
第一讲面板数据
因家庭调查得到的面板数据越来越多,面板数据的计量分析可以说是过去三十年社会应用研究领域所取得的最重要的进展。
-Fitzgerald, Gottschalk和Moffitt(1998, P252)
第一讲介绍的内容
面板数据
面板数据的优点与缺陷
扩展的面板数据
面板数据
“面板数据”一词指的是一部分家庭、国家或企业等在一段时期内的观测值所构成的集合。这样的数据可以通过在一段时期内对一些家庭或个体进行跟踪调查来获得。
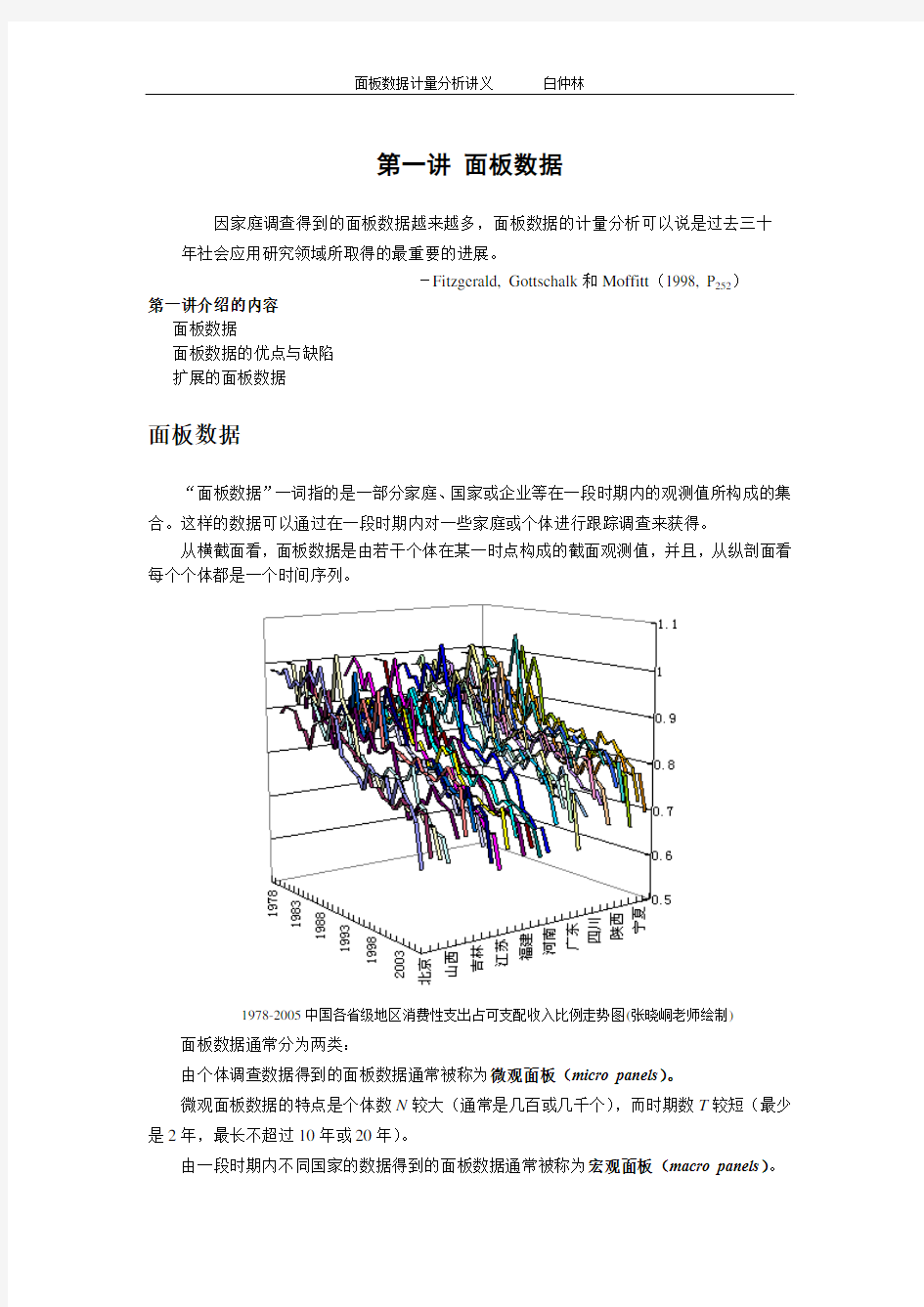
从横截面看,面板数据是由若干个体在某一时点构成的截面观测值,并且,从纵剖面看每个个体都是一个时间序列。
1978-2005中国各省级地区消费性支出占可支配收入比例走势图(张晓峒老师绘制)面板数据通常分为两类:
由个体调查数据得到的面板数据通常被称为微观面板(micro panels)。
微观面板数据的特点是个体数N较大(通常是几百或几千个),而时期数T较短(最少是2年,最长不超过10年或20年)。
由一段时期内不同国家的数据得到的面板数据通常被称为宏观面板(macro panels)。
这类数据一般具有适度规模的个体N (从7到100或200不等,如七国集团,OECD ,欧盟,发达国家或发展中国家),时期数T 一般在20年到60年之间。
因数据结构上的区别,微观面板和宏观面板要求使用不同的计量方法。
样本容量的区别
微观面板必须研究T 固定而N 较大时的渐近特性,而宏观面板的渐近特性则是指T 和N 都较大时的情况。
平稳性
对于宏观面板,当时间序列较长时需要考虑数据的非平稳问题,如单位根、结构突变以及协整等;而微观面板不需要处理非平稳问题,特别是每个家庭或个体的时期数T 较短时。
个体相关性
在处理宏观面板时必须考虑国家之间的相关性,而在微观面板中,如果个体是随机抽样产生,则个体之间不大可能存在相关性,因此不需要考虑此问题。
为什么使用面板数据?它们的优点和局限性
1 面板数据的优点
使用面板数据具有下列一些好处:
(1)可以控制个体异质性
面板数据能反映个体、企业、州或国家之间存在的异质性,即时间上和空间上的异质效应。而时间序列数据和横截面分析没有控制这种异质性,因而其结果很可能是有偏的。
例如,Baltagi 和Levin (1992)研究1963-88年美国46个州的香烟需求问题时,设定需求模型
(),1
it i t it it i i t D f D p I reli edu adv ?=
则模型中解释变量包括四类。 z 第一类是随个体(州)和时间的变化而变化的变量,如香烟消费量的滞后项、价格
和收入等可观测的变量;
z 第二类是随个体(州)变化而不随时间变化的可观测变量,如宗教(religion )和
教育等变量;
z 第三类是不随个体(州)变化而随时间变化的可观测变量,如电视和广播中的广告
等变量;
z 最后一类是一些不可观测变量,它们包括三种
非时变异质性不可观测因素(i u )——个体效应
时变同质性不可观测因素(t v )——时间效应
时变异质性不可观测因素(it w )——剩余效应
这样,模型可设定为
(),1it i t it it i i t i t it D f D p I reli edu adv u v w ?=+++
事实上,对于宗教变量,人们不可能得到每年每个州某一宗教人数占总人口的百分比,所以一般认为不同年份的百分比也不会有太大变化。同样,完成高中或大学学业的人数占总人口的百分比也是如此。电视和广播中的广告是全国性的,不会随着州的不同而变化。
显然,遗漏第四类中任何一种不可观测因素就会导致估计结果的偏倚,面板数据模型能够基于这四类中的所有变量建模,而纯时间序列和横截面分析就无法做到。
另外,Hajivassiliou (1987)给出了一个宏观经济的例子,他使用1970-82年79个发展中国家的面板数据研究了外债偿付问题。这些发展中国家在殖民历史、金融机构、宗教信仰和政治体制等方面存在差异,所有这些反映国家特征的特定变量都会影响它们在借债或拖欠方面的态度,同时也会影响债权国对待它们的方式。如果不考虑这些国家之间的异质性就会出现严重的设定错误。
(2)面板数据模型容易避免多重共线性问题
z 面板数据具有更多的信息;
z 面板数据具有更大的变异;
z 面板数据的变量间更弱的共线性;
z 面板数据模型具有更大的自由度以及更高的效率。
时间序列研究中令人苦恼的就是多重共线性;比如在上述香烟需求的研究中,如果从总量的角度看价格和收入就具有很强的共线性,而使用美国各州的面板数据,存在共线性的可能就很小了,因为增加截面个体维度的同时也增加了数据的变异,也增加了更多有关价格和收入的信息。
事实上,数据中的变异可以分为两个部分,一是州与州之间由于规模和特征的不同所表现出的变异性;二是各州内部不同时间上表现出的变异性,前者的变异程度往往更大。使用更多、更有信息的数据就可以得到更可靠的参数估计值。当然,这要求不同州的变量间应具有相同的关系式,换句话说,这要求数据是可混合的(poolable )。
(3)面板数据更适合于研究动态调整过程
面板数据适用于研究失业、贫困等经济状态的持续性问题的研究。如果这些面板数据的时期数足够长,它们就能够清楚地反映对经济政策变化的调整速度。
比如,在衡量失业问题时,横截面数据可以估计出人口中多大一部分比例在给定的时间处于失业状态,多个截面可以表明这一比例如何随时间而变化。但是,只有面板数据才能估计出在某个时期失业人中有多大一部分在另一个时期仍处于失业状态。
Deaton (1995)指出,与横截面调查不同,面板调查可以获得家庭或个体变化的数据。它可以使我们观测到个体生活标准在社会发展过程中如何变化;可以使我们确定谁从社会发展中受益;而且还可以使我们观测到 “在收入动态变化中,贫困到底是暂时性的还是长期的状态。”
由于面板数据可以将个体在某个时点的经历和行为与另一个时点的其他经历和行为联系起来,因此,面板数据在估计短期关系、生命周期模型和代际模型时也是必需的。
(4)面板数据还可以识别、测量单纯使用横截面或时间序列数据无法估计的影响。
对于由妇女组成的横截面样本,其中年平均就业率是50%. 这可能是由于下面两种原因导致的:(a)每个妇女在任一给定年份有50%的概率就业;(b)样本中有50%的人一直有工作,50%的人根本不工作。情况(a)中的工作转换频率很高,而情况(b)中没有工作转换,只有使用面板数据才能区分这两种情况。
(5)与纯横截面数据或时间序列数据相比,面板数据模型允许构建并检验更复杂的行为模型。
比如,对技术效率问题使用面板数据建模研究效果更好(Baltagi和Griffin,1988;Baltagi,Griffin和Rich,1995;Koop和Steel,2001)。另外,在分布滞后模型中使用面板数据比使用纯时间序列数据需要的约束条件更少(Hsiao,2003),因为通常使用GMM估计。
