
统计建模与R软件第六章习题答案(回归分析)
Ex6.1
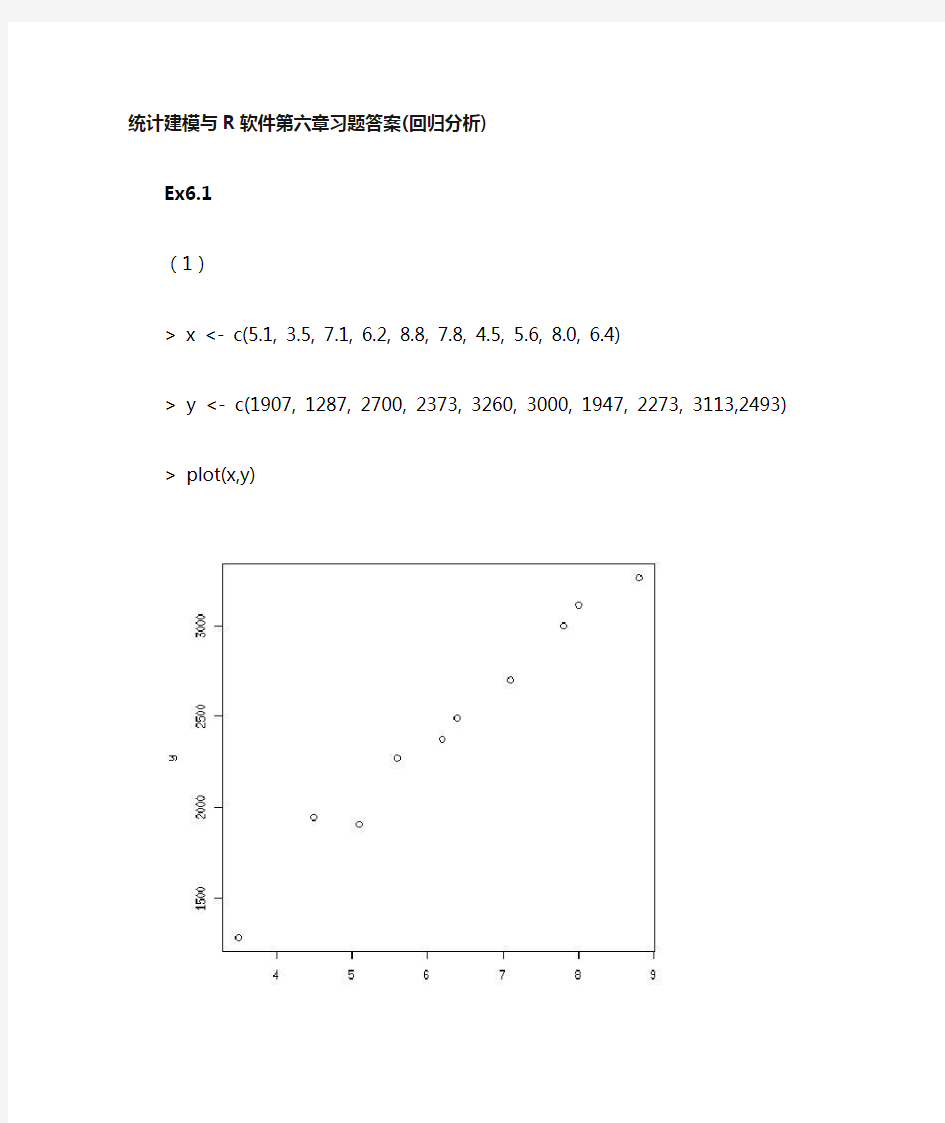
(1)
> x <- c(5.1, 3.5, 7.1, 6.2, 8.8, 7.8, 4.5, 5.6, 8.0, 6.4)
> y <- c(1907, 1287, 2700, 2373, 3260, 3000, 1947, 2273, 3113,2493) > plot(x,y)
由此判断,Y和X有线性关系。
(2)
> lm.sol<-lm(y~1+x)
> summary(lm.sol)
Call:
lm(formula = y ~ 1 + x)
Residuals:
Min 1Q Median 3Q Max
-128.591 -70.978 -3.727 49.263 167.228
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 140.95 125.11 1.127 0.293
x 364.18 19.26 18.908 6.33e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 96.42 on 8 degrees of freedom
Multiple R-squared: 0.9781, Adjusted R-squared: 0.9754
F-statistic: 357.5 on 1 and 8 DF, p-value: 6.33e-08
回归方程为Y=140.95+364.18X
(3)
β1项很显著,但常数项β0不显著。
回归方程很显著。
(4)
> new <- data.frame(x=7)
> lm.pred<-predict(lm.sol,new,interval="prediction")
> lm.pred
fit lwr upr
1 2690.227 2454.971 2925.484
故Y(7)= 2690.227, [2454.971,2925.484]
Ex6.2
(1)
>pho<-data.frame(x1 <- c(0.4,0.4,3.1,0.6,4.7,1.7,9.4,10.1,11.6,12.6,10.9,23.1,23.1,21.6,23.1,1.9,26 .8,29.9), x2 <- c(52,34,19,34,24,65,44,31,29,58,37,46,50,44,56,36,58,51), x3 <- c(158,163,37,157,59,123,46,117,173,112,111,114,134,73,168,143,202,124), y <- c(64,60,71,61,54,77,81,93,93,51,76,96,77,93,95,54,168,99))
> lm.sol<-lm(y~x1+x2+x3,data=pho)
> summary(lm.sol)
Call:
lm(formula = y ~ x1 + x2 + x3, data = pho)
Residuals:
Min 1Q Median 3Q Max
-27.575 -11.160 -2.799 11.574 48.808
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 44.9290 18.3408 2.450 0.02806 *
x1 1.8033 0.5290 3.409 0.00424 **
x2 -0.1337 0.4440 -0.301 0.76771
x3 0.1668 0.1141 1.462 0.16573
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 19.93 on 14 degrees of freedom Multiple R-squared: 0.551, Adjusted R-squared: 0.4547
F-statistic: 5.726 on 3 and 14 DF, p-value: 0.009004
回归方程为y=44.9290+1.8033x1-0.1337x2+0.1668x3 (2)
回归方程显著,但有些回归系数不显著。
(3)
> lm.step<-step(lm.sol)
Start: AIC=111.2
y ~ x1 + x2 + x3
Df Sum of Sq RSS AIC
- x2 1 36.0 5599.4 109.3
- x3 1 849.8 6413.1 111.8
- x1 1 4617.8 10181.2 120.1
Step: AIC=109.32
y ~ x1 + x3
Df Sum of Sq RSS AIC
- x3 1 833.2 6432.6 109.8
- x1 1 5169.5 10768.9 119.1
> summary(lm.step)
Call:
lm(formula = y ~ x1 + x3, data = pho)
Residuals:
Min 1Q Median 3Q Max
-29.713 -11.324 -2.953 11.286 48.679
Coefficients:
Estimate Std. Error t value Pr(>|t|) (Intercept) 41.4794 13.8834 2.988 0.00920 **
x1 1.7374 0.4669 3.721 0.00205 **
x3 0.1548 0.1036 1.494 0.15592
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 19.32 on 15 degrees of freedom
Multiple R-squared: 0.5481, Adjusted R-squared: 0.4878
F-statistic: 9.095 on 2 and 15 DF, p-value: 0.002589
x3仍不够显著。
再用drop1函数做逐步回归。
> drop1(lm.step)
Single term deletions
Model:
y ~ x1 + x3
Df Sum of Sq RSS AIC
x1 1 5169.5 10768.9 119.1
x3 1 833.2 6432.6 109.8
可以考虑再去掉x3.
> lm.opt<-lm(y~x1,data=pho);summary(lm.opt)
Call:
lm(formula = y ~ x1, data = pho)
Residuals:
Min 1Q Median 3Q Max
-31.486 -8.282 -1.674 5.623 59.337
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 59.2590 7.4200 7.986 5.67e-07 ***
x1 1.8434 0.4789 3.849 0.00142 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 20.05 on 16 degrees of freedom
Multiple R-squared: 0.4808, Adjusted R-squared: 0.4484
F-statistic: 14.82 on 1 and 16 DF, p-value: 0.001417
皆显著。
Ex6.3
> x<-c(1,1,1,1,2,2,2,3,3,3,4,4,4,5,6,6,6,7,7,7,8,8,8,9,11,12,12,12)
>
y<-c(0.6,1.6,0.5,1.2,2.0,1.3,2.5,2.2,2.4,1.2,3.5,4.1,5.1,5.7,3.4,9.7,8.6,4.0,5 .5,10.5,17.5,13.4,4.5,30.4,12.4,13.4,26.2,7.4)
> plot(x,y)
> lm.sol<-lm(y~1+x)
> summary(lm.sol)
Call:
lm(formula = y ~ 1 + x)
Residuals:
Min 1Q Median 3Q Max
-9.8413 -2.3369 -0.0214 1.0592 17.8320
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.4519 1.8353 -0.791 0.436
x 1.5578 0.2807 5.549 7.93e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.168 on 26 degrees of freedom
Multiple R-squared: 0.5422, Adjusted R-squared: 0.5246
F-statistic: 30.8 on 1 and 26 DF, p-value: 7.931e-06
线性回归方程为y=-1.4519+1.5578x,通过F 检验。常数项参数未通过t 检验。> abline(lm.sol)
> y.yes<-resid(lm.sol)
> y.fit<-predict(lm.sol)
> y.rst<-rstandard(lm.sol) > plot(y.yes~y.fit)
> plot(y.rst~y.fit)
残差并非是等方差的。
修正模型,对相应变量Y做开方。
> lm.new<-update(lm.sol,sqrt(.)~.)
> summary(lm.new)
Call:
lm(formula = sqrt(y) ~ x)
Residuals:
Min 1Q Median 3Q Max
-1.54255 -0.45280 -0.01177 0.34925 2.12486 Coefficients:
Estimate Std. Error t value Pr(>|t|) (Intercept) 0.76650 0.25592 2.995 0.00596 **
x 0.29136 0.03914 7.444 6.64e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.7206 on 26 degrees of freedom
Multiple R-squared: 0.6806, Adjusted R-squared: 0.6684
F-statistic: 55.41 on 1 and 26 DF, p-value: 6.645e-08
此时所有参数和方程均通过检验。
对新模型做标准化残差图,情况有所改善,不过还是存在一个离群值。第24和第28个值存在问题。
Ex6.4
> toothpaste<-data.frame( X1=c(-0.05, 0.25,0.60,0,0.20, 0.15,-0.15, 0.15,0.10,0.40,0.45,0.35,0.30,
0.50,0.50,0.40,-0.05,-0.05,-0.10,0.20,0.10,0.50,0.60,-0.05,0,0.05,0.55),X2 =c(5.50,6.75,7.25,5.50,6.50,6.75,5.25,6.00,6.25,7.00,6.90,6.80,6.80,7.10,7 .00,6.80,6.50,6.25,6.00,6.50,7.00,6.80,6.80,6.50,5.75,5.80,6.80),Y=c(7.38, 8.51,9.52,7.50,8.28,8.75,7.10,8.00,8.15,9.10,8.86,8.90,8.87,9.26,9.00,8.75, 7.95, 7.65,7.27,8.00,8.50,8.75,9.21,8.27,7.67,7.93,9.26))
> lm.sol<-lm(Y~X1+X2,data=toothpaste); summary(lm.sol)
Call:
lm(formula = Y ~ X1 + X2, data = toothpaste)
Residuals:
Min 1Q Median 3Q Max
-0.37130 -0.10114 0.03066 0.10016 0.30162
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.0759 0.6267 6.504 1.00e-06 ***
X1 1.5276 0.2354 6.489 1.04e-06 ***
X2 0.6138 0.1027 5.974 3.63e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1767 on 24 degrees of freedom
Multiple R-squared: 0.9378, Adjusted R-squared: 0.9327
F-statistic: 181 on 2 and 24 DF, p-value: 3.33e-15
回归诊断:
> influence.measures(lm.sol)
Influence measures of
lm(formula = Y ~ X1 + X2, data = toothpaste) :
dfb.1_ dfb.X1 dfb.X2 dffit cov.r cook.d hat inf
1 0.00908 0.00260 -0.00847 0.0121 1.366 5.11e-05 0.1681
2 0.06277 0.04467 -0.06785 -0.1244 1.159 5.32e-0
3 0.0537
3 -0.02809 0.0772
4 0.02540 0.1858 1.283 1.19e-02 0.1386
4 0.11688 0.0505
5 -0.11078 0.1404 1.377 6.83e-03 0.1843 *
5 0.01167 0.01887 -0.0176
6 -0.103
7 1.141 3.69e-03 0.0384
6 -0.43010 -0.42881 0.45774 0.6061 0.814 1.11e-01 0.0936
7 0.07840 0.01534 -0.07284 0.1082 1.481 4.07e-03 0.2364 *
8 0.01577 0.00913 -0.01485 0.0208 1.237 1.50e-04 0.0823
9 0.01127 -0.02714 -0.00364 0.1071 1.156 3.95e-03 0.0466
10 -0.07830 0.00171 0.08052 0.1890 1.155 1.22e-02 0.0726
11 0.00301 -0.09652 -0.00365 -0.2281 1.127 1.76e-02 0.0735
12 -0.03114 0.01848 0.03459 0.1542 1.132 8.12e-03 0.0514
13 -0.09236 -0.03801 0.09940 0.2201 1.071 1.62e-02 0.0522
14 -0.02650 0.03434 0.02606 0.1179 1.235 4.81e-03 0.0956
15 0.00968 -0.11445 -0.00857 -0.2545 1.150 2.19e-02 0.0910
16 -0.00285 -0.06185 0.00098 -0.1608 1.146 8.83e-03 0.0594
17 0.07201 0.09744 -0.07796 -0.1099 1.364 4.19e-03 0.1731
18 0.15132 0.30204 -0.17755 -0.3907 1.087 5.04e-02 0.1085
19 0.07489 0.47472 -0.12980 -0.7579 0.731 1.66e-01 0.1092
20 0.05249 0.08484 -0.07940 -0.4660 0.625 6.11e-02 0.0384 *
21 0.07557 0.07284 -0.07861 -0.0880 1.471 2.69e-03 0.2304 *
22 -0.17959 -0.39016 0.18241 -0.5494 0.912 9.41e-02 0.1022
23 0.06026 0.10607 -0.06207 0.1251 1.374 5.42e-03 0.1804
24 -0.54830 -0.74197 0.59358 0.8371 0.914 2.13e-01 0.1731
25 0.08541 0.01624 -0.07775 0.1314 1.249 5.97e-03 0.1069
26 0.32556 0.11734 -0.30200 0.4480 1.018 6.49e-02 0.1033
27 0.17243 0.32754 -0.17676 0.4127 1.148 5.66e-02 0.1369
> source("Reg_Diag.R");Reg_Diag(lm.sol) #薛毅老师自己写的程序residual s1 standard s2 student s3 hat_matrix s4 DFFITS s5
1 0.00443843 0.02753865 0.02695925 0.16811819 0.01211949
2 -0.09114255 -0.53021138 -0.52211469 0.05369239 -0.1243672 7
3 0.07726887 0.47112863 0.46335666 0.13857353 0.18584310
4 0.0480566
5 0.30111062 0.29532912 0.18427663 0.14036860
5 -0.09130271 -0.52689847 -0.5188140
6 0.03838430 -0.1036544 2
6 0.30162101 1.79287913 1.88596579 0.09362223 0.60613406
7 0.03066005 0.19855842 0.19453763 0.23641540 * 0.1082462 6
8 0.01199519 0.07085860 0.06937393 0.08226537 0.02077047
9 0.08491891 0.49217591 0.48426323 0.04664158 0.10711246
10 0.11625405 0.68315814 0.67537315 0.07261134 0.1889796 9
11
-0.13874451 -0.81570765 -0.80983786 0.07348894 -0.22807820 12 0.11540228 0.67051940 0.66263761 0.05137589 0.1542086 4
13 0.16178406 0.94041623 0.93806144 0.05219432 0.2201320 4
14 0.06210727 0.36957277 0.36282531 0.09557411 0.1179454 6
15
-0.13650951 -0.81026658 -0.80428349 0.09101221 -0.25449541 16
-0.11097950 -0.64757782 -0.63955524 0.05943308 -0.16076716 17
-0.03939381 -0.24515626 -0.24029557 0.17309048 -0.10993940 18
-0.18593575 -1.11438446 -1.12029013 0.10845395 -0.39073410 19 -0.33609591 -2.01522068 * -2.16439284 * 0.10922236 -0.75789180 *
20 -0.37130271 * -2.14274943 * -2.33258738 *
0.03838430 -0.46603012
21 -0.02545527 -0.16420856 -0.16084153 0.23042354 * -0.08801075
22
-0.26374306 -1.57517595 -1.62848498 0.10217431 -0.54936198 23 0.04349338 0.27187605 0.26656251 0.18041800 0.1250670 2
24 0.28060619 1.74627363 1.82969510 0.17309048 0.8371173 1 *
25 0.06459859 0.38683016 0.37987153 0.10691352 0.1314335 7
26 0.21752520 1.29995371 1.31989945 0.10329116 0.4479677 0
27 0.16987516 1.03474390 1.03633781 0.13685835 0.4126634 1
cooks_distance s6 COVRATIO s7
1 5.108777e-05 1.3656752
2 5.316885e-0
3 1.1589547
3 1.190200e-02 1.2827036
4 6.827446e-03 1.3771332
5 3.693897e-03 1.1410104
6 1.106753e-01 0.8143179
7 4.068871e-03 1.4806452 *
8 1.500251e-04 1.2372586
9 3.950358e-03 1.1560508
10 1.218047e-02 1.1550557
11 1.759216e-02 1.1271148
12 8.116460e-03 1.1316638
13 1.623390e-02 1.0710597
14 4.811117e-03 1.2349272
15 2.191171e-02 1.1501502
16 8.832858e-03 1.1457602
17 4.193532e-03 1.3637206
18 5.035591e-02 1.0866343
19 1.659840e-01 0.7313914
20 6.109050e-02 0.6248838
21 2.691197e-03 1.4714103
22 9.412101e-02 0.9121786
23 5.423856e-03 1.3735324
24 2.127740e-01 * 0.9139942
25 5.971157e-03 1.2485557
26 6.488529e-02 1.0178195
27 5.658922e-02 1.1479080
为什么两种方法检测结果不一样呢...不继续了
Ex6.5
> cement<-data.frame(X1=c( 7, 1, 11, 11, 7, 11, 3, 1, 2, 21, 1, 11, 10),X2=c(26, 29, 56, 31, 52, 55, 71, 31, 54, 47, 40, 66, 68),X3=c( 6, 15, 8, 8, 6, 9, 17, 22, 18, 4, 23, 9, 8),X4=c(60, 52, 20, 47, 33, 22, 6, 44, 22, 26, 34, 12, 12),Y =c(78.5, 74.3, 104.3, 87.6, 95.9, 109.2, 102.7, 72.5, 93.1,115.9, 83.8, 113.3, 109.4))
> xx<-cor(cement[1:4])
> kappa(xx,exact=T)
[1] 1376.881
大于1000,认为有严重的多重共线性。
> eigen(xx)
$values
[1] 2.235704035 1.576066070 0.186606149 0.001623746
$vectors
[,1] [,2] [,3] [,4]
[1,] -0.4759552 0.5089794 0.6755002 0.2410522
[2,] -0.5638702 -0.4139315 -0.3144204 0.6417561
[3,] 0.3940665 -0.6049691 0.6376911 0.2684661
[4,] 0.5479312 0.4512351 -0.1954210 0.6767340
即2.235704035X1+1.576066070X2+0.186606149X3+0.001623746X4=0
可以忽略X4项,可以看出X1,X2,X3存在共线性。
删去X3和X4后:
> xx<-cor(cement[1:2])
> kappa(xx,exact=T)
[1] 1.59262
共线性消失了。
如果去掉X3呢?
> cement1<-cbind(cement$X1,cement$X2,cement$X4)
> xx<-cor(cement1)
> kappa(xx,exact=T)
[1] 77.25113
如果去掉X4呢?
> xx<-cor(cement[1:3])
> kappa(xx,exact=T)
[1] 11.12112
看起来去掉X3和X4是合理的。
Ex6.6
>infection<-data.frame(x1<-c(0,1,0,0,0,1,1,1),x2<-c(0,0,1,0,1,0,1,1),x3<-c (0,0,0,1,1,1,0,1),success<-c(0,0,23,8,28,0,11,1),fail<-c(9,0,3,32,30,2,87,17 ))
> infection$Ymat<-cbind(infection$success,infection$fail)
> glm.sol<-glm(Ymat~x1+x2+x3,family=binomial,data=infection)
> summary(glm.sol)
Call:
glm(formula = Ymat ~ x1 + x2 + x3, family = binomial, data = infection) Deviance Residuals:
1 2 3 4 5 6 7 8
-2.56229 0.00000 1.49623 1.21563 -0.78520 -0.15231 -0.07162 0. 26470
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.8207 0.4947 -1.659 0.0971 .
x1 -3.2544 0.4813 -6.761 1.37e-11 ***
x2 2.0299 0.4553 4.459 8.25e-06 ***
x3 -1.0720 0.4254 -2.520 0.0117 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 83.491 on 6 degrees of freedom
Residual deviance: 10.997 on 3 degrees of freedom
AIC: 36.178
Number of Fisher Scoring iterations: 5
回归模型为
P=exp(-0.8207-3.2544x1+2.0299x2-1.0720x3)/(1+exp(-0.8207-3.2544x1+2 .0299x2-1.0720x3))
Ex6.7
(1)
> x<-c(rep(0:6,rep(2,7)))
>
y<-c(508.1,498.4,568.2,577.3,651.7,657.0,713.4,697.5,755.3,758.9,787.6,7 92.1,841.4,831.8)
> lm.sol<-lm(y~1+x)
> summary(lm.sol)
Call:
lm(formula = y ~ 1 + x)
Residuals:
Min 1Q Median 3Q Max
-25.400 -11.484 -3.779 14.629 24.921
Coefficients:
Estimate Std. Error t value Pr(>|t|) (Intercept) 523.800 8.474 61.81 < 2e-16 ***
x 54.893 2.350 23.36 2.26e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 17.59 on 12 degrees of freedom Multiple R-squared: 0.9785, Adjusted R-squared: 0.9767 F-statistic: 545.5 on 1 and 12 DF, p-value: 2.265e-11
线性回归模型为y=523.800+54.893x,通过t检验和F检验。(2)
> lm.sol<-lm(y~1+x+I(x^2));summary(lm.sol)
Call:
lm(formula = y ~ 1 + x + I(x^2))
Residuals:
Min 1Q Median 3Q Max
-10.6643 -5.6622 -0.4655 5.5000 10.6679 Coefficients:
Estimate Std. Error t value Pr(>|t|) (Intercept) 502.5560 4.8500 103.619 < 2e-16 ***
x 80.3857 3.7861 21.232 2.81e-10 ***
I(x^2) -4.2488 0.6063 -7.008 2.25e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 7.858 on 11 degrees of freedom Multiple R-squared: 0.9961, Adjusted R-squared: 0.9953
F-statistic: 1391 on 2 and 11 DF, p-value: 5.948e-14
多项式回归模型为:
y=502.5560+80.3857x-4.2488x^2,通过t检验和F检验。(3)作散点图和拟合曲线:
> plot(x,y)
> xfit<-seq(0,6,0.01)
> yfit<-predict(lm.sol,data.frame(x=xfit))
> lines(xfit,yfit)
Ex6.8
读入数据:
> cancer<-read.table("data",header=T) > cancer
x1 x2 x3 x4 x5 y
1 70 64 5 1 1 1
2 60 6
3 9 1 1 0
3 70 65 11 1 1 0
4 40 69 10 1 1 0
5 40 63 58 1 1 0
6 70 48 9 1 1 0
7 70 48 11 1 1 0
8 80 63 4 2 1 0
9 60 63 14 2 1 0
10 30 53 4 2 1 0
11 80 43 12 2 1 0
12 40 55 2 2 1 0
13 60 66 25 2 1 1
14 40 67 23 2 1 0
15 20 61 19 3 1 0
16 50 63 4 3 1 0
17 50 66 16 0 1 0
18 40 68 12 0 1 0
19 80 41 12 0 1 1
20 70 53 8 0 1 1
21 60 37 13 1 1 0
22 90 54 12 1 0 1
23 50 52 8 1 0 1
24 70 50 7 1 0 1
25 20 65 21 1 0 0
26 80 52 28 1 0 1
27 60 70 13 1 0 0
28 50 40 13 1 0 0
29 70 36 22 2 0 0
30 40 44 36 2 0 0
31 30 54 9 2 0 0
32 30 59 87 2 0 0
33 40 69 5 3 0 0
34 60 50 22 3 0 0
35 80 62 4 3 0 0
36 70 68 15 0 0 0
37 30 39 4 0 0 0
38 60 49 11 0 0 0
39 80 64 10 0 0 1
40 70 67 18 0 0 1
>
glm.sol<-glm(y~x1+x2+x3+x4+x5,family=binomial,data=cancer);summary( glm.sol)
Call:
glm(formula = y ~ x1 + x2 + x3 + x4 + x5, family = binomial, data = cancer)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.71500 -0.66725 -0.22254 0.09936 2.23936
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -7.01140 4.47534 -1.567 0.1172
x1 0.09994 0.04304 2.322 0.0202 *
x2 0.01415 0.04697 0.301 0.7631
x3 0.01749 0.05458 0.320 0.7486
x4 -1.08297 0.58721 -1.844 0.0651 .
x5 -0.61309 0.96066 -0.638 0.5233
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 44.987 on 39 degrees of freedom Residual deviance: 28.392 on 34 degrees of freedom AIC: 40.392
Number of Fisher Scoring iterations: 6
有的系数并不显著。
下面做逐步回归:
> glm.new<-step(glm.sol)
Start: AIC=40.39
y ~ x1 + x2 + x3 + x4 + x5
Df Deviance AIC
- x3 1 28.484 38.484
- x2 1 28.484 38.484
- x5 1 28.799 38.799
- x4 1 32.642 42.642
- x1 1 38.306 48.306
Step: AIC=38.48
y ~ x1 + x2 + x4 + x5
Df Deviance AIC
- x2 1 28.564 36.564
- x5 1 28.993 36.993
- x4 1 32.705 40.705
- x1 1 38.478 46.478
Step: AIC=36.56
y ~ x1 + x4 + x5
Df Deviance AIC
- x5 1 29.073 35.073
- x4 1 32.892 38.892
- x1 1 38.478 44.478
Step: AIC=35.07
y ~ x1 + x4
Df Deviance AIC
- x4 1 33.535 37.535
- x1 1 39.131 43.131
只留下x1和x4两个变量。
> summary(glm.new)
Call:
glm(formula = y ~ x1 + x4, family = binomial, data = cancer)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.4825 -0.6617 -0.1877 0.1227 2.2844
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -6.13755 2.73844 -2.241 0.0250 *
x1 0.09759 0.04079 2.393 0.0167 *
x4 -1.12524 0.60239 -1.868 0.0618 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 44.987 on 39 degrees of freedom
Residual deviance: 29.073 on 37 degrees of freedom
AIC: 35.073
Number of Fisher Scoring iterations: 6
回归方程为
P=exp(-6.13755+0.09759x1-1.12524x4)/(1+exp(-6.13755+0.09759x1-1.12 524x4))
概率估计略。
Ex6.9
我表示不想做了...
我没弄明白nls()函数里所说的start即初始值怎么设置。好像可以随便设置,只要保证函数收敛即可??
社会统计学课程期末复习题 一、填空题(计算结果一般保留两位小数) 1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。 2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。 3、在回归分析中,各实际观测值y 与估计值y ?的离差平方和称为 剩余 变差。 4、平均增长速度= 平均发展速度 —1(或100%)。 5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。 6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。 7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。 8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为 100%7% A 100% 1.06%100%6% -=-=-产品单位成本计划超额完成程度 ;若某厂计划规定B 产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为 100%10% 100% 4.76%100%5% +=-=+B 产品产量计划超额完成程度 。 9、按照标志表现划分,学生的民族、性别、籍贯属于 品质 标志;学生的体重、年龄、成绩属于 数量 标志。 10、从内容上看,统计表由 主词 和 宾词 两个部分组成;从格式上看,统计表由 总标题 、 横行标题 、 纵栏标题 和 指标数值(或统计数值); 四个部分组成。 11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于 正 相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于 负 相关。 12、按指标所反映的数量性质不同划分,国民生产总值属于 数量 指标;单位成本属于 质量 指标。 13、如果相关系数r=0,则表明两个变量之间 不存在线性相关关系 。 二、判断题
第六章抽样调查 1.当研究目的一旦确定,全及总体也就相应确定,而从全及总体中抽取的抽样 总体则是不确定的。(V )2.从全部总体单位中按照随机原则抽取部分单位组成样本,只可能组成一个样 本。( X )3.在抽样推断中,作为推断的总体和作为观察对象的样本都是确定的、唯一的。 (X )4.我们可以任取某一次抽样所得的抽样误差,来作为衡量抽样指标对于全及指 标的代表性程度。(X ) 5.由于没有遵守随机原则而造成的误差,通常称为随机误差。(X ) 6.抽样平均误差是表明抽样估计的准确度,抽样极限误差则是表明抽样估计准 确程度的范围;两者既有区别,又有联系。( V ) 7.抽样平均均误差反映抽样的可能误差范围,实际上每次的抽样误差可能大于 抽样平均误差,也可能小于抽样平均误差。( V ) 8.所有可能的样本平均数的平均数等于总体平均数。(V ) 9.按有关标志排队,随机起点的等距抽样可能产生系统性误差。( V ) 10.抽样推断是利用样本资料对总体的数量特征进行估计的一种统计分析方法, 因此不可避免的会产生误差,这种误差的大小是不能进行控制的。(X )11.重复抽样时,其他条件不变,允许误差扩大一倍,则抽样数目为原来的2倍。 (X) 12.扩大或缩小抽样误差范围的倍数叫概率度,其代表符号是V。(V) 13.重复抽样时若其它条件一定,而抽样单位数目增加3倍,则抽样平均误差为 原来的2倍。(X) 14.由于抽样调查存在抽样误差,所以抽样调查资料的准确性要比全面调查资料 的准确性差。(X) 15.在保证概率度和总体方差一定的条件下允许误差大小与抽样数目多少成正 比。(X) 16.扩大或缩小了以后的抽样误差范围叫抽样极限误差。(X) 17.如果总体平均数落在区间(960,1040)内的概率为0.9545,则抽样平均误 差等于30。(X) 18.抽样估计置信度就是表明抽样指标和总体指标的误差不超过一定范围的概 率保证程度。(V )19.扩大抽样误差的范围,会降低推断的把握程度,但会提高推断的准确度。(X)
