数据类型
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需要定义不同的数据类型。在Python中,能够直接处理的数据类型有以下几种:
一、整数
Python可以处理任意大小的整数,当然包括负整数,在Python程序中,整数的表示方法和数学上的写法一模一样,例如:1,100,-8080,0,等等。
计算机由于使用二进制,所以,有时候用十六进制表示整数比较方便,十六进制用0x前缀和0-9,a-f表示,例如:0xff00,0xa5b4c3d2,等等。
二、浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x10^9和12.3x10^8是相等的。浮点数可以用数学写法,如1.23,3. 14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x10^9就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差。
三、字符串
字符串是以''或""括起来的任意文本,比如'abc',"xyz"等等。请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这3个字符。
四、布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来。
布尔值可以用and、or和not运算。
and运算是与运算,只有所有都为True,and运算结果才是True。
or运算是或运算,只要其中有一个为True,or 运算结果就是True。
not运算是非运算,它是一个单目运算符,把True 变成False,False 变成True。
五、空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
此外,Python还提供了列表、字典等多种数据类型,还允许创建自定义数据类型,我们后面会继续讲到
print语句
print语句可以向屏幕上输出指定的文字。比如输出'hello, world',用代码实现如下:
>>> print 'hello, world'
注意:
1.当我们在Python交互式环境下编写代码时,>>>是Python解释器的提示符,不是代码的一部分。
2.当我们在文本编辑器中编写代码时,千万不要自己添加 >>>。
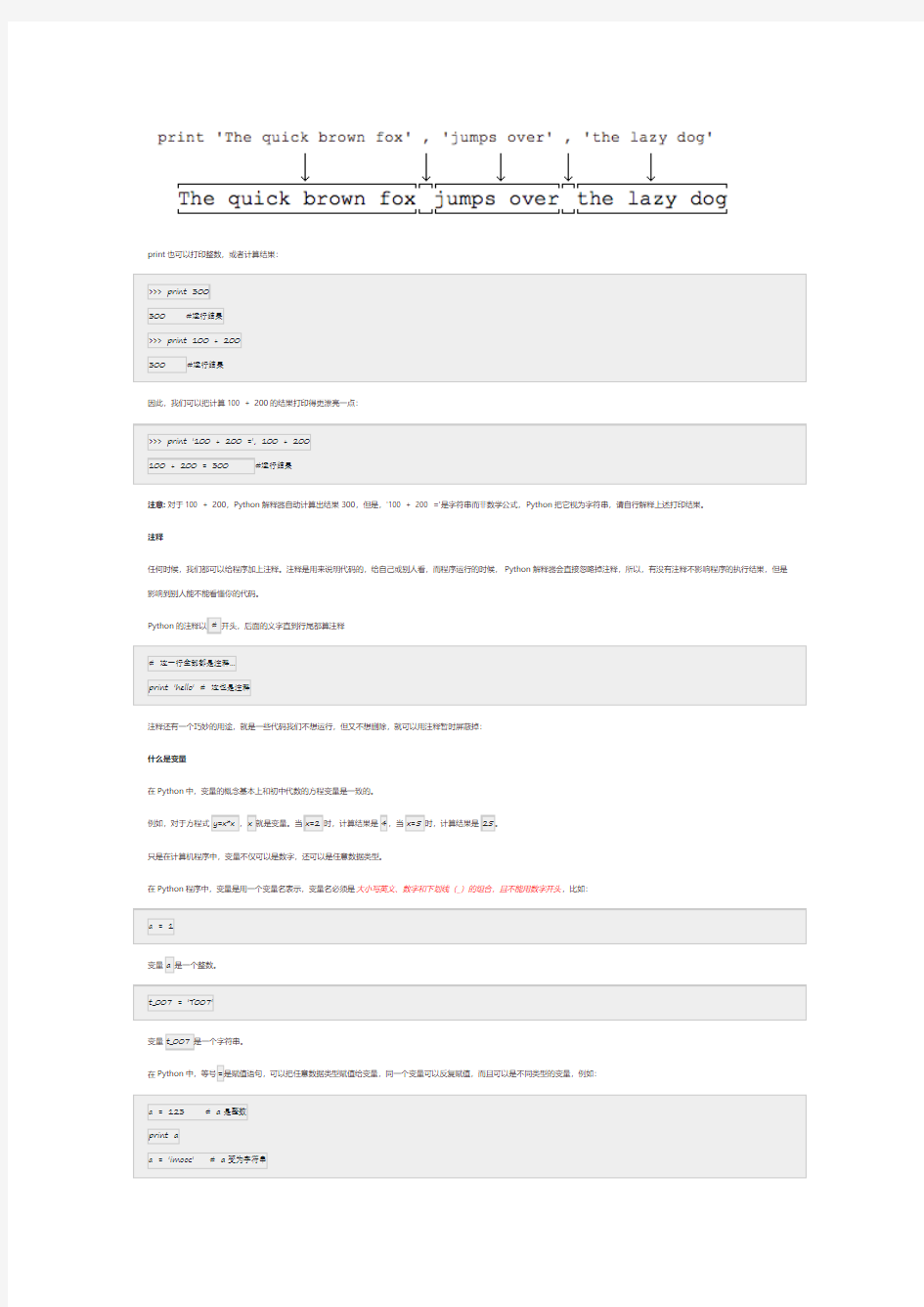
print语句也可以跟上多个字符串,用逗号“,”隔开,就可以连成一串输出:
>>> print 'The quick brown fox', 'jumps over', 'the lazy dog'
The quick brown fox jumps over the lazy dog
print会依次打印每个字符串,遇到逗号“,”会输出一个空格,因此,输出的字符串是这样拼起来的:
print也可以打印整数,或者计算结果:
>>> print 300
300 #运行结果
>>> print 100 + 200
300 #运行结果
因此,我们可以把计算100 + 200的结果打印得更漂亮一点:
>>> print '100 + 200 =', 100 + 200
100 + 200 = 300 #运行结果
注意:对于100 + 200,Python解释器自动计算出结果300,但是,'100 + 200 ='是字符串而非数学公式,Python把它视为字符串,请自行解释上述打印结果。
注释
任何时候,我们都可以给程序加上注释。注释是用来说明代码的,给自己或别人看,而程序运行的时候,Python解释器会直接忽略掉注释,所以,有没有注释不影响程序的执行结果,但是影响到别人能不能看懂你的代码。
Python的注释以 # 开头,后面的文字直到行尾都算注释
# 这一行全部都是注释...
print 'hello' # 这也是注释
注释还有一个巧妙的用途,就是一些代码我们不想运行,但又不想删除,就可以用注释暂时屏蔽掉:
什么是变量
在Python中,变量的概念基本上和初中代数的方程变量是一致的。
例如,对于方程式y=x*x ,x就是变量。当x=2时,计算结果是4,当x=5时,计算结果是25。
只是在计算机程序中,变量不仅可以是数字,还可以是任意数据类型。
在Python程序中,变量是用一个变量名表示,变量名必须是大小写英文、数字和下划线(_)的组合,且不能用数字开头,比如:
a = 1
变量a是一个整数。
t_007 = 'T007'
变量t_007是一个字符串。
在Python中,等号=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量,例如:
a = 123 # a是整数
print a
a = 'imooc' # a变为字符串
print a
这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。
静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java是静态语言,赋值语句如下(// 表示注释):
int a = 123; // a是整数类型变量
a = "mooc"; // 错误:不能把字符串赋给整型变量
和静态语言相比,动态语言更灵活,就是这个原因。
请不要把赋值语句的等号等同于数学的等号。比如下面的代码:
x = 10
x = x + 2
如果从数学上理解x = x + 2那无论如何是不成立的,在程序中,赋值语句先计算右侧的表达式x + 2,得到结果12,再赋给变量x。由于x之前的值是10,重新赋值后,x的值变成12。最后,理解变量在计算机内存中的表示也非常重要。当我们写:a = 'ABC'时,Python解释器干了两件事情:
1. 在内存中创建了一个'ABC'的字符串;
2. 在内存中创建了一个名为a的变量,并把它指向'ABC'。
也可以把一个变量a赋值给另一个变量b,这个操作实际上是把变量b指向变量a所指向的数据,例如下面的代码:
a = 'ABC'
b = a
a = 'XYZ'
print b
最后一行打印出变量b的内容到底是'ABC'呢还是'XYZ'?如果从数学意义上理解,就会错误地得出b和a相同,也应该是'XYZ',但实际上b的值是'ABC',让我们一行一行地执行代码,就可以看到到底发生了什么事:
执行a = 'ABC',解释器创建了字符串 'ABC'和变量a,并把a指向'ABC':
执行b = a,解释器创建了变量b,并把b指向a 指向的字符串'ABC':
执行a = 'XYZ',解释器创建了字符串'XYZ',并把a的指向改为'XYZ',但b并没有更改:
所以,最后打印变量b的结果自然是'ABC'了。
定义字符串
前面我们讲解了什么是字符串。字符串可以用''或者""括起来表示。
如果字符串本身包含'怎么办?比如我们要表示字符串 I'm OK ,这时,可以用" "括起来表示:
"I'm OK"
类似的,如果字符串包含",我们就可以用' '括起来表示:
'Learn "Python" in imooc'
如果字符串既包含'又包含"怎么办?
