以下为一个最简单的report+XML报表开发过程。
例子为《库存现有量报表》
首先安装好report builder、PL/SQL Developer或其他数据库工具、FTP工具(如WinSCP)、Oracle BI Publisher Destop(用于编码RTF格式)
配置好HOSTS、TNS、数据库连接等。
打开report builder
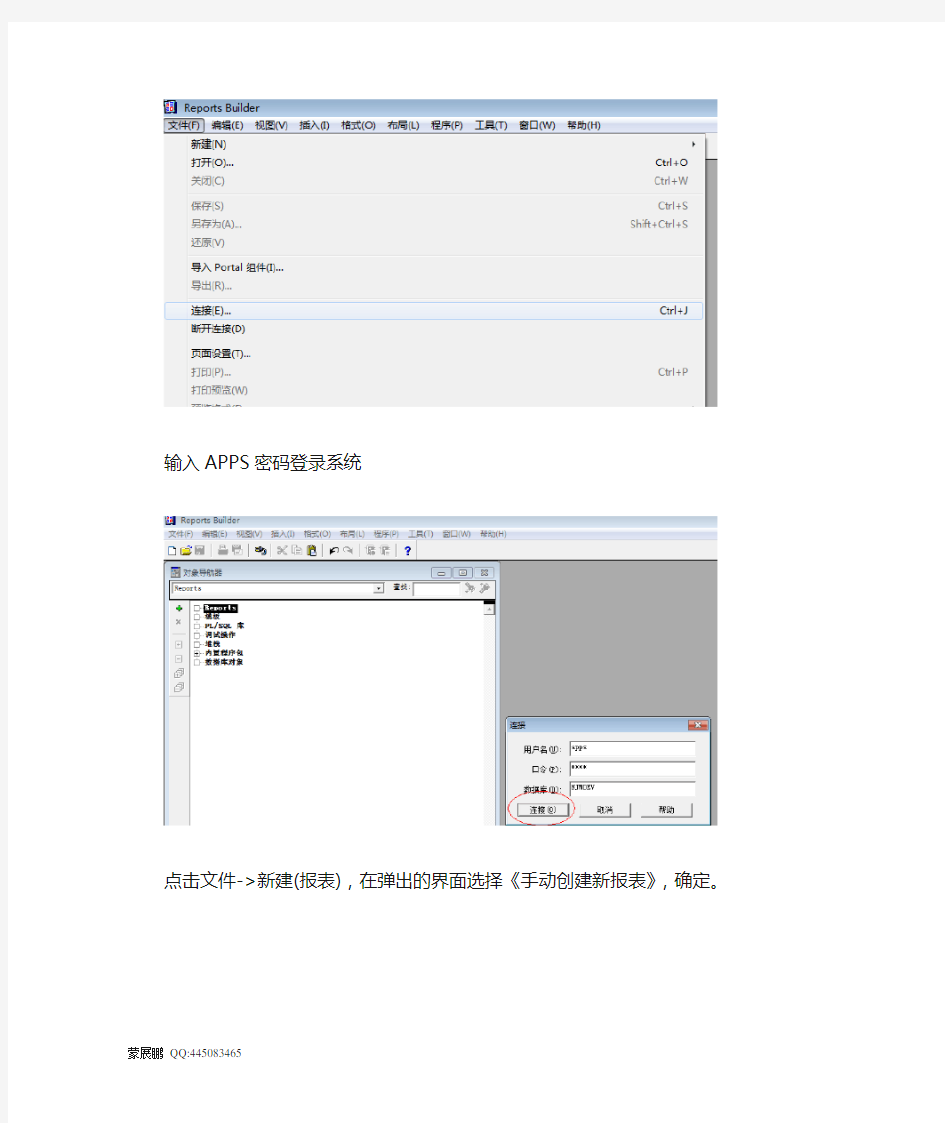
点击文件->连接登录系统。
输入APPS密码登录系统
点击文件->新建(报表),在弹出的界面选择《手动创建新报表》,确定。
在弹出的报表编辑器界面,左边有一列工具列表,点击《SQL》这时鼠标会变成‘+’号,在右边空白区域点击一下,弹出要求填写SQL语句的界面。
打开PL/SQL Developer 工具并登录
编写好报表的SQL语句。
将报表SQL语句放到report builder的SQL查询方框内,确定。
点击确定之后,会得到一个查询数据源,默认名称为《Q_1》
得到一个rdf文件。
关掉报表编辑器
得到的结果如下图。
保存后,点击程序->编译->全部,对文件进行编译。
完成编译。再次点一次保存(编译时会更新一些信息)。
点击文件->生成到文件(G)->XML
选择好路径-保存(一般默认跟前面一样的文件名),得到一个XML文件。
打开WORD程序(是打开程序,不是新建一个WORD文档再打开),点击Oracle BI Publisher->数据->导入XML数据示例
浏览到刚才保存的XML文件,确定。
数据进来之后的效果:
保存,输入文件名字,保存为RTF格式。
双击某一个字段,会弹出一个窗体,如下图。可以修改默认文字,也可以修改文字的格式、类型、长度等。。。
再点击《添加帮助文字》
在弹出的帮助文字框如下图。注意文字都为大写。
可以看到表格前面有个《F》字母,打开看到帮助文字如下图。也是固定格式,其中的G_SEGMENG1 为report中的分组名,如下图2。
同样打开表格右边的《E》字母,如下图,格式是固定的,表示输出的结束。
每次的循环输出都会有对应的《F》和《E》出现,多重循环就会多个《F》和《E》
到此得到了3个文件,分别为rdf、RTF、XML格式,其实到这一步,XML已经使用过了,不再需要了。
打开FTP工具登录,将INV_ONHAND.rdf文件上传到$CUX_TOP/reports/ZHS 路径中(如果是中文繁体环境,路径是$CUX_TOP/reports/ZHT)
其中$CUX_TOP 环境和路径都是DBA提前设置好的。
登录EBS系统。
给自己的用户添加职责《应用开发员》《Oracle XML Publisher 管理员》
切换到《应用开发员》职责
注册应用产品路径。
打开并发程序:路径:应用开发员->程序
按下图填写并发程序的信息,保存。(参数部分到后面再详细讲解)
切换职责到《系统管理员》,选择《请求》
将对应职责的请求组查询出来,将报表添加到该职责的请求组中。
切换到职责《Oracle XML Publisher 管理员》
点击《数据定义》
在弹出的网页中,点击《创建数据定义》
按图中填写信息后,点击《应用》
创建数据定义成功。
点击左上角的《模板》
在弹出的网页点击《创建模板》
按下图填写完成,点击《应用》
创建成功
至此。报表的最简单流程已经走完了。
切换到刚才添加了报表权限的职责,提交创建的报表(因为还没创建参数,所以不用填写参数),点击《选项》
