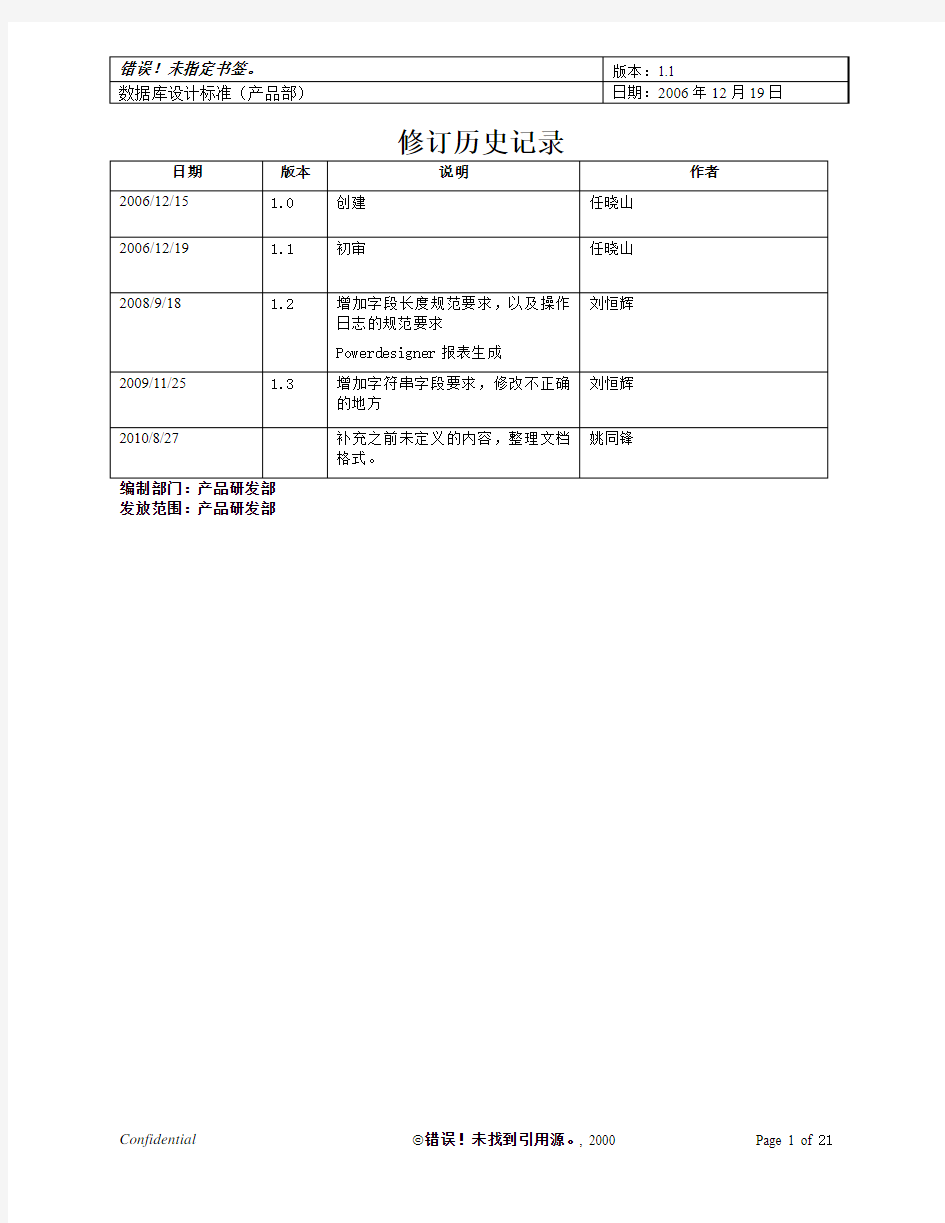

修订历史记录
日期版本说明作者2006/12/15 1.0 创建任晓山
2006/12/19 1.1初审任晓山
2008/9/18 1.2 增加字段长度规范要求,以及操作
刘恒辉
日志的规范要求
Powerdesigner报表生成
2009/11/25 1.3 增加字符串字段要求,修改不正确
刘恒辉
的地方
2010/8/27 补充之前未定义的内容,整理文档
姚同锋
格式。
编制部门:产品研发部
发放范围:产品研发部
目录
1.概述5
2.数据库设计的基本原则6
3.数据库建模7
3.1数据分析7
3.2数据关系分析7
3.3数据量分析7
3.4扩展性分析7
3.5数据字典(参考)7
3.5.1数据项7
3.5.2数据结构7
3.5.3数据流7
3.5.4数据存储8
3.5.5处理过程8
3.6E-R图8
3.7分析描述工具8
4.数据库对象设计9
4.1表的设计原则9
4.1.1命名规则9
4.1.2公用包的命名规则9
4.1.3表说明9
4.2字段设计原则9
4.2.1命名规则9
4.2.2字段说明9
4.2.3字段的一致性9
4.2.4建议字段9
4.2.5日期时间字段10
4.2.6数字和文本字段10
4.3键和索引10
4.3.1命名规则10
4.3.2键设计原则10
4.4视图设计原则(参考)10
4.4.1命名规则10
4.4.2视图说明11
4.5物化视图11
4.5.1命名规则11
4.5.2物化视图说明11
4.6触发器11
4.6.1命名规则11
4.6.2触发器说明11
4.7临时表设计原则11
4.7.1命名规则11
4.7.2临时表说明12
4.8有效组织数据库对象12
4.8.1存储过程分包存储12
4.9包设计原则12
4.9.1命名规则12
4.9.2包说明12
4.10存储过程设计原则(参考)12
4.10.1命名规则12
4.11函数设计原则(参考)13
4.11.1命名规则13
5.数据完整性设计(参考)13
5.1完整性实现机制13
5.2用约束而非商务规则强制数据完整性13
5.3强制指示完整性13
5.4使用查找控制数据完整性13
5.5采用视图13
6.数据库安全性设计14
6.1保证数据的完整性14
6.2保证数据可恢复性14
6.3其他安全原则14
7.数据库的物理实现15
7.1数据库的选择15
7.1.1数据库和版本的选择15
7.1.2其他数据库和版本比较15
7.1.3数据库版权15
7.2数据库运行环境15
7.2.1数据库硬件配置15
7.2.2数据库运行操作系统和版本16
7.2.3数据库运行操作系统的版权16
7.3数据库应用环境的物理结构(参考)16
7.3.1存储结构设计16
7.3.2数据存放位置16
7.3.3存取方法设计16
7.4数据库性能和测试方法(参考)17
7.4.1数据库性能17
7.4.2测试方法17
8.数据库的管理18
8.1数据库管理员18
8.2数据库导入、导出18
8.3数据库备份、恢复18
8.4数据库记录清除18
8.5数据库维护18
9.数据库的升级19
9.1数据库升级方式19
附录20
9.2附录一数据库设计文档说明20
9.2.1命名规则20
9.2.2数据库表创建文本20
9.2.3全部应用SQL语句列表20
9.2.4数据库设计文档必须有版本号20
9.3附录二数据库设计说明书评审表20
数据库设计标准(产品部)
1.概述
本文档是数据库设计执行标准,其所涉及的内容是数据库设计部分,不包括应用程序中数据库访问实现。
2.数据库设计的基本原则
数据库设计三个范式规定;
第一范式(1NF):不存在多值字段
第二范式(2NF):非主键字段依赖于主键的整体
第三范式(3NF):非主键字段只依赖于主键
3.数据库建模
3.1数据分析
根据项目的《需求分析》列出全部数据,包括:
1)输入数据:原始数据。
2)输出数据:用户需要检索的数据,包括原始数据和派生的数据。
3.2数据关系分析
1)数据分类:根据应用将数据表分类。
2)类关系:表之间的相互关系。
3)数据关系:表之间字段之间的关系。
3.3数据量分析
1)数据量分析:最大可能的记录数量。适当考虑记录信息的备份、过期删除等。
2)数据流量分析:结合于用户需求的单位时间可能进出的数据量分析。
3)响应速度分析:为满足用户需求的响应速度分析。
3.4扩展性分析
1)在项目《需求分析》的基础上,充分考虑用户未来可能的需求,在设计上为这种需求保留余地
和可能的更改措施。
2)注意考虑的内容是“结构”性的,而不是“内容”性的。
3.5数据字典(参考)
3.5.1数据项
1)数据项名
2)数据项含义说明
3)别名
4)数据类型
5)长度
6)取值范围
7)取值含义
8)与其他数据项的逻辑关系
3.5.2数据结构
1)数据结构名
2)含义说明
3)组成:数据项或数据结构
3.5.3数据流
1)数据流名
2)说明
3)数据流来源
4)数据流去向
5)组成:数据结构
6)平均流量
7)高峰期流量
3.5.4数据存储
1)数据存储名
2)说明
3)编号
4)流入的数据流
5)流出的数据流
6)组成:数据结构
7)数据量
8)存取方式
3.5.5处理过程
1)处理过程名
2)说明
3)输入:数据流
4)输出:数据流
5)处理:简要说明
3.6E-R图
1)E-R图也即实体-关系图(Entity Relationship Diagram),提供了表示实体型、属性和关系的
方法,用来描述现实世界的概念模型。
2)要遵循E-R的设计规范,例如:
实体(Entity):用矩形表示
属性(Attribute):用椭圆形表示
关系(Relationship):用菱形表示,菱形框内写明关系名,并用无向边分别与有关实体连接起
来,同时在无向边旁标上联系的类型(1 : 1,1 : n或m : n)。
3.7分析描述工具
1)统一使用PowerDesign。
2)使用PowerDesign生成报表工具生成文档
4.数据库对象设计
4.1表的设计原则
4.1.1命名规则
1)只允许使用英文字母“A-Z”、数字“0-9”和符号“_”。
2)全部大写,不允许大小写混合。
3)格式“[应用名] [_类型名]_表单词1[_表单词2]”。
4)尽量使用英文单词或英文缩略语,各英文单词或缩略语中间使用符号“_”分割开,如
“T_USER_MESSAGE”。
5)不允许使用描述不明确的字母或数字。
6)长度限制在20字节内。
7)表示表名称的单词限定为2个。
4.1.2公用包的命名规则
1)础公用包相关表,命名以SY_开头
2)业务公用包相关表,以业务名_开头,业务名原则上不长于4个字符,例:SHOP_ (商城,<=4) 4.1.3表说明
每个表需要中文说明,该说明最终放到数据库中。
1)版本标记
增加一个版本表,或在同类表中增加一个版本字段,用于说明当前数据库的版本。
2)尽量不要使用数据库特殊功能
不要过多的依赖后台数据库系统软件的某些特殊功能。
4.2字段设计原则
4.2.1命名规则
1)只允许使用英文字母“A-Z”、数字“0-9”和符号“_”。
2)格式:单词1[_单词2][_单词3]
3)尽量使用英文单词或英文缩略语,各英文单词或缩略语中间使用符号“_”分割开,如
“USER_TYPE”,不建议使用汉语拼音。
4)不允许使用描述不明确的字母或数字。
5)字段名长度限制在20字节内。
6)表示字段名称的单词限定为3个。
4.2.2字段说明
如果数据库允许的话,每个字段需要附加中文名称或简短说明,该说明最终放到数据库中。
4.2.3字段的一致性
相同属性的字段,要保证在各个表中的一致。
1)名称一致。
2)类型一致。
3)长度一致。
4.2.4建议字段
1)主键:每个表必须提供主键,可以采用UUID(32位字符串)或SEQUENCE来作为主键,建议一
般项目用UUID,便于维护,“XXX_ID”。
2)创建时间:添加记录的当前时间。名称统一为“CREATE_TIME”。“日期时间”类型;默认当
前时间;
3)删除标记:使用删除标志,而不是直接删除记录。名称统一为“DELETE_SIGN”。布尔型;默
认为“false”;如果是oracle数据库则使用NUMBER(1)来存储0/1。
4)最后变更时间,具体看实际应用决定是否添加。如需考虑操作日志相关信息,必须新增操作日
志表。
5)说明:
一般的表中应该包含上述字段,对临时或小型反复操作的表除外。
记录的删除,通过统一机制完成,比如“清除”等功能实现。
4.2.5日期时间字段
尽量使用“DATETIME”类型,在特殊情况下可以使用纯日期类型的字段,某些统计表中可以使用其他类型表示时间的字段。
