
As the Java Virtual Machine is a stack-based machine, almost all of its instructions involve the operand stack in some way. Most instructions push values, pop values, or both as they perform their functions.
Java虚拟机是基于栈的(stack-based machine)。几乎所有的java虚拟机的指令,都与操作数栈(operand stack)有关.绝大多数指令都会在执行自己功能的时候进行入栈、出栈操作。
1Java体系结构介绍
Javaís architecture arises out of four distinct but interrelated technologies, each of which is defined by a separate specification from Sun Microsystems:
1.1 Java体系结构包括哪几部分?
Java体系结构包括4个独立但相关的技术
the Java programming language →程序设计语言
the Java class file format →字节码文件格式
the Java Application Programming Interface→应用编程接口
the Java Virtual Machine →虚拟机
1.2 什么是JVM
java虚拟机和java API组成了java运行时。
1.3 JVM的主要任务。
Java虚拟机的主要任务是装载class文件并执行其中的字节码。
Java虚拟机包含了一个类装载器。
类装载器的体系结构
二种类装载器
启动类装载器
用户定义的类装载器
启动类装载器是JVM实现的一部分
当被装载的类引用另外一个类时,JVM就是使用装载第一个类的类装载器装载被引用的类。
1.4 为什么java容易被反编译?
●因为java程序是动态连接的。从一个类到另一个类的引用是符号化的。在静态连接的
可执行程序中。类之间的引用只是直接的指针或者偏移量。相反在java的class文件中,指向另一个类的引用通过字符串清楚的标明了所指向的这个类的名字。
●如果引用是指向一个字段的话。这个字段的名字和描述符(字段的类型)会被详细说明。
●如果引用指向一个成员方法,那么这个成员方法的名字和描述符(方法的返回值类型,
方法参数的数量和类型)会被详细说明。
●包含对自己字段和成员方法的符号引用。
●包含可选的调试信息。(包括局部变量的名称和类型)
1.5 垃圾回收器缺点:
无法确认什么时候开始回收垃圾,无法确认是否已经开始收集,也无法确认要持续多长时间2平台无关
3安全
4网络移动性
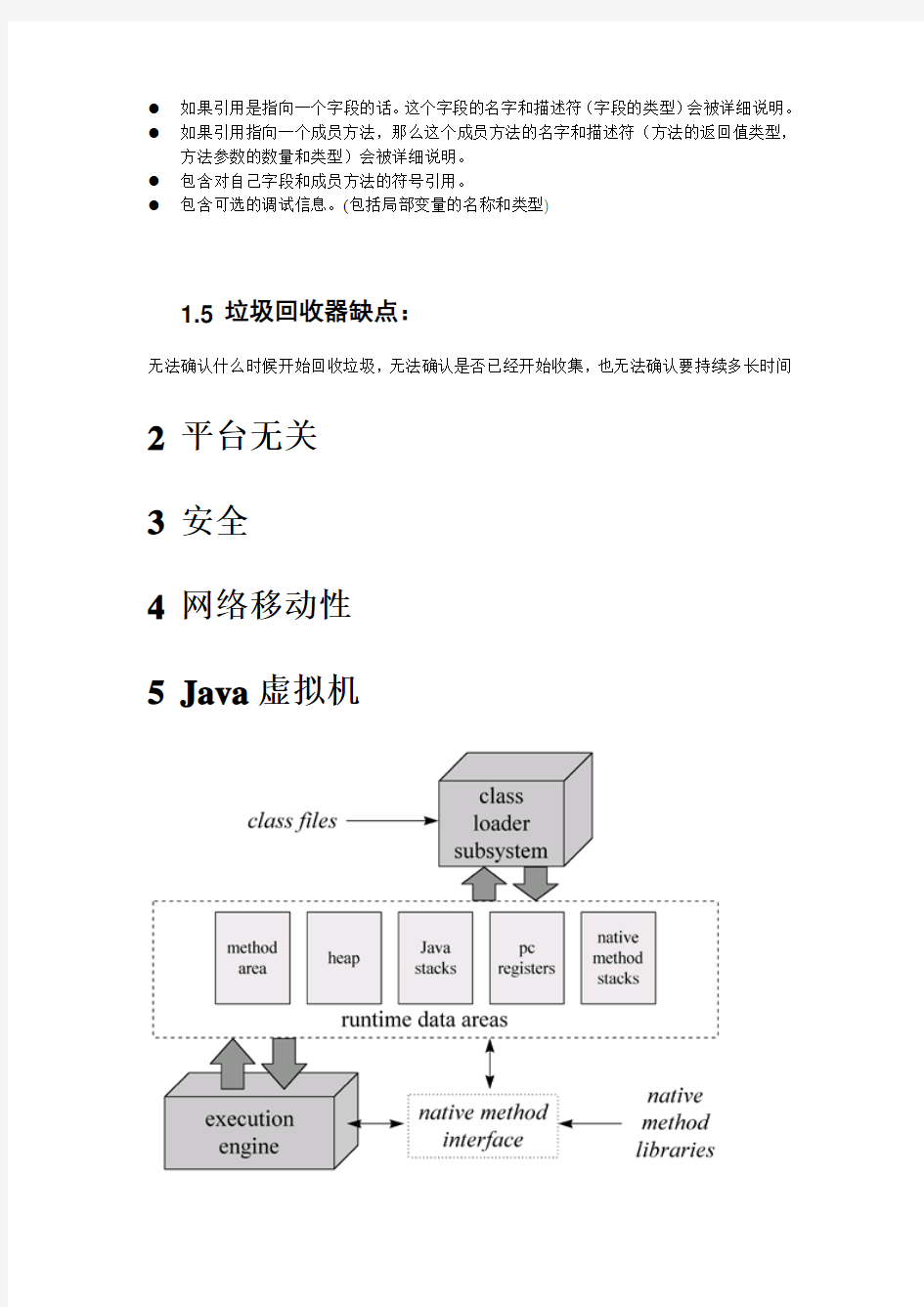
5Java虚拟机
●每个JVM都有一个类装载子系统。
●运行时数据区:方法区,堆,java栈,pc寄存器,本地方法栈
●每个JVM实例都有一个方法区和堆。他们是由该虚拟机中所有线程共享的。
●每个线程都会得到自己的pc寄存器和java栈,
?pc寄存器的值指示下一条将被执行的指令。
?java栈记录存储该线程中java方法调用的状态。(包括局部变量,参数,返回值,
运算的中间结果。)
?这些内存区域是私有的。任何线程都不能访问另一个线程的pc寄存器和java栈
●java栈由许多栈帧组成。一个栈帧包含一个java方法的调用的状态。
?当线程调用一个方法的时候,虚拟机压入一个新的栈桢到该线程的java栈中。
?当方法返回时,这个栈桢被从java栈中弹出并抛弃。
●引用有3中,类类型,接口类型,数组类型。
●JVM中,最基本的数据单元是字。至少选择32位作为字长。
●JVM有两种类装载器:
?启动类装载器(JVM实现的一部分,每个JVM都必须有一个)
?用户自定义的类装载器(JA V A程序的一部分,必须继承https://www.doczj.com/doc/9b7744216.html,ng.CloassLoader)。
●由不同的类装载器装载的类被放在虚拟机内部的不同的命名空间中。
●方法区:
?大小不固定,根据需要动态调整
?方法区可以被垃圾回收
?包含
◆提取装载的类的信息,放到方法区
●JVM总能通过存储于方法区的内存信息来确定一个对象需要多少内存
◆类的静态变量也放到方法区。
?虚拟机为装载的每个类存储如下信息:
◆这个类型的全限定名
◆这个类型的直接超类的全限定名
◆这个类型是类类型还是接口类型
◆这个类的访问权限修饰符
◆任何直接超接口的全限定名的有序列表
◆该类型的常量池
●该类型所用常量的一个有序集合,包括直接常量(String,Integer,floating
point),和对其他类型,字段,方法的符号引用
◆字段信息
●字段名
●字段类型
●字段的修饰符
●声明的顺序
◆方法信息
●方法名
●方法的返回值类型
●方法的参数和类型,顺序
●方法的修饰符
●方法的操作码
●操作数栈和该方法的栈帧中局部变量区的大小
●异常表
◆除了常量以外的所有类(静态)变量
◆一个到类CloassLoader的引用
◆一个到Class类的引用
◆方法表
●虚拟机为每一个装载的非抽象类都生成一个方法表
●堆
◆
◆一个java程序独占一个JVM,一个JVM中只存在一个堆。所以,每个java
程序有它自己的堆,但同一个java程序的多个线程共享一个堆
◆运行时创建的所有类实例
◆数组对象
●垃圾回收器
◆回收内存
◆移动对象以减少碎片
◆不必是连续的内存,可以动态的扩展和收缩
◆一个JVM的实现的方法区可以在堆顶实现
●栈帧frame
◆栈帧由3部分组成:局部变量区,操作数栈,帧数据区。
◆局部变量区,操作数栈的大小在编译的时候就确定了。
◆局部变量区(variable Table)
●以字长为单位,从0开始计数的数组。
●int,float,reference,return address只占据一个字长
●byte,short,char存入数组前转换成int,占据一个字长
●long,double占据2个字长。
●包含对应方法的参数和局部变量,
●方法的局部变量任意决定顺序,甚至一个索引指代两个变量,(当2个变
量的作用域不重复时)
◆操作数栈
●以字长为单位的数组,但不是通过索引来访问,而是通过标准的栈操作
●存贮数据的方式和局部变量区一样(就数据长度而言)。
●帧数据区
●帧数据区保存常量池解析,正常方法返回,异常派发机制等信息
●执行引擎
●线程:
●JVM只规定了最高级别的线程会得到大多数的CPU时间,
●较低优先级别的线程,只有在所有比它优先级更高的线程全部阻塞的情况
下才能保证得到CPU时间。
●级别低的线程在级别高的线程没有被阻塞的时候,也可能得到CPU时间,
但是这没有任何保证。
●每个虚拟机都有一个主存,用于保存所有的程序变量(对象的实例变量,
数组的元素,以及类变量)。每一个线程都有一个工作内存,线程用它保
存所使用和赋值的“工作拷贝”。
●局部变量和参数,因为他们是每个线程私有的,可以逻辑上看成是工作内
存或者主存的一部分。
6字节码文件
8位字节的二进制流
常量池标志
每一个标志都有一个相对应的表。表名通过在标志后面加上"_info"后缀来产生
7类型的声明周期
●装载
?通过该类型的完全限定名,产生一个该类型的二进制数据流
?解析这个二进制数据流为方法区内的内部数据结构
?(并在堆上)创建一个表示该类型的https://www.doczj.com/doc/9b7744216.html,ng.Class类的实例
●连接(已读入的二进制形式的类型数据合并到虚拟机的运行时状态中去)
?验证(保证java类型数据格式正确并适合JVM使用)
?准备(分配内存,默认初始化在此时发生)
?解析(把常量池中的符号引用(类,接口,字段,方法)转换为直接引用,虚拟机
的实现可以推迟解析这一步,它可以在当运行中的程序真正使用某个符号引用是再
去解析它)
●初始化(将类变量赋予适当的初始值(显式初始化),所有JVM的实现必须在每个类或
接口首次主动使用是被初始化)
对象的生命周期
●类实例化有四种途径:
?new
?调用Class或者https://www.doczj.com/doc/9b7744216.html,ng.reflect.Constructor的newInstance ( )
?clone ( )
?java.io.ObjectInputStream的getObject ( )
8连接模型
●动态连接和解析
●常量池:
?class文件把它所有的引用符号保存在一个地方,常量池
?每个文件有一个常量池
?每一个被JVM装载的类或者接口都有一份内部版本的常量池,被称作运行时常量
池
?运行时常量池映射到class文件的常量池
?JVM为每一个装载的类和接口保存一份独立的常量池。
?来自相同方法或不同方法中的几条指令,可能指向同一个常量池入口。
?每个常量池入口只被解析一次。
●解析
?在程序运行的某些时刻,如果某个特定的符号引用将要被使用,它首先要被解析。
?解析过程就是根据符号引用查找到实体,在把符号引用替换成直接引用的过程。
?所有的符号引用都保持在常量池,所以这个过程也被称作常量池解析。
?解析分为早解析和迟解析。
9垃圾收集
10栈和局部变量操作Stack and Local Variable Operations
10.1 常量入栈操作
Pushing Constants Onto the Stack
10.1.1将一个字长的常量压入栈
10.1.2将两个字长的常量压入栈
long and double values occupy 64 bits. Each time a long or double is pushed onto the stack, its value occupies two slots on the stack.
long和double类型的值是64位长度的值,每当一个long或者double类型的值被压入栈,将占据2个位置
10.1.3将空的对象引用(null)压入栈
One other opcode pushes an implicit constant value onto the stack. The aconst_null opcode, pushes a null object reference onto the stack.
Opcode Operand(s) Description
aconst_null (none) pushes a null object reference onto the stack
10.1.4将byte和short类型常量压入栈
10.1.5将常量池入口压入栈
Pushing constant pool entries onto the stack
Opcode Operand(s) Description
ldc indexbyte1 pushes single-word value from constant pool entry
specified by indexbyte1 onto the stack
ldc_w indexbyte1,
indexbyte2 pushes single-word value from constant pool entry specified by indexbyte1, indexbyte2 onto the stack
ldc2_w indexbyte1,
indexbyte2 pushes dual-word value from constant pool entry specified by indexbyte1, indexbyte2 onto the stack
10.2 通用栈操作
Generic Stack Operations
10.2.1栈操作
Stack manipulation
Opcode Operand(s) Description
nop (none) do nothing
pop (none) pop the top word from the operand stack
