来源[邮电规划]
【关键词】移动用户预测
利用S曲线及BASS扩散模型预测移动用户发展
贺丰吴丽凤
在ITU-8F对B3G的研究中,为确定市场规模推荐了多种方法,其中以法国建议的S曲线模型和以美国建议的Bass扩散模型比较典型。这里介绍这两种模型,并结合中国移动通信发展情况,进行一定程度的应用。
1、预测方法介绍
·法国S曲线模型
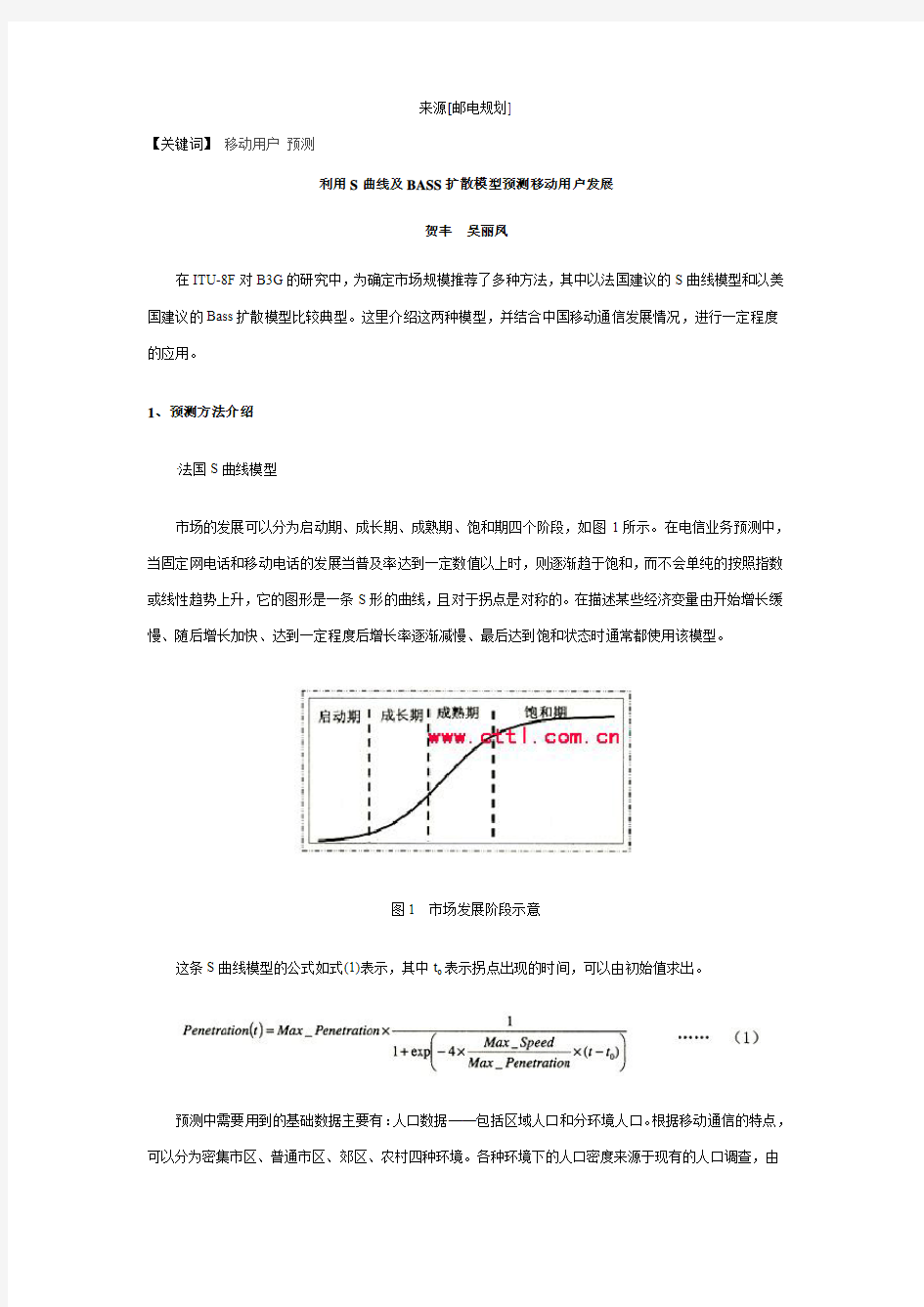
市场的发展可以分为启动期、成长期、成熟期、饱和期四个阶段,如图1所示。在电信业务预测中,当固定网电话和移动电话的发展当普及率达到一定数值以上时,则逐渐趋于饱和,而不会单纯的按照指数或线性趋势上升,它的图形是一条S形的曲线,且对于拐点是对称的。在描述某些经济变量由开始增长缓慢、随后增长加快、达到一定程度后增长率逐渐减慢、最后达到饱和状态时通常都使用该模型。
图1市场发展阶段示意
这条S曲线模型的公式如式(1)表示,其中t o表示拐点出现的时间,可以由初始值求出。
预测中需要用到的基础数据主要有:人口数据——包括区域人口和分环境人口。根据移动通信的特点,可以分为密集市区、普通市区、郊区、农村四种环境。各种环境下的人口密度来源于现有的人口调查,由
于移动用户具有较强的流动性,不能简单地引用人口普查中的行政区划中的人口密度。通过在现有网络中采集数据分析,典型的密集情况下的人口密度是普查中的3-4倍(Vodafone资料中显示该值为3.75)。
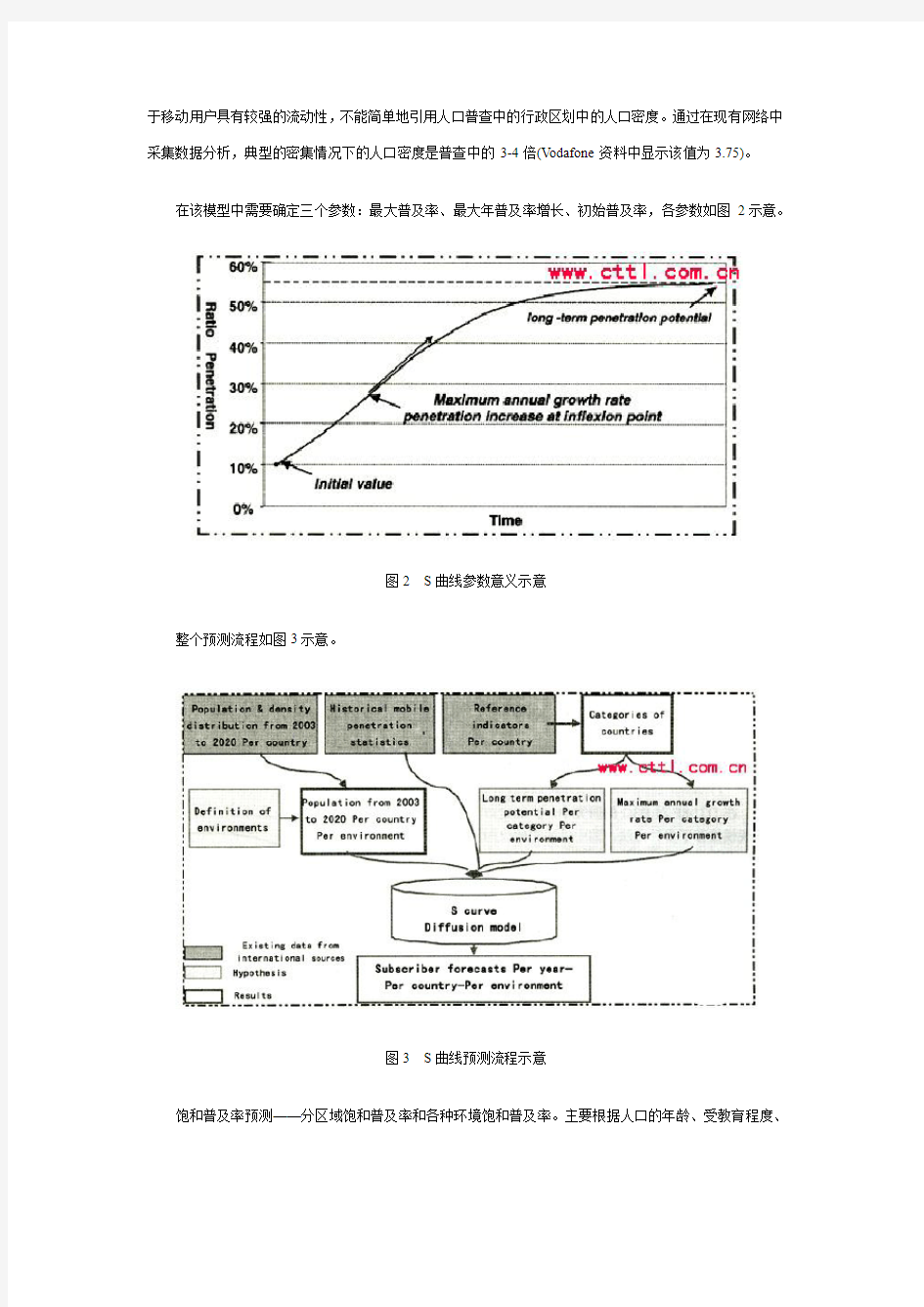
在该模型中需要确定三个参数:最大普及率、最大年普及率增长、初始普及率,各参数如图2示意。
图2S曲线参数意义示意
整个预测流程如图3示意。
图3S曲线预测流程示意
饱和普及率预测——分区域饱和普及率和各种环境饱和普及率。主要根据人口的年龄、受教育程度、
区域经济发展、人均收入等基础数据,同时结合其它地区发展进行类比判断。
普及率年增长的最大值表明了用户发展的速度,分最大全国年增长率和各种环境下的年增长率。
历史数据用户验证参数的吻合程度,也可以用来进行拟和参数。
图4为对西欧地区预测和实际发展情况的对比,两者有较高的拟和。
·美国Bass扩散模型
Bass模型最早是由美国的Frank Bass提出来的,它是一个用于预测耐用消费品销售情况的模型。该模型在1968年用于预测彩色电视的销售上被证明非常成功,逐渐用于各个领域的预测,特别是用于高新技术领域,在1992年也用于预测卫星电视的销售。美国认为比较适合用于宽带技术、PC、手机、3G技术的预测。
该模型有潜在市场(即用户数)、市场普及率和模型系数等几个参数。
图4西欧S曲线预测与实际发展比较示意图
模型系数P和Q,分别表示外部和内部的影响。Bass模型假设一项新产品投入市场后,它的扩散速度主要受到两种传播途径的影响:一是大众传播媒介,如广告等外部影响,它传播产品性能中容易得到验证的部分如价格、尺寸、色彩以及功能等;二是口头交流,即已采纳者对未采纳者的宣传等内部影响,它传播产品某些一时难以验证的性能如可靠性、使用方便性以及耐用程度等。Bass据此将采用者分为两个
群体,一个群体只受大众媒体的影响,另一个群体只受口头传播的影响,Bass将前者称为创新者,后者称为模仿者,分别用P、Q表示,称P为创新系数,称Q为模仿系数。P值是表示初期用户发展的速度,具体值在0.00-1.00之间,该数值越接近于1表示创新者接受产品的速度越快;Q值是表示产品扩散速度的参数,即表示跟随者在使用产品的持续程度,它的具体值也在0.00-1.00之间,该数值越接近于1表示产品在潜在用户群中的扩散越快。P和Q可以从类似产品的历史销售情况中得到。
根据该模型的数学公式,在时间点t发展的用户数占潜在市场的比例可以表示为式(2):
其中:F(t)表示到时间点t累计发展的用户在潜在用户市场的比例
图5分别表示固定P值下变化Q值和固定Q值下变化P值时的市场普及率。在同样P值时,Q值越大,越快进入饱和;在同样Q值时,P值越大,越快进入饱和。
图5不同P、Q情况下市场普及率的变化情况
美国采用该法对移动数据业务进行预测。将用户分为专业人员、青少年、其他三类,早期使用者主要为专业人员和青少年。
专业人员定义为年龄在25-45岁的人群,在专业人员中潜在用户的渗透率假设为60%,考虑三种情况:市场普及率为75%(Base)、90%(High)和60%(Low);参数P值取0.03(反映初期较低的应用),Q值取0.5反映了较强的发展势头。
青少年定义为年龄在14-22岁之间的人群,其潜在的市场规模为85%的渗透率,同样也考虑三种情况下的市场普及率为75%(Base)、90%(High)和60%(Low);参数P值取0.06(因为相对于专业人员青少年更
容易较快地接受新业务),Q值取0.4反映了较强的发展势头。
其他为除以上两类外年龄大于14岁的人。其潜在的市场规模为100%的渗透率,考虑三种市场普及率为75%(Base)、85%(High)和50%(Low);参数P值取0.01(初期发展缓慢),Q值取05反映了较强的发展势头。三类用户发展如6-8图所示。
图6工作人员用户预测
(业务起始年为2003年)
图7年轻人用户预测
(业务起始年为2003年)
图8其它用户预测
(业务起始年为2003年)
S曲线模型需要确定三个参数,Bass扩散模型需要确定四个参数。两个模型都需要确定长期的饱和普及率和初始普及率;S模型还需要确定最大年普及率增长,这个参数可以通过历史数据进行拟和;Bass
模型需要确定P、Q参数,也可以用历史参数进行拟和,但在对新兴市场进行预测时确定这两个参数相对困难,通常采用类比方式或者经验值方式确定,易于给出多方案。
2、预测方法应用实例
法国S曲线模型
在前面的介绍已经说了,最好能够将全国分为密集市区、市区、郊区、农村等环境分别进行预测,但因为一些基础数据如人口、用户的发展等都没有进行相应的分类,所以在此仅对全国情况进行分析和预测。
■Max_Pennetration:普及率的最大值,即饱和普及率
主要根据我国人口的年龄构成来分析饱和普及率。
根据第五次人口普查数据,我国人口的年龄分布如下(参见图9):
图9全国人口年龄构成
0~14岁的人口为28979万人,占总人口的22.89%;
15~64岁的人口为88793万人,占总人口的70.15%;
65岁及以上的人口为8811万人,占总人口的6.96%。
同1990年第四次全国人口普查相比,0~14岁人口的比重下降了4.80个百分点,65岁及以上人口的比重上升了1.39个百分点。
由于移动用户群体主要集中在15~64岁人群中,0~14岁群体移动用户较少,65岁以上群体的使用情况也比较少;结合人口分布比例和参考其它国家的用户普及情况,取定我国移动电话用户普及率的饱和值为70%;考虑到经济发展的水平可能会对移动电话的用户群造成影响,在此分别取80%、70%、60%三个目标普及率讲行预测。
■Max_Speed:每年普及率增加的最大值
在1990-2000年期间,我国移动用户的增长率很高,但由于用户基数小每年增加的用户普及率是非常低的;近几年,每年新增的移动用户基本维持在6000万左右,年增普及率在4.7%左右:预计我国每年增加的移动电话普及率的最大值也在5%左右,即年增用户在7000万左右。
以2003年的用户数为起始点、并将上诉参数代入模型,得到2004-2015年我国移动电话用户规模如以下表1和图10所示。
表12004-2015年不同饱和普及率时
我国移动电话用户规模单位:亿用户
饱和普及率2004 2005 2008 2010 2015 80% 3.30 3.98 6.20 7.61 9.98
70% 3.29 3.93 5.96 7.14 8.96
60% 3.25 3.89 5.74 6.69 7.94
图10S曲线用户预测
从上述图表可以看出:在2008前,三种饱和普及率情况下的用户规模差异不大,对应的用户分别为6.2亿、5.96亿、5.74亿;2010年在6.7-7.6亿,随后用户发展才逐渐进入饱和;到2015年,用户在8亿-10亿。
·美国Bass扩散模型
相关参数的取定:
关于饱和普及率的分析见S曲线模型相关内容;参数P值取0.01、Q值取0.33。得到2004-2015年我国移动电话用户规模如以下表2和图11所示。
表22004-2015年我国移动电话用户规模单位:亿用户
年份2004 2005 2008 2010 2015 80%饱和普及率 3.49 4.40 7.08 8.47 10.40
70%饱和普及率 3.38 4.22 6.57 7.72 9.22
60%饱和普及率 3.27 4.03 6.02 6.91 8.00
图11BASS扩散模型用户预测
从图表看到,在2005-2010年,我国移动电话用户仍然保持较快的增长,但三种饱和普及率情况的差异显现,2010年的用户规模分别为8.5、7.7、6.9;2010年后逐渐进入饱和,到2015年用户在8-10亿之间。比较上述两种模型的预测结果,我们发现:在远期两种模型的预测结果是完全一致的:80%饱和普及率下的用户规模为10亿、70%的为9亿、60%的为8亿;而在近期和中期,Bass模型的结果比S曲线模型较高;我们认为在进行近期和中期的用户预测时,S曲线模型相对来说更为合适,而在对一些新业务种类的预测中采用BASS模型更能体现P参数(创新者)的作用。
承诺书 我们仔细阅读了中国大学生数学建模竞赛的竞赛规则. 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们将受到严肃处理。 我们参赛选择的题号是(从A/B/C/D中选择一项填写): 我们的参赛报名号为(如果赛区设置报名号的话): 所属学校(请填写完整的全名): 参赛队员(打印并签名) :1. 2. 3. 指导教师或指导教师组负责人(打印并签名): 日期:年月日赛区评阅编号(由赛区组委会评阅前进行编号):
编号专用页 赛区评阅编号(由赛区组委会评阅前进行编号): 全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):
基于系统综合评价的城市表层土壤重金属污染分析 摘要 本文针对城市表层土壤重金属污染问题,首先对各重金属元素进行分析,然后对各种重金属元素的基本数据进行统计分析及无量纲化处理,再对各金属元素进行相关性分析,最后针对各个问题建立模型并求解。 针对问题一,我们首先利用EXCEL 和 SPSS 统计软件对各金属元素的数据进行处理,再利用Matlab 软件绘制出该城区内8种重金属元素的空间分布图最后通过内梅罗污染 模型:2 /12 max 22?? ? ? ??+=P P P 平均综,其中平均P 为所有单项污染指数的平均值,max P 为土壤环境中 针对问题二,我们首先利用EXCELL 软件画出8种元素在各个区内相对含量的柱状图,由图可以明显地看出各个区内各种元素的污染情况,然后再根据重金属元素污染来源及传播特征进行分析,可以得出工业区及生活区重金属的堆积和迁移是造成污染的主要原因,Cu 、Hg 、Zn 主要在工业区和交通区如公路、铁路等交通设施的两侧富集,随时间的推移,工业区、交通区的土壤重金属具有很强的叠加性,受人类活动的影响较大。同时城市人口密度,土地利用率,机动车密度也是造成重金属污染的原因。 针对问题三,我们从两个方面考虑建模即以点为传染源和以线为传染源。针对以点为传染源我们建立了两个模型:无约束优化模型()[]()[]() 22y i y x i x m D -+-=,得到污染源的位置坐标()6782,5567;有衰减的扩散过程模型得位置坐标(8500,5500),模型为: u k z u c y u b x u a h u 222 2222222-??+??+??=??, 针对以线为传染源我们建立了l c be u Y ?-+=0模型,并通过线性拟合分析线性污染源的位置。 针对问题四,我们在已有信息的基础上,还应收集不同时间内的样点对应的浓度以及各污染源重金属的产生率。根据高斯浓度模型建立高斯修正模型,得到浓度关于时间和空间的表达式ut e C C -?=0。 在本题求解过程中,我们所建立的模型与实际紧密联系,有很好的通用性和推广性。但在求点污染源时,我们假设只有一个污染源,而实际上可能有多个点污染源,从而使得误差增大,或者使污染源的位置够不准确。 关键词 内梅罗污染模型 无量纲化 相关性 回归模型 高斯浓度模型