这个时候,就需要对字符串的某些特殊字符进行“转义”,Python字符串用\进行转义。
要表示字符串Bob said "I'm OK".
由于' 和" 会引起歧义,因此,我们在它前面插入一个\表示这是一个普通字符,不代表字符串的起始,因此,这个字符串又可以表示为
'Bob said \"I\'m OK\".'
注意:转义字符\ 不计入字符串的内容中。
常用的转义字符还有:
\n 表示换行
\t 表示一个制表符
\\ 表示\ 字符本身
raw字符串与多行字符串
如果一个字符串包含很多需要转义的字符,对每一个字符都进行转义会很麻烦。为了避免这种情况,我们可以在字符串前面加个前缀r ,表示这是一个 raw 字符串,里面的字符就不需要转义了。例如:
r'\(~_~)/ \(~_~)/'
但是r'...'表示法不能表示多行字符串,也不能表示包含'和"的字符串(为什么?)
如果要表示多行字符串,可以用'''...'''表示:
'''Line 1
Line 2
Line 3'''
上面这个字符串的表示方法和下面的是完全一样的:
'Line 1\nLine 2\nLine 3'
还可以在多行字符串前面添加 r ,把这个多行字符串也变成一个raw字符串:
r'''Python is created by "Guido".
It is free and easy to learn.
Let's start learn Python in imooc!'''
Unicode字符串
字符串还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),0 - 255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A 的编码是65,小写字母z 的编码是1 22。
如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
类似的,日文和韩文等其他语言也有这个问题。为了统一所有文字的编码,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。
因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串'ABC'在Python内部都是ASCII编码的。
Python在后来添加了对Unicode的支持,以Unicode表示的字符串用u'...'表示,比如:
print u'中文'
中文
注意:不加u ,中文就不能正常显示。
Unicode字符串除了多了一个u之外,与普通字符串没啥区别,转义字符和多行表示法仍然有效:
转义:
u'中文\n日文\n韩文'
多行:
u'''第一行
第二行'''
raw+多行:
ur'''Python的Unicode字符串支持"中文",
"日文",
"韩文"等多种语言'''
如果中文字符串在Python环境下遇到UnicodeDecodeError,这是因为.py文件保存的格式有问题。可以在第一行添加注释
# -*- coding: utf-8 -*-
目的是告诉Python解释器,用UTF-8编码读取源代码。然后用Notepad++ 另存为... 并选择UTF-8格式保存。
整数和浮点数
Python支持对整数和浮点数直接进行四则混合运算,运算规则和数学上的四则运算规则完全一致。
基本的运算:
1 +
2 +
3 # ==> 6
4 *
5 -
6 # ==> 14
7.5 / 8 + 2.1 # ==> 3.0375
使用括号可以提升优先级,这和数学运算完全一致,注意只能使用小括号,但是括号可以嵌套很多层:
(1 + 2) * 3 # ==> 9
(2.2 + 3.3) / (1.5 * (9 - 0.3)) # ==> 0.42145593869731807
和数学运算不同的地方是,Python的整数运算结果仍然是整数,浮点数运算结果仍然是浮点数:
1 +
2 # ==> 整数3
1.0 +
2.0 # ==> 浮点数
3.0
但是整数和浮点数混合运算的结果就变成浮点数了:
1 + 2.0 # ==> 浮点数3.0
为什么要区分整数运算和浮点数运算呢?这是因为整数运算的结果永远是精确的,而浮点数运算的结果不一定精确,因为计算机内存再大,也无法精确表示出无限循环小数,比如0.1换成二进制表示就是无限循环小数。
那整数的除法运算遇到除不尽的时候,结果难道不是浮点数吗?我们来试一下:
11 / 4 # ==> 2
令很多初学者惊讶的是,Python的整数除法,即使除不尽,结果仍然是整数,余数直接被扔掉。不过,Python提供了一个求余的运算% 可以计算余数:
11 % 4 # ==> 3
如果我们要计算11 / 4 的精确结果,按照“整数和浮点数混合运算的结果是浮点数”的法则,把两个数中的一个变成浮点数再运算就没问题了:
11.0 / 4 # ==> 2.75
布尔类型
我们已经了解了Python支持布尔类型的数据,布尔类型只有True和False两种值,但是布尔类型有以下几种运算:
与运算:只有两个布尔值都为True 时,计算结果才为True。
True and True # ==> True
True and False # ==> False
False and True # ==> False
False and False # ==> False
或运算:只要有一个布尔值为True,计算结果就是True。
True or True # ==> True
True or False # ==> True
False or True # ==> True
False or False # ==> False
非运算:把True变为False,或者把False变为True:
not True # ==> False
not False # ==> True
布尔运算在计算机中用来做条件判断,根据计算结果为True或者False,计算机可以自动执行不同的后续代码。
在Python中,布尔类型还可以与其他数据类型做and、or和not运算,请看下面的代码:
a = True
print a and 'a=T' or 'a=F'
计算结果不是布尔类型,而是字符串'a=T',这是为什么呢?
因为Python把0、空字符串''和None看成False,其他数值和非空字符串都看成 True,所以:
True and 'a=T' 计算结果是'a=T'
继续计算'a=T' or 'a=F' 计算结果还是'a=T'
要解释上述结果,又涉及到and 和or 运算的一条重要法则:短路计算。
1. 在计算a and b时,如果a 是False,则根据与运算法则,整个结果必定为False,因此返回a;如果a 是True,则整个计算结果必定取决与b,因此返回b。
2. 在计算a or b时,如果a 是True,则根据或运算法则,整个计算结果必定为True,因此返回a;如果a 是False,则整个计算结果必定取决于b,因此返回b。所以Python解释器在做布尔运算时,只要能提前确定计算结果,它就不会往后算了,直接返回结果。
第四章
创建list
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
比如,列出班里所有同学的名字,就可以用一个list表示:
>>> ['Michael', 'Bob', 'Tracy']
['Michael', 'Bob', 'Tracy']
list是数学意义上的有序集合,也就是说,list中的元素是按照顺序排列的。
构造list非常简单,按照上面的代码,直接用[ ]把list的所有元素都括起来,就是一个list对象。通常,我们会把list赋值给一个变量,这样,就可以通过变量来引用list:
>>> classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates # 打印classmates变量的内容
['Michael', 'Bob', 'Tracy']
由于Python是动态语言,所以list中包含的元素并不要求都必须是同一种数据类型,我们完全可以在list中包含各种数据:
>>> L = ['Michael', 100, True]
一个元素也没有的list,就是空list:
>>> empty_list = []
按照索引访问list
由于list是一个有序集合,所以,我们可以用一个list按分数从高到低表示出班里的3个同学:
>>> L = ['Adam', 'Lisa', 'Bart']
那我们如何从list中获取指定第N 名的同学呢?方法是通过索引来获取list中的指定元素。
需要特别注意的是,索引从0 开始,也就是说,第一个元素的索引是0,第二个元素的索引是1,以此类推。因此,要打印第一名同学的名字,用L[0]:
>>> print L[0]
Adam
要打印第二名同学的名字,用L[1]:
>>> print L[1]
Lisa
要打印第三名同学的名字,用L[2]:
>>> print L[2]
Bart
要打印第四名同学的名字,用L[3]:
>>> print L[3]
Traceback (most recent call last):
File "
IndexError: list index out of range
报错了!IndexError意思就是索引超出了范围,因为上面的list只有3个元素,有效的索引是0,1,2。
所以,使用索引时,千万注意不要越界。
倒序访问list
我们还是用一个list按分数从高到低表示出班里的3个同学:
>>> L = ['Adam', 'Lisa', 'Bart']
这时,老师说,请分数最低的同学站出来。
要写代码完成这个任务,我们可以先数一数这个list,发现它包含3个元素,因此,最后一个元素的索引是2:
>>> print L[2]
Bart
有没有更简单的方法?
有!
Bart同学是最后一名,俗称倒数第一,所以,我们可以用-1 这个索引来表示最后一个元素:
>>> print L[-1]
Bart
Bart同学表示躺枪。
类似的,倒数第二用-2 表示,倒数第三用-3 表示,倒数第四用-4 表示:
>>> print L[-2]
Lisa
>>> print L[-3]
Adam
>>> print L[-4]
Traceback (most recent call last):
File "
IndexError: list index out of range
L[-4] 报错了,因为倒数第四不存在,一共只有3个元素。
使用倒序索引时,也要注意不要越界。
添加新元素
现在,班里有3名同学:
>>> L = ['Adam', 'Lisa', 'Bart']
今天,班里转来一名新同学Paul,如何把新同学添加到现有的list 中呢?
