
IBM V7000 存储配置实施说明
IBM V7000是一款中端的存储系统,据性能测试报告性能要优于DS5000,但略低于DS8000。
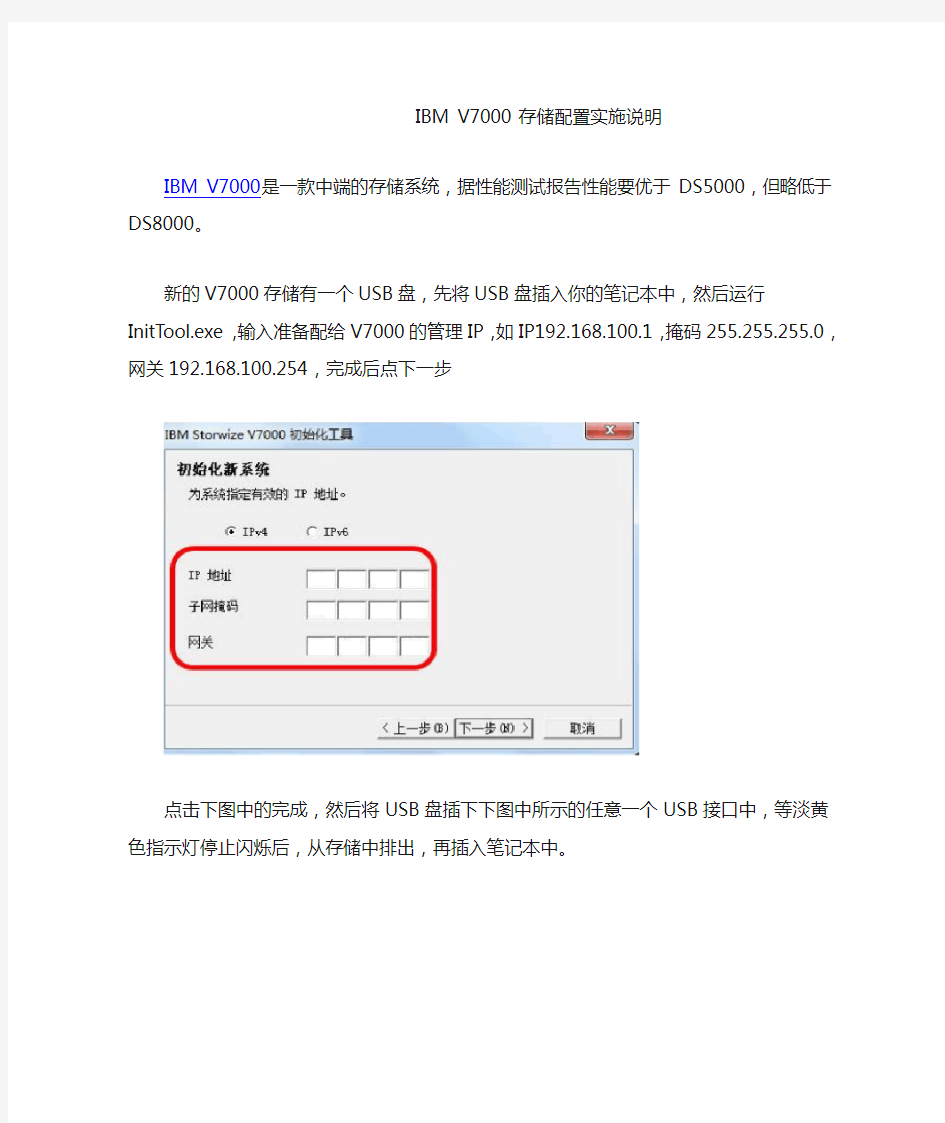
新的V7000存储有一个USB盘,先将USB盘插入你的笔记本中,然后运行InitTool.exe,输入准备配给V7000的管理IP,如IP192.168.100.1,掩码255.255.255.0,网关192.168.100.254,完成后点下一步
点击下图中的完成,然后将USB盘插下下图中所示的任意一个USB接口中,等淡黄色指示灯停止闪烁后,从存储中排出,再插入笔记本中。
再在浏览器中输入https://192.168.100.1,用户名superuser,密码passw0rd,然后进行初始化设置,包括时间、许可证、配置存储器等。完成后,再次进入存储,进行Mdisk的创建工作,再进行Pool(池)的创建,并将新建的两个Mdisk 加入此pool中。
接下来进行卷的创建工作,首先登陆系统
登陆后,就进入了存储管理主界面,主界面为一幅存储的各部分的逻辑关系图,如下图所示。
点击“系统”可以查看存储的机柜图信息,左边为已使用容量的信息、中间为存储机柜图、右边为存储面板图,如下图所示。
下面开始创建卷,选择左边卷->卷菜单,
点击新建卷
选择“通用”,选择pool,命名卷名及卷的大小,点击“创建”即可。
开始新建主机,
点击“新建主机”
选择主机类型,这里为光纤通道主机
命名主机名,然后将光纤卡的WWPN号添加至列表中,其它默认,创建主机
完成了主机的创建后,下面开始将刚才新建的卷映射给新创建的主机,进入卷->卷菜单,点击“操作”->“映射到主机”
如下图,主机选择刚才新建的,这里为vmwareserver,然后将需要映射的卷通过箭头移至右边的方框中,最后点击“映射卷”即可。
然后在vCenter的存储适配器里,重新扫描存储器即可看见刚才映射的卷了。
第3章栈和队列 一选择题 1. 对于栈操作数据的原则是()。【青岛大学 2001 五、2(2分)】 A. 先进先出 B. 后进先出 C. 后进后出 D. 不分顺序 2. 在作进栈运算时,应先判别栈是否( ① ),在作退栈运算时应先判别栈是否( ② )。当栈中元素为n个,作进栈运算时发生上溢,则说明该栈的最大容量为( ③ )。 为了增加内存空间的利用率和减少溢出的可能性,由两个栈共享一片连续的内存空间时,应将两栈的 ( ④ )分别设在这片内存空间的两端,这样,当( ⑤ )时,才产生上溢。①, ②: A. 空 B. 满 C. 上溢 D. 下溢 ③: A. n-1 B. n C. n+1 D. n/2 ④: A. 长度 B. 深度 C. 栈顶 D. 栈底 ⑤: A. 两个栈的栈顶同时到达栈空间的中心点. B. 其中一个栈的栈顶到达栈空间的中心点. C. 两个栈的栈顶在栈空间的某一位置相遇. D. 两个栈均不空,且一个栈的栈顶到达另一个栈的栈底. 【上海海运学院 1997 二、1(5分)】【上海海运学院 1999 二、1(5分)】 3. 一个栈的输入序列为123…n,若输出序列的第一个元素是n,输出第i(1<=i<=n)个元素是()。 A. 不确定 B. n-i+1 C. i D. n-i 【中山大学 1999 一、9(1分)】 4. 若一个栈的输入序列为1,2,3,…,n,输出序列的第一个元素是i,则第j个输出元素是()。 A. i-j-1 B. i-j C. j-i+1 D. 不确定的 【武汉大学 2000 二、3】 5. 若已知一个栈的入栈序列是1,2,3,…,n,其输出序列为p1,p2,p3,…,p N,若p N是n,则p i是( )。 A. i B. n-i C. n-i+1 D. 不确定 【南京理工大学 2001 一、1(1.5分)】 6. 有六个元素6,5,4,3,2,1 的顺序进栈,问下列哪一个不是合法的出栈序列?