
Hadoop分布式文件系统:架构和设计要点(翻译)
一、前提和设计目标
1、硬件错误是常态,而非异常情况,HDFS可能是有成百上千的server组成,任何一个组件都有可能一直失效,因此错误检测和快速、自动的恢复是HDFS的核心架构目标。
2、跑在HDFS上的应用与一般的应用不同,它们主要是以流式读为主,做批量处理;比之关注数据访问的低延迟问题,更关键的在于数据访问的高吞吐量。
3、HDFS以支持大数据集合为目标,一个存储在上面的典型文件大小一般都在千兆至T字节,一个单一HDFS实例应该能支撑数以千万计的文件。
4、 HDFS应用对文件要求的是write-one-read-many访问模型。一个文件经过创建、写,关闭之后就不需要改变。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。典型的如MapReduce框架,或者一个web crawler应用都很适合这个模型。
5、移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效,这在数据达到海量级别的时候更是如此。将计算移动到数据附近,比之将数据移动到应用所在显然更好,HDFS提供给应用这样的接口。
6、在异构的软硬件平台间的可移植性。
二、Namenode和Datanode
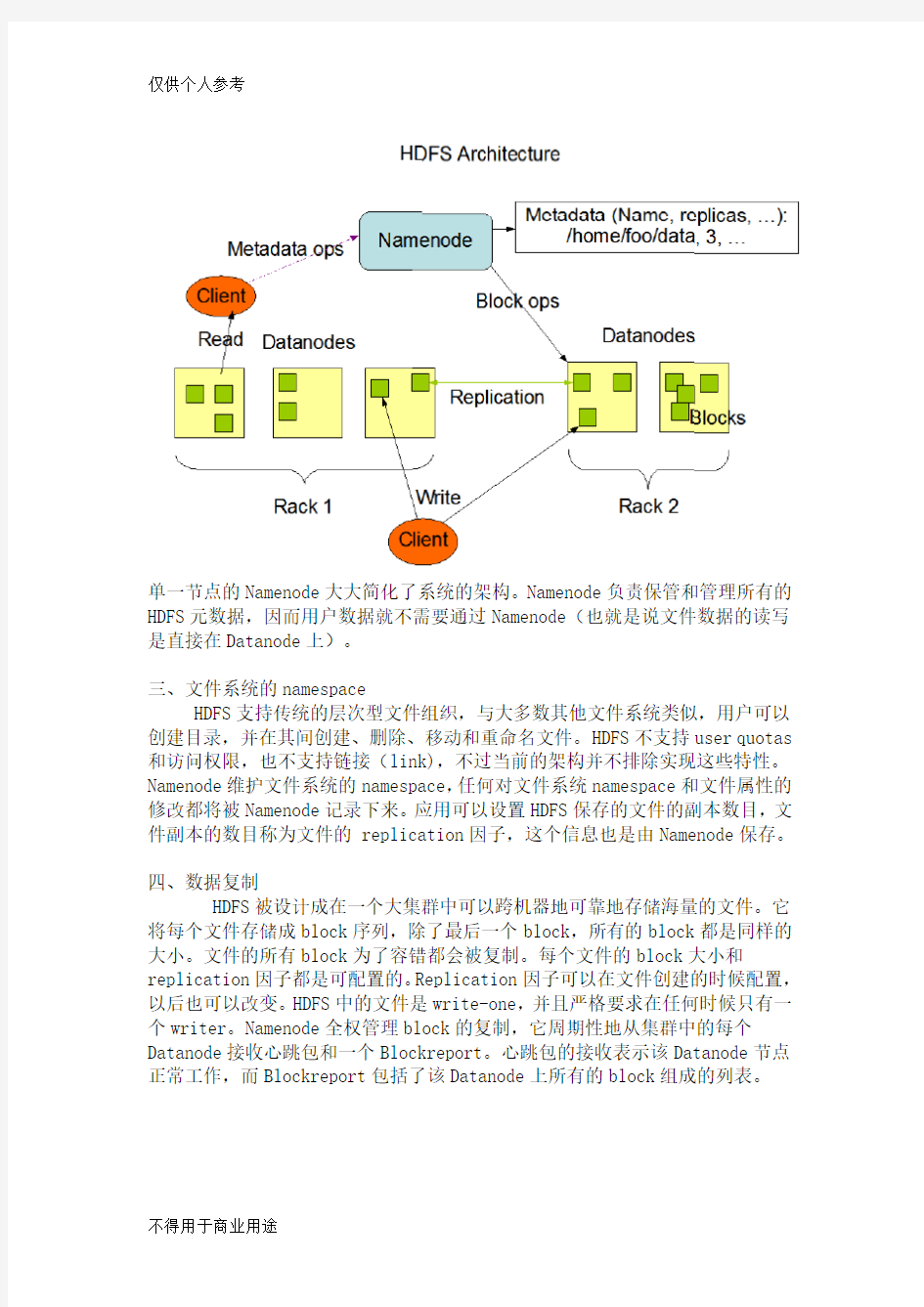
HDFS采用master/slave架构。一个HDFS集群是有一个Namenode和一定数目的Datanode组成。Namenode是一个中心服务器,负责管理文件系统的namespace和客户端对文件的访问。Datanode在集群中一般是一个节点一个,负责管理节点上它们附带的存储。在内部,一个文件其实分成一个或多个block,这些block存储在Datanode集合里。Namenode执行文件系统的namespace操作,例如打开、关闭、重命名文件和目录,同时决定block到具体Datanode节点的映射。Datanode在Namenode的指挥下进行block的创建、删除和复制。Namenode 和Datanode都是设计成可以跑在普通的廉价的运行linux的机器上。HDFS采用java语言开发,因此可以部署在很大范围的机器上。一个典型的部署场景是一台机器跑一个单独的Namenode节点,集群中的其他机器各跑一个Datanode实例。这个架构并不排除一台机器上跑多个Datanode,不过这比较少见。
单一节点的Namenode大大简化了系统的架构。Namenode负责保管和管理所有的HDFS元数据,因而用户数据就不需要通过Namenode(也就是说文件数据的读写是直接在Datanode上)。
三、文件系统的namespace
HDFS支持传统的层次型文件组织,与大多数其他文件系统类似,用户可以创建目录,并在其间创建、删除、移动和重命名文件。HDFS不支持user quotas 和访问权限,也不支持链接(link),不过当前的架构并不排除实现这些特性。Namenode维护文件系统的namespace,任何对文件系统namespace和文件属性的修改都将被Namenode记录下来。应用可以设置HDFS保存的文件的副本数目,文件副本的数目称为文件的 replication因子,这个信息也是由Namenode保存。
四、数据复制
HDFS被设计成在一个大集群中可以跨机器地可靠地存储海量的文件。它将每个文件存储成block序列,除了最后一个block,所有的block都是同样的大小。文件的所有block为了容错都会被复制。每个文件的block大小和replication因子都是可配置的。Replication因子可以在文件创建的时候配置,以后也可以改变。HDFS中的文件是write-one,并且严格要求在任何时候只有一个writer。Namenode全权管理block的复制,它周期性地从集群中的每个Datanode接收心跳包和一个Blockreport。心跳包的接收表示该Datanode节点
正常工作,而Blockreport包括了该Datanode上所有的block组成的列表。
1、副本的存放,副本的存放是HDFS可靠性和性能的关键。HDFS采用一种称为rack-aware的策略来改进数据的可靠性、有效性和网络带宽的利用。这个策略实现的短期目标是验证在生产环境下的表现,观察它的行为,构建测试和研究的基础,以便实现更先进的策略。庞大的HDFS实例一般运行在多个机架的计算机形成的集群上,不同机架间的两台机器的通讯需要通过交换机,显然通常情况下,同一个机架内的两个节点间的带宽会比不同机架间的两台机器的带宽大。
通过一个称为Rack Awareness的过程,Namenode决定了每个Datanode 所属的rack id。一个简单但没有优化的策略就是将副本存放在单独的机架上。这样可以防止整个机架(非副本存放)失效的情况,并且允许读数据的时候可以从多个机架读取。这个简单策略设置可以将副本分布在集群中,有利于组件失败情况下的负载均衡。但是,这个简单策略加大了写的代价,因为一个写操作需要传输block到多个机架。
在大多数情况下,replication因子是3,HDFS的存放策略是将一个副本存放在本地机架上的节点,一个副本放在同一机架上的另一个节点,最后一个副本放在不同机架上的一个节点。机架的错误远远比节点的错误少,这个策略不会影响到数据的可靠性和有效性。三分之一的副本在一个节点上,三分之二在一个机架上,其他保存在剩下的机架中,这一策略改进了写的性能。
2、副本的选择,为了降低整体的带宽消耗和读延时,HDFS会尽量让reader读最近的副本。如果在reader的同一个机架上有一个副本,那么就读该副本。如果一个HDFS集群跨越多个数据中心,那么reader也将首先尝试读本地数据中心的副本。
3、SafeMode
Namenode启动后会进入一个称为SafeMode的特殊状态,处在这个状态的Namenode是不会进行数据块的复制的。Namenode从所有的 Datanode接收心跳包和Blockreport。Blockreport包括了某个Datanode所有的数据块列表。每
个block都有指定的最小数目的副本。当Namenode检测确认某个Datanode的数据块副本的最小数目,那么该Datanode就会被认为是安全的;如果一定百分比(这个参数可配置)的数据块检测确认是安全的,那么Namenode将退出SafeMode 状态,接下来它会确定还有哪些数据块的副本没有达到指定数目,并将这些block 复制到其他Datanode。
五、文件系统元数据的持久化
Namenode存储HDFS的元数据。对于任何对文件元数据产生修改的操作,Namenode都使用一个称为Editlog的事务日志记录下来。例如,在HDFS中创建一个文件,Namenode就会在Editlog中插入一条记录来表示;同样,修改文件的replication因子也将往 Editlog插入一条记录。Namenode在本地OS的文件系统中存储这个Editlog。整个文件系统的namespace,包括block到文件的映射、文件的属性,都存储在称为FsImage的文件中,这个文件也是放在Namenode 所在系统的文件系统上。
Namenode在内存中保存着整个文件系统namespace和文件Blockmap的映像。这个关键的元数据设计得很紧凑,因而一个带有4G内存的 Namenode足够支撑海量的文件和目录。当Namenode启动时,它从硬盘中读取Editlog和FsImage,将所有Editlog中的事务作用(apply)在内存中的FsImage ,并将这个新版本的FsImage从内存中flush到硬盘上,然后再truncate这个旧的Editlog,因为这个旧的Editlog的事务都已经作用在FsImage上了。这个过程称为checkpoint。在当前实现中,checkpoint只发生在Namenode启动时,在不久的将来我们将实现支持周期性的checkpoint。
Datanode并不知道关于文件的任何东西,除了将文件中的数据保存在本地的文件系统上。它把每个HDFS数据块存储在本地文件系统上隔离的文件中。Datanode并不在同一个目录创建所有的文件,相反,它用启发式地方法来确定每个目录的最佳文件数目,并且在适当的时候创建子目录。在同一个目录创建所有的文件不是最优的选择,因为本地文件系统可能无法高效地在单一目录中支持大量的文件。当一个Datanode启动时,它扫描本地文件系统,对这些本地文件产生相应的一个所有HDFS数据块的列表,然后发送报告到Namenode,这个报告就是Blockreport。
六、通讯协议
所有的HDFS通讯协议都是构建在TCP/IP协议上。客户端通过一个可配置的端口连接到Namenode,通过ClientProtocol与 Namenode交互。而Datanode 是使用DatanodeProtocol与Namenode交互。从ClientProtocol和Datanodeprotocol抽象出一个远程调用(RPC),在设计上,Namenode不会主动发起RPC,而是是响应来自客户端和 Datanode 的RPC请求。
七、健壮性
HDFS的主要目标就是实现在失败情况下的数据存储可靠性。常见的三种失败:Namenode failures, Datanode failures和网络分割(network partitions)。
1、硬盘数据错误、心跳检测和重新复制
每个Datanode节点都向Namenode周期性地发送心跳包。网络切割可能
导致一部分Datanode跟Namenode失去联系。 Namenode通过心跳包的缺失检测到这一情况,并将这些Datanode标记为dead,不会将新的IO请求发给它们。寄存在dead Datanode上的任何数据将不再有效。Datanode的死亡可能引起一些block的副本数目低于指定值,Namenode不断地跟踪需要复制的 block,在任何需要的情况下启动复制。在下列情况可能需要重新复制:某个Datanode节点失效,某个副本遭到损坏,Datanode上的硬盘错误,或者文件的replication 因子增大。
2、集群均衡
HDFS支持数据的均衡计划,如果某个Datanode节点上的空闲空间低于特定的临界点,那么就会启动一个计划自动地将数据从一个Datanode搬移到空闲的Datanode。当对某个文件的请求突然增加,那么也可能启动一个计划创建该文件新的副本,并分布到集群中以满足应用的要求。这些均衡计划目前还没有实现。
3、数据完整性
从某个Datanode获取的数据块有可能是损坏的,这个损坏可能是由于Datanode的存储设备错误、网络错误或者软件bug造成的。HDFS客户端软件实现了HDFS文件内容的校验和。当某个客户端创建一个新的HDFS文件,会计算这个文件每个block的校验和,并作为一个单独的隐藏文件保存这些校验和在同一个HDFS namespace下。当客户端检索文件内容,它会确认从Datanode获取的数据跟相应的校验和文件中的校验和是否匹配,如果不匹配,客户端可以选择从其他Datanode获取该block的副本。
4、元数据磁盘错误
FsImage和Editlog是HDFS的核心数据结构。这些文件如果损坏了,整个HDFS实例都将失效。因而,Namenode可以配置成支持维护多个FsImage和Editlog的拷贝。任何对FsImage或者Editlog的修改,都将同步到它们的副本上。这个同步操作可能会降低 Namenode每秒能支持处理的namespace事务。这个代价是可以接受的,因为HDFS是数据密集的,而非元数据密集。当Namenode 重启的时候,它总是选取最近的一致的FsImage和Editlog使用。
Namenode在HDFS是单点存在,如果Namenode所在的机器错误,手工的干预是必须的。目前,在另一台机器上重启因故障而停止服务的Namenode这个功能还没实现。
5、快照
快照支持某个时间的数据拷贝,当HDFS数据损坏的时候,可以恢复到过去一个已知正确的时间点。HDFS目前还不支持快照功能。
八、数据组织
1、数据块
兼容HDFS的应用都是处理大数据集合的。这些应用都是写数据一次,读却是一次到多次,并且读的速度要满足流式读。HDFS支持文件的write-
once-read-many语义。一个典型的block大小是64MB,因而,文件总是按照64M
切分成chunk,每个chunk存储于不同的 Datanode
2、步骤
某个客户端创建文件的请求其实并没有立即发给Namenode,事实上,HDFS 客户端会将文件数据缓存到本地的一个临时文件。应用的写被透明地重定向到这个临时文件。当这个临时文件累积的数据超过一个block的大小(默认64M),客户端才会联系Namenode。Namenode将文件名插入文件系统的层次结构中,并且分配一个数据块给它,然后返回Datanode的标识符和目标数据块给客户端。客户端将本地临时文件flush到指定的 Datanode上。当文件关闭时,在临时文件中剩余的没有flush的数据也会传输到指定的Datanode,然后客户端告诉Namenode文件已经关闭。此时Namenode才将文件创建操作提交到持久存储。如果Namenode在文件关闭前挂了,该文件将丢失。
上述方法是对通过对HDFS上运行的目标应用认真考虑的结果。如果不采用客户端缓存,由于网络速度和网络堵塞会对吞估量造成比较大的影响。
3、流水线复制
当某个客户端向HDFS文件写数据的时候,一开始是写入本地临时文件,假设该文件的replication因子设置为3,那么客户端会从Namenode 获取一张Datanode列表来存放副本。然后客户端开始向第一个Datanode传输数据,第一个Datanode一小部分一小部分(4kb)地接收数据,将每个部分写入本地仓库,并且同时传输该部分到第二个Datanode节点。第二个Datanode也是这样,边收边传,一小部分一小部分地收,存储在本地仓库,同时传给第三个Datanode,第三个Datanode就仅仅是接收并存储了。这就是流水线式的复制。
九、可访问性
HDFS给应用提供了多种访问方式,可以通过DFSShell通过命令行与HDFS 数据进行交互,可以通过java API调用,也可以通过C语言的封装API访问,并且提供了浏览器访问的方式。正在开发通过WebDav协议访问的方式。具体使用参考文档。
十、空间的回收
1、文件的删除和恢复
用户或者应用删除某个文件,这个文件并没有立刻从HDFS中删除。相反,HDFS将这个文件重命名,并转移到/trash目录。当文件还在/trash目录时,该文件可以被迅速地恢复。文件在/trash中保存的时间是可配置的,当超过这个时间,Namenode就会将该文件从namespace中删除。文件的删除,也将释放关联该文件的数据块。注意到,在文件被用户删除和HDFS空闲空间的增加之间会有一个等待时间延迟。
当被删除的文件还保留在/trash目录中的时候,如果用户想恢复这个文件,可以检索浏览/trash目录并检索该文件。/trash目录仅仅保存被删除文件的最近一次拷贝。/trash目录与其他文件目录没有什么不同,除了一点:HDFS 在该目录上应用了一个特殊的策略来自动删除文件,目前的默认策略是删除保留超过6小时的文件,这个策略以后会定义成可配置的接口。
2、Replication因子的减小
当某个文件的replication因子减小,Namenode会选择要删除的过剩的
副本。下次心跳检测就将该信息传递给Datanode, Datanode就会移除相应的block并释放空间,同样,在调用setReplication方法和集群中的空闲空间增加之间会有一个时间延迟。
参考资料:
HDFS Java API: /docs/current/api/
HDFS source code: /version_control.html
仅供个人用于学习、研究;不得用于商业用途。
For personal use only in study and research; not for commercial use.
Nur für den pers?nlichen für Studien, Forschung, zu kommerziellen Zwecken verwen det werden.
Pour l 'étude et la recherche uniquement à des fins personnelles; pas à des fins commerciales.
толькодля людей, которые используются для обучения, исследований и не должны использоваться в коммерческих целях.
以下无正文
(新人教版)高中历史必修二第21课《二战后苏联的经济改革》 精品教案 一、赫鲁晓夫改革(重点在农业) 1.背景: ⑴二战结束后,苏联进入和平建设时期,斯大林模式的弊端日益暴露。 ⑵1953年斯大林逝世后,赫鲁晓夫上台,他在稳固了自己的地位之后开始调整政策, 试图对斯大林模式进行改革。 ⑶苏共“二十大”的召开,打破了对斯大林的个人崇拜。(P98历史纵横,了解) ▲注意:斯大林模式的弊端: ⑴农业集体化的消极影响越来越明显(①② P98 第一段) ⑵片面发展重工业,忽视农业和轻工业的发展,也不利于人民生活水平的提 高 2.内容: ⑴农业——经济改革的重点 主要内容:P98第二段①②③ ⑵工业:P99第一段①②③ 3.评价 ⑴一定程度上冲击了斯大林模式(这是其改革的最大功绩) ⑵但是改革成效甚微,基本失败。 4.失败的原因: 根本原因:没有从根本上改变斯大林体制 具体原因: ⑴改革缺乏正确的指导思想和实事求是的精神(如:玉米运动),提出一些不切实 际的口号与目标(如:提出“20年内基本建成共产主义社会”)。 ⑵具体做法上,对斯大林模式的弊端缺乏科学的认识,只对斯大林模式进行小修小 补,没有从根本上破除“斯大林模式”。 二、勃列日涅夫的改革(重点在工业) 1.内容: ①②③见P99第3段 ④为了维持超级大国的地位,与美国争霸(目的),注重发展苏联的重工业,特别是与军 事有关的工业部门。 2.结果: ①②③见P99第4段 ▲注意: ⑴赫鲁晓夫和勃列日涅夫的改革都以失败而告终,其根本原因是:都没有改变高度集中的 政治、经济体制。 ⑵这两次改革的相同点:都取得一定成效;都没有从根本上触动原有体制;结果都失败。 三、戈尔巴乔夫改革
本科毕业设计(论文)外文翻译 译文: ASP ASP介绍 你是否对静态HTML网页感到厌倦呢?你是否想要创建动态网页呢?你是否想 要你的网页能够数据库存储呢?如果你回答:“是”,ASP可能会帮你解决。在2002年5月,微软预计世界上的ASP开发者将超过80万。你可能会有一个疑问什么是ASP。不用着急,等你读完这些,你讲会知道ASP是什么,ASP如何工作以及它能为我们做 什么。你准备好了吗?让我们一起去了解ASP。 什么是ASP? ASP为动态服务器网页。微软在1996年12月推出动态服务器网页,版本是3.0。微软公司的正式定义为:“动态服务器网页是一个开放的、编辑自由的应用环境,你可以将HTML、脚本、可重用的元件来创建动态的以及强大的网络基础业务方案。动态服务器网页服务器端脚本,IIS能够以支持Jscript和VBScript。”(2)。换句话说,ASP是微软技术开发的,能使您可以通过脚本如VBScript Jscript的帮助创建动态网站。微软的网站服务器都支持ASP技术并且是免费的。如果你有Window NT4.0服务器安装,你可以下载IIS(互联网信息服务器)3.0或4.0。如果你正在使用的Windows2000,IIS 5.0是它的一个免费的组件。如果你是Windows95/98,你可以下载(个人网络服务器(PWS),这是比IIS小的一个版本,可以从Windows95/98CD中安装,你也可以从微软的网站上免费下载这些产品。 好了,您已经学会了什么是ASP技术,接下来,您将学习ASP文件。它和HTML文 件相同吗?让我们开始研究它吧。 什么是ASP文件? 一个ASP文件和一个HTML文件非常相似,它包含文本,HTML标签以及脚本,这些都在服务器中,广泛用在ASP网页上的脚本语言有2种,分别是VBScript和Jscript,VBScript与Visual Basic非常相似,而Jscript是微软JavaScript的版本。尽管如此,VBScript是ASP默认的脚本语言。另外,这两种脚本语言,只要你安装了ActiveX脚本引擎,你可以使用任意一个,例如PerlScript。 HTML文件和ASP文件的不同点是ASP文件有“.Asp”扩展名。此外,HTML标签和ASP代码的脚本分隔符也不同。一个脚本分隔符,标志着一个单位的开始和结束。HTML标签以小于号(<)开始(>)结束,而ASP以<%开始,%>结束,两者之间是服务端脚本。
分布式汽车电气电子系统设计和实现 架构
分布式汽车电气/电子系统设计和实现架构在过去的十几年里,汽车的电气和电子系统已经变得非常的复杂。今天汽车电子/电气系统开发工程师广泛使用基于模型的功能设计与仿真来迎接这一复杂性挑战。新兴标准定义了与低层软件的标准化接口,最重要的是,它还为功能实现工程师引入了一个全新的抽象级。 这提高了软件组件的可重用性,但不幸的是,关于如何将基于模型的功能设计的结果转换成高度环境中的可靠和高效系统实现方面的指导却几乎没有。 另外,论述设计流程物理端的文章也非常少。本文概述了一种推荐的系统级设计方法学,包括、分布在多个ECU中的网络和任务调度、线束设计和规格生成。 为什么需要AUTOSAR? 即使在同一家公司,“架构设计”对不同的人也有不同的含义,这取决于她们站在哪个角度上。物理架构处理系统的有形一面,如布线和连接器,逻辑架构定义无形系统的结构和分配,如软件和通信协议。当前设计物理架构和逻辑架构的语言是独立的,这导致相同一个词的意思能够完全不同,设计团队和流程也是独立的,这也导致了一个非常复杂的设计流程(如图1所示)。
图1:物理和逻辑设计流程。 这种复杂性导致了次优设计结果,整个系统的正确功能是如此的难于实现,以致于几乎没有时间去寻求一种替代方法,它可导致更坚固的、可扩展性更好的和更具成本效益的解决方案。为了实现这样一种解决方案,设计师需要新的方法,它能够将物理和逻辑设计流程紧密相连,并依然允许不同的设计团队做她们的工作。 新兴的AUTOSAR标准为系统级汽车电子/电气设计方法学提供了一个技术上和经济上都可行的选择,尽管它主要针对软件层面,即逻辑系统的设计。不过,大量广泛的AUTOSAR元模型及其丰富的接口定义允许系统级电子/电气架构师以标准的格式表示她的设计思想。从经济上看,AUTOSAR标准打开了一个巨大的、统一的市场,它使得能够创立合适的设计工具。
控制系统基础论文中英文资料外文翻译文献 文献翻译 原文: Numerical Control One of the most fundamental concepts in the area of advanced manufacturing technologies is numerical control (NC).Prior to the advent of NC, all machine tools were manual operated and controlled. Among the many limitations associated with manual control machine tools, perhaps none is more prominent than the limitation of operator skills. With manual control, the quality of the product is directly related to and limited to the skills of the operator . Numerical control represents the first major step away from human control of machine tools. Numerical control means the control of machine tools and other manufacturing systems though the use of prerecorded, written symbolic instructions. Rather than operating a machine tool, an NC technician writes a program that issues operational instructions to the machine tool, For a machine tool to be numerically controlled , it must be interfaced with a device for accepting and decoding the p2ogrammed instructions, known as a reader. Numerical control was developed to overcome the limitation of human operator , and it has done so . Numerical control machines are more accurate than manually operated machines , they can produce parts more uniformly , they are faster, and the long-run tooling costs are lower . The development of NC led to the development of several other innovations in manufacturing technology: 1.Electrical discharge machining. https://www.doczj.com/doc/7010036259.html,ser cutting. 3.Electron beam welding.
6苏州大学学报(工科版)第30卷 图1I-IDFS架构 2HDFS与LinuxFS比较 HDFS的节点不管是DataNode还是NameNode都运行在Linux上,HDFS的每次读/写操作都要通过LinuxFS的读/写操作来完成,从这个角度来看,LinuxPS是HDFS的底层文件系统。 2.1目录树(DirectoryTree) 两种文件系统都选择“树”来组织文件,我们称之为目录树。文件存储在“树叶”,其余的节点都是目录。但两者细节结构存在区别,如图2与图3所示。 一二 Root \ 图2ItDFS目录树围3LinuxFS目录树 2.2数据块(Block) Block是LinuxFS读/写操作的最小单元,大小相等。典型的LinuxFSBlock大小为4MB,Block与DataN-ode之间的对应关系是固定的、天然存在的,不需要系统定义。 HDFS读/写操作的最小单元也称为Block,大小可以由用户定义,默认值是64MB。Block与DataNode的对应关系是动态的,需要系统进行描述、管理。整个集群来看,每个Block存在至少三个内容一样的备份,且一定存放在不同的计算机上。 2.3索引节点(INode) LinuxFS中的每个文件及目录都由一个INode代表,INode中定义一组外存上的Block。 HDPS中INode是目录树的单元,HDFS的目录树正是在INode的集合之上生成的。INode分为两类,一类INode代表文件,指向一组Block,没有子INode,是目录树的叶节点;另一类INode代表目录,没有Block,指向一组子INode,作为索引节点。在Hadoop0.16.0之前,只有一类INode,每个INode都指向Block和子IN-ode,比现有的INode占用更多的内存空间。 2.4目录项(Dentry) Dentry是LinuxFS的核心数据结构,通过指向父Den姆和子Dentry生成目录树,同时也记录了文件名并 指向INode,事实上是建立了<FileName,INode>,目录树中同一个INode可以有多个这样的映射,这正是连
毕业设计(论文)外文资料翻译 学院:机械工程学院 专业:机械设计制造及其自动化 姓名: 学号:XXXXXXXXXX 外文出处:《Computational Intelligence and (用外文写)Design》 附件: 1.外文资料翻译译文;2.外文原文。 注:请将该封面与附件装订成册。
附件1:外文资料翻译译文 基于微型计算机的步进电机控制系统设计 孟天星余兰兰 山东理工大学电子与电气工程学院 山东省淄博市 摘要 本文详细地介绍了一种以AT89C51为核心的步进电机控制系统。该系统设计包括硬件设计、软件设计和电路设计。电路设计模块包括键盘输入模块、LED显示模块、发光二极管状态显示和报警模块。按键可以输入设定步进电机的启停、转速、转向,改变转速、转向等的状态参数。通过键盘输入的状态参数来控制步进电机的步进位置和步进速度进而驱动负载执行预订的工作。运用显示电路来显示步进电机的输入数据和运行状态。AT89C51单片机通过指令系统和编译程序来执行软件部分。通过反馈检测模块,该系统可以很好地完成上述功能。 关键词:步进电机,AT89C51单片机,驱动器,速度控制 1概述 步进电机因为具有较高的精度而被广泛地应用于运动控制系统,例如机器人、打印机、软盘驱动机、绘图仪、机械式阀体等等。过去传统的步进电机控制电路和驱动电路设计方法通常都极为复杂,由成本很高而且实用性很差的电器元件组成。结合微型计算机技术和软件编程技术的设计方法成功地避免了设计大量复杂的电路,降低了使用元件的成本,使步进电机的应用更广泛更灵活。本文步进电机控制系统是基于AT89C51单片机进行设计的,它具有电路简单、结构紧凑的特点,能进行加减速,转向和角度控制。它仅仅需要修改控制程序就可以对各种不同型号的步进电机进行控制而不需要改变硬件电路,所以它具有很广泛的应用领域。 2设计方案 该系统以AT89C51单片机为核心来控制步进电机。电路设计包括键盘输入电路、LED显示电路、发光二极管显示电路和报警电路,系统原理框图如图1所示。 At89c51单片机的P2口输出控制步进电机速度的时钟脉冲信号和控制步进电机运转方向的高低电平。通过定时程序和延时程序可以控制步进电机的速度和在某一
论俄罗斯的激进性改革 顾名思义,改革就是对事物的改造和革新,它是对事物的辩证否定,是事物发展的连续性和非连续性的辩证统一。生产力与生产关系的矛盾运动推动着社会的发展,生产力发展到一定阶段,便同它一直在其中运动的生产关系发生矛盾,这时社会革命或改革的时代就到来了。因此,—个社会的改革可以看作是社会的自我调整和自我完善。改革也是社会发展的必然要求,随着社会的发展,选择科学、合理的改革来更新旧的社会体制便成为必然。 改革的方式主要有激进式改革和渐进式改革两种。激进式改革,是指在改革时,改革者一开始就将所有的改革目标和计划全盘推出,用设计好的全新的社会关系代替旧的社会关系。这种改革的过程与时间一般相对较短,有利于缩短新旧体制转换所带来的社会“阵痛期”和“混乱期”。而渐进式改革是将设计好的目标,按计划分期分批地加以实施。一般来说,这种改革所需时间长,但可以随时根据需要调整改革计划,在改革进程中及时纠正失误,从而减轻改革所带来的经济衰退、社会动荡等诸多消极影响。判断—个国家究竟该采取哪一种改革方式,一定要同改革国家的地理环境、文化传统等各种因素结合起来分析。 上个世纪90年代,俄罗斯本想通过改革来解决社会矛盾,以推动社会的快速发展。但是,这场改革带来的并不是广大人民所期待的幸福生活,而是国力下降,社会混乱。究其原因,正是因为俄罗斯没有选择科学、合理的改革,盲目的选择了激进性改革,现将这场改革失败的具体原因分析如下。 俄罗斯的改革之所以失败,首要原因就是当时的俄罗斯并不具备激进改革实施所需要的国情。俄罗斯国土面积大,国情复杂,计划体制影响深远,依据这样的国情,改革理应选择“渐进改革”模式。可是,俄罗斯却选择了另一种,它试图通过一场迅猛的改革潮流,用市场经济的雏型取代中央计划经济。虽然,这种改革方式有一些优势,但是,由于它将改革的目标和进程严格的置于预定的计划之下,而没有为俄罗斯这一特殊国情下的改革留下足够的调试时期,所以在改革中,国有企业在短时间内一方面既不能适应新体制,又不能迅速有效地私有化,旧的机制停转,而新的机制尚未确立,造成一种过渡时期的体制真空和机制瘫痪,整个经济处于无序状态,改革最后无果而终。 推行改革除了要依据现实国情选择恰当的改革模式以外,它还必须具备必要的客观条件,而俄罗斯在推行激进改革时,并不很具备其所需要的客观条件。下面将分别从政治和文化两方面进行分析。 政治稳定是改革的首要条件,它为其提供政治资源是其得以顺利进行的政治保证。但俄罗斯在激进改革中,不但没有营造这样的政治条件,反而使政治环境更加恶化。多党制下各派政治力量围绕最重大的政治原则和根本问题一直进行着激烈的斗争,政府领导人的不停更换等等。这一切导致政府在制定改革方案时,左右摇摆,难以找到改革的均衡点。 同时,改革必须要形成一种“革新”的文化,它是改革得以推动和成功的社会心理基础。然而,任何一种文化都具有连续性。在俄罗斯,不仅有着几百年的传统文化,而且还承载了70年苏联制度和社会主义文化的影响,这种影响涉及好几代人。可是,在俄罗斯激进改革中,“革新”文化就是在否定一切传统文化,采取“拿来主义”的方针,用不被人们普遍接受和认同的西方文化来规范、引导迷惘的人们,从而使社会一度陷入严重的思想混乱之中。 改革的成功不仅取决于各项客观条件的满足,它还必须要具备一定的主观条件,必须事
附件1:外文资料翻译译文 基于FPGA的停车场管理系统的设计与实现 摘要 由于汽车数量在快速的增加。它造成污染(噪声和空气)交通挤塞的问题。为了克服这个问题。提出了基于FPGA 的停车系统。在本文,停车场系统实现了利用有限状态机模型。该系统具有两个主要模块即识别模块和检查模块的插槽,识别模块标识位访客,插槽检查模块检查有关插槽的状态,这些模块是在高密度脂蛋白中建模,在FPGA上实现。结合传感器接口、步进电机、液晶屏的各种接口设计了一个原型的停车系统。 关键词︰有限状态机;停车场系统;容量-5 1.介绍 车辆交通拥堵是一个世界性的问题。近年来,已经全力在实现一种方法来减少拥堵、事故和灾害等停车问题。 图1:城市交通拥堵趋势 如中所示图 1 拥塞显然逐年增加,它显示了一些问题。图中表明拥塞需要花更长的时间才能到从工作中"尖峰时刻"。停车场系统还可以利用创新技术提高
付费停车方便和快捷。现今,刷一下智能卡就可以实现付费功能,减少交易时间。移动设备也可以用于支付交易。公共地区需要停车系统,能够有效的运作,与其他城市公用地区相结合。因为没有适当方式,所以分配车位的停车场管理系统在协调和集中管理中呈现了失败的效果。为了避免这些问题,提出智能停车系统的设计,用基于FPGA 来检查某些功能块。 近年来,FPGA 的可重构是有效的方法来实现的设计,因为FPGA 提供通用处理器和ASIC 之间的协调。基于FPGA 的设计也更灵活,可编程,可重新加载。基于FPGA 的设计可以方便地修改软件部分。 2.相关工作 宫俊燕等相关人士,提出一种新颖,安全,智能的停车系统(智能停车)主要是基于保护无线网络与传感器通信。停车空间利用率高和免费、快速的现时间是提出研究的目的。苏春、安康山等,提出了用停车系统中的驱动程序来了解在停车场的帮助下SMS 服务空间的可用性。驱动程序可以发送短信实现请求新的空间,如果前一个被填满,驱动程序可以找到最近的空间停车使用基于无线移动的汽车停车系统。结果,表明该系统有效地分配的插槽和充分利用停车空间。安古普塔等,描述了阿克曼转向配置高效汽车停车算法。该算法利用几何计算路径规划。结果显示了一个快速、高效、安全的停车系统。花春潭等,提出了用于大型停车场的高效停车搜索技术。在这篇文章中,提出在道路附近的停车场安装摄像机和捕获关于汽车颜色和车牌识别的信息,并保存到数据库中。谢刚等,提出了一个停车系统,消除了关于空档停车的问题。作者使用无线技术来提高停车效率。宫俊燕等,提出通知基于停车系统。在这停车系统中,驱动程序可以查询及预订停车位,以及为安全目的加密/解密技术使用,仿真结果都是高效的。InsopSo ng等提出基于FPGA 停车系统,采用模糊逻辑控制器(FLC),主要优点是计算时间大量减少了。在这项研究工作中,模拟真实环境中使用VHDL代码测试机器人小车,并在基于FPGA 的基础上进行测试。 3.停车场管理系统
大型电商分布式架构设计与优化 本文主题为电商网站架构案例,将介绍如何从电商网站的需求,到单机架构,逐步演变为常用的、可供参考的分布式架构原型。除具备功能需求外,还具备一定的高性能、高可用、可伸缩、可扩展等非功能质量需求(架构目标)。
本文大纲: 1. 使用电商案例的原因 2. 电商网站需求 3. 网站初级架构 4. 系统容量估算 5. 网站架构分析 6. 网站架构优化 根据实际需要,进行改造、扩展、支持千万PV,是没问题的。 使用电商案例的原因 分布式大型网站,目前看主要有几类: 1.大型门户(比如网易、新浪等); 2.SNS网站(比如校内、开心网等); 3.电商网站(比如阿里巴巴、京东商城、国美在线、汽车之家等)。
大型门户一般是新闻类信息,可以使用CDN、静态化等方式优化。而开心网等交互性比较多,可能会引入更多的NoSQL、分布式缓存、使用高性能的通信框架等。电商网站具备以上两类的特点,比如产品详情可以采用CDN,静态化,交互性高的需要采用NoSQL等技术。因此,我们采用电商网站作为案例,进行分析。 电商网站需求 客户需求: ?建立一个全品类的电子商务网站(B2C),用户可以在线购买商品,可以在线支付,也可以货到付款; ?用户购买时可以在线与客服沟通; ?用户收到商品后,可以给商品打分和评价; ?目前有成熟的进销存系统,需要与网站对接; ?希望能够支持3~5年,业务的发展; ?预计3~5年用户数达到1000万; ?定期举办双11、双12、三八男人节等活动; ?其他的功能参考京东或国美在线等网站。 客户就是客户,不会告诉你具体要什么,只会告诉你他想要什么,我们很多时候要引导、挖掘客户的需求。好在提供了明确的参考网站。因此,下一步要进行大量的分析,结合行业以及参考网站,给客户提供方案。其它的这里暂不展开。
译文 流体传动及控制技术已经成为工业自动化的重要技术,是机电一体化技术的核心组成之一。而电液比例控制是该门技术中最具生命力的一个分支。比例元件对介质清洁度要求不高,价廉,所提供的静、动态响应能够满足大部分工业领域的使用要求,在某些方面已经毫不逊色于伺服阀。比例控制技术具有广阔的工业应用前景。但目前在实际工程应用中使用电液比例阀构建闭环控制系统的还不多,其设计理论不够完善,有待进一步的探索,因此,对这种比例闭环控制系统的研究有重要的理论价值和实践意义。本论文以铜电解自动生产线中的主要设备——铣耳机作为研究对象,在分析铣耳机组各构成部件的基础上,首先重点分析了铣耳机的关键零件——铣刀的几何参数、结构及切削性能,并进行了实验。用电液比例方向节流阀、减压阀、直流直线测速传感器等元件设计了电液比例闭环速度控制系统,对铣耳机纵向进给装置的速度进行控制。论文对多个液压阀的复合作用作了理论上的深入分析,着重建立了带压差补偿型的电液比例闭环速度控制系统的数学模型,利用计算机工程软件,研究分析了系统及各个组成环节的静、动态性能,设计了合理的校正器,使设计系统性能更好地满足实际生产需要 水池拖车是做船舶性能试验的基本设备,其作用是拖曳船模或其他模型在试验水池中作匀速运动,以测量速度稳定后的船舶性能相关参数,达到预报和验证船型设计优劣的目的。由于拖车稳速精度直接影响到模型运动速度和试验结果的精度,因而必须配有高精度和抗扰性能良好的车速控制系统,以保证拖车运动的稳速精度。本文完成了对试验水池拖车全数字直流调速控制系统的设计和实现。本文对试验水池拖车工作原理进行了详细的介绍和分析,结合该控制系统性能指标要求,确定采用四台直流电机作为四台车轮的驱动电机。设计了电流环、转速环双闭环的直流调速控制方案,并且采用转矩主从控制模式有效的解决了拖车上四台直流驱动电机理论上的速度同步和负载平衡等问题。由于拖车要经常在轨道上做反复运动,拖动系统必须要采用可逆调速系统,论文中重点研究了逻辑无环流可逆调速系统。大型直流电机调速系统一般采用晶闸管整流技术来实现,本文给出了晶闸管整流装置和直流电机的数学模型,根据此模型分别完成了电流坏和转速环的设计和分析验证。针对该系统中的非线性、时变性和外界扰动等因素,本文将模糊控制和PI控制相结合,设计了模糊自整定PI控制器,并给出了模糊控制的查询表。本文在系统基本构成及工程实现中,介绍了西门子公司生产的SIMOREGDC Master 6RA70全数字直流调速装置,并设计了该调速装置的启动操作步骤及参数设置。完成了该系统的远程监控功能设计,大大方便和简化了对试验水池拖车的控制。对全数字直流调速控制系统进行了EMC设计,提高了系统的抗干扰能力。本文最后通过数字仿真得到了该系统在常规PI控制器和模糊自整定PI控制器下的控制效果,并给出了系统在现场调试运行时的试验结果波形。经过一段时间的试运行工作证明该系统工作良好,达到了预期的设计目的。 提升装置在工业中应用极为普遍,其动力机构多采用电液比例阀或电液伺服阀控制液压马达或液压缸,以阀控马达或阀控缸来实现上升、下降以及速度控制。电液比例控制和电液伺服控制投资成本较高,维护要求高,且提升过程中存在速度误差及抖动现象,影响了正常生产。为满足生产要求,提高生产效率,需要研究一种新的控制方法来解决这些不足。随着科学技术的飞速发展,计算机技术在液压领域中的应用促进了电液数字控制技术的产生和发展,也使液压元件的数字化成为液压技术发展的必然趋势。本文以铅电解残阳极洗涤生产线中的提升装置为研究
一个汉英机器翻译系统的 计算模型与语言模型* 刘群+詹卫东++常宝宝++刘颖+ (+中国科学院计算技术研究所二室北京100080) (++北京大学计算语言学研究所北京100871) 摘要:本文介绍我们所设计并实现的一个汉英机器翻译系统。在概要介绍本系统的主要目标和设计原则的基础上,着重说明系统的计算模型和语言模型,最后给出实验结果和进一步的打算。 关键词:自然语言处理机器翻译中文信息处理 一、引言 我国的机器翻译研究近年来取得了很大的发展。特别是英汉机器翻译系统的研制已经取得了较大的成功,达到了初步实用的阶段。相对而言,汉英机器翻译的研究却进展比较缓慢,离实用化还有相当的距离[1]。我们的目的是利用目前最新的计算机软件技术、相对成熟的机器翻译方法和先进的汉语语法理论,构造一个初步实用的汉英机器翻译系统。本文将对我们所开发的系统所采用的计算模型和语言模型作一个总体性的介绍,而不涉及过多的细节。 下面我们简要介绍一下本系统的几个主要设计原则: ⑴采用成熟的技术 我们的目的是构造一个真正实用的汉英机器翻译系统,因而在可供选择的若干技术路线面前,我们将尽量选用比较成熟的技术,而在现有技术难以解决问题时再尝试一些新技术。 ⑵开放的体系结构 开放的体系结构主要体现在系统的实现上所采用的软件构件技术[8]。整个系统采用一些相对独立的软件构件组成,因而可以方便地对系统进行修改、维护和扩充。翻译的过程严格按照独立分析、独立生成的原则进行组织,每一阶段的算法相互独立,对其中一个阶段算法的修改不会对其他算法造成影响。 ⑶方便的调试环境 本系统强调为语言工作者提供一个方便的调试环境。系统提供多窗口图形界面的知识库调试工具,支持课题组中多人同时通过网络对一个知识库进行操作。提供对翻译过程直观显示,用户可以清晰地看到翻译过程的每一步操作。提供翻译出错原因查找机制,用户 *本项目的研究受到863-306资助,合同号为863-306-03-06-2
Hadoop分布式文件系统:架构和设计 引言 (2) 一前提和设计目标 (2) 1 hadoop和云计算的关系 (2) 2 流式数据访问 (2) 3 大规模数据集 (2) 4 简单的一致性模型 (3) 5 异构软硬件平台间的可移植性 (3) 6 硬件错误 (3) 二HDFS重要名词解释 (3) 1 Namenode (4) 2 secondary Namenode (5) 3 Datanode (6) 4 jobTracker (6) 5 TaskTracker (6) 三HDFS数据存储 (7) 1 HDFS数据存储特点 (7) 2 心跳机制 (7) 3 副本存放 (7) 4 副本选择 (7) 5 安全模式 (8) 四HDFS数据健壮性 (8) 1 磁盘数据错误,心跳检测和重新复制 (8) 2 集群均衡 (8) 3 数据完整性 (8) 4 元数据磁盘错误 (8) 5 快照 (9)
引言 云计算(cloud computing),由位于网络上的一组服务器把其计算、存储、数据等资源以服务的形式提供给请求者以完成信息处理任务的方法和过程。在此过程中被服务者只是提供需求并获取服务结果,对于需求被服务的过程并不知情。同时服务者以最优利用的方式动态地把资源分配给众多的服务请求者,以求达到最大效益。 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS 能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。 一前提和设计目标 1 hadoop和云计算的关系 云计算由位于网络上的一组服务器把其计算、存储、数据等资源以服务的形式提供给请求者以完成信息处理任务的方法和过程。针对海量文本数据处理,为实现快速文本处理响应,缩短海量数据为辅助决策提供服务的时间,基于Hadoop云计算平台,建立HDFS分布式文件系统存储海量文本数据集,通过文本词频利用MapReduce原理建立分布式索引,以分布式数据库HBase 存储关键词索引,并提供实时检索,实现对海量文本数据的分布式并行处理.实验结果表 明,Hadoop框架为大规模数据的分布式并行处理提供了很好的解决方案。 2 流式数据访问 运行在HDFS上的应用和普通的应用不同,需要流式访问它们的数据集。HDFS的设计中更多的考虑到了数据批处理,而不是用户交互处理。比之数据访问的低延迟问题,更关键的在于数据访问的高吞吐量。 3 大规模数据集 运行在HDFS上的应用具有很大的数据集。HDFS上的一个典型文件大小一般都在G字节至T字节。因此,HDFS被调节以支持大文件存储。它应该能提供整体上高的数据传输带宽,能在一个集群里扩展到数百个节点。一个单一的HDFS实例应该能支撑数以千万计的文件。
英文原文 Introductions to Control Systems Automatic control has played a vital role in the advancement of engineering and science. In addition to its extreme importance in space-vehicle, missile-guidance, and aircraft-piloting systems, etc, automatic control has become an important and integral part of modern manufacturing and industrial processes. For example, automatic control is essential in such industrial operations as controlling pressure, temperature, humidity, viscosity, and flow in the process industries; tooling, handling, and assembling mechanical parts in the manufacturing industries, among many others. Since advances in the theory and practice of automatic control provide means for attaining optimal performance of dynamic systems, improve the quality and lower the cost of production, expand the production rate, relieve the drudgery of many routine, repetitive manual operations etc, most engineers and scientists must now have a good understanding of this field. The first significant work in automatic control was James Watt’s centrifugal governor for the speed control of a steam engine in the eighteenth century. Other significant works in the early stages of development of control theory were due to Minorsky, Hazen, and Nyquist, among many others. In 1922 Minorsky worked on automatic controllers for steering ships and showed how stability could be determined by the differential equations describing the system. In 1934 Hazen, who introduced the term “ervomechanisms”for position control systems, discussed design of relay servomechanisms capable of closely following a changing input. During the decade of the 1940’s, frequency-response methods made it possible for engineers to design linear feedback control systems that satisfied performance requirements. From the end of the 1940’s to early 1950’s, the root-locus method in control system design was fully developed. The frequency-response and the root-locus methods, which are the
第10课苏联的改革与解体 一、课程标准: (1)了解赫鲁晓夫改革。 (2)知道戈尔巴乔夫改革和苏联解体。 二、知识结构: 1、苏联的改革和挫折 (1)苏共二十大 1956年;赫鲁晓夫;揭露批判斯大林 (2)经济改革 赫鲁晓夫改革:以农业为主;失败原因:缺乏正确的指导思想 勃列日涅夫改革:以重工业为主;成效:一跃而为超级大国 失败原因:对原有体制仅进行修补 2、苏联解体 (1)经过: “改革”:戈尔巴乔夫进行经济改革和政治改革,无法打开局面 动荡:多党制,经济滑坡,民族分离,党内斗争 剧变:《苏维埃主权共和国联盟条约》,“八一九事件” “明斯克协定”和“独联体”,《阿拉木图宣言》和苏联解体 (2)原因 历史原因:体制弊端和政策错误,社会问题和民族矛盾 直接原因:戈氏的错误路线和政策背离了科学社会主义 外部原因:西方国家的“和平演变”战略造成严重后果 三、教学过程: (本课内容涉及的历史人物多有争议,苏联的解体过程及缘由至今仍有诸多历史之谜,众说纷纭。教材的叙述简约概括。教师在上本课前,多搜集各种资料,上课时可适当地给学生补充。在课前布置学生查询资料,在课堂教学中学生互相交流,这样使学生更好地了解这段历史,并能有自己的分析。) 导入 1.复习旧知:第一个社会主义国家是怎么建立的?
2.音像资料:有关苏联的解体的片断。 (为什么会解体?给我们留下哪些思考?) (一)赫鲁晓夫改革 人物介绍:赫鲁晓夫 小组活动:赫鲁晓夫采取了哪些改革措施 (经济、政治方面) 线索梳理:赫鲁晓夫为什么要进行改革? 为了推行改革,赫鲁晓夫采取了什么做法? 畅所欲言:你如何看待赫鲁晓夫的改革? (强调赫鲁晓夫将苏联出现的问题仅仅归结为斯大林的个人品质问题,没有从经济政治体制上去寻找原因。所以改革也没有从根本上改变苏联高度集中的政治、经济体制,改革成效不大。) (二)苏联的解体 戈尔巴乔夫的改革 说一说:戈尔巴乔夫上台后,首先把什么作为改革的重点?结果怎样?为什么? (教师强调首先以经济体制改革为重点。结果效果不佳,80年代后期苏联经济增长速度和人民生活水平进一步下降。这是由于改革没有对苏联长期形成的畸形经济结构予以重点调整,改革仓促,阻力较大。) 课堂讨论:戈尔巴乔夫对苏联的影响。 (80年代后期,改革转向于政治体制方面。在党的建设方面放弃民主集中制原则,要建立人道的、民主的社会主义的党。在政治体制上推行多元化,实现多党制和西方式三权分力。) 苏联的解体 思维拓展:1991年8月戈尔巴乔夫提出把苏联的国名改为“苏维埃主权共和国联盟”,意味着什么? (苏联国家体制将面临重大变化,而且意味着对民族分裂活动的让步和认可。苏联瓦解开始。在关键时刻,苏联一些高级官员发动了“八一九事变”)“加油站”:播放反映“八一九”事变的历史记录片
信息服务管理系统的设计与研究 Li Yang, Daiyun Weng 1引言 随着市场竞争的日益激烈,企业是否能够利用这个竞争,企业需要知道他们的客户需要哪种类型的产品,与此同时做到将价格低廉,质量优良,表现优秀的产品提供给客户。这个问题的关键在于公司受到客户驱动的程度,通过提供高质量的产品和服务,及时的交付,低廉的价格来赢得顾客的满意。为了降低库存提高订单完成率,公司必须采用计算机管理技术,重视利用各种资源从而实现库存优化和效率的提升。 但是计算机管理系统并不是仅仅是去设置一个机制,如果这个系统能够良好的运转,那一定是有高效收集数据的方法的。管理信息系统依靠输入信息来实现系统的准确可靠;输入的信息不准确也将会导致管理信息系统错误。在传统的管理中,主要是依靠人工来录入数据,发生错误是难免的。根据有关的信息统计资料,在不同的条件下至少会有千分之三的几率产生人工录入错误,最高率可能达到百分之五。在一定程度上这个过程能够通过加强管理和员工培训来提高,但是该解决方法的本质依靠于先进的技术。信息管理技术是通过采用先进的数学理论来高效的自动收集数据,在数据收集,数据传播方面,条形码有着独天得厚的优势,例如收集产品的状态数据来实现有效的监测,极大的提升了在数据采集流程是的效率,为供应链企业的数据共享提供了基本条件。 2 管理信息系统开发技术 如近已经步入了信息时代。在现阶段,信息已经成为在土地,资金,劳动力和其他因素之后的另一个重要经济资源。那么一个公司能否在众多强势的市场中所向披靡取决于公司有效利用信息的程度。为了达到这个目的,很有必要建立系统的,科学的企业信息管理。企业信息管理的建立是对企业信息有效管理的方法。 一般来说,管理信息系统指的是基于服务的所有管理实务以及计算机系统的管理实务,例如办公自动化系统,企业资源计划系统等等。MIS一般来说就是管理信息系统,在1980年逐渐成为了一门新的学科,然而对于它的概念还没有准确的定义,而且它的理论基础还不完善。但是,从国内外的学者们对管理信息系统的定义来看,人们对管理信息系统的理解逐步加深;管理信息系统的定义正逐步发展和成熟。 管理信息系统的三个主要功能是:信息处理,事务处理,辅助支持组织决策的支持与管理。信
高并发分布式服务架构方案 下图是一个非常全面的架构蓝图,针对不同的应用系统需要的模块各有不同。此架构方案主要包括以下几个方面的设计:数据存储和读取,基础服务,应用层(APP/业务/Proxy),日志监控等,下面对这些主要的问题提供具体的各项针对性技术方案。 数据的存储和读取 分布式系统应该根据应用对数据不同的一致性、可用性等要求和数据的不同特性,采用不同的数据存储和读取方案,主要有以下几种可选方案: 1)内存型数据库。内存型的数据库,以高并发高性能为目标,在事务性方面没那么严格, 适合进行海量数据的存储和读取。例如开源nosql数据库mongodb、redis等。 2)关系型数据库。关系型数据库在满足并发性能的同时,也需要满足事务性,可通过 读写分离,分库分表来应对高并发大数据量的情况。例如Oracle,Mysql等。 3)分布式数据库。对于数据的高并发的访问,传统的关系型数据库提供读写分离的方案, 但是带来的确实数据的一致性问题提供的数据切分的方案;对于越来越多的海量数据,传统的数据库采用的是分库分表,实现起来比较复杂,后期要不断的进行迁移维护;对
于高可用和伸缩方面,传统数据采用的是主备、主从、多主的方案,但是本身扩展性比较差,增加节点和宕机需要进行数据的迁移。对于以上提出的这些问题,分布式数据库HBase有一套完善的解决方案,适用于高并发海量数据存取的要求。 基础服务 基础服务主要是指数据层之上的数据路由,Cache,搜索等服务。 1)路由Router。对于数据库切分方案中的分库分表问题,需要解决在请求对应的数据时 定位需要访问的位置,可根据一致性Hash,维护路由表至内存数据库等方案解决。 2)Cache。对于高并发的系统来讲,使用Cache可以减轻对后端系统的压力,所有Cache 可承担大部分热数据的读操作。当前用的比较多的是redis和memcache,redis比memcache有丰富的数据操作的API,redis对数据进行了持久化,而memcache没有这个功能,因此memcache更加适合在关系型数据库之上的数据的缓存。 3)搜索。搜索可以支持应用系统的按照关键词的检索,搜索提示,搜索排序等功能。开源 开源的企业级搜索引擎主要有lucene, sphinx,选择搜索引擎主要考虑以下三个方面: a)搜索引擎是否支持分布式的索引和搜索,来应对海量的数据,支持读写分离,提高 可用性 b)索引的实时性 c)搜索引擎的性能 Solr是基于Lucene开发的高性能的全文搜索服务器,满足以上三个方面的考虑,而且目前在企业中应用非常广泛。 应用层 应用层主要包括面向用户的应用,网站、APP等,还包括相关的业务处理的运算等。 1)负载均衡-反向代理。一个大型的平台包括很多个业务域,不同的业务域有不同的集群, 可以用DNS做域名解析的分发或轮询,DNS方式实现简单。但是因存在cache而缺乏灵活性;一般基于商用的硬件F5、NetScaler或者开源的软负载lvs在做分发,当然会采用做冗余(比如lvs+keepalived)的考虑,采取主备方式。Nginx是基于事件驱动的、异步非阻塞的架构、支持多进程的高并发的负载均衡器/反向代理软件,可用作反向代理的工具。