pb11+webservice开发分布式三层应用
一、WEBSERVICE服务端的开发
1、新建立一个workspace工作区
先择FILE菜单下的NEW,新建一个工作区。
点击后出现下图
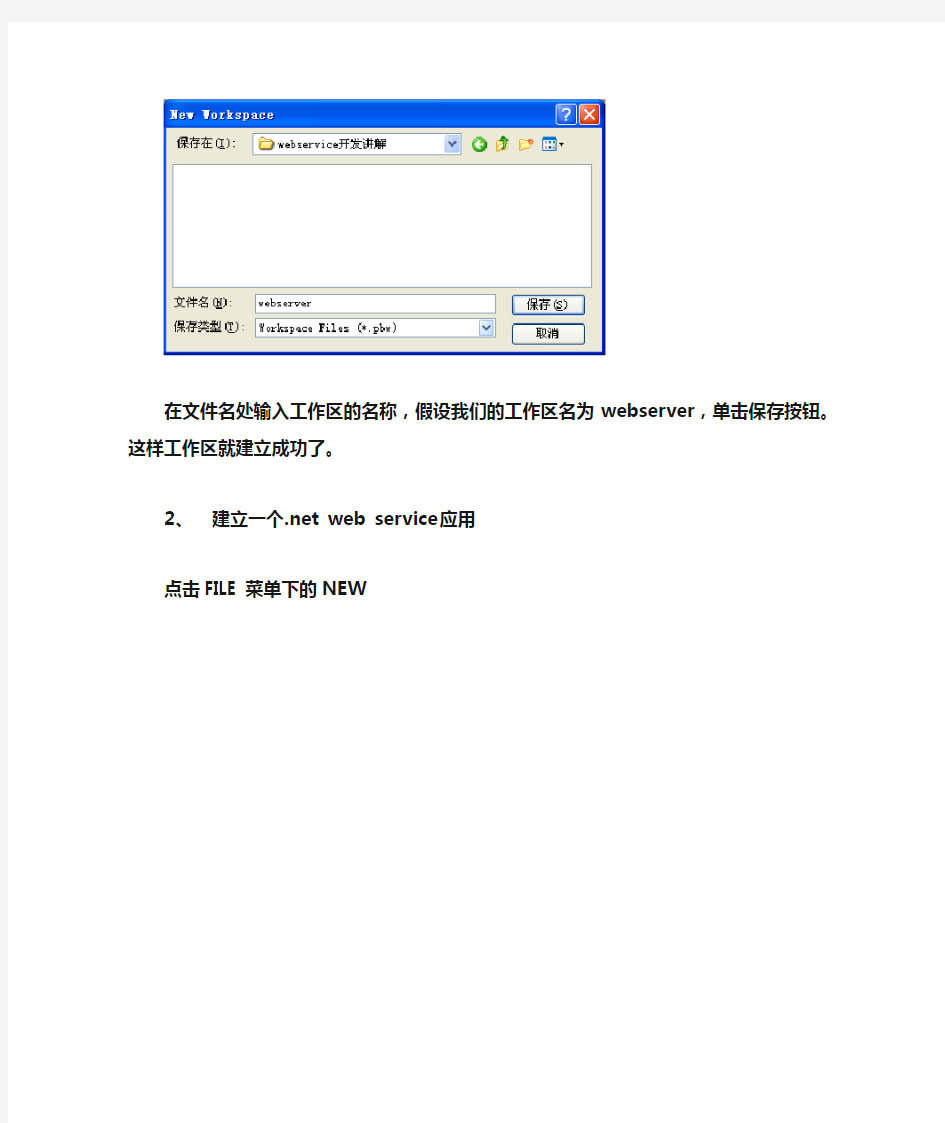
在文件名处输入工作区的名称,假设我们的工作区名为webserver,单击保存按钮。这样工作区就建立成功了。
2、建立一个.net web service 应用
点击FILE菜单下的NEW
选中.net web service 点击ok按钮
点击next按钮
点击next按钮
这里我们不修改pbl库名,当然你可以按你的意思修改库名,点击next 按钮。
一直点next按钮直到出现
这里需要注意一点,如果你当前的IIS端口,不是默认的80 ,那么在localhost后面要加上“:81”,假设你的端口号是81的话。
再点击一次next直到finish按钮。
3、连接数据库
我们先来建立一个数据库的连接以为后期的webservice服务提供一个连接。
打开系统生成的n_webservice对像
在里面写上
// Profile EAS Demo DB V110
SQLCA.DBMS = "ODBC"
SQLCA.AutoCommit = False
SQLCA.DBParm = "ConnectString='DSN=EAS Demo DB V110;UID=dba;PWD=sql'"
我是拷贝了,安装PB11默认的安装的ASA数据库,这里你可以修改成你的数据库连接参数。
数据库建立完成后,我们再建立一个ue_retrieve的方法用来提取数据库数据
1、在N_webservice对像里创建立一个名为DS1的数据存储datastore
2、在DS1 的dberror里面写上
ls_err_a=sqlerrtext////////
注意:将ls_err_a 定义为一个实例变量,如果你看不清楚出入参定义可以将本图片另存放大就可以看到了。
////////////////////////////////////////////////////////////////////////////
// 用于取单一的数据窗口blob值//
// //
// 将数据窗口检索到blob,并将blob返到客户端//
// //
// guoac //
// //
// 入参ls_syntax--传入一个字符串的数据窗口对像语法用于重构数窗//
// 入参ls_sql 传入一个条件字符串,用于附加where 条件// //
// 出参dwo_blob 传出一个存储数据窗口对像的blob //
// //
// dwo_blob 回传参数//
////////////////////////////////////////////////////////////////////////////
long ll_row,ll_returnrow
string ls_returnmodiy
string ls_oldsql,ls_newsql,ls_error
string csa
int i,LI_WHERE
connect;
if SQLCA.SQLCode <> 0 then
as_returnerr="连接数据库出错,请检查数据库连接参数。"+string(sqlca.sqlerrtext) return -1////创建数据窗口出错
end if
if ds1.create(as_syntax,ls_error)<>1 then
disconnect using sqlca;
as_returnerr="服务端重建数据窗口出错! "+ls_error
return -1////创建数据窗口出错
end if
int li_a
li_a=ds1.settransobject(sqlca)
if li_a<>1 then
disconnect using sqlca;
as_returnerr="服务端设置数据存储事务出错!"
return -1///设置对像事物出错
end if
ls_oldsql=ds1.getsqlselect()
if trim(ls_oldsql)='' or isnull(trim(ls_oldsql)) then
disconnect using sqlca;
as_returnerr="传入的数据窗口对像sql语法为空!"
return -1 //取新窗口语法出错
end if
LI_WHERE = pos(UPPER(ls_oldsql),'WHERE',1)
IF LI_WHERE = 0 THEN
ls_oldsql=ls_oldsql + " WHERE 1=1 "
END IF
ls_newsql=ls_oldsql +' '+as_sql
if trim(ls_newsql)='' or isnull(trim(ls_newsql)) then
disconnect using sqlca;
as_returnerr="连结后的sql语法为空!请检查传入的数据窗口对像sql语法。"
return -1 //取新窗口语法出错
end if
if Match ( ls_newsql, '"' ) then
disconnect using sqlca;
as_returnerr="重组后的sql语法出错,数据窗口语法不能包含双引号!"+ls_newsql
return -1//设置新窗口语法出错
elseif not Match ( upper(ls_newsql), "WHERE" ) then
disconnect using sqlca;
as_returnerr="重组后的sql语法出错,数据窗口必须包含一个where条件"+ls_newsql
return -1//设置新窗口语法出错
end if
if ds1.modify( 'DataWindow.Table.Select="' + ls_newsql+'"' )<>"" then
disconnect using sqlca;
as_returnerr="重组后的sql语法出错,请检查数据窗口对像SQL语法。"+ls_newsql
return -1//设置新窗口语法出错
end if
ll_row=ds1.retrieve()
if ll_row<0 or isnull(ll_row) then
disconnect using sqlca;
as_returnerr="数据检索出错!"+ls_err_a+ls_newsql
return -1//服务端检索数据出错
end if
if ds1.modify('DataWindow.Table.Select="' + ls_oldsql+'"' ) <>"" then
disconnect using sqlca;
as_returnerr="还原旧数据窗口语法出错,请检查数据窗口对像语法是否含有双引号。"+ls_oldsql
return -1 //还原旧数据窗口语法出错
end if
ll_returnrow=ds1.getfullstate(dwo_blob)
if ll_returnrow<0 or isnull(ll_returnrow) then
disconnect using sqlca;
as_returnerr="服务端进行blob时,获取数据行出错!"
return -1 //封装到blob变量时出错
end if
disconnect using sqlca;
destroy ds1;
as_returnerr="数据检索成功!"
// destroy n_webservice
return ll_returnrow
3、把服务端发布到IIS服务
打开我们的P_webservice_webservice编译object 。点击编译,pb11会自动将webservice发布到我们原来定义的IIS服务器上
发布的时候要注意一点就是在objects选项卡上,必须先中我们上面的函数(或者叫方法),library list选项卡上要选上我们的pbl库文件。点击第一辆小车deploy project其它就交给pb 自已去完成了。
4、编译完成后run一下我们的webservice看看是否发布成功,
出现上图并能看到我们定义的函数(我总是喜欢叫它们方法),webservice就算是发布成功了。
这样我们就完成了一个服务端检索方法。下一节我们接着继续讲解如何用客户端检索数据。
二、客户端调用webservice
1、建立一个PB应用
点击确定后
点击finish 完成
2、给工程附加pbsoapclient110.pbd
这个文件通常在pb11的安装目录里,可以通过搜索找到它,然后将这个文件拷贝到我们新建应用的目录下,并附加到工程里面来。
3、为应用添加一个webservice proxy
函数添加完成后在工程里面添加一个窗口,我们来实验一下我们前面的工作
注意:应用程序要与webservice通讯都要通过webservice proxy来完成,所以我们首先要建立一个proxy
Ok后
这里的wsdl file name
如果你记不住就打开webservice 端,工程文件的object项上面去找
然后一直下一步到下图
写上一个proxyname 我写的是myproxy
一直到下一步完成。
打开我们刚才定义的代理,并编译,顺利的话会看到库文件中添加了很多结构,这些我们都不用管,接着做我们后面的工作就好。
4、新建一个custom class
5、给新建立的对像添加一个函数
这个函数就是代替二层开发模式下的retrieve函数的,这里你可以将这个函数多次重载以方便前台开发人员调用,目前这个函数支持给窗口添加where条件,检索并返回错误或成功的信息。以及返回检索到的行数。还是不太明白的可以加我的QQ:47570471,我的文笔从上幼儿园开始就不是强项,估计说得也不是太明白,不过欢迎大家QQ骚扰。总之就是重载到前端开发人员分不出是在开发二层还是三层就算ok了,见下图:
为对像添加二个实例变量
SoapConnection i_conn
myproxyn_webservicesoap pb_soap //// myproxyn_webservicesoap这个名称如果你前面建立代理的时候用的是myproxy那应该就是这个,如果不是就去找你生成的代理对像名称。Constructor 事件里面写上
i_conn=create SoapConnection
//i_conn.setsoaplogfile( "mis.log")
i_conn.createinstance( pb_soap,"myproxyn_webservicesoap")
destructor事件里面写上
destroy pb_soap;
destroy i_conn;
对像到这里建立完成。
1、给应用添加一个全局变量
soapserver mis
注意:soapserver为上面定义的对像的名称。
在窗口的open事件里面上
mis =create soapserver
2、做一个数据窗口(这个不用说了吧)
3、把数据窗口拖到我们的测试窗体
4、拖一个commandbutton
里面写上:mis.retrieve(dw_1)//////
如果数据检索到数据窗口了,那么我们本次的实验就算成功了。
下一节我们接着讲单数据窗口及多数据窗口的update
以及存储过程的调用及oracle序列的通用方法………
Guoac qq:47570471
三、三层结构的更新
1、webservice端方法
新建立一个函数
int li_change=0
string ls_error=""
connect;
if SQLCA.SQLCode <> 0 then
as_err_return="连接数据库出错,请检查数据库连接参数。"
return -1////创建数据窗口出错
end if
if ds1.create(as_syntax,ls_error)<>1 then
disconnect using sqlca;
as_err_return="服务端重建数据窗口出错,请检查您传入的数据窗口对像!"+ls_error return -1
end if
if ds1.settransobject(sqlca)<>1 then
disconnect using sqlca;
as_err_return="服务端设置数据存储事务出错!"+ls_err_a
return -1
end if
li_change=ds1.SetChanges(dwo_object)
if li_change = 1 then
if ds1.Update()= 1 then
commit using sqlca;
disconnect using sqlca;
as_err_return="数据更新成功!"
return 1
else
as_err_return=ls_err_a
rollback using sqlca;
disconnect using sqlca;
return -1
end if
else
disconnect using sqlca;
as_err_return= "取更新行封装到blob时出错!"
