
《编译原理》课程
实验报告
题目词法分析
专业华侨大学09软件工程
班级1班
学号
姓名
日期2012-4-5
源码下载地址:https://www.doczj.com/doc/633415050.html,/file-1179505.html
一. 实验题目
词法分析
二. 实验环境(操作系统,开发语言)
操作系统:Windows 7
开发语言:JAVA语言
开发工具:MyEclipse8.5
调试环境:JDK-1.7.0
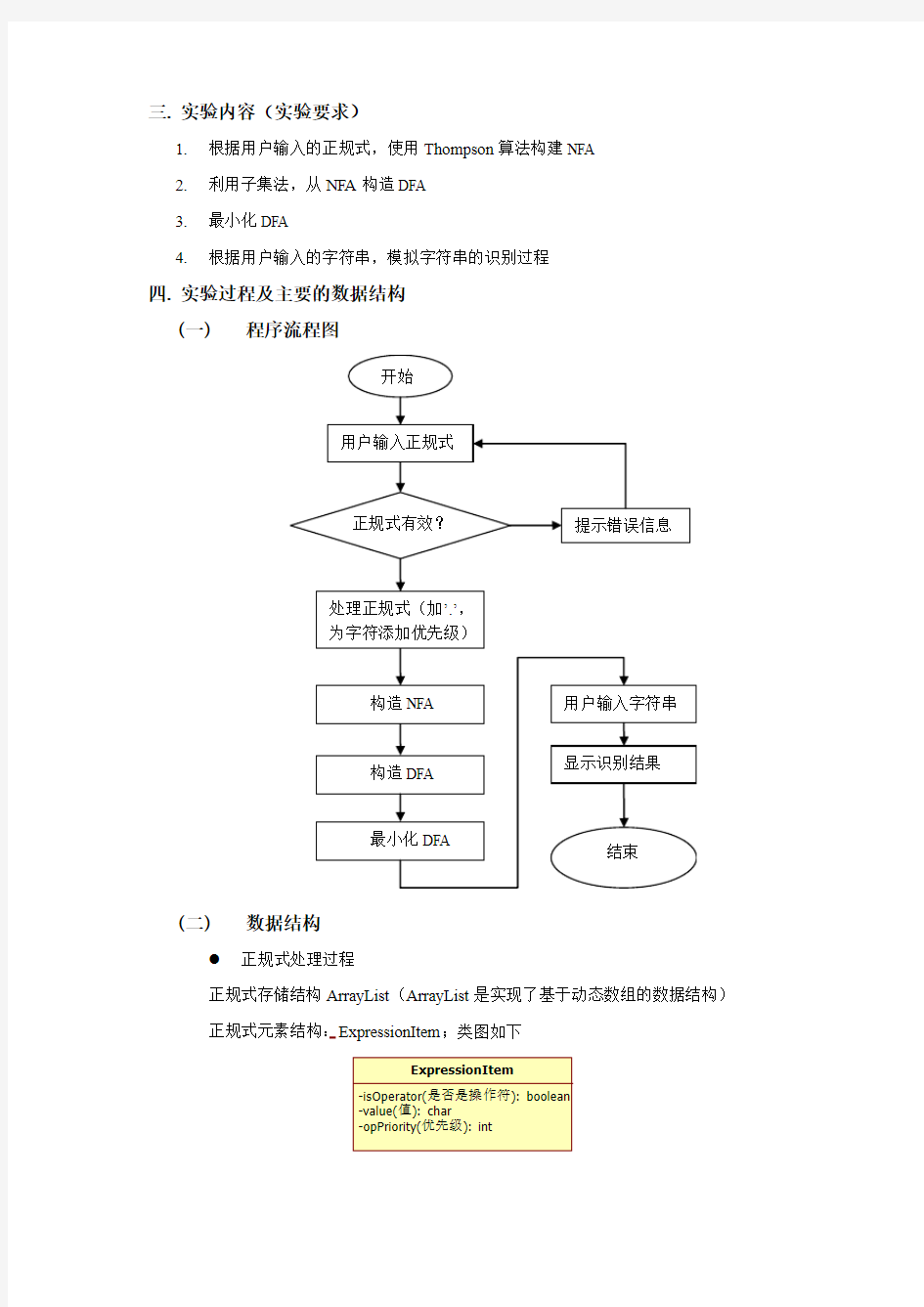
三. 实验内容(实验要求)
1.根据用户输入的正规式,使用Thompson算法构建NFA
2.利用子集法,从NFA构造DFA
3.最小化DFA
4.根据用户输入的字符串,模拟字符串的识别过程
四. 实验过程及主要的数据结构
(一)程序流程图
(二)数据结构
正规式处理过程
正规式存储结构ArrayList(ArrayList是实现了基于动态数组的数据结构)
例:正规式(a|b )*ab 经过处理后的结构如下:
NFA 结构
正规式“a|b ”的邻接表结构 5
正规式“a|b ”的邻接表结构
NFA 结构代码实现
public class NFA {
private ArrayList
private ArrayList
private NFAStateNode startState ;
字符集charList 状态表 states
private NFAStateNode endState;
StatePair(NFAStateNode start,NFAStateNode end){ this.startState=start;
this.endState=end;
}
}
}
NFA状态节点结构代码实现
public class NFAStateNode {
static int stateNum=0;
private int id;
private ArrayList
public NFAStateNode(){
edgeList=new ArrayList
id=stateNum++;
}
}
NFA或DFA图的边Edge结构代码实现
public class Edge
private T next;
private char value;
public Edge(T next,char value){
this.next=next;
this.value=value;
}
}
DFA数据结构
DFA结构代码实现
public class DFA {
private ArrayList
private DFAStateNode startState;//开始状态
private ArrayList
private ArrayList
private NFA nfa;//被转化的NFA
}
DFA状态节点代码实现
public class DFAStateNode {
static int stateNum=0;
private int id;
private ArrayList
private HashSet nfaStateSet;
}
(三)核心代码
构造NFA
//用于存放输入正规式中的操作符
Stack
Stack
/**
* 构造NFA
* @param list 为经处理的正规式链表
*
*/
private void createNFA(ArrayList
while(index ExpressionItem item=list.get(index); if(!item.isOperator){ addToCharList(item.value); resultStack.push(singleCharCreate(item.value)); index++; } else{ if(operatorStack.isEmpty()) { operatorStack.push(item); index++; } else{ if(item.opPriority>operatorStack.peek().opPriority &&item.value!=')'){ operatorStack.push(item); index++; continue; } if((item.opPriority<=operatorStack.peek().opPriority) &&item.value!='('){ calculate(operatorStack.peek().value); index++; operatorStack.push(item); continue; } if(item.value=='('){ operatorStack.push(item); index++; continue; } if(item.value==')'){ calculate(item.value); index++; continue; } } } } while(!operatorStack.isEmpty()){ calculate(operatorStack.peek().value); } startState=resultStack.peek().startState; endStates.add(resultStack.peek().endState); } 构造DFA /** *利用子集法将NFA转换成DFA */ public void NFAtoDFA(){ //DFA的开始状态为NFA开始状态的空闭包 startState =new DFAStateNode(nfa.getStartState().getNullClosure()); Dstates.add(startState); if(isEndState(startState)){ endStates.add(startState); } //创建DFA状态队列 Queue queue.add(startState); while(!queue.isEmpty()){ DFAStateNode state = queue.poll(); for(int i=0;i HashSet resultSet = state.getSet(charList.get(i)); if(resultSet.size()==0) continue;//如果不接受字符,则继续测试下一个字符 DFAStateNode findRuselt=getNextState(resultSet); if(findRuselt==null){ DFAStateNode newState=new DFAStateNode(resultSet); Dstates.add(newState); if(isEndState(newState)) endStates.add(newState); state.addEdge(newState,charList.get(i)); queue.add(newState); }else{ state.addEdge(findRuselt,charList.get(i)); } } } } 最小化DFA 最小化DFA采用子集法,但算法和书上的不一样 我的算法类似最小生成树中的避圈法,而书上则类似于破圈法。我认为“避圈法”更适合理解,下面是DFA的最小化过程: public void minimize(){ boolean changed=true; while(changed){ changed=false; ArrayList ArrayList for(DFAStateNode state : Dstates){ ArrayList ArrayList for(char eachChar : charList){ DFAStateNode next=state.move(eachChar); if(next==null){ moveList.add(-1); } else{ moveList.add(next.getId()); } } moveTable.add(moveList); } for(int i=0;i ArrayList ArrayList DFAStateNode curState=Dstates.get(i); equalStateList.add(curState); for(int j=i+1;j DFAStateNode nextState=Dstates.get(j); if(moveTable.get(i).equals(moveTable.get(j) )){ if (endStates.contains(curState) &&endStates.contains(nextState) ||!endStates.contains(curState) &&!endStates.contains(nextState)) { equalStateList.add(nextState); } } } if(equalStateList.size()>1){ changed=true; changeDFA(equalStateList); break; }//for j }//for i }//while } 五. 测试结果 (一)功能测试 (二)健壮性测试 六. 实验总结 此次实验,个人感觉相对较难。不仅要对书上的概念、算法理解通透,更要掌握数据结构的相关知识。在实验过程中,我把书上的算法看了好几遍,同时,还重新看了数据结构书中关于表达式求值、图的邻接矩阵表示法等章节。通过此次实验不仅对词法分析有了进一步的掌握,也让我巩固了一些常用算法及数据结构知识。 实验一词法分析 一、实验目的 通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。 编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的内部编码及单词符号自身值。(遇到错误时可显示“Error”,然后跳过错误部分继续显示) 二、实验要求 使用一符一种的分法 关键字、运算符和分界符可以每一个均为一种 标识符和常数仍然一类一种 三、实验内容 功能描述: 1、待分析的简单语言的词法 (1)关键字: begin if then while do end (2)运算符和界符: := + –* / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(NUM),通过以下正规式定义: ID=letter(letter| digit)* NUM=digit digit * (4)空格由空白、制表符和换行符组成。空格一般用来分隔ID、NUM,运算符、界符和关键字,词法分析阶段通常被忽略。 2、各种单词符号对应的种别码 图 1 程序结构描述: 图 2 四、实验结果 输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列:(begin 1)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图3所示: 图3 输入private x:=9;if x>0 then x:=2*x+1/3; end#后经词法分析输出如下序列:(private 10)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图4所示: 图4 显然,private是关键字,却被识别成了标示符,这是因为图1中没有定义private关键字的种别码,所以把private当成了标示符。 输入private x:=9;if x>0 then x:=2*x+1/3; @ end#后经词法分析输出如下序列:(private 10)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图5所示 数据分析实验报告 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58- 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 统计量 全国居民 农村居民 城镇居民 N 有效 22 22 22 缺失 均值 1116.82 747.86 2336.41 中值 727.50 530.50 1499.50 方差 1031026.918 399673.838 4536136.444 百分位数 25 304.25 239.75 596.25 50 727.50 530.50 1499.50 75 1893.50 1197.00 4136.75 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。 (2 )W 检验 结果:在Shapiro-Wilk 检验结果972.00 w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5 多维正态数据的统计量 数据: 编译技术 班级网络0802 学号3080610052姓名叶晨舟 指导老师朱玉全2011年 7 月 4 日 一、目的 编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。 二、任务及要求 基本要求: 1.词法分析器产生下述小语言的单词序列 这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表: 单词符号种别编码助记符内码值 DIM IF DO STOP END 标识符 常数(整)= + * ** , ( )1 2 3 4 5 6 7 8 9 10 11 12 13 14 $DIM $IF $DO $STOP $END $ID $INT $ASSIGN $PLUS $STAR $POWER $COMMA $LPAR $RPAR - - - - - - 内部字符串 标准二进形式 - - - - - - 对于这个小语言,有几点重要的限制: 首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。例如,下面的写法是绝对禁止的: IF(5)=x 其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。也就是说,对于关键字不专设对应的转换图。但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。 再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。例如,一个条件语句应写为 实验一词法分析实验报告 实验一词法分析 一、实验目的 通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。 编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的内部编码及单词符号自身值。(遇到错误时可显示“Error”,然后跳过错误部分继续显示) 二、实验要求 使用一符一种的分法 关键字、运算符和分界符可以每一个均为一种标识符和常数仍然一类一种 三、实验内容 功能描述: 1、待分析的简单语言的词法 (1)关键字: begin if then while do end (2)运算符和界符: := + –* / < <= <> > > = = ; ( ) # (3)其他单词是标识符(ID)和整型常数(NUM),通过以下正规式定义: ID=letter(letter| digit)* NUM=digit digit * (4)空格由空白、制表符和换行符组成。空格一般用来分隔ID、NUM,运算符、界符和关键字,词法分析阶段通常被忽略。 2、各种单词符号对应的种别码 图 1 程序结构描述: 是 否 是 调用scanner() 字母 数 其他 运算符、 符号 界符等符号 否 是 图 2 四、实验结果 输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如 变量忽略 是否输入返 拼数 syn=11返 对不同报拼字是否关syn 为对syn=10 SPSS相关分析实验报告 篇一:spss对数据进行相关性分析实验报告 实验一 一.实验目的 掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。 二.实验原理 相关性分析是考察两个变量之间线性关系的一种统计分析方法。更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。P值是针对原假设H0:假设两变量无线性相关而言的。一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。越小,则相关程度越低。而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。三、实验内容 掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。 (1)检验人均食品支出与粮价和人均收入之间的相关关系。 a.打开spss软件,输入“回归人均食品支出”数据。 b.在spssd的菜单栏中选择点击,弹出一个对话窗口。 C.在对话窗口中点击ok,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.0000.01,拒绝零假设,表明两个变量之间显著相关。人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为 0.0000.01,拒绝零假设,表明两个变量之间也显著相关。 (2)研究人均食品支出与人均收入之间的偏相关关系。 读入数据后: A.点击系统弹出一个对话窗口。 B.点击OK,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.0000.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.86650.921,说明它们之间的显著性关系稍有减弱。通过相关关系与偏相关关系的比较可以得知:在粮价的影响下,人均收入对人均食品支出的影响更大。 三、实验总结 1、熟悉了用spss软件对数据进行相关性分析,熟悉其操作过程。 2、通过spss软件输出的数据结果并能够分析其相互之间的关系,并且解决实际问题。 3、充分理解了相关性分析的应用原理。 . 编译原理实验专业:13级网络工程 语法分析器1 一、实现方法描述 所给文法为G【E】; E->TE’ E’->+TE’|空 T->FT’ T’->*FT’|空 F->i|(E) 递归子程序法: 首先计算出五个非终结符的first集合follow集,然后根据五个产生式定义了五个函数。定义字符数组vocabulary来存储输入的句子,字符指针ch指向vocabulary。从非终结符E函数出发,如果首字符属于E的first集,则依次进入T函数和E’函数,开始递归调用。在每个函数中,都要判断指针所指字符是否属于该非终结符的first集,属于则根据产生式进入下一个函数进行调用,若first集中有空字符,还要判断是否属于该非终结符的follow集。以分号作为结束符。 二、实现代码 头文件shiyan3.h #include #include int a=0; cout<<"按1结束程序"< 编译原理实验报告 实验名称:分析调试语义分析程序 TEST抽象机模拟器完整程序 保证能用!!!!! 一、实验目的 通过分析调试TEST语言的语义分析和中间代码生成程序,加深对语法制导翻译思想的理解,掌握将语法分析所识别的语法范畴变换为中间代码的语义翻译方法。 二、实验设计 程序流程图 extern int TESTScan(FILE *fin,FILE *fout); FILE *fin,*fout; //用于指定输入输出文件的指针 int main() { char szFinName[300]; char szFoutName[300]; printf("请输入源程序文件名(包括路径):"); scanf("%s",szFinName); printf("请输入词法分析输出文件名(包括路径):"); scanf("%s",szFoutName); if( (fin = fopen(szFinName,"r")) == NULL) { printf("\n打开词法分析输入文件出错!\n"); return 0; } if( (fout = fopen(szFoutName,"w")) == NULL) { printf("\n创建词法分析输出文件出错!\n"); return 0; } int es = TESTScan(fin,fout); fclose(fin); fclose(fout); if(es > 0) printf("词法分析有错,编译停止!共有%d个错误!\n",es); else if(es == 0) { printf("词法分析成功!\n"); int es = 0; 企业实习相关分析报告范文 本次外出实习,部里安排我到xx会计师事务所实习,主要任务是协助各注册会计师到各街道进行查账,主要工作有编制工作底稿,查阅凭证,帐簿,报表发现问题,提出审计意见,进行现金盘点,资产清查,编制审计报告等。 本次外出实习,我感觉收获特别大。第一:收集了很多教学素材案例,在审计过程中,一旦我发现有对我以后教学有用的东西,我都会用笔记本记录下来。故此,这次外出企业实习,我做的笔记就有3本。我相信这些素材将会对我以,后教学提供很多帮助。本学期我讲授企业单项实训课程,在授课时就经常顺手拈来我外出审计中碰到的很多案例感觉教学效果很好。第二:了解目前企业会计现状以及他们在做帐过程中存在的各种问题及种种舞弊现象。第三:向注册会计师学习了很多知识,对于我在审计过程中碰到的各种问题,我都会虚心地向xx会计师事务所的老师询问,对于我提出的各种轰炸式提问,他们都很耐心地给予回答。第四:近距离接触,真正了解到对会计人员各方面素质及要求,为我以后在讲授课程时对于授课内容如何有所侧重更有帮助。本次发言,张部长主要让我谈一谈目前企业对会计人员要求,我们在教学中应注重培养学生哪些方面知识.我以为主要有以下几方面:一,会计电算化知识 本次外出企业查帐,我发现大部分企业已实现用电脑做帐,而且大部分企业公司都是采用金蝶财务软件做帐,少部分采用用友软件做帐。故此,我们应重点加强这方面知识讲授,让每位同学都能达到熟练运用这2个财务软件.既然是用电脑做帐,对打字速度有一定要求,一般要求学生每分钟要达到40-50个字左右。 二,税务知识 本次外出企业查帐,我发现很多公司因为规模较小,只设有一名会计人员,会计人员可以说是一名多面手、做帐、报税等均是他的工作。所以,我们以后应加强税务知识讲授,尤其是税务实务操作练习,教会每会学生如何申请报税、计税、缴税、尤其是几个主要税种,如个人所得税、企业所得税、营业税、房产税等更要重点讲授。 三,出纳方面知识 由于我们的学生学历较低,很多同学毕业后只能担任出纳,故此,对于出纳工作主要职责(如登记现金日记帐、银行存款日记帐、保管库存现金、有价证券、空白发票、支票印章)以及应具备技能(如点钞、计算器、辩别真假钞票)等应让学生熟练掌握。 四,财会法规知识 词法分析器实验报告 词法分析器设计 一、实验目的: 对C语言的一个子集设计并实现一个简单的词法分析器,掌握利用状 态转换图设计词法分析器的基本方法。利用该词法分析器完成对源程 序字符串的词法分析。输出形式是源程序的单词符号二元式的代码, 并保存到文件中。 二、实验内容: 1. 设计原理 词法分析的任务:从左至右逐个字符地对源程序进行扫描,产生一个个单词符号。 理论基础:有限自动机、正规文法、正规式 词法分析器(Lexical Analyzer) 又称扫描器(Scanner):执行词法分析的程序 2. 词法分析器的功能和输出形式 功能:输入源程序、输出单词符号 程序语言的单词符号一般分为以下五种:关键字、标识符、常数、运算符,界符 3. 输出的单词符号的表示形式: 单词种别用整数编码,关键字一字一种,标识符统归为一种,常数一种,各种符号各一种。 4. 词法分析器的结构 单词符号 5. 状态转换图实现 三、程序设计 1.总体模块设计 /*用来存储目标文件名*/ string file_name; /*提取文本文件中的信息。*/ string GetText(); /*获得一个单词符号,从位置i开始查找。并且有一个引用参数j,用来返回这个单词最后一个字符在str的位置。*/ string GetWord(string str,int i,int& j); /*这个函数用来除去字符串中连续的空格和换行 int DeleteNull(string str,int i); /*判断i当前所指的字符是否为一个分界符,是的话返回真,反之假*/ bool IsBoundary(string str,int i); /*判断i当前所指的字符是否为一个运算符,是的话返回真,反之假*/ bool IsOperation(string str,int i); 《数据分析》实验报告 班级:07信计0班学号:姓名:实验日期2010-3-11 实验地点:实验楼505 实验名称:样本数据的特征分析使用软件名称:MATLAB 实验目的1.熟练掌握利用Matlab软件计算均值、方差、协方差、相关系数、标准差与变异系数、偏度与峰度,中位数、分位数、三均值、四分位极差与极差; 2.熟练掌握jbtest与lillietest关于一元数据的正态性检验; 3.掌握统计作图方法; 4.掌握多元数据的数字特征与相关矩阵的处理方法; 实验内容安徽省1990-2004年万元工业GDP废气排放量、废水排放量、固体废物排放量以及用于污染治理的投入经费比重见表6.1.1,解决以下问题:表6.1.1废气、废水、固体废物排放量及污染治理的投入经费占GDP比重 年份 万元工业GDP 废气排放量 万元工业GDP 固体物排放量 万元工业GDP废 水排放量 环境污染治理投 资占GDP比重 (立方米)(千克)(吨)(%)1990 104254.40 519.48 441.65 0.18 1991 94415.00 476.97 398.19 0.26 1992 89317.41 119.45 332.14 0.23 1993 63012.42 67.93 203.91 0.20 1994 45435.04 7.86 128.20 0.17 1995 46383.42 12.45 113.39 0.22 1996 39874.19 13.24 87.12 0.15 1997 38412.85 37.97 76.98 0.21 1998 35270.79 45.36 59.68 0.11 1999 35200.76 34.93 60.82 0.15 2000 35848.97 1.82 57.35 0.19 2001 40348.43 1.17 53.06 0.11 2002 40392.96 0.16 50.96 0.12 2003 37237.13 0.05 43.94 0.15 2004 34176.27 0.06 36.90 0.13 1.计算各指标的均值、方差、标准差、变异系数以及相关系数矩阵; 2.计算各指标的偏度、峰度、三均值以及极差; 3.做出各指标数据直方图并检验该数据是否服从正态分布?若不服从正态分布,利用boxcox变换以后给出该数据的密度函数; 4.上网查找1990-2004江苏省万元工业GDP废气排放量,安徽省与江苏省是 否服从同样的分布? 数据分析实验报告 【最新资料,WORD文档,可编辑修改】 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 方差1031026.918399673.8384536136.444百分位数25304.25239.75596.25 50727.50530.501499.50 751893.501197.004136.75 3画直方图,茎叶图,QQ图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民Stem-and-Leaf Plot Frequency Stem & Leaf 9.00 0 . 122223344 5.00 0 . 56788 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 单样本Kolmogorov-Smirnov 检验 身高N60正态参数a,,b均值139.00 标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z.686 渐近显着性(双侧).735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验 词法分析器实验报告 一、实验目的及要求 本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。 运行环境: 硬件:windows xp 软件:visual c++6.0 二、实验步骤 1.查询资料,了解词法分析器的工作过程与原理。 2.分析题目,整理出基本设计思路。 3.实践编码,将设计思想转换用c语言编码实现,编译运行。 4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。 三、实验内容 本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。标识符、常数是在分析过程中不断形成的。 对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。 输出形式例如:void $关键字 流程图、程序流程图: 程序: #include 《词法分析》实验报告 目录 目录错误!未定义书签。 1 实验目的错误!未定义书签。 2 实验内容错误!未定义书签。 TINY计算机语言描述错误!未定义书签。 实验要求错误!未定义书签。 3 此法分析器的程序实现错误!未定义书签。状态转换图错误!未定义书签。 程序源码错误!未定义书签。 实验运行效果截图错误!未定义书签。 4 实验体会错误!未定义书签。 实验目的 1、学会针对DFA转换图实现相应的高级语言源程序。 2、深刻领会状态转换图的含义,逐步理解有限自动机。 3、掌握手工生成词法分析器的方法,了解词法分析器的内部工作原理。 实验内容 TINY计算机语言描述 TINY计算机语言的编译程序的词法分析部分实现。 从左到右扫描每行该语言源程序的符号,拼成单词,换成统一的内部表示(token)送给语法分析程序。 为了简化程序的编写,有具体的要求如下: 1、数仅仅是整数。 2、空白符仅仅是空格、回车符、制表符。 3、代码是自由格式。 4、注释应放在花括号之内,并且不允许嵌套 TINY语言的单词 要求实现编译器的以下功能 1、按规则拼单词,并转换成二元式形式 2、删除注释行 3、删除空白符(空格、回车符、制表符) 4、列表打印源程序,按照源程序的行打印,在每行的前面加上行号,并且打印出每行包含的记号的二元形式 5、发现并定位错误 词法分析进行具体的要求 1、记号的二元式形式中种类采用枚举方法定义;其中保留字和特殊字符是每个都一个种类,标示符自己是一类,数字是一类;单词的属性就是表示的字符串值。 2、词法分析的具体功能实现是一个函数GetToken(),每次调用都对剩余的字符串分析得到一个单词或记号识别其种类,收集该记号的符号串属性,当识别一个单词完毕,采用返回值的形式返回符号的种类,同时采用程序变量的形式提供当前识别出记号的属性值。这样配合语法分析程序的分析需要的记号及其属性,生成一个语法树。 实验课程专业统计软件应用 上课时间2012 学年 1 学期15 周(2012 年12 月18日—28 日) 学生姓名李艳学号2010211587 班级0331002 所在学院经济管 上课地点经管3 楼指导教师胡大权理学院 实验内容写作 第六章 一实验目的 1、理解方差分析的基本概念 2、学会常用的方差分析方法 二实验内容 实验原理:方差分析的基本原理是认为不同处理组的均值间的差别基本来源有两个:随机误差,如测 量误差造成的差异或个体间的差异,称为组内差异 根据老师的讲解和课本的习题完成思考与练习的5、6、7、8题。 第5题:为了寻求适应某地区的高产油菜品种,今选5个品种进行试验,每一种在4块条件完全相同的试验田上试种,其他施肥等田间管理措施完全一样。表 6.20所示为每一品种下每一块田的亩产量,根 据这些数据分析不同品种油菜的平均产量在显著水平0.05下有无显著性差异。 第一步分析 由于考虑的是控制变量对另一个观测变量的影响,而且是5个品种,所以不宜采用独立样本T检验,应该采用单因素方差分析。 第二步数据的组织 从实验材料中直接导入数据 第三步方差相等的齐性检验 由于方差分析的前提是各水平下的总体服从方差相等的正态分布,而且各组的方差具有齐性,其中正 态分布的要求并不是非常严格,但是对于方差相等的要求还是比较严格的,因此必须对方差相等的前提进 行检验。 第四步多重比较分析 通过上面的步骤,只能判断不同的施肥等田间操作效果是否有显著性差异,如果要想进一步了解究竟那 个品种与其他的有显著性均值差别等细节问题,就需要单击上图中的两两比较按钮。 第五步运行结果及分析 多重比较结果表:从该表可以看出分别对几个不同的品种进行的两两比较。最后我们可以得出结论第4品种是最好的。其他的次之。 第6题:某公司希望检测四种类型类型轮胎A,B,C,D的寿命,如表 6.21所示。其中每种轮胎应用在随选择的6种汽车上,在显著性水平0.05下判断不同类型轮胎的寿命间是否存在显著性差异。 第一步分析 由于考虑的是一个控制变量对另一个控制变量的影响,而且是4种轮胎,所以不宜采用独立样本T 检验,应该采用单因素方差分析。 第二步数据的组织 从实验材料中直接导入数据。 第三步方差相等的齐性检验 由于方差分析的前提是各水平下的总体服从方差相等的正态分布,而且各组的方差具有齐性,其中正态分 布的要求并不是非常严格,但是对于方差相等的要求还是比较严格的,因此必须对方差相等的前提进行检 验。选择菜单“分析”—均值比较—单因素ANOVA。 编译原理语法分析器实验报告 班级: 学号: 姓名: 实验名称语法分析器 一、实验目的 1、根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。 2、本次实验的目的主要是加深对自上而下分析法的理解。 二、实验内容 [问题描述] 递归下降分析法: 0.定义部分:定义常量、变量、数据结构。 1.初始化:从文件将输入符号串输入到字符缓冲区中。 2.利用递归下降分析法分析,对每个非终结符编写函数,在主函数中调用文法开始符号的函数。 LL(1)分析法: 模块结构: 1、定义部分:定义常量、变量、数据结构。 2、初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体等); 3、运行程序:让程序分析一个text文件,判断输入的字符串是否符合文法定义的规则; 4、利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式 符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示简 单的错误提示。 [基本要求] 1. 对数据输入读取 2. 格式化输出分析结果 2.简单的程序实现词法分析 public static void main(String args[]) { LL l = new LL(); l.setP(); String input = ""; boolean flag = true; while (flag) { try { InputStreamReader isr = new InputStreamReader(System.in); BufferedReader br = new BufferedReader(isr); System.out.println(); System.out.print("请输入字符串(输入exit退出):"); input = br.readLine(); } catch (Exception e) { e.printStackTrace(); } if(input.equals("exit")){ flag = false; }else{ l.setInputString(input); l.setCount(1, 1, 0, 0); l.setFenxi(); System.out.println(); System.out.println("分析过程"); System.out.println("----------------------------------------------------------------------"); System.out.println(" 步骤| 分析栈 | 剩余输入串| 所用产生式"); System.out.println("----------------------------------------------------------------------"); boolean b = l.judge(); System.out.println("----------------------------------------------------------------------"); if(b){ System.out.println("您输入的字符串"+input+"是该文法的一个句子"); }else{ System.out.println("您输入的字符串"+input+"有词法错误!"); 编译原理实验一 姓名:朱彦荣 学号: 专业:软件工程2 实验题目:词法分析 完成语言:C/C++ 上级系统:VC++6.0 日期:2015/11/7 词法分析 设计题目:手工设计c语言的词法分析器 (可以是c语言的子集) 设计内容: 处理c语言源程序,过滤掉无用符号,判断源程序中单词的合法性,并分解出正确的单词,以二元组形式存放在文件中。 设计目的: 了解高级语言单词的分类,了解状态图以及如何表示并识别单词规则,掌握状态图到识别程序的编程。 结果要求:课程设计报告。 完成日期:第十五周提交报告 一.分析 要想手工设计词法分析器,实现C语言子集的识别,就要明白什么是词法 主要是对源程序进行编译预处理(去除注释、无用的回车换行找到包含的文件等)之后,对整个源程序进行分解,分解成一个个单词,这些单词有且只有五类,分别是标识符、保留字、常数、运算符、界符。以便为下面的语法分析和语义分析做准备。可以说词法分析面向的对象是单个的字符,目的是把它们组成有效的单词(字符串);而语法的分析则是利用词法分析的结果作为输入来分析是否符合语法规则并且进行语法制导下的语义分析,最后产生四元组(中间代码),进行优化(可有可无)之后最终生成目标代码。可见词法分析是所有后续工作的基础,如果这一步出错,比如明明是‘<=’却被拆分成‘<’和‘=’就会对下文造成不可挽回的影响。因此,在进行词法分析的时候一定要定义好这五种符号的集合。下面是我构造的一个C语言子集。 第一类:标识符letter(letter | digit)* 无穷集 第二类:常数(digit)+ 无穷集 第三类:保留字(32) auto break case char const continue default do double else enum extern float for goto if int long register return short signed sizeof static struct switch typedef union unsigned void volatile while 第四类:界符‘/*’、‘//’、() { } [ ] " " ' 等 第五类:运算符<、<=、>、>=、=、+、-、*、/、^、等 对所有可数符号进行编码: <$,0> 课程论文 题目统计学实验 学院数学与统计学院 专业金融数学 班级14金融数学 学生姓名罗星蔓 指导教师胡桂华 职称教授 2016 年 6 月21 日 相关与回归分析实验报告 一、实验目的:用EXCEL进行相关分析和回归分析. 二、实验内容: 1.用EXCEL进行相关分析. 2.用EXCEL进行回归分析. 三、实验步骤 采用下面的例子进行相关分析和回归分析. 相关分析: 数学分数(x)统计学分数(y) 数学分数(x) 1 统计学分数(y) 0.986011 1 回归分析: SUMMARY OUTPUT 回归统计 Multiple R 0.986011 R Square 0.972217 Adjusted R 0.968744 Square 标准误差 2.403141 观测值 x 方差分 析 df SS MS F Significance F 回归分析1 1616.69 9 1616.69 9 279.943 8 1.65E-07 残差8 46.2006 9 5.77508 6 总计9 1662.9 Coefficie nts 标准误 差 t Stat P-valu e Lower 95% Upper 95% 下限 95.0% 上限 95.0% Intercept 12.32018 4.2862 79 2.8743 3 0.0206 91 2.4360 05 22.204 36 2.4360 05 22.204 36 数学分数(x)0.896821 0.0536 01 16.731 52 1.65E- 07 0.7732 18 1.0204 24 0.7732 18 1.0204 24 RESIDUAL OUTPUT 观测值预测统计学分数 (y) 残差标准残差 1 84.06587 0.934133 0.412293 2 93.03408 -1.03408 -0.4564 3 66.12945 3.87055 4 1.708324 4 93.03408 -3.03408 -1.33913 5 82.27223 0.727775 0.321214 6 90.34361 -0.34361 -0.15166 7 93.03408 0.965922 0.426323 8 52.67713 -2.67713 -1.18159 9 90.34361 2.656385 1.172433 10 84.06587 -2.06587 -0.9118 PROBABILITY OUTPUT 百分比排 位统计学分数 (y) 5 50 15 70 25 82 35 83 45 85 55 90 65 90 75 92 语法分析器的设计实验报告 一、实验内容 语法分析程序用LL(1)语法分析方法。首先输入定义好的文法书写文件(所用的文法可以用LL(1)分析),先求出所输入的文法的每个非终结符是否能推出空,再分别计算非终结符号的FIRST集合,每个非终结符号的FOLLOW集合,以及每个规则的SELECT集合,并判断任意一个非终结符号的任意两个规则的SELECT 集的交集是不是都为空,如果是,则输入文法符合LL(1)文法,可以进行分析。对于文法: G[E]: E->E+T|T T->T*F|F F->i|(E) 分析句子i+i*i是否符合文法。 二、基本思想 1、语法分析器实现 语法分析是编译过程的核心部分,它的主要任务是按照程序的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行词法检查,为语义分析和代码生成作准备。这里采用自顶向下的LL(1)分析方法。 语法分析程序的流程图如图5-4所示。 语法分析程序流程图 该程序可分为如下几步: (1)读入文法 (2)判断正误 (3)若无误,判断是否为LL(1)文法 (4)若是,构造分析表; (5)由句型判别算法判断输入符号串是为该文法的句型。 三、核心思想 该分析程序有15部分组成: (1)首先定义各种需要用到的常量和变量; (2)判断一个字符是否在指定字符串中; (3)读入一个文法; (4)将单个符号或符号串并入另一符号串; (5)求所有能直接推出&的符号; (6)求某一符号能否推出‘& ’; (7)判断读入的文法是否正确; (8)求单个符号的FIRST; (9)求各产生式右部的FIRST; (10)求各产生式左部的FOLLOW; (11)判断读入文法是否为一个LL(1)文法; (12)构造分析表M; (13)句型判别算法; (14)一个用户调用函数; (15)主函数; 下面是其中几部分程序段的算法思想: 1、求能推出空的非终结符集 Ⅰ、实例中求直接推出空的empty集的算法描述如下: void emp(char c){ 参数c为空符号 char temp[10];定义临时数组 int i; for(i=0;i<=count-1;i++)从文法的第一个产生式开始查找 { if 产生式右部第一个符号是空符号并且右部长度为1, then将该条产生式左部符号保存在临时数组temp中 将临时数组中的元素合并到记录可推出&符号的数组empty中。 } Ⅱ、求某一符号能否推出'&' int _emp(char c) { //若能推出&,返回1;否则,返回0 int i,j,k,result=1,mark=0; char temp[20]; temp[0]=c; temp[1]='\0'; 存放到一个临时数组empt里,标识此字符已查找其是否可推出空字 如果c在可直接推出空字的empty[]中,返回1 for(i=0;;i++) { if(i==count) return(0); 找一个左部为c的产生式 j=strlen(right[i]); //j为c所在产生式右部的长度 if 右部长度为1且右部第一个字符在empty[]中. then返回1(A->B,B可推出空) if 右部长度为1但第一个字符为终结符,then 返回0(A->a,a为终结符) else 相关与回归分析实验报告 学 2014106146 号: 课程论文 题目统计学实验 学院数学与统计学院 专业金融数学 班级14金融数学 学生姓名罗星蔓 指导教师胡桂华 职称教授 2016 年 6 月21 日 相关与回归分析实验报告 一、实验目的:用EXCEL进行相关分析和回归 分析. 二、实验内容: 1.用EXCEL进行相关分析. 2.用EXCEL进行回归分析. 三、实验步骤 采用下面的例子进行相关分析和回归分析. 学生数学分数(x)统计学分数 (y) 1 2 3 4 5 6 7 8 9 10 80 90 60 90 78 87 90 45 87 80 85 92 70 90 83 90 94 50 93 82 相关分析: 数学分数(x)统计学分数(y) 数学分数(x) 1 统计学分数(y) 0.986011 1 回归分析: SUMMARY OUTPUT 回归统计 Multiple R 0.98601 1 R Square 0.97221 7 Adjusted R Square 0.96874 4 标准误差2.40314 1 观测值 x 方差分 析 df SS MS F Significanc e F 回归分析1 1616.69 9 1616.69 9 279.943 8 1.65E-07 残差8 46.2006 9 5.77508 6 总计9 1662.9 Coeffici ents 标准误 差 t Stat P-valu e Lower 95% Upper 95% 下限 95.0% 上限 95.0% Intercept 12.32018 4.2862 79 2.8743 3 0.0206 91 2.4360 05 22.204 36 2.4360 05 22.204 36 数学分数(x)0.896821 0.0536 01 16.731 52 1.65E- 07 0.7732 18 1.0204 24 0.7732 18 1.0204 24 RESIDUAL OUTPUT 观测值预测统计学分数 (y) 残差 标准残 差 1 84.06587 0.93413 3 0.41229 3 2 93.03408 -1.0340 8 -0.4564 3 66.12945 3.87055 4 1.70832 4 4 93.03408 -3.0340 8 -1.3391 3 5 82.27223 0.72777 5 0.32121 4 6 90.34361 -0.3436 1 -0.1516 6 7 93.03408 0.96592 2 0.42632 3 8 52.67713 -2.6771 3 -1.1815 9 9 90.34361 2.65638 5 1.17243 3 10 84.06587 -2.0658 7 -0.9118 PROBABILITY OUTPUT 百分比排 位统计学分数 (y) 5 50 15 70 25 82 35 83实验一词法分析实验报告
数据分析实验报告
编译原理词法分析器语法分析器实验报告
实验一词法分析实验报告
【实验报告】SPSS相关分析实验报告
编译原理实验报告(语法分析器)
TEST语言 -语法分析,词法分析实验报告
(实习报告)企业实习相关分析报告范文
词法分析器实验报告
数据分析实验报告
数据分析实验报告
词法分析器实验报告
词法分析的实验报告
spss实验报告最终版本
编译原理语法分析器实验报告
词法分析实验报告
相关与回归分析实验报告
语法分析器实验报告
相关与回归分析实验报告
相关主题
文本预览