
统计整理
3.1 计量数据的频数表与直方图
例3.1 (3-1)
一、指定接受区域直方图
在应用此工具前,用户应先决定分布区间。否则,Excel将用一个大约等于数据集中某数值的平方根作区间,在数据集的最大值与最小值之间用等宽间隔。如果用户自己定义区间,可用2、5或10的倍数,这样易于分析。
对于工资数据,最小值是100,最大值是298。一个紧凑的直方图可从区间100开始,区间宽度用10,最后一区间为300结束,需要21个区间。这里所用的方法在两端加了一个空区间,在低端是区间“100或小于100”,高端是区间“大于300”。
参考图3.3,利用下面这些步骤可得到频率分布和直方图:
1.为了方便,将原始数据拷贝到新工作表“指定频数直方图”中。
2.在B1单元中输入“组距”作为一标记,在B2单元中输入100,B3单元中输入110,选取B2:B3,向下拖动所选区域右下角的+到B22单元。
3.按下列步骤使用“直方图”分析工具:
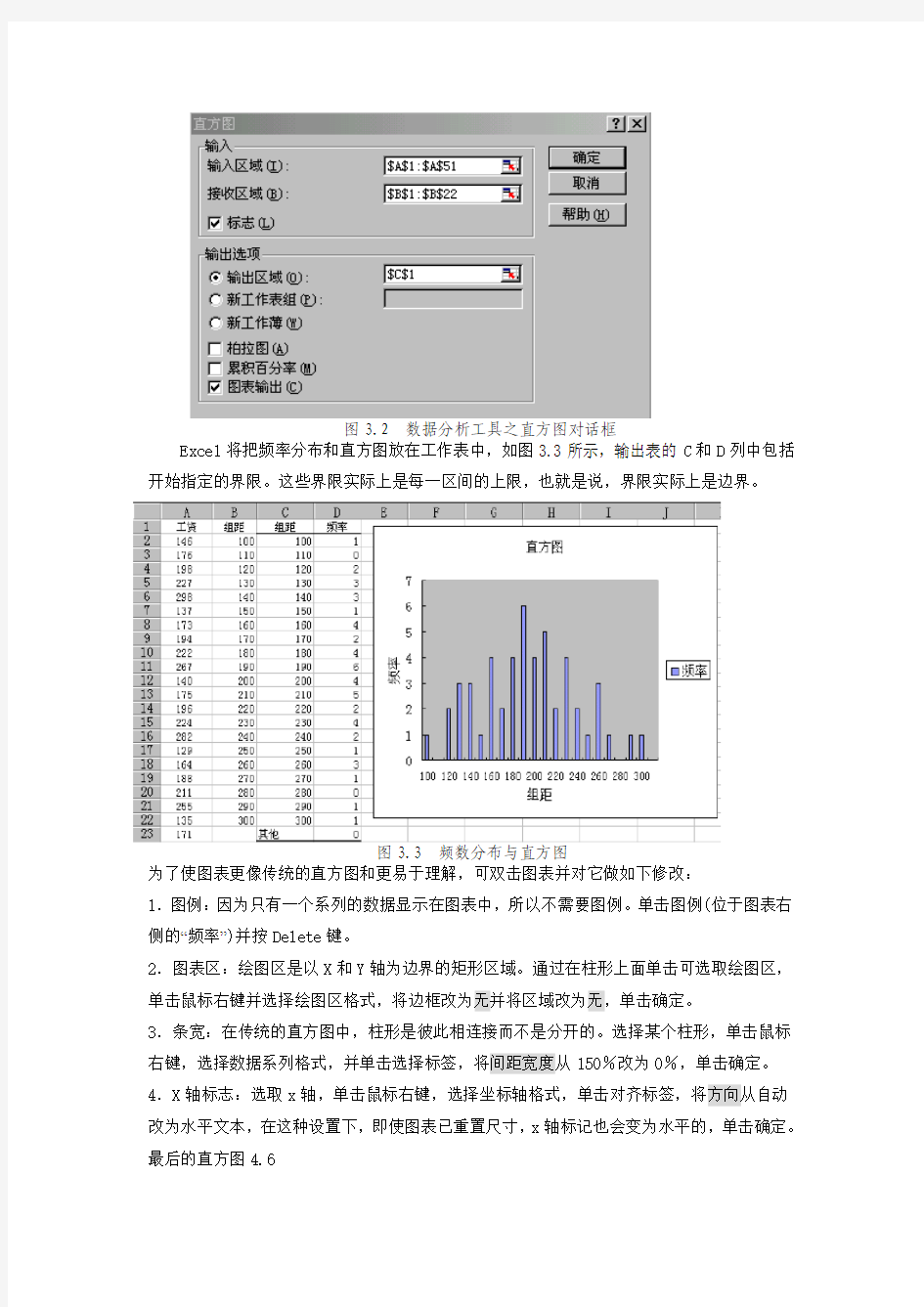
(1)选择工具菜单之数据分析选项, 在分析工具框中“直方图”。如图4所示。
图3.1 数据分析工具之直方图对话框
1) 输入
输入区域:A1:A51
接受区域:B1:B22 (这些区间断点或界限必须按升序排列)
选择标志
2) 输出选项
输出区域: C1
选定图表输出
(2).单击确定,Excel将计算出结果显示在输出区域中。
图3.2 数据分析工具之直方图对话框
Excel将把频率分布和直方图放在工作表中,如图3.3所示,输出表的C和D列中包括开始指定的界限。这些界限实际上是每一区间的上限,也就是说,界限实际上是边界。
图3.3 频数分布与直方图
为了使图表更像传统的直方图和更易于理解,可双击图表并对它做如下修改:
1.图例:因为只有一个系列的数据显示在图表中,所以不需要图例。单击图例(位于图表右侧的“频率”)并按Delete键。
2.图表区:绘图区是以X和Y轴为边界的矩形区域。通过在柱形上面单击可选取绘图区,单击鼠标右键并选择绘图区格式,将边框改为无并将区域改为无,单击确定。
3.条宽:在传统的直方图中,柱形是彼此相连接而不是分开的。选择某个柱形,单击鼠标右键,选择数据系列格式,并单击选择标签,将间距宽度从150%改为0%,单击确定。4.X轴标志:选取x轴,单击鼠标右键,选择坐标轴格式,单击对齐标签,将方向从自动改为水平文本,在这种设置下,即使图表已重置尺寸,x轴标记也会变为水平的,单击确定。最后的直方图4.6
图3.4 修改后的直方图
二、不指定接受区域直方图
在进行探索性分析时,为了方便,通常不指定接受区域作直方图,步骤如下:(1)选择工具菜单之数据分析选项, 在分析工具框中“直方图”。如图4所示。
1) 输入
输入区域:A1:A51
接受区域:(该处为空)
选择标志
2) 输出选项
输出区域: B1
选定图表输出
(2).单击确定,得结果。
(3)按前面方法对直方图进行进一步修饰即得图3.5
图3.5 修改后的直方图
3.2 计数数据的透视表与条图
例3.2(3-3)数据见图
步骤如下:
(1)选择数据菜单之数据透视表和图表报告选项, 如图4所示。
(2).选择数据源区域
(3)选定数据透视表位置,完成
(4)将“性别”作为行字段拖至G列,并将“性别”作为数据拖至数据项处,得下表结果
同理可得“文化程度”的透视表
此时如点击图形按钮,立即得到如下的透视图
(5)将“性别”作为行字段拖至行字段处,并将“文化程度”作为列字段拖至列字段处,将“性别”或“文化程度”作为列字段拖至数据字段处得下表结果
第四章总量指标和相对指标
例4.1 (4-13)
计算步骤:
(1)计算各厂计划完成% E3=D3/C3*100, …
(2)2000年实际产量为1999年的% F3=D3/B3*100, …
第五章平均指标
5.1 简单平均数
例5.1.某组有学生10人统计课考试成绩为65,82,76,80,82,86,84,88,95,98分,试求其平均指标。
平均数的计算步骤如下:
(1)将数据输入到A列,根据Excel提供的公式计算各种平均数
(2)用Ctrl+` 可切换到下面的结果:
5.2 加权平均数
例5.2(5-1)原始数据见下图A-D列,其中A、B列放日产量的下限和上限
平均数的计算步骤如下:
(1)计算日产量的组中值 E3=(A3+B3)/2, …
(2)计算每个组段的总产量 F3=C3*E3, G3=D3*E3, …
(3)计算每月的总产量 F8=SUM(F3:F7), G8=Sum(G3:G7),
(4)计算平均数公式如下:
均数F9=F8/C8 G9=G8/D8
众数F10=A4+(C4-C3)/(C4-C3+C4-C5)*10 G10=A6+(D6-D5)/(D6-D5+D6-D7)*10 中位数F11=A4+(C8/2-A4)/C4*10 G11=A5+(D8/2-C5)/D5*10
第六章变异度指标
6.1 简单变异度指标
例6.1(6-1)
变异度指标的计算步骤如下:
(1)将甲乙两组数据输入到A, B列,根据Excel提供的公式计算各种变异度指标
