
东华大学管理学院管理科学与工程专业2010级
统计学实验报告
——居民消费价格指数的统计学分析
学号:100750324
姓名:
指导老师:周力
分数
居民消费价格指数的统计学分析
背景描述:
统计学在经济管理领域有着广泛的应用,本文将应用统计学对中国1978年至2006年的居民消费者价格指数进行分析,分析的方面包括(1)历年居民消费价格指数,(2)历年城市居民消费价格指数,(3)历年农村居民消费者价格指数,(4)历年商品零售价格指数,(5)历年工业品出厂价格指数,以及(6)2006年居民消费价格分类指数,其中前五个指数均以1978或者1985年为基年,最后一个指数以2005年为基年。本文一共应用了统计描述、散点图、箱形图、回归、移动平均法、指数平滑法、假设检验、方差分析、定基指数、环比指数等方法进行统计学分析。
其中对历年商品零售价格指数进行回归,以探究其回归方程,把握数据的变动规律;对历年商品零售价格指数进行移动平均预测和指数平滑预测;对城市居民消费价格指数和农村居民消费价格指数做假设检验,检验两者均值是否有显著性差异;对商品零售价格指数和工业品出厂价格指数做价格检验,检验两者均值是否有显著性差异;对居民消费价格分类指数中的各类(共有“食品”、“烟酒及用品”、“衣着”、“家庭设备用品及服务”、“医疗保健和个人用品”、“交通和通信”、“娱乐教育文化用品及服务”、“居住”八大类)进行方差分析,检验各类消费价格指数的均值是否有显著性差异,探究此案例中分类型自变量是否对数值型自变量有显著性影响;将定比指数换算环比指数,探究环比指数之下变动情况并且与定比指数的情况进行对比。
数据采集方式:
《中国统计年鉴(2007年版)》第309页
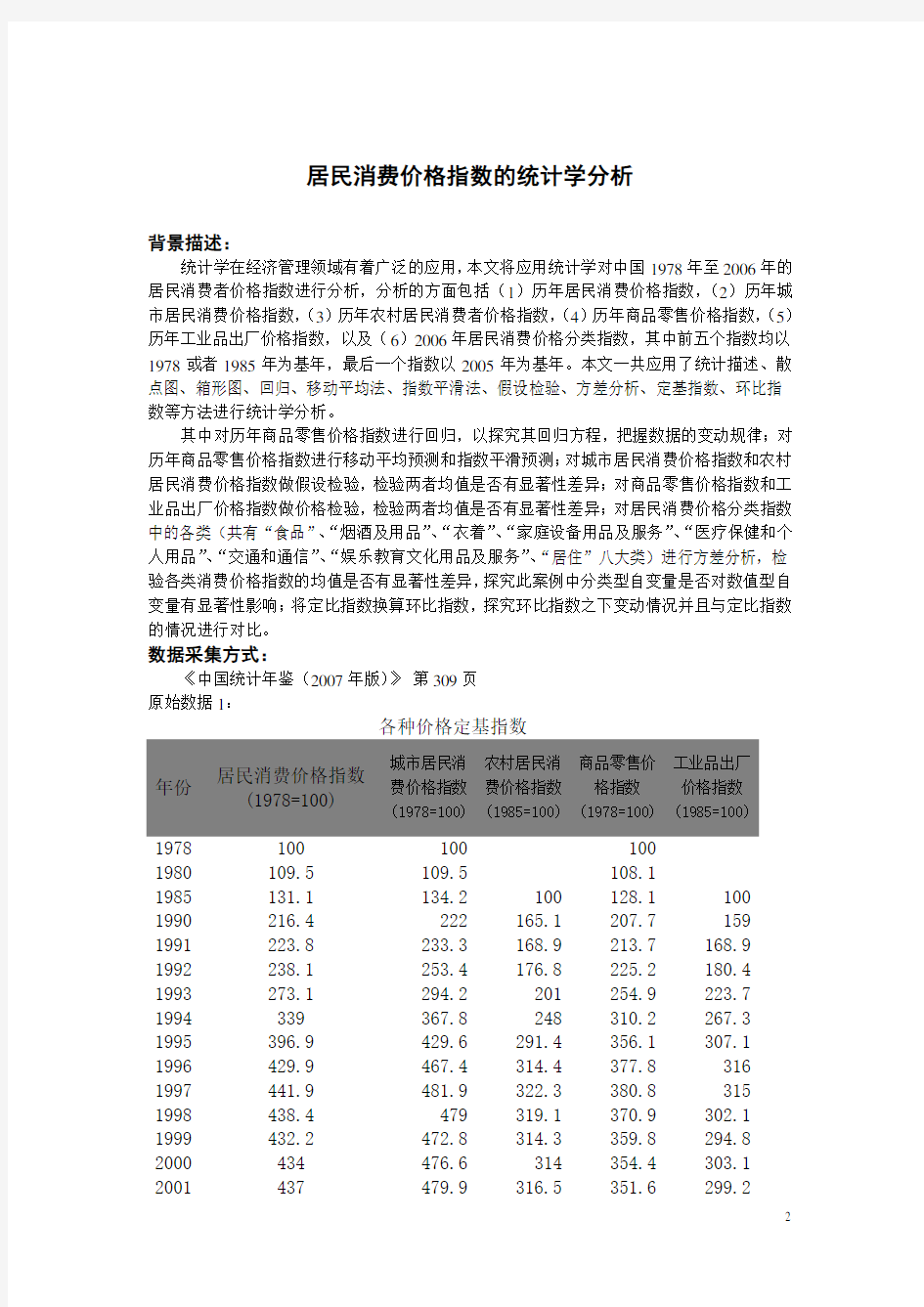
原始数据1:
各种价格定基指数
年份居民消费价格指数
(1978=100)
城市居民消
费价格指数
(1978=100)
农村居民消
费价格指数
(1985=100)
商品零售价
格指数
(1978=100)
工业品出厂
价格指数
(1985=100)
1978 100 100 100
1980 109.5 109.5 108.1
1985 131.1 134.2 100 128.1 100 1990 216.4 222 165.1 207.7 159 1991 223.8 233.3 168.9 213.7 168.9 1992 238.1 253.4 176.8 225.2 180.4 1993 273.1 294.2 201 254.9 223.7 1994 339 367.8 248 310.2 267.3 1995 396.9 429.6 291.4 356.1 307.1 1996 429.9 467.4 314.4 377.8 316 1997 441.9 481.9 322.3 380.8 315 1998 438.4 479 319.1 370.9 302.1 1999 432.2 472.8 314.3 359.8 294.8 2000 434 476.6 314 354.4 303.1 2001 437 479.9 316.5 351.6 299.2
2002 433.5 475.1 315.2 347 292.6 2003 438.7 479.4 320.2 346.7 299.3 2004 455.8 495.2 335.6 356.4 317.6 2005 464 503.1 343 359.3 333.2 2006 471 510.6 348.1 362.9 343.2
原始数据2:
居民消费价格分类指数(2006年)
项目全国
居民消费价格指数
食品
粮食
大米104.3
面粉99.7
淀粉101.8
干豆类及豆制品100.8
油脂98.6
肉禽及其制品97.1
蛋96
水产品101.2
菜
鲜菜108.2
调味品102.3
糖111.2
茶及饮料
茶叶101.2
饮料100.9
干鲜瓜果
鲜果121.5
糕点饼干面包101.3
液体乳及乳制品100.9
在外用膳食品101.6
其他食品101.2
烟酒及用品
烟草100.2
酒101.2
吸烟、饮酒用品100.7
衣着
服装99
衣着材料100.5
鞋袜帽100.2
衣着加工服务费101.5
家庭设备用品及服务
耐用消费品
家具100.2
家庭设备101.2 室内装饰品100 床上用品99.6 家庭日用杂品101.1 家庭服务及加工维修服务费105.8 医疗保健和个人用品
医疗保健
医疗器具及用品97.2
中药材及中成药99.9
西药98.4 保健器具及用品100.3
医疗保健服务103 个人用品及服务
化妆美容用品99.7
清洁化妆用品99.9
个人饰品110.8
个人服务102.5 交通和通信
交通
交通工具97.8 车用燃料及零配件112.8
车辆使用及维修费102.4
市内公共交通费104.8
城市间交通费105.6 通信
通信工具82.2
通信服务100 娱乐教育文化用品及服务
文娱用耐用消费品及服务94.2 教育
教材及参考书100.3
学杂托幼费100 文化娱乐
文化娱乐用品99.6
书报杂志100.7
文娱费102.6 旅游103.1 居住
建房及装修材料103.9 租房102.7 自有住房103.7 水电燃料105.9
针对原始数据1的分析:
预处理:所有数据来源于《中国统计年鉴(2007年版)》,确保真实、完整、有效。
描述性统计:
统计量
Consumer Price Index
N 有效20
缺失20
均值345.215
均值的标准误29.0203
中值431.050
众数100.0a
标准差129.7827
方差16843.546
偏度-.858
偏度的标准误.512
峰度-.839
峰度的标准误.992
全距371.0
极小值100.0
极大值471.0
百分位数25 227.375
50 431.050
75 438.625
a. 存在多个众数。显示最小值
由SPSS19中的描述统计中的频率可以得到上表,均值为345.215,中值为431.050,标准差为129.7827,正负三个标准差的范围为-44.1331~734.5631,所有数据均在此范围内,无异常值。偏度为-0.858,为左偏,峰度为-0.839.最大值为471,最小值为100,全距为371.
