2012/5/22(计量软件)
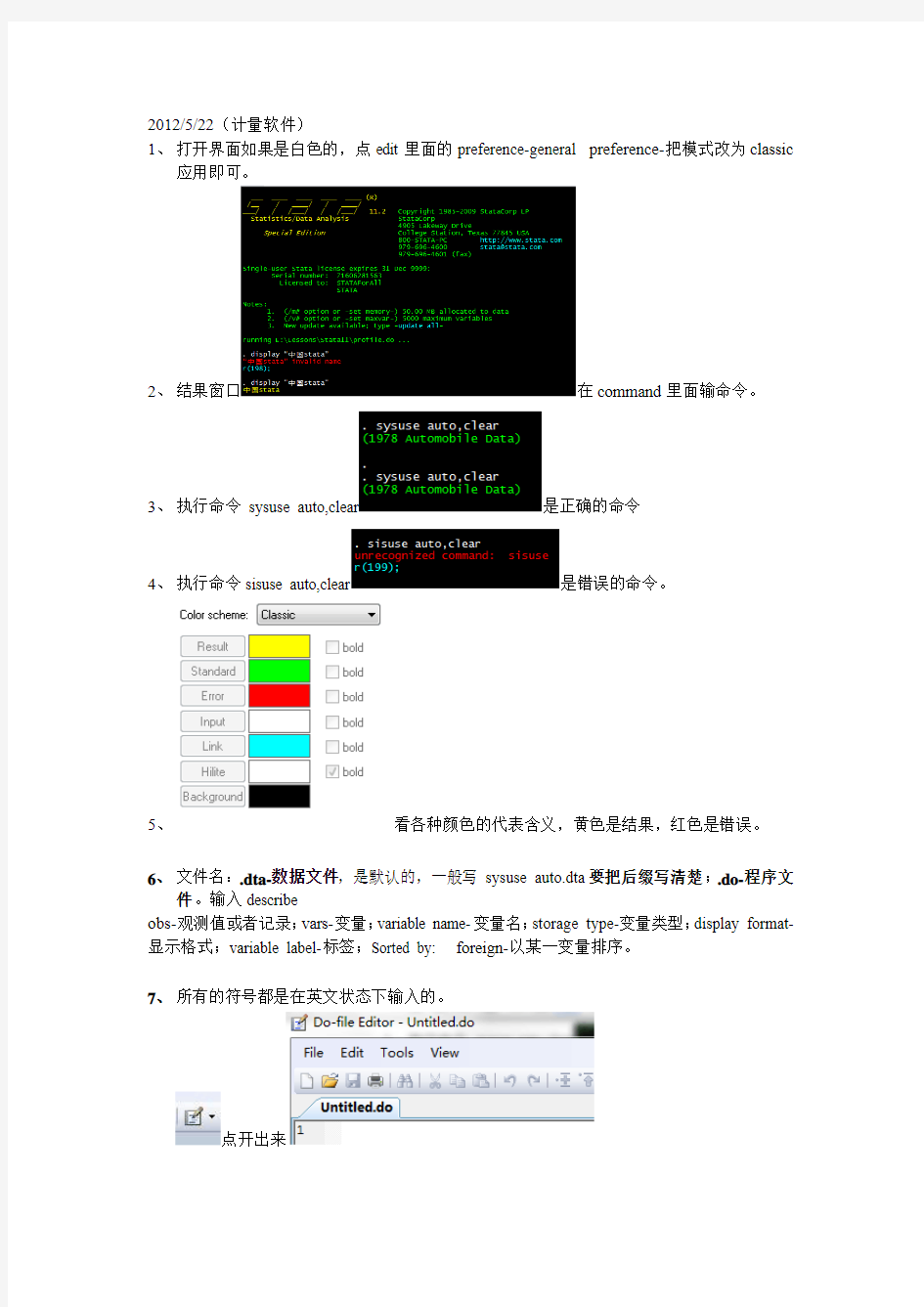
1、打开界面如果是白色的,点edit里面的preference-general preference-把模式改为classic
应用即可。
2、结果窗口在command里面输命令。
3、执行命令sysuse auto,clear是正确的命令
4、执行命令sisuse auto,clear是错误的命令。
5、看各种颜色的代表含义,黄色是结果,红色是错误。
6、文件名:.dta-数据文件,是默认的,一般写sysuse auto.dta要把后缀写清楚;.do-程序文
件。输入describe
obs-观测值或者记录;vars-变量;variable name-变量名;storage type-变量类型;display format-显示格式;variable label-标签;Sorted by: foreign-以某一变量排序。
7、所有的符号都是在英文状态下输入的。
点开出来
8、在commond里面输clear,在Do-file里输sysuse auto,clear然后点击执行。
输入命令,可以只选择几个命令来执行。
9.记住这些命令表示符号取余运算;int()取整;sqrt(开方);abs();ln()
数据类型:byte(字节,只要一位);int;long(长整型);double;float(可有小数)从左到右所占空间越来越大,表示数字范围越大。
10.帮助手册help describe里面的中括号describe [varlist] [,memory_options]里面都是可选的,即可写可不写;黑色的是不能变的,蓝色的是自己写的。主体和Option之间是用逗号分隔的,其他都是以空格分隔。
11.Pwd-系统工作目录,文件操作-insheet using d:\stata\1.txt(将这一文件读出来)通过路径-文件来写。凡有文件夹的地方用右斜线(\)来写文件目录,将路径,文件全部用引号引起来,代表是一个整体部分;一定要把文件的后缀名写清楚。
12.in-memory:当前内存,现在所有的操作都在内存里操作,然后再保存在磁盘里。
13.看help里面的Examples
14.E:\Lessons\Stata11\ado\plus – O文件里面的help outreg(是自己安装的)就可以与describe一样执行命令。(ado存放的是系统文件)
15.findit outreg如果想不起来某一命令,只知道大致的,就可以用此命令进行模糊查找。
16.在findit outreg里面找stb,只有stb里面的可以下载安装。
点click here to install 重新安装ado里面的O文件help outreg
17.输入update然后再输update query最后是update all,三个命令,升级系统。
2012/5/23
保存文件是的时候一定不能乱加符号,可以用下划线,不要用点,空格或者其他的符号。
1.文本文件制表符分隔是stata可识别的文件
输入help insheet 了解命令写法。
命令格式:insheet [varlist] using filename [, options] filename是文件名,中括号里面的可写可不写,不过最好写着。其他都是必须要写的。
重要:都在do文档里输,do文档里面的命令必须逻辑连贯,从同到尾要读通。
输入命令 insheet using E:\Lessons\Stata11\数据\2005年\2005.1.txt 将数据导入。输入命令 browse 查看数据。
输入命令 describe 看数据性质
输入命令 save E:\Lessons\Stata11\数据\2005年\2005.1.dta 保存数据(可以不写.dta 他是默认格式)
2.stata一次只能读入一个数据
现在导入第二个数据:
输入命令 insheet using E:\Lessons\Stata11\数据\2005年\2005.2.txt
出现错误:you must start with an empty dataset(要先把之前的命令清空才可以)
因此输入命令 clear 或者输入 insheet using E:\Lessons\Stata11\数据\2005年
\2005.2.txt,clear(逗号前是主体,逗号后是option)
只执行这一条
或者:
输入insheet using E:\Lessons\Stata11\数据\2005年\2005.1.txt,clear save E:\Lessons\Stata11\数据\2005年\2005.1.dta,replace(将已存在文件覆盖掉)insheet using E:\Lessons\Stata11\数据\2005年\2005.2.txt,clear
三条一起执行
再次输入命令 save E:\Lessons\Stata11\数据\2005年\2005.2.dta保存第二个数据
3.Do文档里面的绿色字体不会被执行。(先输入*)用这种方式直接在do文档里写注释。
4.完成所有数据保存insheet using E:\Lessons\Stata11\数据\2006年\2006.txt,clear
save E:\Lessons\Stata11\数据\2006年\2006.dta
insheet using E:\Lessons\Stata11\数据\2007年\2007.txt,clear
save E:\Lessons\Stata11\数据\2007年\2007.dta
一条条执行。
5.用stata把数据合并,这些数据必须是.dta的格式,所以要先一个个把数据导入。
现在是相同变量,因为他们的变量名是相同的,因此合并数据只是增加观测值。
输入命令 help append 了解其意思
合并的命令是append
先打开一个文件,打开.dta文件用use,打开其他格式的文件用的是insheet using
(use和insheet后面最好都要加一个,clear防止之前的数据没被清空而出错。)
先输入打开命令use E:\Lessons\Stata11\数据\2005年\2005.1.dta,clear
合并命令 append using E:\Lessons\Stata11\数据\2005年\2005.2.dta
将2005年的两个数据合并
继续输入命令 append using E:\Lessons\Stata11\数据\2006年\2006.dta
append using E:\Lessons\Stata11\数据\2007年\2007.dta
将2006年和2007年的数据与前面的数据再合并
保存数据 save E:\Lessons\Stata11\数据\全三年交易数据.dta
6.输入命令 clear(每次一定都要clear,但是他不可逆,清空之前保存。)
输入命令 set mem 900m(分配900兆的内存) mem是memory的简写。900后面一定要加m 代表兆,因为他默认的是kb
7.循环
foreach –for循环
forvalues
while –while循环
循环命令:共四行
foreach file in 2005.1 2005.2 2006 2007{
insheet using E:\Lessons\Stata11\数据\lesson1\txt\\`file'.txt,clear读取数据save E:\Lessons\Stata11\数据\lesson1\txt\\`file'.dta,replace保存数据
}
file in 2005.1 2005.2 2006 2007取四个变量,大括号里面是两个命令,第一个是读数据,第二个是存数据,四个数据循环执行,一直到四个数据读完为止。
`file'左引号是波浪线键;右引号就是回车键旁边的键
这个过程不断循环。
file是局部宏名,是一个循环变量(他只是一个代号,可以换成其他的,因为现在是对文件的操作,所以用file)
in 取值范围{
命令1循环体
命令2
.
.
.
执行结束后,文件夹里面有四个.dta文件。
8.do文件的前三行一定要输入这三句命令:
clear(清空)
set mem 200m(设置内存)
set more off(滚屏显示)
9.一部分代码写完了最后用回车把他分隔
命令之间的换行用Tab键分隔。
10.输入命令 set more off
输入命令 list stkcd trddt(直接在旁边的点变量就可以了,不用自己输入)这样只显示这三个变量的数据
2012/5/24
第一部分:append(纵向合并)
1.现将今天拷的数据转换成txt格式,并读入stata中保存成dta文件
输入命令:
clear
set mem 200m
set more off(每一次必写)
insheet using E:\Lessons\Stata11\数据\Lesson2\txt\income1.txt
save E:\Lessons\Stata11\数据\Lesson2\txt\income1.dta
insheet using E:\Lessons\Stata11\数据\Lesson2\txt\income2.txt,clear
save E:\Lessons\Stata11\数据\Lesson2\txt\income2.dta
将利润表的两个dta文件合并
输入命令:
append using E:\Lessons\Stata11\数据\Lesson2\txt\income1.dta
save E:\Lessons\Stata11\数据\Lesson2\txt\allincome.dta
2.用循环命令将现金流量表一个个转换成dta格式并一个个保存。
输入命令:
3.用循环命令将现金流量表的三个dta文件合并
首先输入命令:
use E:\Lessons\Stata11\数据\Lesson2\txt\cash1,clear(打开第一个数据)
再输入合并命令:
file后面是取值范围,大括号里是循环命令,即分别将cash2 cash3与cash1合并
save不能写在大括号里面,因为如果这样写的话就是合并一个保存一个,这样是错的,要全部合并完之后再保存。
最后保存数据
一般最后都加个,replace以防出错。
第二部分:date()函数
1.日期表示方式:
1959 12 31 记为第-1天
1960 01 01 记为第0天
1960 01 02 记为第1天
1960 01 31 记为第30天
1960 02 01 记为第31天
2.输入命令:
set obs 4(假定有四个观测值)
gen 是generate生成变量
gen int bday =uniform()*1000-200 生成一个整数型int的变量bday 是变量名
uniform()是一个函数,即生成从0到1的随机数,*1000将范围扩大到0到1000,再减200意思是随机从-200到800之间取四个随机数。
format 改变一个数值的显示形式,即当这个数值是日期的时候可以显示出是哪一年哪一日,(CY是century years的简写,如果不写C的话只显示两位的年份;N代表阿拉伯数字显示的月份;m代表英文简写显示的月份。)
format bday1 %d
format bday2 %dCYND
format bday3 %dCY_N_D
format bday4 %dN_D_CY
format bday5 %dCY_m_D
每一种都是同一日期但是不一样的年月日的表示方法。
命令里的下划线dCY_N_D显示出来的是空格
4.date(变量名,“YMD”)函数
YMD是代表年月日,都要大写
第一个格子里输入变量的名字,是字符型变量;后面一个格子固定是“YMD”
date函数就是将所有的字符型变量反映成stata里面的代表日期的数值型变量
例可以将19600101这一字符串反映成0这一数值
browse里面红色的是字符型变量,不能直接加减;黑色的是数值型变量,可以直接加减。accper在browse里面是代表日期的字符型变量,是红色的
输入命令:
gen date=date(accper,“YMD”)
完成以下转换:将红色的字符型变量转变成黑色的数值型变量
5.要是想看17987代表的到底是哪一天就要改变他的显示形式
format都是以百分号开头,12.0g代表在小数点前可以显示12位数字
输入命令:
将其全部转换成以年月日显示的数值型变量。
format后面只能跟数值型的数据,将其改变成所需要的形式。
输入命令:
gen year=year(date)
将日期中的年份以数值型的数据提取出来,但是要先将字符型的变量变成数值型的。
年月日单独的函数是以g(x)的形式表示;而date函数是以f(x,y)的形式显示的
gen month=month(date)
gen day=day(date)
第三部分:merge(横向合并)
1.看help merge里面的Basic description
2.1:1型的merge,第一个读入的数据是master,用的数据是using
输入命令:(id是唯一确定的变量的名字,1:1代表一个变量只取一个值即id1对应age22 merge 1:1 id using 路径\数据名.dta
3.命令形式:
merge 1:1 varlist using filename [, options]
先打开利润表,然后将现金流量表与他merge
输入命令:
merge 1:1 stkcd accper using E:\Lessons\Stata11\数据\Lesson2\txt\allcash
如果出现错误:
代表在using表即现金流量表里变量与日期字符值不是唯一对应的
所以将命令改为:
merge 1:m stkcd accper using E:\Lessons\Stata11\数据\Lesson2\txt\allcash即可。
其中全部可以matched就显示出数值3;如果master表里有using表里没有,显示1;如果using表里有,master表里没有,显示2.
3.打开利润表,将日期变成数值型数据,并显示成日期型的格式。
输入命令:
4.改变新形成的日期数值型数据的位置,把在最后面的位置换在stkcd后面
输入命令:
order stkcd date
如果输入命令:
sort stkcd accper(意思是先对stkcd排序,再对accper排序,都是以升序排列)
gsort 可以按升序也可以按降序排列,按降序排列的话在变量前加负号即可
gsort -stkcd accper(意思是先stkcd降序排列,再对accper升序排列)
4.输入命令:
duplicates drop stkcd accper,force (意思是对于这两个变量,如果完全相同的话就把后面的删掉,只保留第一个记录) 只要drop后面跟变量就加 force,是强制执行的意思。
最后保存数据:
save E:\Lessons\Stata11\数据\Lesson2\txt\allincome.dta,replace
5.再把现金流量表与利润表merge
先打开现金流量表,然后把字符型的日期转为数值型,并改变其显示形式,以年月日表示:输入命令:
use E:\Lessons\Stata11\数据\Lesson2\txt\allcash.dta,clear
gen date=date(accper,"YMD")
format date %dCY_N_D
然后把数值型的date从最后移到stkcd后面,再把stkcd和date以升序排列
order stkcd date
sort stkcd date
把重复的数据删掉:
duplicates drop stkcd date,force
只保留现金流量表和利润表里面的年报数据,把一些半年报的和季度报的数据删除:
这条命令一定要加在保存命令之前。
keep if month(date)==12(有两个等号哦,一个是赋值号,一个是逻辑号)
只要是逻辑语句都是要双等号,双等号才是真的等号
最后再以1:1的形式将两表合并:
merge 1:1 stkcd date using E:\Lessons\Stata11\数据\Lesson2\txt\allincome
现在是全部匹配的状态。
merge之后如果再重复merge的话会出现错误,提示你
所以一般在merge命令之后直接再紧跟一个命令:drop _merge
即将之前的_merge删除。
保证已写命令全部再次执行时不会出错。
6.以后在写gen date之前先写capture drop date
其作用就是如果在gen date之后的命令有错误,需要全部重新执行时,因为已经生成了date,所以再次执行的时候会有错误,即提示你date已经存在了,所以如果加一条命令:capture drop date,就可以把date删除,然后再生成一个date;
而如果在第一次执行的时候就输入命令:
capture drop date
gen date
虽然这时候还没有date函数,capture 这一函数就可以保证程序不出错,先把后面的命令执行了,即生成date
2012/5/25
1.输入命令:
dir E:\Lessons\Stata11\数据\Lesson3\CSV\*.CSV
dir是反映文件的信息:大小,日期,时间,巴拉巴拉…
2.输出外部文件的命令
log是日志的意思;text是文本类文件
输入命令:
capture log close (一般都直接写在前面,要是打开过log就关闭,如果没打开也先保证后面程序的运行,不会出错。)
log using E:\Lessons\Stata11\数据\Lesson3\log.txt,text replace
dir E:\Lessons\Stata11\数据\Lesson3\CSV\*.CSV
log close
把之前输入到stata里面的文件的信息全部保存输出到E:\Lessons\Stata11\数据\Lesson3 是以log.txt为格式和名字的。
,text replace是防止重复执行的时候出错。
3.因为stata是默认以回车表示一条命令结束,到下一命令,回车的代号是:cr
所以为了读入多个文件,不能横着写,只能竖着写,但是这是一个命令整体,因此要告诉stata,现在的回车不是结束命令,把结束命令换一个符号,换成分号,即
输入命令:
# delimit ;
4.输入命令:
local j=1就是把1赋值给j
local就是生成局部宏的语法,即:local 宏名 =宏的取值
将CSV文件全部读入,保存
输入命令:
local j=`j'+1就是将这些CSV文件全部保存成以1,2,3...为文件名的dta文件。
记得每个命令之后要加“;”因为现在是以;表示命令结束的
最后再输入命令#delimit cr,将命令结束语再换成回车。
如果输入命令:
Local J=`j’-1(执行完最后一次local命令之后,j=2026,这样J表示的就是之前保存的dta文件总数)
6.将前面生成的2025个dta文件合并
用新的for循环:即forvalues i=1/2025{}(即i是从第1个一直取值到第2025个)
输入命令:
先把第2025个dta打开,然后把1到2024个dta与他合并
现在用`i'来代表这些dta文件;且局部宏前面全部都是两个斜线
基本语法与foreach相同,append后面记得加force
2012/5/28
1.计算收益率rit
Dretnd [不考虑现金红利的日个股回报率]
Dsmvosd [日个股流通市值]
先把之前做的全三年交易数据打开
_n是一个向量,取值是1到最后一个,命令本事就是一个循环,n是循环变量
_N是有几个观测值大N就是几。
2.输入命令:
capture drop date
gen date=date(trddt,"YMD")
sort stkcd date
format date %dCY_N_D
先将日期转化成数值型数据,然后用sort命令按照股票代码和日期排序,把原来的数据变成顺序型的,并改变日期显示格式。
可以把trddt删掉,再把date命名成trddt
输入命令:
drop trddt
rename date trddt
输入命令:
将数据按股票代码分组,
sort stkcd
by stkcd :gen rit =clsprc[_n]/clsprc[_n-1]-1
by stkcd就是以股票为分组依据。
命令就是代表:生成一个股票收益率函数,这个函数等于本期收盘价减去前一天收盘价,除以前一天收盘价,这个比值减去1就是这只股票的收益率。开始的时候小n等于1,一直执行到最后一个等于236930,这个命令本身就是一个循环,可以从开始执行到最后一只股票。
执行之后第一条是一个“.”点,代表缺失值,因为第一条之前没有前一天的收盘价。
每一只股票的第一条都是缺失的。
bro dretnd rit 只看这两个变量,两者是相似的,代表计算出的收益率和公司给的原收益率是一样的。但是在这样比较之前一定要先把数据按日期排序,不然就是错误的。
2.计算股票的日算术平均收益率
先算算术平均值,mean()函数就是计算平均值的函数
by date ,sort:egen rmt=mean(rit)
gen后面一般不跟函数,跟的是表达式;如果后面跟的是函数,则用egen
按日期分组,sort:是直接把日期以升序排列。
每只股票的算术平均收益率等于所有股票在某一天的收益率加总除以股票总数。
命令含义:计算所有股票每一天的平均收益率。
股票每一天的平均值都是一样的
3.计算股票日加权平均收益率
Dsmvosd [日个股流通市值]
先计算这一天所有股票的市值总和.
输入命令:
by date ,sort:egen t_dsmvosd=total(dsmvosd)
t_dsmvosd是变量名,随机取得名字。
加逗号是为了分组之前同时sort,把日期以升序排列,如果不这样写的话可以先写sort再换一行写by date。
输入命令:
by date ,sort:gen temp=sum(dsmvosd)
与之前的命令不同的是,total是每一个后面对应的是相同的值,等于从1加到最后一个值的总和;而sum是累加计算,加到最后一个值的时候才和total算出来的是一样的,用的是gen,而不是egen。
计算每只股票当天对应的权重:
gen w= dsmvosd/ t_dsmvosd
计算股票加权收益率就是每只股票的收益率乘以他的权重
gen w_rit=w*rit
再计算市场回报率,即把计算的每只股票的加权收益率全部加总起来,是以日期来分组的,也就是把所有股票每天的值加总。
by date,sort:egen rmt1= total(w_rit)
输入命令:
keep if year(date)>2004&year(date)<2008
keep if markettype==1|markettype==4 (“|”这个符号是或的意思,即市场类型是1或者4,而“&”的意思是与,年份时间既要大于2004又要小于2008年)
keep命令是保留一部分变量,即把数据保留在2005年到2008年,并且把市场类型控制在1和4,即1=上海A 4=深圳A
这句命令要放在生成日期型数值型数据之后,因为keep if year 后面只能跟数值型数据。
drop与keep差不多,一个是保留一部分变量,一个是删除一部分变量,后面跟的命令就是这些要保留或者要删除的变量的范围或者满足条件。
4.周回报率
week()= 第几周
dow()=星期几
day()=第几天
因为stata语言里没有累乘只有累加
(1+r1)(1+r2)(1+r3)…(1+r5)-1
如果把数据用ln函数表示,就可以把连乘的问题转换成连加。
输入命令:
gen week=week(date)
创建一个week函数,把每一天都表示成一年里的第几周。
tab就是把变量的取值在stata里面列表出来。
tab week就是把总共的52周列表出来。
因为每一周的周一和周五的股价波动很大,所以算周收益率的时候把天数换成从第一周的礼拜三到第二周的礼拜二为一个礼拜,这样算出来的收益率更有代表性。
输入命令:
gen year=year(date)
gen lnrit=ln(1+rit)
replace week=week-1 if dow(date)<3
先创建出年的数值型数据
gen lnrit=ln(1+rit)创建ln函数,其值等于收益率加1,将连乘的算法转换成连加
dow(date)<3是如果这一天代表的星期几是小于三的(即为星期一和星期二的时候)把这一天代表的第几周的周数减一,这样得到的就是我们以某一周的星期三为第一天,下一周的星期二为最后一天所代表的一种新的周数。
输入命令:
by stkcd year week,sort:gen week_rit=sum(lnrit)
即以stkcd year week这三个变量分组,把这些组里面的,即每一股票的每一年的每周的lnrit值全部加起来。
输入命令:
replace week_rit=exp(week_rit)-1
最后再把ln函数变成e*ln,再把得到的值减1,得到最终周收益率的结果。
类此于rit,计算rmt的周收益率
输入命令:
capture drop year
gen year=year(date)
gen lnrmt=ln(1+rmt)
by stkcd year week,sort:gen week_rmt=sum(lnrmt)
replace week_rmt=exp(week_rmt)-1
by stkcd year week ,sort:keep if _n==_N
其中不需要再输入:replace week=week-1 if dow(date)<3
不然第一个周数的值就变成-1了。
说明:by stkcd year week,sort:gen week_rmt=sum(lnrmt)
由于sum是累加计算,所以算出来的每一周的周收益率是不一样的,这样才跟每天的数据对应起来,才有意义;而如果用的是total函数的话,算出来的每一周的几个收益率就是一样的。这样我们可以把一周前面的数据都删除,只留下最后一条记录,这条记录就等于用sum 算出来的周收益率。
输入命令:
by stkcd year week ,sort:keep if _n==_N
即把其他数据都删掉,最后只留下每一周的最后一条数据,把其他一样的数据都删除。
_n==_N的意义在于:_n取值是从1到N,现在给n赋值,使他等于N,大N就是最后一个值,即把数据都保留最后一个。
因为每一年的第一周和最后一周的股价波动大,代表性不强,
所以先把无意义的数据,即是.的数据删掉,再把第一周及以前的和最后一周及以后的零散数据都删掉。
输入命令:
drop if week_rit==.|week_rmt==.
drop if week<=1|week>=51
5.单因素模型,求一元回归模型
输入命令:
regress week_rit week_rmt
week_rit是被解释变量;week_rmt(之前用错了,应该用rmt1,即应该用加权平均值)算出来的week_rmt的系数coef0.9866就是CAPM模型里面的贝塔值。
报告结果有三部分,都是计量里面的东西,回去复习。
输入命令:
by stkcd,sort:regress week_rit week_rmt
是对每个公司的回归,不同股票输出不同的贝塔值。
6.在每次by前都记得要sort一下,by后面也要sort一下,而by后面最好加一个by date,sort:
这次大家的结果一致,过程见第五次课改进版!
2012/5/29
1.计算每一年每一公司有多少个分析师对他进行评级
Stkcd:证券代码
Rptdt:报告公布日
Fenddt:预测终止日
Feps:每股收益
Ananm:分析师姓名
2.把四个txt文件导入并转换成dta文件,并全部合并起来。
用之前学过的命令,即foreach循环
3.将两个字符型的日期,一个报告期,一个预测期都转成数值型的日期;
并改变其显示格式,同时将原变量删除,再重命名。
输入命令:
gen date=date(rptdt,"YMD")
format date %dCY_N_D
drop rptdt
rename date rptdt
order stkcd rptdt
gen date=date(fenddt,"YMD")
format date %dCY_N_D
drop fenddt
rename date fenddt
order stkcd rptdt fenddt
并且将生成的两个日期再生成其对应的年变量,分别命名为ryear和fyear
输入命令:
gen ryear=year(rptdt)——报告期年份
gen fyear=year(fenddt)——预测期年份
4.保留ryear和fyear之间的差距在0和1之前的数据,这样的数据准确性比较高
先生成一个变量,这个变量等于两个年份之差
输入命令:
gen apartyear=fyear-ryear
输入命令:
keep if apartyear==0|apartyear==1
即保留apartyear的值为0或者1的数据
5.split命令,以逗号为界把这些变量分开
输入命令:
split ananm,parse(",")
save E:\Lessons\Stata11\数据\Lesson5\计算分析师人数课程\whole.dta,replace
split后面先跟要分离的变量的名字,然后在输入变量分隔的符号。
命令解释:把分析师名字里面每一条记录里的人名都分开来,生成几个新的变量,保证每个变量里面只有一个名字。并将这些数据全部保存到一个dta文件里。
但是现在人名是横向的,要把所有的单个的姓名放到一列里面。
输入命令:
clear all
命令说明:
forvalues i=1(1)6——小括号里面的1代表一个步长,也可以写成1/6
keep stkcd fenddt brokern fpe febit fturnover brokercd fyear ananm`i' rptdt feps fnetpro febitda fcfps ryear apartyear
即把数据中除了ananm的所有变量保留,每次只留下ananm1,或者2,3一直到6,然后将ananm`i’重命名成ananm,并将其保存成以,123456命令的各个dta文件。最后得到六个dta文件。
合并数据:即将以上六个dta文件合并成一个总文件
输入命令:
或者
即先打开第一个文件,再将第2到6个文件与其合并,合并完成后循环结束,然后再保存。
一般以数字命名的dta文件都用forvalues执行循环,这样只需输入i=2/6,不用再输入其单独的名字,比较方便;而如果是其他文件型dta文件则一般用foreach循环。
2012/5/30
接上节课
1.输入命令:
use E:\Lessons\Stata11\数据\Lesson5\计算分析师人数课程\ananm,clear
打开上次保存的合并好的总分析师名字的文件
输入命令:
drop if ananm==""
删掉所有空白的没有意义的数据,记得是双等号
输入命令:
duplicates drop stkcd ryear ananm,force
或者输入:
by stkcd ryear ananm,sort:keep if _n==1
把同一只股票同一报告年份的同一分析师,这三者完全一样的数据删掉,只保留第一个数据。
以上两个命令的结果是一样的,第二个命令的意思就是以股票,年份,人名分组,只保留这些变量里面全部相同的记录里面的第一条,其他都删除。
输入命令:
capture drop ananmber
by stkcd ryear,sort:gen ananumber=_N
或者输入命令:
by stkcd ryear,sort:egen ananumber=count(ananm)
即按照股票代码,报告年份排序,并以这两个变量分类,创建一个变量叫ananumber,让其等于_N,这样就得到每只股票在每一报告期年份所对应的分析师的名字和人数。
2.常用的egen后面跟的函数形式*total()count()sd()mean()p10()p25()median()
新任务:
3.分离列里面的人名和基金代号
首先导入历任基金经理txt文件
输入命令:
clear all
set mem 200m
set more off
insheet using E:\Lessons\Stata11\数据\Lesson7\基金经理\历任基金经理.txt,clear
然后把第一行的表头删掉,输入命令
drop if _n==1
*或者输入:drop in 1(如果删除1到n很多行的话,就输入 drop in 1/n)
把前面两列v1 v2的名字改了,输入命令:
rename v1 fund_id
rename v2 fund_name
4.real()函数可以把字符型的数据转化成数值型的数据
5.substr()是提取字符串的一部分(取子串,第一个变量就是定义母串)
substr(var,1,4)代表从第一个开始提取,一直到第四个
var代表提取的数据是属于哪一个变量,即母串;中间的数字代表要提取的子串是从第几个开始的,最后面的一个数字代表总共要提取的数据个数,即子串的长度。
输入命令:
gen r=real(substr(fund_id,1,1))==.
生成虚拟变量:
r是一个虚拟变量,第一个等号是赋值等号,第二个是逻辑等号,对后面的命令进行判断,这是一个逻辑表达式:
substr(fund_id,1,1)是提取一列变量的第一个数据,只提取这一个:
STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令 εαβit ++=x y it i it 固定效应模型 μβit +=x y it it ε αμit +=it it 随机效应模型 (一)数据处理 输入数据 ●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构 ●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析) ●gen lag_y=L.y /////// 产生一个滞后一期的新变量
gen F_y=F.y /////// 产生一个超前项的新变量 gen D_y=D.y /////// 产生一个一阶差分的新变量 gen D2_y=D2.y /////// 产生一个二阶差分的新变量 (二)模型的筛选和检验 ●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe 对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。 ●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量) (原假设:使用OLS混合模型) ●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0
可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。可见,随机效应模型也优于混合OLS模型。 ●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验) 原假设:使用随机效应模型(个体效应与解释变量无关) 通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下: Step1:估计固定效应模型,存储估计结果 Step2:估计随机效应模型,存储估计结果 Step3:进行Hausman检验 ●qui xtreg sq cpi unem g se5 ln,fe est store fe qui xtreg sq cpi unem g se5 ln,re est store re hausman fe (或者更优的是hausman fe,sigmamore/ sigmaless) 可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。此时,需要采用工具变量法和是使用固定效应模型。
stata save命令 FileSave As 例1. 表1.为某一降压药临床试验数据,试从键盘输入Stata,并保存为Stata格式文件。 STATA数据库的维护 排序 SORT 变量名1 变量名2 …… 变量更名 rename 原变量名新变量名 STATA数据库的维护 删除变量或记录 drop x1 x2 /* 删除变量x1和x2 drop x1-x5 /* 删除数据库中介于x1和x5间的所有变量(包括x1和x5) drop if x<0 /* 删去x1<0的所有记录 drop in 10/12 /* 删去第10~12个记录 drop if x==. /* 删去x为缺失值的所有记录 drop if x==.|y==. /* 删去x或y之一为缺失值的所有记录 drop if x==.&y==. /* 删去x和y同时为缺失值的所有记录 drop _all /* 删掉数据库中所有变量和数据 STATA的变量赋值 用generate产生新变量 generate 新变量=表达式 generate bh=_n /* 将数据库的内部编号赋给变量bh。 generate group=int((_n-1)/5)+1 /* 按当前数据库的顺序,依次产生5个1,5个2,5个3……。直到数据库结束。 generate block=mod(_n,6) /* 按当前数据库的顺序,依次产生1,2,3,4,5,0。generate y=log(x) if x>0 /* 产生新变量y,其值为所有x>0的对数值log(x),当x<=0时,用缺失值代替。 egen产生新变量 set obs 12 egen a=seq() /*产生1到N的自然数 egen b=seq(),b(3) /*产生一个序列,每个元素重复#次 egen c=seq(),to(4) /*产生多个序列,每个序列从1到# egen d=seq(),f(4)t(6) /*产生多个序列,每个序列从#1到#2 encode 字符变量名,gen(新数值变量名) 作用:将字符型变量转化为数值变量。 STATA数据库的维护 保留变量或记录 keep in 10/20 /* 保留第10~20个记录,其余记录删除 keep x1-x5 /* 保留数据库中介于x1和x5间的所有变量(包括x1和x5),其余变量删除keep if x>0 /* 保留x>0的所有记录,其余记录删除
Stata软件基本操作和数据分析入门 第一讲Stata操作入门 张文彤赵耐青 第一节概况 Stata最初由美国计算机资源中心(Computer Resource Center)研制,现在为Stata公司的产品,其最新版本为7.0版。它操作灵活、简单、易学易用,是一个非常有特色的统计分析软件,现在已越来越受到人们的重视和欢迎,并且和SAS、SPSS一起,被称为新的三大权威统计软件。 Stata最为突出的特点是短小精悍、功能强大,其最新的7.0版整个系统只有10M左右,但已经包含了全部的统计分析、数据管理和绘图等功能,尤其是他的统计分析功能极为全面,比起1G以上大小的SAS系统也毫不逊色。另外,由于Stata在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此运算速度极快。 由于Stata的用户群始终定位于专业统计分析人员,因此他的操作方式也别具一格,在Windows席卷天下的时代,他一直坚持使用命令行/程序操作方式,拒不推出菜单操作系统。但是,Stata的命令语句极为简洁明快,而且在统计分析命令的设置上又非常有条理,它将相同类型的统计模型均归在同一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。更为令人叹服的是,Stata语句在简洁的同时又拥有着极高的灵活性,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。
除了操作方式简洁外,Stata的用户接口在其他方面也做得非常简洁,数据格式简单,分析结果输出简洁明快,易于阅读,这一切都使得Stata成为非常适合于进行统计教学的统计软件。 Stata的另一个特点是他的许多高级统计模块均是编程人员用其宏语言写成的程序文件(ADO文件),这些文件可以自行修改、添加和下载。用户可随时到Stata网站寻找并下载最新的升级文件。事实上,Stata的这一特点使得他始终处于统计分析方法发展的最前沿,用户几乎总是能很快找到最新统计算法的Stata程序版本,而这也使得Stata自身成了几大统计软件中升级最多、最频繁的一个。 由于以上特点,Stata已经在科研、教育领域得到了广泛应用,WHO的研究人员现在也把Stata作为主要的统计分析工作软件。 第二节Stata操作入门 一、Stata的界面 图1即为Stata 7.0启动后的界面,除了Windows版本的软件都有的菜单栏、工具栏,状态栏等外,Stata的界面主要是由四个窗口构成,分述如下: 1.结果窗口:位于界面右上部,软件运行中的所有信息,如所执行的命令、执行结果和出错信息等均在这里列出。窗口中会使用不同的颜色区分不同的文本,如白色表示命令,红色表示错误信息。 2.命令窗口:位于结果窗口下方,相当于DOS软件中的命令行,此处用于键入需要执行的命令,回车后即开始执行,相应的结果则会在结果窗口中显示出来。
用help命令熟悉以下命令的功能: cd:(Change directory)改变stata的工作路径 用法:(cd changes the current working directory to the specified drive and directory.) ●指定全路径:cd e:\ ●指定相对路径(如果当前路径已经指向e:\那么下面命令将达到和上面全路 径命令同样效果): ●cd .. 返回上一级目录 dir:(Display filenames)显示当前目录下的文件信息 用法:(list the names of files in the specified,the names of the commands come from names popular on Unix and Windows,filespec may be any valid Mac, Unix, or Windows file path or file)工作列表文件中指定的名称目录,命令的名称来自名字流行的Unix和Windows文件规范可以是任何有效的Mac,Unix或Windows文件路径或文件。 . dir, w . dir *.dta . dir \mydata\*.dta List:(List values of variables)列出指定变量的取值 用法:(st displays the values of variables. If no varlist is specified, the values of all the variables are displayed)列表显示变量的值。如果没有指定varlist,所有的值显示的变量。list [varlist] [if] [in] [, options] . list in 1/10 . list mpg weight . list mpg weight in 1/20 . list if mpg>20 . list mpg weight if mpg>20 . list mpg weight if mpg>20 in 1/10 Describe:(Describe data in memory or in file)描述内存或者文件中的数 据(样本数、变量类型等信息) 用法:(describe produces a summary of the dataset in memory or of the data stored in a Stata-format dataset. For a compact listing of variable names, use describe, simple.) ●描述内存数据: ●描述文件数据:describe [varlist] using filename [, file_options] Use:(Load Stata dataset)调用数据,打开数据文件(以dta结尾)文 件名+.dta 数据读入stata 用法:(use loads into memory a Stata-format dataset previously saved by save. If filename is specified without an extension, .dta is assumed. If your
[推荐] Stata基本操作汇总——常用命令 help和search都是查找帮助文件的命令,它们之间的 区别在于help用于查找精确的命令名,而search是模糊查找。 如果你知道某个命令的名字,并且想知道它的具体使用方法,只须在stata的命令行窗口中输入help空格加上这个名字。回车后结果屏幕上就会显示出这个命令的帮助文件的全部 内容。如果你想知道在stata下做某个估计或某种计算,而 不知道具体该如何实现,就需要用search命令了。使用的 方法和help类似,只须把准确的命令名改成某个关键词。回车后结果窗口会给出所有和这个关键词相关的帮助文件名 和链接列表。在列表中寻找最相关的内容,点击后在弹出的查看窗口中会给出相关的帮助文件。耐心寻找,反复实验,通常可以较快地找到你需要的内容.下面该正式处理数据了。我的处理数据经验是最好能用stata的do文件编辑器记下你做过的工作。因为很少有一项实证研究能够一次完成,所以,当你下次继续工作时。能够重复前面的工作是非常重要的。有时因为一些细小的不同,你会发现无法复制原先的结果了。这时如果有记录下以往工作的do文件将把你从地狱带到天堂。因为你不必一遍又一遍地试图重现做过的工作。在stata 窗口上部的工具栏中有个孤立的小按钮,把鼠标放上去会出
现“bring do-file editor to front”,点击它就会出现do文件编 辑器。 为了使do文件能够顺利工作,一般需要编辑do文件的“头”和“尾”。这里给出我使用的“头”和“尾”。capture clear (清空内存中的数据)capture log close (关闭所有 打开的日志文件)set more off (关闭more选项。如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。你按空格键后再输出下一屏,直到全部输完。如果关闭则中间不停,一次全部输出。)set matsize 4000 (设置矩阵的最大阶数。我用的是不是太大了?)cd D: (进入数据所在的盘符和文件夹。和dos的命令行很相似。)log using (文件名).log,replace (打开日志文件,并更新。日志文件将记录下所有文件运行后给出的结果,如果你修改了文件内容,replace选项可以将其更新为最近运行的结果。)use (文件名),clear (打开数据文件。)(文件内容)log close (关闭日志文件。)exit,clear (退出并清空内存中的数据。) 实证工作中往往接触的是原始数据。这些数据没有经过整理,有一些错漏和不统一的地方。比如,对某个变量的缺失观察值,有时会用点,有时会用-9,-99等来表示。回归时如果 使用这些观察,往往得出非常错误的结果。还有,在不同的数据文件中,相同变量有时使用的变量名不同,会给合并数
STATA命令应用及详细解释(汇总) 调整变量格式: format x1 .3f ——将x1的列宽固定为10,小数点后取三位 format x1 .3g ——将x1的列宽固定为10,有效数字取三位 format x1 .3e ——将x1的列宽固定为10,采用科学计数法 format x1 .3fc ——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符 format x1 .3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符 format x1 %-10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“-”表示左对齐 合并数据: use "C:\Documents and Settings\xks\桌面\2006.dta", clear merge using "C:\Documents and Settings\xks\桌面\1999.dta" ——将1999和2006的数据按照样本(observation)排列的自然顺序合并起来 use "C:\Documents and Settings\xks\桌面\2006.dta", clear merge id using "C:\Documents and Settings\xks\桌面
\1999.dta" ,unique sort ——将1999和2006的数据按照唯一的(unique)变量 id来合并,在合并时对id进行排序(sort) 建议采用第一种方法。 对样本进行随机筛选: sample 50 在观测案例中随机选取50%的样本,其余删除 sample 50,count 在观测案例中随机选取50个样本,其余删除 查看与编辑数据: browse x1 x2 if x3>3 (按所列变量与条件打开数据查看器)edit x1 x2 if x3>3 (按所列变量与条件打开数据编辑器)数据合并(merge)与扩展(append) merge表示样本量不变,但增加了一些新变量;append表示样本总量增加了,但变量数目不变。 one-to-one merge: 数据源自stata tutorial中的exampw1和exampw2 第一步:将exampw1按v001~v003这三个编码排序,并建立临时数据库tempw1 clear use "t:\statatut\exampw1.dta" su
常用到的sta命令 闲话不说了。help和search都是查找帮助文件的命令,它们之间的区别在于help用于查找精确的命令名,而search是模糊查找。如果你知道某个命令的名字,并且想知道它的具体使用方法,只须在sta的命令行窗口中输入help空格加上这个名字。回车后结果屏幕上就会显示出这个命令的帮助文件的全部内容。如果你想知道在sta下做某个估计或某种计算,而不知道具体该如何实现,就需要用search命令了。使用的方法和help类似,只须把准确的命令名改成某个关键词。回车后结果窗口会给出所有和这个关键词相关的帮助文件名和链接列表。在列表中寻找最相关的内容,点击后在弹出的查看窗口中会给出相关的帮助文件。耐心寻找,反复实验,通常可以较快地找到你需要的内容。 下面该正式处理数据了。我的处理数据经验是最好能用sta的do文件编辑器记下你做过的工作。因为很少有一项实证研究能够一次完成,所以,当你下次继续工作时。能够重复前面的工作是非常重要的。有时因为一些细小的不同,你会发现无法复制原先的结果了。这时如果有记录下以往工作的do文件将把你从地狱带到天堂。因为你不必一遍又一遍地试图重现做过的工作。在sta窗口上部的工具栏中有个孤立的小按钮,把鼠标放上去会出现“bring do-file editor to front”,点击它就会出现do文件编辑器。 为了使do文件能够顺利工作,一般需要编辑do文件的“头”和“尾”。这里给出我使用的“头”和“尾”。 /*(标签。简单记下文件的使命。)*/ capture clear(清空内存中的数据) capture log close(关闭所有打开的日志文件) set mem 128m(设置用于sta使用的内存容量) set more off(关闭more选项。如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。你按空格键后再输出下一屏,直到全部输完。如果关闭则中间不停,一次全部输出。) set matsize4000(设置矩阵的最大阶数。我用的是不是太大了?)
第一讲Stata操作入门 第一节概况 Stata最初由美国计算机资源中心(Computer Resource Center)研制,现在为Stata公司的产品,其最新版本为7.0版。它操作灵活、简单、易学易用,是一个非常有特色的统计分析软件,现在已越来 越受到人们的重视和欢迎,并且和SAS、SPSS一起,被称为新的三大权威统计软件。 Stata最为突出的特点是短小精悍、功能强大,其最新的7.0版整个系统只有10M左右,但已经包含了全部的统计分析、数据管理和绘图等功能,尤其是他的统计分析功能极为全面,比起1G以上大小的SAS系统也毫不逊色。另外,由于Stata在分析时是将数据全部读入内存,在计算全部完成后才 和磁盘交换数据,因此运算速度极快。 由于Stata的用户群始终定位于专业统计分析人员,因此他的操作方式也别具一格,在Windows席卷天下的时代,他一直坚持使用命令行/程序操作方式,拒不推出菜单操作系统。但是,Stata的命令语句极为简洁明快,而且在统计分析命令的设置上又非常有条理,它将相同类型的统计模型均归在同 一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。更为令人叹 服的是,Stata语句在简洁的同时又拥有着极高的灵活性,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。 除了操作方式简洁外,Stata的用户接口在其他方面也做得非常简洁,数据格式简单,分析结果输出简洁明快,易于阅读,这一切都使得Stata成为非常适合于进行统计教学的统计软件。 Stata的另一个特点是他的许多高级统计模块均是编程人员用其宏语言写成的程序文件(ADO文件),这些文件可以自行修改、添加和下载。用户可随时到Stata网站寻找并下载最新的升级文件。 事实上,Stata的这一特点使得他始终处于统计分析方法发展的最前沿,用户几乎总是能很快找到最新统计算法的Stata程序版本,而这也使得Stata自身成了几大统计软件中升级最多、最频繁的一个。 由于以上特点,Stata已经在科研、教育领域得到了广泛应用,WHO的研究人员现在也把Stata作为主要的统计分析工作软件。 第二节Stata操作入门 一、Stata的界面 图1即为Stata 7.0启动后的界面,除了Windows版本的软件都有的菜单栏、工具栏,状态栏等外,Stata的界面主要是由四个窗口构成,分述如下: 1.结果窗口 位于界面右上部,软件运行中的所有信息,如所执行的命令、执行结果和出错信息等均在这里列出。窗口中会使用不同的颜色区分不同的文本,如白色表示命令,红色表示错误信息。
Stata统计分析常用命令汇总 一、winsorize极端值处理 范围:一般在1%和99%分位做极端值处理,对于小于1%的数用1%的值赋值,对于大于99%的数用99%的值赋值。 1、Stata中的单变量极端值处理: stata 11.0,在命令窗口输入“findit winsor”后,系统弹出一个窗口,安装winsor模块 安装好模块之后,就可以调用winsor命令,命令格式:winsor var1, gen(new var) p(0.01) 或者在命令窗口中输入:ssc install winsor安装winsor命令。winsor命令不能进行批量处理。 2、批量进行winsorize极端值处理: 打开链接:https://www.doczj.com/doc/7310667175.html,/judson.caskey/data.html,找到winsorizeJ,点击右键,另存为到stata中的ado/plus/目录下即可。命令格式:winsorizeJ var1var2var3,suffix(w)即可,这样会生成三个新变量,var1w var2w var3w,而且默认的是上下1%winsorize。如果要修改分位点,则写成如下格式:winsorizeJ var 1 var2 var3,suffix(w) cuts(5 95)。 3、Excel中的极端值处理:(略) winsor2 命令使用说明 简介:winsor2 winsorize or trim (if trim option is specified) the variables in varlist at particular percentiles specified by option cuts(# #). In defult, new variables will be generated with a suffix "_w" or "_tr", which can be changed by specifying suffix() option. The replace option replaces the variables with their winsorized or trimmed ones. 相比于winsor命令的改进: (1) 可以批量处理多个变量; (2) 不仅可以winsor,也可以trimming; (3) 附加了by() 选项,可以分组winsor 或trimming; (4) 增加了replace 选项,可以不必生成新变量,直接替换原变量。 范例: *- winsor at (p1 p99), get new variable "wage_w" . sysuse nlsw88, clear . winsor2 wage *- left-trimming at 2th percentile . winsor2 wage, cuts(2 100) trim *- winsor variables by (industry south), overwrite the old variables . winsor2 wage hours, replace by(industry south) 使用方法: 1. 请将winsor 2.ado 和winsor2.sthlp 放置于stata12\ado\base\w 文件夹下; 2. 输入help winsor2 可以查看帮助文件;
stata11常用命令 注:JB统计量对应的p大于0.05,则表明非正态,这点跟sktest和swilk 检验刚好相反; dta为数据文件; gph为图文件; do为程序文件; 注意stata要区别大小写; 不得用作用户变量名: _all _n _N _skip _b _coef _cons _pi _pred _rc _weight double float long int in if using with 命令: 读入数据一种方式 input x y 1 4 2 5.5 3 6.2 4 7.7 5 8.5 end su/summarise/sum x 或 su/summarise/sum x,d 对分组的描述: sort group by group:su x %%%%% tabstat economy,stats(max) %返回变量economy的最大值 %%stats括号里可以是:mean,count(非缺失观测值个数),sum(总和),max,min,range, %% sd,var,cv(变易系数=标准差/均值),skewness,kurtosis,median,p1(1%分位 %% 数,类似地有p10, p25, p50, p75, p95, p99),iqr(interquantile range = p75 – p25) _all %描述全部 _N 数据库中观察值的总个数。 _n 当前观察值的位置。 _pi 圆周率π的数值。 list gen/generate %产生数列 egen wagemax=max(wage) clear use by(分组变量)
调整变量格式: format x1 %10.3f ——将x1的列宽固定为10,小数点后取三位 format x1 %10.3g ——将x1的列宽固定为10,有效数字取三位 format x1 %10.3e ——将x1的列宽固定为10,采用科学计数法 format x1 %10.3fc ——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符 format x1 %10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符 format x1 %-10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“-”表示左对齐 合并数据: use "C:\Documents and Settings\xks\桌面\2006.dta", clear merge using "C:\Documents and Settings\xks\桌面\1999.dta" ——将1999和2006的数据按照样本(observation)排列的自然顺序合并起来 use "C:\Documents and Settings\xks\桌面\2006.dta", clear merge id using "C:\Documents and Settings\xks\桌面\1999.dta" ,unique sort ——将1999和2006的数据按照唯一的(unique)变量id来合并,在合并时对id进行排序(sort)建议采用第一种方法。 对样本进行随机筛选: sample 50 在观测案例中随机选取50%的样本,其余删除 sample 50,count 在观测案例中随机选取50个样本,其余删除 查看与编辑数据: browse x1 x2 if x3>3 (按所列变量与条件打开数据查看器) edit x1 x2 if x3>3 (按所列变量与条件打开数据编辑器) 数据合并(merge)与扩展(append) merge表示样本量不变,但增加了一些新变量;append表示样本总量增加了,但变量数目不变。one-to-one merge: 数据源自stata tutorial中的exampw1和exampw2 第一步:将exampw1按v001~v003这三个编码排序,并建立临时数据库tempw1 clear use "t:\statatut\exampw1.dta" su ——summarize的简写 sort v001 v002 v003 save tempw1 第二步:对exampw2做同样的处理 clear use "t:\statatut\exampw2.dta" su sort v001 v002 v003 save tempw2 第三步:使用tempw1数据库,将其与tempw2合并: clear use tempw1 merge v001 v002 v003 using tempw2
面板数据估计 首先对面板数据进行声明: 前面是截面单元,后面是时间标识: tsset company year tsset industry year 产生新的变量:gen newvar=human*lnrd 产生滞后变量Gen fiscal(2)=L2.fiscal 产生差分变量Gen fiscal(D)=D.fiscal 描述性统计: xtdes :对Panel Data截面个数、时间跨度的整体描述 Xtsum:分组内、组间和样本整体计算各个变量的基本统计量 xttab 采用列表的方式显示某个变量的分布 Stata中用于估计面板模型的主要命令:xtreg xtreg depvar [varlist] [if exp] , model_type [level(#) ] Model type 模型 be Between-effects estimator fe Fixed-effects estimator re GLS Random-effects estimator pa GEE population-averaged estimator mle Maximum-likelihood Random-effects estimator 主要估计方法: xtreg: Fixed-, between- and random-effects, and population-averaged linear models xtregar:Fixed- and random-effects linear models with an AR(1) disturbance xtpcse :OLS or Prais-Winsten models with panel-corrected standard errors xtrchh :Hildreth-Houck random coefficients models
stata常用命令 stata save命令 FileSave As 例1. 表1.为某一降压药临床试验数据,试从键盘输入Stata,并保存为Stata格式文件。STATA数据库的维护 排序 SORT 变量名1 变量名2 …… 变量更名 rename 原变量名新变量名 STATA数据库的维护 删除变量或记录 drop x1 x2 /* 删除变量x1和x2 drop x1-x5 /* 删除数据库中介于x1和x5间的所有变量(包括x1和x5) drop if x<0 /* 删去x1<0的所有记录 drop in 10/12 /* 删去第10~12个记录 drop if x==. /* 删去x为缺失值的所有记录 drop if x==.|y==. /* 删去x或y之一为缺失值的所有记录 drop if x==.&y==. /* 删去x和y同时为缺失值的所有记录 drop _all /* 删掉数据库中所有变量和数据 STATA的变量赋值 用generate产生新变量 generate 新变量=表达式 generate bh=_n /* 将数据库的内部编号赋给变量bh。 generate group=int((_n-1)/5)+1 /* 按当前数据库的顺序,依次产生5个1,5个2,5个3……。直到数据库结束。 generate block=mod(_n,6) /* 按当前数据库的顺序,依次产生1,2,3,4,5,0。generate y=log(x) if x>0 /* 产生新变量y,其值为所有x>0的对数值log(x),当x<=0时,用缺失值代替。 egen产生新变量 set obs 12 egen a=seq() /*产生1到N的自然数 egen b=seq(),b(3) /*产生一个序列,每个元素重复#次 egen c=seq(),to(4) /*产生多个序列,每个序列从1到# egen d=seq(),f(4)t(6) /*产生多个序列,每个序列从#1到#2
我常用到的stata命令 最重要的两个命令莫过于help和search了。即使是经常使用stata的人也很难,也没必要记住常用命令的每一个细节,更不用说那些不常用到的了。所以,在遇到困难又没有免费专家咨询时,使用stata自带的帮助文件就是最佳选择。stata的帮助文件十分详尽,面面俱到,这既是好处也是麻烦。当你看到长长的帮助文件时,是不是对迅速找到相关信息感到没有信心? 闲话不说了。help和search都是查找帮助文件的命令,它们之间的区别在于help用于查找精确的命令名,而search是模糊查找。如果你知道某个命令的名字,并且想知道它的具体使用方法,只须在stata的命令行窗口中输入help空格加上这个名字。回车后结果屏幕上就会显示出这个命令的帮助文件的全部内容。如果你想知道在stata下做某个估计或某种计算,而不知道具体该如何实现,就需要用search命令了。使用的方法和help类似,只须把准确的命令名改成某个关键词。回车后结果窗口会给出所有和这个关键词相关的帮助文件名和链接列表。在列表中寻找最相关的内容,点击后在弹出的查看窗口中会给出相关的帮助文件。耐心寻找,反复实验,通常可以较快地找到你需要的内容。 下面该正式处理数据了。我的处理数据经验是最好能用stata的do文件编辑器记下你做过的工作。因为很少有一项实证研究能够一次完成,所以,当你下次继续工作时。能够重复前面的工作是非常重要的。有时因为一些细小的不同,你会发现无法复制原先的结果了。这时如果有记录下以往工作的do文件将把你从地狱带到天堂。因为你不必一遍又一遍地试图重现做过的工作。在stata窗口上部的工具栏中有个孤立的小按钮,把鼠标放上去会出现“bring do-file editor to front”,点击它就会出现do文件编辑器。 为了使do文件能够顺利工作,一般需要编辑do文件的“头”和“尾”。这里给出我使用的“头”和“尾”。 /*(标签。简单记下文件的使命。)*/ capture clear (清空内存中的数据) capture log close (关闭所有打开的日志文件) set mem 128m (设置用于stata使用的内存容量) set more off (关闭more选项。如果打开该选项,那么结果分屏输出,即一次只输出一屏结果。你按空格键后再输出下一屏,直到全部输完。如果关闭则中间不停,一次全部输出。)set matsize 4000 (设置矩阵的最大阶数。我用的是不是太大了?) cd D: (进入数据所在的盘符和文件夹。和dos的命令行很相似。) log using (文件名).log,replace (打开日志文件,并更新。日志文件将记录下所有文件运行后给出的结果,如果你修改了文件内容,replace选项可以将其更新为最近运行的结果。) use (文件名),clear (打开数据文件。) (文件内容)
调整变量格式: format x1 % ——将x1的列宽固定为10,小数点后取三位 format x1 % ——将x1的列宽固定为10,有效数字取三位 format x1 % ——将x1的列宽固定为10,采用科学计数法 format x1 % ——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符 format x1 % ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符 format x1 % ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“-”表示左对齐合并数据: use "C:\Documents and Settings\xks\桌面\", clear merge using "C:\Documents and Settings\xks\桌面\" ——将1999和2006的数据按照样本(observation)排列的自然顺序合并起来 use "C:\Documents and Settings\xks\桌面\", clear merge id using "C:\Documents and Settings\xks\桌面\" ,unique sort ——将1999和2006的数据按照唯一的(unique)变量id来合并,在合并时对id进行排序(sort)建议采用第一种方法。 对样本进行随机筛选: sample 50 在观测案例中随机选取50%的样本,其余删除 sample 50,count 在观测案例中随机选取50个样本,其余删除 查看与编辑数据: browse x1 x2 if x3>3 (按所列变量与条件打开数据查看器) edit x1 x2 if x3>3 (按所列变量与条件打开数据编辑器) 数据合并(merge)与扩展(append) merge表示样本量不变,但增加了一些新变量;append表示样本总量增加了,但变量数目不变。one-to-one merge: 数据源自stata tutorial中的exampw1和exampw2 第一步:将exampw1按v001~v003这三个编码排序,并建立临时数据库tempw1 clear use "t:\statatut\" su ——summarize的简写 sort v001 v002 v003 save tempw1 第二步:对exampw2做同样的处理 clear use "t:\statatut\" su sort v001 v002 v003 save tempw2 第三步:使用tempw1数据库,将其与tempw2合并: clear use tempw1 merge v001 v002 v003 using tempw2 第四步:查看合并后的数据状况:
*********面板数据计量分析与软件实现********* 说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。本人做了一定 的修改与筛选。 *----------面板数据模型 * 1.静态面板模型:FE 和RE * 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验 * 4.动态面板模型(DID-GMM,SYS-GMM) * 5.面板随机前沿模型 * 6.面板协整分析(FMOLS,DOLS) *** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。 * 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA) *** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog 生产函数,一步法与两步法的区别。常应用于地区经济差异、FDI溢出效应(Spillovers Effect)、工业行业效率状况等。 * 空间计量分析:SLM模型与SEM模型 *说明:STATA与Matlab结合使用。常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。 * --------------------------------- * --------一、常用的数据处理与作图----------- * --------------------------------- * 指定面板格式 xtset id year (id为截面名称,year为时间名称) xtdes /*数据特征*/ xtsum logy h /*数据统计特征*/ sum logy h /*数据统计特征*/ *添加标签或更改变量名 label var h "人力资本" rename h hum *排序 sort id year /*是以STATA面板数据格式出现*/ sort year id /*是以DEA格式出现*/ *删除个别年份或省份 drop if year<1992 drop if id==2 /*注意用==*/
stata 常用命令 (2012-07-29 17:22:25) 转载▼ 分类:stata 标签: 杂谈 save命令 FileSave As 例1. 表1.为某一降压药临床试验数据,试从键盘输入Stata,并保存为Stata格式文件。STATA数据库的维护 排序 SORT 变量名1 变量名2 …… 变量更名 rename 原变量名新变量名 STATA数据库的维护 删除变量或记录 drop x1 x2 /* 删除变量x1和x2 drop x1-x5 /* 删除数据库中介于x1和x5间的所有变量(包括x1和x5) drop if x<0 /* 删去x1<0的所有记录 drop in 10/12 /* 删去第10~12个记录 drop if x==. /* 删去x为缺失值的所有记录 drop if x==.|y==. /* 删去x或y之一为缺失值的所有记录 drop if x==.&y==. /* 删去x和y同时为缺失值的所有记录 drop _all /* 删掉数据库中所有变量和数据 STATA的变量赋值 用generate产生新变量 generate 新变量=表达式 generate bh=_n /* 将数据库的内部编号赋给变量bh。 generate group=int((_n-1)/5)+1 /* 按当前数据库的顺序,依次产生5个1,5个2,5个 3……。直到数据库结束。 generate block=mod(_n,6) /* 按当前数据库的顺序,依次产生1,2,3,4,5,0。generate y=log(x) if x>0 /* 产生新变量y,其值为所有x>0的对数值log(x),当x<=0时,用缺失值代替。 egen产生新变量 set obs 12 egen a=seq() /*产生1到N的自然数 egen b=seq(),b(3) /*产生一个序列,每个元素重复#次 egen c=seq(),to(4) /*产生多个序列,每个序列从1到# egen d=seq(),f(4)t(6) /*产生多个序列,每个序列从#1到#2 encode 字符变量名,gen(新数值变量名) 作用:将字符型变量转化为数值变量。