() A. 5 4 3 6 1 2 B. 4 5 3 1 2 6 C. 3 4 6 5 2 1 D. 2 3 4 1 5 6 【北方交通大学 2001 一、3(2分)】 7. 设栈的输入序列是1,2,3,4,则()不可能是其出栈序列。【中科院计算所2000一、10(2分)】 A. 1,2,4,3, B. 2,1,3,4, C. 1,4,3,2, D. 4,3,1,2, E. 3,2,1,4, 8. 一个栈的输入序列为1 2 3 4 5,则下列序列中不可能是栈的输出序列的是()。 A. 2 3 4 1 5 B. 5 4 1 3 2 C. 2 3 1 4 5 D. 1 5 4 3 2 【南开大学 2000 一、1】【山东大学 2001 二、4 (1分)】【北京理工大学 2000 一、2(2分)】 9. 设一个栈的输入序列是 1,2,3,4,5,则下列序列中,是栈的合法输出序列的是()。 A. 5 1 2 3 4 B. 4 5 1 3 2 C. 4 3 1 2 5 D. 3 2 1 5 4 【合肥工业大学 2001 一、1(2分)】 10. 某堆栈的输入序列为a, b,c ,d,下面的四个序列中,不可能是它的输出序列的是
图 1. 填空题 ⑴ 设无向图G中顶点数为n,则图G至少有()条边,至多有()条边;若G为有向图,则至少有()条边,至多有()条边。 【解答】0,n(n-1)/2,0,n(n-1) 【分析】图的顶点集合是有穷非空的,而边集可以是空集;边数达到最多的图称为完全图,在完全图中,任意两个顶点之间都存在边。 ⑵ 任何连通图的连通分量只有一个,即是()。 【解答】其自身 ⑶ 图的存储结构主要有两种,分别是()和()。 【解答】邻接矩阵,邻接表 【分析】这是最常用的两种存储结构,此外,还有十字链表、邻接多重表、边集数组等。 ⑷ 已知无向图G的顶点数为n,边数为e,其邻接表表示的空间复杂度为()。 【解答】O(n+e) 【分析】在无向图的邻接表中,顶点表有n个结点,边表有2e个结点,共有n+2e个结点,其空间复杂度为O(n+2e)=O(n+e)。 ⑸ 已知一个有向图的邻接矩阵表示,计算第j个顶点的入度的方法是()。 【解答】求第j列的所有元素之和 ⑹ 有向图G用邻接矩阵A[n][n]存储,其第i行的所有元素之和等于顶点i的()。 【解答】出度
⑺ 图的深度优先遍历类似于树的()遍历,它所用到的数据结构是();图的广度优先遍历类似于树的()遍历,它所用到的数据结构是()。 【解答】前序,栈,层序,队列 ⑻ 对于含有n个顶点e条边的连通图,利用Prim算法求最小生成树的时间复杂度为(),利用Kruskal 算法求最小生成树的时间复杂度为()。 【解答】O(n2),O(elog2e) 【分析】Prim算法采用邻接矩阵做存储结构,适合于求稠密图的最小生成树;Kruskal算法采用边集数组做存储结构,适合于求稀疏图的最小生成树。 ⑼ 如果一个有向图不存在(),则该图的全部顶点可以排列成一个拓扑序列。 【解答】回路 ⑽ 在一个有向图中,若存在弧、、,则在其拓扑序列中,顶点vi, vj, vk的相对次序为()。 【解答】vi, vj, vk 【分析】对由顶点vi, vj, vk组成的图进行拓扑排序。 2. 选择题 ⑴ 在一个无向图中,所有顶点的度数之和等于所有边数的()倍。 A 1/2 B 1 C 2 D 4 【解答】C 【分析】设无向图中含有n个顶点e条边,则。
(1)开始界面(2)初始化线性表 3.插入:下面是插入第一个元素的图(3),插入后再一次插入其他元素,最终插完元素,见图(4)
(4)插入最后一个元素(第五个) 5.取栈顶元素,如图( (5)删除栈顶元素(6)取栈顶元素 6.置空顺序栈,如图(7) (7)置空顺序表 7. 数值转换(将一个十进制数转换为任意进制) 三进制数2220。
(9)回文数判断a (10)回文数判断b 实验结论:实验成功 八.我对本次实验的总结: 1.通过对该程序的调试和运行,使的对顺序栈的功能及其构成有了进一步的了解。 2.通过多个函数出现在同一个程序中的实现,便于熟悉全局变量和局部变量在程序中 可以重新熟悉函数在编程中的设置方法
void InitStack(SqStack *p) {if(!p) printf("内存分配失败!"); p->top =-1; } /*入栈*/ void Push(SqStack *p,ElemType x) {if(p->top
一、图的邻接矩阵存储 1.存储表示 #define vexnum 10 typedef struct{ vextype vexs[vexnum]; int arcs[vexnum][vexnum]; }mgraph; 2.建立无向图的邻接矩阵算法 void creat(mgraph *g, int e){ for(i=0;i
for(i=0;i
第3章栈和队列 一、选择题 1.栈结构通常采用的两种存储结构是(A )。 A、顺序存储结构和链表存储结构 B、散列和索引方式 C、链表存储结构和数组 D、线性链表结构和非线性存储结构 2.设栈ST 用顺序存储结构表示,则栈ST 为空的条件是( B ) A、ST.top-ST.base<>0 B、ST.top-ST.base==0 C、ST.top-ST.base<>n D、ST.top-ST.base==n 3.向一个栈顶指针为HS 的链栈中插入一个s 结点时,则执行( C ) A、HS->next=s; B、s->next=HS->next;HS->next=s; C、s->next=HS;HS=s; D、s->next=HS;HS=HS->next; 4.从一个栈顶指针为HS 的链栈中删除一个结点,用x 保存被删除结点的值,则执行( C) A 、x=HS;HS=HS->next; B 、HS=HS->next;x=HS->data; C 、x=HS->data;HS=HS->next; D 、s->next=Hs;Hs=HS->next; 5.表达式a*(b+c)-d 的后缀表达式为( B ) A、abcdd+- B、abc+*d- C、abc*+d- D、-+*abcd 6.中缀表达式A-(B+C/D)*E 的后缀形式是( D ) A、AB-C+D/E* B、ABC+D/E* C、ABCD/E*+- D、ABCD/+E*- 7.一个队列的入列序列是1,2,3,4,则队列的输出序列是( B ) A、4,3,2,1 B、1,2,3,4 C、1,4,3,2 D、3,2,4,1 8.循环队列SQ 采用数组空间SQ.base[0,n-1]存放其元素值,已知其头尾指针分别是front 和rear,则判定此循环队列为空的条件是() A、Q.rear-Q.front==n B、Q.rear-Q.front-1==n C、Q.front==Q.rear D、Q.front==Q.rear+1 9.循环队列SQ 采用数组空间SQ.base[0,n-1]存放其元素值,已知其头尾指针分别是front 和rear,则判定此循环队列为满的条件是() A、Q.front==Q.rear B、Q.front!=Q.rear C、Q.front==(Q.rear+1)%n D、Q.front!=(Q.rear+1)%n 10.若在一个大小为6 的数组上实现循环队列,且当前rear 和front 的值分别为0 和3,当从 队列中删除一个元素,再加入两个元素后,rear 和front 的值分别为() A、1,5 B、2, 4 C、4,2 D、5,1 11.用单链表表示的链式队列的队头在链表的()位置 A、链头 B、链尾 C、链中 12.判定一个链队列Q(最多元素为n 个)为空的条件是() A、Q.front==Q.rear B、Q.front!=Q.rear C、Q.front==(Q.rear+1)%n D、Q.front!=(Q.rear+1)%n 13.在链队列Q 中,插入s 所指结点需顺序执行的指令是() A 、Q.front->next=s;f=s; B 、Q.rear->next=s;Q.rear=s;