现在针对“居民消费者价格指数”做回归分析:
SPSS输入页面如下,其中AdjustedYear为调整后的年份
作出散点图如下:
回归分析表如下:
曲线拟合
模型描述
模型名称MOD_3
因变量 1 Consumer Price Index
方程 1 线性
2 对数
3 倒数
4 二次
5 三次
6 复合a
7 幂a
8 S a
9 增长a
10 指数a
11 Logistic a
自变量调整后年份
常数包含
其值在图中标记为观测值的变量未指定
用于在方程中输入项的容差.0001 a. 该模型要求所有非缺失值为正数。
个案处理摘要
N
个案总数40
已排除的个案a20
已预测的个案0
新创建的个案0
a. 从分析中排除任何变量中带有
缺失值的个案。
变量处理摘要
变量
因变量自变量
Consumer Price
Index 调整后年份正值数20 20
零的个数0 0
负值数0 0
缺失值数用户自定义缺失0 0
系统缺失20 20
模型汇总和参数估计值
因变量:Consumer Price Index
方程
模型汇总参数估计值
R 方 F df1 df2 Sig. 常数b1 b2 b3
线性.892 148.210 1 18 .000 57.189 15.611
对数.716 45.348 1 18 .000 -17.181 133.117
倒数.383 11.190 1 18 .004 387.879 -368.306
二次.894 71.830 2 17 .000 40.539 18.563 -.095
三次.955 112.643 3 16 .000 132.432 -23.187 3.293 -.073 复合.898 157.897 1 18 .000 100.784 1.063
幂.827 86.271 1 18 .000 67.968 .560
S .505 18.330 1 18 .000 5.936 -1.654
增长.898 157.897 1 18 .000 4.613 .061
指数.898 157.897 1 18 .000 100.784 .061
Logi
stic
.898 157.897 1 18 .000 .010 .941
自变量为调整后年份。
根据R方值可以看出三次方拟合是最好的,可以得出回归方程为
此时曲线拟合图为:
但是由明显可以看出,预测曲线在末尾是下降趋势,而实际数据在末尾确实上升趋势。所以以1998年(AdjusterY aer=21)为临界点,1998年前后各做回归分析。
首先是1918~1998年:
SPSS曲线回归输出结果如下:
模型汇总和参数估计值因变量:consuner
方程
模型汇总参数估计值
R 方 F df1 df2 Sig. 常数b1 b2 b3
线性.842 48.034 1 9 .000 29.316 17.897
对数.598 13.377 1 9 .005 26.225 102.295
倒数.348 4.810 1 9 .056 309.483 -258.397
二次.980 194.326 2 8 .000 123.610 -12.634 1.464
三次.983 134.540 3 7 .000 102.404 .763 -.040 .046 复合.953 181.816 1 9 .000 80.422 1.085
幂.757 27.996 1 9 .000 74.490 .493
S .484 8.453 1 9 .017 5.688 -1.306
增长.953 181.816 1 9 .000 4.387 .082
指数.953 181.816 1 9 .000 80.422 .082
Logistic .953 181.816 1 9 .000 .012 .922
自变量为 AdjustedYear
根据R方值可以看出三次方拟合是最好的,可以得出回归方程为
y=102.404+0.763x-0.04x2+0.046x3
此时拟合曲线为:
其次是1998~2006年:
SPSS曲线回归输出结果如下:
模型汇总和参数估计值因变量:consumer
方程
模型汇总参数估计值
R 方 F df1 df2 Sig. 常数b1 b2 b3
线性.713 17.391 1 7 .004 331.997 4.518
对数.674 14.500 1 7 .007 94.526 109.050
倒数.634 12.132 1 7 .010 550.160 -2601.821
二次.950 56.439 2 6 .000 1042.211 -52.911 1.149
三次.948 54.635 2 6 .000 805.653 -24.269 .000 .015 复合.713 17.401 1 7 .004 346.108 1.010
幂.675 14.519 1 7 .007 204.283 .242
S .635 12.154 1 7 .010 6.331 -5.777
增长.713 17.401 1 7 .004 5.847 .010
指数.713 17.401 1 7 .004 346.108 .010
Logistic .713 17.401 1 7 .004 .003 .990
自变量为 AdjustedYear。
根据R方值可以看出二次方拟合是最好的,可以得出回归方程为y=1042.211-52.911x+1.149x2
此时曲线拟合图为:
然后用移动平均值法对“居民消费价格指数”做预测:
操作数据如下:
由图可见三期移动平均预测的“标准误差”更小,预测的2007年的消费价格指数为463.6
随后用指数平滑法进行预测:
可见用α=0.5的指数平滑产生的标准误差最小,预测2007年消费价格指数为463.014
α=0.5
α=0.4
α=0.3
然后针对“城市居民消费价格指数”和“农村居民消费价格指数”做假设检验:H0:μ1=μ 2 H1:μ1≠μ2
SPSS输入如下:
SPSS作箱型图如下:
独立样本T检验输出结果如下:
组统计量
分组1 Statistic
Bootstrap a
偏差标准误差
95% 置信区间
下限上限
urban&rural 1.0 N 20
均值373.250 .931 32.006 303.293 435.137
标准差145.7669 -4.9874 17.4844 102.6945 171.3394
均值的标准
误
32.5945
2.0 N 20
均值280.250 -.587 16.514 246.332 310.801
标准差75.1542 -2.7073 12.1777 46.3390 93.0758
均值的标准
误
16.8050
a. Unless otherwise noted, bootstrap results are based on 1000 bootstrap samples
独立样本检验
方差方程的
Levene 检验均值方程的 t 检验
F Sig. t df Sig.(双
侧)
均值差
值
标准误
差值
差分的 95% 置信
区间
下限上限
urban&rural 假设方
差相等
14.547 .000 2.536 38 .015 93.0000 36.6716 18.7622 167.2378
假设方
差不相
等
2.536 28.435 .017 9
3.0000 36.6716 17.9333 168.0667
