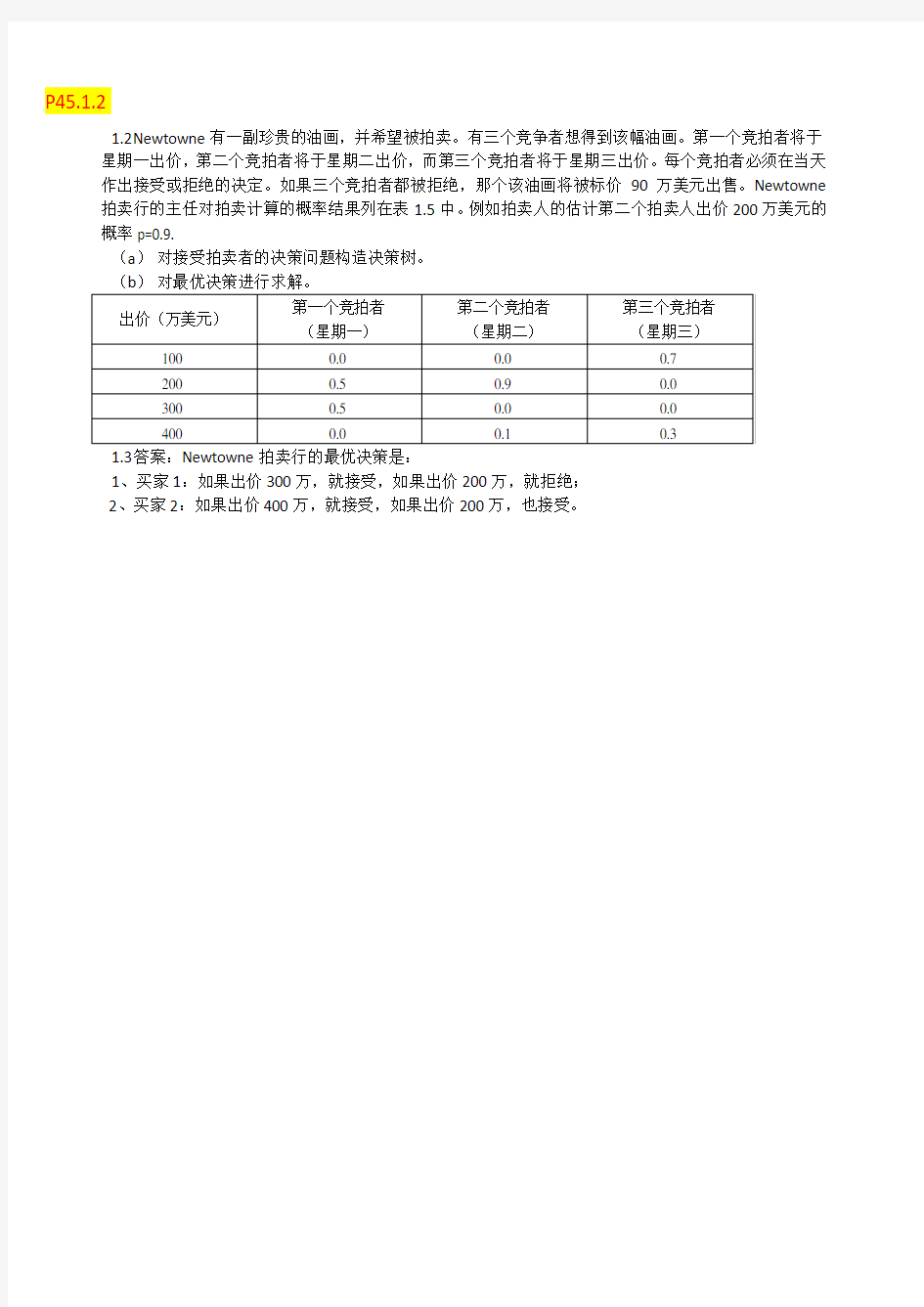

P45.1.2
1.2N ewtowne有一副珍贵的油画,并希望被拍卖。有三个竞争者想得到该幅油画。第一个竞拍者将于
星期一出价,第二个竞拍者将于星期二出价,而第三个竞拍者将于星期三出价。每个竞拍者必须在当天作出接受或拒绝的决定。如果三个竞拍者都被拒绝,那个该油画将被标价90万美元出售。Newtowne 拍卖行的主任对拍卖计算的概率结果列在表1.5中。例如拍卖人的估计第二个拍卖人出价200万美元的概率p=0.9.
(a)对接受拍卖者的决策问题构造决策树。
1、买家1:如果出价300万,就接受,如果出价200万,就拒绝;
2、买家2:如果出价400万,就接受,如果出价200万,也接受。
接受买家1
200 200200
接受买家2
200
200200
0.50.9接受买家3
买家1出价200万买家2出价200万0.7100 21买家3出价100万100100 022002001
0100
拒绝买家3
90
拒绝买家29090
0190
接受买家3
0.3400
买家3出价400万400400
拒绝买家11
0400
0220拒绝买家3
90
9090
接受买家2
400
400400
0.1接受买家3
买家2出价400万0.7100
1买家3出价100万100100
04001
0100
260拒绝买家3
90
拒绝买家29090
0190
接受买家3
0.3400
买家3出价400万400400
1
0400
拒绝买家3
90
9090
接受买家1
300 300300
接受买家2
200
200200
0.50.9接受买家3
买家1出价300万买家2出价200万0.7100 11买家3出价100万100100 030002001
0100
拒绝买家3
90
拒绝买家29090
0190
接受买家3
0.3400
买家3出价400万400400
拒绝买家11
0400
0220拒绝买家3
90
9090
接受买家2
400
400400
0.1接受买家3
买家2出价400万0.7100
1买家3出价100万100100
04001
0100
拒绝买家3
90
拒绝买家29090
0190
接受买家3
0.3400
买家3出价400万400400
1
0400
拒绝买家3
90
9090
2.9在美国有55万人感染HIV病毒。所有这些人中,27.5万人是吸毒者,其余的人是非吸毒者。美国总人口为2.5亿。在美国有10000万人吸毒。HIV感染的标准血液检测并不总是准确的。某人感染HIV,检测HIV为肯定的概率是0.99.某人没有感染HIV,检测HIV为否定的概率也是0.99。回答下列问题,清晰的说明你需要作出的任何假设。
(A)假设随机选择一个人进行HIV标准血液测试,测试结果是肯定的。这个人感染HIV的概率是多少?你的答案令人吃惊吗?
(B)假设随机选择一个吸毒者进行HIV标准血液测试,测试结果是肯定的。这个人感染HIV的概率是多少?
第一问:
答:设:P(x)为随机抽取一个人为HIV感染者的概率;
P(y)为从美国人中随机抽取一个人检测HIV为肯定的概率。
那么:假设随机选择一个人进行HIV标准血液测试,测试结果是肯定的,这个人感染HIV的概率:
P(X|Y)= P(Y|X)P(X)/P(Y)
P(Y|X)=0.99
P(X)=550000/250000000*100%=0.0022
P(Y)= P(X)*0.99+(1-P(x))*0.01=0.012156
因此:假设随机选择一个人进行HIV标准血液测试,测试结果是肯定的,这个人感染HIV的概率P(X|Y)为17.92%。
第二问:
答:设P(X)为随机抽取一个吸毒者为HIV感染者的概率;
P(Y)为从吸毒者中随机抽取一个人检测HIV为肯定的概率。
那么假设随机选择一个吸毒者进行HIV标准血液测试,结果是肯定的,这个人感染HIV的概率表示为:P(X|Y)= P(Y|X)P(X)/P(Y)
P(Y|X)=0.99
P(X)=275000/10000000*100%=0.0275
那么假设随机选择一个吸毒者进行HIV标准血液测试,结果是肯定的,这个人感染HIV的概率P(X|Y)为74.59%。
2.16在一个小型造船厂每月制造的木质航海船的树木是一个随机变量,它服从下表中所给出的概率分布。
假设航海船的制造商已经固定了每月的造船费用为3万美元,每只船的附加的建造费用为4800美元。
(A)计算每月制造船的费用的均值和标准离差。
(B)制造航海船的月费用的均值和标准离差是多少。
(C)如果每月的固定费用从3万每月增加到5.3万美元,在问题(B)中,答案会怎样变化?请仅利用(B)中计算的结果,重新计算答案。
(D)如果每支船的建造费用从4800美元增加到7000美元,但每月的固定费用仍是3万美元,在问题(B)中,你的答案会如何变化?请仅利用(A)和(B)中计算的结果,重新计算你的答案。
答案:
均值=2×0.25+3×0.20+4×0.30+5×0.25+6×0.05+7×0.05=3
(1)此教授退休金购买的基金为Z=30%X + 70%Y。
由于X~N(0.07,0.02),Y~N(0.13,0.08)
E(X)=0.07,E(Y)=0.13。
因此E(Z)= 30%E(X) + 70%E(Y)=0.021 + 0.091=0.112
(2)教授退休金年收益率标准离差σz
σz2=(0.3σx)2+(0.7σy)2+2×0.3×0.7×σx×σy×CORR(X,Y)
将相关数值代入σz2=0.000036+0.003136-0.0002688
σz2=0.0029032
σz =0.054
(3)教授退休金年收益率的分布服从正态分布
Z~N (0.112 ,0.054)
(4)教授年收益在10%和15%之间的概率P
设K为服从一个均值μz=0.112和标准差σz =0.054的正态分布
那么:P(0.1≤K≤0.15)=P(Z≤(0.15-μz)/σz)- P(Z≤(0.1-μz)/σz)
将相关数值代入公式:
P(0.1≤K≤0.15)
=P(Z≤(0.15-0.112)/0.054)- P(Z≤(0.1-0.112)/0.054)
= P(Z≤0.704)- P(Z≤-0.22)
检查表A.1 在表中得到数字:
P(0.1≤K≤0.15)=0.758-0.4129=0.3451
因此,教授年收益在10%和15%之间的概率为34.51%。
P193 4.4
一个制造立体声音响系统的公司宣称,其个人CD播放机在利用碱性电池的情况下能够连续播放近8小时。为了给出这个干劲冲天,共测试了35个利用新的碱性电池的CD播放机,并记录播放机电池的使用时间,平均时间是8.3小时,寿标准利离差是1.2小时。
(A)构造一个新的利用新的碱性电池的CD播放机电池使用的平均时间的95%的致信区间。
(B)为了估计利用新的碱性电池的CD播放机电池使用的平均时间位于正或负10分钟范围内,以及99%的置信水平,确定所要求的样本大小。
答案:样本数大于30的为大样本。
P195 4.17
在一家百货商店的两个分店,民意调查者随机地在第一个分店抽取了100个顾客,在第二个分店抽取了80个顾客,所有的调查都是在同一天进行的。在第一个分店,平均每个顾客的消费金额是41.25美元,样本标准离差是24.25美元。在第二个分店,平均每个顾客的消费金额是45.74美元,样本标准利差是34.76美元。 (A ) 构造两个分店中每个分店每个顾客消费金额均值的一个95%的置信区间。 (B ) 构造两个分店中每个顾客消费金额均值差异的一个95%的置信区间。
(1)答
第一个分店每个顾客消费金额均值的一个95%的置信区间应为:
??
????+---
n C X n C X x x x x σσ,
-
X 为第一个分店随机抽取顾客消费额均值,-
X =41.5,样本大小为n, n x =100;同时,当βx =95% 时
C x =1.96,则 σx 表示样本的标准离差σx =24.25。 将以上数值代入,则:
第一个分店每个顾客消费金额均值的一个95%的置信区间应为:
??
????
X +X -10025.2496.125.41,10025.2496.125.41
[]
003.46,497.36
同理,第二个分店每个顾客消费金额均值的一个95%的置信区间将表示为:
??
????+---
n C Y n C Y y y y y σσ,
??
????
X +X -8076.3496.175.45,8076.3496.175.45
[]
367.53,133.38
(2)答
两个分店顾客消费金额均值之差的一个95%的置信区间应表示为:
??
?
?????++-+------y y x x y y x x n n C Y X n n C Y X 2222,σσσσ 100=x n 80=y n
将相关数值代入:
???
?
????+
+-+--8076.3410025.2496.175.4525.41,8076.3410025.2496.175.4525.412222[]3101
.0,311.9-
解:(a)对于表6.31提出的自变量,设:
Y:欠税($)
X1:税前总收入($)
X2:细目单A扣除部分($)
X3:细目单C收入部分($)
X4:细目单C部分扣除百分比(%)
X5:家庭办公室指标
则预测纳税人欠税的回归模型为:
Y= aX1 + bX2 + cX3 + dX4 + eX5 + ε
根据计算机的回归计算结果,代入系数得:
Y= 0.292X1 - 0.012X2 + 0.188X3 + 104.625X4 - 3784.564X5 + 3572.406 回归统计
Multiple R0.937041964
R Square0.878047641
Adjusted R Square0.844171986
标准误差3572.406308
观测值24
方差分析
df SS MS F Significance F
回归分析5 1.65E+09 3.31E+0825.91972 1.23631E-07
残差18 2.3E+0812762087
总计23 1.88E+09
Coefficients标准误差t Stat P-value Lower 95%Upper 95%下限 95.0%上限 95.0% Intercept-8414.7227796239.235-1.348680.194165-21522.869874693.424-21522.94693.424税前总收入($)0.2929550870.02917710.040778.39E-090.2316574330.3542530.2316570.354253细目单A扣除部分($)-0.0120617160.161062-0.074890.941129-0.3504394710.326316-0.350440.326316细目单C收入部分($)0.1877365280.167179 1.1229680.276207-0.1634932270.538966-0.163490.538966细目单C部分扣除百分比(%)104.624828443.09016 2.4280440.0258914.09575311195.153914.09575195.1539家庭办公室指标-3784.5647911827.084-2.071370.052973-7623.12520153.99562-7623.1353.99562-5000
5000
10000
50000100000
显然,从回归统计结果上看,这些自变量的组合对欠税预测值Y的影响并不显著。
(b)利用后向消元法,逐个消去P值小于0.5的自变量后重新回归计算,得新的比较好的回归模型为:
Y:欠税($)
X1:税前总收入($)
X4:细目单C部分扣除百分比(%)
X5:家庭办公室指标
Y= aX1 + dX4 + eX5 + ε
根据计算机的回归计算结果,代入系数得:
Y= 0.293X1 + 94.564X4 - 3387.18 X5 + 3510.828
SUMMARY OUTPUT
回归统计
Multiple R0.932271
R Square0.869129
Adjusted R Square0.849498
标准误差3510.828
观测值24
方差分析
df SS MS F Significance F
回归分析3 1.64E+09 5.46E+0844.2739 5.12E-09
残差20 2.47E+0812325910
总计23 1.88E+09
Coefficients标准误差t Stat P-value Lower 95%Upper 95%下限 95.0%上限 95.0% Intercept-4656.492824.734-1.648470.114877-10548.81235.805-10548.81235.805税前总收入($)0.2931980.02866810.22751 2.16E-090.2333980.3529970.2333980.352997细目单C部分扣除百分比(%)94.5645436.80787 2.5691390.01830717.78466171.344417.78466171.3444家庭办公室指标-3387.181594.774-2.123920.046341-6713.82-60.5371-6713.82-60.5371(C)
(1)为了检验(B)的模型的异方差性,观察计算机输出的残差图:
由于残差分布并没有显著地随着自变量的增大而增大,因此认为(b)中构造的模型没有呈现异方差性的证据。
(2)绘制残差的直方图,观察得基本呈现钟状,因此认为满足正态性假设。
(3)模型Y= aX1 + dX4 + eX5 + ε回归系数的95%的置信区间为:
a £ [0.233398 ,0.352997]
d £ [17.78466059 , 171.3444212]
e £ [-6713.817765 ,-60.53712371]
(D)将题设数据代入模型,则得对该纳税人欠税额的预测值:
? = 0.293X1 + 94.564X4 - 3387.18 X5 + 3510.828
=0.293 X 130000 + 94.564 X 25 – 3387.18 X 1 + 3510.828
= 38090 + 2364.1 - 3387.18 + 3510.828
=40577.75 ($)
P414 7.8
解:
(a)线性优化模型的构造见附件xls文件;
蔬菜生产计划
料胡萝卜蘑菇青辣椒花茎甘蓝玉米量: 盎司/月150000 80000 135000 140000 150000
变量油炸小黄鱼烤烧野餐热情蘑菇微渴松脆
贡献:元/袋$0.22 $0.20 $0.18 $0.18
的数量(袋)26666.66667 18333.33 0 12666.67
函数
利($)11813.33333
条件
矩阵炸小黄鱼烧野餐情蘑菇渴松脆
卜 2.5 2.0 0.0 2.5
3.0 0.0
4.0 0.0
椒 2.5 2.0 3.0 2.5
甘蓝 2.0 3.0 3.0 2.5
0.0 3.0 0.0 2.5
约束函数关系右边值
消耗(胡萝卜)135000 <= 150000
消耗(蘑菇)80000 <= 80000
消耗(青辣椒)135000 <= 135000
消耗(花茎甘蓝)140000 <= 140000
消耗(玉米)86666.66667 <= 150000
运算结果报告
单元格名字初值终值
6 利($)油炸小黄鱼11813.33311813.333
单元格名字初值终值
3 的数量(袋)油炸小黄鱼26666.66626666.666
3 的数量(袋)烤烧野餐18333.33318333.333
3 的数量(袋)热情蘑菇
3 的数量(袋)微渴松脆12666.66612666.666
单元格名字单元格值公式状态型数值
7<=$D$27 限制值150
7 消耗(胡萝卜)约束函数1350
8<=$D$28 限制值
8 消耗(蘑菇)约束函数800
9<=$D$29 限制值
9 消耗(青辣椒)约束函数1350
0<=$D$30 限制值
0 消耗(花茎甘蓝)约束函数1400
1<=$D$31 限制值63333.333
1 消耗(玉米)约束函数86666.666
3>=0 限制值26666.666
3 的数量(袋)油炸小黄鱼26666.666
3>=0 限制值18333.333
3 的数量(袋)烤烧野餐18333.333
3 的数量(袋)热情蘑菇3>=0 限制值
3>=0 限制值12666.666
3 的数量(袋)微渴松脆12666.666
敏感性报告
终递减目标式允许的允许的单元格名字值成本系数增量减量的数量(袋)油炸小黄鱼26666.6601E0.
的数量(袋)烤烧野餐18333.330.0.
的数量(袋)热情蘑菇-0.12666600.1266661E
的数量(袋)微渴松脆12666.6600.0485710.013333
终阴影约束允许的允许的
单元格名字值价格限制值增量减量消耗(胡萝卜)约束函数1351501E15消耗(蘑菇)约束函数800.0226668027142.8580消耗(青辣椒)约束函数1350.1351510555.55消耗(花茎甘蓝)约束函数1400.14015833.3318333.33消耗(玉米)约束函数86666.661501E63333.33
(b)用计算机求解,得最优产品的混合蔬菜结果是生产:
油炸小黄鱼26666袋;
烤烧野餐18333袋
热情蘑菇0袋
微渴松脆12666袋;
(c)青辣椒的额外盎司值(影子价格)是:$0.016
试卷一 一、单项选择题(共10小题,每题1分,共10分) 1 统计预测方法中,以逻辑判断为主的方法属于()。 A 回归预测法 B 定量预测法 C 定性预测法 D 时间序列预测法 2 下列哪一项不是统计决策的公理()。 A 方案优劣可以比较 B 效用等同性 C 效用替换性 D 效用递减性 3 根据经验D-W统计量在()之间表示回归模型没有显著自相关问题。 A 1.0-1.5 B 1.5-2.5 C 1.5-2.0 D 2.5-3.5 4 当时间序列各期值的二阶差分相等或大致相等时,可配合( )进行预测。 A 线性模型 B抛物线模型 C指数模型 D修正指数模型 5 ()是指国民经济活动的绝对水平出现上升和下降的交替。 A 经济周期 B 景气循环 C 古典经济周期 D 现代经济周期 6 灰色预测是对含有()的系统进行预测的方法。 A 完全充分信息 B 完全未知信息 C 不确定因素 D 不可知因素 7 状态空间模型的假设条件是动态系统符合()。 A 平稳特性 B 随机特性 C 马尔可夫特性 D 离散性 8 不确定性决策中“乐观决策准则”以()作为选择最优方案的标准。 A 最大损失 B 最大收益 C 后悔值 D α系数 9 贝叶斯定理实质上是对()的陈述。 A 联合概率 B 边际概率 C 条件概率 D 后验概率 10 景气预警系统中绿色信号代表()。 A 经济过热 B 经济稳定 C 经济萧条 D 经济波动过大 二、多项选择题(共5小题,每题3分,共15分) 1 构成统计预测的基本要素有()。 A 经济理论 B预测主体 C数学模型 D实际资料 2 统计预测中应遵循的原则是()。 A 经济原则 B连贯原则 C可行原则 D 类推原则 3 按预测方法的性质,大致可分为()预测方法。 A 定性预测 B 情景预测 C时间序列预测 D回归预测
山东大学管理学院秋季MBA2011级(石家庄班) 数据、模型与决策试题2012年6月 1.(10分)线性回归模型是否满足假设要通过哪几个方面来检验?每个方面的含义是什么?根据什么指标或图形来检验好坏? 2.(15分)以下结果是应用什么软件的什么方法计算输出的,简述软件操作过程。并从结果中分析计算过程、各部分数据的意义及最后的方程(T值除外)。 --------------------------------------------------------------- XXXX: EARN 与 SIZE, EMPL, ... 入选用 Alpha: 0.05 删除用 Alpha: 0.1,响应为 14 个自变量上的 EARN,N = 50 步骤 1 2 3 4 5 常量 11.85 -348.99 -413.26 -403.41 -368.55 P45 0.0351 0.0321 0.0304 0.0321 0.0319 T 值 5.94 6.65 7.43 9.46 10.00 P 值 0.000 0.000 0.000 0.000 0.000 INC 11.9 12.9 10.3 10.3 T 值 5.11 6.55 5.98 6.34 P 值 0.000 0.000 0.000 0.000 NREST 1.29 1.43 1.40 T 值 4.49 5.96 6.22 P 值 0.000 0.000 0.000 SIZE 0.54 0.56 T 值 4.76 5.27 P 值 0.000 0.000 PRICE -2.13 T 值 -2.61 P 值 0.012 S 67.4 54.6 46.0 37.9 35.7 R-Sq 42.33 62.90 74.21 82.85 85.15 R-Sq(调整) 41.13 61.32 72.53 81.32 83.47 Mallows Cp 120.5 63.1 32.5 9.5 4.9 ------------------------------------------------------------------------------- 3.(20分)桑杰伊·托马斯(Sanjay Thomas)是斯隆管理学院的二年级MBA学生。作为上学期有关企业家课程设计的一部分,桑杰伊实际上已经对东海岸城市具有印度烹调风格的饭店的样本进行了概率分析,并首先对他婶婶的饭店进行了分析。在调整了有关波士顿地区的标准生活费用的数据以后,桑杰伊利用这些资料制定了温馨小扁豆饭店的成本和收入的标准。这些数据是基于饭店位于哈佛广场,拥有50个座位,并贷款进行了饭店的内部结构装修,以及租赁了饭店的所有资本性设备。桑杰伊估计经营温馨小扁豆饭店每月的非劳动固定成本是3995美元。他还估计了食品的可变成本是每餐为11美元。在饭店事务的许多不确定因素中,有三种不确定变量在概率等式中趋向于起主导作用:每月销售膳食的数量,每餐饭的收入,以及饭店的(固定)劳动力成本。根据他与许多饭店业主的交流,桑杰伊能够估计这三个关键性的不确定变量的实际分布,这些变量如下: ----销售膳食的数量。像温馨小扁豆饭店这样坐落于哈佛广场,并拥有50个座位容量的饭店,每月销售的膳食数量将服从一个均值为μ=3 000和标准离差为σ=1 000 的正态分布。
教材习题答案 1.2 工厂每月生产A 、B 、C 三种产品 ,单件产品的原材料消耗量、设备台时的消耗量、资源限量及单件产品利润如表1-22所示. 和130.试建立该问题的数学模型,使每月利润最大. 【解】设x 1、x 2、x 3分别为产品A 、B 、C 的产量,则数学模型为 1231231 23123123max 1014121.5 1.2425003 1.6 1.21400 150250260310120130,,0 Z x x x x x x x x x x x x x x x =++++≤??++≤??≤≤?? ≤≤??≤≤?≥?? 1.3 建筑公司需要用6m 长的塑钢材料制作A 、B 两种型号的窗架.两种窗架所需材料规格及数量 如表1-23所示: 【解】 设x j (j =1,2,…,14)为第j 种方案使用原材料的根数,则 (1)用料最少数学模型为
14 1 12342567891036891112132347910121314 min 2300322450 232400 23234600 0,1,2,,14 j j j Z x x x x x x x x x x x x x x x x x x x x x x x x x x x x x j ==?+++≥? ++++++≥?? ++++++≥??++++++++≥??≥=?∑ 用单纯形法求解得到两个基本最优解 X (1)=( 50 ,200 ,0 ,0,84 ,0,0 ,0 ,0 ,0 ,0 ,200 ,0 ,0 );Z=534 X (2)=( 0 ,200 ,100 ,0,84 ,0,0 ,0 ,0 ,0 ,0 ,150 ,0 ,0 );Z=534 (2)余料最少数学模型为 13413141234256789103689111213 2347910121314 min 0.60.30.70.40.8230032245023240023234600 0,1,2,,14 j Z x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x j =+++++?+++≥? ++++++≥??++++++≥??++++++++≥??≥=? 用单纯形法求解得到两个基本最优解 X (1)=( 0 ,300 ,0 ,0,50 ,0,0 ,0 ,0 ,0 ,0 ,200 ,0 ,0 );Z=0,用料550根 X (2)=( 0 ,450 ,0 ,0,0 ,0,0 ,0 ,0 ,0 ,0 ,200 ,0 ,0 );Z=0,用料650根 显然用料最少的方案最优。 1.7 图解下列线性规划并指出解的形式: (1) 12 121212 max 2131,0Z x x x x x x x x =-++≥?? -≥-??≥? 【解】最优解X =(1/2,1/2);最优值Z=-1/2
经济与管理学院 Economics and Management School of Wuhan University ×××级×××班《数据、模型与决策》试题 出题人:刘 伟 考试形式:闭卷 考试时间:2007年7月×日 120分钟 姓名_______ 学号_______ 记分_______ 一、名词解释及简答题(各题5分) 1、众数 2、直方图 3、变异系数 4、相关系数 5、虚拟变量 6、置信区间 7、最小二乘(平方)法 8、线性回归模型 9、多重共线性 10、完全多重共线性 11、不完全多重共线性 12、虚拟变量模型 13、总体回归函数 14、何为虚变量回归模型?为什么将虚变量值设为取 0、1 ? 15、回归方程的显著性检验与回归系数的显著性检验什么区别与联系? 16、在回归方程的最小二乘法估计中,对回归模型有哪些基本假设? 17、回归方程的显著性检验与回归系数的显著性检验什么区别与联系? 18、为什么从计量经济学模型得到的预测值不是一个确定的值?预测值的置信区间和置 信度的含义是什么?在相同的置信度下如何才能缩小置信区间? 19、影子价格 20、对偶规划 21、模型 22、约束条件 23、目标函数 24、决策变量 25、协方差 26、拟合优度检验 二、计算题(各题10分) 1、500家美国公司1993年底的平均资产为11270(单位:百万美元),标准差为2780(百万美元)。这些公司的平均价格收益比为31,标准差为8。请问哪一个指标的差异大? 2、有一种电子元件,要求其使用寿命不得低于1000小时,现抽25件,测 得其均值950小时,方差为900小时。已知该种元件寿命服从正态分布, (1)写出该种电子元件使用寿命的置信区间,取α=005.; (2)若已知使用寿命的标准差σ=100,写出该种电子元件使用寿命的 置信区间,取α=005.;在 α=005.下,且已知σ=100这批元件合格否? 3、某商店的日销售额服从正态分布,据统计去年的日均销售额是2.74万元, MBA
第二章习题(P46) 14.某天40只普通股票的收盘价(单位:元/股)如下: 29.625 18.000 8.625 18.500 9.250 79.375 1.250 14.000 10.000 8.750 24.250 35.250 32.250 53.375 11.500 9.375 34.000 8.000 7.625 33.625 16.500 11.375 48.375 9.000 37.000 37.875 21.625 19.375 29.625 16.625 52.000 9.250 43.250 28.500 30.375 31.125 38.000 38.875 18.000 33.500 (1)构建频数分布*。 (2)分组,并绘制直方图,说明股价的规律。 (3)绘制茎叶图*、箱线图,说明其分布特征。 (4)计算描述统计量,利用你的计算结果,对普通股价进行解释。 解:(1)将数据按照从小到大的顺序排列 1.25, 7.625, 8, 8.625, 8.75, 9, 9.25, 9.25, 9.375, 10, 11.375, 11.5, 14, 16.5, 16.625, 18, 18, 18.5, 19.375, 21.625, 24.25, 28.5, 29.625, 29.625, 30.375, 31.125, 3 2.25, 3 3.5, 33.625, 34, 35.25, 37, 37.875, 38, 38.875, 43.25, 48.375, 52, 53.375, 79.375,结合(2)建立频数分布。 (2)将数据分为6组,组距为10。分组结果以及频数分布表。为了方便分组数据样本均值与样本方差的计算,将基础计算结果也列入下表。 根据频数分布与累积频数分布,画出频率分布直方图与累积频率分布的直方图。
2014年7月江苏省高等教育自学考试30447数据、模型与决策一、单项选择题(每小题1分,共10分) 在下列每小题的四个备选答案中选出一个正确答案,并将其字母标号填入题干的括号内。1.运用数据模型开展定量分析,其根本目标是( ) A.管理决策B.数量分析C.理论指导D.科学管理 2.主要为搜集某一时点或一定时期内现象总量资料而专门组织的、一次性全面调查称为( ) A.抽样调查B.实验设计C.普查D.参与观察 3.从总体N个单位中抽取n个单位组成样本时,保证每一个单位被抽出来的概率相等,这种抽样方法叫做( ) A.等距抽样B.简单随机抽样C.分层抽样D.整群抽样 4.把非定量的文献史料、语言习惯等带有特征的因素设法转化成可以量化处理的数据,然后对这些数据进行定量分析并做出判断的方法叫做( ) A.内容分析法B.间接调查法C.判断调查法D.阶段抽样调查 5.语义上表现出明显的等级或顺序关系的定类资料,称为( ) A.定量资料B.定类数据C.调查资料D.定序资料 6.各个组中的频数与所有组频数之和的比率叫做( ) A.累积频数B.频率C.频数D.累积频率 7.观察值之间的差异程度或频数分布的分散程度,称为( ) A.集中趋势B.离散趋势C.方差D.极差 8.从总体N个单位中抽取n个单位作为样本,每次从总体中抽取一个单位,凡是被抽中的单位不再放回到原来的总体中,接下来抽选的样本单位,只是从剩下的总体单位中进行抽取,这种抽样方式叫做( ) A.不重复抽样B.简单抽样C.随机抽样D.双相抽样 9.EXCEL中,拟合优度系数计算的函数是( ) A.INTERCEPT B.SLOPE C.RSQD.LINEST 10.在单因素等重复实验中,因素影响的均方为0.2986、误差影响均方0.0472,则F统计量的值是( ) A.0.1581 B.0.2514 C.0 3458 D.6.3263 二、填空题(每小题1分,共10分) 11.从定量角度研究管理问题,是主要工具。 12.先从总体中随机抽取一个较大的样本,获得第一重样本,然后再从第一重样本中随机抽取一个较小的样本即第二重样本,利用这第一二重样木,对研究目标进行统计推断,这种抽样组织方式叫做。 13.在单因素不等重复实验中,因素影响的均方6889.13、实验误差影响均方1408.97,则统计量的值是。 14.相比于定距资料,定比资料拥有。 15.均匀分布的离散程度最大,因此若的计算结果越大,意味着频数分布的离散程度也越大。16.X1,X2,…,X n为f(x;θ)的一个简单随机样本,θ是总体参数,由样本确定的估计量为1=1(X1,X2,…,X n)和2=2(X1,X2,…,X n),对于给定的α(0<α<1),能使P(1≤θ≤2)=1-α成立,则称1-α为。 17.在若干个能够互相比较的资料组中,把产生变异的原因加以明确区分的方法和技术叫做。18.多元回归分析中,拟合优度系数R2是的递增函数。
1、某企业目前的损益状况如在下: 销售收入(1000件×10元/件) 10 000 销售成本: 变动成本(1000件×6元/件) 6 000 固定成本 2 000 销售和管理费(全部固定) 1 000 利润 1 000 (1)假设企业按国家规定普调工资,使单位变动成本增加4%,固定成本增加1%,结果将会导致利润下降。为了抵销这种影响企业有两个应对措施:一是提高价格5%,而提价会使销量减少10%;二是增加产量20%,为使这些产品能销售出去,要追加500元广告费。请做出选择,哪一个方案更有利? (2)假设企业欲使利润增加50%,即达到1 500元,可以从哪几个方面着手,采取相应的措施。 2、某企业每月固定制造成本1 000元,固定销售费100元,固定管理费150元;单位变动制造成本6元,单位变动销售费0.70元,单位变动管理费0.30元;该企业生产一种产品,单价10元,所得税税率50%;本月计划产销600件产品,问预期利润是多少?如拟实现净利500元,应产销多少件产品? 3、某企业生产甲、乙、丙三种产品,固定成本500000元,有关资料见下表(单位:元): 要求: (1)计算各产品的边际贡献; (2)计算加权平均边际贡献率; (3)根据加权平均边际贡献率计算预期税前利润。 4、某企业每年耗用某种材料3 600千克,单位存储成本为2元,一次订货成本25元。则经济订货批量、每年最佳订货次数、最佳订货周期、与批量有关的存货总成本是多少? 5.有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:
(1)说明两变量之间的相关方向; (2)建立直线回归方程; (3)估计生产性固定资产(自变量)为1100万元时总产值(因变量)的可能值。 6、某商店的成本费用本期发生额如表所示,采用账户分析法进行成本估计。 首先,对每个项目进行研究,根据固定成本和变动成本的定义及特点结合企业具体情况来判断,确定它们属于哪一类成本。例如,商品成本和利息与商店业务量关系密切,基本上属于变动成本;福利费、租金、保险、修理费、水电费、折旧等基本上与业务量无关,视为固定成本。 其次,剩下的工资、广告和易耗品等与典型的两种成本性态差别较大,不便归入固定成本或变动成本。对于这些混合成本,要使用工业工程法、契约检查法或历史成本分析法,寻找一个比例,将其分为固定和变动成本两部分。 7、某企业每年耗用某种材料3 600千克,单位存储成本为2元,一次订货成本25元。 则经济订货批量、每年最佳订货次数、最佳订货周期、与批量有关的存货总成本是多少? 8、某生产企业使用A零件,可以外购,也可以自制。如果外购,单价4元,一次订
2014年4月江苏省高等教育自学考试 30447数据、模型与决策 一、单项选择题(每小题1分,共10分) 在下列每小题的四个备选答案中选出一个正确答案,并将其字母标号填入题干的括号内。1.从调查对象(总体)中抽取一部分单位组成样本,然后根据样本调查的结果,对总体情况进行推断,称之为抽样调查。抽取一部分单位时应遵照( ) A.判断原则B.参与原则C.随机原则D.程序原则 2.先从总体中随机抽取一个较大的样本,获得第一重样本,然后再从第一重样本中随机抽取一个较小的样本即第二重样本,利用这第二重样本,对研究目标进行统计推断,这种抽样组织方式叫做( ) A.类型抽样调查B.简单抽样调查 C.阶段抽样调查D.双相抽样调查 3.在调查工作已经完成,进入数据编辑和整理阶段所用的评估数据质量的方法统称为( ) A.相对技术B.抽样技术C.后验技术D.误差分析 4.在统计分组的基础上形成的样本单位在各个组间的分配,叫做( ) A.直方图B.交叉分类表C.频数D.频数分布 5.在频数分布中,观察值中出现次数最多的数值就是( ) A.算术平均数B.众数C.四分位数D.中位数 6.在若干个能够互相比较的资料组中,把产生变异的原因明确区分出来的方法,叫做( ) A.方差分析B.回归分析C.描述分析D.样本推断 7.对一元线性回归y i=α+βx i+εi,β反映了自变量对因变量的( ) A.正向影响B.负向影响C.边际影响D.回归影响 8.时间序列中各项观察的一阶差分为常数,可拟合( ) A.指数曲线模型B.直线趋势方程C.抛物线模型D.指数平滑模型 9.顾客在排队系统中等待时间和服务时间的和叫做( ) A.排队长B.队长C.等待时间D.逗留时间 10.在库存管理中,需求是库存系统的( ) A.输出B.输入C.订货D.变量 二、填空题(每小题1分,共10分) 11.运用数据模型开展分析,是根本目标。 12.文化程度属于定性资料中的资料。 13.各个组中的频数与所有组频数之和的比率叫做。 14.把每个观察数据划分成两个部分,一是主部一是余部,并分别用植物的“茎”和“叶”形象地称呼,然后把数据的主部按从小到大的顺序纵向排列,再在每个数据的主部后面列出余部,由此得到的统计图称之为。 15.对顾客就某款产品使用效果询问的结果是:很不满意、不满意、满意、满意、很满意、很满意、不满意、满意、满意,则顾客的代表性意见是。 16.χ2分布的形状随自由度n的增大而逐渐趋向于。 17.在单因素方差分析中,S b2为组间离差平方和,反映了各组平均数与的差异情况。18.时间序列中的每一项观察值,称为时间序列的,反映客观现象发展变化在各个不同时间上所达到的状态、规模或水平。
2008—2009第二学期《数据模型与决策》课 考试题 姓名:学号:成绩: 【说明:共5题,答题时间共计120分钟】 一、试述你对以下概念的理解:(32分) (1)企业内部数据,即通常从企业会计、营销、生产运行中收集的数据。 (2)样本,即总体的一个子集。 (3)回归模型,即刻画因变量与一个或多个自变量之间相互关系的模型。 (4)德尔斐法,是判断预测的普遍方法,通过让许多专家匿名回答一系列调查问卷来实现。在每一轮回答后,答案将匿名共享,让专家知道其他专家的意见。通过了解其他专家的意见,将增加看法的统一性并促使意见不一致的人去考虑其他因素。 (5)正态分布,其形态就是钟形曲线。正态分布是对称的且中位数等于平均数,即有一半的面积在平均数以上,另一半的面积在平均数以下。正态分布可以用两个参数来描述;均值(位置参数)、方差(刻度参数)。当均值变化时,分布在x轴上的位置也会变化;而当方差增加或减少时,分布相应地会变宽或窄。 (6)变异系数,是一种间接测度数据离散程度的方法,它一般由平均数求得:变异系数(CV)=标准方差/平均数 (7)标准差,是测度离散程度的一种方法。它是方差的开平方求得的。总体和样本标准差分别为:
(8)显著性水平,即发生第一类错误(即原假设事实上是正确的,但是假设检验错误的拒绝了它)的概率a。 二、对于下表这样一组给定的数据,我们可以用表格、图形、回归模型3种方式来表达10个公司销售收入与营销费用之间的关系。试问:这3种方式的表达思路有什么异同?(15分) 公司编号12345678910销售收入(Y)5000 3000 1200 2000 10000 4000 800 7000 9000 12000 营销费用(X)675 550 275 325 1375 525 193 950 975 1650 答: 表格:我们仅从数据中可以看到营销费用与销售收入大约成正向关系,即营销费用增加,销售收入增加。 图形:我们可以从图形中更加直观的揭示数据中包含的特征与规律,即能够大体的看清营销费用变动导致销售收入变动的程度。 回归:通过回归分析可以确定自变量变化时对因变量产生影响的大小,即能够确认营销费用的变化时销售费用能够变化的大小。 三、在“数据模型与决策”课程中,有许多定量分析的模型与方法。请回答下面的问题:(18分) (1)归纳总结各种模型方法的共同点; (2)根据你的喜好选择一种方法,举例说明其解决问题的思路。 答:在课程中,我们主要应用图表、假设检验、回归分析的定量分析模型与方法,这些模型与方法共同组成一整套决策模型体系,都是对量化的数据进行分析,得出可以量化的模型来揭示数据内在联系。 个人而言,回归分析的是比较好的方法,因为它包含图表、假设检验的方法,
《数据模型与决策》复习题及参考答案 第一章绪言 一、填空题 1.运筹学的主要研究对象是各种有组织系统的管理问题,经营活动。 2.运筹学的核心是运用数学方法研究各种系统的优化途径及方案,为决策者提供科学决策的依据。 3.模型是一件实际事物或现实情况的代表或抽象。 4、通常对问题中变量值的限制称为约束条件,它可以表示成一个等式或不等式 的集合。 5.运筹学研究和解决问题的基础是最优化技术,并强调系统整体优化功能。运筹学研究和解决问题的效果具有连续性。 6.运筹学用系统的观点研究功能之间的关系。 7.运筹学研究和解决问题的优势是应用各学科交叉的方法,具有典型综合应用特性。 8.运筹学的发展趋势是进一步依赖于_计算机的应用和发展。 9.运筹学解决问题时首先要观察待决策问题所处的环境。 10.用运筹学分析与解决问题,是一个科学决策的过程。 11.运筹学的主要目的在于求得一个合理运用人力、物力和财力的最佳方案。12.运筹学中所使用的模型是数学模型。用运筹学解决问题的核心是建立数学模型,并对模型求解。 13用运筹学解决问题时,要分析,定议待决策的问题。 14.运筹学的系统特征之一是用系统的观点研究功能关系。 15.数学模型中,“s·t”表示约束。 16.建立数学模型时,需要回答的问题有性能的客观量度,可控制因素,不可控因素。 17.运筹学的主要研究对象是各种有组织系统的管理问题及经营活动。 二、单选题 1.建立数学模型时,考虑可以由决策者控制的因素是(A )