(2)用Ctrl+` 可切换到下面的公式:
6.2 加权变异度指标
例6.2(6-2)甲品种的原始数据见下图B-C列,乙品种的原始数据见下图G-H列
下面以甲品种的数据计算为例:
(1)计算单产值 D4=C4/B4, …
(2)计算单产均值 D9=C9/B9
(3)计算次数X离差平方 E4=B4*(D4-$D$9)^2 ,…并求和 E9=SUM(E4:E8) (4)计算标准差:D11=SQRT(E9/B9)=68.91
(5)计算变异系数:D12=D11/D9*100=6.9%
同理可得乙品种的标准差为162.71, 变异系数为16.30%
第七章抽样调查
例7.1 (7-5) 期望
求 E(X)的公式 B4=SUM((B1:F1)*(B2:F2)), 由于此处用到数组乘积求和,所以要得到结果,需用Ctrl+Shift+Enter组合键。
例7.2 (7-6) 二项分布
计算公式:
P(5<=x<=10)=P(x<=10)-P(x<5)=P(x<=10)-P(x<=4)
P(x>=9)=1-P(x<9)=1-P(x<=8)
Excel 计算结果:
Excel 计算公式:
(Ctrl+` 互换)
例7.3 (7-6) 泊松分布
计算公式:
P(x>=5)=1-P(x<=4)
Excel 计算结果:
Excel 计算公式:
(Ctrl+` 互换)
例7.4 (7-9) 超几何分布
例7.5 (7-10) 正态分布
其中 F2=1-D2, D4=D3-D2
第八章假设检验
8.1 大样本——使用正态分布的假设检验
例8.1 商店经理想为商店的持信用卡的顾客建一新的付款系统,经过详细的经济分析,她判定如果新系统每月平均利润低于70元的话就不能有效地使用资金。于是随机抽取了200个月的利润,其平均月利润为66元。如果 =0.05,有无充分的证据说明新系统不是一项节省资金的系统?假设总体的标准偏差为30元。
图8.1 正态假设检验的标记和公式---已知均值标准差计算公式
上图所示的工作表可用于正态分布平均值的左尾、右尾和双尾假设检验。检验结果包括基于α判决法和P值报告法。输入样本大小、样本平均值和标准偏差作为值、公式或引用,指定假设的平均值(Mean)和显著水平α作为值。
下面各步骤描述了如何建立该工作表:
(1)打开一新工作表并输入B列所示标记。
(2)要在C列的公式使用B列中的名称,选取单元B4:C12,从插入菜单中选择名称 指定,在指定名称对话框中复选名称创建于最左列,单击确定。
(3)输入C列所示的公式(按图所示键入公式或通过单击适当的已命名的单元插入函数来建立公式)。
(4)要得图8.1的A列所示的外观,按Ctrl+`。
因为经理想知道平均月利润是否小于70元,所以备择假设为Hd:Mean<70,零假设为Ho:Mean>70或简单地为Ho:Mean=70。由于数据已经总结过了,可直接在工作表单元中输入样本大小n、样本平均值、总体的标准偏差、假设总体平均值和显著水平。
图8.2 正态假设检验
结论:得到Z小于-1.886的概率是0.0297。如果零假设为真(每月平均利润为70元),得到样本平均值为66元或小于它的概率约为3%,即有充分的证据说明新系统是一项节省资金的系统。
8.2 小样本——使t分布的假设检验
家保险公司用代理的方式支付其客户,赔偿假定每年的平均代理赔偿费用为32000元,如果平均支付费用与计划不同,就需要对计划进行修改。对一个有36个代理的样本,上一年的平均支付费用为27500元,标准偏差为8400元,如果整个公司的平均支付变化与该样本的情况不同,那么可用管理计划来修改赔偿计划。根据这一结果的P值,这一样本能充分说明平均值变化了吗?
本例已知均值标准差,下面各步骤描述了如何建立计算工作表:
1.打开一新工作表,输入A列所示标记。
2.要在C列的公式使用B列中的名称,选取单元B4:C13,从插入菜单中选择名称 指定,在指定名称对话框中复选名称创建于最左列,单击确定。
图8.3 已知均值标准差计算公式---t假设检验的标记和公式
因为经理想知道平均支付是否发生了变化(不用指出变化的方向),所以备择假设为H1:Mean≠32000,零假设为Ho:Mean=32000。由于数据已经总结过了,可以直接向工作表的单元中输入样本大小n、样本平均值、总体的标准偏差和假设总体的平均值。尽管例中未指明显著水平可输入为0.05。
结论:由于P=0.0028<0.05,所以,有足够的理由拒绝在显著水平为5%(双尾检验)时的零假设,可得出如下结论:平均支付值不等于32000,明确说明平均值改变了。
图8.4 t假设检验
例8.3(已知原始数据)一家制造商生产钢棒,为了提高质量,如果某新的生产工艺生产出的钢棒的断裂强度大于现有平均断裂强度标准的话,公司将采用该工艺。当肪钢棒的平均断裂强度标准是500公斤。对新工艺生产的钢捧进行抽样,12件棒材的断裂强度如下:502,496,510,508,506,498,512,497,515,503,510和506,假设断裂强度的分布比较近似于正态分布,将样本数据画图,所画图形能表明平均断裂强度有所提高吗?
