
Pseudogenes
Protein Structures
Amino acids are linked by peptide bonds
30
35
43
48
49
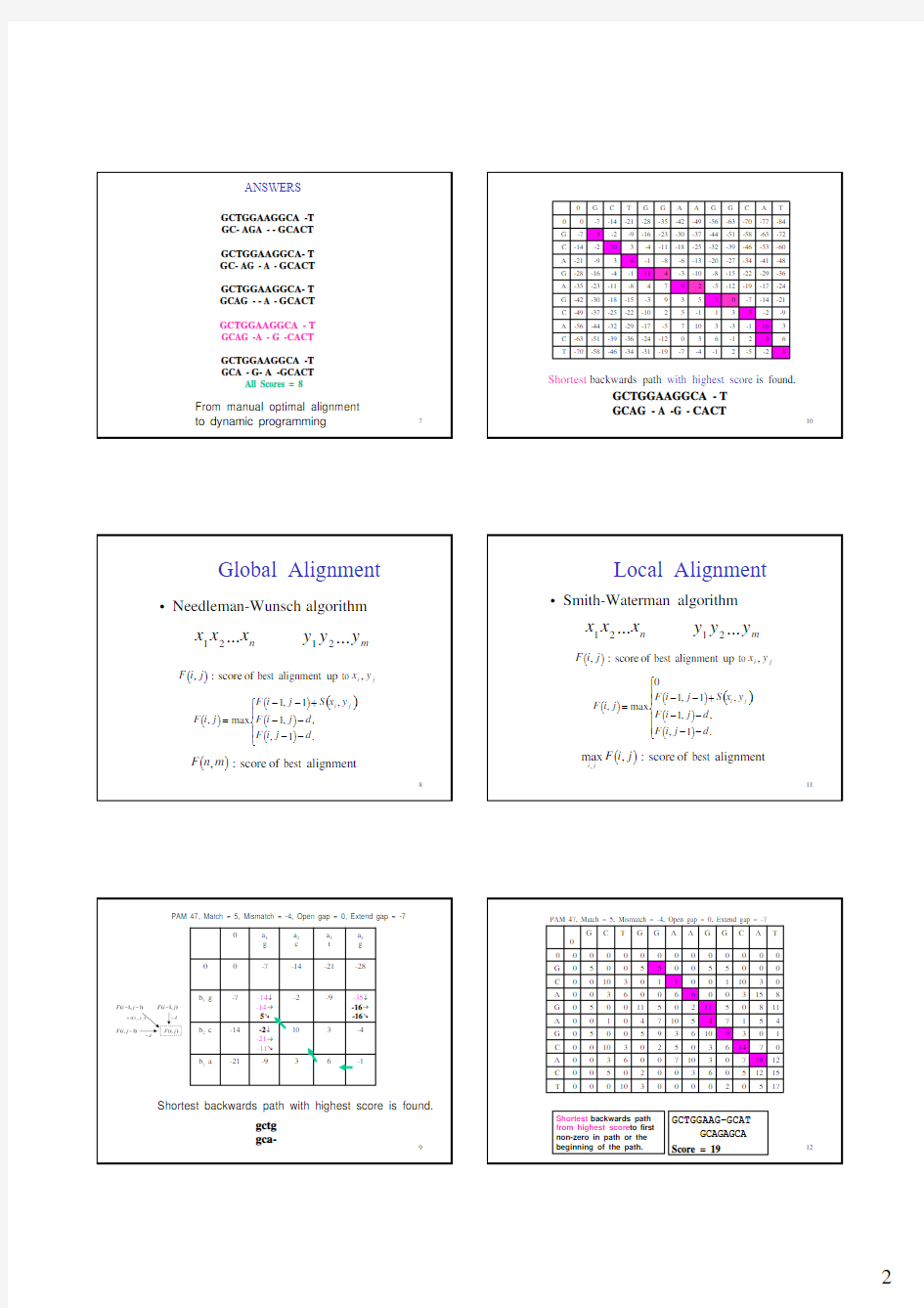
Bayesian Networks Approach
L cut = 600
Jansen R, et al. SCIENCE, 302: 449-453, 2003
55
V5-tag 5ˊGGT AAG CCT ATC CCT AAC CCT CTC CTC GGT CTC GAT TCT ACG 3ˊ G K P I P N P L L G L D S T 6 X His tag CAT CAT CAC CAT CAC CAT H H H H H H S-tag AAA GAA ACC GCT GCT GCT AAA TTC GAA CGC CAG CAC A TG GAC A GC KETAAAKFERQHMDS Flag-Tag GAT TAC AAG GAT GAC GAC GAT AAG D Y K D D D D K
Myc-Tag GAG CAG AAA CTC ATC TCT GAA GAG GAT CTG HA-Tag TAC CCA TAC GAC GTC CCA GAC TAC GCT VSV-G: TATACAGACATAGAGATGAACCGACTTGGAAAG Thrombin recognises the consensus sequence Leu-Val-Pro-Arg-Gly-Ser Sequence:CTG GTT CCG CGT GGA TCC 重组蛋白表达技术现已经广泛应用于生物学各个具体领域。特别是体内功能研究和蛋白质的大规模生产都需要应用重组蛋白表达载体。 美国GeneCopoeia的蛋白表达载体按照表达宿主的不同新推出3类,分别为表达宿主为 大肠杆菌,哺乳动物细胞的,以及慢病毒载体,宿主可以为哺乳动物细胞和原代细胞。 除了必要的复制和筛选的元件,协助表达和翻译的元件外,本文将各类载体分别按照功能标签的不同确定种类并将个标签的功能初步介绍如下: His6: His6是指六个组氨酸残基组成的融合标签,可插入在目的蛋白的C末端或N末端。当某 一个标签的使用,一是能构成表位利于纯化和检测;二是构成独特的结构特征(结合配体)利于纯化。组氨酸残基侧链与固态的镍有强烈的吸引力,可用于固定化金属螯合层析(IMAC),对重组蛋白进行分离纯化。 使用His-tag有下面优点: 1.标签的分子量小,只有~0.84KD,而GST和蛋白A分别为~26KD和~30KD,一般不影响目标蛋白的功能; 2.His标签融合蛋白可以在非离子型表面活性剂存在的条件下或变性条件下纯化,前者在纯
蛋白质结构解析的方法对比综述 工程硕士李瑾 摘要:到目前为止,蛋白质结构解析的方法主要是两种,x射线衍射法和NMR法,这两种方法各有优点和不足。 关键词:x射线衍射法 NMR法 到目前为止,蛋白质结构解析的方法主要是两种,x射线衍射法和NMR法。其中X射线的方法产生的更早,也更加的成熟,解析的数量也更多,第一个解析的蛋白的结构,就是用x晶体衍射的方法解析的。而NMR方法则是在90年代才成熟并发展起来的。这两种方法各有优点和不足[1]。 首先是X射线晶体衍射法。该方法的前提是要得到蛋白质的晶体。通常是将表达目的蛋白的基因经PCR扩增后克隆到一种表达载体中,然后转入大肠杆菌中诱导表达,目的蛋白提纯之后摸索结晶条件,等拿到晶体之后,将晶体进行x射线衍射,收集衍射图谱,通过一系列的计算,得到蛋白质的原子结构[2]。 x射线晶体衍射法的优点是:速度快,通常只要拿到晶体,最快当天就能得出结构,另外不受肽链大小限制,无论是多大分子量的蛋白质或者RNA、DNA,甚至是结合多种小分子的复合体,只要能够结晶就能够得到其原子结构。所以x射线方法解析蛋白的关键是摸索蛋白结晶的条件。该方法得到的是蛋白质分子在晶体状态下的空间结构,这种结构与蛋白质分子在生物细胞内的本来结构有较大的差别。晶体中的蛋白质分子相互间是有规律地、紧密地排列在一起的,运动性较差;而自然界的生物细胞中的蛋白质分子则是处于一种溶液状态,周围是水分子和其他的生物分子,具有很好的运动性。而且,有些蛋白质只能稳定地存在于溶液状态,无法结晶[2]。 核磁共振NMR(nuclear magnetic resonance)现象很早就被科研人员观察到了,但将这种方法用来解析蛋白质结构,却是近一二十年的事情。NMR法具体原理是对水溶液中的蛋白质样品测定一系列不同的二维核磁共振图谱,然后根据已确定的蛋白质分子的一级结构,通过对各种二维核磁共振图谱的比较和解析,在图谱上找到各个序列号氨基酸上的各种氢原子所对应的峰。有了这些被指认的峰,就可以根据这些峰在核磁共振谱图上所呈现的相互之间的关系得到它们所对应的氢原子之间的距离。[3]可以想象,正是因为蛋白质分子具有空间结构,在序列上相差甚远的两个氨基酸有可能在空间距离上是很近的,它们所含的氢原子所对应的NMR峰之间就会有相关信号出现[4] 。通常,如果两个氢原子之间距离小于0.5纳米的话,它们之间就会有相关信号出现。一个由几十个氨基酸残基组成的蛋白质分子可以得到几百个甚至几千个这样与距离有关的信号,按照信号的强弱把它们转换成对应的氢原子之间的距离,然后运用计算机程序根据所得到的距离条件模拟出该蛋白质分子的空间结构。该结构既要满足从核磁共振图谱上得到的所有距离条件,还要满足化学上有关原子与原子结合的一些基本限制条件,如原子间的化学键长、键角和原子半径等[4]。 