第一章
1*.下面的列联表是根据一个小城市的居民教育水平(以获得了高中文凭和没有获得高中文凭分类)和就业状况(以全职和非全职分类)所做出
如果原假设即在教育水平和工作状态之间没有联系为真,那么下列哪一个选项表明了获得了高中文凭并且是全职工作的期望值? A.
9252157g B. 9282157g C.528292g D. 655292g E. 9252
82
g 1*. Answer :B
Analysis :本题考查二维表中两个变量的独立性,如果原假设独立成立,那么cell “earned at least a high school diploma ”和“ employed full time ”的期望值为:
92829282
(,)()()157157157157
P Earned Employed Total P Earned P Employed Total ==
=
g g g g g g
2*.一次实验中,每一个随机样本中的成人都有他的最喜爱的颜色,下表展示了按年龄分组
的试验结果。
如果对于颜色的偏好是同年龄组相互独立,下列哪一个选项表明了年龄组30到50岁,喜爱
绿色的人数的期望值? A.
(99)(108)314 B. (69)(108)314 C. (99)(35)108 D. (35)(108)314 E. (99)(35)
314
2*. Answer :A Analysis :本题考查二维表中两个变量的独立性,如果两个变量独立,那么cell “aged 30 to 50”和“prefer green ”的期望值为:
1089999108
(3050,)(3050)()314314314314
P green Total P P green Total -=-=
=
g g g g g g 第二章
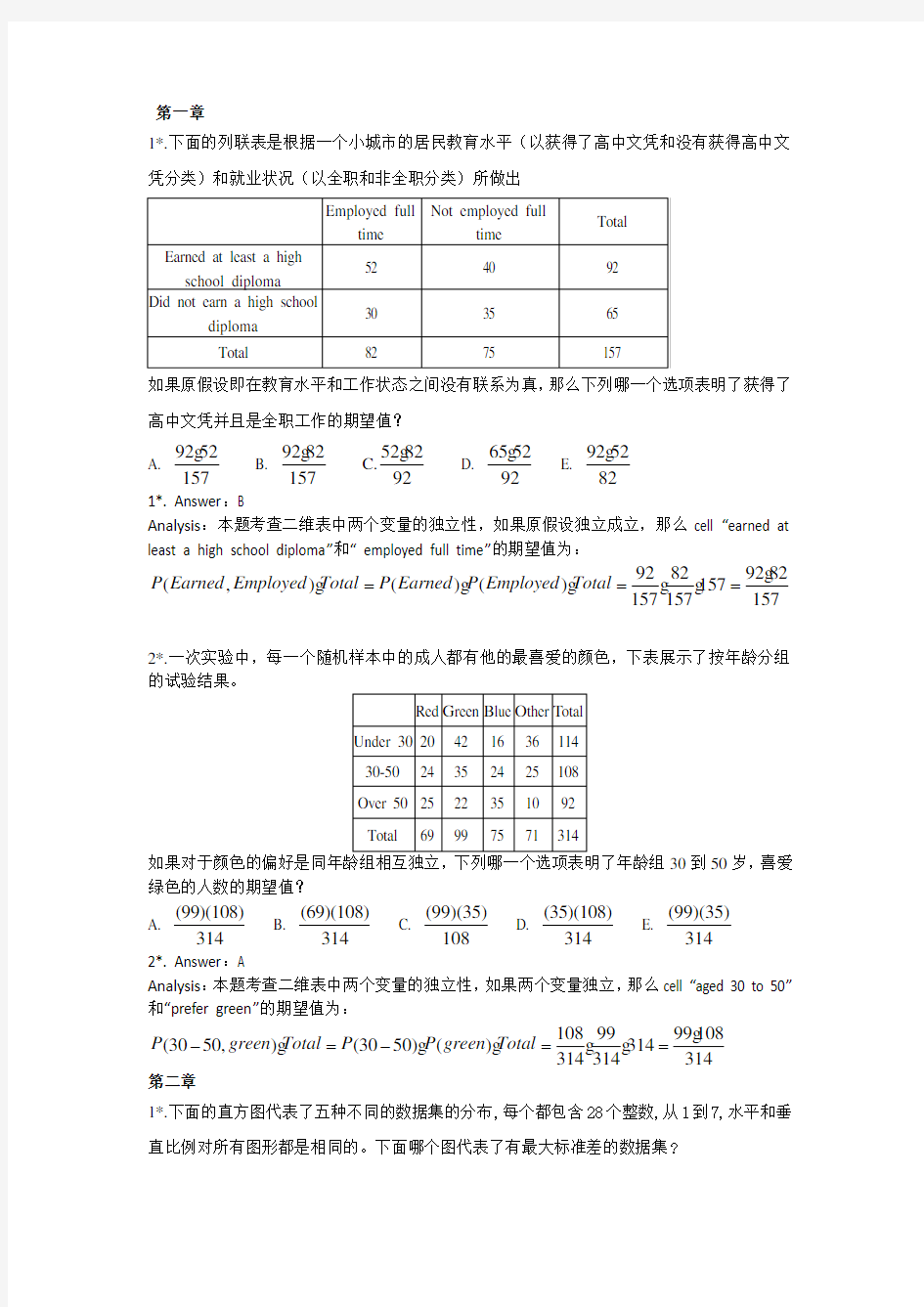
1*.下面的直方图代表了五种不同的数据集的分布,每个都包含28个整数,从1到7,水平和垂直比例对所有图形都是相同的。下面哪个图代表了有最大标准差的数据集?
A. B.
C. D.
E.
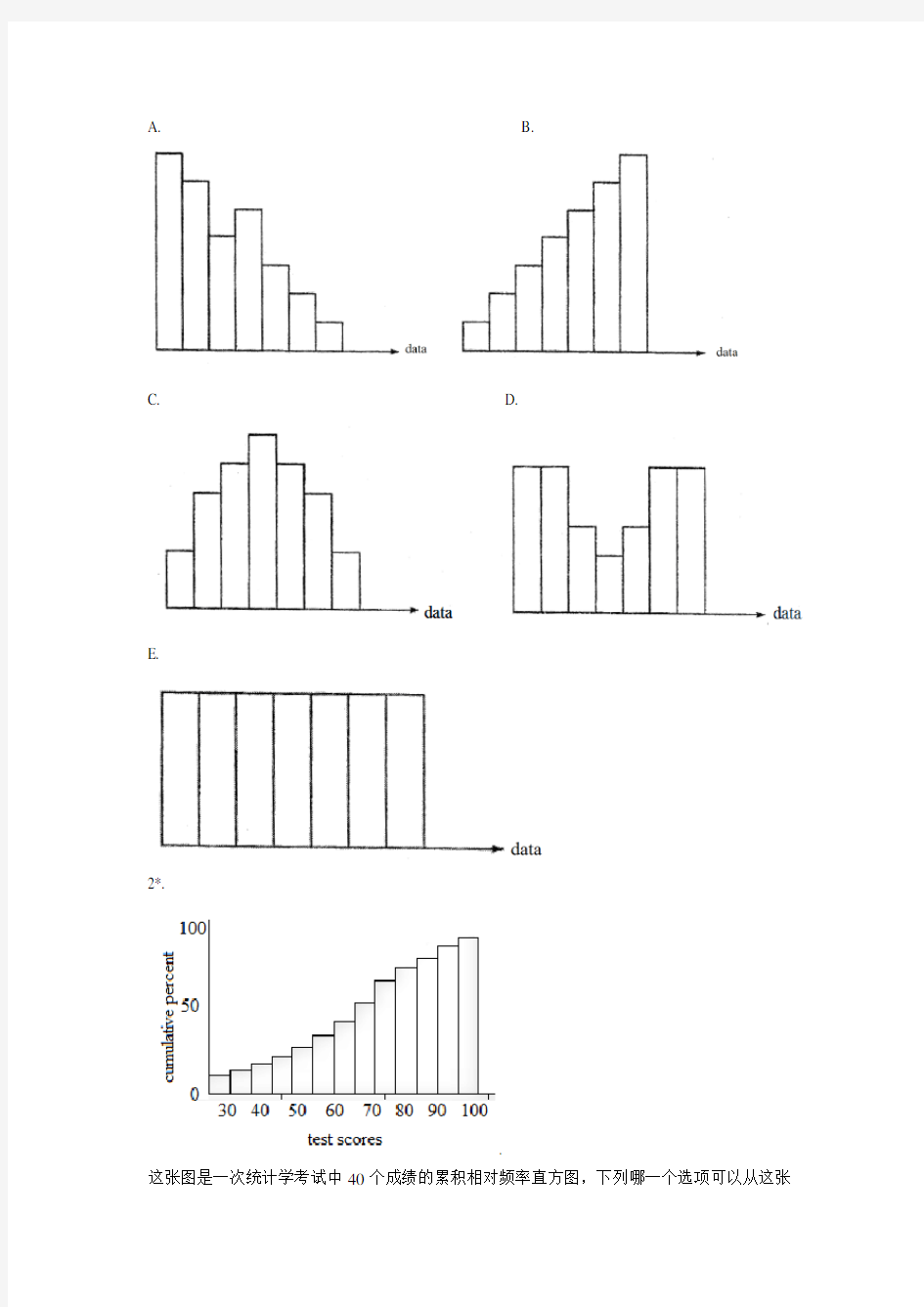
2*.
.
这张图是一次统计学考试中40个成绩的累积相对频率直方图,下列哪一个选项可以从这张
A.较低的20个分数的差异大于较高的20个分数的差异
B.中位数小于50
C.60%的学生的分数高于80分
D.如果设定及格线是70,那么大多数人没通过这次考试
E.这张图的平均水平组是60分,低于这个组的分数出现的频率更高
F.1*. Answer:D
G.Analysis:本题考查如何判断直方图的spread,显然,图D的标准差是最大的。
1*. Answer:D
Analysis:本题考查如何判断直方图的spread,显然,图D的标准差是最大的。
这张图是一次统计学考试中40个成绩的累积相对频率直方图,下列哪一个选项可以从这张图中得出?