图8.5显示了假设检验所需的数据。因为经理想检查是否有提高,备择假设为H1:Mean >500,所以用右尾检验比较合适。零假设为Ho:Mean<500,或简单地Ho:Mean=500。如例8.2所述,D2:D13单元已命名为Data,单元B5:B7包含了公式COUNT(Data), AVERAGE(Data)和STDEV(Data)。尽管例5.5未指定一显著水平, 在B10单元中入了显著水平为0.05。包含了左尾检验结果的15到18行被隐藏。
图8.5 小样本t假设检验公式
结论:P=0.0131<0.05,说明有充分证据来拒绝零假设。可得出如下结论:新工艺在统计上可带来平均断裂强度的显著提高。
图8.6 小样本t假设检验结果
第九章相关与回归
简单线性相关分析
例9.1 (9-1)
1.Excel进行相关分析:
(1)输数据: 将数据输入A1:C9单元格。
(2)绘制散点图:
图9.1 简单相关系数及散点图
3. 计算相关系数
(1)选择工具菜单之数据分析选项, 在分析工具框中“相关系数”。
相关系数对话框将显示为图9.2所示,它带输入输出的提示。
图9.2 相关系数对话框
1) 输入
输入区域:B1:C9
分组方式:逐列
选择标志位于第一行
2) 输出选项
输出区域: A13
(2).单击确定,Excel将计算出结果显示在输出区域中。
4. 相关系数假设检验
(1)在单元格F14中输入公式 =B15/SQRT((1-B15^2)/(8-2)) 计算得相关系数的t值
为49.46
(2)在单元格F15中输入公式 =TDIST(ABS(F14),B-2,2) 计算得 p=0.0001
(3) 结论: 由于r=-0.9689, 且p<0.05, 所以, 在0.05水平上拒绝原假设, 认为产品
产量与单位成本间有负的线性相关关系
9.2简单回归分析
上面的简单相关分析只是说明两变量之间的线性关系密切的程度,如果要建立它们之间
线性依存的关系式,就需用回归分析。可按下列步骤使用“回归”分析工具:
1. 输数据: 将数据输入A1:C9单元格。
2. 回归分析:
(1) 选择工具菜单之数据分析选项, 在分析工具框中“回归”。回归对话框将显示为图
9.3所示,
图9.3 回归分析对话框
1) 输入
Y值输入区域:C1:C9
X值输入区域:B1:B9
标志: 选择
常数为零: 只有当用户想强制使回归线通过原点(0,0)时才选此框
置信度: Excel自动包括了回归系数的95%置信区间。要使用其他置信区间, 选择该框并在Confidence Levet框中输入置信水平
2) 输出选项
输出区域: D1
3) 残差
残差(R):选择此框可得到预测值和残差(Residual)。
残差图(D): 选择此框可得到残差和每一x值的图表。
标准残差(T):选择此框可得到标准化的残差,每一残差被估计标准误差除)。这一输
出可使曲线较容易分层。
线性拟合图(I):选择此框可得到一含有y输入数据和拟合的y值的散点图。
4) 正态概率图: 绘制因变量的正态概率图
(2).单击确定,Excel将计算出结果显示在输出区域中。
图9.4 回归分析结果
3. 回归解释
拟合回归线的截距和斜率放在图9.4的总结输出中标记有“Coeffients’’的左下部。截距系数77.30769是线性回归方程中的常数项,x系数-0.80769是斜率。回归方程是:
y=77.30769-0.80769 * x
图9.5 残差及拟合线
在图9.5所示的残差输出中,预测 y,有时又称拟合值,是用这个回归方程计算的单位成本的估计值。残差是实际值和拟合值之间的差值。
回答“拟合关系怎么样”问题的最通用的四个方法是标准误差,R2,t统计值和方差分析。标准误差0.83205显示在图9.4的单元E7中。作为残数的标准偏差,它衡量单位成本在回归线周围的分散情况,标准误差通常称为估计标准误差。
R2(R Square),如图9.4的单元E5所示,衡量用回归线解释的因变量变化的比例。这一比例必击是0和1之间的一个数据,经常以百分数表示。这里,约有的94%的单位成本的变化是在线性方程中用产品产量做为预测因子来解释的。单元E6显示的Adjusted R square在用附加解释变量把此模型和其他模型比较时很有用。
第十章时间序列分析指标
例10.1 (10-2) 1995-2000的销售额见下图B列,则其速度分析指标计算如下:
Excel计算公式如下:
(Ctrl+` 切换)
例10.2 (10-3)
计算步骤:
(1)各季平均每月总产值计算公式
说明单元格公式
一季B16 = A VERAGE(B2:B4)
二季B17 = A VERAGE(B5:B7)
三季B18 = A VERAGE(B8:B10)
四季B19 = A VERAGE(B11:B13)
全年B20 = A VERAGE(B2:B13)
(2)全年平均职工人数:
C16 = (C2/2+C3+C4+C5+C6+C7+C8+C9+C10+C11+C12+C13+C14/2)/13
(3)月平均劳动生产率:C17 =B20/C16*10000
年平均劳动生产率:C18 =SUM(B2:B13)/C16*10000
(4)全年职工构成指标:
C19 = (D2/2+D3+D4+D5+D6+D7+D8+D9+D10+D11+D12+D13+D14/2)/
(C2/2+C3+C4+C5+C6+C7+C8+C9+C10+C11+C12+C13+C14/2)*100
例10.3 (10-5)
计算步骤:
(1)计算每年的增长速度A2=1+A1/100, …
(2)5年平均增长速度F3 = (PRODUCT(A2:E2)^(1/5)-1)*100
(3)国民生产总值翻两翻需要时间F4 = LOG(4,10)/LOG(1+F3/100,10)
第十一章时间数列预测方法
例11.1 (11-1)
(1)计算按5日扩大时距的时间数列和计算按5日平均日产量的时间数列,结果如下表
Excel计算公式
使用Excel可以完成很多专业软件才能完成的数据统计、分析工作,比如:直方图、相关系数、协方差、各种概率分布、抽样与动态模拟、总体均值判断,均值推断、线性、非线性回归、多元回归分析、时间序列等。本专题将教您完成几种最常用的专业数据分析工作。 注意:所有操作将通过Excel“分析数据库”工具完成,如果您没有安装这项功能,请依次选择“工具”-“加载宏”,在安装光盘中加载“分析数据库”。加载成功后,可以在“工具”下拉菜单中看到“数据分析”选项。 直方图 某班进行期中考试后,需要统计各分数段人数,并给出频数分布和累计频数表的直方图以供分析。 以往手工分析的步骤是先将各分数段的人数分别统计出来制成一张新的表格,再以此表格为基础建立数据统计直方图。使用Excel可以直接完成此任务。 [具体方法] 描述统计 某班进行期中考试后,需要统计成绩的平均值、区间,并给出班级内部学生成绩差异的量化标准,借此来作为解决班与班之间学生成绩的参差不齐的依据。要求得到标准差等统计数值。 样本数据分布区间、标准差等都是描述样本数据范围及波动大小的统计量,统计标准差需要得到样本均值,计算较为繁琐。这些都是描述样本数据的常用变量,使用Excel 数据分析中的“描述统计”即可一次完成。[具体方法] 排位与百分比排位 某班级期中考试进行后,按照要求仅公布成绩,但学生及家长要求知道排名。故欲公布成绩排名,学生可以通过成绩查询到自己的排名,并同时得到该成绩位于班级百分比排名(即该同学是排名位于前“X%”的学生)。 排序操作是Excel的基本操作, Excel“数据分析”中的“排位与百分比排位”可以使这个工作简化,直接输出报表。[具体方法]
1-1 土地面积、人口密度、户数、人口数 1-5 国民经济和社会发展总量指标
从业人员数 406.12 407.3 412 417.5 421.8 429.6 #职工人数 180.39 171.67 169.04 173.06 169.78 165.78 宏观经济 国民核算 生产总值(亿元) 1335.4 1467.8 1622.18 1882.2 4 2238.23 2590.75 第一产业 85 90.4 95.13 102.23 109.57 115.91 第二产业 582.4 635.5 701.87 825.78 1019.26 1195.74 工 业 472.6 514 567.89 680.13 852.53 1000.74 建筑业 109.8 121.5 133.98 145.65 166.73 195 第三产业 668 741.9 825.18 954.23 1109.4 1279.1 物价指数(上年=100) 商品零售价格总指数 96 97.7 100.4 101 100.9 100.7 居民消费价格总指数 99.5 98.6 102.3 103.3 102.7 101.4 工 业 工业总产值 (亿元) 1611.76 1769.93 1994.9 2402.3 4 2674.41 3162.06 主要工业产品产量 纱 (吨) 80302 90250 96694 96385 92893 89697 布(万米) 18852 27694 31472.6 5 3346 6 33625 50563 原油加工量(万吨) 