
MTT结果分析
MTT数据结果形式(EXCEL):
拷贝灰色区间所需的数据包括分组浓度(我们做的时候左右是重复的,所以先选择一边分析,本次选择了右侧数据)。
在Fx中选择计算平均值AVEREGE(区域选择各列)计算各列平均值:
计算各数值相对0浓度组的平均值0.220697249的吸光率:
利用Fx公式STEDV计算标准差,用100-各组平均相对吸光率计算抑制率:
如此即可得到所需要的部分数据,可将上表原始数据用SPSS单因素分析各组的差异P 值等(此处略,查一下SPSS单因素分析的步骤就知道了),综合上述数据用Original lab 绘制直方图,即可用于发表等(不做重点讲述)。
SPSS计算IC50值的方法
SPSS软件在IC50计算中的应用:
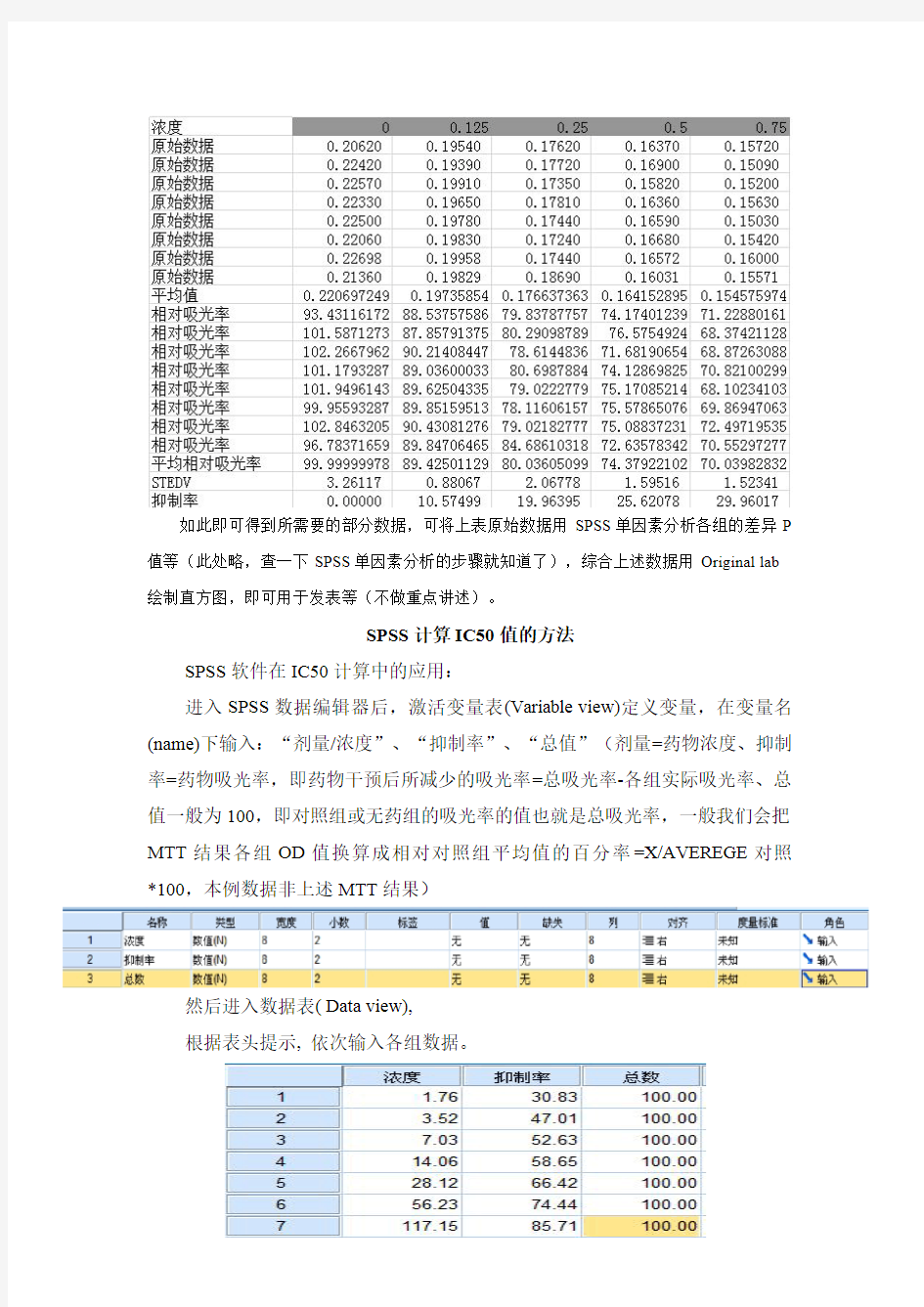
进入SPSS数据编辑器后,激活变量表(Variable view)定义变量,在变量名(name)下输入:“剂量/浓度”、“抑制率”、“总值”(剂量=药物浓度、抑制率=药物吸光率,即药物干预后所减少的吸光率=总吸光率-各组实际吸光率、总值一般为100,即对照组或无药组的吸光率的值也就是总吸光率,一般我们会把MTT结果各组OD值换算成相对对照组平均值的百分率=X/AVEREGE对照*100,本例数据非上述MTT结果)
然后进入数据表(Data view),
根据表头提示,依次输入各组数据。
选择参数Analysis regression probit,调出“Probit analysis”对话框
将“剂量/浓度”选入“Covariates”栏中,“抑制率”选入“Response frequency”栏中,“总值”选入“Total observed”栏中。
在“Transform”栏中,选择“Log base10”,在‘Mode l’栏中选择“Probit”概率单位模型,在“Options”栏中选择“calculate from Data”即依据现有数量所得的在缺少刺激条件下的响应率来估计自然响应率,其他保持默认选项,然后单击“OK”即可。
完成上述操作,SPSS会自动显示全部分析结果(Spssviewer),首先显示共有几组数据进行了概率单位模型分析,回归方程经过几次叠代运算后确定,该方程拟合优度检验X2值、P值(P>0.05),说明曲线拟合良好。接着,系统显示剂量对数值(X)、个体总数(Number of Subjects)、观察到的反应数(Observed Responses)、预期反应数(Expec ted Responses)、残差(Residual)和效应的概率(Prob)之后,显示各效应概率水平的剂量值(包括0.50,即IC50)及其95%可信区间值,以及对数单位与概率单位的关系曲线图。
科研常用的实验数据分析与处理方法 对于每个科研工作者而言,对实验数据进行处理是在开始论文写作之前十分常见的工作之一。但是,常见的数据分析方法有哪些呢?常用的数据分析方法有:聚类分析、因子分析、相关分析、对应分析、回归分析、方差分析。 1、聚类分析(Cluster Analysis) 聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。 2、因子分析(Factor Analysis) 因子分析是指研究从变量群中提取共性因子的统计技术。因子分析就是从大量的数据中寻找内在的联系,减少决策的困难。因子分析的方法约有10多种,如重心法、影像分析法,最大似然解、最小平方法、阿尔发抽因法、拉奥典型抽因法等等。这些方法本质上大都属近似方法,是以相关系数矩阵为基础的,所不同的是相关系数矩阵对角线上的值,采用不同的共同性□2估值。在社会学研究中,因子分析常采用以主成分分析为基础的反覆法。