NMR解析蛋白结构常规步骤如下:首先通过基因工程的方法,得到提纯的目的蛋白,在蛋白质稳定的条件下,将未聚合,而且折叠良好的蛋白样品(通常是1mM-3mM,500ul,PH6-7的PBS)装入核磁管中,放入核磁谱仪中,然后由写好的程序控制谱仪,发出一系列的电磁波,激发蛋白中的H、13N、13C原子,等电磁波发射完毕,再收集受激发的原子所放出的“能量”,通过收集数据、谱图处理、电脑计算从而得到蛋白的原子结构[5] [6]。 用NMR研究蛋白质结构的方法,可以在溶液状态进行研究,得到的是蛋白质分子在溶液中的结构,这更接近于蛋白质在生物细胞中的自然状态[7]。此外,通过改变溶液的性质,还可以模拟出生物细胞内的各种生理条件,即蛋白质分子所处的各种环境,以观察这些周围环境的变化对蛋白质分子空间结构的影响。在溶液环境中,蛋白质分子具有与自然环境中类
细胞内蛋白质的合成与运输 摘要:蛋白质是一切生命的物质基础,这不仅是因为蛋白质是构成机体组织器官的基本成分,更重要的是蛋白质本身不断地进行合成与分解。这种合成、分解的对立统一过程,推动生命活动,调节机体正常生理功能,保证机体的生长、发育、繁殖、遗传及修补损伤的组织。根据现代的生物学观点,蛋白质和核酸是生命的主要物质基础。 关键字:多肽链、蛋白质、翻译、核糖体、运输途径、运输方式,研究前景 前言:国家重大科学研究计划对中国的四项重要科学研究所涉及的领域分别作了详细说明,四个项目分别是蛋白质研究,量子调控研究,纳米研究,发育与生殖研究。尽管现在已有多个物种的基因组被测序,但在这些基因组中通常有一半以上基因的功能是未知的。目前功能基因组中所采用的策略,如基因芯片、基因表达序列分析等,都是从细胞中mRNA的角度来考虑的,其前提是细胞中mRNA的水平反映了蛋白质表达的水平。但事实并不完全如此,从DNA mRNA蛋白质,存在三个层次的调控,即转录水平调控,翻译水平调控,翻译后水平调控。从mRNA角度考虑,实际上仅包括了转录水平调控,并不能全面代表蛋白质表达水平。毋庸置疑,蛋白质是生理功能的执行者,是生命现象的直接体现者,对蛋白质结构和功能的研究将直接阐明生命在生理或病理条件下的变化机制。蛋白质本身的存在形式和活动规律,如翻译后修饰、蛋白质间相互作用以及蛋白质构象等问题,仍依赖于直接对蛋白质的研究来解决。虽然蛋白质的可变性和多样性等特殊性质导致了蛋白质研究技术远远比核酸技术要复杂和困难得多,但正是这些特性参与和影响着整个生命过程。 一、蛋白质生物合成过程
遗传密码表在mRNA的开放式阅读框架区,以每3个相邻的核苷酸为一组,代表一种氨基酸或其他信息,这种三联体形势称为密码子(codon)。如图,通常的开放式阅读框架区包含500个以上的密码子。 遗传密码的特点 一方向性:密码子及组成密码子的各碱基在mRNA序列中的排列具有方向性(direction),翻译时的阅读方向只能是5ˊ→3ˊ。 二连续性:mRNA序列上的各个密码子及密码子的各碱基是连续排列的,密码子及密码子的各个碱基之间没有间隔,每个碱基只读一次,不重叠阅读。 三简并性:一种氨基酸可具有两个或两个以上的密码子为其编码。遗传密码表中显示,每个氨基酸都有2,3,4或6个密码子为其编码(除甲硫氨酸只有一个外),但每种密码子只对应一个氨基酸,或对应终止信息。 四通用性:生物界的所有生物,几乎都通用这一套密码子表 五摆动性:tRNA的最后一位,和mRNA的对应不完全,导致了简并性 氨基酸活化 在进行合成多肽链之前,必须先经过活化,然后再与其特异的tRNA合,带到mRNA 相应的位置上,这个过程靠tRNA合成酶催化,此酶催化特定的氨基酸与特异的tRNA 相结合,生成各种氨基酰tRNA.每种氨基酸都靠其特有合成酶催化,使之和相对应的tRNA结合,在氨基酰tRNA合成酶催化下,利用A TP供能,在氨基酸羧基上进行活化,形成氨基酰-AMP,再与氨基酰tRNA合成酶结合形成三联复合物,此复合物再与特异的tRNA作用,将氨基酰转移到tRNA的氨基酸臂(即3'-末端CCA-OH)上(图1)。原核细胞中起始氨基酸活化后,还要甲酰化,形成甲酰蛋氨酸tRNA,由N10甲酰四氢叶酸提供甲酰基。而真核细胞没有此过程。前面讲过运载同一种氨基酸的一组不同tRNA称为同功tRNA。一组同功tRNA由同一种氨酰基tRNA合成酶催化。氨基酰tRNA合成酶对tRNA和氨基酸两者具有专一性,它对氨基酸的识别特异性很高,而对tRNA识别的特异性较低。氨基酰tRNA合成酶是如何选择正确的氨基酸和tRNA 呢?按照一般原理,酶和底物的正确结合是由二者相嵌的几何形状所决定的,只有适合的氨基酸和适合的tRNA进入合成酶的相应位点,才能合成正确的氨酰基tRNA。现在已经知道合成酶与L形tRNA的内侧面结合,结合点包括接近臂,DHU臂和反密码子臂(图2)。氨基酰-tRNA合成酶与tRNA的相互作用,可见氨酸接受柄、乍看起来,反密码子似乎应该与氨基酸的正确负载有关,对于某些tRNA也确实如此,然而对于大多数tRNA来说,情况并非如此,人们早就知道,当某些tRNA上的反密码子突变后,但它们所携带的氨工酸却没有改变。1988年,候稚明和Schimmel的实验证明丙氨酸tRNA酸分子的氨基酸臂上G3:U70这两个碱基发生突变时则影响到丙氨酰tRNA合成酶的正确识别,说明G3:U70是丙氨酸tRNA分子决定其本质的主要因素。tRNA分子上决定其携带氨基酸的区域叫做副密码子。一种氨基酰tRNA合成酶可以识别以一组同功tRNA,这说明它们具有共同特征。例如三种丙氨酸tRNA