256 274.48 285.41 370.85 396.2 403.66 合成洗涤剂 (吨) 15224 17888 7179 317 化学原料药 (吨) 3956 6145 6378 4846 5395 5183 中成药 (吨) 7487 8756 8208 7710 11852 10022 通讯电缆(万对公里) 330.52 74.37 48.26 78.83 68.93 47.79 家用洗衣机 (台) 26.39 28.27 22.93 12.22 6.43 房间空调器 (万台) 96.99 74.22 97.32 177.91 239.94 342.08 手 机 (部) 17.22 33.97 163.83 182.6 248.49 107.63 钢 (万吨) 713.11 761.14 850.3 925.71 1062.89 1125.33 生 铁 (万吨) 675.06 725.77 802.13 886.11 1015.49 1100.25 成品钢材 (万吨) 593.97 613.94 699.84 850.7 963.91 1010.8 汽 车 (辆) 58884 90303 112322 103258 167853 268056 国有及年销售收入在500万元以上的非国有企 固定资产原价 (亿元) 1117.5 1 1146.5 1207.58 固定资产净值年平均余额(亿元) 719.74 712.91 722.11 786.5 1156.16 1168.75 利润总额 (亿元) 66.97 64.79 77.13 115.91 128.1 149.11 农 业 年末耕地面积 (千公顷) 216.1 214.95 205.78 206.06 207.74 210.4 农林牧渔业劳动力(万人) 78.06 77.78 73.2 71.73 70.08 69.87
Excel工作表数据汇总 一、复制一张工作表并清空数据,作为汇总统计表,在要统计的第一个单元格内输入: =SUM('路径1[工作簿名1]工作表名1'!单元格名1+'路径1[工作簿名1]工作表名1'!单元格名1+……) 有多少张表,就得输入多少个'路径[工作簿名]工作表名'!单元格名。第一个单元格输好后,其它单元格用填充柄拉一下就可。 二、将所有要统计的工作表都使用“编辑”中的“移动或复制工作表”的命令复制到一个工作簿中,复制一张工作表并清空数据,作为汇总统计表,选中汇总统计表中要汇总的第一个单元格并点一下工具栏上的自动求和图标,选择要统计的第一张工作表,按住Shift键选择最后一张工作表,然后选择要统计的最后一张工作表中的第一个单元格并回车,怎么样,一个单元格的汇总数据出来了吧,其它单元格用填充柄拉一下就可。 三、把所有要统计的工作簿都打开,如果你用WINXP的话,最好右键点一下最下面的任务栏,在属性中选择“分组相似任务栏按钮”,以免工作簿太多找不到。复制一张工作表并清空数据,作为汇总统计表,选中汇总统计表中要统计的区块,在数据菜单中选择“合并计算”,点引用位置右边的那个小方框图标,选择表一的数据区域,点添加,然后再点应用位置右边的那个小方框图标,选择表二的数据区域,点添加,重复以上过程,最后点确定即可统计出结果。引用位置添加时
可用快捷键ALT+A来加快添加速度,如果选中“创建连至源数据的链接”则源数据更新,汇总数据也更新。 四、在网上搜寻EXCEL文件累加器或Excel报表汇总助手等小工具,利用它进行汇总。 比较一下: 第一种方法适合输入速度较快的人,优点是不打开所有工作表也能汇总,缺点是容易输错,且烦琐; 第二种方法适合于在同一工作簿的多工作表统计,如不在同一工作表内,需要复制到同一工作簿中,复制的过程比较麻烦; 第三种方法比较方便,汇总的速度也比较快,要鼠标就能完成,除进行相同格式的工作表汇总外,还可以通过分类来合并计算数据(方法和通过位置来合并计算数据类似,但要连分类一起选择并标志分类标签位置),推荐这一方法,缺点是所有工作簿都要打开,当工作簿有几百张时容易影响速度; 第四种方法优点是速度快且不用打开所有的工作表,不过要借用工具,很多工具都要注册才能使用,而且要先制作一个统计模板,适合工作表数量特别多时的统计。
长三角地区二省一市统计年鉴在线浏览网站汇总 浙江省: 浙江统计年鉴2004-2009 https://www.doczj.com/doc/bb13449339.html,/col/col1321/index.html 杭州统计年鉴2001-2009 https://www.doczj.com/doc/bb13449339.html, 宁波统计年鉴2003-2009https://www.doczj.com/doc/bb13449339.html,/tjnj/2004njbg.htm 嘉兴统计年鉴1997-2008 https://www.doczj.com/doc/bb13449339.html,/tjnj/Def.asp?cdate=2008 湖州统计年鉴2003-2008 https://www.doczj.com/doc/bb13449339.html,/default.asp 绍兴年鉴2000-2008 https://www.doczj.com/doc/bb13449339.html,/main/zjsx.jsp?catalog_id=20090318000002 舟山统计年鉴2002-2008 https://www.doczj.com/doc/bb13449339.html,/info/tjnj/Category.aspx 台州统计年鉴2000-2007 https://www.doczj.com/doc/bb13449339.html,/tjnj.asp# 上海市: 上海统计年鉴2010年的官方网址: https://www.doczj.com/doc/bb13449339.html,/2004shtj/tjnj/tjnj2010.htm 江苏省: 江苏统计局:https://www.doczj.com/doc/bb13449339.html,/jstj/tjsj/tjnj/ 南京统计年鉴(1949-2009):https://www.doczj.com/doc/bb13449339.html,/2004/ 无锡统计年鉴(2000-2009):https://www.doczj.com/doc/bb13449339.html,/tjxx/tjsj/tjnj/index.shtml 常州统计数据:https://www.doczj.com/doc/bb13449339.html,/node/TongjiShuju/index.html 苏州统计年鉴(2002-2009):https://www.doczj.com/doc/bb13449339.html,/Info.asp?ParentID=64 南通统计年鉴(暂缺) 扬州统计年鉴(2003-2009):https://www.doczj.com/doc/bb13449339.html,/dzkw/index.asp 镇江统计数据:https://www.doczj.com/doc/bb13449339.html,/tjzl/ 泰州统计数据(2003-2010):https://www.doczj.com/doc/bb13449339.html,/web/index.php?cat=2502 本文来自: 人大经济论坛数据交流中心版,详细出处参考:https://www.doczj.com/doc/bb13449339.html,/bbs/viewthread.php?tid=881273&page=1&fromuid=765815
EXCEL中常用函数及使用方法 Excel函数一共有11类:数据库函数、日期与时间函数、工程函数、财务函数、信息函数、逻辑函数、查询和引用函数、数学和三角函数、统计函数、文本函数以及用户自定义函数。 1.数据库函数 当需要分析数据清单中的数值是否符合特定条件时,可以使用数据库工作表函数。例如,在一个包含销售信息的数据清单中,可以计算出所有销售数值大于1,000 且小于2,500 的行或记录的总数。Microsoft Excel 共有12 个工作表函数用于对存储在数据清单或数据库中的数据进行分析,这些函数的统一名称为Dfunctions,也称为D 函数,每个函数均有三个相同的参数:database、field 和criteria。这些参数指向数据库函数所使用的工作表区域。其中参数database 为工作表上包含数据清单的区域。参数field 为需要汇总的列的标志。参数criteria 为工作表上包含指定条件的区域。 2.日期与时间函数 通过日期与时间函数,可以在公式中分析和处理日期值和时间值。 3.工程函数 工程工作表函数用于工程分析。这类函数中的大多数可分为三种类型:对复数进行处理的函数、在不同的数字系统(如十进制系统、十六进制系统、八进制系统和二进制系统)间进行数值转换的函数、在不同的度量系统中进行数值转换的函数。 4.财务函数 财务函数可以进行一般的财务计算,如确定贷款的支付额、投资的未来值或净现值,以及债券或息票的价值。财务函数中常见的参数: 未来值(fv)--在所有付款发生后的投资或贷款的价值。 期间数(nper)--投资的总支付期间数。 付款(pmt)--对于一项投资或贷款的定期支付数额。 现值(pv)--在投资期初的投资或贷款的价值。例如,贷款的现值为所借入的本金数额。 利率(rate)--投资或贷款的利率或贴现率。 类型(type)--付款期间内进行支付的间隔,如在月初或月末。 5.信息函数 可以使用信息工作表函数确定存储在单元格中的数据的类型。信息函数包含一组称为IS 的工作表函数,在单元格满足条件时返回TRUE。例如,如果单元格包含一个偶数值,ISEVEN 工作表函数返回TRUE。如果需要确定某个单元格区域中是否存在空白单元格,可以使用COUNTBLANK 工作表函数对单元格区域中的空白单元格进行计数,或者使用ISBLANK 工作表函数确定区域中的某个单元格是否为空。 6.逻辑函数 使用逻辑函数可以进行真假值判断,或者进行复合检验。例如,可以使用IF 函数确定条件为真还是假,并由此返回不同的数值。