4.2.6数字和文本字段
1)数字和文本字段要充分考虑长度。在设计文档中必须明确的说明用户需求可能的最大允许范
围。
2)数值型:除标志位字段(1位的数据),其他数值型字段设计为10位(为了扩展方便)。
3)字符串:字符串默认设置长度为128位的VARCHAR2(保证字段足够长),标识性、标志性和类
型的字段根据实际情况确定长度,必须使用CHAR(X) 或NUMBER。
4.3键和索引
4.3.1命名规则
1)只允许使用英文字母“A_Z”、数字“0-9”和符号“_”。
2)不允许使用小写字母。
3)主键“PK_表名_主键名”;外键“FK_表名_外键名”。
4)尽量使用英文单词或英文缩略语,各英文单词或缩略语中间使用符号“_”分割开。
5)不允许使用描述不明确的字母或数字。
6)名称长度限制在30字节内。
4.3.2键设计原则
1)为关联字段创建外键。
2)所有的键都必须唯一。
3)避免使用复合键。
4)外键总是关联唯一的键字段。
5)使用系统生成的主键:尽量采用系统生成的键作为主键。
6)不要用用户的键:用户输入或可编辑的数据字段不要用于键,保障键值的正确性。
7)索引外键:表之间的关系通过外键相连接,这些字段应该增加索引。
8)不要索引注释字段:不要索引memo/note 字段,不要索引大型字段(有很多字符)。
9)不要索引常用的小型表:不要为小型数据表设置任何键,假如它们经常有插入和删除操作就更
别这样作了。
10)建立索引主要是出于增强数据访问性能的考虑。索引的种类很多,需要根据实际情况来建立适合的索引。对于可选择范围较小的字段,如地市等字段可以使用位图索引;对于聚簇表,可以使用聚簇索引;对于复杂条件的情况,可以考虑使用函数索引等。
4.4视图设计原则(参考)
4.4.1命名规则
1)只允许使用英文字母“A_Z”、数字“0-9”和符号“_”。
2)不允许使用小写字母。
3)格式“V_表1_表2…_表n”。
4)尽量使用英文单词或英文缩略语,各英文单词或缩略语中间使用符号“_”分割开。
5)不允许使用描述不明确的字母或数字。
4.4.2视图说明
视图的创建主要是为了简化查询,视图自己并不存储数据,而是在每次使用时查询数据,所以在效率上并不是很好。对于非常大的基表,如果仅仅是为了方便查询,不建议使用视图,但是可以考虑使用物化视图。
4.5物化视图
4.5.1命名规则
1)只允许使用英文字母“A_Z”、数字“0-9”和符号“_”。
2)不允许使用小写字母。
3)格式“MV_表1_表2…_表n”。
4)尽量使用英文单词或英文缩略语,各英文单词或缩略语中间使用符号“_”分割开。
5)不允许使用描述不明确的字母或数字。
4.5.2物化视图说明
1)物化视图适用于大表用于查询的时候,可以根据查询条件把大表查分成多个物化视图,以简化
查询。
2)物化视图有全量和增量刷新机制,可以根据应用系统的需要进行定制。
4.6触发器
4.6.1命名规则
1)只允许使用英文字母“A_Z”、数字“0-9”和符号“_”。
2)不允许使用小写字母。
3)格式“TRI_表_操作”。
4)尽量使用英文单词或英文缩略语,各英文单词或缩略语中间使用符号“_”分割开。
5)不允许使用描述不明确的字母或数字。
4.6.2触发器说明
1)触发器是一种特殊的存储过程,通过数据表的DML 操作而触发执行,其作用为确保数据的完
整性和一致性不被破坏而创建,实现数据的完整性约束。
2)触发器的before 或after 事务属性的选择时候,对表操作的事务属性必须与应用程序保持一
致,以避免死锁发生,在大型导入表中,尽量避免使用触发器。
4.7临时表设计原则
4.7.1命名规则
1)只允许使用英文字母“A_Z”、数字“0-9”和符号“_”。
2)不允许使用小写字母。
3)格式“TMP_表1_表2…_表n”。
4)尽量使用英文单词或英文缩略语,各英文单词或缩略语中间使用符号“_”分割开。
5)不允许使用描述不明确的字母或数字。
4.7.2临时表说明
1)对于复杂处理的中间结果可以用临时表来存储,尽量减少使用游标。
2)临时表分类
3)On commit delete rows :事务级临时表
4)On commit preserve rows:会话级临时表
5)区别:事务临时表,在提交事务后,表中的数据就消失了,但是会话临时表不会!~
会话临时表,提交事务后,依旧能查询,但是关闭数据后,重新连接时,表中的数据才会消失
4.8有效组织数据库对象
4.8.1存储过程分包存储
1)对不同模块或相似功能划分的集合使用包来分类保存。
每个模块的存储过程和函数放在同一个包内。如果有全局公用的函数,则创建单独的公用函数
包,大家可以资源共享,避免重复开发。
2)脚本统一保存
所有人员创建数据库对象的脚本都集中到相关负责人处,并在VSS或CVS上按内容分开存放:
1).创建数据类型脚本
2).创建业务表脚本
3).创建临时表脚本
4).创建视图脚本
5).创建主外键脚本
6).创建索引脚本
7).创建触发器脚本
8).创建存储过程脚本
9).初始化数据脚本
10).创建作业脚本
4.9包设计原则
4.9.1命名规则
1)只允许使用英文字母“A_Z”、数字“0-9”和符号“_”。
2)不允许使用小写字母。
3)格式“PKG_模块名(或功能类名)”。
4)尽量使用英文单词或英文缩略语,各英文单词或缩略语中间使用符号“_”分割开。
5)不允许使用描述不明确的字母或数字。
6)名称长度限制在30字节内。
4.9.2包说明
把同一个业务模块,或者相同功能的存储过程和函数,统一整理放入包内。
包内必须有完整的说明。
4.10存储过程设计原则(参考)
4.10.1命名规则
1)只允许使用英文字母“A_Z”、数字“0-9”和符号“_”。
2)不允许使用小写字母。
3)格式“P _动作_表名”。
4)尽量使用英文单词或英文缩略语,各英文单词或缩略语中间使用符号“_”分割开。
5)不允许使用描述不明确的字母或数字。
6)名称长度限制在30字节内。
7)过程内需要有异常处理。
4.11函数设计原则(参考)
4.11.1命名规则
1)只允许使用英文字母“A_Z”、数字“0-9”和符号“_”。
2)不允许使用小写字母。
3)格式“F_动作_表名”。
4)尽量使用英文单词或英文缩略语,各英文单词或缩略语中间使用符号“_”分割开。
5)不允许使用描述不明确的字母或数字。
6)名称长度限制在30字节内。
5.数据完整性设计(参考)
5.1完整性实现机制
1)实体完整性:主键
2)参照完整性:
父表中删除数据:级联删除;受限删除;置空值;
父表中插入数据:受限插入;递归插入;
父表中更新数据:级联更新;受限更新;置空值;
DBMS对参照完整性可以有两种方法实现:外键实现机制(约束规则)和触发器实现机制
3)用户定义完整性:
NOT NULL;CHECK;触发器;
5.2用约束而非商务规则强制数据完整性
采用数据库系统实现数据的完整性。这不但包括通过标准化实现的完整性而且还包括数据的功能性。在写数据的时候还可以增加触发器来保证数据的正确性。不要依赖于商务层保证数据完整性;它不能保证表之间(外键)的完整性所以不能强加于其他完整性规则之上。
5.3强制指示完整性
在有害数据进入数据库之前将其剔除。激活数据库系统的指示完整性特性。这样可以保持数据的清洁而能迫使开发人员投入更多的时间处理错误条件。
5.4使用查找控制数据完整性
控制数据完整性的最佳方式就是限制用户的选择。只要有可能都应该提供给用户一个清晰的价值列表供其选择。这样将减少键入代码的错误和误解同时提供数据的一致性。某些公共数据特别适合查找:国家代码、状态代码等。
5.5采用视图
为了在数据库和应用程序代码之间提供另一层抽象,可以为应用程序建立专门的视图而不必非要应用程序直接访问数据表。这样做还等于在处理数据库变更时给你提供了更多的自由。
6.数据库安全性设计
6.1保证数据的完整性
6.2保证数据可恢复性
1)数据库应该有定期的备份(物理的、逻辑的)。
2)生产库一定要开启归档。
3)对于生产库,应该开启闪回来避免用户误操作导致的数据丢失。
a)包括闪回数据库、闪回表、闪回数据。
6.3其他安全原则
1)采用数据加密
2)数据访问权限采用最小授权的原则
对数据库用户应该有针对性的细粒度授权。具体到方案、表等。
3)取消操作系统认证
4)为SYSMAN/DBSNMP修改密码
5)设置密码过期,并设置密码复杂度校验
6)锁定不常用的默认用户
7)为监听设置密码
8)采用角色授权
9)启用审计(一般情况不建议使用)
7.数据库的物理实现
7.1数据库的选择
7.1.1数据库和版本的选择
到底要选择什么样的数据库,需要依据现实的条件和环境。主要应该考虑以下的因素:
1)你要实现的目标(业务/功能要求,性能/可靠性/可扩展性/可用性要求);