因P值=0.000<0.05,<0.05,因此拒绝原假设,两组数据均值有显著性差异。
可见我国城市居民与农村居民的消费价格指数有显著差异,城市居民消费价格指数要明显高于农村居民消费价格指数。
之后对“商品零售价格指数”和“工业品出厂价格指数”做假设检验:
H0:μ1=μ 2 H1:μ1≠μ2
用SPSS绘制箱形图如下所示:
用SPSS做独立样本T检验输出结果如下:
组统计量
分组2 Statistic
Bootstrap a
偏差标准误差
95% 置信区间
下限上限
商品零售&工业品出厂 1.0 N 20
均值293.580 .550 20.520 250.207 331.421
标准差95.7651 -3.7847 14.4635 61.5798 114.5060
均值的标准误21.4137
2.0 N 18
均值267.917 -.715 16.163 233.959 296.480
标准差70.1435 -2.4848 12.6125 39.6609 89.3613
均值的标准误16.5330
a. Unless otherwise noted, bootstrap results are based on 1000 bootstrap samples
本科生实验报告 实验课程统计学 学院名称商学院 专业名称会计学 学生姓名苑蕊 学生学号0113 指导教师刘后平 实验地点成都理工大学南校区 实验成绩 二〇一五年十月二〇一五年十月
依据上述资料编制组距变量数列,并用次数分布表列出各组的频数和频率,以及向上、向下累计的频数和频率, 并绘制直方图、折线图。 学生 实验 心得
2.已知2001-2012年我国的国内生产总值数据如表2-16所示。 学生 实验 心得 要求:(1)依据2001-2012年的国内生产总值数据,利用Excel软件绘制线图和条形图。
(2)依据2012年的国内生产总值及其构成数据,绘制环形图和圆形图。 学生 实验 心得 3.计算以下数据的指标数据 1100 1200 1200 1400 1500 1500 1700 1700 1700 1800 1800 1900 1900 2100 2100 2200 2200 2200 2300 2300 2300 2300 2400 2400 2500 2500 2500 2500 2600 2600 2600 2700 2700 2800 2800 2800 2900 2900 2900 3100 3100 3100 3100 3200 3200 3300 3300 3400 3400 3400 3500 3500 3500 3600 3600 3600 3800 3800 3800 4200
4.一家食品公司,每天大约生产袋装食品若干,按规定每袋的重量应为100g。为对产品质量进行检测,该企业质检部门采用抽样技术,每天抽取一定数量的食品,以分析每袋重量是否符合质量要求。现从某一天生产的一批食品8000袋中随机抽取了25袋(不重复抽样),测得它们的重量分别为: 学生实验心得 101 103 102 95 100 102 105 已知产品重量服从正态分布,且总体方差为100g。试估计该批产品平均重量的置信区间,置信水平为95%.
案例题亚太商学院MBA教育 亚太商学院 商业界追求高学历目前流行于全世界。《亚洲公司》1997 年9 月份的一项调查表明,越来越多的亚洲人选择攻读工商管理硕士学位以求在公司取得成功。在亚太地区商学院申请MBA 课程的人数大约每年增长30% 。1997 年,亚太地区的74 个商学院公布了多达170000 个申请人的记录,其中11000 人将在1999 年获得全日制MBA 学位。需求飙升的主要原因是MBA 可以大大提高赚钱的能力。 在该地区,成千上万的亚洲人显得越来越愿意暂时离开工作,而花上两年的时间去追求商业理论证书。这些学校的课程非常难学,包括经济学、银行学、营销学、行为学、劳资关系学、决策学、战略思考、商法等。《亚洲公司》搜集了部分商学院的如下数据,该数据集显示了最佳商学院的某些特征。 注:GMAT、英语测试、工作经验中的“0,1”为虚拟变量,0表示“要求”,1表示“不要求” 请利用所学统计学知识,依据上表所列示的部分亚太商学院MBA教育的样本数据,对整个亚太地区商学院MBA教育情况做出深入分析及解读,譬如MBA教育样本数据的整体分布态势、本国学费与外国学费差异、要
求和不要求英语测试的商学院学生起薪的差异、要求和不要求工作经验的商学院学生起薪平均数的差异等等。 一.描述性统计分析 就总体来看,这25个知名商学院的招生名额较多;无论本国或是外国学生的学费都较为昂贵,并且外国学生学费普遍高于或者等于本国学生学费,但是相差不会太大;国外学生占的比例约为30%,较多;决大部分(72%)商学院要求工作经验,超半数(56%)要求GMAT,一小部分(32%)学院要求英语测试。各个商学院毕业生的起薪差别较大。 二.本国学生学费和外国学生学费比较分析
《统计学》第一次作业 一、单选题(共10个) 1.统计工作的成果是( C )。 A. 统计学 B. 统计工作 C. 统计资料 D. 统计分析和预测 2. 社会经济统计的研究对象是( C )。 A. 抽象的数量关系 B. 社会经济现象的规律性 C. 社会经济现象的数量特征和数量关系 D. 社会经济统计认识过程的规律和方法 3. 对某地区的全部产业依据产业构成分为第一产业、第二产业和第三产业,这里所使用的计量尺度是( A )。 A. 定类尺度 B. 定序尺度 C. 定距尺度 D. 定比尺度 4.某城市工业企业未安装设备普查,总体单位是( D )。 A. 工业企业全部未安装设备 B. 工业企业每一台未安装设备 C. 每个工业企业的未安装设备 D. 每一个工业企业 5.统计总体的同质性是指( B )。 A. 总体各单位具有某一共同的品质标志或数量标志 B. 总体各单位具有某一共同的品质标志属性或数量标志值 C. 总体各单位具有若干互不相同的品质标志或数量标志 D. 总体各单位具有若干互不相同的品质标志属性或数量标志值 6.下列调查中,调查单位与填报单位一致的是(D ) A. 企业设备调查 B. 人口普查 C. 农村耕地调查 D. 工业企业现状调查 7.某灯泡厂为了掌握该厂的产品质量,拟进行一次全厂的质量大检查,这种检查应当选择( D)
A. 统计报表 B. 重点调查 C. 全面调查 D. 抽样调查 8.重点调查中重点单位是指(A ) A. 标志总量在总体中占有很大比重的单位 B. 具有典型意义或代表性的单位 C. 那些具有反映事物属性差异的品质标志的单位 D. 能用以推算总体标志总量的单位 9.书籍某分组数列最后一组是500以上,该组频数为10,又知其相邻组为400-450,则最后一组的频数密度为( A) A. 0.2 B. 0.3 C. 0.4 D. 0.5 10.在组距分组中,确定组限时(B ) A. 第一组的下限应等于最小变量值 B. 第一组的下限应小于最小变量值 C. 第一组的下限应大于最小就量值 D. 最后一组的上限应小于最大变量值 二、多选题(共5个) 1. 按照统计数据的收集方法,可将统计数据分为( AC )。 A. 观测数据 B. 截面数据 C. 实验数据 D. 间数列数据 2. 定比尺度的特点是( ACDE) A. 它有一个绝对固定的零点 B. 它没有绝对零点 C. 它具有定类、定序、定距尺度的全部特性 D. 它所计量的结果不会出现“0”值 E. 它可以计算两个测度值之间的比值 3.下列标志中,属于品质标志的有( BD )。 A. 工资 B. 所有制 C. 耕地面积 D. 产品质量
一.小组成员分配表
二. 调查背景,意义及其可行 选题背景及研究意义: 步入大学的我们,学习的压力不再那么大,竞争意识不断增强,生存的压力和工作的前途越来越逼近我们。但是,对于丰富的周末时间,我校的学生怎么安排,做什么事情,我小组组织了一次调查。 通过这次调查我们可以更好的了解同学们的周末课余时间安排,对于我们如何合理的安排自己的课余时间有借鉴指导意义,并学会安排自己的课余时间做一些积极有益的事。 研究的可行性分析: 1、研究团队了解大学生周末时间安排及其状况,设计调查问卷、在大学里实施比较方便,从而能够获取可靠数据。 2、研究团队学习了应用统计学,掌握了获取数据的有效方法,能够撰写大学生周末时间安排调查报告。 3、能够利用Excel统计软件处理数据,达到预期目的。 三 . 具体实施计划 第一部分调查方案设计 1.调查方案 a)调查目的:通过调查了解大学生的周末时间安排的主要状况,使同学们树 立科学合理的时间观,合理安排周末时间,使同学们能够度过充实的有意义的周末生活。 b)调查对象:济南大学在校生 c)调查单位:抽取的样本学生
d)调查程序: ①设计调查问卷,明确调查方向和内容。 ②分发调查问卷。随机抽取山东科技大学在校大。 ③大一大二大三各30人左右作为调查单位。 2.根据回收有效问卷进行数据分析,具体内容如下: (一)大学生时间安排按各年级分析 ( 二)课余时间安排结构分析 1.看书复习2.兼职3.娱乐 4.社团活动5.其他 3主要思路: 1)根据样本的时间分配安排,分布状况的均值、置信区间等分布的数字特征,推断大学生总体分布的相应参数。 2)根据时间结构安排的各项时间花费安排进行均值之差的比较以及方差比的区间估计. 3)根据大一、大二、大三进行三个总体娱乐及学习和其他时间安排均值之差及方差比的区间估计. 4)根据对时间安排主要分配结构的分析算出频数频率 5)作出结论 4调查时间:2015年5月
“统计学实验”课程实验报告课程编号:21090261K 课程序号:24 课程名称:统计学实验 实验教师: 学生班级: 学生姓名: 学生学号: 实验地点: 实验日期:年月日 实验成绩:
Ⅰ【实验编号】2014_2(数据的图表描述与描述性统计量) Ⅱ【实验内容】 A.第2章机上作业3 某投资者为了对沪深证券市场金融类上市公司有一个全面了解,对其34家金融类上市公司的行业细分、现价等指标整理成如下表格形式: 表2.12 某日沪深金融类上市公司行业细分表 要求: (1)根据上述资料建立SPSS数据集。 (2)绘制金融业行业细分频数分布表、条形图、饼形图。 (3)制作公司现价的频数分布茎叶图、直方图与盒形图。 B.(第2章机上作业6) 为了解和掌握商品广告次数与商品销售额的关联性,某商场记录了10个星期里面广告次数与销售额数据: 表2.13 10个星期里面的广告次数与销售额
要求:绘制散点图,并观察广告次数与销售额两者之间的关系。 C.(第3章机上作业7) 下表是一组大学生外出就餐的月费用样本数据: 表3.14 25名大学生外出吃饭的月费用 253 101 245 467 131 0 225 80 113 69 198 95 129 124 11 178 104 161 0 118 151 55 152 134 169 要求: (1)计算均值、中位数和众数。 (2)确定上下四分位数。 (3)计算极差和四分位差。 (4)计算方差和标准差。 Ⅲ【实验结果】 (实验结果应包括的内容:SPSS主要操作步骤的截屏、主要输出结果的截屏以及必要的分析与结论) Ⅳ【教师评定成绩】
《统计学原理》作业(二) (第四章) 一、判断题 1、总体单位总量和总体标志总量是固定不变的,不能互相变换。(×) 2、相对指标都是用无名数形式表现出来的。(×) 3、能计算总量指标的总体必须是有限总体。(×) 4、按人口平均的粮食产量是一个平均数。(×) 5、在特定条件下,加权算术平均数等于简单算术平均数。(√) 6、用总体部分数值与总体全部数值对比求得的相对指标。说明总体内部的组成状况,这个相对指标是比例相对指标。(×) 7、国民收入中积累额与消费额之比为1:3,这是一个比较相对指标。(×) 8、总量指标和平均指标反映了现象总体的规模和一般水平。但掩盖了总体各单位的差异情况,因此通过这两个指标不能全面认识总体的特征。(√) 9、用相对指标分子资料作权数计算平均数应采用加权算术平均法。(×) 10、标志变异指标数值越大,说明总体中各单位标志值的变异程度就越大,则平均指标的代表性就越小。(√) 二、单项选择 1、总量指标数值大小(A) A、随总体范围扩大而增大 B、随总体范围扩大而减小 C、随总体范围缩小而增大 D、与总体范围大小无关
2、直接反映总体规模大小的指标是(C) A、平均指标 B、相对指标 C、总量指标 D、变异指标 3、总量指标按其反映的时间状况不同可以分为(D) A、数量指标和质量指标 B、实物指标和价值指标 C、总体单位总量和总体标志总量 D、时期指标和时点指标 4、不同时点的指标数值(B) A、具有可加性 B、不具有可加性 C、可加或可减 D、都不对 5、由反映总体各单位数量特征的标志值汇总得出的指标是(B) A、总体单位总量 B、总体标志总量 C、质量指标 D、相对指标 6、计算结构相对指标时,总体各部分数值与总体数值对比求得的比重之和(C) A、小于100% B、大于100% C、等于100% D、小于或大于100% 7、相对指标数值的表现形式有( D ) A、无名数 B、实物单位与货币单位 C、有名数 D、无名数与有名数 8、下列相对数中,属于不同时期对比的指标有(B) A、结构相对数 B、动态相对数 C、比较相对数 D、强度相对数
重庆大学 学生实验报告 实验课程名称统计学 开课实验室DS1421 学院建管学院年级2011级 专业班级财管1班 学生姓名丁朝飞学号20110730 开课时间至学年第学期 总成绩 教师签名
建设管理及房地产学院制 《统计学》实验报告 开课实验室:年月日学院建管学院年级、专业、班11级财管01班姓名丁朝飞成绩 课程名称统计学 实验项目 名称 统计学实验 指导教 师 陈政辉 教师 评语教师签名: 年月日
一、实验目的: 通过对具体的搜集到的资料进行计算机操作、处理的训练,熟练掌握分组与分布数列编制的原则,并能根据实际资料设计出适当的统计表和统计图,通过对反映数据分布特征的重要指标的计算练习,使学生更加熟悉普及的Excel在统计学中的运用,切实感受到利用计算机实现资料的整理、计算和分析能够减轻在实践中进行资料处理的负担,进一步提高学生发现问题、分析问题、解决问题的能力。 二、实验内容: A 1. 要求筛选出(1)统计学成绩等于75分的学生;(2)数学成绩高的前3名学生;(3)4门课程成绩都大于70分的学生。 姓名统计学成绩数学成绩英语成绩经济学成绩 张已69 68 84 86 王翔91 75 95 94 田雨54 88 67 78 李华81 60 86 64 赵颖75 96 81 83 宋华83 72 66 71 袁方75 58 76 90 陈云87 76 92 77 刘文55 84 61 82 周克66 62 88 79 程前75 60 72 88 胡纳75 88 90 92 1.选中原始数据,点击“筛选”,出现下图所示窗口