第一个办法是用list 的append()方法,把新同学追加到list 的末尾:
>>> L = ['Adam', 'Lisa', 'Bart']
>>> L.append('Paul')
>>> print L
['Adam', 'Lisa', 'Bart', 'Paul']
append()总是把新的元素添加到list 的尾部。
如果Paul 同学表示自己总是考满分,要求添加到第一的位置,怎么办?
方法是用list的insert()方法,它接受两个参数,第一个参数是索引号,第二个参数是待添加的新元素:
>>> L = ['Adam', 'Lisa', 'Bart']
>>> L.insert(0, 'Paul')
>>> print L
['Paul', 'Adam', 'Lisa', 'Bart']
L.insert(0, 'Paul')的意思是,'Paul'将被添加到索引为0 的位置上(也就是第一个),而原来索引为0 的Adam同学,以及后面的所有同学,都自动向后移动一位。
从list删除元素
Paul同学刚来几天又要转走了,那么我们怎么把Paul 从现有的list中删除呢?
如果Paul同学排在最后一个,我们可以用list的pop()方法删除:
>>> L = ['Adam', 'Lisa', 'Bart', 'Paul']
>>> L.pop()
'Paul'
>>> print L
['Adam', 'Lisa', 'Bart']
pop()方法总是删掉list的最后一个元素,并且它还返回这个元素,所以我们执行L.pop() 后,会打印出'Paul'。
如果Paul同学不是排在最后一个怎么办?比如Paul同学排在第三:
>>> L = ['Adam', 'Lisa', 'Paul', 'Bart']
要把Paul踢出list,我们就必须先定位Paul的位置。由于Paul的索引是2,因此,用pop(2)把Paul删掉:
>>> L.pop(2)
'Paul'
>>> print L
['Adam', 'Lisa', 'Bart']
替换元素
假设现在班里仍然是3名同学:
>>> L = ['Adam', 'Lisa', 'Bart']
现在,Bart同学要转学走了,碰巧来了一个Paul同学,要更新班级成员名单,我们可以先把Bart删掉,再把Paul添加进来。
另一个办法是直接用Paul把Bart给替换掉:
>>> L[2] = 'Paul'
>>> print L
L = ['Adam', 'Lisa', 'Paul']
对list中的某一个索引赋值,就可以直接用新的元素替换掉原来的元素,list包含的元素个数保持不变。
由于Bart还可以用-1 做索引,因此,下面的代码也可以完成同样的替换工作:
>>> L[-1] = 'Paul'
创建tuple
tuple是另一种有序的列表,中文翻译为“元组”。tuple 和list 非常类似,但是,tuple一旦创建完毕,就不能修改了。
同样是表示班里同学的名称,用tuple表示如下:
>>> t = ('Adam', 'Lisa', 'Bart')
创建tuple和创建list唯一不同之处是用( )替代了[ ]。
现在,这个t就不能改变了,tuple没有append()方法,也没有insert()和pop()方法。所以,新同学没法直接往tuple 中添加,老同学想退出tuple 也不行。获取tuple 元素的方式和list 是一模一样的,我们可以正常使用t[0],t[-1]等索引方式访问元素,但是不能赋值成别的元素,不信可以试试:
>>> t[0] = 'Paul'
Traceback (most recent call last):
File "
TypeError: 'tuple' object does not support item assignment
创建单元素tuple
tuple和list一样,可以包含0 个、1个和任意多个元素。
包含多个元素的tuple,前面我们已经创建过了。
包含0 个元素的tuple,也就是空tuple,直接用()表示:
>>> t = ()
>>> print t
()
创建包含1个元素的tuple 呢?来试试:
>>> t = (1)
>>> print t
1
好像哪里不对!t 不是tuple ,而是整数1。为什么呢?
因为()既可以表示tuple,又可以作为括号表示运算时的优先级,结果(1) 被Python解释器计算出结果1,导致我们得到的不是tuple,而是整数1。正是因为用()定义单元素的tuple有歧义,所以Python 规定,单元素tuple 要多加一个逗号“,”,这样就避免了歧义:
>>> t = (1,)
>>> print t
(1,)
Python在打印单元素tuple时,也自动添加了一个“,”,为了更明确地告诉你这是一个tuple。
多元素tuple 加不加这个额外的“,”效果是一样的:
>>> t = (1, 2, 3,)
>>> print t
(1, 2, 3)
“可变”的tuple
前面我们看到了tuple一旦创建就不能修改。现在,我们来看一个“可变”的tuple:
>>> t = ('a', 'b', ['A', 'B'])
注意到t 有3 个元素:'a','b'和一个list:['A', 'B']。list作为一个整体是tuple的第3个元素。list对象可以通过t[2] 拿到:
>>> L = t[2]
然后,我们把list的两个元素改一改:
>>> L[0] = 'X'
>>> L[1] = 'Y'
再看看tuple的内容:
>>> print t
('a', 'b', ['X', 'Y'])
不是说tuple一旦定义后就不可变了吗?怎么现在又变了?
别急,我们先看看定义的时候tuple包含的3个元素:
当我们把list的元素'A'和'B'修改为'X'和'Y'后,tuple变为:
表面上看,tuple的元素确实变了,但其实变的不是tuple 的元素,而是list的元素。
tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
理解了“指向不变”后,要创建一个内容也不变的tuple怎么做?那就必须保证tuple的每一个元素本身也不能变
第五章
if语句
计算机之所以能做很多自动化的任务,因为它可以自己做条件判断。
比如,输入用户年龄,根据年龄打印不同的内容,在Python程序中,可以用if语句实现:
age = 20
if age >= 18:
print 'your age is', age
print 'adult'
print 'END'
注意:Python代码的缩进规则。具有相同缩进的代码被视为代码块,上面的3,4行print 语句就构成一个代码块(但不包括第5行的print)。如果if 语句判断为True,就会执行这个代码块。
缩进请严格按照Python的习惯写法:4个空格,不要使用Tab,更不要混合Tab和空格,否则很容易造成因为缩进引起的语法错误。
注意: if 语句后接表达式,然后用:表示代码块开始。
如果你在Python交互环境下敲代码,还要特别留意缩进,并且退出缩进需要多敲一行回车:
>>> age = 20
>>> if age >= 18:
... print 'your age is', age
... print 'adult'
...
your age is 20
adult
if-else
当if 语句判断表达式的结果为True时,就会执行if 包含的代码块:
if age >= 18:
print 'adult'
如果我们想判断年龄在18岁以下时,打印出'teenager',怎么办?
方法是再写一个if:
if age < 18:
print 'teenager'
或者用not 运算:
if not age >= 18:
print 'teenager'
细心的同学可以发现,这两种条件判断是“非此即彼”的,要么符合条件1,要么符合条件2,因此,完全可以用一个 if ... else ...语句把它们统一起来:
if age >= 18:
print 'adult'
else:
print 'teenager'
利用if ... else ... 语句,我们可以根据条件表达式的值为True或者False,分别执行 if 代码块或者 else 代码块。
注意: else 后面有个“:”
if-elif-else
有的时候,一个if ... else ... 还不够用。比如,根据年龄的划分:
条件1:18岁或以上:adult
条件2:6岁或以上:teenager
条件3:6岁以下:kid
我们可以用一个if age >= 18 判断是否符合条件1,如果不符合,再通过一个if 判断age >= 6 来判断是否符合条件2,否则,执行条件3:
if age >= 18:
print 'adult'else:
if age >= 6:
print 'teenager'
else:
print 'kid'
这样写出来,我们就得到了一个两层嵌套的if ... else ... 语句。这个逻辑没有问题,但是,如果继续增加条件,比如3岁以下是baby:
if age >= 18:
print 'adult'else:
if age >= 6:
print 'teenager'
else:
if age >= 3:
print 'kid'
else:
print 'baby'
这种缩进只会越来越多,代码也会越来越难看。
要避免嵌套结构的if ... else ...,我们可以用 if ... 多个elif ... else ...的结构,一次写完所有的规则:
if age >= 18:
print 'adult'elif age >= 6:
print 'teenager'elif age >= 3:
print 'kid'else:
print 'baby'
elif意思就是else if。这样一来,我们就写出了结构非常清晰的一系列条件判断。
特别注意: 这一系列条件判断会从上到下依次判断,如果某个判断为True,执行完对应的代码块,后面的条件判断就直接忽略,不再执行了。
请思考下面的代码:
age = 8
if age >= 6:
print 'teenager'
elif age >= 18:
print 'adult'
else:
print 'kid'
当age = 8 时,结果正确,但age = 20 时,为什么没有打印出adult?
如果要修复,应该如何修复?