2)当前数据库存储了多少数据,或者要构建的系统大概要多大的数据量,并需要考虑可扩展
性;
3)应用程序要选择的操作系统和语言平台;考虑客户既有的数据库系统。
4)预算有多少;
5)是否有专业人员(DBA)对数据库进行日常维护。
6)如果选定了数据库,对于具体版本,应该选择较新但是已经相对稳定的版本。
7.1.2其他数据库和版本比较
针对oracle来讲,到底是选择单实例,RAC,还是HACMP需要根据客户的具体需求来进行确定。
1)一般要求的数据库,可以使用单实例;
2)对于7*24的系统,而且不允许宕机(例如银行系统)则优先选择RAC。
3)对于某些7*24的系统,可以允许有几分钟的实例中断,则可以选择HACMP
4)更高要求的系统则需要选择MAA
7.1.3数据库版权
1)不管是oracle,SQL SERVER,还是DB2,对于商业用途都都要维护自己的版权,都是需要花钱
购买的,而且价格不菲。但是他们的功能和性能,都是经过考验的,售后的服务支持也做得很
好。对于大系统的适用性也非常好。
2)现在还有一些小型的数据库是免费的,但是一般对于较大的系统不适用。
3)MySQL采用双重授权(Dual Licensed),他们是GPL和MySQL AB制定的商业许可协议。如果你
在一个遵循GPL的自由(开源)项目中使用MySQL,那么你可以遵循GPL协议使用MySQL。否
则,你需要购买MySQL
AB制定的那个商业许可协议。这里最重要的一点就是要想免费使用MySQL,你所开发的软件
必须是遵循GPL的自由(开源)软件,虽然被批准的自由(开源)许可协议有很多个。
7.2数据库运行环境
7.2.1数据库硬件配置
数据库安装多需要的硬件配置需要根据选定的具体数据库的具体版本来决定。具体的要求需要查看相关文档。
例如在oracle10.2 for Linux x86的安装硬件要求如下:
1)内存:至少 1024 MB物理内存
2)内存和交换区的配置要求
RAM Swap Space
Between 1024 MB and 2048 MB 1.5 times the size of RAM
Between 2049 MB and 8192 MB Equal to the size of RAM
More than 8192 MB 0.75 times the size of RAM
3)/tmp目录至少 400 MB
4)Oracle 软件根据安装类型的不同设置在1.5 GB 到 3.5 GB 之间
5)如果选择文件系统安装,需要1.2 GB的空间存放数据库预配置信息。
7.2.2数据库运行操作系统和版本
数据库所选择的操作系统,很大程度上取决于用户的现有硬件环境。如果新搭的环境,还要看用户的预算。
1)新环境,且用户期望较高,预算充足,建议选择IBM小机,并安装AIX操作系统。不论从对数据库的支持,OS的性能,还是易操作性,安全性方面都是首选。
2)如果预算较窘迫,可以选择性能良好的PC,选择Linux操作系统。现在Linux系统已经越来越流行,而且对服务器配置要求不高;又可以配置RAC,也方便之后的升级。
3)不太建议使用windows系统。但是Oracle对windows的支持还是比较好的,且在windows上的操作也很简单。如果有的用户对系统要求不高,那么可以选择windows系统。
7.2.3数据库运行操作系统的版权
1)对于IBM, HP,SUN等的服务器的版权问题在购买时厂家都会很详细的说明。
2)如果选择Linux系统,则需要按规定购买。
3)Windows也需要买正版。
4)对于响应的oracle软件,需要根据自己选定的服务器和操作系统选择特定的版本,oracle公司会提供后期的帮助。
7.3数据库应用环境的物理结构(参考)
7.3.1存储结构设计
1)1)存储的设计也需要和具体的环境相结合。到底是选择直连存储还是网络存储,都和用户的实际需求密切相关。
2)底层存储设备是否采用RAID,采用那种RAID方式也和用户对系统的要求,以及预算密切相关。
a)对于安全优先的用户可以采用RAID5,RAID1;
b)性能优先的用户可以采用RAID0,RAID10;
3)如果是AIX,HP操作系统建议条件运行的情况下选择裸设备,以提高性能。
4)Linux及Windows操作系统无所谓裸设备。
5)数据文件和备份文件分开存放。
7.3.2数据存放位置
1)不同的应用建议放在不同的表空间存储。
2)有专门的索引表空间。
3)有专门的临时表空间。
4)数据文件进行分布在不同的磁盘存放,均衡磁盘I/O。
5)对于某些大表建议单独创建表空间存放,并建立分区表。
6)对于经常进行查询的大表,建议建立物化视图,提高查询性能。
7.3.3存取方法设计
1)尽量避免全表扫描。
2)查询尽量使用索引。
3)能在数据库端完成的操作在数据库端完成,减少交互。
4)JAVA应用程序与oracle的接口使用JDBC
.NET应用程序与oracle的接口使用ODBC
7.4数据库性能和测试方法(参考)
7.4.1数据库性能
数据的性能主要体现在处理能力和I/O两个方面。
1)服务器的CPU,I/O性能都是数据库性能的影响因素。
2)大多数数据库性能瓶颈都是应用的不合理设计引起的。
3)如果有大数据量的查询进行采用报表的方式,在系统空闲时间产出。
4)导入、导出等操作尽量放在业务不繁忙的时间段来完成。
5)数据处理尽量放在数据库端使用存储过程来完成。
6)数据库的性能问题很多是处在SQL的编写上,所以SQL编写要严格遵循规范。
7)性能调优是一个循序渐进的过程。
7.4.2测试方法
1)数据库的性能测试可以采用常规的性能测试工具如LOADRUNNER等来完成。
2)上面的测试结果可以与ADDM诊断工具相结合参照完成。
8.数据库的管理
8.1数据库管理员
系统数据库必须考虑数据库的管理问题。对于SQL SERVER数据库对DBA的要求比较低,但是对于ORACLE,DB2等数据库,对DBA的要求都非常高。要做好日常备份,监测,升级等工作;还需要进行应急恢复等紧急事务处理。DBA的主要工作职责包括:
a)数据库安装
b)数据库配置和管理
c)权限设置和安全管理
d)监控和性能调节
e)备份和恢复
f)解决一般的问题
8.2数据库导入、导出
如果数据库选用oracle10g,则尽量使用expdp/impdp进行导入导出。可以导出整个数据库,也可以分模式或具体到表进行导出。较低的版本使用exp/imp进行导入/导出。但是exp/imp的方式对大的系统,性能较差。
8.3数据库备份、恢复
1)每个系统为了保护自己的数据,及保证数据库正常运行,都需要制定适合自己的备份策略。并
可以写脚本在业务量较少的时间进行自动备份。对于备份应该有定期或不定期的测试。
2)如果客户方有自己正在使用的数据库/系统备份工具,则使用工具。
3)在没有第三方工具的情况下,使用RMAN进行备份和恢复。对于具体的系统应该制定响应的备
份策略。一般来讲,应该是全备和增量备份相结合的方式。
4)拷贝数据文件。
8.4数据库记录清除
8.5数据库维护
1)定期检查系统性能。
2)定期检查数据文件的使用情况,如果空间不够,需要增加存储设备。
3)定期对经常进行删除和更新操作的表进行索引的重建。
4)定期或不定期的进行表统计信息的收集,以提高效率。
5)定期对归档进行整理或清除,以释放空间。
6)对数据性能进行实时监测,发现问题及早解决。
9.数据库的升级
9.1数据库升级方式
数据库的升级参照oracle文档进行。主要分为四种方式:
a)导入导出。
b)DBUA
c)手动升级
d)数据复制
到底要采用哪一种升级方式,还需要根据具体的情况进行选择。1、2种都是非常简单的方式,但是在数据量大的情况下导入导出可能要消耗大量的时间。
附录
9.2附录一数据库设计文档说明
数据库设计文档除了本文档其他章节所述内容外,还应包含下列内容。
9.2.1命名规则
表的命名规则:格式说明(按类型区分)。
字段的命名规则:格式说明。
9.2.2数据库表创建文本
数据库设计完成后,应该根据相应的数据库,编写创建文本。
9.2.3全部应用SQL语句列表
为保障数据库设计的应用的完整性,在设计阶段即将项目需要的全部SQL列出,从而检查数据库结构设计的完整性和使用的便利性,不至于在程序设计阶段发现数据库设计结构问题。
这里的SQL语句是指完整的应用样例语句,不是程序中合成的语句,某些字段值就是具体的值,是直接可在数据库中运行的语句。
要求SQL语句中关键字和表名使用大写,其它一律使用小写字母。
9.2.4数据库设计文档必须有版本号
数据库设计文档必须包含相应的版本号。
9.3附录二数据库设计说明书评审表
编号YHXX-ZLJL-26No.:
