
统计学导论习题参考解答
第一章(15-16)
一、判断题
1.答:错。统计学和数学具有不同的性质特点。数学撇开具体的对象,以最一般的形式研究数量的联系和空间形式;而统计学的数据则总是与客观的对象联系在一起。特别是统计学中的应用统计学与各不同领域的实质性学科有着非常密切的联系,是有具体对象的方法论。
2.答:对。
3.答:错。实质性科学研究该领域现象的本质关系和变化规律;而统计学则是为研究认识这些关系和规律提供合适的方法,特别是数量分析的方法。
4.答:对。
5.答:错。描述统计不仅仅使用文字和图表来描述,更重要的是要利用有关统计指标反映客观事物的数量特征。
6.答:错。有限总体全部统计成本太高,经常采用抽样调查,因此也必须使用推断技术。
7.答:错。不少社会经济的统计问题属于无限总体。例如要研究消费者的消费倾向,消费者不仅包括现在的消费者而且还包括未来的消费者,因而实际上是一个无限总体。
8.答:对。
二、单项选择题
1. A;
2. A;
3.A;
4. B。
三、分析问答题
1.答:定类尺度的数学特征是“=”或“≠”,所以只可用来分类,民族可以区分为汉、藏、回等,但没有顺序和优劣之分,所以是定类尺度数据。;定序尺度的数学特征是“>”或“<”,所以它不但可以分类,还可以反映各类的优劣和顺序,教育程度可划分为大学、中学和小学,属于定序尺度数据;定距尺度的主要数学特征是“+”或“-”,它不但可以排序,还可以用确切的数值反映现象在两方面的差异,人口数、信教人数、进出口总额都是定距尺度数据;定比尺度的主要数学特征是“?”或“÷”,它通常都是相对数或平均数,所以经济增长率是定比尺度数据。
2.答:某学生的年龄和性别,分别为20和女,是数量标志和品质标志;而全校学生资料汇总以后,发现男生1056,女生802人,其中平均年龄、男生女生之比都是质量指标,而年龄合计是数量指标。数量指标是个绝对数指标,而质量指标是指相对指标和平均指标。品质标志是不能用数字表示的标志,数量标志是直接可以用数字表示的标志。
3.答:如考察全国居民人均住房情况,全国所有居民构成统计总体,每一户居民是总体单位,抽查其中5000户,这被调查的5000户居民构成样本。
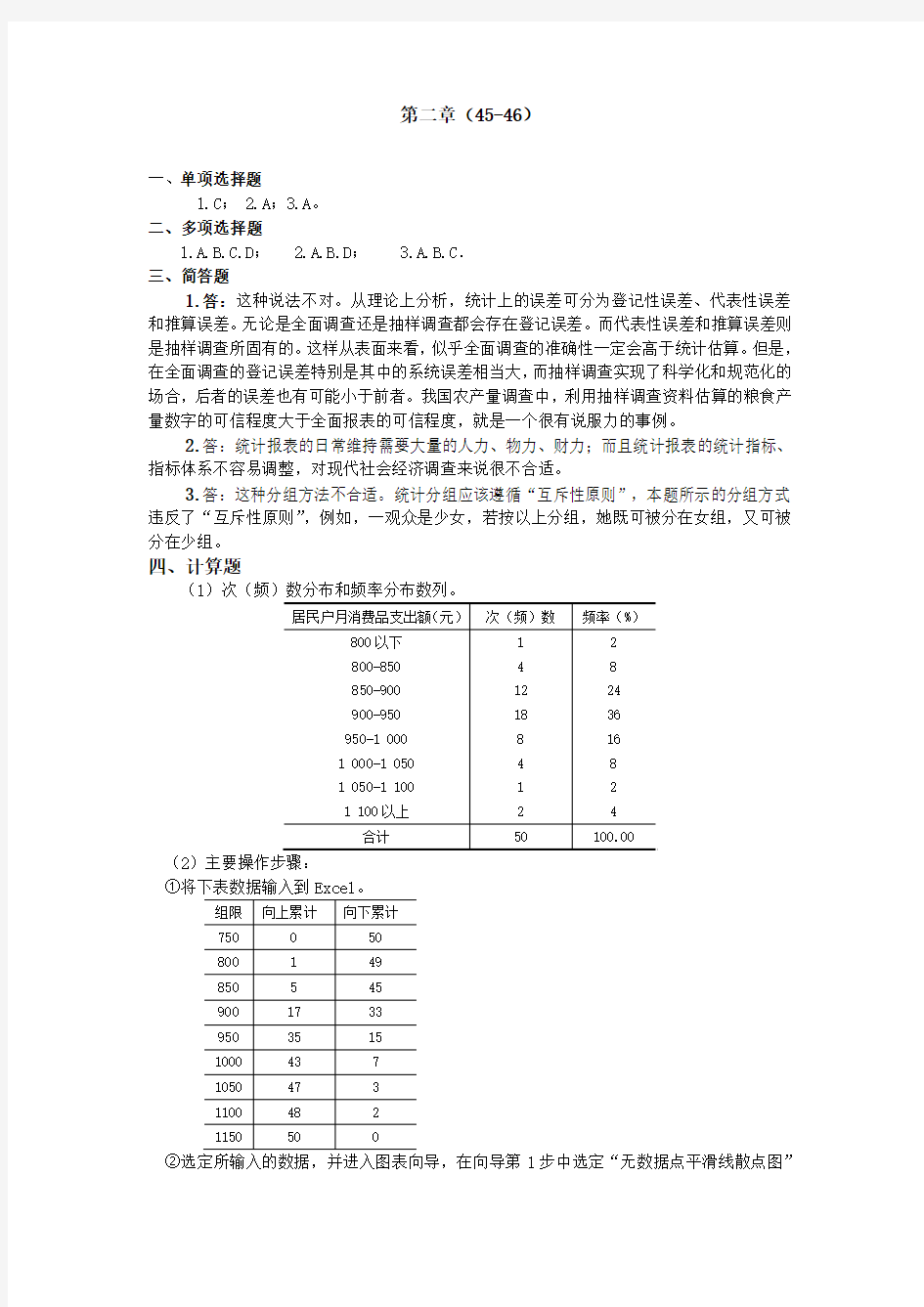
第二章(45-46)
一、单项选择题
1.C;
2.A;
3.A。
二、多项选择题
1.A.B.C.D;
2.A.B.D;
3.A.B.C.
三、简答题
1.答:这种说法不对。从理论上分析,统计上的误差可分为登记性误差、代表性误差和推算误差。无论是全面调查还是抽样调查都会存在登记误差。而代表性误差和推算误差则是抽样调查所固有的。这样从表面来看,似乎全面调查的准确性一定会高于统计估算。但是,在全面调查的登记误差特别是其中的系统误差相当大,而抽样调查实现了科学化和规范化的场合,后者的误差也有可能小于前者。我国农产量调查中,利用抽样调查资料估算的粮食产量数字的可信程度大于全面报表的可信程度,就是一个很有说服力的事例。
2.答:统计报表的日常维持需要大量的人力、物力、财力;而且统计报表的统计指标、指标体系不容易调整,对现代社会经济调查来说很不合适。
3.答:这种分组方法不合适。统计分组应该遵循“互斥性原则”,本题所示的分组方式违反了“互斥性原则”,例如,一观众是少女,若按以上分组,她既可被分在女组,又可被分在少组。
四、计算题
(1)次(频)数分布和频率分布数列。
(2
②选定所输入的数据,并进入图表向导,在向导第1步中选定“无数据点平滑线散点图”
类型,单击“完成”,即可绘制出累计曲线图。
(3)绘制直方图、折线图、曲线图和向上、向下累计图。
(4)
主要操作步骤:
①次数和频率分布数列输入到Excel 。
②选定分布数列所在区域,并进入图表向导,在向导第1步中选定“簇状柱形图”类型,单击“完成”,即可绘制出次数和频率的柱形图。
③将频率柱形图绘制在次坐标轴上,并将其改成折线图。
主要操作步骤:在“直方图和折线图”基础上,将频率折线图改为“平滑线散点图”即可。
第三章(74-76)
一、
单项选择题
1. D ;
2.A ;
3.B ;
4.B ;
5. A
6.C 。
二、判断分析题
1.答:均值。呈右偏分布。由于存在极大值,使均值高于中位数和众数,而只有较少的数据高于均值。
2.任意一个变量数列都可以计算算术平均数和中位数,但可能无法计算众数,同样,算术平均数和中位数可以衡量变量集中趋势,但是众数有时则不能。因为有时有两个众数有时又没有众数。
3.答:可计算出总体标准差为10,总体方差为100,于是峰度系数K=34800/10000=3.48,可以认为总体呈现非正态分布。
峰度系数48.03%)10100(34800
34
4
4
=-?=
-=
σm K ,属于尖顶分布。
4.答:股票A 平均收益的标准差系数为2.71/
5.63=0.48135,股票B 平均收益的标准差系数为4.65/
6.94=0.670029,股票C 平均收益的标准差系数为9.07/8.23=1.102066
5.答:为了了解房屋价格变化的走势,宜选择住房价格的中位数来观察,因为均值受极端值影响;如果为了确定交易税率,估计相应税收总额,应利用均值,因为均值才能推算总体有关的总量。
6.答:(1)均值、中位数、众数分别增加200元;(2)不变;(3)不变;(4)不同
三、计算题
1.解:基期总平均成本=
1800
12001800
7001200600+?+?=660
报告期总平均成本=1600
24001600
7002400600+?+?=640
总平均成本下降的原因是该公司产品的生产结构发生了变化,即成本较低的甲企业产
量占比上升而成本较高的乙企业产量占比相应下降所致。
甲班乙班甲班乙班全部
60 91 平均72.704 平均76.018 平均74.391
79 74 标准误差 1.998 标准误差 1.905 标准误差1.382
48 62 中位数74.5 中位数78.5 中位数76.5
76 72 众数78 众数60 众数78
67 90 (样本)标准差14.681 标准差14.257 标准差14.496
58 94 (样本)方差215.533 方差203.254 方差210.130
65 76 峰度 1.664 峰度-0.305 峰度0.685
78 83 偏度-0.830 偏度-0.5905 偏度-0.700
64 92 区域74 区域58 区域74
75 85 最小值25 最小值41 最小值25
76 94 最大值99 最大值99 最大值99
78 83 求和3926 求和4257 求和8183
84 77 观测数54 观测数56 观测数110
48 82 总体方差211.542 199.625 208.22
25 84 组内方差平均数205.475
90 60 组间方差 2.745
98
70
77
78
68
74 80 50-60 7 55 385 2928.719
95
85
68
80
92
88
73
65
72
74
99
69
72
74
85 67 33 94 57 60 61 78
83 66 77 82 94 55 76 75 80
61
3.解:根据总体方差的计算公式n
x x n
i i ∑-=
=1
2
2)(σ可得:
5418.211542593.114232==
甲σ;6247.19956
9821
.111782==乙σ
全部学生成绩的方差2199.208110
193
.229042==
全部σ
4749.205110
56
6247.199545418.211112
2=?+?=
∑∑===k
i i
k
i i
i n n σσ
∑∑-=
==k
i i
k
i i
i n n x x B
1
1
2
2)(σ110
56
)3909.740179.76(54)3909.747037.72(22?-+?-=
=2.745 总体方差(208.2199)=组内方差平均数(205.4749)+组间方差(2.745) 4. 5.解: (元)收购总量
收购总额
6268.130
.18320
60.11664000.2127008320
1664012700)()
(11
=++++=
∑
∑=
=
==k
i i i i k
i i i X f X f X X
平均价格: 1.6267819
6.均值=164;标准差=4;总人数=1200
7.解:用1代表“是”(即具有某种特征),0代表“非”(即不具有某种特征)。设总次数为N ,1出现次数为N 1,频率(N 1/N )记为P 。由加权公式来不难得出:是非变量的均值=P ;方差=P(1-P);标准差=)1(P P -。
第五章
一、
单项选择题
(1)BC ;(3)A ;(5)AC 。 二、计算题 1.解:
样本平均数 X =425, S 2
n-1=72.049, S 14=8.488
X S 2.1916= 1510.05/2()t -=2.1448
?==
/2(n-1)t α=2.1448×2.1916=4.7005
所求μ的置信区间为:425-4.70<μ<425+4.70,即(420.30,429.70)。 2.解:
样本平均数 X =12.09, S 2
n-1=0.005, S 15=0.0707
X S t 15
0.025=2.131
(12.09-0.038, 12.09+0.038)
3.解:
n=600,p=0.1,n P=60≥5,可以认为n 充分大,α=0.05,0.0252
1.96z z α==。
0.0122?==
因此,一次投掷中发生1点的概率的置信区间为 0.1-0.024<ρ<0.1+0.024,即(0.076,0.124)。
5.解:
根据已知条件可以计算得:
14820y n 1
i i =∑= 8858600
y
n
1
i 2i
=∑= 估计量
n
i i 1
1y y n μ===∑
=301*14820= 494(分钟)
估计量的估计方差
2s n
v()v(y)(1)n N μ==-
=30
1*291537520*)2200301(-
=1743.1653 其中 ()
???
? ??==∑∑==2n 1
i 2i n 1i 2i 2y n -y 1-n 1y -y 1-n 1s =
()
2494*308858600*1301
-- =29
1537520=53017.93, S=230.26
6.已知: N=400,n=80,p=0.1, α=0.05, Z α/2=Z 0.025=1.96 △x =1.96*sqrt(0.1*0.9/80)=0.0657, (0.043,0.1657)
7.解:
2(40)0.97524.433χ=,2(40)0.02559.342χ=,置信度为0.95的置信区间为:
()()221122212
(1)(1),n n n S n S ααχχ---??-- ? ???=2240124012,(97.064,235.747)59.34224.433??
??= ???
9.解:
()
()222
2222
2
11500 1.960.25(10.25)
115000.05 1.960.25(10.25)
P Nz P P n N z P P αα-???-==?+-?+??- 241.695=
应抽取242户进行调查。
第六章
一、
单项选择题
1(B ) 2(B) 3(A) 4(D) 5(A)
二、问答题
1.答:双侧检验;检验统计量的样本值2.22;观察到的显著性水平0.0132;显著性水平为0.05时,96.1025.0=z ,拒绝原假设;显著性水平为0.01时,575.2005.0=z ,不能拒绝原假设。
2.答:不是。α大则β小,α小则β大,因为具有随机性,但其和并不一定为1。 3. 答:(1)拒绝域]33.2,(--∞;(2)样本均值为23,24,25.5时,犯第一类错误的概率都是0.01。
三、计算题
1.解:(1)提出假设:
H 0 :μ=5 H 1 :μ≠5
(2)构造检验统计量并计算样本观测值
在H 0 :μ=5成立条件下:
50
6.058.42-= -2.3570
(3)确定临界值和拒绝域
Z 0.025=1.96
∴拒绝域为 (][)+∞-∞-,96.196.1, (4)做出检验决策
∵Z =2.3570> Z 0.025=1.96
检验统计量的样本观测值落在拒绝域。
∴拒绝原假设H 0,接受H 1假设,认为生产控制水平不正常。 2.
3.解:α=0.05时 (1)提出假设:
H 0 :μ=60 H 1 :μ≠60
(2)构造检验统计量并计算样本观测值
在H 0 :μ=60成立条件下:
=
400
4.14606.612
-= 2.222
(3)确定临界值和拒绝域 Z 0.025=1.96
∴拒绝域为 (][)+∞-∞-,96.196.1, (4)做出检验决策
∵Z =2.222> Z0.025=1.96
检验统计量的样本观测值落在拒绝域。
∴拒绝原假设H0,接受H1假设,认为该县六年级男生体重的数学期望不等于60公斤。α=0.01时
(1)提出假设:
H0:μ=60 H1:μ≠60
(2)构造检验统计量并计算样本观测值
在H0:μ=60成立条件下:
=
400
4.
14
60
6.
61
2
-
= 2.222
(3)确定临界值和拒绝域
Z0.005=2.575
∴拒绝域为(][)
+∞
-
∞
-,
575
.2
575
.2
,
(4)做出检验决策
∵Z =2.222 检验统计量的样本观测值落在接受域。 ∴不能拒绝H0,即没有显著证据表明该县六年级男生体重的数学期望不等于60公斤。 4. 5.解:(1)提出假设: H0:ρ=11% H1:ρ≠11% (2)构造检验统计量并计算样本观测值 在H0:ρ=11%成立条件下: 样本比例p= 600 12.2 4900 =% =2.68 (3)确定临界值和拒绝域 Z0.025=1.96 ∴拒绝域为(][) +∞ - ∞ -, 96 .1 96 .1 , (4)做出检验决策 ∵Z=2.68> Z0.025=1.96 检验统计量的样本观测值落在拒绝域。 ∴拒绝原假设H0,接受H1假设,即能够推翻所作的猜测。 6. 7.解:(1)提出假设: H0:μ1=μ 2 H1:μ1≠μ 2 (2)构造检验统计量并计算样本观测值 在H0成立条件下: Z= 2 22 121 21n s n s y y +-= 200 20 2002562672 2 +-=2.209 (3)确定临界值和拒绝域 Z 0.025=1.96 ∴拒绝域为 (][)+∞-∞-,96.196.1, (4)做出检验决策 ∵Z=2.209> Z 0.025=1.96 检验统计量的样本观测值落在拒绝域。 ∴拒绝原假设H 0,接受H 1假设,即两地的教育水平有差异。 8. 9.解:(1)提出假设: H 0 :ρ1= ρ 2 H 1 :ρ1≠ ρ 2 (2)构造检验统计量并计算样本观测值 在H 0成立条件下: p=(n 1p 1+n 2p 2)/(n 1+n 2)=(400*0.1+600*0.05)/(400+600)=0.07 )600 14001( 93.0*07.01.005.0+-= -3.036 (3)确定临界值和拒绝域 Z 0.05=1.645 ∴拒绝域为(][)+∞-∞-,645.1645.1, (4)做出检验决策 ∵Z =3.036>Z 0.05=1.645 检验统计量的样本观测值落在拒绝域。 ∴拒绝原假设H 0,接受H 1假设,即甲乙两地居民对该电视节目的偏好有差异。 10. 11.解:(一) (1)提出假设: H 0 :μ1=μ 2 H 1 :μ1≠μ 2 (2)计算离差平方和 m=2 n 1=26 n 2=24 n=50 ?∑1y =11122 ?∑2y =10725 ??∑y = 21847 21y ?∑=4930980 22y ?∑=5008425 2y ??∑=9939405 组间变差 SSR= ∑=?m 1 i i i 2 y n -n 2 y ?? =26* 22611122)(+24*22410725)(-50*2 50 21847)( =9550383.76-9545828.18 =4555.58 组内变差 SSE= ∑∑==m 1i n 1 j 2ij i y -∑=?m 1 i i i 2 y n =9939405-9550383.76 =389021.24 (3)构造检验统计量并计算样本观测值 F= )/()1/(m n SSE m SSR --=) 250/(24.389021) 12/(58.4555--=0.5621 (4)确定临界值和拒绝域 F 0.05(1,48)=4.048 ∴拒绝域为:[)+∞,048.4 (5)做出检验决策 临界值规则: ∵F=0.5621< F 0.05(1,48)=4.048 检验统计量的样本观测值落在接受域。 ∴不能拒绝H 0,即没有显著证据表明性别对成绩有影响。 P -值规则: 根据算得的检验统计量的样本值(F 值)算出P-值=0.457075。由于P -值=0.457075>显著水平标准05.0=α,所以不能拒绝0H ,即没有得到足以表明性别对成绩有影响的显著证据。 (二)(1)提出假设: H 0 :μ1=μ2=μ3=μ4 H 1 :μ1、μ2、μ3、μ4不全相等 (2)计算离差平方和 m=4 n 1=11 n 2=15 n 3=12 n 4=12 n=50 ?∑1y =5492 ?∑2y =6730 ?∑3y =5070 ?∑4y =4555 ??∑y = 21847 2 1y ?∑=2763280 22y ?∑=3098100 23y ?∑=2237900 24y ?∑=1840125 2y ??∑=9939405 组间变差 SSR= ∑=?m 1 i i i 2 y n -n 2 y ?? =11*2115492)( +15*2156730)(+12*2125070)(+12*212 4555) (-50*25021847)( =9632609.568-9545828.18 =86781.388 组内变差 SSE= ∑∑==m 1i n 1 j 2ij i y -∑=?m 1 i i i 2 y n =9939405-9632609.568=306795.432 (3)构造检验统计量并计算样本观测值 F= )/()1/(m n SSE m SSR --=) 450/(432.306795) 14/(388.86781--=4.3372 (4)确定临界值和拒绝域 F 0.05(3,46)=2.816 ∴拒绝域为:[)+∞,816.2 (5)做出检验决策 临界值规则: ∵F=4.3372> F 0.05(3,46)=2.816 检验统计量的样本观测值落在拒绝域。 ∴拒绝原假设H 0,接受H 1假设,即父母文化程度对孩子的学习成绩有影响。 P -值规则: 根据算得的检验统计量的样本值(F 值)算出P-值=0.008973。由于P -值=0.008973小于显著水平标准05.0=α,所以拒绝0H ,接受H 1,即得到足以表明父母文化程度对孩子的学习成绩有影响的显著证据。 12. 第七章 一、选择题 1. B 、C 、D ; 3. A 、B 、D 二、判断分析题 1.错。应是相关关系。单位成本与产量间不存在确定的数值对应关系。 3.对。因果关系的判断还有赖于实质性科学的理论分析。 5.对。总体回归函数中的回归系数是有待估计的参数,因而是常数,样本回归函数中的回归系数的估计量的取值随抽取的样本不同而变化,因此是随机变量。 7.错。由于各种原因,偏相关系数与单相关系数的符号有不一致的可能。 三、证明题 1. 证明: 教材中已经证明2 ?β 是现行无偏估计量。此处只要证明它在线形无偏估计量中具有最小方差。 设∑= t t Y a 2~ β为2 β的任意线性无偏估计量。 221212 )()()~ (β βββββ=++=++=∑∑∑∑t t t t t t t t u E a X a a u X E a E 也即, 作为2β的任意线性无偏估计量,必须满足下列约束条件: ∑=0t a ;且∑=1t t X a 又因为2 var σ=t Y ,所以: ∑∑∑===2222var var )~var(t t t t t a Y a Y a σβ ∑∑∑∑∑∑∑∑∑∑∑∑∑-+--- =-----+--+---=--+--- =2 222 22 22222 2222 2 2 22)(1 ]) ([])(][)([2])([)(])([] )()([X X X X X X a X X X X X X X X a X X X X X X X X a X X X X X X X X a t t t t t t t t t t t t t t t t t t t σσσσσσ 分析此式:由于第二项∑-2 2 ) (1X X t σ 是常数,所以)~ var(2β只能通过第一项∑∑--- 2 22])([X X X X a t t t σ的处理使之最小化。明显,只有当 ∑--=2 )(X X X X a t t t 时,)~var(2β才可以取最小值,即: )?var()(1)~var(min 22 22βσβ=-=∑X X t 所以,2 ?β是标准一元线性回归模型中总体回归系数2β的最优线性无偏估计量。 四、计算题 1. 解: (1)7863.073.42505309.334229 ) ())((?2 2 ==---=∑∑X X X X Y Y t t t β 3720.4088.647*7863.08.549??2 1=-=-=X Y ββ (2)∑∑∑----= 2 2 2 2 ) ()(] ))(([ Y Y X X X X Y Y r t t t t 999834.025 .262855*73.42505309.3342292 == 6340.43)()1(222 =--=∑∑Y Y r e t 0889.22 2 =-= ∑n e S t e (3)0:,0:2120≠=ββH H 003204.073 .4250530889 .2)(2 ?2 == -= ∑X X S S t e β 4120.245003204 .07863 .0?2 2 ? 2?== = βββS t 228.2)10()2(05.02/==-t n t α t 值远大于临界值2.228,故拒绝零假设,说明2β在5%的显著性水平下通过了显著性检验。 (4)41.669800*7863.03720.40=+=f Y (万元) 1429.273.425053)88.647800(12110089.2)()(112 2 2=-++=--++=∑ X X X X n S S t f e f 3767.241.6690667.1*228.214.696)2(2/±=±=-±f e f S n t Y α 即有: 18.46764.466≤≤f Y 3.解: (1)回归分析的Excel 操作步骤为: 步骤一:首先对原先Excel 数据表作适当修改,添加“滞后一期的消费”数据到表中。 步骤二:进行回归分析 选择“工具” →“数据分析” →“回归”,在该窗口中选定自变量和因变量的数据区域,最后点击“确定”完成操作: 得到回归方程为: 12640.04471.07965.466-++=t t t C Y C (2)从回归分析的结果可知: 随机误差项的标准差估计值:S =442.2165 修正自由度的决定系数:Adjusted R Squares =0.9994 各回归系数的t 统计量为: 3533.31 ?=βt ;6603.152 ?=βt ;9389.43 ?=βt F 统计量为16484.6,远远大于临界值3.52,说明整个方程非常显著。 (3)预测 使用Excel 进行区间估计步骤如下: 步骤一:构造工作表 步骤二:为方便后续步骤书写公式,定义某些单元格区域的名称 步骤三:计算点预测值f C 步骤四:计算t 临界值 步骤五:计算预测估计误差的估计值f e S 步骤六:计算置信区间上下限 最终得出f C 的区间预测结果:33.5866205.56380≤≤f C 第九章 一、选择题 1.C 3.B 5.C 二、判断分析题 1.正确; 3.正确。 5.错误。前10年的平均增长速度为7.177%,后4年的平均增长速度为8.775%。这14年间总的增长速度为180%(即2004年比1990年增长180%)。 三、计算题 1. 解:第一季度的月平均商品流转次数为: 61.11530333 .2466)14/()2 15601510131021980(3/)234021702880(==-+++++=第一季度的平均库存额额第一季度的月平均销售 第一季度的平均商品流通费用率为: %48.8333.2466209 3/)234021702880(3/202195230==++++=)(额第一季度的月平均销售费用第一季度的月平均流通 3.解:平均增长速度=%8078.6139.15=-,增长最快的是头两年。 5.解:两种方法计算的各月季节指数(%)如下: 7.解:对全社会固定资产投资额,二次曲线和指数曲线拟合的趋势方程和预测值(单位:亿元)分别为: 269.14708.2862.2727?t t y t +-=,R 2=0.9806,2005年预测值=56081.60; t t t e y )19244.1(2.21692.2169?176.0==,R 2=0.9664,2005年预测值=73287.57。 国有经济固定资产投资额,可用二次曲线和直线来拟合其长期趋势,趋势方程和预测值(单位:亿元)分别为: 2075.3039.55777.186?t t y t ++=,R 2=0.9792,2005年预测值=23364.57; t y t 9.11585.1918?+-=,R 2=0.9638,2005年预测值=21259.50。 9.解:加权移动平均的预测值为: 95301 234519630298103101554957059180?26=++++?+?+?+?+?=y 二次指数平滑预测的结果为: 1.9372107.5418.94261?252526=?-=?+=b a y 一阶自回归模型预测的结果为: 84.9205918083754.02228.1517?26=?+=y 。 第十章 一、选择题 1.D ; 3.A ; 5.B ; 7.D ; 9.C 。 二、判断分析题 1.实际收入水平只提高了9.1%(=120%/110%-100%)。 3.不正确。对于总指数而言,只有当各期指数的权数固定不变时,定基指数才等于相应环比指数的连乘积。 5.同度量因素与指数化指标的乘积是一个同度量、可加总的总量。同度量因素具有权衡影响轻重的作用,故又称为权数。平均指数中的权数一般是基期和报告期总量(总值),或是固定的比重权数。 7.将各因素合理排序,才便于确定各个因素固定的时期;便于指标的合并与细分;也便于大家都按统一的方法进行分析,以保证分析结果的规范性和可比性。“连锁替代法”适用于按“先数量指标、后质量指标”的原则对各个因素进行合理排序的情况。 三、计算题 拉氏指数较大,帕氏指数较小,而理想指数和马埃指数都居中且二者很接近。 3. 解:%75.1035 4.305317 02.12295.011010.118522110185/1110111==++++=∑∑=P q p p p q I p 农产品收购价格提高使农民收入增加11.46 (=317-305.54) 万元。 5.解:已知各部门生产量增长率(从而可知类指数),可采用比重权数加权的算术平均指数公式计算工业生产指数,即: %77.108%2705.1%1814.1%251.1%3008.1=?+?+?+?。 7.解:先分别计算出基期总成本(00p q ∑=342000)、报告期总成本(11p q ∑=362100)和假定的总成本(01p q ∑=360000)。 总成本指数:%88.1053420003621000 01 1==∑∑= p q p q I qp 总成本增加额:∑∑-0011p q p q =362100-342000=20100(元) 产量指数:%26.105342000360000000 1==∑∑= p q p q I q 产量变动的影响额:∑-∑0001p q p q =360000-342000=18000(元) 单位成本指数:%58.1003600003621000 11 1==∑∑= p q p q I p 单位成本的影响额:∑∑-0111p q p q =362100-360000=2100(元) 三者的相对数关系和绝对数关系分别为: 105.88%=105.26%×100.58%,20100=18000+2100(元) 计算结果表示:两种产品的总成本增加了5.88%,即增加了20100元。其中,由于产量增加而使总成本增加5.26%,即增加了18000元;由于单位成本提高而使总成本增加了0.58%,即增加了2100元。 9.解:先计算出基期总平均价格0x =26.2(元),报告期总平均价格1x =32.7692(元), 假定的总平均价格1 1 0f f x ∑∑=28.3846(元)。再计算对总平均价格进行因素分析所需的三个指 数以及这三个指数分子分母的绝对数差额。详细计算过程和文字说明此不赘述。三者的相对数关系和绝对数关系分别为:125.07%=115.45%×108.34%,6.5692=4.3846+2.1846(元)。 产品质量变化体现在产品的等级结构变化方面,因此,根据结构影响指数可知,质量变化使总平均价格上升8.34%,即提高了2.1846元,按报告期销售量计算,质量变化使总收入增加了28400(元),即: 2.1846(元)×130(百件)=284 (百元)=28400(元) 第十一章 一、选择题 1.A.B.C.D 。 3. B.C 。 二、计算题 1.解: (1)根据最大的最大收益值准则,应该选择方案一。 (2)根据最大的最小收益值准则,应该选择方案三。 (3)在市场需求大的情况下,采用方案一可获得最大收益,故有: 400),(max 1=θi i a Q 在市场需求中的情况下,采用方案二可获得最大收益,故有: 200),(max 2=θi i a Q 在市场需求小的情况下,采用方案三可获得最大收益,故有: 0),(max 3=θi i a Q 根据后悔值计算公式ij j i i ij q a Q r -=),(max θ,可以求得其决策问题的后悔矩阵,如 下表: 根据最小的最大后悔值准则,应选择方案一。 (4) 0 0)6.01(06.0))((112)20()6.01(2006.0))((184 )140()6.01(4006.0))((321=?-+?==-?-+?==-?-+?=a Q E a Q E a Q E 由于在所有可选择的方案中,方案一的期望收益值最大,所以根据折中原则,应该选择方案一 (5) 0 )000(3 1))((67.126)20200200(31))((120 )140100400(31))((321=++==-+==-+=a Q E a Q E a Q E 因为方案二的期望收益值最大,所以按等可能性准则,应选择方案二。 3.解:设由于飞机自身结构有缺陷造成的航空事故为1θ,由于其它原因造成的航空事故为2θ,被判定属于结构缺陷造成的航空事故为k e ,则根据已知的条件有: )(1θP =0.35, )(2θP =0.65, )/(1θk e P =0.80, )/(2θk e P =0.30 当某次航空事故被判断为结构缺陷引起的事故时,该事故确实属于结构缺陷的概率为: ∑=??= 2 1 111) /()() /()()/(j j k j k k e P P e P P e P θθ θθθ= 589.03 .00.658.035.08 .035.0=?+?? 5.解:决策树图 略。 (1) 根据现有信息,生产该品种的期望收益为41.5万元大于不生产的期望收益,因此可生产。 (2) 自行调查得出受欢迎结论的概率=0.65*0.7+0.35*0.30=0.56, 市场欢迎的后验概率=0.65*0.7/0.56=0.8125 期望收益值=(77*0.8125 -33*0.1875)0.56+(-3*0.44) =30.25万元 自行调查的可靠性不高,并要花费相应的费用,其后验分析最佳方案的期望收益值小于先验分析最佳方案的期望收益,所以不宜采用该方案。 (3) 委托调查得出受欢迎结论的概率=0.65*0.95 +0.35*0.05 =0.6825 市场欢迎的后验概率= 0.65*0.95 /0.6825=0.9744 期望收益=(75*0.9744 -35*0.0256)0.6825 +(-5*0.3175)=47.67万元 委托调查虽然要付出较高的费用,但比较可靠,其后验分析最佳方案的期望收益大于先验分析最佳方案的期望收益,所以应采用该方案。 第十二章 一、判断题 1.错;3.错;5.对 二、计算题 1. 解:由题中所给的指标间相关系数矩阵,可得距离矩阵表如下: 将距离d 排序,可知d34=0.11最小,d12=0.15次之,d57=0.20再次之(如此类推),又该题中项目的评价指标体系指标容量为4,所以可在指标3和指标4中选择一个指标,将它确定为第一个评价指标,又在指标1和指标2中选择一个指标,将它确定为第二个评价指标,在指标5和指标7之间选择一个指标,将它确定为第三个评价指标,确定指标6为第四个评价指标。该题的聚类图绘制如下: 3. 解:(1)功效系数法计算公式为:() *()() 4060s i i i h s i i x x d x x -=?+- 依据题中所给数据,用功效系数法对其进行同度量处理如下: (2)题中所示5个指标中,每天污水处理量、BOD S 去除率、悬浮物去除率三项指标为正指标;处理1吨污水消耗空气量、去除1公斤BOD S 耗电量两项指标为逆指标。 根据相对化处理公式:正指标:/i i m x x x '=,逆指标:/i m i x x x '= 依据题中所给数据,用相对化法对其进行同度量处理如下: (3) 加权算术平均实际值得分=90.5 加权几何平均实际值得分≈89.72 (4)加权算术平均与最优值相对距离=0.07877 指标 3 4 1 2 5 7 社会统计学课程期末复习题 一、填空题(计算结果一般保留两位小数) 1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。 2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。 3、在回归分析中,各实际观测值y 与估计值y ?的离差平方和称为 剩余 变差。 4、平均增长速度= 平均发展速度 —1(或100%)。 5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。 6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。 7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。 8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为 100%7% A 100% 1.06%100%6% -=-=-产品单位成本计划超额完成程度 ;若某厂计划规定B 产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为 100%10% 100% 4.76%100%5% +=-=+B 产品产量计划超额完成程度 。 9、按照标志表现划分,学生的民族、性别、籍贯属于 品质 标志;学生的体重、年龄、成绩属于 数量 标志。 10、从内容上看,统计表由 主词 和 宾词 两个部分组成;从格式上看,统计表由 总标题 、 横行标题 、 纵栏标题 和 指标数值(或统计数值); 四个部分组成。 11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于 正 相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于 负 相关。 12、按指标所反映的数量性质不同划分,国民生产总值属于 数量 指标;单位成本属于 质量 指标。 13、如果相关系数r=0,则表明两个变量之间 不存在线性相关关系 。 二、判断题 统计学(第五版)贾俊平课后思考题答案(完整版) 第一章思考题 1.1什么是统计学 统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据 并从中得出结论。 1.2解释描述统计和推断统计 描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。 推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。 1.3统计学的类型和不同类型的特点 统计数据;按所采用的计量尺度不同分; (定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分 类的结果,数据表现为类别,用文字来表述; (定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这些类别是有序的。 (定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数 值。 统计数据;按统计数据都收集方法分; 观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。 实验数据:在实验中控制实验对象而收集到的数据。 统计数据;按被描述的现象与实践的关系分; 截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。 时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。1.4解释分类数据,顺序数据和数值型数据 答案同1.3 1.5举例说明总体,样本,参数,统计量,变量这几个概念 对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。 1.6变量的分类 变量可以分为分类变量,顺序变量,数值型变量。 变量也可以分为随机变量和非随机变量。经验变量和理论变量。 1.7举例说明离散型变量和连续性变量 离散型变量,只能取有限个值,取值以整数位断开,比如"企业数" Hah 和网速是无形的 1:各章练习题答案 2.1 (1)属于顺序数据。 (2)频数分布表如下: 服务质量等级评价的频数分布 服务质量等级家庭数(频率)频率% A1414 B2121 C3232 D1818 E1515 合计100100 (3)条形图(略) 2.2 (1)频数分布表如下: 40个企业按产品销售收入分组表 按销售收入分组(万元)企业数 (个) 频率 (%) 向上累积向下累积 企业数频率企业数频率 100以下100~110 110~120 120~130 130~140 140以上 5 9 12 7 4 3 12.5 22.5 30.0 17.5 10.0 7.5 5 14 26 33 37 40 12.5 35.0 65.0 82.5 92.5 100.0 40 35 26 14 7 3 100.0 87.5 65.0 35.0 17.5 7.5 合计40 100.0 ————(2)某管理局下属40个企分组表 按销售收入分组(万元)企业数(个)频率(%) 先进企业良好企业一般企业落后企业11 11 9 9 27.5 27.5 22.5 22.5 合计40 100.0 2.3 频数分布表如下: 某百货公司日商品销售额分组表 按销售额分组(万元)频数(天)频率(%) 25~30 30~35 35~40 40~45 45~50 4 6 15 9 6 10.0 15.0 37.5 22.5 15.0 合计40 100.0 直方图(略)。 2.4 (1)排序略。 (2)频数分布表如下: 100只灯泡使用寿命非频数分布 按使用寿命分组(小时)灯泡个数(只)频率(%) 650~660 2 2 660~670 5 5 670~680 6 6 680~690 14 14 690~700 26 26 700~710 18 18 710~720 13 13 720~730 10 10 730~740 3 3 740~750 3 3 合计100 100 直方图(略)。 (3)茎叶图如下: 65 1 8 66 1 4 5 6 8 67 1 3 4 6 7 9 68 1 1 2 3 3 3 4 5 5 5 8 8 9 9 69 0 0 1 1 1 1 2 2 2 3 3 4 4 5 5 6 6 6 7 7 8 8 8 8 9 9 70 0 0 1 1 2 2 3 4 5 6 6 6 7 7 8 8 8 9 71 0 0 2 2 3 3 5 6 7 7 8 8 9 72 0 1 2 2 5 6 7 8 9 9 73 3 5 6 74 1 4 7 张厚粲现代心理与教育统计学第一章答案 1名词概念 (1 )随机变量 答:在统计学上把取值之前,不能准确预料取到什么值的变量,称为随机变量。 (2)总体 答:总体(population )又称为母全体或全域,是具有某种特征的一类事物的总体,是研究对象的全体。 (3)样本 答:样本是从总体中抽取的一部分个体。 (4)个体 答:构成总体的每个基本单元。 (5)次数 是指某一事件在某一类别中出现的数目,又称作频数,用f表示。 (6)频率 答:又称相对次数,即某一事件发生的次数除以总的事件数目,通常用比例或百分数来表示。 (7)概率 答:概率(probability), 概率论术语,指随机事件发生的可能性大小度量指标。其描述性定义。随机事件A在所有试验中发生的可能性大小的量值,称为事件A的概率,记为P(A)。 (8)统计量 答:样本的特征值叫做统计量,又称作特征值。 (9)参数 答:又称总体参数,是描述一个总体情况的统计指标。 (10)观测值 答:随机变量的取值,一个随机变量可以有多个观测值。 2何谓心理与教育统计学?学习它有何意义? 答:(1)心理与教育统计学是专门研究如何运用统计学原理和方法,搜集、整理、分析心理 与教育科学研究中获得的随机性数据资料,并根据这些数据资料传递的信息,进行科学推论 找出心理与教育统计活动规律的一门学科。具体讲,就是在心理与教育研究中,通过调查、实验、测量等手段有意地获取一些数据,并将得到的数据按统计学原理和步骤加以整理、计 算、绘制图表、分析、判断、推理,最后得出结论的一种研究方法。 (2)学习心理与教育统计学有重要的意义。 ①统计学为科学研究提供了一种科学方法。 科学是一种知识体系。它的研究对象存在于现实世界各个领域的客观事实之中。它的主 要任务是对客观事实进行预测和分类,从而揭示蕴藏于其中的种种因果关系。要提高对客观 事实观测及分析研究的能力,就必须运用科学的方法。统计学正是提供了这样一种科学方法。统计方法是从事科学研究的一种必不可少的工具。 ②心理与教育统计学是心理与教育科研定量分析的重要工具。 凡是客观存在事物,都有数量的表现。凡是有数量表现的事物,都可以进行测量。心理 与教育现象是一种客观存在的事物,它也有数量的表现。虽然心理与教育测量具有多变性而 且旨起它发生变化的因素很多,难以准确测量。但是它毕竟还是可以测量的。因此,在进行 心理与教育科学研究时,在一定条件下,是可以对心理与教育现象进行定量分析的。心理与 教育统计就是对心理与教育问题进行定量分析的重要的科学工具。 ③广大心理与教育工作者学习心理与教育统计学的具体意义。 a. 可经顺利阅读国内外先进的研究成果。 b. 可以提高心理与教育工作的科学性和效率。 统计学导论(第二版)习题详解 第一章 一、判断题 一、判断题 1.统计学是数学的一个分支。 答:错。统计学和数学都是研究数量关系的,两者虽然关系非常密切,但两个学科有不同的性质特点。数学撇开具体的对象,以最一般的形式研究数量的联系和空间形式;而统计学的数据则总是与客观的对象联系在一起。特别是统计学中的应用统计学与各不同领域的实质性学科有着非常密切的联系,是有具体对象的方法论。。从研究方法看,数学的研究方法主要是逻辑推理和演绎论证的方法,而统计的方法,本质上是归纳的方法。统计学家特别是应用统计学家则需要深入实际,进行调查或实验去取得数据,研究时不仅要运用统计的方法,而且还要掌握某一专门领域的知识,才能得到有意义的成果。从成果评价标准看,数学注意方法推导的严谨性和正确性。统计学则更加注意方法的适用性和可操作性。 2.统计学是一门独立的社会科学。 答:错。统计学是跨社会科学领域和自然科学领域的多学科性的科学。 3.统计学是一门实质性科学。 答:错。实质性的科学研究该领域现象的本质关系和变化规律;而统计学则是为研究认识这些关系和规律提供数量分析的方法。 4.统计学是一门方法论科学。 答:对。统计学是有关如何测定、收集和分析反映客观现象总体数量的数据,以帮助人们正确认识客观世界数量规律的方法论科学。 5.描述统计是用文字和图表对客观世界进行描述。 答:错。描述统计是对采集的数据进行登记、审核、整理、归类,在此基础上进一步计算出各种能反映总体数量特征的综合指标,并用图表的形式表示经过归纳分析而得到的各种有用信息。描述统计不仅仅使用文字和图表来描述,更重要的是要利用有关统计指标反映客观事物的数量特征。 6.对于有限总体不必应用推断统计方法。 答:错。一些有限总体,由于各种原因,并不一定都能采用全面调查的方法。例如,某一批电视机是有限总体,要检验其显像管的寿命。不可能每一台都去进行观察和实验,只能应用抽样调查方法。 7.经济社会统计问题都属于有限总体的问题。 答:错。不少社会经济的统计问题属于无限总体。例如要研究消费者的消费倾向,消费者不仅包括现在的消费者而且还包括未来的消费者,因而实际上是一个无限总体。 8.理论统计学与应用统计学是两类性质不同的统计学。 答:对。理论统计具有通用方法论的性质,而应用统计学则与各不同领域的实质性学科有 统计学课后习题答案 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】 第四章 统计描述 【】某企业生产铝合金钢,计划年产量40万吨,实际年产量45万吨;计划降低成本5%,实际降低成本8%;计划劳动生产率提高8%,实际提高10%。试分别计算产量、成本、劳动生产率的计划完成程度。 【解】产量的计划完成程度=%5.112100%40 45 100%=?=?计划产量实际产量 即产量超额完成%。 成本的计划完成程=84%.96100%5%-18% -1100%-1-1≈?=?计划降低百分比实际降低百分比 即成本超额完成%。 劳动生产率计划完= 85%.101100%8%110% 1100%11≈?++=?++计划提高百分比实际提高百分比 即劳动生产率超额完成%。 【】某煤矿可采储量为200亿吨,计划在1991~1995年五年中开采全部储量的%, 试计算该煤矿原煤开采量五年计划完成程度及提前完成任务的时间。 【解】本题采用累计法: (1)该煤矿原煤开采量五年计划完成=100% ?数 计划期间计划规定累计数 计划期间实际完成累计 = 75%.1261021025357 4 =?? 即:该煤矿原煤开采量的五年计划超额完成%。 (2)将1991年的实际开采量一直加到1995年上半年的实际开采量,结果为2000万吨,此时恰好等于五年的计划开采量,所以可知,提前半年完成计划。 【】我国1991年和1994年工业总产值资料如下表: 要求: (1)计算我国1991年和1994年轻工业总产值占工业总产值的比重,填入表中; (2)1991年、1994年轻工业与重工业之间是什么比例(用系数表示) (3)假如工业总产值1994年计划比1991年增长45%,实际比计划多增长百分之几? 1991年轻工业与重工业之间的比例=96.01.144479 .13800≈; 1994年轻工业与重工业之间的比例=73.04.296826 .21670≈ (3) %37.25 1%) 451(2824851353 ≈-+ 即,94年实际比计划增长%。 【】某乡三个村2000年小麦播种面积与亩产量资料如下表: 要求:(1)填上表中所缺数字; (2)用播种面积作权数,计算三个村小麦平均亩产量; (3)用比重作权数,计算三个村小麦平均亩产量。 第一章 1*.下面的列联表是根据一个小城市的居民教育水平(以获得了高中文凭和没有获得高中文凭分类)和就业状况(以全职和非全职分类)所做出 如果原假设即在教育水平和工作状态之间没有联系为真,那么下列哪一个选项表明了获得了高中文凭并且是全职工作的期望值? A. 9252157g B. 9282157g C.528292g D. 655292g E. 9252 82 g 1*. Answer :B Analysis :本题考查二维表中两个变量的独立性,如果原假设独立成立,那么cell “earned at least a high school diploma ”和“ employed full time ”的期望值为: 92829282 (,)()()157157157157 P Earned Employed Total P Earned P Employed Total == = g g g g g g 2*.一次实验中,每一个随机样本中的成人都有他的最喜爱的颜色,下表展示了按年龄分组 的试验结果。 如果对于颜色的偏好是同年龄组相互独立,下列哪一个选项表明了年龄组30到50岁,喜爱 绿色的人数的期望值? A. (99)(108)314 B. (69)(108)314 C. (99)(35)108 D. (35)(108)314 E. (99)(35) 314 2*. Answer :A Analysis :本题考查二维表中两个变量的独立性,如果两个变量独立,那么cell “aged 30 to 50”和“prefer green ”的期望值为: 1089999108 (3050,)(3050)()314314314314 P green Total P P green Total -=-= = g g g g g g 第二章 1*.下面的直方图代表了五种不同的数据集的分布,每个都包含28个整数,从1到7,水平和垂直比例对所有图形都是相同的。下面哪个图代表了有最大标准差的数据集? 教育统计学课后作业 一、P118 1 题目:10位大一学生平均每周所花的学习时间与他们的期末考试成绩见表6-17.试问: (1)学习时间与考试成绩之间是否相关? (2)比较两组数据谁的差异程度大一些? (3)比较学生2与学生9的期末考试测验成绩。 表6-17 学习时间与期末考试成绩 1 2 3 4 5 6 7 8 9 10 学习时间考试成绩40 58 43 73 18 56 10 47 25 58 33 54 27 45 17 32 30 68 47 69 解题步骤: (1)第一步:定义变量:“xuexishijian”、“xuexichengji”后,输入数据.如下图: 1 第二步:单击选择“分析(Analyze)”中的“相关(Correlate)”中的“双变量(Bivariate Correlations)”, 将上图中的“xuexishijian”和“xuexichengji”添加到右边变量框中,如下图: 第三步:点击“确定“后,输出结果如下图: 第四步:分析结果 3 由上图可知:学习时间与学习成绩之间的pearson 相关系数为0.714,p (双侧)为0.20。自由度 df=10-2=8时,查“皮尔逊积差相关系数显著临界值表”知:r 0.05= 0.623 ; r 0.01=0.765。 因为0.765 > 0.714 >0.623,所以在0.05水平上学习时间和学习成绩是相关显著的。 (2)SPSS 软件分析结果如下图: 由上图可知:学习时间标准差和平均值为:S 1=12.037 ?X 1= 29.00 ;学习时间标准差和平均值为:S 2=12.437?X 2=56.00 根据差异系数公式可知: 学习时间差异系数为:%100?=X S CV S =12.037/29.00×100%=41.51% 学习成绩差异系数为:%100?= X S CV S =12.437/56.00×100%=22.27% 有上述结果可知学习时间差异程度大于学习成绩差异程度。 (4) 把学生2和学生9的期末考试成绩转化成标准分数: Z 2=(X -?X) /S= (73—56)/12.437=1.367 Z 9=(X-?X)/S=(68—56)/12.437=0.965 由上计算可知:学生2期末考试测验成绩优于学生9的期末考试测验成绩。 二、P119 2 题目:某班数学的平均成绩为90,标准差10;化学的平均分为85,标准差为8;物理的平均分为79,标准差为15.某生这三科成绩分别为95,80,80.试问 (1) 该生在哪一学科上突出一些? (2) 该班三科成绩的差异度如何?有无学习分化现象? (3) 该生的学期分数是多少? (4) 三科的总平均和总标准差是多少? 解题步骤: 第八章 对比分析与统计指数思考与练习 一、选择题: 1.某企业计划要求本月每万元产值能源消耗率指标比去年同期下降5%,实际降低了%,则该项计划的计划完成百分比为( d )。 a. % b. % c. % d. % 2.下列指标中属于强度相对指标的是( b )。 a..产值利润率 b.基尼系数 c. 恩格尔系数 d.人均消费支出 3.编制综合指数时,应固定的因素是(c )。 a .指数化指标 b.个体指数 c.同度量因素 d.被测定的因素 4.指出下列哪一个数量加权算术平均数指数,恒等于综合指数形式的拉氏数量指标指数(c )。 a . 1 010p q p q k q ∑∑;b. 1 111p q p q k q ∑∑;c. 000p q p q k q ∑∑; d. 101p q p q k q ∑∑ 5.之所以称为同度量因素,是因为:(a )。 a. 它可使得不同度量单位的现象总体转化为数量上可以加总; b. 客观上体现它在实际经济现象或过程中的份额; c. 是我们所要测定的那个因素; d. 它必须固定在相同的时期。 6.编制数量指标综合指数所采用的同度量因素是(a ) a . 质量指标 b .数量指标 c .综合指标 d .相对指标 7.空间价格指数一般可以采用( c )指数形式来编制。 a .拉氏指数 b.帕氏指数 c.马埃公式 d.平均指数 二、问答题: 1.报告期与基期相比,某城市居民消费价格指数为110%,居民可支配收入增加了20%,试问居民的实际收入水平提高了多少? 解:(1+20%)/110%-100%=%-100%=% 2.某公司报告期能源消耗总额为万元,与去年同期相比,所耗能源的价格平均上升了20%,那么按去年同期的能源价格计算,该公司报告期能源消耗总额应为多少? 解:÷(1+20%)=24万元 3.编制综合指数时,同度量因素的选择与指数化指标有什么关系?同度量因素为什么又称为权数?它与平均指数中的权数是否一致? 解:(略) 4.结构影响指数的数值越小,是否说明总体结构的变动程度越小?一般说来,当总体结构发生什么样的变动时,结构影响指数就会大于1。可结合具体事例来说明。 解:(略) 5.为什么在多因素指数分析中要强调各因素的排列顺序?“连锁替代法”是否适用于任一种排序的多因素分析? 解:(略) 6.某厂工人分为技术工和辅助工两类,技术工人的工资水平大大高于辅助工。最近,该厂一位财务人员对全厂工人的平均工资变动情况进行了动态对比,他发现与上年相比,全厂工人的平均工资下降了5%。而另一人则通过分析认为,全厂工人的工资水平并没有下降,而实际上工人的工资平均提高了5%。你认为这两人的分析结论是否矛盾?为什么? 解:不矛盾。前者依据的是可变构成指数的计算结果;后者依据的是固定构成指数的计算结果。 三、计算题 1. 某企业生产A、B两种产品,报告期和基期产量、出厂价格资料如下 要求:(1)用拉氏公式编制产品产量和出厂价格指数;(2)用帕氏公式编制产品产量和出厂价格指数;(3)比较两种公式编制的产量和销售量指数的差异。 解:(1)产品出厂量的拉氏指数: 第十二章 相关与回归分析 第一节 变量之间的相关关系 相关程度与方向·因果关系与对称关系 第二节 定类变量的相关 双变量交互分类(列联表)·削减误差比例(PRE )·λ系数与τ系数 第三节 定序变量的相关分析 同序对、异序对和同分对·Gamma 系数·肯德尔等级相关系数(τa 系数、τb 与τc 系数)·萨默斯系数(d 系数)·斯皮尔曼等级相关(ρ相关)·肯德尔和谐系数 第四节 定距变量的相关分析 相关表和相关图·积差系数的导出和计算·积差系数的性质 第五节 回归分析 线性回归·积差系数的PRE 性质·相关指数R 第六节 曲线相关与回归 可线性化的非线性函数·实例分析(二次曲线指数曲线) 一、填空 1.对于表现为因果关系的相关关系来说,自变量一般都是确定性变量,依变量则一般是( 随机性 )变量。 2.变量间的相关程度,可以用不知Y 与X 有关系时预测Y 的全部误差E 1,减去知道Y 与X 有关系时预测Y 的联系误差E 2,再将其化为比例来度量,这就是( 削减误差比例 )。 3.依据数理统计原理,在样本容量较大的情况下,可以作出以下两个假定:(1)实际观察值Y 围绕每个估计值c Y 是服从( );(2)分布中围绕每个可能的c Y 值的( )是相同的。 4.在数量上表现为现象依存关系的两个变量,通常称为自变量和因变量。自变量是作为( 变化根据 )的变量,因变量是随( 自变量 )的变化而发生相应变化的变量。 5.根据资料,分析现象之间是否存在相关关系,其表现形式或类型如何,并对具有相关关系的现象之间数量变化的议案关系进行测定,即建立一个相关的数学表达式,称为( 回归方程 ),并据以进行估计和预测。这种分析方法,通常又称为( 回归分析 )。 6.积差系数r 是( 协方差 )与X 和Y 的标准差的乘积之比。 二、单项选择 1.当x 按一定数额增加时,y 也近似地按一定数额随之增加,那么可以说x 与y 之间 存在( A )关系。 A 直线正相关 B 直线负相关 C 曲线正相关 D 曲线负相关 第1章导论 1、某森林公园的一项研究试图确定哪些因素有利于成年松树长到60英尺以上的高度。经估计,森林公园生长着25000颗成年松树,该研究需要从中随机抽取250颗成年松树并丈量它们的高度后进行分析。该研究的总体是() A、250颗成年松树 B、公园中25000颗成年松树 C、所有高于60英尺的成年松树 D、森林公园中所有年龄的松树 2、某森林公园的一项研究试图确定成年松树的高度。该研究需要从中随机抽取250颗成年松树并丈量它们的高度后进行分析。该研究所感兴趣的变量是() A、森林公园中松树的年龄 B、森林公园中松树的数量 C、森林公园中松树的高度 D、森林公园中数目的种类 3、推断统计的主要功能是() A、应用总体的信息描述样本 B、描述样本中包含的信息 C、描述总体中包含的信息 D、应用样本信息描述总体 4、对高中生的一项抽样调查表明,85%的高中生愿意接受大学教育。这一叙述是()的结果 A、定性变量 B、试验 C、描述统计 D、推断统计 5、一名统计学专业的学生为了完成其统计学作业,在图书馆找到一本参考书中包含美国50个州的家庭收入中位数。在该生的作业中,他应该将此数据报告来源于() A、试验 B、实际观察 C、随机抽样 D、已发表的资料 6、某大公司的人力资源部主任需要研究公司雇员的饮食习惯。他注意到,雇员的午饭要么从家里带来,要么在公司餐厅就餐,要么在外面的餐馆就餐。该研究的目的是为了改善公司餐厅的现状。这种数据的收集方式可以认为是() A、观察研究 B、设计的试验 C、随机抽样 D、全面调查 7、下列不属于描述统计问题的是() A、根据样本信息对总体进行的推断 B、感兴趣的总体或样本 C、图、表或其他数据汇总工具 D、了解数据分布特征 8、某大学的一位研究人员希望估计该大学一年级新生在教科书上的花费,为此,他观察了200名新生在教科书上的花费,发现他们每个学期平均在教科书上的花费是250元。该研究人员感兴趣的总体是() A、该大学的所有学生 B、所有的大学生 C、该大学所有的一年级新生 D、样本中的200名新生 9、某大学的一位研究人员希望估计该大学一年级新生在教科书上的花费,为此,他观察了200名新生在教科书上的花费,发现他们每个学期平均在教科书上的花费是250元。该研究人员感兴趣的变量是()A、该大学一年级新生的教科书费用 B、该大学的学生数 C、该大学新生的年龄 D、大学生的生活成本 10、在下列叙述中,关于推断统计的描述是() A、一个饼图描述了某医院治疗过的癌症类型,其中2%是肾癌,19%是乳腺癌; B、.从一个果园中采摘36个橘子,利用这36个橘子的平均重量估计 《教育统计学》复习题及答案一、填空题 1.教育统计学的研究对象是.教育问题。 2.一般情况下,大样本是指样本容量.大于30 的样本。 3.标志是说明总体单位的名称,它有.品质标志和数量标志两种。 4.统计工作的三个基本步骤是:、和。 5.集中量数是反映一组数据的趋势的。 6.“65、66、72、83、89”这组数据的算术平均数是。 7.6位学生的身高分别为:145、135、128、145、140、130厘米,他们的众数是。 8.若某班学生数学成绩的标准差是8分,平均分是80分,其标准差系数是。 9.参数估计的方法有和两种。 10.若两个变量之间的相关系数是负数,则它们之间存在。 11.统计工作与统计资料的关系是和的关系。 12.标准差越大,说明总体平均数的代表性越,标准差越小,说明总体平均数的代表性越。 13.总量指标按其反映的内容不同可以分为和。 二、判断题 1、教育统计学属于应用统计学。() 2、标志是说明总体特征的,指标是说明总体单位特征的。() 3、统计数据的真实性是统计工作的生命() 4、汉族是一个品质标志。() 5、描述一组数据波动情况的量数称为差异量数。() 6、集中量数反映的是一组数据的集中趋势。() 7、在一个总体中,算术平均数、众数、中位数可能相等。() 8、同一总体各组的结构相对指标数值之和不一定等于100%。() 9、不重复抽样误差一定大于重复抽样误差。() 10. 一致性是用样本统计量估计统计参数时最基本的要求。() 三、选择题 1.某班学生的平均年龄为22岁,这里的22岁为( )。 A.指标值 B.标志值 C.变量值 D.数量标志值 2.统计调查中,调查标志的承担者是( )。 A.调查对象 B.调查单位 C.填报单位 D.调查表 3.统计分组的关键是( )。 A.确定组数和组距 B.抓住事物本质 C.选择分组标志和划分各组界限 D.统计表的形式设计 4.下列属于全面调查的有( )。 A.重点调查 B.典型调查 C.抽样调查 D.普查 5.统计抽样调查中,样本的取得遵循的原则是( )。 A.可靠性 B.准确性 C.及时性 D.随机性 6. 在直线回归方程Yc =a+bx中,b表示( )。 增加1个单位,y增加a的数量增加1个单位,x增加b的数量 增加1个单位,x的平均增加量增加1个单位,y的平均增加量 7.下列统计指标中,属于数量指标的有() A、工资总额 B、单位产品成本 C、合格品率 D、人口密度 8.在其他条件不变情况下,重复抽样的抽样极限误差增加1倍,则样本单位数变为( )。 A.原来的2倍 B.原来的4倍 C.原来的1/2倍 D.原来的1/4倍 四、简答题 1.学习教育统计学有哪些意义? 第三章 一、单项选择题 1.统计整理的中心工作是() A.对原始资料进行审核B.编制统计表 C.统计汇总问题D.汇总资料的再审核 2.统计汇总要求资料具有() A.及时性B.正确性 C.全面性D.系统性 3.某连续变量分为五组:第一组为40—50,第二组为50—60,第三组为60—70,第四组为70—80,第五组为80以上,依习惯上规定() A.50在第一组,70在第四组B.60在第二组,80在第五组 C.70在第四组,80在第五组D.80在第四组,50在第二组 4.若数量标志的取值有限,且是为数不多的等差数值,宜编制() A.等距式分布数列B.单项式分布数列 C.开口式数列D.异距式数列 5.组距式分布数列多适用于() A.随机变量B.确定型变量 C.连续型变量D.离散型变量 6.向上累计次数表示截止到某一组为止() A.上限以下的累计次数B.下限以上的累计次数 C.各组分布的次数D.各组分布的频率 7.次数分布有朝数量大的一边偏尾,曲线高峰偏向数量小的方向,该分布曲线属于()A.正态分布曲线B.J型分布曲线 C.右偏分布曲线D.左偏分布曲线 8.划分连续变量的组限时,相临组的组限一般要() A.交叉B.不等 C.重叠D.间断 二、多项选择题 1.统计整理的基本内容主要包括() A.统计分组B.逻辑检查 C.数据录入D.统计汇总 E.制表打印 2.影响组距数列分布的要素有() A.组类B.组限 C.组距D.组中值 E.组数据 3.常见的频率分布类型主要有() A.钟型分布B.χ型分布 C.U型分布D.J型分布 E.F型分布 4.根据分组标志不同,分组数列可以分为() A.组距数列B.品质数列 C.单项数列D.变量数列 E.开口数列 5.下列变量一般是钟型分布的有() 教育统计学课后练习参考答案 第一章 1、教育统计学,就是应用数理统计学的一般原理和方法,对教育调查和教育实验等途径所获得的数据资料进行整理、分析,并以此为依据,进行科学推断,从而揭示蕴含在教育现象中的客观规律的一门科学。 教育统计学既是统计科学中的一个分支学科,又是教育科学中的一个分支学科,是两种科学相互结合、相互渗透而形成的一门交叉学科。从学科体系来看,教育统计学属于教育科学体系的一个方法论分支;从学科性质来看,教育统计学又属于统计学的一个应用分支。 2、描述统计主要是通过对数据资料进行整理,计算出简单明白的统计量数来描述庞大的资料,以显示其分布特征的统计方法。 推断统计又叫分析统计,它根据统计学的原理和方法,从我们所研究的全体对象(即总体)中,按照等可能性原则采取随机抽样的方法,抽出总体中具有代表性的部分个体组成样本,在样本所提供的数据的基础上,运用概率理论进行分析、论证,在一定可靠程度上对总体的情况进行科学推断的一种统计方法。 3、在自然界或教育研究中,一种事物常存在几种可能出现的情况或获得几种可能的结果,这类现象称为随机现象。 随机现象具的特点: (1)一次条件完全相同的实验有多种可能的结果(这样的实验称为随机实验); (2)在实验之前不能确切知道哪种结果会发生; (3)在相同的条件下可以重复进行这样的实验。 4、总体,也叫做母体或全域,是指具有某种共同特征的个体的总和。 当所研究的总体数量非常大时,可以从总体中抽取其中一部分个体来观测,由此来推断总体的信息,从总体中抽出的这部分个体就称为样本,它是用以表征总体的个体的集合。 通常将样本中样本个数大于或等于30个的样本称为大样本,小于30个的称为小样本。 5、复置抽样指每次抽出的个体经观测后,仍放回原总体,然后再从总体中抽取下一个个体。 6、反映总体特征的量数叫做总体参数,简称参数。反映样本特征的量数叫做样本统计量,简称统计量。 参数是总体的真正数值,是固定的常量,理论上应该通过计算总体中全部个体的数值而获得,但由于总体中个体的数量通常很大,总体参数往往很难获得,在统计分析中一般通过样本的数值来估计。在进行推断统计时,就是根据样本统计量来推断总体相应的参数。 第二章 1、按照数据的来源,可分为计数数据和度量数据;按照数据的取值情况,可分为间断性数据和连续性数据;按照数据的测量水平,可分为称名数据、顺序数据、等距数据和比率数据。 2、数据整理的基本方法包括对数据进行排序、统计分组、绘制统计图表等。 3、表的结构要简洁明了;表的层次要清晰;主谓分明。 4、连续性数据:(2),(3);间断性数据:(1),(4)。 5、略 6、(1)50;(2)75;(3)34;(4)5;(5)45 《统计学概论》第八章课后练习答案 一、思考题 1.什么是相关系数?它与函数关系有什么不同?P237- P238 2.什么是正相关、负相关、无线性相关?试举例说明。P238- P239 3.相关系数r的意义是什么?如何根据相关系数来判定变量之间的相关系数?P245 4.简述等级相关系数的含义及其作用?P250 5.配合回归直线方程有什么要求?回归方程中参数a、b的经济含义是什么?P256 6.回归系数b与相关系数r之间有何关系?P258 7.回归分析与相关分析有什么联系与区别?P254 8.什么是估计标准误差?这个指标有什么作用?P261 9.估计标准误差与相关系数的关系如何?P258-P264 10.解释判定系数的意义和作用。P261 二、单项选择题 1.从变量之间相互关系的方向来看,相关关系可以分为()。A.正相关和负相关B.直线关系与曲线关系 C.单相关和复相关D.完全相关和不完全相关 2.相关分析和回归分析相比较,对变量的要求是不同的。回归分析中要求()。 A.因变量是随机的,自变量是给定的B.两个变量都是随机的 C.两个变量都不是随机的D.以上三个答案都不对 3.如果变量x与变量y之间的相关系数为-1,这说明两个变量之间是()。 A.低度相关关系B.完全相关关系 C.高度相关关系D.完全不相关 4.初学打字时练习的次数越多,出现错误的量就越少,这里“练习次数”与“错误量”之间的相关关系为()。 A.正相关B.高相关 C.负相关D.低相关 5.假设两变量呈线性关系,且两变量均为顺序变量,那么表现两变量相关关系时应选用()。 A.简单相关系数r B.等级相关系数r s C.回归系数b D.估计标准误差S yx 6.变量之间的相关程度越低,则相关系数的数值()。A.越大B.越接近0 C.越接近-1 D.越接近1 7.下列各组中,两个变量之间的相关程度最高的是()。A.商品销售额和商品销售量的相关系数是0.9 社会统计学复习题有答 案 集团标准化工作小组 #Q8QGGQT-GX8G08Q8-GNQGJ8-MHHGN# 社会统计学课程期末复习题 一、填空题(计算结果一般保留两位小数) 1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。 2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。 3、在回归分析中,各实际观测值y 与估计值y ?的离差平方和称为 剩余 变差。 4、平均增长速度= 平均发展速度 —1(或100%)。 5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。 6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。 7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。 8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为 100%7% A 100% 1.06%100%6% -=- =-产品单位成本计划超额完成程度 ;若某厂计划规定B 产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为 100%10% 100% 4.76%100%5% += -=+B 产品产量计划超额完成程度 。 9、按照标志表现划分,学生的民族、性别、籍贯属于品质标志;学生的体重、年龄、成绩属于数量标志。 10、从内容上看,统计表由主词和宾词两个部分组成;从格式上看,统计表由 总标题、横行标题、纵栏标题和指标数值(或统计数值); 四个部分组成。 11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于正相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于负相关。 12、按指标所反映的数量性质不同划分,国民生产总值属于数量指标;单位成本属于质量指标。 13、如果相关系数r=0,则表明两个变量之间不存在线性相关关系。 二、判断题 1、在季节变动分析中,若季节比率大于100%,说明现象处在淡季;若季节比率小于100%,说明现象处在旺季。(×;答案提示:在季节变动分析中,若季节比率大于100%,说明现象处在旺季;若季节比率小于100%,说明现象处在淡季。 ) 2、工业产值属于离散变量;设备数量属于连续变量。(×;答案提示:工业产值属于连续变量;设备数量属于离散变量) 3、中位数与众数不容易受到原始数据中极值的影响。(√;) 4、有意识地选择十个具有代表性的城市调查居民消费情况,这种调查方式属于典型调查。(√) 第1章导论 1.1复习笔记 一、统计学的对象和方法 1.统计和统计学 (1)统计工作的产生和发展 统计工作就是通过社会调查或科学实验,搜集客观现象的现实数据,用来描述和分析自然、社会、经济、政治、文化现象的变化情况。其产生和发展过程包括: ①适应市场经济的发展以及国家对外扩张的需要,大大拓展了统计的活动范围。 ②设立统计专业机构,促成统计活动专业化、独立化。 ③统计方法的完善,大大提高了统计的认识能力。 ④电子计算技术为统计活动的现代化进程提供了手段。 (2)统计学的产生和发展 最初的统计学是作为国家重大事项的记述。这一学派称为国势学派或记述学派,其创始人是17、18世纪德国的海尔曼·康令(H.Conring,1606—1681)和高特弗洛里特·阿亨瓦尔(G.Achenwall,1719—1772)。 经历18世纪到19世纪中叶,把概率论引入统计学,使统计方法发生了重大的飞跃。其代表人物有法国的拉普拉斯(https://www.doczj.com/doc/b110244706.html,place,1749—1827)和比利时统计学家阿道夫·凯特勒(A.Quetelet,1796—1874)。政治算术派是以总体数量比较的方法对社会经济问题进行分析,代表人物有威廉·配第(W.Petty,1623—1687)和约翰·格朗特(J.Graunt,1620—1674)。 此后,应用概率论研究随机现象数量规律的数理统计方法及其在各个领域的应用迅速得 到发展。描述统计学以卡尔·皮尔逊(K.Pearson,1857—1936)为代表,到了20世纪20年代的推断统计学以费歇尔(R.A.Fisher,1880一1962)为创始人。 2.统计学的研究对象 统计学的研究对象是指统计研究所要认识的事物客体。统计对象的特点包括数量性、总体性、单位的变异性的特点。而社会经济统计学的研究对象除了具有上述的数量性、总体性、变异性外还具有社会性。 3.统计学的研究方法 (1)统计的组织系统 ①统计的社会系统 统计活动系统包括统计主体、统计客体和统计宿体三个组成部分。其统计流程图,如图1-1所示。 图1-1统计流程图 ②统计工作系统 统计主体的认识活动,有一个严密的工作系统。这个系统具有明显的层次性和阶段性。 统计工作过程一般分为统计设计、统计资料搜集、统计资料整理、统计资料分析、统计资料提供和管理等阶段。 2.统计研究的方法 (1)大量观察法 大量观察法:统计研究客观现象和过程的规律,是从现象总体上加以考察,就总体中的 思考题与练习题 参考答案 【友情提示】请各位同学完成思考题与练习题后再对照参考答案。回答正确,值得肯定;回答错误,请找出原因更正,这样使用参考答案,能力会越来越高,智慧会越来越多。学而不思则罔,如果直接抄答案,对学习无益,危害甚大。想抄答案者,请三思而后行! 第一章绪论 思考题参考答案 1.不能,英军所有战机=英军被击毁的战机+英军返航的战机+英军没有弹孔的战机,因为英军被击毁的战机有的掉入海里、敌军占领区,或因堕毁而无形等,不能找回;没有弹孔的战机也不可能自己拿来射击后进行弹孔位置的调查。即便被击毁的战机找回或没有弹孔的战机自己拿来射击进行实验,也不能从多个弹孔中确认那个弹孔就是危险的。 2.问题:飞机上什么区域应该加强钢板?瓦尔德解决问题的思想:在她的飞机模型上逐个不重不漏地标示返航军机受敌军创伤的弹孔位置,找出几乎布满弹孔的区域;发现:没有弹孔区域就是军机的危险区域。 3.能,拯救与发展自己的参考路径为:①找出自己的优点,②明确自己大学阶段的最佳目标,③拟出一个发扬自己优点,实现自己大学阶段最佳目标的可行计划。 练习题参考答案 一、填空题 1.调查。 2.探索、调查、发现。 3、目的。 二、简答题 1.瓦尔德;把剩下少数几个没有弹孔的区域加强钢板。 2.统计学解决实际问题的基本思路,即基本步骤就是:①提出与统计有关的实际问题;②建立有效的指标体系;③收集数据;④选用或创造有效的统计方法整理、显示所收集数据的特征;⑤根据所收集数据的特征、结合定性、定量的知识作出合理推断;⑥根据合理推断给出更好决策的建议。不解决问题时,重复第②-⑥步。 3.在结合实质性学科的过程中,统计学就是能发现客观世界规律,更好决策,改变世界与培养相应领域领袖的一门学科。 三、案例分析题 1.总体:我班所有学生;单位:我班每个学生;样本:我班部分学生;品质标志:姓名;数量标志:每个学生课程的成绩;指标:全班学生课程的平均成绩 ;指标体系:上学期全班同学学习的科目 ;统计量:我班部分同学课程的平均成绩 ;定性数据:姓名 ;定量数据: 课程成绩 ;离散型变量:学习课程数;连续性变量:学生的学习时间;确定性变量:全班学生课程的平均成绩;随机变量:我班部分同学课程的平均成绩,每个同学进入教室的时间;横截面数据:我班学生月门课程的出勤率;时间序列数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;面板数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;选用描述统计。 2.(1)总体:广州市大学生;单位:广州市的每个大学生。(2)如果调查中了解的就是价格高低,为定序尺度;如果调查中了解的就是商品丰富、价格合适、节约时间,为定类尺度。(3)广州市大学生在网上购物的平均花费。(4)就是用统计量作为参数的估计。(5)推断统计。 3.(1)10。(2)6。(3)定类尺度:汽车名称,燃油类型;定序尺度:车型大小;定距尺度:引擎的汽缸数;定比尺度:市区驾车的油耗,公路驾车的油耗。(4)定性变量:汽车名称,车型大小,燃油类型;定量变量:引擎的汽缸数,市区驾车的油耗,公路驾车的油耗。(5)40%;(6)30%。 第二章收集数据 思考题参考答案社会统计学复习题(有答案)
贾平俊统计学第五版课后思考题答案(完整版)
统计学(第三版课后习题答案
心理和教育统计学课后题答案解析
统计学导论第二版习题详解
统计学课后习题答案完整版
统计学课后习题和答案
教育统计学与SPSS课后作业答案祥解题目
统计学概论课后答案 统计指数习题解答
社会统计学习题和答案--相关与回归分析报告
统计学课后第一章习题答案.doc
教育统计学复习题及答案
统计学第三章课后题及答案解析
教育统计学课后练习参考答案
《统计学概论》第八章课后练习题答案
社会统计学复习题有答案
黄良文《统计学》(第2版)笔记和课后习题(含考研真题)详解 第1章 导 论【圣才出品】
统计学课后习题参考答案
相关主题
文本预览