return -1
end if
2、前端更新方法
建立的方法见前面,RETRIEVE的方法,这里我们建立一个update函数
int li_return,li_dwreturn
long ll_rv
string ls_syntax
blob lblb_data
as_dwoname.accepttext( )
li_dwreturn=as_dwoname.GetChanges(lblb_data)
if li_dwreturn=0 then
as_err_return='客户端数据窗口没有需要更新的数据。'
return 1
end if
if li_dwreturn =-1 then
as_err_return="客户端取数据窗口变更封装到blob时出错。"
return -1
end if
ls_syntax=as_dwoname.describe('datawindow.syntax')
if ls_syntax='' or ls_syntax="" then
as_err_return="客户端数据窗口语法为空。"
return -1
end if
if MIS.uf_update(lblb_data,ls_syntax,as_err_return)=1 then
as_dwoname.ResetUpdate()
return 1
else
return -1
end if
近期因为项目的原因,可能没什么时候来整理这个文档了,只能先写到这里,如果有什么问题可以给我留言。另外关于多数窗的更新问题,我希望大家也能自已动手去试一下,方法就是传入一个数据窗口数组到WEBSERVICE,WEBSERVICE端进行多表多更的事务控制。
PB11+WEBSERVICE+WINFROM应用方式是我们目前一个大型系统的开发模式。这样模式只需要发布WINFROM到IIS后,客户端就不需要安装任何技撑的东西,对于以后版本的的更新也由PB全自动管理。让PB的开发模式发生了很大的改变。另正式应用过程中还会涉及到应用服务器集群及数据库连接池的问题,不然每一次检索或更新都要连接数据库,可能谁都认为这不是个好的解决方案。更多需要优化及相关的领域的有待大家去研究。也希望有更多的人回到PB的开发阵营,呵,最起码招人的选择更多一些!开个玩笑。
另外在项目中可能还会有比如二层模式下通用查询,子数据窗口检索,存储过程通用方法等一些问题。希望有更多的人来研究这些东西。
利用分布式能源系统建立新建机场能源站实施方案(采用BOT联合体或EPC形式)的探讨 长沙黄花国际机场分布式能源站正式实现商业运营 长沙黄花国际机场分布式能源站项目是湖南省第一个分布式能源项目,也是我国民航系统第一个采用BOT方式建设的能源供应项目,实现了分布式能源从项目开发到设计、建设、商业化运营的一体化服务模式。 分布式能源站主要为15.4万m2新建航站楼提供全年冷、热以及部分电力供应。能源站采用以燃气冷热电分布式能源技术为核心,结合常规直燃机、离心式电制冷机组、燃气锅炉、热泵及冰蓄冷(二期工程)等先进能源技术。设计总规模为27MW制冷量,18MW制热量和2×1160KW发电量。能源站一期配备2*1160kW 的燃气内燃发电机组、2*4652kW的烟气热水型余热直燃机、1*4652kW的燃气直燃机、2*4571kW 水冷离心式制冷机组、1*2.8MW燃气热水锅炉。发电机所发电力采用并网不上网的方式运行,供给能源站及黄花机场新航站楼。 在制冷工况运行时,天然气先进入燃气内燃机发电,燃气内燃机排烟和缸套水直接驱动烟气热水型余热直燃机组制冷。燃气发电余热制冷用于满足基本负荷,不足部分采用燃气直燃机组和离心式电制冷机组调峰补充。在制热工况运行时,天然气进入燃气内燃机发电,燃气内燃机排烟驱动烟
气热水型余热直燃机组制热,缸套水直接进入板式换热器,不足部分的热量由燃气直燃机组和燃气锅炉直接燃烧天然气补充。 能源站采用了新奥自主开发的智能平台技术,实现了系统能效数据分析、负荷预测、系统优化运算和设备智能化调度等功能。 黄花机场分布式能源站实现了能源的梯级利用,先将燃气燃烧产生的高温热能转化为高品位的电能,然后再将发电后的中低品位热能回收利用,用于航站楼的冷热供应。与常规能源供应方式相比,一次能源节能率约41%,年节约标煤3640吨,年二氧化碳减排量为8956吨。 黄花机场分布式能源站已于2011年7月8日顺利完成竣工验收,7月19日正式实现商业营运。该项目作为新奥第一个成功交付的分布式能源示范项目,在分布式能源技术应和商业化运营方面均作出了有意的尝试,为分布式能源在湖南、民航系统及全国的发展奠定了坚实的基础。 冷热电三联供系统在浦东国际机场的应用浦东国际机场能源中心是机场规划设计时“大集中,小分散”供冷供热方案中最为关键的“集中”供冷供热主站,通过燃气轮机热电联供系统,采用“汽电共生,冷、热、电三联供”这一新的制冷供热方式,推动这一先进技术在国内
分布式能源与微电网技术 摘要:在现代城市化进程加快发展下,能源需求量逐渐增长。分布式能源和微 电网技术能促进城市的绿色化和清洁能源的应用,达到节能减排的目的,也能为 现代智能电网建设提供有效依据,保证电网的安全与稳定。 关键词:分布式;能源;微电网技术 在中国经济快速提升下,工业化和城镇化进程加快发展,其存在的能源安全 问题更为突出。尤其是二氧化碳带来的全球变暖问题,引起社会的关注。在该发 展背景下,对城市的建设思想和发展模式有序转变,加大力度引进风力发电、太 阳能发电模式等,促进整体的规模化发展。 一、分布式能源和微电网技术的研究意义 第一,加强对分布式能源和微电网技术的研究,能确保清洁能源的有效应用。基于太阳能、风能等多个形式清洁能源的应用,能保证能源的灵活接入和智能化 控制,将其应用到智能终端进行消费,促使低碳城市建设目标的实现。第二,加 强对分布式能源和微电网技术的研究,也能提升总体的供电可靠性。基于分布式 发电的投入以及微网的统一管理,在先进系统和设备下,为电网运行提供强大保障,促使电能质量更可靠。第三,分布式能源和微电网技术的研究,也能为其提 供双向互动用电服务模式。基于微网、智能家居和分布式发电,能为系统提供统 一接口,维护用户和电网之间的相互沟通和交流,也能使用户获得新的体验。加 强对分布式能源和微电网技术的研究,将其作为智能电网建设中的主要部分,是 新时期建设与发展下的主要模式,也承担者社会建设职责。其中的分布式能源, 在智能集成模式下,能保证接入系统的安全与可靠,也能确保微网更灵活。所以,加强对分布式能源和微电网技术的应用,是城市绿色、清洁能源推动和应用的主 要条件,在节能减排工作中,将其渗透到工作中,对电网的安全运行也具备十分 重要的作用[1]。 二、分布式能源和微电网技术的关键 (一)容量配置 清洁能源具备明显的间歇式能源特点,受到天气情况影响较大,电能的输出 波动大。基于对分布式能源和微电网技术的应用,能够在各个单位组成模式下, 对其容量有效配置,确保风能、太阳能相互应用,发电单位和储能单元之间也能 互补。在整个分布式能源和微电网中,结合时间功率,为其输出曲线,也能避对 电网产生的影响。通过对储能系统应用,对分布式能源和微电网技术有效调度, 以达到清洁能源的充分应用。比如:储能电池,能对分布式能源生产中存在的问 题有效解决,尤其是在较小负荷下,达到电能的储存目的。如果负荷较大,将释 放电能,保证系统的科学稳定运行。如:将储存电池和系统交流侧进行链接,基 于储能单元和发电单元的协调,为其提供对平滑分布式能源的波动,避免给电力 系统带来较大冲击,维护其稳定性。储能电池也能对当地的交流负荷需要无功功率、负荷电流谐波的获取,以免电压波动、闪变现象的发生,这样才能达到有效 的节能效率[2]。 (二)接入方式 结合当前的建设标准和规程,需要在谐波、电压波动和电压不平衡度上给予 全面控制和探讨,也要为分布式能源和微电网技术的应用提出合理对策。分布式 能源和微电网利用分布发电和集中并网接入方式来实现。集中并网多为直流母线 汇流、各个发电单元在电能控制模式下,将其转变为直流母线。基于逆变器,将