EXCEL电子表格中四个常用函数的用法 (2010-01-16 09:59:27) 转载▼ 分类:Excel学习 标签: 杂谈 EXCEL电子表格中四个常用函数的用 法 现在介绍四个常用函数的用法:COUNT(用于计算单元格区域中数字值的个数)、COUNTA(用于计算单元格区域中非空白单元格的个数)、COUNTBLANK(用于计算单元格区域中空白单元格的个数)、COUNTIF(用于计算符合一定条件的COUNTBLANK单元格个数)。 结合例子将具体介绍:如何利用函数COUNTA统计本班应考人数(总人数)、利用函数COUNT统计实际参加考试人数、利用函数COUNTBLANK统计各科缺考人数、利用函数COUNTIF统计各科各分数段的人数。首先,在上期最后形成的表格的最后添加一些字段名和合并一些单元格,见图1。 一、利用函数COUNTA统计本班的应考人数(总人数) 因为函数COUNTA可以计算出非空单元格的个数,所以我们在利用此函数时,选取本班学生名字所在单元格区域(B3~B12)作为统计对象,就可计算出本班的应考人数(总人数)。 1.选取存放本班总人数的单元格,此单元格是一个经过合并后的大单元格(C18~G18); 2.选取函数;单击菜单“插入/函数”或工具栏中的函数按钮f*,打开“粘贴函数”对话框,在“函数分类”列表中选择函数类别“统计”,然后在“函数名”列表中选择需要的函数“COUNTA”,按“确定”按钮退出“粘贴函数”对话框。 3.选取需要统计的单元格区域;在打开的“函数向导”对话框中,选取需要计算的单元格区域B3~B13,按下回车键以确认选取;“函数向导”对话框图再次出现在屏幕上,按下“确定”按钮,就可以看到计算出来本班的应考人数(总人数)了。
计算机等级考试 =公式名称(参数1,参数2,。。。。。) =sum(计算范围) =average(计算范围) =sumifs(求和范围,条件范围1,符合条件1,条件范围2,符合条件2,。。。。。。) =vlookup(翻译对象,到哪里翻译,显示哪一种,精确匹配) =rank(对谁排名,在哪个范围里排名) =max(范围) =min(范围) =index(列范围,数字) =match(查询对象,范围,0) =mid(要截取的对象,从第几个开始,截取几个) =int(数字) =weekday(日期,2) =if(谁符合什么条件,符合条件显示的内容,不符合条件显示的内容) =if(谁符合什么条件,符合条件显示的内容,if(谁符合什么条件,符合条件显示的内容,不符合条件显示的内容)) EXCEL的常用计算公式大全 一、单组数据加减乘除运算: ①单组数据求加和公式:=(A1+B1) 举例:单元格A1:B1区域依次输入了数据10和5,计算:在C1中输入=A1+B1 后点击键盘“Enter(确定)”键后,该单元格就自动显示10与5的和15。 ②单组数据求减差公式:=(A1-B1) 举例:在C1中输入=A1-B1即求10与5的差值5,电脑操作方法同上; ③单组数据求乘法公式:=(A1*B1) 举例:在C1中输入=A1*B1即求10与5的积值50,电脑操作方法同上; ④单组数据求乘法公式:=(A1/B1) 举例:在C1中输入=A1/B1即求10与5的商值2,电脑操作方法同上; ⑤其它应用: 在D1中输入=A1^3即求5的立方(三次方); 在E1中输入=B1^(1/3)即求10的立方根 小结:在单元格输入的含等号的运算式,Excel中称之为公式,都是数学里面的基本 运算,只不过在计算机上有的运算符号发生了改变——“×”与“*”同、“÷”与 “/”同、“^”与“乘方”相同,开方作为乘方的逆运算,把乘方中和指数使用成分数 就成了数的开方运算。这些符号是按住电脑键盘“Shift”键同时按住键盘第二排 相对应的数字符号即可显示。如果同一列的其它单元格都需利用刚才的公式计算,只 需要先用鼠标左键点击一下刚才已做好公式的单元格,将鼠标移至该单元格的右下 角,带出现十字符号提示时,开始按住鼠标左键不动一直沿着该单元格依次往下拉到 你需要的某行同一列的单元格下即可,即可完成公司自动复制,自动计算。
2012年太原市统计年鉴 2012年,面对复杂严峻的宏观经济形势,市委、市政府带领全市人民,认真贯彻落实中央和省委、省政府的各项决策部署,坚持科学发展主题、加快转变经济发展方式主线和“稳中求进”总基调,抓投资、稳增长、调结构、促转型、惠民生,对标一流、攻坚克难,努力推动经济社会发展,建设一流省会城市迈出了坚实步伐,为全面建成小康社会奠定了良好基础。 一、综合 经济增长:初步统计,全市实现地区生产总值(GDP)2311.43亿元,比上年增长10.5%。其中:第一产业增加值36.02亿元,增长5.2%;第二产业增加值1035.57亿元,增长9.7%;第三产业增加值1239.84亿元,增长11.3%。第三产业中,交通运输、仓储和邮政业增加值168.44亿元,增长7.6%;批发零售及住宿餐饮业增加值430.13亿元,增长14.8%;金融保险业增加值241.22亿元,增长14.4%。 人均地区生产总值54440元,比上年增长9.8%,按2012年平均汇率计算达到8624美元。 产业结构:三次产业比重为1.6%、44.8%、53.6%,分别拉动经济增长0.1、4.4和6.0个百分点。与上年相比,第一产业比重持平,第二产业比重下降0.8 个百分点,第三产业比重提高0.8个百分点。
财政:全市财政总收入454.49亿元,比上年增长15.6%。其中:市级财政 完成246.16亿元,增长18.2%;县(区)级财政完成208.33亿元,增长12.7%。 全市一般预算收入215.67亿元,增长23.4%。其中:税收收入172.38亿元,增长21.7%,国内增值税、营业税、企业所得税、个人所得税、资源税共计完成税收112.20亿元。 全年一般预算支出277.51亿元,比上年增长16.0%。其中:一般公共服务 支出增长7.3%,教育支出增长22.9%,科学技术支出增长23.1%,文化体育与传媒支出增长17.1%,社会保障和就业支出增长4.0%,医疗卫生支出增长21.9%,节能环保支出增长106.5%,农林水事务支出增长65.9%,城乡社区事务支出下降5.4%。 物价:居民消费价格总水平比上年上涨2.1%。其中:食品价格上涨3.8%,非食品价格上涨1.4%;消费品价格上涨1.8%,服务项目价格上涨2.7%。商品零售价格上涨1.2%。工业生产者出厂价格下降8.1%。工业生产者购进价格下降4.4%。
统计分析方法常用的(功能)函数(包括统计处理、统计分布) 一、加载分析工具库,工具—>数据分析 抽样 随机数发生器 z-检验---双样本均值差检验 t-检验---双样本等方差检验 t-检验--双样本异方差检验 t-检验—平均值得成对二样本检验 F-检验—双样本方差 方差分析:单因素方差分析 方差分析:可重复双因素方差分析 方差分析:无重复双因素方差分析 相关系数 协方差 回归 移动平均 指数平滑 二、统计函数 算术平均AVERAGE (number1,number2,…) 求和SUM(number) 几何平均GEOMEAN (number1,number2,…) 调和平均HARMEAN(number1,number2,…) 计算众数MODE (number1,number2,…) 中位数MEDIAN (number1,number2,…) 方差V AR (number1,number2,…) 标准差STDEV (number1,number2,…) 计算数据的偏度SKEW (number1,number2,…) 计算数据的峰度KURT (number1,number2,…) 频数统计COUNTIF(range,criteria) 组距式分组的频数统计FREQUENCY(data_array,bins_array) 随机实数RAND() 区间的随机整数RANDBETWEEN (a,b) 二项分布的概率值BINOMDIST(number_s,trials,probability_s,cumulative) 泊松分布的概率值POISSON(x,mean,cumulative) 正态分布的概率值NORMDIST(x,mean,standard_dev,cumulative) 计算正态分布的P值NORMSDIST(z)
工作中最常用的excel函数公式大全 一、数字处理 1、取绝对值 =ABS(数字) 2、取整 =INT(数字) 3、四舍五入 =ROUND(数字,小数位数) 二、判断公式 1、把公式产生的错误值显示为空 公式:C2 =IFERROR(A2/B2,"") 说明:如果是错误值则显示为空,否则正常显示。
2、IF多条件判断返回值 公式:C2 =IF(AND(A2<500,B2="未到期"),"补款","") 说明:两个条件同时成立用AND,任一个成立用OR函数。 三、统计公式 1、统计两个表格重复的内容 公式:B2
=COUNTIF(Sheet15!A:A,A2) 说明:如果返回值大于0说明在另一个表中存在,0则不存在。 2、统计不重复的总人数 公式:C2 =SUMPRODUCT(1/COUNTIF(A2:A8,A2:A8)) 说明:用COUNTIF统计出每人的出现次数,用1除的方式把出现次数变成分母,然后相加。
四、求和公式 1、隔列求和 公式:H3 =SUMIF($A$2:$G$2,H$2,A3:G3) 或 =SUMPRODUCT((MOD(COLUMN(B3:G3),2)=0)*B3:G3) 说明:如果标题行没有规则用第2个公式
2、单条件求和 公式:F2 =SUMIF(A:A,E2,C:C) 说明:SUMIF函数的基本用法 3、单条件模糊求和
公式:详见下图 说明:如果需要进行模糊求和,就需要掌握通配符的使用,其中星号是表示任意多个字符,如"*A*"就表示a前和后有任意多个字符,即包含A。 4、多条件模糊求和 公式:C11 =SUMIFS(C2:C7,A2:A7,A11&"*",B2:B7,B11) 说明:在sumifs中可以使用通配符*
Excel统计指定内容出现次数 excel中数据较多且某一数据重复出现的情况下,需要统计它出现的次数,可以用到countif函数直接求解,本文就通过该函数来统计某一出现次数。 方法/步骤 1.语法: countif(range,criteria) 其中range 表示要计算非空单元格数目的区域 其中criteria 表示以数字、表达式或文本形式定义的条件 2.以这个例子说明怎么统计其中“赵四”出现的次数。 3.在E2单元格中输入=COUNTIF(A2:A14,"赵四"),其中A2:A14表示统计的区域,后面赵四需要带 引号,表示要统计的条件。 4.回车以后得到结果是3,与前面区域中的数量是一致的。
注意事项:countif函数中"赵四"引号是半角状态下,否则函数错误。 2. =COUNTIF(B:B,C1) 假设查找A列不同数据 1、按A列进行复制,字体统一,排序 2、将B1复制到C1,C2=IF(B2=B1,"",B2),复制下拉,可列出B列中所有不同的数据 3、把C列的数据通过选择性粘贴,把公式转为数据 4、按C列进行排序,罗列出所有不同的数据。 5、再通过CountIf()函数,如: D1=Countif(B1:B100,"="&C1)求B1:B100中出现"C1"单元格所含数据的个数, 再将D1的公式复制下拉。 (如果要使统计数据区复制时不变可表为:B$1:B$100) 6.按出现次数排序,下边“3.排序”所述(第一行不能放待排序内容) 3.排序 2、填入数据 为了好演示,这里小编填入4行数据,标题和记录,如下图所示。
3、选择一行数据 先选排序数据,排序的时候必须要指定排序的单元格了。如下图所示,选定所有数据。 4、打开排序对话框 点击菜单栏的“数据”,选择排序子菜单,如下图所示。 5、选择排序方式 在打开的排序对话框中,选择排序方式。例如我选择按照语文降序,数学降序,如下图所示。 主要关键字是语文,次要关键字是数学,都是降序! 6、排序结果 排序结果如下,王五语文最高,所有排到第一了。张三虽然数学最高,但是数学是第二排序关键字,因他语文最低,所以排第三了。如下图所示。
Excel表格不同类型数据的计算方法 在许多具有数值计算的表格中,计算合计项容易实现;但要分类计算统计,即求得分类相同项的小计就比较麻烦;如下表中,如果想统计分项各种车型的数量(费用)、各公司的费用使用手工排序方法可以计算,如果表格有上成百上千项工作量就非常大。下面介绍一种通过表格公式可以轻松实现分项统计的方法。 一、排序,按我们需要统计的项进行;如果需要统计不同车型数据,用鼠标将表格全选,点击菜单“数据”-“排序”,排序选择“车型”或“C列”,默认升序。相同车型即排列在一起。
二、在表格右侧增加两列,车型和数量,在其下单元格输入公式。 1、车型列用来判断有什么车型,每种车型只显示一次;判断下一个车型是否变化,不变显示值为空字符(无显示);值不同(有变化)则显示本行对应C列车型。I3单元格中输入公式: =IF(C3<>C4,C3,""),并下拉公式至表格最后一行,见下表: 2、数量列用来计算每一种车型的数量,并且显示在车型单元格的对应行中,每种车型也只显示一次,并且在没有车型显示的单元格中显示为空字符; 在J3单元格中输入公式: =IF(I3<>"",SUM(INDIRECT("E"&ROW()):INDIRECT("E"&(ROW()+1-COUN
TIF(C$3:C3,C3)))),"")并下拉至表格底部行;公式解释:首先判断左单元格I列车型是否为空字符值,如果是,不显示任何值,否则计算这种车型E列数量的和值(公式中sum()项);公式中: INDIRECT("E"&ROW()):INDIRECT("E"&(ROW()+1-COUNTIF(C$3:C3,C3)) ))相当于“Em:En”—单元格区域,同一车型的数量值(E列)的单元格区域。 函数解释:INDIRECT()为单元格引用函数,对于一些变化的单元格(非固定值,可以使用计算得到);INDIRECT("E"&ROW())表示公式所在行的E列对应单元格。COUNTIF(C$3:C3,C3)))),"")函数用来计算单元格区域中包含某个值的个数,本式中表示计算从C3到本行C 列单元格区域中包含本行C列单元格(车型)的单元格数量。IF(x,y,n)函数为条件判断函数,x项为条件,为真(条件成立)时值为y,为假(条件不成立)时值为n。 3、将I列车型和J列数量下的所有单元格复制,使用选择粘贴数值的方法,粘在新表或原来表格的下方,选择刚粘贴的所有数据行,按车型列、降序排序,车型和数量则排列在一起,见下图:
1Excel 统计函数一览表 函数名称函数功能 AVEDEV 返回一组数据与其均值的绝对偏差的平均值,用于评测这组数据的离散度。 AVERAGE 返回指定序列算术平均值。 AVERAGEA 计算参数清单中数值的算数平均值。不仅数字,而且文本和逻辑值(如TRUE 和FALSE)也将计算在内。 BETADIST 返回Beta 分布累积函数的函数值。Beta 分布累积函数通常用于研究样本集合中某些事物的发生和变化情况。 BETAINV 返回beta 分布累积函数的逆函数值。即,如果probability = BETADIST(x,...) ,则BETAINV(probability,...) = x。beta 分布累积函数可用于项目设计,在给定期望的完成时间和变化参数后,模拟可能的完成时间。 BINOMDIST 返回一元二项式分布的概率值。函数BINOMDIST 适用于固定次数的独立实验,实验的结果只包含成功或失败二种情况,且成功的概率在实验期间固定不变。 例如,函数BINOMDIST 可以计算三个婴儿中两个是男孩的概率CHIDIST 返回X2 分布的单尾概率。X2 分布与X2 检验相关。使用X2 检验可以比较观察值和期望值。例如,某项遗传学实验假设下一代植物将呈现出某一组颜色。使用此函数比较观测结果和期望值,可以确定初始假设是否有效。
CHIINV 返回X2 分布单尾概率的逆函数。如果probability =CHIDIST(x,?),则CHIINV(probability,?)= x。使用此函数比较观测结果和期望值,可以确定初始假设是否有效。 CHITEST 返回独立性检验值。函数CHITEST 返回X2 分布的统计值及相应的自由度。可以使用X2 检验确定假设值是否被实验所证实。CONFIDENCE 返回总体平均值的置信区间。置信区间是样本平均值任意一侧的区域。例如,如果通过邮购的方式订购产品,依照给定的置信度,可以确定最早及最晚到货的时间。 CORREL 返回单元格区域array1 和array2 之间的相关系数。使用相关系数可以确定两种属性之间的关系。例如,可以检测某地的平均温度和空调使用情况之间的关系。 COUNT 返回参数的个数。利用函数COUNT 可以计算数组或单元格区域中数字项的个数。 COUNTA 回参数组中非空值的数目。利用函数COUNTA 可以计算数组或单元格区域中数据项的个数。 COVAR 返回协方差,即每对数据点的偏差乘积的平均数,利用协方差可以决定两个数据集之间的关系。例如,可利用它来检验教育程度与收入档次之间的关系。 CRITBINOM 返回使累积二项式分布大于等于临界值的最小值。此函数可以用于质量检验。例如,使用函数CRITBINOM来决定最多允许出现多少个有缺陷的部件,才可以保证当整个产品在离开装配线时检验合格。DEVSQ 返回数据点与各自样本均值偏差的平方和。
Excel在统计中的应用 Excel与数据统计分析 一、实验说明 (一中文Excel 简介 Microsoft Excel 是美国微软公司开发的Windows 环境下的电子表格系统,它是目前应用最为广泛的办公室表格处理软件之一。自Excel 诞生以来 Excel 历经了Excel5.0、Excel95、Excel97 和Excel2000 等不同版本。随着版本的不断提高,Excel 软件的强大的数据处理功能和操作的简易性逐渐走入了一个新的境界,整个系统的智能化程度也不断提高,它甚至可以在某些方面判断用户的下一步操作,使用户操作大为简化。Excel 具有强有力的数据库管理功能、丰富的宏命令和函数、强有力的决策支持工具、图表绘制功能、宏语言功能、样式功能、对象连接和嵌入功能、连接和合并功能,并且操作简捷,这些特性,已使Excel 成为现代办公软件重要的组成部分。 由于大家对Excel的常用办公功能都比较熟悉,本实验重点介绍Excel在统计分析中的应用。 (二实验目的与要求 本实验重点介绍Excel在统计分析中的应用,包括Excel在描述统计中的应用以及Excel在推断统计中的应用,要求学生熟练掌握运用Excel 进行统计分析的方法,并能够对分析结果进行解释。 二、实验 实验一 Excel 在描述统计中的应用 实验目的及要求
要求学生掌握运用Excel进行描述统计分析、绘制各种图表和运用数据透视表工具的技术。 实验内容及步骤 (一描述统计分析 例1-1:表1-1是1978-2005年我国城镇居民可支配收入数据,试求城镇居民可支配收入时间序列的基本统计量。 表1-1 1978-2005年我国城镇居民可支配收入(元
求参数的和,就是求指定的所有参数的和。 2.SUMIF 1.条件求和,Excel中sumif函数的用法是根据指定条件对若干单元格、区域或引用求和。 2.sumif函数语法是:SUMIF(range,criteria,sum_range) sumif函数的参数如下: 第一个参数:Range为条件区域,用于条件判断的单元格区域。 第二个参数:Criteria是求和条件,由数字、逻辑表达式等组成的判定条件。 第三个参数:Sum_range为实际求和区域,需要求和的单元格、区域或引用。 当省略第三个参数时,则条件区域就是实际求和区域。 (注:criteria 参数中使用通配符(包括问号(?)和星号(*))。问号匹配任意单个字符;星号匹配任意一串字符。如果要查找实际的问号或星号,请在该字符前键入波形符(~)。) 3.实例:计算人员甲的营业额($K$3:$K$26:绝对区域,按F4可设定) 3.COUNT 1.用途:它可以统计数组或单元格区域中含有数字的单元格个数。 2.函数语法:COUNT(value1,value2,...)。 参数:value1,value2,...是包含或引用各种类型数据的参数(1~30个),其中只有数字类型的
数据才能被统计。 3.实例:如果A1=90、A2=人数、A3=〞〞、A4=54、A5=36,则公式“=COUNT(A1:A5) ”返回得3。 4.COUNTA 1.说明:返回参数组中非空值的数目。参数可以是任何类型,它们包括空格但不包括空白单元格。如果不需要统计逻辑值、文字或错误值,则应该使用COUNT函数。 2.语法:COUNTA(value1,value2,...) 3.实例:如果A1=6.28、A2=3.74,A3=“我们”其余单元格为空,则公式“=COUNTA(A1:A5)”的计算结果等于3。 5.COUNTBLANK 1.用途:计算某个单元格区域中空白单元格的数目。 2.函数语法:COUNTBLANK(range) 参数:Range为需要计算其中空白单元格数目的区域。 3.实例:如果A1=88、A2=55、A3=(空格)、A4=72、A5=(空格),则公式“=COUNTBLANK(A1:A5)”返回得2。
9-2自然地理(2008年) 位置:重庆位于北纬28度10分-32度13分,东经105度11分-110度11分之间,地处较为发达的东部地区和资源丰富的西部地区的结合部,东邻湖北、湖南,南靠贵州,西接四川,北连陕西,是长江上游最大的经济中心、西南工商业重镇和水陆交通枢纽。1997年3月14日,第八届全国人民代表大会第五次会议通过了设立重庆直辖市的决议,与北京、天津、上海同为四大直辖市。 面积:重庆幅员面积8.24万平方公里,南北长450公里,东西宽470公里。2008年全市共辖19个区:万州区、涪陵区、渝中区、大渡口区、江北区、沙坪坝区、九龙坡区、南岸区、北碚区、万盛区、双桥区、渝北区、巴南区、黔江区、长寿区、江津区、合川区、永川区、南川区;21个县(自治县):綦江县、潼南县、铜梁县、大足县、荣昌县、璧山县、开县、忠县、梁平县、云阳县、奉节县、巫山县、巫溪县、城口县、垫江县、武隆县、丰都县、石柱县土家族自治县、彭水苗族土家族县、酉阳土家族苗族县、秀山土家族苗族县。 地势:重庆地势由南北向长江河谷逐级降低,西北部和中部以丘陵、低山为主,东南部靠大巴山和武陵山两座大山脉。 河流:主要河流有长江、嘉陵江、乌江、涪江、綦江、大宁河等。 气候:重庆属中亚热带湿润季风气候区,具有夏热冬暖,光热同季,无霜期长,雨量充沛,湿润多阴等特点。2008年平均气温18.6℃,年总降雨量985.3毫米。 Natural Environment (2008) Location: Chongqing locates at 28°10'~32°13' north latitude and 105°11'~110°11' east longitude. Chongqing has a favorable geographical location with a vast hinterland. With Hubei Province and Hu'nan Province to the east, Guizhou Province to the south, Sichuan Province to the west, Shanxi Province to the north, Chongqing is a large commercial and industrial center, and enjoys convenient communications. Chongqing municipality was established on March 14, 1997. Area: Covering an area of 0.0824 million square kilometers, the municipality is 470 kilometers wide from east to west and 450 kilometers long from north to south. There was a total of 19 districts in Chongqing in 2008: Wanzhou, Fuling Yuzhong (center of Chongqing), Dadukou, Jiangbei, Shapingba, Jiulongpo, Nan'an, Beibei, Wansheng, Shuangqiao, Yubei, Ba'nan, Qianjiang, Changshou, Jiangjin, Hechuan, Yongchuan, Nanchuan;And 21 counties in Chongqing: Qijiang, Tongnan, Tongliang, Dazu, Rongchang, Bishan, Kaixian, Zhongxian, Liangping, Yunyang, Fengjie, Wushan, Wuxi, Chengkou, Dianjiang, Wulong, Fengdu, Shizhu, Pengshui, Youyang, Xiushan. Topography: Chongqing's eastern is lower than the western, lots of hills in the northwest and the middle areas, with Daba Mountain and Wuling Mountain to the southeast. River: The main rivers are Yangtze River, Jialing River, Wujiang River, Fujiang River, Qijiang River and Daning River. Climate: Chongqing has a subtropical humid monsoon climate with four distinct seasons. Summer of Chongqing is hot and winter is warm, with a long frost-free period. In 2008 annual average temperature was 18.6 ℃, and annual precipitation was 985.3 mm.
常用的excel函数公式大全 一、数字处理 1、取绝对值 =ABS(数字) 2、取整 =INT(数字) 3、四舍五入 =ROUND(数字,小数位数) 二、判断公式 1、把公式产生的错误值显示为空 公式:C2 =IFERROR(A2/B2,"") 说明:如果是错误值则显示为空,否则正常显示。
2、IF多条件判断返回值 公式:C2 =IF(AND(A2<500,B2="未到期"),"补款","") 说明:两个条件同时成立用AND,任一个成立用OR函数。 三、统计公式 1、统计两个表格重复的内容 公式:B2 =COUNTIF(Sheet15!A:A,A2) 说明:如果返回值大于0说明在另一个表中存在,0则不存在。
2、统计不重复的总人数 公式:C2 =SUMPRODUCT(1/COUNTIF(A2:A8,A2:A8)) 说明:用COUNTIF统计出每人的出现次数,用1除的方式把出现次数变成分母,然后相加。 四、求和公式
1、隔列求和 公式:H3 =SUMIF($A$2:$G$2,H$2,A3:G3) 或 =SUMPRODUCT((MOD(COLUMN(B3:G3),2)=0)*B3:G3)说明:如果标题行没有规则用第2个公式 2、单条件求和 公式:F2 =SUMIF(A:A,E2,C:C) 说明:SUMIF函数的基本用法
3、单条件模糊求和 公式:详见下图 说明:如果需要进行模糊求和,就需要掌握通配符的使用,其中星号是表示任意多个字符,如"*A*"就表示a前和后有任意多个字符,即包含A。
4、多条件模糊求和 公式:C11 =SUMIFS(C2:C7,A2:A7,A11&"*",B2:B7,B11) 说明:在sumifs中可以使用通配符* 5、多表相同位置求和 公式:b2 =SUM(Sheet1:Sheet19!B2) 说明:在表中间删除或添加表后,公式结果会自动更新。 6、按日期和产品求和
2013 各省市行业统计年鉴 (请按ctrl+单击打开链接) 国家、地方统计年鉴 中国中国统计年鉴2013中国统计摘要2013 北京市北京统计年鉴2013房山区统计年鉴2013 昌平区统计年鉴2013怀柔区统计年鉴2013北京教育年鉴2013北京经济技术开发区年鉴2013 天津市天津统计年鉴2013天津区县年鉴2013 天津滨海新区统计年鉴2013天津科技年鉴2013 河北省河北经济年鉴2013石家庄统计年鉴2013保定经济统计年鉴2013河北农村统计年鉴2013邯郸统计年鉴2013 山西省山西统计年鉴2013太原统计年鉴2013忻州统计年鉴2013长治统计年鉴2013晋中统计年鉴2013阳泉统计年鉴2013临汾统计年鉴2013晋城统计年鉴2013朔州统计年鉴2013大同统计年鉴2013 内蒙古内蒙古统计年鉴2013包头统计年鉴2013呼和浩特经济统计年鉴2013辽宁省辽宁统计年鉴2013沈阳统计年鉴2013大连统计年鉴2013 吉林省吉林统计年鉴2013 黑龙江黑龙江统计年鉴2013黑龙江垦区统计年鉴2013 上海市上海统计年鉴2013上海浦东新区统计年鉴2013松江统计年鉴2013上海保险年鉴2013上海居民生活和价格年鉴2013 江苏省江苏统计年鉴2013无锡统计年鉴2013苏州统计年鉴2013南京统计年鉴2013扬州统计年鉴2013江阴统计年鉴2013徐州教育年鉴2013吴江年鉴2013南通统计年鉴2013淮安统计年鉴2011常州统计年鉴2013徐州统计年鉴2013丹阳统计年鉴2013盐城统计年鉴2013镇江统计年鉴2013 浙江省浙江统计年鉴2013宁波统计年鉴2013绍兴统计年鉴2013台州统计年鉴2013温州年鉴2013杭州统计年鉴2013杭州科技年鉴2013嘉兴统计年鉴2013 安徽省安徽统计年鉴2013合肥统计年鉴2013马鞍山统计年鉴2013安庆年鉴2013安徽年鉴2013 福建省福建统计年鉴2013南平统计年鉴2013宁德统计年鉴2013 福建调查资料2013厦门统计年鉴2013福州统计年鉴2013福州经济技术开发区年鉴2013 江西省江西统计年鉴2013新余统计年鉴2013南昌统计年鉴2013 山东省山东统计年鉴2013青岛统计年鉴2013济宁统计年鉴2011 临沂统计年鉴2013东营统计年鉴2013济南统计年鉴2013威海统计年鉴2013潍坊统计年鉴2013山东广播电视年鉴2013 河南省河南统计年鉴2013河南文化文物年鉴2013卫东区年鉴安阳统计年鉴2013 河南教育年鉴2013郑州统计年鉴2013河南金融年鉴2013洛阳统计年鉴2013三门峡统计年鉴2013 湖北省湖北统计年鉴2013武汉统计年鉴2013咸宁统计年鉴2013宜昌统计年鉴2013荆门统计年鉴2013 湖南省湖南统计年鉴2013长沙统计年鉴2013邵阳统计年鉴2013 广东省广东统计年鉴2013番禺统计年鉴2013江门统计年鉴2013佛山统计年鉴2013中山统计年鉴2013深圳统计年鉴2013云浮统计年鉴2013 揭阳统计年鉴2013 广西广西统计年鉴2013南宁年鉴2013