。 3、数据备份完毕即可重装您的电脑操作系统。 4、电脑操作系统重装完之后,找到您的计费系统安装光盘,没有光盘,请您到 中科官方网站https://www.doczj.com/doc/eb16142807.html,上下载,下载完成后,重新安装您的计费系统。 5、安装好之后,找到您软件的安装目录,方法如上1所述,将您U盘里的备份 数据,都拷贝到这个安装目录下面,覆盖新安装的计费系统。 6、 覆盖之后,请打开计费系统主控台,点击第二个“帐套管理”,登陆之后,点击 “恢复”按钮,。弹出
备份数据选择窗口,在这个窗口空白处右击鼠标,选择“排列图标”-“按修改时间排序”。 7、找到修改时间最近的后缀是.bak的文件。选中它,点击“打开”按钮,系统 会提示您是否恢复数据,您选择是 8、恢复之前会提示您备份数据,您选择“是”,等个一分钟左右,系统就会提 示恢复成功。 9、恢复成功之后,请退出“系统管理”,重新进入主控台,点击“日常计费”, 您的系统就会跟重做操作系统之前一摸一样了。
我换了台电脑或者换了个电脑硬盘,计费系统如何安装会员数据才不会丢失? 1、先把您旧电脑上的(或者旧电脑硬盘里的)计费系统备份数据拷贝到您的U 盘上。方法如下:请您鼠标右键点击旧电脑桌面上的“中科计费系统主控台”快捷图 标,会出现右键菜单,选择“属性”,弹出属性界面,如下图所示,点 击“查找目标”按钮,,即可达到软件的安装目录。如