pop2 (none) pop the top two words from the operand stack
swap (none) swap the top operand stack two words
dup (none) duplicate top operand stack word
dup2 (none) duplicate top two operand stack words
dup_x1 (none) duplicate top operand stack word and put two down
dup_x2 (none) duplicate top operand stack word and put three down
dup2_x1 (none) duplicate top two operand stack words and put three down dup2_x2 (none) duplicate top two operand stack words and put four down
10.3 把局部变量压入栈
Pushing Local Variables Onto the Stack
10.3.1将1个字长的局部变量压入栈
Pushing single-word local variables onto the stack
Opcode Operand(s) Description
iload vindex pushes int from local variable position vindex
iload_0 (none) pushes int from local variable position zero
iload_1 (none) pushes int from local variable position one
iload_2 (none) pushes int from local variable position two
iload_3 (none) pushes int from local variable position three
fload vindex pushes float from local variable position vindex
fload_0 (none) pushes float from local variable position zero
fload_1 (none) pushes float from local variable position one
fload_2 (none) pushes float from local variable position two
fload_3 (none) pushes float from local variable position three
10.3.2将2个字长的局部变量压入栈
Pushing dual-word local variables onto the stack
Opcode Operand(s) Description
lload vindex pushes long from local variable positions vindex and (vindex
+ 1)
lload_0 (none) pushes long from local variable positions zero and one
lload_1 (none) pushes long from local variable positions one and two
lload_2 (none) pushes long from local variable positions two and three
lload_3 (none) pushes long from local variable positions three and four dload vindex pushes double from local variable positions vindex and
(vindex + 1)
dload_0 (none) pushes double from local variable positions zero and one dload_1 (none) pushes double from local variable positions one and two dload_2 (none) pushes double from local variable positions two and three dload_3 (none) pushes double from local variable positions three and four
10.3.3将对象引用局部变量压入栈
Table 10-9. Pushing object reference local variables onto the stack
Opcode Operand(s) Description
aload vindex pushes object reference from local variable position vindex aload_0 (none) pushes object reference from local variable position zero aload_1 (none) pushes object reference from local variable position one aload_2 (none) pushes object reference from local variable position two aload_3 (none) pushes object reference from local variable position three
10.4 弹出栈顶部元素,将其赋给局部变量
Popping to Local Variables
10.4.1弹出一个字长的值,将其赋给局部变量
Popping single-word values into local variables
Opcode Operand(s) Description
istore vindex pops int to local variable position vindex
istore_0 (none) pops int to local variable position zero
istore_1 (none) pops int to local variable position one
istore_2 (none) pops int to local variable position two
istore_3 (none) pops int to local variable position three
fstore vindex pops float to local variable position vindex
fstore_0 (none) pops float to local variable position zero
fstore_1 (none) pops float to local variable position one
fstore_2 (none) pops float to local variable position two
fstore_3 (none) pops float to local variable position three
10.4.2弹出2个字长的值,将其赋给局部变量
Popping dual-word values into local variables
Opcode Operand(s) Description
lstore vindex pops long to local variable positions vindex and (vindex + 1) lstore_0 (none) pops long to local variable positions zero and one
lstore_1 (none) pops long to local variable positions one and two
lstore_2 (none) pops long to local variable positions two and three
lstore_3 (none) pops long to local variable positions three and four
dstore vindex pops double to local variable positions vindex and (vindex +
1)
dstore_0 (none) pops double to local variable positions zero and one
dstore_1 (none) pops double to local variable positions one and two
dstore_2 (none) pops double to local variable positions two and three
dstore_3 (none) pops double to local variable positions three and four
10.4.3弹出对象引用,将其赋给局部变量
Popping object references into local variables
Opcode Operand(s) Description
astore vindex pops object reference to local variable position vindex
astore_0 (none) pops object reference to local variable position zero
astore_1 (none) pops object reference to local variable position one
astore_2 (none) pops object reference to local variable position two
astore_3 (none) pops object reference to local variable position three
10.5 wide指令
The wide Instruction
10.5.1弹出对象引用,将其赋给局部变量
Popping object references into local variables
无符号8位局部变量索引,把方法中的局部变量限制在256以下。
一条单独的wide指令,可将8位的索引再扩展8位。这样就可以把局部变量的限制扩展到65536
Opcode Operand(s) Description
wide iload, indexbyte1,
indexbyte2
pushes int from local variable position index
wide lload, indexbyte1,
indexbyte2
pushes long from local variable position index
wide fload, indexbyte1,
indexbyte2
pushes float from local variable position index
wide dload, indexbyte1,
indexbyte2 pushes double from local variable position index
wide aload, indexbyte1,
indexbyte2 pushes object reference from local variable position index
wide istore, indexbyte1,
indexbyte2
pops int to local variable position vindex
wide lstore, indexbyte1,
indexbyte2
pops long to local variable position index wide fstore, indexbyte1,
indexbyte2
pops float to local variable position index wide dstore, indexbyte1,
indexbyte2
pops double to local variable position index
wide astore, indexbyte1,
indexbyte2 pops object reference to local variable position index
11类型转换Type Conversion
11.1 long s, float s, and double s类型之间的转换
11.2 int数据类型向byte,char,short类型的转换
Converting ints, bytes, chars, and shorts.
No opcodes exist that convert directly from a long, float, or double to the types smaller than int
Java虚拟机中没有把long, float, or double类型值直接转换成比int类型占据更小的空间的数据类型的操作码。
Therefore converting from a float to a byte, for example, requires two steps. First the float must be converted to an int with f2i, then the resulting int can be converted to a byte with i2b.
因此,把float类型值转换为byte类型需要两个步骤,首先,float类型值必须通过f2i指令转换为int类型值,然后,所得的int值,再通过i2b指令转换为byte类型值
Although opcodes exist that convert an int to primitive types smaller than int (byte, short, and char), no opcodes exist that convert in the opposite direction. This is because any bytes, shorts, or chars are effectively converted to int before being pushed onto the stack.
尽管有操作码可以把int类型的值转换为比int类型值占据更小空间的数据类型(byte, short, and char),但并不存在执行相反方向转换操作的操作码,因为任何byte, short, and char类型值在压入栈的时候,就已经有效的被转换成int类型值了。
Arithmetic operations upon byte s, short s, and char s are done by first converting the values to int, performing the arithmetic operations on the int s, and being happy with an int result.
涉及byte s, short s, and char s类型的运算操作首先会把这些值转换成int类型,然后对int
类型的值进行计算,最后得到int类型的结果。
12整数运算Integer Arithmetic
two's complement 补码
All integer types supported by the Java Virtual Machine--byte s, short s, int s, and long s--are signed two's-complement numbers.
Java虚拟机支持的所有整数类型,byte s, short s, int s, and long s,他们都是带符号的二进制补码数。
The two's-complement scheme allows both positive and negative integers to be represented.
二进制补码方案,既能描述正整数,又能描述负整数
The most significant bit of a two's-complement number is its sign bit. The sign bit is one for negative numbers and zero for positive numbers and for the number zero.
符号位为1表示负整数,符号为0表示表示正整数和数字0
The number of unique values that can be represented by the two's-complement scheme is two raised to the power of the total number of bits
能被二进制补码方案表示的数的范围为:2的总位数次幂
For example, the short type in Java is a 16-bit signed two's-complement integer. The number of unique integers that can be represented by this scheme is 216, or 65,536.
例如,short在java中是16位的带符号的二进制补码整数,能够唯一表示的整数为216, 或者65,536
Half of the short type's range of values are used to represent zero and positive numbers; the other half of the short type's range are used to represent negative numbers.
Short类型值范围的一半用来表示0和正整数,另一般用来表示负整数。
The range of negative values for a 16-bit two's-complement number is -32,768 (0x8000) to -1 (0xffff). Zero is 0x0000. The range of positive values is one (0x0001) to 32,767 (0x7fff).
16位2进制补码负数的范围是-32,768 (0x8000) to -1 (0xffff). 0用0x0000来表示. 正整数的范围是(0x0001) to 32,767 (0x7fff).
Positive numbers are intuitive in that they are merely the base two representation of the number. Negative numbers can be calculated by adding the negative number to two raised to the power of the total number of bits.
整数直觉上只不过是数的两种表示法之一。负数可以通过负数和2的某次方幂相加而得出。For example, the total number of bits in a short is 16, so the two's-complement representation of a negative number in the valid range for a short (-32,768 to -1) can be calculated by adding the negative number to 216, or 65,536. The two's-complement representation for -1 is 65,536 + (-1) or 65,535 (0xffff). The two's-complement representation for -2 is 65,536 + (-2) or 65,534 (0xfffe).
例如,short类型的长度为16位。因此2进制补码表示法可以通过一个负数和2的16次幂
的相加来得到一个有效范围内的负数。-1 的二进制补码表示为65,536 + (-1) or 65,535 (0xffff).-2的二进制补码表示为65,536 + (-2) or 65,534 (0xfffe).
Addition is performed on two's-complement signed numbers in the same way it would be performed on unsigned binary numbers. The two numbers are added, overflow is ignored, and the result is interpreted as a signed two's-complement number. This will work as long as the result is actually within the range of valid values for the type. For example, to add 4 + (-2), just add 0x00000004 and 0xfffffffe. The result is actually 0x100000002, but because there are only 32 bits in an int, the overflow is ignored and the result becomes 0x00000002.
在带符号的二进制补码数上进行加法运算,与在无符号二进制数上进行加法运算一样。两个数相加(忽略溢出),结果被解释为一个带符号的二进制补码数。这个过程将在运算结果是该类型的有效范围内的情况下运行。例如要获得 4 + (-2)的结果, 只要把0x00000004 and 0xfffffffe相加即可. 结果是0x100000002, 但因为int类型只有32位,于是溢出部分被忽略,
Overflow in integer operations does not throw any exception in the Java Virtual Machine. The result is merely truncated to fit into the result type (either int or long). For example, adding ints 0x7fffffff and 1 yields 0x80000000. This means that the Java Virtual Machine will report that 2,147,483,647 + 1 = -2,147,483,648, if the type of the values being added are ints and not longs. As you program in Java, you must keep in mind that overflow can happen and make sure you choose the appropriate type, int or long, in each situation. Integer division by zero does throw an ArithmeticException, so you should also keep in mind that this exception could be thrown and catch it if necessary.