根据did you know(https://www.doczj.com/doc/9e3951256.html,/)的数据,目前互联网上可访问的信息数量接近1秭= 1百万亿亿 (1024)。毫无疑问,各个大型网站也都存储着海量的数据,这些海量的数据如何有效存储,是每个大型网站的架构师必须要解决的问题。分布式存储技术就是为了解决这个问题而发展起来的技术,下面让将会详细介绍这个技术及应用。 分布式存储概念 与目前常见的集中式存储技术不同,分布式存储技术并不是将数据存储在某个或多个特定的节点上,而是通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落。 具体技术及应用: 海量的数据按照结构化程度来分,可以大致分为结构化数据,非结构化数据,半结构化数据。本文接下来将会分别介绍这三种数据如何分布式存储。 结构化数据的存储及应用 所谓结构化数据是一种用户定义的数据类型,它包含了一系列的属性,每一个属性都有一个数据类型,存储在关系数据库里,可以用二维表结构来表达实现的数据。 大多数系统都有大量的结构化数据,一般存储在Oracle或MySQL的等的关系型数据库中,当系统规模大到单一节点的数据库无法支撑时,一般有两种方法:垂直扩展与水平扩展。 ? 垂直扩展:垂直扩展比较好理解,简单来说就是按照功能切分数据库,将不同功能的数据,存储在不同的数据库中,这样一个大数据库就被切分成多个小数据库,从而达到了数据库的扩展。一个架构设计良好的应用系统,其总体功能一般肯定是由很多个松耦合的功能模块所组成的,而每一个功能模块所需要的数据对应到数据库中就是一张或多张表。各个功能模块之间交互越少,越统一,系统的耦合度越低,这样的系统就越容易实现垂直切分。 ? 水平扩展:简单来说,可以将数据的水平切分理解为按照数据行来切分,就是将表中的某些行切分到一个数据库中,而另外的某些行又切分到其他的数据库中。为了能够比较容易地判断各行数据切分到了哪个数据库中,切分总是需要按照某种特定的规则来进行的,如按照某个数字字段的范围,某个时间类型字段的范围,或者某个字段的hash值。 垂直扩展与水平扩展各有优缺点,一般一个大型系统会将水平与垂直扩展结合使用。 实际应用:图1是为核高基项目设计的结构化数据分布式存储的架构图。
海量数据下分布式数据库系统的探索与研究 摘要:当前,互联网用户规模不断扩大,这些都与互联网的快速发展有关。现 在传统的数据库已经不能满足用户的需求了。随着云计算技术的飞速发展,我国 海量数据快速增长,数据量年均增速超过50%,预计到2020年,数据总量全球 占比将达到20%,成为数据量最大、数据类型最丰富的国家之一。采用分布式数 据库可以显著提高系统的可靠性和处理效率,同时也可以提高用户的访问速度和 可用性。本文主要介绍了分布式数据库的探索与研究。 关键词:海量数据;数据库系统 1.传统数据库: 1.1 层次数据库系统。 层次模型是描述实体及其与树结构关系的数据模型。在这个结构中,每种记 录类型都由一个节点表示,并且记录类型之间的关系由节点之间的一个有向直线 段表示。每个父节点可以有多个子节点,但每个子节点只能有一个父节点。这种 结构决定了采用层次模型作为数据组织方式的层次数据库系统只能处理一对多的 实体关系。 1.2 网状数据库系统。 网状模型允许一个节点同时具有多个父节点和子节点。因此,与层次模型相比,网格结构更具通用性,可以直接描述现实世界中的实体。也可以认为层次模 型是网格模型的特例。 1.3 关系数据库系统。 关系模型是一种使用二维表结构来表示实体类型及其关系的数据模型。它的 基本假设是所有数据都表示为数学关系。关系模型数据结构简单、清晰、高度独立,是目前主流的数据库数据模型。 随着电子银行和网上银行业务的创新和扩展,数据存储层缺乏良好的可扩展性,难以应对应用层的高并发数据访问。过去,银行使用小型计算机和大型存储 等高端设备来确保数据库的可用性。在可扩展性方面,主要通过增加CPU、内存、磁盘等来提高处理能力。这种集中式的体系结构使数据库逐渐成为整个系统的瓶颈,越来越不适应海量数据对计算能力的巨大需求。互联网金融给金融业带来了 新的技术和业务挑战。大数据平台和分布式数据库解决方案的高可用性、高可靠 性和可扩展性是金融业的新技术选择。它们不仅有利于提高金融行业的业务创新 能力和用户体验,而且有利于增强自身的技术储备,以满足互联网时代的市场竞争。因此,对于银行业来说,以分布式数据库解决方案来逐步替代现有关系型数 据库成为最佳选择。 2.分布式数据库的概念: 分布式数据库系统:分布式数据库由一组数据组成,这些数据物理上分布在 计算机网络的不同节点上(也称为站点),逻辑上属于同一个系统。 (1)分布性:数据库中的数据不是存储在同一个地方,更准确地说,它不是 存储在同一台计算机存储设备中,这可以与集中数据库区别开来。 (2)逻辑整体性:这些数据在逻辑上是相互连接和集成的(逻辑上就像一个 集中的数据库)。 分布式数据库的精确定义:分布式数据库由分布在计算机网络中不同计算机
国外分布式能源发展现状 一、分布式发电概况 分布式发电是指位于用户所在地附近的,所生产的电力除由用户自用和就近利用外,多余电力送入 当地配电网的发电设施、发电系统或有电力输出的多联供系统。分布式发电形式多种多样,因资源条件和 用能需求而异,发电方式包括三大类:1、天然气分布式能源,主要是热电联产和冷热电多联供等;2、可再生能源分布式发电:主要包括小型水能、太阳能、风能、生物质能、地热能等;3、废弃资源综合利用,涵盖工业余压、余热、废弃可燃性气体发电和城市垃圾、污泥发电等。 由于发达国家的热电联产主要采用天然气在用户端或靠近用户区域发电供热,故均被纳入分布式能源。“国际热电联产联盟”已将其名字更改为“国际分布式能源联盟”WADE(World Alliance Decentralized Energy),Decentralized在英文中强调了分散化或非集中化的含义,是受到“互联网革命”去中心化的影响,而Energy强调并非单一供电,能源就地供应的种类可以是多样性的。但该组织更加侧重天然气为燃料的 分布式能源,兼顾了燃煤的热电联产,未覆盖中小水电等可再生能源发电。据统计,世界主要国家及地区 的热电联产(CHP)2006年装机容量已达到32,920万千瓦(表-1)。 美国将分布式能源称为(Distributed Energy)或DER(Distributed Energy Resources),Distributed虽 然也是指“分布式”,但是更多地应用于互联网式的分布信息处理分散化的扁平式解决方案,显示了能源行 业受到互联网革命的启迪,暗喻了这些分布在用户端或资源现场的系统是相互联系或相互连接的,更向一