1.7/1.3埃分辨率下蚯蚓肌红蛋白的结构 >2MHR: |PDBID|CHAIN|SEQUENCE GWEIPEPYVWDESFRVFYEQLDEEHHHIFHGIFDCIRDNSAPNLATLVHVTTNHFTHEEAMMDAAHYSEVVP HHHMHHDF LEHIGGLSAPVDAHNVDYCHEWLVNHIHGTDFHYHGHL 牛的超氧化物歧化酶-1晶体结构 >1E9O:A|PDBID|CHAIN|SEQUENCE MATSAVCVLSGDGPVQGTIHFEAHGDTVVVTGSITGLTEGDHGFHVHQFGDNTQGCTSAGPHFNPLSHHHG GPHDEERHV GDLGNVTADSNGVAIVDIVDPLISLSGEYSIIGRTMVVHEHPDDLGRGGNEESTHTGNAGSRLACGVIGIAH >1E9O:B|PDBID|CHAIN|SEQUENCE MATHAVCVLHGDGPVQGTIHFEAHGDTVVVTGSITGLTEGDHGFHVHQFGDNTQGCTSAGPHFNPLSHHHG GPHDDERHV GDLGNVTADHNGVAIVDIVDPLISLSGEYSIIGRTMVVHEHPDDLGRGGNEESTSTGNAGSRLACGVIGIAH 花生过氧化物酶 >1PLU:A|PDBID|CHAIN|SEQUENCE ATDTGGYAATAGGNVTGAVSHTATSMQDIVNIIDAARLDANGHHVHGGAYPLVITYTGNEDSLINAAAANICG QWSHDPR GVEIHEFTHGITIIGANGSSANFGIWIHHSSDVVVQNMRIGYLPGGAHDGDMIRVDDSPNVWVDHNELFAAN HECDGTPD NDTTFESAVDIHGASNTVTVSYNYIHGVHHVGLDGSSSSDTGRNITYHHNYYNDVNARLPLQRGGLVHAYNNL YTNITGS GLNVRQNGQALIENNWFEHAINPVTSRYDGHNFGTWVLHGNNITHPADFSTYSITWTADTHPYVNADSWTS TGTFPTVAY NYSPVSAQCVHDHLPGYAGVGHNLATL TSTACH 大豆过氧化物酶结构 >1FHF:A|PDBID|CHAIN|SEQUENCE QLTPTFYRETCPNLFPIVFGVIFDASFTDPRIGASLMRLHFHDCFVQGCDGSVLLNNTDTIESEQDALPNINSIRG LDVV NDIHTAVENSCPDTVSCADILAIAAEIASVLGGGPGWPVPLGRRDSLTANRTLANQNLPAPFFNLTQLHASFAVQ GLNTL DLVTLSGGHTFGRARCSTFINRLYNFSNTGNPDPTLNTTYLEVLRARCPQNATGDNLTNLDLSTPDQFDNRYYS NLLQLN GLLQSDQELFSTPGADTIPIVNSFSSNQNTFFSNFRVSMIHMGNIGVLTGDEGEIRLQCNFVNG >1FHF:B|PDBID|CHAIN|SEQUENCE
蛋白质结构及性质论文 ——动科一班黄细旺(1207010127)&冯志(1207010126) 摘要:蛋白质结构及其理化性质 关键词:蛋白质、结构、理化性质 前言: 蛋白质分子是由许多氨基酸通过肽键相连形成的生物大分子。人体内具有生理功能的蛋白质都是有序结构,每种蛋白质都有其一定的氨基酸百分组成及氨基酸排列顺序,以及肽链空间的特定排布位置。因此由氨基酸排列顺序及肽链的空间排布等所构成的蛋白质分子结构,才真正体现蛋白质的个性,是每种蛋白质具有独特生理功能的结构基础。 蛋白质结构 蛋白质分子结构分成一级、二级、三级、四级结构四个层次,后三者统称为高级结构或空间构象。并非所有的蛋白质都有四级结构,由一条肽链形成的蛋白质只有一级、二级和三级结构,由二条或二条以上多肽链形成的蛋白质才可能有四级结构。 1.蛋白质的一级结构 蛋白质分子中氨基酸的排列顺序称为蛋白质的一级结构。一级结构的主要化学键是肽键,有些蛋白质还包含二硫键,它是由两个半胱氨酸巯基脱氢氧化而成。 2.蛋白质的二级结构 蛋白质的二级是指蛋白质分子中某一段肽链的局部空间结构,也就是该段肪酸主链骨架原子的相对空间位置,并不涉及氨基酸残基侧链构象。 (一)肽单元20世纪30年代末L.Panling和R.B.Cory应用X线衍射技术研究氨基酸和寡肽的晶体结构其目的是要获得一组标准键长和键角以推导肽的构象最终提出了肽单元概念。他们发现参与肽健的6个原子位于同一平面Cα1和Cα2在平面上所处的位置为反构型,此同一平面上的6个原子构成了所谓的肽单元其中肽键(C-N)的键长为0132nm.介于C-N的单健长(0149nm)和双键长(0127nm)之问,所以有一定程度双键性能,不能自由旋转。而Cα分别与N和羰基碳相连的键都是典型的单键可以自由旋转。 (二)α-螺旋Paulαing和Core根据实验数据提出了两种肽链局部主链原子空间构象的分子模型,称为α-螺旋和β-折叠,它们是蛋白质二级结构的主要形式,在α-螺旋结构中多肽键的主链围绕中心轴是有规律的螺旋式上升,螺旋的走向为顺时钟方向即右手螺旋,其氨基酸恻键伸向螺旋外侧。每36个氨基酸残基螺旋上升一圈,螺距为0.54nm。a一螺旋的每个肽键N-H和第四个的羧基氧形成氨键,氢键的方向与螺旋长轴基本平行。肽链中的全部肽键都可形成氢键以稳固α-螺旋结构。肌红蛋白和血红蛋白分子中有许多肽链段落呈a一螺旋结构,毛发的角蛋白、肌肉的肌球蛋白以及血凝块中的纤维蛋白它们的多肽链几乎全长