。for循环
list或tuple可以表示一个有序集合。如果我们想依次访问一个list中的每一个元素呢?比如list:
L = ['Adam', 'Lisa', 'Bart']
print L[0]
print L[1]
print L[2]
如果list只包含几个元素,这样写还行,如果list包含1万个元素,我们就不可能写1万行print。
这时,循环就派上用场了。
Python的for循环就可以依次把list或tuple的每个元素迭代出来:
L = ['Adam', 'Lisa', 'Bart']for name in L:
print name
注意: name 这个变量是在for 循环中定义的,意思是,依次取出list中的每一个元素,并把元素赋值给name,然后执行for循环体(就是缩进的代码块)。这样一来,遍历一个list或tuple就非常容易了。
while循环
和for 循环不同的另一种循环是while 循环,while 循环不会迭代list 或tuple 的元素,而是根据表达式判断循环是否结束。
比如要从0 开始打印不大于N 的整数:
N = 10
x = 0while x < N:
print x
x = x + 1
while循环每次先判断x < N,如果为True,则执行循环体的代码块,否则,退出循环。
在循环体内,x = x + 1 会让 x 不断增加,最终因为 x < N 不成立而退出循环。
如果没有这一个语句,while循环在判断x < N 时总是为True,就会无限循环下去,变成死循环,所以要特别留意while循环的退出条件。
break退出循环
用for 循环或者while 循环时,如果要在循环体内直接退出循环,可以使用break 语句。
比如计算1至100的整数和,我们用while来实现:
sum = 0
x = 1while True:
sum = sum + x
x = x + 1
if x > 100:
break
print sum
咋一看,while True 就是一个死循环,但是在循环体内,我们还判断了 x > 100条件成立时,用break语句退出循环,这样也可以实现循环的结束。
continue继续循环
在循环过程中,可以用break退出当前循环,还可以用continue跳过后续循环代码,继续下一次循环。
假设我们已经写好了利用for循环计算平均分的代码:
L = [75, 98, 59, 81, 66, 43, 69, 85]
sum = 0.0
n = 0for x in L:
sum = sum + x
n = n + 1
print sum / n
现在老师只想统计及格分数的平均分,就要把x < 60 的分数剔除掉,这时,利用continue,可以做到当x < 60的时候,不继续执行循环体的后续代码,直接进入下一次循环:
for x in L:
if x < 60:
continue
sum = sum + x
n = n + 1
多重循环
在循环内部,还可以嵌套循环,我们来看一个例子:
for x in['A', 'B', 'C']:
for y in['1', '2', '3']:
print x + y
x 每循环一次,y 就会循环3 次,这样,我们可以打印出一个全排列:
A1
A2
A3
B1
B2
B3
C1
C2
C3
第六章
什么是dict
我们已经知道,list 和tuple 可以用来表示顺序集合,例如,班里同学的名字:
['Adam', 'Lisa', 'Bart']
或者考试的成绩列表:
[95, 85, 59]
但是,要根据名字找到对应的成绩,用两个list 表示就不方便。
如果把名字和分数关联起来,组成类似的查找表:
'Adam' ==> 95
'Lisa' ==> 85
'Bart' ==> 59
给定一个名字,就可以直接查到分数。
Python的dict 就是专门干这件事的。用dict 表示“名字”-“成绩”的查找表如下:
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
我们把名字称为key,对应的成绩称为value,dict就是通过key来查找value。
花括号{}表示这是一个dict,然后按照 key: value, 写出来即可。最后一个key: value 的逗号可以省略。
由于dict也是集合,len() 函数可以计算任意集合的大小:
>>> len(d)
3
注意:一个key-value 算一个,因此,dict大小为3。
访问dict
我们已经能创建一个dict,用于表示名字和成绩的对应关系:
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
那么,如何根据名字来查找对应的成绩呢?
可以简单地使用d[key]的形式来查找对应的value,这和list 很像,不同之处是,list 必须使用索引返回对应的元素,而dict使用key:
>>> print d['Adam']
95
>>> print d['Paul']
Traceback (most recent call last):
File "index.py", line 11, in
print d['Paul']
KeyError: 'Paul'
注意:通过key 访问dict 的value,只要key 存在,dict就返回对应的value。如果key不存在,会直接报错:KeyError。
要避免KeyError 发生,有两个办法:
一是先判断一下key 是否存在,用in 操作符:
if 'Paul' in d:
print d['Paul']
如果'Paul' 不存在,if语句判断为False,自然不会执行print d['Paul'] ,从而避免了错误。
二是使用dict本身提供的一个get 方法,在Key不存在的时候,返回None:
>>> print d.get('Bart')
59
>>> print d.get('Paul')
None
dict的特点
dict的第一个特点是查找速度快,无论dict有10个元素还是10万个元素,查找速度都一样。而list的查找速度随着元素增加而逐渐下降。
不过dict的查找速度快不是没有代价的,dict的缺点是占用内存大,还会浪费很多内容,list正好相反,占用内存小,但是查找速度慢。
由于dict是按key 查找,所以,在一个dict中,key不能重复。
dict的第二个特点就是存储的key-value序对是没有顺序的!这和list不一样:
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
当我们试图打印这个dict时:
>>> print d
{'Lisa': 85, 'Adam': 95, 'Bart': 59}
打印的顺序不一定是我们创建时的顺序,而且,不同的机器打印的顺序都可能不同,这说明dict内部是无序的,不能用dict存储有序的集合。
dict的第三个特点是作为key 的元素必须不可变,Python的基本类型如字符串、整数、浮点数都是不可变的,都可以作为key。但是list是可变的,就不能作为key。可以试试用list作为key时会报什么样的错误。
不可变这个限制仅作用于key,value是否可变无所谓:
{
'123': [1, 2, 3], # key 是str,value是list
123: '123', # key 是int,value 是str
('a', 'b'): True # key 是tuple,并且tuple的每个元素都是不可变对象,value是boolean }
最常用的key还是字符串,因为用起来最方便。
更新dict
dict是可变的,也就是说,我们可以随时往dict中添加新的key-value。比如已有dict:
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
要把新同学'Paul'的成绩72 加进去,用赋值语句:
>>> d['Paul'] = 72
再看看dict的内容:
>>> print d
{'Lisa': 85, 'Paul': 72, 'Adam': 95, 'Bart': 59}
如果key 已经存在,则赋值会用新的value 替换掉原来的value:
>>> d['Bart'] = 60
>>> print d
{'Lisa': 85, 'Paul': 72, 'Adam': 95, 'Bart': 60}
遍历dict
由于dict也是一个集合,所以,遍历dict和遍历list类似,都可以通过for 循环实现。
直接使用for循环可以遍历dict 的key:
>>> d = { 'Adam': 95, 'Lisa': 85, 'Bart': 59 }
>>> for key in d:
... print key
...
Lisa
Adam
Bart
由于通过key 可以获取对应的value,因此,在循环体内,可以获取到value的值。
什么是set
dict的作用是建立一组key 和一组value 的映射关系,dict的key是不能重复的。
有的时候,我们只想要dict 的key,不关心key 对应的value,目的就是保证这个集合的元素不会重复,这时,set就派上用场了。
set 持有一系列元素,这一点和list 很像,但是set的元素没有重复,而且是无序的,这点和dict 的key很像。
创建set 的方式是调用set() 并传入一个list,list的元素将作为set的元素:
>>> s = set(['A', 'B', 'C'])
可以查看set 的内容:
>>> print s
set(['A', 'C', 'B'])
请注意,上述打印的形式类似list,但它不是list,仔细看还可以发现,打印的顺序和原始list 的顺序有可能是不同的,因为set内部存储的元素是无序的。因为set不能包含重复的元素,所以,当我们传入包含重复元素的list 会怎么样呢?
>>> s = set(['A', 'B', 'C', 'C'])
>>> print s
set(['A', 'C', 'B'])
>>> len(s)
3
结果显示,set会自动去掉重复的元素,原来的list有4个元素,但set只有3个元素。
访问set
由于set存储的是无序集合,所以我们没法通过索引来访问。
访问set中的某个元素实际上就是判断一个元素是否在set中。
例如,存储了班里同学名字的set:
>>> s = set(['Adam', 'Lisa', 'Bart', 'Paul'])
我们可以用in 操作符判断:
Bart是该班的同学吗?
>>> 'Bart' in s
True
Bill是该班的同学吗?
>>> 'Bill' in s
False
bart是该班的同学吗?
