
用RLS算法实现自适应均衡器的MATLAB程序
考虑一个线性自适应均衡器的原理方框图如《现代数字信号处理导论》p.275自适应均衡器应用示意图。随机数据产生双极性的随机序列x[n],它随机地取+1和-1。随机信号通过一个信道传输,信道性质可由一个三系数FIR滤波器刻画,滤波器系数分别是0.3,0.9,0.3。在信道输出加入方差为σ平方高斯白噪声,设计一个有11个权系数的FIR结构的自适应均衡器,令均衡器的期望响应为x[n-7],选择几个合理的白噪声方差σ平方(不同信噪比),进行实验。
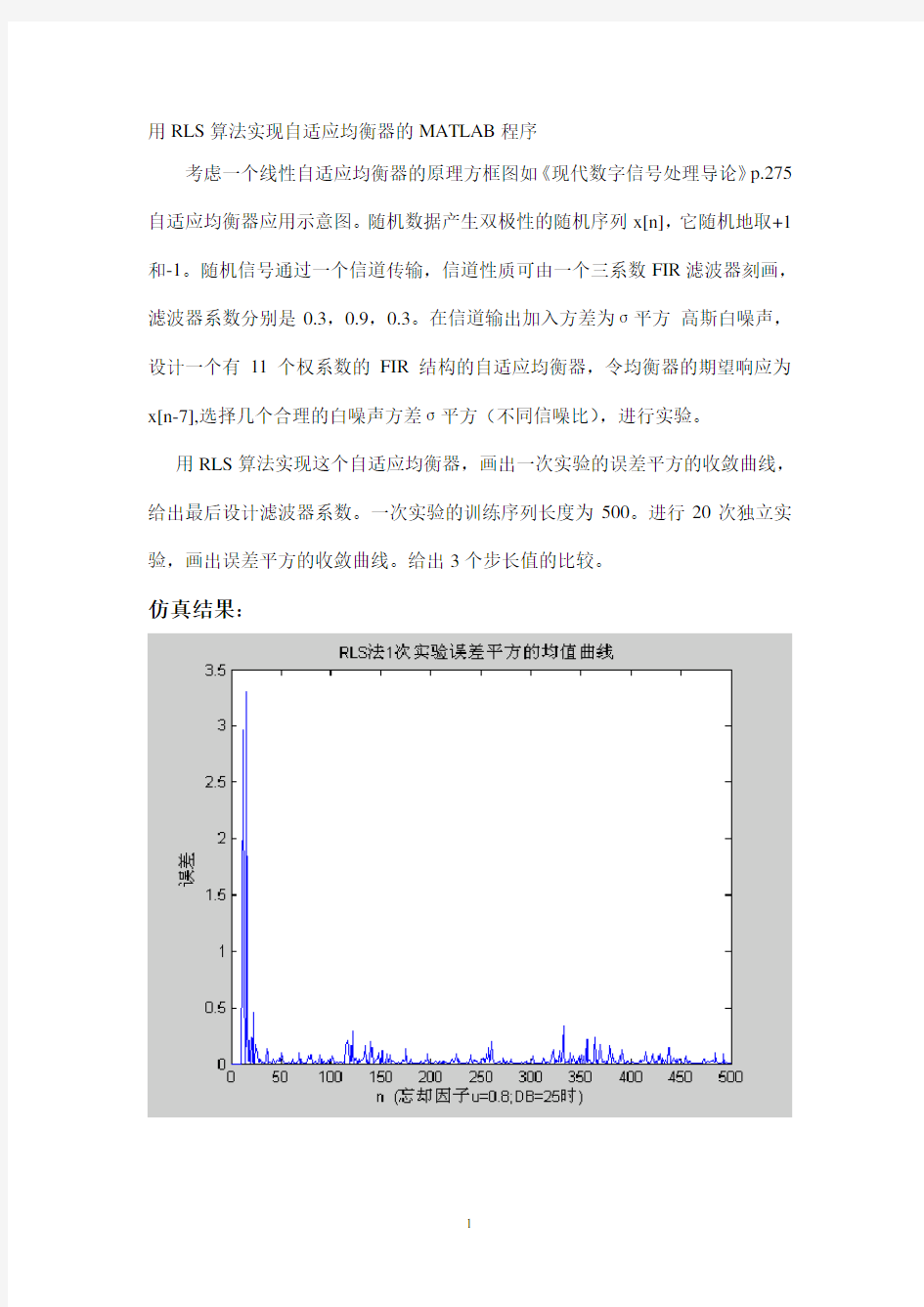
用RLS算法实现这个自适应均衡器,画出一次实验的误差平方的收敛曲线,给出最后设计滤波器系数。一次实验的训练序列长度为500。进行20次独立实验,画出误差平方的收敛曲线。给出3个步长值的比较。
仿真结果:
用RLS算法设计的自适应均衡器系数
结果分析:
可以看到,RLS算法的收敛速度明显比LMS算法快,并且误差也比LMS算法小,但是当用更小的忘却因子时,单次实验结果明显变坏,当忘却因子趋于0时,LS算法也就是LMS算法。
附程序:
1. RLS法1次实验
% written in 2005.1.13
% written by li***
clear;
N=500;
db=25;
sh1=sqrt(10^(-db/10));
u=1;
m=0.0001*sh1^2;
error_s=0;
for loop=1:1
w=zeros(1,11)';
p=1/m*eye(11,11);
V=sh1*randn(1,N );
Z=randn(1,N)-0.5;
x=sign(Z);
for n=3:N;
M(n)=0.3*x(n)+0.9*x(n-1)+0.3*x(n-2);
end
z=M+V;
for n=8:N;
d(n)=x(n-7);
end
for n=11:N;
z1=[z(n) z(n-1) z(n-2) z(n-3) z(n-4) z(n-5) z(n-6) z(n-7) z(n-8) z(n-9) z(n-10)]';
k=u^(-1).*p*z1./(1+u^(-1).*z1'*p*z1);
e(n)=d(n)-w'*z1;
w=w+k.*conj(e(n));
p=u^(-1).*p-u^(-1).*k*z1'*p;
y(n)=w'*z1;
e1(n)=d(n)-w'*z1;
end
error_s=error_s+e.^2;
end
w
error_s=error_s./1;
n=1:N;
plot(n,error_s);
xlabel('n (忘却因子u=1;DB=25时)');
ylabel('误差');
title('RLS法1次实验误差平方的均值曲线');
2. RLS法20次实验
% written in 2005.1.13
% written by li***
clear;
N=500;
db=25;
sh1=sqrt(10^(-db/10));
u=1;
m=0.0001*sh1^2;
error_s=0;
for loop=1:20
w=zeros(1,11)';
p=1/m*eye(11,11);
V=sh1*randn(1,N );
Z=randn(1,N)-0.5;
x=sign(Z);
for n=3:N;
M(n)=0.3*x(n)+0.9*x(n-1)+0.3*x(n-2);
end
z=M+V;
for n=8:N;
d(n)=x(n-7);
end
for n=11:N;
z1=[z(n) z(n-1) z(n-2) z(n-3) z(n-4) z(n-5) z(n-6) z(n-7) z(n-8) z(n-9) z(n-10)]';
k=u^(-1).*p*z1./(1+u^(-1).*z1'*p*z1);
e(n)=d(n)-w'*z1;
w=w+k.*conj(e(n));
p=u^(-1).*p-u^(-1).*k*z1'*p;
y(n)=w'*z1;
e1(n)=d(n)-w'*z1;
end
error_s=error_s+e.^2;
end
w
error_s=error_s./20;
n=1:N;
plot(n,error_s);
xlabel('n (忘却因子u=1;DB=25时)');
ylabel('误差');
title('RLS法20次实验误差平方的均值曲线');
2. Matlab程序 2.1 一次聚类法 X=[11978 12.5 93.5 31908;…;57500 67.6 238.0 15900]; T=clusterdata(X,0.9) 2.2 分步聚类 Step1 寻找变量之间的相似性 用pdist函数计算相似矩阵,有多种方法可以计算距离,进行计算之前最好先将数据用zscore 函数进行标准化。 X2=zscore(X); %标准化数据 Y2=pdist(X2); %计算距离 Step2 定义变量之间的连接 Z2=linkage(Y2); Step3 评价聚类信息 C2=cophenet(Z2,Y2); //0.94698 Step4 创建聚类,并作出谱系图 T=cluster(Z2,6); H=dendrogram(Z2); Matlab提供了两种方法进行聚类分析。 一种是利用 clusterdata函数对样本数据进行一次聚类,其缺点为可供用户选择的面较窄,不能更改距离的计算方法; 另一种是分步聚类:(1)找到数据集合中变量两两之间的相似性和非相似性,用pdist函数计算变量之间的距离;(2)用 linkage函数定义变量之间的连接;(3)用 cophenetic函数评价聚类信息;(4)用cluster函数创建聚类。 1.Matlab中相关函数介绍 1.1 pdist函数 调用格式:Y=pdist(X,’metric’) 说明:用‘metric’指定的方法计算 X 数据矩阵中对象之间的距离。’ X:一个m×n的矩阵,它是由m个对象组成的数据集,每个对象的大小为n。 metric’取值如下: ‘euclidean’:欧氏距离(默认);‘seuclidean’:标准化欧氏距离; ‘mahalanobis’:马氏距离;‘cityblock’:布洛克距离; ‘minkowski’:明可夫斯基距离;‘cosine’: ‘correlation’:‘hamming’: ‘jaccard’:‘chebychev’:Chebychev距离。 1.2 squareform函数 调用格式:Z=squareform(Y,..) 说明:强制将距离矩阵从上三角形式转化为方阵形式,或从方阵形式转化为上三角形式。 1.3 linkage函数 调用格式:Z=linkage(Y,’method’) 说明:用‘method’参数指定的算法计算系统聚类树。 Y:pdist函数返回的距离向量;
增量式PID控制算法Matlab仿真程序设一被控对象G(s)=50/(0.125s^2+7s),用增量式PID控制算法编写仿真程序(输入分别为单位阶跃、正弦信号,采样时间为1ms,控制器输出限幅:[-5,5],仿真曲线包括系统输出及误差曲线,并加上注释、图例)。程序如下clear all; close all; ts=0.001; sys=tf(50,[0.125,7, 0]); dsys=c2d(sys,ts,'z'); [num,den]=tfdata(dsys,'v'); u_1=0.0;u_2=0.0; y_1=0.0;y_2=0.0; x=[0,0,0]'; error_1=0; error_2=0; for k=1:1:1000 time(k)=k*ts; S=2; if S==1 kp=10;ki=0.1;kd=15; rin(k)=1; % Step Signal elseif S==2 kp=10;ki=0.1;kd=15; %Sin e Signal rin(k)=0.5*sin(2*pi*k*ts); end du(k)=kp*x(1)+kd*x(2)+ki*x(3); % PID Controller u(k)=u_1+du(k); %Restricting the output of controller if u(k)>=5 u(k)=5; end if u(k)<=-5 u(k)=-5; end %Linear model yout(k)=-den(2)*y_1-den(3)*y_2+nu m(2)*u_1+num(3)*u_2; error(k)=rin(k)-yout(k); %Return of parameters u_2=u_1;u_1=u(k); y_2=y_1;y_1=yout(k); x(1)=error(k)-error_1; %C alculating P x(2)=error(k)-2*error_1+error_2; %Calculating D x(3)=error(k); %Calculating I error_2=error_1; error_1=error(k); end figure(1); plot(time,rin,'b',time,yout,'r'); xlabel('time(s)'),ylabel('rin,yout'); figure(2); plot(time,error,'r') xlabel('time(s)');ylabel('error'); 微分先行PID算法Matlab仿真程序%PID Controler with differential in advance clear all; close all; ts=20; sys=tf([1],[60,1],'inputdelay',80); dsys=c2d(sys,ts,'zoh'); [num,den]=tfdata(dsys,'v'); u_1=0;u_2=0;u_3=0;u_4=0;u_5=0;
本文在阐述聚类分析方法的基础上重点研究FCM 聚类算法。FCM 算法是一种基于划分的聚类算法,它的思想是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小。最后基于MATLAB实现了对图像信息的聚类。 第 1 章概述 聚类分析是数据挖掘的一项重要功能,而聚类算法是目前研究的核心,聚类分析就是使用聚类算法来发现有意义的聚类,即“物以类聚” 。虽然聚类也可起到分类的作用,但和大多数分类或预测不同。大多数分类方法都是演绎的,即人们事先确定某种事物分类的准则或各类别的标准,分类的过程就是比较分类的要素与各类别标准,然后将各要素划归于各类别中。确定事物的分类准则或各类别的标准或多或少带有主观色彩。 为获得基于划分聚类分析的全局最优结果,则需要穷举所有可能的对象划分,为此大多数应用采用的常用启发方法包括:k-均值算法,算法中的每一个聚类均用相应聚类中对象的均值来表示;k-medoid 算法,算法中的每一个聚类均用相应聚类中离聚类中心最近的对象来表示。这些启发聚类方法在分析中小规模数据集以发现圆形或球状聚类时工作得很好,但当分析处理大规模数据集或复杂数据类型时效果较差,需要对其进行扩展。 而模糊C均值(Fuzzy C-means, FCM)聚类方法,属于基于目标函数的模糊聚类算法的范畴。模糊C均值聚类方法是基于目标函数的模糊聚类算法理论中最为完善、应用最为广泛的一种算法。模糊c均值算法最早从硬聚类目标函数的优化中导出的。为了借助目标函数法求解聚类问题,人们利用均方逼近理论构造了带约束的非线性规划函数,以此来求解聚类问题,从此类内平方误差和WGSS(Within-Groups Sum of Squared Error)成为聚类目标函数的普遍形式。随着模糊划分概念的提出,Dunn [10] 首先将其推广到加权WGSS 函数,后来由Bezdek 扩展到加权WGSS 的无限族,形成了FCM 聚类算法的通用聚类准则。从此这类模糊聚类蓬勃发展起来,目前已经形成庞大的体系。 第 2 章聚类分析方法 2-1 聚类分析 聚类分析就是根据对象的相似性将其分群,聚类是一种无监督学习方法,它不需要先验的分类知识就能发现数据下的隐藏结构。它的目标是要对一个给定的数据集进行划分,这种划分应满足以下两个特性:①类内相似性:属于同一类的数据应尽可能相似。②类间相异性:属于不同类的数据应尽可能相异。图2.1是一个简单聚类分析的例子。
算法描述: 输入图G,源点v0,输出源点到各点的最短距离D 中间变量v0保存当前已经处理到的顶点集合,v1保存剩余的集合 1.初始化v1,D 2.计算v0到v1各点的最短距离,保存到D for each i in v0;D(j)=min[D(j),G(v0(1),i)+G(i,j)] ,where j in v1 3.将D中最小的那一项加入到v0,并且从v1删除这一项。 4.转到2,直到v0包含所有顶点。 %dijsk最短路径算法 clear,clc G=[ inf inf 10 inf 30 100; inf inf 5 inf inf inf; inf 5 inf 50 inf inf; inf inf inf inf inf 10; inf inf inf 20 inf 60; inf inf inf inf inf inf; ]; %邻接矩阵 N=size(G,1); %顶点数 v0=1; %源点 v1=ones(1,N); %除去原点后的集合 v1(v0)=0; %计算和源点最近的点 D=G(v0,:); while 1 D2=D; for i=1:N if v1(i)==0 D2(i)=inf; end end D2 [Dmin id]=min(D2); if isinf(Dmin),error,end v0=[v0 id] %将最近的点加入v0集合,并从v1集合中删除 v1(id)=0; if size(v0,2)==N,break;end %计算v0(1)到v1各点的最近距离 fprintf('计算v0(1)到v1各点的最近距离\n');v0,v1 id=0; for j=1:N %计算到j的最近距离 if v1(j)
function [R_best,L_best,L_ave,Shortest_Route,Shortest_Length]=ACATSP(C,NC_max,m,Alpha,Beta ,Rho,Q) %%===================================================== ==================== %% ACATSP.m %% Ant Colony Algorithm for Traveling Salesman Problem %% ChengAihua,PLA Information Engineering University,ZhengZhou,China %% Email:aihuacheng@https://www.doczj.com/doc/6f7272201.html, %% All rights reserved %%------------------------------------------------------------------------- %% 主要符号说明 %% C n个城市的坐标,n×4的矩阵 %% NC_max 最大迭代次数 %% m 蚂蚁个数 %% Alpha 表征信息素重要程度的参数 %% Beta 表征启发式因子重要程度的参数 %% Rho 信息素蒸发系数 %% Q 信息素增加强度系数 %% R_best 各代最佳路线 %% L_best 各代最佳路线的长度 %%===================================================== ==================== %%第一步:变量初始化 n=size(C,1);%n表示问题的规模(城市个数) D=zeros(n,n);%D表示完全图的赋权邻接矩阵 for i=1:n for j=1:n if i~=j D(i,j)=max( ((C(i,1)-C(j,1))^2+(C(i,2)-C(j,2))^2)^0.5,min(abs(C(i,3)-C(j,3)),144- abs(C(i,3)-C(j,3))) );%计算城市间距离 else D(i,j)=eps; end D(j,i)=D(i,j); end end Eta=1./D;%Eta为启发因子,这里设为距离的倒数 Tau=ones(n,n);%Tau为信息素矩阵 Tabu=zeros(m,n);%存储并记录路径的生成 NC=1;%迭代计数器 R_best=zeros(NC_max,n);%各代最佳路线
题目:matlab实现Kmeans聚类算法 姓名吴隆煌 学号41158007
背景知识 1.简介: Kmeans算法是一种经典的聚类算法,在模式识别中得到了广泛的应用,基于Kmeans的变种算法也有很多,模糊Kmeans、分层Kmeans 等。 Kmeans和应用于混合高斯模型的受限EM算法是一致的。高斯混合模型广泛用于数据挖掘、模式识别、机器学习、统计分析。Kmeans 的迭代步骤可以看成E步和M步,E:固定参数类别中心向量重新标记样本,M:固定标记样本调整类别中心向量。K均值只考虑(估计)了均值,而没有估计类别的方差,所以聚类的结构比较适合于特征协方差相等的类别。 Kmeans在某种程度也可以看成Meanshitf的特殊版本,Meanshift 是一种概率密度梯度估计方法(优点:无需求解出具体的概率密度,直接求解概率密度梯度。),所以Meanshift可以用于寻找数据的多个模态(类别),利用的是梯度上升法。在06年的一篇CVPR文章上,证明了Meanshift方法是牛顿拉夫逊算法的变种。Kmeans 和EM算法相似是指混合密度的形式已知(参数形式已知)情况下,利用迭代方法,在参数空间中搜索解。而Kmeans和Meanshift相似是指都是一种概率密度梯度估计的方法,不过是Kmean选用的是特殊的核函数(uniform kernel),而与混合概率密度形式是否已知无关,是一种梯度求解方式。 k-means是一种聚类算法,这种算法是依赖于点的邻域来决定哪些
点应该分在一个组中。当一堆点都靠的比较近,那这堆点应该是分到同一组。使用k-means,可以找到每一组的中心点。 当然,聚类算法并不局限于2维的点,也可以对高维的空间(3维,4维,等等)的点进行聚类,任意高维的空间都可以。 上图中的彩色部分是一些二维空间点。上图中已经把这些点分组了,并使用了不同的颜色对各组进行了标记。这就是聚类算法要做的事情。 这个算法的输入是: 1:点的数据(这里并不一定指的是坐标,其实可以说是向量) 2:K,聚类中心的个数(即要把这一堆数据分成几组) 所以,在处理之前,你先要决定将要把这一堆数据分成几组,即聚成几类。但并不是在所有情况下,你都事先就能知道需要把数据聚成几类的。但这也并不意味着使用k-means就不能处理这种情况,下文中会有讲解。 把相应的输入数据,传入k-means算法后,当k-means算法运行完后,该算法的输出是: 1:标签(每一个点都有一个标签,因为最终任何一个点,总会被分到某个类,类的id号就是标签) 2:每个类的中心点。 标签,是表示某个点是被分到哪个类了。例如,在上图中,实际上
最短距离聚类的matlab实现-1 【2013-5-21更新】 说明:正文中命令部分可以直接在Matlab中运行, 作者(Yangfd09)于2013-5-21 19:15:50在MATLAB R2009a(7.8.0.347)中运行通过 %最短距离聚类(含距离计算,含聚类图) %说明:此程序的优点在于每一步都是自己编写的,很少用matlab现成的指令, %所以更适合于初学者,有助于理解各种标准化方法和距离计算方法。 %程序包含了极差标准化(两种方法)、中心化、标准差标准化、总和标准化和极大值标准化等标准化方法, %以及绝对值距离、欧氏距离、明科夫斯基距离和切比雪夫距离等距离计算方法。 %==========================>>导入数据<<============================== %变量名为test(新建一个以test变量,双击进入Variable Editor界面,将数据复制进去即可)%数据要求:m行n列,m为要素个数,n为区域个数(待聚类变量)。 % 具体参见末页测试数据。 testdata=test; %============================>>标准化<<=============================== %变量初始化,m用来寻找每行的最大值,n找最小值,s记录每行数据的和 [M,N]=size(testdata);m=zeros(1,M);n=9999*ones(1,M);s=zeros(1,M);eq=zeros(1,M); %为m、n和s赋值 for i=1:M for j=1:N if testdata(i,j)>=m(i) m(i)=testdata(i,j); end if testdata(i,j)<=n(i) n(i)=testdata(i,j); end s(i)=s(i)+testdata(i,j); end eq(i)=s(i)/N; end %sigma0是离差平方和,sigma是标准差 sigma0=zeros(M); for i=1:M for j=1:N sigma0(i)=sigma0(i)+(testdata(i,j)-eq(i))^2; end end sigma=sqrt(sigma0/N);
先新建一个主程序M文件ACATSP.m 代码如下: function [R_best,L_best,L_ave,Shortest_Route,Shortest_Length]=ACATSP(C,NC_max,m,Alpha,Beta,Rho,Q) %%================================================== ======================= %% 主要符号说明 %% C n个城市的坐标,n×2的矩阵 %% NC_max 蚁群算法MATLAB程序最大迭代次数 %% m 蚂蚁个数 %% Alpha 表征信息素重要程度的参数 %% Beta 表征启发式因子重要程度的参数 %% Rho 信息素蒸发系数 %% Q 表示蚁群算法MATLAB程序信息素增加强度系数 %% R_best 各代最佳路线 %% L_best 各代最佳路线的长度 %%================================================== =======================
%% 蚁群算法MATLAB程序第一步:变量初始化 n=size(C,1);%n表示问题的规模(城市个数) D=zeros(n,n);%D表示完全图的赋权邻接矩阵 for i=1:n for j=1:n if i~=j D(i,j)=((C(i,1)-C(j,1))^2+(C(i,2)-C(j,2))^2)^0.5; else D(i,j)=eps; % i = j 时不计算,应该为0,但后面的启发因子要取倒数,用eps(浮点相对精度)表示 end D(j,i)=D(i,j); %对称矩阵 end end Eta=1./D; %Eta为启发因子,这里设为距离的倒数 Tau=ones(n,n); %Tau为信息素矩阵 Tabu=zeros(m,n); %存储并记录路径的生成
用matlab做聚类分析 Matlab提供了两种方法进行聚类分析。 一种是利用clusterdata函数对样本数据进行一次聚类,其缺点为可供用户选择的面较窄,不能更改距离的计算方法; 另一种是分步聚类:(1)找到数据集合中变量两两之间的相似性和非相似性,用pdist函数计算变量之间的距离;(2)用linkage函数定义变量之间的连接;(3)用cophenetic函数评价聚类信息;(4)用cluster函数创建聚类。1.Matlab中相关函数介绍 1.1pdist函数 调用格式:Y=pdist(X,’metric’) 说明:用‘metric’指定的方法计算X数据矩阵中对象之间的距离。’X:一个m×n的矩阵,它是由m个对象组成的数据集,每个对象的大小为n。 metric’取值如下: ‘euclidean’:欧氏距离(默认);‘seuclidean’:标准化欧氏距离; ‘mahalanobis’:马氏距离;‘cityblock’:布洛克距离; ‘minkowski’:明可夫斯基距离;‘cosine’: ‘correlation’:‘hamming’: ‘jaccard’:‘chebychev’:Chebychev距离。 1.2squareform函数 调用格式:Z=squareform(Y,..)
说明:强制将距离矩阵从上三角形式转化为方阵形式,或从方阵形式转化为上三角形式。 1.3linkage函数 调用格式:Z=linkage(Y,’method’) 说明:用‘method’参数指定的算法计算系统聚类树。 Y:pdist函数返回的距离向量; method:可取值如下: ‘single’:最短距离法(默认);‘complete’:最长距离法; ‘average’:未加权平均距离法;‘weighted’:加权平均法; ‘centroid’:质心距离法;‘median’:加权质心距离法; ‘ward’:内平方距离法(最小方差算法) 返回:Z为一个包含聚类树信息的(m-1)×3的矩阵。 1.4dendrogram函数 调用格式:[H,T,…]=dendrogram(Z,p,…) 说明:生成只有顶部p个节点的冰柱图(谱系图)。 1.5cophenet函数 调用格式:c=cophenetic(Z,Y) 说明:利用pdist函数生成的Y和linkage函数生成的Z计算cophenet相关系数。 1.6cluster函数 调用格式:T=cluster(Z,…) 说明:根据linkage函数的输出Z创建分类。
CG程序代码 function [x,y] = cg(A,b,x0) %%%%%%%%%%%%%%%%%CG算法%%%%%%%%%%%% r0 = A*x0-b; p0 = -r0; k = 0; r = r0; p = p0; x = x0; while r~=0 alpha = -r'*p/(p'*A*p); x = x+alpha*p; rold = r; r = rold+alpha*A*p; beta = r'*r/(rold'*rold); p = -r+beta*p; plot(k,norm(p),'.--'); hold on k = k+1; end y.funcount = k; y.fval = x'*A*x/2-b'*x;
function [x,y] = cg_FR(fun,dfun,x0) %%%%%%%%%%%%%%%CG_FR算法%%%%%%%%%%%%%%% error = 10^-5; f0 = feval(fun,x0); df0 = feval(dfun,x0); p0 = -df0; f = f0; df = df0; p = p0; x = x0; k = 0; while ((norm(df)>error)&&(k<1000)) f = feval(fun,x); [alpha,funcNk,exitflag] = lines(fun,0.01,0.15,0.85,6,f,df'*p,x,p);%%用线搜索找下降距离%% if exitflag == -1 disp('Break!!!'); break; end x = x+alpha*p; dfold = df; df = feval(dfun,x); beta = df'*df/(dfold'*dfold); p = -df+beta*p; plot(k,norm(df),'.--'); hold on k = k+1; end y.funcount = k; y.fval = feval(fun,x); y.error = norm(df);
蚁群算法的matlab源码,同时请指出为何不能优化到已知的最好解 % % % the procedure of ant colony algorithm for VRP % % % % % % % % % % % % %initialize the parameters of ant colony algorithms load data.txt; d=data(:,2:3); g=data(:,4); m=31; % 蚂蚁数 alpha=1; belta=4;% 决定tao和miu重要性的参数 lmda=0; rou=0.9; %衰减系数 q0=0.95; % 概率 tao0=1/(31*841.04);%初始信息素 Q=1;% 蚂蚁循环一周所释放的信息素 defined_phrm=15.0; % initial pheromone level value QV=100; % 车辆容量 vehicle_best=round(sum(g)/QV)+1; %所完成任务所需的最少车数V=40; % 计算两点的距离 for i=1:32; for j=1:32;
dist(i,j)=sqrt((d(i,1)-d(j,1))^2+(d(i,2)-d(j,2))^2); end; end; %给tao miu赋初值 for i=1:32; for j=1:32; if i~=j; %s(i,j)=dist(i,1)+dist(1,j)-dist(i,j); tao(i,j)=defined_phrm; miu(i,j)=1/dist(i,j); end; end; end; for k=1:32; for k=1:32; deltao(i,j)=0; end; end; best_cost=10000; for n_gen=1:50; print_head(n_gen); for i=1:m; %best_solution=[]; print_head2(i);
clc clear all close all %% 常量定义 Freqs=1.6e9; %工作频率 c=3e8; %光速 lamda=c/Freqs; %波长 d=0.5*lamda; %单元间距 M=16; %天线阵元数 fs=2e6; %采样频率 pd=10; %快拍数 %% 模型建立 %--------------第一个干扰模型-------------------- thetaJ1=20*pi/180; %干扰方向 FreqJ1=5e5; %第一个干扰的频率 J1NR=sqrt(10^(60/10)); J1one=J1NR*exp(j*(2*pi*FreqJ1*(1:1:pd)/fs)); %1*pd %--------------第二个干扰模型-------------------- ThetaJ2=60*pi/180; %干扰方向 FreqJ2=6e5; %第二个干扰的频率 J2NR=sqrt(10^(60/10)); J2one=J2NR*exp(j*(2*pi*FreqJ2*(1:1:pd)/fs)); %1*pd %--------------信号模型-------------------- ThetaS=30*pi/180; FreqS=7e5; SNR=sqrt(10^(40/10)); Sone=SNR*exp(j*(2*pi*FreqS*(1:1:pd)/fs)); %1*pd %--------------空域处理------------------------- I1=zeros(M,1); I2=zeros(M,1); IS=zeros(M,1); for n=1:M I1(n)=exp(j*2*pi*(n-1)*d*sin(thetaJ1)/lamda); I2(n)=exp(j*2*pi*(n-1)*d*sin(ThetaJ2)/lamda); IS(n)=exp(j*2*pi*(n-1)*d*sin(ThetaS)/lamda); end J1=I1*J1one; J1=J1.'; J2=I2*J2one; J2=J2.'; %------------产生噪声------------------------- noise=sqrt(1/2)*randn(pd,M)+j*sqrt(1/2)*randn(pd,M);
图论实验三个案例 单源最短路径问题 Dijkstra 算法 Dijkstra 算法是解单源最短路径问题的一个贪心算法。其基本思想是,设置一个顶点集合S 并不断地作贪心选择来扩充这个集合。一个顶点属于集合S 当且仅当从源到该顶点的最短路径长度已知。设v 是图中的一个顶点,记()l v 为顶点 v 到源点v 1的最短距离, ,i j v v V ?∈,若 (,)i j v v E ?,记i v 到j v 的权ij w =∞。 Dijkstra 算法: ① 1{}S v =,1()0l v =;1{}v V v ??-,()l v =∞,1i =,1{}S V v =-; ② S φ=,停止,否则转③; ③ ()min{(),(,)} j l v l v d v v =, j v S ∈,v S ?∈; ④ 存在 1 i v +,使 1()min{()} i l v l v +=,v S ∈; ⑤ 1{} i S S v +=, 1{} i S S v +=-,1i i =+,转②; 实际上,Dijkstra 算法也是最优化原理的应用:如果12 1n n v v v v -是从1v 到 n v 的最短路径,则 12 1 n v v v -也必然是从1v 到 1 n v -的最优路径。 在下面的MATLAB 实现代码中,我们用到了距离矩阵,矩阵第i 行第j 行元 素表示顶点i v 到j v 的权ij w ,若i v 到j v 无边,则realmax ij w =,其中realmax 是 MATLAB 常量,表示最大的实数+308)。 function re=Dijkstra(ma)
function [y,val]=QACStic load att48 att48; MAXIT=300; % 最大循环次数 NC=48; % 城市个数 tao=ones(48,48);% 初始时刻各边上的信息最为1 rho=0.2; % 挥发系数 alpha=1; beta=2; Q=100; mant=20; % 蚂蚁数量 iter=0; % 记录迭代次数 for i=1:NC % 计算各城市间的距离 for j=1:NC distance(i,j)=sqrt((att48(i,2)-att48(j,2))^2+(att48(i,3)-att48(j,3))^2); end end bestroute=zeros(1,48); % 用来记录最优路径 routelength=inf; % 用来记录当前找到的最优路径长度 % for i=1:mant % 确定各蚂蚁初始的位置 % end for ite=1:MAXIT for ka=1:mant %考查第K只蚂蚁 deltatao=zeros(48,48); % 第K只蚂蚁移动前各边上的信息增量为零 [routek,lengthk]=travel(distance,tao,alpha,beta); if lengthk matlab实现Kmeans聚类算法 1.简介: Kmeans和应用于混合高斯模型的受限EM算法是一致的。高斯混合模型广泛用于数据挖掘、模式识别、机器学习、统计分析。Kmeans 的迭代步骤可以看成E步和M步,E:固定参数类别中心向量重新标记样本,M:固定均值只考虑(估计)了均值,而没有估计类别的方差,所以聚类的结构比较适合于特征协方差相等的类别。 Kmeans在某种程度也可以看成Meanshitf的特殊版本,Meanshift 是所以Meanshift可以用于寻找数据的多个模态(类别),利用的是梯度上升法。在06年的一篇CVPR文章上,证明了Meanshift方法是牛顿拉夫逊算法的变种。Kmeans和EM算法相似是指混合密度的形式已知(参数形式已知)情况下,利用迭代方法,在参数空间中搜索解。而Kmeans和Meanshift相似是指都是一种概率密度梯度估计的方法,不过是Kmean选用的是特殊的核函数(uniform kernel),而与混合概率密度形式是否已知无关,是一种梯度求解方式。 k-means是一种聚类算法,这种算法是依赖于点的邻域来决定哪些点应该分在点,也可以对高维的空间(3维,4维,等等)的点进行聚类,任意高维的空间都可以。 上图中的彩色部分是一些二维空间点。上图中已经把这些点分组了,并使用了不同的颜色对各组进行了标记。这就是聚类算法要做的事情。 这个算法的输入是: 1:点的数据(这里并不一定指的是坐标,其实可以说是向量) 2:K,聚类中心的个数(即要把这一堆数据分成几组) 所以,在处理之前,你先要决定将要把这一堆数据分成几组,即聚成几类。但并不是在所有情况下,你都事先就能知道需要把数据聚成几类的。意味着使用k-means就不能处理这种情况,下文中会有讲解。 把相应的输入数据,传入k-means算法后,当k-means算法运行完后,该算法的输出是: 1:标签(每一个点都有一个标签,因为最终任何一个点,总会被分到某个类,类的id号就是标签) 2:每个类的中心点。 标签,是表示某个点是被分到哪个类了。例如,在上图中,实际上有4中“标签”,每个“标签”使用不同的颜色来表示。所有黄色点我们可以用标签以看出,有3个类离的比较远,有两个类离得比较近,几乎要混合在一起了。 当然,数据集不一定是坐标,假如你要对彩色图像进行聚类,那么你的向量就可以是(b,g,r),如果使用的是hsv颜色空间,那还可以使用(h,s,v),当然肯定可以有不同的组合例如(b*b,g*r,r*b) ,(h*b,s*g,v*v)等等。 在本文中,初始的类的中心点是随机产生的。如上图的红色点所示,是本文随机产生的初始点。注意观察那两个离得比较近的类,它们几乎要混合在一起,看看算法是如何将它们分开的。 类的初始中心点是随机产生的。算法会不断迭代来矫正这些中心点,并最终得到比较靠5个中心点的距离,选出一个距离最小的(例如该点与第2个中心点的距离是5个距离中最小的),那么该点就归属于该类.上图是点的归类结果示意图. 经过步骤3后,每一个中心center(i)点都有它的”管辖范围”,由于这个中心点不一定是这个管辖范围的真正中心点,所以要重新计算中心点,计算的方法有很多种,最简单的一种是,直接计算该管辖范围内所有点的均值,做为心的中心点new_center(i). 如果重新计算的中心点new_center(i)与原来的中心点center(i)的距离大于一定的阈值(该阈值可以设定),那么认为算法尚未收敛,使用new_center(i)代替center(i)(如图,中心点从红色点 遗传算法程序(一): 说明: fga.m 为遗传算法的主程序; 采用二进制Gray编码,采用基于轮盘赌法的非线性排名选择, 均匀交叉,变异操作,而且还引入了倒位操作! function [BestPop,Trace]=fga(FUN,LB,UB,eranum,popsize,pCross,pMutation,pInversion,options) % [BestPop,Trace]=fmaxga(FUN,LB,UB,eranum,popsize,pcross,pmutation) % Finds a maximum of a function of several variables. % fmaxga solves problems of the form: % max F(X) subject to: LB <= X <= UB % BestPop - 最优的群体即为最优的染色体群 % Trace - 最佳染色体所对应的目标函数值 % FUN - 目标函数 % LB - 自变量下限 % UB - 自变量上限 % eranum - 种群的代数,取100--1000(默认200) % popsize - 每一代种群的规模;此可取50--200(默认100) % pcross - 交叉概率,一般取0.5--0.85之间较好(默认0.8) % pmutation - 初始变异概率,一般取0.05-0.2之间较好(默认0.1) % pInversion - 倒位概率,一般取0.05-0.3之间较好(默认0.2) % options - 1*2矩阵,options(1)=0二进制编码(默认0),option(1)~=0十进制编 %码,option(2)设定求解精度(默认1e-4) % % ------------------------------------------------------------------------ T1=clock; if nargin<3, error('FMAXGA requires at least three input arguments'); end if nargin==3, eranum=200;popsize=100;pCross=0.8;pMutation=0.1;pInversion=0.15;options=[0 1e-4];end if nargin==4, popsize=100;pCross=0.8;pMutation=0.1;pInversion=0.15;options=[0 1e-4];end if nargin==5, pCross=0.8;pMutation=0.1;pInversion=0.15;options=[0 1e-4];end if nargin==6, pMutation=0.1;pInversion=0.15;options=[0 1e-4];end if nargin==7, pInversion=0.15;options=[0 1e-4];end if find((LB-UB)>0) error('数据输入错误,请重新输入(LB 蚁群算法matlab精讲及仿真 4.1基本蚁群算法 4.1.1基本蚁群算法的原理 蚁群算法是上世纪90年代意大利学者M.Dorigo,v.Maneizz。等人提出来的,在越来越多的领域里得到广泛应用。蚁群算法,是一种模拟生物活动的智能算法,蚁群算法的运作机理来源于现实世界中蚂蚁的真实行为,该算法是由Marco Dorigo 首先提出并进行相关研究的,蚂蚁这种小生物,个体能力非常有限,但实际的活动中却可以搬动自己大几十倍的物体,其有序的合作能力可以与人类的集体完成浩大的工程非常相似,它们之前可以进行信息的交流,各自负责自己的任务,整个运作过程统一有序,在一只蚂蚁找食物的过程中,在自己走过的足迹上洒下某种物质,以传达信息给伙伴,吸引同伴向自己走过的路径上靠拢,当有一只蚂蚁找到食物后,它还可以沿着自己走过的路径返回,这样一来找到食物的蚂蚁走过的路径上信息传递物质的量就比较大,更多的蚂蚁就可能以更大的机率来选择这条路径,越来越多的蚂蚁都集中在这条路径上,蚂蚁就会成群结队在蚁窝与食物间的路径上工作。当然,信息传递物质会随着时间的推移而消失掉一部分,留下一部分,其含量是处于动态变化之中,起初,在没有蚂蚁找到食物的时候,其实所有从蚁窝出发的蚂蚁是保持一种随机的运动状态而进行食物搜索的,因此,这时,各蚂蚁间信息传递物质的参考其实是没有价值的,当有一只蚂蚁找到食物后,该蚂蚁一般就会向着出发地返回,这样,该蚂蚁来回一趟在自己的路径上留下的信息传递物质就相对较多,蚂蚁向着信息传递物质比较高的路径上运动,更多的蚂蚁就会选择找到食物的路径,而蚂蚁有时不一定向着信 息传递物质量高的路径走,可能搜索其它的路径。这样如果搜索到更短的路径后,蚂蚁又会往更短的路径上靠拢,最终多数蚂蚁在最短路径上工作。【基于蚁群算法和遗传算法的机器人路径规划研究】 该算法的特点: (1)自我组织能力,蚂蚁不需要知道整体环境信息,只需要得到自己周围的信息,并且通过信息传递物质来作用于周围的环境,根据其他蚂蚁的信息素来判断自己的路径。 (2)正反馈机制,蚂蚁在运动的过程中,收到其他蚂蚁的信息素影响,对于某路径上信息素越强的路径,其转向该路径的概率就越大,从而更容易使得蚁群寻找到最短的避障路径。 (3)易于与其他算法结合,现实中蚂蚁的工作过程简单,单位蚂蚁的任务也比较单一,因而蚁群算法的规则也比较简单,稳定性好,易于和其他算法结合使得避障路径规划效果更好。 (4)具有并行搜索能力探索过程彼此独立又相互影响,具备并行搜索能力,这样既可以保持解的多样性,又能够加速最优解的发现。 4.1.2 基本蚁群算法的生物仿真模型 a为蚂蚁所在洞穴,food为食物所在区,假设abde为一条路径,eadf为另外一条路径,蚂蚁走过后会留下信息素,5分钟后蚂蚁在两条路径上留下的信息素的量都为3,概率可以认为相同,而30分钟后baed路径上的信息素的量为60,明显大于eadf路径上的信息素的量。最终蚂蚁会完全选择abed这条最短路径,由此可见,matlab实现Kmeans聚类算法
三个遗传算法matlab程序实例
matlab蚁群算法精讲及仿真图
相关主题
文本预览