方案概述 面临挑战 随着信息化建设的飞速发展,我国各级单位的信息化建设也取得了显著的进步和成就。在这期间,信息化起步早的企业,10年前甚至20年前就开始实施面向业务操作层面的部门业务计算机应用,这些单位主要从部门内部的业务出发,开发了满足部门业务操作的管理系统,每建立一个应用系统就单独建立一个数据库,这样不同的应用就拥有不同的数据库。这些数据库可能来自不同的厂商、不同版本,各个数据库自成体系,互相之间没有联系,数据编码和信息标准也不统一。 随着信息化的发展以及政府、企业内部网络系统和网络环境的建设,以各单位发展为目标的信息化要求日益迫切,各单位的业务需要在统一的环境下、在部门之间进行处理。原先各自为政所实施的局部应用使得各系统之间彼此独立,信息不能共享,成为一个个“信息孤岛”,不能满足业务处理的需要。有条件的单位投入资金将以前的系统重新升级、设计,在一定范围内实现了信息的共享。经过一段时间后,又有新的系统要上,又发现这些系统所需要的数据不能从现有系统中提取,又出现了信息孤岛。此外,单位之间,上下级之间、行业之间由于系统的差异,信息更是不能共享,这也是新的信息孤岛。 所以,信息孤岛是信息化应用推广和普及的必然结果,也是信息化进程中暴露的主要问题之一。如果没有日益扩大的信息化要求,信息孤岛仅仅是在一定范围内的出现,也容易得到解决。只要信息化、网络化进程在推进,政府之间、企业之间、行业之间网络沟通的需求日益密切,就会产生新需求下的信息孤岛 问题关键 基于以上考虑,构建一个功能强大、易于扩展、兼容并蓄的数据交换平台是今后信息化建设取得成功的有力保障,为此需要解决以下几个问题: 1. 数据交换平台能够在保持原有业务应用的情况下,利用现有资源构建新的应用,并能方便的集成待建与在建项目; 2. 数据交换平台应支持分布式异构系统的快速集成,支持各种不同的操作系统及数据源; 3. 数据交换平台应具备灵活的策略定义与配置,应提供简单易用的工具或界面,便于掌握及使用; 4. 基于各部门的共享数据,建设数据中心,统一数据标准,以便对各类数据进行综合利用,提供对各类信息的综合分析和展示。 数据整合的主要收益
一、何为分布式数据库系统?一个分布式数据库系统有哪些特点? 答案:分布式数据库系统通俗地说,是物理上分散而逻辑上集中的数据库系统。分布式数据库系统使用计算机网络将地理位置分散而管理和控制又需要不同程度集中的多个逻辑单位连接起来,共同组成一个统一的数据库系统。因此,分布式数据库系统可以看成是计算机网络与数据库系统的有机结合。一个分布式数据库系统具有如下特点: 物理分布性,即分布式数据库系统中的数据不是存储在一个站点上,而是分散存储在由计算机网络连接起来的多个站点上,而且这种分散存储对用户来说是感觉不到的。 逻辑整体性,分布式数据库系统中的数据物理上是分散在各个站点中,但这些分散的数据逻辑上却构成一个整体,它们被分布式数据库系统的所有用户共享,并由一个分布式数据库管理系统统一管理,它使得“分布”对用户来说是透明的。 站点自治性,也称为场地自治性,各站点上的数据由本地的DBMS管理,具有自治处理能力,完成本站点的应用,这是分布式数据库系统与多处理机系统的区别。 另外,由以上三个分布式数据库系统的基本特点还可以导出它的其它特点,即:数据分布透明性、集中与自治相结合的控制机制、存在适当的数据冗余度、事务管理的分布性。 二、简述分布式数据库的模式结构和各层模式的概念。 分布式数据库是多层的,国内分为四层: 全局外层:全局外模式,是全局应用的用户视图,所以也称全局试图。它为全局概念模式的子集,表示全局应用所涉及的数据库部分。 全局概念层:全局概念模式、分片模式和分配模式 全局概念模式描述分布式数据库中全局数据的逻辑结构和数据特性,与集中式数据库中的概念模式是集中式数据库的概念视图一样,全局概念模式是分布式数据库的全局概念视图。分片模式用于说明如何放置数据库的分片部分。分布式数据库可划分为许多逻辑片,定义片段、片段与概念模式之间的映射关系。分配模式是根据选定的数据分布策略,定义各片段的物理存放站点。 局部概念层:局部概念模式是全局概念模式的子集。局部内层:局部内模式 局部内模式是分布式数据库中关于物理数据库的描述,类同集中式数据库中的内模式,但其描述的内容不仅包含只局部于本站点的数据的存储描述,还包括全局数据在本站点的存储描述。 三、简述分布式数据库系统中的分布透明性,举例说明分布式数据库简单查询的 各级分布透明性问题。 分布式数据库中的分布透明性即分布独立性,指用户或用户程序使用分布式数据库如同使用集中式数据库那样,不必关心全局数据的分布情况,包括全局数据的逻辑分片情况、逻辑片段的站点位置分配情况,以及各站点上数据库的数据模型等。即全局数据的逻辑分片、片段的物理位置分配,各站点数据库的数据模型等情况对用户和用户程序透明。
?我国分布式能源扶持政策总汇 ?2014-05-09 09:45:31 发布:中国分布式能源网来源:网络 ? 摘要:2014年2月11日,国家能源局宣布,2014年中国将新增光伏发电装机1400万千瓦,其中分布式光伏发电8GW占比60%。 2014年2月11日,国家能源局宣布,2014年中国将新增光伏发电装机1400万千瓦,其中分布式光伏发电8GW占比60%。至此,光伏装机到底是10GW还是14GW的数字掐架终告一段落。目标是确定了,执行却似乎稍有难度。 观望者众,实践者少。是补贴力度刺激不够吗?业界一直预想等待能源局将分布式光伏补贴提高至0.60元/千瓦时以上,然而,一个消息却打破了业者们的美好愿想。 2014年4月17日,光伏电站投资与金融峰会上,针对于业内最为关注的分布式电站政策调整问题,国家能源局新能源司副司长梁志鹏表示不会提高分布式光伏补贴。四毛二还是四毛二,而分布式发电补贴以及8GW分布式目标能否完成的问题再度成为业界“头条”。 值得一提的是,除了国家层面的补贴外,地方政府对于光伏发电还另有补贴。当你发现有某个地方政府的政策补贴竟然比国家补贴还高,会不会是一个惊喜呢?不管目前进程多么缓慢,分布式大戏帷幕终究要拉开,相关的扶持政策无疑是大戏开场前的最佳前声。 相关链接:我国各省市太阳能发电补贴政策汇总 李克强:积极发展光伏风电等清洁能源 3月21日,中共中央政治局常委、国务院总理李克强主持召开节能减排及应对气候变化工作会议,推动落实《政府工作报告》,促进节能减排和低碳发展,研究应对气候变化相关工作。 李克强指出,节能减排与促进发展并不完全矛盾,关键是要协调处理好,找到二者的合理平衡点,使之并行不悖、完美结合。淘汰落后产能,关停高耗能、高排放企业,会对增长带来影响,但其中也蕴含着很大商机,会为新能源、节能环保等新兴产业成长提供广阔空间。我们要善抓机遇,进退并举,控制能源消费总量,提高使用效率,调整优化能源结构,积极发展风电、核电、水电、光伏发电等清洁能源和节能环保产业,开工一批新项目,大力推广分布式能源,发展智能电网,逐步把煤炭比重降下来。尤其是要着力发展服务业特别是生产性服务业。 随着各地分布式推广工作的进一步开展,越来越多的地区开始了其辖内“首个”家庭分布式光伏项目建设。可惜反响差强人意。到目前为止,除了江西、浙江、上海等少数几个省市地区外,大部分省份的分布式光伏项目仍只是小规模尝试,还未有大规模启动的迹象。从2014年3月到现在,新出炉的各地地方政策,除了在补贴上予以优惠外,还在申请、备案、并网等多方面全范围覆盖解疑投资者们顾虑。如果我们将这些政策动态联系起来,我们或许会有这种感觉,政策高潮才刚刚开始。 能源局:6MW以下的太阳能项目无须电力业务许可 【国能资质〔2014〕151号国家能源局关于明确电力业务许可管理有关事项的通知】 一直以来,《电力业务许可证》是困扰分布式光伏项目、可再生能源项目售电合法化的五法逾越的障碍。近日,国家能源局发布政策【国能资质〔2014〕151号国家能源局关于明确电力业务许可管理有关事项的通知】(下简称“文件”),从根本上明确了项目装机容量6MW(不含)以下的太阳能、风能、生物质能、海洋能、地热能等新能源发电项目豁免发电业务的电力业务许可; 《电力业务许可证》是为规范电力业务许可维护电力市场秩序,保障电力系统安全、优质、经济运行,根据《中华人民共和国行政许可法》、《电力监管条例》和有关法律、行政法规的规定,在中华人民共和国境内从事电力业务,应当按照《电力业务许可证管理规定》的条件、方式取得电力业务许可证。除电监会规定的特殊情况外,任何单位或者个人未取得电力业务许可证,不得从事电力业务。本许可所称电力业务,是指发电、输电、供电业务。其中,供电业务包括配电业务和售电业务。 上海:个人分布式光伏发电补贴达0.4元/kWh 《2014年度分布式光伏发电示范应用建设规模申报工作通知》
分布式坐席管理解决方案图文 一、前言 指挥中心里面都会有不同的坐席负责不同的业务,但事实上他们又特别需要协同处理一些信息,或者信息之间需要互联互通。传统的方式处理起来就会比较麻烦,需要人为切换信号。而分布式KVM坐席协作本质就是快速便捷地解决坐席之间的信息共享和处理的问题。
根据海量数据处理等场景越来越多,如何实现网站的高可用、易伸缩、可扩展、安全等目标就显得越来越重要。为了解决这样一系列问题,大型平台的架构也在不断发展。提高大型项目平台的高可用架构,分布式的应用可以在基本系统架构上扩展节点增加设备,这样更易于理解,输入节点端连接电脑主机、工作站、摄像头以及机顶盒等,输出节点端需要连接电脑显示器、大屏幕、投影机以及键盘鼠标等,现在越来越重视操作便利性和突破空间局限,还可以增加可视化管控的触碰移动端。 二、分布式KVM坐席系统有哪些应用
为什么分布式KVM坐席协作管理系统被频繁应用在中小型指挥中心等场景?我们可以从它的功能、应用价值、能够为用户解决哪些问题中找到答案。 1. 控制室数据量已呈现爆发式增长,分布式KVM系统拥有强大的信号接入与管理能力,可以同时接入不同分辨率、不同接口等不同类型的数据信号,然后输出至坐席工位显示端、大屏幕或其他设备。 2. 控制室每一个坐席工位承担的工作繁重,常常需要一位坐席操作员处理多个显示器的业务,一人对2屏、3屏、4屏......信号一键切换与分发功能极大增加了操作员的工作效率。
1、采用专属的音视频网络平台、分布式架构、模块化设计。可通过控制平台获取实时状态显示,在线查看系统各节点运行情况,并可对各节点进行远程维护,不会影响系统的整体使用。 2、提供网络分布式管理,不受空间、距离限制。可以通过分级用户管理模式,对相应的管理人员设置不同的访问和管理权限。 3、支持操作坐席与工作站数据间的协作交互,包括快捷键操作、获取、推送、绑定及语音、文字广播等内容,实现高效的数据比对、研判。
分布式能源技术在数据中心的应用 对河北某数据中心的用能情况进行深入分析及核算,并设计了分布式能源冷电联供方案,通过天然气分布式能源,为某数据中心进行冷电联供,可保障某数据中心用能安全和降低能源费用,减少污染排放,并將传统供能方式作为比较对象,从经济效益、节能减排等方面进行分析。 标签:分布式能源;数据中心;天然气;燃气内燃发电机组 引言 据GE收集的数据,包括IBM的数据,整体上一个云计算基地的运营成本,接近于75%来自于能源方面的消耗。机房设备发热量大且全年不间断运行,冷负荷全年变化幅度小,波动范围为0.8~1.0[1]。 因此如何降低云计算基地的用能成本,采用清洁能源以减少云计算基地能耗对环境的影响,显得越来越重要。 天然气分布式能源技术是近年来在国内逐步推广的一种先进清洁能源绿色高效利用技术。该技术是集燃气轮机、内燃机、吸收式冷热水机、能效控制等高新技术和设备为一体的先进环保型能源系统,目前在发达国家得到了广泛应用,近年来得到了我国政府的积极倡导。 本文主要介绍河北某数据中心燃气分布式能源站的项目情况,对能源站的前期调研,项目建成后的经济指标进行分析。最后,依据上述分析,给出项目开发建议。 1 项目基本介绍 河北某数据中心项目为燃气分布式能源项目,位于河北省廊坊市,能源站所占建筑面积为1200m2。包括高、低压配电室、制冷机房、控制室等用房,其中分布式能源所用辅助用电引自自配动力变压器。本项目采用天然气分布式供能技术,以天然气内燃机发电机组、烟气热水型溴化锂机组为核心设备组成分布式能源站,结合数据中心原设计方案的市电和电制冷机,稳定地为数据中心提供电力和冷量,在冬季工况,数据中心采用自然冷却。 项目总建筑面积约为24566.6m2,设有满足T3标准的机柜1780个,其中电负荷19080kW、冷负荷13465kW。 2 负荷预测分析 2.1 气象条件
国内外分布式能源发展状况及政策支持 (1)丹麦是世界上能源利用效率最高的国家,自1990 年以来,丹麦大型凝气发电厂容量没有增加,新增电力主要依靠安装在用户侧的、特别是工业用户和小型区域化的分布式能源电站(热电站)和可再生能源项目,热电发电量占总发电量的61.6%。2005年7月,丹麦政府宣布计划铺设全球最长的智能化电网基础设施,这将使分布式能源系统成为丹麦主要的供电渠道。 丹麦对于分布式能源采取了一系列明确的鼓励政策,先后制定了《供热法》《电力供应法》和《全国天然气供应法》等,在法律上明确了保护和支持立场。《电力供应法》规定,电网公司必须优先购买热电联产生产的电能,而消费者有义务优先使用热电联产生产的电能(否则将做出补偿)。 (2)1988年,荷兰启动了一个热电联产激励计划,制定了重点鼓励发展小型的热电机组的优惠政策。实践证明,荷兰的分布式能源为电力增长做出巨大贡献,热电联产装机容量由1987年的2 700 MW猛增到1998年的7 000 MW,占总发电量的48.2%。荷兰实行了能源税机制,标准为6.02欧分/kWh,但绿色电力可返还2欧分。荷兰颁布了新的《电力法》,赋予分布式能源(热电联产)特别的地位,使电力部门须接受此类项目电力,政府对其售电仅征收最低税率。由荷兰能源分配部门起草的《环境行动计划》中,电力部门将积极使用清洁高效能源技术以承担其对环境的责任。其中分布式能源是最为重要的手段,将负担40%的二氧化碳减排任务。 (3)日本是亚洲能源利用效率最高的国家,自1981 年东京国立竞技场第一号热电机组运行起,截至2000 年,分布式能源项目共1 413个,总容量2 212 MW。分布式能源能够在日本快速发展,关键是政府的有效干预。1986年5月日本通产省发布了《并网技术要求指导方针》,使分布式能源可以实现合法并网。1995年12月又更改了《电力法》,并进一步修改了《并网技术要求指导方针》,使拥有分布式能源装置的业主,可以将多余的电能反卖给供电公司,并要求供电公司为分布式能源业主提供备用电力保障。此外,分布式能源业主不仅能够得到融资、政府补贴等优惠政策,还能享受减免税等鼓励。
分布式数据库技术在大数据中的应用
分布式数据库技术在大数据中的应用 摘要随着当前运营商对数据管理和应用需求的不断增加,分布式数据库技术得到极大的发展。在本文中首先对当前大数据环境下的分布式数据库技术进行介绍,然后分析分布式数据库技术在大数据中的具体应用。 关键词分布式数据库;数据管理;数据处理 中图分类号 TP3 文献标识码 A 文章编号 1674-6708(2016)165-0108-01 随着当前移动互联网技术的迅猛发展,数据的种类和数量呈现快速的增长,传统的处理方式逐渐的不能够适应当前的发展需要,基于此种背景下,分布式数据库技术需要得到更快的发展,以达到对大数据的存储、管理以及分析等处理要求。 1 大数据中发展分布式数据库的意义 在面对当前的大数据时代,传统的集中式数据库已经逐渐的不能够满足人们的使用要求,需要找到新的处理方式来进行更新,分布式数据库就是在这样的背景下逐渐的被发展和应用。分布式数据库在使用中有着许多传统集中式数据库不具备的优点:第一,分布式数据库有着极为强大的扩展能力,这是传统数据库所不具备的,在数据的存储方面表现出巨大的优势;第二,来自于成本上的优势。
在大数据中,如果仍旧采用原有的数据库,在进行扩容的时候,会花费大量的资金,使得成本上花费巨大,而且所取得的效果也是有限的。分布式数据库则只需要较少的资金就能够完成扩容处理,占据着特别大的优势[1];第三,分布式数据库在用户上有着很大的优势,分布式数据库让人们对大数据的存储、分析和处理变得容易和快捷。 2 分布式数据库技术分析 在大数据中,分布式数据库技术得到极大的发展,也正是由于分布式数据库技术表现出来的先进性能,才使得分布式数据库得到广泛的使用。在分布式数据库中,其由很多个并行的处理单元组成,而且每个处理单元都是一个完整的系统,其中包括数据的存储,数据的分析等,对于每一个处理单元来说,其所处的位置和作用都是对等的,而且是相对独立的。混合存储技术:突破传统行存的限制,实现行列混合存储。该项技术对于分布式数据库的性能有着很大的提升,使得分布式数据库在运行速度和运行的灵活性上都有很大的提高。再就是智能索引技术,该种技术所占用的空间减少,并且能够很好的解决后面数据库慢的问题,不会对后面的索引数据造成影响[2]。除此之外,分布式数据库中还具有许多先进的技术,如并行处理技术、高效透明压缩技术等,都是传统数据库中所不具备
国外分布式能源发展状况 一、分布式发电概况 分布式发电是指位于用户所在地附近的,所生产的电力除由用户自用和就近利用外,多余电力送入当地配 电网的发电设施、发电系统或有电力输岀的多联供系统。分布式发电形式多种多样,因资源条件和用能需求而异,发电方式包括三大类:1、天然气分布式能源,主要是热电联产和冷热电多联供等;2、可再生能源分布式发电: 主要包括小型水能、太阳能、风能、生物质能、地热能等;3、废弃资源综合利用,涵盖工业余压、余热、废弃 可燃性气体发电和城市垃圾、污泥发电等。 由于发达国家的热电联产主要采用天然气在用户端或靠近用户区域发电供热,故均被纳入分布式能源。国际热电联产联盟"已将其名字更改为国际分布式能源联盟"WADE (World Alliance Decentralized Energy ),Decentralized在英文中强调了分散化或非集中化的含义,是受到互联网革命"去中心化的影响,而Energy强调 并非单一供电,能源就地供应的种类可以是多样性的。但该组织更加侧重天然气为燃料的分布式能源,兼顾了燃煤的热电联产,未覆盖中小水电等可再生能源发电。据统计,世界主要国家及地区的热电联产(CHP )2006年装机容量已达到32,920万千瓦(表-1 )。 表if 球主要国貳热电联产英机富童*' 美国将分布式能源称为( Distributed Energy )或DER (Distributed Energy Resources ) ,Distributed 虽然也是指分布式”但是更多地应用于互联网式的分布信息处理分散化的扁平式解决方案,显示了能源行业受到
互联网革命的启迪,暗喻了这些分布在用户端或资源现场的系统是相互联系或相互连接的,更向一个网络化的能 源系统。加入Resources 一词,反应了人们将阳光普照的可再生能源和分散化的废弃资源视为一种资源,充分涵盖的可再生能源和废弃能源资源的分散化利用。全球分布式风电2008年装机容量达到0.4万千瓦(表-2)。2010 年底,全球光伏发电装机总量高达3,950万千瓦(表-3),其中日本、欧洲等地分布式光伏发电位居世界前列。 M ?金球小型凤电克场艾机情乱- 1 ' wind global D13, rkst 2008+-1 <3^^主要国家和地区太阳能光伏发电娄札恬况£忑土屁八 来溥:0P昭-(中卜和Qw UE「yr 訂帚U" U 1M】” 国外分布式能源的发展主要是通过支持市场化的独立发电商(IPP )和能源服务商(ESCO )为用户提 供了专业化的能源服务与节能服务,因地制宜、因需而异、因势利导,建设个性化的能源梯级利用设施,转变了传统低效的所谓集约化”、规模化”的能源生产供应模式,直接对社会分工进行了重构,为未来不断提高能源利用 效率和大量利用可再生能源,吸引更多企业和个人参与清洁能源供应和提高能效,推动信息技术与能源系统的整合优化进行了制度设计和法律保障。 美国、欧洲和日本在先进的分布式发电基础上推动智能电网建设,为各种分布式能源提供自由接入的动态 平台;为节能和需求侧管理提供智能化控制管理平台;为高效利用天然气冷热电联供梯级利用;为因地制宜地利用小水电资源、生物质资源及可再生能源;为清洁回收利用各种废弃的资源能源来增加电力和其他能量供应提供
分布式能源系统的国内外发展现状
合优化—能源供应系统集成化。八是能源企业从生产型转向服务型—投资经营市场化。某种意义上说分布式供能就是一局域的智能能源网。 作为21世纪科学用能的最佳方式,“分布式能源的发展利用”在30年间已逐渐得到世界各国的广泛重视。分布式能源系统是一种高效、节能、环保的用户端能源综合利用系统,分布式能源技术已成为世界能源技术的发展潮流。国际分布式能源联盟主席汤姆·卡斯顿曾说过:“分布式能源的革命即将发生,将像30年前发生的绿色革命一样产生深远的影响。而在这样一场革命中,最先认识到它的人将获得最大的收益。”随着新能源革命和智能电网的发展再次将分布式供能系统赋予更多的新意。 二、分布式能源系统的国外现状 分布式供能系统具有多重社会效益和经济效益,是世界能源供应方式发展的一个重要方向,美日、欧盟等国已将发展分布式供能作为能源安全、节能和能源经济发展的重要战略。美国、欧洲和日本在先进的分布式发电基础上推动智能电网建设,为各种分布式能源提供自由接入的动态平台;为节能和需求侧管理提供智能化控制管理平台;为高效利用天然气冷热电联供梯级利用;为因地制宜地利用小水电资源、生物质资源及可再生能源;为清洁回收利用各种废弃的资源能源来增加电力和其他能量供应提供支撑。美国和西欧目前基本不再建设大型电源及大型能源设施,正是这些依附于用户终端市场的能源梯级利用系统、可再生能源系统和资源综合利用系统,将他们的能源利用效率不断提高,排放不断减少,能源结构不断优化。 在欧盟,欧洲委员会正在进行一个SA VE Ⅱ的能效行动计划,包含许多不同的能效措施,来推动分布式能源系统的发展。 多年来,英国政府一直试图通过能源效率最佳方案计划(EEBPP)促进分布式能源系统的发展。英国在过去20年中,已超过1000个分布式能源系统被安装,遍布英国的各大饭店、休闲中心、医院、综合性大学和学院、园艺、机场、公共建筑、商业建筑、购物商城及其它相应场所。 美国新能源战略的实施核心就包括力推分布式能源系统和建立与之相适应的强大的智能电网。美国从1978年开始提倡发展分布式能源系统,现在美国能源部(U.S.DOE)的Distributed Energy Resources计划是带领全国共同努力发展下一代洁净、高效、可靠、用户能够买的起的分布式能源系统。具体的操作方式是与能源设备的制造商、能源服务者、能源项目的开发者、州政府和联邦机构、公众利益组织、用户进行合作,研究、开发一系列先进的、能够进行就地生产的、小规模、模块化设计的发电、储能技术,用于工业、商业和民用方面,这些技术包括先进的燃气轮机、微型燃气轮机、内燃机、燃料电池、热驱动技术和能量储存技术,同时也进行先进的材料、电力电子、复合系统以及通讯、控制系统等方面技术的开发。美国能源部提出2020年的长期目标:通过最大程度地使用具有
分布式数据库管理系统简介 一、什么是分布式数据库: 分布式数据库系统是在集中式数据库系统的基础上发展来的。是数据库技术与网络技术结合的产物。 分布式数据库系统有两种:一种是物理上分布的,但逻辑上却是集中的。这种分布式数据库只适宜用途比较单一的、不大的单位或部门。另一种分布式数据库系统在物理上和逻辑上都是分布的,也就是所谓联邦式分布数据库系统。由于组成联邦的各个子数据库系统是相对“自治”的,这种系统可以容纳多种不同用途的、差异较大的数据库,比较适宜于大范围内数据库的集成。 分布式数据库系统(DDBS)包含分布式数据库管理系统(DDBMS)和分布式数据库(DDB)。 在分布式数据库系统中,一个应用程序可以对数据库进行透明操作,数据库中的数据分别在不同的局部数据库中存储、由不同的DBMS进行管理、在不同的机器上运行、由不同的操作系统支持、被不同的通信网络连接在一起。 一个分布式数据库在逻辑上是一个统一的整体:即在用户面前为单个逻辑数据库,在物理上则是分别存储在不同的物理节点上。一个应用程序通过网络的连接可以访问分布在不同地理位置的数据库。它的分布性表现在数据库中的数据不是存储在同一场地。更确切地讲,不存储在同一计算机的存储设备上。这就是与集中式数据库的区别。从用户的角度看,一个分布式数据库系统在逻辑上和集中式数据库系统一样,用户可以在任何一个场地执行全局应用。就好那些数据是存储在同一台计算机上,有单个数据库管理系统(DBMS)管理一样,用户并没有什么感觉不一样。 分布式数据库中每一个数据库服务器合作地维护全局数据库的一致性。 分布式数据库系统是一个客户/服务器体系结构。 在系统中的每一台计算机称为结点。如果一结点具有管理数据库软件,该结点称为数据库服务器。如果一个结点为请求服务器的信息的一应用,该结点称为客户。在ORACLE客户,执行数据库应用,可存取数据信息和与用户交互。在服务器,执行ORACLE软件,处理对ORACLE 数据库并发、共享数据存取。ORACLE允许上述两部分在同一台计算机上,但当客户部分和服务器部分是由网连接的不同计算机上时,更有效。 分布处理是由多台处理机分担单个任务的处理。在ORACLE数据库系统中分布处理的例子如: 客户和服务器是位于网络连接的不同计算机上。 单台计算机上有多个处理器,不同处理器分别执行客户应用。
分布式应用解决方案——linkbase 一、分布式linkbase背景 1、背景介绍 网页链接库(简称linkbase)是百度搜索引擎中重要的一部分,它存储的链接数量、更新速度等直接影响到从整个互联网抓取网页的效率和质量,从而影响搜索结果。 下面的示意图说明了linkbase在网页抓取和处理中的位置以及和其他模块、系统的关系。 ?Link库存储spider所需要的链接数据 ?Select将待抓取的链接从link库中选出,发送给抓取系统CS到互联网上抓取网页 ?Saver将收到的新链接合并到link库中 ?EC将CS抓取的网页进行分析,交给DC分发给不同的存储系统,DC将网页数据发送到webinfoDB存储,将链接数据发送给saver处理 2、分布式网页链接库三个阶段的发展
百度的分布式网页链接库近几年经历了三个阶段的发展: 第一阶段:基于主域分环的静态分布式linkbase。 整个linkbase按照链接的主域进行划分到144台机器,每个主域的所有链接仅在一台机器存储和处理。主要问题是随着链接数大规模增长,存在严重的机器负载不均情况。 第二阶段:基于分布式基础架构的分布式linkbase。 采用分布式文件系统HDFS存储linkbase链接数据,分布式计算模型MapReduce 进行linkbase的更新和挖掘。主要问题是linkbase存储为多个HDFS文件,这些文件大小差别很大(如10倍)时造成处理起来时间被最大的文件拖长。 第三阶段:基于分布式基础架构的自动均衡分布式linkbase。 采用增加索引的存储方式和自动均衡输入数据的处理方式,解决文件大小不均的问题。 二、基于主域分环的分布式linkbase 1、背景 基于单机架构的分布式linkbase将整个linkbase按照链接的主域进行划分,每个主域的链接仅被一台机器存储和处理,一台机器可以处理多个主域的链接。例如https://www.doczj.com/doc/9e3951256.html,的所有链接由A机器处理,https://www.doczj.com/doc/9e3951256.html,的所有链接由B机器处理,某几个小站点的链接由X机器处理。 2、存在的问题 这种架构缓解了用一台机器存储和处理所有linkbase数据的压力,在链接大量增长的情况下,存在下面几个严重的问题: (1)扩展性问题: 机器数量是固定的144台,增加机器相当困难,无法应对互联网数据不断增长的需求。 (2)负载均衡问题: 部分主域(如baidu, sina, qq)的链接明显比其他主域多,而一个主域的链接是不能分到多台机器的,所以链接最多的主域对应的机器就成为短板,它的硬盘和CPU压力都比其他机器大,一方面这个主域的链接处理会比其他机器慢,另一方面这个主域的机器出现故障的可能行和影响也比其他机器要大。
虚拟电厂在分布式能源中的应用 当前,社会发展对于电力能源的需求量逐渐提升。虚拟电厂的应用可对分布式的发电单元以及负荷高效管理。本文对虚拟电厂内容和组成结构进行简要介绍,并分析其对分布式能源控制方式,阐述虚拟电厂的实际运用。 标签:虚拟电厂;分布式能源;远程控制 引言:虚拟电厂属于先进的通信技术,利用软件系统,可实现对分布式能源的高效控制。当前,社会发展,对电能的需求变化较大,对电网的削峰填谷相关工作提出挑战,高效管理用电高峰,能够缓解电网用电负荷,下文重点介绍虚拟电厂在储能和分布式光伏当中的应用。 一、虚拟电厂概述 虚拟电厂的应用转变了分布式发电并网形式以及用户消费方式。借助智能技术、控制理论、通信技术,将分布式单元、储能系统以及可控负荷的加以聚合,统一调度,最终实现对发电、用电等资源优化协调控制,展现虚拟电厂配置资源方面的优势。虚拟电厂组成结构包括如下系统:风力发电、水力发电、光伏发电、储能、(工业、商业、家用)负荷,电动汽车、微燃气轮机,上述系统之间可借助通信系统,完成信息共享,系统可接收虚拟电厂指令,对各单元进行分别控制。图1为虚拟电厂结构图: 二、虚拟电厂对分布式能源的控制方式 使用传统控制方式,利用光伏发電、可控负荷、储能等系统,由于分布式发电各个单元具有功率波动,负载功率固定等特点。为实现精准负荷控制,通过储能系统,可迅速调节功率,按照供需特点,为分布式能源以及可供负荷并网之后,系统经济运行奠定基础。下文将按照光伏发电、可控负荷功率、负载功率实际变化进行调整,利用模糊控制虚拟电厂,精准控制负荷减载。 储能系统设计目的为完成负荷消减,实施精准控制。利用传统控制方式,将辅助空调的负荷抑制为目的,完成分布发电单元与用电负荷产生的功率波动二者之间产生的负荷偏差的消减。将实时电价考虑其中,保证负荷运行经济性,利用虚拟电厂,将分布式能源集中控制,通过模糊理论,将模糊电量设置为实时电价、负荷消减,并利用加权系数,将其看作控制器输出变量[1]。 三、虚拟电厂在分布式能源中的应用 (一)储能电站中的应用 虚拟电厂可通过储能电站的形式应用。电能存储方式包括电池、电感器、电容器等,其中电池储能系统,下文简称BESS,主要利用铅、锂电池作为储能