3、相关分析(Correlation Analysis) 相关分析(correlation analysis),相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度。相关关系是一种非确定性的关系,例如,以X和Y 分别记一个人的身高和体重,或分别记每公顷施肥量与每公顷小麦产量,则X与Y显然有关系,而又没有确切到可由其中的一个去精确地决定另一个的程度,这就是相关关系。 4、对应分析(Correspondence Analysis) 对应分析(Correspondence analysis)也称关联分析、R-Q 型因子分析,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。 5、回归分析 研究一个随机变量Y对另一个(X)或一组(X1,X2,…,Xk)变量的相依关系的统计分析方法。回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的自变量的多少,可分为一
数据分析实验报告 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-
第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 统计量 全国居民 农村居民 城镇居民 N 有效 22 22 22 缺失 均值 1116.82 747.86 2336.41 中值 727.50 530.50 1499.50 方差 1031026.918 399673.838 4536136.444 百分位数 25 304.25 239.75 596.25 50 727.50 530.50 1499.50 75 1893.50 1197.00 4136.75 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】
2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验
结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。 (2 )W 检验 结果:在Shapiro-Wilk 检验结果972.00 w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5 多维正态数据的统计量 数据:
比对试验数据处理的3种方法 摘要引入比对试验的定义,结合两个实验室进行的一组比对试验数据实例,介绍比对试验数据处理的3种基本方法,即(:rubbs检验、F检验、t检验,并阐述三者关系。 在实验室工作中,经常遇到比对试验,即按照预先规定的条件,由两个或多个实验室或实验室内部 对相同或类似的被测物品进行检测的组织、实施和评价。实验室间的比对试验是确定实验室的检测能 力,保证实验室数据准确,检测结果持续可靠而进行的一项重要的试验活动,比对试验方法简单实用,广 泛应用于企事业、专业质检、校准机构的实验室。国家实验室认可准则明确提出,实验室必须定期开展 比对试验。虽然比对试验的形式较多,如:人员比对、设备比对、方法比对、实验室间比对等等,但如何 将比对试验数据归纳、处理、分析,正确地得出比对试验结果是比对试验成败的关键。 以下笔者结合实验室A和B两个实验室200年进行的比对试验中的拉力试验数据实例,介绍比对试验数据处理的3种最基本的方法,即格鲁布斯(Grubbs)检验、F检验、t检验。 1 数据来源情况 试样 在实验室的半成品仓库采取正交方法取样,样品为01. 15 mm制绳用钢丝。在同一盘上截取20 段长度为lm试样,按顺序编号,单号在实验室A测试,双号在实验室B测试。 试验方法及设备 试验方法见 GB/T 228-1987,实验室A : LJ-500(编号450);实验室B : LJ-1 000(编号2)。 测试条件 两实验室选择有经验的试验员,严格按照标准方法进行测试,技术人员现场监督复核,确认无误后 记录。对断钳口的试样进行重试。试验时两实验室环境温度(28 T )、拉伸速度(50 mm/min )、钳口距 离(150 mm)相同。 试验数据 测试得出的两组原始试验数据见表to 表1 实验室A,B试验数据
习题4.5实验报告 一、实验目的 问题描述:在习题1.5表1.9中,列出了历年人口出生率、死亡率和自然增长率(单位:%)。设对应于人口出生率、人口死亡率、自然增长率的数据变量分别为x1,x2,x3。 (1)分别从样本协方差矩阵S及样本相关矩阵R出发,求x1,x2,x3的样本主成分y1,y2,计算各样本主成分的贡献率。 (2)分别从样本协方差矩阵S及样本相关矩阵R出发,将第一样本主成分y1从小到大排序,并给与分析。 二、所用方法及工具 (1)主成分分析法与贡献率: 主成分分析法即构造原变量的一系列线性组合,使各线性组合在彼此不相关的前提下尽可能多地反映原变量的信息,即使其方差最大。 求的各主成分,等价于求它的协方差矩阵的各特征值及相应的正交单位化特征向量.按特征值由大到小所对应的正交单位化特征向量为组合系数的X,Xz ,…,X,的线性组合分别为X的第一,第二、直至第p个主成分,而各主成分的方差等于相应的特征值。 (2)SAS编程: SAS语言是一种专用的数据管理与分析语言,它提供了一种完善的编程语言。类似于计算机的高级语言,SAS用户只需要熟悉其命令、语句及简单的语法规则就可以做数据管理和分析处理工作。因此,掌握SAS编程技术是学习SAS的关键环节。在SAS中,把大部分常用的复杂数据计算的算法作为标准过程调用,用户仅需要指出过程名及其必要的参数。这一特点使得SAS编程十分简单。 三、实验内容 本次实验采用SAS编程实现,代码如下: data a; set sjfx.rk1; run; proc princomp n=2 cov out=out1; var x1 x2 x3; run; proc sort data=out1 out=a1; by prin1; run; proc print data=a1; run; proc princomp n=2 out=out2; var x1 x2 x3; run; proc sort data=out2 out=a2; by prin1;
《数据分析》实验报告 班级:07信计0班学号:姓名:实验日期2010-3-11 实验地点:实验楼505 实验名称:样本数据的特征分析使用软件名称:MATLAB 实验目的1.熟练掌握利用Matlab软件计算均值、方差、协方差、相关系数、标准差与变异系数、偏度与峰度,中位数、分位数、三均值、四分位极差与极差; 2.熟练掌握jbtest与lillietest关于一元数据的正态性检验; 3.掌握统计作图方法; 4.掌握多元数据的数字特征与相关矩阵的处理方法; 实验内容安徽省1990-2004年万元工业GDP废气排放量、废水排放量、固体废物排放量以及用于污染治理的投入经费比重见表6.1.1,解决以下问题:表6.1.1废气、废水、固体废物排放量及污染治理的投入经费占GDP比重 年份 万元工业GDP 废气排放量 万元工业GDP 固体物排放量 万元工业GDP废 水排放量 环境污染治理投 资占GDP比重 (立方米)(千克)(吨)(%)1990 104254.40 519.48 441.65 0.18 1991 94415.00 476.97 398.19 0.26 1992 89317.41 119.45 332.14 0.23 1993 63012.42 67.93 203.91 0.20 1994 45435.04 7.86 128.20 0.17 1995 46383.42 12.45 113.39 0.22 1996 39874.19 13.24 87.12 0.15 1997 38412.85 37.97 76.98 0.21 1998 35270.79 45.36 59.68 0.11 1999 35200.76 34.93 60.82 0.15 2000 35848.97 1.82 57.35 0.19 2001 40348.43 1.17 53.06 0.11 2002 40392.96 0.16 50.96 0.12 2003 37237.13 0.05 43.94 0.15 2004 34176.27 0.06 36.90 0.13 1.计算各指标的均值、方差、标准差、变异系数以及相关系数矩阵; 2.计算各指标的偏度、峰度、三均值以及极差; 3.做出各指标数据直方图并检验该数据是否服从正态分布?若不服从正态分布,利用boxcox变换以后给出该数据的密度函数; 4.上网查找1990-2004江苏省万元工业GDP废气排放量,安徽省与江苏省是 否服从同样的分布?
实验数据处理基本方法 实验必须采集大量数据,数据处理是指从获得数据开始到得出最后结 论的整个加工过程,它包括数据记录、整理、计算与分析等,从而寻找出 测量对象的内在规律,正确地给出实验结果。因此,数据处理是实验工作 不可缺少的一部分。数据处理涉及的内容很多,这里只介绍常用的四种方 法。 1列表法 对一个物理量进行多次测量,或者测量几个量之间的函数关系,往往 借助于列表法把实验数据列成表格。其优点是,使大量数据表达清晰醒目, 条理化,易于检查数据和发现问题,避免差错,同时有助于反映出物理量 之间的对应关系。所以,设计一个简明醒目、合理美观的数据表格,是每 一个同学都要掌握的基本技能。 列表没有统一的格式,但所设计的表格要能充分反映上述优点,应注意以下几点:1.各栏目均应注明所记录的物理量的名称(符号 )和单位; 2.栏目的顺序应充分注意数据间的联系和计算顺序,力求简明、齐全、有条理; 3.表中的原始测量数据应正确反映有效数字,数据不应随便涂改,确实要修改数据时, 应将原来数据画条杠以备随时查验; 4.对于函数关系的数据表格,应按自变量由小到大或由大到小的顺序排列,以便于判 断和处理。 2图解法 图线能够明显地表示出实验数据间的关系,并且通过它可以找出两个 量之间的数学关系,因此图解法是实验数据处理的重要方法之一。图解法 处理数据,首先要画出合乎规范的图线,其要点如下: 1.选择图纸作图纸有直角坐标纸 ( 即毫米方格纸 ) 、对数坐标纸和 极坐标纸等,根据 作图需要选择。在物理实验中比较常用的是毫米方格纸,其规格多为17 25 cm 。 2.曲线改直由于直线最易描绘 , 且直线方程的两个参数 ( 斜率和截距 ) 也较易算得。所以对于两个变量之间的函数关系是非线性的情形,在用图解法时 应尽可能通过变量代换 将非线性的函数曲线转变为线性函数的直线。下面为几种常用的变换方法。 ( 1) xy c ( c 为常数 ) 。 令 z 1,则 y cz,即 y 与 z 为线性关系。 x ( 2) x c y ( c 为常x2,y 1 z ,即 y 与为线性关系。
数据分析实验报告 【最新资料,WORD文档,可编辑修改】 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出:
方差1031026.918399673.8384536136.444百分位数25304.25239.75596.25 50727.50530.501499.50 751893.501197.004136.75 3画直方图,茎叶图,QQ图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民Stem-and-Leaf Plot Frequency Stem & Leaf 9.00 0 . 122223344 5.00 0 . 56788 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689
1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 单样本Kolmogorov-Smirnov 检验 身高N60正态参数a,,b均值139.00
标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z.686 渐近显着性(双侧).735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验
实验数据处理的几种方法 物理实验中测量得到的许多数据需要处理后才能表示测量的最终结果。对实验数据进行记录、整理、计算、分析、拟合等,从中获得实验结果和寻找物理量变化规律或经验公式的过程就是数据处理。它是实验方法的一个重要组成部分,是实验课的基本训练内容。本章主要介绍列表法、作图法、图解法、逐差法和最小二乘法。 1.4.1 列表法 列表法就是将一组实验数据和计算的中间数据依据一定的形式和顺序列成表格。列表法可以简单明确地表示出物理量之间的对应关系,便于分析和发现资料的规律性,也有助于检查和发现实验中的问题,这就是列表法的优点。设计记录表格时要做到:(1)表格设计要合理,以利于记录、检查、运算和分析。 (2)表格中涉及的各物理量,其符号、单位及量值的数量级均要表示清楚。但不要把单位写在数字后。 (3)表中数据要正确反映测量结果的有效数字和不确定度。列入表中的除原始数据外,计算过程中的一些中间结果和最后结果也可以列入表中。 (4)表格要加上必要的说明。实验室所给的数据或查得的单项数据应列在表格的上部,说明写在表格的下部。 1.4.2 作图法 作图法是在坐标纸上用图线表示物理量之间的关系,揭示物理量之间的联系。作图法既有简明、形象、直观、便于比较研究实验结果等优点,它是一种最常用的数据处理方法。 作图法的基本规则是: (1)根据函数关系选择适当的坐标纸(如直角坐标纸,单对数坐标纸,双对数坐标纸,极坐标纸等)和比例,画出坐标轴,标明物理量符号、单位和刻度值,并写明测试条件。 (2)坐标的原点不一定是变量的零点,可根据测试范围加以选择。,坐标分格最好使最低数字的一个单位可靠数与坐标最小分度相当。纵横坐标比例要恰当,以使图线居中。 (3)描点和连线。根据测量数据,用直尺和笔尖使其函数对应的实验点准确地落在相应的位置。一张图纸上画上几条实验曲线时,每条图线应用不同的标记如“+”、“×”、“·”、“Δ”等符号标出,以免混淆。连线时,要顾及到数据点,使曲线呈光滑曲线(含直线),并使数据点均匀分布在曲线(直线)的两侧,且尽量贴近曲线。个别偏离过大的点要重新审核,属过失误差的应剔去。 (4)标明图名,即做好实验图线后,应在图纸下方或空白的明显位置处,写上图的名称、作者和作图日期,有时还要附上简单的说明,如实验条件等,使读者一目了然。作图时,一般将纵轴代表的物理量写在前面,横轴代表的物理量写在后面,中间用“~”
《数据分析方法与技术》上机实验——实验1描述性统计方法 学号: 姓名: 日期:
实验项目(一):描述性统计方法 一、实验内容 1.实验目的 掌握常用的描述性图表展示方法的原理及操作,包括:频数分布表、分组频数表、列联表、茎叶图、箱线图、误差图、散点图等; 掌握常用的描述性统计方法的原理及操作,包括:算术平均值、中位数、众数、四分位数、极差、平均差、方差、标准差、标准分数、离散系数等。 2. 实验内容和要求 实验内容:基于标准数据集,属性描述性图表展示方法(数分布表、分组频数表、列联表、茎叶图、箱线图、误差图、散点图等),对统计指标(算术平均值、中位数、众数、极差、平均差、方差、标准差、标准分数、离散系数、偏态峰态)进行计算。 实验要求:掌握各种描述性统计指标的计算思路及其在SPSS或EXCEL环境下的操作方法,掌握输出结果的解释。 二、实验过程 1、数据集介绍 1.数据库标题:鲍鱼数据 2.该数据库共计4177行数据 3.该数据有八个属性(包含性别共有九项) 4.以下是关于属性的描述,包括属性的名称,数据类型,测量单元和一个简短的描述: Name Data TypeMeas.Description ---- --------- ----- ----------- Sex nominal M, F, and I (infant)鲍鱼宝宝 Length continuousmm Longest shell measurement最长壳 Diameter continuousmm perpendicular to length垂直长度 Height continuousmm with meat in shell有肉的壳高度 Whole weightcontinuousgramswhole abalone整个鲍鱼 Shucked weightcontinuousgramsweight of meat肉的重量 Viscera weightcontinuousgramsgut weight (after bleeding)放血后内脏重 Shell weightcontinuousgramsafter being dried弄干后重量 Rings integer +1.5 gives the age in years +1.5=年龄 5.数据的值域
电子科技大学政治与公共管理学院本科教学实验报告 (实验)课程名称:数据分析技术系列实验 电子科技大学教务处制表
电 子 科 技 大 学 实 验 报 告 学生姓名: 学 号: 指导教师: 一、实验室名称: 电子政务可视化实验室 二、实验项目名称:描述性统计方法 三、实验原理 通过调查或观察,采集到样本以后,常用一些统计量描述这些数据的分布状态,并通过这种认识,对数据的总体特征进行总结和归纳。数据的分布状态常通过数据的进行描写。 本实验主要对数据统计分析的最基础分析——描述性统计分析进行实验,主要包括集中趋势和离中趋势分析,其主要算法原理如下: 1. 描述集中趋势的统计 (1) 算术平均值(Mean):样本数据的总和除以样本数据的个数即是算术平均值。 ∑∑==?= n i i n i i i f f X X 1 1 (2) 中位数(Median ,Me) 首先将样本数据(假设有n 个数)按升序或降序排列,如果 n 为奇数,则数列中间的数值为中位数;如果n 为偶数,则中位数为其中两数值的均值。 (3) 众数(Mode ,Mo) 样本数据中出现频数(次数)最多的那个数称为众数。众数不易确定,与中位数一样,它不受极值影响。但有时会出现两个甚至多个众数,有时又没有众数。所以,众数的使用受到严格限制。 (4) 几何平均数(Geometric Mean) 假定银行每年本利(本金加利率)为 X 1 有 f 1 年,年本利为 X 2 有f 2 年,银行年本利为X 3 有 f 3 年,? ,年本利为X n 有 f n 年,则n 年银行平均本利为G ,银行平均年利率G -1。
数据分析与挖掘实验报告
《数据挖掘》实验报告 目录 1.关联规则的基本概念和方法 (1) 1.1数据挖掘 (1) 1.1.1数据挖掘的概念 (1) 1.1.2数据挖掘的方法与技术 (2) 1.2关联规则 (5) 1.2.1关联规则的概念 (5) 1.2.2关联规则的实现——Apriori算法 (7) 2.用Matlab实现关联规则 (12) 2.1Matlab概述 (12) 2.2基于Matlab的Apriori算法 (13) 3.用java实现关联规则 (19) 3.1java界面描述 (19) 3.2java关键代码描述 (23) 4、实验总结 (29) 4.1实验的不足和改进 (29) 4.2实验心得 (30)
1.关联规则的基本概念和方法 1.1数据挖掘 1.1.1数据挖掘的概念 计算机技术和通信技术的迅猛发展将人类社会带入到了信息时代。在最近十几年里,数据库中存储的数据急剧增大。数据挖掘就是信息技术自然进化的结果。数据挖掘可以从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的,人们事先不知道的但又是潜在有用的信息和知识的过程。 许多人将数据挖掘视为另一个流行词汇数据中的知识发现(KDD)的同义词,而另一些人只是把数据挖掘视为知识发现过程的一个基本步骤。知识发现过程如下: ·数据清理(消除噪声和删除不一致的数据)·数据集成(多种数据源可以组合在一起)·数据转换(从数据库中提取和分析任务相关的数据) ·数据变换(从汇总或聚集操作,把数据变换和统一成适合挖掘的形式) ·数据挖掘(基本步骤,使用智能方法提取数
据模式) ·模式评估(根据某种兴趣度度量,识别代表知识的真正有趣的模式) ·知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。 1.1.2数据挖掘的方法与技术 数据挖掘吸纳了诸如数据库和数据仓库技术、统计学、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成等许多应用领域的大量技术。数据挖掘主要包括以下方法。神经网络方法:神经网络由于本身良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性非常适合解决数据挖掘的问题,因此近年来越来越受到人们的关注。典型的神经网络模型主要分3大类:以感知机、bp反向传播模型、函数型网络为代表的,用于分类、预测和模式识别的前馈式神经网络模型;以hopfield 的离散模型和连续模型为代表的,分别用于联想记忆和优化计算的反馈式神经网络模型;以art 模型、koholon模型为代表的,用于聚类的自组
摘要:物理学是实验性学科,而物理实验在物理学的研究中占有非常重要的地位。本文着重介绍工科大学物理实验蕴涵的实验方法,提出工科大学物理实验的新类型。并介绍相关的数据处理的方法。 关键词:大学物理实验方法数据处理 正文: 一、大学物理实验方法 实验的目的是为了揭示与探索自然规律。掌握有关的基本实验方法,对提高科学实验能力有重要作用。实验离不开测量,如何根据测量要求,设计实验途径,达到实验目的?是一个必须思考的重要问题。有许多实验方法或测量方法,就是同一量的测量、同一实验也会体现多种方法且各种方法又相互渗透和结合。实验方法如何分类并无硬性规定。下面总结几种常用的基本实验方法。 根据测量方法和测量技术的不同,可以分为比较法、放大法、平衡法、转换法、模拟法、干涉法、示踪法等。 (一)比较法 根据一定的原理,通过与标准对象或标准量进行比较来确定待测对象的特征或待测量数值的实验方法称为比较法。它是最普遍、最基本、最常用的实验方法,又分直接比较法、间接比较法和特征比较法。直接比较法是将被测量与同类物理量的标准量直接进行比较,直接读数直接得到测量数据。例如,用游标卡尺和千分尺测量长度,用钟表测量时间。间接比较法是借助于一些中间量或将被测量进行某种变换,来间接实现比较测量的方法。例如,温度计测温度,电流表测电流,电位差计测电压,示波器上用李萨如图形测量未知信号频率等。特征比较法是通过与标准对象的特征进行比较来确定待测对象的特征的观测过程。例如,光谱实验就是通过光谱的比较来确定被测物体的化学成分及其含量的。 (二)放大法 由于被测量过小,用给定的某种仪器进行测量会造成很大的误差,甚至小到无法被实验者或仪器直接感觉和反应。此时可以先通过某种途径将被测量放大,然后再进行测量。放大被测量所用的原理和方法称为放大法。放大法分累计放大法、机械放大法、电磁放大法和光学放大法等。 1、累计放大法在被测物理量能够简单重叠的条件下,将它展延若干倍再进行测量的方法称为累计放大法。例如,在转动惯量的测量中用秒表测量三线摆的周期。
表1-1:不同频率下的遏止电压表 λ(nm)365 404.7 435.8 546.1 577 v(10^14)8.219 7.413 6.884 5.493 5.199 |Ua|(v) 1.727 1.357 1.129 0.544 0.418 表1-2:λ=365(nm)时不同电压下对应的电流值 U/(v)-1.927 -1.827 -1.727 -1.627 -1.527 -1.427 -1.327 I/(10^-11)A-0.4 -0.2 0 0.9 3.9 8.2 14 -1.227 -1.127 -1.027 -0.927 -0.827 -0.727 -0.718 24.2 38.1 52 66 80 97.2 100 表1-3:λ=404.7(nm)时不同电压下对应的电流值 U/(v) -1.477 -1.417 -1.357 -1.297 -1.237 -1.177 -1.117 I/(10^-11)A -1 -0.4 0 1.8 4.1 10 16.2 -1.057 -0.997 -0.937 -0.877 -0.817 -0.757 -0.737 24.2 36.2 49.8 63.9 80 93.9 100 表1-4:λ=435.8(nm)时不同电压下对应的电流值 U/(v)-1.229 -1.179 -1.129 -1.079 -1.029 -0.979 -0.929 I/(10^-11)A-1.8 -0.4 0 2 4.2 10.2 17.9 -0.879 -0.829 -0.779 -0.729 -0.679 -0.629 -0.579 -0.575 24.8 36 47 59 71.6 83.8 98 100 表1-5:λ=546.1(nm)时不同电压下对应的电流值 U/(v)-0.604 -0.574 -0.544 -0.514 -0.484 -0.454 -0.424 I/(10^-11)A-4 -2 0 3.8 10 16.2 24 -0.394 -0.364 -0.334 -0.304 -0.274 -0.244 -0.242 34 46 56.2 72 84.2 98.2 100 表1-6:λ=577(nm)时不同电压下对应的电流值 U/(v)-0.478 -0.448 -0.418 -0.388 -0.358 -0.328 -0.298 I/(10^-11)A-3.1 -1.8 0 2 6 10.2 16.1 -0.268 -0.238 -0.208 -0.178 -0.148 -0.118 -0.088 -0.058 22.1 31.8 39.8 49 58 68.2 79.8 90.1 -0.04 100
实验五相关分析实验报关费 一、实验目的: 学习利用spss对数据进行相关分析(积差相关、肯德尔等级相关)、偏相关分析。利用交叉表进行相关分析。 二、实验内容: 某班学生成绩表1如实验图表所示。 1.对该班物理成绩与数学成绩之间进行积差相关分析和肯德尔等级相关 分析。 2.在控制物理成绩不变的条件下,做数学成绩与英语成绩的相关分析(这 种情况下的相关分析称为偏相关分析)。 3.对该班物理成绩与数学成绩制作交叉表及进行其中的相关分析。 三、实验步骤: 1.选择分析→相关→双变量,弹出窗口,在对话框的变量列表中选变量 “数学成绩”、“物理成绩”,在相关系数列进行选择,本次实验选择 皮尔逊相关(积差相关)和肯德尔等级相关。单击选项,对描述统计 量进行选择,选择标准差和均值。单击确定,得出输出结果,对结果 进行分析解释。 2.选择分析→相关→偏相关,弹出窗口,在对话框的变量列表选变量“数 学成绩”、“英语成绩”,在控制列表选择要控制的变量“物理成绩” 以在控制物理成绩的影响下对变量数学成绩与英语成绩进行偏相关分 析;在“显著性检验”框中选双侧检验,单击确定,得出输出结果, 对结果进行分析解释。 3.选择分析→描述统计→交叉表,弹出窗口,对交叉表的行和列进行选 择,行选择为数学成绩,列选择为物理成绩。然后对统计量进行设置, 选择相关性,点击继续→确定,得出输出结果,对结果进行分析解释。 四、实验结果与分析:
表1
五、实验结果及其分析:
分析一:由实验结果可观察出,数学成绩与物理成绩的积差相关系数r=,肯德尔等级相关系数r=可知该班物理成绩和数学成绩之间存在显著相关。
1.4 实验数据处理的几种方法 物理实验中测量得到的许多数据需要处理后才能表示测量的最终结果。对实验数据进行记录、整理、计算、分析、拟合等,从中获得实验结果和寻找物理量变化规律或经验公式的过程就是数据处理。它是实验方法的一个重要组成部分,是实验课的基本训练内容。本章主要介绍列表法、作图法、图解法、逐差法和最小二乘法。 1.4.1 列表法 列表法就是将一组实验数据和计算的中间数据依据一定的形式和顺序列成表格。列表法可以简单明确地表示出物理量之间的对应关系,便于分析和发现资料的规律性,也有助于检查和发现实验中的问题,这就是列表法的优点。设计记录表格时要做到:(1)表格设计要合理,以利于记录、检查、运算和分析。 (2)表格中涉及的各物理量,其符号、单位及量值的数量级均要表示清楚。但不要把单位写在数字后。 (3)表中数据要正确反映测量结果的有效数字和不确定度。列入表中的除原始数据外,计算过程中的一些中间结果和最后结果也可以列入表中。 (4)表格要加上必要的说明。实验室所给的数据或查得的单项数据应列在表格的上部,说明写在表格的下部。 1.4.2 作图法 作图法是在坐标纸上用图线表示物理量之间的关系,揭示物理量之间的联系。作图法既有简明、形象、直观、便于比较研究实验结果等优点,它是一种最常用的数据处理方法。 作图法的基本规则是: (1)根据函数关系选择适当的坐标纸(如直角坐标纸,单对数坐标纸,双对数坐标纸,极坐标纸等)和比例,画出坐标轴,标明物理量符号、单位和刻度值,并写明测试条件。 (2)坐标的原点不一定是变量的零点,可根据测试范围加以选择。,坐标分格最好使最低数字的一个单位可靠数与坐标最小分度相当。纵横坐标比例要恰当,以使图线居中。 (3)描点和连线。根据测量数据,用直尺和笔尖使其函数对应的实验点准确地落在相应的位置。一张图纸上画上几条实验曲线时,每条图线应用不同的标记如“+”、“×”、“·”、“Δ”等符号标出,以免混淆。连线时,要顾及到数据点,使曲线呈光滑曲线(含直线),并使数据点均匀分布在曲线(直线)的两侧,且尽量贴近曲线。个别偏离过大的点要重新审核,属过失误差的应剔去。 (4)标明图名,即做好实验图线后,应在图纸下方或空白的明显位置处,写上图的名称、作者和作图日期,有时还要附上简单的说明,如实验条件等,使读者一目了然。作图时,一般将纵轴代表的物理量写在前面,横轴代表的物理量写在后面,中间用“~”
统计分析综合实验报告 学院: 专业: 姓名: 学号:
统计分析综合实验考题 一.样本数据特征分析: 要求收集国家统计局2011年全国人口普查与2000年全国人口普查相关数据,进行二者的比较,然后写出有说明解释的数据统计分析报告,具体要求如下: 1.报告必须包含所收集的公开数据表,至少包括总人口,流动人口,城乡、性别、年龄、民族构成,教育程度,家庭户人口八大指标; 2.报告中必须有针对某些指标的条形图,饼图,直方图,茎叶图以及累计频率条形图;(注:不同图形针对不同的指标)3.采用适当方式检验二次调查得到的人口年龄比例以及教育程度这两个指标是否有显著不同,写明检验过程及结论。 4.报告文字通顺,通过数据说明问题,重点突出。 二.线性回归模型分析: 自选某个实际问题通过建立线性回归模型进行研究,要求: 1.自行搜集问题所需的相关数据并且建立线性回归模型; 2.通过SPSS软件进行回归系数的计算和模型检验; 3.如果回归模型通过检验,对回归系数以及模型的意义进行 解释并且作出散点图
一、样本数据特征分析 2010年全国人口普查与2000年全国人口普查相关数据分析报告 2011年第六次全国人口普查数据显示,总人口数为1370536875,比2000年的第五次人口普查的1265825048人次,总人口数增加73899804人,增长5.84%,平均年增长率为0.57%。
做茎叶图分析: 描述 年份统计量标准误 人口数量2000年均值40084265.35 4698126.750 均值的 95% 置信区间 下限30489410.50 上限49679120.21 5% 修整均值39305445.50 中值35365072.00 方差 68424424372574 4.400 标准差26158062.691 极小值2616329
1.方差分析在科学研究中有何意义?如何进行平方和与自由度的分解?如何进行F检验和 多重比较? (1)方差分析的意义 方差分析,又称变量分析,其实质是关于观察值变异原因的数量分析,是科学研究的重要工具。方差分析得最大公用在于:a. 它能将引起变异的多种因素的各自作用一一剖析出来,做出量的估计,进而辨明哪些因素起主要作用,哪些因素起次要作用。b. 它能充分利用资料提供的信息将试验中由于偶然因素造成的随机误差无偏地估计出来,从而大大提高了对实验结果分析的精确性,为统计假设的可靠性提供了科学的理论依据。 (2)平方和及自由度的分解 方差分析之所以能将试验数据的总变异分解成各种因素所引起的相应变异,是根据总平方和与总自由度的可分解性而实现的。 (3)F检验和多重比较 ①F检验的目的在于,推断处理间的差异是否存在,检验某项变异原因的效应方差是否为零。实际进行F检验时,是将由试验资料算得的F值与根据df1=df t(分子均方的自由度)、df2=df e(分母均方的自由度)查附表4(F值表)所得的临界F值(F0.05(df1,df2)和F0.01(df1,df2))相比较做出统计判断。若F< F0.05(df1,df2),即P>0.05,不能否定H0,可认为各处理间差异不显著;若F0.05(df1,df2)≤F<F0.01(df1,df2),即0.01 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 2.00 1 . 03 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验 数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下: (1)K—S检验 单样本 Kolmogorov-Smirnov 检验 身高 N 60 正态参数a,,b均值139.00 标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z .686 渐近显着性(双侧) .735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验 正态性检验 结果:在Shapiro-Wilk 检验结果972.00=w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5多维正态数据的统计量 均值向量为:)767.33,505.4,836.27,219.18(=- X . 信息工程学院资源环境学院《GIS原理》实验报告 实验名称矢量及栅格数据分析 实验时间2015.4.22 实验地点资环楼229 姓名 学号 班级遥感科学与技术131 《GIS原理》实验报告 一、实验目的及要求 1)掌握矢量数据插值分析、栅格数据重分类、叠加分析的基本原理; 2)熟悉ArcGis 中离散点数据插值分析的基本方法; 3)熟悉ArcGis 中栅格数据重分类、栅格计算器的基本操作; 4)熟悉ArcGis 中栅格数据分区统计的基本方法; 5)了解ArcGis 中缓冲区分析、按掩膜提取的基本方法。 二、实验设备及软件平台 ArcCatalog 10、ArcMap 10.2 三、实验原理 1)数据插值分析 2)栅格数据重分类原理 3)叠加分析的基本原理 四、实验容与步骤 1 空间插值分析 1)打开ArcMap中,将数据框更名为“任务1”,加入省边界图层。 2)将2011 年02 月27 日08 时观测资料.xls、2011 年02 月27日14 时.xls 通过Add Xy Data 功能,生成点图层。导出数据,分别命名为Obs2708.shp 和Obs2714.shp。 3)对Obs2708.shp 中的属性“温度”在四川围进行插值分析。可以通过“Arctoolbox->Spatial Analyst(空间分析)工具中的Interpolate to Raster(插值)工具选择。(本实验采用反距离权重法IDW),点插值成栅格表面。 4)通过属性中的符号系统,修改显示样式。 2 多栅格局域运算 1)启动ArcMap,添加数据框,并更名为“任务2”,将温度栅格数据IDW2708、IDW2714 加入。 2)确认是否选择扩展模块的许可。“自定义菜单(Customize)”中的“扩展模块Extensions”功能对话框中的Spatial Analyst 均已打钩。 实验8-1 数据分析 一、实验目的 1.理解数据挖掘的一般流程。 2.掌握数据探索和预处理的方法。 3.使用PHSTAT软件,结合Excel对给定的数据进行手工预处理。 4.使用WEKA软件,对给定的数据进行预处理。 二、实验容 在D盘中以“班级-学号-”命名一个文件夹,将下发的数据拷贝到该文件夹下,根据不同要求,对下发的文件进行相应的数据分析和处理。 0. 数据集介绍 银行资产评估数据bank-data.xlsx,数据里有12个属性,分别是id(编号), age(年龄), sex(性别), region(地区), income(收入),married(婚否), children(子女数), car(是否有私家车), save_act(是否有定期存款), current_act(是否有活期账户), mortgage(是否有资产抵押), pep(目标变量,是否买个人理财计划Personal Equity Plan)。 1.数据探索之数据质量分析 新建“1-数据质量分析.xlsx”文件,导入“0-bank_data.xlsx”文件数据,请你用EXCEL对其进行数据质量分析。 【要求】 (1)请找出bank_data.xlsx表中的含有缺失值的记录。 (2)请你用PHSTAT软件绘制“income(收入)”属性的箱线图和点比例图,筛选出异常值。 (3)计算Whisker上限、Whisker下限,并利用高级筛选,找出该属性的异常值记录。 【提示】 (1)请找出bank_data.xlsx表中的含有缺失值的记录。 方法1:条件格式法 1)选取A1:L601区域。 2)开始 --> 条件格式 --> 新建规则(N)...,在"新建格式规则"对话框中,选择空值。如图8-1所示。数据分析实验报告p
矢量及栅格数据分析实验报告
实验8-1数据分析报告
相关主题
文本预览