武汉东湖学院 实验报告 学院:计算机科学学院—专业计算机科学与技术2016年11月18日 1.实验目的 (1)了解邻接矩阵存储法和邻接表存储法的实现过程。 (2)了解图的深度优先遍历和广度优先遍历的实现过程。 2.实验内容 1.采用图的邻接矩阵存储方法,实现下图的邻接矩阵存储,并输出该矩阵 2.设计一个将第1小题中的邻接矩阵转换为邻接表的算法,并设计一个在屏幕上显示邻接表的算法 3.实现基于第2小题中邻接表的深度优先遍历算法,并输出遍历序列 4.实现基于第2小题中邻接表的广度优先遍历算法,并输出遍历序列
3.实验环境Visual C++ 6.0
4 .实验方法和步骤(含设计) 我们通过二维数组中的值来表示图中节点与节点的关系。通过上图可 知, 其邻接矩阵示意图为如下: V0 v1 v2 v3 v4 v5 V0 1 0 1 0 1 V1 1 0 1 1 1 0 V2 0 1 0 0 1 0 V3 1 1 0 0 1 1 V4 0 1 1 1 0 0 V5 1 1 此时的 “1 ” 表示这两个节点有关系,“ 0”表示这两个节点无关系 我们通过邻接表来在计算机中存储图时,其邻接表存储图如下:
5.程序及测试结果 #include
栈的顺序表示和实现 2.2基础实验 2.2.1实验目的 (1)掌握栈的顺序表示和实现 (2)掌握栈的链式表示和实现 (3)掌握队列的顺序表示和实现 (4)掌握队列的链式表示和实现 2.2.2实验内容 实验一:栈的顺序表示和实现 【实验内容与要求】 编写一个程序实现顺序栈的各种基本运算,并在此基础上设计一个主程序,完成如下功能: (1)初始化顺序栈 (2 )插入元素 (3)删除栈顶元素 (4)取栈顶元素 (5)遍历顺序栈 (6)置空顺序栈 【知识要点】 栈的顺序存储结构简称为顺序栈,它是运算受限的顺序表。 对于顺序栈,入栈时,首先判断栈是否为满,栈满的条件为:p->top= =MAXNUM-1 ,栈满时,不能入栈;否则岀现空间溢岀,引起错误,这种现象称为上溢。 岀栈和读栈顶元素操作,先判栈是否为空,为空时不能操作,否则产生错误。通常栈空作为一种控制转移的条件。 注意: (1)顺序栈中元素用向量存放 (2)栈底位置是固定不变的,可设置在向量两端的任意一个端点 (3)栈顶位置是随着进栈和退栈操作而变化的,用一个整型量top (通常称top为栈顶指针)来指示当前栈顶位置 【实现提示】 /*定义顺序栈的存储结构*/
typedef struct { ElemType stack[MAXNUM]; int top; }SqStack; /*初始化顺序栈函数*/ void lnitStack(SqStack *p) {q=(SqStack*)malloc(sizeof(SqStack)/* 申请空间*/) /*入栈函数*/ void Push(SqStack *p,ElemType x) {if(p->top
实验三栈的顺序和链式存储的表示和实现 实验目的: 1.熟悉栈的特点(先进后出)及栈的基本操作,如入栈、出栈等。 2.掌握栈的基本操作在栈的顺序存储结构和链式存储结构上的实现。 实验内容: 1.栈的顺序表示和实现 编写一个程序实现顺序栈的各种基本运算,并在此基础上设计一个主程序,完成如下功能。 (1)初始化顺序栈 (2)插入一个元素 (3)删除栈顶元素 (4)取栈顶元素 (5)便利顺序栈 (6)置空顺序栈 #include
//获取栈顶元素 elemtype gettop(sqstack *p) { elemtype x; if(p->top!=-1) { x=p->stack[p->top]; return x; } else { printf("Underflow!\n"); return 0; } } //遍历顺序栈 void outstack(sqstack *p) { int i; printf("\n"); if(p->top<0) printf("这是一个空栈!\n"); for(i=p->top;i>=0;i--) printf("第%d个数据元素是:%6d\n",i,p->stack[i]); } //置空顺序栈 void setempty(sqstack *p) { } //主函数 main() { sqstack *q; int y,cord; elemtype a;
《图的邻接表存储结构实验报告》1.需解决的的问题 利用邻接表存储结果,设计一种图。 2.数据结构的定义 typedef struct node {//边表结点 int adj;//边表结点数据域 struct node *next; }node; typedef struct vnode {//顶点表结点 char name[20]; node *fnext; }vnode,AList[M]; typedef struct{ AList List;//邻接表 int v,e;//顶点树和边数 }*Graph; 3.程序的结构图 4.函数的功能
1)建立无向邻接表 Graph Create1( )//建立无向邻接表 { Graph G; int i,j,k; node *s; G=malloc(M*sizeof(vnode)); printf("输入图的顶点数和边数:"); scanf("%d%d",&G->v,&G->e);//读入顶点数和边数 for(i=0;i
分别以邻接矩阵和邻接表作为图的存储结构,给出连通图的深度优先 遍历的递归算法 算法思想: (1)访问出发点vi,并将其标记为已访问过。 (2)遍历vi的的每一个邻接点vj,若vi未曾访问过,则以vi为新的出发点继续进行深度优先遍历。 算法实现: Boolean visited[max]; // 访问标志数 void DFS(Graph G, int v) { // 算法7.5从第v个顶点出发递归地深度优先遍历图G int w; visited[v] = TRUE; printf("%d ",v); // 访问第v个顶点for (w=FirstAdjVex(G, v); w>=0; w=NextAdjVex(G, v, w)) if (!visited[w]) // 对v的尚未访问的邻接顶点w递归调用DFS DFS(G, w); } /*****************************************************/ /*以邻接矩阵作为存储结构*/ DFS1(MGraph G,int i) {int j; visited[i]=1; printf("%c",G.vexs[i]); for(j=1;j<=G.vexnum;j++) if(!visited[j]&&G.arcs[i][j]==1) DFS1(G,j); } /*以邻接表作为存储结构*/ DFS2(ALGraph G,int i) {int j; ArcPtr p; visited[i]=1; printf("%c",G.vertices[i].data); for(p=G.vertices[i].firstarc;p!=NULL;p=p->nextarc) {j=p->adjvex; if(!visited[j]) DFS2(j); } }
《数据结构》实验报告 ◎实验题目:无向图的存储和遍历 ◎实验目的:1、掌握使用Visual C++6.0上机调试程序的基本方法; 2、掌握图的邻接表存储结构和深度优先遍历的非递归算法。 3、提高自己分析问题和解决问题的能力,在实践中理解教材上的理论。 ◎实验内容:建立有10个顶点的无向图的邻接表存储结构,然后对其进行深度优先遍历,该无向图可以是无向连通图或无向非连通图。 一、需求分析 1、输入的形式和输入值的范围:根据提示,首先输入图的所有边建立邻接表存储结构,然后输入遍历的起始顶点对图或非连通图的某一连通分量进行遍历。 2、输出的形式:输出对该图是连通图或非连通图的判断结果,若是非连通图则输出各连通分量的顶点,之后输出队连通图或非连通图的某一连通分量的遍历结果。 3、程序所能达到的功能:输入图的所有边后,建立图的邻接表存储结构,判断该图是连通图或非连通图,最后对图进行遍历。 4、测试数据: 输入10个顶点(空格分隔):A B C D E F G H I J 输入边的信息(格式为x y):AB AC AF CE BD DC HG GI IJ HJ EH 该图为连通图,请输入遍历的起始顶点:A 遍历结果为:A F C D B E H J I G 是否继续?(是,输入1;否,输入0):1 输入10个顶点(空格分隔):A B C D E F G H I J 输入边的信息(格式为xy):AB AC CE CA AF HG HJ IJ IG 该图为非连通图,各连通分量中的顶点为: < A F C E B > < D > < G I J H > 输入第1个连通分量起始顶点:F 第1个连通分量的遍历结果为:F A C E B 输入第2个连通分量起始顶点:I 第2个连通分量的遍历结果为:I G H J 输入第3个连通分量起始顶点:D 第3个连通分量的遍历结果为:D 是否继续?(是,输入1;否,输入0):0 谢谢使用! Press any key to continue 二概要设计 1、邻接表是图的一种顺序存储与链式存储结构结合的存储方法。邻接表表示法类似于树的孩子链表表示法。就是对图G中的每个顶点Vi,将所有邻接于Vi的顶点Vj链成一个单链表,这个单链表就称为顶点Vi的邻接表,再将所有邻接表的表头放到数组中,就构成了图的邻接表,邻接表表示中的两种结点结构如下所示。
数据结构实验报告 班级:计 学号: 姓名: 设计日期: 西安计算机学院
实验题目 1)栈的顺序存储结构 2)栈的链式存储结构 3)队列的链式存储结构 4)队列的循环存储结构 2.需求分析 本演示程序用C语言编写,完成栈和列的初始化,入栈、出栈、输出操作。 1)对于顺序栈,入栈时要先判断栈是否满了,栈满不能入栈,否则出现空间溢出;在进栈出栈和读取栈顶时先判栈是否为空,为空时不能操作。 2)在一个链队表中需设定两个指针分别指向队列的头和尾。 3)队列的存储结构:注意要判断队满和队空。 4)程序所能达到的功能:完成栈的初始化,入栈,出栈和输出操作;完成队列的初始化,入队列,出队列和输出操作。 3.概要设计 本程序包含 1、栈的顺序存储结构包含的函数: 1)主函数main() 2)入栈函数Push() 3)出栈函数Pop()
2、栈的链式存储结构包含的函数: 1)主函数main() 2)入栈函数PushStack() 3)退栈函数PopStack() 4)取栈顶元素函数Getstack top() 3、队列的链式存储结构所包含的函数:1)主函数main() 2)入队函数EnQueue() 3)出队函数DeQueue() 4 队列的循环所包含的函数: 1)主函数main() 2)初始化循环函数CircSeqQueue() 3)入队函数EnQueue() 4)出队函数DeQueue() 5)取队首元素函数GetFront() 4.详细设计 1)栈的顺序存储结构 #include
课程设计题目九:图的广度优先遍历 基本要求: 采用邻接表存储结构实现图的广度优先遍历。 (2)对任意给定的图(顶点数和边数自定),建立它的邻接表并输出;(3)实现图的广度优先遍历*/ #include
