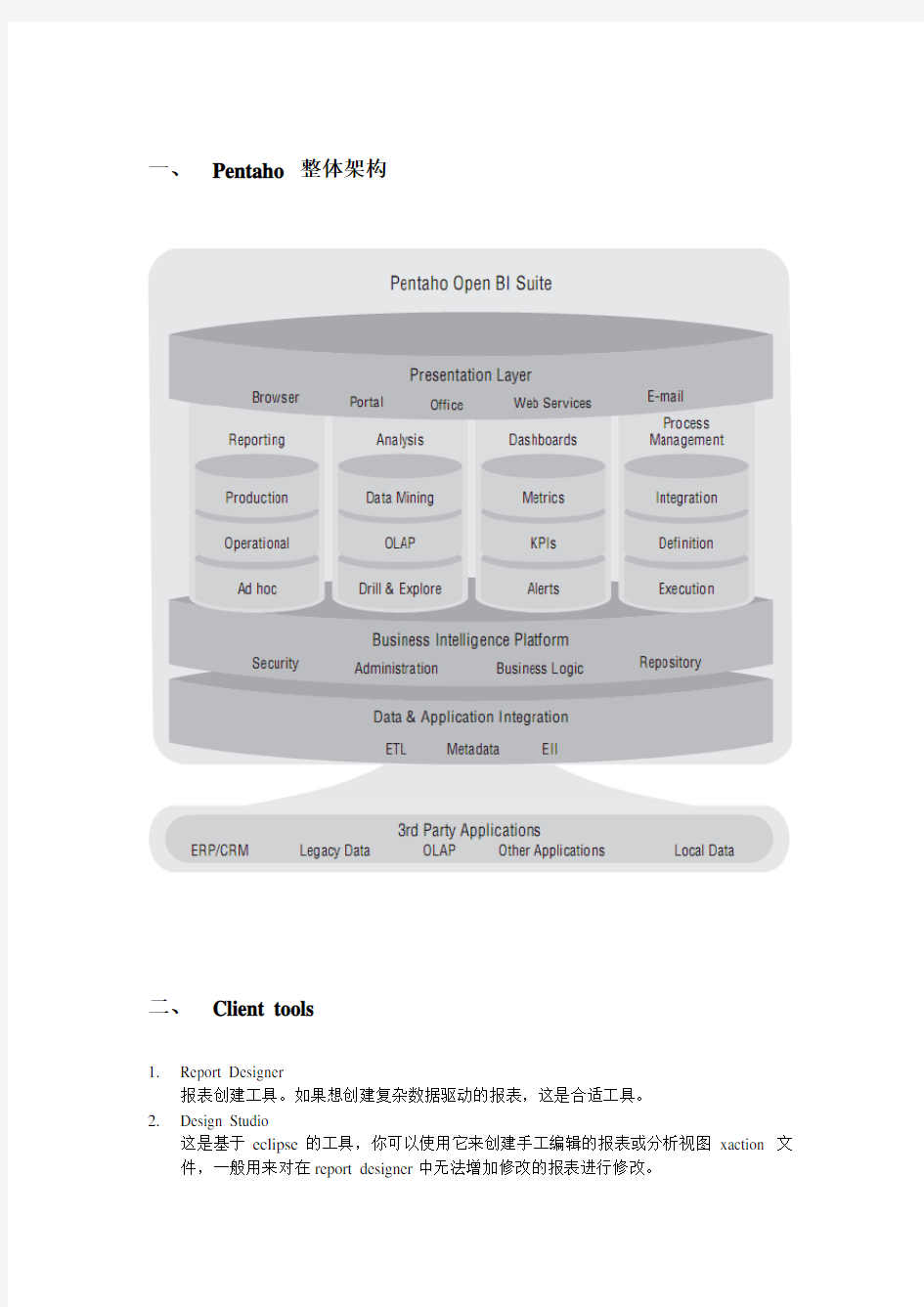

一、Pentaho 整体架构
二、Client tools
1.Report Designer
报表创建工具。如果想创建复杂数据驱动的报表,这是合适工具。
2.Design Studio
这是基于eclipse的工具,你可以使用它来创建手工编辑的报表或分析视图xaction 文件,一般用来对在report designer中无法增加修改的报表进行修改。
3.Aggregation Designer
帮助改善Mondrian cube 性能的图形化工具。
4.Metadata Editor
用来添加定制的元数据层到已经存在的数据源。一般不需要,但是它对应业务用户在创建报表时解析数据库比较容易。
5.Pentaho Data Integration
这是kettle etl工具。
6.Schema Workbench
帮助你创建rolap的图形化工具。这是为分析准备数据的必须步骤。
三、Pentaho BI suit community editon安装
硬件要求:
RAM:At least 2GB
Hard drive space:At least 1GB
Processor:Dual-core AMD64 or EM64T
软件要求:
需要JRE 1.5版本,1.4版本已经不再支持。
修改默认的端口8080,打开\biserver-ce\tomcat\conf目录下的server.xml文件,修改 四、配置数据库连接 如果要是pentaho bi server能连接到关系数据库,需要将相应数据库driver的jar包拷贝到server/biserver-ce/tomcat/common/lib目录。 为了能在administration console中创建数据库连接并测试,需要将相应的数据库driver 的jar包拷贝到server/administration console/jdbc目录。下面是具体关系数据库连接设置说明。 1、连接oracle数据库。 需要将oracle的driver类class12.jar包拷贝到 /Pentaho/server/enterprise-console-server/jdbc/ 或 /biserver-ee/server/enterprise-console-server/jdbc/ /Pentaho/server/bi-server/tomcat/common/lib/ 或 /biserver-ee/server/bi-server/tomcat/common/lib/目录。 执行\Pentaho\Server\administration-console目录下的start-pac.bat启动admin console或 bi server。 在Adminstrator console中配置数据库连接: 在iE中输入http://localhost:8099/后进入管理界面,点左边的administrator,在右边窗口中点database connection进入下面的界面。 在name中输入要创建的数据库连接的名称,在driver class中选择要使用的driver类,user name中输入访问数据库的用户、password中输入相应的密码,在url中输入访问数据库的连接信息:jdbc:oracle:thin:@xzq:1521:oradata。在@之前的是固定信息,@之后分别是服务器名称或IP:端口号:数据库服务名。 2、连接MS Sql server数据库 在iE中输入http://localhost:8099/后进入管理界面,点左边的administrator,在右边窗口中点database connection进入下面的界面。 在name中输入要创建的数据库连接的名称,在driver class中选择要使用的driver类,user name中输入访问数据库的用户、password中输入相应的密码,在url中输入访问数据库的连接信息: jdbc:Microsoft:sqlserver://localhost:41433;DatabaseName=GOSLDW。//前的字符是固定的,//后是数据库服务器名或ip地址:端口号;DatabaseName=数据库名。 五、Report Designer创建报表 5.1. 创建步骤 第一步:定义数据源,创建dataset 第二步:定义report layout,report layout有一组band构成,包括report header、report footer、group header、group footer以及detail构成。 第三步:部署报表到BI server. 5.2. 创建report title 在左边的工具栏上拖一个label报表元素到report header band中,双击label报表元素输入你想要的report title,如图5-2。你可以在右边的属性窗口中对该title进行属性定义,包括字体大小、颜色、样式等。 图5-2 创建report title 5.3. 创建column header 在report title下加几个label报表元素,构成你需要的column header,如图5.3所示。 图5-3 创建column header 5.4. 创建report detail 报表的Detail本身将产生报表的明细记录,这些记录有dataset提供,因此需要将dataset 中的字段拖入report detail band即可,如图5-4。 图5-4 产生report detail 5.5. 创建report summary 在report footer band加上汇总元素的描述标签和相应的汇总计算字段,如图5-5所示。 这里的关键是需要生产汇总计算字段,图中生成了两个library count 和total library size,要产生这两个汇总字段,需要在右边data页的function中增加function字段,分别利用了count(running)和summary(running)函数 5.6. 画布大小设置 点击菜单file->page setup,出现图5.6所示的界面,在该界面中可以设置画布的大小 图5.6 5.7. 创建图表 所有图表都有一个show label属性,默认是hide label,在这种情况下,图表上不会显示相应的值,图表上能显示的值一般有三种情况,分别是0、1、2(对pie chart有3),分别表示系列的描述、category 描述、项值,如果需要组合显示,可以采用{0},{2}这样的格式来表示。 5.7.1.Bar chart Bar chart对比较不同类别数据的大小是有用的。 在左边的工具按钮中拖入chart图标到report header,如图5.7.1 图5.7.1 双击该图出现图5.7.2所示的属性窗口 图5.7.2 bar chart属性设置 在左边窗口中设置相关的显示属性,在右边窗口中指定显示的数据字段。这样就完成了图形报表的创建。 技巧: Pentaho中的数据集是同报表绑定的,如果想在同一报表中显示多张chart报表,需要利用sub report,在不同的sub report中分别创建报表完成。 5.7.2.区域图(Area chart) 区域图用于比较两个或多个数据集间的差异是有用的。 5.7.3.线性图(line chart) 线性图对分析发展趋势是有用的。 注意,堆积和堆积百分比(stack and stack percent)不能用于line chart。 5.7.4.饼图(pie chart) 饼图一般用来分析不同category占总值的占比分析。 饼图有一个label format属性,该属性值有以下几种: {0}:series name, {1}::series raw value {2}:percentage value {3}:total raw value 5.7.5.环形图(ring chart) 环形图类似于饼图,除了它呈现为环形,而饼图是实体填充外,没有什么差异。 5.7. 6.多饼图(muti pie chart) 根据category呈现一组饼图,每一个category对应一个饼图。 5.7.7.