2.统计学成绩等于75分的学生,点击“统计学成绩”上的,弹出下图所示对话框,在标识框 处输入“75” 单击“确定”按钮结果如下: 3.数学成绩高的前3名学生,点击“数学成绩”上的,选择“十个最大的值”,弹出如图所示
统计学实验报告1 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
实验报告
二、打开文件“数据 3.XLS”中“城市住房状况评价”工作表,完成以下操作。 1)通过函数,计算出各频率以及向上累计次数和向下累计次数;2)根据两城市频数分布数据,绘制出两城市满意度评价的环形图三、打开文件“数据 3.XLS”中“期末统计成绩”工作表,完成以下操作。 1)要求根据数据绘制出雷达图,比较两个班考试成绩的相似情况。 实验过程: 实验任务一: 1)利用函数frequency制作一张频数分布表 步骤1:打开文件“数据 3. XLS”中“某公司4个月电脑销售情况”工作表 步骤 2.在“频率(%)”的右侧加入一列“分组上限”,因统计分组采用“上限不在内”,故每组数据的上限都比真正的上限值小0.1,例如:“140-150”该组的上限实际值应为“150”,但我们为了计算接下来的频数取“149.9”. 步骤3.选定C20:C29,再选择“插入函数”按钮 3 步骤 4.选择类别“统计”—选择函数“FREQUENCY”
步骤5.在“data_array”对话框中输入“A2:I13”,在“bins_array”对话框中输入“E20:E29 该函数的第一个参数指定用于编制分布数列的原始数据,第二个参数指定每一组的上限. 步骤6.选定C20:C30区域,再按“自动求和” 按钮,即可得到频数的合计
步骤7.在D20中输入“=(C20/$C$30)*1OO” 步骤8:再将该公式复制到D21:D29中,并按“自动求和”按钮计算得出所有频率的合计。
实验报告 课程名称统计学学号 11学生姓名辅导教师 系别经济与管理系实验室名称实验时间 1.实验名称 统计指数分析 2.实验目的 掌握各项指数的计算及因素分析法的运用。 在 Excel 中完成各项指数及有关数值的计算,主要用到的是公式和公式复制 3.实验内容 甲乙丙三种商品基期和报告期各项数据如下: 价格(元) P销量 q 商品计量单位 基期 p0报告期 p1基期 q0报告期 q1 甲个302810001200 乙双202120001600 丙公斤232515001500 合计 1)计算三种商品的个体销售量指数和个体价格指数。 2)三种商品的销售额总指数。 3)三种商品的销售量总指数和价格总指数。 4)分析销售量变动和价格变动对销售额影响的绝对额。(这一问分析要手写完成) 4.实验原理 在 Excel 中实现综合指数及其相关数值的计算,主要用到的是公式和公式的复制功 能 5.实验过程及步骤 (1)在工作表中输入已知数据的名称和数值(包括商品名称,计量单位,基期价格,报告 期价格,基期销售量和报告期销售量) (2)计算综合指标的各个综合总量在单元格G4中输入公式“ =C4*E4”,在H4中输入“=D4*F4”, 在 I4 中输入“ =C4*F4”, 在 J4 中输入“ =D4*E4”, 公式复制 在 A7 中输入合计,在单元格中输入“=SuM(G4:G6),再将单元格 G7的公式向右复制到 J7 (3)分别计算各个综合指标及其分子分母之差额 在单元格 A10 中输入“销售额总额指数” ,在单元格 F10 中输入公式“ =H7/G7*100” , 在单元格 H10 中输入公式” =H7-G7”
学院:经济管理学院班级:食品经济管理(1)班姓名:张从容学号:0846112 日期:2010年6月 应用统计学大作业 题目: 校友捐赠是高等学校收入的重要来源。如果学校的管理人员能确定影响捐赠的校友所占比例增长的因素,他们就可能制定使学校收入增长的政策。研究表明,对与老师的沟通交往感到比较满意的学生,他们很可能更容易毕业。于是人们可能猜测,人数比较少的班级和比较低的学生—教师比可能有一个比较高的令人满意的毕业率,随后又可能引起给予学校捐赠的校友所占比例的增长。EXCEL文件Alumin给出了48所美国国立大学的有关统计数据。“学生教师比”是注册学生人数除以全体教师人数,单位是倍;“捐赠校友的比例”是给予学校捐赠的校友所占的百分比。 要求: 1、对这些数据做出数值和图示的概述 2、利用回归分析求出估计的回归方程,使这个方程在学生人数少于20人的班级所占的比例已知时,能被用来预测给予学校捐赠的校友所占的比例。 3、利用回归分析求出估计的回归方程,使这个方程在学生教师比已知时,能被用来预测给予学校捐赠的校友所占的比例。 4、从你的分析中,你能得到什么结论或提出什么建议吗? 案例数据:
答:1/1) 首先制作学生人数少于20人的学生比例的图表: 10 20 30 40 50 60 70 80 90 Boston College California Institute of College of William and Mary Dartmouth College Georgetown University Lehigh University Northwestern University Rice University Tulane University U. of California-Irvine U. of California-Santa Barbara U. of Illinois-Urbana Champaign U. of Notre Dame U. of Southern California U. of Washington Wake Forest University 数值和图示的概述: 如果设学生人数少于20人班级的比例为x ,则755.7291666=x 。 从图表(条形图)中可以看出,学生人数少于20人的学校的比例都很高,平均水平在50%以上,约等于55.73%,最高达到了77%,最小值为29%,可以看出美国大学班级学生人数基本都在20人以下,班级人数比较少。 1/2) 其次制作学生教师比例的图表: 数值和图示的概述: 如果设学生与教师的比例为x ,则711.5416666=x 。 从图表(饼图)中可以得出这样的结论,学生和老师人数之间的比例平均在11倍左右,也就是说平均为一个老师带11个学生,而且各学校之间的差异也不是很大(最大值为23,最小值为3)。 20
[标签:标题] 篇一:统计学实验心得体会 统计学实验心得体会 为期半个学期的统计学实验就要结束了,这段以来我们主要通过excl软件对一些数据进行处理,比如抽样分析,方差分析等。经过这段时间的学习我学到了很多,掌握了很多应用软件方面的知识,真正地学与实践相结合,加深知识掌握的同时也锻炼了操作能力,回顾整个学习过程我也有很多体会。 统计学是比较难的一个学科,作为工商专业的一名学生,统计学对于我们又是相当的重要。因此,每次实验课我都坚持按时到实验室,试验期间认真听老师讲解,看老师操作,然后自己独立操作数遍,不懂的问题会请教老师和同学,有时也跟同学商量找到更好的解决方法。几次实验课下来,我感觉我的能力确实提高了不少。统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析、总结,并进而进行推断和预测,为相关决策提供依据和参考。它被广泛的应用在各门学科之上,从物理和社会科学到人文科学,甚至被用来工商业及政府的情报决策之上。可见统计学的重要性,认真学习显得相当必要,为以后进入社会有更好的竞争力,也为多掌握一门学科,对自己对社会都有好处。 几次的实验课,我每次都有不一样的体会。个人是理科出来的,对这种数理类的课程本来就很感兴趣,经过书本知识的学习和实验的实践操作更加加深了我的兴趣。每次做实验后回来,我还会不定时再独立操作几次为了不忘记操作方法,这样做可以加深我的记忆。根据记忆曲线的理论,学而时习之才能保证对知识和技能的真正以及掌握更久的掌握。就拿最近一次实验来说吧,我们做的是“平均发展速度”的问题,这是个比较容易的问题,但是放到软件上进行操作就会变得麻烦,书本上只是直接给我们列出了公式,但是对于其中的原理和意义我了解的还不够多,在做实验的时候难免会有很多问题。不奇怪的是这次试验好多人也都是不明白,操作不好,不像以前几次试验老师讲完我们就差不多掌握了,但是这次似乎遇到了大麻烦,因为内容比较多又是一些没接触过的东西。我个人感觉最有挑战性也最有意思的就是编辑公式,这个东西必须认真听认真看,稍微走神就会什么都不知道,很显然刚开始我是遇到了麻烦。还好在老师的再次讲解下我终于大致明白了。回到寝室立马独自专研了好久,到现在才算没什么问题了。 实验的时间是有限的,对于一个文科专业来说,能有操作的机会不是很多,而真正利用好这些难得的机会,对我们的大学生涯有很大意义。不仅是学习上,能掌握具体的应用方法,我感觉更大的意义是对以后人生路的作用。我们每天都在学习理论,久而久之就会变成书呆子,问什么都知道,但是要求做一次就傻了眼。这肯定是教育制度的问题和学校的设施问题,但是如果我们能利用好很少的机会去锻炼自己,得到的好处会大于他自身的价值很多倍。例如在实验过程中如果我们要做出好的结果,就必须要有专业的统计人才和认真严肃的工作态度。这就在我们的实践工作中,不知觉中知道一丝不苟的真正内涵。以后的工作学习我们再把这些应用于工作学习,肯定会很少被挫 折和浮躁打败,因为统计的实验已经告知我们只有专心致志方能做出好的结果,方能正确的做好一件事。 最后感谢老师的耐心指导,教会我们知识也教会我们操作,老师总是最无私最和蔼的人,我一定努力学习,用自己最大的努力去回报。 篇二:统计学实验报告与总结
统计学实验报告 一、实验主题:大学生专业与实习工作的关系 二、实验背景: 二十一世纪的今天大学生已是一个普遍的社会群体,高校毕业人数日益增加,社会、企业所提供的职位日益紧张,大学生就业问题是当今社会关注的焦点。面对日益沉重的就业压力,越来越多的大学毕业生选择了企业需求的职业,而这种职业与自己在校所学专业根本“无关”或相去甚远,大学毕业生就业专业不对口的现象非常严重。专业对口是个广义的概念,就是说你所学的专业与你所作的工作相关,比如你专业是会计,工作后你到了一个企业做会计,或者到银行做柜员,这都是与经济相关的,这就是对口。如果你学机械设计,但工作后却做了统计员,业务员等于你所学专业无关的工作,这就叫专业不对口。专业不对口导致毕业生所学知识没有用武之地,所以这是一种人力资源的浪费。 三、实验目的: 大学生就业专业不对口是客观存在的问题,我们研究此问题有这几点目的:①了解当代大学生实习工作与专业是否对口的情况,当代大学生对工作与专业不对口现象的态度。②分析大学生就业结构和
专业对口问题,了解当今大学生专业对口情况,为以后大学生选择专业、选择工作岗位提供有效的信息和借鉴。③寻找导致专业不对口的原因,以减少社会普遍存在的人力资源的浪费。 四、实验要求:就相关问题收集一定数量的数据,用EXCEL进行如下 分析:1进行数据筛选、排序、分组;2、制作饼图并进行简要解释;3、制作频数分布图,直方图等并进行简要解释。 五、实验设备及材料:计算机,手机,EXCEL软件,WORD软件。 六、实验过程: (一)制作并发放调查问卷。 (二)收回并统计原始数据:收回了102名大学生填写的调查问卷,并对相关数据进行统计。 (三)筛选与实验相关问题: 1.您的性别( ): A. 男B.女
《统计学原理》作业(一) (第一~第三章) 一、判断题(每小题0.5分,共5分) 1、社会经济统计工作的研究对象是社会经济现象总体的数量方面。(√ ) 2、统计调查过程中采用的大量观察法,是指必须对研究对象的所有单位进行调查。( × ) 3、全面调查包括普查和统计报表。(×) 4、统计分组的关键是确定组限和组距( ×) 5、在全国工业普查中,全国企业数是统计总体,每个工业企业是总体单位。(×) 6、我国的人口普查每十年进行一次,因此它是一种连续性调查方法。(×) 7、对全同各大型钢铁生产基地的生产情况进行调查,以掌握全国钢铁生 产的基本情况。这种调查属于非全面调查。(√) 8、对某市工程技术人员进行普查,该市工程技术人员的工资收入水平是数量标志。(×) 9、对我国主要粮食作物产区进行调查,以掌握全国主要粮食作物生长的 基本情况,这种调查是重点调查。(√) 10、我国人口普查的总体单位和调查单位都是每一个人,而填报单位是户。(√) 二、单项选择题(每小题0.5,共4.5分) 1、设某地区有670家工业企业,要研究这些企业的产品生产情况,总体单位是(C ) A、每个工业企业; B、670家工业企业; C、每一件产品; D、全部工业产品 2、某市工业企业2003年生产经营成果年报呈报时间规定在2004年1月31 日,则调查期限为(B)。 A、一日 B、一个月 C、一年 D、一年零一个月
3、在全国人口普查中(B)。 A、男性是品质标志 B、人的年龄是变量 C、人口的平均寿命是数量标志 D、全国人口是统计指标 4、某机床厂要统计该企业的自动机床的产量和产值,上述两个变量是(D)。 A、二者均为离散变量 B、二者均为连续变量 C、前者为连续变量,后者为离散变量 D、前者为离散变量,后者为连续变量 5、下列调查中,调查单位与填报单位一致的是(D ) A、企业设备调查 B、人口普查 C、农村耕地调查 D、工业企业现状调查 6、抽样调查与重点调查的主要区别是(D)。 A、作用不同 B、组织方式不同 C、灵活程度不同 D、选取调查单位的方法不同 7、下列调查属于不连续调查的是(A)。 A、每月统计商品库存额 B、每旬统计产品产量 C、每月统计商品销售额 D、每季统计进出口贸易额 8、全面调查与非全面调查的划分是以( C ) A、时间是否连续来划分的 B、最后取得的资料是否完全来划分的 C、调查对象所包括的单位是否完全来划分的 D、调查组织规模的大小划分的 9、下列分组中哪个是按品质标志分组( B ) A、企业按年生产能力分组 B、产品按品种分组 C、家庭按年收入水平分组 D、人口按年龄分组 三、多项选择题(每小题0.7分,共4.2分) 1、总体单位是总体的基本组成单位,是标志的直接承担者。因此(A、D) A、在国营企业这个总体下,每个国营企业就是总体单位;
统计分析综合实验报告 学院: 专业: 姓名: 学号:
统计分析综合实验考题 一.样本数据特征分析: 要求收集国家统计局2011年全国人口普查与2000年全国人口普查相关数据,进行二者的比较,然后写出有说明解释的数据统计分析报告,具体要求如下: 1.报告必须包含所收集的公开数据表,至少包括总人口,流动人口,城乡、性别、年龄、民族构成,教育程度,家庭户人口八大指标; 2.报告中必须有针对某些指标的条形图,饼图,直方图,茎叶图以及累计频率条形图;(注:不同图形针对不同的指标)3.采用适当方式检验二次调查得到的人口年龄比例以及教育程度这两个指标是否有显著不同,写明检验过程及结论。 4.报告文字通顺,通过数据说明问题,重点突出。 二.线性回归模型分析: 自选某个实际问题通过建立线性回归模型进行研究,要求: 1.自行搜集问题所需的相关数据并且建立线性回归模型; 2.通过SPSS软件进行回归系数的计算和模型检验; 3.如果回归模型通过检验,对回归系数以及模型的意义进行 解释并且作出散点图
一、样本数据特征分析 2010年全国人口普查与2000年全国人口普查相关数据分析报告 2011年第六次全国人口普查数据显示,总人口数为1370536875,比2000年的第五次人口普查的1265825048人次,总人口数增加73899804人,增长5.84%,平均年增长率为0.57%。
做茎叶图分析: 描述 年份统计量标准误 人口数量2000年均值40084265.35 4698126.750 均值的 95% 置信区间 下限30489410.50 上限49679120.21 5% 修整均值39305445.50 中值35365072.00 方差 68424424372574 4.400 标准差26158062.691 极小值2616329
统计学大作业 Revised as of 23 November 2020
一.小组成员分配表
二. 调查背景,意义及其可行 选题背景及研究意义: 步入大学的我们,学习的压力不再那么大,竞争意识不断增强,生存的压力和工作的前途越来越逼近我们。但是,对于丰富的周末时间,我校的学生怎么安排,做什么事情,我小组组织了一次调查。 通过这次调查我们可以更好的了解同学们的周末课余时间安排,对于我们如何合理的安排自己的课余时间有借鉴指导意义,并学会安排自己的课余时间做一些积极有益的事。 研究的可行性分析: 1、研究团队了解大学生周末时间安排及其状况,设计调查问卷、在大学里实施比较方便,从而能够获取可靠数据。 2、研究团队学习了应用统计学,掌握了获取数据的有效方法,能够撰写大学生周末时间安排调查报告。 3、能够利用Excel统计软件处理数据,达到预期目的。 三 . 具体实施计划 第一部分调查方案设计 1.调查方案 a)调查目的:通过调查了解大学生的周末时间安排的主要状况,使同学们树立科学合理的时间 观,合理安排周末时间,使同学们能够度过充实的有意义的周末生活。 b)调查对象:济南大学在校生 c)调查单位:抽取的样本学生 d)调查程序: ①设计调查问卷,明确调查方向和内容。 ②分发调查问卷。随机抽取山东科技大学在校大。 ③大一大二大三各30人左右作为调查单位。 2.根据回收有效问卷进行数据分析,具体内容如下: (一)大学生时间安排按各年级分析
( 二)课余时间安排结构分析 1.看书复习2.兼职3.娱乐 4.社团活动5.其他 3主要思路: 1)根据样本的时间分配安排,分布状况的均值、置信区间等分布的数字特征,推断大学生总体分布的相应参数。 2)根据时间结构安排的各项时间花费安排进行均值之差的比较以及方差比的区间估计. 3)根据大一、大二、大三进行三个总体娱乐及学习和其他时间安排均值之差及方差比的区间估计. 4)根据对时间安排主要分配结构的分析算出频数频率 5)作出结论 4调查时间:2015年5月 第二部分调查问卷设计 大学生周末时间安排状况问卷调查 您好,我是会计学专业的学生,为了解大学生的周末课余时间安排状况,帮助大学生树立科学合理的时间观,我们为此进行了一次社会调查。我们的调查需要您的配合,此问卷采用匿名填写方式,调查对象采用简单随机抽样的方法随机挑选。若无特殊说明,均为单选。您的参与对我们的调查十分重要,谢谢。 1.您的性别( ) A、男 B、女 2.您所在的年级( ) A、大一 B、大二 C、大三
统计学 实验报告册 姓名: 学号: 专业: 华北水利水电大学管理与经济学院
第一次实验课数据的图表展示及概括性度量 环节1: 统计图表的制作 一、实验目的 熟悉Excel统计软件,学会数据整理与显示。 二、实验要求 利用Excel统计软件,绘制统计图表。 三、实验原理及内容 数据收集后要进行整理和显示,熟悉统计软件,掌握数据整理与显示的操作步骤;学会制作频数分布表;绘制直方图、累计百分比的折线图是最基础的要求。 本节实验要求完成以下内容: 1、数据排序与分组; 2、编制次数分布表与累计次数分布表; 3、制作统计图直方图、累计百分比的折线图表。 四、实验步骤及结论分析 (一)数值型数据数据分组及统计图表的绘制 1、录入数据(某地区60家企业2014年的产品销售收入数据如下表1(单位:万元) 表1某地区60家企业2014年的产品销售收入 152 103 123 105 88 95 105 137 116 117 129 142 117 138 115 97 114 136 97 92 110 124 105 146 124 118 115 119 127 117 119 120 100 100 135 113 108 112 87 87 117 138 107 119 88 129 88 95 125 114 108 105 115 97 107 119 103 104 103 123 2、对数据进行排序 实验步骤: 3、进行数据分组,制作频数分布表(关键点:(1)选择和接收区域同样行数的区域(2)使用=FREQUENCY(原始数据区域,接受数据区域)(3)同时按下Ctrl+Shift+Enter ) 实验步骤:
上海交通大学统计学原 理大作业 公司内部档案编码:[OPPTR-OPPT28-OPPTL98-OPPNN08]
一、案例讨论题 根据中华人民共和国国家统计局网站(,2006年1-8月份全国工业实现利润及同比增长如下图所示。 2006年1-8月份全国工业实现利润及同比增长图 2006年1-8月份,全国规模以上工业企业(全部国有工业企业和年产品销售收入500万元以上的非国有工业企业,下同)实现利润11327亿元,比去年同期增长%。工业经济效益综合指数,比去年同期提高点。 在规模以上工业企业中,国有及国有控股企业实现利润5086亿元,比去年同期增长%;集体企业实现利润339亿元,增长%;股份制企业实现利润6113亿元,增长31%;外商及港澳台商投资企业利润3136亿元,增长%;私营企业实现利润1672亿元,增长%。在39个工业大类中,石油和天然气开采业利润同比增长%,有色金属冶炼及压延加工业增长%,交通运输设备制造业增长53%,专用设备制造业增长%,电力行业增长%,电子通信行业增长%,煤炭行业增长%,化工行业增长%,钢铁行业利润同比下降%,石油加工及炼焦业净亏损378亿元。
规模以上工业企业税金总额8497亿元,同比增长%,其中,国有及国有控股企业税金总额4803亿元,增长%。规模以上工业实现主营业务收入191357亿元,同比增长%,其中,国有及国有控股企业63618亿元,增长%。8月末,规模以上工业企业应收帐款净额30454亿元,同比增长%,其中,国有及国有控股企业应收帐款净额7898亿元,增长9%。工业产成品资金14054亿元,同比增长%,其中,国有及国有控股企业产成品资金3861亿元,增长%。 讨论题: (1)试描述该研究的统计目的; 答:该研究的统计目的是掌握2006年1-8月份全国工业实现利润及同比增长情况. (2)由2006年1-8月份全国工业实现利润及同比增长图可以看出哪些统计数据。 答:由2006年1-8月份全国工业实现利润及同比增长图可以看出的统计数据如下: 2006年1-8月份,全国规模以上工业企业(全部国有工业企业和年产品销售收入500万元以上的非国有工业企业,下同)实现利润11327亿元,比去年同期增长%。 (3)调查了哪些企业; 答:调查了全国规模以上工业企业(全部国有工业企业和年产品销售收入500万元以上的非国有工业企业),其中包括:国有及国有控股企业、集体企业、外商及港澳台商投资企业、私营企业等。 (4)试描述该研究的统计分析过程。
统计学实践作业
参数估计练习题 1. 某大学为了解学生每天上网的时间,在全校7500名学生中采取不重复抽样方法随机抽取36人,调查他们每天上网的时间(单位:小时),得到的数据见book3.1表。 求该校大学生平均上网时间的置信区间,置信水平分别为90%、95%和99%。 平均 3.316666667 标准误差0.268224616 中位数 3.25 众数 5.4 标准差 1.609347694 方差 2.59 峰度-0.887704917 偏度0.211008874 区域 5.9 最小值0.5 最大值 6.4 求和119.4 观测数36 最大(1) 6.4 最小(1) 0.5 置信度 (90.0%) 0.453184918 置信区间 2.863481748 3.769851585 平均 3.316666667 标准误 差0.268224616 中位数 3.25 众数 5.4 标准差 1.609347694 方差 2.59 峰度-0.887704917 偏度0.211008874 区域 5.9 最小值0.5 最大值 6.4 求和119.4 观测数36 最大(1) 6.4 最小(1) 0.5
置信度 (95.0%) 0.544524915 置信区 间 2.772141751 3.861191582 平均 3.316666667 标准误 差0.268224616 中位数 3.25 众数 5.4 标准差 1.609347694 方差 2.59 峰度-0.887704917 偏度0.211008874 区域 5.9 最小值0.5 最大值 6.4 求和119.4 观测数36 最大(1) 6.4 最小(1) 0.5 置信度 (99.0%) 0.730591706 置信区 间 2.58607496 4.047258373 2.某机器生产的袋茶重量(g)的数据见book 3.2。构造其平均重量的置信水 平为90%、95%和99%的置信区间。 平均 3.32952381 标准误 差0.05272334 中位数 3.25 众数 3.2 标准差0.241608696 方差0.058374762 峰度0.413855703 偏度0.776971476 区域0.95 最小值 2.95 最大值 3.9
统计学大作业 啤酒的生产和销售所需的时间相对比较短,库存量比较低。原因是啤酒在短时间内可能会变质,而且库存费用和生产费用相比也比较高。要减少库存量,又要保持较强的市场竞争能力,就需要对生产和需求量的变化及趋势进行分析。以作为制定下一年度生产计划的依据。 时至2010年年底,一家啤酒生产企业要对市场需求量作出定量分析,为制定计划的作准备。现将该企业15年的销售量数据提供如下: 您认为应从哪几个方面进行分析。 序号年份年销售量(万吨) 1 1998 30 2 1999 44 3 2000 57 4 2001 66 5 2002 81 6 2003 98 7 2004 105 8 2005 120 9 2006 140 10 2007 153 11 2008 157 12 2009 164 13 2010 169 14 2011 178
经理室要求计划财务部提供下列有关数据: 1、这些年平均每年啤酒销售的增长量是多少?若按此增长量,2010 年啤酒销售量将达到多少万吨? 2、这些年平均每年啤酒销售的增长率是多少?若按此增长速度增长, 2010年啤酒销售量将达到多少万吨? 3、判断这些年啤酒销售量的变动趋势,并用适当的方法预测2010年 企业啤洒销售量。 4、充分利用最近四年的资料对企业啤酒销售量进一步作季节变动分 析,并预测2010年和2011年各个季的销售量。 5、尽快提出你的建议和意见。 长期趋势测定可以通过对长期趋势的研究和测定,掌握现象的变化的规律性;其次,测定长期趋势,以便消除原有数列中长期的影响,以便更精确的研究季节变动的规律。 1、移动平均法: 序号年份年销售量四项移动平均 1 1998 30 - 2 1999 44 - 3 2000 57 49.25 4 2001 66 62.00 5 2002 81 75.50 6 2003 98 87.50 7 2004 105 101.00 8 2005 120 115.75 9 2006 140 129.50 10 2007 153 142.50 11 2008 157 153.50 12 2009 164 160.75 13 2010 169 - 14 2011 178 -
统计学实验报告
实验一:数据特征的描述 实验内容包括:众数、中位数、均值、方差、标准差、峰度、偏态等实验资料:某月随机抽取的50户家庭用电度数数据如下: 88 65 67 454 65 34 34 9 77 34 345 456 40 23 23 434 34 45 34 23 23 45 56 5 66 33 33 21 12 23 3 345 45 56 57 58 56 45 5 4 43 87 76 78 56 65 56 98 76 55 44 实验步骤: (一)众数 第一步:将50个户的用电数据输入A1:A50单元格。 第二步:然后单击任一空单元格,输入“=MODE(A1:A50)”,回车后即可得众数。 (二)中位数 仍采用上面的例子,单击任一空单元格,输入“=MEDIAN(A1:A50)”,回车后得中位数。 (三)算术平均数 单击任一单元格,输入“=AVERAGE(A1:A50)”,回车后得算术平均数。 (四)标准差 单击任一单元格,输入“=STDEV(A1:A50)”,回车后得标准差。 故实验结果如下图所示:
上面的结果中,平均指样本均值;标准误差指样本平均数的标准差;中值即中位数;模式指众数;标准偏差指样本标准差,自由度为n-1;峰值即峰度系数;偏斜度即偏度系数;区域实际上是极差,或全距。 实验二:制作统计图 实验内容包括: 1.直方图:用实验一资料 2.折线图、柱状图(条形图)、散点图:自编一时间序列数据, 不少于10个。 3.圆形图:自编有关反映现象结构的数据,不少于3个。 实验资料:1.直方图所用数据:某月随机抽取的50户家庭用电度数数据如下: 88 65 67 454 65 34 34 9 77 34 345 456 40 23 23 434 34 45 34 23 23 45 56 5 66 33 33 21 12 23 3 345 45 56 57 58 56 45 5 4 43 87 76 78 56 65 56 98 76 55 44 2.折线图、柱状图(条形图)、散点图、圆形图所用数据: 2005年至2014年各年GDP总量统计如下: 年份 GDP (亿元) 2005 184575.8 2006 217246.6 2007 268631 2008 318736.1 2009 345046.4 2010 407137.8 2011 479576.1 2012 532872.1 2013 583196.7 2014 634043.4 实验步骤: