
计量经济学张晓峒第二章习题
1.最小二乘法对随机误差项u作了哪些假定?说明这些假定条件的意义。 答:假定条件: (1)均值假设:E(u i)=0,i=1,2,…; (2)同方差假设:Var(u i)=E[u i-E(u i)]2=E(u i2)=σu2 ,i=1,2,…;(3)序列不相关假设:Cov(u i,u j)=E[u i-E(u i)][u j-E(u j)]=E(u i u j)=0,i≠j,i,j=1,2,…; (4)Cov(u i,X i)=E[u i-E(u i)][X i-E(X i)]=E(u i X i)=0; (5)u i服从正态分布, u i~N(0,σu2)。 意义:有了这些假定条件,就可以用普通最小二乘法估计回归模型的参数。 2.阐述对样本回归模型拟合优度的检验及回归系数估计值显著性检验的步骤。 答:样本回归模型拟合优度的检验:可通过总离差平方和的分解、样本可决系数、样本相关系数来检验。 回归系数估计值显著性检验的步骤: (1)提出原假设H0 :β1=0; (2)备择假设H1 :β1≠0;
(3)计算t=β1/Sβ1; (4)给出显著性水平α,查自由度v=n-2的t分布表,得临界值tα/2(n-2); (5)作出判断。如果|t|
第四章 一、练习题 (一)简答题 1、多元线性回归模型的基本假设是什么?试说明在证明最小二乘估计量的无偏性和有效性的过程中,哪些基本假设起了作用? 2、多元线性回归模型与一元线性回归模型有哪些区别? 3、某地区通过一个样本容量为722的调查数据得到劳动力受教育的一个回归方程为 fedu medu sibs edu 210.0131.0094.036.10++-= R 2=0.214 式中,edu 为劳动力受教育年数,sibs 为该劳动力家庭中兄弟姐妹的个数,medu 与fedu 分别为母亲与父亲受到教育的年数。问 (1)若medu 与fedu 保持不变,为了使预测的受教育水平减少一年,需要sibs 增加多少? (2)请对medu 的系数给予适当的解释。 (3)如果两个劳动力都没有兄弟姐妹,但其中一个的父母受教育的年数为12年,另一个的父母受教育的年数为16年,则两人受教育的年数预期相差多少? 4、以企业研发支出(R&D )占销售额的比重为被解释变量(Y ),以企业销售额(X1)与利润占销售额的比重(X2)为解释变量,一个有32容量的样本企业的估计结果如下: 099 .0)046.0() 22.0() 37.1(05.0)log(32.0472.022 1=++=R X X Y 其中括号中为系数估计值的标准差。 (1)解释log(X1)的系数。如果X1增加10%,估计Y 会变化多少个百分点?这在经济上是一个很大的影响吗? (2)针对R&D 强度随销售额的增加而提高这一备择假设,检验它不虽X1而变化的假设。分别在5%和10%的显著性水平上进行这个检验。 (3)利润占销售额的比重X2对R&D 强度Y 是否在统计上有显著的影响? 5、什么是正规方程组?分别用非矩阵形式和矩阵形式写出模型: i ki k i i i u x x x y +++++=ββββ 22110,n i ,,2,1 =的正规方程组,及其推导过程。 6、假设要求你建立一个计量经济模型来说明在学校跑道上慢跑一英里或一英里以上的人数,以便决定是否修建第二条跑道以满足所有的锻炼者。你通过整个学年收集数据,得到两个可能的解释性方程: 方程A :3215.10.10.150.125?X X X Y +--= 75.02 =R 方程B :4217.35.50.140.123?X X X Y -+-= 73.02 =R 其中:Y ——某天慢跑者的人数
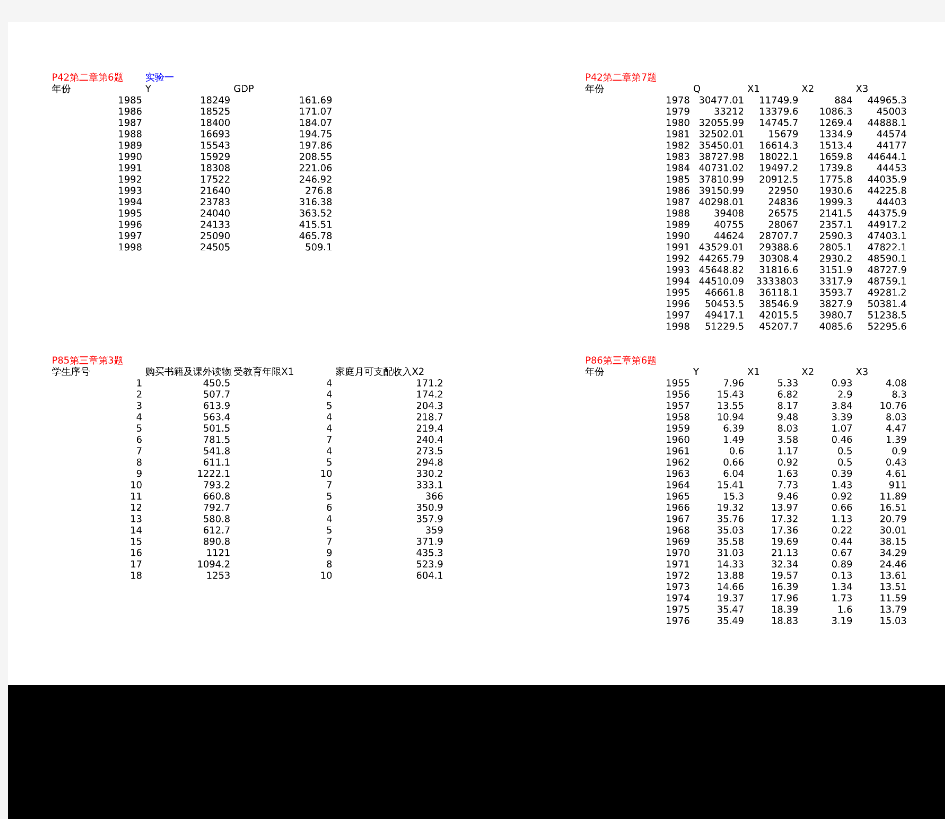
计量经济学答案第二单元课后第六题答案 Dependent Variable: Y Method: Least Squares Date: 04/05/13 Time: 00:07 Sample: 1985 1998 Included observations:14 VariableCoefficien tStd.Et-Statisti c Prob. C 12596.27 1244.567 10.121010.0000 R-squared0.781002Mean dependent var 20168.57 Adjusted R-squared 0.76275 2 S.D. dependent var 3512.4 87 S.E. of regression 1710.865 Akaike info c riterion 17.85895 Sum squared resid Schwarz criterion 17.95 024Log likelihood -123.0126 F-statistic 42.7 9505 Durbin-Watson stat0.85999 8 Prob(F-statisti c) 0.00002 8 obs Y GDP 1985 18249 161.69 198618525 171.071987 18400184.07 1988 16693194.75 1989 15543 197.86 1990 15929 208.55 1991 18308 221.06 1992 17522 246.92 1993 21640 276.8 1994 23783 316.38199524040 363.52 1996 24133 415.51 1997 25090465.78 1998 24505 509.1