蛋白质组学关键技术研究进展 摘要:蛋白质组学是对蛋白质特别是其结构和功能的大规模研究,是在90年代初期,由Marc Wikins 和学者们首先提出的新名词。蛋白质组的研究不仅能为生命活动规律提供物质基础,也能为众多种疾病机理的阐明及攻克提供理论根据和解决途径。本文综述了蛋白质组学的一些关键技术的应用研究进展。 关键词:蛋白质组学;蛋白质组技术;研究方法 蛋白质组学的概念[1]最早是在1995年提出的,它在本质上指的是在大规模水平上研究蛋白质的特征,包括蛋白质的表达水平,翻译后的修饰,蛋白与蛋白相互作用等,由此获得蛋白质水平上的关于疾病发生,细胞代谢等过程的整体而全面的认识。近年来,高通量蛋白质分离与鉴定技术,如双向电泳、生物质谱、蛋白质芯片、酵母双杂交系统、生物信息学等相继建立并日趋完善,加速了蛋白质组学的发展。 1蛋白质组学概述 随着人类基因组计划的完成和功能基因组时代的到来,蛋白质结构与功能研究越来越重要,蛋白质组学、生物信息学等相关学科已逐渐成为生命科学的前沿。 随着人类基因组计划的实施和推进,生命科学研究已进入了后基因组时代。在这个时代,生命科学的主要研究对象是功能基因组学,包括结构基因组研究和蛋白质组研究等。尽管现在已有多个物种的基因组被测序,但在这些基因组中通常有一半以上基因的功能是未知的。 目前功能基因组中所采用的策略,如基因芯片、基因表达序列分析(Serial analysis of gene expression, SAGE)等,都是从细胞中mRNA的角度来考虑的,其前提是细胞中mRNA的水平反映了蛋白质表达的水平。但事实并不完全如此,从DNA、mRNA、蛋白质,存在三个层次的调控,即转录水平调控(Transcriptional control),翻译水平调控(Translational control),翻译后水平调控(Post-translational control)。从mRNA 角度考虑,实际上仅包括了转录水平调控,并不能全面代表蛋白质表达水平。实验也证明,组织中mRNA丰度与蛋白质丰度的相关性并不好,尤其对于低丰度蛋白质来说,相
生物化学论文 —蛋白质 蛋白质(protein)是生命的物质基础,没有蛋白质就没有生命。因此,它是与生命及与各种形式的生命活动紧密联系在一起的物质。机体中的每一个细胞和所有重要组成部分都有蛋白质参与。蛋白质占人体重量的16%~20%,即一个60kg重的成年人其体内约有蛋白质9.6~12kg。人体内蛋白质的种类很多,性质、功能各异,但都是由20多种氨基酸按不同比例组合而成的,并在体内不断进行代谢与更新 蛋白质是由α—氨基酸按一定顺序结合形成一条多肽链,再由一条或一条以上的多肽链按照其特定方式结合而成的高分子化合物。蛋白质就是构成人体组织器官的支架和主要物质,在人体生命活动中,起着重要作用,可以说没有蛋白质就没有生命活动的存在。每天的饮食中蛋白质主要存在于瘦肉、蛋类、豆类及鱼类中。、 蛋白质是荷兰科学家格利特·马尔德在1838年发现的。他观察到有生命的东西离开了蛋白质就不能生存 。 蛋白质是生物体内一种极重要的高分子有机物,占人体干重的54%。蛋白质主要由氨基酸组成,因氨基酸的组合排列不同而组成各种类型的蛋白质。人体中估计有10万种以上的蛋白质。生命是物质运动的高级形式,这种运动方式是通过蛋白质来实现的,所以蛋白质有极其重要的生物学意义。人体的生长、发育、运动、遗传、繁殖等一切生命活动都离不开蛋白质。生命运动需要蛋白质,也离不开蛋白质。 人体内的一些生理活性物质如胺类、神经递质、多肽类激素、抗体、酶、核蛋白以及细胞膜上、血液中起“载体”作用的蛋白都离不开蛋白质,它对调节生理功能,维持新陈代谢起着极其重要的作用。人体运动系统中肌肉的成分以及肌肉在收缩、作功、完成动作过程中的代谢无不与蛋白质有关,离开了蛋白质,体育锻炼就无从谈起。
蛋白质预测在线分析常用软件推荐 蛋白质预测分析网址集锦 物理性质预测: Compute PI/MW http://expaxy.hcuge.ch/ch2d/pi-tool.html Peptidemasshttp://expaxy.hcuge.ch/sprot/peptide-mass.html TGREASE ftp://https://www.doczj.com/doc/8e19014443.html,/pub/fasta/ SAPS http://ulrec3.unil.ch/software/SAPS_form.html 基于组成的蛋白质识别预测 AACompIdent http://expaxy.hcuge.ch ... htmlAACompSim http://expaxy.hcuge.ch/ch2d/aacsim.html PROPSEARCH http://www.e mbl-heidelberg.de/prs.html 二级结构和折叠类预测 nnpredict https://www.doczj.com/doc/8e19014443.html,/~nomi/nnpredict Predictprotein http://www.embl-heidel ... protein/SOPMA http://www.ibcp.fr/predict.html SSPRED http://www.embl-heidel ... prd_info.html 特殊结构或结构预测 COILS http://ulrec3.unil.ch/ ... ILS_form.html MacStripe https://www.doczj.com/doc/8e19014443.html,/ ... acstripe.html 与核酸序列一样,蛋白质序列的检索往往是进行相关分析的第一步,由于数据库和网络技校术的发展,蛋白序列的检索是十分方便,将蛋白质序列数据库下载到本地检索和通过国际互联网进行检索均是可行的。 由NCBI检索蛋白质序列 可联网到:“http://www.ncbi.nlm.ni ... gi?db=protein”进行检索。 利用SRS系统从EMBL检索蛋白质序列 联网到:https://www.doczj.com/doc/8e19014443.html,/”,可利用EMBL的SRS系统进行蛋白质序列的检索。 通过EMAIL进行序列检索 当网络不是很畅通时或并不急于得到较多数量的蛋白质序列时,可采用EMAIL方式进行序列检索。 蛋白质基本性质分析 蛋白质序列的基本性质分析是蛋白质序列分析的基本方面,一般包括蛋白质的氨基酸组成,分子质量,等电点,亲水性,和疏水性、信号肽,跨膜区及结构功能域的分析等到。蛋白质的很多功能特征可直接由分析其序列而获得。例如,疏水性图谱可通知来预测跨膜螺旋。同时,也有很多短片段被细胞用来将目的蛋白质向特定细胞器进行转移的靶标(其中最典型的
蛋白质的改性 摘要:介绍蛋白质的功能特性,以及物理、化学、摘要介绍蛋白质的功能特性,以及物理、化学、酶法等各种改性方法及其对蛋白质功能特性和营养安全性的影响,展望蛋白质改性的应用前景。 0 前言 蛋白质具有营养功能,添加到食品中可以有效地提高产品的营养价值,更重要的是蛋白质在食品中可以体现出不同的功能特性,影响食品的感官特性,而且对食品在制造、加工或保藏中的物理化学性质起着重要的作用。因此蛋白质广泛用于食品加工的各个领域。但是,不少天然蛋白质的这些特性尚不突出,不能满足现代食品开发与加工的需要,往往通过特定的方法来提高其功能特性,使其应用领域更广阔。 1 蛋白质的功能特性 蛋白质的功能性质主要分三类: (l)水化性质,包括水吸收及保留、湿润性、溶胀、粘着性、分散性、溶解度和粘度。由蛋白质肤链骨架上的极性基团与水分子发生水化作用。 (2)与蛋白质一蛋白质相互作用有关的性质,包括产生沉淀作用、凝胶作用和形成各种其它结构(如蛋白质面团和纤维)。蛋白质分子受热舒展,内部的疏水基团暴露出来,通过疏水作用(高温能提高此类作用)、静电作用(通过ca和其它二价离子桥接的)、氢键(冷却能提高此类作用)或二硫交联形成空间网状结构。 (3)表面活性,包括表面张力、乳化作用和泡沫特征。蛋白质结构中既有亲水基又有亲油基,能够吸附在油一水或空气一水界面上,一旦被界面吸附,蛋白质形成一层膜,可阻止小液滴或气泡聚集,有助于稳定乳化液和气泡。这些功能特性在食品中常被应用。 (4)蛋白质的功能特性与其结构有关,即氨基酸组成、排列顺序、构象、分子的形状和大小、电荷分布以及分子内和分子间键的作用。高比例的极性残基影响肤链间相互作用、水化作用、溶解性和表面活性,疏水性相互作用在蛋白质三级折叠中相当重要,它影响乳化作用、起泡性和风味结合能力。带电氨基酸能增强静力相互作用,起到稳定球蛋白,结合水分的作用,以及水化作用、溶解度、凝胶作用和表面活性。琉基(SH)能被氧化形成二硫键,硫醇和二硫化物的相互转化会影响流变性。共价键和非共价键的性质和数量决定了蛋白质的大小、形状、表面电荷。所有这些性质又受PH、温度等环境因素及加工处理的影响。 2蛋白质改性 2.1物理改性 所谓蛋白质物理改性是指利用热、机械振荡、电磁场、射线等物理作用形式改变蛋白质的高级结构和分子间的聚集方式, 一般不涉及蛋白质的一级结构。如蒸煮、搅打等均属于物理改性技术。
蛋白质结构预测和序列分析软件蛋白质数据库及蛋白质序列分析 第一节、蛋白质数据库介绍 一、蛋白质一级数据库 1、 SWISS-PROT 数据库 SWISS-PROT和PIR是国际上二个主要的蛋白质序列数据 库,目前这二个数据库在EMBL和GenBank数据库上均建 立了镜像 (mirror) 站点。 SWISS-PROT数据库包括了从EMBL翻译而来的蛋白质序 列,这些序列经过检验和注释。该数据库主要由日内瓦大 学医学生物化学系和欧洲生物信息学研究所(EBI)合作维 护。SWISS-PROT的序列数量呈直线增长。 2、TrEMBL数据库: SWISS-PROT的数据存在一个滞后问题,即 进行注释需要时间。一大批含有开放阅读 了解决这一问题,TrEMBL(Translated E 白质数据库,它包括了所有EMBL库中的 质序列数据源,但这势必导致其注释质量 3、PIR数据库: PIR数据库的数据最初是由美国国家生物医学研究基金 会(National Biomedical Research Foundation, NBRF) 收集的蛋白质序列,主要翻译自GenBank的DNA序列。 1988年,美国的NBRF、日本的JIPID(the Japanese International Protein Sequence Database日本国家蛋 白质信息数据库)、德国的MIPS(Munich Information Centre for Protein Sequences摹尼黑蛋白质序列信息 中心)合作,共同收集和维护PIR数据库。PIR根据注释 程度(质量)分为4个等级。 4、 ExPASy数据库: 目前,瑞士生物信息学研究所(Swiss I 质分析专家系统(Expert protein anal 据库。 网址:https://www.doczj.com/doc/8e19014443.html, 我国的北京大学生物信息中心(www.cbi.
利用蛋白质组学分析技术研究 p53 蛋白的技术路线 课 程 论 文 姓名:高小琪 学号:82101082436 指导老师:邱德文 年级: 08 级 班级:硕士13班
利用蛋白质组学分析技术研究p53蛋白的技术路线指导老师:邱德文学生:高小琪学号:82101082436 p53 基因是一种具有阻滞细胞周期、启动细胞凋亡、维持基因组稳定性作用的、重要的抑瘤基因。p53 基因突变与大多数人类肿瘤发生、发展有关, 至少50 %以上的人类肿瘤存在p53 基因高频率突变失活。p53 蛋白功能失活的主要原因有 4 个, 最常见的原因是p53 基因点突变或缺失。其他3 个p53蛋白功能失活的原因不涉及p53 基因突变, 属于非遗传原因(extragenic)。其一是细胞蛋白与野生型p53蛋白结合, 如MDM2 瘤蛋白与p53 结合后、加速p53 蛋白泛素化和降解; 其二是野生型p53蛋白核外排(nuclear exclusion) , 即p53 蛋白被分隔(sequestration) 于细胞浆, 不能进入细胞核而发挥作用, 如热休克蛋白70 (HSP270) 和HSP290 家族成员可通过此种方式使p53 蛋白功能失活; 其三是病毒蛋白与野生型p53 蛋白结合, 如SV40 大T抗原、HPV E6蛋白、腺病毒E1B 和E4/ F4 蛋白,以及乙肝病毒x 抗原(HBx) 等与p53 蛋白结合使之失活。本路线以p53 蛋白为诱饵,先采用抗p53 抗体免疫共沉淀, 从鼻咽癌细胞中的p53 结合蛋白, 再采用SDS-聚丙烯酰胺凝胶电泳技术对含p53 结合蛋白的复合物进行分离, 然后采用液相色谱-电喷雾串联质谱结合数据库搜索鉴定p53 结合蛋白, 试图阐明鼻咽癌中p53 蛋白聚集及功能异常的分子机制。
生物信息学论文 学院:生命科学技术学院 专业:生物科学 班级:2013级 老师:高亚梅 学生:王秉政 学号:20134083038
黑曲霉GH75及米曲霉GH76-5基因生物信息学分析王秉政(黑龙江八一农垦大学,生命科学技术学院,2013级生物科学专业,黑龙江省,大庆市) 【摘要】目的:分析和预测黑曲霉GH75和米曲霉GH76-5基因及其编码蛋白质的结构和特征。方法:利用NCBI、CBS和ExPASy网站中的各种信息分析工具,并结合VectorNTIsuite8.0生物信息分析软件包,分析预测黑曲霉GH75和米曲霉GH76-5基因并预测该基因编码蛋白结构的特征和功能。结果:GH75基因全长174bp,编码区具有57个氨基酸,在GenBank同源序列中,其与Aspergillus niger contig An04c0140, genomic contig 基因氨基酸序列一致性达到100%,且有GH75保守域。GH75蛋白相对分子量预测为26257.2,理论等电点为4.69。预测GH75编码蛋白α螺旋(H ) 、β折叠(E )、无规则卷(L )的比例分别是11.07%、25.41%、63.52%,1个GTPase结构域。GH75蛋白为亲水蛋白,有跨膜区,有信号肽。GH76-5基因全长309bp,编码区具有102个氨基酸,在GenBank同源序列中,其与Aspergillus niger contig An14c0130, genomic contig基因氨基酸序列一致性达到100%,且有GH76-5保守域。GH76-5蛋白相对分子量预测为46029.3,理论等电点为5.28。预测GH76-5编码蛋白α螺旋(H ) 、β折叠(E )、无规则卷(L )的比例分别是26.90%、20.71%、52.38%,2个GTPase结构域。GH76-5蛋白为疏水蛋白,无跨膜区,无信号肽。结论:成功预测GH75和GH76-5基因及其编码蛋白生化及其结构特征,为下一步对其进行克隆和表达奠定基础。 【关键词】黑曲霉、米曲霉;糖基水解酶家族(GH75);糖基水解酶家族(GH76-5)生物信息学 黑曲霉是一种重要工业微生物,在酶制剂、异源蛋白、有机酸等领域应用广泛。2007年黑曲霉基因组的公布将黑曲霉的研究引入后基因组时代,各种组学数据如雨后春笋般涌现,人们对黑曲霉高效生产机制的理解上升到系统、分子层次;与此同时,黑曲霉遗传操作系统也不断成熟,为系统地研究和改造黑曲霉、将黑曲霉打造成通用细胞工厂奠定了基础。 米曲霉是一类产复合酶的菌株,除产蛋白酶外,还可产淀粉酶、糖化酶、纤维素酶、植酸酶等。在淀粉酶的作用下,将原料中的直链、支链淀粉降解为糊精及各种低分子糖类,如麦芽糖、葡萄糖等;在蛋白酶的作用下,将不易消化的大分子蛋白质降解为蛋白胨、多肽及各种氨基酸,而且可以使辅料中粗纤维、植酸等难吸收的物质降解,提高营养价值、保健功效和消化率,广泛应用于食品、饲料、生产曲酸、酿酒等发酵工业,并已被安全地应用了1000多年。米曲霉是理想的生产大肠杆菌不能表达的真核生物活性蛋白的载体。米曲霉基因组所包含的信息可以用来寻找最适合米曲霉发酵的条件,这将有助于提高食品酿造业的生产效率和产品质量。 一、资料与方法 1.1资料 通过ExPASy 数据库的UniProtKB(https://www.doczj.com/doc/8e19014443.html,或https://www.doczj.com/doc/8e19014443.html,/uniprot)获得黑曲霉的GH75与米曲霉GH76-5基因序列。GH75基因编号为4990860.,NCBI的登录号为XM_001401782.1. ,其他物种的GH75的氨基酸序列均来自Genbank,登录号见图1。GH76-5基因编号为4987208.,NCBI的登录号为XM_001400940.2. ,其他物种的GH76-5的氨基酸序列均来自Genbank,登录号见图2。 1.2方法 利用美国国家生物技术信息中心(NCBI,https://www.doczj.com/doc/8e19014443.html,)的基本局部比对搜索工具(BLAST,https://www.doczj.com/doc/8e19014443.html,/blast/),运用Blastx完成基因同源性分析。 应用ORF finder(https://www.doczj.com/doc/8e19014443.html,/gorf/orfig.cgi)寻找其开放读码框,并推导出可编码蛋白序列。 利用保守结构域(https://www.doczj.com/doc/8e19014443.html,/Structure/cdd/wrpsb.cgi)分析预测其保守域。 通过瑞士生物信息学研究所的蛋白分析专家系统(ExPASy,https://www.doczj.com/doc/8e19014443.html,)所提供的蛋白组学和分
蛋白质组学 【摘要】当今分子生物学领域内,蛋白质组已成为研究的热点。基因组相对较稳定,而且各种细胞或生物体的基因组结构有许多基本相似的特征;蛋白质组是动态的,随内外界刺激而变化。对蛋白质组的研究可以使我们更容易接近对生命过程的认识。蛋白质组学是在细胞的整体蛋白质水平上进行研究、从蛋白质整体活动的角度来认识生命活动规律的一门新学科,简要介绍蛋白质组学的科学背景及其最新发展。 【关键词】蛋白质组实验技术差异蛋白质组学应用前景 【正文】1、蛋白质组学产生的科学背景 众所周知,始于20世纪90年代初的庞大的人类基因组计划业已取得了巨大的 成就,几个物种(包括人类)的基因组序列已经或即将完成。生命科学已实质性 地跨入了后基因组时代,研究重心已开始从揭示生命的所有遗传信息转移到在分 子整体水平对功能的研究上。这种转向的第一个标志是产生了功能基因组学 (functional genomics)这一新学科,即从基因组整体水平上对基因的活动规 律进行阐述_如在RNA水平上通过DNA芯片技术检测大量基因的表达模式。而第二 个标志则是蛋白质组学的兴起。 蛋白质组(proteome)一词是澳大利亚Macquarie大学的Wilkins和Williams 在1994首次提出,最早见诸于文献是在1995年7月的《Electrophoresis》杂志上 【1~4】。它是指基因组表达的全部蛋白质及其存在方式。蛋白质组学旨在阐明生物 体全部蛋白质的表达模式及功能模式,其内容包括鉴定蛋白质的表达、存在方式 (修饰形式)、结构、功能和相互作用等_国内已有多篇综述文章介绍了蛋白质 组学的产生背景与科学意义,从蛋白质组的定义上就可以清楚看出,蛋白质组学 不同于传统的蛋白质学科之处在于它的研究是在生物体或其细胞的整体蛋白质 水平上进行的,它从一个机体或一个细胞的蛋白质整体活动的角度来揭示和阐明 生命活动的基本规律。 2、概念及相关内容 蛋白质组用来描述一个细胞、组织或有机体表达的所有蛋白质,蛋白质组学 (proteomics)则是研究特定时间或特定条件下这些蛋白质表达情况的科学【5】。 蛋白质组学从其研究目标方面可分为表达蛋白质组学和结构蛋白质组学。前 者主要研究细胞或组织在不同条件如药物或疾病状态下蛋白质的表达和功能,这 将有助于识别疾病特异蛋白、药物作用靶点、药物功效和毒性标记等, 目前蛋白
2 极性不带电荷7种:甘氨酸(Gly)丝氨酸(Ser)苏氨酸(Thr)半胱氨酸(Cys)酪氨酸(Tyr)天冬酰胺(Asn)谷氨酰胺(Gln) 3 极性带正电(碱性氨基酸)3种:赖氨酸(Lys)精氨酸(Arg)组氨酸(His) 4极性带负电(酸性氨基酸)2种:天冬氨酸(Asp)谷氨酸(Glu) 5 脂肪族氨基酸:丙、缬、亮、异亮、蛋、天冬、谷、赖、精、甘、丝、苏、半胱、天冬酰胺、谷氨酰胺 6 芳香族氨基酸:苯丙氨酸、酪氨酸 7 杂环族氨基酸:组氨酸、色氨酸 8 杂环亚氨基酸:脯氨酸 9 由于一个晶体中分子的有序排列通常只有在分子单元相同的情况下才能形成,许多蛋白质都能结晶这一事实,强有力地证明,即使是非常大的蛋白质,也是有特定结构的不连续的化学实体。 10 稳定一个特定蛋白质结构的最重要的作用力是非共价相互作用。蛋白质行使功能经常伴有两种或更多结构形式的相互转变。 11 蛋白质中原子的空间排列叫做蛋白质的构象。蛋白质的可能构象包括任何无须破坏共价键而达成的结构状态。具有功能和折叠构象的任何一种蛋白质称为天然蛋白质。 12 弱相互作用力是稳定蛋白质构象的主要作用力,因为它们数目众多。自由能最低的蛋白质构象(即最稳定的构象)就是弱相互作用力数目最多的一种构象。 13 蛋白质中基团是协同形成氢键的,一个氢键的形成有利于其
他氢键的形成。 14 蛋白质结构模式规则:疏水残基主要包埋在蛋白质内部,远离水;蛋白质内氢键的数目达到最大值。肽键是刚性的平面。 15 蛋白质是以氨基酸为基本单位构成的生物高分子,蛋白质分子上氨基酸的序列和由此形成的立体结构构成了蛋白质结构的多样性。蛋白质具有一级、二级、三级、四级结构,蛋白质分子的结构决定了它的功能。 一级结构:蛋白质多肽链中氨基酸的排列顺序,以及二硫键的位置。二级结构(α-螺旋、β-折叠):蛋白质分子局区域内,多肽链沿一定方向盘绕和折叠的方式。三级结构:蛋白质的二级结构基础上借助各种次级键卷曲折叠成特定的球状分子结构的空间构象。四级结构:多亚基蛋白质分子中各个具有三级结构的多肽链,以适当的方式聚合所形成的蛋白质的三维结构。 16 蛋白质中发现的α-螺旋都是右手螺旋,α-螺旋是α角蛋白中最主要的结构,它最佳地利用了内部的氢键。氨基酸序列影响α螺旋稳定性。脯氨酸和甘氨酸残基的存在阻碍α-螺旋的形成。 17 影响α-螺旋稳定性的因素:连续性的R基团带电的氨基酸残基之间的静电排斥(或吸引);相邻的基团体积庞大;间隔三个或四个残基的氨基酸侧链之间的相互作用;脯氨酸和甘氨酸残基的存在;螺旋节段末端的氨基酸残基与α-螺旋固有的电偶极的相互作用。 18 β构象使多肽链折叠成片状结构。锯齿状的多肽链并排排列,形成一系列的片层结构,这种排列叫β-折叠片。氢键在多肽链的相
蛋白质预测分析网址集锦? 物理性质预测:? Compute PI/MW?? ?? SAPS?? 基于组成的蛋白质识别预测? AACompIdent???PROPSEARCH?? 二级结构和折叠类预测? nnpredict?? Predictprotein??? SSPRED?? 特殊结构或结构预测? COILS?? MacStripe?? 与核酸序列一样,蛋白质序列的检索往往是进行相关分析的第一步,由于数据库和网络技校术的发展,蛋白序列的检索是十分方便,将蛋白质序列数据库下载到本地检索和通过国际互联网进行检索均是可行的。? 由NCBI检索蛋白质序列? 可联网到:“”进行检索。? 利用SRS系统从EMBL检索蛋白质序列? 联网到:”,可利用EMBL的SRS系统进行蛋白质序列的检索。? 通过EMAIL进行序列检索?
当网络不是很畅通时或并不急于得到较多数量的蛋白质序列时,可采用EMAIL方式进行序列检索。? 蛋白质基本性质分析? 蛋白质序列的基本性质分析是蛋白质序列分析的基本方面,一般包括蛋白质的氨基酸组成,分子质量,等电点,亲水性,和疏水性、信号肽,跨膜区及结构功能域的分析等到。蛋白质的很多功能特征可直接由分析其序列而获得。例如,疏水性图谱可通知来预测跨膜螺旋。同时,也有很多短片段被细胞用来将目的蛋白质向特定细胞器进行转移的靶标(其中最典型的例子是在羧基端含有KDEL序列特征的蛋白质将被引向内质网。WEB中有很多此类资源用于帮助预测蛋白质的功能。? 疏水性分析? 位于ExPASy的ProtScale程序(?)可被用来计算蛋白质的疏水性图谱。该网站充许用户计算蛋白质的50余种不同属性,并为每一种氨基酸输出相应的分值。输入的数据可为蛋白质序列或SWISSPROT数据库的序列接受号。需要调整的只是计算窗口的大小(n)该参数用于估计每种氨基酸残基的平均显示尺度。? 进行蛋白质的亲/疏水性分析时,也可用一些windows下的软件如,bioedit,dnamana等。? 跨膜区分析? 有多种预测跨膜螺旋的方法,最简单的是直接,观察以20个氨基酸为单位的疏水性氨基酸残基的分布区域,但同时还有多种更加复杂的、精确的算法能够预测跨膜螺旋的具体位置和它们的膜向性。这些技术主要是基于对已知
考点二蛋白质的结构和功能(5年6考) 1.蛋白质的结构及其多样性 (1)氨基酸的脱水缩合 ①过程:一个氨基酸分子中的氨基(—NH2)和另一个氨基酸分子中的羧基(—COOH)相连接,同时脱去一分子水。 ②二肽形成示例 ③肽键:连接两个氨基酸分子的化学键可表示为—CO—NH—。 (2)蛋白质的结构层次 ①肽的名称确定:一条多肽链由几个氨基酸分子构成就称为几肽。 ②H2O中各元素的来源:H来自—COOH和—NH2,O来自—COOH。 ③一条肽链上氨基数或羧基数的确定:一条肽链上至少有一个游离的氨基和一个游离的羧基,分别位于肽链的两端;其余的氨基(或羧基)在R基上。 (3)蛋白质的结构多样性与功能多样性
■助学巧记 巧用“一、二、三、四、五”助记蛋白质的结构与功能 2.氨基酸脱水缩合与相关计算 (1)蛋白质相对分子质量、氨基酸数、肽链数、肽键数和失去水分子数的关系 ①肽键数=失去水分子数=氨基酸数-肽链数; ②蛋白质相对分子质量=氨基酸数目×氨基酸平均相对分子质量-脱去水分子数×18。(不考虑形成二硫键) 肽链 数目 氨基 酸数 肽键 数目 脱去水 分子数 多肽链相 对分子量 氨基 数目 羧基 数目1条m m-1 m-1 am-18(m-1) 至少1个至少1个n条m m-n m-n am-18(m-n) 至少n个至少n个注:氨基酸平均分子质量为a。 (2)蛋白质中游离氨基或羧基数目的计算 ①至少含有的游离氨基或羧基数=肽链数×1。 ②游离氨基或羧基数目=肽链数×1+R基中含有的氨基或羧基数。
(3)利用原子守恒法计算肽链中的原子数 ①N原子数=肽键数+肽链数+R基上的N原子数=各氨基酸中N原子总数。 ②O原子数=肽键数+2×肽链数+R基上的O原子数=各氨基酸中O原子总数-脱去水分子数。 1.在分泌蛋白的合成、加工、运输和分泌的过程中,用含35S标记的氨基酸作为原料,则35S存在于图示①~④中的哪个部位? 提示35S存在于氨基酸的R基上,题图中①处是R基,②处是肽键,③处连接的是肽键或羧基,④处连接的是碳原子,故35S存在于①部位。 2.蛋白质是生命活动的主要承担者,在组成细胞的有机物中含量最多。下图为有关蛋白质分子的简要概念图,请思考: (1)图示a中一定具有S吗? (2)图示①为何种过程?该过程除产生多肽外,还会产生何类产物? (3)图中b、c、d内容是什么?请写出b、c的化学表达式。 (4)甲硫氨酸的R基是—CH2—CH2—S—CH3,则它的分子式是________? 提示(1)不一定。 (2)①为“脱水缩合”过程,该过程还可产生H2O。 (3)b、c、d依次为“氨基酸”、“肽键”、“蛋白质功能多样性”; b的化学表达式为 c的化学表达式为—CO—NH—。 (4)氨基酸共性部分为C2H4O2N,则甲硫氨酸分子式为C2+3H4+7O2NS即