>>> 'bart' in s
False
看来大小写很重要,'Bart' 和'bart'被认为是两个不同的元素。
set的特点
《Python程序设计》习题与参考答案 第1章基础知识 简单说明如何选择正确的Python版本。 答: 在选择Python的时候,一定要先考虑清楚自己学习Python的目的是什么,打算做哪方面的开发,有哪些扩展库可用,这些扩展库最高支持哪个版本的Python,是Python 还是Python ,最高支持到Python 还是Python 。这些问题都确定以后,再做出自己的选择,这样才能事半功倍,而不至于把大量时间浪费在Python的反复安装和卸载上。同时还应该注意,当更新的Python版本推出之后,不要急于更新,而是应该等确定自己所必须使用的扩展库也推出了较新版本之后再进行更新。 尽管如此,Python 3毕竟是大势所趋,如果您暂时还没想到要做什么行业领域的应用开发,或者仅仅是为了尝试一种新的、好玩的语言,那么请毫不犹豫地选择Python 系列的最高版本(目前是Python )。 为什么说Python采用的是基于值的内存管理模式 答: Python采用的是基于值的内存管理方式,如果为不同变量赋值相同值,则在内存中只有一份该值,多个变量指向同一块内存地址,例如下面的代码。 >>> x = 3 >>> id(x) >>> y = 3 >>> id(y) >>> y = 5 >>> id(y) >>> id(x) 在Python中导入模块中的对象有哪几种方式 答:常用的有三种方式,分别为 import 模块名 [as 别名]
from 模块名 import 对象名[ as 别名] from math import * 使用pip命令安装numpy、scipy模块。 答:在命令提示符环境下执行下面的命令: pip install numpy pip install scipy 编写程序,用户输入一个三位以上的整数,输出其百位以上的数字。例如用户输入1234,则程序输出12。(提示:使用整除运算。) 答: 1)Python 代码: x = input('Please input an integer of more than 3 digits:') try: x = int(x) x = x else: print(x) except BaseException: print('You must input an integer.') 2)Python 代码: import types x = input('Please input an integer of more than 3 digits:') if type(x) != : print 'You must input an integer.' elif len(str(x)) != 4: print 'You must input an integer of more than 3 digits.' else: print xoin(map(str,result)) 2)Python 代码 x = input('Please input an integer less than 1000:') t = x i = 2 result = [] while True: if t==1:
通信网课程设计 Project2_Kruskal算法 (基于union_find实现) 一源代码 # -*- coding: utf-8 -*- """ Created on Wed May 23 09:31:49 2018 @author: 15193 """ import numpy as np import time start=time.clock() class Graph(object): def __init__(self): #初始化 self.nodes=[] self.edge={} def insert(self,a,b,c): #添加相应的边 if not(a in self.nodes): self.nodes.append(a) self.edge[a]={} if not(b in self.nodes): self.nodes.append(b) self.edge[b]={} self.edge[a][b]=c self.edge[b][a]=c def succ(self,a): #返回点的有关的边 return self.edge[a] def getnodes(self): #返回点集 return self.nodes class union_find(object): #搭建union-find数据结构 def __init__(self,size): self.parent=[] self.rank=[] self.count=size for i in range(0,size): self.parent.append(i) self.rank.append(1)
Python的应用领域有哪些? Python是一门简单、易学并且很有前途的编程语言,很多人都对Python感兴趣,但是当学完Python基础用法之后,又会产生迷茫,尤其是自学的人员,不知道接下来的Python学习方向,以及学完之后能干些什么?以下是Python十大应用领域! 1. WEB开发 Python拥有很多免费数据函数库、免费web网页模板系统、以及与web服务器进行交互的库,可以实现web开发,搭建web框架,目前比较有名气的Python web框架为Django。从事该领域应从数据、组件、安全等多领域进行学习,从底层了解其工作原理并可驾驭任何业内主流的Web框架。 2. 网络编程 网络编程是Python学习的另一方向,网络编程在生活和开发中无处不在,哪里有通讯就有网络,它可以称为是一切开发的“基石”。对于所有编程开发人员必须要知其然并知其所以然,所以网络部分将从协议、封包、解包等底层进行深入剖析。 3. 爬虫开发 在爬虫领域,Python几乎是霸主地位,将网络一切数据作为资源,通过自动化程序进行有针对性的数据采集以及处理。从事该领域应学习爬虫策略、高性能异步IO、分布式爬虫等,并针对Scrapy框架源码进行深入剖析,从而理解其原理并实现自定义爬虫框架。 4. 云计算开发 Python是从事云计算工作需要掌握的一门编程语言,目前很火的云计算框架OpenStack就是由Python开发的,如果想要深入学习并进行二次开发,就需要具备Python 的技能。
5. 人工智能 MASA和Google早期大量使用Python,为Python积累了丰富的科学运算库,当AI 时代来临后,Python从众多编程语言中脱颖而出,各种人工智能算法都基于Python编写,尤其PyTorch之后,Python作为AI时代头牌语言的位置基本确定。 6. 自动化运维 Python是一门综合性的语言,能满足绝大部分自动化运维需求,前端和后端都可以做,从事该领域,应从设计层面、框架选择、灵活性、扩展性、故障处理、以及如何优化等层面进行学习。 7. 金融分析 金融分析包含金融知识和Python相关模块的学习,学习内容囊括Numpy\Pandas\Scipy数据分析模块等,以及常见金融分析策略如“双均线”、“周规则交易”、“羊驼策略”、“Dual Thrust 交易策略”等。 8. 科学运算 Python是一门很适合做科学计算的编程语言,97年开始,NASA就大量使用Python 进行各种复杂的科学运算,随着NumPy、SciPy、Matplotlib、Enthought librarys等众多程序库的开发,使得Python越来越适合做科学计算、绘制高质量的2D和3D图像。 9. 游戏开发 在网络游戏开发中,Python也有很多应用,相比于Lua or C++,Python比Lua有更高阶的抽象能力,可以用更少的代码描述游戏业务逻辑,Python非常适合编写1万行以上的项目,而且能够很好的把网游项目的规模控制在10万行代码以内。 10. 桌面软件 Python在图形界面开发上很强大,可以用tkinter/PyQT框架开发各种桌面软件!
上 海 交 通 大 学 试 卷( A 卷) ( 2010 至 2011 学年 第 2 学期 ) 班级号 _________________ 学号 ________ ___ 姓名 课程名称 程序设计思想和方法 成绩 一、选择题 : 将唯一正确的选项写在题前. 每题 2 分 . 【 】 (1) 本课程的目标定位是什么 ? [A ] 学习 Python 语言 [B ] 学习计算机的工作原理 [C ] 学习各种算法 [D ] 学习用计算机解决问题 【 】 (2) 下列哪个标识符是合法的 ? [A var-name [B] !@#$% [C] _100 [D] elif 【 】 (3) 执行下列语句后的显示结果是什么 ? >>> s = ”hi ” >>> print “hi ”, 2*s [A] hihihi [B] ”hi ”hihi [C] hi hihi 【 】 (4) 如何解释下面的执行结果 ? >>> print 1.2 - 1.0 == 0.2 False [A] Python 的实现有错误 [B] 浮点数无法精确表示 [C] 布尔运算不能用于浮点数比较 [D] Python 将非 0 数视为 False 】 (5) 想用一个变量来表示出生年份 , 下列命名中哪个最可取 ? 【 】 (6) 执行下列语句后的显示结果是什么 >>> a = 1 >>> b = 2 * a / 4 >>> a = “one ” >>> print a,b [A] one 0 [B] 1 0 [C] one 0.5 【 】 (7) 执行下列语句后的显示结果是什么 >>> s = ”GOOD MORNING ” >>> print s[3:-4] [A] b_y [B] birth_year [C] __birthYear__ [D] birthyear [A] D MOR [B] D MORN [C] OD MOR [D] OD MORN [D] hi hi hi [D] one,0.5