瀑布图(warterfall chart) 瀑布图呈现了唯一一个跨category的stacked bar chart。这种图形对于一个category同另一个category进行比较时是有用的。通常最后一个category等于所有别的category的总和。 5.7.8.条形和线形组合图(bar line chart) 在比较category值的同时查看趋势。这是一个需要两个category 数据集的图形,第一个产生bar chart,第二个产生line chart。 5.7.9.冒泡图(bubble chart) 冒泡图允许你查看三维数据,前两维是传统的X/Y维,也就是域和范围(domain and range)。第三维代表单个气泡的大小。 六、将pentaho的资料库迁移到oracle数据库 默认情况下是使用HSQLDB数据库作为pentaho的资料库。 迁移步骤: 1、将oracle JDBC驱动class12.jar拷贝到..\tomcat\webapps\pentaho\WEB-INF\lib 或..\tomcat\common\lib目录,供pentaho BI服务器访问oracle 数据库使用。另外也 需要将oracle JDBC驱动拷贝到administration-console\jdbc目录,否则用户不能正常 使用pentaho管理控制台。 2、初始化Oracle 10g数据库。依次执行下面的sql包,在执行sql包前先创建两个用户, quartz/password,用于存储quartz相关信息,另一个用户hibuser/password用户存储 pentaho bi服务本身资料库。Sql包说明: ●Create_repository_Ora.sql,用于创建pentaho_tablespace表空间、新增 hibuser/password用户,以及datasource 表。 ●Create_sample_datasource_Ora.sql,往datasource表中增加外部业务资料库连接 信息。 ●Create_quartz_ora.sql,创建pentaho_user/password用户,quartz数据库、quartz 表等。 3、修改contex.xml中配置数据库连接的信息。这个文件位于 \biserver-ce\tomcat\webapps\pentaho\META-INF位置。修改该文件中的数据库连接相 关信息。 4、打开biserver-ce\pentaho-solutions\system\hibernate中的hibernate-settings.xml配置文 件,并启用oracle10g.hibernate.cfg.xml配置文件,配置示例如下。 5、调整oracle10g.hibernate.cfg.xml文件,主要是连接数据库的相关信息。 6、修改applicationContext-spring-security-hibernate.properties配置文件,它位于 biserver-ce\pentaho-solutions\system。下面是配置示例。 Jdbc.driver=oracle.jdbc.driver.OracleDriver Jdbc.url=jdbc:oracle:thin@localhost:1521:ORCL https://www.doczj.com/doc/6b6485821.html,ername=hibuser Jdbc.password=password Hibernate.dialect=org.hibernate.dialect.Oracle10Dialect 7、修改quartz.properties,位于biserver-ce\pentaho-solutions\system\quartz目录。当使用 oracle存储quartz的各种信息时,需要启动如下实现类,即默认的 org.quartz.impl.jdbcjobstore.StdJDBCDelegate被替换成OracleDelegate。 Org.quartz.impl.jobstore.driverDelegateClass=org.quartz.impl.jdbcstore.oracle.OracleDe legate 8、可选地,用户需要修改start_hypersonic.bat中的相关信息。 七、设置publication口令 Pentaho设置工具用来定义BI 内容,如report 、olap cube和metadata。在这些工具中创建的内容文件要部署到BI server上,可以通过手工拷贝这些内容文件到pentaho相应的solution文件夹下来完成部署,但典型的方式还是通过publication来完成部署。 为了能完成publication,需要设置相应的口令,默认情况下是没有设置口令的。为了设置这个口令,需要在pentaho-solution/system目录下的publisher_config.xml文件中添加 这个例子中将password设置为”password”。 八、Pentaho Data integration Pentaho DI包含的主要工具和实用程序: Spoon –图形化的DI IDE,用于创建Transformation 和job Kitchen –运行job的命令行工具 Pan –运行transformation的命令行工具 Carte –在远程主机上运行transformation和job的轻量级服务器。默认的登录用户是cluster/cluster.可以使用Encr –carte Encr—这个用来加密口令,用法为Encr –kettle 下图是关于pentaho DI 各个工具和组件工作情况说明。 Data integration engine负责解释和执行数据集成job和transformation。Data integration engine在物理上是以java库的形式存在,前端可以通过调用公共的api来执行job和 transformation。 Data integration engine也包括pentaho BI server,将job和transformation作为action sequence 的一部分来执行。 Repository。Job 和transformation可以存储在数据库知识库中,前端工具可以通过连接知识库来装载job和tranformation定义。 8.1 自动连接知识库 在user的home目录下的.kettle目录中打开kettle.properties文件,然后添加: KETTLE_REPOSITORY = KETTLE_MD –repository name KETTLE_USER = admin -- credential user name KETTLE_PASSWORD = admin --user password 这样每次启动spoon时,可以自动登录默认的repository。 8.2使用集群 要使用集群,首先要定义相关的子服务器(slave server),然后定义cluster schema,最后将定义好的cluster schema分配给相应的Transformation step。 8.3创建数据库连接 在spoon IDE中在Transformation 树结构中右键单击“数据库连接”->新建连接或新建数据库连接向导或按快捷键F3进入“创建数据连接”窗口。 目前支持几乎所有的数据库连接。 数据库连接选项: 1) Connection name:定义转换或者任务访问的连接的唯一名称,可以自行设置; 2) Connection type:连接的数据类型; 3) Method of access:可以是Native(JDBC),ODBC,或者OCI,一般选择JDBC; 4) Server host name:指定数据库部署的主机或者服务器的名称,也可以指定IP 地 址; 5)Database name:指定连接的数据库的名称,如果是ODBC 方式就指定DSN 名称; 6)Port number:设定数据库监听的TCP/IP 端口号 7)User name/password:指定连接数据库的用户名和密码; 数据库用法: 8.4 Transformation Step 8.4.1.Text File input 这个step用来读取各种不同类型的text-file类型文件,常见的是由excel生成的cvs文件和固定宽度的flat file。 该组件提供了指定文件列表或文件目录列表的能力,支持正则表达式,还可以接收前面步骤生成的文件。 8.4.2.表输入(table input) 该组件用来从数据库获取信息。主要的属性有数据库连接、sql等。在sql中可以使用变量,如果使用了变量,则必须勾选上“替换sql 语句中的变量”选项,否则变量不能传入,sql 语句将报错。 “允许延迟转换”选项可以避免不必要的数据类型转换,改善数据处理性能。 8.4.3.获取系统信息(get system info) 该组件用来获取kettle环境中可用的信息。 8.4.4.行发生器(generate rows) 产生多行,具体产生多少行可以通过设置limit(限制)来做设定。可以通过field(字段)列表来指定字段名称及类型。 8.4.5.输入(De-serialize from file,原名cube输入) 从二进制的kettle cube文件中读取记录行数据。 8.4.6.XBase输入 使用这一步可以读取大多数被称为XBase family派生的DBF文件。 8.4.7.Excel输入 该组件可以从一个或多个excel文件中读取数据,可以使用正则表达式来指定文件。 8.4.8.插入或更新(insert/update) 这个组件首先使用一个或多个对照key来查询表中的一行,如果找到,则更新,如果没有找到则插入。 选项 1、步骤名称:步骤的名称,在单个转换中必须唯一。 2、连接:目标表所在的数据库连接名称。 3、Target schema:要写入数据的表的Schema 名称。允许表名中包含“.”是很重要的。 4、目标表:想插入或者更新的表的名称。 5、Commit size:提交之前要改变(插入/更新)的行数。 6、不执行任何更新:如果被选择,数据库的值永远不会被更新。仅仅可以插入。 7、用来查询的关键字:可以指定字段值或者比较符。可以用以下比较符:=, <>,<,<=,>,LIKE,BETWEEN,IS NULL,IS NOT NULL。 8、更新字段:指定你想要插入/更新的字段 8.4.9.更新(Update) 这个步骤类似于插入/更新步骤,除了对数据表不作插入操作之外。它仅仅执行更新操作。 8.4.10.删除(Delete) 这个步骤类似于上一步,除了不更新操作。所有的行均被删除。 8.4.11.XML 输出(XML output) 这个步骤允许你从源中写入行到一个或者多个XML 文件。 选项 8.4.12.数据库查询(Database lookup) 这个步骤类型允许你在数据库表中查找值。 选项 步骤名称:在单一转换中步骤名称必须唯一。 数据库连接:想要写入数据的连接。 查询表:想要查询的表名。 使用缓存:数据库查询是否使用缓存。这意味着在某种查询值的条件下,每次数据 库都能返回同样的结果。 8.4.13.流查询(Stream lookup) 这个步骤类型允许你从其它步骤中查询信息。首先,“源步骤(lookup step)”的数据被读到内存中, 然后被用来从主要的流中查询数据。 选项 步骤名称:在单个转换中步骤名必须唯一。 源步骤:数据来源的步骤名称 查询值所需要的关键字:允许你来指定用来查询值的字段名称。值总是用“等于” 比较符来搜索。 接收的字段:你可以指定用来接收字段的名称,或者在值没有找到的情况下的缺省 值,或者你不喜欢旧的字段名称的情况下的新字段名称 Preserve Memory:排序的时候对数据行进行编码以保护内存 Key and value are exactly one integer field: 排序的时候对数据行进行编码 以保护内存 Use sorted list:是否用一个排序列表来存储值,它提供更好的内存使用。 这个步骤的使用类似于数据库查询步骤,区别在于数据库查询使用的是数据库表,而流查询是从文本文件等数据流中查询。 8.4.14.调用数据库存储过程(Call DB Procedure) 这个步骤允许你运行一个数据库存储过程,获取返回结果。 8.4.15.字段选择(select value) 该组件对于选择、重命名或修改字段的长度和精度方面很有用。这几方面被放在了不同的category中,在组件上分别放在不同的tab中。 8.4.16.过滤记录(Filter rows) 这个步骤允许你根据条件和比较符来过滤记录。 一旦这个步骤连接到先前的步骤中,你可以简单的单击“ 选项 步骤名称:步骤的名称,在单一转换中必须唯一。技术资料,【Kette3.0用户手册】 发送“true”数据给步骤:指定条件返回true的数据将发送到此步骤。 发送“false”数据给步骤:指定条件返回false 的数据将发送到此步骤。 8.4.17.空操作(什么也不做)(dummy(do nothing)) 该组件什么也不做,只是用来做一些测试时的占位符。 8.4.18.Row DeNormalizer(行转列) 该组件做行转列。在“构成分组的字段”中指定分组字段,在“目标字段”中指定“目标字段”的名称,目标字段的值字段(从哪个字段中获取值)和“关键字值”。如下图所示的样例: 8.4.19.列转行(Row normaliser) 用于将列转行 例如下表的数据 转换成下表所示的数据 Row normaliser步骤的设置如下图 8.4.20.拆分字段(split field) 基于指定的分割符信息进行字段拆分。 8.4.21.去重(Unique Rows) 从输入流中去除重复的记录。需要确保输入流是排了序的,否则只有相邻连续的记录会去重。 8.4.22.分组(group by) 这个组件用来根据一组分组字段进行计算。 选项 步骤名称:步骤的名称,在单一转换中必须唯一。 分组字段:指定分组的字段。 聚合:指定需要聚合的字段、方法以及新字段结果的名称 包含所有的行:如果选择这个,输出中就包含所有的行,不仅仅是聚合。临时文件目录:临时文件存储的目录。 临时文件前缀:指定命名临时文件时的文件文件前缀。 添加行号,每一个分组重启:如果你想添加行号,就选择这个。 字段名行数:指定行号将插入的字段的名称。 8.4.23.设置为空值(Null if) 如果某个字符串的值等于指定的值,设置那个值为空。 8.4.24.计算器(Calculator) 这个步骤提供一个功能列表,可以在字段值上运行。 计算器的一个重要优势是,它有着几倍于常用的JavaScript 脚本的速度。 8.4.25.行扁平化(flattener) 这个操作类似行转列(分组字段,对某一列进行行转列) KETTLE 开源ETL软件】【安装配置与使用说明】 2015 年09 月 修订记录 目录 修订记录 (2) 1.安装与配置 (4) 1.1ETL 与K ETTLE概述 (4) 1.2K ETTLE的下载与安装 (7) 1.2.1Windows下安装配置 ............................................ Kettle 8 1.2.2Linux 下安装配置.................................................. Kettle 10 1.2.3Kettle 下安装..................................................... JDBC数据库驱动15 1.2.4下配置资源库连接 (15) 1.2.5Kettle 下 Hadoop Plugin 插件配置 (17) 2.KETTLE组件介绍与使用 (19) 2.1K ETTLE SPOON使用 (19) 2.1.1组件树介绍 (20) 2.1.2使用示例.......................................................... 1 23 2.1.3使用示例.......................................................... 2 37 2.1.4使用Kettle 装载数据到..................................... HDFS 48 2.1.5使用Kettle 装载数据到 (iv) 52 2.1.6使用 Kettle 进行 hadoop的 mapreduce图形化开发 (52) 2.2K ETTLE PAN的使用 (63) 2.3K ETTLE KITECHEN的使用 (64) 2.4C ARTE添加新的ETL执行引擎 (65) 2.5E NCR加密工具 (68) pentaho-kettle-6.1.0.1-R 源码搭建ecplise工程 Pentaho Data Integration(Kettle) 插件开发调试环境搭建(上) 本文转自:https://www.doczj.com/doc/6b6485821.html,/thread-576-1-1.html1. 下载源码https://https://www.doczj.com/doc/6b6485821.html,/pentaho/pentaho-kettle/ https://https://www.doczj.com/doc/6b6485821.html,/pentaho/pentaho-kettle/releases2. 下载kettle发行版本 https://www.doczj.com/doc/6b6485821.html,/projects/data-integration/ (主要是为了获取依赖的jar包)以上两者版本请尽量保持一致。源码的readme文件中描述了源码编译方法,你可以照着步骤作,此方法需要联网下载所有的依赖包,一般非常慢,多数情况会出错。本文所述方法不需要联网下载依赖包,因为几乎所有需要下载的jar包已经在发行版中了。3. 将源码拷贝到eclipse的当前workspace目录下(如 /path/to/eclipse/workspace/pentaho-kettle-master)4. 在当前workspace中新建工程,名称与刚拷贝的目录名称相同(如pentaho-kettle-master)此时eclipse会自动引入编译时代码目录,暂时不理会编译错误。5. 在工程目录下新建libs目录(名称可自己自定义),此目录用于存放源码编译依赖的jar包,来源如下:1) 将kettle发行版本中lib 目录下所有jar包复制到新建的libs目录下2) 将kettle发行版本中libswt目录下相应平台的swt.jar复制到新建的libs目录下(请注意jvm版本,如果系统是win64,但jvm是32,则要选择win32下的swt.jar文件)3) 将kettle发行版本中plugins目录下所有插件目录中lib目录下的jar文件复制到新建的libs目录下4) 如要消除import中mockito相关错误,需要下载mockito-all,并复制到新建的libs目录下,参考下载地址 https://www.doczj.com/doc/6b6485821.html,/maven2/org/mockito/mockito-all/1. 9.5/mockito-all-1.9.5.jar6. 在工程属性中java build path部分,libraries标签页下点击add library,选择JUnit并确定。然后点击add jars,选择libs目录下所有的jar文件(如果未显示libs目录,试试刷新工程再操作),此时基本上编译没 问题了。7. 源码中单元测试部分可能有冲突的类名,此时在工程属性中java build path部分,source标签页下,排除相应的文件即可。8. 修改工程目录(源码目录)中的https://www.doczj.com/doc/6b6485821.html,unch文件,重命名为<工程名>.launch,如https://www.doczj.com/doc/6b6485821.html,unch,然后修改内容,将所有 "@@@"替换为工程名,如pentaho-kettle-master9. 在eclipse中刷新工程,右键点击https://www.doczj.com/doc/6b6485821.html,unch,选择run as 工程名,如果工程编译无错误,此时应该可以启动spoon。10. 在eclipse 工具栏中debug,run中已经有 一、Pentaho 整体架构 cc 二、Client tools 1. Report Designer 报表创建工具。如果想创建复杂数据驱动的报表,这是合适工具。 2. Design Studio 这是基于eclipse的工具,你可以使用它来创建手工编辑的报表或分析视图xaction 文件,一般用来对在report designer中无法增加修改的报表进行修改。 3. Aggregation Designer 帮助改善Mondrian cube 性能的图形化工具。 4. Metadata Editor 用来添加定制的元数据层到已经存在的数据源。一般不需要,但是它对应业务用户在创建报表时解析数据库比较容易。 5. Pentaho Data Integration 这是kettle etl工具。 6. Schema Workbench 帮助你创建rolap的图形化工具。这是为分析准备数据的必须步骤。 三、Pentaho BI suit community editon安装 硬件要求: RAM:At least 2GB Hard drive space:At least 1GB Processor:Dual-core AMD64 or EM64T 软件要求: 需要JRE 1.5版本,1.4版本已经不再支持。 修改默认的端口8080,打开\biserver-ce\tomcat\conf目录下的server.xml文件,修改 目录 1. ETL知识 (3) 1.1. ETL定义 (3) 1.1.1. 定义 (3) 1.1.2. 前提 (3) 1.1.3. 原则 (3) 1.2. 模式及比较 (4) 1.3. ETL过程 (7) 1.3.1. 总流程 (7) 1.3.2. 数据抽取流程 (8) 1.3.3. 数据清洗流程 (8) 1.3.4. 数据转换流程 (10) 1.3.5. 数据加载流程 (11) 1.4. 问题分析 (12) 1.4.1. 字符集问题 (12) 1.4.2. 缓慢变化维处理 (14) 1.4.3. 增量、实时同步的处理 (14) 1.4.4. 断点续传 (15) 1.5. ETL工具 (15) 2. Kettle简介及使用 (16) 2.1. 什么Kettle? (16) 2.2. 下载及安装Kettle (17) 2.3. Kettle简单例子 (19) 2.3.1. 启动Kettle (19) 2.3.2. 创建transformation过程 (20) 2.3.3. 创建job过程 (41) 2.3.4. 命令行运行ktr和kjb (45) 1.ETL知识 1.1.ETL定义 1.1.1.定义 ●定义: 数据的抽取(Extract)、转换(Transform)、装载(Load)的过程。 ●目标: 数据优化。以最小代价(包括对日常操作的影响和对技能的要求) 将针对日常业务操作的数据转化为针对数据仓库而存储的决策支持型数据。 1.1. 2.前提 ●确定ETL范围 通过对目标表信息的收集,确定ETL的范围 ●选择ETL工具 考虑资金 运行的平台、对源和目标的支持程度、可编程的灵活性、对源数据变化的监测、数据处理时间的控制、管理和调度功能、对异常情况的处理 ●确定解决方案 抽取分析、变化数据的捕获、目标表的刷新策略、数据的转换及数据验证 1.1.3.原则 ●应尽量利用数据中转区对运营数据进行预处理。保证数据的安全性、集 成与加载的高效性。 Kettle安装及使用说明 1.什么Kettle? Kettle是一个开源的ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)项目,项目名很有意思,水壶。按项目负责人Matt的说法:把各种数据放到一个壶里,然后呢,以一种你希望的格式流出。Kettle包括三大块: Spoon——转换/工作(transform/job)设计工具(GUI方式) Kitchen——工作(job)执行器(命令行方式) Span——转换(trasform)执行器(命令行方式) Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高 效稳定。Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。 2.Kettle简单例子 2.1下载及安装Kettle 下载地址:https://www.doczj.com/doc/6b6485821.html,/projects/pentaho/files 现在最新的版本是 3.6,为了统一版本,建议下载 3.2,即下载这个文件pdi-ce-3.2.0-stable.zip。 解压下载下来的文件,把它放在D:\下面。在D:\data-integration文件夹里,我们就可以看到Kettle的启动文件Kettle.exe或Spoon.bat。 2.2 启动Kettle 点击D:\data-integration\下面的Kettle.exe或Spoon.bat,过一会儿,就会出现Kettle的欢迎界面: 稍等几秒,就会出现Kettle的主界面: 2.3 创建transformation过程 a.配置数据环境 在做这个例子之前,我们需要先配置一下数据源,这个例子中,我们用到了三个数据库,分别是:Oracle、MySql、SQLServer,以及一个文本文件。而且都放置在不同的主机上。 Oralce:ip地址为192.168.1.103,Oracle的实例名为scgtoa,创建语句为:create table userInfo( id int primary key, Pentaho 开放源码的商业智能平台 技术白皮书 摘要 所有组织都希望在业务过程和总性能中通过改善效率和有效性来提高收入,降低成本,达到改善收益的目的。而商业智能(BI) 软件供应商声称他们有相应技术来满足这种需求。 这些软件供应商销售用于构建这些解决方案(Solution)的产品或工具,但很少关注客户 面临的真正问题。客户为了新需求,而不断去联系新的供应商,买进新的工具,聘请新的顾问。最终,公司的BI initiative 变成了众多相互独立的解决方案(Solution),为了维护和协调它们,需要使用各种昂贵的调度管理程序来整合各个方案。 在现有方案中,每为解决一个特定问题,就设计一个应用平台,这样在实际应用中,一个业务问题被分割成许多单独的任务,如报表,分析,数据挖掘,工作流等等,而没有应用负责初始化,管理,验证或调整结果,最终需要人手动的来弥补这些不足。 这个白皮书描述了Pentaho 商业智能平台:一个面向解决方案(Solution)的BI 平台,其将开放源码组件/公开标准和流程驱动引擎集成在一起。它显示了这个BI 平台如何通过将BI 和工作流/流程管理相结合,并对之进行改善,并以开放源码的形式发布平台来解决BI 问题。 问题描述 传统的商业智能(BI) 工具昂贵、复杂,并且在效率和性能方面具有很大不足,难于让 企业获得真正益处。各个软件供应商均承诺其BI 将提供整合,分析和报表等必要功能, 将数据转换成蕴涵价值的知识,使管理者得到更及时有用的决策信息。不幸的是,这种 BI 系统和报表系统几乎并没有什么太大的差别,仅仅如此是不能满足需求的。 当传送一个报表,或遇到一个特定情形时,需要触发一些特定的应对操作:重新响应决 策,并需要发现引发这些变化的原因,或启动一个特定流程。在这些案例中,信息展示, 分析和传送(BI) 是一个较大流程里的一部分。我们需要这样的流程来解决商业问题。 (译者注:作者强调业务流程是商业问题的关键。BI只是业务流程的一部分。) 为澄清: 通常一个商业问题的解决方案(Solution)是一个包含商业智能(BI) 的流程。 开源商业智能分析工具和报表工具介绍 在大数据和开放数据的重要性日益增长的经济体中,为了以精确和可读的格式分析和呈现数据,企业应当采用什么工具? 此文涵盖了有助于解决此问题的一些工具,包括顶级的开源商业智能(BI)工具以及报表工具。如有其它同类优秀项目,欢迎回复补充。 01BIRT BIRT 是一个开源技术平台,用于创建可视化数据和报表。它源自开源的Eclipse 项目,于2004 年首次发布。 BIRT 由多个组件组成,主要组件包括报表设计器和BIRT 运行时。另外还提供三个额外的组件:报表引擎、报表设计器和报表阅读器。使用这些组件,可以作为独立解决方案来进行开发和发布报表。 BIRT 是用Java 编写的,根据EPL 许可证授权,最新的版本可在Windows、Linux 和Mac 上运行。 02JasperReport JasperReport 是广为流行的开源报表工具之一,在数十万个生产环境中使用,分社区和商业支持版本。JasperReport 同样由多个组件组成,包括JasperReport Library、JasperReport Studio 和JasperReport Server。ETL、OLAP 和服务器组件为JasperReport 提供了良好的企业环境,使其更容易与现有的IT 体系结构集成。 JasperReport 有优秀的文档、wiki 和一些其他资源的支持,以Java 编写,可运行在Windows、Linux 和Mac 上,根据AGPL 许可证授权。 03Pentaho Pentaho 是一个完整的商业智能套件,涵盖从报告到数据挖掘的各种用例。Pentaho BI 套件包含多个开源项目,Pentaho Reporting 就是其中之一。像其他工具一样,Pentaho Reporting 具有丰富的功能集,可以在企业组织中使用。 Pentaho BI 套件还包含Pentaho BI 服务器。这是一个J2EE 应用程序,通过基于Web 的用户界面提供运行和查看报告的基础架构。 KETTLE使用自己总结的Kettle使用方法和成果说明 简介 Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。 Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。 Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。 Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。 Kettle可以在https://www.doczj.com/doc/6b6485821.html,/网站下载到。 注:ETL,是英文Extract-Transform-Load 的缩写,用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程。ETL 一词较常用在数据仓库,但其对象并不限于数据仓库。 下载和安装 首先,需要下载开源免费的pdi-ce软件压缩包,当前最新版本为5.20.0。 下载网址:https://www.doczj.com/doc/6b6485821.html,/projects/pentaho/files/Data%20Integration/然后,解压下载的软件压缩包:pdi-ce-5.2.0.0-209.zip,解压后会在当前目录下上传一个目录,名为data-integration。 由于Kettle是使用Java开发的,所以系统环境需要安装并且配置好JDK。 ?Kettle可以在https://www.doczj.com/doc/6b6485821.html,/网站下载 ? 下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可。运行Kettle 进入到Kettle目录,如果Kettle部署在windows环境下,双击运行spoon.bat 或Kettle.exe文件。Linux用户需要运行spoon.sh文件,进入到Shell提示行窗口,进入到解压目录中执行下面的命令: # chmod +x spoon.sh # nohup ./spoon.sh &后台运行脚本 这样就可以打开配置Kettle脚本的UI界面。 下载社区版的几个文件: Pe nt a h o5.4 部署到o ra l ce 11g 解压:b i s er v er -c e 进入b i s er v er -c e 目录,运行s t ar t -pen t ah o .ba t 脚本,启动用户端服务器,访问地址:h tt p ://l o c a l h o s t:8080/pen t ah o 访问用户admin/password 访问成功表示系统环境没有问题。 F:\pen t ah o \b i s er v er -c e -5.1.0.0-752\b i s er v er -c e \d a t a \o ra c l e10g 下有O R A C L E 建库脚本,需要自己修改,这里提供已经改好的: 创建oracle 的表空间,用户等:通过oracle 的PL/SQL 执行脚本,记得执行脚本时,登录PL/SQL 需要切换登录用户。 PentahoBIServer 有两个功能性的数据库(除了案例的数据库)——theHibernatedatabaseandtheQuartz d a t aba s e . A 、TheHibernatedatabase 的功能是负责PentahoBIServer 的内容储存和运行; B 、 TheQuartzdatabase 的功能是负责PentahoBI S o l u ti o n 计划任务的调度管理; 1.执行以上脚本。 2. oracle11g 使用ojdbc6.jar ,oracle10用o j d b c 14.j ar 包,放到b i s er v er -c e \t o m c a t \li b 目录下,o ra c l e j d b c 驱动包,并要重启bi 服务器 3. 完成后,修改对应的配置文件指向新的数据库即可: Pentaho工具 使用手册 目录 BI 介绍 (2) Pentaho产品介绍 (2) Pentaho产品线设计 (3) Pentaho BI Platform安装 (4) Pentaho Data Integration-------Kettle (8) Pentaho Report Designer (13) Saiku (24) Schema Workbench (28) 附件 (33) BI 介绍 1. BI基础介绍 挖掘技术对客户数据进行系统地储存和管理,并通过各种数据统计分析工具对客户数据进行分析,提供各种分析报告,为企业的各种经营活动提供决策信息。其中的关键点是数据管理,数据分析,支持决策。 根据要解决问题的不同,BI系统的产出一般包括以下三种: 2. BI系统的产出 2.1 固定格式报表 固定格式报表是BI最基本的一种应用,其目的是展示当前业务系统的运行状态。固定格式报表一旦建立,用户就不可以更改报表的结构,只能依据数据库的数据不断刷新报表,以便取得较新的数据。在pentaho产品线中,我们使用pentaho report designer来实现固定格式报表的需求。 2.2 OLAP分析 OLAP分析是指创建一种动态的报表展示结构,用户可以在一个IT预定义的数据集中自由选择自己感兴趣的特性和指标,运用钻取,行列转换等分析手段实现得到知识,或者验证假设的目的。在pentaho产品线中,我们使用Saiku来实现OLAP分析的需求。 2.3 数据挖掘 数据挖掘是BI的一种高级应用。数据挖掘是指从海量数据中通过数据挖掘技术得到有用的知识,并且以通俗易懂的方式表达知识,以便支持业务决策。在pentaho产品线中,我们使用weka来实现数据挖掘的需求。 Pentaho产品介绍 1. 产品介绍 Pentaho产品文档 1 Pentaho公司介绍 (1) 2 Pentaho产品简介 (1) 2.1 Pentaho mobile BI (1) 2.1.1实时和交互式可视化 (1) 2.1.2功能齐全的移动优化界面 (2) 2.2 Pentaho Business Analytics (2) 2.2.1 功能强大的交互可视化 (2) 2.2.2 用于商业洞察的分析面板 (3) 2.2.3 易于使用的交互式动态报表 (3) 2.2.4 流线型管理 (4) 2.2.5 完整的数据集成 (4) 2.2.6 简单的拖拽可视化设计器 (5) 2.2.7 预测性分析方案 (5) 2.3 Pentaho Big Data Analytics (6) 2.3.1 完整的大数据平台 (6) 2.3.2 交互式的分析方案、报表、可视化功能和面板 (7) 2.3.3 自适应大数据层 (8) 2.3.4 强大的数据挖掘和预测分析方案 (8) 2.4 Pentaho Data Integration (9) 2.4.1 针对拖拽式开发的简单可视化设计器 (9) 2.4.2 零编码要求的大数据集成 (10) 2.4.3 本地灵活支持所有大数据源 (10) 2.4.4 强大的管理 (12) 2.4.5 数据剖析数据质量信息 (12) 2.5 Embedding Pentaho Analytics (12) 2.5.1 提供定制化分析方案 (12) 2.5.2 Pentaho支撑程序 (13) 2.5.3 开放的架构和标准,支持广泛的扩展 (13) 2.5.4 正确的合作伙伴和商业条款 (13) 3 版本介绍 (14) 4 成功案例 (14) 5 Pentaho全球合作伙伴 (15) demo,利用kettle的api,将一个数据源中的信息导入到另外一个数据源中:[java]view plain copy 1.package https://www.doczj.com/doc/6b6485821.html,.saidi.job; 2. 3.import https://www.doczj.com/doc/6b6485821.html,mons.io.FileUtils; 4.import org.pentaho.di.core.KettleEnvironment; 5.import org.pentaho.di.core.database.DatabaseMeta; 6.import org.pentaho.di.core.exception.KettleDatabaseException; 7.import org.pentaho.di.core.exception.KettleXMLException; 8.import org.pentaho.di.core.plugins.PluginRegistry; 9.import org.pentaho.di.core.plugins.StepPluginType; 10.import org.pentaho.di.trans.TransHopMeta; 11.import org.pentaho.di.trans.TransMeta; 12.import org.pentaho.di.trans.step.StepMeta; 13.import org.pentaho.di.trans.steps.insertupdate.InsertUpdateMeta; 14.import org.pentaho.di.trans.steps.tableinput.TableInputMeta; 15. 16.import java.io.File; 17. 18./** 19. * Created by 戴桥冰 on 2017/1/16. 20. */ 21.public class TransDemo { 22. 23.public static TransDemo transDemo; 24. 25./** 26. * 两个库中的表名 27. */ 28.public static String bjdt_tablename = "test1"; 29.public static String kettle_tablename = "test2"; 30. 31./** 32. * 数据库连接信息,适用于DatabaseMeta其中一个构造器 DatabaseMeta(String xml) 33. */ 34.public static final String[] databasesXML = { 35. 36."" + 37." 云计算大数据处理分析六大最好工具 2016年12月 一、概述 来自传感器、购买交易记录、网络日志等的大量数据,通常是万亿或EB的大小,如此庞大的数据,寻找一个合适处理工具非常必要,今天我们为大家分享在大数据处理分析过程中六大最好用的工具。 我们的数据来自各个方面,在面对庞大而复杂的大数据,选择一个合适的处理工具显得很有必要,工欲善其事,必须利其器,一个好的工具不仅可以使我们的工作事半功倍,也可以让我们在竞争日益激烈的云计算时代,挖掘大数据价值,及时调整战略方向。 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设计的硬件和软件工具进行处理。该数据集通常是万亿或EB的大小。这些数据集收集自各种各样的来源:传感器、气候信息、公开的信息、如杂志、报纸、文章。大数据产生的其他例子包括购买交易记录、网络日志、病历、事监控、视频和图像档案、及大型电子商务。大数据分析是在研究大量的数据的过程中寻找模式,相关性和其他有用的信息,可以帮助企业更好地适应变化,并做出更明智的决策。 二、第一种工具:Hadoop Hadoop 是一个能够对大量数据进行分布式处理的软件框架。但是 Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理 PB 级数据。此外,Hadoop 依赖于社区服务器,因此它的成本比较低,任何人都可以使用。 Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:●高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。 ●高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的, 这些集簇可以方便地扩展到数以千计的节点中。 Kettle配置使用文档说明 一、安装配置Kettle系统环境 1.安装前准备 JAVA安装文件下载地址: https://www.doczj.com/doc/6b6485821.html,/technetwork/java/javase/downloads/java-archive-downloa ds-javase6-419409.html 1.Windows下安装JDK1.6,并配置环境变量 ##下载Jdk1.6.exe直接执行安装程序 2.Linux下配置JDK1.6,并配置环境变量 ###下载JDK1.6到目录/usr/java/ ###更改JDK可执行权限 chmod +755 jdk1.6.xx.bin ###执行安装 ./jdk1.6.xx.bin ###配置JAVA环境变量 vi /etc/profile # java 1.6 setup JAVA_HOME=/usr/java/jdk1.6.0_43 PATH=$JAVA_HOME/bin:$PATH CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export JAVA_HOME PATH CLASSPATH ###应用环境变量 source /etc/profile ###查看JAVA版本信息 java -version 2.Kettle下载解压到指定目录,下载kettle标准版工具包: https://www.doczj.com/doc/6b6485821.html,/project/pentaho/Data%20Integration/4.4.0-stable/p di-ce-4.4.0-stable.zip 解压到目录: D:\data-integration (目录可根据实际情况自定义) 二、Kettle基本操作过程 数据库操作说明: 生产数据库: 10.176.0.221 DB : e2tms4 用户名: e2tms4 密码:1234567 本地文本文件: D:\Db_file\outfile.txt Kettle数据仓库: 10.176.0.221 DB : kettledb用户名: kettle 密码:1234567 1.启动Kettlet应用程序, 打开D:\data-integration\下面的Kettle.exe或Spoon.bat,出现Kettle的欢迎界面之后出现用户登录界面,先不加载配置,点击”没有资源库”,打开程序主界面, Pentaho BI安装及配置手册 安装 下载 资源说明 准备工作 注:由于Pentaho BI服务器默认是从自带的Tomcat中启动的,如果机器上本来就安装了Tomcat,并设置了相关环境变量,就有可能启动Pentaho BI时会启动之前安装的Tomcat。 运行 注意: Pentaho BI在登录时默认可能列出用户列表,或者显示示例用户的用户名和,如下: 需要将biserver-ce\pentaho-solutions\system\pentaho.xml文件里的配置为如下才可以避免: 配置 JVM参数 为了优化性能,一般需要调整JVM参数。 修改文件biserver-ce\start-pentaho.bat: 通常-Xmx参数取值不超过物理内存的1/2,-Xms取值最好不要低于-Xmx的1/2。不过,不同生产环境的差异性太大,建议用户能够在生产前进行严格的压力及调优测试,并灵活调整JVM参数。 日志输出策略 Pentaho BI服务器默认采用Log4j记录各种日志。 配置文件位于biserver-ce\tomcat\webapps\pentaho\WEB-INF\classes\log4j.xml 可根据需要修改日志输出策略。 Tomcat参数 为提高BI 服务器的并行吞吐能力,除了调整JVM参数外,还需要调整Tomcat参数。 配置文件位于biserver-ce\tomcat\conf\server.xml 通常,我们需要调整maxThreads、minSpareThreads、maxSpareThreads、acceptCount等参数取值。大部分情况下,可以考虑将它们的取值设置成默认的2倍左右,即maxThreads设置成300、minSpareThreads设置成50、maxSpareThreads设置成150、acceptCount设置成200。 报表发布密码设置 设置完发布密码,可直接将report-design程序设计的报表发布到服务器上。 参见:https://www.doczj.com/doc/6b6485821.html,/display/Reporting/8.+Publishing+a+Report 数据库迁移到Oracle 默认数据库为HSQLDB,用biserver-ce\data\start_hypersonic.bat可启动。 由于HSQLBD不能支撑真实企业应用,所以生产环境必须替换,这里以迁移到Oracle为例。 关于Pentaho ETL工具Kettle转换实现原理的研究·ETL和Kettle简介 ETL即数据抽取(Extract)、转换(Transform)、装载(Load)的过程。它是构建数据仓库的重要环节。数据仓库是面向主题的、集成的、稳定的且随时间不断变化的数据集合,用以支持经营管理中的决策制定过程。 Kettle 是”Kettle E.T.T.L. Envirnonment”只取首字母的缩写,这意味着它被设计用来帮助你实现你的ETTL 需要:抽取、转换、装入和加载数据;翻译成中文名称应该叫水壶,名字的起源正如该项目的主程序员MATT 在一个论坛里说的哪样:希望把各种数据放到一个壶里然后以一种指定的格式流出。 Kettle的四大块: Chef——工作(job)设计工具(GUI方式) Kitchen——工作(job)执行器(命令行方式) Spoon——转换(transform)设计工具(GUI方式) Pan——转换(trasform)执行器(命令行方式) Spoon 是一个图形用户界面,它允许你运行转换或者任务,其中转换是用Pan 工具来运行,任务是用Kitchen 来运行。Pan 是一个数据转换引擎,它可以执行很多功能,例如:从不同的数据源读取、操作和写入数据。Kitchen 是一个可以运行利用XML 或数据资源库描述的任务。通常任务是在规定的时间间隔内用批处理的模式自动运行。下面将具体介绍Pan,和Kitchen在ETL中的实现过程。 ·数据转换原理及具体实现过程 大致步骤如下: 转换的过程中(在windows环境下),首先会调用Pan.bat,这一步主要是做一些初始化,连接验证,环境设置,检查之类;然后在Pan的最后一步会调用launcher.jar包,这个包用于启动JDBC驱动,并向JDBC传入相关连接信息和参数,然后开始传数据,最后是完成数据传输,关闭相关协议,写入日志。 首先来看Kitchen的实现,Kitchen在一个job中一般包含以下几个步骤: 转换:指定更细的转换任务,通过Spoon生成。通过Field来输入参数; SQL:sql语句执行; FTP:下载ftp文件; 邮件:发送邮件; 检查表是否存在; 检查文件是否存在; 执行shell脚本:如dos命令。 批处理:(注意:windows批处理不能有输出到控制台)。 Job包:作为嵌套作业使用。 SFTP:安全的Ftp协议传输; HTTP方式的上/下传。 以下是一个简单的ETL过程: Pentaho BI套件的架构与使用权威指南 罗时飞著 https://www.doczj.com/doc/6b6485821.html, 2010年4月23日 【版权所有、侵权必究】 目录 序 ........................................................................................................................................ VIII 前言 ....................................................................................................................................... X 1 商业智能概述 .. (1) 1.1 BI发展动向及趋势 (1) 1.1.1 从察觉已实施BI项目的问题启程 (1) 1.1.2 开源BI在导演BI行业的未来 (2) 1.1.3 一些客户对开源BI软件的担忧 (4) 1.2 主流开源BI套件 (5) 1.2.1 Pentaho BI套件 (6) 1.3 小结 (7) 2 迈入Pentaho BI 3.5开源套件 (8) 2.1 下载及安装Pentaho BI平台 (8) 2.1.1 初识Pentaho BI服务器 (9) 2.1.2 启用Pentaho管理控制台 (10) 2.2 配置Pentaho BI平台 (11) 2.2.1 调整宿主BI服务器的JVM参数 (11) 2.2.2 调整BI服务器的日志输出策略 (12) 2.2.3 调整宿主BI服务器的Apache Tomcat参数 (12) 2.2.4 将Pentaho BI服务器的资料库迁移到Oracle数据库 (13) 2.2.5 将Pentaho BI服务器的资料库迁移到MySQL数据库 (17) 2.2.6 保护Pentaho管理控制台 (19) 2.3 小结 (20) 3 数据加工王者-Kettle (21) 3.1 ETL及Kettle概述 (21) Pentaho报表设计器入门 本文档版权所有?2011 Pentaho Corporation。未经Pentaho Corporation书面许可,不得转载。所有商标均为其各自所有者的财产。 帮助和支持资源 如果您有本指南未涉及的问题,或者如果要报告文档中的错误,请联系您的Pentaho技术支持代表。 支持相关问题应通过Pentaho客户支持门户网站https://www.doczj.com/doc/6b6485821.html,提交。 有关如何购买支持或启用其他命名支持联系人的信息,请联系您的销售代表,或发送电子邮件 至sales@https://www.doczj.com/doc/6b6485821.html,。 有关本指南涵盖的讲师指导的培训信息,请访问https://www.doczj.com/doc/6b6485821.html,/training。 责任限制和免责声明 本文作者在编写内容及其中包含的方案时,尽最大的努力。这些努力包括开发,研究和测试理论和程序,以确定其有效性。作者和发行人对这些程序或本书中包含的文档不作任何明示或暗示的保证。 作者和Pentaho不对因提供,表演或使用程序,相关说明和/或声明而造成的或由此产生的附带或后果性损害负责。 商标 Pentaho(TM)和Pentaho标志是Pentaho Corporation的注册商标。所有其他商标均为其各自所 有者的财产。商标名称可能会出现 贯穿本文档。 Pentaho不是列出拥有商标的名称和实体,也不是每次提到商标名称都插入商标符号,Pentaho表示,它只是为了编辑而使用这些名称,并且为了商标所有者的利益,无意侵犯对该商标。 公司信息 百度公司 Citadel International, Suite 340 5950 Hazeltine National Drive Orlando,FL 32822 电话:+1 407 812-OPEN(6736) 传真:+1 407 517-4575 https://www.doczj.com/doc/6b6485821.html, E- 邮箱:communityconnection@https://www.doczj.com/doc/6b6485821.html, 销售查询:sales@https://www.doczj.com/doc/6b6485821.html, 文件建议:documentation@https://www.doczj.com/doc/6b6485821.html, 注册我们的通讯:https://www.doczj.com/doc/6b6485821.html,/newsletter/ ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少,这里我介绍一个我在工作中使用了3年左右的ETL工具Kettle,本着好东西不独享的想法,跟大家分享碰撞交流一下!在使用中我感觉这个工具真的很强大,支持图形化的GUI 设计界面,然后可以以工作流的形式流转,在做一些简单或复杂的数据抽取、质量检测、数据清洗、数据转换、数据过滤等方面有着比较稳定的表现,其中最主要的我们通过熟练的应用它,减少了非常多的研发工作量,提高了我们的工作效率,不过对于我这个.net研发者来说唯一的遗憾就是这个工具是Java编写的。 1、Kettle概念 Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。 Kettle中文名称叫水壶,该项目的主程序员MATT希望把各种数据放到一个壶里,然后以一种指定的格式流出。 Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。 Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。 2、下载和部署 Kettle可以在https://www.doczj.com/doc/6b6485821.html,/网站下载 下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可 3、Kettle环境配置(有Java环境的直接忽略此章节) 3、1安装java JDK 1)首先到官网上下载对应JDK包,JDK1.5或以上版本就行; 2)安装JDK; 3)配置环境变量,附配置方式:Kettle开源ETL平台_安装配置及使用说明v1.1
pentaho-kettle-6.1.0.1-R 源码搭建ecplise工程
pentaho介绍
ETL及kettle介绍
pentaho-Kettle安装及使用说明(例子)
Pentaho 开放源码的商业智能平台技术白皮书
开源商业智能分析工具和报表工具介绍
自己总结的Kettle使用方法和成果
pentaho5.4部署到oralce11g-ok
pentaho 4.5工具使用手册
Pentaho产品文档
ETL之kettle进行二次开发简单demo
大数据分析的六大工具介绍
Kettle4.4配置使用文档说明
Pentaho BI的安装及配置手册
Pentaho ETL工具Kettle转换实现原理
Pentaho BI套件的架构与使用权威指南
pentaho_report_designer汉译版官方使用文档
ETL利器KETTLE实战应用解析系列一 KETTLE使用介绍
相关主题
文本预览