1.最小二乘法对随机误差项u作了哪些假定?说明这些假定条件的意义。 答:假定条件: (1)均值假设:E(u i)=0,i=1,2,…; (2)同方差假设:Var(u i)=E[u i-E(u i)]2=E(u i2)=σu2 ,i=1,2,…; (3)序列不相关假设:Cov(u i,u j)=E[u i-E(u i)][u j-E(u j)]=E(u i u j)=0,i≠j,i,j=1,2,…; (4)Cov(u i,X i)=E[u i-E(u i)][X i-E(X i)]=E(u i X i)=0; (5)u i服从正态分布, u i~N(0,σu2)。 意义:有了这些假定条件,就可以用普通最小二乘法估计回归模型的参数。 2.阐述对样本回归模型拟合优度的检验及回归系数估计值显著性检验的步骤。 答:样本回归模型拟合优度的检验:可通过总离差平方和的分解、样本可决系数、样本相关系数来检验。 回归系数估计值显著性检验的步骤: (1)提出原假设H0 :β1=0; (2)备择假设H1 :β1≠0; (3)计算t=β1/Sβ1; (4)给出显著性水平α,查自由度v=n-2的t分布表,得临界值tα/2(n-2); (5)作出判断。如果|t|
《计量经济学》数学基础 数学基础 (Mathematics) 第一节 矩阵(Matrix)及其二次型(Quadratic Forms) 第二节 分布函数(Distribution Function),数学期望(Expectation)及方差(Variance) 第三节 数理统计(Mathematical Statistics ) 第一节 矩阵及其二次型(Matrix and its Quadratic Forms) 1.1 矩阵的基本概念与运算 一个m ×n 矩阵可表示为: v a a a a a a a a a a A mn m m n n ij ? ???? ???????== 2122221 11211][ 矩阵的加法较为简单,若C=A +B ,c ij =a ij +b ij 但矩阵的乘法的定义比较特殊,若A 是一个m ×n 1的矩阵,B 是一个n 1×n 的矩阵,则C =AB 是一个m ×n 的矩阵,而且∑==n k kj ik ij b a c 1,一般来讲,AB ≠BA ,但如下运算是成 立的: ● 结合律(Associative Law ) (AB )C =A (BC ) ● 分配律(Distributive Law ) A (B +C )=AB +AC 问题:(A+B)2=A 2+2AB+B 2是否成立? 向量(Vector )是一个有序的数组,既可以按行,也可以按列排列。 行向量(row v ector)是只有一行的向量,列向量(column vector)只有一列的向量。 如果α是一个标量,则αA =[αa ij ]。 矩阵A 的转置矩阵(transpose matrix)记为A ',是通过把A 的行向量变成相应的列向量而得到。 显然(A ')′=A ,而且(A +B )′=A '+B ', ● 乘积的转置(Transpose of production ) A B AB ''=')(,A B C ABC '''=')(。 ● 可逆矩阵(inverse matrix ),如果n 级方阵(square matrix)A 和B ,满足AB=BA=I 。
计量经济学复习资料 一、名词解释 1.广义计经济学:利用经济理论、统计学和数学定量研究经济现象的经济计量方法的统称,包括回归分析 方法、投入产出分析方法、时间序列分析方法等。 2.狭义计经济学以揭示经济现象中的因果关系为目的,在数学上主要应用回归分析方法。 3.总体回归函数:指在给定Xi下Y分布的总体均值与Xi所形成的函数关系(或者说总体被解释变量的条 件期望表示为解释变量的某种函数)。 4.样本回归函数:指从总体中抽出的关于Y, x的若干组值形成的样本所建立的回归函数。6、随机的总体 回归函数:含有随机千扰项的总体回归函数(是相对于条件期望形式而言的)。 5.线性回归模型:既指对变量是线性的,也指对参数β为线性的,即解释变量与参数β只以他们的I次方 出现。 6.随机干扰项:即随机误差项,是一个随机变量,是针对总体回归函数而言的。9、残差项:是一随机变量, 是针对样本回归函数而言的。 7.条件期望:即条件均值,指X取特定值Xi时Y的期望值。 8.回归系数:回归模型中βo, β1等未知但却是固定的参数。 9.回归系教的估计量:指用β0^ β1^等表示的用已知样本提供的信息所估计出来总体未知参数的结果。 10.最小二乘法:又称最小平方法,指根据使估计的剩余平方和最小的原则确定样本回归函数的方法。 11.最大似然法:又称最大或然法,指用生产该样本概率最大的原则去确定样本回归函数的方法。 12.估计的标准差:度量一个变量变化大小的测量值。 13.总离差平方和:用TSS表示,用以度量被解释变量的总变动。 14.回归平方和:用ESS表示:度量由解释变量变化引起的被解释变量的变化部分。 15.残差平方和:用RSS表示:度量实际值与拟合值之间的差异,是由除解释变量以外的其他因素引起的被 解释变量变化的部分。 16.协方差:用Cov(X, Y)表示,度量XY两个变量关联程度的统计量。 17.拟合优度检验:检验模型对样本观测值的拟合程度,用R2表示,该值越接近1,模型对样木观测值拟合 得越好。 18.t检验是针对每个解释变量进行的显著性检验,即构适一个t统计量,如果该统计量的值落在置信区 间外,就拒绝原假设。 19.相关分析:研究随机变量间的相关形式 20.回归分析:研究一个变量关于另一个(些)变量的依赖关系的计算方法和理论。
计量经济学(第四版)习题参考答案 潘省初
第一章 绪论 1.1 试列出计量经济分析的主要步骤。 一般说来,计量经济分析按照以下步骤进行: (1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项? 为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。 1.3什么是时间序列和横截面数据? 试举例说明二者的区别。 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。 横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。 1.4估计量和估计值有何区别? 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。在一项应用中,依据估计量算出的一个具体的数值,称为估计值。如Y 就是一个估计量,1 n i i Y Y n == ∑。现有一样本,共4个数,100,104,96,130,则 根据这个样本的数据运用均值估计量得出的均值估计值为 5.1074 130 96104100=+++。 第二章 计量经济分析的统计学基础 2.1 略,参考教材。 2.2请用例2.2中的数据求北京男生平均身高的99%置信区间
N S S x = =45 =1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684 也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。 2.3 25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体? 原假设 120:0=μH 备择假设 120:1≠μH 检验统计量 () 10/25X X μσ-Z == == 查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。 2.4 某月对零售商店的调查结果表明,市郊食品店的月平均销售额为2500元,在下一个月份中,取出16个这种食品店的一个样本,其月平均销售额为2600元,销售额的标准差为480元。试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化? 原假设 : 2500:0=μH 备择假设 : 2500:1≠μH ()00) 100/1200 .83?X X t μσ-= === 查表得 131.2)116(025.0=-t 因为t = 0.83 < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。
7、已知我国粮食产量Q (万吨、农业机械总动力1x (万千瓦)、化肥施用量2x (万吨)、土地灌溉面积3x (千公顷)。 (1) 试估计一元线性回归模型 011?? t t t Q X e α α=++ 10,000 15,00020,00025,00030,00035,000 40,00045,00050,00030,000 35,00040,000 45,00050,00055,000 Q X 1 Dependent Variable: Q Method: Least Squares Date: 10/09/12 Time: 21:20 Sample: 1978 1998 Included observations: 21 Coefficient Std. Error t-Statistic Prob. X1 0.608026 0.039102 15.54972 0.0000 C 25107.08 1085.940 23.12012 0.0000 R-squared 0.927146 Mean dependent var 41000.89 Adjusted R-squared 0.923311 S.D. dependent var 6069.284 S.E. of regression 1680.753 Akaike info criterion 17.78226 Sum squared resid 53673653 Schwarz criterion 17.88174 Log likelihood -184.7138 Hannan-Quinn criter. 17.80385 F-statistic 241.7938 Durbin-Watson stat 1.364650 Prob(F-statistic) 0.000000
计量经济学张晓峒第二版实验第5章异方差 2.已知我国29个省、直辖市、自治区1994年城镇居民人均生活费支出Y,可支配收入X的截面数据见下表(表略)。 (1)用等级相关系数和戈德菲尔徳- 夸特方法检验支出模型的扰动项是否存在 异方差性。支出模型是 Y i =β0 +β 1 X i +u i (2)无论{u i}是否存在异方差性,用EViews练习加权最小二乘法估计模型,并 用模型进行预测。 解析: Dependent Variable: Y Method: Least Squares Date: 11/12/13 Time: 12:38 Sample: 1 29 Included observations: 29 Variable Coefficient Std. Error t-Statistic Prob. X 0.795570 0.018373 43.30193 0.0000 C 58.31791 49.04935 1.188964 0.2448 R-squared 0.985805 Mean dependent var 2111.931 Adjusted R-squared 0.985279 S.D. dependent var 555.5470 S.E. of regression 67.40436 Akaike info criterion 11.32577 Sum squared resid 122670.4 Schwarz criterion 11.42006 Log likelihood -162.2236 Hannan-Quinn criter. 11.35530 F-statistic 1875.057 Durbin-Watson stat 1.893970 Prob(F-statistic) 0.000000
计量经济学答案 第二单元课后第六题答案 Dependent Variable: Y Method: Least Squares Date: 04/05/13 Time: 00:07 Sample: 1985 1998 Included observations: 14 Variable Coefficient Std. Error t-Statistic Prob. C 12596.27 1244.567 10.12101 0.0000 GDP 26.95415 4.120300 6.541792 0.0000 R-squared 0.781002 Mean dependent var 20168.57 Adjusted R-squared 0.762752 S.D. dependent var 3512.487 S.E. of regression 1710.865 Akaike info criterion 17.85895 Sum squared resid 35124719 Schwarz criterion 17.95024 Log likelihood -123.0126 F-statistic 42.79505 Durbin-Watson stat 0.859998 Prob(F-statistic) 0.000028 obs Y GDP 1985 18249 161.69 1986 18525 171.07 1987 18400 184.07 1988 16693 194.75 1989 15543 197.86 1990 15929 208.55 1991 18308 221.06 1992 17522 246.92 1993 21640 276.8 1994 23783 316.38 1995 24040 363.52 1996 24133 415.51 1997 25090 465.78 1998 24505 509.1