
消耗在准备新的SQL语句的时间是Oracle SQL语句执行时间的最重要的组成部分。但是通过理解Oracle内部产生执行计划的机制,你能够控制Oracle花费在评估连接顺序的时间数量,并且能在大体上提高查询性能。
准备执行SQL语句
当SQL语句进入Oracle的库缓存后,在该语句准备执行之前,将执行下列步骤:
1) 语法检查:检查SQL语句拼写是否正确和词序。
2) 语义分析:核实所有的与数据字典不一致的表和列的名字。
3) 轮廓存储检查:检查数据字典,以确定该SQL语句的轮廓是否已经存在。
4) 生成执行计划:使用基于成本的优化规则和数据字典中的统计表来决定最佳执行计划。
5) 建立二进制代码:基于执行计划,Oracle生成二进制执行代码。
一旦为执行准备好了SQL语句,以后的执行将很快发生,因为Oracle认可同一个SQL语句,并且重用那些语句的执行。然而,对于生成特殊的SQL语句,或嵌入了文字变量的SQL 语句的系统,SQL执行计划的生成时间就很重要了,并且前一个执行计划通常不能够被重用。对那些连接了很多表的查询,Oracle需要花费大量的时间来检测连接这些表的适当顺序。
评估表的连接顺序
在SQL语句的准备过程中,花费最多的步骤是生成执行计划,特别是处理有多个表连接的查询。当Oracle评估表的连接顺序时,它必须考虑到表之间所有可能的连接。例如:六个表的之间连接有720(6的阶乘,或6 * 5 * 4 * 3 * 2 * 1 = 720)种可能的连接线路。当一个查询中含有超过10个表的连接时,排列的问题将变得更为显著。对于15个表之间的连接,需要评估的可能查询排列将超过1万亿(准确的数字是1,307,674,368,000)种。
使用optimizer_search_limit参数来设定限制
通过使用optimizer_search_limit参数,你能够指定被优化器用来评估的最大的连接组合数量。使用这个参数,我们将能够防止优化器消耗不定数量的时间来评估所有可能的连接组合。如果在查询中表的数目小于optimizer_search_limit的值,优化器将检查所有可能的连接组合。
例如:有五个表连接的查询将有120(5! = 5 * 4 * 3 * 2 * 1 = 120)种可能的连接组合,因此如果optimizer_search_limit等于5(默认值),则优化器将评估所有的120种可能。optimizer_search_limit参数也控制着调用带星号的连接提示的阀值。当查询中的表的数目比optimizer_search_limit小时,带星号的提示将被优先考虑。
另一个工具:参数optimizer_max_permutations
初始化参数optimizer_max_permutations定义了优化器所考虑组合数目的上限,且依赖于初始参数optimizer_search_limit。optimizer_max_permutations的默认值是80,000。
参数optimizer_search_limit和optimizer_max_permutations一起来确定优化器所考虑的组合数目的上限:除非(表或组合数目)超过参数optimizer_search_limit 或者optimizer_max_permutations设定的值,否则优化器将生成所有可能的连接组合。一旦优化器停止评估表的连接组合,它将选择成本最低的组合。
使用ordered提示指定连接顺序
你能够设定优化器所执行的评估数目的上限。但是即使采用有很高价值的排列评估,我们仍然拥有使优化器可以尽早地放弃复杂的查询的重要机会。回想一下含有15个连接查询的例子,它将有超过1万亿种的连接组合。如果优化器在评估了80,000个组合后停止,那么它才仅仅评估了0.000006%的可能组合,而且或许还没有为这个巨大的查询找到最佳的连接顺序。
在Oracle SQL中解决此问题的最好的方法是手工指定表的连接顺序。为了尽快创建最小的解决方案集,这里所遵循的规则是将表结合起来,通常优先使用限制最严格的WHERE子句来连接表。
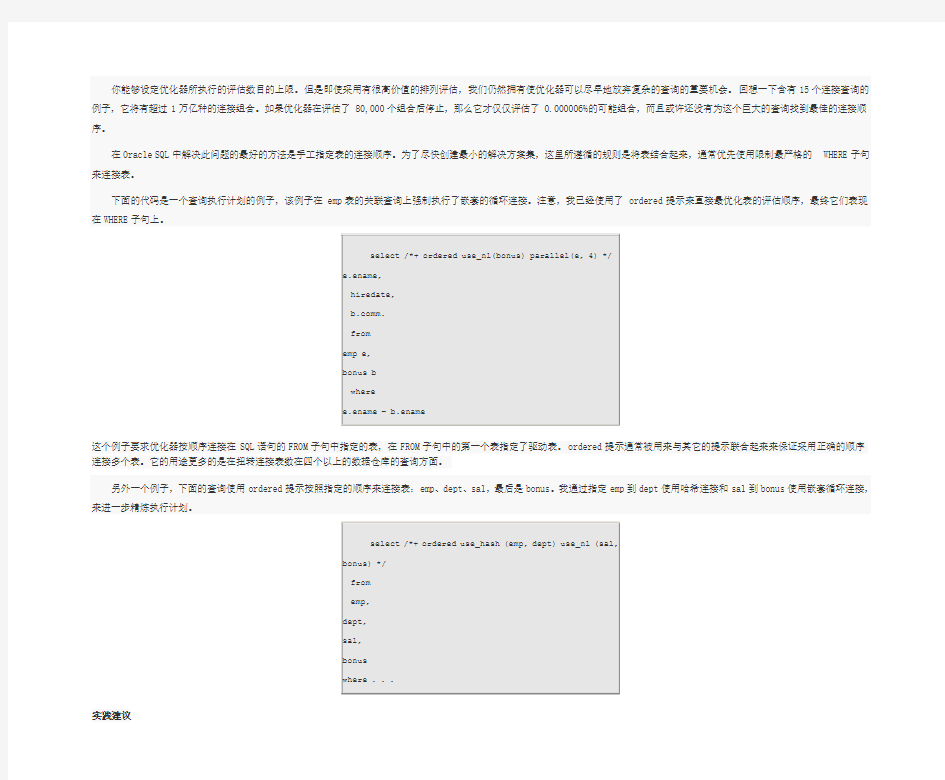
下面的代码是一个查询执行计划的例子,该例子在emp表的关联查询上强制执行了嵌套的循环连接。注意,我已经使用了ordered提示来直接最优化表的评估顺序,最终它们表现在WHERE子句上。
select /*+ ordered use_nl(bonus) parallel(e, 4) */
e.ename,
hiredate,
https://www.doczj.com/doc/854896536.html,m.
from
emp e,
bonus b
where
e.ename = b.ename
这个例子要求优化器按顺序连接在SQL语句的FROM子句中指定的表,在FROM子句中的第一个表指定了驱动表。ordered提示通常被用来与其它的提示联合起来来保证采用正确的顺序连接多个表。它的用途更多的是在扭转连接表数在四个以上的数据仓库的查询方面。
另外一个例子,下面的查询使用ordered提示按照指定的顺序来连接表:emp、dept、sal,最后是bonus。我通过指定emp到dept使用哈希连接和sal到bonus使用嵌套循环连接,来进一步精炼执行计划。
select /*+ ordered use_hash (emp, dept) use_nl (sal,
bonus) */
from
emp,
dept,
sal,
bonus
where . . .
实践建议
实际上,更有效率的做法是在产品环境中减小optimizer_max_permutations参数的大小,并且总是使用稳定的优化计划或存储轮廓来防止出现耗时的含有大量连接的查询。一旦找到最佳的连接顺序,您就可以通过增加ordered提示到当前的查询中,并保存它的存储轮廓,来为这些表手工指定连接顺序,从而使其持久化。
当你打算使用优化器来稳定计划,则可以照下面的方法使执行计划持久化,临时将optimizer_search_limit设置为查询中的表的数目,从而允许优化器考虑所有可能的连接顺序。然后,通过重新编排WHERE子句中表的名字,并使用ordered提示,与存储轮廓一起使变更持久化,来调整查询。在查询中包含四个以上的表时,ordered提示和存储轮廓将排除耗时的评估SQL连接顺序解析的任务,从而提高查询的速度。
一旦检测到最佳的连接顺序,我们就可以使用ordered提示来重载optimizer_search_limit和optimizer_max_permutations参数。ordered提示要求表按照它们出现在FROM子句中的顺序进行连接,所以优化器没有加入描述。
作为一个Oracle专业人员,你应该知道在SQL语句第一次进入库缓存时可能存在重大的启动延迟。但是聪明的Oracle DBA和开发人员能够改变表的搜索限制参数或者使用ordered 提示来手工指定表的连接顺序,从而显著地减少优化和执行新查询所需的时间。
来源:网络编辑:联动北方技术论坛
ORACLE优化总结和注意事项 本文档中对优化方法进行详述,并对在优化过程中发现的一些问题进行总结。列出ORACLE的一些注意事项 注意事项: 1.安装的过程中,请务必进行正确安装。 2.当安装过程中出现错误的时候,最好清除原有遗留信息,进行重装,否则在数据库运行 的过程中可能会出现各种诡异的问题。 3.当数据库安装的过程中如果有警告信息,请记录下来,存档,方便排查数据库问题 4.安装的过程中请选择OLTP的数据模板Transaction Processing 5.安装过程中文件的创建
Controlfile、Datafiles、Redo Log Groups如果条件允许,最好分别放于不同的磁盘上。其中Controlfile和Redo Log Groups要尽量保证放在不同的磁盘上 6.其中Redo Log Groups重做日志组最好建5组以上,每个文件大小在1G以上,最大不超 过3G,避免出现进行check_point的时候造成buffer wait 导致数据库宕机 7.检查/etc/hosts文件 配置最后一行信息,将当前的主机名和ip配对起来,避免应用服务连接数据库导致的性能损耗 8.安装完成后,请启动数据库确保数据库基本安装成功 步骤: sqlplus /nolog connect /as sysdba startup//启动数据库实例 exit//退出sqlplus lsnrctl start//启动监听
emctl start dbconsole 上述步骤如果执行完,没有报错,则说明数据库基本安装正确,并可正常运行。如果执行上述操作的时候出现了问题,则说明数据库安装的过程中出现了某些问题,即使数据库实例当前可以启动连接,但是在以后稳定服务的过程中也是有可能会出现一些数据库问题的。 配置OCI连接 因为当前应用服务采用OCI连接的方式,因此在运行应用服务之前要配置OCI的连接条件 1、需求软件: 如果应用服务是跟ORACLE数据库安装在一台机器上,则不需要额外软件,直接进入第2步即可 如果应用服务是跟ORACLE数据库分开部署,则需要在部署应用服务的机器上安装一个客户端(精简客户端即可大小几M)需要从官方网站下载三个文件instantclient-basic-linux-x86-64-10.2.0.3-20070103.zip instantclient-sqlplus-linux-x86-64-10.2.0.3-20070103.zip instantclient-jdbc-linux-x86-64-10.2.0.3-20070103.zip 解压到同一个目录中,同时在该目录下新建一个文件tnsnames.ora文件,文件中添加以下内容 # Generated by Oracle configuration tools. HMS = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 10.10.15.61)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = hms) ) )
(Oracle管理)Oracle SQL性能优化方法
OracleSQL性能优化方法探讨 Oracle性能优化方法(SQL篇)1 1综述2 2表分区的应用2 3访问Table的方式3 4共享SQL语句3 5选择最有效率的表名顺序5 6WHERE子句中的连接顺序.6 7SELECT子句中避免使用’*’6 8减少访问数据库的次数6 9使用DECODE函数来减少处理时间7 10整合简单,无关联的数据库访问8 11删除重复记录8 12用TRUNCATE替代DELETE9 13尽量多使用COMMIT9 14计算记录条数9 15用Where子句替换HAVING子句9 16减少对表的查询10 17通过内部函数提高SQL效率.11 18使用表的别名(Alias)12 19用EXISTS替代IN12 20用NOT EXISTS替代NOT IN13 21识别低效执行的SQL语句13
22使用TKPROF 工具来查询SQL性能状态14 23用EXPLAIN PLAN 分析SQL语句14 24实时批量的处理16
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要经过反反复复的过程。在数据库建立时,就能根据应用的需要合理设计分配表空间以及存储参数、内存使用初始化参数,对以后的数据库性能有很大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积累经验,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用问题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来说明对数据库性能如何进行优化。 2表分区的应用 对于海量数据的表,可以考虑建立分区以提高操作效率。建立分区一般以关键字为分区的标志,也可以以其他字段作为分区的标志,但效率不如关键字高。建立分区的语句在建表时可以进行说明: createtableTABLENAME(
OracleSQL性能优化方法 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访咨询Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访咨询数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访咨询 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14运算记录条数 (9) 15用Where子句替换HA VING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11) 18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16)
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及储备参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存体会,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用咨询题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建立分区一样以关键字为分区的标志,也能够以其他字段作为分区的标志,但效率不如关键字高。建立分区的语句在建表时能够进行讲明: create table TABLENAME(
ORACLE 数据库性能优化 参考书目: 《ORACLE 9i Database Performance Tuning Guide and Reference》《ORACLE 9i Database Reference》 《ORACLE 9i SQL Reference》 《ORACLE 9i Database Administrator’s Guide》
一、数据库实例创建过程参数确定 在创建数据库实例过程中,需要确定以下几个参数: 1. 数据块大小(DB_BLOCK_SIZE) 该参数指明了ORACLE所处理的数据存贮于数据文档以及SGA内存中的数据块大小。 该参数的可选择的范围为:4k,8k,16k,32k,64k。对于OLTP系统而言,取值可以为4K或8K,对于DSS系统而言,则可以取较大的数据,如32K或64K 建议统一取8K(即8192) 说明 DB_BLOCK_SIZE的大小将影响创建表时的EXTENT的大小。例如指定db_block_size=16K,某表空间的EXTENT MANAGEMENT 为local autoallocate,则其系统将extent的大小最小指定为1M.所以将可能导致空间的浪费。 2. 字符集(Character set) 该参数确定数据库以何种字符集来存贮CHAR以及V ARCHAR、V ARCHAR2等字符类型的值。对于ORACLE数据字典中的字符(如表及字段的COMMENT 内容)具有同样的作用。因此需要考虑如字符集的使用。对于国际项目,因为数据库中的comment内容(包括表及字符、存贮过程中的中文字符等内容)可能性需要以中文存贮,而用户业务数据使用的字符可能性是使用本地的语言,基于此,该参数需要选择支持UNICODE的字符编码的字符集。目前ORACLE9i支持以下二种UNICODE字符集: ?UTF8 ?AL32UTF8 建议统一取AL32UTF8
(O管理)ORACLESL性能优化(内部培训资料)
ORACLESQL性能优化系列(一) 1.选用适合的ORACLE优化器 ORACLE的优化器共有3种: a.RULE(基于规则) b.COST(基于成本) c.CHOOSE(选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS.你当然也在SQL句级或是会话(session)级对其进行覆盖. 为了使用基于成本的优化器(CBO,Cost-BasedOptimizer),你必须经常运行analyze命令,以增加数据库中的对象统计信息(objectstatistics)的准确性. 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze命令有关.如果table已经被analyze过,优化器模式将自动成为CBO,反之,数据库将采用RULE形式的优化器. 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(fulltablescan),你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器.
2.访问Table的方式 ORACLE采用两种访问表中记录的方式: a.全表扫描 全表扫描就是顺序地访问表中每条记录.ORACLE采用一次读入多个数据块(databaseblock)的方式优化全表扫描. b.通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率,,ROWID包含了表中记录的物理位置信息..ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系.通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高. 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在内存中.这块位于系统全局区域SGA(systemglobalarea)的共享池(sharedbufferpool)中的内存可以被所有的数据库用户共享.因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同,ORACLE就能很快获得已经被解析的语句以及最好的执行路
一、SGA 1、Shared pool tunning Shared pool的优化应该放在优先考虑,因为一个cache miss在shared pool中发生比在data buffer中发生导致的成本更高,由于dictionary数据一般比library cache中的数据在内存中保存的时间长,所以关键是library cache的优化。 Gets:(parse)在namespace中查找对象的次数; Pins:(execution)在namespace中读取或执行对象的次数; Reloads:(reparse在执行阶段library cache misses的次数,导致sql需要重新解析。 1)检查v$librarycache中sql area的gethitratio是否超过90%,如果未超过90%,应该检查应用代码,提高应用代码的效率。Select gethitratio from v$librarycache where namespace=’sql area’; 2 v$librarycache中reloads/pins的比率应该小于1%,如果大于1%,应该增加参数shared_pool_size的值。Select sum(pins “executions”,sum(reloads “cache misses”,sum(reloads/sum(pins from v$librarycache; reloads/pins>1%有两种可能,一种是library cache空间不足,一种是sql中引用的对象不合法。 3)shared pool reserved size一般是shared pool size的10%,不能超过50%。 V$shared_pool_reserved中的request misses=0或没有持续增长,或者free_memory 大于shared pool reserved size的50%,表明shared pool reserved size过大,可以压缩。 4)将大的匿名pl/sql代码块转换成小的匿名pl/sql代码块调用存储过程。 5)从9i开始,可以将execution plan与sql语句一起保存在library cache中,方便进行性能诊断。从v$sql_plan中可以看到execution plans。 6)保留大的对象在shared pool中。大的对象是造成内存碎片的主要原因,为了腾出空间许多小对象需要移出内存,从而影响了用户的性能。因此需要将一些常用的大的对象保留在shared pool中,下列对象需要保留在shared pool中: a. 经常使用的存储过程; b. 经常操作的表上的已编译的触发器 c. Sequence,因为Sequence移出shared pool后可能产生号码丢失。查找没有保存在library cache中的大对象: Select * from v$db_object_cache where sharable_mem>10000 and type in ('PACKAGE','PROCEDURE','FUNCTION','PACKAGE BODY' and kept='NO'; 将这些对象保存在library cache中:Execute dbms_shared_pool.keep(‘package_name’; 对应脚本:dbmspool.sql 7查找是否存在过大的匿名pl/sql代码块。两种解决方案:A.转换成小的匿名块调用存储过程 B.将其保留在shared pool中查找是否存在过
Oracle SQL性能优化方法探讨 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访问Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访问数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访问 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14计算记录条数 (9) 15用Where子句替换HAVING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11)
18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16)
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及存储参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存经验,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用问题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建
1.ORACLE的优化器共有3种 A、RULE (基于规则) b、COST (基于成本) c、CHOOSE (选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS 。你当然也在SQL句级或是会话(session)级对其进行覆盖。 为了使用基于成本的优化器(CBO,Cost-Based Optimizer) ,你必须经常运行analyze 命令,以增加数据库中的对象统计信息(object statistics)的准确性。 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze 命令有关。如果table已经被analyze过,优化器模式将自动成为CBO ,反之,数据库将采用RULE 形式的优化器。 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(full table scan) ,你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器。 2.访问Table的方式 ORACLE 采用两种访问表中记录的方式: A、全表扫描 全表扫描就是顺序地访问表中每条记录。ORACLE采用一次读入多个数据块(database block)的方式优化全表扫描。 B、通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率,ROWID包含了表中记录的物理位置信息。ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系。通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高。 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在内存中。这块位于系统全局区域SGA(system global area)的共享池(shared buffer pool)中的内存可以被所有的数据库用户共享。因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同,ORACLE就能很快获得已经被解析的语句以及最好的执行路径。ORACLE的这个功能大大地提高了SQL 的执行性能并节省了内存的使用。 可惜的是ORACLE只对简单的表提供高速缓冲(cache buffering),这个功能并不适用于多表连接查询。 数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越大,就可以保留更多的语句,当然被共享的可能性也就越大了。 当你向ORACLE提交一个SQL语句,ORACLE会首先在这块内存中查找相同的语句。这里需要注明的是,ORACLE对两者采取的是一种严格匹配,要达成共享,SQL语句必须完全相同(包括空格,换行等)。 数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越大,就可以保留更多的语句,当然被共享的可能性也就越大了。 共享的语句必须满足三个条件: A、字符级的比较:当前被执行的语句和共享池中的语句必须完全相同。 B、两个语句所指的对象必须完全相同: C、两个SQL语句中必须使用相同的名字的绑定变量(bind variables)。 4.选择最有效率的表名顺序(只在基于规则的优化器中有效) ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表driving table)将被最先处理。在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。当ORACLE处理多个表时,会运用排序及合并的方式连接它们。首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行派序,然后扫描第二个表(FROM子句中最后第二个表),最后将所有从第二个表中检索出的记录与第一个表中合适记录进行合并。 如果有3个以上的表连接查询,那就需要选择交叉表(intersection table)作为基础表,交叉表是指
ORACLE的优化器共有3种 A、RULE (基于规则) b、COST (基于成本) c、CHOOSE (选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS 。你当然也在SQL句级或是会话(session)级对其进行覆盖。 为了使用基于成本的优化器(CBO, Cost-Based Optimizer) ,你必须经常运行analyze 命令,以增加数据库中的对象统计信息(object statistics)的准确性。 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze命令有关。如果table已经被analyze过,优化器模式将自动成为CBO ,反之,数据库将采用RULE形式的优化器。 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(full table scan) ,你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器。 2.访问Table的方式 ORACLE 采用两种访问表中记录的方式: A、全表扫描 全表扫描就是顺序地访问表中每条记录。ORACLE采用一次读入多个数据块(database block)的方式优化全表扫描。 B、通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率, ROWID 包含了表中记录的物理位置信息。ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系。通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高。 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在存中。这块位于系统全局区域SGA(system global area)的共享池(shared buffer pool)中的存可以被所有的数据库用户共享。因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同, ORACLE就能很快获得已经被解析的语句以及最好的执行路径。ORACLE的这个功能大提高了SQL的执行性能并节省了存的使用。 可惜的是ORACLE只对简单的表提供高速缓冲(cache buffering),这个功能并不适用于多表连接查询。
y物理模型CheckList (Oracle,性能) 1. 系统级优化 数据库参数配置 合理分配SGA及其内部参数(经验值如下): SGA=phy*(60%-80%) Share pool=SAG*45% DB Cache=SGA*45% Log Buffer: 1~3M 注:Oracle9i在Windows下有bug,是由Windows下的SGA最大 值有2G的限制造成的 注意调整process和open cursor参数,这两个参数直接影响 数据库的session量 分离表和索引:将表和索引建立在不同的表空间,决不要将 不属于Oracle内部系统的对象存放到SYSTEM表空间。同 时,确保数据表空间和索引表空间置于不同的硬盘,减少I/O 竞争; 如果是企业版数据库,大表可以考虑采取分区存储措施,提 高系统的性能; 优化Export和Import工作:使用较大的BUFFER(比如10MB , 10,240,000)可以提高EXPORT和IMPORT的速度 定期分析查询计划,提高数据库的性能;
2. 索引相关 要对经常查询的字段建立索引,但是由于索引管理的开销, 在增删改操作频繁的情况下避免建立不必要的索引; 对于只读或者接近只读的场合,如数据仓库,对于势值比较 小的列可以考虑使用bitmap索引; 如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引. 3. SQL相关 Oracle的From子句表的顺序:记录越多的表放在越前面 (左); Oracle的where子句表达式的顺序:过滤掉最大数目记录的条 件放到where子句的末尾; Select子句中避免使用‘*’,增加了查询表的列的开销; 在执行结果等效的情况下,使用Truncate代替Delete; 为了在查询过程中要尽量使用索引,对于like语句避免使用 右匹配或者中间匹配的模糊查询; 将过滤条件尽可能放到Where子句中,而不是放到Having子 句中; 在SQL语句中,要减少对表的查询,特别是在含有子查询的 SQL子句中; 使用表的别名可以减少解析的时间并避免引起歧义; 使用exists替代in; 用NOT EXISTS替代NOT IN; 通常情况下,采用表连接的方式比exists更有效率; 当提交一个包含一对多表信息(比如部门表和雇员表)的查询
个人理解,数据库性能最关键的因素在于IO,因为操作内存是快速的,但是读写磁盘是速度很慢的,优化数据库最关键的问题在于减少磁盘的IO,就个人理解应该分为物理的和逻辑的优化,物理的是指oracle产品本身的一些优化,逻辑优化是指应用程序级别的优化物理优化: 一、优化内存
V$ROWCACHE视图结构
3.管理员可以通过下述语句来查看数据缓冲区的使用情况 select name,value from v$sysstat where name in ('db block gets', 'consistent gets ', 'physical reads'); 数据缓冲区使用命中率(physical reads除以db block gets加consistent gets之和)一定要小于10%,否则需要增加数据缓冲区大小 4.管理员可以通过执行下述语句,查看日志缓冲区的使用情况 select name,value from v$sysstat where name in ('redo entries','redo log space requests') 根据查询出的结果可以计算出日志缓冲区的申请失败率:requests除以entries 申请失败率应该解决与0,否则说明日志缓冲区开设太小,需要增加Oracle数据库的日志缓冲区 二、物理I/0的优化 1.在磁盘上建立数据文件前首先运行磁盘碎片整理程序 为了安全地整理磁盘碎片,需关闭打开数据文件的实例,并且停止服务。如果有足够的连续磁盘空间建立数据文件,那么就容易避免数据文件产生碎片。 2.不要使用磁盘压缩(Oracle文件不支持磁盘压缩) 3.不要使用磁盘加密
理解Oracle的日志机制 ? Oracle的日志是用来记录用户对数据库的改变,这样,当出现服务器硬件故障或者用户错误而丢失数据时,可以通过重做这些日志来恢复已提交的事务,Oracle日志机制包含以下组件: ?日志缓存SGA的一部分,用于缓存服务器进程产生的日志,包括DML和DDL; ? LGWR进程这个后台进程负责将日志缓存的数据写到联机日志文件,每个实例只有一个; ?数据库检查点检查点用于同步数据文件和日志文件,一个检查点事件的完成,代表在这个事件开始之前发生的所有对数据文件的改变都已实际记录到了数据文件,数据库在这个时间点是一致的,在实例恢复的时候,只有在最后一个检查点之后的日志才需要重做; ?联机日志文件用于存放从日志缓存中写出的日志数据,每个数据库最少需要两个日志文件,当前日志文件填满以后,发生日志切换,然后才可以继续写下一个日志文件; ?日志归档LGWR写满所有组的联机日志文件以后,会回头再写第一个组的日志文件,在非归档模式下,被重用的日志文件中的日志会被丢弃,在归档模式下,日志文件被重用前会被ARC0进程复制到归档日志文件; ? 一些可选的日志机制,如归档和Standby,因为附加的I/O会降低系统的性能,同时提供了可靠的灾难恢复能力,不建议因这些性能的下降而关闭生产系统的归档功能。 调整日志缓存 ? 日志缓存的管理机制可以类似理解成一个漏斗,日志数据不断地从漏斗上方加入,然后偶尔打开漏斗下方的开关将加入的数据清空,这个开关就是LGWR进程,为了日志缓存有空间容纳不断加进来的日志数据,LGWR在下面列出的任何一个条件下都会执行写出日志缓存的操作: ?应用程序发出Commit命令时; ?三秒间隔已到时; ?日志缓存三分之一满时; ?日志缓存达到1M时; ?数据库检查点发生时; ? 测量日志缓存的性能通过服务器进程放置日志条到日志缓存时发生等待的次数和时间来测量; Select Name, Value From V$sysstat Where Name In ('redo entries', 'redo buffer allocation retries','redo log space requests'); redo entries 服务器进程放进日志缓存的日志条的总数量; redo buffer allocation retries 服务器放置日志条时必须等待然后再重试的次数; redo log space requests LGWR进程写出日志缓存时等待日志切换的次数; 这个查询用于计算日志缓存重试率,这个比率应该小于百分之一; Select Retries.Value / Entries.Value "Redo log Buffer Retry Ratio" From V$sysstat Entries, V$sysstat Retries Where https://www.doczj.com/doc/854896536.html, = 'redo entries' And https://www.doczj.com/doc/854896536.html, = 'redo buffer allocation retries'; 这个查询用来显示哪些会话的LGWR正在进行写等待;
ORACLE SQL性能优化 我要讲的题目是Oracle SQL性能优化,只是Oracle性能优化中的一项。Oracle的性能优化包含很多方面,比如调整物理存取,调整逻辑存取,调整内存使用,减少网络流量等。这里选择SQL性能优化是因为这部分内容我们测试人员最容易接触到,另外开发人员写SQL脚本时有时很随意,不知不觉就会造成程序性能上的下降。 1.选择最有效率的表名顺序(只在基于规则的优化器中有效) ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表 driving table)将被最先处理. 在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基 础表.当ORACLE处理多个表时, 会运用排序及合并的方式连接它们.首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行派序,然后扫描 第二个表(FROM子句中最后第二个表),最后将所有从第二个表中检索出 的记录与第一个表中合适记录进行合并. 例如: 表 TAB1 16,384 条记录 表 TAB2 1 条记录 选择TAB2作为基础表 (最好的方法) select count(*) from tab1,tab2 执行时间0.96秒 选择TAB2作为基础表 (不佳的方法)
select count(*) from tab2,tab1 执行时间26.09秒 如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表. 例如: EMP表描述了LOCATION表和CATEGORY表的交集. SELECT * FROM LOCATION L , CATEGORY C, EMP E WHERE E.EMP_NO BETWEEN 1000 AND 2000 AND E.CAT_NO = C.CAT_NO AND E.LOCN = L.LOCN 将比下列SQL更有效率 SELECT * FROM EMP E , LOCATION L , CATEGORY C WHERE E.CAT_NO = C.CAT_NO AND E.LOCN = L.LOCN AND E.EMP_NO BETWEEN 1000 AND 2000 2.WHERE子句中的连接顺序. ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾.
--数据库巡检或性能优化方法各异,但首要的是要发现数据库性能瓶颈,系统自带的statspack,或awr太耗时, --以下是本人常用的方法,共享之 --1、查询数据库等待事件top10,关注前前几个等待事件,关注前三个等待事件是否有因果或关联关系 --oracle 9i select t2.event,round(100*t2.time_waited/(t1.w1+t3.cpu),2) event_wait_percent from ( SELECT SUM(time_waited) w1 FROM v$system_event WHERE event NOT IN ('smon timer','pmon timer','rdbms ipc message','Null event','parallel query dequeue','pipe get', 'client message','SQL*Net message to client','SQL*Net message from client','SQL*Net more data from client', 'dispatcher timer','virtual circuit status','lock manager wait for remote message','PX Idle Wait', 'PX Deq: Execution Msg','PX Deq: Table Q Normal','wakeup time manager','slave wait','i/o slave wait', 'jobq slave wait','null event','gcs remote message','gcs for action','ges remote message','queue messages') ) t1, (select * from ( select t.event,t.total_waits,t.total_timeouts,t.time_waited,t.average_wait,rownum num from (select event,total_waits,total_timeouts,time_waited,average_wait from v$system_event where event not in ('smon timer','pmon timer','rdbms ipc message','Null event','parallel query dequeue','pipe get', 'client message','SQL*Net message to client','SQL*Net message from client','SQL*Net more data from client', 'dispatcher timer','virtual circuit status','lock manager wait for remote message','PX Idle Wait', 'PX Deq: Execution Msg','PX Deq: Table Q Normal','wakeup time manager','slave wait','i/o slave wait', 'jobq slave wait','null event','gcs remote message','gcs for action','ges remote message','queue messages') order by time_waited desc ) t) where num<11) t2, (SELECT VALUE CPU FROM v$sysstat WHERE NAME LIKE 'CPU used by this session' ) t3 --oracle10g select t2.event,round(100*t2.time_waited/(t1.w1+t3.cpu),2) event_wait_percent from ( SELECT SUM(time_waited) w1 FROM v$system_event WHERE event NOT IN ('smon timer','pmon timer','rdbms ipc message','Null event','parallel query dequeue','pipe get','client message','SQL*Net message to client','SQL*Net message from client','SQL*Net more data from client','dispatcher timer','virtual circuit status','lock manager wait for remote message','PX Idle Wait','PX Deq: Execution Msg','PX Deq: Table Q Normal','wakeup time manager','slave wait', 'i/o slave wait','jobq slave wait','null event','gcs remote message','gcs for action','ges remote
个人理解,数据库性能最关键的因素在于IO,因为操作存是快速的,但是读写磁盘是速度很慢的,优化数据库最关键的问题在于减少磁盘的IO,就个人理解应该分为物理的和逻辑的优化,物理的是指oracle产品本身的一些优化,逻辑优化是指应用程序级别的优化 物理优化: 一、优化存
3.管理员可以通过下述语句来查看数据缓冲区的使用情况 select name,value from v$sysstat where name in('db block gets','consistent gets','physica l reads'); 数据缓冲区使用命中率(physical reads除以db block gets加consistent gets之和)一定要小于10%,否则需要增加数据缓冲区大小 4.管理员可以通过执行下述语句,查看日志缓冲区的使用情况 select name,value from v$sysstat where name in ('redo entries','redo log space requests') 根据查询出的结果可以计算出日志缓冲区的申请失败率:requests除以entries 申请失败率应该解决与0,否则说明日志缓冲区开设太小,需要增加Oracle数据库的日志缓冲区 二、物理I/0的优化 1.在磁盘上建立数据文件前首先运行磁盘碎片整理程序 为了安全地整理磁盘碎片,需关闭打开数据文件的实例,并且停止服务。如果有足够的连续磁盘空间建立数据文件,那么就容易避免数据文件产生碎片。 2.不要使用磁盘压缩(Oracle文件不支持磁盘压缩) 3.不要使用磁盘加密 加密像磁盘压缩一样加了一个处理层,降低磁盘读写速度。如果担心自己的数据可能泄露,可以使用dbms_obfuscation包和label security选择性地加密数据的敏感部分 4.使用RAID raid使用应注意: 选择硬件raid超过软件raid;日志文件不要放在raid5卷上,因为raid5读性能高而写性能差;把日志文件和归档日志放在与控制文件和数据文件分离的磁盘控制系统上 5.分离页面交换文件到多个磁盘物理卷 跨越至少两个磁盘建立两个页面文件。可以建立四个页面文件并在性能上受益,确保所有页面文件的大小之和至少是物理存的两倍。
Oracle性能优化学习心得 一,优化总的原则 1,查看系统的使用情况 2,查看SGA分配情况,结合系统具体情况进行分析。 3,表的设计分析 4,SQL语句分析 实施要则 1,查看系统的使用情况,CPU占用,内存,I/O读取等 Oracle10G提供的Oracle Enterprise Manager图形化工具中的ADDM 和SQL Tuning Advisor等可以方便的查看系统状况 2,OPS上负载均衡,不同查询用不同Instance 3,提供脚本查看SGA使用情况 4,分析SQL执行情况(trace及其他工具) 实施细节 1,外部调整:我们应该记住Oracle并不是单独运行的。因此我们将查看一下通过调整Oracle服务器以得到高的性能。 2,Row re-sequencing以减少磁盘I/O:我们应该懂得Oracle调优最重要的目标是减少I/O。 3,Oracle SQL调整。Oracle SQL调整是Oracle调整中最重要的领域之一,只要通过一些简单的SQL调优规则就可以大幅度地提升SQL语句的性能,这是一点都不奇怪的。 4,调整Oracle排序:排序对于Oracle性能也是有很大影响的。 5,调整Oracle的竞争:表和索引的参数设置对于UPDATE和INSERT的性能有很大的影响。 二,调优分类: 对Oracle数据库进行性能调整时,应当按照一定的顺序进行,因为系统在前面步骤中进行的调整可以避免后面的一些不必要调整或者代价很大的调整。一般来说可以从两个阶段入手: 1、设计阶段:对其逻辑结构和物理结构进行优化设计,使之在满足需求条件的情况下,系统性能达到最佳,系统开销达到最小; 2、数据库运行阶段:采取操作系统级、数据库级的一些优化措施来使系统性能最佳; ㈠设计阶段: A,数据库设计优化 较多修改较少查询的数据和较多查询较少修改的数据分别对待。 a,结构优化 1,根据应用程序进行数据库设计。 即应用程序采用的是传统的C/S两层体系结构,还是B/W/D三层体系结构。不同的应用程序体系结构要求的数据库资源是不同的。 2,遵循3大范式规范化数据结构,减少不必要的冗余。 3,反规范设计,增加必要冗余,提高查询速度。 4,针对变化较少的数据,合理创建临时表和视图,需注意对临时表和视图的及时同步更新