A.较低的20个分数的差异大于较高的20个分数的差异
B.中位数小于50
C.60%的学生的分数高于80分
D.如果设定及格线是70,那么大多数人没通过这次考试
E.这张图的平均水平组是60分,低于这个组的分数出现的频率更高
2*. Answer:A
Analysis:本题考查累计频数分布图,较低的20个分数累积的比较快,较高的20个分数累积的比较慢,所以,较低的20个分数的变异性较大。
Set I
Set II
20 30 45 50 60
这张箱线图表明了两个统计数据组,根据这张箱线图,下列哪一个选项不能推断出来?
A.1组的范围和2组的范围一样
B.1组的四分位差和2组的四分位差一样
C.1组的中位数比2组的中位数小
D.1组的数据同2组的数据有相同的数据量
E.2组大约75%的数据大于或等于1组中大约50%的数据
Analysis:本题考查平行箱线图的数值特征。I和II的极差相同;IQR就是箱子的宽度,I和II 相同;中间的竖线是中位数,I小于II;从图中看不出I和II的数据量是否相同;I的中位数和II的下四分位数相同,所以II中至少有75%的数据比I中50%的数据大。
4*.
植物学家正在研究两种不同种类的百合花的花瓣长度(以毫米计)。上面的箱线图是选取两个不同物种的相同大小的样本的花瓣长度收集的数据。根据这个箱线图,哪一个选项是这次研究出的正确结果?
A.两组的四分位差相同
B.B种花的长度范围大于A种花
C.A种花的长度同B种花的长度相比有更多长于70mm的花瓣
D.B种花的长度同A种花的长度相比有更多长于40mm的花瓣
E.B种花的长度同A种花的长度相比有更多少于30mm的花瓣
4*. Answer:E
Analysis:本题考查平行箱线图的数值特征。A的IQR比B的小;A和B的极差相同;大于70的数据A比B的少;大于40的数据A比B多;大于30的数据A比B多。
5*.詹妮尔收集了一个大样本中每一个顾客在当地一个商店中停留的时间。这些数据被分为男士组和女士组。下图是这些数据的箱线图。
下面哪一个说法是正确的?
A.男士组在商店停留的时间的极差是40分钟
B.男士组平均在商店停留的时间大约为20分钟
C.男士组的3/4位数大约是45分钟
D.样本中女士组的四分位差是15分钟
E.样本中大约一半的男士在商店停留的时间至少同女士一样多
Analysis:本题考查平行箱线图的数值特征。解题思路同第3、4题,不再赘述。
6*.在1830年,土地测量员开始调查路易斯安那州的土地购买。他们的部分任务是调查该区
下列哪一个选项表示了累积相对频率表中树木直径在12到16英寸的组
A. 0.615 - 0.325
B. 0.615 - 0.473
C. 0.726 - 0.325
D. 0.726 - 0.473
E. 0.731 - 0.325 6*. Answer :C
Analysis :本题考查通过累积频率计算相应的区间。注意,题目问的是直径在12到16英尺之间,包括12和16。所以应该是11对应的相对频率0.325到16对应的相对频率0.726。
B. 问答题
1*.美国每个州每年公立学校招收学生与雇佣老师的数量的数据由美国每个州记录。从这些记录中,每个州学生和老师的数量比值(p-t 比)可以被计算出来。下面的柱状图显示了每个州在2001 - 2002学年的p-t 比。左边的柱状图显示了密西西比河以西的24个周的比率,右边的柱状图显示了密西西比河以东的26和州的比率
(a ) 描述你如何估计这两组数据的中位数的方法。然后用你所描述的方法估计西部地区
的中位数和东部地区的中位数。
(b ) 简单用几句话比较2001-2002学年这两组数据p-t 值。
(c ) 用你从(a )和(b )中的答案,来比较2001-2002学年这两组p-t 值的均值大小 1*. Analysis :本题考查直方图的相关知识。 (a) 找出中位数,根据中位数的定义M e 的位置是
1
2
n ,n 1 = 24,n 2 = 26。所以两个中位数所在的组都是15~16。
(b) shape :west 右偏,east 接近对称;center :中位数相同;spread :the range of west = 22 – 12 = 10,the range of east = 19 – 12 = 7。
(c) west 右偏,有mean > median ;east 接近对称,有mean = median 。两者中位数相同,所以,mean west > mean east 。
第三章
1*.下面的茎叶图显示了16年来两家不同的公司股票每股收益的比较
下列哪一个选项是正确的?
A.A公司的收益的中位数小于B公司收益的中位数
B.A公司收益的范围小于B公司的收益范围
C.A公司的3/4位数小于B公司的3/4位数
D.A公司收益的均值比B公司收益的均值大
E.A公司的四分位差是B公司的四分位差的两倍
1*. Answer:D
Analysis:本题考查背靠背茎叶图的数值特征。A的中位数为1.955,B的中位数为1.32;A 的极差为3.32,B的极差为1.71;A的上四分位数为2.49,B的上四分位数为1.65;A的均值为2.1475,B的均值为1.38625;A的IQR为1.06,B的IQR为0.67。
2*. 一个公司想要确定员工的医疗费用。对一个25个雇员的样本进行采访,确定他们上一年的医疗花费。后来该公司发现,最高的医疗费用在样本被错误地记录为10倍的实际金额。但是,在纠正错误之后,正确的数字依然大于或等于样本中任何其他的医疗花费数字。下列哪个样本统计量必须在更正后保持不变?
A. Mean 均值
B. Median 中位数
C. Mode 众数
D. Range 范围
E. Variance 方差
2*. Answer:B
Analysi:本题考查变量取值的变化对变量数字特征的影响。题中把数据错误变为原来的10倍。改正后数据还是偏大,那么和正确的相比,只有中位数不会变化。
3*. 从总人口中随机选取一个10人大小的随机样本。这个样本的方差是0。下列哪一个选项是正确的?
1:总人口的方差也是0。
2:样本的均值和样本的中位数一样。
3:这10个样本数据数学上相等
A. I only 只有1
B. II only 只有2
C. III only 只有3
D. I and II 1和2
E. II and III 2和3
3*. Answer:E
Analysis:本题考查样本均值与中位数的关系受方差变化的影响。样本方差为0,说明样本数据没有波动,即样本中每个数据都是相同的,但这并不意味着总体也是如此。所以样本均值和中位数相等。
4*.一个教授教两个统计学班。早上的课有25个学生,他们的第一次测试平均分是82。晚上的课有15个学生,他们的第一次测试成绩是74。考虑他两个班的情况,教授所教全部学生
的平均测试成绩是多少? A. 76 B. 78 C. 79 D. 80
E. The average cannot be calculated since individual scores of each student are not available. 由于不是每个学生成绩都知道所以不可计算 4*. Answer :C
Analysis :本题考查平均数的计算。两个班级的平均成绩为:
25821574
792515
?+?=+
5*. 从芒廷维尤学区抽取一个25个家庭的随机样本进行调查。在这次调查中,收集的数据是每一个家庭中生活的最小的小孩。下面的直方图展示了这次调查中得到的数据。
下面哪一个组包含了这次调查中的均值
A. 0 years old to less than 2 years old 0岁到小于2岁
B. 4 years old to less than 6 years old 4岁到小于6岁
C. 6 years old to less than 8 years old 6岁到小于8岁
D. 8 years old to less than 10 years old 8岁到小于10岁
E. 10 years old to less than 12 years old 10岁到小于12岁 5*. Answer :D
Analysis :本题考查中位数的计算。n = 25,所以median 是第13个数,它落在8—10之间。
6*.下面的数据选取自随机抽取的一个200小孩的样本,提供了一个汇总的统计分布的身高。 均值:46英尺
中位数:45英尺7*. 标准差:3英尺 /4位数:43英尺 3/4位数:48英尺
大概样本中的100个小孩的身高范围是 A.小于43英尺 B.小于48英尺
C.在43到48英尺间
D.在40到52英尺间
E.多于46英尺
6*. Answer:C
Analysis:本题考查两个四分位数之间的数据比例为50%。所以约有100个children的身高在43—48 inches之间。
7.上表展示了测量的两个样本的大小,均值,中位数。哪一个数值表示了这47个样本的总
n Mean Median
Sample I 21 42.6 45.0
Sample II 26 49.2 48.5
A.
2B.
48.5
2
C.
2142.62649.2
2
?+?
D.
2145.02648.5
2
?+?
E. It can not be determined from the given information.
E.由给定数据不能计算出
7*. Answer:E
Analysis:本题考查中位数计算。必须知道两个样本各自的直方图或者具体的数据,才能计算两个样本合在一起的median。
8*. 下面哪个分布的均值大于中位数
8*. Answer:A
Analysis:本题考查中位数和均值的比较。一般来说,均值大于中位数就是右偏。
9*. 一个当地的房地产杂志在报道被古弗兰高中录取的学生的平均SAT成绩时,用中位数替代均值。一个图形显示被古弗兰高中录取的学生SAT成绩强烈向右倾斜。下列哪个选项解释了在这种情况下为什么中位数是一个比均值更准确的测量学生SAT平均水平的标准。
A. 均值被右偏影响,而中位数不会
B. 均值总是更接近原始数据
C. 当数据强烈右偏时均值会少于中位数
D. 只有数据左偏时才应该使用均值
E. 中位数等于古弗兰高中SAT 成绩最大和最小的和的一半 9*. Answer :A
Analysis :本题考查使用mean 还是median 来代表center 。由于考试分数是右偏的,所以magazine 使用median 来表示centre 。
10*.成年雄性灰鲸的体重大约按照均值为18000kg ,标准差为4000kg 的正态分布。成年雄性座头鲸的体重大约按照均值为30000kg ,标准差为6000kg 。一只成年雄性灰鲸重24000kg 。这只鲸应该和以下哪一头成年雄性座头鲸体重有相同的标准化分数? A. 21,000 B. 24,000 C. 30,000 D. 36,000 E. 39,000 10*. Answer :E
Analysis :本题考查Z 分数的应用(转换)。gray whales~N(18,000, 4,000),humpback whales~N(30,000, 6,000)。某个gray whale 是24,000千克,它和humpback whales 的Z 分数相同。那么Z gray whale = Z humpback whale =
24000180004000-=1.5 =
30000
6000
x -,所以x = 39000。
11*. 在一所大学,学生们的化学期末考试成绩大约服从均值为75,标准差为12正态分布.微积分期末考试成绩大约服从均值为80,标准差为8的正态分布。一个学生期末化学考了81,微积分考了84,相对于这些学生在各自班级中,下面那个课程这个学生学得更好? A.这个学生化学学得更好 B.这个学生微积分学得更好 C.这个学生两门课一样好 D.信息不足不能判断 11*. Answer :C
Analysis :本题考查Z 分数的应用,不同数据的比较。计算各自的Z 分数,
81750.512chemistry Z -=
=,8480
0.58
calculus Z -==,所以,两门考试成绩一样好。
12*. 劳伦参加了一个非常大的大学微积分班。在第一次考试中,班级平均分是75,标准偏差是10。在第二次考试中,班级平均分是70,标准偏差是15。劳伦在两个考试中都得了85分。假设每个考试分数约为正态分布,劳伦在哪一次考试中表现更好? A.她第一次考得好 B.她第二次考得好 C.两次一样好
D.由于班级人数未知所以不能判断
E.由于两个考试间相关性未给出所以不能判断 12*. Answer :C
Analysis :本题考查Z 分数的应用,不同数据的比较。计算各自的Z 分数,8575
110
first Z -==,sec 8570
15
ond Z -=
=,所以,两场考试成绩一样好。
13*.下图记录了一种遥控汽车每一次充满电所能运行的时间。这种类型的汽车运行时间的分
布,在电池第一次使用后的初始时期,大约服从均值为80分钟,标准差为2.5分钟的正态分布。阴影面积表示了下列选项中哪一个的概率?
A.任意选定汽车初次充电后使用时间范围在75到82.5分钟的概率
B.任意选定汽车初次充电后使用时间范围在75到85分钟的概率
C.任意选定汽车初次充电后使用时间范围在77.5到82.5分钟的概率
D.任意选定汽车初次充电后使用时间范围在77.5到85分钟的概率
E.任意选定汽车初次充电后使用时间范围在77.5到87.5分钟的概率 13*. Answer :A
Analysis :本题考查用Z 分数计算x 的值。均值减去两个标准差等于75,均值加上一个标准差等于82.5。
14*.下列哪一个选项是下图所示分布的标准差的最佳估计
A. 5
B. 10
C. 30
D. 50
E. 60 14*. Answer :B
Analysis :本题考查经验法则的应用。均值为50,均值加减两个标准差的范围内包含95%的数据,从图形上看,30~70的范围包含近似95%的数据,所以,47030σ≈-,10σ≈。
15*.有一次测试的成绩不是对称分布的下列哪一个数是第三四分位数的z 值的最佳估计A. 0.67 B. 0.75
D. 1.41
E. This z-score cannot be estimated from the information given.
E.这个z值不能从给定的信息得出
15*. Answer:E
Analysis:本题考查经验法则的应用。由于分布不是对称的,不能使用经验法则。
16*. Suppose that the distribution of a set of scores has a mean of 47 and a standard deviation of 14. 一组数据符合均值为47标准差为14的正态分布。如果每一组数据加4,哪一组数据将成为新的分布的均值和标准差?
Mean Standard Deviation
A. 51 14
B. 51 18
C. 47 14
D. 47 16
E. 47 18
16*. Answer:A
Analysis:本题考查变量取值变化对均值和标准差的影响。
17*.将一组测试数据按照下面的式子进行转换
转化后的数据=3.5(原始数据)+6.2
下列哪一个选项是错误的?
A.转换后的均值=3.5(原始数据)+6.2
B.转换后的中位数=3.5(原始数据)+6.2
C.转换后的极差=3.5(原始数据)+6.2
D.转换后的标准差=3.5(原始数据)
E.转换后的四分位距=3.5(原始数据)
17*. Answer:C
Analysis:本题考查变量取值变化对均值和标准差的影响。
18.
上图展示了一组数据的描述性变量。一次测试中,一个学生的标准化分数z= -1.2。这个学生在测试中得了多少分?
A. 266.28
B. 779.42
C. 1008.02
D.1083.38
E. 1311.98
18. Answer:B
Analysis:本题考查Z分数和x的关系。z = –1.2=
1045.7
221.9
x
,x = 779.42。
1*.一个专业的运动队用两个标准评价运动员的潜力,速度和力量。
(a)速度的比较是通过40码赛跑进行,用时更少则有更令人满意的速度。所有同位置运动员的用时均值为4.6秒,标准差为0.15秒,最小值为4.40秒,如下图所示
根据均值,标准差,最小值的时间,我们有理由相信40码赛跑的成绩大约按正态分布吗?请解释。
(b)力量是用举重所举起的重量衡量,举起重量更大则成绩更令人满意。所有同位置运
计算并说明一个举重成绩为370磅的运动员的z分数为多少。
(c)力量和速度在选拔运动员时被认为具有同样的重要性。根据下表所示的A运动员和B
1*. Analysis:本题主要考查Z分数的相关应用。
(a) 不能认为是正态分布。可以计算最小值的Z分数,,如果是正态分布,那么P(z < -1.33) = 0.092,不是0,所以不是正态的。
(b) 本题只需要计算Z分数并解释。,说明370比均值大2.4个标准差。
(c) 要比较孰优孰劣,就需先标准化。跑步:Player A:,Player B:;举重:Player A:,Player B:。所以两者在跑步上差距较大,所以选择A。
2*.宾州周立大学的调查员发现奖励可以提高智商,尤其是对于较低基线智商。他们发现一
(a)分析离群值
(b)说明每一组的集中趋势度量
(c)两个样本的智商的3/4位数是多少?
2. Analysis:本题考查数据的数值性度量。
(a) outlier 定义为大于Q3 + 1.5IQR,或小于Q1 - 1.5IQR,计算后发现不存在。
(b) 由于没有outlier,也没有明显的偏斜,mean和median都可以表示central。No Incentive: mean = 97.9, median = 95.0; Incentive: mean = 105.0, median = 98.0。
(c) 上四分位数就是处于75%位置的数。No Incentive: 109.75, Incentive: 131.39。
第四章
1*. 在下列情形中,哪一项活动是最难以运用普查的?
A.确定大学校园里持有拍照的自行车中有灯的车子所占的比例
B.确定某所高中支持穿校服的学生所占的比例
C.确定某所大学里注册就读的学生中,每周工作二十小时以上的学生所占的比例
D.确定某个小镇上一个家庭住宅里拥有两个车库的房子所占的比例
E.确定密歇根湖里的鱼中,鲈鱼所占的比例
1*. Answer:E
Analysis:本题考查普查的使用。普查需要调查到总体的每一个个体,选项E需要抽到该湖里每一条鱼,所以难度很大。
2*.一个小学里有十五间教室,每间教室有24个学生。一个样本容量为30的样本按照如下程序来抽取学生。
这15个教师每人从他的班上抽取两名学生进入样本。每个班的学生按照从1到24的顺序排序,然后用随机数表在01到24之间来选择两个不同的随机数字,被选中的两个数字所对应的两个学生进入样本。
这是程序是不是从这个小学中抽取了一个样本容量为30的简单随机样本?
A.不是,因为老师不是随机选择的
B.不是,因为所有的学生被选中的可能性不是相等的
C.不是,因为不是所有的学生都有被选中的可能
D.是的,因为每个学生被选中的可能性是相等的
E.是的,因为数字是随机分配给这些学生的
2*. Answer:B
Analysis:本题考查SRS抽样的概念。按照题目的描述,该方法不是SRS。
3*. 某所高中的学生管理中心想要进行一项关于学生意愿的问卷调查,他们想要获取一个样本容量为60的简单随机样本,下列哪项调查方法可以获得一个简单随机样本?
A.调查早晨前六十位到学校的学生
B.调查每十个学生中第十个进入图书馆的学生,直到调查60人为止
C.用随机数表从一年级、二年级、三年级、四年级学生中各抽15人
D.给咖啡厅的座位排序,用随机数表选择座位并调查这个学生直到调查60位学生
E.在官方名册中给学生排序,用随机数表从这份名册中选择60位学生调查
3*. Answer:E
Analysis:本题考查SRS的概念。先编号,然后使用随机数表来选择60个学生。
4*. 一家电视台的新闻编辑想知道当地的注册选民会怎样来回答这样一个问题:“在接下来的特别的选举中你赞成?”一个调查在晚间新闻的间歇进行,两个电话号码在屏幕上并排列出来。一个供支持者拨打,另外一个供反对者拨打。由于很多原因,这种调查方法会给调查结果带来偏差。下列哪一个是最明显的原因?
A.他们用了分层抽样而不是简单随机抽样
B.对这个问题比较敏感的人更可能做出回应
C.在调查之前,应当把这个问题告诉观看者
D.一些打来电话的选民可能不会再选举中投票
E.问题的表达存在偏差
4*. Answer:B
Analysis:本题考查自愿回答偏差(voluntary response bias)的问题。去回答这个问题的,一般是和这个television news editor的观点相同的人。
5*. 杰森想要确定在他的家乡年龄和性别与党派偏好之间是什么关系。选民名单按照年龄和
性别分层。杰森从20到29岁组抽取了一个样本容量为50的男性样本,并记录他们的年龄,性别以及注册党派(民主党,共和党或者都不是)。同时他也从40到49岁组抽取了一个独立的样本容量为60的女性样本,并记录相同的信息。下列选项中,关于杰森的计划哪一项是最重要的观点?
A.计划地很周密,应该服务于预期的目的
B.样本容量太小
C.他应该采用同样大小的样本容量
D.他应该随即的选择两个年龄段的人群,而不是非随机的选择
E.他将无法辨别不同的年龄段或者不同的性别是否与党派的差异有关
5*. Answer:E
Analysis:本题考查如何抽样。age和gender对political party preference都有影响,两组的age和gender都不同,所以不能区分出是age影响了political party preference还是gender影响了political party preference。
6*. 根据密歇根州现有的27,000个涉及儿童的车祸记录,研究发现,当时系了安全带的儿童(系安全带组)中大约有百分之十受伤,没系安全带的儿童(没系安全带组)中大约有百分之十五受伤。下列哪个陈述不应该作为这项研究的结论?
A.司机的驾驶行为可能是一个潜在的混淆变量
B.儿童在车里的位置可能是一个潜在的混淆变量
C.这项研究不是实验,不能得出关于因果关系的推论
D.这项研究清楚的表明安全带使儿童免于受伤
E.得出安全带使儿童免于受伤的结论是不妥的,至少要等到研究独立的复制
6*. Answer:D
Analysis:本题考查因果关系。观测研究不能找出因果关系
7*. 一个涉及22,000名男性医生的医学实验想要知道是否阿司匹林能够预防心脏病。在这项研究中,11,000名隔日吃一片阿司匹林的医生被分为一组,而控制组吃安慰剂。几年之后,可以确定,吃阿司匹林的处理组得心脏病的机会显著地低于控制组。下列哪项陈述解释了为什么不能说每个人都应该隔日吃一片阿司匹林?
I.该研究只包括医生,其他职业个人中可能出现不同的结果。
II.该研究只包括男性,女性的结果可能会不同
III.虽然服用阿司匹林可能在预防心脏病方面有帮助,但是他可能在其他的方面对健康有害
A.只有I
B.只有II
C.只有III
D.只有II和III
E.I,II,III
7*. Answer:E
Analysis:本题考查实验的控制组处理组。这个实验的对象只是males physicians,所以对其他和其他性别人不一定有相同的结论。并且吃药会有其他的影响。
8*. 一群学生有一个大的容器,装有60个家蝇,为了做一个实验需要往标记为A,B和C 的三组中各分配20只。它们可以在家蝇进入有诱饵的侧腔室中的容器中时,一次捕获一只苍蝇时。下列方法中的哪一个将是最有可能产生三个具有可比性而且每组有20只家蝇的
组?
A.抓到的前二十只标记为A组,中间20只标记为B组,后20只标记为C组
B.在每个单独的纸条上写下字母A,B和C。随机挑一个纸条,并分配捕捉到的前20只苍
蝇进入该组。拿起另一个纸条,接下来的20苍蝇分配给该组。剩余的苍蝇分配给剩下的组。
C.每抓到一个苍蝇,掷骰子。如果骰子显示一个偶数,苍蝇记为A组,如果骰子示出了奇
数,苍蝇记为B组。当20只苍蝇已被标记为A组和20只已被标记为B组,然后将剩余的苍蝇标记为C组
D.将每个苍蝇放在自己的编号的容器中(编号从1到60)。把数字1到60写在纸条上,把
纸条放到一个盒子里,拌匀。从盒子中拿出20个号码。把与这些数字对应的容器中的苍蝇放入A组。再从盒子中拿出20个数字,并分配与这些数字对应容器中的苍蝇进入B组,分配剩余的20只苍蝇入C组
E.每抓到一个苍蝇,掷骰子。如果骰子点数为1或2,则标记苍蝇为A组;如果骰子点数
为3或4,则标记苍蝇为B组;如果骰子点数为5或6,则标记苍蝇为C组。重复此过程直到取满60只苍蝇。
8*. Answer:D
Analysis:本题考查实验分组。分组要符合随机化(randomization),如何实现随机化。
9*. 检验低温对两个品牌的橡皮的弹性的影响。一个盒子装A品牌的橡皮筋,一个盒子装B 品牌的橡皮筋。10根取自A品牌盒子的橡皮筋在更冷的环境下放置两小时,同时10根取自B品牌盒子的橡皮筋存放在室温环境中。拉伸每根橡皮筋,测量断裂前的长度。用冷橡皮筋的长度均值与其他的橡皮筋的长度均值相比。这是一个好的实验设计吗?
A.不是,因为均值不是一个合适的、用来比较的统计量。
B.不是,因为应该加入更多的品牌,而不是两个。
C.不是,因为应该采用更多的温度。
D.不是,因为温度与品牌相混淆了。
E.是的
9*. Answer:D
Analysis:本题考查何为好的实验。这里测试温度对橡胶弹性的影响,但是使用两个品牌的橡胶作对比,所以temperature 和brand会confound。
10*. 一个研究人员想要测验一种新开发的治疗高血压的药。一组由40位高血压的男性和60位高血压女性组成的样本参与实验。实验者随机分配20名男性和30名女性进入安慰剂组,剩下的进入处理组。按照不同性别来设计实验的主要原因是:
A.这是一个样本容量为100的大样本实验
B.新药可能对男性和女性的作用不同
C.新药可能对高血压患者和飞高血压患者的作用不同
D.这个设计使用了配对样本来测试新药的作用
E.安慰剂组和处理组的样本容量必须一样
10*. Answer:B
Analysis:本题考查实验区集。新药的效果根据性别的不同而不同。
11*. 一家狗粮公司想要测试一种新的高蛋白的狗粮配方,以确定它是否比现有的配方更好地促进小狗的体重增长。参加实验的小狗将在断奶的时候测量体重(开始吃狗粮的时候),
并且将在一年当中每个月末称重一次。在这个实验的设计中,调查中想要见笑自然差异导致的小狗的生长率方面的差异。为了达到这个目的,下面方法当中那个是最合适的?
A.按照小狗的品种区集,在每个品种下随机分配小狗至现有的配方组和新的配方组。
B.按照地理位置区集,在每个地理位置下随机分配小狗至现有的配方组和新的配方组。
C.按照小狗的品种分层,并从每个品种的小狗中随机抽样。然后随机分配小狗至现有的配方组和新的配方组。
D.按照小狗所在的地理位置分层,并从每个地理区域中随机抽样。然后随机分配小狗至现有的配方组和新的配方组。
E.按照性别分层,并从每个性别的小狗中随机抽样。然后随机分配小狗至现有的配方组和新的配方组。
11*. Answer:A
Analysis:本题考查实验区集。小狗的成长率会因狗的品种的不同而不同。
12*. 汽车是刹车片分为金属的和非金属的。一个实验为了确定不同种类的刹车片的汽车的制动距离是否是一样的。在之前的研究中,已经发现汽车的制动距离与汽车的大小(小型,中型,大型)有关,但是与汽车的种类(轿车,旅行车,轿跑)无关。这个实验最好能够这样进行:
A.按照车的大小区集
B.按照车的种类区集
C.按照车的制动距离区集
D.按照刹车片的种类区集
E.不区集
12*. Answer:A
Analysis:本题考查实验区集。Car size会影响stoppiing distance,所以,要根据car size来block。
13*. 在设计一个实验的时候,运用区集主要是为了减少:
A.实验的敏感行
B.变异
C.随机性的需要
D.偏差
E.混淆
3*. Answer:B
Analysis:本题考查为何使用block。使用block就是为了减少变异。
14*. 一家新开的餐厅很有兴趣确定焙烧羊肉的最佳时间和温度组合。在350℉和425的℉的环境下,分别焙烤45分钟、60分钟、90分钟各一次,并且期待最佳组合为90分钟——425℉。该组合最终被淘汰,因为这样会过分焙烤羊肉剩下了五种组合。从10片相同的羊肉中,随机选择两个,在相同的炉子中,用每种时间——温度组合焙烤。并且对每一个焙烤后的成品进行评估。下面哪项是正确的?
A.解释变量是成品羊肉的质量
B.相应变量是焙烤羊肉的时间
C.如果重复的做实验,可以预料结果是相同的。
D.应该设置一个控制组(比如一个没有接受处理的组)
E.两片羊肉逐次在每个时间——温度组合下焙烤就是一个复制的例子
14*. Answer:C
Analysis:本题考查实验复制。如何根据题目里的方法再做一遍实验的话,我们期望结果是相似的。
15*. 下列哪项是实验和观测研究的主要区别?
A.实验的主体比观测研究多
B.道德的约束阻碍了大规模的观测研究
C.实验比观测研究的成本低
D.实验可以反映直接的因果关系,但是观测研究不能
E.观测研究得来的数据不能进行显著性检验
15*. Answer:D
Analysis:本题考查观察研究和实验的关键区别——因果关系。实验能为变量之间的因果关系提供良好的证据,而观测研究不可以。
16. 下列哪种情况下用分层抽样比简单随机抽样更好?
A.总体可以被分成很多层,每一层所包含的个体都比较少
B.总体可以被分成很少层,每一层所包含的个体都比较多
C.总体可以被分层,每一层当中的个体要尽可能的相像
D.总体可以被分层,每一层当中的个体要尽可能的不同
E.总体可以被分成同等大小的层,所以总体中的个体依然有相等的可能被抽中
16. Answer:C
Analysis:本题考查分层抽样和SRS的比较。SRS抽出的样本可能对总体没有好的代表性。
17. 一个样本容量为2000 人的简单随机样本中,每个人都会接受一项调查。其中317人回应了调查。不回应会给结果造成怎样的偏差?
A.不回应导致样本减少,小样本比大样本的偏差大
B.不回应违反了独立性的假设
C.难以区分不回应的人和没有收到调查问卷的人
D.没有回应的人代表了一个层,这把简单随机抽样变成了分层抽样
E.回应的人可能在很多重要的方面与不回应的人不同
17. Answer:E
Analysis:本题考查无回答误差。有可能无回答的被调查者很重要。
18.乔治和米歇尔都声称自己有更好的配方来制作巧克力饼干。他们决定进行一项研究来确定到底谁的饼干更好。他们每个人都用自己的烤箱焙烤了一批饼干。乔治用简单随机抽样的方式邀请他的朋友来品尝他的饼干,并且来完成一份调查问卷。米歇尔也用简单随机抽样的方式邀请她的朋友来品尝她的饼干,并且来完成一份相同的调查问卷。然后他们对比得到的结果。关于这项研究,下列哪项说法的错误的?
A.因为乔治和米歇尔各自的朋友的总体是不同的,所以她们的抽样方法导致了难以比较他
们的配方
B.因为乔治和米歇尔都按照他们各自的配方,他们的手艺会与配方的质量相混淆
C.因为乔治和米歇尔都在自己家中用各自的烤箱,配方的质量会与烤箱的特性相混淆
D.因为乔治和米歇尔都用相同的调查问卷,调查结果可以推广到他们的朋友的总体
E.因为乔治和米歇尔都只焙烤了一批,饼干的配方没有复制
18. Answer:D
Analysis:本题考查自发性回答。这里调查没有可比性,因为问的是各自的朋友,有自发性取向。
B. 问答题
1*. 一座公寓楼有九层,每层都有四间公寓。在更换整座楼所有的地毯之前,公寓楼的所有者想要在其中的8间公寓铺上新地毯先看看效果。
下图显示了每层楼的公寓及其编号,标有一个星号(*)的房间表示家中有小孩。
(a)为了方便起见,公寓楼的所有者想要采取整群抽样的方法,楼层表示群,要从中抽取8间公寓。请描述用这种方法随机选择8间公寓的过程。
(b)另外一种抽样方法是用分层抽样随机选择8间公寓,有小孩和没有小孩的公寓分别表示2种不同的层。这种方法抽取的样本包括两间有小孩的公寓和6间没有小孩的公寓。请说出用这种抽样方法选择8间公寓而不是整群抽样以楼层表示群的方法,在统计方面的优势。
1*. Analysis:本题考查分层抽样和整群抽样的区别
(a) 整群抽样。从1~9个数字中随机抽取两个数字,如1,2,那么第1层和第2层所有8个房间都入选样本。
(b)整群抽样和分层抽样的区别。本题考查铺地毯对儿童的影响,整群抽样有可能抽到的房间中没有儿童。例如抽到3,4两层。而分层抽样不会有这样的问题,按照有无儿童分为两层,有儿童的随机抽2个房间,没儿童的随机抽6个房间。
2*. 患有恐高症的人有时候通过参加治疗课程来帮助克服这种恐惧心理。通常情况下,经过七八个疗程才会有所改善。现进行一项研究,为了确定使用D-环丝氨酸是否在帮助克服恐高症的同时可以缩短治疗过程。
在参与研究27人中每人都可以在两个疗程之前得到一颗药丸。27人中随机分配17人拿到D-环丝氨酸的药丸,剩下的10人拿到安慰剂。两个疗程之后,27人中没有人得到额外的药丸或者治疗。三个月之后,27个人都要接受评估,以确定他(或她)的情况有没有改善。(a)这项研究是实验还是观测研究?请就你的回答给出解释。
(b)在分析数据的时候,D-环丝氨酸组与安慰几组相比有了显著的改善。在这个结果的基础上,研究者有理由认为D-环丝氨酸药丸配上两个疗程比8个疗程没有药丸更有效吗?解释你的答案。
(c)一篇报纸载文称:这项实验的结果不能解释他们是如何确定哪些是接受D-环丝氨酸的人和哪些是接受安慰剂的人。假设研究者允许治疗专家来选择谁来接受D-环丝氨酸,谁来接受安慰剂,那就没有了随机性。解释为什么这种方法可能导致得出不正
确的结论。
2*. Analysis:本题考查实验相关知识。
(a) 很明显,这是一个实验。receive a D-cycloserine pill就是treatment group。
(b) 不能。本实验只能看出服用药物与否会不会有用,不能知道服药多或少的区别。
(c) 如果允许选择安慰剂还是药物,结果就会有不同。
3. 一个社区大学认为学生的出勤率和GPA之间是有关系的。他们选择了6个修初级概率论与数理统计的班级,每个班有50名学生。
(a)应该用什么方法来确定出勤率与GPA之间的关系?
(b)这是一项什么类型的研究?能够找出因果关系吗?
(c)假设这个大学认为老师通过小组作业的方式可以提高出勤率,进而导致更高的GPA。
应该怎样检验这个假设?
(d)加入结果显示进行分组作业的班级与传统教学的班级之间在GPA方面没有显著的差异,那么能够用什么来解释这个结果?
3. Analysis:本题考查实验中的因果关系、混淆变量等。
(a) 要观察GPA的数值和attendance的数量。
(b) 这是一个观察研究(observational study),不能找出cause and effect。
(c) 可以让一半的教师group work in the class,作为treatment group;一半的教师traditional instruction,作为control group。
(d) Attendance 会和其他变量混淆,如income, illness, family responsibility, risky behavior。
第五章
1*. Lynn计划从纽约飞往洛杉矶,并且将会乘坐Airtight航空公司早晨8点起飞的航班。她预定机票的网站说航班准点抵达洛杉矶的概率是0.7。下列选项中,就如何估计出的这个概率,哪项解释是最合理的?
A.通过用天气预报的方式,她所乘坐的航班起飞的那天有30%的概率是恶劣的天气
B.通过假设飞机是如何工作的,以及所有影响飞机工作的因素所组成的等式来估算出这个
概率
C.通过以往的事实,所有的飞往加利福尼亚的航班中,70%的准时抵达的
D.通过以往的事实,美国的所有航班中,70%是准时的
E.通过以往的事实,之前所有的这个航班路线,70%的是准时的
1*. Answer:E
Analysis:本题考查概率的含义。概率实际上是一个relative frequency。
2*. 交通数据显示,在沿州际公路部分路段运行的汽车中35%的汽车超过法定限速。通过高速公路摄像机和车牌登记,还确定52%的跑车也在该公路同样的路段超速。在该路段随机选择一辆汽车是超速行驶的跑车的概率是多少?
A. 0.870
B. 0.673
C. 0.182
D. 0.170
E.给出的信息无法确定
2*. Answer:E
Analysis:本题考查计算概率的条件。这里没有交代所有的car中有多少是sports car。
北京工业大学经济与管理学院2007-2008年度 第一学期期末 应用统计学 主考教师 专业: 学号: 姓名: 成绩: 1 C 2 B 3 A 4 C 5 B 6 B 7 A 8 A 9 C 10 C 一.单选题(每题2分,共20分) 1. 在对工业企业的生产设备进行普查时,调查对象是 A 所有工业企业 B 每一个工业企业 C 工业企业的所有生产设备 D 工业企业的每台生产设备 2. 一组数据的均值为20, 离散系数为0.4, 则该组数据的标准差为 A 50 B 8 C 0.02 D 4 3.某连续变量数列,其末组为“500以上”。又知其邻组的组中值为480,则末组的组中值为 A 520 B 510 C 530 D 540 4. 已知一个数列的各环比增长速度依次为5%、7%、9%,则最后一期的定基增长速度为 A .5%×7%×9% B. 105%×107%×109% C .(105%×107%×109%)-1 D. 1%109%107%1053 5.某地区今年同去年相比,用同样多的人民币可多购买5%的商品,则物价增(减)变化的百分 比为 A. –5% B. –4.76% C. –33.3% D. 3.85%
6.对不同年份的产品成本配合的直线方程为x y 75.1280? -=, 回归系数b= -1.75表示 A. 时间每增加一个单位,产品成本平均增加1.75个单位 B. 时间每增加一个单位,产品成本平均下降1.75个单位 C. 产品成本每变动一个单位,平均需要1.75年时间 D. 时间每减少一个单位,产品成本平均下降1.75个单位 7.某乡播种早稻5000亩,其中20%使用改良品种,亩产为600 公斤,其余亩产为500 公 斤,则该乡全部早稻亩产为 A. 520公斤 B. 530公斤 C. 540公斤 D. 550公斤 8.甲乙两个车间工人日加工零件数的均值和标准差如下: 甲车间:x =70件,σ=5.6件 乙车间: x =90件, σ=6.3件 哪个车间日加工零件的离散程度较大: A 甲车间 B. 乙车间 C.两个车间相同 D. 无法作比较 9. 根据各年的环比增长速度计算年平均增长速度的方法是 A 用各年的环比增长速度连乘然后开方 B 用各年的环比增长速度连加然后除以年数 C 先计算年平均发展速度然后减“1” D 以上三种方法都是错误的 10. 如果相关系数r=0,则表明两个变量之间
社会统计学课程期末复习题 一、填空题(计算结果一般保留两位小数) 1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。 2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。 3、在回归分析中,各实际观测值y 与估计值y ?的离差平方和称为 剩余 变差。 4、平均增长速度= 平均发展速度 —1(或100%)。 5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。 6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。 7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。 8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为 100%7% A 100% 1.06%100%6% -=-=-产品单位成本计划超额完成程度 ;若某厂计划规定B 产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为 100%10% 100% 4.76%100%5% +=-=+B 产品产量计划超额完成程度 。 9、按照标志表现划分,学生的民族、性别、籍贯属于 品质 标志;学生的体重、年龄、成绩属于 数量 标志。 10、从内容上看,统计表由 主词 和 宾词 两个部分组成;从格式上看,统计表由 总标题 、 横行标题 、 纵栏标题 和 指标数值(或统计数值); 四个部分组成。 11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于 正 相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于 负 相关。 12、按指标所反映的数量性质不同划分,国民生产总值属于 数量 指标;单位成本属于 质量 指标。 13、如果相关系数r=0,则表明两个变量之间 不存在线性相关关系 。 二、判断题
统计学第四版答案(贾 俊平)
请举出统计应用的几个例子: 1、用统计识别作者:对于存在争议的论文,通过统计量推出作者 2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的 3、挑战者航天飞机失事预测 请举出应用统计的几个领域: 1、在企业发展战略中的应用 2、在产品质量管理中的应用 3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用 你怎么理解统计的研究内容: 1、统计学研究的基本内容包括统计对象、统计方法和统计规律。 2、统计对象就是统计研究的课题,称谓统计总体。 3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。 举例说明分类变量、顺序变量和数值变量: 分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等 顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。 定性数据和定量数据的图示方法各有哪些: 1、定性数据的图示:条形图、帕累托图、饼图、环形图 2、定量数据的图示: a、分组数据看分布:直方图 b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图 c、两个变量间的关系:散点图 d、比较多个样本的相似性:雷达图和轮廓图 直方图与条形图有何区别: 1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。 2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。 3、条形图主要用于展示定性数据,而直方图则主要用于展示定量数据。 一组数据的分布特征可以从哪几个方面进行描述: 1、数据的水平,反映数据的集中程度 2、数据的差异,反映各数据的离散程度 3、分布的形状,反映数据分布的偏态和峰态 说明平均数、中位数和众数的特点及应用场合: 平均数也称为均值,它是一组数据相加后除以数据的个数而得到的结果。平均数是度量数据水平的常用统计量,在参数估计以及假设检验中经常用到。
统计学课后习题答案 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】
第四章 统计描述 【】某企业生产铝合金钢,计划年产量40万吨,实际年产量45万吨;计划降低成本5%,实际降低成本8%;计划劳动生产率提高8%,实际提高10%。试分别计算产量、成本、劳动生产率的计划完成程度。 【解】产量的计划完成程度=%5.112100%40 45 100%=?=?计划产量实际产量 即产量超额完成%。 成本的计划完成程=84%.96100%5%-18% -1100%-1-1≈?=?计划降低百分比实际降低百分比 即成本超额完成%。 劳动生产率计划完= 85%.101100%8%110% 1100%11≈?++=?++计划提高百分比实际提高百分比 即劳动生产率超额完成%。 【】某煤矿可采储量为200亿吨,计划在1991~1995年五年中开采全部储量的%, 试计算该煤矿原煤开采量五年计划完成程度及提前完成任务的时间。 【解】本题采用累计法: (1)该煤矿原煤开采量五年计划完成=100% ?数 计划期间计划规定累计数 计划期间实际完成累计 = 75%.1261021025357 4 =?? 即:该煤矿原煤开采量的五年计划超额完成%。 (2)将1991年的实际开采量一直加到1995年上半年的实际开采量,结果为2000万吨,此时恰好等于五年的计划开采量,所以可知,提前半年完成计划。 【】我国1991年和1994年工业总产值资料如下表:
要求: (1)计算我国1991年和1994年轻工业总产值占工业总产值的比重,填入表中; (2)1991年、1994年轻工业与重工业之间是什么比例(用系数表示) (3)假如工业总产值1994年计划比1991年增长45%,实际比计划多增长百分之几? 1991年轻工业与重工业之间的比例=96.01.144479 .13800≈; 1994年轻工业与重工业之间的比例=73.04.296826 .21670≈ (3) %37.25 1%) 451(2824851353 ≈-+ 即,94年实际比计划增长%。 【】某乡三个村2000年小麦播种面积与亩产量资料如下表: 要求:(1)填上表中所缺数字; (2)用播种面积作权数,计算三个村小麦平均亩产量; (3)用比重作权数,计算三个村小麦平均亩产量。
应用统计学试题及答案 LG GROUP system office room 【LGA16H-LGYY-LGUA8Q8-LGA162】
二、单项选择题(每题1分,共10分) 1.重点调查中的重点单位是指( ) A.处于较好状态的单位 B.体现当前工作重点的单位 C.规模较大的单位 D.在所要调查的数量特征上占有较大比重的单位 2.根据分组数据计算均值时,利用各组数据的组中值做为代表值,使用这一代表值的假定条件是()。 A.各组的权数必须相等 B.各组的组中值必须相等 C.各组数据在各组中均匀分布 D.各组的组中值都能取整数值 3.已知甲、乙两班学生统计学考试成绩:甲班平均分为70分,标准差为分;乙班平均分为75分,标准差为分。由此可知两个班考试成绩的离散程度() A.甲班较大 B.乙班较大 C.两班相同 D.无法作比较 4.某乡播种早稻5000亩,其中20%使用改良品种,亩产为600公斤,其余亩产为500公斤,则该乡全部早稻平均亩产为() 公斤公斤公斤公斤 5.时间序列若无季节变动,则其各月(季)季节指数应为() A.100% % % % 6.用最小平方法给时间数列配合直线趋势方程y=a+bt,当b<0时,说明现象的发展趋势是() A.上升趋势 B.下降趋势 C.水平态势 D.不能确定 7.某地区今年和去年相比商品零售价格提高12%,则用同样多的货币今年比去年少购买()的商品。 8.置信概率表达了区间估计的() A.精确性 B.可靠性 C.显着性 D.规范性 9.H 0:μ=μ ,选用Z统计量进行检验,接受原假设H 的标准是() A.|Z|≥Z α B.|Z|
function FindProxyForURL(url, host){ if(isPlainHostName(host)) return 'DIRECT'; if(!shExpMatch(url, 'http*')) return 'DIRECT'; var ip = dnsResolve(host); // no dns result if(!ip) return 'PROXY 127.0.0.1:8083;'; // ipv6 if(shExpMatch(ip, '*:*')) return 'DIRECT'; // local else if(isInNet(ip,'127.0.0.0','255.0.0.0')) return 'DIRECT'; else if(isInNet(ip,'10.0.0.0','255.0.0.0')) return 'DIRECT'; else if(isInNet(ip,'192.168.0.0','255.255.0.0')) return 'DIRECT'; else if(isInNet(ip,'172.16.0.0','255.240.0.0')) return 'DIRECT'; else if(isInNet(ip,'169.254.0.0','255.255.0.0')) return 'DIRECT'; // video rules else if(shExpMatch(url, '*.flv')) return 'PROXY ' + host + 'https://www.doczj.com/doc/7d7364671.html,:8081;'; else if(shExpMatch(url, '*.mp4')) return 'PROXY ' + host + 'https://www.doczj.com/doc/7d7364671.html,:8081;'; else if(shExpMatch(url, 'http:*/flv/*.flv?*&key=*')) return 'PROXY ' + host + 'https://www.doczj.com/doc/7d7364671.html,:8081;'; else if(shExpMatch(url, 'http:*/mp4/*.f4v?*&key=*')) return 'PROXY ' + host + 'https://www.doczj.com/doc/7d7364671.html,:8081;'; else if(shExpMatch(url, '*.flv?start=*')) return 'PROXY ' + host + 'https://www.doczj.com/doc/7d7364671.html,:8081;'; else if(shExpMatch(url, '*.mp4?start=*')) return 'PROXY ' + host + 'https://www.doczj.com/doc/7d7364671.html,:8081;'; else if (isInNet(ip, '58.154.0.0','255.254.0.0')) return 'DIRECT'; else if (isInNet(ip, '58.192.0.0','255.254.0.0')) return 'DIRECT'; else if (isInNet(ip, '58.194.0.0','255.254.0.0')) return 'DIRECT'; else if (isInNet(ip, '58.196.0.0','255.254.0.0')) return 'DIRECT'; else if (isInNet(ip, '58.198.0.0','255.254.0.0')) return 'DIRECT'; else if (isInNet(ip, '58.200.0.0','255.248.0.0')) return 'DIRECT'; else if (isInNet(ip, '59.64.0.0','255.252.0.0')) return 'DIRECT'; else if (isInNet(ip, '59.68.0.0','255.252.0.0')) return 'DIRECT'; else if (isInNet(ip, '59.72.0.0','255.254.0.0')) return 'DIRECT'; else if (isInNet(ip, '59.74.0.0','255.254.0.0')) return 'DIRECT'; else if (isInNet(ip, '59.76.0.0','255.255.0.0')) return 'DIRECT'; else if (isInNet(ip, '59.77.0.0','255.255.0.0')) return 'DIRECT'; else if (isInNet(ip, '59.78.0.0','255.254.0.0')) return 'DIRECT'; else if (isInNet(ip, '110.64.0.0','255.254.0.0')) return 'DIRECT'; else if (isInNet(ip, '111.114.0.0','255.254.0.0')) return 'DIRECT'; else if (isInNet(ip, '111.116.0.0','255.254.0.0')) return 'DIRECT'; else if (isInNet(ip, '111.186.0.0','255.254.0.0')) return 'DIRECT';
●3.2.某行业管理局所属40个企业2002年的产品销售收入数据如下(单位:万元): 1521241291161001039295127104 10511911411587103118142135125 117108105110107137120136117108 9788123115119138112146113126 (1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率; (2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业,105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。 解:(1)要求对销售收入的数据进行分组, 全部数据中,最大的为152,最小的为87,知数据全距为152-87=65; 为便于计算和分析,确定将数据分为6组,各组组距为10,组限以整10划分; 为使数据的分布满足穷尽和互斥的要求,注意到,按上面的分组方式,最小值87可能落在最小组之下,最大值152可能落在最大组之上,将最小组和最大组设计成开口形式; 按照“上限不在组内”的原则,用划记法统计各组内数据的个数——企业数,也可以用Excel 进行排序统计(见Excel练习题2.2),将结果填入表内,得到频数分布表如下表中的左两列;将各组企业数除以企业总数40,得到各组频率,填入表中第三列; 在向上的数轴中标出频数的分布,由下至上逐组计算企业数的向上累积及频率的向上累积,由上至下逐组计算企业数的向下累积及频率的向下累积。 整理得到频数分布表如下: 40个企业按产品销售收入分组表 (2)按题目要求分组并进行统计,得到分组表如下: 某管理局下属40个企分组表 按销售收入分组(万元)企业数(个)频率(%) 先进企业良好企业一般企业落后企业11 11 9 9 27.5 27.5 22.5 22.5 合计40100.0
六、计算题:(要求写出计算公式、过程,结果保留两位小数,共4题,每题10分) 1、某快餐店对顾客的平均花费进行抽样调查,随机抽取了49名顾客构成一个简单随机样本,调查结果为:样本平均花费为元,标准差为元。试以%的置信水平估计该快餐店顾客的总体平均花费数额的置信区 间;(φ(2)=)49=n 是大样本,由中心极限定理知,样本均值的极限分布为正态分布,故可用正态分布对总体均值进行区间估计。 已知:8.2,6.12==S x 0455.0=α 则有: 202275 .02 ==Z Z α 平均误差=4.07 8 .22==n S 极限误差8.04.022 2 =?==? n S Z α 据公式 x x ±=±? 代入数据,得该快餐店顾客的总体平均花费数额%的置信区间为(,) 3 要求:①、利用最小二乘法求出估计的回归方程;②、计算判定系数R 。 附:10805 1 2 ) (=∑-=i x x i 8.3925 1 2 ) (=∑-=i y y i 58=x 2.144=y 3题 解 ① 计算估计的回归方程: ∑∑∑∑∑--= )(22 1x x n y x xy n β) ==-??-?290 217900572129042430554003060 = =-= ∑∑n x n y ββ)) 1 0 – ×58= 估计的回归方程为:y ) =+x ② 计算判定系数: 4 计算下列指数:①拉氏加权产量指数;②帕氏单位成本总指数。 4题 解: ① 拉氏加权产量指数
= 1 000 00 1.1445.4 1.13530.0 1.08655.2 111.60%45.430.055.2q p q q p q ?+?+?==++∑∑ ② 帕氏单位成本总指数= 11100053.633.858.5 100.10%1.1445.4 1.13530.0 1.08655.2q p q q p q ++==?+?+?∑∑ 模拟试卷(二) 一、填空题(每小题1分,共10题) 1、我国人口普查的调查对象是 ,调查单位是 。 2、___ 频数密度 =频数÷组距,它能准确反映频数分布的实际状况。 3、分类数据、顺序数据和数值型数据都可以用 饼图 条图 图来显示。 4、某百货公司连续几天的销售额如下:257、276、297、252、238、310、240、236、265,则其下四分位数 5、某地区2005年1季度完成的GDP=30亿元,2005年3季度完成的GDP=36亿元,则GDP 年度化增长率6、某机关的职工工资水平今年比去年提高了5%,职工人数增加了2%,则该企业工资总额增长了 % 。 7、对回归系数的显着性检验,通常采用的是 t 检验。 8、设置信水平=1-α,检验的P 值拒绝原假设应该满足的条件是 p e M >o M ③、x >o M >e M 3、比较两组工作成绩发现σ甲>σ乙,x 甲>x 乙,由此可推断 ( )
第十二章 相关与回归分析 第一节 变量之间的相关关系 相关程度与方向·因果关系与对称关系 第二节 定类变量的相关 双变量交互分类(列联表)·削减误差比例(PRE )·λ系数与τ系数 第三节 定序变量的相关分析 同序对、异序对和同分对·Gamma 系数·肯德尔等级相关系数(τa 系数、τb 与τc 系数)·萨默斯系数(d 系数)·斯皮尔曼等级相关(ρ相关)·肯德尔和谐系数 第四节 定距变量的相关分析 相关表和相关图·积差系数的导出和计算·积差系数的性质 第五节 回归分析 线性回归·积差系数的PRE 性质·相关指数R 第六节 曲线相关与回归 可线性化的非线性函数·实例分析(二次曲线指数曲线) 一、填空 1.对于表现为因果关系的相关关系来说,自变量一般都是确定性变量,依变量则一般是( 随机性 )变量。 2.变量间的相关程度,可以用不知Y 与X 有关系时预测Y 的全部误差E 1,减去知道Y 与X 有关系时预测Y 的联系误差E 2,再将其化为比例来度量,这就是( 削减误差比例 )。 3.依据数理统计原理,在样本容量较大的情况下,可以作出以下两个假定:(1)实际观察值Y 围绕每个估计值c Y 是服从( );(2)分布中围绕每个可能的c Y 值的( )是相同的。 4.在数量上表现为现象依存关系的两个变量,通常称为自变量和因变量。自变量是作为( 变化根据 )的变量,因变量是随( 自变量 )的变化而发生相应变化的变量。 5.根据资料,分析现象之间是否存在相关关系,其表现形式或类型如何,并对具有相关关系的现象之间数量变化的议案关系进行测定,即建立一个相关的数学表达式,称为( 回归方程 ),并据以进行估计和预测。这种分析方法,通常又称为( 回归分析 )。 6.积差系数r 是( 协方差 )与X 和Y 的标准差的乘积之比。 二、单项选择 1.当x 按一定数额增加时,y 也近似地按一定数额随之增加,那么可以说x 与y 之间 存在( A )关系。 A 直线正相关 B 直线负相关 C 曲线正相关 D 曲线负相关
第三章节:数据的图表展示 (1) 第四章节:数据的概括性度量 (15) 第六章节:统计量及其抽样分布 (26) 第七章节:参数估计....................................................... (28) 第八章节:假设检验........................................................ (38) 第九章节:列联分析........................................................ (41) 第十章节:方差分析........................................................ (43) 3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C E E A B D D C A D B C C A E D C B C B C E D B C C B C 要求: (1)指出上面的数据属于什么类型。 顺序数据 (2)用Excel制作一张频数分布表。 用数据分析——直方图制作: 接收频率 E16 D17 C32 B21 A14 (3)绘制一张条形图,反映评价等级的分布。 用数据分析——直方图制作: (4)绘制评价等级的帕累托图。 逆序排序后,制作累计频数分布表:
应用统计学练习题 第一章绪论 一、填空题 1.统计工作与统计学的关系是__统计实践____和___统计理论__的关系。 2.总体是由许多具有_共同性质_的个别事物组成的整体;总体单位是__总体_的组成单位。 3.统计单体具有3个基本特征,即__同质性_、__变异性_、和__大量性__。 4.要了解一个企业的产品质量情况,总体是_企业全部产品__,个体是__每一件产品__。 5.样本是从__总体__中抽出来的,作为代表_这一总体_的部分单位组成的集合体。 6.标志是说明单体单位特征的名称,按表现形式不同分为__数量标志_和_品质标志_两种。 7. 8.统计指标按其数值表现形式不同可分为__总量指标__、__相对指标_和__平均指标__。 9.指标与标志的主要区别在于: (1)指标是说明__总体__特征的,而标志则是说明__总体单位__特征的。 (2)标志有不能用__数量__表示的_品质标志_与能用_数量_表示的_数量标志_,而指标都是能用_数量_表示的。 10.一个完整的统计工作过程可以划分为_统计设计_、_统计调查_、_统计整理_和__统计分析__4个阶段。 二、单项选择题 1.统计总体的同质性是指(A)。 A.总体各单位具有某一共同的品质标志或数量标志 B.总体各单位具有某一共同的品质标志属性或数量标志值 C.总体各单位具有若干互不相同的品质标志或数量标志 D.总体各单位具有若干互不相同的品质标志属性或数量标志值 2.设某地区有800家独立核算的工业企业,要研究这些企业的产品生产情况,总体是( D)。
A.全部工业企业 B.800家工业企业 C.每一件产品 D.800家工业企业的全部工业产品 3.有200家公司每位职工的工资资料,如果要调查这200家公司的工资水平情况,则统计总体为(A)。 A.200家公司的全部职工 B.200家公司 C.200家公司职工的全部工资 D.200家公司每个职工的工资 4.一个统计总体( D)。 A.只能有一个标志 B.可以有多个标志 C.只能有一个指标 D.可以有多个指标 5.以产品等级来反映某种产品的质量,则该产品等级是(C)。 A.数量标志 B.数量指标 C.品质标志 D.质量指标 6.某工人月工资为1550元,工资是( B )。 A.品质标志 B.数量标志 C.变量值 D.指标 7.某班4名学生金融考试成绩分别为70分、80分、86分和95分,这4个数字是( D)。 A.标志 B.指标值 C.指标 D.变量值 8.工业企业的职工人数、职工工资是(D)。 A.连续变量 B.离散变量 C.前者是连续变量,后者是离散变量 D.前者是离散变量,后者是连续变量 9.统计工作的成果是(C)。 A.统计学 B.统计工作 C.统计资料 D.统计分析和预测 10.统计学自身的发展,沿着两个不同的方向,形成(C)。 A.描述统计学与理论统计学 B.理论统计学与推断统计学 C.理论统计学与应用统计学 D.描述统计学与推断统计学
《应用统计学》习题解答 第一章绪论 【1.1】指出下列变量的类型: (1)汽车销售量; (2)产品等级; (3)到某地出差乘坐的交通工具(汽车、轮船、飞机); (4)年龄; (5)性别; (6)对某种社会现象的看法(赞成、中立、反对)。 【解】(1)数值型变量 (2)顺序变量 (3)分类变量 (4)数值型变量 (5)分类变量 (6)顺序变量 【1.2】某机构从某大学抽取200个大学生推断该校大学生的月平均消费水平。 要求: (1)描述总体和样本。 (2)指出参数和统计量。 (3)这里涉及到的统计指标是什么? 【解】(1)总体:某大学所有的大学生 样本:从某大学抽取的200名大学生 (2)参数:某大学大学生的月平均消费水平 统计量:从某大学抽取的200名大学生的月平均消费水平 (3)200名大学生的总消费,平均消费水平 【1.3】下面是社会经济生活中常用的统计指标: ①轿车生产总量,②旅游收入,③经济发展速度,④人口出生率,⑤安置再就业人数,⑥全国第三产业发展速度,⑦城镇居民人均可支配收入,⑧恩格尔系数。 在这些指标中,哪些是数量指标,哪些是质量指标?如何区分质量指标与数量指标?【解】数量指标有:①、②、⑤ 质量指标有:③、④、⑥、⑦、⑧ 数量指标是说明事物的总规模、总水平或工作总量的指标,表现为绝对数的形式,并附有计量单位。而质量指标是说明总体相对规模、相对水平、工作质量和一般水平的统计指标,通常是两个有联系的统计指标对比的结果。 【1.4】某调查机构从某小区随机地抽取了50为居民作为样本进行调查,其中60%的居民对自己的居住环境表示满意,70%的居民回答他们的月收入在6000元以下,生活压力大。 回答以下问题: (1)这一研究的总体是什么? (2)月收入是分类变量、顺序变量还是数值型变量? (3)对居住环境的满意程度是什么变量? 【解】(1)这一研究的总体是某小区的所有居民。
北京工业大学经济与管理学院2007-2008 年度 第一学期期末应用统计学 主考教师 专业:学号:姓名:成绩: 1C2B3A4C5B6B7A8A9C10C 一.单选题(每题 2 分,共 20 分) 1.在对工业企业的生产设备进行普查时,调查对象是 A 所有工业企业 B 每一个工业企业 C 工业企业的所有生产设备 D 工业企业的每台生产设备 2.一组数据的均值为20, 离散系数为0.4, 则该组数据的标准差为 A50B8C0.02D4 3.某连续变量数列,其末组为“ 500 以上”。又知其邻组的组中值为 480,则末组的组中值为 A 520 B 510 C 530 D 540 4.已知一个数列的各环比增长速度依次为5%、7%、 9%,则最后一期的定基增长速度为 A .5%× 7%× 9% B. 105% × 107%× 109% C.(105%× 107%× 109%)- 1 D. 3 105%107%109%1 5.某地区今年同去年相比,用同样多的人民币可多购买5%的商品 ,则物价增 (减 )变化的百分比为 A. –5% B. –4.76% C. –33.3% 6.对不同年份的产品成本配合的直线方程为 D. 3.85% ? y 280 1.75x ,回归系数b=-1.75表示 A.时间每增加一个单位,产品成本平均增加 1.75 个单位 B.时间每增加一个单位,产品成本平均下降 1.75 个单位 C. 产品成本每变动一个单位,平均需要 1.75 年时间 D. 时间每减少一个单位,产品成本平均下降 1.75 个单位 7.某乡播种早稻5000 亩,其中20%使用改良品种,亩产为600 公斤,其余亩产为500 公斤,则该乡全部早稻亩产为 A. 520公斤 B. 530公斤 C. 540公斤 D. 550公斤 8. 甲乙两个车间工人日加工零件数的均值和标准差如下: 甲车间 : x =70 件,=5.6 件乙车间 :x =90件,=6.3 件 哪个车间日加工零件的离散程度较大: A 甲车间 B.乙车间 C.两个车间相同 D.无法作比较 9.根据各年的环比增长速度计算年平均增长速度的方法是
社会统计学复习题有答 案 集团标准化工作小组 #Q8QGGQT-GX8G08Q8-GNQGJ8-MHHGN#
社会统计学课程期末复习题 一、填空题(计算结果一般保留两位小数) 1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。 2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。 3、在回归分析中,各实际观测值y 与估计值y ?的离差平方和称为 剩余 变差。 4、平均增长速度= 平均发展速度 —1(或100%)。 5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。 6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。 7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。 8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为 100%7% A 100% 1.06%100%6% -=- =-产品单位成本计划超额完成程度 ;若某厂计划规定B 产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为 100%10% 100% 4.76%100%5% += -=+B 产品产量计划超额完成程度 。
9、按照标志表现划分,学生的民族、性别、籍贯属于品质标志;学生的体重、年龄、成绩属于数量标志。 10、从内容上看,统计表由主词和宾词两个部分组成;从格式上看,统计表由 总标题、横行标题、纵栏标题和指标数值(或统计数值); 四个部分组成。 11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于正相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于负相关。 12、按指标所反映的数量性质不同划分,国民生产总值属于数量指标;单位成本属于质量指标。 13、如果相关系数r=0,则表明两个变量之间不存在线性相关关系。 二、判断题 1、在季节变动分析中,若季节比率大于100%,说明现象处在淡季;若季节比率小于100%,说明现象处在旺季。(×;答案提示:在季节变动分析中,若季节比率大于100%,说明现象处在旺季;若季节比率小于100%,说明现象处在淡季。 ) 2、工业产值属于离散变量;设备数量属于连续变量。(×;答案提示:工业产值属于连续变量;设备数量属于离散变量) 3、中位数与众数不容易受到原始数据中极值的影响。(√;) 4、有意识地选择十个具有代表性的城市调查居民消费情况,这种调查方式属于典型调查。(√)
第1章统计和统计数据 1.1 指出下面的变量类型。(1)年龄。(2)性别。(3)汽车产量。 (4)员工对企业某项改革措施的态度(赞成、中立、反对)。(5)购买商品时的支付方式(现金、信用卡、支票)。详细答案:(1)数值变量。(2)分类变量。(3)数值变量。(4)顺序变量。(5)分类变量。 1.2 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。 (1)这一研究的总体是什么?样本是什么?样本量是多少?(2)“月收入”是分类变量、顺序变量还是数值变量?(3)“消费支付方式”是分类变量、顺序变量还是数值变量?详细答案: (1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。(2)数值变量。 (3)分类变量。 1.3 一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。 (1)这一研究的总体是什么? (2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的网上购物者”。(2)分类变量。 1.4 某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。 (1)这种抽样方式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。(2)100。
第3章用统计量描述数据
偏度 1.08 极差26 最小值15 最大值41 从集中度来看,网民平均年龄为24岁,中位数为23岁。从离散度来看,标准差在为6.65岁,极差达到26岁,说明离散程度较大。从分布的形状上看,年龄呈现右偏,而且偏斜程度较大。 3.2 某银行为缩短顾客到银行办理业务等待的时间,准备采用两种排队方式进行试验。一种是所有顾客都进入一个等待队列;另一种是顾客在3个业务窗口处列队3排等待。为比较哪种排队方式使顾客等待的时间更短,两种排队方式各随机抽取9名顾客,得到第一种排队方式的平均等待时间为7.2分钟,标准差为1.97分钟,第二种排队方式的等待时间(单位:分钟)如下: 5.5 6.6 6.7 6.8 7.1 7.3 7.4 7.8 7.8 (1)计算第二种排队时间的平均数和标准差。 (2)比两种排队方式等待时间的离散程度。 (3)如果让你选择一种排队方式,你会选择哪一种?试说明理由。 详细答案: (1)(岁);(岁)。 (2);。第一中排队方式的离散程度大。 (3)选方法二,因为平均等待时间短,且离散程度小。
统计学 费宇石磊(主编) 第2章练习题参考答案 2.1解:(1)首先将顾客态度分别用代码1、2、3表示,然后在数据文件的Varible View窗口Values栏定义变量值标签:1代表“喜欢并愿意购买”;2代表“不喜欢”,3代表“喜欢并愿意购买”。操作步骤: 依次点击File→点击open→点击Data→打开数据文件ex2.1→点击Analyze→点击Descriptive Statistics→点击Frequencies→将“态度”选入Variable框→点击OK。输出结果如表2.1所示: (2)根据表2.1频数分布表资料建立的数据文件为 绘制条形图操作步骤:依次点击File→点击open→点击Data→打开数据文件,选中Summaries for groups of cases→单击Define→选中Other Summary function→将“人数”选入Variable(纵轴),将“态度分类”选入Category Axis (横轴)→点击OK。输出结果如图2.1所示:
图2.1 30名顾客满意程度分布条形图 绘制饼图操作步骤:依次点击File→点击open→点击Data→打开数据文件 of individual cases→点击Define→将“人数”选入Slices Represent栏,将“态度分类”选入Variable栏→点击OK。输出结果如图2.2所示: 2.2解:首先列计算表如表2.2所示: 表2.2 120名学生英语成绩的均值、中位数、众数、偏态系数、峰度系数计算表
(1)均值151 872072.67120 i i i i i x f x f === = =∑∑(分) 表2.2中,分布次数最多的组是“40~50”组,这就是众数所在组;2 N =60,中位数大约在第60位,可确定中位数也在“40~50”组。 众数10124230 701073.333018M L i ?-=+ ?=+?=?+?-+-(分) (42)(42) 中位数11204922701072.6242 m e m N S M L i f ---=+?=+?=(分) (2)首先计算标准差:11.65s = =(分) 3 1 1 3 3 () /38389.64/120 0.202311.65k k i i i i x x f f SK s ==-= = =∑∑ 由计算结果可看出,偏态系数为正值,但与零的差距不大,说明120名大学生英语成绩为轻微右偏分布,成绩较低的同学占有一定的比例,但偏斜程度不大。 4 1 1 4 4 () /5108282.61/120 330.689111.65k k i i i i x x f f K s ==-= -= -=-∑∑ 由计算结果可看出,峰度系数为负值,说明120名大学生英语成绩为平峰分布,成绩较低的同学占一定比例,但低成绩区域的集中程度并不很高。 2.3解(1)整理的组距数列如表 表2.3.1 连续60天计算机销售量频数分布表