■初次评审□修订(原文件评审表记录号:)
文件名称:编号:
发起人:参与人:
评审文件
评审时间要求_____年月日时之前,各专家完成评审。
_____年月日时之前,召开评审会议、形成评审结论。
编号评测项
评测结果
Y/TBD/N/NA 填表说明:Y-是,TBD-不确定,N-否,NA-不适用
1 是否满足用户信息要求和处理要求
2 是否从技术、经济、效益、法律等方面对建立数据库的可行性进行分析
3 是否有数据库硬件的描述,数据库软件及版本等描述
4 是否分析用户活动涉及的数据,是否有数据流图
5 是否分析系统数据,是否有数据字典
数据库设计规范、技巧与命名规范 一、数据库设计过程 数据库技术是信息资源管理最有效的手段。 数据库设计是指:对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,有效存储数据, 满足用户信息要求和处理要求。 数据库设计的各阶段: A、需求分析阶段:综合各个用户的应用需求(现实世界的需求)。 B、在概念设计阶段:形成独立于机器和各DBMS产品的概念模式(信息世界模型),用E-R图来描述。 C、在逻辑设计阶段:将E-R图转换成具体的数据库产品支持的数据模型,如关系模型,形成数据库逻辑模式。 然后根据用户处理的要求,安全性的考虑,在基本表的基础上再建立必要的视图(VIEW)形成数据的外模式。 D、在物理设计阶段:根据DBMS特点和处理的需要,进行物理存储安排,设计索引,形成数据库内模式。 1. 需求分析阶段 需求收集和分析,结果得到数据字典描述的数据需求(和数据流图描述的处理需求)。 需求分析的重点:调查、收集与分析用户在数据管理中的信息要求、处理要求、安全性与完整性要求。 需求分析的方法:调查组织机构情况、各部门的业务活动情况、协助用户明确对新系统的各种要求、确定新系统的边界。 常用的调查方法有:跟班作业、开调查会、请专人介绍、询问、设计调查表请用户填写、查阅记录。 分析和表达用户需求的方法主要包括自顶向下和自底向上两类方法。自顶向下的结构化分析方法(Structured Analysis, 简称SA方法)从最上层的系统组织机构入手,采用逐层分解的方式分析系统,并把每一层用数据流图和数据字典描述。 数据流图表达了数据和处理过程的关系。系统中的数据则借助数据字典(Data Dictionary,简称DD)来描述。 2. 概念结构设计阶段 通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型,可以用E-R图表示。 概念模型用于信息世界的建模。概念模型不依赖于某一个DBMS支持的数据模型。概念模型可以转换为计算机上某一 DBMS 支持的特定数据模型。 概念模型特点: (1) 具有较强的语义表达能力,能够方便、直接地表达应用中的各种语义知识。 (2) 应该简单、清晰、易于用户理解,是用户与数据库设计人员之间进行交流的语言。 概念模型设计的一种常用方法为IDEF1X方法,它就是把实体-联系方法应用到语义数据模型中的一种语义模型化技术, 用于建立系统信息模型。 使用IDEF1X方法创建E-R模型的步骤如下所示:
数据库设计方法及命名规范
- - 2 数据库设计方法、规范与技巧 (5) 一、数据库设计过程 (5) 1. 需求分析阶段 (6) 2. 概念结构设计阶段 (9) 2.1 第零步——初始化工程 (10) 2.2 第一步——定义实体 (10) 2.3 第二步——定义联系 (11) 2.4 第三步——定义码 (11) 2.5 第四步——定义属性 (12) 2.6 第五步——定义其他对象和规则 (12) 3. 逻辑结构设计阶段 (13) 4. 数据库物理设计阶段 (15) 5. 数据库实施阶段 (15) 6. 数据库运行和维护阶段 (16) 7.建模工具的使用 (16) 二、数据库设计技巧 (18) 1. 设计数据库之前(需求分析阶段) (18) 2. 表和字段的设计(数据库逻辑设计) (19) 1) 标准化和规范化 (19) 2) 数据驱动 (20)
- - 3 3) 考虑各种变化 (21) 4) 对地址和电话采用多个字段 (22) 5) 使用角色实体定义属于某类别的列 (22) 6) 选择数字类型和文本类型尽量充足 (23) 7) 增加删除标记字段 (24) 3. 选择键和索引(数据库逻辑设计) (24) 4. 数据完整性设计(数据库逻辑设计) (27) 1) 完整性实现机制: (27) 2) 用约束而非商务规则强制数据完整性 (27) 3) 强制指示完整性 (28) 4) 使用查找控制数据完整性 (28) 5) 采用视图 (28) 5. 其他设计技巧 (29) 1) 避免使用触发器 (29) 2) 使用常用英语(或者其他任何语言)而不 要使用编码 (29) 3) 保存常用信息 (29) 4) 包含版本机制 (30) 5) 编制文档 (30) 6) 测试、测试、反复测试 (31) 7) 检查设计 (31) 三、数据库命名规范 (31) 1. 实体(表)的命名 (31) 2. 属性(列)的命名 (34)
数据库设计规范
1概述 1.1目的 软件研发数据库设计规范作为数据库设计的操作规范,详细描述了数据库设计过程及结果,用于指导系统设计人员正确理解和开展数据库设计。 1.2适用范围 1.3术语定义 DBMS:数据库管理系统,常见的商业DBMS有Oracle, SQL Server, DB2等。 数据库设计:数据库设计是在给定的应用场景下,构造适用的数据库模式,建立数据库及其应用系统,有效存储数据,满足用户信息要求和处理要求。 概念数据模型:概念数据模型以实体-关系(Entity-RelationShip,简称E-R)理论为基础,并对这一理论进行了扩充。它从用户的观点出发对信息进行建模,主要用于数据库概念级别的设计,独立于机器和各DBMS产品。能够用Sybase PowerDesigner工具来建立概念数据模型(CDM)。 逻辑数据模型:将概念数据模型转换成具体的数据库产品支持的数据模型,如关系模型,形成数据库逻辑模式。能够用Sybase PowerDesigner工具直接建立逻辑数据模型(LDM),或
者经过CDM转换得到。 物理数据模型:在逻辑数据模型基础上,根据DBMS特点和处理的需要,进行物理存储安排,设计索引,形成数据库内模式。能够用Sybase PowerDesigner工具直接建立物理数据模型(PDM),或者经过CDM / LDM转换得到。 2数据库设计原则 按阶段实施并形成该阶段的成果物 一般符合3NF范式要求;兼顾规范与效率 使用公司规定的数据库设计软件工具 命名符合公司标准和项目标准 3数据库设计目标 规范性:一般符合3NF范式要求,减少冗余数据。 高效率:兼顾规范与效率,适当进行反范式化,满足应用系统的性能要求。 紧凑性:例如能用char(10)的就不要用char(20),提高存储的利用率和系统性能,但同时也要兼顾扩展性和可移植性。 易用性:数据库设计清晰易用,用户和开发人员均能容易地理解。
平安金融科技数据库(MySQL)开发规范 作者: 简朝阳 Last Updated: 25/02/14 19:30:18 历史修订记录: 版本修订人修订时间修订内容 1.0 1.1 李海军2013-03-11 增加部分说明及修改 1.2 李海军2013-07-29 增加连接池使用说明和memory引擎的控制 1.3 李海军2014-02-25 增加了char类型,修改了timestamp的使用场合。 说明 ?本规范包含平安金融科技使用MySQL 数据库时所需要遵循的所有对象设计(数据库,表,字段),所需要遵循的命名,对象设计,SQL 编写等的规范约定。 ?所有内容都为必须严格执行的项目,执行过程中有任何疑问,请联系DBA Team 取得帮助。 概述 ?禁止明文传播数据库帐号和密码。 ?禁止开发工程师通过应用帐号登录生产数据库。 ?禁止应用在服务器安装MySQL客户端(可以安装开发包)。 ?禁止开发人员在SQL中添加Hint,Hint只能由DBA审核后添加。 ?禁止使用悲观锁定,即读锁select … for update。 ?禁止在开发代码中使用DDL语句,比如truncate,alter table … 等。 ?禁止DML语句的where条件中包含恒真条件(如:1=1)。
1. 命名规范 总则 ?数据库对象名仅可包含小写英文字母、数字、下划线(_)三类字符,并以英文字母开头。 ?数据库对象命名禁止使用MySQL保留字。 ?多个单词之间用下划线(_)分隔。 ?对象名称长度若超过限制,则使用简写/缩写命名。 1.1. 数据库命名 ?数据库以"db_"前缀+ "站点名_"前缀及其所服务的应用名称命名。 1.2. 表命名 ?所属同一模块的表必须以模块名作为前缀命名。 ?历史数据表在原表基础上增加"_his"后缀命名。 1.3. 字段命名 ?布尔意义的字段以"_flag"作为后缀,前接动词。如:表示逻辑删除意义的字段可命名为delete_flag。 ?各表间相同意义的字段(如:作为连接关系的引用字段)使用相同的字段名。 1.4. 索引命名 ?唯一索引以uk_tablename_columnnames 方式命名 ?普通索引以idx_tablename_columnnames 方式命名 ?组合索引以idx_tablename_column1_column2... 方式命名 示例 ?站点名:maymay ?模块名:order ; ?数据表:item; ?字段组成:order_item_id,add_time,raw_update_time,c1,c2,c3,c4,c5 ?标准数据库名:db_maymay_order; ?标准数据表名:order_item; ?历史数据表名:order_item_his;
数据库设计方法、规范与技巧 一、数据库设计过程 数据库技术是信息资源管理最有效的手段。数据库设计是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,有效存储数据,满足用户信息要求和处理要求。 数据库设计中需求分析阶段综合各个用户的应用需求(现实世界的需求),在概念设计阶段形成独立于机器特点、独立于各个DBMS产品的概念模式(信息世界模型),用E-R图来描述。在逻辑设计阶段将E-R图转换成具体的数据库产品支持的数据模型如关系模型,形成数据库逻辑模式。然后根据用户处理的要求,安全性的考虑,在基本表的基础上再建立必要的视图(VIEW)形成数据的外模式。在物理设计阶段根据DBMS特点和处理的需要,进行物理存储安排,设计索引,形成数据库内模式。 1. 需求分析阶段 需求收集和分析,结果得到数据字典描述的数据需求(和数据流图描述的处理需求)。 需求分析的重点是调查、收集与分析用户在数据管理中的信息要求、处理要求、安全性与完整性要求。 需求分析的方法:调查组织机构情况、调查各部门的业务活动情况、协助用户明确对新系统的各种要求、确定新系统的边界。 常用的调查方法有:跟班作业、开调查会、请专人介绍、询问、设计调查表请用户填写、查阅记录。 分析和表达用户需求的方法主要包括自顶向下和自底向上两类方法。自顶向下的结构化分析方法(Structured Analysis,简称SA方法)从最上层的系统组织机构入手,采用逐层分解的方式分析系统,并把每一层用数据流图和数据字典描述。 数据流图表达了数据和处理过程的关系。系统中的数据则借助数据字典(Data Dictionary,简称DD)来描述。 数据字典是各类数据描述的集合,它是关于数据库中数据的描述,即元数据,而不是数据本身。数据字典通常包括数据项、数据结构、数据流、数据存储和处理过程五个部分(至少应该包含每个字段的数据类型和在每个表内的主外键)。 数据项描述={数据项名,数据项含义说明,别名,数据类型,长度, 取值范围,取值含义,与其他数据项的逻辑关系} 数据结构描述={数据结构名,含义说明,组成:{数据项或数据结构}} 数据流描述={数据流名,说明,数据流来源,数据流去向, 组成:{数据结构},平均流量,高峰期流量} 数据存储描述={数据存储名,说明,编号,流入的数据流,流出的数据流, 组成:{数据结构},数据量,存取方式} 处理过程描述={处理过程名,说明,输入:{数据流},输出:{数据流}, 处理:{简要说明}} 2. 概念结构设计阶段 通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型,可以用E-R图表示。概念模型用于信息世界的建模。概念模型不依赖于某一个DBMS支持的数据模型。概念模型可以转换为计算机上某一DBMS支持的特定数据模型。 概念模型特点: (1) 具有较强的语义表达能力,能够方便、直接地表达应用中的各种语义知识。 (2) 应该简单、清晰、易于用户理解,是用户与数据库设计人员之间进行交流的语言。 概念模型设计的一种常用方法为IDEF1X方法,它就是把实体-联系方法应用到语义数据模型中的一种语义模型化技术,用于建立系统信息模型。 使用IDEF1X方法创建E-R模型的步骤如下所示: 2.1 第零步——初始化工程
MySQL DB规范
目录 简介 (3) 目的 (3) 适用范围 (3) 数据库设计 (3) 引擎及版本选择 (3) 基础规范 (3) 命名规范 (5) 库表设计规范 (5) 字段设计 (6) 常用数据类型: (6) 数据类型使用建议: (6) 索引规范 (8) 索引准则 (8) 索引禁忌 (8) 不使用外键 (9) SQL设计 (10)
简介 介绍在使用mysql中各种注意事项和优化细节 目的 供开发人员参考,合理利用MySQL特性,开发出更高效的代码减少后端数据库压力,让整个系统高效稳定运行适用范围 业务数据库使用的是MySQL的数据库。 数据库设计 实现目标:业务功能实现、数据的扩展性、普遍性适用性 业务中80%+的性能优化是来自架构设计的优化 引擎及版本选择 根据业务特性选择合适的存储引擎,默认选择InnoDB存储引擎,原因如下(MyISAM与InnoDB比较): 基础规范 所有库表默认使用INNODB存储引擎,MyISAM适用场景非常少
●库表字符集使用UTF8,原因如下: 使用utf8字符集,如果是汉字,占3个字节,但ASCII码字符还是1个字节;统一不会有转换产生乱码风险;其他地区的用户(美国、印度、台湾)无需安装简体中文支持,就能正常看您的文字,并且不会出现乱码。 UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。 UTF-8的编码规则很简单,只有二条: 1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。 2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。 ●所有表和字段都需要添加注释,以方便其它开发及dba了解 ●单表数据量纯int型建议控制在1000w以内,含char型的建议500w以内,行平均长度控制在16KB以内, 单表20GB以内 ●不在数据库中存储图片、文件等大数据.原因如下: 1、对数据库的读写速度永远赶不上文件系统的处理速度 2、数据库备份会变的很臃肿,备份很耗时间 3、对文件的访问需要通过你的应用和数据库 ●临时短命数据尽量不要存到数据库中,建议存放于前端的memcache、redis等nosql中,减少后端数据库压 力 ●禁止在线上做压力测试 ●禁止从测试、开发环境直接连接线上数据库 ●用数据库来持久化存储以及保证事务一致性,不是运算器,在应用层实现计算 ●读写分离,主库只写和少量实时读取请求,使用从库来查询。 ●采用队列方式合并多次写请求,持续写入避免瞬间压力 ●超长text/blob进行垂直拆分,并先行压缩 ●冷热数据进行水平拆分(如6个月前后数据),LRU原则 ●快速更新频繁和大数据表禁止直接运行count(*)统计 ●压力分散,在线表和归档表(日志表)分开存储;不重要的非实时查询日志不要存数据库,以文件方式 在应用端统计分析。 ●禁止明文存储机密数据,需至少两次加密(部分数据可逆运算)
规范和设计技巧在数据库设计的探讨 摘要医院的信息收集工作在信息化产业中属于非常关键的构成部分,而且这方面的工作水平,能够对医院数据收集的水平起到决定性的作用,而想要做好这方面的工作,就一定要创建完善的数据库,并对其进行完美的规范和设计。具体的讨论一下数据库设计规范化的意义,信息收集的基本要求和存有的缺陷及设计的主要阶段中需要注意的技巧等问题。 关键词企业信息收集工作;数据库设计;信息化 目前,怎样让信息收集工作的质量得到增强,成为了医院发展过程中的一项重要工作。而且随着我国市场化发展的进步,医院的数据库设计也迎来了全新的发展时代,现如今数据收集的复杂化、智能化的实现,是这项工作取得进步的最好证明。该就以企业信息收集的意义为角度,来具体地讨论一下如何对数据库进行规范化的设计。 1数据库设计工作的规范化
在医院信息收集工作中的意义医院在对信息收集的时候,一定要 确保数据能够具有较高的质量,同时还要确保收集的高效率。医院若 想在竞争激烈的环境中保持一定的竞争力,就必须要做好信息收集工作,这样才能够跟得上时代发展的脚步,同时也是医院能够得到持续 发展的重要一步。随着我国现代化水平的提升,信息产业也迎来了发 展机遇。特别是医院的信息收集工作,它独特的信息化特点已经成为 了医院发展的重要构成部分。医院若想完成信息化建设,就一定要和 信息收集工作相结合,如此一来,就可以很大水准地提升工作效率, 而且也能够为长远发展打下一个坚实的基础。另外,数据库设计质量 如何,更是能够决定医院信息化发展的水准,确保数据库设计的质量,可以作信息化建设工作更加的具有意义。不过现在,很多医院在信息 收集工作方面是存有很大的问题,不仅没有体现出其应该具备的效果,而且还对医院的各方面工作造成了一定的影响,影响了医院信息化发展。而之所以会出现这方面的问题,主要的原因在于数据库设计人员 的能力有限。医院之所以开展数据库设计,主要是想让医院能够找到 更多的数据搜索方式,不过这也因此增加了数据库设计工作的难度, 从而让医院的相关工作人员在梳理信息收集工作和信息化建设这两者 的关系上显得并不合理。 怎样以最快的速度让医院获得更加方便的数据收集方式,成为了 相关工作人员急需到的重要工作项目。医院信息收集工作本身具有统 一性,而且所有部分的工作都存有着一定的联系,对于所有医院工作 人员来说,必须要准确的掌握好数据收集工作和信息化建设的关系, 数据库设计工作才能够取得进步。医院的相关负责人若想通过磋商的 办法来解决收集工作和信息化之间的关系,那么就一定要创建出一套 合理的数据库设计规范制度。医院的数据库设计工作在信息化建设中 占据着重要的位置,而从信息收集的角度考虑的话,增强数据库的建设,可以充分展现出其智能化、高效化的重要举措。而且也意味着在
数据库设计和编码规范 Version
目录
简介 读者对象 此文档说明书供开发部全体成员阅读。 目的 一个合理的数据库结构设计是保证系统性能的基础。一个好的规范让新手容易进入状态且少犯错,保持团队支持顺畅,系统长久使用后不至于紊乱,让管理者易于在众多对象中,获取所需或理清问题。 同时,定义标准程序也需要团队合作,讨论出大家愿意遵循的规范。随着时间演进,还需要逐步校订与修改规范,让团队运行更为顺畅。 数据库命名规范 团队开发与管理信息系统讲究默契,而制定服务器、数据库对象、变量等命名规则是建立默契的基本。 命名规则是让所有的数据库用户,如数据库管理员、程序设计人员和程序开发人员,可以直观地辨识对象用途。而命名规则大都约定俗成,可以依照公司文化、团队习惯修改并落实。 规范总体要求 1.避免使用系统产品本身的惯例,让用户混淆自定义对象和系统对象或关键词。 例如,存储过程不要以sp_或xp_开头,因为SQL SERVER的系统存储过程以 sp_开头,扩展存储过程以xp_开头。 2.不要使用空白符号、运算符号、中文字、关键词来命名对象。 3.名称不宜过于简略,要让对象的用途直观易懂,但也不宜过长,造成使用不方 便。 4.不用为数据表内字段名称加上数据类型的缩写。 5.名称中最好不要包括中划线。
6.禁止使用[拼音]+[英语]的方式来命名数据库对象或变量。 数据库对象命名规范 我们约定,数据库对象包括表、视图(查询)、存储过程(参数查询)、函数、约束。对象名字由前缀和实际名字组成,长度不超过30。避免中文和保留关键字,做到简洁又有意义。前缀就是要求每种对象有固定的开头字符串,而开头字符串宜短且字数统一。可以讨论一下对各种对象的命名规范,通过后严格按照要求实施。例如:
任务引入[5分钟] 课程介绍[20分钟] 认识数据库 提问:按自己的理解,说说数据库是什么? 展示各类网站 商城网站页面是大家在熟悉不过的了,商城网站上的商品琳琅满目, 让人流连忘返。但是在大家欣赏自己喜爱的商品之余,是否想过商城网站 上的文字信息、图片信息等存放在哪里呢?当大家在商城网站上进行注册 用户时,自己的信息又存在哪里呢?当客户在商城网站上留言的时候,留 言信息又放在哪里了呢?这就是本门课程——《WEB数据库应用》要解决 的问题。 主要让学生明确以下几个问题: 1.明确课程定位与作用 专业基础课,与《程序设计基础》一起,为《网站建设》奠定基础。 同时兼顾计算机二级考试相关内容。通过任务引领型和项目活动形式,掌 握简单的数据库设计、数据管理和维护方法,能进行web服务器的设置, 具备使用web数据库与高级程序设计语言或动态网页结合完成简单程序 开发的基本职业能力。 2.明确课程内容 内容的确定遵循两个原则:一是满足后续课程的基本需求,二是为学 生进一步的学习提供必要的准备。通过对学生就业岗位和用人单位对本专 业毕业生设置的招聘岗位等分析,课程内容应基本包括数据库系统概述、 关系理论、关系数据库查询语言SQL、数据库设计与关系规范化理论、MySQL 数据中管理系统与高级程序设计语言或动态网页技术结合的简单应用。 3.强调学习方法 (1)与以往《计算机基础》、《办公软件应用》在学习方法上不同, 知识与操作的连续性更强,在学习上要坚持一贯,持之以恒。 提问 展示 展示课程 标准、课程 体系图 与教材配 合
新知识[45分钟] (2)课程难度加大,要求大家认真听、认真做,尤其要认真思考。逐渐养成举一反三的习惯、锻炼独立进行逻辑思维的能力。 (3)要学会自学。 (4)要善于和老师沟通。 (5)要学会团队协作。 4.明确考核方式 (1)日常评价 由三个部分组成:出勒(20%)、学习积极主动性(40%)、任务完成情况(40%) (2)终结评价 平时:20% 期中:20% 期末:40% 一、数据库基本概念 请学生回忆从小学——初中——高中——大学,每个期末处理成绩的过程,大部分都有帮助老师统计分数的经历。提问: 1.你用过哪些方式协助老师统计分数? 2.在这个过程中你发现了什么变化?为什么产生这样的变化? 经过充分的讨论发言之后,让学生总结为什么产生数据库技术,并简单说明其发展阶段: 第一代:网状、层次数据库系统 第二代:关系型数据库系统 第三代:以面向对象模型为主要特征的数据库系统 二、数据库基本概念 1.数据 数据是存储在数据库中的基本对象,包括数字、文字、图形、图像和声音等。 2.数据库 数据库简单地说就是存放数据的仓库。这些数据是按照一定的格式存放在计算的存储设备上。
如果把企业的数据比做生命所必需的血液,那么数据库的设计就是应用中最重要的一部分。有关数据 库设计的材料汗牛充栋,大学学位课程里也有专门的讲述。不过,就如我们反复强调的那样,再好的 老师也比不过经验的教诲。所以我们最近找了些对数据库设计颇有造诣的专业人士给大家传授一些设 计数据库的技巧和经验。我们的编辑从收到的个反馈中精选了其中的个最佳技巧,并把这些 技巧编写成了本文,为了方便索引其内容划分为个部分: 第部分—设计数据库之前 这一部分罗列了个基本技巧,包括命名规范和明确业务需求等。 第部分—设计数据库表 总共个指南性技巧,涵盖表内字段设计以及应该避免的常见问题等。 第部分—选择键 怎么选择键呢?这里有个技巧专门涉及系统生成的主键的正确用法,还有何时以及如何索引字段 以获得最佳性能等。 第部分—保证数据完整性 讨论如何保持数据库的清晰和健壮,如何把有害数据降低到最小程度。 第部分—各种小技巧 不包括在以上个部分中的其他技巧,五花八门,有了它们希望你的数据库开发工作会更轻松一些。 第部分—设计数据库之前 . 考察现有环境 在设计一个新数据库时,你不但应该仔细研究业务需求而且还要考察现有的系统。大多数数据库 项目都不是从头开始建立的;通常,机构内总会存在用来满足特定需求的现有系统(可能没有实 现自动计算)。显然,现有系统并不完美,否则你就不必再建立新系统了。但是对旧系统的研究 可以让你发现一些可能会忽略的细微问题。一般来说,考察现有系统对你绝对有好处。 — 我曾经接手过一个为地区运输公司开发的数据库项目,活不难,用的是数据库。我设置 了一些项目设计参数,而且同客户一道对这些参数进行了评估,事先还查看了开发环境下所采取 的工作模式,等到最后部署应用的时候,只见终端上出了几个提示符然后立马在我面前翘辫子 了!抓耳挠腮的折腾了好几个小时,我才意识到,原来这家公司的网络上跑着两个数据库应用, 而对网络的访问需要明确和严格的用户帐号及其访问权限。明白了这一点,问题迎刃而解:只需 采用客户的系统即可。这个项目给我的教训就是:记住,假如你在诸如或者这 类公共环境下开发应用程序,一定要从表面下手深入系统内部搞清楚你面临的环境到底是怎
数据库设计规范 V 1.0 2007-8-28
目录 1) 目的 (3) 2) 范围 (3) 3) 术语 (3) 4) 设计概要 (3) 5) 命名规范(逻辑对象) (4) 6) 数据库对象命名 (6) 7) 脚本注释 (8) 8) 数据库操作原则 (9) 9) 常用字段命名(参考) (9)