预测方法的分类 郑XX 预测方法的分类 由于预测的对象、目标、内容和期限不同,形成了多种多样的预测方法。据不完全统计,目前世界上共有近千种预测方法,其中较为成熟的有150多种,常用的有30多种,用得最为普遍的有10多种。 1-1预测方法的分类体系 1)按预测技术的差异性分类 可分为定性预测技术、定量预测技术、定时预测技术、定比预测技术和评价预测 技术,共五类。 2)按预测方法的客观性分类 可分为主观预测方法和客观预测方法两类。前者主要依靠经验判断,后者主要借 助数学模型。 3)按预测分析的途径分类 可分为直观型预测方法、时间序列预测方法、计量经济模型预测方法、因果分析 预测方法等。 4)按采用模型的特点分类 可分为经验预测模型和正规的预测模型。后者包括时间关系模型、因果关系模 型、结构关系模型等。 1-2 常用的方法分类 1)定性分析预测法 定性分析预测法是指预测者根据历史与现实的观察资料,依赖个人或集体的经验与智慧,对未来的发展状态和变化趋势作出判断的预测方法。 定性预测优缺点 定性预测的优点在于: 注重于事物发展在性质方面的预测,具有较大的灵活性,易于充分发挥人的主观能动作用,且简单的迅速,省时省费用。
定性预测的缺点是: 易受主观因素的影响,比较注重于人的经验和主观判断能力,从而易受人的知识、经验和能力的多少大小的束缚和限制,尤其是缺乏对事物发展作数量上的精确描述。 2)定量分析预测法 定量分析预测法是依据调查研究所得的数据资料,运用统计方法和数学模型,近似地揭示预测对象及其影响因素的数量变动关系,建立对应的预测模型,据此对预测目标作出定量测算的预测方法。通常有时间序列分析预测法和因果分析预测法。 ⅰ时间序列分析预测法 时间序列分析预测法是以连续性预测原理作指导,利用历史观察值形成的时间数列,对预测目标未来状态和发展趋势作出定量判断的预测方法。
大气污染扩散 第一节大气结构与气象 有效地防止大气污染的途径,除了采用除尘及废气净化装置等各种工程技术手段外,还需充分利用大气的湍流混合作用对污染物的扩散稀释能力,即大气的自净能力。污染物从污染源排放到大气中的扩散过程及其危害程度,主要决定于气象因素,此外还与污染物的特征和排放特性,以及排放区的地形地貌状况有关。下面简要介绍大气结构以及气象条件的一些基本概念。 一、大气的结构 气象学中的大气是指地球引力作用下包围地球的空气层,其最外层的界限难以确定。通常把自地面至1200 km左右范围内的空气层称做大气圈或大气层,而空气总质量的98.2%集中在距离地球表面30 km以下。超过1200 km的范围,由于空气极其稀薄,一般视为宇宙空间。 自然状态的大气由多种气体的混合物、水蒸气和悬浮微粒组成。其中,纯净干空气中的氧气、氮气和氩气三种主要成分的总和占空气体积的99.97%,它们之间的比例从地面直到90km高空基本不变,为大气的恒定的组分;二氧化碳由于燃料燃烧和动物的呼吸,陆地的含量比海上多,臭氧主要集中在55~60km高空,水蒸气含量在4%以下,在极地或沙漠区的体积分数接近于零,这些为大气的可变的组分;而来源于人类社会生产和火山爆发、森林火灾、海啸、地震等暂时性的灾害排放的煤烟、粉尘、氯化氢、硫化氢、硫氧化物、氮氧化物、碳氧化物为大气的不定的组分。 大气的结构是指垂直(即竖直)方向上大气的 密度、温度及其组成的分布状况。根据大气温度在 垂直方向上的分布规律,可将大气划分为四层:对 流层、平流层、中间层和暖层,如图5-1所示。 1. 对流层 对流层是大气圈最靠近地面的一层,集中了大 气质量的75%和几乎全部的水蒸气、微尘杂质。受 太阳辐射与大气环流的影响,对流层中空气的湍流 运动和垂直方向混合比较强烈,主要的天气现象云 雨风雪等都发生在这一层,有可能形成污染物易于 扩散的气象条件,也可能生成对环境产生有危害的 逆温气象条件。因此,该层对大气污染物的扩散、输送和转化影响最大。 大气对流层的厚度不恒定,随地球纬度增高而降低,且与季节的变化有关,赤道附近约
关于金属汞扩散的问题 引言: 我们都知道,重金属丢弃到土地后会严重污染环境,同时对人体健康造成危害。著名的秦始皇陵墓,据专家在陵墓周围取数据观测,周围的汞含量呈现出外渗的趋势。也就是说,随着外围半径的扩大,汞含量浓度递减,并且随着时间的增加,汞渗透的半径越来越大。这就证明了汞金属在泥土中会发生扩散。因此,我们就提出,能否通过在外部取样的观察数据,建立一个数学模型,来判断陵墓中心处汞的浓度呢? 模型的提出: 由于汞的扩散快慢跟本身的化学性质,物理性质有关。还有,由于在土堆里头,在各个方向上受到的力不相同和各种因素的影响,因此扩散的速度也会有差异。例如东西方向和南北方向会因为地球的自传而扩散速度会不一样。另一方面,汞在扩散的过程,由于泥土的吸收,化学反应等因数的影响,也会影响到汞的扩散。 为此我们引入一个函数u(x, y, z, t),它表示t时刻在(x,y,z)处汞的浓度。我们的目标就是利用所观测到的数据,来推断出这个函数的表达式。 模型符号的引入: 为了表示汞在想x,y,z 方向上的扩散速度,我们在此引
入扩散系数: 2 a :x 方向上的扩散系数 2 b :y 方向上的扩散系数 2 c :z 方向上的扩散系数 2 k :由于泥土吸收,化学反应而引起的衰减系数 M :扩散源汞的质量 模型假设: 1。假设有一汞扩散源,汞从扩散源沿 x ,y ,z 三个方向向四周扩散。 2。扩散前周围空间此物质的浓度为零。 3。扩散过程中没有人为因素的影响。 模型建立: u(x, y, z, t) 是 t 时刻点 (x, y , z) 处某物质的浓度。任取一个闭曲面 S ,它所围的区域是Ω,由于扩散,从 t 到 t t +? 时刻这段时间内,通过 S 流入Ω的质量为 1 M 2 2 2 1(cos cos cos )d d t t t S u u u M a b c S t x y z αβγ+????= ++???? ?? 其中 2 a ,2 b ,2 c 分别是沿 x ,y ,z 方向的扩散系数。 由高斯公式 : ? ??? ?+Ω ??+??+??= t t t t z y x z u c y u b x u a M d d d d )(2 2 2 2 2 2 2 2 2 1
扩散焊的原理及应用 姓名:乐雄学号:153112113 专业:材料工程 摘要:简介扩散焊的原理、分类及特点,从扩散焊加热温度、压力及保温时间等工艺参数和中间层材料选择以及焊后质量检测方面进行了综述,并探讨了扩散焊应用的发展趋势,认为新材料或难焊材料及其构件的扩散焊工艺、中间层的研制和开发、工艺参数的优化、工艺标准和焊后检测验收标准的建立及完善、扩散焊的数值模拟和仿真等方面研究会成为今后研究重点。 关键词:扩散焊;瞬时液相扩散焊;真空扩散焊 The theory and application of diffusion bonding Abstract:The theory, classification and characteristics of diffusion bonding are introduced. The technology parameters, intermediate layer material selection and welding quality inspection are summarized. The development and improvement of new materials or hard materials, the optimization of process parameters, the establishment and improvement of the standard of welding, numerical simulation and Simulation of diffusion welding are discussed. Key words: diffusion bonding;transient liquid phase diffusion bonding;vacuum diffusion bonding 扩散焊也称扩散连接,是指在一定的温度和压力下使待焊表面相互接触,通过微观塑性变形或通过在待焊表面上产生液相而扩大待焊表面的物理接触,然后经过较长的时间的原子相互扩散来实现结合的一种焊接方法[1]。扩散焊是异种金属、耐热合金、复合材料、陶瓷等的主要连接方法,有着广泛的应用前景。 扩散焊在导电装置和元件的加工制造、电真空器件制造、机械制造工业以及航空航天等方面都有着广泛的应用。尤其在航空航天方面,航空工业是扩散焊最重要的应用领域。据报道,[2]美国在近十年间,用扩散焊接和超塑性成形扩散焊接组合工艺制造了大量B-1轰炸机的性合金组件,包括重要的翼板、平衡器支座、
预测模型分类及优缺点分析 灰色(系统)预测模型 神经网络预测模型 趋势平均预测法 1 微分方程模型 当我们描述实际对象的某些特性随时间(或空间)而演变的过程、分析它的变化规律、预测它的未来性态、研究它的控制手段时,通常要建立对象的动态微分方程模型。微分方程大多是物理或几何方面的典型.问题,假设条件已经给出,只需用数学符号将已知规律表示出来,即可列出方程,求解的结果就是问题的答案,答案是唯一的,但是有些问题是非物理领域的实际问题,要分析具体情况或进行类比才能给出假设条件。作出不同的假设,就得到不同的方程。比较典型的有:传染病的预测模型、经济增长预测模型、正规战与游击战的预测模型、药物在体内的分布与排除预测模型、人口的预测模型、烟雾的扩散与消失预测模型以及相应的同类型的预测模型。其基本规律随着时间的增长趋势是指数的形式,根据变量的个数建立初等微分模型。微分方程模型的建立基于相关原理的因果预测法。该法的优点:短、中、长期的预测都适合,而.既能反映内部规律,反映事物的内在关系,也能分析两个因素的相关关系,精度相应的比较高,另外对初等模型的改进也比较容易理解和实现。该法的缺点:虽然反映的是内部规律,但是由于方程的建立是以局部规律:的独立性假定为基础,故做中长期预测时,偏差有点大,而且微分方程的解比较难以得到。 2 时间序列法 将预测对象按照时问顺序排列起来,构成一个所谓的时间序列,从所构成的这一组时间序列过去的变化规律,推断今后变化的可能性及变化趋势、变化规律,就是时间序列预测法。时间序列预测一般反映三种实际变化规律:趋势变化、周期性变
化、随机性变化。考虑一组给定的随时间变化的观察值,t=1,2,3,?,n},如何选取合适模型预报,t=n+1,n+3, n+k}的值。 上面的模型统称ARMA模型,是时间序列建模中最重要和最常用的预测手段。 事实上,对实际中发生的平稳时间序列做恰当的描述,往往能够得到自回归、滑动平均或混合的模型,其阶数通常不超过2。时间序列模型其实也是一种回归模型,属于定量预测,其基于的原理是,一方面承认事物发展的延续性,运用过去时间序列的数据进行统计分析就能推测事物的发展趋势;另一方面又充分考虑到偶然因素影响而产生的随机性,为了消除随机波动的影响,利用历史数据,进行统计分析,并对数据进行适当的处理,进行趋势预测。优点是简单易行,便于掌握,能够充分运用原时间序列的各项数据,计算速度快,对模型参数有动态确定的能力,精度较好,采用组合的时间序列或者把时间序列和其他模型组合效果更好。缺点是不能反映事物的内在联系,不能分析两个因素的相关关系,常数的选择对数据修匀程度影响较大,不宜取得太小,只适用于短期预测 3 灰色预测理论模型 灰色预测的基本思路是将已知的数据序列按照某种规则构成动态或非动态的 白色模块,再按照某种变化、解法来求解未来的灰色模型。它的主要特点是模型使用的不是原始数据序列,而是生成的数据序列。其核心体系是灰色模型(GM),即对原始数据作累加生成(或其他方法生成)得到近似的指数规律再进行建模的模型方法。优点是不需要很多的数据,一般只需要4个数据就够,能解决历史数据少、序列的完整性及可靠性低的问题;能利用微分方程来充分挖掘系统的本质,精度高;能将无规律的原始数据进行生成得到规律性较强的生成数列,运算简便,易于检验,具有不考虑分布规律,不考虑变化趋势。缺点是只适用于中长期的预测,只适合指数增长的预测,对波动性不好的时间序列预测结果较差。 4 BP神经网络模型
1 云团扩散模型 根据物质泄漏后所形成的气云的物理性质的不同,可以将描述气云扩散的模型分为非重气云模型和重气云模型两种[5-13]。 1.1 非重气云模型 高斯模型是一种常用的非重气扩散模型,高斯烟羽(Plume model)模型又称高架点连续点源扩散模型,适用于连续源的扩散,即连续源或泄放时间大于或等于扩散时间的扩散。 高斯烟团(Puff model)模型适用于短时间泄漏的扩散,即泄放时间相对于扩散时间比较短的情形,如突发性泄放等。若假设气体云内空间上的分布为高斯分布,则地面地处风向的烟团浓度分布算式为 式中, c(x,y,H)——点(x,y,H)处浓度值,mg/m3; Q——源强,即单位时问的排放量,mg/s; u——环境平均风速,m/s; σx,σy,σz——扩散参数; H——源高(烟团高度),m; x——下方向到泄漏原点的距离,m; y,z——侧风方向、垂直向上方向离泄漏原点的距离,m。 高斯模式的实际应用效果很大程度上依赖于如何给定模式中的一些参数,尤其要注意源强、扩散参数等的确定。 源强与污染物的物理化学属性、扩散方式、释放点的地理环境等有关。扩散参数表征大气边界层内
湍流扩散的强弱,是高斯模式的一项重要数据。高斯扩散模式所描述的扩散过程(实质上也包含了在实际应用中对高斯模式的一些限制)主要有: 1)下垫面平坦、开阔、性质均匀,平均流场稳定,不考虑风场的切变。 2)扩散过程中,污染物本身是被动、保守的,即污染物和空气无相对运动,且扩散过程中污染物无损失、无转化,污染物在地面被反射。 3)扩散在同一温度层结中发生,平均风速大于1.0 m/s。 4)适用范围一般小于10~20 km。 1.2 重气云模型 由于重气本身的特殊性,在重气扩散领域也有大量基于不同理论的模型。鉴于重气扩散与中性或浮性气体扩散有着明显的区别,目前国内外已开发大量的不同复杂程度的重气扩散模型,如箱模型、相似模型、LTA-HGDM模型、CFD模型等。 1.2.1 箱(BOX)模型 箱模型是指假定浓度、温度和其他场,在任何下风横截面处为矩形分布等简单形状,这里的矩形分布是指在某些空间范围内场是均匀的,而在其他地方为零。该类模型预报气云的总体特征,如平均半径、平均高度和平均气云温度,而不考虑其在空间上的细节特征。重气效应消失后其行为表现为被动气体扩散,所以该类模型还包括被动扩散的高斯模型及对它的修正。 1.2.2 层流及湍流大气环境中的重气扩散(LTA-HGDM)模型 LTA-HGDM模型(Heavy Gas Dispersion Model in Lsaminar and Turbulent Atmosphere层流及湍流大气环境中的重气扩散模型)以箱模型为基础,结合虚点源模型,能描述重气泄漏扩散整个过程。模型同三维有限元模型相比,具有形式简单、原始输入数据运算速度快等优点。 LTA-HGDM模型的建立基于以下几点假设: 1)危险性气体初时泄漏时,其外形呈正圆柱形(H=2R)。 2)初始时刻泄漏源即此核电站内部的浓度、温度呈均匀分布。 3)扩散过程不考虑泄漏源即此核电站内部温度的变化,忽略热传递、热对流及热辐射。
基于修正高斯扩散模型的城市表层土壤重金属污染探究 (标题,3号黑体) 摘要(4号黑体) (小4号宋体)本文基于修正的高斯扩散模型,针对城市表层土壤重金属污染问题,考虑到重金属的传播特征,建立了一系列逐步完善和精确化的数学模型,很好地解决了重金属污染物分布、污染程度评价及污染源确定的问题。 对于问题一,首先利用MATLAB软件分别做出了8种重金属污染物浓度的等高线空间分布图。然后综合使用内梅罗单因子和综合因子指数法评价该城区不同功能区域的污染程度。具体过程如下:先对每个取样点使用内梅罗单因子指数法确定其污染程度,再按功能区域的划分将监测点分为5类,对每一类都使用内梅罗综合指数法便可得到各区域综合污染指数,其中综合指数的大小反映了污染程度的轻重。结果显示该城区5个功能区域的污染程度从重到轻的排序依次为:工业区>交通区>生活区>公园绿地区>山地区。 对于问题二,使用主因子分析法研究各功能区的重金属污染原因。通过使用SPSS 软件处理数据我们可以得到如下结论:对于工业区来说造成土壤重金属污染的主要原因是工业生产过程中排放的废气、废水和废渣;对于交通区来说造成区内土壤重金属污染的主要原因是汽车排放的气;对于生活区来说造成其重金属污染的主要原因是生活垃圾的废弃及来自工业区和交通区的废气污染;对于公园绿地区来说造成其重金属污染的主要原因是来自工业区与交通区的废气污染以及植物 对重金属的富集作用;山地区域污染较轻气污染主要原因是工业废气和汽车尾气。对于问题三,首先分析重金属污染物的传播特征,得到了重金属有如下几种基本运动方式:随介质迁移的传播运动、分散运动、被环境介质吸收或降解、沉积、传播中转化。其次考虑到重金属污染物传播过程与流体介质的不同,对适用于流体的高斯模型进行了修正,得到了能反映本题要求的修正后的高斯扩散模型。接着对修正后的高斯扩散模型微分方程组进行了求解,得到了3个主要污染源的位 对于问题四,首先评价问题三中所建立模型,模型的优点是充分考虑了重金属的传播特征,对求出污染源非常有效;缺点在于未能考虑当地降雨及常年风向等影响重金属污染传播的因素,对污染的预测不能很好反映。鉴于此,在改进模型时增加收集当地降水及常年风向这两项信息。最后在改进模型时给原微分方程组增加降水和风向两个控制因子,通过求解改进后的微分方程组,相信会得到更加贴近实际的结果。 关键字:内梅罗指数法主因子分析修正高斯扩散模型
实验1分类预测模型——神经网络 一、实验目的 1.了解和掌握神经网络的基本原理。 2.熟悉一些基本的建模仿真软件(比如SPSS、Matlab等)的操作和使用。 3.通过仿真实验,进一步理解和掌握神经网络的运行机制,以及其运用的场景,特别是在 分类和预测中的应用。 二、实验环境 PC机一台,SPSS、Matlab等软件平台。 三、理论分析 神经网络起源于生物神经元的研究,其研究的主要对象是人脑。人脑是一个高度复杂的、非线性的、并行处理系统,其中大约有1011个称为神经元的微处理单元。这些神经元之间互相连接,连接数目高达1015.人脑具有联想、推理、判决、和决策的能力,对人脑活动机理的研究一直是一种挑战。通常认为,人脑智能的核心在于其连接机制,即有大量简单处理单元(神经元)的巧妙连接,使得人脑称为一个高度复杂的大规模非线性自适应系统。人工神经网络(Artificial Neural Network, ANN)是一种人脑的抽象计算模型,是一种人脑思维的计算机建模方式。 神经网络是一种运算模型,由大量的节点(或称神经元)和之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则跟据网络的连接方式、权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。 神经网络需要很长的训练时间,对于足够长的训练时间的应用更合适。同时,还需要大量的参数,通常主要靠经验确定,如网络拓扑或结构。神经网络常常因其可解释性差而受到批评。例如,人们很难解释网络中学习的权重和“隐藏单元”的符号含义。 然而,神经网络的优点包括其对噪声数据的高承受能力,以及对未经训练的数据的模式分类能力。因此,在缺乏属性与分类之间联系的知识时,仍然可以使用神经网络。而且,神经网络非常适合连续值的输入和输出,这是大多数决策树算法所不能比拟的。神经网络的算法是固有并行的,我们可以使用并行技术加快计算过程。 人工神经网络是由大量处理单元互联组成的非线性、自适应信息处理系统。它是在现代神经科学研究成果的基础上提出的,试图通过模拟大脑神经网络处理、记忆信息的方式进行信息处理。人工神经网络具有四个基本特征:
赛区评阅编号(由赛区组委会填写): 2015高教社杯全国大学生数学建模竞赛 承诺书 我们仔细阅读了《全国大学生数学建模竞赛章程》和《全国大学生数学建模竞赛参赛规则》(以下简称为“竞赛章程和参赛规则”,可从全国大学生数学建模竞赛网站下载)。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛章程和参赛规则的,如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛章程和参赛规则,以保证竞赛的公正、公平性。如有违反竞赛章程和参赛规则的行为,我们将受到严肃处理。 我们授权全国大学生数学建模竞赛组委会,可将我们的论文以任何形式进行公开展示(包括进行网上公示,在书籍、期刊和其他媒体进行正式或非正式发表等)。 我们参赛选择的题号(从A/B/C/D中选择一项填写): C 我们的报名参赛队号(12位数字全国统一编号): 参赛学校(完整的学校全称,不含院系名):温州医科大学 参赛队员 (打印并签名) :1. 章成俊 2. 杨超 3. 谢锦 指导教师或指导教师组负责人 (打印并签名): 日期:年月日
赛区评阅编号(由赛区组委会填写): 2015高教社杯全国大学生数学建模竞赛 编号专用页 送全国评阅统一编号(由赛区组委会填写): 全国评阅随机编号(由全国组委会填写):
对垃圾处理厂污染的动态监控及居民补偿 摘要 城市垃圾处理问题是一个世界性难题。目前垃圾焚烧正逐步成为中国垃圾处理的主要手段之一。本论文构根据题目设置的垃圾处理厂规模,建立了环境动态监控体系,并根据潜在污染风险对周围居民进行了合理经济补偿的设计。 对于问题(1),为了实现对垃圾焚烧厂烟气排放及相关环境影响状况的动态监控,本论文在高斯烟羽模型的基础上进行改进,引入温度、降雨对污染物扩散的影响,建立了新的污染物扩散模型。本论文创新性的提出了风雨影响指数M,用来衡量风向、降雨对颗粒物扩散的影响。本论文将抽象的污染物含量形象化,利用空气污染指数API描述具体的污染程度及其给周围居民带来的影响。并且从不同角度给出了模型检验,验证了所建模型的准确性。 对于问题(1)具体赔偿方案的制定,在综合考虑了不同方位风向频率、受污染时间、受污染程度的基础上,本论文使用了层次分析法,并且进行了一致性检验,使得赔偿方案具有说服力。通过MATLAB编程,计算出当政府和垃圾处理厂共支付风险赔偿金为N时,得出居住地的每位居民应得的赔偿金额计算公式。对于监测点的设置,经计算共需21个,具体布置情况见后文。 对于问题(2),在题目所述的发生事故的情况下,对污染物的具体含量进行了合理的预测与假设。模拟出酸性物质与颗粒物的影响范围,并根据具体的污染程度设置不同的污染区。对每个污染区的不同情况设置更改监测点的设置,并且在问题(1)的基础上对居民的经济补偿进行合理修改。 关键词:高斯烟羽模型,层次分析法,空气污染指数,烟气抬升公式 一、问题重述 “垃圾围城”是世界性难题,在今天的中国显得尤为突出。数据显示,目前全国三分之二以上的城市面临“垃圾围城”问题,垃圾堆放累计侵占土地75万亩。因此,垃圾焚烧正逐步成为中国垃圾处理的主要手段之一。然而,由于政府监管不力、投资者目光短浅等多方面的原因,致使前些年各地建设的垃圾焚烧电厂在运营中出现了环境污染问题,给垃圾焚烧技术在我国的推广造成了很大阻力,许多城市的新建垃圾焚烧厂选址都出现因居民反对而难以落地的局面。在垃圾焚烧厂运行监管方面,目前主要是在垃圾焚烧厂内进行测量监控,缺少从周边环境视角出发的外围动态监控,因而难以形成为民众所信服的全方位垃圾焚烧厂环境监控体系。 深圳市某地点计划建立一个中型的垃圾焚烧厂,计划处理垃圾量1950吨/天(设置三台可处理垃圾650吨/天的焚烧炉,排烟口高度80米,每天24小时运转)。从构建环境动态监控体系、并根据潜在污染风险对周围居民进行合理经济补偿的需求出发,有关部门希望能综合考虑垃圾焚烧厂对周围带来环境污染以及其他危害的多种因素(例如,焚烧炉的污染物排放量、居住点离开垃圾焚烧厂的距离、风力和风向及降雨等气象条件、地形地貌以及建筑物的遮挡程度等等),在进行科学定量分析的基础
焊接温度场仿真和热变形、应力仿真的基本理论和仿真流程 1 前言焊接作为现代制造业必不可少的工艺,在材料加工领域一直占有重要地位。焊接是一个涉及到电弧物理、传热、冶金和力学等各学科的复杂过程,其涉及到的传热过程、金属的融化和凝固、冷却时的相变、焊接应力和变形等是企业制造部门和设计人员关心的重点问题。焊接过程中产生的焊接应力和变形,不仅影响焊接结构的制造过程,而且还影响焊接结构的使用性能。这些缺陷的产生主要是焊接时不合理的热过程引起的。由于高能量的集中的瞬时热输入,在焊接过程中和焊后将产生相当大的残余应力和变形,影响结构的加工精度和尺寸的稳定性。因此对于焊接温度场合应力场的定量分析、预测有重要意义。 传统的焊接温度场和应力测试依赖于设计人员的经验或基于统计基础的半经验公式,但此类方法带有明显的局限性,对于新工艺无法做到前瞻性的预测,从而导致实验成本急剧增加,因此针对焊接采用数值模拟的方式体现出了巨大优势。 ANSYS作为世界知名的通用结构分析软件,提供了完整的分析功能,完备的材料本构关系,为焊接仿真提供了技术保障。文中以ANSYS为平台,阐述了焊接温度场仿真和热变形、应力仿真的基本理论和仿真流程,为企业设计人员提供了一定的参考。 2 焊接数值模拟理论基础焊接问题中的温度场和应力变形等最终可以归结为求解微分方程组,对于该类方程求解的方式通常为两大类:解析法和数值法。由于只有在做了大量简化假设,并且问题较为简单的情况下,才可能用解析法得到方程解,因此对于焊接问题的模拟通常采用数值方法。在焊接分析中,常用的数值方法包括:差分法、有限元法、数值积分法、蒙特卡洛法。 差分法:差分法通过把微分方程转换为差分方程来进行求解。对于规则的几何特性和均匀的材料特性问题,编程简单,收敛性好。但该方法往往仅局限于规则的差分网格(正方形、矩形、三角形等),同时差分法只考虑节点的作用,而不考虑节点间单元的贡献,常常用来进行焊接热传导、氢扩散等问题的研究。 有限元法:有限元法是将连续体转化为由有限个单元组成的离散化模型,通过位移函数对
航空发动机空心风扇叶片扩散连接焊缝建模与 优化分析技术 The Modeling and Optimization for Diffusion Bonding Seam of Hollow Fan Blade in Aero Engine 柴象海1,2,侯亮1,2 (1.中航商用航空发动机有限责任公司设计研发中心,上海市200241; 2.上海商用飞机发动机工程技术研究中心,上海市200241) 摘要: 扩散连接钛合金空心瓦伦结构已经被成功地应用于航空发动机零部件,如风扇叶片、导流叶片等结构。研究发现,瓦伦结构的几何特征对零件的抗冲击强度,例如抗鸟撞性能,有很大的影响,通过优化设计空心瓦伦结构来提升零件的抗冲击性能一直是工业界追求的目标。本文针对典型的用于发动机空心风扇叶片的三层板空心瓦伦结构,采用HyperWorks工具包,通过基于试验的仿真优化研究了几个重要的瓦伦结构特征参数对抗冲击性能的影响。首先通过有限元数值模拟和逆向分析的手段估算出钛合金空心瓦伦焊缝的失效强度。然后通过数值模拟的结果得到了相邻瓦伦夹角、焊缝长度与扩散连接焊焊缝在冲击载荷下失效强度之间的关系。本项研究可以为钛合金空心瓦伦结构零部件设计和抗冲击强度校核提供参考。 关键词:扩散连接;碰撞试验;HyperWorks建模优化;鸟撞;瓦伦结构 Abstract: Diffusion-bonded titanium hollow components with a Warren girder internal structure, such as fan blade, OGV, etc., has been successfully used on aircraft engines. It was found that the geometric features of such Warren girder structure have significant effect on the impact strength of the component. Such design has provided the possibility for the designer to improve bird-strike resistance of the component by optimizing its internal Warren girder structure based HyperWorks. At first, a set of ballistic impact tests with titanium hollow panels with various internal geometric parameters were conducted, and the failure stresses of the diffusion-bonding area of the hollow structure were estimated through an inverse method based on test-analysis correlation. Then, a qualitative relation between the failure stress of the diffusion bonds and two important geometric parameters, skew angle of the girder and length of the diffusion bond, was established through numerical simulations. This study provided useful reference for the optimal design of components with Warren girder hollow structures.
放射性气体扩散浓度预估模型 【摘要】本文是以日本地震引起的福岛核电站的核泄漏为背景,并以给出的数据为基础,研究某一假设核电站的核泄漏问题。我们通过收集相关的资料,并结合题目给出的数据,建立了高斯模型、连续点源高斯扩散模型解决了题目提出的四个问题。 针对问题一:考虑到泄漏源是连续、均匀和稳定的,我们运用散度、梯度、流量等数学概念,通过“泄漏放射性物质质量守恒”、“气体泄漏连续性定理”、 Guass 公式及积分中值定理得到了无界区域的抛物线型偏微分方程,然后再通过电源函数解出空间任意一点的放射性物质浓度的表达式,把此表达式定为模型一的前身。鉴于放射性物质的扩散受到诸多因素的影响,如:泄漏源的实际高度、地面反射等。我们以泄漏口为坐标原点建立三维坐标系,通过“像源法”处理地面反射对放射性物质浓度的影响,并由此对模型一的前身进行修正完善,得到模型一:高斯模型,即放射性物质浓度的预测模型。最后我们模拟了放射性物质无风扩散仿真图。 针对问题二:当风速为k m/s 时,我们根据放射性核素云团在大气中迁移和扩散的数值计算的基本方法和步骤,并以泄漏点源在地面的投影点为坐标原点,以风向方向为x 轴,铅直方向为z 轴,与x 轴水平面垂直方向为y 轴建立三维坐标系,地面的反射作用同样利用“像源法”进行处理,得到连续点源高斯扩散模型。考虑到地面反射、烟云抬升、放射性物质自身的沉降及雨水的吸附等对浓度的影响,我们对连续点源高斯扩散模型进行了修正,建立了修正的连续点源高斯扩散模型。最后利用大气稳定度确定了扩散参数,进而求解了模型。 针对问题三:经分析,问题三的提出是以问题二为基础的,模型三的建立只需要将模型二加以调整即可。我们以风速方向为x 轴正方向,将风速与放射性物质的扩散速度进行矢量运算,此问题则转化为求(,0,)L z 和(,0,)L z -两点处的放射性物质浓度,由此建立模型三,即上风和下风L 公里处放射性物质浓度浓度的预测模型。 针对问题四:首先,我们通过网络收集了相关数据,然后,我们结合模型二、模型三对数据进行整理代入,算出了日本福岛核电站泄漏的放射性物质扩散到中国东海岸和美国西海岸的浓度分别为334.242910/g m -?、432.385410/g m -?。 关键词:高斯模型 连续点源高斯扩散模型 核泄漏
高斯扩散模型及其适用条件 (1)一般表达式 根据质量守恒原理和梯度输送理论,污染物在大气中一般运动规律为:(3分) 1N x y z p p c c c c c c c u v w k k k S t x y z x x y y z z =????????????????+++=+++ ? ? ?????????????????∑ C :污染物质平均浓度; X ,y ,z :三个方向坐标; u ,v ,w :三个方向速度分量; k x ,k y ,k z :三个方向扩散系数; t :为污染物扩散时间; S P :污染物源、汇强度。 (2)高斯模型的适用条件:①大气流动稳定,表明污染物浓度不随时间改变,即0t ?=?; ②有主导风向,表明u=常数,且v=w=0; ③污染物在大气中只有物理运动,物化学 和生物变化,且预测范围内无其他同类 污染的源和汇。表明S P =0(p=1,2,….n ) 此时三维的动态模型就可简化为三维的稳态模型,得: x y z c c c c u k k k x x x y y z z ?????????????=++ ? ? ???????????? ?? (3分) ④有主导风情况下,主导风对污染物输送 应远远大于湍流运动引起污染物在主导风方
向上扩散。即c u x ??(平流输送作用)远远大于x c k x x ???? ????? (湍流弥散作用)。 此时方程又可以简化为: y z c c c u k k x y y z z ?????????=+ ? ???????? ?? (2分) (3)由于y 和z 方向上污染物浓度不发生变化,故规定y k 与y 无关,z k 与z 无关,即: 22z 22z y c c c u k k x y ???=+??? (1分) (4)由质量守恒原,理运用连续点源源强计算方式,按照单元体积(3)简化得到的方程进行积分ucdydz=Q ∞∞ -∞-∞??,结合边界条件 {0c=x y z c=0x y z ===∞ →∞时,,,时,对方程进行求解。(2分) (5)设x=ut ,令22y y z z =2k t =2k t σσ;。化简求解得到高斯扩散模型的标准 形式: ()2222y z 1c ,,exp 22y z Q y z x y z u πσσσσ????=-+?? ? ??????? (1分)
大气污染物扩散的高斯模型模拟:可视化模拟点源大气污染的扩散Gaussian Atmospheric Dispersion Model 突发性大气污染事故时有发生,对大气污染扩散进行模拟和分析,有利于减小事故的危害,减轻人员伤亡和财产损失。高斯扩散模型是国际原子能机构(IAEA)推荐使用于重气云扩散模拟的数学模型,该模型在非重气云扩散的应用日益广泛。高斯扩散模型是描述大气对有害气体的输移、扩散和稀释作用的物理或数学模型,是进行灾害预测和救援指挥的有力手段之一。 高斯扩散模型 高斯模型又分为高斯烟团模型和高斯烟羽模型。大气污染物泄漏分为瞬时泄漏和连续泄漏,瞬时泄漏是指污染物泄放的时间相对于污染物扩散的时间较短如突发泄漏等的情形,连续泄漏则是指污染物泄放的时间较长的情形。瞬时泄漏采用高斯烟团模型模拟,而连续泄漏采用高斯模型烟羽模型模拟。高斯模型适用于非重气云气体,包括轻气云和中性气云气体。要求气体在扩散过程中,风速均匀稳定。 在高斯烟团模型中,选择风向建立坐标系统,即取泄漏源为坐标原点,x轴指向风向,y轴表示在水平面内与风向垂直的方向,z轴则指向与水平面垂直的方向,具体公式见式: (mg/s); x、y、z轴上的扩散系数,需根据大气稳定度选择参数计算得到(m);x、y、z表示x、y、z上的坐标值(m);u 表示平均风速(m/s);t表示扩散时间(s);H 表示泄漏源的高度(m)。 同理,高斯烟羽模型的表达式如: 技术方法 若用高斯模型算出空间每一个点在一个时刻的污染浓度,这个计算量是很大的。因此所设计的系统一般都是采用先进行图层网格化,由高斯模型计算出有限个网格点的上的污染物浓度,在进行空间内插得到面上每一个点的污染物浓度,并由此得到污染物浓度的等值线。整个过程的示意图如图所示
数学建模高斯扩散模 型
§4-2高斯扩散模式 ū —平均风速; Q—源强是指污染物排放速率。与空气中污染物质的浓度成正比,它是研究空气污染问题的基础数据。通常: (ⅰ)瞬时点源的源强以一次释放的总量表示; (ⅱ)连续点源以单位时间的释放量表示; (ⅲ)连续线源以单位时间单位长度的排放量表示; (ⅳ)连续面源以单位时间单位面积的排放量表示。 δy—侧向扩散参数,污染物在y方向分布的标准偏差,是距离y的函数,m; δz—竖向扩散参数,污染物在z方向分布的标准偏差,是距离z的函数,m; 未知量—浓度c、待定函数A(x)、待定系数a、b; 式①、②、③、④组成一方程组,四个方程式有四个未知数,故方程式可解。 二、高斯扩散模式 (一)连续点源的扩散 连续点源一般指排放大量污染物的烟囱、放散管、通风口等。排放口安置在地面的称为地面点源,处于高空位置的称为高架点源。 1. 大空间点源扩散 高斯扩散公式的建立有如下假设:①风的平均流场稳定,风速均匀,风向平直;②污染物的浓度在y、z轴方向符合正态分布;③污染物在输送扩散中质量守恒; ④污染源的源强均匀、连续。 图5-9所示为点源的高斯扩散模式示意图。有效源位于坐标原点o处,平均风向与x轴平行,并与x轴正向同向。假设点源在没有任何障碍物的自由空间扩散,不考虑下垫面的存在。大气中的扩散是具有y与z两个坐标方向的二维正态分布,当两坐
标方向的随机变量独立时,分布密度为每个坐标方向的一维正态分布密度函数的乘积。由正态分布的假设条件②,参照正态分布函数的基本形式式(5-15),取μ=0,则在点源下风向任一点的浓度分布函数为: (5-16)式中 C—空间点(x,y,z)的污染物的浓度,mg/m3; A(x)—待定函数; σy、σz—分别为水平、垂直方向的标准差,即y、x方向的扩散参数,m。 由守恒和连续假设条件③和④,在任一垂直于x轴的烟流截面上有: (5-17) 式中 q—源强,即单位时间内排放的污染物,μg/s; u—平均风速,m/s。 将式(5-16)代入式(5-17), 由风速稳定假设条件①,A与y、z无关,考虑到③和④,积分可得待定函数A(x): (5-18) 将式(5-18)代入式(5-16),得大空间连续点源的高斯扩散模式 (5-19) 式中,扩散系数σy、σz与大气稳定度和水平距离x有关,并随x的增大而增加。当y=0,z=0时,A(x)=C(x,0,0),即A(x)为x轴上的浓度,也是垂直于x轴截面上污染物的最大浓度点C max。当x→∞,σy及σz→∞,则C→0,表明污染物以在大气中得以完全扩散。 2.高架点源扩散