(6)基于个体、企业或家庭所搜集的微观面板数据与在宏观层次上所搜集的类似变量相比更加准确,而且还可能消除企业或个体数据汇总所导致的偏倚。
(7)例如,与时间序列分析中进行单位根检验遇到的非标准分布问题不同,面板单位根检验通常具有标准的渐近分布。
2 面板数据的局限性
面板数据的局限性包括:
(1)微观调查面板数据极少
Kasprzyk等(1989)详细讨论了有关设计面板调查、数据收集和数据管理的问题。这些问题包括:覆盖面问题(样本没覆盖研究总体)、不响应问题(由于回答者不合作或提问者的失误)、回忆问题(回答者的记忆不准确)、采访的频率问题、采访的时间间隔问题、询问的时间问题和样本期内偏倚问题。
(2)测量误差的扭曲(distortions)严重
在面板数据调查中,问题不清晰,记忆错误,故意歪曲回答(例如威望偏倚),不合适的被调查者,错误记录回答者的应答以及采访者的影响等导致出现严重的测量误差。
(3)面板数据调查的样本选择问题
z自选择
例如,由于个人保留工资高于工作工资,人们通常选择不去工作。在这种情况下,观测到的只是这些人的特征,而观测不到他们的保留工资。由于他们的工资数据缺失,产生删失样本。但是,如果这些人的所有数据都不可观测,这就成为一个截断样本。因此,面板数据调查容易产生样本的选择有偏性。
z未回答
面板数据调查容易产生单项(或部分)未回答或完全未回答。这时,除了由于数据缺失导致的效率损失之外,面板数据调查中的未回答还可以导致严重的总体参数识别问
题。
z非随机样本流失
在面板数据的随后调查,由于调查对象的非随机流动(如,低收入区域向高收入区域的流动)或发现回答的成本过高等原因,会产生调查对象的严重流失。Fitzgerald等(1998)指出,面板数据使用价值的最大潜在威胁是有偏性流失。Lillard和Panis(1998)研究发现,PSID的样本流失有很强的选择性。
例如,受教育程度较低的个体以及年龄较大的个体最容易从样本中剔除,而已婚的人继续留在样本内的可能性较大。被调查者在样本内的时期越长,继续参与调查的倾向就越小。在欧洲,(第一次和第二次调查之间的)样本流失率从意大利的6%到英国的40%不等。平均的样本流失率大约是10%. 为了解决样本非随机流失的影响,人们逐渐使用轮换面板(rotating panel)和伪面板(pseudo-panel)。
(4)时间维度短
微观面板通常是年度数据,每个个体的时期数较短。因此,主要依赖个体数趋于无穷进行渐近统计分析。
(5)截面相关性
国家或地区的宏观面板数据,如果时间序列较长而且没有考虑到国家之间的相关性就会导致错误的推断结论。事实上,考虑截面相关非常重要,而且会影响到统计推断的结论。为此,人们也提出了考虑这种相关性的面板单位根检验方法。
扩展的面板数据
1 伪面板数据
1985年,Deaton(1985)指出“由于统计调查的样本轮换和样本非随机流失问题,绝大多数国家并不存在较长时间跨度的真正面板数据,或者这样的真正面板数据是难以获得的,对于发展中国家的微观经济变量尤其如此。”
并且,Deaton发现“虽然某变量的统计抽样不能连续调查到各个体的观测数据,但是,如果按照某种属性(例如,年龄、职业和身份等)将各期调查对象分成不同的群(Cohort);对于各个观测期,选择各群内观测数据的均值(中位数或分位数),即可构造以群为‘个体’单位的面板数据”。于是,对于截面时间序列的统计调查数据,基于某种属性分群,称以群为个体而构造的人工面板数据为伪面板数据(Pseudo Panel Data)。
众所周知,面板数据的本质是在观测期内的每期都能观测到相同个体的相关数据,然而,伪面板显然并非如此。在观测期内,它允许每期观测的个体不同,并且重点关注的是个体群的统计特征,即通过群均值和群方差的发展变化,来揭示相关变量的总体分布特征。
例如,为了基于城市住户抽样调查数据研究城市居民收入的动态行为,常见的分群标准是户主年龄段、户主出生年的区间和户主职业类别。
户主按出生年的区间分群,在各观测期,同群中的不同家庭都是户主在同一出生年区间的家庭,不同群的家庭是户主在不同出生年区间的家庭。
如,对于1963-1967年出生的群,在1988年调查时,该群内的家庭是户主为21-25岁的家庭;1989年调查时,该群内的家庭是户主为22-26岁的家庭;依此类推,2008年调查时,该群内的家庭是户主为41-45岁的家庭。然后,在各调查年,对该群群内的家庭人均收入求均值。这样,对于1963-1967年出生的群,可得到该群的人均收入时间序列。于是,对于不同的群就可构造一个关于家庭人均收入的面板数据,称之为按出生年分群的家庭人均收入伪面板数据。
类似地,也可以构造按年龄段分群的人均收入伪面板数据。
应用群体分析方法得到的伪面板数据还具有以下优点。一是伪面板数据是由各群群内个体属性的总体统计量组成,与一般面板中的个体数据相比,前者消除了个体的测量误差,且避免了样本流失。二是由于不需要在每期中追踪固定的个体,这样可得到更长时间跨度的数据。
2 轮换面板
因为同一个家庭可能不愿被一次又一次的被回访,为了保持调查中家庭数目相同,在第二期调查中退出的部分家庭,被相同数目的新的家庭所替代,这在获得调查面板数据时是必要的。Biorn (1981)研究了这种轮换面板的情况。在Biorn 和Jansen (1983)的研究中,他们基于挪威家庭预算调查的数据,其中一半的样本在每次调查中被轮换掉。换句话说,就是每一期调查的样本中将有一半家庭退出调查,并被新的家庭替代。
为了说明轮换面板的基本含义,我们假设2T =,并且每期调查中有一半的样本被轮换,在这种情况下,不失一般性,在第2期,家庭1,2,,/2N 被家庭1,2,,/2N N N N +++ 所替代,很明显,只有家庭/21,/22,,N N N ++ 被观测了两期。这个例子中有3/2N 个
不同的家庭,只有/2N 个家庭被观测了两期。最初和最后的/2N 个家庭只被观测了一期。
如果考虑建立单因素误差分量模型
it it
it y u α′=++X βit i it u v μ=+ 其中,2(0,)i IID μμσ~和2(0,)it v v IID σ~相互独立,且与it x 也相互独立。
按照先家庭后时间的顺序对观测值进行排序,即,家庭为“快指标(faster index )”,时间为“慢指标(slower index )”这不同于从传统面板数据中的排序情况。在这种情况下, 11211/21,23/2,2(,,,,,,)N N N μμμμμμ+′= ,且
2/222/2/222/2/22/200000()00000N N N N N N I I I E uu I I I μμσσσσσσ??????′=Ω=????????
(10.16) 其中,222
v μσσσ=+,容易看出Ω是块对角矩阵,并且中间的分块具有通常的单因素误差模型的误差形式222/22/2()()N v N J I I I μσσ?+?,因此, /21/222/2*1/2100110
()0100
N N v N I J E I I σσσσ?????????Ω=+??????????? (10.17) 其中,222E I J =?,22/2J J =和*22212v μσσσ=+。用1/2?Ω
左乘回归模型并进行OLS
估计,即可得到轮换面板的GLS 估计量。 轮换面板允许研究者检验 “抽样时间(time-in-sample )”偏倚效应的存在性。“抽样时间”偏倚是指初次采访和随后的采访之间的回答有显著的改变。对于轮换面板,每批加到面板的新个体组提供了检验抽样时间偏倚效应的方法。
例如,Solon (1986)等研究发现第一次轮换所报告的失业率比基于全样本的失业率高出10个百分点。这些发现表明在面板数据调查中普遍存在着轮换组偏倚效应,而实践中调查条件并没有保持不变,因而很难把抽样时间偏倚效应同其他效应区分开。
3 空间面板数据
在个体水平的随机抽样样本中,人们很少担心截面之间的相关性。然而,当考虑国家,地区,州,县等相关截面数据时,这些总量个体可能表现出必须处理的截面相关性。现在有大量运用空间数据的文献处理这种相关性。这种空间相依模型在区域科学和城市经济学中比较普遍。具体来说,这些模型使用经济距离测度设定了面板数据的空间自相关性和空间结构(空间异质性),这方面文献的详尽介绍可以参见Anselin(1988, 2001)。近年来,在经济学的实证研究中,空间面板模型变得越来越有吸引力。
在包含空间误差自相关和空间滞后被解释变量的情形下,Elhorst(2003)讨论了固定效应和随机效应面板数据模型的ML 估计。他们也对随机系数模型作了相应的扩展。在包含空间误差自相关,或者空间滞后被解释变量的情形下,Elhorst(2005)研究了固定效应动态面板数据模型的估计。
4 计数面板数据
被解释变量是计数面板数据的例子很多。例如,一段时间内一家公司的竟标次数、一个
人去看医生的次数、每天吸烟者的数量及一个研发机构登记专利的数目。虽然可以运用传统面板回归模型对计数面板数据建模,但鉴于被解释变量具有0及非负离散取值的特征,运用泊松面板回归模型建模更为合适。
在计数面板数据的文献中,尽管泊松模型设定非常流行,但由于其均值与方差相等的性质而备受批评。在实证分析中更常见的是过度离差的情形。为了对过度离差建模,经常设定数据服从负二项分布,Hausman et al.(1984)研究了负二项分布面板数据模型。而且,负二项分布面板数据模型也能够在Stata软件xtpoisson,fe and re软件包中实现。
然而,面板数据不是灵丹妙药,它并不能解决时间序列或横截面研究中解决不了的所有问题。例如,面板单位根检验比单一时间序列的单位根检验功效更高,这应该能更好地推断购买力平价(PPP)和增长收敛问题。事实上,在导致大量经验应用研究的同时,也引来了一些批评,Maddala(1999)和Banerjee等(2004,2005)认为面板数据也不能解决PPP以及增长收敛的问题。
熵值法 1.算法简介 熵值法是一种客观赋权法,其根据各项指标观测值所提供的信息的大小来确定指标权重。设有m 个待评方案,n 项评价指标,形成原始指标数据矩阵n m ij x X ?=)(,对于某项指标j x ,指标值ij X 的差距越大,则该指标在综合评价中所起的作用越大;如果某项指标的指标值全部相等,则该指标在综合评价中不起作用。 在信息论中,熵是对不确定性的一种度量。信息量越大,不确定性就越小,熵也就越小;信息量越小,不确定性就越大,熵也越大.根据熵的特性,我们可以通过计算熵值来判断一个方案的随机性及无序程度,也可以用熵值来判断某个指标的离散程度,指标的离散程度越大,该指标对综合评价的影响越大!因此,可根据各项指标的变异程度,利用信息熵这个工具,计算出各个指标的权重,为多指标综合评价提供依据! 2.算法实现过程 2.1 数据矩阵 m n nm n m X X X X A ?????? ??=ΛM M M Λ1111其中ij X 为第i 个方案第j 个指标的数值 2.2 数据的非负数化处理 由于熵值法计算采用的是各个方案某一指标占同一指标值总和的比值,因此不存在量纲的影响,不需要进行标准化处理,若数据中有负数,就需要对数据进行非负化处理!此外,为了避免求熵值时对数的无意义,需要进行数据平移: 对于越大越好的指标: m j n i X X X X X X X X X X X nj j j nj j j nj j j ij ij ,,2,1;,,2,1,1),,,min(),,,max() ,,,min(212121'ΛΛΛΛΛ==+--=对于越小越好的指标: m j n i X X X X X X X X X X X nj j j nj j j ij nj j j ij ,,2,1;,,2,1,1),,,min(),,,max(),,,max(212121'ΛΛΛΛΛ==+--=为了方便起见,仍记非负化处理后的数据为ij X
面板数据分析简要步骤与注意事项(面板单位根检验—面板协整—回归分析) 面板数据分析方法: 面板单位根检验—若为同阶—面板协整—回归分析 —若为不同阶—序列变化—同阶建模随机效应模型与固定效应模型的区别不体现为R2的大小,固定效应模型为误差项和解释变量是相关,而随机效应模型表现为误差项和解释变量不相关。先用hausman检验是fixed 还是random,面板数据R-squared值对于一般标准而言,超过0.3为非常优秀的模型。不是时间序列那种接近0.8为优秀。另外,建议回归前先做stationary。很想知道随机效应应该看哪个R方?很多资料说固定看within,随机看overall,我得出的overall非常小0.03,然后within是53%。fe和re输出差不多,不过hausman检验不能拒绝,所以只能是re。该如何选择呢? 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993)很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al.(2002)的改进,提出了检验面板单位根的LLC法。Levin et al.(2002)指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250之间,截面数介于10~250之间)的面板单位根检验。Im et al.(1997)还提出了检验面板单位根的IPS法,但Breitung(2000)发现IPS法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher和PP-Fisher5种方法进行面板单位根检验。 其中LLC-T、BR-T、IPS-W、ADF-FCS、PP-FCS、H-Z分别指Levin,Lin&Chu t*
5.2 面板数据模型理论 5.2.1 面板数据模型及类型。 面板数据(panel data )也称时间序列截面数据(time series and cross section data )或混合数据(pool data )。面板数据是同时在时间和截面空间上取得的二维数据。面板数据从横截面(cross section )上看,是由若干个体(entity, unit, individual )在某一时刻构成的截面观测值,从纵剖面(longitudinal section )上看是一个时间序列。 面板数据用双下标变量表示。例如: it y , N i ,,2,1 ;T t ,,2,1 其中,N 表示面板数据中含有的个体数。T 表示时间序列的时期数。若固定t 不变,?i y ),,2,1(N i 是横截面上的N 个随机变量;若固定i 不变,t y ?,),,2,1(T t 是纵剖面 上的一个时间序列。对于面板数据来说,如果从横截面上看,每个变量都有观测值,从纵剖面上看,每一期都有观测值,则称此面板数据为平衡面板数据(balanced panel data )。若在面板数据中丢失若干个观测值,则称此面板数据为非平衡面板数据(unbalanced panel data )。 面板数据模型是建立在面板数据之上、用于分析变量之间相互关系的计量经济模型。面板数据模型的解析表达式为: it it it it it x y T j N i ,2,1;,2,1 其中,it y 为被解释变量;it 表示截距项,),,,(21k it it it it x x x x 为k 1维解释变量向量;' 21),,,(k it it it it 为1 k 维参数向量;i 表示不同的个体;t 表示不同的时间;it 为 随机扰动项,满足经典计量经济模型的基本假设),0(~2 IIDN it 。 面板数据模型通常分为三类。即混合模型、固定效应模型和随机效应模型。 ⑴ 混合模型。 如果一个面板数据模型定义为: it it it x y T j N i ,2,1;,2,1 则称此模型为混合模型。混合模型的特点是无论对任何个体和截面,回归系数 和 都是相同的 ⑵ 固定效应模型。 固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model )、时间固定效应模型(time fixed effects regression model )和时间个体固定效应模型(time and entity fixed effects regression model )。 ① 个体固定效应模型。 个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序
熵权法简介 “熵”的物理意义 物质微观热运动时,混乱程度的标志。热力学中表征物质状态的参量之一,通常用符号S表示。在经典热力学中,可用增量定义为dS=(dQ/T),式中T为物质的热力学温度;dQ为熵增过程中加入物质的热量;下标“可逆”表示加热过程所引起的变化过程是可逆的。若过程是不可逆的,则dS>(dQ/T)不可逆。单位质量物质的熵称为比熵,记为s。熵最初是根据热力学第二定律引出的一个反映自发过程不可逆性的物质状态参量。热力学第二定律是根据大量观察结果总结出来的规律,有下述表述方式:①热量总是从高温物体传到低温物体,不可能作相反的传递而不引起其他的变化;②功可以全部转化为热,但任何热机不能全部地、连续不断地把所接受的热量转变为功(即无法制造第二类永动机);③在孤立系统中,实际发生的过程,总使整个系统的熵值增大,此即熵增原理。摩擦使一部分机械能不可逆地转变为热,使熵增加。热量dQ由高温(T1)物体传至低温(T2)物体,高温物体的熵减少dS1=dQ/T1,低温物体的熵增加dS2=dQ/T2,把两个物体合起来当成一个系统来看,熵的变化是dS=dS2-dS1>0,即熵是增加的。 在不同领域中“熵”也有不同意义 ◎物理学上指热能除以温度所得的商,标志热量转化为功的程度。 ◎科学技术上泛指某些物质系统状态的一种量(liàng)度,某些物质系统状态可能出现的程度。亦被社会科学用以借喻人类社会某些状态的程度。 ◎在信息论中,熵表示的是不确定性的量度。 熵权法是一种客观赋权方法。它十分复杂,计算步骤如下: a.构建各年份各评价指标的判断矩阵: b.将判断矩阵进行归一化处理, 得到归一化判断矩阵: c.根据熵的定义,根据各年份评价指标,可以确定评价指标的熵。 d.定义熵权。定义了第n个指标的熵后,可得到第n个指标的熵权。 f.计算系统的权重值。 熵权法的主要根据 按照信息论基本原理的解释,信息是系统有序程度的一个度量,熵是系统无序程度的一个度量;如果指标的信息熵越小,该指标提供的信息量越大,在综合评价中所起作用理当越大,权重就应该越高。
面板数据的分析步骤 面板数据的分析方法或许我们已经了解许多了,但是到底有没有一个基本的步骤呢?那些步骤是必须的?这些都是我们在研究的过程中需要考虑的,而且又是很实在的问题。面板单位根检验如何进行?协整检验呢?什么情况下要进行模型的修正?面板模型回归形式的选择?如何更有效的进行回归?诸如此类的问题我们应该如何去分析并一一解决?以下是我近期对面板数据研究后做出的一个简要总结,和大家分享一下,也希望大家都进来讨论讨论。 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher5种方法进行面板单位根检验。 其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS 、H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square 统计量、Hadri Z统计量,并且Levin, Lin & Chu t* 统计量、Breitung t统计量的原假设为存在普通的单位根过程,lm Pesaran & Shin W 统计量、ADF- Fisher Chi-square统计量、PP-Fisher Chi-square统计量的原假设为存在有效的单位根过程,Hadri Z统计量的检验原假设为不存在普通的单位根过程。 有时,为了方便,只采用两种面板数据单位根检验方法,即相同根单位根检验LLC (Levin-Lin-Chu)检验和不同根单位根检验Fisher-ADF检验(注:对普通序列(非面板序列)的单位根检验方法则常用ADF检验),如果在两种检验中均拒绝存在单位根的原假设则我们
1.什么是面板数据? 面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是截面数据与时间序列综合起来的一种数据资源,是同时在时间和截面空间上取得的二维数据。 如:城市名:北京、上海、重庆、天津的GDP分别为10、11、9、8(单位亿元)。这就是截面数据,在一个时间点处切开,看各个城市的不同就是截面数据。如:2000、2001、2002、2003、2004各年的北京市GDP分别为8、9、10、11、12(单位亿元)。这就是时间序列,选一个城市,看各个样本时间点的不同就是时间序列。 如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP分别为: 北京市分别为8、9、10、11、12; 上海市分别为9、10、11、12、13; 天津市分别为5、6、7、8、9; 重庆市分别为7、8、9、10、11(单位亿元)。 这就是面板数据。 2.面板数据的计量方法 利用面板数据建立模型的好处是:(1)由于观测值的增多,可以增加估计量的抽样精度。(2)对于固定效应模型能得到参数的一致估计量,甚至有效估计量。(3)面板数据建模比单截面数据建模可以获得更多的动态信息。例如1990-2000 年30 个省份的农业总产值数据。固定在某一年份上,它是由30 个农业总产值数字组成的截面数据;固定在某一省份上,它是由11 年农业总产值数据组成的一个时间序列。面板数据由30 个个体组成。共有330 个观测值。 面板数据模型的选择通常有三种形式:混合估计模型、固定效应模型和随机效应模型 第一种是混合估计模型(Pooled Regression Model)。如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。 第二种是固定效应模型(Fixed Effects Regression Model)。在面板数据散点图中,如果对于不同的截面或不同的时间序列,模型的截距是不同的,则可以采用在模型中加虚拟变量的方法估计回归参数,称此种模型为固定效应模型(fixed effects regression model)。 固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model)、时刻固定效应模型(time fixed effects regression model)和时刻个体固定效应模型(time and entity fixed effects regression model)。(1)个体固定效应模型。 个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序列(个体)截距是不同的,但是对于不同的横截面,模型的截距没有显著性变化,那么就应该建立个体固定效应模型。注意:个体固定效应模型的EViwes输出结果中没有公共截距项。 (2)时刻固定效应模型。 时刻固定效应模型就是对于不同的截面(时刻点)有不同截距的模型。如果确知
EViews 6.0 beta在面板数据模型估计中的应用 来自免费的minixi 1、进入工作目录cd d:\nklx3,在指定的路径下工作是一个良好的习惯 2、建立面板数据工作文件workfile (1)最好不要选择EViews默认的blanaced panel 类型 Moren_panel (2)按照要求建立简单的满足时期周期和长度要求的时期型工作文件
3、建立pool对象 (1)新建对象 (2)选择新建对象类型并命名 (3)为新建pool对象设置截面单元的表示名称,在此提示下(Cross Section Identifiers: (Enter identifiers below this line )输入截面单元名称。,建议采用汉语拼音,例如29个省市区的汉语拼音,建议在拼音名前加一个下划线“_”,如图
关闭建立的pool对象,它就出现在当前工作文件中。 4、在pool对象中建立面板数据序列 双击pool对象,打开pool对象窗口,在菜单view的下拉项中选择spreedsheet (展开表) 在打开的序列列表窗口中输入你要建立的序列名称,如果是面板数据序列必须在序列名后添加“?”。例如,输入GDP?,在GDP后的?的作用是各个截面单元的占位符,生成了29个省市区的GDP的序列名,即GDP后接截面单元名,再在接时期,就表示出面板数据的3维数据结构(1变量2截面单元3时期)了。
请看工作文件窗口中的序列名。展开表(类似excel)中等待你输入、贴入数据。 (1)打开编辑(edit)窗口
(2)贴入数据 (3)关闭pool窗口,赶快存盘见好就收6、在pool窗口对各个序列进行单位根检验 选择单位根检验 设置单位根检验
基于面板数据模型及其固定效应的模型分析 在20世纪80年代及以前,还只有很少的研究面板数据模型及其应用的文献,而20世纪80年代之后一直到现在,已经有大量的文献使用同时具有横截面和时间序列信息的面板数据来进行经验研究(Hsiao,20XX)。同时,大量的面板数据计量经济学方法和技巧已经被开发了出来,并成为现在中级以上的计量经济学教科书的必备内容,面板数据计量经济学的理论研究也是现在理论计量经济学最热的领域之一。 面板数据同时包含了许多横截面在时间序列上的样本信息,不同于只有一个维度的纯粹横截面数据和时间序列数据,面板数据是同时有横截面和时序二维的。使用二维的面板数据相对于只使用横截面数据或时序数据,在理论上被认为有一些优点,其中一个重要的优点是面板数据被认为能够控制个体的异质性。在面板数据中,人们认为不同的横截面很可能具有异质性,这个异质性被认为是无法用已知的回归元观测的,同时异质性被假定为依横截面不同而不同,但在不同时点却是稳定的,因此可以用横截面虚拟变量来控制横截面的异质性,如果异质性是发生在不同时期的,那么则用时期虚拟变量来控制。而这些工作在只有横截面数据或时序数据时是无法完成的。 然而,实际上绝大多数时候我们并不关心这个异质性究竟是多少,我们关心的仍然是回归元参数的估计结果。使用面板数据做过实际研究的人可能会发现,使用的效应①不同,对回归元的估计结果经常有十分巨大的影响,在某个固定效应设定下回归系数为正显着,而另外一个效应则变为负显着,这种事情经常可以碰到,让人十分困惑。大多数的研究文献都将这种影响解释为控制了固定效应后的结果,因为不可观测的异质性(固定效应)很可能和回归元是相关的,在控制了这个效应后,由于变量之间的相关性,自然会对回归元的估计结果产生影响,因而使用的效应不同,估计的结果一般也就会有显着变化。 然而,这个被广泛接受的理论假说,本质上来讲是有问题的。我们认为,估计的效应不同,对应的自变量估计系数的含义也不同,而导致估计结果有显着变化的可能重要原因是由于面板数据是二维的数据,而在这两个不同维度上,以及将两个维度的信息放到一起时,样本信息所显现出来的自变量和因变量之间的相关关系可能是不同的。因此,我们这里提出另外一种异质性,即样本在不同维度上的相关关系是不同的,是异质的,这个异质性是发生在回归元的回归系数上,而
熵值法的原理及实例讲解 熵值法 1.算法简介熵值法是一种客观赋权法,其根据各项指标观测值所提供的信息的大小来确定指标权重。设有m个待评方案,n项评价指标,形成原始指标数据矩阵X?(xij)m?n,对于某项指标xj,指标值Xij的差距越大,则该指标在综合评价中所起的作用越大;如果某项指标的指标值全部相等,则该指标在综合评价中不起作用。在信息论中,熵是对不确定性的一种度量。信息量越大,不确定性就越小,熵也就越小;信息量越小,不确定性就越大,熵也越大.根据熵的特性,我们可以通过计算熵值来判断一个方案的随机性及无序程度,也可以用熵值来判断某个指标的离散程度,指标的离散程度越大,该指标对综合评价的影响越大!因此,可根据各项指标的变异程度,利用信息熵这个工具,计算出各
个指标的权重,为多指标综合评价提供依据! 2.算法实现过程数据矩阵?X11?X1m??????其中Xij为第i个方案第j个指标的数值A????X??n1?Xnm?n? 数据的非负数化处理于熵值法计算采用的是各个方案某一指标占同一指标值总和的比值,因此不存在量纲的影响,不需要进行标准化处理,若数据中有负数,就需要对数据进行非负化处理!此外,为了避免求熵值时对数的无意义,需要进行数据平移:对于越大越好的指标:’Xij?Xij?min(X1j,X2j,?,Xn j)max(X1j,X2j,?,Xnj)?min(X1j,X2j,?,Xnj) ?1,i?1,2,?,n;j?1,2,?,m对于越小越好的指标:’Xij?max(X1j,X2j,?,Xnj)?Xijm ax(X1j,X2j,?,Xnj)?min(X1j,X2j,?,Xnj)?1,i ?1,2,?,n;j?1,2,?,m为了方便起见,仍记非负化处理后的数据为Xij 计算第j 项指标下第i个方案占该指标的比重Pij?Xij?Xi?1n(j?1,2,?m) 计算第j项指标的熵值ej??k*?Pijlog(Pij),其中
面板数据的计量方法 1.什么是面板数据? 面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是截面数据与时间序列综合起来的一种数据资源,是同时在时间和截面空间上取得的二维数据。 如:城市名:北京、上海、重庆、天津的GDP分别为10、11、9、8(单位亿元)。这就是截面数据,在一个时间点处切开,看各个城市的不同就是截面数据。如:2000、2001、2002、2003、2004各年的北京市GDP分别为8、9、10、11、12(单位亿元)。这就是时间序列,选一个城市,看各个样本时间点的不同就是时间序列。 如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP分别为: 北京市分别为8、9、10、11、12; 上海市分别为9、10、11、12、13; 天津市分别为5、6、7、8、9; 重庆市分别为7、8、9、10、11(单位亿元)。 这就是面板数据。 2.面板数据的计量方法 利用面板数据建立模型的好处是:(1)由于观测值的增多,可以增加估计量的抽样精度。(2)对于固定效应模型能得到参数的一致估计量,甚至有效估计量。(3)面板数据建模比单截面数据建模可以获得更多的动态信息。例如1990-2000 年30 个省份的农业总产值数据。固定在某一年份上,它是由30 个农业总产值数字组成的截面数据;固定在某一省份上,它是由11 年农业总产值数据组成的一个时间序列。面板数据由30 个个体组成。共有330 个观测值。 面板数据模型的选择通常有三种形式:混合估计模型、固定效应模型和随机效应模型 第一种是混合估计模型(Pooled Regression Model)。如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。 第二种是固定效应模型(Fixed Effects Regression Model)。在面板数据散点图中,如果对于不同的截面或不同的时间序列,模型的截距是不同的,则可以采用在模型中加虚拟变量的方法估计回归参数,称此种模型为固定效应模型(fixed effects regression model)。 固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model)、时刻固定效应模型(time fixed effects regression model)和时刻个体固定效应模型(time and entity fixed effects regression model)。(1)个体固定效应模型。 个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序列(个体)截距是不同的,但是对于不同的横截面,模型的截距没有显著性变化,那么就应该建立个体固定效应模型。注意:个体固定效应模型的EViwes输
MATLAB 空间面板数据模型操作简介 MATLAB 安装: 在民主湖资源站上下载 MA TLAB 2009a ,或者 2010a ,按照其中的安装说明 安装 MATLAB 。( MATLAB 较大,占用内存较大,安装的话可能也要花费一定的时间) 一、数据布局 首先我们说一下 MA TLAB 处理空间面板数据时,数据文件是怎么布局的,熟悉 eviews 的同学 可能知道, eviews 中面板数据布局是:一个省份所有年份的数据作为一个单元(纵截面:一个时间 序列),然后再排放另一个省份所有年份的数据,依次将所有省份的数据排放完,如下图,红框中 “1-94”“1-95” “1-96” “ 1-97”中, 1是省份的代号, 94,95,96,97 表示年份, eviews 是将每个省 份的数据放在一起,再将所有省份堆放在一起。 与 eviews 不同, MATLAB 处理空间面板数据时,面板数据的布局是(在 excel 中说明): 先排 放一个横截面上的数据(即某年所有省份的数据) ,再将不同年份的横截面按时间顺序堆放在一起。 如图:
这里需要说明的是, MA TLAB 中省份的序号需要与空间权重矩阵中省份一一对应,我们一般就采用《中国统计年鉴》分地区数据中省份的排列顺序。(二阶空间权重矩阵我会在附件中给出)。二、数据的输入: MATLAB 与 excel链接:在 excel中点击“工具→加载宏→浏览” ,找到 MA TLAB 的安装目录,一般来说,如果安装时没有修改安装路径,此安装目录为: C:\Programfiles\MATLAB\R2009a\toolbox\exlink ,点击 excllink.xla 即可完成 excel 与 MATLAB 的链接。这样的话 excel 中的数据就可以直接导入 MATLAB 中形成 MATLAB 的数据文件。操作完成后 excel 的加载宏界面如图: 选中“Spreadsheet Link EX3.0.3 for use with MATLAB ”即表示我们希望 excel 与
1.面板数据分析方法步骤 面板数据的分析方法或许我们已经了解许多了,但是到底有没有一个基本的步骤呢?那些步骤是必须的?这些都是我们在研究的过程中需要考虑的,而且又是很实在的问题。面板单位根检验如何进行?协整检验呢?什么情况下要进行模型的修正?面板模型回归形式的选择?如何更有效的进行回归?诸如此类的问题我们应该如何去分析并一一解决?以下是我近期对面板数据研究后做出的一个简要总结,和大家分享一下,也希望大家都进来讨论讨论。 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher5种方法进行面板单位根检验。 其中LLC-T 、BR-T、IPS-W 、ADF-FCS、PP-FCS 、H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、lm Pesaran & Shin W 统计量、
第十四章 面板数据模型 在第五章,当我们分析城镇居民的消费特征时,我们使用的是城镇居民的时间序列数据;而当分析农村居民的消费特征时,我们使用农村居民的时间序列数据。如果我们想要分析全体中国居民的消费特征呢?我们有两种选择:一是使用中国居民的时间序列数据进行分析,二是把城镇居民和农村居民的样本合并,实际上就是两个时间序列的样本合并为一个样本。 多个观测对象的时间序列数据所组成的样本数据,被称为面板数据(Panel Data )。通常也被称为综列数据,意即综合了多个时间序列的数据。当然,面板数据也可以看成多个横截面数据的综合。在面板数据中,每一个观测对象,我们称之为一个个体(Individual )。例如城镇居民是一个观测个体,农村居民是另一个观测个体。 如果面板数据中各观测个体的观测区间是相同的,我们称其为平衡的面板数据,反之,则为非平衡的面板数据。基于面板数据所建立的计量经济学模型则被称为面板数据模型。例如,表5.3.1中城镇居民和农村居民的样本数据具有相同的采样区间,所以,它是一个平衡的面板数据。 §14.1 面板数据模型 一、两个例子 1. 居民消费行为的面板数据分析 让我们重新回到居民消费的例子。在表5.1.1中,如果我们将城镇居民和农村居民的时间序列数据作为一个样本,以分析中国居民的消费特征。那么,此时模型(5.1.1)的凯恩斯消费函数就可以表述为: it it it Y C εββ++=10 (14.1.1) it t i it u ++=λμε (14.1.2) 其中:it C 和it Y 分别表示第i 个观测个体在第t 期的消费和收入。i =1、2分别表示城镇居民和农村居民两个观测个体,t =1980、…、2008表示不同年度。it u 为经典误差项。 在(14.1.2)中,i μ随观测个体的变化,而不随时间变化,它反映个体之间不随时间变化的差异性,被称为个体效应。t λ反映不随个体变化的时间上的差异性,被称为时间效应。在本例中,城镇居民和农村居民的消费差异一部分来自收入差异和随机扰动,还有一部分差
《产经评论》2014年5月第3期 [收稿日期]2014-03-23 [基金项目]工业和信息化部通信软科学项目(项目编号:2012-R-54,主持人:刘跃)。 [作者简介]刘跃,重庆邮电大学经济管理学院副院长,教授,主要从事财务管理、信息经济研究;彭艳,重庆邮电大学经济管理学院硕士研究生,主要研究方向为信息经济研究;周亮,重庆邮电大学经济管理学院硕士研究生,主要研究方向为信息经济研究。 我国区域信息产业发展与经济增长质量关系研究 刘 跃 彭 艳 周 亮 [摘要]在综述相关理论和研究方法的基础上,建立我国区域信息产业和经济增长质量的评价指标体系,并利用我国30个省级相关数据,对各区域的信息产业发展水平和经济增长质量水平进行了测度。根据测算所得到的面板数据实证考察我国区域信息产业与经济增长质量之间的关系及其演化规律,揭示了我国区域信息产业的发展对经济增长质量提升的影响作用。 [关键词]信息产业;经济增长质量;指标体系[中图分类号]F49[文献标识码]A [文章编号]1674-8298(2014)03-0040-10[引用方式]刘跃,彭艳,周亮.我国区域信息产业发展与经济增长质量关系研究[J ] .产经评论,2014,5(3):40-49. 一引言 我国自1978年改革开放以来,国民经济得到了快速发展。近几年,信息技术的迅猛发展使得信 息资源得到了充分利用,极大程度地推动了人类社会政治、经济和文化的变革,人们的生活变得更加现代化。随着信息经济时代的来临,各国信息化水平也日益提高,信息产业在国民经济中所占的比例逐渐加大。信息技术在各个行业的广泛渗透也使得人们更加关注信息技术在社会发展和经济增长中的作用。信息产业发展水平已成为衡量一个地区甚至一个国家经济、社会发展的重要标志,信息产业在世界经济发展中扮演着越来越重要的角色,并成为推动世界经济快速发展的动力。 但是为了追求信息产业的高速发展,人们往往忽视了经济质量的同步增长。Liu (2008)[1] 认为自1978年改革开放以来,中国的制造工业得到了快速发展,但与其相伴的却是对环境的严重破坏; 虽然中央政府建立了相关的法律制度来控制环境污染,但地方政府认为环境保护会拖累地方经济,因 此常常把环境监管放置一旁,而尽量去寻求经济的高速度增长。Kuijs (2012)[2] 对中国和印度的经济增长模式及策略进行了分析,认为中国的大规模投资和重工业的发展为近几十年经济的稳定增长提供 了条件,但这也导致了中国产业结构的失衡。沈利生(2009)[3] 则采用增加值率来反映经济增长的质量,通过研究发现自2002年以来,我国产业结构变动趋势是工业变重,服务业变轻,这导致了我国经济增长质量的降低。当前,世界各国都对经济增长质量给予了高度的关注,同时许多国家也通过提高资源的利用效率、减少生产活动中的环境污染以及转变经济的增长方式等途径来提升经济增长质量。如今,如何促进经济增长质量的提升已成为各国经济发展中最重要课题之一,同时这也是中国现在以及未来经济发展中需要进一步解决的突出问题。本研究重点探讨我国区域信息产业发展与经济增长质量的关系,力争寻求对策,使信息产业发展的同时经济增长质量得到同步提高。 · 04·
STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令 εαβit ++=x y it i it 固定效应模型 μβit +=x y it it εαμit +=it it 随机效应模型 (一)数据处理 输入数据 ●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构 ●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析) ●gen lag_y=L.y /////// 产生一个滞后一期的新变量
gen F_y=F.y /////// 产生一个超前项的新变量 gen D_y=D.y /////// 产生一个一阶差分的新变量 gen D2_y=D2.y /////// 产生一个二阶差分的新变量 (二)模型的筛选和检验 ●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe 对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。 ●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量) (原假设:使用OLS混合模型) ●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0
可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。可见,随机效应模型也优于混合OLS模型。 ●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验) 原假设:使用随机效应模型(个体效应与解释变量无关) 通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下: Step1:估计固定效应模型,存储估计结果 Step2:估计随机效应模型,存储估计结果 Step3:进行Hausman检验 ●qui xtreg sq cpi unem g se5 ln,fe est store fe qui xtreg sq cpi unem g se5 ln,re est store re hausman fe (或者更优的是hausman fe,sigmamore/ sigmaless) 可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。此时,需要采用工具变量法和是使用固定效应模型。
熵值法 在信息论中熵是对系统的一种不确定性度量,若某一个指标的信息量越大,信息越明确,则表明该指标的不确定性就越小,变异程度就越小,熵就越小;反之信息量越的指标小,其指标变异度就越大,熵就越大。 熵值法求解权重的一般步骤如下: 设有m 个备选方案,n 项评价指标,原始指标数据矩阵为()ij m n X x ?=。 111212122212m m n n nm x x x x x x X x x x ??????=?????? L L M M O M L 其中,xij 为第i 个评价指标下的第j 个评价对象的数值()1,2,;1,2,i n j m ==L L (1)对原始指标数据矩阵进行标准化处理 将最优指标标准化后为1,最劣指标标准化后为0,ij r 为标准化后的指标。 对于成本型指标: max max min ij ij i ij ij ij i i x x r x x -= - (1-5) 对于效益型指标: min max min ij ij i ij ij ij i i x x r x x -=- (1-4) 依据熵权法的理论,可计算得出第i 个评价指标下第j 个评价对象占该指标的比重p 1,2,, 1,2,, ij i n j m =?=?=(;) ()1p ij ij m ij j r r ==∑ (1-5) (2)计算信息熵 第j 项指标的熵值j H 的计算公式如下: ()11ln ln m j ij ij j H p p m ==-∑ (1-6) 式中,若0ij p =,则ln 0ij ij p p =。 (3)计算权系数 第j 项指标的权系数j β的计算公式如下:
面板数据分析方法步骤全解 面板数据的分析方法或许我们已经了解许多了,但是到底有没有一个基本的步骤呢?那些步骤是必须的?这些都是我们在研究的过程中需要考虑的,而且又是很实在的问题。面板单位根检验如何进行?协整检验呢?什么情况下要进行模型的修正?面板模型回归形式的选择?如何更有效的进行回归?诸如此类的问题我们应该如何去分析并一一解决?以下是我近期对面板数据研究后做出的一个简要总结, 和大家分享一下,也希望大家都进来讨论讨论。 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈 曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归, 尽管有较高的R 平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正 含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势 以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时 有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性, 我们必须对各面板序 列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项, 从而为进一步的单位根检验的检验模式做准备。 单位根检验方法的文献综述:在非平稳的面板数据渐进过程中丄evin
an dLi n(1993)很早就发现这些估计量的极限分布是高斯分布,这些结 果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al. (2002的改进,提出了检验面板单 位根的LLC法。Levin et al. (2002)指出,该方法允许不同截距和时间趋 势,异方差和高阶序列相关,适合于中等维度(时间序列介于25?250 之间,截面数介于10?250之间)的面板单位根检验。Im et al. (1997) 还提出了检验面板单位根的IPS法,但Breitung(2000)发现IPS法对 限定性趋势的设定极为敏感,并提出了面板单位根检验的Breit ung 法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位 根检验方法。 由上述综述可知,可以使用LLC IPS Breintung、ADF-Fisher和 PP-Fisher5种方法进行面板单位根检验。 其中LLC-T、BR-T IPS-W、ADF-FCS PP-FCS H-Z 分别指Levin, Lin & Chu t* 统计量、Breitung t 统计量、Im Pesaran & Shin W 统计量、 ADF- Fisher Chi-square统计量、PP-FisherChi-square统计量、Hadri Z 统计量,并且Levin, Lin & Chu t*统计量、Breitung t统计量的原假设 为存在普通的单位根过程,Im Pesaran & Shin W统计量、ADF- Fisher Chi-square统计量、PP -Fisher Chi-square统计量的原假设为存在有效 的单位根过程,Hadri Z统计量的检验原假设为不存在普通的单位根 过程。