润乾报表常用函数 1.to函数说明:生成一组连续的整数数据 语法:to(startExp,endExp{,stepExp}) 参数说明: startExp 整数数据开始的表达式 endExp 整数数据结束的表达式 stepExp 整数数据步长的表达式 函数示例: to(1,5)=list(1,2,3,4,5) to(1,5,2)=list(1,3,5) to(-5,-10,-2)=list(-5,-7,-9) to(-10,-8)=list(-10,-9,-8) 2.select函数说明:从数据集的当前行集中选取符合条件的记录 语法: datasetName.select(
sort_exp: 数据排序表达式。当此项为空时先检查desc_exp是否为空,如果为空,则不排序,否则使用select_exp排序。rootGroupExp 是否root数据集表达式 返回值:一组数据的集合,数据类型由select_exp的运算结果决定函数示例: 例1:ds1.select( name ) 从数据源ds1中选取name字段列的所有值, 不排序 例2:ds1.select( #2, true ) 从数据源ds1中选取第二个字段列的所有值并降序排列 例3:ds1.select( name,false,sex=='1') 从数据源ds1中选取性别为男性的name字段列的值并升序排列 例4:ds1.select( name, true, sex=='1', id ) 从数据源ds1中选取性别为男性的name字段列的值并按id字段降序排列 3.Int函数说明:将字符串或数字转换成整数 语法:int( string ) int( number ) 参数说明: string 需要转换的字符串表达式 number 数字,如果带有小数位,转换后小数位被截掉
Cognos报表—知识整理 一、提示页自动加载 1、功能需求背景 华中电网概况报表首页需要有日期参数,但是每次进入首页时出现日期选择框影响美观,所以为其增加提示页面,但根据要求不能增加提示页面,所以设计出提示页面自动加载。通俗的讲就比如:出现提示页面,电脑自动点击确定进入主页面…… 2、功能实现方法 步骤1: 新建提示页面,新页面中内容包括:onload项目、完成按钮、日期提示框以及针对提示框的html项目。如下图1 图1 步骤2: Onload项目中函数:详见图1
二、进入页面后自动刷新一次 1、功能需求背景 电网概况报表电厂容量分析主页面中,需要自动根据日期刷新一次页面(具体原因参见三、特殊的日期过滤) 2、功能实现方法 步骤1: Onload项目加载函数,如图2 图2 步骤2: Js中函数新加一行代码,如图3 图3
3、可参考报表 电网概况报表>>1.电厂容量分析 三、特殊的日期过滤 1、功能需求背景 电网概况中发电情况包括水、火、风三种发电方式,在数据库中体现即为水(火、风)电机组管理(参数)表。根据用户要求,需要对全网水(火、风)当年新投机组容量等进行数据统计, 2、设计思想 1)将水、火、风机组管理表分别对应查询中取相同数据项,为U联做准备。 2)在三个查询中新建“投运年”数据项,取得机组投运年份。表达式:substr(【投运日期】,1,4) 3)将三个查询进行U联,给U联后的查询设置过滤条件,如图4 图4 3、出现问题分析 根据2、设计思想中进行操作,报表验证报错,不能对substr进行集操作,经查询得知,dm 数据库不支持在两层(原层和U联层)查询中同时使用substr。 4、新的解决方法 思路如下图:
1COGNOS的使用 1.1模型定义 1,打开Frame Manager程序,如下图: 2,新建一个项目,建完后,打开该项目,如下图:
3,在界面左边中选择“Packages”,然后单击右键新建一个包。按照提示一步步做,其中有一步是从数据库的表选所要用到的表,打勾为选用。 4,点击”Diagram”显示表,但表之间还没有建立联接关系,通过建立各表关系后如下图
5,然后将该包发布,点击右键该包选择“Publish Package”将其发布。 1.2模型的物理和逻辑定义 1,模型定义的规范:将模型分为2个部分,分别为物理层和逻辑层,物理层为从数据源引入表的物理定义和连接关系,逻辑层为业务视角下的逻辑定义。 2,物理层的建立:根据数据分析,设计模型中需创建的物理表,以便尽可能的提高查询语句的运行效率(比较理想的结构是星形结构,一个中间表和多个物理维表)。 在根名字空间(和数据源同名)下,建立一个名为物理层的目录,在物理层文件夹下执行Run Metedate Wizard将数据源中相关的物理表引入这个目录,然后将这些表建立连接关系,建议不要有Orphan表。如下图:
3,逻辑层的定义:在根名字空间下,建立一个名为逻辑层的目录,在逻辑层文件夹下生成Query Subject,Query Subject的字段都是根据业务逻辑从物理层从引入,建议字段名都为中文。逻辑层中的表为事实表和维表的结构,在事实表中包含维度的编码值和指标的值,维表中包括每个维度上编码值和其名称的对应关系。也可以根据需要建立Regular Dimension(3.4说明),在逻辑层中不要建立逻辑表之间的关系。如下图:
润乾报表与帆软报表产品对比
目录 (2) 前言 (3) 第一章报表设计 (3) 1.1对EXCEL的支持 (3) 1.1.1设计器打开Excel文件 (3) 1.1.2对Excel的公式支持 (4) 1.1.3复制粘贴Excel的内容 (4) 1.2制作报表 (4) 1.3制作统计图 (7) 1.4远程设计 (8) 第二章功能性 (9) 2.1中国式复杂报表 (9) 2.2.1多源分片 (9) 2.2.2动态格间运算 (10) 2.2.3行列对称 (10) 2.2.4不规则分组 (11) 2.2数据源 (11) 2.3主子表 (12) 2.4行类型 (13) 2.5折叠报表 (13) 2.6统计图 (16) 2.7超链接 (16) 2.8参数与宏 (17) 第三章集成性 (18) 3.1WEB应用集成 (18) 3.2API接口 (19) 3.3自定义数据接口 (19) 3.4移动端展现 (19) 第四章性能与容量 (21) 4.1多源关联 (21) 4.2容量 (21) 4.3响应 (22) 4.4并发 (22) 第五章美观性 (23) 4.1设计器UI (23) 4.2统计图 (24) 第六章总结 (25)
多年以来,我们经常被客户询问关于润乾报表与帆软报表的不同之处,对此我们的态度一直是避而不谈,因为从心底里不愿意去做这样的对比,我们坚信“你若盛开,清风自来”,也一直在秉行只说自己好,不去评判竞争者好坏的商业原则。如果客户在面对选型时有所纠结,我们都是建议客户自己去对比选择并积极配合。但是现在这样的客户反馈越来越多,而且确实有许多客户对报表工具不熟悉,不知道在选型时该对比哪些内容。另外,市场上长期以来充斥着一些倾向性非常明显、内容却很片面且与实际不符的对比材料,其编造者也不敢署名,这些错误的材料误导了客户对报表市场的感知能力。因此,不管是客户需求,还是市场需要,还是自我澄清,我们现在都有必要做个回应。下面对两种产品进行了详细测评,并整理汇总出文档供业界参考。我们力求做到客观公正,但由于对友商的产品不是非常熟悉(我们的精力更多的是研究客户需求,而不是竞争者),因此难免有错,敬请广大业内人士指正,特别是敬请友商指正。 润乾报表和帆软报表都是国内知名的报表解决方案供应商,两者的共同特点都是类Excel的纯Java的Web报表工具,但在技术细节和发展方向上存在差异。 本文主要考察这两款报表工具在制作固定报表时的差异。固定报表是指由报表开发人员预先定义好报表样式、取数规则、查询条件、业务逻辑等,报表的使用人员仅在Web端进行报表的查看,不涉及报表结构的修改。固定报表是业务系统中最常用的、开发工作量最大的任务,其制作方便性及能力对项目开发周期有很大的影响。另外,由于固定报表主要是在应用程序中使用,其集成性也是非常重要。本文将对这些方面进行客观的测评。 第一章报表设计 1.1对EXCEL的支持 既然润乾和帆软都是类Excel的设计模型,那么我们先来看看二者对Excel 的支持情况。对Excel的支持从以下几方面进行: 1.1.1设计器打开Excel文件
润乾常用函数数值计算 函数说明:abs(numberExp) 计算参数的绝对值 语法: abs(numberExp) 参数说明: numberExp 待计算绝对值的数据 返回值: 数值型 示例: 例1:abs(-3245.54) 返回:3245.54 例2:abs(-987) 返回:987 函数说明:cos(numberExp) 计算参数的余弦值,其中参数以弧度为单位 相关的函数有sin() 计算参数的正弦值 tan() 计算参数的正切值 语法: cos(numberExp) 参数说明: numberExp 待计算余弦值的弧度数 返回值:double型 示例: 例1:cos(pi()) 返回:-1 例2:cos(pi(2)) 返回:1
函数说明:eval( StringExp ) 动态解析并计算表达式 语法: eval( StringExp ) eval( StringExp, SubRptExp ) eval( StringExp, DataSetExp ) 参数说明: StringExp 待计算的表达式串 SubRptExp 嵌入式子报表对象,一般是含有子报表的单元格 DataSetExp 数据集对象,一般是ds函数 返回值:表达式的结果值,数据类型由表达式决定 示例: 例1:eval( "1+5" ) 返回6 例2:eval("B2+10", A1) 其中A1为嵌入式子报表,表示计算A1子报表中的B2+10 例3:eval("salary+100", ds("ds1")) 表示计算数据集ds1中salary加100 函数说明:exp(nExp) 计算e的n次幂 语法: exp(nExp) 参数说明: nExp 指定次幂数 返回值:数值型 示例: 例1:exp(4.3) 返回:73.69979369959579 函数说明:fact(nExp) 计算参数的阶乘 语法: fact(nExp)
润乾集算报表实现动态层次钻取报表(一) 在报表项目中有时会有动态层次报表,而且还需要层次钻取的场景,开发难度较大。这里记录了使润乾集算报表开发《各级部门KPI报表》的过程。 《各级部门KPI报表》初始状态如下图: 当前节点是根节点“河北省”,要求报表显示当前节点的下一级节点“地市”汇总的KPI 数值。Kpi又分为普通指标和VIP指标两类,共四项。如果点击“石家庄”来钻取的时候,要求能够将石家庄下一级的KPI汇总指标显示出来,如下图: 点击“中心区”钻取,要求能够将下一级的KPI汇总指标显示出来,以此类推,直到显示到最后一级。如下图: 前四级固定是“省、地市、区县、营业部”,后边则是动态的“架构4、架构5、架构6. . . 架构13”(根节点“省”对应“架构0”)。 这个报表对应的oracle数据库表有两个,tree(树形结构维表)和kpi(指标事实表),如下图:
Tree表 Kpi表 Tree表的叶子节点,通过id字段与kpi表关联。这个报表的难点在于1、动态的多层数据、标题;2、树形结构数据与事实表关联。 采用润乾集算报表实现的第一步:编写集算脚本tree.dfx,完成源数据计算。集算脚本 A1:连接预先配置好的oracle数据库。 A2:新建一个序列,内容是“省、地市、区县、营业部、架构4、架构5、架构6. . . 架构13”。 A3:使用oracle数据库提供的connect by语句编写sql,从数据库中取出指定id(节点编号)
的所有父节点id、name。id是预先定义的网格参数,如果传进来的值是104020,那么A3的计算结果是: A4:为A3增加一个字段title,按照顺序,对应A2中的层级。结果是: A5:计算变量level,是A3序表的长度,也就是输入节点“104020”的层级号“4”(“省”为第一级)。 A6:计算输入节点“104020”的下一级对应的层级名称“架构4”,赋值给变量xtitle。 A7:编写sql,从tree表中取出输入节点“104020”的所有叶子节点,并拆分sys_connect_by_path字符串,得到这些叶子节点对应的输入节点“104020”的下一级节点。形成临时表leaf与kpi表关联分组汇总。为了能够得到输入节点“104020”的下一级节点的name,leaf还需要与tree关联一次。需要注意的是,如果输入节点号本身就是叶子节点,结果中的name将为空。完整的sql如下: with leaf as( SELECT tree.id id,REGEXP_SUBSTR(SYS_CONNECT_BY_PATH(id, ';'),'[^;]+',1,2) x FROM tree where connect_by_isleaf=1 START WITH ID = ? CONNECT BY NOCYCLE PRIOR id = pid ) select nvl(leaf.x,max(leaf.id)) id,'"+xtitle+"' title,max(https://www.doczj.com/doc/8112185150.html,) name, sum(kpi.kpi1) kpi1,sum(kpi.kpi2) kpi2,sum(kpi.vipkpi1) vipkpi1,sum(kpi.vipkpi2) vipkpi2 from leaf left join kpi on leaf.id = kpi.id left join tree on leaf.x=tree.id group by leaf.x order by leaf.x 计算的结果是: A8:关闭数据库连接。 A9:向报表返回A4、A7两个结果集。 第二步:在报表设计器中定义报表参数和集算数据集,调用tree.dfx。如下图:
1实现行属性的目录树展开功能。 1.1在LIST报表中的现实 1.拖入6个字段,并且对产品系列、产品类型分组,如下图: 2.添加产品系列、产品类型的页眉
3.拆分产品系列、产品类型的单元格 4.将产品系列、和产品类型的汇总拖到产品名称处
5.删除产品系列,产品类型 6.打开列表的锁
7.按住CTRL,拖动数量、单位成本、单价到产品类型,产品系列的页眉处 8.在report page中插入HTML控件,然后拷贝如下代码进去,下面代码主要是定义了两个函数,一个用于目录树的展开与缩进,另一个用于页面初始化时隐藏一些数据,下面代码只支持到2层目录,更详细的含义可参考的在交叉表中实现目录树功能的注释。 代码如下: