练习题8.1:
1. 结果解释
依据给定的估计检验结果数据,对数人均收入对期望寿命在统计上并没有显著影响,截距和变量()ln 7i i D X -在统计上对期望寿命有显著影响;同时,
()()2.40 3.3679.39 3.36ln ((ln 7)) 1 2.409.39ln 0 i i i i i i i X D X D Y X D ?-+?+---==?
-+=?
富国时
穷国时 表明贫富国之间的期望寿命存在差异。
2. 回归方程中引入()ln 7i i D X -的原因是从截距和斜率两个方面考证收入因素对期望寿命的影响。这个回归解释变量可解释为对期望寿命的影响存在截距差异和斜率差异的共同因素。
3. 对穷国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X αα=+≤,其中,为美元时的寿命; 对富国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X ββ=+>,其中,为美元时的寿命;
4. 一般的结论为富国的期望寿命药高于穷国的期望寿命,并且随着收入的增加,在平均意义上,富国的期望寿命的增加变化趋势优于穷国,贫富国之间的期望寿命的确存在显著差异。
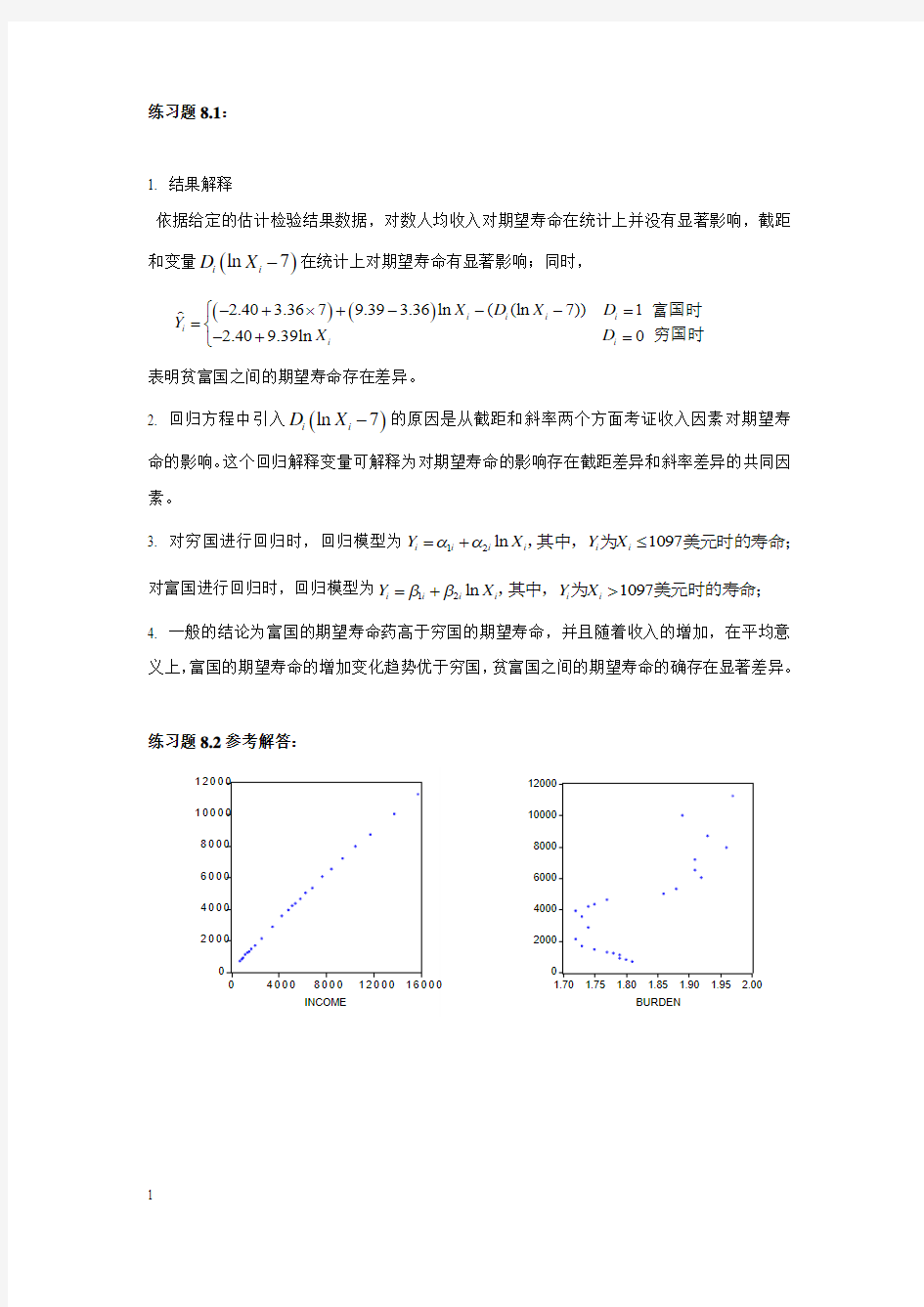
练习题8.2参考解答:
录入如下数据
Dependent Variable: CONSUME Method: Least Squares
Date: 08/24/09 Time: 13:14
Sample (adjusted): 1986 2008
Included observations: 23 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 744.7966 378.0662 1.970017 0.0676
CONSUME(-1) 0.084873 0.050907 1.667221 0.1162 INCOME 0.633118 0.035198 17.98729 0.0000 LOG(EMPLOYMENT) -762.9720 478.5280 -1.594414 0.1317 D1 37.43460 50.23445 0.745198 0.4677
D2 221.0765 38.30840 5.770966 0.0000
D3 -122.0493 73.81439 -1.653461 0.1190
D4 -178.8688 65.87071 -2.715452 0.0160
R-squared 0.999861 Mean dependent var 4428.906 Adjusted R-squared 0.999796 S.D. dependent var 3060.917 S.E. of regression 43.70477 Akaike info criterion 10.66100 Sum squared resid 28651.61 Schwarz criterion 11.05595 Log likelihood -114.6015 F-statistic 15413.79 Durbin-Watson stat 2.977604 Prob(F-statistic) 0.000000
Dependent Variable: CONSUME
Method: Least Squares
Date: 08/24/09 Time: 13:14
Sample (adjusted): 1986 2008
Included observations: 23 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 871.9310 332.6627 2.621067 0.0185
CONSUME(-1) 0.083576 0.050165 1.666017 0.1152 INCOME 0.629922 0.034447 18.28676 0.0000 LOG(EMPLOYMENT) -889.4616 441.1508 -2.016230 0.0609 D2 226.0361 37.19791 6.076579 0.0000
D3 -110.8884 71.26752 -1.555946 0.1393
D4 -171.6924 64.25105 -2.672211 0.0167
R-squared 0.999856 Mean dependent var 4428.906 Adjusted R-squared 0.999802 S.D. dependent var 3060.917 S.E. of regression 43.09316 Akaike info criterion 10.61040 Sum squared resid 29712.33 Schwarz criterion 10.95598 Log likelihood -115.0196 F-statistic 18496.74 Durbin-Watson stat 2.787479 Prob(F-statistic) 0.000000
Dependent Variable: CONSUME
Method: Least Squares
Date: 08/24/09 Time: 13:15
Sample (adjusted): 1986 2008