用python进行数据分析 一、样本集 本样本集来源于某高中某班78位同学的一次月考的语文成绩。因为每位同学的成绩都是独立的随机变量,遂可以保证得到的观测值也是独立且随机的 样本如下: grades=[131,131,127,123,126,129,116,114,115,116,123,122,118, 121,126,121,126,121,111,119,124,124,121,116,114,116, 116,118,112,109,114,116,116,118,112,109,114,110,114, 110,113,117,113,121,105,127,110,105,111,112,104,103, 130,102,118,101,112,109,107,94,107,106,105,101,85,95, 97,99,83,87,82,79,99,90,78,86,75,66]; 二、数据分析 1.中心位置(均值、中位数、众数) 数据的中心位置是我们最容易想到的数据特征。借由中心位置,我们可以知道数据的一个平均情况,如果要对新数据进行预测,那么平均情况是非常直观地选择。数据的中心位置可分为均值(Mean),中位数(Median),众数(Mode)。其中均值和中位数用于定量的数据,众数用于定性的数据。 均值:利用python编写求平均值的函数很容易得到本次样本的平均值 得到本次样本均值为109.9 中位数:113 众数:116 2.频数分析 2.1频数分布直方图 柱状图是以柱的高度来指代某种类型的频数,使用Matplotlib对成绩这一定性变量绘制柱状图的代码如下:
ARIMA时间序列建模过程——原理及python实现 ARIMA模型的全称叫做自回归查分移动平均模型,全称是(ARIMA, Autoregressive Integrated Moving Average Model),是统计模型(statistic model)中最常见的一种用来进行时间序列预测的模型,AR、MA、ARMA模型都可以看作它的特殊形式。 1. ARIMA的优缺点 优点:模型十分简单,只需要内生变量而不需要借助其他外生变量。 缺点:要求时序数据是稳定的(stationary),或者是通过差分化(differencing)后是稳定的;本质上只能捕捉线性关系,而不能捕捉非线性关系。 2. ARIMA的参数与数学形式 ARIMA模型有三个参数:p,d,q。 p--代表预测模型中采用的时序数据本身的滞后数(lags) ,也叫做 AR/Auto-Regressive项; d--代表时序数据需要进行几阶差分化,才是稳定的,也叫Integrated项; q--代表预测模型中采用的预测误差的滞后数(lags),也叫做MA/Moving Average项。 差分:假设y表示t时刻的Y的差分。 if d=0, yt=Yt, if d=1, yt=Yt?Yt?1, if d=2, yt=(Yt?Yt?1)?(Yt?1?Yt ?2)=Yt?2Yt?1+Yt?2 ARIMA的预测模型可以表示为: Y的预测值= 白噪音+1个或多个时刻的加权+一个或多个时刻的预测误差。 假设p,q,d已知,
ARIMA用数学形式表示为: yt?=μ+?1?yt?1+...+?p?yt?p+θ1?et?1+...+θq?et?q 其中,?表示AR的系数,θ表示MA的系数 3.Python建模 ##构建初始序列 import numpy as np import matplotlib.pyplot as plt import statsmodels.api as sm from statsmodels.graphics.tsaplots import acf,pacf,plot_acf,plot_pacf from statsmodels.tsa.arima_model import ARMA from statsmodels.tsa.arima_model import ARIMA #序列化 time_series_ = pd.Series([151.0, 188.46, 199.38, 219.75, 241.55, 262.58, 328.22, 396.26, 442.04, 517.77, 626.52, 717.08, 824.38, 913.38, 1088.39, 1325.83, 1700.92, 2109.38, 2499.77, 2856.47, 3114.02, 3229.29, 3545.39, 3880.53, 4212.82, 4757.45, 5633.24, 6590.19, 7617.47, 9333.4, 11328.92, 12961.1, 15967.61]) time_series_.index = pd.Index(sm.tsa.datetools.dates_from_range('1978','2010')) time_series_.plot(figsize=(12,8)) plt.show() 3.1 异常值及缺失值处理 异常值一般采用移动中位数方法: frompandasimportrolling_median threshold =3#指的是判定一个点为异常的阈值 df['pandas'] = rolling_median(df['u'], window=3, center=True).fillna(method='bfill').fillna(method='ffill') #df['u']是原始数据,df['pandas'] 是求移动中位数后的结果,window指的 是移动平均的窗口宽度 difference = np.abs(df['u'] - df['pandas']) outlier_idx = difference > threshold 缺失值一般是用均值代替(若连续缺失,且序列不平稳,求查分时可能出现nan) 或直接删除。
Python学习之Python应用领域介绍(一) 最近Python这个词可是在我们的生活里火了,无论是朋友圈还是身边的人,几乎所有人都知道Python,那Python到底有多大魅力呢,今天我们就从Python的一方面来分析,就是Python的应用领域有哪些。 下面就让我们一起来看看它的强大功能: Python(派森),它是一个简单的、解释型的、交互式的、可移植的、面向对象的超高级语言。这就是对Python语言的最简单的描述。 Python有一个交互式的开发环境,因为Python是解释运行,这大大节省了每次编译的时间。Python语法简单,且内置有几种高级数据结构,如字典、列表等,使得使用起来特别简单,程序员一个下午就可学会,一般人员一周内也可掌握。Python具有大部分面向对象语言的特征,可完全进行面向对象编程。它可以在MS-DOS、Windows、Windows NT、Linux、Soloris、Amiga、BeOS、OS/2、VMS、QNX等多种OS上运行。
编程语言 Python语言可以用来作为批处理语言,写一些简单工具,处理些数据,作为其他软件的接口调试等。Python语言可以用来作为函数语言,进行人工智能程序的开发,具有Lisp语言的大部分功能。Python语言可以用来作为过程语言,进行我们常见的应用程序开发,可以和VB等语言一样应用。Python 语言可以用来作为面向对象语言,具有大部分面向对象语言的特征,常作为大型应用软件的原型开发,再用C++改写,有些直接用Python来开发。 数据库 Python在数据库方面也很优秀,可以和多种数据库进行连接,进行数据处理,从商业型的数据库到开放源码的数据库都提供支持。例如:Oracle,Ms SQL Server等等。有多种接口可以与数据库进行连接,至少包括ODBC。有许多公司采用着Python+MySql的架构。因此,掌握了Python使你可以充分利用面向对象的特点,在数据库处理方面如虎添翼。
破釜沉舟: 为网站站长.设计师.编程开发者. 提供资源!https://www.doczj.com/doc/8017907113.html, 用Python实现数据库编程 文章类别:Python 发表日期:2004-11-11 来源: CSDN 作者: wfh_178 <用PYTHON进行数据库编程> 老巫 2003.09.10 19 September, 2003 用PYTHON语言进行数据库编程, 至少有六种方法可供采用. 我在实际项目中采用,不但功能强大,而且方便快捷.以下是我在工作和学习中经验总结. 方法一:使用DAO (Data Access Objects) 这个第一种方法可能会比较过时啦.不过还是非常有用的. 假设你已经安装好了PYTHONWIN,现在开始跟我上路吧…… 找到工具栏上ToolsàCOM MakePy utilities,你会看到弹出一个Select Library的对话框, 在列表中选择'Microsoft DAO 3.6 Object Library'(或者是你所有的版本). 现在实现对数据的访问: #实例化数据库引擎 import win32com.client engine = win32com.client.Dispatch("DAO.DBEngine.35") #实例化数据库对象,建立对数据库的连接 db = engine.OpenDatabase(r"c:\temp\mydb.mdb") 现在你有了数据库引擎的连接,也有了数据库对象的实例.现在就可以打开一个recordset了. 假设在数据库中已经有一个表叫做 'customers'. 为了打开这个表,对其中数据进行处理,我们使用下面的语法: rs = db.OpenRecordset("customers") #可以采用SQL语言对数据集进行操纵 rs = db.OpenRecordset("select * from customers where state = 'OH'") 你也可以采用DAO的execute方法. 比如这样: db.Execute("delete * from customers where balancetype = 'overdue' and name = 'bill'") #注意,删除的数据不能复原了J
《Python数据分析与应用》教学大纲课程名称:Python数据分析与应用 课程类别:必修 适用专业:大数据技术类相关专业 总学时:64学时(其中理论36学时,实验28学时) 总学分:4.0学分 一、课程的性质 大数据时代已经到来,在商业、经济及其他领域中基于数据和分析去发现问题并做出科学、客观的决策越来越重要。数据分析技术将帮助企业用户在合理时间内获取、管理、处理以及整理海量数据,为企业经营决策提供积极的帮助。数据分析作为一门前沿技术,广泛应用于物联网、云计算、移动互联网等战略新兴产业。有实践经验的数据分析人才已经成为了各企业争夺的热门。为了推动我国大数据,云计算,人工智能行业的发展,满足日益增长的数据分析人才需求,特开设Python数据分析与应用课程。 二、课程的任务 通过本课程的学习,使学生学会使用Python进行科学计算、可视化绘图、数据处理,分析与建模,并详细拆解学习聚类、回归、分类三个企业案例,将理论与实践相结合,为将来从事数据分析挖掘研究、工作奠定基础。 三、课程学时分配
四、教学内容及学时安排 1.理论教学
2.实验教学
五、考核方式 突出学生解决实际问题的能力,加强过程性考核。课程考核的成绩构成= 平时作业(10%)+ 课堂参与(20%)+ 期末考核(70%),期末考试建议采用开卷形式,试题应包括基本概念、绘图、分组聚合、数据合并、数据清洗、数据变换、模型构建等部分,题型可采用判断题、选择、简答、应用题等方式。 六、教材与参考资料 1.教材 黄红梅,张良均.Python数据分析与应用[M].北京:人民邮电出版社.2018. 2.参考资料
南方科技大学生物医学工程系超分辨显微成像李依明课题组2020年招聘博士后、博士和 超分辨显微成像技术由于其为细胞分子生物学研究提供了一个全新的研究窗口,在2006年被提出之后的不到十年内,就于2014年 获得了诺贝尔奖。李依明博士先后在上海交通大学,海德堡大学, 卡尔斯鲁厄理工学院,欧洲分子生物实验室总部(EMBL)和耶鲁大学 等多个国际一流机构学习和工作,并取得了一系列突出的研究成果,以第一作者在NatureMethods,ACSNano等国际权威期刊发表多篇论文。其开发的软件获得领域内权威挑战赛的第一名,赢得了广泛的 声誉和影响力。目前和包括来自耶鲁大学,牛津大学和剑桥大学等 多个实验室有合作关系。课题组将依托南方科技大学-悉尼科技大学 生物医学材料与仪器联合研究中心,建立以超分辨成像平台为核心的,物理,工程,生物和化学等多学科交叉的一流显微成像实验室。实验室目前诚聘多个层次的研究学者,并将积极提供海外交流学习 机会,期待各位有志于开发下一代显微成像技术的青年才俊加盟。 一、博士后招聘 仪器设计方向 1.获得物理,光学工程、计算机、生物医学工程、机械工程或其它相关专业博士学位 2.具有以下任一领域专长:图像处理、硬件控制软件开发、机械设计、光学显微成像技术开发 3.熟练掌握至少一种以下或具备相同功能软件:Matlab、C/C++、Python、Labview、Java、Zemax、SolidWorks 4.拥有显微成像技术,如PALM/STORM、SIM、LightSheetMicroscopy、STED等技术相关开发经验优先 生物医学方向
1.获得生物工程、生物医学工程、生物技术、生物化学或其它相关专业博士学位 2.具有以下任一领域专长:分子生物学、细胞生物学、生物化学方向的丰富研究经验,熟练掌握哺乳动物细胞培养、免疫荧光、荧光蛋白标记、小分子荧光探针标记,DNA-PAINT、FISH等技术 3.拥有超分辨显微成像技术,如PALM/STORM、SIM、LightSheetMicroscopy、STED等使用经验者优先 岗位待遇: (1)年薪不低于27万人民币,其中含深圳市财政生活补贴支持18万元/年(免税)和学校住房补贴。特别优秀者可以申请校长卓越博士后奖,年薪30万元 (2)享受住房补贴以及医疗、养老、工伤等社会保险;享受过节费、餐补、计划生育奖励、高温补贴、免费体检等福利 (3)学校为每位博士后提供每两年2.5万元的资助用于学术交流(含国际会议),支持作为项目负责人申请各项研究基金 (4)出站留深工作满3年,符合深圳市后备级条件的可获80-100万元的住房补贴和可申请30万元科研启动经费 (5)海外博士或具有一年以上留学经历留深工作可以申请深圳市孔雀计划160-200万住房补贴 (6)条件优秀、有高校工作经历、博士后经历者也可以申请研究副教授或助理教授职位,年薪35万起 二、研究助理招聘 要求:物理,光学工程,生物医学工程,生物工程等相关专业本科或硕士毕业,有攻读博士学位意愿的候选人优先,已发表SCI论文者优先 岗位待遇: 月薪5000-7000元(本科)或7000-9000元(硕士)
7 用 Python 实现基本数据结构——栈与队列 最近学习《算法导论》 ,看了栈与队列,觉得用 C 实现 没意思 (以前实现过,不过不能通用 ),遂用最近在研究的 Python 实现这两个基本的数据结构! 在一个 basicds 模块里用实现了两个类: Stack 和 Queue 及 其各自所支持的操作,写得比较笨: -) 其实完全可以写个 基类 List ,然后从 List 中派生出类 Stack 和 Queue ,这样做 可以避免一些重复代码,因为两个类有很多类似的方法,比 如 isempty, length 等等。(当然这些改进还是等待下一版再 做吧,: -)以下是模块 basicds 模块源码: basicds.py Python 语言 : 高亮代码由发芽网提供 01 class Stack(object) : 02 def __init__(self) : 03 self.stack = [] 04 05 def push(self, item) : 06 self.stack.append(it em) 08 def pop(self) :
30 09 if self.stack != [] : 10 return self.stack.pop(-1) 11 else : 12 return None 13 14 def top(self) : 15 if self.stack != [] : 16 return self.stack[-1] 17 else : 18 return None 19 20 def length(self) : 21 return len(self.stack) 22 23 def isempty(self) : 24 return self.stack == [] 25 26 27 class Queue(object) : 28 def __init__(self) : 29 self.queue = []
使用Websocket对于客户端来说无疑十分简单。websocket提供了三个简单的函数,onopen,onclose以及onmessage,顾名思义,他们分别监听socket的开启、断开和消息状态。 例如在一个WebSocket的客户端例子中,你可以这样写: 在代码中,首先创建了一个新的socket,指向websocket服务器端: var s = new WebSocket(“ws://localhost:8000/”); 然后利用三个基本函数实现状态监听。 当然这个例子并不完善,它参考了麻省理工一位研究生Mr. Yang的文章(https://www.doczj.com/doc/8017907113.html,/wp/web-sockets-tutorial-with-simple-python- server/),而你如果需要更好的客户端测试代码,可以看这里:http://cl.ly/3N3Y3t2s3U1v1h0A433u我们在新的代码里提供了完成的和服务器交互数据的功能,发送数据我们使用的函数是send(),你可以在代码中看到。 我们之所以不直接引用Yang的文章是因为Yang对服务器的理解不够完善,或者用他的话来说就是outdate。 感谢Yang为我们提供了一个简单的socket server的例子,不过可惜放在现在来说它是有问题的,当然我们还是把例子引述如下: #!/usr/bin/env python import socket, threading, time
上海交通大学试卷(A 卷) (2010 至2011学年第2学期) 班级号______________________ 学号____________________ 姓名_______________ 课程名称程序设计思想和方法成绩 一、选择题:将唯一正确的选项写在题前括号中.每题2分. 【】(1)本课程的目标定位是什么? [A] 学习Python 语言 [B] 学习计算机的工作原理 [C] 学习各种算法 [D] 学习用计算机解决问题 【】(2)下列哪个标识符是合法的? [A] var-n ame [B] !@#$% [C]. _100 [D] elif 【】(3)执行下列语句后的显示结果是什么? >>> s = ” hi ” >>> print “hi” , 2*s [A] hihihi [B] ” hi ” hihi [C] hi hihi [D] hi hi hi 【】(4)如何解释下面的执行结果? >>> pri nt 1.2 - 1.0 == 0.2 False [A] Python 的实现有错误 [B] 浮点数无法精确表示 [C] 布尔运算不能用于浮点数比较 [D] Python 将非0数视为False 【】(5)想用一个变量来表示出生年份,下列命名中哪个最可取? [A] b_y [B] birth_year [C] _birthYear_ [D] birthyear
【】(6)执行下列语句后的显示结果是什么 >>> a = 1 >>> b = 2 * a / 4 >>> a = 'One ” >>> pri nt a,b [A] o ne 0 [B] 1 0 [C] o ne 0.5 [D] o ne,0.5 【】(7)执行下列语句后的显示结果是什么 >>> s = ” GOOD MORNING' >>> print s[3:-4] [A] D MOR [B] D MORN [C] OD MOR [D] OD MORN
Python现在越来越火,特别是想要今后转行人工智能的同学,学习Python是必须的。在编程语言中,有些人对于Java和Python是比较纠结的,到底要学习哪个呢?举个例子,现在人工智能和大数据都比较火,如果你想发展大数据的话,那就学习Java。 以上只是一个简单的距离,下面我们就来看看Java的就业前景和就业方向。 一、Java软件工程师就业前景 Java软件工程师就业前景的如何?主要从Java的应用领域来看,Java语言的应用方向主要表现在以下三个方面: 1.大中型的商业应用 包括我们常说的企业级应用(主要指复杂的大企业的软件系统)、各种类型的网站,Java 的安全机制以及它的跨平台的优势使它在分布式系统领域开发中有广泛应用。 2.桌面应用 就是常说的C/S应用主要用来开发运行于不同的操作系统上的桌面应用程序。 3.再次是移动领域应用 主要表现在消费和嵌入式领域是指在各种小型设备上的应用包括手机、PDA、机顶盒、汽车通信设备等。 二、学习Java开发的就业方向 Java行业是一个大方向,岗位不同工作内容也多有不同,掌握一门Java技术之后就业的机会是很广泛的,现在根据已入职工作的达内Java学员的就业方向,给大家提供个参考:Java开发的就业方向一:Java企业级应用开发 目前Java在许多行业的企业信息应用方面的应用非常多,比如OA、邮箱、股票、金融、考试、物流、医疗、矿山等信息方面的系统。该方向和行业密切相关,所以,这是一个经验型的发展方向。Java开发者在这方面的需求也非常大,待遇也相当不错,有三到五年
工作经验的年薪在15至20万这是一个很正常的水平。 Java开发的就业方向二:Java网站建设 近几年来,网站建设业务一直呈快速上升势头,行业市场越来越大。新技术的应用将促使企业网站建设更具魅力。Java编程语言也将使网站结构更紧密,访问更流畅,更能适应新的要求。特别是像大企业更偏向于使用Java技术。 Java开发的就业方向三:Android开发 Android是一种基于Linux的自由及开放源代码的操作系统,主要使用于移动设备,如智能手机和平板电脑,由Google公司和开放手机联盟领导及开发。Android在国内的市场份额愈来愈额高。最近几年发展非常快速,但人才积累却没有跟上,优秀的Android 开发工程师仍然存在不小的缺口。Android应用的主要开发语言就是Java,所以选择这个方向还是蛮不错的。 Java开发的就业方向四:Java游戏开发 Java本身就可以用来编写游戏脚本,目前也有例如beanshellgroovy等脚本语言可以方便的无缝的和Java语言进行交互,这些都极大的方便了Java游戏编程。 在未来的几年,Java工程师人才的需求还在不断的加大,由于人才的紧缺,这一门职业相对于其它专业薪资待遇还是不错的,JAVA工程师待遇是与你的工作经验直接挂勾的,当你有了丰富的经验以后,你在这个社会上就比较抢手了,而且企业所出的薪酬也是相当高的,到时只有你选择他们了。 北大青鸟沈阳三好的教学,都是根据学员的实际情况设计,并且能循序渐进提高学员能力的课程内容。学习总体时间分为三个阶段,一阶段学习程序基础,二阶段学习程序编写,三阶段学习程序框架构建。
在学习神经网络之前,我们需要对神经网络底层先做一个基本的了解。我们将在本节介绍感知机、反向传播算法以及多种梯度下降法以给大家一个全面的认识。 一、感知机 数字感知机的本质是从数据集中选取一个样本(example),并将其展示给算法,然后让算法判断“是”或“不是”。一般而言,把单个特征表示为xi,其中i是整数。所有特征的集合表示为,表示一个向量: , 类似地,每个特征的权重表示为其中对应于与该权重关联的特征 的下标,所有权重可统一表示为一个向量: 这里有一个缺少的部分是是否激活神经元的阈值。一旦加权和超过某个阈值,感知机就输出1,否则输出0。我们可以使用一个简单的阶跃函数(在图5-2中标记为“激活函数”)来表示这个阈值。
一般而言我们还需要给上面的阈值表达式添加一个偏置项以确保神经元对全0的输入具有弹性,否则网络在输入全为0的情况下输出仍然为0。 注:所有神经网络的基本单位都是神经元,基本感知机是广义神经元的一个特例,从现在开始,我们将感知机称为一个神经元。 二、反向传播算法 2.1 代价函数 很多数据值之间的关系不是线性的,也没有好的线性回归或线性方程能够描述这些关系。许多数据集不能用直线或平面来线性分割。比如下图中左图为线性可分的数据,而右图为线性不可分的数据:
在这个线性可分数据集上对两类点做切分得到的误差可以收敛于0,而对于线性不可分的数据点集,我们无法做出一条直线使得两类点被完美分开,因此我们任意做一条分割线,可以认为在这里误差不为0,因此我们需要一个衡量误差的函数,通常称之为代价函数: 而我们训练神经网络(感知机)的目标是最小化所有输入样本数据的代价函数 2.2 反向传播 权重通过下一层的权重()和()来影响误差,因此我们需要一种方法来计算对误差的贡献,这个方法就是反向传播。 下图中展示的是一个全连接网络,图中没有展示出所有的连接,在全连接网络中,每个输入元素都与下一层的各个神经元相连,每个连接都有相应的权
python应用领域介绍Python作为一种功能强大且通用的编程语言而广受好评,它具有非常清晰的语法特点,适用于多种操作系统,目前在国际上非常流行,正在得到越来越多的应用。下面就让我们一起来看看它的强大功能:Python(派森),它是一个简单的、解释型的、交互式的、可移植的、面向对象的超高级语言。这就是对Python语言的最简单的描述。Python 有一个交互式的开发环境,因为Python是解释运行,这大大节省了每次编译的时间。Python 语法简单,且内置有几种高级数据结构,如字典、列表等,使得使用起来特别简单,程序员一个下午就可学会,一般人员一周内也可掌握。Python具有大部分面向对象语言的特征,可完全进行面向对象编程。它可以在MS-DOS、Windows、Windows NT、Linux、Soloris、Amiga、BeOS、OS/2、VMS、QNX等多种OS上运行。编程语言Python语言可以用来作为批处理语言,写一些简单工具,处理些数据,作为其他软件的接口调试等。Python语言可以用来作为函数语言,进行人工智能程序的开发,具有Lisp语言的大部分功能。Python语言可以用来作为过程语言,进行我们常见的应用程序开发,可以和VB等语言一样应用。Python语言可以用来作为面向对象语言,具有大部分面向对象语言的特征,常作为大型应用软件的原型开发,再用C++改写,有些直接用Python来开发。数据库Python在数据库方面也很优秀,可以和多种数据库进行连接,进行数据处理,从商业型的数据库到开放源码的数据库都提供支持。例如:Oracle,Ms SQL Server等等。有多种接口可以与数据库进行连接,至少包括ODBC。有许多公司采用着Python+MySql的架构。因此,掌握了Python使你可以充分利用面向对象的特点,在数据库处理方面如虎添翼。Windows编程Python不仅可以在Unix类型的操作系统上应用,同样可以在Windows系统里有很好的表现。通过添加PythonWin模块,就可以通过COM形式调用和建立各种资源,包括调用注册表、ActiveX控件以及各种COM等工作,最常见的例子就是通过程序对Office文档进行处理,自动生成文档和图表。通过Python,还可以利用py2exe模块生成exe应用程序。还有许多其他的日常维护和管理工作也可以交给Python来做,从而减少维护的工作量。利用Python,你还可以开发出象VB,VC,Delphi那样的GUI程序,但却可以在多个平台上执行。这在许多方面并不逊色于Java。多媒体利用PIL、Piddle、ReportLab等模块,你可以处理图象、声音、视频、动画等,从而为你的程序添加亮丽的光彩。动态图表的生成、统计分析图表都可以通过Python来完成。另外,还有OpenGL。利用PyOpenGl模块,你可以非常迅速的编写出三维场景。科学计算Python可以广泛的在科学计算领域发挥独特的角色。有许多模块可以帮助你在计算巨型数组、矢量分析、神经网络等方面高效率完成工作。尤其是在教育科研方面,可以发挥出独特的优势。网络编程Python可以非常方便的完成网络编程的工作,提供了众多的解决方案和模块,可以非常方便的定制出自己的服务器软件,无论是c/s,还是b/s模式,都有很好的解决方法。工具集: Soket编程CGI,Freeform Zope,CMF,Plone,Silva,Nuxeo CPS... WebWare Twisted CherryPy SkunkWeb Quixote 4Suite Server Spyce Albatross Cheetah mod_python 协议: http ftp gopher XML-PRC SOAP POP SMTP 图形用户界面Python可以非常方便的实现GUI编程,通过Tkinter,wxPython,QT等等模块,你就可以根据需要编写出强大的跨平台的用户界面程序。开发环境与编辑器Python程序的开发工具比较多,目前主要的工具既有IDLE,PythonWin这样的免费工具, 也有一些商业性的工具。通过这些工具,可以让你更为快速的完成工作。集成开发环境(IDE):IDLE:这是Python里边自带的,基本上可以满足一般开发需要,请参考cnIDLE。PythonWin:这是基于Windows平台的编辑开发环境,基本上可以满足一般开发需要。PythonWorks Pro Wing IDE Komodo 代码编辑器:LEO:完全由Python编写的程序代码编写辅助工具,可运行在多种操作系统中,支持独特的程序代码管理方式。gVim:相当专业的代码编辑器,可运行在多种操作系统中,支持Python扩展。Emacs:Unix系统中常用的工具。SciTE:简单易用的代码编辑器,支持unicode编辑。嵌入和扩展Python可以嵌入到其它应用程序中,也可以通过C/C++编写扩展模块,从而可以提高程序的
一.选择题: 将唯一正确的选项写在题前括号中(每题1分,共15分) 【】1.表达式'%d%%%d' %(3 / 4, 3 % 4)的值是: A.'0%3' B.'0%%3' C.'3/4%3%4' D.'3/4%%3%4' 【】2.下面标识符中不是python语言的保留字的是: A.continue B.except C.init D.pass 【】3.以下程序的输出结果是(提示:ord(' a ')==97): lista = [1,2,3,4,5,'a','b','c','d','e'] print lista[2] + lista[5] A.100 B.'d' C.d D.TypeEror 【】4.下面的循环体执行的次数与其它不同的是: A.i = 0 while( i <= 100): print i, i = i + 1 B.for i in range(100): print i, C.for i in range(100, 0, -1): print i, D.i = 100 while(i > 0): print i, i = i – 1 【】5.自顶向下逐步求精的程序设计方法是指: A.将一个大问题简化为同样形式的较小问题。 B.先设计类,再实例化为对象。 C.解决方案用若干个较小问题来表达,直至小问题很容易求解。 D.先设计简单版本,再逐步增加功能。 【】6.简单变量作为实参时,它和对应的形参之间数据传递方式是:A.由形参传给实参B.由实参传给形参 C.由实参传给形参,再由形参传给实参D.由用户指定传递方向 【】7.以下说法不正确的是: A.在不同函数中可以使用相同名字的变量。 B.函数可以减少代码的重复,也使得程序可以更加模块化。 C.主调函数内的局部变量,在被调函数内不赋值也可以直接读取。 D.函数体中如果没有return语句,也会返回一个None值。 【】8.关于list和string下列说法错误的是: A.list可以存放任意类型。 B.list是一个有序集合,没有固定大小。 C.用于统计string中字符串长度的函数是string.len()。 D.string具有不可变性,其创建后值不能改变。