
医学统计学思考练习
第1章绪论思考与练习参考答案
一、最佳选择题
1. 研究中的基本单位是指( D )。
A.样本 B. 全部对象C.影响因素 D. 个体 E. 总体
2. 从总体中抽取样本的目的是( B )。
A.研究样本统计量 B. 由样本统计量推断总体参数
C.研究典型案例 D. 研究总体统计量E. 计算统计指标3. 参数是指( B )。
A.参与个体数 B. 描述总体特征的统计指标
C.描述样本特征的统计指标 D. 样本的总和 E. 参与变量数4. 下列资料属名义变量的是(E)。
A.白细胞计数B.住院天数
C.门急诊就诊人数D.患者的病情分级 E. ABO血型5.关于随机误差下列不正确的是(C)。
A.受测量精密度限制B.无方向性 C. 也称为偏倚D.不可避免 E. 增加样本含量可降低其大小
三、思考题
2. 某年级甲班、乙班各有男生50人。从两个班各抽取10人测量身高,并求其平均身高。如果甲班的平均身高大于乙班,能否推论甲班所有同学的平均身高大于乙班?为什么?
答:不能。因为,从甲、乙两班分别抽取的10人,测量其身高,得到的分别是甲、乙两班的一个样本。样本的平均身高只是甲、乙两班所有同学平均身高的一个点估计值。即使是按随机化原则进行抽样,由于存在抽样误差,样本均数与总体均数一般很难恰好相等。因此,不能仅凭两个样本均数高低就作出两总体均数熟高熟低的判断,而应通过统计分析,进行统计推断,才能作出判断。
3. 某地区有10万个7岁发育正常的男孩,为了研究这些7岁发育正常男孩的身高和体重,在该人群中随机抽取200个7岁发育正常的男孩,测量他们的身高和体重,请回答下列问题。
(1) 该研究中的总体是什么?答:某地区10万个7岁发育正常的男孩。
(2) 该研究中的身高总体均数的意义是什么?答:身高总体均数的意义是: 10万个7岁发育正常的男孩的平均身高。
(3) 该研究中的体重总体均数的意义是什么?答:体重总体均数的意义是: 10万个7岁发育正常的男孩的平均体重
(4) 该研究中的总体均数与总体是什么关系?答:总体均数是反映总体的统计学特征的指标。
(5)该研究中的样本是什么?答:该研究中的样本是:随机抽取的200个7岁发育正常的男孩。(宇传华方积乾)
第2章统计描述思考与练习参考答案
一、最佳选择题
1. 编制频数表时错误的作法是( E )。
A. 用最大值减去最小值求全距
B. 组距常取等组距,一般分为10~15组
C. 第一个组段须包括最小值
D. 最后一个组段须包括最大值
E. 写组段,如“1.5~3,3~5,5~6.5,…”
2. 描述一组负偏峰分布资料的平均水平时,适宜的统计量是(A)。
A. 中位数
B. 几何均数
C. 调和均数
D. 算术均数
E. 众数
3. 比较5年级小学生瞳距和他们坐高的变异程度,宜采用(A)。
A. 变异系数
B. 全距
C. 标准差
D. 四分位数间距
E. 百分位数P2.5与P97.5的间距
4. 均数X和标准差S的关系是(A)。
A. S越小,X对样本中其他个体的代表性越好
B. S越大,X对样本中其他个体的代表性越好
C. X越小,S越大
D. X越大,S越小
E. S必小于X
5. 计算乙肝疫苗接种后血清抗-HBs的阳转率,分母为(B)。
A. 阳转人数
B. 疫苗接种人数
C. 乙肝患者数
D. 乙肝病毒携带者数
E. 易感人数
6. 某医院的院内感染率为5.2人/千人日,则这个相对数指标属于(C)。
A. 频率
B. 频率分布
C. 强度
D. 相对比
E. 算术均数
7. 纵坐标可以不从0开始的图形为(D)。
A. 直方图
B. 单式条图
C. 复式条图
D. 箱式图
E. 以上均不可
二、简答题
2. 举例说明频率和频率分布的区别和联系。
答:2005年某医院为了调查肺癌患者接受姑息手术治疗1年后的情况,被调查者150人,分别有30人病情稳定,66人处于进展状态,54人死亡。
当研究兴趣只是了解死亡发生的情况,则只需计算死亡率54/150=36%,属于频率指标。当研究者关心患者所有可能的结局时,则可以算出反映3种结局的频率分别为20%、44%、36%,它们共同构成所有可能结局的频率分布,是若干阳性率的组合。
两者均为“阳性率”,都是基于样本信息对总体特征进行估计的指标。不同的是:频率只是一种结局发生的频率,计算公式的分子是某一具体结局的发生数;频率分布则由诸结局发生的频率组合而成,计算公式的分子分别是各种可能结局的发生数,而分母则与频率的计算公式中分母相同,是样本中被观察的单位数之和。
3. 应用相对数时应注意哪些问题?
答:(1)防止概念混淆相对数的计算是两部分观察结果的比值,根据这两部分观察结果的特点,就可以判断所计算的相对数属于前述何种指标。
(2)计算相对数时分母不宜过小样本量较小时以直接报告绝对数为宜。(3)观察单位数不等的几个相对数,不能直接相加求其平均水平。
(4)相对数间的比较须注意可比性,有时需分组讨论或计算标准化率。
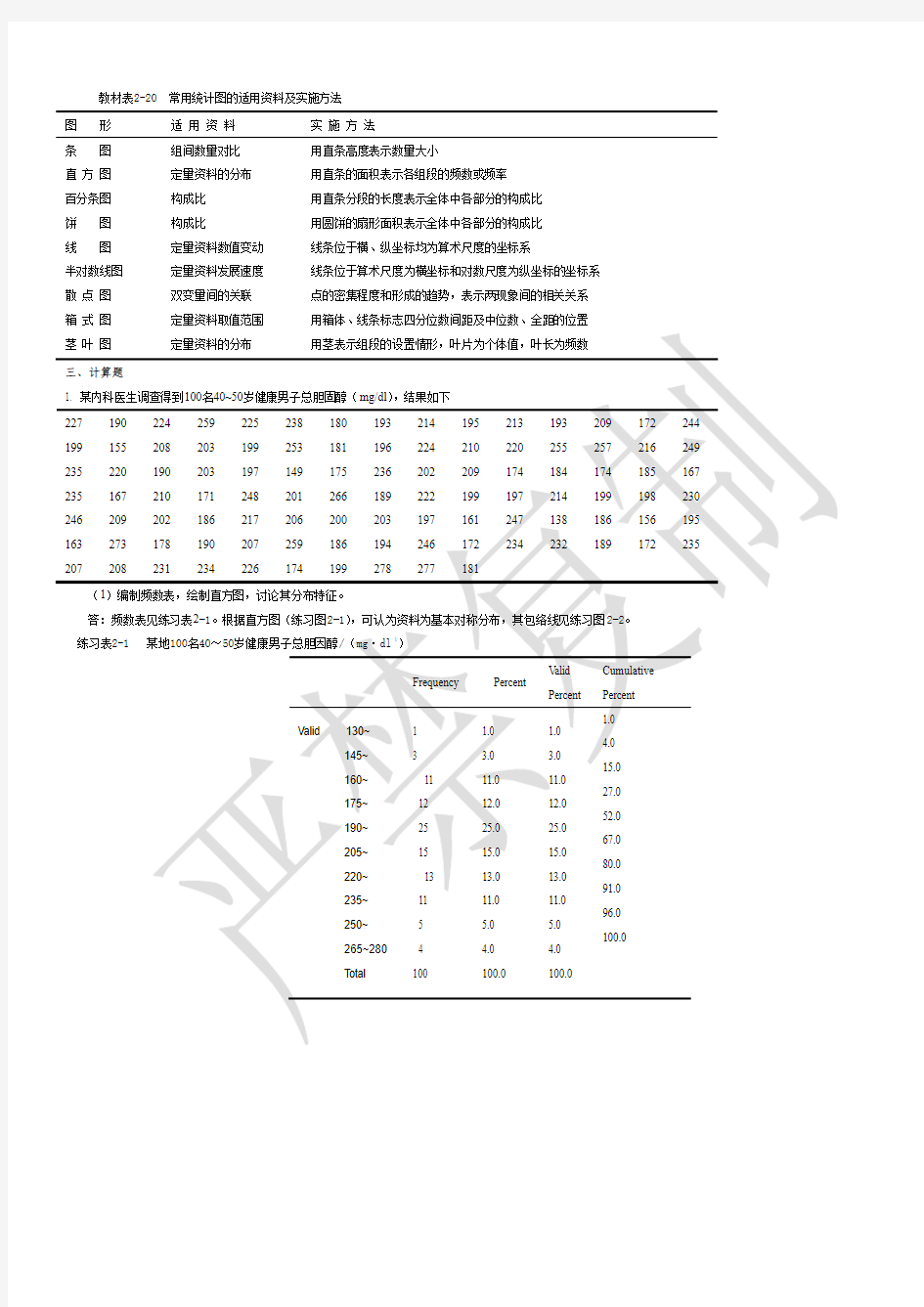
4. 常用统计图有哪些?分别适用于什么分析目的?
答:详见教材表2-20。
教材表2-20 常用统计图的适用资料及实施方法
图形适用资料实施方法
条图组间数量对比用直条高度表示数量大小
直方图定量资料的分布用直条的面积表示各组段的频数或频率
百分条图构成比用直条分段的长度表示全体中各部分的构成比
饼图构成比用圆饼的扇形面积表示全体中各部分的构成比
线图定量资料数值变动线条位于横、纵坐标均为算术尺度的坐标系
半对数线图定量资料发展速度线条位于算术尺度为横坐标和对数尺度为纵坐标的坐标系
散点图双变量间的关联点的密集程度和形成的趋势,表示两现象间的相关关系
箱式图定量资料取值范围用箱体、线条标志四分位数间距及中位数、全距的位置
茎叶图定量资料的分布用茎表示组段的设置情形,叶片为个体值,叶长为频数
三、计算题
1. 某内科医生调查得到100名40~50岁健康男子总胆固醇(mg/dl),结果如下227190224259225238180193214195213193209172244 199155208203199253181196224210220255257216249 235220190203197149175236202209174184174185167 235167210171248201266189222199197214199198230 246209202186217206200203197161247138186156195 163273178190207259186194246172234232189172235 207208231234226174199278277181
(1)编制频数表,绘制直方图,讨论其分布特征。
答:频数表见练习表2-1。根据直方图(练习图2-1),可认为资料为基本对称分布,其包络线见练习图2-2。
练习表2-1 某地100名40~50岁健康男子总胆因醇/(mg·dl-1)
Frequency Percent Valid
Percent
Cumulative
Percent
Valid 130~
145~
160~
175~
190~
205~
220~
235~
250~
265~280
Total 1
3
11
12
25
15
13
11
5
4
100
1.0
3.0
11.0
12.0
25.0
15.0
13.0
11.0
5.0
4.0
100.0
1.0
3.0
11.0
12.0
25.0
15.0
13.0
11.0
5.0
4.0
100.0
1.0
4.0
15.0
27.0
52.0
67.0
80.0
91.0
96.0
100.0
280
260
240
220
200
180
160
140
总胆固醇
25
20
15
10
5
0F r e q u e n c y
M ean = 207.41S t d. D ev. = 29.82N = 100
练习图2-1 直方图
280
260
240
220
200
180
160
140
总胆固醇
25
20
15
10
5
F r e q u e n c y
M ean = 207.41
S t d. D ev. = 29.82N = 100
练习图2-2 包络线图
(2)根据(1)的讨论结果,计算恰当的统计指标描述资料的平均水平和变异度。 答:利用原始数据,求出算术均数
4.207=X mg/dl 和标准差8.29=S mg/dl 。
(3)计算P 25,P 75和P 95。 答:利用原始数据,求出P 25=186.8 mg/dl ,P 75=229.3 mg/dl ,P 95=259.0 mg/dl 。 2. 某地对120名微丝蚴血症患者治疗3个疗程后,用IFA 间接荧光抗体试验测得抗体滴度如下,求抗体滴度的平均水平。 抗体滴度 1:5 1:10 1:20 1:40 1:80 1:160 1:320 例 数
5
16
27
34
22
13
3
利用上述频数表,得平均滴度为1:36.3。
3. 某地1975-1980年出血热发病和死亡资料如教材表2-21,设该地人口数在此6年间基本保持不变。 教材表2-21 某地6年间出血热的发病与死亡情况
年 份 发病数 病死数 1975 32 4 1976 56 5 1977 162 12 1978 241 13 1979 330 10 1980
274
5
试分析:(1)粗略判断发病率的变化情况怎样。
答:该地人口数在此6年间基本保持不变,发病人数在1979年前逐年上升,1980年略有下降。可以认为发病率大致呈上升趋势,1980年略有下降。
(2)病死率的变化情况怎样? 答: 病死率由各年度病死数除以发病数获得,病死率依次为12.5%、8.9%、7.4%、5.4%、3.0%和1.8%,呈逐年下降趋势。 (3)上述分析内容可用什么统计图绘制出来? 答:由于没有给出该地人口数,故不能计算发病率,可用普通线图表示发病数变化情况。病死率的下降情况可以用普通线图表示,下降速度则可以用半对数线图表示。
(4)评述该地区出血热防治工作的效果。 答:随着时间的推移,预防工作做得不好,治疗水平则逐年提高(体现在病死率下降)。 (张晋昕) 第3章 概率分布思考与练习参考答案 一、最佳选择题
1. 某资料的观察值呈正态分布,理论上有( C )的观察值落在S
X 96.1±范围内。
A. 68.27%
B. 90%
C. 95%
D. 99%
E. 45% 2. 正态曲线下,从均数
μ到σ
μ64.1+的面积为( A )。
A. 45%
B. 90%
C. 95%
D. 47.5%
E. 99% 3. 若正常人的血铅含量X 近似服从对数正态分布,则制定X 的95%参考值范围,最好采用(其中
X
Y lg =,
Y
S 为Y 的标准差)( C )。
A.
1.96X S ± B.5.975.2~P P
C.)64.1(lg
1
Y S Y +- D.)69.1(lg 1Y S Y +- E.955~P P
4. 在样本例数不变的情况下,若( D ),则二项分布越接近对称分布。 A. 总体率π越大 B. 样本率p 越大 C. 总体率π越小
D. 总体率π越接近0.5
E. 总体率π接近0.1或0.5
5. 铅作业工人周围血象点彩红细胞在血片上的出现数近似服从( D )。
A. 二项分布
B. 正态分布
C. 偏态分布
D. Poisson 分布
E. 对称分布
6. Poisson 分布的均数λ与标准差σ的关系是( E )。
A.
σ
λ= B.
σ
λ< C.
σ
λ> D.
σ
λ=
E.
2σλ=
二、思考题
1. 服从二项分布及Poisson 分布的条件分别是什么?
简答:二项分布成立的条件:①每次试验只能是互斥的两个结果之一;②每次试验的条件不变;③各次试验独立。 Poisson 分布成立的条件:除二项分布成立的三个条件外,还要求试验次数n 很大,而所关心的事件发生的概率π很小。
2. 二项分布、Poisson 分布分别在何种条件下近似正态分布?
简答: 二项分布的正态近似:当n 较大,π不接近0也不接近1时,二项分布B (
n ,π)近似正态分布N (πn , )1(ππ-n )
。 Poisson 分布的正态近似:Poisson 分布)(λ∏,当λ相当大时(≥20),其分布近似于正态分布。 三、计算题
1. 已知某种非传染性疾病常规疗法的有效率为80%,现对10名该疾病患者用常规疗法治疗,问至少有9人治愈的概率是多少?
解:对10名该疾病患者用常规疗法治疗,各人间对药物的反应具有独立性,且每人服药后治愈的概率均可视为0.80,这相当于作10次独立重复试验,即π=0.80,n =10的贝努利试验,因而治愈的人数X 服从二项分布
0.80) (10,B 。至少有9人治愈的概率为:
∑=----≤-=≥8
1010)801(80C 1)19(1)9(k k
k k
..X P X P =
37.58%83750262401=..=-=
至少有9人治愈的概率是37.58%。 或者)10()9()9(=+==≥X P X P X P 010*******
10)801(80C )801(80C ..
..-+-=53780.=
以上是SPSS 输出结果,得到均数(Mean )为174.766 cm ,标准差(Std. Deviation )为4.150 9 cm 。估计当年该市20岁男性青年中,身高在175.0~178.0 cm 内的比例为25.956%,身高在175.0~178.0 cm 内的约有29人。 估计当年该市95%的20岁男青年身高范围为166.63~182.90 cm ,99% 的20岁男青年身高范围为164.06~185.48 cm 。 由该市随机抽查1名20岁男青年,估计其身高超过180 cm 的概率约为10%。 (祁爱琴 高 永 石德文) 第4章 参数估计
一、最佳选择题
1.关于以0为中心的t 分布,错误的是( E )
A. t 分布的概率密度图是一簇曲线
B.t 分布的概率密度图是单峰分布
C. 当ν→∞时,t 分布→Z 分布
D.t 分布的概率密度图以0为中心,左右对称
E. ν相同时,
t
值越大,P 值越大
2.某指标的均数为
X
,标准差为S ,由公式
()
1.96, 1.96X S X S -+计算出来的区间常称为( B )。
A. 99%参考值范围
B. 95%参考值范围
C. 99%置信区间
D. 95%置信区间
E. 90%置信区间 3.样本频率
p 与总体概率π均已知时,计算样本频率p 的抽样误差的公式为
( C )。
A.
()
1p p n
- B.
()
11
p p n --
C.
()
1n
ππ- D.
()
11
n ππ-- E.
()
12
n ππ--
4.在已知均数为
μ, 标准差为 σ 的正态总体中随机抽样, X μ->
( B )的概率为5%。 A.1.96
σ
B.
1.96X σ C.0.05/2,t S ν D.0.05/2,X t S ν
E.0.05/2,X t
ν
σ
5. ( C )小,表示用样本均数估计总体均数的精确度高。
A. CV
B. S
C.
X σ D. R E. 四分位
数间距 6. 95%置信区间的含义为( C ):
A. 此区间包含总体参数的概率是95%
B. 此区间包含总体参数的可能性是95%
C. “此区间包含总体参数”这句话可信的程度是95%
D. 此区间包含样本统计量的概率是95%
E. 此区间包含样本统计量的可能性是95%
二、思考题
1. 简述标准误与标准差的区别。
答: 区别在于:(1)标准差反映个体值散布的程度,即反映个体值彼此之间的差异;标准误反映精确知道总体参数(如总体均数)的程度。(2)标准误小于标准差。(3)样本含量越大,标准误越小,其样本均数更有可能接近于总体均数,但标准差不随样本含量的改变而有明显方向性改变,随着样本含量的增大,标准差有可能增大,也有可能减小。
2. 什么叫抽样分布的中心极限定理?
答: 样本含量n 越大,样本均数所对应的标准差越小,其分布也逐渐逼近正态分布,这种现象统计学上称为中心极限定理(central limit theorem )。当有足够的样本含量(如30n
≥)时,从任何总体中抽取随机样本的样本均数近似地服从正态分布。样本含量越大,X
抽样分布越接近于正态分布。正态分布的近似程度与总体自身的
概率分布和样本含量有关。如果总体原本就是正态分布,那么对于所有
n 值,抽样分布均为正态分布。如果总体为非正态分布,X
仅在n 值较大情况下近似服从正态
分布。一般说,30n ≥时的X
抽样分布近似为正态分布;但是,如果总体分布极度非正态(如双峰分布、极度偏峰分布),即使有足够大的
n 值,抽样分布也将为
非正态。
3. 简述置信区间与医学参考值范围的区别。 答: 置信区问与医学参考值范围的区别见练习表4-1。 练习表4-1 置信区间与医学参考值范围的区别
区别 置信区间
参考值范围
含义
用途 计算公式
总体参数的波动范围,即按事先给定的概率100(1-α)%所确定的包含未知总体参数的一个波动范围
估计未知总体均数所在范围 σ未知:
/2,X X t S αν±
σ已知或σ未知但n ≥30,有/2X X Z ασ±或
/2X X Z S α±
个体值的波动范围,即按事先给定的范围100(1-α)%所确定的“正常人”的解剖、生理、生化指标的波动范围
供判断观察个体某项指标是否“正常”时参考(辅助诊断) 正态分布:/2X
Z S α±
偏峰分布:P X ~P 100-X
4. 何谓置信区间准确度与精确度?如何协调两者间的关系。
答:置信区间有准确度(accuracy )与精密度(precision )两个要素。准确度由置信度 (1-α) 的大小确定,即由置信区间包含总体参数的可能性大小来反映。从准确度的角度看,置信度愈接近于1愈好,如置信度99%比95%好。精密度是置信区间宽度的一半(即2,X t
S αν、2,p Z S αν)
,意指置信区间的两端点值离样本统计量(如
X
、p )的距离。从精密度的角度看,置信区间宽度愈窄愈好。在抽样误差确定的情况下,两者是相互矛盾的。为了同时兼顾置信区间的准确度与精密
度,可适当增加样本含量。 三、计算题
1.随机抽取了100名一年级大学生,测得空腹血糖均数为4.5 mmol/L ,标准差为0.61 mmol/L 。试估计一年级大学生空腹血糖总体均数及方差的95%置信区间。 答:总体均数95%置信区间为(4.379,4.621),方差的95%置信区间为(0.286 9, 0.502 1)。
2.调查某地蛲虫感染情况,随机抽样调查了260人,感染人数为100。试估计该地蛲虫感染率的95%置信区间。 答:该地蛲虫感染率的95%置信区间为(32.55%,44.38%)。(宇传华) 第5章 假设检验 思考与练习参考答案 一、最佳选择题
1. 样本均数比较作t 检验时,分别取以下检验水准,以( E )所取Ⅱ类错误最小。
A.
0.01α= B. 0.05α= C. 0.10α= D. 0.20α= E. 0.30α=
2. 在单组样本均数与一个已知的总体均数比较的假设检验中,结果t =
3.24,t 0.05,v =2.086, t 0.01,v =2.845。正确的结论是( E )。 A. 此样本均数与该已知总体均数不同 B. 此样本均数与该已知总体均数差异很大
C. 此样本均数所对应的总体均数与该已知总体均数差异很大
D. 此样本均数所对应的总体均数与该已知总体均数相同
E. 此样本均数所对应的总体均数与该已知总体均数不同 3. 假设检验的步骤是( A )。
A. 建立假设,选择和计算统计量,确定P 值和判断结果
B. 建立无效假设,建立备择假设,确定检验水准
C. 确定单侧检验或双侧检验,选择t 检验或Z 检验,估计Ⅰ类错误和Ⅱ类错
误
D. 计算统计量,确定P 值,作出推断结论
E. 以上都不对
4. 作单组样本均数与一个已知的总体均数比较的t 检验时,正确的理解是
( C )。
A. 统计量t 越大,说明两总体均数差别越大
B. 统计量t 越大,说明两总体均数差别越小
C. 统计量t 越大,越有理由认为两总体均数不相等
D. P 值就是α
E. P 值不是α,且总是比α小
???5. 下列( E )不是检验功效的影响因素的是:
A. 总体标准差
σ B. 容许误差δ C. 样本含量n
D. Ⅰ类错误α
E. Ⅱ类错误β
二、思考题
1.试述假设检验中α与P 的联系与区别。
答:α值是决策者事先确定的一个小的概率值。P 值是在0H 成立的条件下,出现当前检验统计量以及更极端状况的概率。 P ≤α时,拒绝0H 假设。
2. 试述假设检验与置信区间的联系与区别。 答:区间估计与假设检验是由样本数据对总体参数作出统计学推断的两种主要方法。置信区间用于说明量的大小,即推断总体参数的置信范围;而假设检验用于推断质的不同,即判断两总体参数是否不等。
3. 怎样正确运用单侧检验和双侧检验?
答:选用双侧检验还是单侧检验需要根据数据的特征及专业知识进行确定。若比较甲、乙两种方法有无差异,研究者只要求区分两方法有无不同,无需区分何者为优,则应选用双侧检验。若甲法是从乙法基础上改进而得,已知如此改进可能有效,也可能无效,但不可能改进后反不如以前,则应选用单侧检验。在没有特殊专业知识说明的情况下,一般采用双侧检验即可。 4. 试述两类错误的意义及其关系。
答:Ⅰ类错误(type Ⅰerror ):如果检验假设0H 实际是正确的,由样本数据计算获得的检验统计量得出拒绝0H 的结论,此时就犯了错误,统计学上将这种拒绝了正确的零假设0H (弃真)的错误称为Ⅰ类错误。
Ⅱ类错误(type Ⅱ error):假设检验的另一类错误称为Ⅱ类错误(type Ⅱ error),即检验假设0H 原本不正确(1H 正确),由样本数据计算获得的检验统计量得出不拒绝0H (纳伪)的结论,此时就犯了Ⅱ类错误。Ⅱ类错误的概率用β 表示。
在假设检验时,应兼顾犯Ⅰ类错误的概率(α)和犯Ⅱ类错误的概率(β)
。犯Ⅰ类错误的概率(α)和犯Ⅱ类错误的概率(β)成反比。如果把Ⅰ类错误的
概率定得很小,势必增加犯Ⅱ类错误的概率,从而降低检验效能;反之,如果把Ⅱ类错误的概率定得很小,势必增加犯Ⅰ类错误的概率,从而降低了置信度。为了同时减小
α和β,只有通过增加样本含量,减少抽样误差大小来实现。
5.试述检验功效的概念和主要影响因素。
答:拒绝不正确的0H 的概率,在统计学中称为检验功效(power of test),记为1β-
。检验功效的意义是:当两个总体参数间存在差异时(如备择假设1H :
0μμ≠成立时),所使用的统计检验能够发现这种差异(拒绝零假设0H :0μμ=)的概率,一般情况下要求检验功效应在0.8以上。
影响检验功效的四要素为总体参数的差异δ
、总体标准差
σ、检验水准α及犯Ⅱ类错误的概率β。
6.简述假设检验的基本思想。
答:假设检验是在H 0成立的前提下,从样本数据中寻找证据来拒绝0H 、接受1H 的一种“反证”方法。如果从样本数据中得到的证据不足,则只能不拒绝0H ,暂且认为0H 成立(因为拒绝的证据不足),即样本与总体间的差异仅仅是由于抽样误差所引起。拒绝0H 是根据某个界值,即根据小概率事件确定的。所谓小概率事件是指如果比检验统计量更极端(即绝对值更大)的概率较小,比如小于等于0.05(各种科研杂志习惯上采用这一概率值),则认为零假设的事件在某一次抽样研究中不会发生,此时有充分理由拒绝0H ,即有足够证据推断差异具有统计学意义。 三、计算题
1. 一般正常成年男子血红蛋白的平均值为140 g/L ,某研究者随机抽取25名高原地区成年男子进行检查,得到血红蛋白均数为155 g/L ,标准差25 g/L 。问:高原地区成年男子的血红蛋白是否比一般正常成年男子的高? 解:0H :
0μμ= 1H :0μμ> 0.05α=(单侧) n
S X t /0
μ-=
=3.00
t =3,01.0005.0<
常成年男子的高。
2. 一般而言,对某疾病采用常规治疗,其治愈率约为45%。现改用新的治疗方法,并随机抽取180名该疾病患者进行了新疗法的治疗,治愈117人。问新治疗方法与常规疗法的效果是否有差别?
解:0H :
0ππ=,1H :0ππ≠,0.05α=
00(1)/p
p p Z n
ππσππ--=
=
-=5.41
Z =5.41,001.0
优于常规疗法。(林爱华 宇传华)
第6章 两样本定量资料的比较思考与练习参考答案 一、 最佳选择题
1. 正态性检验,按α =0.10检验水准,认为其总体服从正态分布,此时若推断有错,其错误的概率为( D )。
A. 大于0.10
B. 等于0.10
C. 小于0.10
D. 等于β,而β未知
E. 等于1-β,而β未知
???2. 甲、乙两人分别从同一随机数字表抽取30个(各取两位数字)随机数字作为两个样本,求得
2
1
1S X 和、
2
2
2S X 和,则理论上( C )。
A.
21X X = B. 2
2
2
1S S =
C. 由甲、乙两样本均数之差求出的总体均数95%可信区间,很可能包括0
D. 作两样本均数比较的t 检验,必然得出无统计学意义的结论
E. 作两样本方差比较的F 检验,必然方差齐
3. 两样本均数比较时,能用来说明两组总体均数间差别大小的是( D )。 A. t 值 B. P 值 C. F 值 D . 两总体均数之差的95%置信区
间
E. 上述答案均不正确
4. 两小样本均数比较,方差不齐时,下列说法不正确的是( C )。 A. 采用秩和检验 B. 采用t ′检验 C. 仍用t 检验 D . 变量变换后再作决定 E. 要结合正态性检验结果方能作出决定
5. 两样本秩和检验的0H 是 ( B )。
A. 两样本秩和相等
B. 两总体分布相同
C. 两样本分布相同
D. 两总体秩和相等
E. 两总体均数相等 6. 在统计检验中是否选用非参数统计方法( A )。
A. 要根据研究目的和数据特征作决定
B. 可在算出几个统计量和得出初步结论后进行选择
C. 要看哪个统计结论符合专业理论
D. 要看哪个
P 值更小
E. 既然非参数统计对资料没有严格的要求,在任何情况下均能直接使用 7. 配对样本差值的Wilcoxon 符号秩和检验,确定P 值的方法是( D )。
A. T 越大,P 值越小
B. T 越大,P 值越大
C. T 值在界值范围内,P 值小于相应的α
D. T 值>界值,P 值大于相应的α值
E. T 值在界值范围上,P 值大于相应的α
8. 成组设计两样本比较的秩和检验,其检验统计量T 是( C )。
A. 为了查T 界值表方便,一般以秩和较小者为T
B. 为了查T 界值表方便,一般以秩和较大者为T
C. 为了查T 界值表方便,一般以例数较小者秩和为T
D. 为了查T 界值表方便,一般以例数较大者秩和为T
E. 当两样本例数不等时,任取一样本的秩和为T 都可以查T 界值表
二、思考题
1.假设检验中,P 值和α的含义是什么?两者有什么关系?
答:P 是指H 0成立时出现目前样本情形的概率最多是多大, α是事先确定的检验水准。但P 值的大小和α没有必然关系。
2. 既然假设检验的结论有可能有错,为什么还要进行假设检验?
答:假设检验中,无论拒绝不拒绝H 0,都可能会犯错误,表现为拒绝H 0时,会犯Ⅰ类错误,不拒绝H 0时,会犯Ⅱ类错误,但这并不能否认假设检验的作用。只要涉及到抽样,就会有抽样误差的存在,因此就需要进行假设检验。只是要注意,假设检验的结论只是个概率性的结论,它的理论基础是“小概率事件不可能原理”。
3. 配对设计资料能否用完全随机设计资料的统计检验方法?为什么?
答:不能。采用完全随机设计资料的t 检验会使检验效能降低,从而可能会使应有的差别检验不出来。
4. 对于完全随机设计两样本定量资料的比较,如何选择统计方法?
答:完全随机设计两样本定量资料比较统计方法的选择最关键的是看是否满足正态性(样本量较大时不必进行正态性检验)和方差齐性。如果资料来自正态
总体且总体方差齐,采用t 检验;如果满足正态性但总体方差不齐,采用t ′检验;当两者都不满足时,才考虑选用秩和检验。当然,我们也可采用变量变换的方法使其满足t 或t ′检验的条件。
5. 为什么在秩和检验编秩次时不同组间出现相同数据要给予“平均秩次”,而同一组的相同数据不必计算“平均秩次”?
答:秩和检验编秩次时不同组间出现相同数据要给予“平均秩次”,而同一组的相同数据不必计算“平均秩次”,是因为取不取“平均秩次”对该组的总的秩和没有影响。
三、计算题
1. 某单位研究饲料中维生素E 缺乏对肝中维生素A 含量的影响,将同种属、同年龄、同性别、同体重的大白鼠配成8对,并将每对动物随机分配到正常饲料组和缺乏维生素E 的饲料组,定期将大白鼠杀死,测定其肝中维生素A 的含量(教材表6-12),问饲料中维生素E 缺乏对肝中维生素A 的平均含量有无影响?
教材表6-12 正常饲料组与维生素E 缺乏组大白鼠肝中维生素A 含量/(U ·mg -
1)
大白鼠对别 1 2 3 4 5 6 7 8 正常饲料组 3.55 2.60 3.00 3.95 3.80 3.75 3.45 3.05 维生素E 缺乏组
2.45
2.40
1.80
3.20
3.25
2.70
2.40
1.75
解:此题是个配对设计的资料,差值的正态性检验结果表明:差值来自正态总体(W 检验:P =0.268),所以采用配对t 检验。结果为:t =6.837,ν=7,P <0.001,
拒绝H 0,可以认为维生素E 缺乏对肝中维生素A 含量有影响。
2. 某实验室观察局部温热治疗小鼠移植性肿瘤的疗效,以生存日数作为观察指标。实验结果如下,请比较两组的平均生存日数有无差别。
实验组 10 12 14 15 15 17 18 20 26 80 对照组
2
3
6
7
8
9
10
12
12
13
30
解:此题是个完全随机设计的资料。两组资料的正态性检验结果表明,差值来自正态总体(W 检验:P1<0.001,P2=0.011),所以采用两样本比较的秩和检验。
结果为:T1=150.5, T2=80.5,本例中n1=10,n2-n1=1,对应双侧0.05的界值为81~139,故在α=0.05的水平上拒绝H0,认为两组小鼠生存日数不同。 (施学忠 杨永利 赵耐青)
第7章 多组定量资料的比较思考与练习参考答案 一、最佳选择题
1. 完全随机设计资料的方差分析中,必然有( C )。 A.
组间SS >组内SS B. 组内组间总MS MS MS +=
C.
总ss
=组间SS +组内SS D. 组内组间MS MS >
E.
组间组内νν>
2. 定量资料两样本均数的比较,可采用( D )。 A. t 检验 B.F 检
验 C. Bonferroni 检验 D.
t 检验与F 检验均可 E. LSD 检验 3. 当组数等于2时,对于同一资料,方差分析结果与t 检验结果相比,( C )。 A. t 检验结果更为准确 B. 方差分析结果更为准确 C. 完全等价且F t = D. 完全等价且t F = E. 两者结果可能出现矛盾
4. 若单因素方差分析结果为),(01.021ννF F >,则统计推断是( D )
。 A. 各样本均数都不相等 B. 各样本均数不全相等 C. 各总体均数都不相等
D. 各总体均数不全相等
E. 各总体均数全相等
5. 完全随机设计资料的方差分析中,组间均方表示( C )。
A. 抽样误差的大小
B. 处理效应的大小
C. 处理效应和抽样误差综合结果
D.
N
个数据的离散程度 E. 随机因素的效应大小
6. 多样本定量资料比较,当分布类型不清时应选择( D )。 A. 方差分析 B. t 检验 C. Z 检验 D. Kruskal-Wallis 检验 E. Wilcoxon 检
验
7. 多组样本比较的Kruskal-Wallis 检验中,当相同秩次较多时,如果用H 值而
不用校正后的c H 值,则会( C )。
A . 提高检验的灵敏度
B .把一些无差别的总体推断成有差别 C. 把一些有差别的总体推断成无差别 D .Ⅰ、Ⅱ类错误概率不变 E. 以上说法均不对
二、思考题
1. 方差分析的基本思想和应用条件是什么?
答:方差分析的基本思想是,对于不同设计的方差分析,其思想都一样,即均将处理间平均变异与误差平均变异比较。不同之处在于变异分解的项目因设计不同而异。具体来讲, 根据试验设计的类型和研究目的,将全部观测值总的离均差平方和及其自由度分解为两个或多个部分,除随机误差作用外,每个部分的变异可由某个因素的作用加以解释,通过比较不同变异来源的均方,借助F 分布作出统计推断,从而推论各种研究因素对试验结果有无影响。
其应用条件是,① 各样本是相互独立的随机样本,均服从正态分布;② 各样本的总体方差相等,即方差齐性。 2. 多组定量资料比较时,统计处理的基本流程是什么?
答:多组定量资料比较时首先应考虑用方差分析,对其应用条件进行检验,即方差齐性及各样本的正态性检验。若方差齐性,且各样本均服从正态分布,选单因素方差分析。若方差不齐,或某样本不服从正态分布,选Kruskal-Wallis 秩和检验,或通过某种形式的数据变换使其满足方差分析的条件。若方差分析或秩和检验结果有统计学意义,则需选择合适的方法(如Bonferonni 、LSD 法等)进行两两比较。 三、计算题:
1. 根据教材表7-11资料,大白鼠感染脊髓灰质炎病毒后,再作伤寒或百日咳接种是否影响生存日数?若结论为“有影响”,请作多重比较(与对照组比)。 教材表7-11 各组大鼠接种后生存日数/天
伤寒 百日咳 对照 5 6 8 7 6 9 8 7 10 9 8 10 9 8 10 10 9 11 10 9 12 11 10 12 11 10 14 12
11
16
解:本题资料可考虑用完全随机设计的单因素方差分析进行统计处理。 (1)建立检验假设,确定检验水准。
0H :大白鼠感染脊髓灰质炎病毒后,再接种伤寒或百日咳菌苗生存日数相等。
1H :大白鼠感染脊髓灰质炎病毒后,再接种伤寒或百日咳菌苗生存日数不等或不全相等,α=0.05。
(2)方差分析应用前提条件的检验 首先进行正态性及方差齐性检验,三组均服从正态分布(P1=0.684,P2=0.591,P3=0.507),三个总体的方差齐(P =0.715),
符合单因素方差分析的条件,可行方差分析。
(3)各组可分别采用均数和标准差描述其集中趋势和离散趋势,各组的统计描述及总体均数的置信区间如下:
表1三组大鼠接种后生存日数的描述性统计量/天
N
均数
标准差
95%置信区间
下限
上限 伤寒 10 9.20 2.10 7.70 10.70 百日咳 10 8.40 1.71 7.17 9.63 对照 10 11.2 2.39 9.49 12.91 合计
30
9.60
2.34
8.73
10.47
(4)资料的方差分析见方差分析表 方差分析结果7764.F =,0170.P =,即大白鼠感染脊髓灰质炎病毒后,再接种伤寒或百日咳菌苗生存日数不等或
不全相等。
表2三组大鼠接种后生存日数差别有无统计学意义的方差分析表
变异来源 SS df MS F P 组间 41.6 2 20.800 4.776 0.017 组内 117.6 27 4.356 合计
159.2
29
进一步行多重比较(LSD 检验),结果两实验组均与对照组有统计学差异。认为大白鼠感染脊髓灰质炎病毒后,再接种伤寒或百日咳菌苗对生存日数有影响,生存日数减少。
表3三组大鼠接种后生存日数两两比较的结果 对比组
-A B X X
-A B
X X S
P 均数差值的95%置信区间 下限 上限 伤寒组与对照组 2.0 0.9333 0.041 -3.92 -0.09 百日咳组与对照组
2.8
0.9333
0.006
-4.72
-0.89
2. 将18名乙脑患者随机分为三组,分别用单克隆抗体、胸腺肽和利巴韦林三种药物治疗,观察指标为治疗后的退热时间,结果见教材表7-12。问三组治疗结果的差异是否具有统计学意义? 教材表7-12 三组乙脑患者的退热时间/天
治疗分组 退热时间 单克隆抗体组 0 2 0 0 5 9 胸腺肽组 32 13 6 7 10 2 利巴韦林组
11
15
11
3
1
解:从专业上考虑,退热时间一般不服从正态分布,可采用Kraskal -Wallis 检验分析三组乙脑患者的退热时间差异有无统计学意义。 (1)
各组可分别采用四份位数描述其集中趋势和离散趋势,各组的统计描述如下:
表1三组乙脑患者退热时间的描述性统计量/天 组别 N P25 P50 P75 单克隆抗体组 6 0.00 1.00 6.00 胸腺肽组 6 5.00 8.50 17.75 利巴韦林组
6
0.75
7.00
12.00
(2)建立检验假设,确定检验水准。
0H :三组乙脑患者的退热时间相等,
1H :三组乙脑患者的退热时间不等或不全相等,
α=0.05。
(3)Kraskal -Wallis 检验结果,2
χ=4.799,ν=2,P=0.091>0.05。结论为,在α=0.05的水平上尚不能认为三组治疗结果的差异具有统计学意义。
(王 玖 徐天和 高 永 石德文) 第8章 定性资料的比较思考与练习参考答案 一、最佳选择题
1. 定性资料的统计推断常用( D )。 A.
t 检验 B. 正态检验 C. F 检验 D. 2
χ
检验 E. t ′检验
2. 两组二分类资料发生率比较,样本总例数100,则
2
χ
检验自由度为( A )。
A. 1
B. 4
C. 95
D. 99
E. 100 3. 四格表
2χ检验中,2χ<1 ,05.02χ,可以认为( B )
。 A. 两总体率不同 B. 不能认为两总体率不同
C. 两样本率不同
D. 不能认为两样本率不同
E. 以上都不对 4.等级资料比较宜采用( E )。
A. t
检验 B.
2χ检验 C. F 检验 D. 正态检验 E. 秩和检验
)
m n A n()m n A n()
n m n n
A m n A (
n m n /n)m (n /n m n A A n
/n
m n /n)m n (A T )T (A χR
i C
j j
i ij
R
i C
j j
i ij j i ij R
i C
j j
i ij R
i C
j j
i j i j i ij ij R i C
j j i j i ij R
i C
j ij
ij ij 112221
12
112
2
112
112
2
11
2
112
2-=+-=+
-
=+-=-=-=∑∑
∑∑
∑∑∑∑∑∑
∑∑
============5. 为比较治疗某病的新疗法与常规方法,试验者将100名患者按性别、年龄等情况配成对子,分别接受两疗法治疗。观察得到有28对患者同时有效,5对患者同时无效,11对患者新药有效常规治疗无效。欲比较两种疗法的有效率是否相同,应选择的统计分析方法为( D )。 A. 独立的两组二分类资料比较
2χ检验 B. 独立的两组二分类资料比较校
正
2χ检验 C. 配对的两组二分类资料比较2χ检验 D. 配对的两组二
分类资料比较校正
2χ检验 E. Fisher 确切概率法
二、思考题 1. 简述
2χ检验适用的数据类型。
答:提示:卡方检验是应用较广的一种定性资料的假设检验方法,常用于检验两个或多个样本率(或构成比)之间有无差别。 2. 两组二分类资料的设计类型有几类?其相应的检验方法是什么?
答:提示:两组二分类资料的设计类型主要有2类,即完全随机设计和配对设计。完全随机设计和配对设计资料在假设检验方法上均采用卡方检验。完全随机设计资料应用公式(8-1)或(8-4),配对设计资料应用公式(8-7)或(8-8)。 3. 什么资料适合用秩和检验进行检验?简述秩和检验步骤。
答:提示:进行有序资料的比较时宜采用秩和检验。秩和检验步骤为:① 建立假设10H H 和,并确定检验水准α;② 根据不同的设计类型对资料进行编秩并计算秩和;③ 根据计算的秩和直接查表或计算相应的统计量再查表,确定P 值下结论。进行有序资料的比较时宜采用秩和检验。
4. 试证明对于R ×C 式(8-11)与式(8-1)等价。
提示: 三、计算题
1.
某医院观测了28例肝硬化患者和14例再生障碍性贫血患者血清中抗血小板抗体, 结果
是:肝硬
化患者中有2例阳性,再生障碍性贫血患者中有5例阳性。问:两类患者血清抗血小板抗体阳性率有无差别?
解:
将资料进行整理列表(练习表8-1)。
练习表8-1 两类患者血清抗血小板抗体检测结果
患者类型 阳性 阴性 合计 肝硬化患者 再生障碍性贫血患者
2 26 28 5 9 14
资料属于独立的两组二分类资料比较。理论频数分别为4.67、23.33、2.33、11.67,应选用校正公式计算。假设0H :两种疾病患者血清抗血小板抗体检测阳性率相同,
α=0.05。计算统计量校正卡方=3.621 4,自由度=1,P =0.057 0, 无统计学意义,尚不能认为两种疾病患者血清抗血小板抗体检测阳性率不同。
2. 对100名钩端螺旋体病患者同时用间接免疫抗体试验和显微镜凝集试验进行血清学诊断,结果见教材表8-18。试比较用两种方法检验的阳性率有无差别?
教材表8-18 两种方法的检验结果比较(例数)
间接免疫 荧光
显微镜凝集
合计
+
- + 66 11 77 - 6 17 23 合计
72
28
100 解: 答案提示,本资料属于配对的两组二分类资料比较,b +
c =11+6=17<40,应选用校正配对卡方公式计算。假设0H :两种方法检测的阳性率相同,α=0.05。
计算统计量
=2χ 0.9412,df
=1,
P =0.332,无统计学意义,尚不能认为两种方法检测的阳性率不同。
3. 研究两种不同的治疗训练方案对肥胖症患者的减肥效果情况,结果见教材表8-19。问这两种治疗训练方案对肥胖症患者的减肥效果是否相同? 教材表8-19 两种治疗训练方案对肥胖症患者的减肥效果(例数)
治疗方案 效果较好 效果一般 效果较差 合计 甲 16 22 8 46 乙 28 17 5 50 合计
44
39
13
96
解:该资料属于结果变量为有序变量的定性资料,应选用秩和检验。假设0H :两种治疗方案对肥胖症患者的减肥效果相同,
α=0.05。按照治疗效果由差到好编
秩,计算秩和=甲
T 9741,统计量U
=-2.064,
P =0.039,有统计学意义,可以认为两种治疗方案的减肥效果不同,由两组平均秩和看,甲组为1 974÷46=42.91,
乙组为2 682÷50=53.64,因为编秩是由差到好,因此可认为乙治疗方案的效果好于甲治疗方案。 4. 比较三种中药方剂对骨质疏松症的治疗效果,结果见教材表8-20。三种方剂的治疗效果是否有差异?
教材表8-20 三种中药方剂对骨质疏松症的治疗效果(例数) 分组 有效 无效 合计 A 方剂 18 6 24 B 方剂 12 14 26 C 方剂 11 15 26 合计
41
35
76
解:本题属于独立的多组二分类资料比较。假设0H :三种方剂对骨质疏松症的治疗效果相同,α=0.05。计算统计量=2χ 6.3350,df
=2,
P =0.042,差
别有统计学意义,拒绝H 0,接受H 1,尚不能认为这三种方剂的治疗效果不相同。(郭秀花 罗艳侠) 第9章 关联性分析 思考与练习参考答案 一、最佳选择题
1. 对简单相关系数作假设检验,
)(v t t >,统计结论为( B )
。 A. 两变量不相关 B. 两变量有线性关系
C. 两变量无线性关系
D. 两变量不会是曲线关系,一定是线性关系
E. 上述说法都不准确
2. 计算积矩相关系数要求( C )。
A. Y 是正态变量,X
可以不满足正态的要求 B.
X 是正态变量,Y 可以不满足正态的要求
C. 两变量都要求满足正态分布规律
D. 两变量只要是测量指标就行
E.
Y 是定量指标,X
可以是任何类型的数据
3. 对两个分类变量的频数表资料作关联性分析,可用( C )。 A. 积矩相关 B.秩相关 C. 关联系数 D. 线性相关 E.以上均可
4. 由样本算得相关系数
r ,t 检验结果为P <0.01,说明( D )
。 A. 两变量之间有高度相关性 B. r 来自高度相关的总体
C. r 来自总体相关系数为0的总体
D. r 来自总体相关系数不为0的总体
E. r 来自总体相关系数大于0的总体 二、思考题
1. 1988年某地抽查0~7岁儿童营养不良患病情况如教材表9-10,某医师要想了解年龄与营养不良患病率是否有关,你认为应选用什么统计方法?为什么? 教材表9-10 1988年某地抽查0~7岁儿童营养不良患病情况
年龄/岁
0~ 1~ 2~ 3~ 4~ 5~ 6~7 患病人数
98 278 86 29 59 82 34 患病率/%
15.7 11.7 12.9 7.4 8.9 7.3 5.1 解:提示,用秩相关分析年龄与患病率的关系,因患病率资料一般不服从正态分布。
2. 请查找最近三年主题为相关分析或关联分析的已发表国内医学文献,至少认真阅读其中3篇(建议分别选取Pearson 、Spearman 相关分析和关联分析各1篇),找出其中不妥之处。
3. 在讲散点图时,我们曾提到分层应慎重,有可能出现分层分析与总体情况大相径庭的结果。请举一两个实例说明这种现象。 三、计算分析题
1. 某学校随机抽取18名学生,测定其智商(IQ )值,连同当年数学和语文两科总成绩如表教材9-11。试计算数学成绩与智商、语文成绩与智商以及数学与语文成绩的相关系数,并检验总体相关系数是否为零。能否认为数学好的原因是语文好,或者语文好的原因是数学好? 教材表9-11 18名学生的智商、数学成绩和语文成绩 编号 1 2 3 4 5 6 7 8 9 数学成绩X 语文成绩Y 智商得分Z
78 84 61 52 93 89 98 98 65 83 76 70 58 82 78 89 95 61 95
100
100
75
105
97
110
120
76
编号 10 11 12 13 14 15 16 17 18 数学成绩X 语文成绩Y 智商得分Z
73 48 45 67 75 95 88 99 81 75 53 43 70 78 97 92 92 88 92
61
60
88
96
125
113
126
102
解:提示,数学与智商的相关系数(Pearson )为0.918,语文与智商的相关系数为0.958,数学与语文的相关系数为0.932。各总体相关系数均不为0。 数学好或者语文好与智商有关系。不能认为数学好的原因是语文好,或者语文好的原因是数学好,两者之间不存在因果关系。 2. 将10份研究生院的入学申请书让两位老师排序,结果见教材表9-12。请问两人的排序是否相关? 教材表9-12 两位老师对10份入学申请书的排序 申请书编号 1 2 3 4 5 6 7 8 9 10 A 老师的排序 6 10 5 1 7 2 8 9 3 4 B 老师的排序 7 8 5 4 6
3 9 10 1 2
解:提示,Spearman 相关系数为0.842,总体相关系数不为0(P =0.002),可以认为两人的排序相关。
3. 关于丈夫和妻子关节炎的患病率分析中,100对中年夫妇的患病情况见教材表9-13,试分析丈夫和妻子关节炎的患病有无关系。 教材表9-13 100对中年夫妇的患病情况
妻子患病情况 丈夫患病情况
合计
有病 无病
有病 16 24 40 无病 24 36 60 合计 40 60 100
解:提示,运用交叉分类2×2列联表的关联分析,2χ=0.00,2
05.0χ=3.84>0.00,在α=0.05的水平下,不拒绝H0,尚不能认为中年夫妇中丈夫患关节炎和
妻子患关节炎有关联。(凌 莉 刘清海) 第10章 简单线性回归分析思考与练习参考答案 一、 最佳选择题 1.如果两样本的相关系数21
r r =,样本量21n n =,那么( D )
。 A. 回归系数21b b = B .回归系数12b b <
C. 回归系数21b b > D .t 统计量11r b t t =
E. 以上均错
2.如果相关系数r
=1,则一定有( C )。
A .总SS =残差SS
B .残差SS =回归
SS
C .总SS =回归SS
D .总SS >回归SS
E.
回归MS =残差
MS
3.记ρ为总体相关系数,r 为样本相关系数,b 为样本回归系数,下列( D )
正确。 A .
ρ=0时,r =0 B .|r |>0时,b >0
C .r
>0时,b <0 D .r
<0时,b <0 E. |
r |=1时,b =1
4.如果相关系数r
=0,则一定有( D )。
A .简单线性回归的截距等于0
B .简单线性回归的截距等于Y 或
X C .简单线性回归的残差SS 等于0 D .简单线性回归的残差SS 等于SS 总
E .简单线性回归的总SS 等于0
5.用最小二乘法确定直线回归方程的含义是( B )。
A .各观测点距直线的纵向距离相等
B 各观测点距直线的纵向距离平方和最小
C .各观测点距直线的垂直距离相等
D 各观测点距直线的垂直距离平方和最小
E .各观测点距直线的纵向距离等于零
二、思考题
1.简述简单线性回归分析的基本步骤。 答:① 绘制散点图,考察是否有线性趋势及可疑的异常点;② 估计回归系数;③ 对总体回归系数或回归方程进行假设检验;④ 列出回归方程,绘制回归直线;⑤ 统计应用。 2.简述线性回归分析与线性相关的区别与联系。
答:区别:(1)资料要求上,进行直线回归分析的两变量,若X 为可精确测量和严格控制的变量,则对应于每个X 的Y 值要求服从正态分布;若X 、Y 都
是随机变量,则要求
X 、Y 服从双变量正态分布。直线相关分析只适用于双变量正态分布资料。(2)应用上,说明两变量线性依存的数量关系用回归(定量分析),说明两变量的相关关系用相关(定性分析)。(3)两个系数的意义不同。r 说明具有直线关系的两变量间相互关系的方向与密切程度,b 表示X 每变化一个单位所导致Y 的平均变化量。(4)两个系数的取值范围不同:-1≤r ≤1,∞<<∞-b 。(5)两个系数的单位不同:r 没有单位,b 有单位。
联系:(1)对同一双变量资料,回归系数b 与相关系数r 的正负号一致。b >0时,r >0,均表示两变量X 、Y 同向变化;b <0时,r <0,均表示两变量X 、Y 反向变化。(2)回归系数b 与相关系数r 的假设检验等价,即对同一双变量资料,r b t t =。由于相关系数r 的假设检验较回归系数b 的假设检验简单,
故在实际应用中常以r 的假设检验代替b 的假设检验。(3)用回归解释相关:由于决定系数2
R =SS 回
/SS 总
,当总平方和固定时,回归平方和的大小决定了相关的密切
程度。回归平方和越接近总平方和,则2
R 越接近1,说明引入相关的效果越好。例如当r =0.20,n =100时,可按检验水准0.05拒绝H 0,接受H 1,认为两变量有相关关系。但2
R =(0.20)2=0.04,表示回归平方和在总平方和中仅占4%,说明两变量间的相关关系实际意义不大。 3. 决定系数与相关系数的意义相同吗?如果不一样,两者关系如何?
答:现将相关系数、决定系数与Y 的总变异的关系阐释如下:假如在一回归分析中,回归系数的变异数回归SS =9,而Y 的总变异数总SS =13,则
决定系数2R
=
回归SS / 总SS =9/14=0.642 9/1,相关系数R =0.801 8即将决定系数表示为一比值关系,当总SS = l 时,则回归SS = 0.642 9,我们可以采用直
角三角形的“勾股定理”图示决定系数与相关系数的关系,如练习图10-1所示。
练习图10-1 相关系数、决定系数与总变异的关系
三、计算题
1. 以例10-1中空气一氧化氮(NO )为因变量,风速(X 4
)为自变量,采用统计软件完成如下分析:
(1)试用简单线性回归方程来描述空气中NO 浓度与风速之间的关系。(2)对回归方程和回归系数分别进行假设检验。(3)绘制回归直线图。(4)根据以上的计算结果,SS 残差
面积=4
SS 回归
面积=9 边长=3 SS 残差 SS 回归 面积=0.642 9 边长=0.801 8
进一步求其总体回归系数的95%置信区间。(5)风速为1.50 m/s 时,分别计算个体
Y 值的95%容许区间和Y 的总体均数的95%置信区间,并说明两者的意义。
解:运用SPSS 进行处理,主要分析结果如下:
(1)简单线性回归方程、假设检验结果及总体回归系数的95%置信区间如下: Coefficients(a)
Unstandardized Coefficients Standardized Coefficients t
Sig.
95% Confidence Interval for B B
Std. Error Beta Lower Bound Upper Bound Constant 0.159 0.019 8.422 0.000 0.120 0.198 风速
-0.053
0.012
-0.680
-4.345
0.000
-0.078
-0.028
(2)方差分析结果: ANOVA(b)
Sum of Squares df Mean Square F Sig. Regression 0.038 1 0.038 18.878 0.000(a) Residual 0.044 22 0.002 Total
0.081
23
(3)回归直线如练习图10-2。
练习图10-2 回归直线图
2. 教材表10-8为本章例10-1回归分析的部分结果,依次为
X 、Y 、Y 的估计值(Y ?)与残差(e ),请以相关分析考察四者之间的关系,以回归分析考察Y
?与X 、
Y 与Y
?、Y 与Y Y ?-、Y Y ?-与X 之间的关系,并予以解释。 教材表10-8 案例分析中回归分析的部分结果
X Y
Y
? Y
Y ?- X Y
Y
? Y
Y ?- X Y
Y
? Y
Y ?- 1.30 0.07
0.070 7 -0.004 7
1.20 0.10 0.054 8 0.045 2
1.12 0.04 0.041 5 -0.002 5 1.44 0.08 0.093 5 -0.017 5 1.48 0.13 0.098 6 0.030 4 1.66 0.06 0.127 1 -0.068 1 0.79 0.00 -0.010 8 0.011 8 1.82 0.14 0.153 1 -0.018 1 1.54 0.09 0.108 1 -0.021 1 1.65 0.17 0.126 5 0.043 5 1.44 0.10 0.092 2 0.006 8 0.96 0.04 0.016 8 0.022 2 1.76 0.16 0.142 9 0.013 1 0.95 0.01 0.014 9 -0.009 9 1.78 0.22 0.147 4 0.074 6 1.75 0.12 0.142 6 -0.022 6 1.44 0.01 0.092 9 -0.081 9 1.50 0.15 0.101 7 0.043 3 1.20 0.04 0.054 8 -0.014 8 1.08 0.00 0.036 5 -0.033 5 1.06 0.03 0.032 7 -0.003 7 1.50 0.12
0.102 4
0.017 6
1.84
0.14
0.156 9
-0.016 9
1.44
0.10
0.092 2
0.006 8
解:主要分析结果: (1)四者之间的相关系数 Correlations
X Y
Y hat
Y Y -hat
X 1 0.809 1.000 0.000 Y
0.809
1
0.809
0.586
Y hat
1.000 0.809 1 0.000 Y Y -hat
0.000
0.586
0.000
1
** Correlation is significant at the 0.01 level (2-tailed).
(2)四个变量间的回归系数 因变量
自变量
截距 回归系数 t P Y
? X
-0.136
0.159
456.016
0.000
Y Y
? 1.005 0.001 6.457 0.000 Y Y
Y ?- 0.088 0.999 3.394 0.003 Y
Y ?- X 0.000 014 7 0.000 010 5 0.000 1.000 Y
?与X 呈完全正相关关系,回归系数t 检验结果P =0.000,表明Y ?的变异可由X 完全解释。 Y 与Y
?的相关系数与Y 与X 的相关系数相同,表明正是由于X 的影响引起Y 的变异,Y 与Y ?关系即体现了Y 与X 的变化关系。 Y 与Y
Y ?-体现了扣除X 的影响后,Y 与残差仍呈正相关关系。 Y Y ?-与X 呈零相关关系,表明扣除了X 的影响,回归方程的残差与X 不再有相关或回归关系。(张岩波 郝元涛)
第11章 多重线性回归分析思考与练习参考答案 一、 最佳选择题
1. 逐步回归分析中,若增加自变量的个数,则( D )。
A. 回归平方和与残差平方和均增大
B. 回归平方和与残差平方和均减小
C. 总平方和与回归平方和均增大
D. 回归平方和增大,残差平方和减小
E. 总平方和与回归平方和均减小
2. 下面关于自变量筛选的统计学标准中错误的是( E )。 A. 残差平方和(残差SS )缩小 B. 确定系数(2
R )增大
C. 残差的均方(残差MS )缩小
D. 调整确定系数(2
ad R )增大
E.
p C 统计量增大
3. 多重线性回归分析中能直接反映自变量解释因变量变异百分比的指标为C A. 复相关系数B.简单相关系数C.确定系数 D. 偏回归系数E. 偏相关系数
4. 多重线性回归分析中的共线性是指( E )。
A.Y 关于各个自变量的回归系数相同
B.Y 关于各个自变量的回归系数与
截距都相同 C.Y 变量与各个自变量的相关系数相同
D.
Y 与自变量间有较高的复相关 E. 自变量间有较高的相关性
5. 多重线性回归分析中,若对某一自变量的值加上一个不为零的常数K ,则有
( D )。
A. 截距和该偏回归系数值均不变
B. 该偏回归系数值为原有偏回归系数值的
K 倍 C. 该偏回归系数值会改变,但无规律 D. 截距改变,但所有偏
回归系数值均不改变 E. 所有偏回归系数值均不会改变
二、思考题
1. 多重线性回归分析的用途有哪些?
答:多重线性回归在生物医学研究中有广泛的应用,归纳起来,可以包括以下几个方面:定量地建立一个反应变量与多个解释变量之间的线性关系,筛选危险因素,通过较易测量的变量估计不易测量的变量,通过解释变量预测反应变量,通过反应变量控制解释变量。 2. 多重线性回归模型中偏回归系数的含义是什么?
答:偏回归系数的含义是:在控制其他自变量的水平不变的情况下,该自变量每改变一个单位,反应变量平均改变的单位数。 3. 请解释用于多重线性回归参数估计的最小二乘法的含义。 答:最小二乘法的含义是:残差的平方和达到最小。 4. 如何判断和处理多重共线性?
答:如果自变量之间存在较强的相关,则存在多重共线性。可以通过分析自变量之间的相关系数、计算方差膨胀因子和容忍度等指标判断是否存在多重共线性。如果自变量间存在多重共线性,最简单的处理办法是删除变量,即在相关性较强的变量中删除测量误差大的、缺失数据多的、从专业上看意义不是很重要的或者在其他方面不太满意的变量。其次,也可采用主成分回归方法。
5. 如何判断、分析自变量间的交互作用? 答:基于专业背景知识,构造可能的交互作用项,并检验交互作用项是否有统计学意义。
6. 多重线性回归模型的基本假定有哪些?如何判断资料是否满足这些假定?如果资料不满足假定条件,常用的处理方法有哪些?
答:多重线性回归的前提条件是线性、独立性、正态性和等方差性,可以借助残差分析等方法判断资料是否满足条件。如果资料不满足前提条件,可以采用变量变换和非线性回归等方法处理。 三、计算题
为确定老年妇女进行体育锻炼还是增加营养会减缓骨骼损伤,一名研究者用光子吸收法测量了骨骼中无机物含量,对三根骨头主侧和非主侧记录了测量值,结果见教材表11-20。分别用两种桡骨测量结果作为反应变量对其他骨骼测量结果作多重线性回归分析,提出并拟合适当的回归模型,分析残差。
解:答案提示,需要对自变量进行筛选,而且要考虑是否存在多重共线性,如果存在,应进行适当的处理。 教材表11-20 骨骼中无机物的含量 受试者编号 主侧桡骨 桡骨 主侧肱骨 肱骨 主侧尺骨 尺骨 1 1.103 1.052 2.139 2.238 0.873 0.872 2 0.842 0.859 1.873 1.741 0.590 0.744 3
0.925
0.873
1.887
1.809
0.767
0.713
4 0.857 0.744 1.739 1.547 0.706 0.674
5 0.795 0.809 1.734 1.715 0.549 0.654
6 0.78
7 0.779 1.509 1.474 0.782 0.571
7 0.933 0.880 1.695 1.656 0.737 0.803
8 0.799 0.851 1.740 1.777 0.618 0.682
9 0.945 0.876 1.811 1.759 0.853 0.777
10 0.921 0.906 1.954 2.009 0.823 0.765
11 0.792 0.825 1.624 1.657 0.686 0.668
12 0.815 0.751 2.204 1.846 0.678 0.546
13 0.755 0.724 1.508 1.458 0.662 0.595
14 0.880 0.866 1.786 1.811 0.810 0.819
15 0.900 0.838 1.902 1.606 0.723 0.677
16 0.764 0.757 1.743 1.794 0.586 0.541
17 0.733 0.748 1.863 1.869 0.672 0.752
18 0.932 0.898 2.028 2.032 0.836 0.805
19 0.856 0.786 1.390 1.324 0.578 0.610
20 0.890 0.950 2.187 2.087 0.758 0.718
21 0.688 0.532 1.650 1.378 0.533 0.482
22 0.940 0.850 2.334 2.225 0.757 0.731
23 0.493 0.616 1.037 1.268 0.546 0.615
24 0.835 0.752 1.509 1.422 0.618 0.664
25 0.915 0.936 1.971 1.869 0.869 0.868
资料来源:《实用多元统计分析》(第4版),Richard A. Johnson & Dean W. Wichern,陆璇译,清华大学出版社。(郝元涛张岩波)
第12章实验设计思考与练习参考答案
一、最佳选择题
1. 处理因素作用于受试对象的反映须通过观察指标来表达,则选择指标的依据具有( E )。A.客观性 B. 特异性 C. 敏感性 D. 特异性和敏感性 E. A 与D
2. 以前的许多研究表明,血清三酰甘油的含量与冠心病危险性有关,即三酰甘油的含量越高,患冠心病的危险性就越大,有的医生以此筛选危险人群。后来的研究表明,冠心病还与其他因素有关,特别是血清中高含量胆固醇和低含量的高密度脂蛋白,它们常与冠心病同时发生联系,采用严格的实验设计平衡了其他因素的作用后,发现三酰甘油的含量与冠心病发病的危险性之间的联系就不复存在了。这是以下选项中的(B)选项把握得较好所致。
A. 重复实验次数较多
B.均衡性原则考虑得周到
C.用多因素设计取代单因素设计
D.提高实验人员的技术水平
E.严格按随机化原则进行分组
3. 实验共设4个组,每组动物数均为4只,在4个不同的时间点上对每只犬都进行了观测,资料概要列于教材表12-7中,此资料取自(B)。(注:B100 mg代表用B药的剂量)
教材表12-7 Beagle犬受6.5 Gy不均匀γ射线照射再用B药后外周血白细胞总数的结果
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
X ,×109/L)
时间白细胞总数(S
───────────────────────────────────────
/天照射对照照射+B100 mg 照射+阳性对照药照射+B100 mg+阳性对照药
────────────────────────────────────────────
照射前 14.30±3.77 14.70±2.83 14.08±1.60 13.98±1.37
照射后: 6 3.68±0.82 4.26±1.40 5.28±1.52 6.90±0.97
12 7.23±0.83 7.44±1.10 8.75±1.02 10.53±1.57
18 6.87±1.50 9.26±1.36 9.87±1.23 12.78±1.83
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
A. 具有一个重复测量的两因素
B.具有一个重复测量的三因素设计
C.两因素析因设计
D. 三因素析因设计
E.交叉设计
4. 已知A、B、C都是三水平因素,且根据预试验结果得知,三个因素之间的各级交互作用都很重要,需要考察。好在这个实验作起来比较方便,需要的费用和时间都比较少。最好选用(A)。A析因设计B. 交叉设计C. 随机区组设计D. 配对设计 E. 单因素三水平设计
二、思考题
1. 在行走速度和行程固定的前提下,负荷越重,体能消耗越多。为研究在4种不同的负荷量条件下,消耗的体能之间的差别是否有统计学意义,拟用4名战士,在4个不同日期进行实验,并且每人每天只接受1种负荷量实验1次。已知因素之间的交互作用可忽略不计,用energy代表体能消耗量,请选用合适的实验设计方法并以表格形式给出具体的安排。
答:本题中涉及一个实验因素(即负荷)、两个区组因素(即受试对象和试验日期),这三个因素间的交互作用可以忽略,可选用拉丁方设计。设计方案见练习表12-1。练习表12-1 拉丁方设计的格式与实验结果
受试对象编号负荷代号与energy
*: 1 2 3 4
1 A(1) B(2) C(3) D(4)
2 B(5) C(6) D(7) A(8)
3 C(9) D(10) A(11) B(12)
4 D(13) A(14) B(15) C(16)
注:A、B、C和D分别代表4种负荷,括号中的编号形式上代表观测的energy值;*代表“试验顺序”。
2. 如果某项实验研究中需要考察3个实验因素,各因素均取4个水平,拟用析因设计来安排此项实验,问至少要进行多少次实验才便于考察各级交互作用对观测结果的影响?请说出计算的依据。答:至少要进行128次实验。计算方法为4?4?4?2=128。因为析因设计中不同的实验条件数为全部因素的水平数相乘,各实验条件下至少要作2次独立重复实验。
3.欲探讨用微型角膜刀行角膜深板层内皮移植术的适应证、临床疗效及并发症的预防及处理,用微型角膜刀对6例患者6只患有大疱性角膜病变眼行深板层角膜内皮移植术。术后随访6~9个月。结果表明,5例患者视力明显提高,患者术后平均角膜内皮细胞密度为(2 481±212) 个/ mm,角膜中央厚度平均为(549±61) μm ,散光为(2 104±1 119)D,未发生严重并发症。得如下结论:用微型角膜刀行角膜深板层内皮移植术是治疗大疱性角膜病变的可选术式。与传统的穿透性角膜移植相比,该术式有望成为角膜内皮移植的技术平台,但远期疗效尚需继续随访。请问该研究是否遵循了实验设计的基本原则?应如何设计该实验?
答:该实验仅凭选取了6例患者6只患有大疱性角膜病变眼行深板层角膜内皮移植术后5例患者视力明显提高,就得出“该方法是治疗大疱性角膜病变的可选术式”的结论,与传统的穿透性角膜移植相比,该术式有望成为角膜内皮移植的技术平台。首先该研究违反了对照的原则。没有设立对照组,仅凭6例中5例术后视力明显提高,但没有与传统的穿透性角膜移植相比,不具有说服力。正确的做法是:首先选取一定数量的患有大疱性角膜病变眼的患者,将患有大疱性角膜病变眼随机分成两组,接受两种手术方法的治疗。若病情、病程等非处理因素对预后有影响,则应尽量保证两组之间在重要的非处理因素上均衡。然后再对两种手术方法术后的治疗效果进行比较。
4. 某人将教材表12-8资料所对应的实验设计看成了多个成组设计用t检验进行分析是不正确的,究其原因是没能正确判断该实验设计的类型,故不能选用正确的分析方法。请分析该实验所涉及的因素及其水平数,确定该实验设计类型。
教材表12-8 不同药物对小鼠迟发超敏反应的影响结果()S
X±
药物剂量/(g·kg-1)鼠数/只耳肿重量/mg
对照- 10 21.2±2.7
补肾药 5 10 22.3±3.5
补肾药10 10 18.8±3.1
补肾药20 10 16.5±2.4
Cy 0.025 10 11.2±1.5
Cy+补肾药0.025+5 10 14.3±2.9
Cy+补肾药0.025+10 10 18.6±3.6
Cy+补肾药0.025+20 10 19.2±3.4
注:补肾药全称为补肾益寿胶囊。
答:采用t检验处理该资料是很不妥当的。因为它不是多个单因素2水平的设计定量资料。按教材表12-8的列表方式,使人不易看出实验设计的类型。像单因素8水平设计问题,又像是两个单因素4水平设计问题或是某种多因素设计问题。这是缺乏有关设计类型概念的人们习惯的列表方式,在选用统计分析方法时将起着严重的误导作用。
仔细看看教材表12-8中以“药物”和“剂量”为总称的这两列,似乎该实验涉及了“药物”和“剂量”这样两个因素,事情是否果真如此,不妨试列出由它们组合成的表格(练习表12-2)。
练习表12-2 教材表12-8资料的第一种变形结果(S
X±)
药物种类
耳肿重量/mg
#: 0 0.025 5 10 20
补肾药21.2±2.7 . 22.3±3.5 18.8±3.1 16.5±2.4
Cy药 21.2±2.7 11.2±1.5 * * *
注:各组均有10只小鼠,“.”表示补肾药未用的剂量;“*”表示Cy药未用的剂量;“#”代表“补肾药的剂量”。
显然,练习表12-2未全面、正确地表达教材表12-8所包含的信息,又无法反映出两种药合用的结果,故从原表中抽象出“药物”和“剂量”这样两个因素是不够正确的转换方式。事实上,原表中所反映的是两种药具有各自的用药剂量,故将“补肾药的剂量”和“Cy药的剂量”视为两个实验因素,问题就迎刃而解了(练习表12-3)。
练习表12-3 教材表12-8资料的第二种变形结果(S
X )
Cy药剂量/(g·kg-1)耳肿重量/mg
*: 0 5 10 20
0 21.2±2.7 22.3±3.5 18.8±3.1 16.5±2.4
0.025 11.2±1.5 14.3±2.9 18.6±3.6 19.2±3.4
注:*代表“补肾药的剂量”;各组均有10只小鼠。
由练习表12-3可以清楚地看出,原表中的8个组,其本质是分别具有2水平和4水平的两个因素的水平组合,即两因素(或称2×4)析因设计,而不是单因素8水平设计,也不是两个单因素4水平设计问题。
5. 请从公开发表的学术论文中去查找使用频率最高的三种实验设计类型,即单因素设计、析因设计和重复测量设计。如果论文中将这些实验设计类型表达得不够清楚,请采用“结构变形”或“拆分组别”等技巧重新表达,并清楚地指出其真正的实验设计类型。(答案略)(胡良平李长平)
第13章临床试验设计思考与练习参考答案
一、最佳选择题
1. 赫尔辛基宣言问世的年份是( D )。
A. 1961年
B. 1962年
C. 1963年
D. 1964年
E. 1965年
2. 以下未参加ICH的国家是( E )。
A. 美国
B. 日本
C. 加拿大
D. 欧盟
E. 澳大利亚3. 我国《药品注册管理办法》规定,新药Ⅱ期临床试验,试验组病例数不得少于( B )。A. 60 B. 100 C. 200 D. 300 E. 400
4. 在一般临床试验中,通常受试者的服药量在( C )以下,认为依从性比较差。A. 60% B. 70% C. 80% D. 90% E. 95%
5. 在注册药品的临床试验中,盲底可以保存在(A)处。
A.申办者
B.研究者
C.监察员
D.统计人员
E.稽查员
二、思考题
1.临床试验通常分为哪四期,各期的主要目的分别是什么?
答:Ⅰ期临床试验:初步的临床药理学及人体安全性评价试验。观察人体对于新药的耐受程度和药代动力学,为制定给药方案提供依据。Ⅱ期临床试验:治疗作用初步评价阶段。其目的是初步评价药物对目标适应证患者的治疗作用和安全性,也包括为Ⅲ期临床试验研究设计和给药剂量方案的确定提供依据。此阶段的研究设计可以根据具体的研究目的采用多种形式,包括随机盲法对照临床试验。Ⅲ期临床试验:治疗作用确证阶段。其目的是进一步验证药物对目标适应证患者的治疗作用和安全性,评价利益与风险关系,最终为药物注册申请的审查提供充分的依据。试验一般应为具有足够样本量的随机盲法对照试验。Ⅳ期临床试验:新药上市后由申请人进行的应用研究阶段。其目的是考察在广泛使用条件下的药物的疗效和不良反应、评价在普通或者特殊人群中使用的利益与风险关系以及改进给药剂量等。
2.在临床试验开始之前,应做哪些必要的准备工作?
答:应了解临床试验相关法规,了解临床试验相关指导原则,了解临床试验的伦理学原则,了解在哪里以及作哪些临床试验。
3. 临床试验方案是指导参与临床试验所有研究者如何启动和实施临床试验的研究计划书,也是试验结束后进行资料统计分析的重要依据。临床试验方案中应包括哪些主要内容?
答:通常临床试验方案应包括首页、方案摘要、研究背景资料、试验目的、试验设计、受试者的选择和退出、治疗方案、临床试验步骤、不良事件的观察、观察指标、数据管理、期中分析(无)、统计分析、试验的质量控制和保证、伦理学要求、资料保存、参考文献、主要研究者签名和日期。
4. 病例报告表(简称CRF)是药品临床研究中十分重要的研究资料。CRF在设计上没有统一的格式,但是需要遵循一定的原则,其原则有哪些?
答:CRF在设计上没有统一的格式,但是需要遵循一定的原则。例如,CRF必须全部体现临床试验方案中要求观测的内容;CRF条目应当尽量使用选择方式;CRF的每一页都必须有研究者的签字和日期;同一观测指标在不同时点的观测值不能在同一页CRF中填写,CRF中不能出现患者姓名、地址等相关信息;CRF中不能出现受试者化验单等原始资料。
5. 临床试验设计的基本原则包括哪些?答:临床试验必须遵循对照、随机、重复和均衡的原则。
6. 在新药临床试验中,数据管理过程中的盲态审核是十分重要的环节之一。请谈谈盲态审核的操作程序。
答:盲态审核是指最后一个病历报告表输入数据库以后,直到第一次揭盲之前,对数据库数据进行的核对和评价。当所有病例报告表经双份输入并核对无误后,由数据管理员写出数据库检查报告,其内容包括试验完成情况(含脱落受试者清单)、入选/排除标准检查、完整性检查、逻辑一致性检查、离群数据检查、时间窗检查、合并用药检查、不良事件检查等。在盲态审核会议上,由主要研究者、申办者、监查员、数据管理员和生物统计专业人员对受试者签署的知情同意书、试验过程盲态保持情况和试验过程的紧急揭盲情况等作出审核,对数据库检查报告中提出的问题作出决议,并写出盲态审核报告,数据库同时将被锁定。
7. 谈谈双盲临床试验中应急信件的准备、发放和回收。
答:信封上印有×××药物的临床试验的应急信件、药品编号和遇紧急情况揭盲的规定。如果拆阅,需注明拆阅者、拆阅日期、原因等,并在病例报告表中记录。信纸上印有×××药物临床研究、药品编号及分组。信纸装入相应的信封后密封,随药物发往各个临床试验中心,在试验结束后统一收回。信纸上写明该药盒所放置的具体药物名称、处理方法及应立即汇报的单位和地址。(胡良平吴圣贤葛毅李长平方亚)
第14章调查设计思考与练习参考答案一、最佳选择题1. 为了解某校锡克试验的阳性率,研究者从该校80个班中随机抽取8个班,然后调查这些班中的所有学生。此种抽样方法属于( D )。
A. 单纯随机抽样
B. 系统抽样
C. 分层抽样
D. 整群抽样
E. 多阶段抽样
2. 在下列研究中,研究者不能人为设置各种处理因素的是( A )。
A. 调查研究
B. 实验研究
C. 临床试验
D. 社区干预试验
E. 横断面研究 3. 统计工作的关键步骤是( A )。
A. 调查或实验设计
B. 收集资料
C. 整理资料
D. 分析资料
E. 归纳资料
4. 理论而言,在同样条件下,下列抽样方法中抽样误差最大的是( C )。 A. 单纯随机抽样 B. 系统抽样 C. 整群抽样 D .分层抽样 E. 多阶段抽样
5. 在相同条件下对同一调查对象重复测量结果的一致性程度称作( C )。 A. 内容效度 B. 结构效度 C. 重测信度
D. 内部信度
E. 分半信度
6. 衡量问卷是否包含足够的反映所测特征的条目的指标是( A )。 A. 内容效度 B. 结构效度C. 重测信度 D. 内部信度 E. 分半信度
7. 为使调查结果具有更高的可信度,在开展抽样调查工作中,应遵循的原则是( E )。 A. 随机 B. 重复 C. 对照 D. 均衡 E. 以上均是
8. 关于调查表的设计,下列说法不妥的是( D )。 A. 每个项目要具体、明确
B. 要考虑将来数据处理的方法
C. 调查项目的确定取决于调查目的
D. 必须先作大型的预调查
E. 必要的项目一项不少,不必要的项目一项不列 9. 下列( A )不是普查的目的。 A. 验证病因假设 B. 早期发现患者 C. 描述疾病的分布特征 D. 可向群众普及医学知识 E. 可提供病因线索
10. 在调查研究中,保护调查对象隐私的主要方法是( D )。 A. 将调查对象的电话与其他信息分开
B. 将调查对象的家庭住址与其他信息分开
C. 将调查对象的工作单位与其他信息分开
D. 将调查对象的姓名与其他信息分开
E. 将调查对象的性别与其他信息分开
11. 某研究者在对某地区20~25岁所有妇女进行的一项调查中发现,口服避孕药的妇女,其宫颈癌的年发病率为5/10万,而未服用避孕药的妇女,其宫颈癌的年发病率为2/10万,由此作出口服避孕药引起宫颈癌的推论( E )。 A. 正确
B. 不正确,因为未在年龄分布方面可能存在的差异进行调整
C. 不正确,因为没有区分发病率与患病率
D. 不正确,因为需要用率而不是比率来支持这一推论
E. 不正确,因为在其他有关因素上,这两组妇女可能存在差异
12. 为研究吸烟与肺癌的关系,某研究者采取了两种研究方法:一种是将人群分为吸烟组与不吸烟组,然后随访两组发生肺癌的结局;另一种是将吸烟者随机分组,一组采取戒烟干预,而另一组不戒烟,然后盲法观察两组的肺癌结局。这两种研究方法的根本区别是( D )。
A. 是否设立对照组
B. 是否进行统计学检验
C. 是否在现场人群中进行
D. 是否人为控制研究条件
E. 是否检验病因假设
二、思考题
1. 在某项关于近视眼发病因素的病例对照研究中,研究者发现,越是作眼保健操的人越易患近视眼。其实,这是一种假象。请解释导致这种假象的原因。
答:也许存在患有近视的人作眼保健操的多,即病例组因患有近视而重视眼保健操,而对照组因未患近视而忽视眼保健操。
2. 某从事政治教育的机构,对在押妓女进行教育,观察以后是否从良。研究结果表明,在未失访的全部被教育对象中,彻底改掉原先恶习的人所占的比例相当高,故得出结论:所采取的教育方法非常得力,教育成果巨大。请问:这个评价结论是否科学?为什么?
答:这个评价结论不科学。因在未失访的全部被教育对象中,彻底改掉原先恶习的人所占的比例相当高,这里未交待失访情况,也许这些失访者并未改掉原先恶习,故对教育方法是否得力作出评价需慎重。
3. 病例-对照研究为什么不能计算患病率?横断面研究可否计算患病率?可否计算时点患病率?队列研究可否计算患病率和发病率?为什么?
答:病例-对照研究不能计算患病率,因为总人口中的病例数及未病人数不详;横断面研究可计算时点患病率,因它可获得某地某时点的总人数;队列研究可计算患病率和发病率,因它可获得总人口中的新旧病例数及未病人数。
4. 某研究者在进行吸烟与肺癌关系的调查研究中,以肺结核患者和慢性支气管炎患者作为对照人群。请问:这样选择对照组有何不妥?
答:在该研究中,肺结核和慢性支气管炎是混杂因素。
5. 诱导性问题是指由于问题的措辞、内容等方面的原因使调查对象有意无意地不得不选择某种答案。有鉴于此,在调查表的设计中,不可使用诱导性问题。请问:在调查设计中,一旦使用了诱导性问题,将意味着什么?
答:在调查设计中,一旦使用了诱导性问题,将意味着存在应答信息偏倚。(方 亚 胡良平 高 永 周诗国) 第15章 样本含量估计思考与练习参考答案 一、最佳选择题
1. 在假设检验中,样本含量的确定( C )。
A. 只与Ⅰ类错误概率
α有关 B. 只与Ⅱ类错误概率β有关 C. 与α、β都有关 D. 与α、β都无关 E. 只与α、β
有关
2. 以下关于检验功效的描述,不正确的是( C )。
A. 假设检验中,若0H 客观上不成立,但根据假设检验的规则,将有β
大小的概率错误地得出“差异无统计学意义”的推断结论,这种错误称为Ⅱ类错误,相应
地,推断正确的概率为β-
1,称为检验功效。
B. 检验功效受客观事物差异的大小、个体间变异的大小、样本量和α值等要素的影响。
C. 假设检验的“阴性”结果(
P >0.05)可以作为“总体参数之间的差异无统计学意义”这一结论的证据。
D. 假设检验得出“阴性”结果(P >0.05)是“总体参数之间的差异无统计学意义”这一结论的必要条件而非充分条件。
E. 当假设检验出现“阴性”结果(P >0.05)时,有必要复核样本含量和检验功效是/否偏低,以便正确分析假设检验“阴性”结论的正确性。
3.在调查研究中,计算配对设计均数比较所需样本含量的公式为( A )。
A. 2])([
δ
βαS
t t n += B. 2])([
2δ
βαS
t t n +?= C. 2])([
δ
βαS
t t N += D. 2
2
21)()
)(1(2p p Z Z p p n -+-=
βα
E.
=
n 2
2
212211)
(]
)1()1()1(2[p p p p p p Z p p Z --+-+-βα
4. 在调查研究中,计算两样本率比较所需样本含量的公式为( E )。
A. 2])([
δ
βαS
t t n += B. 2])([
2δ
βαS
t t n +?= C. 2])([
δ
βαS
t t N += D. 2
2
21)()
)(1(2p p Z Z p p n -+-=
βα
E. 2
2
212211)(]
)1()1()1(2[p p p p p p Z p p Z n --+-+-=
βα
5. 有很多人都认为,只要样本含量大于30就可以称其为大样本,可用大样本条件下推导出来的一切公式进行相应的统计分析。下列说法中( C )最正确。 A 题中所说的条件和结论都正确 B. 题中所说的条件正确,但结论不正确C. 题中所说的条件和结论都不正确 D. 题中所说的条件不正确,但结论正确E. 题中所说的条件和结论正确概率为70%,错误概率为30%
6.在研究一个因变量依赖多个自变量变化规律时,估计样本含量非常复杂,有人提供了一个经验估算方法,即样本含量N (即拟观测的个体数目)至少应当是自变量个数的10倍。下列说法中( B )最正确。
A 此法无任何参考价值
B 在没有精确算法时,此法有一定的参考价值
C 此法根本不能用 D. 此法永远是正确的 E. 此法正确的概率为80%,错误的概率为20% 二、思考题
1. 决定样本含量的依据有哪些?
答:决定样本含量的依据有:① 犯Ⅰ类错误的概率
α,即检验水准。② 犯Ⅱ类错误的概率β
。③ 总体平均数
μ(或总体概率π)、总体标准差σ。μ(π)、
σ一般未知,通常以样本的)(p X 、S 作为估计值,多由预实验、查阅文献、经验估计而获得。④ 处理组间的差别δ(所比较的两个总体参数间的差别
δ
),如
21μμδ-=或12μμδ-=。若研究者无法得到总体参数的信息,可作预实验来估计,也可根据专业要求由研究者规定。
2. 当假设检验的结果为“阴性”(
P >0.05)时,对样本含量和检验功效进行复核有何意义?
答:当假设检验的结果为“阴性”(P >0.05)时,对样本含量和检验功效进行复核具有重要意义。通过对样本含量和检验功效进行复核(主要是计算检验功效),
可以检查样本含量和检验功效是否偏低,以便正确认识假设检验的结果,避免得出错误的研究结论。若检验功效偏低,则说明样本含量不足,应加大样本含量,重新进行实验。 三、计算题
1. 据说某民族正常人体温平均高于37℃,为了进行核实,拟进行抽样调查。如果就总体而言平均高出0.1℃便不可忽略,而已知正常人体温的标准差约为0.2℃,那么,为了将Ⅰ、Ⅱ类错误的概率控制在
05.0=α和05.0=β,试估计样本含量。
解:据题意,要核实某民族正常人平均体温是否高于37℃,就是要通过抽样对该民族正常人的平均体温作出估计,并检验该平均体温是否高于37℃。很显然,应采
用单侧检验。又已知δ
=0.10,
σ=0.20,05.0=α,05.0=β,先取∞=df ,则
)
(05.0)(∞∞=t t α=1.645,
)
(05.0)(∞∞=t t β=1.645,将数据代入公式
(15-1),得
2
)
1()(??????+=δβαS t t n =2
1.02.0)645.1645.1(???????+=43.3≈44
取
431)1(=-=n df ,则
(43)0.05(43) 1.681t t α==,
(43)0.05(43) 1.681
t t β==,代入公式算得:
2
)
2()(?
?
????+=δβαS t t n
=
2
(1.681 1.681)0.20.1+???
????=45.2
≈46
取
(1)
145df n =-=,则 (45)0.05(45) 1.679t t α==,
(45)0.05(45) 1.679
t t β==,代入公式计算得:
2
)
2()(?
?
????+=δβαS t t n
=
2
(1.679 1.679)0.20.1+???
????=45.1
≈46
可取46=n ,即需从该民族的正常人群中随机抽取46人进行调查。
2. 某人在进行上述调查之前未经估算便人为决定取样本量25=n 。试估计检验功效。
解:据题意,有25=n
,δ
=0.10,
σ=0.20,05.0=α,645.105.0==Z Z α,将数据代入公式(15-20),得
855.0645.12
.0251.0=-=-=
αβσδZ n Z 查表,得检验功效
2
1
805.03802.01+≈
-β=0.803 7。
3. 为了比较两类片剂的溶解速率,决定各随机抽取10片,测定5 min 溶解量,然后作
05.0=α水平的检验。据预实验,两类片剂的变异性相同,标准差约为6个
单位,均数之差也约为6个单位,问该项研究的功效有多大?欲使功效达到95%,样本量应当多大?
解:已知101
=n ,102=n ,6=δ,6=σ,双侧05.0=α,96.12/05.02/==Z Z α,将数据代入公式(15-23),得
2/2
1/1/1αβσδZ n n Z -+=
=
96.110
/110/166-+=0.276 1
查表,得检验功效
4608.02
)
3610.04606.0(1=+≈
-β
要使功效达到95%,需重新估计样本含量: 将数据
6=δ,6=σ,96.1)(2/05.0)(2/==∞∞t t α,)(05.0)(∞∞=t t β=1.645代入公式(15-6),得
5298.516
6)645.196.1(4)(42222
2
22/)
1(≈=?+=+=
δβαS t t N
取502)1(=-=N df
,则
()5010.22/)000.2021.2()60(2/05.0)40(2/05.0)50(2/05.0)50(2/=+=+≈=t t t t α()5677.12/)671.1684.1()60(05.0)40(05.0)50(05.0)50(=+=+≈=t t t t β
将有关数据代入公式(15-6),得
5641.5466)5 677.15 010.2(4)(42
2
22
2
22/)
2(≈=?+=+=
δβαS t t N
(取比计算结果稍大的偶数)
医学统计学试题及答案集团文件发布号:(9816-UATWW-MWUB-WUNN-INNUL-DQQTY-
医学统计学试题及答案 习??题 《医学统计学》第二版??(五年制临床医学等本科生用)(一)??单项选择题 1.观察单位为研究中的( d??)。 A.样本? ?? ??B. 全部对象 C.影响因素? ?? ?????D. 个体2.总体是由( c )。 A.个体组成? ?? ?B. 研究对象组成 C.同质个体组成? ?? ? D. 研究指标组成 3.抽样的目的是(b??)。 A.研究样本统计量? ?? ?? ???B. 由样本统计量推断总体参数 C.研究典型案例研究误差? ???D. 研究总体统计量 4.参数是指(b? ?)。 A.参与个体数? ???B. 总体的统计指标 C.样本的统计指标? ? ??D. 样本的总和 5.关于随机抽样,下列那一项说法是正确的( a )。 A.抽样时应使得总体中的每一个个体都有同等的机会被抽取 B.研究者在抽样时应精心挑选个体,以使样本更能代表总体 C.随机抽样即随意抽取个体 D.为确保样本具有更好的代表性,样本量应越大越好 6.各观察值均加(或减)同一数后( b )。 A.均数不变,标准差改变? ?? ? B.均数改变,标准差不变 C.两者均不变? ?? ?? ?? ?? ??? D.两者均改变 7.比较身高和体重两组数据变异度大小宜采用( a??)。 A.变异系数? ?? B.差 C.极差? ?? ?? ? D.标准差 8.以下指标中(? ?d)可用来描述计量资料的离散程度。 A.算术均数? ? B.几何均数 C.中位数? ?? ? D.标准差 9.偏态分布宜用(? ?c)描述其分布的集中趋势。 A.算术均数? ?? B.标准差 C.中位数? ?? D.四分位数间距 10.各观察值同乘以一个不等于0的常数后,(? ?b)不变。 A.算术均数? ??? B.标准差 C.几何均数? ?? ???D.中位数 11.( a??)分布的资料,均数等于中位数。 A.对称? ? B.左偏态 C.右偏态? ?? ?? D.偏态 12.对数正态分布是一种( c )分布。
预防医学复习题(统计部分) 复习重点(及简答题) 1. 医学统计学的基本概念 如:总体与样本的联系区别 2. 资料的分类 如:请列举资料的类型并举例说明 3. 定量资料统计描述的指标(集中与离散趋势) 如:定量统计描述指标有哪些? 如:正态分布与偏态分布资料统计描述方法有何区别 4. 定性资料统计描述的指标 5. 正态分布、标准正态分布、t分布的概念、特征、曲线下面积规律 如:正态分布、标准正态分布与t分布的区别联系 6. 小概率事件在医学统计学的应用(P值的含义) 如:P值的含义是什么,对统计结论有何意义 7. 假设检验的基本原理与步骤 8. 四种主要统计假设检验方法及其应用场合 9. 统计表的绘制 选择题 1.样本是总体中: A、任意一部分 B、典型部分 C、有意义的部分 D、有代表性的部分 E、有价值的部分 2、参数是指: A、参与个体数 B、研究个体数 C、总体的统计指标 D、样本的总和 E、样本的统计指标 3、抽样的目的是: A、研究样本统计量 B、研究总体统计量 C、研究典型案例 D、研究误差 E、样本推断总体参数 4、脉搏数(次/分)是: A、观察单位 B、数值变量 C、名义变量 D.等级变量 E.研究个体 5、疗效是: A、观察单位 B、数值变量 C、名义变量 D、等级变量 E、研究个体 6、统计学常将P≤0.05或P≤0.01的事件称 A、必然事件 B、不可能事件 C、随机事件 D、小概率事件 E、偶然事件7.统计中所说的总体是指:
A根据研究目的确定的同质的研究对象的全体 B随意想象的研究对象的全体 C根据地区划分的研究对象的全体 D根据时间划分的研究对象的全体E根据人群划分的研究对象的全体 8.概率P=0,则表示 A某事件必然发生B某事件必然不发生C某事件发生的可能性很小 D某事件发生的可能性很大E以上均不对 9.总体应该由 A.研究对象组成B.研究变量组成C.研究目的而定D.同质个体组成E.个体组成 10. 在统计学中,参数的含义是 A.变量B.参与研究的数目C.研究样本的统计指标D.总体的统计指标E.与统计研究有关的变量 11.调查某单位科研人员论文发表的情况,统计每人每年的论文发表数应属于A.计数资料 B.计量资料 C.总体 D.个体 E.样本 12.统计学中的小概率事件,下面说法正确的是: A.反复多次观察,绝对不发生的事件 B.在一次观察中,可以认为不会发生的事件 C.发生概率小于0.1的事件 D.发生概率小于0.001的事件 E.发生概率小于0.1的事件 13、统计上所说的样本是指: A、按照研究者要求抽取总体中有意义的部分 B、随意抽取总体中任意部分 C、有意识的抽取总体中有典型部分 D、按照随机原则抽取总体中有代表性部分 E、总体中的每一个个体 14、以舒张压≥12.7KPa为高血压,测量1000人,结果有990名非高血压患者,有10名高血压患者,该资料属()资料。 A、计算 B、计数 C、计量 D、等级 E、都对 15、红细胞数是: A、观察单位 B、数值变量 C、名义变量 D、等级变量 E、研究个体 16、某次研究进行随机抽样,测量得到该市120名健康成年男子的血红蛋白数,则本次研究总体为: A.所有成年男子 B.该市所有成年男子 C.该市所有健康成年男子 D.120名该市成年男子 E.120名该市健康成年男子 17、某地区抽样调查1000名成年人的血压值,此资料属于: A、集中型资料 B、数值变量资料 C、无序分类资料 D、有序分类资料 E、离散型资料 18、抽样调查的目的是: A、研究样本统计量 B、研究总体统计量 C、研究典型案例 D、研究误差 E、样本推断总体参数 19、测量身高、体重等指标的原始资料叫: A计数资料 B计量资料 C等级资料 D分类资料E有序分类资料 20、某种新疗法治疗某病患者41人,治疗结果如下: 治疗结果治愈显效好转恶化死亡 治疗数8 23 6 3 1
1、某医院用中药治疗7例再生障碍性贫血患者,现将血红蛋白(g/L)变化的数据列在下面,假定资料满足各种参数检验所要求的前提条件,问:治疗前后之间的差别有无显著性意义(15分) 患者编号1234567 治疗前血红蛋白65755076657268 治疗后血红蛋白821121258580105128 2、活动型结核患者的平均心率一般为86次/分,标准差为次/分。现有一医生测量了36名该院的活动型结核患者的心率,得心率均数为90次/分,标准差为次/分,试问该院活动型结核患者与一般活动型结核患者的心率有无差别 3、某医院将200名乙型肝炎患者随机分为甲、乙两组,各100人。甲组患者用常规治疗法,乙组患者用常规治疗加心理治疗,用一种权威评分法对两组患者的疗效进行评价,结果测得甲组均数为分,标准差为3分,乙组患者均数为分,标准差为4分,问心理治疗有无效果 4、某医院病理科研究人体两肾的重量,20例男性尸解时的左、右肾的称重记
录如下表,问左右肾重量有无不同 20例男性尸解时的左、右肾的称重记录 编号 左肾 (克) 右肾 (克) 编号 左肾 (克) 右肾 (克) 117015011155150 215514512110125 314010513140150 411510014145140 52352221512090 612511516130120 713012017105100 81451051895100 91051251910090 1014513520105125 5、为了研究冠心病与血总胆固醇有无关系,某医生随机收集得冠心病患者和健康人的血总胆固醇(mmol/L)数据如下表,请作分析。 冠心病患者和健康人的血总胆固醇(mmol/L) 组别例数均数标准差 冠心病患者45 健康人46
医学统计学试题及答案 The latest revision on November 22, 2020
医学统计学 一、选择题 1、根据某医院对急性白血病患者构成调查所获得的资料应绘制( B ) A 条图 B 百分条图或圆图 C线图 D直方图 2、均数和标准差可全面描述 D 资料的特征 A 所有分布形式B负偏态分布C正偏态分布D正态分布和近似正态分布 3、要评价某市一名5岁男孩的身高是否偏高或偏矮,其统计方法是( A ) A 用该市五岁男孩的身高的95%或99%正常值范围来评价 B 用身高差别的假设检验来评价 C 用身高均数的95%或99%的可信区间来评价 D 不能作评价 4、比较身高与体重两组数据变异大小宜采用( A ) A 变异系数 B 方差 C 标准差 D 四分位间距 5、产生均数有抽样误差的根本原因是( A ) A.个体差异 B. 群体差异 C. 样本均数不同 D. 总体均数不同
6. 男性吸烟率是女性的10倍,该指标为( A ) (A)相对比(B)构成比(C)定基比(D)率 7、统计推断的内容为( D ) A.用样本指标估计相应的总体指标 B.检验统计上的“检验假设” C. A和B均不是 D. A和B均是 8、两样本均数比较用t检验,其目的是检验( C ) A两样本均数是否不同 B两总体均数是否不同 C两个总体均数是否相同 D两个样本均数是否相同 9、有两个独立随机的样本,样本含量分别为n1和n2,在进行成组设计资料的t 检验时,自由度是( D ) (A) n1+ n2 (B) n1+ n2 –1 (C) n1+ n2 +1 (D) n1+ n2 -2 10、标准误反映( A ) A 抽样误差的大小 B总体参数的波动大小
1 医学统计学题库 一、最佳选择题 1. 比较相同人群的身高和体重的变异程度,宜用的统计指标是__ __。 A. 全距 B. 标准差 C. 中位数 D. 变异系数 2. 反映一组偏态分布资料平均水平的指标宜用_ __。 A.变异系数 B. 几何均数 C. 中位数 D. 均数 3. 下述_ ___种资料为计数资料。 A. 血红蛋白( g/L ) B. 红细胞计数( 31012 /L ) C. 抗体滴度 D. 血型 4. 表示事物内部各个组成部分所占比重的相对数是___ ____。 A. 相对比 B. 率 C. 构成比 D. 率的标准误 5. 说明样本均数抽样误差大小的指标是___ _____。 A. 变异系数 B. 标准差 C. 标准误 D. 全距 6. 正态分布曲线下中间面积为99% 的变量值范围为___ _____。 A. μσ±196 . B. μσ±258. C. μσ±1 D. μσ±125. 7. 8名新生儿的身长(cm )依次为:50, 53, 58, 54, 55, 52, 54, 52。 中位数M 为__ __。 A. 53.5 B. 54.5 C. 54 D. 53 8. 表示两个变量之间的直线相关关系的密切程度和方向的统计指标是_ _。 A. 变异系数 B. 相关系数 C. 均数 D. 回归系数 9. 某市1955年和2015年的三种死因别死亡率,若用统计图表示宜 选用____ _______。 A. 直条图 B. 直方图 C. 百分直条图 D. 统计地图 10. 下述___ ____为第一类错误的定义。 A.拒绝了实际上是不成立的H 0 B.接受了实际上是不成立的H 0 C.拒绝了实际上是成立的H 0
一、单向选择题 1. 医学统计学研究的对象是 E.有变异的医学事件 2. 用样本推论总体,具有代表性的样本指的是E.依照随机原则抽取总体中的部分个体 3. 下列观测结果属于等级资料的是 D.病情程度 4. 随机误差指的是 E. 由偶然因素引起的误差 5. 收集资料不可避免的误差是 A.随机误差 1.某医学资料数据大的一端没有确定数值,描述其集中趋势适用的统计指标是 A. 中位数 2. 算术均数与中位数相比,其特点是 B.能充分利用数据的信息 3. 一组原始数据呈正偏态分布,其数据的特点是 D.数值分布偏向较小一侧 4. 将一组计量资料整理成频数表的主要目的是E.提供数据和描述数据的分布特征 1. 变异系数主要用于 A .比较不同计量指标的变异程度 2. 对于近似正态分布的资料,描述其变异程度应选用的指标是E. 标准差 3.某项指标95%医学参考值范围表示的是D.在“正常”总体中有95%的人在此范围 4.应用百分位数法估计参考值范围的条件是B .数据服从偏态分布 5.已知动脉硬化患者载脂蛋白B 的含量(mg/dl)呈明显偏态分布,描述其个体差异的统计指标应使用 E .四分位数间距 1.样本均数的标准误越小说明 E.由样本均数估计总体均数的可靠性越大 2. 抽样误差产生的原因是D.个体差异 3.对于正偏态分布的的总体,当样本含量足够大时,样本均数的分布近似为C.正态分布 4. 假设检验的目的是 D.检验总体参数是否不同 5. 根据样本资料算得健康成人白细胞计数的95%可信区间为7.2×109 /L ~9.1×109 /L ,其含义是 E.该区间包含总体均数的可能性为95% 1. 两样本均数比较,检验结果05.0 P 说明 D.不支持两总体有差别的结论 2. 由两样本均数的差别推断两总体均数的差别, 其差别有统计学意义是指 E. 有理由认为两总体均数有差别 3. 两样本均数比较,差别具有统计学意义时,P 值越小说明 D.越有理由认为两总体均数不同 4. 减少假设检验的Ⅱ类误差,应该使用的方法是 E.增加样本含量 5.两样本均数比较的t 检验和u 检验的主要差别是B.u 检验要求大样本资料
《医学统计学》课程考试试题(A卷) (评卷总分:100分,考试时间:120分钟,考核方式:□开卷 V 闭卷) 一、选择题(每题1分,共62分,只选一个正确答案) 1、医学科研设计包括( D ) A.物力和财力设计 B.数据与方法设计 C.理论和资料设计 D.专业与统计设计 2、医学统计资料的分析包括( D ) A.数据分析与结果分析 B.资料分析与统计分析 C.变量分析与变量值分析 D.统计描述与统计推断 3、医学资料的同质性指的是( D ) A.个体之间没有差异 B.对比组间没有差异 C.变量值之间没有差异 D.研究事物存在的共性 4、离散型定量变量的测量值指的是( D ) A.可取某区间内的任何值 B、可取某区间内的个别值 C.测量值只取小数的情况 D.测量值只取整数的情况5、变量的观察结果表现为相互对立的两种情况是( A ) A.无序二分类变量 B、定量变量. C.等级变量 D.无序多分类变量 6、计量资料编制频数表时,组距的选择( D ) A.越大越好 B.越小越好 C.与变量值的个数无关 D.与变量值的个数有关
7、比较一组男大学生白细胞数与血红蛋白含量的变异度应选( D )A.极差 B.方差 C.标准差 D.变异系数 8、若要用方差描述一组资料的离散趋势,对资料的要求是( D )A.未知分布类型的资料 B.等级资料 C.呈倍数关系的资料 D.正态分布资料 9、频数分布两端没有超限值时,描述其集中趋势的指标也可用( D ) A.标准差 B.几何均数 C.相关系数 D.中位数 10、医学统计工作的步骤是( A ) A、研究设计、收集资料、整理资料和分析资料 B、计量资料、计数资料、等级资料和统计推断 C、研究设计、统计分析,统计描述和统计推断 D、选择对象、计算均数、参数估计和假设检验 11、下列关于变异系数的说法,其正确的是( A ) A.没有度量衡单位的系数 B.描述多组资料的离散趋势 C.其度量衡单位与变量值的度量衡单位一致 D、其度量衡单位与方差的度量衡单位一致 12、10名食物中毒的病人潜伏时间(小时)分别为3, 4,5,3,2,5.5,2.5,6,6.5, 7,其中位数是( B ) A.4 B.4.5 C.3 D.2 13、调查一组正常成年女性的血红蛋白,如果资料属于正态分布,描
1.假设检验在设计时应确定的是 A.总体参数B.检验统计量C.检验水准 D.P值E.以上均不是 2.如果t≥t0.05/2,υ,,可以认为在检验水准α=0.05处。 A.两个总体均数不同B.两个总体均数相同C.两个样本均数不同D.两个样本均数相同E.样本均数与总体均数相同 3.计量资料配对t检验的无效假设(双侧检验)可写为。 A.μd=0 B.μd≠0 C.μ1=μ2 D.μ1≠μ2E.μ=μ0 4.两样本均数比较的t检验的适用条件是。 A.数值变量资料B.资料服从正态分布C.两总体方差相等 D.以上ABC都不对E.以上ABC都对 5.在比较两组资料的均数时,需要进行t/检验的情况是: A.两总体均数不等B.两总体均数相等C.两总体方差不等D.两总体方差相等E.以上都不是 6.有两个独立的随机样本,样本含量分别为n1和n2,在进行成组设计资料的t检验时,自由度为。 A.n1+n2 B.n1+n2-1 C.n1+n2+1 D.n1+n2-2 E.n1+n2+2 7.已知某地正常人某定量指标的总体均值μ0=5,今随机测得该地特殊人群中的30人该指标的数值。若用t检验推断该特殊人群该指标的总体均值μ与μ0之间是否有差别,则自由度为。 A.5 B.28 C.29 D.4 E.30 8. 两大样本均数比较,推断μ1=μ2是否成立,可用。 A.t检验B.u检验C.方差分析 D.ABC均可以E.χ2检验 9.关于假设检验,下列说法中正确的是 A.单侧检验优于双侧检验 B.采用配对t检验还是成组t检验由实验设计方法决定
C.检验结果若P值大于0.05,则接受H0犯错误的可能性很小 D.用Z检验进行两样本总体均数比较时,要求方差齐性 E.由于配对t检验的效率高于成组t检验,因此最好都用配对t检验 10.为研究新旧两种仪器测量血生化指标的差异,分别用这两台仪器测量同一批样品,则统计检验方法应用。 A.成组设计t检验B.成组设计u检验C.配对设计t检验 D.配对设计u检验E.配对设计χ2检验 11. 阅读文献时,当P=0.001,按α=0.05水准作出拒绝H0,接受H1的结论时,下列说法正确的是。 A.应计算检验效能,以防止假“阴性”结果 B.应计算检验效能,检查样本含量是否足够 C.不必计算检验效能D.可能犯Ⅱ型错误 E.推断正确的概率为1-β 12.两样本均数假设检验的目的是判断 A. 两样本均数是否相等B. 两样本均数的差别有多大 C.两总体均数是否相等D. 两总体均数的差别有多大 E. 两总体均数与样本均数的差别有多大 13.若总例数相同,则成组资料的t检验与配对资料的t检验相比: A.成组t检验的效率高些B.配对t检验的效率高些 C.两者效率相等D.两者效率相差不大E.两者效率不可比 15. 两个总体均数比较的t的检验,计算得t>t0.01/2,n1+n2-2时,可以认为。 A.反复随机抽样时,出现这种大小差异的可能性大于0.01 B.这种差异由随机抽样误差所致的可能性小于0.01 C.接受H0,但判断错误的可能性小于0.01 D.拒绝H0,但犯第一类错误的概率小于0.01 E.拒绝H0,但判断错误的概率未知 16.为研究两种仪器测量血生化指标的差异,分别用这两台仪器测量同一批血样,则统计检验方法应用。 A.配对设计t检验B.成组设计u检验C.成组设计t检验 D.配对设计u检验E.配对设计χ2检验
【共用题干】为评价四川抗菌素工业研究所研制的国产注射用头孢美唑在抗感染治疗中的有效性,以进口分装注射用先锋美他醇为对照,将125例18~70岁、急性、中重度下呼吸道感染患者随机分为试验组和对照组,其中试验组64例,对照组61例,分别采用头孢美唑或先锋美他醇静脉滴注治疗,两组药物用量、用法及疗程均一致。研究结果如表1所示:表1 125例急性、中重度下呼吸道细菌性感染患者临床研究结果 ID 组别性别 年龄 (岁) 疗前体温 (?C) 病型 疗前 用药 疗程 (天) 疗后1天体温 (?C) 疗效 1 对照男56 38.0中度无 6 38.5 进步 2 对照男70 37.5中度无9 36.8 痊愈 3 对照男61 37.5中度无7 37. 4 显效 4 试验女70 36.8中度有8 35.9 痊愈 5 对照女55 36.8中度无7 37.9 进步 6 对照男66 36.5重度无 7 37.5 显效 7 对照男60 36.0中度无 6 33.9 显效 8 对照男70 37.8中度无7 39.5 无效…………………………123 试验男68 39.8重度无10 39.4 痊愈124对照男4838.3中度不详736.0 显效
125试验女5738.0重度不详737.6 显效 一、选择题 1.本研究的设计方案为:( ) A 调查研究 B 病例-对照研究 C 完全随机设计 D 配对设计 2.说明资料中年龄的变量类型:( ) A 连续型定量变量 B 离散型定量变量 C 有序定性变量 D 无序定性变量 3.说明资料中疗效的变量类型:( ) A 连续型定量变量 B 离散型定量变量 C 有序定性变量 D 无序定性变量 4.说明资料中疗前用药的变量类型:( ) A 连续型定量变量 B 离散型定量变量 C 有序定性变量 D 无序定性变量 5.为排除研究中可能的病毒性感染患者,对每个患者均进行了血清呼吸道合 胞病毒、巨细胞病毒、腺病毒、流感病毒、疱疹病毒抗原滴度检测。检测结果表示为:1:2、1:4、1:8、1:16…,一般认为,该类型资料的倒数服
第一套试卷及参考答案 一、选择题(40分) 1、根据某医院对急性白血病患者构成调查所获得的资料应绘制( B ) A 条图 B 百分条图或圆图C线图D直方图 2、均数和标准差可全面描述 D 资料的特征 A 所有分布形式B负偏态分布C正偏态分布D正态分布和近似正态分布 3、要评价某市一名5岁男孩的身高是否偏高或偏矮,其统计方法是(A ) A 用该市五岁男孩的身高的95%或99%正常值范围来评价 B 用身高差别的假设检验来评价 C 用身高均数的95%或99%的可信区间来评价 D 不能作评价 4、比较身高与体重两组数据变异大小宜采用(A ) A 变异系数 B 方差 C 标准差 D 四分位间距 5、产生均数有抽样误差的根本原因是( A ) A.个体差异 B. 群体差异 C. 样本均数不同 D. 总体均数不同 6. 男性吸烟率是女性的10倍,该指标为(A ) (A)相对比(B)构成比(C)定基比(D)率 7、统计推断的内容为( D ) A.用样本指标估计相应的总体指标 B.检验统计上的“检验假设” C. A和B均不是 D. A和B均是 8、两样本均数比较用t检验,其目的是检验( C ) A两样本均数是否不同B两总体均数是否不同C两个总体均数是否相同D两个样本均数是否相同 9、有两个独立随机的样本,样本含量分别为n1和n2,在进行成组设计资料的t检验时,自由度是(D ) (A)n1+ n2(B)n1+ n2–1 (C)n1+ n2 +1 (D)n1+ n2 -2 10、标准误反映(A ) A 抽样误差的大小 B总体参数的波动大小 C 重复实验准确度的高低 D 数据的离散程度 11、最小二乘法是指各实测点到回归直线的(C) A垂直距离的平方和最小B垂直距离最小C纵向距离的平方和最小D纵向距离最小 12、对含有两个随机变量的同一批资料,既作直线回归分析,又作直线相关分析。令对相关系数检验的t值为t r,对回归系数检验的t值为t b,二者之间具有什么关系?(C) A t r>t b B t r
---------------------------------------------------------------最新资料推荐------------------------------------------------------ 医学统计学练习题及答案 1 第一章医学统计中的基本概念练习题一、单向选择题 1 . 医学统计学研究的对象是 A. 医学中的小概率事件B. 各种类型的数据 C. 动物和人的本质 D. 疾病的预防与治疗 E.有变异的医学事件 2. 用样本推论总体,具有代表性的样本指的是A.总体中最容易获得的部分个体B.在总体中随意抽取任意个体 C.挑选总体中的有代表性的部分个体 D.用配对方法抽取的部分个体 E.依照随机原则抽取总体中的部分个体 3. 下列观测结果属于等级资料的是 A.收缩压测量值B.脉搏数C.住院天数D.病情程度 E.四种血型 4. 随机误差指的是 A. 测量不准引起的误差 B. 由操作失误引起的误差 C. 选择样本不当引起的误差 D. 选择总体不当引起的误差 E. 由偶然因素引起的误差 5. 收集资料不可避免的误差是 A. 随机误差B. 系统误差 C. 过失误差 D. 记录误差 E.仪器故障误差答案: E E D E A 二、简答题常见的三类误差是什么?应采取什么措施和方法加以控制? [参考答案] 常见的三类误差是: (1 )系统误差: 在收集资料过程中,由于仪器初始状态未调整到零、标准试剂未经校正、医生掌握疗效标准偏高或偏低等原因,可造成观察结 1 / 3
果倾向性的偏大或偏小,这叫系统误差。 要尽量查明其原因,必须克服。 (2)随机测量误差: 在收集原始资料过程中,即使仪器初始状态及标准试剂已经校正,但是,由于各种偶然因素的影响也会造成同一对象多次测定的结果不完全一致。 譬如,实验操作员操作技术不稳定,不同实验操作员之间的操作差异,电压不稳及环境温度差异等因素造成测量结果的误差。 对于这种误差应采取相应的措施加以控制,至少应控制在一定的允许范围内。 一般可以用技术培训、指定固定实验操作员、加强责任感教育及购置一定精度的稳压器、恒温装置等措施,从而达到控制的目的。 (3)抽样误差: 即使在消除了系统误差,并把随机测量误差控制在允许范围内,样本均数(或其它统计量)与总体均数(或其它参数)之间仍可能有差异。 这种差异是由抽样引起的, 2故这种误差叫做抽样误差,要用统计方法进行正确分析。 抽样中要求每一个样本应该具有哪三性? [参考答案] 从总体中抽取样本,其样本应具有代表性、随机性和可靠性。 (1 )代表性: 就是要求样本中的每一个个体必须符合总体
l.统计中所说的总体是指: A A根据研究目的确定的同质的研究对象的全体B随意想象的研究对象的全体 C根据地区划分的研究对象的全体 D根据时间划分的研究对象的全体 E根据人群划分的研究对象的全体 2.概率P=0,则表示 B A某事件必然发生 B某事件必然不发生 C某事件发生的可能性很小D某事件发生的可能性很大E以上均不对3.抽签的方法属于 D A分层抽样B系统抽样 C整群抽样 D单纯随机抽样 E二级抽样4.测量身高、体重等指标的原始资料叫: B A计数资料B计量资料 C等级资料 D分类资料 E有序分类资料5.某种新疗法治疗某病患者41人,治疗结果如下: 治疗结果治愈显效好转恶化死亡
治疗人数82363 1 该资料的类型是: D A计数资料 B计量资料 C无序分类资料 D有序分类资料 E数值变量资料6.样本是总体的 C A有价值的部分B有意义的部分C有代表性的部分D任意一部分E典型部分7.将计量资料制作成频数表的过程,属于统计工作哪个基本步骤:C A统计设计B收集资料C整理资料D分析资料E以上均不对8.统计工作的步骤正确的是 C A收集资料、设计、整理资料、分析资料 B收集资料、整理资料、设计、统计推断C设计、收集资料、整理资料、分析资料 D收集资料、整理资料、核对、分析资料E搜集资料、整理资料、分析资料、进行推断9.良好的实验设计,能减少人力、物力,提高实验效率;还有助于消除或减少: B
A抽样误差B系统误差C随机误差D责任事故E以上都不对 10.以下何者不是实验设计应遵循的原则 D A对照的原则B随机原则C重复原则D交叉的原则E以上都不对 第八章数值变量资料的统计描述11.表示血清学滴度资料平均水平最常计算 B A算术均数B几何均数C中位数D全距E率12.某计量资料的分布性质未明,要计算集中趋势指标,宜选择 C A X B G C M D S E C V 13.各观察值均加(或减)同一数后: B A均数不变,标准差改变B均数改变,标准差不变 C两者均不变D两者均改变E以上均不对14.某厂发生食物中毒,9名患者潜伏期分别为:16、2、6、3、30、2、l O、2、24+(小时),问该食物中毒的平均潜伏期为多少小时 C A5B5.5C6D10E1 2
第一章绪论习题 一、选择题 1.统计工作与统计研究得全过程可分为以下步骤:(D) A、调查、录入数据、分析资料、撰写论文 B、实验、录入数据、分析资料、撰写论文 C、调查或实验、整理资料、分析资料 D、设计、收集资料、整理资料、分析资料 E、收集资料、整理资料、分析资料 2、在统计学中,习惯上把(B )得事件称为小概率事件。 A、B、或C、 D、E、 3~8 A、计数资料 B、等级资料 C、计量资料 D、名义资料 E、角度资料 3、某偏僻农村144名妇女生育情况如下:0胎5人、1胎25人、2胎70人、3胎30人、4胎14人。该资料得类型就是( A)。 4、分别用两种不同成分得培养基(A与B)培养鼠疫杆菌,重复实验单元数均为5个,记录48小时各实验单元上生长得活菌数如下,A:48、84、90、123、171;B:90、116、124、22 5、84。该资料得类型就是(C )。 5、空腹血糖测量值,属于( C)资料。 6、用某种新疗法治疗某病患者41人,治疗结果如下:治愈8人、显效23人、好转6人、恶化3人、死亡1人。该资料得类型就是(B )。 7、某血库提供6094例ABO血型分布资料如下:O型1823、A型1598、B型2032、AB型641。该资料得类型就是(D )。 8、100名18岁男生得身高数据属于(C )。 二、问答题 1.举例说明总体与样本得概念、 答:统计学家用总体这个术语表示大同小异得对象全体,通常称为目标总体,而资料常来源于目标总体得一个较小总体,称为研究总体。实际中由于研究总体得个体众多,甚至无限多,因此科学得办法就是从中抽取一部分具有代表性得个体,称为样本。例如,关于吸烟与肺癌得研究以英国成年男子为总体目标,1951年英国全部注册医生作为研究总体,按照实验设计随机抽取得一定量得个体则组成了研究得样本。 2.举例说明同质与变异得概念 答:同质与变异就是两个相对得概念。对于总体来说,同质就是指该总体得共同特征,即该总体区别于其她总体得特征;变异就是指该总体内部得差异,即个体得特异性。例如,某地同性别同年龄得小学生具有同质性,其身高、体重等存在变异。 3.简要阐述统计设计与统计分析得关系 答:统计设计与统计分析就是科学研究中两个不可分割得重要方面。一般得,统计设计在前,然而一定得统计设计必
一、最佳选择题 1.卫生统计工作的步骤为C A.统计研究调查、搜集资料、整理资料、分析资料 B.统计资料收集、整理资料、统计描述、统计推断 C.统计研究设计、搜集资料、整理资料、分析资料 D.统计研究调查、统计描述、统计推断、统计图表 E.统计研究设计、统计描述、统计推断、统计图表 2.统计分析的主要内容有D A.统计描述和统计学检验 B.区间估计与假设检验 C.统计图表和统计报告 D.统计描述和统计推断 E.统计描述和统计图表 3.统计资料的类型包括E A.频数分布资料和等级分类资料 B.多项分类资料和二项分类资料 C.正态分布资料和频数分布资料 D.数值变量资料和等级资料 E.数值变量资料和分类变量资料 4.抽样误差是指B A.不同样本指标之间的差别 B.样本指标与总体指标之间由于抽样产生的差别 C.样本中每个体之间的差别 D.由于抽样产生的观测值之间的差别 E.测量误差与过失误差的总称 5.统计学中所说的总体是指B
A.任意想象的研究对象的全体 B.根据研究目的确定的研究对象的全体 C.根据地区划分的研究对象的全体 D.根据时间划分的研究对象的全体 E.根据人群划分的研究对象的全体 6.描述一组偏态分布资料的变异度,宜用D A.全距 B.标准差 C.变异系数 D.四分位数间距 E.方差 7.用均数与标准差可全面描述其资料分布特点的是C A.正偏态分布 B.负偏态分布 C.正态分布和近似正态分布 D.对称分布 E.任何分布 8.比较身高和体重两组数据变异度大小宜采用A A.变异系数 B.方差 C.极差 D.标准差 E.四分位数间距 9.频数分布的两个重要特征是C A.统计量与参数 B.样本均数与总体均数 C.集中趋势与离散趋势 D.样本标准差与总体标准差 E.样本与总体 10.正态分布的特点有B A.算术均数=几何均数 B.算术均数=中位数 C.几何均数=中位数 D.算术均数=几何均数=中位数 E.以上都没有 11.正态分布曲线下右侧5%对应的分位点为D
(一)单项选择题 3.抽样的目的是(b )。 A.研究样本统计量 B. 由样本统计量推断总体参数 C.研究典型案例研究误差 D. 研究总体统计量 4.参数是指(b )。 A.参与个体数 B. 总体的统计指标C.样本的统计指标 D. 样本的总和 5.关于随机抽样,下列那一项说法是正确的( a )。 A.抽样时应使得总体中的每一个个体都有同等的机会被抽取 B.研究者在抽样时应精心挑选个体,以使样本更能代表总体 C.随机抽样即随意抽取个体 D.为确保样本具有更好的代表性,样本量应越大越好 6.各观察值均加(或减)同一数后( b )。 A.均数不变,标准差改变 B.均数改变,标准差不变 C.两者均不变 D.两者均改变 7.比较身高和体重两组数据变异度大小宜采用( a )。 A.变异系数 B.差 C.极差 D.标准差 8.以下指标中(d)可用来描述计量资料的离散程度。 A.算术均数 B.几何均数
C.中位数 D.标准差 9.偏态分布宜用(c)描述其分布的集中趋势。 A.算术均数 B.标准差 C.中位数 D.四分位数间距 10.各观察值同乘以一个不等于0的常数后,(b)不变。A.算术均数 B.标准差 C.几何均数 D.中位数 11.( a )分布的资料,均数等于中位数。 A.对称 B.左偏态 C.右偏态 D.偏态 12.对数正态分布是一种( c )分布。 A.正态 B.近似正态 C.左偏态 D.右偏态 13.最小组段无下限或最大组段无上限的频数分布资料,可用( c )描述其集中趋势。 A.均数 B.标准差 C.中位数 D.四分位数间距 14.( c )小,表示用该样本均数估计总体均数的可靠性大。 A. 变异系数 B.标准差 C. 标准误 D.极差 15.血清学滴度资料最常用来表示其平均水平的指标是( c )。 A. 算术平均数 B.中位数
第1题:下列有关等级相关系数ts的描述中不正确的是 A.不服从双变量正态分布的资料宜计算rS B.等级数据宜计算rs C. rs值-1~+1之间 D.查rs界值表时,rs值越大,所对应的概率P值也越大 E.当变量中相同秩次较多时,宜计算校正rs值,使rs值减小 第2题:对某样本的相关系数r和0的差别进行检验,结果t1 A.两变量的差别无统计意义 B.两变量存在直线相关的可能性小于5% C.两变量肯定不存在相关关系 D.两变量间存在相关关系 E.就本资料尚不能认为两变量存在直线相关关系 第3题:总体率95%可信区间的意义是。 A.95%的正常值在此范围 B.95%的样本率在此范围 C.95%的总体率在此范围 D.总体率在此范围内的可能性为95% E.样本率在此范围内的可能性为95% 第4题:样本含量的确定下面哪种说法合理。 A.样本越大越好 B.样本越小越好 C.保证一定检验效能条件下尽量增大样本含量 D.保证一定检验效能条件下尽量减少样本含量 E.越易于组织实施的样本含量越好 第5题:直线相关与回归分析中,下列描述不正确的是。 A.r值的范围在-1~+1之间 B.已知r来自ρ≠0的总体,则r>0表示正相关,r<0表示负相关
C.已知Y和X相关,则必可计算其直线回归方程 D.回归描述两变量的依存关系,相关描述其相互关系 E.r无单位 第6题:四格表χ2检验的自由度为1,是因为四格表的四个理论频数( ) A.受一个独立条件限制 B.受二个独立条件限制 C.受三个独立条件限制 D.受四个独立条件限制 E.不受任何限制 第7题:对同一双变量(X,Y)的样本进行样本相关系数的tr检验和样本回归系数的tb 检验,有。 A. tb≠tr B. tb=tr C. tb>tr D. tb E. 视具体情况而定 第8题:为了由样本推断总体,样本应该是。 A.总体中任意的一部分 B.总体中的典型部分 C.总体中有意义的一部分 D.总体中有价值的一部分 E.总体中有代表性的一部分 第9题:以下检验方法属非参数法的是。 A.T检验 B.t检验 C.u检验 D.F检验
医学统计学试题及答案 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】
医学统计学试题及答案 第一套试卷及参考答案 一、选择题(40分) 1、根据某医院对急性白血病患者构成调查所获得的资料应绘制( B ) A 条图 B 百分条图或圆图 C线图 D直方图 2、均数和标准差可全面描述 D 资料的特征 A 所有分布形式B负偏态分布C正偏态分布D正态分布和近似正态分 布 3、要评价某市一名5岁男孩的身高是否偏高或偏矮,其统计方法是( A ) A 用该市五岁男孩的身高的95%或99%正常值范围来评价 B 用身高差别的假设检验来评价 C 用身高均数的95%或99%的可信区间来评价 D 不能作评价 4、比较身高与体重两组数据变异大小宜采用( A ) A 变异系数 B 方差 C 标准差 D 四分位间距 5、产生均数有抽样误差的根本原因是( A ) A.个体差异 B. 群体差异 C. 样本均数不同 D. 总体均数不同 6. 男性吸烟率是女性的10倍,该指标为( A ) (A)相对比(B)构成比(C)定基比(D)率 7、统计推断的内容为( D ) A.用样本指标估计相应的总体指标 B.检验统计上的“检验假设” C. A和B均不是 D. A和B均是 8、两样本均数比较用t检验,其目的是检验( C ) A两样本均数是否不同 B两总体均数是否不同 C两个总体均数是否相同 D两个样本均数是否相同 9、有两个独立随机的样本,样本含量分别为n 1和n 2 ,在进行成组设计资料的 t检验时,自由度是( D ) (A)n 1+ n 2 (B)n 1+ n 2 –1 (C)n 1+ n 2 +1 (D)n 1+ n 2 -2 10、标准误反映( A ) A 抽样误差的大小 B总体参数的波动大小 C 重复实验准确度的高低 D 数据的离散程度 11、最小二乘法是指各实测点到回归直线的 (C) A垂直距离的平方和最小B垂直距离最小
第一章 绪论习题 一、选择题 1.统计工作和统计研究的全过程可分为以下步骤:(D ) A. 调查、录入数据、分析资料、撰写论文 B. 实验、录入数据、分析资料、撰写论文 C. 调查或实验、整理资料、分析资料 D. 设计、收集资料、整理资料、分析资料 E. 收集资料、整理资料、分析资料 2.在统计学中,习惯上把(B )的事件称为小概率事件。 A.10.0≤P B. 05.0≤P 或01.0≤P C. 005.0≤P D.05.0≤P E. 01.0≤P 3~8 A.计数资料 B.等级资料 C.计量资料 D.名义资料 E.角度资料 3.某偏僻农村144名妇女生育情况如下:0胎5人、1胎25人、2胎70人、3胎30人、4胎14人。该资料的类型是( A )。 4.分别用两种不同成分的培养基(A 与B )培养鼠疫杆菌,重复实验单元数均为5个,记录48小时各实验单元上生长的活菌数如下,A :48、84、90、123、171;B :90、116、124、225、84。该资料的类型是(C )。 5.空腹血糖测量值,属于( C )资料。 6.用某种新疗法治疗某病患者41人,治疗结果如下:治愈8人、显效23人、好转6人、恶化3人、死亡1人。该资料的类型是(B )。 7.某血库提供6094例ABO 血型分布资料如下:O 型1823、A 型1598、B 型2032、AB 型641。该资料的类型是(D )。 8. 100名18岁男生的身高数据属于(C )。 二、问答题 1.举例说明总体与样本的概念. 答:统计学家用总体这个术语表示小异的对象全体,通常称为目标总体,而资料常来源于目标总体的一个较小总体,称为研究总体。实际中由于研究总体的个体众多,甚至无限多,因此科学的办法是从中抽取一部分具有代表性的个体,称为样本。例如,关于吸烟与肺癌的研究以英国成年男子为总体目标,1951年英国全部注册医生作为研究总体,按照实验设计随机抽取的一定量的个体则组成了研究的样本。 2.举例说明同质与变异的概念 答:同质与变异是两个相对的概念。对于总体来说,同质是指该总体的共同特征,即该总体区别于其他总体的特征;变异是指该总体部的差异,即个体的特异性。例如,某地同性别同年龄的小学生具有同质性,其身高、体重等存在变异。 3.简要阐述统计设计与统计分析的关系 答:统计设计与统计分析是科学研究中两个不可分割的重要方面。一般的,统计设计在前,然而一定的统计设计
1. 要反映某市连续5年甲肝发病率的变化情况,宜选用 A.直条图B.直方图C.线图D.百分直条图 2. 下列哪种统计图纵坐标必须从0开始, A. 普通线图 B.散点图 C.百分分直条图 D.直条图 3. 关于统计表的列表要求,下列哪项是错误的? A.横标目是研究对象,列在表的右侧;纵标目是分析指标,列在表的左侧 B.线条主要有顶线、底线及纵标目下面的横线,不宜有斜线和竖线 C.数字右对齐,同一指标小数位数一致,表内不宜有空格 D.备注用“*”标出,写在表的下面 4. 医学统计工作的基本步骤是 A.统计资料收集、整理资料、统计描述、统计推断 B.调查、搜集资料、整理资料、分折资料 C.设计、搜集资料、整理资料、分析资料 D.设计、统计描述、统计推断、统计图表 5. 统计分析的主要内容有 A. 描述性统计和统计学检验 B.统计描述和统计推断 C.统计图表和统计报告 D.描述性统计和分析性统计 6 制作统计图时要求 A.纵横两轴应有标目。一般不注明单位 B. 纵轴尺度必须从0开始 C.标题应注明图的主要内容,一般应写在图的上方 D. 在制作直条图和线图时,纵横两轴长度的比例一般取5:7 7. 痊愈、显效、好转、无效属于 A. 计数资料 B. 计量资料 C. 等级资料 D.以上均不是 8. 均数和标准差的关系是 A.x愈大,s愈大B.x愈大,s愈小 C.s愈大,x对各变量值的代表性愈好D.s愈小,x对各变量值的代表性愈好 9. 对于均数为μ,标准差为σ的正态分布,95%的变量值分布范围为 A. μ-σ ~ μ+σ B. μ-1.96σ ~ μ+1.96σ C. μ-2.58σ ~ μ+2.58σ D. 0 ~ μ+1.96σ 10. 从一个数值变量资料的总体中抽样,产生抽样误差的原因是 A.总体中的个体值存在差别B.样本中的个体值存在差别 C.总体均数不等于0 D.样本均数不等于0 11 从偏态总体抽样,当n足够大时(比如n > 60),样本均数的分布。 A. 仍为偏态分布 B. 近似对称分布 C. 近似正态分布 D. 近似对数正态分布 12 某市250名8岁男孩体重有95%的人在18~30kg范围内,由此可推知此250名男孩体重的标准差大 约为 A.2.0kg B.2.3kg C.3.1kg D.6.0kg 13. 单因素方差分析中,造成各组均数不等的原因是 A.个体差异B.测量误差C.各处理组可能存在的差异D.以上都有 14. 医学中确定参考值范围是应注意 A.正态分布资料不能用均数标准差法B.正态分布资料不能用百分位数法 C.偏态分布资料不能用均数标准差法D.偏态分布资料不能用百分位数法 15. 方差分析中,当P<0.05时,则 A.可认为各总体均数都不相等B.可认为各样本均数都不相等 C.可认为各总体均数不等或不全相等D.以上都不对 16. 两样本中的每个数据减同一常数后,再作其t检验,则