1) 目的 为了统一公司软件开发的设计过程中关于数据库设计时的命名规范和具体工作时的编程规范,便于交流和维护,特制定此规范。 2) 范围 本规范适用于开发组全体人员,作用于软件项目开发的数据库设计、维护阶段。 3) 术语 数据库对象:在数据库软件开发中,数据库服务器端涉及的对象包括物理结构和逻辑结构的对象。 物理结构对象:是指设备管理元素,包括数据文件和事务日志文件的名称、大小、目录规划、所在的服务器计算极名称、镜像等,应该有具体的配置规划。一般对数据库服务器物理设备的管理规程,在整个项目/产品的概要设计阶段予以规划。 逻辑结构对象:是指数据库对象的管理元素,包括数据库名称、表空间、表、字段/域、视图、索引、触发器、存储过程、函数、数据类型、数据库安全性相关的设计、数据库配置有关的设计以及数据库中其他特性处理相关的设计等。 4) 设计概要 ?设计环境 数据库:ORACLE 9i 、MS SQL SERVER 2000 等 操作系统:LINUX 7.1以上版本,显示图形操作界面; RedHat 9 以上版本 WINDOWS 2000 SERVER 以上 ?设计使用工具 使用PowerDesigner 做为数据库的设计工具,要求为主要字段做详尽说 明。对于SQL Server 尽量使用企业管理器对数据库进行设计,并且要求 对表,字段编写详细的说明(这些将作为扩展属性存入SQL Server中) 通过PowerDesigner 定制word格式报表,并导出word文档,作为数据 字典保存。(PowerDesigner v10 才具有定制导出word格式报表的功能)。
数据库设计规范 一、数据库设计过程 数据库技术是信息资源管理最有效的手段。数据库设计是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,有效存储数据,满足用户信息要求和处理要求。 数据库设计中需求分析阶段综合各个用户的应用需求(现实世界的需求),在概念设计阶段形成独立于机器特点、独立于各个dbms产品的概念模式(信息世界模型),用e-r图来描述。在逻辑设计阶段将e-r图转换成具体的数据库产品支持的数据模型如关系模型,形成数据库逻辑模式。然后根据用户处理的要求,安全性的考虑,在基本表的基础上再建立必要的视图(view)形成数据的外模式。在物理设计阶段根据dbms特点和处理的需要,进行物理存储安排,设计索引,形成数据库内模式。 1. 需求分析阶段 需求收集和分析,结果得到数据字典描述的数据需求(和数据流图描述的处理需求)。 需求分析的重点是调查、收集与分析用户在数据管理中的信息要求、处理要求、安全性与完整性要求。 需求分析的方法:调查组织机构情况、调查各部门的业务活动情况、协助用户明确对新系统的各种要求、确定新系统的边界。 常用的调查方法有:跟班作业、开调查会、请专人介绍、询问、设计调查表请用户填写、查阅记录。 分析和表达用户需求的方法主要包括自顶向下和自底向上两类方法。自顶向下的结构化分析方法(structured analysis,简称sa方法)从最上层的系统组织机构入手,采用逐层分解的方式分析系统,并把每一层用数据流图和数据字典描述。 数据流图表达了数据和处理过程的关系。系统中的数据则借助数据字典(data dictionary,简称dd)来描述。 数据字典是各类数据描述的集合,它是关于数据库中数据的描述,即元数据,而不是数据本身。数据字典通常包括数据项、数据结构、数据流、数据存储和处理过程五个部分(至少应该包含每个字段的数据类型和在每个表内的主外键)。 数据项描述={数据项名,数据项含义说明,别名,数据类型,长度, 取值范围,取值含义,与其他数据项的逻辑关系} 数据结构描述={数据结构名,含义说明,组成:{数据项或数据结构}} 数据流描述={数据流名,说明,数据流来源,数据流去向, 组成:{数据结构},平均流量,高峰期流量} 数据存储描述={数据存储名,说明,编号,流入的数据流,流出的数据流, 组成:{数据结构},数据量,存取方式} 处理过程描述={处理过程名,说明,输入:{数据流},输出:{数据流}, 处理:{简要说明}}
1概述 1.1目的 软件研发数据库设计规范作为数据库设计的操作规范,详细描述了数据库设计过程及结果,用于指导系统设计人员正确理解和开展数据库设计。 1.2适用范围 1.3术语定义 DBMS:数据库管理系统,常用的商业DBMS有Oracle, SQL Server, DB2等。 数据库设计:数据库设计是在给定的应用场景下,构造适用的数据库模式,建立数据库及其应用系统,有效存储数据,满足用户信息要求和处理要求。 概念数据模型:概念数据模型以实体-关系 (Entity-RelationShip,简称E-R)理论为基础,并对这一理论进行了扩充。它从用户的观点出发对信息进行建模,主要用于数据库概念级别的设计,独立于机器和各DBMS产品。可以用Sybase PowerDesigner工具来建立概念数据模型(CDM)。 逻辑数据模型:将概念数据模型转换成具体的数据库产品支持的数据模型,如关系模型,形成数据库逻辑模式。可
以用Sybase PowerDesigner工具直接建立逻辑数据模型(LDM),或者通过CDM转换得到。 物理数据模型:在逻辑数据模型基础上,根据DBMS特点和处理的需要,进行物理存储安排,设计索引,形成数据库内模式。可以用Sybase PowerDesigner工具直接建立物理数据模型(PDM),或者通过CDM / LDM转换得到。 2数据库设计原则 按阶段实施并形成该阶段的成果物 一般符合3NF范式要求;兼顾规范与效率 使用公司规定的数据库设计软件工具 命名符合公司标准和项目标准 3数据库设计目标 规范性:一般符合3NF范式要求,减少冗余数据。 高效率:兼顾规范与效率,适当进行反范式化,满足应用系统的性能要求。 紧凑性:例如能用char(10)的就不要用char(20),提高存储的利用率和系统性能,但同时也要兼顾扩展性和可移植性。 易用性:数据库设计清晰易用,用户和开发人员均能容
全国计算机等级考试二级MySQL数据库程序设计考试大纲(2013年版) 基本要求: 1. 初步掌握数据库技术的基本概念、原理、方法和技术; 2. 熟练掌握MySQL 的安装及配置技能; 3. 熟练使用MySQL 平台下的SQL 语言实现数据库的交互操作; 4. 熟悉一种MySQL 平台下的一个应用系统开发的主语言(C/ Perl/ PHP),并初步具备利用该语言进行简单应用系统的开发能力; 5. 掌握MySQL 平台下的数据库管理与维护技术。 考试内容: 一、基本概念与方法 1. DBS 三级(模式、外模式、内模式)结构; 2. DBS 的运行与应用结构(C/ S、B/ S); 3. 关系规范化的基本方法。 二、数据库设计 1. 概念设计; 2. 逻辑设计; 3. 物理设计。 三、SQL 交互操作 利用MySQL 进行数据库表、数据及索引的创建、使用和维护。 四、MySQL 的日常管理 1. MySQL 安装与配置技能; 2. MySQL 的使用及数据访问的安全控制机制; 3. MySQL 数据库的备份和恢复方法; 4. 性能调优技术。 五、MySQL 的应用编程 1. 触发器、事件及存储过程的使用方法; 2. MySQL 平台下的C 语言(或Perl/ PHP)的应用程序编制。 考试方式: 上机考试120 分钟,满分100 分。 上机考试题型及分值: 单项选择题40 分(含公共基础知识部分10 分)、操作题60 分(包括基本操作题、简单应用题及综合应用 题)。
上机考试内容: 1. 考试环境: 数据库管理系统:MySQL 编程语言:C/ Perl/ PHP 2. 在上述环境下完成如下操作: 创建和管理数据库;数据查询;安全管理;数据库备份与恢复;数据导入与导出。 3. 在上述环境下开发C/ S 或B/ S 结构下的一个简单应用系统。
数据库设计的技巧和规范 第1 部分- 设计数据库之前 1、调研客户的工作环境或研究已有的系统 在设计一个新数据库时,你不但应该仔细研究业务需求而且还要考察现有的系统。大多数数据库项目都不是从头开始建立的;通常,机构内总会存在用来满足特定需求的现有系统(可能没有实现自动计算)。显然,现有系统并不完美,否则你就不必再建立新系统了。但是对旧系统的研究可以让你发现一些可能会忽略的细微问题。一般来说,考察现有系统对你绝对有好处。 2、定义标准的对象命名规范 一定要定义数据库对象的命名规范。对数据库表来说,可给表的别名定义简单规则,可用项目缩写来给表名打前缀,如cjgl_S。表内的列[字段]要针对键采用一整套设计规则。比如,如果字段是数字类型,你可以用_n作为后缀;如果是字符类型则可以采用_c后缀。对列[字段]名应该采用标准的前缀和后缀。再如,假如你的表里有好多“money”字段,你不妨给每个列[字段]增加一个_m 后缀。还有,日期列[字段]最好以d_作为名字打头。 3、在物理实践之前进行逻辑设计 在深入物理设计之前要先进行逻辑设计。随着大量的case 工具不断涌现出来,你的设计也可以达到相当高的逻辑水准,你通常可以从整体上更好地了解数据库设计所需要的方方面面。 4、理解客户需求 在你百分百地确定系统从客户角度满足其需求之前不要在你的ER(实体关系)模式中加入哪怕一个数据表。了解你的用户的业务需求可以在以后的开发阶段节约大量的时间。一旦你明确了业务需求,你就可以自己做出许多决策了。
一旦你认为你已经明确了业务内容,你最好同客户进行一次系统的交流。采用客户的术语并且向他们解释你所想到的和你所听到的。同时还应该用可能、将会和必须等词汇表达出系统的关系基数。这样你就可以让你的客户纠正你自己的理解然后做好下一步的ER设计。 看起来这应该是显而易见的事,但需求就是来自客户(这里要从内部和外部客户的角度考虑)。不要依赖用户写下来的需求,真正的需求在客户的脑袋里。你要让客户解释其需求,而且随着开发的继续,还要经常询问客户保证其需求仍然在开发的目的之中。一个不变的真理是:“只有我看见了我才知道我想要的是什么”必然会导致大量的返工,因为数据库没有达到客户从来没有写下来的需求标准。而更糟的是你对他们需求的解释只属于你自己,而且可能是完全错误的。 5、创建数据字典和ER图 一定要花点时间创建ER图和数据字典。其中至少应该包含每个字段的数据类型和在每个表内的主外键。创建ER图和数据字典确实有点费时但对其他开发人员要了解整个设计却是完全必要的。越早创建越能有助于避免今后面临的可能混乱,从而可以让任何了解数据库的人都明确如何从数据库中获得数据。 有一份诸如ER图等最新文档其重要性如何强调都不过分,这对表明表之间关系很有用,而数据字典则说明了每个字段的用途以及任何可能存在的别名。对以后设计SQL语句来说这是完全必要的。 6、创建模式 一张图表胜过千言万语:开发人员不仅要阅读和实现它,而且还要用它来帮助自己和用户对话。模式有助于提高协作效能,这样在先期的数据库设计中几乎不可能出现大的问题。模式不必弄的很复杂;甚至可以简单到手写在一张纸上就可以了。只是要保证其上的逻辑关系今后能产生效益。
G r e e n p l u m数据库设 计开发规范 集团企业公司编码:(LL3698-KKI1269-TM2483-LUI12689-ITT289-
目录
第一章前言 1.1文档目的 随着Greenplum数据库的正式上线使用。为了保证Greenplum 数据仓库系统平台的平稳运行,保证系统的可靠性、稳定性、可维护性和高性能。特制定本开发规范,以规范基于Greenplum数据库平台的相关应用开发,提高开发质量。 1.2预期读者 Greenplum数据仓库平台应用的设计与开发人员; Greenplum 数据仓库平台的系统管理人员和数据库管理员; Greenplum 数据仓库平台的运行维护人员; 1.3参考资料 参考Greenplum4.3.x版本官方指引: 《GPDB43AdminGuide.pdf》 《GPDB43RefGuide.pdf》 《GPDB43UtilityGuide.pdf》
第二章设计规范 2.1数据库对象数量 数据库对象类型包括数据表、视图、函数、序列、索引等等,在Greenplum数据库中,系统元数据同时保存在Master 服务器和Segment 服务器上,过多的数据库对象会造成系统元数据的膨胀,而过多的系统元数据造成系统运行逐步变慢;同时,类似数据库的备份、恢复、扩容等较大型的操作都导致效率变慢。因此,依据GreenplumDB产品的最佳时间,单个数据库的对象数量,应控制在10万以内。 GP数据库的对象包括:表、视图、索引、分区子表、外部表等。 如果数据表的数量太多,建议按应用域进行分库,尽量将单个数据库的表数量控制在10万以内,可以在一个集群中创建多个数据库。 【备注】:在Greenplum数据库中,一张分区表,在数据库中存储为一张父表、每张分区子表都是一张独立的库表;例如:一张按月进行分区的存储一年数据的表,如果含默认分区,共14张表。 2.2表创建规范 为了避免数据库表数量太多,避免单个数据表的数据量过大,给系统的运行和使用带来困难,在Greenplum数据库中需遵循如下的表创建规范: 1、GP系统表中保存的表名称都是以小写保存。通常SQL语句中表名对大小写不敏感。但不允许在建表语句中使用双引号(“”)包括表
- 茶马古道电子商务有限公司 数据库设计规范 V 1.0 版权所有
文档信息 作者: 创建日期(yyyy-mm-dd): 审核者: 审核日期(yyyy-mm-dd): 最后修订者: 最后修订日期(yyyy-mm-dd): 文档类型: 文档修订历史 版本号修订日期修订者修订内容1.0.0 2011.9.20 金洋初始化
数据库约定 对应于XXXX MYSQL数据库环境的数据库类型定义如下表:1 Development Database 开发环境使用 开发环境数据库 2 Quality Assurance Database 质保环境使用 质保环境数据库 3 Production Database 生产环境使用 生产环境数据库 4 Training Database 培训环境使用 培训环境数据库 5 SIT Database 集成测试环境使用集成测试环境数据库 数据库字符集选择UTF8字符集 (建库时确定) 1. 数据库元素命名规范 长度约定:字段名,表名,视图名称等长度不能超过25个字符1.1. 表命名规范 数据类型数据类型(英文)前缀 主数据Master Data Table TM 业务事务处理数据Transaction Data Table TT 关系表Relationship Table TR 代码列表Code List Table TC 接口表Interface Table TI 系统管理表System administration Table TS 日志表Log Table TL 历史表History Table TH 中间临时表Temparory table TE 汇总表Aggregation Table TA 归档表Archivie Table TZ
神州泰岳 数据库设计规范 北京神州泰岳软件股份有限公司2010年11月11日
文档属性 文档变更 文档送呈
目录 1 前言 (6) 2 数据库的设计方法及流程 (7) 2.1 设计方法 (7) 2.2 设计流程 (8) 2.2.1 需求分析阶段 (8) 2.2.2 概念结构设计阶段 (9) 2.2.3 逻辑设计阶段 (9) 2.2.4 物理设计阶段 (9) 2.2.5 数据库实施阶段 (10) 2.2.6 数据库运行维护阶段 (10) 2.2.7 建模工具 (10) 3 数据库设计规范 (11) 3.1 数据库规范化的五个要求 (11) 3.1.1 要求一:表中应该避免可为空的列 (11) 3.1.2 要求二:表不应该有重复的值或者列 (11) 3.1.3 要求三:表中记录应该有一个唯一的标识符 (12) 3.1.4 要求四:数据库对象要有统一的前缀名 (12) 3.1.5 要求五:尽量只存储单一实体类型的数据 (12) 3.2 对象命名规范 (13) 3.2.1 规则 (13) 3.2.2 表命名规范 (14) 3.2.3 字段命名规范 (14) 3.2.4 索引命名规范 (15) 3.2.5 分区命名规范 (16) 3.2.6 视图/物化视图命名规范 (16) 3.2.7 触发器/函数/存储过程命名规范 (17) 3.3 数据库编程规范 (17) 3.3.1 书写规范 (17)
3.3.2 注释规范 (20) 3.3.3 语法规范 (23) 3.3.4 SQL性能规范 (26) 3.3.5 JOB使用规范 (34) 3.4 索引使用规范 (34) 3.4.1 创建索引原则 (34) 3.4.2 索引使用建议 (35) 3.4.3 总结 (40) 3.5 分区表使用规范 (40) 3.6 物理设计规范 (41) 3.6.1 环境配置 (41) 3.6.2 数据库配置 (41) 3.6.3 其他参数配置 (42) 3.6.4 控制文件 (42) 3.6.5 日志文件 (43) 3.6.6 表空间及数据文件设计原则 (43) 4 数据库安全规范 (45) 4.1 用户密码规范 (45) 4.2 用户权限规范 (48) 4.2.1 不同应用分配不同帐号 (48) 4.2.2 删除或锁定无关帐号 (48) 4.2.3 限制SYSDBA远程登录 (48) 4.2.4 限制业务用户权限 (48) 4.2.5 对用户的属性进行控制, (48) 4.2.6 启用数据字典保护 (48) 4.3 数据库监听规范 (49) 4.3.1 需要时为监听设置密码 (49) 4.3.2 需要时设置信任IP集 (49) 5 数据库评审 (50)