实验三顺序栈的实现 实验类型:验证性实验学时:2学时 一、实验目的: 掌握顺序栈的基本操作,如进栈、出栈、判断栈空和栈满,取栈顶元素等运算在顺序存储结构上的运算;并能够运用栈的基本操作解决问题,实现相应算法。 二、实验要求: 1、完成顺序栈的基本操作算法并上机调试通过。 2、撰写实验报告,提供实验结果和数据。 三、实验内容: 设计你的栈的顺序存储结构体,编程实现栈的基本操作。栈中的数据元素类型最好为字符类型,方便今后对字符串的算法设计和应用。 测试数据示例: (1) 以“ABCDEFG”的字符串顺序进栈; (2) 以合适顺序出栈得到序列“CDBAGFE”; (3) 取栈顶元素得到‘F’; (4) 进栈直到栈满和出栈直到栈空,检验对这两种情形的正确判断和处理。 [实验要点及说明]:借助实验一线性表的顺序存储程序进行改进 栈(stack):是限定仅在表尾进行插入或删除操作的线性表。 栈顶(Top):允许插入和删除的一端,为变化的一端。 栈底(Bottom):栈中固定的一端。 空栈:栈中无任何元素。 特点:根据栈的定义可知,最先放入栈中元素在栈底,最后放入的元素在栈顶,而删除元素刚好相反,最后放入的元素最先删除,最先放入的元素最后删除。也就是说,栈是一种后进先出(Last In First Out)的线性表,简称为LIFO表。 参考:顺序栈的数据类型C语言描述: #define stacksize 100 //定义栈的最大容量 typedef char elemtype; typedef Struct{ elemtype data[stacksize]; //将栈中元素定义为elemtype类型
图 1. 填空题 ⑴设无向图G中顶点数为n,则图G至少有()条边,至多有()条边;若G为有向图,则至少有()条边,至多有()条边。 【解答】0,n(n-1)/2,0,n(n-1) 【分析】图的顶点集合是有穷非空的,而边集可以是空集;边数达到最多的图称为完全图,在完全图中,任意两个顶点之间都存在边。 ⑵任何连通图的连通分量只有一个,即是()。 【解答】其自身 ⑶图的存储结构主要有两种,分别是()和()。 【解答】邻接矩阵,邻接表 【分析】这是最常用的两种存储结构,此外,还有十字链表、邻接多重表、边集数组等。 ⑷已知无向图G的顶点数为n,边数为e,其邻接表表示的空间复杂度为()。 【解答】O(n+e) 【分析】在无向图的邻接表中,顶点表有n个结点,边表有2e个结点,共有n+2e个结点,其空间复杂度为O(n+2e)=O(n+e)。 ⑸已知一个有向图的邻接矩阵表示,计算第j个顶点的入度的方法是()。 【解答】求第j列的所有元素之和 ⑹有向图G用邻接矩阵A[n][n]存储,其第i行的所有元素之和等于顶点i的()。 【解答】出度 ⑺图的深度优先遍历类似于树的()遍历,它所用到的数据结构是();图的广度优先遍历类似于树的()遍历,它所用到的数据结构是()。 【解答】前序,栈,层序,队列 ⑻对于含有n个顶点e条边的连通图,利用Prim算法求最小生成树的时间复杂度为(),利用Kruskal 算法求最小生成树的时间复杂度为()。 【解答】O(n2),O(elog2e) 【分析】Prim算法采用邻接矩阵做存储结构,适合于求稠密图的最小生成树;Kruskal算法采用边集数组做存储结构,适合于求稀疏图的最小生成树。 ⑼如果一个有向图不存在(),则该图的全部顶点可以排列成一个拓扑序列。 【解答】回路 ⑽在一个有向图中,若存在弧、、,则在其拓扑序列中,顶点vi, vj, vk的相对次序为()。 【解答】vi, vj, vk 【分析】对由顶点vi, vj, vk组成的图进行拓扑排序。 2. 选择题 ⑴在一个无向图中,所有顶点的度数之和等于所有边数的()倍。 A 1/2 B 1 C 2 D 4 【解答】C 【分析】设无向图中含有n个顶点e条边,则。 ⑵ n个顶点的强连通图至少有()条边,其形状是()。 A n B n+1 C n-1 D n×(n-1) E 无回路 F 有回路 G 环状 H 树状 【解答】A,G ⑶含n 个顶点的连通图中的任意一条简单路径,其长度不可能超过()。 A 1 B n/2 C n-1 D n
长安大学 算法与数据结构课程设计用顺序栈进行栈的基本操作 专业计算机科学与技术 班级 姓名 指导教师 日期
目录 摘要 (3) 关键字 (3) 内容要求 (3) 流程图 (4) 程序源代码 (4) 编译及调试 (9) 参考文献 (9) 评语........................................................................................................................... 一.摘要
顺序栈,即栈的顺序存储结构是利用一组地址连续的存储单元依次存放自栈低到栈顶的数据元素,同时附设指针top指示栈顶元素在顺序栈的位置。通过对顺序栈的实现进而对栈进行栈的基本操作。 二.关键字 Top Stacksize Base 三.内容要求 先为栈分配一个基本容量,并给存储空间分配增量当栈的空间不够使用时再逐段扩大。其中stacksize指示的是栈的当前可使用的最大容量。而false和true分别指的是栈是否为空,false为1反之亦然;error和ok则是指栈中元素是否可以返回即栈底元素是否为零,error为1反之亦然。分别对从一到十二等十二个元素进行压栈然后弹栈,每当插入新的栈顶元素时,指针top增1;删除栈顶元素时即弹栈时指针top减1,因此非空栈中的栈顶指针始终在栈顶元素的下一个位置上。最后进行销毁栈的操作,并得到top=0,stacksize=0,
base=0的运行结果。 四.流程图 五.程序源代码 // main3-1.cpp 检验bo3-1.cpp的主程序//#include"c1.h" #include
栈的链接存储结构 #include
第2讲图的存储结构——教学讲义 本讲介绍4种较常用的存储表示法:①邻接矩阵表示法;②邻接表;③邻接多重表;④十字链表。由于每种方法各有利弊,因此可以根据实际应用问题来选择合适的存储表示方法。 ①邻接矩阵表示法 图的邻接矩阵表示法(Adjacency Matrix)也称作数组表示法。它采用两个数组来表示图:一个是用于存储顶点信息的一维数组,另一个是用于存储图中顶点之间关联关系的二维数组,这个关联关系数组被称为邻接矩阵。 若G是一具有n个顶点的无权图,G的邻接矩阵是具有如下性质的n×n矩阵A: 上图所示G1和G2的邻接矩阵如下所示。 若图G是一个有n个顶点的网,则它的邻接矩阵是具有如下性质的n×n矩阵A A1= 图G1,G2的邻接矩阵 (a) G1是有向图(b) G2是无向图
例如:下图就是一个有向网及其邻接矩阵的示例。 邻接矩阵表示法的C 语言描述如下: #define MAX_VERTEX_NUM 20 /*最多顶点个数*/ #define INFINITY 32768 /*表示极大值,即∞*/ /* 图的种类:DG 表示有向图, DN 表示有向网, UDG 表示无向图, UDN 表示无向网 */ typedef enum{DG, DN, UDG, UDN} GraphKind; typedef char VertexData; /*假设顶点数据为字符型*/ typedef struct ArcNode{ AdjType adj; /* 对于无权图,用1或0表示是否相邻; 对带权图,则为权值类型 */ OtherInfo info; } ArcNode; typedef struct{ VertexData vertex[MAX_VERTEX_NUM]; /*顶点向量*/ ArcNode arcs [MAX_VERTEX_NUM][MAX_VERTEX_NUM]; /*邻接矩阵*/ int vexnum, arcnum; /*图的顶点数和弧数*/ GraphKind kind; /*图的种类标志*/ } AdjMatrix; /*(Adjacency Matrix Graph )*/ 邻接矩阵法的特点如下: ● 存储空间: 对于无向图而言,它的邻接矩阵是对称矩阵(因为若(v i ,v j ) ∈E (G ),则(v j ,v i )∈E (G )),因此可以采用特殊矩阵的压缩存储法,即只存储其下三角即可,这样,一个具有n 个顶点的无向图G ,它的邻接矩阵需要n (n -1)/2个存储空间即可。但对于有向图而言 ,其中的弧是有方向的,即若