1.描述
上一节中介绍了怎么使用数据可视化工具FineBI提升数据的可读性,是对每个数据表进行操作,但是往往在数据库中的表与表之间也存在关联,比如说外键,即某个字段是一个表的主键,但是该字段同样是另外一张表的外键,那么数据可视化工具FineBI怎么读取这种表间的关联关系呢?
2.读取数据库关联
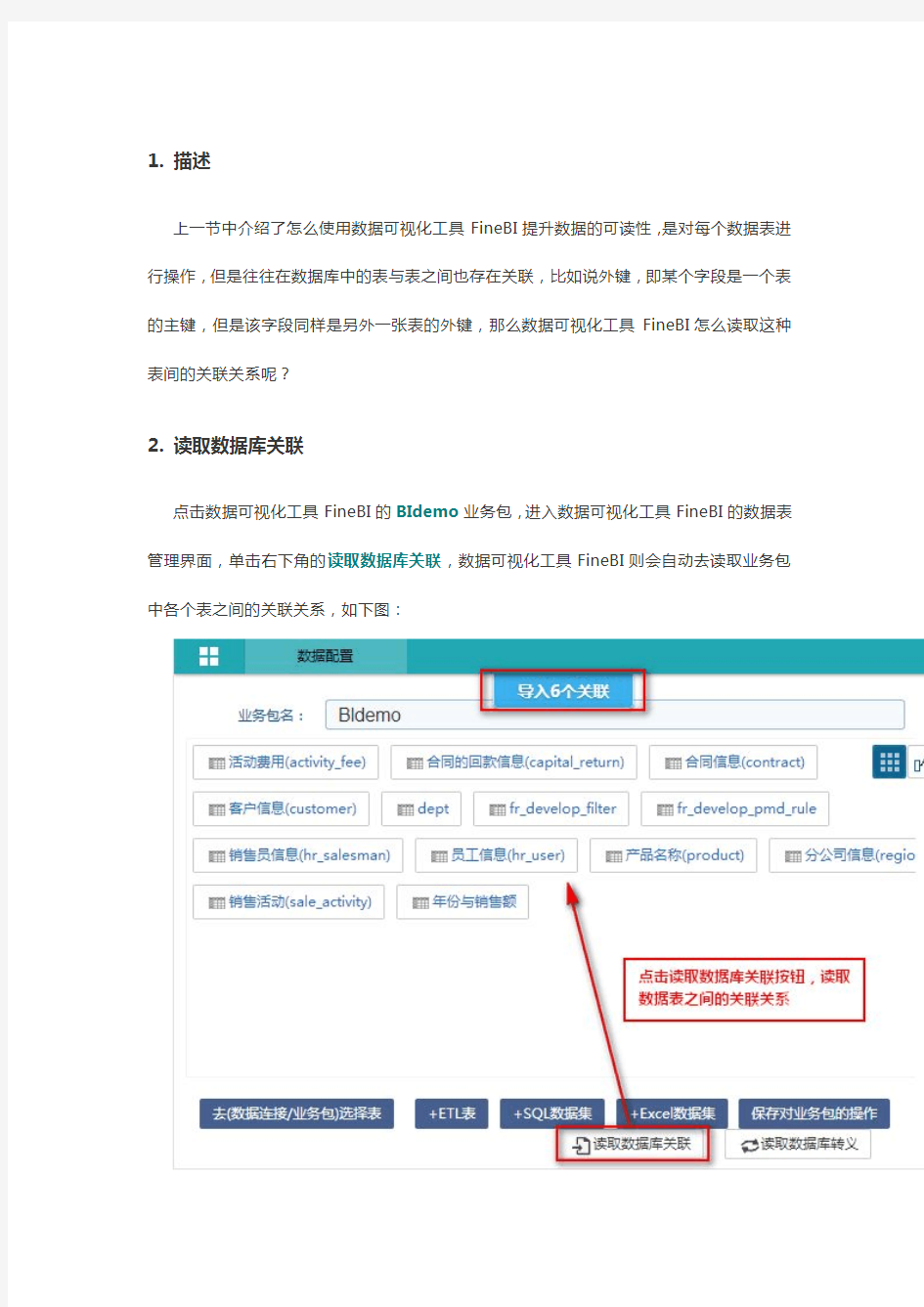
点击数据可视化工具FineBI的BIdemo业务包,进入数据可视化工具FineBI的数据表管理界面,单击右下角的读取数据库关联,数据可视化工具FineBI则会自动去读取业务包中各个表之间的关联关系,如下图:
3.数据库关联查看
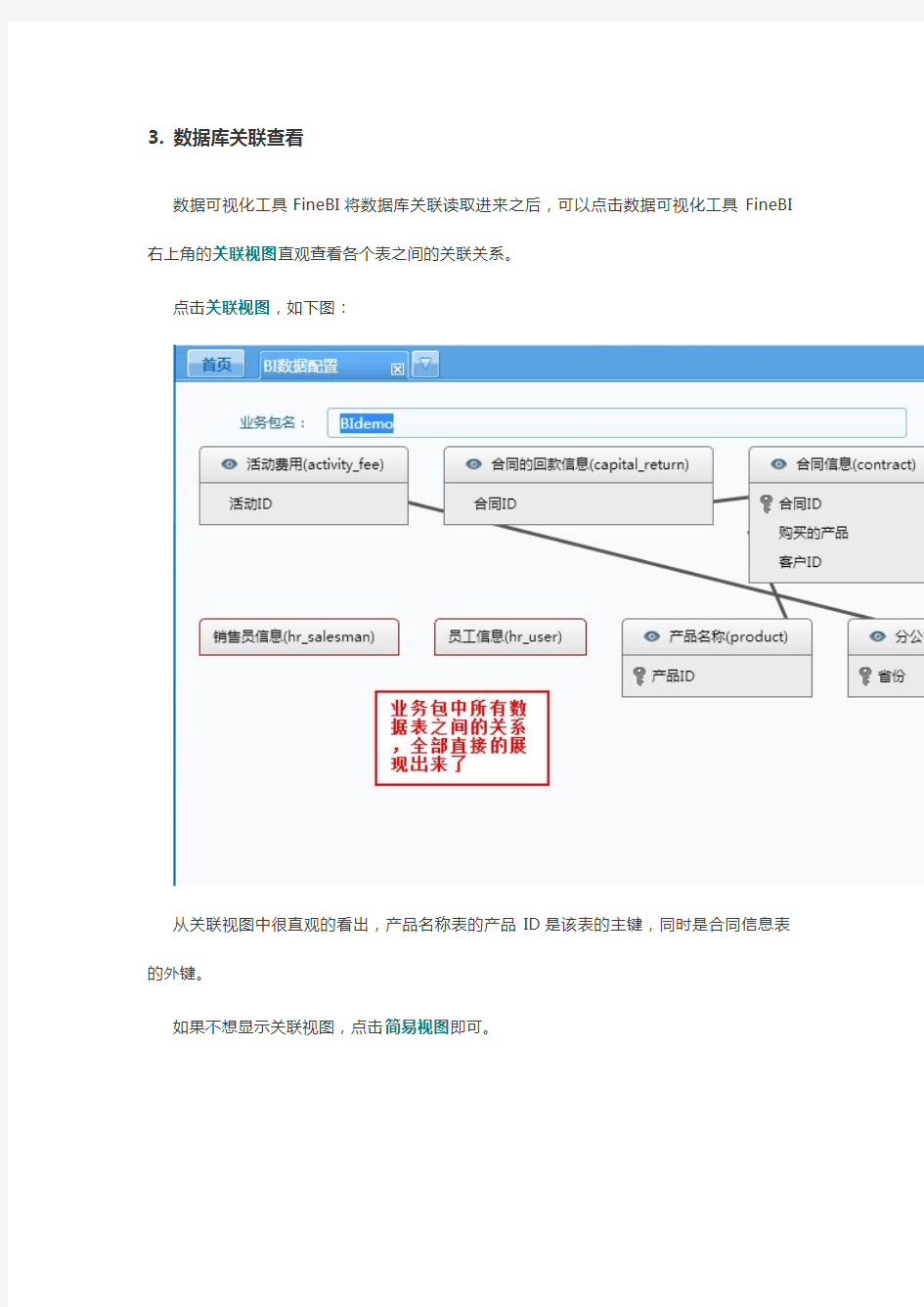
数据可视化工具FineBI将数据库关联读取进来之后,可以点击数据可视化工具FineBI 右上角的关联视图直观查看各个表之间的关联关系。
点击关联视图,如下图:
从关联视图中很直观的看出,产品名称表的产品ID是该表的主键,同时是合同信息表的外键。
如果不想显示关联视图,点击简易视图即可。
数学建模常用软件有哪些哈 MatlabMathematicalingoSAS详细介绍:数学建模软件介绍一般来说学习数学建模,常用的软件有四种,分别是:matlab、lingo、Mathematica和SAS下面简单介绍一下这四种。 1.MA TLAB的概况MA TLAB是矩阵实验室(Matrix Laboratory)之意。除具备卓越的数值计算能力外,它还提供了专业水平的符号计算,文字处理,可视化建模仿真和实时控制等功能。MATLAB的基本数据单位是矩阵,它的指令表达式与数学,工程中常用的形式十分相似,故用MATLAB来解算问题要比用C,FORTRAN等语言完相同的事情简捷得多. 当前流行的MA TLAB 5.3/Simulink 3.0包括拥有数百个内部函数的主包和三十几种工具包(Toolbox).工具包又可以分为功能性工具包和学科工具包.功能工具包用来扩充MATLAB的符号计算,可视化建模仿真,文字处理及实时控制等功能.学科工具包是专业性比较强的工具包,控制工具包,信号处理工具包,通信工具包等都属于此类. 开放性使MATLAB广受用户欢迎.除内部函数外,所有MA TLAB主包文件和各种工具包都是可读可修改的文件,用户通过对源程序的修改或加入自己编写程序构造新的专用工具包. 2.Mathematica的概况Wolfram Research 是高科技计算机运算( Technical computing )的先趋,由复杂理论的发明者Stephen Wolfram 成立于1987年,在1988年推出高科技计算机运算软件Mathematica,是一个足以媲美诺贝尔奖的天才产品。Mathematica 是一套整合数字以及符号运算的数学工具软件,提供了全球超过百万的研究人员,工程师,物理学家,分析师以及其它技术专业人员容易使用的顶级科学运算环境。目前已在学术界、电机、机械、化学、土木、信息工程、财务金融、医学、物理、统计、教育出版、OEM 等领域广泛使用。Mathematica 的特色·具有高阶的演算方法和丰富的数学函数库和庞大的数学知识库,让Mathematica 5 在线性代数方面的数值运算,例如特征向量、反矩阵等,皆比Matlab R13做得更快更好,提供业界最精确的数值运算结果。·Mathematica不但可以做数值计算,还提供最优秀的可设计的符号运算。·丰富的数学函数库,可以快速的解答微积分、线性代数、微分方程、复变函数、数值分析、机率统计等等问题。·Mathematica可以绘制各专业领域专业函数图形,提供丰富的图形表示方法,结果呈现可视化。·Mathematica可编排专业的科学论文期刊,让运算与排版在同一环境下完成,提供高品质可编辑的排版公式与表格,屏幕与打印的自动最佳化排版,组织由初始概念到最后报告的计划,并且对txt、html、pdf 等格式的输出提供了最好的兼容性。·可与C、C++ 、Fortran、Perl、Visual Basic、以及Java 结合,提供强大高级语言接口功能,使得程序开发更方便。·Mathematica本身就是一个方便学习的程序语言。Mathematica提供互动且丰富的帮助功能,让使用者现学现卖。强大的功能,简单的操作,非常容易学习特点,可以最有效的缩短研发时间。 3.lingo的概况LINGO则用于求解非线性规划(NLP—NON—LINEAR PROGRAMMING)和二次规则(QP—QUARATIC PROGRAMING)其中LINGO 6.0学生版最多可版最多达300个变量和150个约束的规则问题,其标准版的求解能力亦再10^4量级以上。虽然LINDO和LINGO不能直接求解目标规划问题,但用序贯式算法可分解成一个个LINDO和LINGO能解决的规划问题。模型建立语言和求解引擎的整合LINGO是使建立和求解线性、非线性和整数最佳化模型更快更简单更有效率的综合工具。LINGO提供强大的语言和快速的求解引擎来阐述和求解最佳化模型。■简单的模型表示LINGO可以将线性、非线性和整数问题迅速得予以公式表示,并且容易阅读、了解和修改。■方便的数据输入和输出选择LINGO建立的模型可以直接从数据库或工作表获取资料。同样地,LINGO可以将求解结果直接输出到数据库或工作表。■强大的求解引擎LINGO内建的求解引擎有线性、非线性(convex and nonconvex)、二次、二次
目标: 本文主要介绍PowerDesigner中概念数据模型CDM的基本概念。 一、概念数据模型概述 数据模型是现实世界中数据特征的抽象。数据模型应该满足三个方面的要求:1)能够比较真实地模拟现实世界 2)容易为人所理解 3)便于计算机实现 概念数据模型也称信息模型,它以实体-联系(Entity-RelationShip,简称E-R)理论为基础,并对这一理论进行了扩充。它从用户的观点出发对信息进行建模,主要用于数据库的概念级设计。 通常人们先将现实世界抽象为概念世界,然后再将概念世界转为机器世界。换句话说,就是先将现实世界中的客观对象抽象为实体(Entity)和联系(Relationship),它并不依赖于具体的计算机系统或某个DBMS系统,这种模型就是我们所说的CDM;然后再将CDM转换为计算机上某个DBMS所支持的数据模型,这样的模型就是物理数据模型,即PDM。 CDM是一组严格定义的模型元素的集合,这些模型元素精确地描述了系统的静态特性、动态特性以及完整性约束条件等,其中包括了数据结构、数据操作和完整性约束三部分。 1)数据结构表达为实体和属性; 2)数据操作表达为实体中的记录的插入、删除、修改、查询等操作; 3)完整性约束表达为数据的自身完整性约束(如数据类型、检查、规则等)和数据间的参照完整性约束(如联系、继承联系等); 二、实体、属性及标识符的定义 实体(Entity),也称为实例,对应现实世界中可区别于其他对象的“事件”或“事物”。例如,学校中的每个学生,医院中的每个手术。 每个实体都有用来描述实体特征的一组性质,称之为属性,一个实体由若干个属性来描述。如学生实体可由学号、姓名、性别、出生年月、所在系别、入学年份等属性组成。 实体集(Entity Set)是具体相同类型及相同性质实体的集合。例如学校所有学生的集合可定义为“学生”实体集,“学生”实体集中的每个实体均具有学号、姓名、性别、出生年月、所在系别、入学年份等性质。 实体类型(Entity Type)是实体集中每个实体所具有的共同性质的集合,例如“患者”实体类型为:患者{门诊号,姓名,性别,年龄,身份证号.............}。实体是实体类型的一个实例,在含义明确的情况下,实体、实体类型通常互换使用。
第五讲数据库表和数据库关系的实现 5.1数据类型 定义数据表的字段、声明程序中的变量时,都需要为他们设置一个数据类型。目的是指定该字段或变量所存放的数据类型,以及需要多少空间。 5.1.1整型:可以用来存放整数数据的字段或变量。有bigint、int、smallint、 两种类型,这两种类型完全相同,一般建议使用numeric。 使用numeric或decimal时,必须指明精确度(即全部有效位数)与小数点位数,例如:numeric(5,2)表示精度为5,总共位数为5位,其中3位整数及2位小数。若不指定,则默认值为numeric(18,0)。精确度可指定的范围为1~38, 取其“近似值”。例如:23456646677799变成 2.3E+13,此类数据类型有float 和real两种。注意:使用float和real类型,若数值的位数超过其有效位数的限
其中varchar及text的实际存储长度会依数据量而调整。如:varchar(10)表示最多可存储10字节,但若只填入5个字符,那么只会占用5字节。char与varchar 最多只能存储8000个字符,若数据超过此长度,请改用text类型。 在使用char及varchar时必须指定字符长度,例如char(50)、varchar(50); 的数据与字符串类型相当类似,Unicode字符串的一个字符是用2个字节存储,而一般字符串是一个字符用1个字节存储。此类数据类型有nchar、nvarchar、ntext。 在使用nchar及nvarchar时必须指定字符长度,例如nchar(50)、nvarchar 据多用16进制表示,而且要加上0x字头)。此类数据类型有binary、varbinary 与image,其特性分别相当于字符串类型的char、varchar、text。image类型还可以用来存放word文件、excel电子表格、以及位图、GIF和JPEG文件。 使用binary及varbinary时须指定字符长度,例如binary(50)、varbinary(30);若未指定,默认值为1。Image类型则不必指定长度。
近年来,计算机技术的发展日新月异,借助于计算机网络而崛起的数据库技术已不断渗透到了社会生活的各个领域.分布式数据库系统是数据库技术的一种,它的产生,使在地理上、组织上分散的单位得以实现信息、数据共享,使系统的可靠性、可用性等得到了明显的改善和提高.因此,如何优化分布式数据库系统,如何更高效地实施数据库查询等问题便显得尤为重要,它关系着整个系统性能和系统效率等诸多关键因素的完善和提高.1分布式数据库的定义 分布式数据库系统的基础是集中式数据库,但是比集中式数据库具有更大的可扩展性,它适用于单位和企业的各下属、分散部门,允许将分工后的针对性较强的各部门数据存储在本地存储设备上,从而提高用户操作应用程序的反馈速度,在一定程度上降低网络通信费用. 分布式数据库系统可以分为两种:一是物理分布逻辑集中,即在物理上是分布的,在逻辑上是一个统一整体,这类数据库系统比较适用于用途单一、专业性强的中小企业或部门;二是无论在物理上或是逻辑上都是分布的,这种分布式数据库系统类型称为联邦式,此类型主要用于集成大 范围数据库,因为该系统主要由用途迥异、 差别明显的数据库组成. 分布式数据库的物理分布性主要表现在数据库中的数据分别存储在不同的地域内或主机上,而逻辑集中性主要表现在无论用户处于哪个位置或使用本局域网中的哪台主机,都可以通过应用程序对数据库进行操作,但这些数据库具体的分布位置用户并不需要知道,就如同数据库存储在本机,并且由本机的数据库管理系统进行管理.2分布式数据库系统的特点 2.1数据的独立性和分布的透明性 数据的独立性可以说是分布式数据库系统的核心和目标,而分布的透明性表现在用户在操作带有数据库的应用程序时,不必了解数据存储的具体物理位置,不必关心数据逻辑集中的区域,也不必验证本地系统支持哪些数据模型.分布透明的特点,在很大程度上增加了应用程序的可移植性. 2.2集中和自治相结合 对于分布式数据库系统来说,数据共享分为两层:局部共享和全局共享.局部共享是相对于局部数据库而言的,存储在局部数据库中的一般是专门针对本地用户的常用数据;全局共享就是说在各个分布的数据库区域,也能够支持 系统在全局上的应用,可以存储可供本网中其他位置的用户共享的数据.那么对于这两层数据共享的分类,就有相应的两种控制方式,即集中和自治,各个局部的数据库管理系统可以对本区域的数据库实施独立管理,称为自治;与此同时,为了协调各个局部数据库管理系统,为了宏观、整体地把握各局部数据库的运行情况等,系统还设置了集中控制的工作方式. 2.3易于扩展性 由于单位、 企业等的数据量越来越庞大,对于数据库服务器的需求也越来越多.如果服务器的应用程序支持水平方向的扩展,那么就可以通过多增加服务器来分担数据的处理任务. 3分布式数据库系统的设计3.1设计的原则 3.1.1分布式数据库系统的主要设计原则是本地和近地.所以,在设计的过程中,应当尽量实现数据的本地化,这样可以有效减少数据节点之间的相互通信,从而提高整个系统的效率. 3.1.2为了改善和提高数据库数据的可用性和可靠性,有时候在分布式数据库系统中可以将数据保存为副本,如果数据的其中一个副本被损坏或者不能使用,那么在网络环境中的另一个节点中可以对损坏的副本进行恢复.不过,在恢复的同时有可能增加冗余的数据,所以在设计分布式数据库系统时应当全面考虑最优的数据冗余程序,从而减少数据库更新的成本. 3.1.3在用户通过应用程序对数据库进行操作的时候,分布式数据库系统应当将总的工作量分流到网络环境中的各局域节点,从而提高了应用程序的执行效率、扩大了数据传输的并行度、充分利用了各局域节点计算机的资源.因此在设计分布式数据库系统的同时,要将负荷合理地分流. 3.1.4在设计分布式数据库系统时,要对网络各局域节点进行存储能力的统筹,对有限的存储控件进行合理的规划.3.2设计的内容 与集中式数据库的设计相类似,分布式数据库系统也包括了数据库和应用.其中,数据库的设计又包括全局的模式设计和局部的模式设计.分布式数据库系统设计的关键是 Vol.28No.10 Oct.2012 赤峰学院学报(自然科学版)JournalofChifengUniversity(NaturalScienceEdition)第28卷第10期(下) 2012年10月分布式数据库系统的设计与优化 左 翔,姜文彪 (安徽医科大学计算机系,安徽 合肥 230032) 摘要:分布式数据库是数据库技术和网络技术相结合的产物,本文从分布式数据库系统的定义和特点入手,介绍了其设计、优化的目标以及优化的方法. 关键词:分布式数据库系统;设计;优化中图分类号:TP310 文献标识码:A 文章编号:1673-260X(2012)10-0020-02 20--
学科实验报告 班级2010级金融姓名陈光伟学科管理系统中计算机应用实验名称数据库的创建与表间关系的各种操作 实验工具Visual foxpro 6.0 实验目的1、掌握数据库结构的创建方式 2、表间的关联关系 实验步骤一、建立数据库。 1、在项目管理器中建立数据库。首先选择数据库,然后单击“新建”建立数据库,出现的界面提示用户输入数据库的名称,按要求输入后单击“保存”则完成数据库的建立,并打开i“数据库设计器”。 2、从“新建”对话框建立数据库。单击工具栏上的“新建”按钮或者选择菜单“文件——新建”打开“新建”对话框,首先在“文件类型”组框中选择“数据库”,然后单击“新建文件”建立数据库,后面的操作和步骤与1相同。 3、用命令交互建立数据库。命令是create database【databasename ▏?】 二、表间关系的各种操作。 1、创建索引文件。可以再创建数据表时建立其结构复合索引文件,但是也可以先建立好数据表,以后再创建或修改索引文件。 2、索引的操作。A、打开与关闭。要使用索引,必须先要打开索引。一旦数据表文件关闭所有相应的索引文件也就自动关闭了。B、确定主控索引。可以使用命令确定当前主控索引。命令格式1:set order to 【tag】<索引标识>【ascending| desceding】命令格式2:use<表文件名>order【tag】<索引标识>【ascending | esceding】C、删除索引标识。要删除结构复合索引文件中的索引标识,应当打开数据表文件,并打开其表设计器对话框。在“索引”页面中选定要删除的索引标识后,单击“删除”按钮删除。 3、创建关联。在创建数据表之间的关联时,把当前数据表叫做父表,而把要关联的表叫做子表。必须保证两个要建立关系的数据表中存在能够建立联系的同类字段;同时要求每个数据表事先分别以该字段建立了索引。A、建立表间的一对一的关系。在“数据库设计器”窗口中选择M表中的字段,并按住左键拖到关联表H中对应字段上,放开鼠标左键。这是可以看到在两个表之间的相关字段上产生了一条连线,表明两个表之间已经建立了“一对一”关系。B、建立表间一对多的关系。将M表的名称字段MC设定为主索引,或者候选索引;H表中的JG字段已经设置成普通索引。在“数据库设计器”窗口中将MC字段拖到关联表中对应字段JG上,放开鼠标左键。这时可以看到在两个表之间的相关字段上产生了一条显然与“一对一”关联不同形式的连线,表明两个表之间已经建立了“一对多”关系。 4、调整或删除关联。A、删除关联。在数据库设计器对话框窗口中,首先必须用鼠标左键单击关联线,该连线变粗了说明它已被选中。如果要删除可敲【del】。也可以单击鼠标右键在弹出对话框窗口中单击“删除关联”选项。B、编辑关联。在数据库设计器对话框窗口中,首先必须用鼠标左键单击关联线,该连线变粗了说明已被选中。在主菜单“数据库”选项的下拉菜单中的“编辑关系”选项,也可以单击鼠标右键在弹出对话框窗口中单击“编辑关系”选项。 5、设置数据表之间的参照完整性。在对数据库表建立关联关系后,就可以设置两个相关数据表之间操作的有效性原则。这些规则可以控制相关表中的记录的插入、删除或修改。
分布式数据库设计报告
目录 1案例背景 (1) 需求分析 (1) 2 分布式数据库设计 (2) 设计目标 (2) 总体设计目标 (2) (4)可靠性: (3) 完成方式及周期 (3) 分布式数据库架构图 (4) 物理设计施工 (5) 3 总结 (5) 4所用设备汇总 (7) 5所使用软件 (7)
成品车间分布式数据库设计 1案例背景 随着成品车间信息化程度越来越高,我们的传统集中式数据库系统的缺点逐渐体现出来主要有: 1、所有数据处理、存储集中在一台计算机上完成,一旦机器损坏或系统崩 溃数据数据很难恢复。 2、单台机器写入/查询处理能力不足,一台机器既要读取数据,又要写入数 据,遇到大批量超过单台数据库的处理能力,就会出现卡顿,在生产时 间不敢批量制造/查询数据。 3、硬件性能瓶颈,包括(硬盘、CPU、内存),使用升级硬件的方法效果有限。 4、出现故障没有备用服务器可以替代。 5、当前成品车间存在2种数据库,oracle,sql sever,交叉使用不方便管 理维护,出现问题排查困难。 6、由于数据库初期创建数据库/表比较混乱,现在对数据的统计管理需要在 两台服务器之间交叉进行,统计难度高,效率低。 需求分析 成品车间信息化程度越来越高,各个节点产生的数据量越来越大,对数据系统要求越来越高,我们所使用的传统集中式数据库已经无法从容应对越来越大的数据。 成品车间生产线数据库主要有oracle和sql server两种,分别分布在2台计算机中,柔性线、自动线、三相线交叉使用两种类型数据库,主要出现的问题有; 1、一旦其中一个数据库出现问题,那么就有很大的几率导致三条线体 的某个节点或全部节点失去数据服务,导致停线。 2、数据库出现故障,必须停线,故障修复之后才可以上线使用。
Database术语表 Access method :访问方法 Alias:别名 Alternate keys:备用键,ER/关系模型Anomalies:异常 Application design:应用程序设计 Application server:应用服务器 Attribute:属性,关系模型 Attribute:属性,ER模型 Attribute inheritance:属性继承 Base table:基本表 Binary relationship:二元关系 Bottom-up approach:自底向上方法 Business rules:业务规则 Candidate key:候选键,ER/关系模型Cardinality:基数 Centralized approach:集中化方法,用于数据库设计Chasm trap:深坑陷阱 Client:客户端 Clustering field:群集字段 Clustering index:群集索引 Column:列,参见属性(attribute) Complex relationship:复杂关系 Composite attribute:复合属性 Composite key:复合键 Concurrency control:并发控制 Constraint:约束 Data conversion and loading:数据转换和加载Data dictionary:数据字典 Data independence:数据独立性 Data model:数据模型 Data redundancy:数据冗余 Data security:数据安全 Database:数据库 Database design:数据库设计 Database integrity:数据库完整性 Database Management System:数据管理系统Database planning:数据库规划 Database server数据库服务器 DBMS engine:DBMS引擎 DBMS selection:DBMS选择 Degree of a relationship:关系的度Denormalization:反规范化
1.大型分布式数据库解决方案 企业数据库的数据量很大时候,即使服务器在没有任何压力的情况下,某些复杂的查询操作都会非常缓慢,影响最终用户的体验;当数据量很大的时候,对数据库的装载与导出,备份与恢复,结构的调整,索引的调整等都会让数据库停止服务或者高负荷运转很长时间,影响数据库的可用性和易管理性。 分区表技术 让用户能够把数据分散存放到不同的物理磁盘中,提高这些磁盘的并行处理能力,达到优化查询性能的目的。但是分区表只能把数据分散到同一机器的不同磁盘中,也就是还是依赖于一个机器的硬件资源,不能从根本上解决问题。 分布式分区视图 分布式分区视图允许用户将大型表中的数据分散到不同机器的数据库上,用户不需要知道直接访问哪个基础表而是通过视图访问数据,在开发上有一定的透明性。但是并没有简化分区数据集的管理、设计。用户使用分区视图时,必须单独创建、管理每个基础表(在其中定义视图的表),而且必须单独为每个表管理数
据完整性约束,管理工作变得非常复杂。而且还有一些限制,比如不能使用自增列,不能有大数据对象。对于全局查询并不是并行计算,有时还不如不分区的响应快。 库表散列 在开发基于库表散列的数据库架构,经过数次数据库升级,最终采用按照用户进行的库表散列,但是这些都是基于自己业务逻辑进行的,没有一个通用的实现。客户在实际应用中要投入很大的研发成本,面临很大的风险。 面对海量数据库在高并发的应用环境下,仅仅靠提升服务器的硬件配置是不能从根本上解决问题的,分布式网格集群通过数据分区把数据拆分成更小的部分,分配到不同的服务器中。查询可以由多个服务器上的CPU、I/O来共同负载,通过各节点并行处理数据来提高性能;写入时,可以在多个分区数据库中并行写入,显著提升数据库的写入速度。
《数据库原理》实验报告 一、实验目的: 1、使用Powderdesigner建模工具完成本实验。 2、完成下列表中所描述数据库的概念数据模型设计,对关键字、空值、域完整性等做出必要的描 述,根据实际情况确定联系的类型。 3、依据所涉及的概念数据模型(CDM)生成相应的物理数据模型(PDM),可以对生成的物理数据模 型作必要的修改。 4、生成建立数据库的目标代码。 二、实验使用环境: SQL server 2012、Powerdesigne:16.5 三、实验内容与完成情况: 1.创建概念模型 客户与订购单是一对多的关系:一个客户可以有多个订购单,但是一个订购单只能属于一个客户订购单与产品是多对多的关系:一个产品可以有多个订购单,一个订购单也可以包括多个产品内容 2.属性数据类型 客户表:
产品表: 订购单表: 3.概念模型转换为物理模型 由于客户与订购单是一对多的关系,所以客户的主键(客户号)存在于订购单中做外键,加入订单日期由于订购单与产品是多对多的关系,所以订购单的主键(订单号)和产品的主键(产品号)存在于两者的关系订单明细中作为主键和外键,另外加入序号和数量作为
4.约束条件 客户号:前两个字符为字母 客户名称:不允许为空值: 邮政编码:6位数字字符 电话:数字字符 电子邮箱:包含@字符
产品号:前两个字符为字母 产品名称:值唯一 单价:>0 客户号:不允许空值
订购日期:默认是系统时间 序号:自增1,初值1 5.生成数据库脚本 得到商店.sql 脚本,见附件 新建数据库
测试结果: 连接数据源 导入数据库:
1、MySQL Workbench MySQL Workbench是一款专为MySQL设计的ER/数据库建模工具。它是著名的数据库设计工具DBDesigner4的继任者。你可以用MySQL Workbench 设计和创建新的数据库图示,建立数据库文档,以及进行复杂的MySQL迁移MySQL Workbench是下一代的可视化数据库设计、管理的工具,它同时有开源和商业化的两个版本。该软件支持Windows和Linux系统,下面是一些该软件运行的界面截图:
2、数据库管理工具Navicat Lite Navicat TM是一套快速、可靠并价格相宜的资料库管理工具,大可使用来简化资料库的管理及降低系统管理成本。它的设计符合资料库管理员、开发人员及中小企业的需求。Navicat是以直觉化的使用者图形介面所而建的,让你可以以安全且简单的方式建立、组织、存取并共用资讯。 界面如下图所示:
Navicat提供商业版Navicat Premium和免费的版本Navicat Lite。免费版本的功能已经足够强大了。 Navicat支持的数据库包括MySQL、Oracle、SQLite、PostgreSQL和SQL Server等。
3、开源ETL工具Kettle Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定(数据迁移工具)。Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
?授权协议:LGPL ?开发语言:Java ?操作系统:跨平台 4、Eclipse SQL Explorer SQLExplorer是Eclipse集成开发环境的一种插件,它可以被用来从Eclipse 连接到一个数据库。 SQLExplorer插件提供了一个使用SQL语句访问数据库的图形用户接口(GUI)。通过使用SQLExplorer,你能够显示表格、表格结构和表格中的数据,以及提取、添加、更新或删除表格数据。 SQLExplorer同样能够生成SQL脚本来创建和查询表格。所以,与命令行客户端相比,使用SQLExplorer可能是更优越的选择,下图是运行中的界面,很好很强大。
用友数据库各表之间的关联 select C.cPBVBillType 发票类型,C.dPBVDate 开票日期,C.dSDate 结算日期,C.cPBVCode 采购发票号,I.cPOID 采购订单----- 号,A.cInvCode 存货编码,D.cinvname as存货名称,D.cinvstd as规格,https://www.doczj.com/doc/6216473187.html,omUnitName 单位, ----- A.iPBVQuantity 发票数量,A.iCost 发票本币单价,A.iMoney 发票本币金额,A.iSum 发票本币价税合计, B.iQuantity 订单数量,B.iNatUnitPrice 订单本币单价,B.iNatMoney 订单本币无税金额,B.iNatSum 订单本币价税合 ------- 计,C.cVenCode 供应商编码,F.cVenName 供应商名称, C.cUnitCode 代垫单位编码,H.cVenName 代垫单位名称,C.cPBVMaker 发票制单人 --------- from PurBillVouchs as A -------- left join PO_Podetails as B on A.iPOsID=B.ID ---------- left join PurBillVouch as C on A.PBVID=C.PBVID ----------- left join inventory as D on A.cInvCode=D.cinvcode left join ComputationUnit as E on https://www.doczj.com/doc/6216473187.html,omUnitCode=https://www.doczj.com/doc/6216473187.html,omunitCode left join Vendor as F on C.cVenCode=F.cVenCode left join Vendor as H on C.cUnitCode =H.cVenCode left join PO_Pomain as I on B.POID=I.POID where dPBVDate between'2016-01-01 00:00:00.000'and'2016-12-31 00:00:00.000'
数据库概念设计及数据建模(一) 一、选择题 1. 数据库概念设计需要对一个企业或组织的应用所涉及的数据进行分析和组织。现有下列设计内容 Ⅰ.分析数据,确定实体集 Ⅰ.分析数据,确定实体集之间的联系 Ⅰ.分析数据,确定每个实体集的存储方式 Ⅰ.分析数据,确定实体集之间联系的基数 Ⅰ.分析数据,确定每个实体集的数据量 Ⅰ.分析数据,确定每个实体集包含的属性 以上内容不属于数据库概念设计的是______。 A.仅Ⅰ、Ⅰ和Ⅰ B.仅Ⅰ和Ⅰ C.仅Ⅰ、Ⅰ和Ⅰ D.仅Ⅰ和Ⅰ 答案:D [解答] 数据库概念设计主要是理解和获取引用领域中的数据需求,分析,抽取,描述和表示清楚目标系统需要储存和管理什么数据,这些数据共有什么样的属性特征以及组成格式,数据之间存在什么样的依赖关系,同时也要说明数据的完整性与安全性。而数据的储存方式和数据量不是概念设计阶段所考虑的。 2. 关于数据库概念设计阶段的工作目标,下列说法错误的是______。 A.定义和描述应用系统设计的信息结构和范围
B.定义和描述应用系统中数据的属性特征和数据之间的联系 C.描述应用系统的数据需求 D.描述需要存储的记录及其数量 答案:D [解答] 数据库概念设计阶段的工作目标包括定义和描述应用领域涉及的数据范围;获取应用领域或问题域的信息模型;描述清楚数据的属性特征;描述清楚数据之间的关系;定义和描述数据的约束;说明数据的安全性要求;支持用户的各种数据处理需求;保证信息模型方便地转换成数据库的逻辑结构(数据库模式),同时也便于用户理解。 3. 需求分析阶段的文档不包括______。 A.需求说明书 B.功能模型 C.各类报表 D.可行性分析报告 答案:D [解答] 数据库概念设计的依据是需求分析阶段的文档;包括需求说明书、功能模型(数据流程图或IDEF0图)以及在需求分析阶段收集到的应用领域或问题域中的各类报表等,因此本题答案为D。 4. 数据库概念设计的依据不包括______。
如何定义数据库表之间的关系 特别说明 数据库的正规化是关系型数据库理论的基础。随着数据库的正规化工作的完成,数据库中的 各个数据表中的数据关系也就建立起来了。 在设计关系型数据库时,最主要的一部分工作是将数据元素如何分配到各个关系数据表中。一旦完成了对这些数据元素的分类,对于数据的操作将依赖于这些数据表之间的关系,通过这些数据表之间的关系,就可以将这些数据通过某种有意义的方式联系在一起。例如,如果你不知道哪个用户下了订单,那么单独的订单信息是没有任何用处的。但是,你没有必要在同一个数据表中同时存储顾客和订单信息。你可以在两个关系数据表中分别存储顾客信息和订单信息,然后使用两个数据表之间的关系,可以同时查看数据表中每个订单以及其相关的客户信息。如果正规化的数据表是关系型数据库的基础的话,那么这些数据表之间的关系则 是建立这些基础的基石。 出发点 下面的数据将要用在本文的例子中,用他们来说明如何定义数据库表之间的关系。通过Boyce-Codd Normal Form(BCNF)对数据进行正规化后,产生了七个关系表: Books: {Title*, ISBN, Price} Authors: {FirstName*, LastName*} ZIPCodes: {ZIPCode*} Categories: {Category*, Description} Publishers: {Publisher*} States: {State*} Cities: {City*} 现在所需要做的工作就是说明如何在这些表之间建立关系。 关系类型 在家中,你与其他的成员一起存在着许多关系。例如,你和你的母亲是有关系的,你只有一位母亲,但是你母亲可能会有好几个孩子。你和你的兄弟姐妹是有关系的——你可能有很多兄弟和姐妹,同样,他们也有很多兄弟和姐妹。如果你已经结婚了,你和你的配偶都有一个配偶——这是相互的——但是一次只能有一个。在数据表这一级,数据库关系和上面所描述现象中的联系非常相似。有三种不同类型的关系: 一对一:在这种关系中,关系表的每一边都只能存在一个记录。每个数据表中的关键字在对应的关系表中只能存在一个记录或者没有对应的记录。这种关系和一对配偶之间的关系非常相似——要么你已经结婚,你和你的配偶只能有一个配偶,要么你没有结婚没有配偶。大多数的一对一的关系都是某种商业规则约束的结果,而不是按照数据的自然属性来得到的。如果没有这些规则的约束,你通常可以把两个数据表合并进一个数据表,而且不会打破任何规 范化的规则。
数据建模目前有两种比较通用的方式1983年,数学建模作为一门独立的课程进入我国高等学校,在清华大学首次开设。1987年高等教育出版社出版了国内第一本《数学模型》教材。20多年来,数学建模工作发展的非常快,许多高校相继开设了数学建模课程,我国从1989年起参加美国数学建模竞赛,1992年国家教委高教司提出在全国普通高等学校开展数学建模竞赛,旨在“培养学生解决实际问题的能力和创新精神,全面提高学生的综合素质”。近年来,数学模型和数学建模这两个术语使用的频率越来越高,而数学模型和数学建模也被广泛地应用于其他学科和社会的各个领域。本文主要介绍了数学建模中常用的方法。 一、数学建模的相关概念 原型就是人们在社会实践中所关心和研究的现实世界中的事物或对象。模型是指为了某个特定目的将原型所具有的本质属性的某一部分信息经过简化、提炼而构造的原型替代物。一个原型,为了不同的目的可以有多种不同的模型。数学模型是指对于现实世界的某一特定对象,为了某个特定目的,进行一些必要的抽象、简化和假设,借助数学语言,运用数学工具建立起来的一个数学结构。 数学建模是指对特定的客观对象建立数学模型的过程,是现实的现象通过心智活动构造出能抓住其重要且有用的特征的表示,常常是形象化的或符号的表示,是构造刻画客观事物原型的数学模型并用以分析、研究和解决实际问题的一种科学方法。 二、教学模型的分类 数学模型从不同的角度可以分成不同的类型,从数学的角度,按建立模型的数学方法主要分为以下几种模型:几何模型、代数模型、规划模型、优化模型、微分方程模型、统计模型、概率模型、图论模型、决策模型等。 三、数学建模的常用方法 1.类比法 数学建模的过程就是把实际问题经过分析、抽象、概括后,用数学语言、数学概念和数学符号表述成数学问题,而表述成什么样的问题取决于思考者解决问题的意图。类比法建模一般在具体分析该实际问题的各个因素的基础上,通过联想、归纳对各因素进行分析,并且与已知模型比较,把未知关系化为已知关系,
免费的数据库建模工具 对于数据模型的建模,最有名的要数ERWin和PowerDesigner,基本上,PowerDesigner 是在中国软件公司中他是非常有名的,其易用性、功能、对流行技术框架的支持、以及它的模型库的管理理念,都深受设计师们喜欢。PowerDesigner是我一直以来非常喜欢的一个设计工具,对于它,我可以用两个字来形容,那就是我能驾驭这个工具! 现在所在的公司自上市以来,对软件版权问题看得非常重,公司从上市以后,对软件的版权做了一些相应的规定,不允许使用破解的软件,软件只能使用开源的、免费的、或者共享的软件!所用软件必须公司注册的!没办法,我也只能放弃我多年的喜好,转向开源、免费的领域! 数据库物理建模是在软件设计当中必不可少的环节,数据库建得怎么样,关系到以后整个系统的扩展、性能方面的优化以及后期的维护。使用一个数据建模工具是非常必须的。那在开源或免费的领域,有没有比较好的工具呢?其实是有很多的,只是开源这一块,功能上、易用性上没有商业软件那么好用! 现在介绍几个相对比较好用的工具: 第一个:ERDesigner NG 官方网址是:https://www.doczj.com/doc/6216473187.html,/?Welcome:ERDesigner_NG 属于sourceforge的一个开源产品,目前版本为1.4 以下是官方所描述的: 程序代码 The Mogwai ERDesigner is a entity relation modeling tool such as ERWin and co. The only difference is that it is Open Source and does not cost anything. It was designed to make database modeling as easy as it can be and to support the developer in the whole development process, from database design to schema and code generation. This tool was also designed to support a flexible plug in architecture, to extend the system simply by installing a new plug in. This way, everybody can implement new featur es and tools to make ERDesigner fit the requirements.
数据库的表关系图 1>:one-to-one(一对一关联)主键关联: 一对一关联一般可分为主键关联和外键关联 主键关联的意思是说关联的两个实体共享一个主键值,但这个主键可以由两个表产生. 现在的问题是: *如何让另一个表引用已经生成的主键值 解决办法: *Hibernate映射文件中使用主键的foreign生成机制 eg:学生表:
一、填空 分布式数据库系统按局部数据库管理系统的数据模型分类,可以分为和两类。 同构型DDBS 异构型DDBS 分布式数据库系统按全避控制系统类型分类,可以分为、 和三类。 全局控制集中型DDBS 全局控制分散型DDBS 全局控制可变型DDBS 分布式数据库是分布式数据库系统中各站点上数据库的逻辑集合,它由和组成。 应用数据库描述数据库 数据分片的三种基本方法是:、和三类。 水平分片垂直分片混合分片 分布式数据库中的数据分布策略有:、、 和四层。 集中式分割式复制式混合式 分布式数据库是多层模式结构,一般划分为、、 和四层。 全局外层全局概念层局部概念层局部内层 一个分布式数据库管理系统一般应包括、、 和四个基本功能模块。 查询处理模块完整性处理模块调度处理模块可靠性处理模块 分布透明性包括、和三个层次。 分片透明性位置透明性局部数据模型透明性 分布式数据库系统的创建方法,大致可分为和两种。 组合法重构法 集中式数据库设计一般包括:需求分析,概念设计,逻辑设计和物理设计四个阶段,分布式数据库设计除了上述四个阶段外,还需增加一些个新的阶段,它位于和之间。 分布设计逻辑设计物理设计 水平分片的方法可归为和两种。 初级分片导出分片 DATAID-D相对于DATAID-1增加了和两个阶段。 分布要求分析分布设计 DATAID-D中的分布设计分成、、 和四个阶段。 分片设计非冗余分配冗余分配局部模式的重新构造 分布式查询优化的准则是。通信费用和响应时间最短 在分布式系统中,查询代价QC=。I/O代价+CPU代价+通信代价 在分布式环境下,查询可分为、和三种类型。局部查询远程查询全局查询 分布式查询处理可以分为、、和四
二、实体、属性及标识符的定义 实体(Entity),也称为实例,对应现实世界中可区别于其他对象的“事件”或“事物”。例如,学校中的每个学生,医院中的每个手术。 每个实体都有用来描述实体特征的一组性质,称之为属性,一个实体由若干个属性来描述。如学生实体可由学号、姓名、性别、出生年月、所在系别、入学年份等属性组成。 实体集(Entity Set)是具体相同类型及相同性质实体的集合。例如学校所有学生的集合可定义为“学生”实体集,“学生”实体集中的每个实体均具有学号、姓名、性别、出生年月、所在系别、入学年份等性质。 实体类型(Entity Type)是实体集中每个实体所具有的共同性质的集合,例如“患者”实体类型为:患者{门诊号,姓名,性别,年龄,身份证号.............}。实体是实体类型的一个实例,在含义明确的情况下,实体、实体类型通常互换使用。 实体类型中的每个实体包含唯一标识它的一个或一组属性,这些属性称为实体类型的标识符(Identifier),如“学号”是学生实体类型的标识符,“姓名”、“出生日期”、“信址”共同组成“公民”实体类型的标识符。 有些实体类型可以有几组属性充当标识符,选定其中一组属性作为实体类型的主标识符,其他的作为次标识符。 目标: 本文主要介绍PowerDesigner中概念数据模型 CDM的基本概念。 一、概念数据模型概述 数据模型是现实世界中数据特征的抽象。数据模型应该满足三个方面的要求:1)能够比较真实地模拟现实世界 2)容易为人所理解 3)便于计算机实现 概念数据模型也称信息模型,它以实体-联系(Entity-RelationShip,简称E-R)理论为基础,并对这一理论进行了扩充。它从用户的观点出发对信息进行建模,主要用于数据库的概念级设计。 通常人们先将现实世界抽象为概念世界,然后再将概念世界转为机器世界。换句话说,就是先将现实世界中的客观对象抽象为实体(Entity)和联系(Relationship),它并不依赖于具体的计算机系统或某个DBMS系统,这种模型就是我们所说的CDM;然后再将CDM转换为计算机上某个DBMS所支持的数据模型,这样的模型就是物理数据模型,即PDM。 CDM是一组严格定义的模型元素的集合,这些模型元素精确地描述了系统的静态