Included observations: 23 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 1204.936 265.1054 4.545122 0.0003
CONSUME(-1) 0.099314 0.051147 1.941709 0.0689 INCOME 0.599165 0.029366 20.40320 0.0000 LOG(EMPLOYMENT) -1325.942 354.4143 -3.741222
0.0016 D2 251.3675 34.81573 7.219940 0.0000 D4 -141.7710 63.81647 -2.221543 0.0402 R-squared 0.999834 Mean dependent var 4428.906 Adjusted R-squared 0.999785 S.D. dependent var 3060.917 S.E. of regression 44.85802 Akaike info criterion 10.66434 Sum squared resid 34208.12 Schwarz criterion 10.96056 Log likelihood -116.6399 F-statistic 20483.46 Durbin-Watson stat 2.638666 Prob(F-statistic)
0.000000
Dependent Variable: CONSUME
Method: Least Squares Date: 08/24/09 Time: 13:16 Sample: 1985 2008 Included observations: 24
Variable Coefficient Std. Error t-Statistic
Prob.
C 1460.937 233.2922 6.262263 0.0000 INCOME 0.653101 0.009132 71.51539 0.0000 LOG(EMPLOYMENT) -1651.937 314.1501 -5.258431
0.0000 D2 277.4048 33.62783 8.249261 0.0000 D4 -154.2742 66.05969 -2.335377 0.0306
R-squared 0.999810 Mean dependent var 4272.418 Adjusted R-squared 0.999769 S.D. dependent var 3090.239 S.E. of regression 46.92598 Akaike info criterion 10.71807 Sum squared resid 41838.91 Schwarz criterion 10.96350 Log likelihood -123.6169 F-statistic 24931.15 Durbin-Watson stat 2.292463 Prob(F-statistic)
0.000000
练习题8.3参考解答:
考虑到班次有三个属性,故在有截距项的回归方程中只能引入两个虚拟变量,按加法形式引入,模型设定形式为:
121
32i i Y D D u βββ=+++ 110D ?=??早班
其他 210D ?=?
?中班其他
其中,i Y 为劳动效率。
在Eviews 中按下列格式录入数据:
obs Y
D1 D2 1
34.00000
1.000000
0.000000
2 37.00000 1.000000 0.000000
3 35.00000 1.000000 0.000000
4 33.00000 1.000000 0.000000
5 33.00000 1.000000 0.000000
6 35.00000 1.000000 0.000000
7 36.00000 1.000000 0.000000
8 49.00000 0.000000 1.000000
9 47.00000 0.000000 1.000000
10 51.00000 0.000000 1.000000
11 48.00000 0.000000 1.000000
12 50.00000 0.000000 1.000000
13 51.00000 0.000000 1.000000
14 51.00000 0.000000 1.000000
15 39.00000 0.000000 0.000000
16 40.00000 0.000000 0.000000
17 42.00000 0.000000 0.000000
18 39.00000 0.000000 0.000000
19 41.00000 0.000000 0.000000
20 42.00000 0.000000 0.000000
21 40.00000 0.000000 0.000000
输入命令:ls y c d1 d2,则有如下结果
Dependent Variable: Y
Method: Least Squares
Date: 06/29/09 Time: 16:56
Sample: 1 21
Included observations: 21
Variable Coefficient Std. Error t-Statistic Prob.
C 40.42857 0.555329 72.80115 0.0000
D1 -5.714286 0.785353 -7.276069 0.0000
D2 9.142857 0.785353 11.64171 0.0000
R-squared 0.952909 Mean dependent var 41.57143 Adjusted R-squared 0.947676 S.D. dependent var *6.423172 S.E. of regression 1.469262 Akaike info criterion 3.738961 Sum squared resid *38.85714 Schwarz criterion 3.888178 Log likelihood -36.25909 F-statistic *182.1176 Durbin-Watson stat 2.331933 Prob(F-statistic) 0.000000
表中的*号部分表示在方差分析中需要用到的数据。
依据上述数据,有:
()26.423172211825.1427708TSS =?-=,
38.85714R S S = 825.1427708
38.857147
E S S T S S R S S =-
=-= 182.1176F = 于是方差分析的结果为
练习题8.4参考解答
1)2β、4β分别是债券的资本化率和利润率的标准差的回归系数。债券的资本化率是长期债券的市值和总资本的市值的比率,若总资本的市值不变,长期债券的市值越高,即债券的资本化率越高,债券风险越高,则债券的信用等级越低,故2β应为负值。同样,利润率的标准差越大,表明债券的变异性越大,风险越高,则债券的信用等级越低,故4β应为负值。 2)如上所述,40β 是不合理的。
3)经济解释:在其他条件不变的情况下,给定资本的债券化率一个水平值b ,资本的债券化率每上升1%,则债券的信用等级为Aa 的概率下降0.0358b%。在其他条件不变的情况下,债券的利润率每上升1%,则债券的信用等级为Aa 的概率上升0.0486%。 4) LPM
^
70.68600.01799.67%0.04867.77%0.05720.5933%0.378103429000.7014
i Y -=-?+?+?+??=Logit
6ln() 1.66220.31859.67%0.62487.77%0.90410.5933%0.92103429000-1.47971i i p
p -=--?-?-?+??=-
练习题8.5参考解答:
在Eviews 中按照给定数据进行录入,点击Quick ,录入grade c gpa tuce psi ,点击method ,在下拉菜单中,选择binary : 并选择logit ,
则有:
Dependent Variable: GRADE Method: ML - Binary Logit (Quadratic hill climbing) Date: 06/29/05 Time: 17:44
Sample: 1 32 Included observations: 32 Convergence achieved after 5 iterations
Covariance matrix computed using second derivatives
Variable Coefficient Std. Error z-Statistic Prob. C -13.02135 4.931324 -2.640537 0.0083 GPA 2.826113 1.262941 2.237723 0.0252 TUCE 0.095158 0.141554 0.672235 0.5014 PSI 2.378688 1.064564 2.234424
0.0255 Mean dependent var 0.343750 S.D. dependent var 0.482559 S.E. of regression 0.384716 Akaike info criterion 1.055602 Sum squared resid 4.144171 Schwarz criterion 1.238819 Log likelihood -12.88963 Hannan-Quinn criter. 1.116333 Restr. log likelihood -20.59173 Avg. log likelihood -0.402801 LR statistic (3 df) 15.40419 McFadden R-squared 0.374038 Probability(LR stat) 0.001502
Obs with Dep=0 21 Total obs 32 Obs with Dep=1 11
边际效应等于
()
2.8260.5340.1890.0950.0182.3790.499f ????
? ?=?= ? ?
? ????? X ββ
其中,
()
()(
)
13.02135 2.82613.11720.095221.9375 2.37870.437522
13.02135 2.82613.11720.095221.9375 2.37870.4375
11e
e f e e -+?+?+?-+?+?+?=
=
++
X βX β
X β
()
2
0.3387
0.1889887460.189
10.3387=
=≈+
GPA TUCE PSI Mean 3.117188 21.93750 0.437500 Median 3.065000 22.50000 0.000000 Maximum 4.000000 29.00000 1.000000 Minimum 2.060000 12.00000 0.000000 Std. Dev. 0.466713 3.901509 0.504016 Skewness 0.122657 -0.525110 0.251976 Kurtosis 2.570068 3.048305 1.063492 Jarque-Bera 0.326695 1.473728 5.338708 Probability 0.849296 0.478612 0.069297 Sum
99.75000 702.0000 14.00000 Sum Sq. Dev. 6.752447 471.8750 7.875000 Observations
32 32 32
练习题8.6参考解答:
依题意可按加法类型引入虚拟变量:其中,1 1 0 d ?=??
股份制
非股份制。键入命令 LS Y C D1,,估
计的回归结果如下:
Dependent Variable: Y
Method: Least Squares Date: 02/22/10 Time: 13:54 Sample: 1 49 Included observations: 49
Variable Coefficient Std. Error t-Statistic
Prob. C 1518.696 122.5373 12.39374 0.0000 D1 568.2274 168.2208 3.377868 0.0015 R-squared 0.195343 Mean dependent var 1820.204 Adjusted R-squared 0.178223 S.D. dependent var 648.2687 S.E. of regression 587.6681 Akaike info criterion 15.63016 Sum squared resid 16231629 Schwarz criterion 15.70738 Log likelihood -380.9390 F-statistic 11.40999 Durbin-Watson stat 1.664603 Prob(F-statistic)
0.001476
回归方程:^
i 1Y =1518.696568.2274D + (122.5373)(168.2208) t =(12.39374) (3.377868)
2
R =0.195343 F=11.40999 DW1.96144
11(0)1518.696
(1)1518.696568.22742086.9234
E Y D E Y D ====+=
可以看出,非股份制超市的销售规模平均为1518.696,而股份制超市的销售规模平均为2086.9234,表明股份制因素对销售规模起到一定的影响。
统计学2班 第三次作业 1、⑴存在.2 3223223232 322 ) ())(() )(())((?∑∑∑∑∑∑∑--=i i i i i i i i i i i x x x x x x x y x x y βΘ 当X 2和X 3之间的相关系数为0时,离差形式的 ∑i i x x 32=0 2 222232 22 322 ?) )(() )((??== =∴∑∑∑∑∑∑i i i i i i i i x x y x x x x y β 同理得:33 ??γβ= ⑵2 ?β会等于1?α和1?γ二者的线性组合。 33221???X X Y βββ--=Θ且221??X Y αα-=,331??X Y γγ-= 由⑴可得22 ??αβ=和33??γβ= 22221???X Y X Y βαα-=-=∴,3 3331???X Y X Y βγγ-=-= 212 ??X Y αβ-=∴,3 1 3??X Y γβ-= 则:33 1 2213 3221?????X X Y X X Y Y X X Y γαβββ----=--=Θ ⑶存在。∑-=)1()?(223 222 2 r x Var i σβΘ X 2和X 3之间相关系数为0,)?() 1()?(2222 223 2 22 2 α σσβVar x r x Var i i == -=∴∑∑ 同理可得)?()?(33 γβVar Var = 2、逐步向前回归和逐步向后回归的程序都存在不足,逐步向前法不能反映引进新的解释变量后的变化情况,即一旦引入新的变量,就保留在方程中,逐步向后法泽一旦剔除一个解释变量就再没有机会重新进入方程。而解释变量之间及其与被解释变量的相关关系与引入的变量个数及同时引入哪些变量而不同。所以采用逐步回归比较好。吸收了逐步向前和逐步向后的优点。
第二章简单线性回归模型 第一节回归分析与回归函数P15 (一)相关分析与回归分析 1、相关关系 2、相关系数 3、回归分析 (二)总体回归函数(条件期望) (三)随机扰动项 (四)样本回归函数 第二节简单线性回归模型参数的估计P26 (一)简单线性回归的基本假定 (二)普通最小二乘法求样本回归函数 (三)OLS回归线的性质 (四)最小二乘估计量的统计性质 1、参数估计量的评价标准(无偏性、有效性、一致性) 2、OLS估计量的统计特性(线性特性、无偏性、有效性、高斯-马尔可夫定理) 第三节拟合优度的度量(RSS、ESS、TSS)P35 (一)总变差的分解 (二)可决系数 (三)可决系数与相关系数的关系 第四节回归系数的区间估计与假设检验P38 (一)OLS估计的分布性质 (二)回归系数的区间估值 (三)回归系数的假设检验 1、Z检验 2、t检验 第五节回归模型预测P43 第六节案例分析P48 第三章多元线性回归模型 第一节多元线性回归模型及古典假定P64 一、多元线性回归模型 二、多元线性回归模型的矩阵形式 三、多元线性回归模型的古典假定 第二节多元线性回归模型的估计P68 一、多元线性回归性参数的最小二乘估计 二、参数最小二乘估计的性质(线性特性、无偏性、有效性) 三、OLS估计的分布性质 四、随机扰动项方差的估计 五、多元线性回归模型参数的区间估计
第三节多元线性回归模型的检验P74 一、拟合优度检验(多重可决系数、修正的可决系数) 二、回归方程的显著性检验(F-检验) 三、回归参数的显著性检验(t-检验) 第四节多元线性回归模型的预测P79 第五节案例分析P81 第四章多重共线性第一节什么是多重共线性P94 第二节多重共线性产生的后果 第三节多重共线性的检验 第四节多重共线性的补救措施 第五节案例分析P109
第二章简单线性回归模型 2.1 (1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: Y Method: Least Squares Date: 12/27/14 Time: 21:00 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134 有上可知,关系式为y=56.64794+0.128360x1 ②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: Y Method: Least Squares Date: 11/26/14 Time: 21:10 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001 由上可知,关系式为y=38.79424+0.331971x2
第四章:多重共线性 二、简答题 1、导致多重共线性的原因有哪些? 2、多重共线性为什么会使得模型的预测功能失效? 3、如何利用辅回归模型来检验多重共线性? 4、判断以下说法正确、错误,还是不确定?并简要陈述你的理由。 (1)尽管存在完全的多重共线性,OLS 估计量还是最优线性无偏估计量(BLUE )。 (2)在高度多重共线性的情况下,要评价一个或者多个偏回归系数的个别显著性是不可能的。 (3)如果某一辅回归显示出较高的2 i R 值,则必然会存在高度的多重共线性。 (4)变量之间的相关系数较高是存在多重共线性的充分必要条件。 (5)如果回归的目的仅仅是为了预测,则变量之间存在多重共线性是无害的。 12233i i i Y X X βββ=++ 来对以上数据进行拟合回归。 (1) 我们能得到这3个估计量吗?并说明理由。 (2) 如果不能,那么我们能否估计得到这些参数的线性组合?可以的话,写出必要的计 算过程。 6、考虑以下模型: 23 1234i i i i i Y X X X ββββμ=++++ 由于2X 和3 X 是X 的函数,那么它们之间存在多重共线性。这种说法对吗?为什么? 7、在涉及时间序列数据的回归分析中,如果回归模型不仅含有解释变量的当前值,同时还含有它们的滞后值,我们把这类模型称为分布滞后模型(distributed-lag model )。我们考虑以下模型: 12313233i t t t t t Y X X X X βββββμ---=+++++ 其中Y ——消费,X ——收入,t ——时间。该模型表示当期的消费是其现期的收入及其滞后三期的收入的线性函数。 (1) 在这一类模型中是否会存在多重共线性?为什么? (2) 如果存在多重共线性的话,应该如何解决这个问题? 8、设想在模型 12233i i i i Y X X βββμ=+++ 中,2X 和3X 之间的相关系数23r 为零。如果我们做如下的回归:
统计学2班 第二次作业 1、?i =-151.0263 + 0.1179X 1i + 1.5452X 2i T= (-3.066806) (6.652983) (3.378064) R 2=0.934331 R 2=0.92964 F=191.1894 n=31 ⑴模型估计结果说明,各省市旅游外汇收入Y 受旅行社职工人数X 1,国际旅游人数X 2的影响。由所估计出的参数可知,在假定其他变量不变的情况下,当旅行社职工人数每增加1人,各省市旅游外汇收入增加0.1179百万美元。在嘉定其他变量不变的情况下。当国际旅游人数每增加1万人,各省市旅游外汇收入增加1.5452百万美元。 ⑵由题已知,估计的回归系数β1的T 值为:t (β1)=6.652983。 β2的T 值分为: t (β2)=3.378064。 α=0.05.查得自由度为n-2=22-2=29的临界值t 0.025(29)=2.045229 因为t (β1)=6.652983≥t 0.025(29)=2.045229.所以拒绝原假设H 0:β1=0。 表明在显著性水平α=0.05下,当其他解释变量不变的情况下,旅行社职工人数X 1对各省市旅游外汇收入Y 有显著性影响。 因为 t (β2)=3.378064≥t 0.025(29)=2.045229,所以拒绝原假设H 0:β2=0 表明在显著性水平α=0.05下,当其他解释变量不变的情况下,和国际旅游人数X 2对各省市旅游外汇收入Y 有显著性影响。 ⑶正对H O :β1=β2=0,给定显著水性水平α=0.05,自由度为k-1=2,n-k=28的临界值 F 0.05(2,28)=3.34038。由题已知F=191.1894>F 0.05(2,28)=3.34038,应拒绝原假设 H O :β1=β2=0,说明回归方程显著,即旅行社职工人数和旅游人数变量联合起来对各省市旅游外汇收入有显著影响。 2、⑴样本容量n=15 残差平方和RSS=66042-65965=77 回归平方和ESS 的自由度为K-1=2 残差平方和RSS 的自由度为n-k=13 ⑵可决系数R 2=TSS ESS =6604265965 =0.99883 调整的可决系数R 2=1-(1-R 2)k n n --1=1-(1-0.99883)1214=0.99863 ⑶利用可决系数R 2=0.99883,调整的可决系数R 2=0.99863,说明模型对样本的拟合很好。不能确定两个解释变量X 2和X 3个字对Y 都有显著影响。
案例 通过构建虚拟变量,建立了分段线性回归模型,结果如下: Variable Coefficient Std. Error t-Statistic Prob. C -697.0977 944.8734 -0.737768 0.4673 GNI 0.132616 0.030143 4.399560 0.0002 (GNI-70142.5)*D1 -0.185777 0.111182 -1.670927 0.1067 (GNI-98000)*D2 0.230666 0.110988 2.078301 0.0477 (GNI-184088.6)*D3 -0.273652 0.075943 -3.603403 0.0013 (GNI-251483.2)*D4 0.458678 0.082565 5.555380 0.0000 R-squared 0.965855 Mean dependent var 10428.57 Adjusted R-squared 0.957976 S.D. dependent var 13612.43 S.E. of regression 2790.516 Akaike info criterion 18.89167 Sum squared resid 2.02E+08 Schwarz criterion 19.20911 Log likelihood -304.7126 F-statistic 122.5782 Durbin-Watson stat 2.989812 Prob(F-statistic) 0.000000 可决系数很大,拟合优度很高;F统计量的P值很小,模型显著性很强;T的P值很小,显著性很强,但第二个解释变量的p值较大,只能在0.10水平勉强通过。 8_3 (1)利用excel做方差分析,结果如下: 方差分析 差异源SS df MS F P-value F crit 组间 3.05E+08 1 3.05E+08 17.11138 9.91E-05 3.981896 组内 1.21E+09 68 17828696 总计 1.52E+09 69 F值较大,P值很小,城镇和农村这一因素对消费水平有显著影响。 (2) C -378.5949 50.52334 -7.493464 0.0000 X1 1.996761 0.259904 7.682677 0.0000 R-squared 0.997087 Mean dependent var 3441.571 Adjusted R-squared 0.996905 S.D. dependent var 3709.172 S.E. of regression 206.3361 Akaike info criterion 13.57871 Sum squared resid 1362387. Schwarz criterion 13.71202 Log likelihood -234.6274 F-statistic 5477.540 Durbin-Watson stat 0.270419 Prob(F-statistic) 0.000000
思考题答案 第一章 绪论 思考题 1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用? 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 1.2理论计量经济学和应用计量经济学的区别和联系是什么? 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 1.3怎样理解计量经济学与理论经济学、经济统计学的关系? 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学主要利用数理统计方法对经济变量间的关系进行计量。 1.4在计量经济模型中被解释变量和解释变量的作用有什么不同? 答:在计量经济模型中,解释变量是变动的原因,被解释变量是变动的结果。被解释变量是模型要分析研究的对象。解释变量是说明被解释变量变动主要原因的变量。 1.5一个完整的计量经济模型应包括哪些基本要素?你能举一个例子吗? 答:一个完整的计量经济模型应包括三个基本要素:经济变量、参数和随机误差项。 例如研究消费函数的计量经济模型:u βX αY ++= 其中,Y 为居民消费支出,X 为居民家庭收入,二者是经济变量;α和β为参数;u 是随机误差项。 1.6假如你是中央银行货币政策的研究者,需要你对增加货币供应量促进经济增长提出建议,
《计量经济学》要点 一、单项选择题 知识点: 第一章 若干定义、概念 时间序列数据定义 横截面数据定义 1.同一统计指标按时间顺序记录的数据称为( B )。 A、横截面数据 B、时间序列数据 C、修匀数据 D、原始数据 2.同一时间,不同单位相同指标组成的观测数据称为( B ) A.原始数据B.横截面数据 C.时间序列数据D.修匀数据 变量定义(被解释变量、解释变量、内生变量、外生变量) 单方程中可以作为被解释变量的是(控制变量、内生变量、外生变量); 3.在回归分析中,下列有关解释变量和被解释变量的说法正确的有( C ) A、被解释变量和解释变量均为随机变量 B、被解释变量和解释变量均为非随机变量 C、被解释变量为随机变量,解释变量为非随机 变量 D、被解释变量为非随机变量,解释变量为随机 变量 什么是解释变量、被解释变量? 从变量的因果关系上,模型中变量可分为解释变量(Explanatory variable)和被解释变量(Explained variable)。 在模型中,解释变量是变动的原因,被解释变量是变动的结果。 被解释变量是模型要分析研究的对象,也常称为“应变量”(Dependent variable)、“回归子”(Regressand)等。 解释变量也常称为“自变量”(Independent variable)、“回归元”(Regressor)等,是说明应变量变动主要原因的变量。 因此,被解释变量只能由内生变量担任,不能由非内生变量担任。 4.单方程计量经济模型中可以作为被解释变量的是( C ) A、控制变量 B、前定变量 C、内生变量 D、外生变量 5.单方程计量经济模型的被解释变量是(A ) A、内生变量 B、政策变量 C、控制变量 D、外生变量 6.在回归分析中,下列有关解释变量和被解释变量的说法正确的有(C) A、被解释变量和解释变量均为随机变量 B、被解释变量和解释变量均为非随机变量 C、被解释变量为随机变量,解释变量为非随机 变量 D、被解释变量为非随机变量,解释变量为随机 变量 双对数模型中参数的含义; 7.双对数模型 01 ln ln ln Y X ββμ =++中,参数1 β的含义是(D ) A .X的相对变化,引起Y的期望值绝对量变化 B.Y关于X的边际变化 C.X的绝对量发生一定变动时,引起因变量Y 的相对变化率 D.Y关于X的弹性 8.双对数模型μ β β+ + =X Y ln ln ln 1 中,参数1 β的含义是( C ) A. Y关于X的增长率 B .Y关于X的发展速度 C. Y关于X的弹性 D. Y关于X 的边际变化 计量经济学研究方法一般步骤 四步12点 9.计量经济学的研究方法一般分为以下四个步骤( B ) A.确定科学的理论依据、模型设定、模型修定、模型应用 B.模型设定、估计参数、模型检验、模型应用C.搜集数据、模型设定、估计参数、预测检验D.模型设定、检验、结构分析、模型应用 对计量经济模型应当进行哪些方面的检验? 经济意义检验:检验模型估计结果,尤其是参数
思考题答案 第一章绪论 思考题 1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用? 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 1.2理论计量经济学和应用计量经济学的区别和联系是什么? 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 1.3怎样理解计量经济学与理论经济学、经济统计学的关系? 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学
班级:金融学×××班姓名:××学号:×××××××C8.1SLEEP75.RAW sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u 解:(ⅰ)写出一个模型,容许u的方差在男女之间有所不同。这个方差不应该取决于其他因素。 在sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u模型下,u方差要取决于性别,则可以写成:Var u︳totwork,educ,age,yngkid,male =Var u︳male =δ0+δ1male。所以,当方差在male=1时,即为男性时,结果为δ0+δ1;当为女性时,结果为δ0。 将sleep对totwork,educ,age,age2,yngkid和male进行回归,回归结果如下: (ⅱ)利用SLEEP75.RAW的数据估计异方差模型中的参数。u的估计方差对于男人和女人而言哪个更高? 由截图可知:u2=189359.2?28849.63male+r
20546.36 (27296.36) 由于male 的系数为负,所以u 的估计方差对女性而言更大。 (ⅲ)u 的方差是否对男女而言有显著不同? 因为male 的 t 统计量为?1.06,所以统计不显著,故u 的方差是否对男女而言并没有显著不同。 C8.2 HPRICE1.RAW price =β0+β1lotsize +β2sqrft +β3bdrms +u 解:(ⅰ)利用HPRICE 1.RAW 中的数据得到方程(8.17)的异方差—稳健的标准误。讨论其与通常的标准误之间是否存在任何重要差异。 ● 先进行一般回归,结果如下: ● 再进行稳健回归,结果如下: 由两个截图可得:price =?21.77+0.00207lotsize +0.123sqrft +13.85bdrms 29.48 0.00064 0.013 (9.01) 37.13 0.00122 0.018 [8.48] n = 88, R 2=0.672 比较稳健标准误和通常标准误,发现lotsize 的稳健标准误是通常下的2倍,使得 t 统计量相差较大。而sqrft 的稳健标准误也比通常的大,但相差不大,bdrms 的稳健标准误比通常的要小些。 (ⅱ)对方程(8.18)重复第(ⅰ)步操作。 n =706,R 2=0.0016
计量经济学 第一章导论 一节什么是计量经济学 统计学,经济学,数学的结合 二节研究步骤 一、模型假定 估计解释变量与被解释变量的关系,设置随机扰动项μ 二、估计参数 通过变量的样本观测值合理的估计总体模型的参数,是计量经济学的核心内容三、模型检验 (1)经济意义检验,检验所估计的模型与经济理论是否相符 (2)统计推断信息,检验参数估计值是否是抽样的偶然结果,需要运用数理统计中统计推断方法对模型及参数的统计可靠性作出说明 (3)计量经济学检验,t检验和F检验 检验模型是否符合计量经济学假定,如多重共线性,随机扰动项的自相关和异方差性 (4)模型预测检验 四、模型应用 三节变量参数数据与模型 一、变量 经济变量:在不同的时间或空间有不同状态,回去不同的数值且可观测 eg.居民家庭收入X和居民消费支出Y 分类: (1)流量与存量(2)解释变量/自变量与被解释变量/因变量(3)内生变量(由模型所决定的变量,是模型求解的结果)和外生变量(由模型以外决定的变量)二、参数的估计
所得到的参数估计值迎“尽可能接近总体参数真实值”原则 三、计量经济学中应用的数据 (1)时间序列数据 (2)截面数据 (3)面板数据 (4)虚拟变量数据 二章简单线性回归模型 一节回归分析与回归函数 一、相关分析与回归分析 (一)经济变量之间的相关关系 经济变量之间有两种关系,一种是确定性的函数关系,另一种是不确定的统计关系,也叫相关关系。 当一个或若干个变量x取一定值时,与之对应的另一个变量Y的值虽然不确定,但按照某种规律在一定范围内变化,称这种变量之间的关系为不确定的统计关系或相关关系。 分类 (1)简单相关关系/多重相关关系 (2)线性相关/非线性相关 (3)正相关/负相关 (4)完全相关/不相关
第八章练习题及参考解答 8.1 Sen 和Srivastava (1971)在研究贫富国之间期望寿命的差异时,利用101个国家的数据,建立了如下的回归模型: 2.409.39ln 3.36((ln 7))i i i i Y X D X =-+-- (4.37) (0.857) (2.42) R 2=0.752 其中:X 是以美元计的人均收入;Y 是以年计的期望寿命; Sen 和Srivastava 认为人均收入的临界值为1097美元(ln10977=),若人均收入超过1097美元,则被认定为富国;若人均收入低于1097美元,被认定为贫穷国。 括号内的数值为对应参数估计值的t-值。 1)解释这些计算结果。 2)回归方程中引入()ln 7i i D X -的原因是什么?如何解释这个回归解释变量? 3)如何对贫穷国进行回归?又如何对富国进行回归? 4)从这个回归结果中可得到的一般结论是什么? 练习题8.1参考解答: 1. 结果解释 依据给定的估计检验结果数据,对数人均收入对期望寿命在统计上并没有显著影响,截距和变量()ln 7i i D X -在统计上对期望寿命有显著影响;同时, ()()2.40 3.3679.39 3.36ln ((ln 7)) 1 2.409.39ln 0 i i i i i i i X D X D Y X D ?-+?+---==? -+=? 富国时 穷国时 表明贫富国之间的期望寿命存在差异。 2. 回归方程中引入()ln 7i i D X -的原因是从截距和斜率两个方面考证收入因素对期望寿命的影响。这个回归解释变量可解释为对期望寿命的影响存在截距差异和斜率差异的共同因素。 3. 对穷国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X αα=+≤,其中,为美元时的寿命; 对富国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X ββ=+>,其中,为美元时的寿命; 4. 一般的结论为富国的期望寿命药高于穷国的期望寿命,并且随着收入的增加,在平均意
第一章 1.计量分析的四个步骤:模型设定——参数估计——模型检验——模型应用 2.计量模型检验:经济意义检验——统计推断检验——计量经济学检验——模型预测检 验 3.计量模型的应用:结构分析——经济预测——政策评价——检验与发展经济理论 4.正确选择解释变量的原则:符合理论、规律——忽略众多次要因素,突出主要经济变 量——数据可得性——每个解释变量之间是独立的 5.参数的数据类型:时间序列数据——截面数据——面板数据——虚拟变量数据 第二章 1.总体相关系数:ρ=Cov(X,Y)/√Var(X)√Var(Y) 2.样本相关系数:rxy=Σ(Xi-X_)(Yi-Y_)/√Σ(Xi-X_)^2√Σ(Yi-Y_)^2 3.总体回归函数中引入随机扰动项的原因:作为未知影响因素的代表——作为无法取得 数据的已知因素代表——作为众多细小影响因素的综合代表——模型的设定误差——变量的观测误差——经济现象的内在随机性 4.简单线性回归模型的基本假定:1、对变量和模型的假定;2、对随机扰动项ui统计分 布的假定(古典假定):零均值假定——同方差假定——无自相关假定——随机扰动项ui与解释变量Xi不相关——正态性假定 5.违反零均值假定:影响截距上的估计(影响小) 6.违反正态性假定:不影响OLS估计是最佳无偏性,但会使t检验F检验失真(影响大) 7.样本回归函数的离差形式:yi^=β2^*xi 8.OLS估计值的离差表达式:β2^=Σ(Xi-X_)(Yi-Y_)/Σ(Xi-X_)^2=Σxiyi/Σxi^2 β1^=Y_-β2^*X_ 9.OLS回归线的性质:样本回归线过(X_,Y_)——估计值均值等于实际值均值——剩余 项ei的均值为零——Cov(Yi^,ei)=0——Cov(Xi,ei)=0 10.β^的评价标准:无偏性——有效性——一致性 11.β^的统计性质:线性——无偏性——有效性 12.Var(^β1)=?^2/Σxi^2——Var(^β2)=ΣXi^2/n*?^2/Σxi^2 13.^?^2=Σei^2/(n-2) 14.总变差平方和:Σ(Yi-Y_)^2=Σyi^2……TSS……n-1 回归平方和:Σ(Yi^-Y_)^2=Σ^yi^2……ESS……k-1 残差平方和:Σ(Yi-Yi^)^2=Σei^2……RSS……n-k 15.可决系数:R^2=ESS/TSS 16.SE(^β1)=√(?^2ΣXi^2)/(nΣxi^2) SE(^β2)=√?^2/Σxi^2 17.t=(^β1-β1)/^SE(^β1)~t(n-2) t=(^β2-β2)/^SE(^β2)~t(n-2) 18.区间估计: 1.当总体方差?^2已知,α=0.1—±1.645,α=0.05—±1.96,α=0.01—± 2.33, P[-tα 第八章 8.1 Sen 和Srivastava (1971)在研究贫富国之间期望寿命的差异时,利用101个国家的数据,建立了如下的回归模型: 2.409.39ln 3.36((ln 7))i i i i Y X D X =-+-- (4.37) (0.857) (2.42) R 2=0.752 其中:X 是以美元计的人均收入;Y 是以年计的期望寿命; Sen 和Srivastava 认为人均收入的临界值为1097美元(ln 10977=),若人均收入超过1097美元,则被认定为富国;若人均收入低于1097美元,被认定为贫穷国。 括号内的数值为对应参数估计值的t-值。 1)解释这些计算结果。 2)回归方程中引入()ln 7i i D X -的原因是什么?如何解释这个回归解释变量? 3)如何对贫穷国进行回归?又如何对富国进行回归? 4)从这个回归结果中可得到的一般结论是什么? 练习题8.1参考解答: 1. 结果解释 依据给定的估计检验结果数据,对数人均收入对期望寿命在统计上并没有显著影响,截距和变量()ln 7i i D X -在统计上对期望寿命有显著影响;同时, ()()2.40 3.3679.39 3.36ln ((ln 7)) 1 2.409.39ln 0 i i i i i i i X D X D Y X D ?-+?+---==?-+=? 富国时 穷国时 表明贫富国之间的期望寿命存在差异。 2. 回归方程中引入()ln 7i i D X -的原因是从截距和斜率两个方面考证收入因素对期望寿命的影响。这个回归解释变量可解释为对期望寿命的影响存在截距差异和斜率差异的共同因素。 3. 对穷国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X αα=+≤,其中,为美元时的寿命; 对富国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X ββ=+>,其中,为美元时的寿命; 4. 一般的结论为富国的期望寿命药高于穷国的期望寿命,并且随着收入的增加,在平均意 第八章 一、名词解释 1、虚拟变量:在建立模型时,有一些影响经济变量的因素无法定量描述,如职业、性别对收入的影响,教育程度,季节因素等往往需要用定性变量度量。为了在模型中反映这类因素的影响,并提高模型的精度,需要将这类变量“量化”。根据这类边另的属性类型,构造仅取“0”或“1”的人工变量,通常称这类变量为“虚拟变量” 2、虚拟变量陷阱:一般在引入虚拟变量时要求如果有m个定性变量,字在模型中引入m-1个虚拟变量。否则,如果引入m个虚拟变量,就会导致模型解释变量间出现完全共线性的情况。我们一般称由于引入虚拟变量个数与定性因素个数相同出现的模型无法估计的问题,称为“虚拟变量陷阱” 二、单项选择题 1、B:“地区”一个,“季节”三个 2、A:将D=1代入估计后的方程即可 3、D:“季节”包含4个类型,只能用3个虚拟变量,用4个虚拟变量会出现完全多重共线的问题,参数将无法估计 4、C:“地区”只有两个类别,引入两个虚拟变量会出现完全多重共线问题 5、A:1α体现了城镇和农村截距上的差异,1β体现了城镇和农村斜率上的差异,当它们为0时,表示无差异 6、A:斜率相同,仅截距不同 7、D:此问题表现为1000前后斜率的变化,B表示截距的变化,不合适;C在D=0时没有解释变量,不正确;A和D相比,D更合适,A会造成曲线在临界值出断开,但D会保证曲线的连贯的。 8、A:虚拟变量表示性别、季节等时,只表示属性的不同,没有等级之分,作为质的因素;表示收入高低时,高与低是有级别的,属于有序数据,可以表示数量的因素。 9、A/B:这题比较牵强,按书上原话应该选择B;但当用加法引入虚拟变量时,会存在问题。【当用加法形式引入虚拟变量时,用一个虚拟变量作为截距项,取值全部为1;其他m-1个表示该因素的前三个类型。如果不引入截距项,当虚拟变量都取0时不能解释该因素第四个类型的作用。】 第二章 简单线性回归模型 2.1 (1) ①首先分析人均寿命与人均GDP 的数量关系,用Eviews 分析: Dependent Variable: Y Method: Least Squares Date: 12/27/14 Time: 21:00 Sample: 1 22 Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134 有上可知,关系式为y=56.64794+0.128360x 1 ②关于人均寿命与成人识字率的关系,用Eviews 分析如下: Dependent Variable: Y Method: Least Squares Date: 11/26/14 Time: 21:10 Sample: 1 22 Included observations: 22 Variable Coefficien t Std. Error t-Statistic Prob. C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 复习题(1)答案 一、 单项选择题 1、全对数模型 u X Y ++=ln ln ln 21ββ 中,参数 2β的含义是( C )。 A. X 对于 Y 的增长率; B. X 对于 Y 的发展速度; C. X 对于 Y 的弹性; D. X 对于 Y 的边际变化; 2、回归分析中的最小二乘法(OLS )准则是( D )。 D. 使 ∑=-n i i i Y Y 1 )?(达到最小值; B. 使 i i Y Y ?min -达到最小值; C. 使 i i Y Y ?max -达到最小值; D. 使 2 1 )?(∑=-n i i i Y Y 达 3、回归模型中具有异方差性时,仍然采用 OLS 估计模型,则以下说法正确的是( A )。 A. 参数估计量无偏、方差非最小; B. 参数估计量无偏、方差最小; C. 常用 F 检验失效; D. 参数的估计量有偏. 4、 在一元线性回归模型中,样本回归方程可表示为( C )。 A . i i i u X Y ++=10ββ B. i i i u X Y E Y +=)|( C. i i X Y 10???ββ+= D. i i X X Y E 10)|(ββ+= 5、 最容易产生异方差的数据为 ( C )。 A. 时序数据; B. 混合数据; C. 截面数据 D. 年度数据 6、 White 检验法可用于检验( A )。 A. 异方差性 B. 多重共线性 C. 序列相关 D. 设定误差 7、在模型 t t t t u X X Y +++=2110ββ的回归分析结果报告中,有F = 263489.23, F 的p 值=0.000 ,则表明( C ) A. 解释变量t X 1对t Y 的影响是显著的; B. 解释变量t X 2对t Y 的影响是显著的; C. 解释变量t X 1和t X 2对t Y 的联合影响是显著的; D. 解释变量t X 1和t X 2对t Y 的影响均不显著; 第八章虚拟变量模型 1. 回归模型中引入虚拟变量的作用是什么? 答:在模型中引入虚拟变量,主要是为了寻找某(些)定性因素对解释变量的影响。加法方式与乘法方式是最主要的引入方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。 2. 虚拟变量有哪几种基本的引入方式? 它们各适用于什么情况? 答:在模型中引入虚拟变量的主要方式有加法方式与乘法方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。 3.什么是虚拟变量陷阱? 答:根据虚拟变量的设置原则,一般情况下,如果定性变量有m个类别,则需在模型中引入m-1个变量。如果引入了m个变量,就会导致模型解释变量出现完全的共线性问题,从而导致模型无法估计。这种由于引入虚拟变量个数与类别个数相等导致的模型无法估计的问题,称为“虚拟变量陷阱”。 4.在一项对北京某大学学生月消费支出的研究中,认为学生的消费支出除受其家庭的每月收入水平外,还受在学校中是否得到奖学金,来自农村还是城市,是经济发达地区还是欠发达地区,以及性别等因素的影响。试设定适当的模型,并导出如下情形下学生消费支出的平均水平: (1) 来自欠发达农村地区的女生,未得到奖学金; (2) 来自欠发达城市地区的男生,得到奖学金; (3) 来自发达地区的农村女生,得到奖学金; (4) 来自发达地区的城市男生,未得到奖学金。 解答: 记学生月消费支出为Y,其家庭月收入水平为X,则在不考虑其他因素的影响时,有如下基本回归模型: Y i=β0+β1X i+μi 有奖学金 1 来自城市 无奖学金0 来自农村 来自发达地区 1 男性 0 来自欠发达地区0 女性 Y i=β0+β1X i+α1D1i+α2D2i+α3D3i+α4D4i+μi 由此回归模型,可得如下各种情形下学生的平均消费支出: (1) 来自欠发达农村地区的女生,未得到奖学金时的月消费支出: E(Y i|= X i, D1i=D2i=D3i=D4i=0)=β0+β1X i (2) 来自欠发达城市地区的男生,得到奖学金时的月消费支出: E(Y i|= X i, D1i=D4i=1,D2i=D3i=0)=(β0+α1+α4)+β1X i计量经济学 (第二版)庞皓 科学出版社 第八章练习题答案
计量经济学习题册第八章、第九章、第十章 答案
计量经济学庞皓第三版课后答案解析
计量经济学(庞皓版)期末考试复习题(1)答案
计量经济学课后习题答案第八章_答案
相关主题
文本预览