Java虚拟机中整数运算的溢出并不会导致抛出异常。其结果只被简单的截断以符合数据类型(或者为int,或者为long)。例如把int值0x7fffffff 和 1 相加,将会得到0x80000000. 因此如果相加的值的类型为int而非long,java虚拟机中2,147,483,647 + 1 的结果将是-2,147,483,648。在java中编程时,你必须随时注意可能发生的溢出,必须在每种情况下确认所选择的数据类型(int or long)是否正确。整数被0除会抛出一个ArithmeticException 异常,所以应该时刻牢记此类异常将会抛出,必须在必要的时候捕获异常。
If you encounter a situation in which long just isn't long enough, you can use the BigInteger class of the java.math package. Instances of this class are arbitrary-length integers. The BigInteger class supports all arithmetic operations on arbitrary-length integers that are provided for the primitive types by the Java Virtual Machine and the https://www.doczj.com/doc/9b7744216.html,ng.Math package.
如果long类型的长度仍然不能满足需要,可以使用java.math 包当中的BigInteger类。这个类可以描述任意长度的整数。BigInteger类支持在任意长度整数上进行的所有数学运算。前提是这些运算是基于java虚拟机和https://www.doczj.com/doc/9b7744216.html,ng.Math包所支持的基本数据类型。.
对于每个执行int类型算数运算的操作码,在long类型的想通运算中有对应的操作码。
运算操作码
12.1.1整数加法
12.1.2将一个常量与局部变量相加
Integer subtraction is performed on ints and longs via the opcodes shown in Table 12-3. Each opcode causes the top two values of the appropriate type to be popped off the stack. The topmost value is subtracted from the value just beneath it. The result is pushed back onto the stack. No exceptions are thrown by these opcodes.
12.1.3整数减法
每个操作码都会从栈中弹出两个相同类型的值。顶端的值充当减数,底端的值充当被减数。进行减法运算,结果被压回栈
12.1.4整数乘法
12.1.5整数除法
操作码从栈中弹出两个相同类型的值。底端的数除以栈顶端的数。换句话说,首先被压入栈的数作为被除数或者分子。其次被压入的数,栈顶端的数,作为除数或者分母。结果被压回栈。对于整数除法所产生的结果,将进行取整操作。如果被0除,将抛出ArithmeticException 异常。
12.1.6整数取余
The opcodes shown in Table 12-7 perform arithmetic negation on ints and longs. The negation opcodes pop the top value from the stack, negate it, and push the result.
12.1.7整数取反
13逻辑运算Logic
13.1.1对int类型值进行移位操作
13.1.2对long类型值进行移位操作
13.1.3对int类型值进行位逻辑操作
这些操作码实现了& | ^操作
13.1.4对long类型值进行位逻辑操作
14浮点运算Floating-Point Arithmetic
The floating point numbers described here conform to the IEEE 754 floating point standard, which is the standard to which all Java Virtual Machine implementations must adhere.
本章描述的浮点数符合IEEE 754浮点数标准,(所有java虚拟机实现都必须遵循的标准)A floating-point number has four parts--a sign, a mantissa, a radix, and an exponent.
浮点数由符号,尾数,基数,指数4部分组成。
The sign is either a 1 or -1.
符号位要么是1,要么是-1
The mantissa, always a positive number, holds the significant digits of the floating-point number
尾数永远是1个正数,它确定浮点数的有效位数
The exponent indicates the positive or negative power of the radix that the mantissa and sign should be multiplied by.
指数指与尾数、符号相乘的基数的幂的值,幂值可以为正,也可以为负。
符号位与尾数相乘,然后在乘以基数的指数次幂。即得到所指的浮点数。
Floating-point numbers have multiple representations, because one can always multiply the mantissa of any floating-point number by some power of the radix and change the exponent to get the original number.
因为同一个浮点数可以表示为多个不同的尾数基数指数的组合,所以浮点数可以有多种表示形式。例如数字-5可以表示为
For each floating-point number there is one representation that is said to be normalized.
对于每一个浮点数来说,都会有一种被称为“规范化”的表示形式
A floating-point number is normalized if its mantissa is within the range defined by the following relation:
1/radix <= mantissa < 1
如果一个浮点数的尾数满足下面所列的关系式,则这个浮点数为规范化的浮点数。
A normalized radix 10 floating-point number has its decimal point just to the left of the first non-zero digit in the mantissa. The normalized floating-point representation of -5 is -1 * 0.5 * 10 1. In other words, a normalized floating-point number's mantissa has no non-zero digits to the left of the decimal point and a non-zero digit just to the right of the decimal point. Any floating-point number that doesn't fit into this category is said to be denormalized. Note that the number zero has no normalized representation, because it has no non-zero digit to put just to the right of the decimal point. "Why be normalized?" is a common exclamation among zeros.
在以10为基数的浮点数中,尾数的小数点位置在第一个不为0 的数字的左边,。因此,-5的规范化浮点数表示为1 * 0.5 * 10 1.,换句话说,一个规范化浮点数的尾数,它的小数点左边的数字一定为0。紧接小数点右边的数字一定不为0。不符合这条规则的浮点数称为非规范化的浮点数。需要注意的是,因为0在小数点右边没有不为0的数字。因此数字0没有规范化的表示。“为什么要规范化”是在处理数字0的时候经常发出的感叹。
Floating-point numbers in the Java Virtual Machine use a radix of two, so they have the following form:
sign * mantissa * 2 exponent
Java虚拟机中的浮点数使用2为基数。因此他们可以表示为如下形式。
sign * mantissa * 2 exponent
一、 JVM简介 JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。JVM工作原理和特点主要是指操作系统装入JVM是通过jdk中Java.exe来完成, 首先来说一下JVM工作原理中的jdk这个东西, .JVM 在整个jdk中处于最底层,负责于操作系统的交互,用来屏蔽操作系统环境,提供一个完整的Java运行环境,因此也就虚拟计算机. 操作系统装入JVM是通过jdk中Java.exe来完成。 通过下面4步来完成JVM环境. 1.创建JVM装载环境和配置 2.装载JVM.dll 3.初始化JVM.dll并挂界到JNIENV(JNI调用接口)实例 4.调用JNIEnv实例装载并处理class类。 对于JVM自身的物理结构,我们可以从下图了解:
JVM的一个重要的特征就是它的自动内存管理机制,在执行一段Java代码的时候,会把它所管理的内存划分 成几个不同的数据区域,其中包括: 1. 程序计数器,众所周知,JVM的多线程是通过线程轮流切换并 分配CPU执行时间的方式来实现的,那么每一个线程在切换 后都必须记住它所执行的字节码的行号,以便线程在得到CPU 时间时进行恢复,这个计数器用于记录正在执行的字节码指令的地址,这里要强调的是“字节码”,如果执行的是Native方法,那么这个计数器应该为null; 2.
3. Java计算栈,可以说整个Java程序的执行就是一个出栈入栈 的过程,JVM会为每一个线程创建一个计算栈,用于记录线程中方法的调用和变量的创建,由于在计算栈里分配的内存出栈后立即被抛弃,因此在计算栈里不存在垃圾回收,如果线程请求的栈深度大于JVM允许的深度,会抛出StackOverflowError 异常,在内存耗尽时会抛出OutOfMemoryError异常; 4. Native方法栈,JVM在调用操作系统本地方法的时候会使用到 这个栈; 5. Java堆,由于每个线程分配到的计算栈容量有限,对于可能会 占据大量内存的对象,则会被分配到Java堆中,在栈中包含了指向该对象内存的地址;对于一个Java程序来说,只有一个Java堆,也就是说,所有线程共享一个堆中的对象;由于Java堆不受线程的控制,如果在一个方法结束之后立即回收这个方法使用到的对象,并不能保证其他线程是否正在使用该对象;因此堆中对象的回收由JVM的垃圾收集器统一管理,和某一个线程无关;在HotSpot虚拟机中Java堆被划分为三代:o新生代,正常情况下新创建的对象会被分配到新生代,但如果对象占据的内存足够大以致超过了新生代的容量限 制,也可能被分配到老年代;新生代对象的一个特点是最 新、且生命周期不长,被回收的可能性高;
As the Java V irtual Machine is a stack-based machine, almost all of its instructions involve the operand stack in some way. Most instructions push values, pop values, or both as they perform their functions. Java虚拟机是基于栈的(stack-based machine)。几乎所有的java虚拟机的指令,都与操作数栈(operand stack)有关.绝大多数指令都会在执行自己功能的时候进行入栈、出栈操作。 1Java体系结构介绍 Javaís architecture arises out of four distinct but interrelated technologies, each of which is defined by a separate specification from Sun Microsystems: 1.1 Java体系结构包括哪几部分? Java体系结构包括4个独立但相关的技术 the Java programming language →程序设计语言 the Java class file format →字节码文件格式 the Java Application Programming Interface→应用编程接口 the Java V irtual Machine →虚拟机 1.2 什么是JVM java虚拟机和java API组成了java运行时。 1.3 JVM的主要任务。 Java虚拟机的主要任务是装载class文件并执行其中的字节码。 Java虚拟机包含了一个类装载器。 类装载器的体系结构 二种类装载器 启动类装载器 用户定义的类装载器 启动类装载器是JVM实现的一部分 当被装载的类引用另外一个类时,JVM就是使用装载第一个类的类装载器装载被引用的类。 1.4 为什么java容易被反编译? ●因为java程序是动态连接的。从一个类到另一个类的引用是符号化的。在静态连接的 可执行程序中。类之间的引用只是直接的指针或者偏移量。相反在java的class文件中,指向另一个类的引用通过字符串清楚的标明了所指向的这个类的名字。
深入理解JVM 1 Java技术与Java虚拟机 说起Java,人们首先想到的是Java编程语言,然而事实上,Java是一种技术,它由四方面组成: Java编程语言、Java类文件格式、Java虚拟机和Java应用程序接口(Java API)。它们的关系如下图所示: 图1 Java四个方面的关系 运行期环境代表着Java平台,开发人员编写Java代码(.java文件),然后将之编译成字节码(.class文件)。最后字节码被装入内存,一旦字节码进入虚拟机,它就会被解释器解释执行,或者是被即时代码发生器有选择的转换成机器码执行。从上图也可以看出Java平台由Java虚拟机和Java应用程序接口搭建,Java 语言则是进入这个平台的通道,用Java语言编写并编译的程序可以运行在这个平台上。这个平台的结构如下图所示:
在Java平台的结构中, 可以看出,Java虚拟机(JVM) 处在核心的位置,是程序与底层操作系统和硬件无关的关键。它的下方是移植接口,移植接口由两部分组成:适配器和Java操作系统, 其中依赖于平台的部分称为适配器;JVM 通过移植接口在具体的平台和操作系统上实现;在JVM 的上方是Java的基本类库和扩展类库以及它们的API,利用Java API编写的应用程序(application) 和小程序(Java applet) 可以在任何Java平台上运行而无需考虑底层平台, 就是因为有Java虚拟机(JVM)实现了程序与操作系统的分离,从而实现了Java 的平台无关性。 那么到底什么是Java虚拟机(JVM)呢?通常我们谈论JVM时,我们的意思可能是: 1. 对JVM规范的的比较抽象的说明; 2. 对JVM的具体实现; 3. 在程序运行期间所生成的一个JVM实例。 对JVM规范的的抽象说明是一些概念的集合,它们已经在书《The Java Virtual Machine Specification》(《Java虚拟机规范》)中被详细地描述了;对JVM的具体实现要么是软件,要么是软件和硬件的组合,它已经被许多生产厂商所实现,并存在于多种平台之上;运行Java程序的任务由JVM的运行期实例单个承担。在本文中我们所讨论的Java虚拟机(JVM)主要针对第三种情况而言。它可以被看成一个想象中的机器,在实际的计算机上通过软件模拟来实现,有自己想象中的硬件,如处理器、堆栈、寄存器等,还有自己相应的指令系统。 JVM在它的生存周期中有一个明确的任务,那就是运行Java程序,因此当Java程序启动的时候,就产生JVM的一个实例;当程序运行结束的时候,该实例也跟着消失了。下面我们从JVM的体系结构和它的运行过程这两个方面来对它进行比较深入的研究。 2 Java虚拟机的体系结构 刚才已经提到,JVM可以由不同的厂商来实现。由于厂商的不同必然导致JVM在实现上的一些不同,然而JVM还是可以实现跨平台的特性,这就要归功于设计JVM时的体系结构了。 我们知道,一个JVM实例的行为不光是它自己的事,还涉及到它的子系统、存储区域、数据类型和指令这些部分,它们描述了JVM的一个抽象的内部体系结构,其目的不光规定实现JVM时它内部的体系结构,更重要的是提供了一种方式,用于严格定义实现时的外部行为。每个JVM都有两种机制,一个是装载具有合适名称的类(类或是接口),叫做类装载子系统;另外的一个负责执行包含在已装载的类或接口中的指令,叫做运行引擎。每个JVM又包括方法区、堆、Java栈、程序计数器和本地方法栈这五个部分,这几个部分和类装载机制与运行引擎机制一起组成的体系结构图为:
我们都知道虚拟机的内存划分了多个区域,并不是一张大饼。那么为什么要划分为多块区域呢,直接搞一块区域,所有用到内存的地方都往这块区域里扔不就行了,岂不痛快。是的,如果不进行区域划分,扔的时候确实痛快,可用的时候再去找怎么办呢,这就引入了第一个问题,分类管理,类似于衣柜,系统磁盘等等,为了方便查找,我们会进行分区分类。另外如果不进行分区,内存用尽了怎么办呢?这里就引入了内存划分的第二个原因,就是为了方便内存的回收。如果不分,回收内存需要全部内存扫描,那就慢死了,内存根据不同的使用功能分成不同的区域,那么内存回收也就可以根据每个区域的特定进行回收,比如像栈内存中的栈帧,随着方法的执行栈帧进栈,方法执行完毕就出栈了,而对于像堆内存的回收就需要使用经典的回收算法来进行回收了,所以看起来分类这么麻烦,其实是大有好处的。 提到虚拟机的内存结构,可能首先想起来的就是堆栈。对象分配到堆上,栈上用来分配对象的引用以及一些基本数据类型相关的值。但是·虚拟机的内存结构远比此要复杂的多。除了我们所认识的(还没有认识完全)的堆栈以外,还有程序计数器,本地方法栈和方法区。我们平时所说的栈内存,一般是指的栈内存中的局部变量表。下面是官方所给的虚拟机的内存结构图
从图中可以看到有5大内存区域,按照是否被线程所共享可分为两部分,一部分是线程独占区域,包括Java栈,本地方法栈和程序计数器。还有一部分是被线程所共享的,包括方法区和堆。什么是线程共享和线程独占呢,非常好理解,我们知道每一个Java进行都会有多个线程同时运行,那么线程共享区的这片区域就是被所有线程一起使用的,不管有多少个线程,这片空间始终就这一个。而线程的独占区,是每个线程都有这么一份内存空间,每个线程的这片空间都是独有的,有多少个线程就有多少个这么个空间。上图的区域的大小并不代表实际内存区域的大小,实际运行过程中,内存区域的大小也是可以动态调整的。下面来具体说说每一个区域的主要功能。
Java虚拟机 一、什么是Java虚拟机 Java虚拟机是一个想象中的机器,在实际的计算机上通过软件模拟来实现。Java虚拟机有自己想象中的硬件,如处理器、堆栈、寄存器等,还具有相应的指令系统。 1.为什么要使用Java虚拟机 Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。一般的高级语言如果要在不同的平台上运行,至少需要编译成不同的目标代码。而引入Java语言虚拟机后,Java语言在不同平台上运行时不需要重新编译。Java语言使用模式Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。 2.谁需要了解Java虚拟机 Java虚拟机是Java语言底层实现的基础,对Java语言感兴趣的人都应对Java虚拟机有个大概的了解。这有助于理解Java语言的一些性质,也有助于使用Java语言。对于要在特定平台上实现Java虚拟机的软件人员,Java语言的编译器作者以及要用硬件芯片实现Java虚拟机的人来说,则必须深刻理解Java 虚拟机的规范。另外,如果你想扩展Java语言,或是把其它语言编译成Java语言的字节码,你也需要深入地了解Java虚拟机。 3.Java虚拟机支持的数据类型 Java虚拟机支持Java语言的基本数据类型如下: byte://1字节有符号整数的补码 short://2字节有符号整数的补码 int://4字节有符号整数的补码 long://8字节有符号整数的补码 float://4字节IEEE754单精度浮点数 double://8字节IEEE754双精度浮点数 char://2字节无符号Unicode字符 几乎所有的Java类型检查都是在编译时完成的。上面列出的原始数据类型的数据在Java执行时不需要用硬件标记。*作这些原始数据类型数据的字节码(指令)本身就已经指出了*作数的数据类型,例如iadd、ladd、fadd和dadd指令都是把两个数相加,其*作数类型别是int、long、 float和double。虚拟机没有给boolean(布尔)类型设置单独的指令。boolean型的数据是由integer指令,包括integer 返回来处理的。boolean型的数组则是用byte数组来处理的。虚拟机使用IEEE754格式的浮点数。不支持IEEE格式的较旧的计算机,在运行 Java数值计算程序时,可能会非常慢。 虚拟机支持的其它数据类型包括: object//对一个Javaobject(对象)的4字节引用 returnAddress//4字节,用于jsr/ret/jsr-w/ret-w指令 注:Java数组被当作object处理。 虚拟机的规范对于object内部的结构没有任何特殊的要求。在Sun公司的实现中,对object的引用是一个句柄,其中包含一对指针:一个指针指向该object的方法表,另一个指向该object的数据。用Java
深入理解Java虚拟机(JVM) 一、什么是Java虚拟机 当你谈到Java虚拟机时,你可能是指: 1、抽象的Java虚拟机规范 2、一个具体的Java虚拟机实现 3、一个运行的Java虚拟机实例 二、Java虚拟机的生命周期 一个运行中的Java虚拟机有着一个清晰的任务:执行Java程序。程序开始执行时他才运行,程序结束时他就停止。你在同一台机器上运行三个程序,就会有三个运行中的Java 虚拟机。 Java虚拟机总是开始于一个main()方法,这个方法必须是公有、返回void、直接受一个字符串数组。在程序执行时,你必须给Java虚拟机指明这个包换main()方法的类名。 Main()方法是程序的起点,他被执行的线程初始化为程序的初始线程。程序中其他的线程都由他来启动。Java中的线程分为两种:守护线程(daemon)和普通线程(non-daemon)。守护线程是Java虚拟机自己使用的线程,比如负责垃圾收集的线程就是一个守护线程。当然,你也可以把自己的程序设置为守护线程。包含Main()方法的初始线程不是守护线程。 只要Java虚拟机中还有普通的线程在执行,Java虚拟机就不会停止。如果有足够的权限,你可以调用exit()方法终止程序。 三、Java虚拟机的体系结构 在Java虚拟机的规范中定义了一系列的子系统、内存区域、数据类型和使用指南。这些组件构成了Java虚拟机的内部结构,他们不仅仅为Java虚拟机的实现提供了清晰的内部结构,更是严格规定了Java虚拟机实现的外部行为。 每一个Java虚拟机都由一个类加载器子系统(class loader subsystem),负责加载程序中的类型(类和接口),并赋予唯一的名字。每一个Java虚拟机都有一个执行引擎(execution engine)负责执行被加载类中包含的指令。 程序的执行需要一定的内存空间,如字节码、被加载类的其他额外信息、程序中的对象、方法的参数、返回值、本地变量、处理的中间变量等等。Java虚拟机将这些信息统统保存在数据区(data areas)中。虽然每个Java虚拟机的实现中都包含数据区,但是Java虚拟机规范对数据区的规定却非常的抽象。许多结构上的细节部分都留给了Java虚拟机实现者自己发挥。不同Java虚拟机实现上的内存结构千差万别。一部分实现可能占用很多内存,而其他以下可能只占用很少的内存;一些实现可能会使用虚拟内存,而其他的则不使用。这种比较精炼的Java虚拟机内存规约,可以使得Java虚拟机可以在广泛的平台上被实现。 数据区中的一部分是整个程序共有,其他部分被单独的线程控制。每一个Java虚拟机
Java跨平台的原理 Java的跨平台是通过Java虚拟机(JVM)来实现的。 Java源文件的编译过程 Java应用程序的开发周期包括编译、下载、解释和执行几个部分。Java编译程序将Java 源程序翻译为JVM可执行代码—字节码。这一编译过程同C/C++的编译有些不同。当C编译器编译生成一个对象的代码时,该代码是为在某一特定硬件平台运行而产生的。因此,在编译过程中,编译程序通过查表将所有对符号的引用转换为特定的内存偏移量,以保证程序运行。Java编译器却不将对变量和方法的引用编译为数值引用,也不确定程序执行过程中的内存布局,而是将这些符号引用信息保留在字节码中,由解释器在运行过程中创建内存布局,然后再通过查表来确定一个方法所在的地址。这样就有效的保证了Java的可移植性和安全性。 Java解释器的执行过程 运行JVM字节码的工作是由解释器来完成的。解释执行过程分三步进行:代码的装入、代码的校验和代码的执行。装入代码的工作由“类装载器”(class loader)完成。类装载器负责装入运行一个程序需要的所有代码,这也包括程序代码中的类所继承的类和被其调用的类。当类装载器装入一个类时,该类被放在自己的名字空间中。除了通过符号引用自己名字空间以外的类,类之间没有其他办法可以影响其它类。在本台计算机上的所有类都在同一地址空间内,而所有从外部引进的类,都有一个自己独立的名字空间。这使得本地类通过共享相同的名字空间获得较高的运行效率,同时又保证它们与从外部引进的类不会相互影响。当装入了运行程序需要的所有类后,解释器便可确定整个可执行程序的内存布局。解释器为符号引用同特定的地址空间建立对应关系及查询表。通过在这一阶段确定代码的内存布局,Java很好地解决了由超类改变而使子类崩溃的问题,同时也防止了代码对地址的非法访问。 随后,被装入的代码由字节码校验器进行检查。校验器可发现操作数栈溢出,非法数据类型转换等多种错误。通过校验后,代码便开始执行了。 Java字节码的两种执行方式 1、即时编译方式:解释器先将字节码编译成机器码,然后再执行该机器码。 2、解释执行方式:解释器通过每次解释并执行一小段代码来完成Java字节码程序的所有操作。 通常采用的是第二种方法。由于JVM规格描述具有足够的灵活性,这使得将字节码翻译为机器代码的工作具有较高的效率。对于那些对运行速度要求较高的应用程序,解释器可将Java字节码即时编译为机器码,从而很好地保证了Java代码的可移植性和高性能。 JVM规格描述 JVM的设计目标是提供一个基于抽象规格描述的计算机模型,为解释程序开发人员提供很好的灵活性,同时也确保Java代码可在符合该规范的任何系统上运行。JVM对其实现的某些方面给出了具体的定义,特别是对Java可执行代码,即字节码(Bytecode)的格式给出了明确的规格。这一规格包括操作码和操作数的语法和数值、标识符的数值表示方式、以及Java类文件中的Java对象、常量缓冲池在JVM的存储映象。这些定义为JVM解释器开发人员提供了所需的信息和开发环境。Java的设计者希望给开发人员以随心所欲使用Java的自由。 JVM是为Java字节码定义的一种独立于具体平台的规格描述,是Java平台独立性的基础。 Java程序执行与C/C++程序执行的对比分析 如果把Java源程序想象成我们的C++源程序,Java源程序编译后生成的字节码就相当
JVM内存分配过程与原理解析 之前对java虚拟机对于内存的分配与管理不是很了解,这段时间工作不是很忙,想借此机会深入的了解一下,在网上看了很多文章,对其详情也有了一定的认识,但是只是看看肯定是不行的,为了加深印象同时使自己能够理解的更深刻,我决定写这篇文章,同时希望对大家也有一定的帮助。文章里引用了其他前辈的一些资源,在这里表示感谢,那么我们就先从内存区域说起吧! 一.内存分区。 首先Java程序运行Java代码是发生在JVM上的,JMV相当于是java程序与操作系统的桥梁,JVM具有平台无关特性,所以java程序便可以在不同的操作系统上运行。Java的内存分配就是发生在JVM上的。对于java的内存回收我们并不用像其他有些语言一样手动回收,虚拟机就帮我们解决了,也正因为如此,如果我们写代码的时候不注意,很容易出现内存泄漏或者内存溢出(OOM),一旦出现问题,排查也不是很容易,所以只有了解了java的内存机制,才能更好的处理代码,优化代码。下边我们看一下java内存的几个部分,如下图: 由上图可知java内存共由java堆区(Heap)、java栈区(Stack)、方法区(Method Area)、本地方法栈(Native Method Stack)、程序计数器五部分组成,下面我们一一简单的讲解一下每一个区间的不同作用。 1.java堆区 首先要讲的就是我们的java堆,也就是人们常说的堆栈堆栈里边的堆,通过上图可知堆区是JVM中所有线程共享的内存区域,当运行一个应用程序的时候就会初始化一个相应的堆区,堆区可以动态扩展,如果我们需要的内存不够了,并且内存不能扩展了,那么就会报OOM了。引用java虚拟机规范中的一段话:所有的对象实例和数据都要在堆上进行分配。比如我们通过new来创建一个对象,创建出来的对象只包含属于各自的成员变量,并不包括成员方法。因为同一个类型的不同对象拥有各自的成员变量,存储在各自的堆中,但是他们共享该类的方法,并不是每创建一个对象就把成员方法复制一次。给对象分配内存就是把一块确定大小的从堆内存中划分出来,一般有两种方式: ①指针碰撞法:假设堆中内存是完整的,已分配的内存和空闲内存分别在不同的一侧, 通过一个指针作为分界点,需要分配内存时,仅仅需要把指针往空闲的一端移动与对象大小相等的距离。②空闲列表法:事实上,Java堆的内存并不是完整的,已分配的内存和空闲内存相互交错,JVM通过维护一个列表,记录可用的内存块信息,当需要分配内存时,从列表中找到一个足够大的内存块分配给对象实例,并更新列表上的记录。然而
As the Java Virtual Machine is a stack-based machine, almost all of its instructions involve the operand stack in some way. Most instructions push values, pop values, or both as they perform their functions. Java虚拟机是基于栈的(stack-based machine)。几乎所有的java虚拟机的指令,都与操作数栈(operand stack)有关.绝大多数指令都会在执行自己功能的时候进行入栈、出栈操作。 1Java体系结构介绍 Javaís architecture arises out of four distinct but interrelated technologies, each of which is defined by a separate specification from Sun Microsystems: 1.1 Java体系结构包括哪几部分? Java体系结构包括4个独立但相关的技术 the Java programming language →程序设计语言 the Java class file format →字节码文件格式 the Java Application Programming Interface→应用编程接口 the Java Virtual Machine →虚拟机 1.2 什么是JVM java虚拟机和java API组成了java运行时。 1.3 JVM的主要任务。 Java虚拟机的主要任务是装载class文件并执行其中的字节码。 Java虚拟机包含了一个类装载器。 类装载器的体系结构 二种类装载器 启动类装载器 用户定义的类装载器 启动类装载器是JVM实现的一部分 当被装载的类引用另外一个类时,JVM就是使用装载第一个类的类装载器装载被引用的类。 1.4 为什么java容易被反编译? ●因为java程序是动态连接的。从一个类到另一个类的引用是符号化的。在静态连接的 可执行程序中。类之间的引用只是直接的指针或者偏移量。相反在java的class文件中,指向另一个类的引用通过字符串清楚的标明了所指向的这个类的名字。
深入理解Java虚拟机 什么是Java虚拟机 Java程序必须在虚拟机上运行。那么虚拟机到底是什么呢?先看网上搜索到的比较靠谱的解释: 虚拟机是一种抽象化的计算机,通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java虚拟机有自己完善的硬体架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。JVM屏蔽了与具体操作系统平台相关的信息,使得Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。 这种解释应该算是正确的,但是只描述了虚拟机的外部行为和功能,并没有针对内部原理做出说明。一般情况下我们不需要知道虚拟机的运行原理,只要专注写java代码就可以了,这也正是虚拟机之所以存在的原因--屏蔽底层操作系统平台的不同并且减少基于原生语言开发的复杂性,使java这门语言能够跨各种平台(只要虚拟机厂商在特定平台上实现了虚拟机),并且简单易用。这些都是虚拟机的外部特性,但是从这些信息来解释虚拟机,未免太笼统了,无法让我们知道内部原理。 从进程的角度解释JVM 让我们尝试从操作系统的层面来理解虚拟机。我们知道,虚拟机是运行在操作系统之中的,那么什么东西才能在操作系统中运行呢?当然是进程,因为进程是操作系统中的执行单位。可以这样理解,当它在运行的时候,它就是一个操作系统中的进程实例,当它没有在运行时(作为可执行文件存放于文件系统中),可以把它叫做程序。 对命令行比较熟悉的同学,都知道其实一个命令对应一个可执行的二进制文件,当敲下这个命令并且回车后,就会创建一个进程,加载对应的可执行文件到进程的地址空间中,并且执行其中的指令。下面对比C语言和Java语言的HelloWorld程序来说明问题。 首先编写C语言版的HelloWorld程序。 编译C语言版的HelloWorld程序:
一、什么是JVM JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。 Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。一般的高级语言如果要在不同的平台上运行,至少需要编译成不同的目标代码。而引入Java语言虚拟机后,Java语言在不同平台上运行时不需要重新编译。Java语言使用Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。这就是Java的能够“一次编译,到处运行”的原因。 从Java平台的逻辑结构上来看,我们可以从下图来了解JVM:
从上图能清晰看到Java平台包含的各个逻辑模块,也能了解到JDK与JRE的区别,对于JVM自身的物理结构,我们可以从下图鸟瞰一下:
二、JAVA代码编译和执行过程 Java代码编译是由Java源码编译器来完成,流程图如下所示: Java字节码的执行是由JVM执行引擎来完成,流程图如下所示: ava代码编译和执行的整个过程包含了以下三个重要的机制: ?Java源码编译机制 ?类加载机制 ?类执行机制
Java源码编译机制 Java 源码编译由以下三个过程组成: ?分析和输入到符号表 ?注解处理 ?语义分析和生成class文件 流程图如下所示: 最后生成的class文件由以下部分组成: ?结构信息。包括class文件格式版本号及各部分的数量与大小的信息 ?元数据。对应于Java源码中声明与常量的信息。包含类/继承的超类/实现的接口的声明信息、域与方法声明信息和常量池 ?方法信息。对应Java源码中语句和表达式对应的信息。包含字节码、异常处理器表、求值栈与局部变量区大小、求值栈的类型记录、调试符号信息 类加载机制 JVM的类加载是通过ClassLoader及其子类来完成的,类的层次关系和加载顺序可以由下图来描述:
Java虚拟机调优原理及技巧 一、相关概念 基本回收算法 1.引用计数(Reference Counting) 比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。 2.标记-清除(Mark-Sweep) 此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对 象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。 3.复制(Copying) 此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。 次算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不过出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。 4.标记-整理(Mark-Compact) 此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,把清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空 间问题。 5.增量收集(Incremental Collecting) 实施垃圾回收算法,即:在应用进行的同时进行垃圾回收。不知道什么原因JDK5.0中的收集器没有使用这种算法的。 6.分代(Generational Collecting) 基于对对象生命周期分析后得出的垃圾回收算法。把对象分为年青代、年老代、持久代,对不同生命周期的对象使用不同的算法(上述方式中的一个)进行回收。现在的垃圾回收器(从J2SE1.2开始)都是使用此算法的。 分代垃圾回收详述
基本结构 从Java平台的逻辑结构上来看,我们可以从下图来了解JVM: 从上图能清晰看到Java平台包含的各个逻辑模块,也能了解到JDK与JRE的区别。JVM自身的物理结构
此图看出jvm内存结构 JVM内存结构主要包括两个子系统和两个组件。两个子系统分别是Classloader子系统和Executionengine(执行引擎)子系统;两个组件分别是Runtimedataarea(运行时数据区域)组件和Nativeinterface(本地接口)组件。 Classloader子系统的作用: 根据给定的全限定名类名(如https://www.doczj.com/doc/9b7744216.html,ng.Object)来装载class文件的内容到Runtimedataarea中的methodarea(方法区域)。Java程序员可以 https://www.doczj.com/doc/9b7744216.html,ng.ClassLoader类来写自己的Classloader。 Executionengine子系统的作用: 执行classes中的指令。任何JVMspecification实现(JDK)的核心都是Executionengine,不同的JDK例如Sun的JDK和IBM的JDK好坏主要就取决于他们各自实现的Executionengine的好坏。 Nativeinterface组件: 与nativelibraries交互,是其它编程语言交互的接口。当调用native方法的时候,就进入了一个全新的并且不再受虚拟机限制的世界,所以也很容易出现JVM无法控制的nativeheapOutOfMemory。 RuntimeDataArea组件: 这就是我们常说的JVM的内存了。它主要分为五个部分—— 1、Heap(堆):一个Java虚拟实例中只存在一个堆空间
Java 虚拟机介绍 Java 体系结构包括四个独立但相关的技术: 1. Java 程序设计语言 2. Java class 文件格式 3. Java 应用编程接口(API) 4. Java 虚拟机 Java 语言的运行机制 首先编写的是.java 格式的源文件,然后由jvm 的编译器编译成.class 二进制字节码文件,接下来由jvm 将class 文件解释为本地系统宿主环境相对应的机器码运行。Java 虚拟机是一台抽象的计算机,其规范定义了每个java 虚拟机都必须实现的特性。当然JVM 也是根据不同操作系统及硬件标准划分为相应的版本来解决基于各操作系统差异和硬件环境(cpu 型号)等因素达到跨平台目的。 编译时环境运行时环境 Java 虚拟机的主要任务是装载class 文件并且执行其中的字节码,JVM 包含一个类装载器(class loader),它可以从API 中装载class 文件,API 中的那些类只有需要时才会被装载,字节码由执行引擎来执行;JVM 在执行字节码时需要经过以下步骤: 1. 由类加载器(class loader),将class 文件加载到JVM 中这时候需要做一次文件规范的校验。 2. 再由字节码校验器(Bytecode Verifier)检查该文件的代码中是否存在非法操作 3. 通过字节码校验器的验证后就由解释器负责把该class 文件解释执行 当然JVM 在上述操作过程中还使用了一种叫“沙箱”模型的安全机制,所谓“沙箱”就是A .class C.class B.class
将java程序代码和数据限制在一定的内存空间里执行,不允许程序访问内存空间以外的内存。 具体详解“沙箱”: 步骤一:“双亲委派类加载模型” 双亲委派方式,指的是优先从顶层启动类加载器,自定向下的方式加载类模型,这种方式在“沙箱”安全模型里面做了第一道安全保障;而且这样的方式使得底层的类加载器加载的类和顶层的类加载器的类不能相互调用,哪怕两种类加载器加载的是同一个包里面的类,只要加载的时候不属于同一个类加载器,就是相互隔绝的,这样的操作称为JVM的“安全隔离” 步骤二:字节码校验 可分为四个步骤: 1.检查class文件的结构正确与否 第一趟扫描的主要目的是保证这个字节序列正确的定义了一个类型,它必须遵从java class文件的固定格式,这样它才能被编译成在方法区中的(基于实现的)内部 数据结构 2.检查是否符合JVM的编译规则 这次检查,class文件检验器不需要查看字节码,也不需要查看和装载任何其他类型。在这趟扫描中,检验器查看每个组成部分,确认它们是否是其所属类型的实例,它 们结构是否正确。还会检查这个类本身是否符合特定的条件,它们是由java编程语言规 定的。比如,除Object外,所有类都必须要有一个超类,final的类不能被子类化,final 方法也没有被覆盖,检查常量池中的条目是合法的,而且常量池的所有索引必须指向正 确类型的常量池条目。 3.检查字节码是否导致JVM崩溃 字节码流代表了java的方法,它是由被称为操作码的单字节指令组成的序列,每一个操作码后都跟着一个或多个操作数。执行字节码时,依次执行操作码,这就在java 虚拟机内构成了执行的线程,每一个线程被授予自己的java栈,这个栈是由不同的栈帧 构成的,每一个方法调用将获得一个自己的栈帧——栈帧其实就是一个内存片段,其中 存储着局部变量和计算的中间结果,用于存储中间结果的部分被称为操作数栈。字节码 检验器要进行大量的检查,以确保采用任何路径在字节码流中都得到一个确定的操作码,确保操作数栈总是包含正确的数值以及正确的类型。它必须保证局部变量在赋予合适的 值以前不能被访问,而且类的字段中必须总是被赋予正确类型的值,类的方法被调用时 总是传递正确数值和类型的参数。字节码检验器还必须保证每个操作码都是合法的,即
Java虚拟机工作原理详解 一、类加载器 首先来看一下java程序的执行过程。 从这个框图很容易大体上了解java程序工作原理。首先,你写好java代码,保存到硬盘当中。 然后你在命令行中输入 [java]view plaincopy 1.javac YourClassName.java
此时,你的java代码就被编译成字节码(.class). 如果你是在Eclipse IDE或者其他开发工具中,你保存代码的时候,开发工具已经帮你完成了上述的编译工作,因此你可以在对应的目录下看到class文件。此时的class文件依然是保存 在硬盘中,因此,当你在命令行中运行 [java]view plaincopy 1.java YourClassName 就完成了上面红色方框中的工作。JRE的来加载器从硬盘中读取class文件,载入到系统分配给JVM的内存区域--运行数据区(Runtime Data Areas). 然后执行引擎解释或者编译类文件,转化成特定CPU的机器码,CPU执行机器码,至此完成整个过程。
接下来就重点研究一下类加载器究竟为何物?又是如何工作的? 首先看一下来加载器的一些特点,有点抽象,不过总有帮助的。 》》层级结构 类加载器被组织成一种层级结构关系,也就是父子关系。其中,Bootstrap是所有类加载器的父亲。如下图所示:
--Bootstrap class loader: 当运行java虚拟机时,这个类加载器被创建,它加载一些基本的java API,包括Object这个类。需要注意的是,这个类加载器不是用java 语言写的,而是用C/C++写的。 --Extension class loader: 这个加载器加载出了基本API之外的一些拓展类,包括一些与安全性能相关的类。(目前了