张厚粲现代心理与教育统计学第一章答案 1名词概念 (1 )随机变量 答:在统计学上把取值之前,不能准确预料取到什么值的变量,称为随机变量。 (2)总体 答:总体(population )又称为母全体或全域,是具有某种特征的一类事物的总体,是研究对象的全体。 (3)样本 答:样本是从总体中抽取的一部分个体。 (4)个体 答:构成总体的每个基本单元。 (5)次数 是指某一事件在某一类别中出现的数目,又称作频数,用f表示。 (6)频率 答:又称相对次数,即某一事件发生的次数除以总的事件数目,通常用比例或百分数来表示。 (7)概率 答:概率(probability), 概率论术语,指随机事件发生的可能性大小度量指标。其描述性定义。随机事件A在所有试验中发生的可能性大小的量值,称为事件A的概率,记为P(A)。 (8)统计量 答:样本的特征值叫做统计量,又称作特征值。 (9)参数 答:又称总体参数,是描述一个总体情况的统计指标。 (10)观测值 答:随机变量的取值,一个随机变量可以有多个观测值。 2何谓心理与教育统计学?学习它有何意义? 答:(1)心理与教育统计学是专门研究如何运用统计学原理和方法,搜集、整理、分析心理 与教育科学研究中获得的随机性数据资料,并根据这些数据资料传递的信息,进行科学推论 找出心理与教育统计活动规律的一门学科。具体讲,就是在心理与教育研究中,通过调查、实验、测量等手段有意地获取一些数据,并将得到的数据按统计学原理和步骤加以整理、计 算、绘制图表、分析、判断、推理,最后得出结论的一种研究方法。 (2)学习心理与教育统计学有重要的意义。 ①统计学为科学研究提供了一种科学方法。 科学是一种知识体系。它的研究对象存在于现实世界各个领域的客观事实之中。它的主 要任务是对客观事实进行预测和分类,从而揭示蕴藏于其中的种种因果关系。要提高对客观 事实观测及分析研究的能力,就必须运用科学的方法。统计学正是提供了这样一种科学方法。统计方法是从事科学研究的一种必不可少的工具。 ②心理与教育统计学是心理与教育科研定量分析的重要工具。 凡是客观存在事物,都有数量的表现。凡是有数量表现的事物,都可以进行测量。心理 与教育现象是一种客观存在的事物,它也有数量的表现。虽然心理与教育测量具有多变性而 且旨起它发生变化的因素很多,难以准确测量。但是它毕竟还是可以测量的。因此,在进行 心理与教育科学研究时,在一定条件下,是可以对心理与教育现象进行定量分析的。心理与 教育统计就是对心理与教育问题进行定量分析的重要的科学工具。 ③广大心理与教育工作者学习心理与教育统计学的具体意义。 a. 可经顺利阅读国内外先进的研究成果。 b. 可以提高心理与教育工作的科学性和效率。
第一章绪论 一、单项选择题 答案 1. D 2. E 3. D 4. B 5. A 6. D 7. A 8. C 9. E 10. D 二、简答题 1答由样本数据获得的结果,需要对其进行统计描述和统计推断,统计描述可以使数据更容易理解,统计推断则可以使用概率的方式给出结论,两者的重要作用在于能够透过偶然现象来探测具有变异性的医学规律,使研究结论具有科学性。 2答医学统计学的基本内容包括统计设计、数据整理、统计描述和统计推断。统计设计能够提高研究效率,并使结果更加准确和可靠,数据整理主要是对数据进行归类,检查数据质量,以及是否符合特定的统计分析方法要求等。统计描述用来描述及总结数据的重要特征,统计推断指由样本数据的特征推断总体特征的方法,包括参数估计和假设检验。 3答统计描述结果的表达方式主要是通过统计指标、统计表和统计图,统计推断主要是计算参数估计的可信区间、假设检验的P 值得出相互比较是否有差别的结论。 4答统计量是描述样本特征的指标,由样本数据计算得到,参数是描述总体分布特征的指标可由“全体”数据算出。 5答系统误差、随机测量误差、抽样误差。系统误差由一些固定因素产生,随机测量误差是生物体的自然变异和各种不可预知因素产生的误差,抽样误差是由于抽样而引起的样本统计量与总体参数间的差异。 6答三个总体一是“心肌梗死患者”所属的总体二是接受尿激酶原治疗患者所属的总体三是接受瑞替普酶治疗患者所在的总体。 第二章定量数据的统计描述 一、单项选择题 答案 1. A 2. B 3. E 4. B 5. A 6. E 7. E 8. D 9. B 10. E 二、计算与分析 2
计算题例题及答案: 1、某校社会学专业同学统计课成绩如下表所示。 社会学专业同学统计课成绩表 学号成绩学号成绩学号成绩101023 76 101037 75 101052 70 101024 91 101038 70 101053 88 101025 87 101039 76 101054 93 101026 78 101040 90 101055 62 101027 85 101041 76 101056 95 101028 96 101042 86 101057 95 101029 87 101043 97 101058 66 101030 86 101044 93 101059 82 101031 90 101045 92 101060 79 101032 91 101046 82 101061 76 101033 80 101047 80 101062 76 101034 81 101048 90 101063 68 101035 80 101049 88 101064 94 101036 83 101050 77 101065 83 要求: (1)对考试成绩按由低到高进行排序,求出众数、中位数和平均数。
(2)对考试成绩进行适当分组,编制频数分布表,并计算累计频数和累计频率。答案: (1)考试成绩由低到高排序: 62,66,68,70,70,75,76,76,76,76,76,77,78,79, 80,80,80,81,82,82,83,83,85,86,86,87,87,88, 88,90,90,90,91,91,92,93,93,94,95,95,96,97, 众数:76 中位数:83 平均数: =(62+66+……+96+97)÷42 =3490÷42 =83.095 (2) 按成绩 分组频数频率(%) 向上累积向下累积 频数频率(%) 频数频率(%) 60-69 3 7.143 3 7.143 42 100.000 70-79 11 26.190 14 33.333 39 92.857 80-89 15 35.714 29 69.048 28 66.667
第六章 一、单项选择题 1.下面的函数关系是( ) A现代化水平与劳动生产率 B圆周的长度决定于它的半径 C家庭的收入和消费的关系 D亩产量与施肥量 2.相关系数r的取值范围( ) A -∞< r <+∞ B -1≤r≤+1 C -1< r < +1 D 0≤r≤+1 3.年劳动生产率x(干元)和工人工资y=10+70x,这意味着年劳动生产率每提高1千元时,工人工资平均( ) A增加70元 B减少70元 C增加80元 D减少80元 4.若要证明两变量之间线性相关程度高,则计算出的相关系数应接近于( ) A +1 B -1 C 0.5 D 1 5.回归系数和相关系数的符号是一致的,其符号均可用来判断现象( ) A线性相关还是非线性相关 B正相关还是负相关 C完全相关还是不完全相关 D单相关还是复相关 6.某校经济管理类的学生学习统计学的时间(x)与考试成绩(y)之间建立线性回归方程?=a+bx。经计算,方程为?=200—0.8x,该方程参数的计算( ) A a值是明显不对的 B b值是明显不对的 C a值和b值都是不对的 D a值和b值都是正确的 7.在线性相关的条件下,自变量的均方差为2,因变量均方差为5,而相关系数为0.8时,则其回归系数为:( ) A 8 B 0.32 C 2 D 12.5 8.进行相关分析,要求相关的两个变量( ) A都是随机的 B都不是随机的 C一个是随机的,一个不是随机的 D随机或不随机都可以 9.下列关系中,属于正相关关系的有( ) A合理限度内,施肥量和平均单产量之间的关系 B产品产量与单位产品成本之间的关系 C商品的流通费用与销售利润之间的关系
教育统计学课后作业 一、P118 1 题目:10位大一学生平均每周所花的学习时间与他们的期末考试成绩见表6-17.试问: (1)学习时间与考试成绩之间是否相关? (2)比较两组数据谁的差异程度大一些? (3)比较学生2与学生9的期末考试测验成绩。 表6-17 学习时间与期末考试成绩 1 2 3 4 5 6 7 8 9 10 学习时间考试成绩40 58 43 73 18 56 10 47 25 58 33 54 27 45 17 32 30 68 47 69 解题步骤: (1)第一步:定义变量:“xuexishijian”、“xuexichengji”后,输入数据.如下图: 1
第二步:单击选择“分析(Analyze)”中的“相关(Correlate)”中的“双变量(Bivariate Correlations)”, 将上图中的“xuexishijian”和“xuexichengji”添加到右边变量框中,如下图: 第三步:点击“确定“后,输出结果如下图: 第四步:分析结果
3 由上图可知:学习时间与学习成绩之间的pearson 相关系数为0.714,p (双侧)为0.20。自由度 df=10-2=8时,查“皮尔逊积差相关系数显著临界值表”知:r 0.05= 0.623 ; r 0.01=0.765。 因为0.765 > 0.714 >0.623,所以在0.05水平上学习时间和学习成绩是相关显著的。 (2)SPSS 软件分析结果如下图: 由上图可知:学习时间标准差和平均值为:S 1=12.037 ?X 1= 29.00 ;学习时间标准差和平均值为:S 2=12.437?X 2=56.00 根据差异系数公式可知: 学习时间差异系数为:%100?=X S CV S =12.037/29.00×100%=41.51% 学习成绩差异系数为:%100?= X S CV S =12.437/56.00×100%=22.27% 有上述结果可知学习时间差异程度大于学习成绩差异程度。 (4) 把学生2和学生9的期末考试成绩转化成标准分数: Z 2=(X -?X) /S= (73—56)/12.437=1.367 Z 9=(X-?X)/S=(68—56)/12.437=0.965 由上计算可知:学生2期末考试测验成绩优于学生9的期末考试测验成绩。 二、P119 2 题目:某班数学的平均成绩为90,标准差10;化学的平均分为85,标准差为8;物理的平均分为79,标准差为15.某生这三科成绩分别为95,80,80.试问 (1) 该生在哪一学科上突出一些? (2) 该班三科成绩的差异度如何?有无学习分化现象? (3) 该生的学期分数是多少? (4) 三科的总平均和总标准差是多少? 解题步骤:
1、什么是统计学? 统计学是一门收集、分析、表述、解释数据的科学和艺术。 2、描述统计:研究的是数据收集、汇总、处理、图表描述、概括与分析等统计方法。 推断统计:研究的是如何利用样本数据来推断总体特征。 3、统计学据可以分成哪几种类型,个有什么特点? 按照计量尺度不同,分为:分类数据、顺序数据、数值型数据。 分类数据:只能归于某一类别的,非数字型数据。 顺序数据:只能归于某一有序类别的,非数字型数据。 数值型数据:按数字尺度测量的观察值,结果表现为数值。 按收集方法不同。分为:观测数据、和实验数据 观测数据:通过调查或观测而收集到的数据;不控制条件; 社会经济领域 实验数据:在试验中收集到的数据;控制条件;自然科学领域。 按时间不同,分为:截面数据、时间序列数据 截面数据:在相同或近似相同的时间点上收集的数据。 时间序列数据:在不同时间收集的数据。 4、举例说明总体、样本、参数、统计量、变量这几个概念。 总体:是包含全部研究个体的集合,包括有限总体和无限总体(围、数目判定) 样本:从总体中抽取的一部分元素的集合。 参数:用来描述总体特征的概括性数字度量。(平均数、标准差、比例等) 统计量:用来描述样本特征的概括性数字度量。(平均数、标准差、比例等) 变量:是说明样本某种特征的概念,其特点:从一次观察到下一次观察结果会呈现出差别或变化。(商品销售额、受教育程度、产品质量等级等) (对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。) 5、变量可以分为哪几类? 分类变量:说明事物类别;取值是分类数据。 顺序变量:说明事物有序类别;取值是顺序数据 数值型变量:说明事物数字特征;取值是数值型数据。 变量也可以分为:随机变量和非随机变量;经验变量和理论变量 6、举例说明离散型变量和连续型变量。 离散型变量:只能取有限个、可数值的变量。(企业个数、产品数量) 连续型变量:可以在一个或多个区间中取任何值的变量。(年龄、温度、零件尺寸误差)7、请举出统计应用的几个例子。 市场调查、人口普查等。 8、请举出应用统计学的几个领域。 社会科学中的经济分析、政府政策制定等;自然科学中的物理、生物领域等。
第十二章 相关与回归分析 第一节 变量之间的相关关系 相关程度与方向·因果关系与对称关系 第二节 定类变量的相关 双变量交互分类(列联表)·削减误差比例(PRE )·λ系数与τ系数 第三节 定序变量的相关分析 同序对、异序对和同分对·Gamma 系数·肯德尔等级相关系数(τa 系数、τb 与τc 系数)·萨默斯系数(d 系数)·斯皮尔曼等级相关(ρ相关)·肯德尔和谐系数 第四节 定距变量的相关分析 相关表和相关图·积差系数的导出和计算·积差系数的性质 第五节 回归分析 线性回归·积差系数的PRE 性质·相关指数R 第六节 曲线相关与回归 可线性化的非线性函数·实例分析(二次曲线指数曲线) 一、填空 1.对于表现为因果关系的相关关系来说,自变量一般都是确定性变量,依变量则一般是( 随机性 )变量。 2.变量间的相关程度,可以用不知Y 与X 有关系时预测Y 的全部误差E 1,减去知道Y 与X 有关系时预测Y 的联系误差E 2,再将其化为比例来度量,这就是( 削减误差比例 )。 3.依据数理统计原理,在样本容量较大的情况下,可以作出以下两个假定:(1)实际观察值Y 围绕每个估计值c Y 是服从( );(2)分布中围绕每个可能的c Y 值的( )是相同的。 4.在数量上表现为现象依存关系的两个变量,通常称为自变量和因变量。自变量是作为( 变化根据 )的变量,因变量是随( 自变量 )的变化而发生相应变化的变量。 5.根据资料,分析现象之间是否存在相关关系,其表现形式或类型如何,并对具有相关关系的现象之间数量变化的议案关系进行测定,即建立一个相关的数学表达式,称为( 回归方程 ),并据以进行估计和预测。这种分析方法,通常又称为( 回归分析 )。 6.积差系数r 是( 协方差 )与X 和Y 的标准差的乘积之比。 二、单项选择 1.当x 按一定数额增加时,y 也近似地按一定数额随之增加,那么可以说x 与y 之间 存在( A )关系。 A 直线正相关 B 直线负相关 C 曲线正相关 D 曲线负相关
第 1 页/共 12 页 1、下表是某保险公司160名推销员月销售额的分组数据。书p26 按销售额分组(千元) 人数(人) 向上累计频数 向下累计频数 12以下 6 6 160 12—14 13 19 154 14—16 29 48 141 16—18 36 84 112 18—20 25 109 76 20—22 17 126 51 22—24 14 140 34 24—26 9 149 20 26—28 7 156 11 28以上 4 160 4 合计 160 —— —— (1) 计算并填写表格中各行对应的向上累计频数; (2) 计算并填写表格中各行对应的向下累计频数; (3)确定该公司月销售额的中位数。 按上限公式计算:Me=U- =18-0.22=17,78 2、某厂工人按年龄分组资料如下:p41 工人按年龄分组(岁) 工人数(人) 20以下 160 20—25 150 25—30 105 30—35 45 35—40 40 40—45 30 45以上 20 合 计 550 要求:采用简捷法计算标准差。《简捷法》 3、试根据表中的资料计算某旅游胜地2004年平均旅游人数。P50 表:某旅游胜地旅游人数 时间 2004年1月1日 4月1日 7月1日 10月1日 2005年1月1 日 旅游人数(人) 5200 5000 5200 5400 5600 4、某大学2004年在册学生人数资料如表3-6所示,试计算该大学2004年平均在册学生人数. 时间 1月1日 3月1日 7月1日 9月1日 12月31日 在册学生人数(人) 3408 3528 3250 3590 3575
《教育统计学》复习题及答案一、填空题 1.教育统计学的研究对象是.教育问题。 2.一般情况下,大样本是指样本容量.大于30 的样本。 3.标志是说明总体单位的名称,它有.品质标志和数量标志两种。 4.统计工作的三个基本步骤是:、和。 5.集中量数是反映一组数据的趋势的。 6.“65、66、72、83、89”这组数据的算术平均数是。 7.6位学生的身高分别为:145、135、128、145、140、130厘米,他们的众数是。 8.若某班学生数学成绩的标准差是8分,平均分是80分,其标准差系数是。 9.参数估计的方法有和两种。 10.若两个变量之间的相关系数是负数,则它们之间存在。 11.统计工作与统计资料的关系是和的关系。 12.标准差越大,说明总体平均数的代表性越,标准差越小,说明总体平均数的代表性越。 13.总量指标按其反映的内容不同可以分为和。 二、判断题 1、教育统计学属于应用统计学。()
2、标志是说明总体特征的,指标是说明总体单位特征的。() 3、统计数据的真实性是统计工作的生命() 4、汉族是一个品质标志。() 5、描述一组数据波动情况的量数称为差异量数。() 6、集中量数反映的是一组数据的集中趋势。() 7、在一个总体中,算术平均数、众数、中位数可能相等。() 8、同一总体各组的结构相对指标数值之和不一定等于100%。() 9、不重复抽样误差一定大于重复抽样误差。() 10. 一致性是用样本统计量估计统计参数时最基本的要求。() 三、选择题 1.某班学生的平均年龄为22岁,这里的22岁为( )。 A.指标值 B.标志值 C.变量值 D.数量标志值 2.统计调查中,调查标志的承担者是( )。 A.调查对象 B.调查单位 C.填报单位 D.调查表 3.统计分组的关键是( )。 A.确定组数和组距 B.抓住事物本质 C.选择分组标志和划分各组界限 D.统计表的形式设计 4.下列属于全面调查的有( )。 A.重点调查 B.典型调查 C.抽样调查 D.普查 5.统计抽样调查中,样本的取得遵循的原则是( )。 A.可靠性 B.准确性 C.及时性 D.随机性 6. 在直线回归方程Yc =a+bx中,b表示( )。 增加1个单位,y增加a的数量增加1个单位,x增加b的数量 增加1个单位,x的平均增加量增加1个单位,y的平均增加量 7.下列统计指标中,属于数量指标的有() A、工资总额 B、单位产品成本 C、合格品率 D、人口密度 8.在其他条件不变情况下,重复抽样的抽样极限误差增加1倍,则样本单位数变为( )。 A.原来的2倍 B.原来的4倍 C.原来的1/2倍 D.原来的1/4倍 四、简答题 1.学习教育统计学有哪些意义?
西安交大统计学考试试卷 一、单项选择题(每小题2分,共20分) 1.在企业统计中,下列统计标志中属于数量标志的是( C) A、文化程度 B、职业 C、月工资 D、行业 2.下列属于相对数的综合指标有(B ) A、国民收入 B、人均国民收入 C、国内生产净值 D、设备台数 3.有三个企业的年利润额分别是5000万元、8000万元和3900万元,则这句话中有( B)个变量 A、0个 B、两个 C、1个 D、3个 4.下列变量中属于连续型变量的是(A ) A、身高 B、产品件数 C、企业人数 D、产品品种 5.下列各项中,属于时点指标的有(A ) A、库存额 B、总收入 C、平均收入 D、人均收入 6.典型调查是(B )确定调查单位的 A、随机 B、主观 C、随意 D盲目 7.总体标准差未知时总体均值的假设检验要用到( A ): A、Z统计量 B、t统计量 C、统计量 D、X统计量 8. 把样本总体中全部单位数的集合称为(A ) A、样本 B、小总体 C、样本容量 D、总体容量 9.概率的取值范围是p(D ) A、大于1 B、大于-1 C、小于1 D、在0与1之间 10. 算术平均数的离差之和等于(A ) A、零 B、 1 C、-1 D、2 二、多项选择题(每小题2分,共10分。每题全部答对才给分,否则不计分) 1.数据的计量尺度包括( ABCD ): A、定类尺度 B、定序尺度 C、定距尺度 D、定比尺度 E、测量尺度 2.下列属于连续型变量的有( BE ): A、工人人数 B、商品销售额 C、商品库存额 D、商品库存量 E、总产值 3.测量变量离中趋势的指标有( ABE ) A、极差 B、平均差 C、几何平均数 D、众数 E、标准差 4.在工业企业的设备调查中( BDE ) A、工业企业是调查对象 B、工业企业的所有设备是调查对象 C、每台设备是 填报单位 D、每台设备是调查单位 E、每个工业企业是填报单位 5.下列平均数中,容易受数列中极端值影响的平均数有( ABC ) A、算术平均数 B、调和平均数 C、几何平均数 D、中位数 E、众数 三、判断题(在正确答案后写“对”,在错误答案后写“错”。每小题1分,共10分) 1、“性别”是品质标志。(对) 2、方差是离差平方和与相应的自由度之比。(错) 3、标准差系数是标准差与均值之比。(对) 4、算术平均数的离差平方和是一个最大值。(错) 5、区间估计就是直接用样本统计量代表总体参数。(错) 6、在假设检验中,方差已知的正态总体均值的检验要计算Z统计量。(错)
第六章 、单项选择题 1. 下面的函数关系是() A 现代化水平与劳动生产率 圆周的长度决定于它的半径 2. 相关系数r 的取值范围 B -1 C -1< r < +1 时,工人工资平均() 6?某校经济管理类的学生学习统计学的时间 (x )与考试成绩(y )之间建立线性回归方程 ? =a+bx 。经计算,方程为 ? =200— 0.8x ,该方程参数的计算() 时,则其回归系数为:() A 8 B 0.32 C 2 D 12 &进行相关分析,要求相关的两个变量 都不是随机的 9?下列关系中,属于正相关关系的有 A 合理限度内,施肥量和平均单产量之间的关系 B 产品产量与单位产品成本之间的关系 C 商品的流通费用与销售利润之间的关系 D 流通费用率与商品销售量之间的关系 C 家庭的收入和消费的关系 亩产量与施肥量 3.年劳动生产率 x (干元)和工人工资 y=10+70x ,这意味着年劳动生产率每提高 1千元 A 增加70元 B 减少70元C 增加 80元D 减少80元 4.若要证明两变量之间线性相关程度高, 则计算出的相关系数应接近于 A +1 B -1 C 0.5 D _1 5?回归系数和相关系数的符号是一致的, 其符号均可用来判断现象 A 线性相关还是非线性相关 B 正相关还是负相关 C 完全相关还是不完全相关 D 单相关还是复相关 Aa 值是明显不对的 值是明显不对的 C a 值和b 值都是不对的 D a 值和b 值都是正确的 7.在线性相关的条件下, 自变量的均方差为 2,因变量均方差为5,而相关系数为0.8 C 一个是随机的,一个不是随机的 随机或不随机都可以 A 都是随机的
教育统计学课后练习参考答案 第一章 1、教育统计学,就是应用数理统计学的一般原理和方法,对教育调查和教育实验等途径所获得的数据资料进行整理、分析,并以此为依据,进行科学推断,从而揭示蕴含在教育现象中的客观规律的一门科学。 教育统计学既是统计科学中的一个分支学科,又是教育科学中的一个分支学科,是两种科学相互结合、相互渗透而形成的一门交叉学科。从学科体系来看,教育统计学属于教育科学体系的一个方法论分支;从学科性质来看,教育统计学又属于统计学的一个应用分支。 2、描述统计主要是通过对数据资料进行整理,计算出简单明白的统计量数来描述庞大的资料,以显示其分布特征的统计方法。 推断统计又叫分析统计,它根据统计学的原理和方法,从我们所研究的全体对象(即总体)中,按照等可能性原则采取随机抽样的方法,抽出总体中具有代表性的部分个体组成样本,在样本所提供的数据的基础上,运用概率理论进行分析、论证,在一定可靠程度上对总体的情况进行科学推断的一种统计方法。 3、在自然界或教育研究中,一种事物常存在几种可能出现的情况或获得几种可能的结果,这类现象称为随机现象。 随机现象具的特点: (1)一次条件完全相同的实验有多种可能的结果(这样的实验称为随机实验); (2)在实验之前不能确切知道哪种结果会发生; (3)在相同的条件下可以重复进行这样的实验。 4、总体,也叫做母体或全域,是指具有某种共同特征的个体的总和。 当所研究的总体数量非常大时,可以从总体中抽取其中一部分个体来观测,由此来推断总体的信息,从总体中抽出的这部分个体就称为样本,它是用以表征总体的个体的集合。 通常将样本中样本个数大于或等于30个的样本称为大样本,小于30个的称为小样本。 5、复置抽样指每次抽出的个体经观测后,仍放回原总体,然后再从总体中抽取下一个个体。 6、反映总体特征的量数叫做总体参数,简称参数。反映样本特征的量数叫做样本统计量,简称统计量。 参数是总体的真正数值,是固定的常量,理论上应该通过计算总体中全部个体的数值而获得,但由于总体中个体的数量通常很大,总体参数往往很难获得,在统计分析中一般通过样本的数值来估计。在进行推断统计时,就是根据样本统计量来推断总体相应的参数。 第二章 1、按照数据的来源,可分为计数数据和度量数据;按照数据的取值情况,可分为间断性数据和连续性数据;按照数据的测量水平,可分为称名数据、顺序数据、等距数据和比率数据。 2、数据整理的基本方法包括对数据进行排序、统计分组、绘制统计图表等。 3、表的结构要简洁明了;表的层次要清晰;主谓分明。 4、连续性数据:(2),(3);间断性数据:(1),(4)。 5、略 6、(1)50;(2)75;(3)34;(4)5;(5)45
社会统计学复习题有答 案 集团标准化工作小组 #Q8QGGQT-GX8G08Q8-GNQGJ8-MHHGN#
社会统计学课程期末复习题 一、填空题(计算结果一般保留两位小数) 1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。 2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。 3、在回归分析中,各实际观测值y 与估计值y ?的离差平方和称为 剩余 变差。 4、平均增长速度= 平均发展速度 —1(或100%)。 5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。 6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。 7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。 8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为 100%7% A 100% 1.06%100%6% -=- =-产品单位成本计划超额完成程度 ;若某厂计划规定B 产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为 100%10% 100% 4.76%100%5% += -=+B 产品产量计划超额完成程度 。
9、按照标志表现划分,学生的民族、性别、籍贯属于品质标志;学生的体重、年龄、成绩属于数量标志。 10、从内容上看,统计表由主词和宾词两个部分组成;从格式上看,统计表由 总标题、横行标题、纵栏标题和指标数值(或统计数值); 四个部分组成。 11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于正相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于负相关。 12、按指标所反映的数量性质不同划分,国民生产总值属于数量指标;单位成本属于质量指标。 13、如果相关系数r=0,则表明两个变量之间不存在线性相关关系。 二、判断题 1、在季节变动分析中,若季节比率大于100%,说明现象处在淡季;若季节比率小于100%,说明现象处在旺季。(×;答案提示:在季节变动分析中,若季节比率大于100%,说明现象处在旺季;若季节比率小于100%,说明现象处在淡季。 ) 2、工业产值属于离散变量;设备数量属于连续变量。(×;答案提示:工业产值属于连续变量;设备数量属于离散变量) 3、中位数与众数不容易受到原始数据中极值的影响。(√;) 4、有意识地选择十个具有代表性的城市调查居民消费情况,这种调查方式属于典型调查。(√)
计算分析题解答参考 1.1.某厂三个车间一季度生产情况如下: 计算一季度三个车间产量平均计划完成百分比和平均单位产品成本。 解:平均计划完成百分比=实际产量/计划产量=733/(198/0.9+315/1.05+220/1.1) =101.81% 平均单位产量成本 X=∑xf/∑f=(15*198+10*315+8*220)/733 =10.75(元/件) 1.2.某企业产品的有关资料如下: 试分别计算该企业产品98年、99年的平均单位产品成本。 解:该企业98年平均单位产品成本 x=∑xf/∑f=(25*1500+28*1020+32*980)/3500 =27.83(元/件) 该企业99年平均单位产品成本x=∑xf /∑(m/x)=101060/(24500/25+28560/28+48000/32) =28.87(元/件) 年某月甲、乙两市场三种商品价格、销售量和销售额资料如下: 1.3.1999 解:三种商品在甲市场上的平均价格x=∑xf/∑f=(105*700+120*900+137*1100)/2700 =123.04(元/件) 三种商品在乙市场上的平均价格x=∑m/∑(m/x)=317900/(126000/105+96000/120+95900/137) =117.74(元/件) 2.1.某车间有甲、乙两个生产小组,甲组平均每个工人的日产量为22件,标准差为 3.5件;乙组工人日产量资料:
试比较甲、乙两生产小组中的哪个组的日产量更有代表性? 解:∵X 甲=22件 σ甲=3.5件 ∴V 甲=σ甲/ X 甲=3.5/22=15.91% 列表计算乙组的数据资料如下: ∵x 乙=∑xf/∑f=(11*10+14*20+17*30+20*40)/100 =17(件) σ 乙=√[∑(x-x)2 f]/∑f =√900/100 =3(件) ∴V 乙=σ乙/ x 乙=3/17=17.65% 由于V 甲<V 乙,故甲生产小组的日产量更有代表性。 2.2.有甲、乙两个品种的粮食作物,经播种实验后得知甲品种的平均产量为998斤,标准差为162.7斤;乙品种实验的资料如下: 试研究两个品种的平均亩产量,确定哪一个品种具有较大稳定性,更有推广价值? 解:∵x 甲=998斤 σ甲=162.7斤 ∴V 甲=σ甲/ x 甲=162.7/998=16.30% 列表计算乙品种的数据资料如下:
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第6章SPSS的方差分析 1、入户推销有五种方法。某大公司想比较这五种方法有无显著的效果差异,设计了一项实验。从应聘人员中尚无推销经验的人员中随机挑选一部分人,并随机地将他们分为五个组,每组用一种推销方法培训。一段时期后得到他们在一个月内的推销额,如下表所示: 第一组20.0 16.8 17.9 21.2 23.9 26.8 22.4 第二组24.9 21.3 22.6 30.2 29.9 22.5 20.7 第三组16.0 20.1 17.3 20.9 22.0 26.8 20.8 第四组17.5 18.2 20.2 17.7 19.1 18.4 16.5 第五组25.2 26.2 26.9 29.3 30.4 29.7 28.2 1)请利用单因素方差分析方法分析这五种推销方式是否存在显著差异。 2)绘制各组的均值对比图,并利用LSD方法进行多重比较检验。 (1)分析→比较均值→单因素ANOV A→因变量:销售额;因子:组别→确定。 ANOVA 销售额 平方和df 均方 F 显著性 组之间405.534 4 101.384 11.276 .000 组内269.737 30 8.991 总计675.271 34 概率P-值接近于0,应拒绝原假设,认为5种推销方法有显著差异。 (2)均值图:在上面步骤基础上,点选项→均值图;事后多重比较→LSD
多重比较 因变量: 销售额 LSD(L) (I) 组别 (J) 组别 平均差 (I-J) 标准 错误 显著性 95% 置信区间 下限值 上限 第一组 第二组 -3.30000* 1.60279 .048 -6.5733 -.0267 第三组 .72857 1.60279 .653 - 2.5448 4.0019 第四组 3.05714 1.60279 .066 -.2162 6.3305 第五组 -6.70000* 1.60279 .000 -9.9733 -3.4267 第二组 第一组 3.30000* 1.60279 .048 .0267 6.5733 第三组 4.02857* 1.60279 .018 .7552 7.3019 第四组 6.35714* 1.60279 .000 3.0838 9.6305 第五组 -3.40000* 1.60279 .042 -6.6733 -.1267 第三组 第一组 -.72857 1.60279 .653 -4.0019 2.5448 第二组 -4.02857* 1.60279 .018 -7.3019 -.7552 第四组 2.32857 1.60279 .157 -.9448 5.6019 第五组 -7.42857* 1.60279 .000 -10.7019 -4.1552 第四组 第一组 -3.05714 1.60279 .066 -6.3305 .2162
《教育统计学》复习题及答案 一、填空题 1.教育统计学的研究对象是.教育问题。 2.一般情况下,大样本是指样本容量.大于30 的样本。 3.标志是说明总体单位的名称,它有.品质标志和数量标志两种。 4.统计工作的三个基本步骤是:、和。 5.集中量数是反映一组数据的趋势的。 6.“65、66、72、83、89”这组数据的算术平均数是。 7.6位学生的身高分别为:145、135、128、145、140、130厘米,他们的众数是。 8.若某班学生数学成绩的标准差是8分,平均分是80分,其标准差系数是。 9.参数估计的方法有和两种。 10.若两个变量之间的相关系数是负数,则它们之间存在。 11.统计工作与统计资料的关系是和的关系。 12.标准差越大,说明总体平均数的代表性越,标准差越小,说明总体平均数的代表性越。 13.总量指标按其反映的内容不同可以分为和。 二、判断题 1、教育统计学属于应用统计学。() 2、标志是说明总体特征的,指标是说明总体单位特征的。() 3、统计数据的真实性是统计工作的生命() 4、汉族是一个品质标志。() 5、描述一组数据波动情况的量数称为差异量数。() 6、集中量数反映的是一组数据的集中趋势。() 7、在一个总体中,算术平均数、众数、中位数可能相等。() 8、同一总体各组的结构相对指标数值之和不一定等于100%。() 9、不重复抽样误差一定大于重复抽样误差。() 10. 一致性是用样本统计量估计统计参数时最基本的要求。() 三、选择题 1.某班学生的平均年龄为22岁,这里的22岁为( )。
A.指标值 B.标志值 C.变量值 D.数量标志值 2.统计调查中,调查标志的承担者是( )。 A.调查对象 B.调查单位 C.填报单位 D.调查表 3.统计分组的关键是( )。 A.确定组数和组距 B.抓住事物本质 C.选择分组标志和划分各组界限 D.统计表的形式设计 4.下列属于全面调查的有( )。 A.重点调查 B.典型调查 C.抽样调查 D.普查 5.统计抽样调查中,样本的取得遵循的原则是( )。 A.可靠性 B.准确性 C.及时性 D.随机性 6. 在直线回归方程Yc =a+bx中,b表示( )。 A.x增加1个单位,y增加a的数量 B.y增加1个单位,x增加b的数量 C.y增加1个单位,x的平均增加量 D.x增加1个单位,y的平均增加量 7.下列统计指标中,属于数量指标的有() A、工资总额 B、单位产品成本 C、合格品率 D、人口密度 8.在其他条件不变情况下,重复抽样的抽样极限误差增加1倍,则样本单位数变为( )。 A.原来的2倍 B.原来的4倍 C.原来的1/2倍 D.原来的1/4倍 四、简答题 1.学习教育统计学有哪些意义? 答:(1)教育统计是教育科学研究的工具; (2)学习教育统计学有利于教育行政和管理工作者正确掌握情况,进行科学决策; (3)教育统计是教育评价不可缺少的工具; (4)学习教育统计学有利于训练科学的推理与思维方法。 2.统计图表的作用有哪几方面? 1)表明同类统计事项指标的对比关系; (2)揭示总体内部的结构; (3)反映统计事项的发展动态; (4)分析统计事项之间的依存关系; (5)说明总体单位的分配; (6)检查计划的执行情况; (7)观察统计事项在地域上的分布。 3.简述相关的含义及种类。 答:相关就是指事物或现象之间的相互关系。