A.销售数量B.销售价格C.顾客的需求D.竞争价格2.我们可以通过(C )来验证模型最优解。 A.观察B.应用C.实验D.调查 3.建立运筹学模型的过程不包括(A )阶段。 A.观察环境B.数据分析C.模型设计D.模型实施4.建立模型的一个基本理由是去揭晓那些重要的或有关的( B ) A数量B变量 C 约束条件 D 目标函数 5.模型中要求变量取值( D ) A可正B可负C非正D非负 6.运筹学研究和解决问题的效果具有( A ) A 连续性 B 整体性 C 阶段性 D 再生性 7.运筹学运用数学方法分析与解决问题,以达到系统的最优目标。可以说这个过 程是一个(C) A解决问题过程B分析问题过程C科学决策过程D前期预策过程 8.从趋势上看,运筹学的进一步发展依赖于一些外部条件及手段,其中最主要的 是( C ) A数理统计B概率论C计算机D管理科学 9.用运筹学解决问题时,要对问题进行( B ) A 分析与考察 B 分析和定义 C 分析和判断 D 分 析和实验 三、多选 1模型中目标可能为(ABCDE ) A输入最少B输出最大 C 成本最小D收益最大E时间最短 2运筹学的主要分支包括(ABDE ) A图论B线性规划 C 非线性规划 D 整数规划 E目标规划 四、简答 1.运筹学的计划法包括的步骤。 答:观察、建立可选择的解、用实验选择最优解、确定实际问题。
数据模型与决策课程大作业 以我国汽油消费量为因变量,乘用车销量、城镇化率和90#汽油吨价与城镇居民人均可支配收入的比值为自变量时行回归(数据为年度时间序列数据)。试根据得到部分输出结果,回答下列问题:1)“模型汇总表”中的R方和标准估计的误差是多少? 2)写出此回归分析所对应的方程; 3)将三个自变量对汽油消费量的影响程度进行说明; 4)对回归分析结果进行分析和评价,指出其中存在的问题。 1)“模型汇总表”中的R方和标准估计的误差是多少? 答案:R方为0.993^2=0.986 ;标准估计的误差为120910.147^(0.5)=347.72 2)写出此回归分析所对应的方程; 答案:假设汽油消费量为Y,乘用车销量为a,城镇化率为b,90#汽油吨价/城镇居民人均可支配收入为c,则回归方程为: Y=240.534+0.00s027a+8649.895b-198.692c 3)将三个自变量对汽油消费量的影响程度进行说明; 乘用车销量对汽油消费量相关系数只有0.00027,数值太小,几乎没有影响,但是城镇化率对汽油消费量相关系数是8649.895,具有明显正相关,当城镇化率每提高1,汽油消费量增加8649.895。乘用90#汽油吨价/城镇居民人均可支配收入相关系数为-198.692,呈
明显负相关,即乘用90#汽油吨价/城镇居民人均可支配收入每增加1个单位,汽油消费量降低198.692个单位。a, b, c三个自变量的sig 值为0.000、0.000、0.009,在显著性水平0.01情形下,乘用车消费量对汽油消费量的影响显著为正。 (4)对回归分析结果进行分析和评价,指出其中存在的问题。 在学习完本课程之后,我们可以统计方法为特征的不确定性决策、以运筹方法为特征的策略的基本原理和一般方法为基础,结合抽样、参数估计、假设分析、回归分析等知识对我国汽油消费量影响因素进行了模拟回归,并运用软件计算出回归结果,故根据回归结果,对具体回归方程,回归准确性,自变量影响展开分析。 Anova表中,sig值是t统计量对应的概率值,所以t和sig两者是等效的,sig要小于给定的显著性水平,越接近于0越好。F是检验方程显著性的统计量,是平均的回归平方和平均剩余平方和之比,越大越好。在图表中,回归模型统计值F=804.627,p值为0.000,因此证明回归模型有统计学意义,表现回归极显著。即因变量与三个自变量之间存在线性关系。 系数表中,除了常数项系数显著性水平大于0.05,不影响,其它项系数都是0.000,小于0.005,即每个回归系数均具有意义。
《海量数据挖掘技术及工程实践》题目 一、单选题(共80题) 1)( D )的目的缩小数据的取值范围,使其更适合于数据挖掘算法的需要,并且能够得到 和原始数据相同的分析结果。 A.数据清洗 B.数据集成 C.数据变换 D.数据归约 2)某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖 掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 3)以下两种描述分别对应哪两种对分类算法的评价标准? (A) (a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (b)描述有多少比例的小偷给警察抓了的标准。 A. Precision,Recall B. Recall,Precision A. Precision,ROC D. Recall,ROC 4)将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 5)当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数 据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 6)建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的 哪一类任务?(C) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 7)下面哪种不属于数据预处理的方法? (D) A.变量代换 B.离散化
C.聚集 D.估计遗漏值 8)假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内? (B) A.第一个 B.第二个 C.第三个 D.第四个 9)下面哪个不属于数据的属性类型:(D) A.标称 B.序数 C.区间 D.相异 10)只有非零值才重要的二元属性被称作:( C ) A.计数属性 B.离散属性 C.非对称的二元属性 D.对称属性 11)以下哪种方法不属于特征选择的标准方法: (D) A.嵌入 B.过滤 C.包装 D.抽样 12)下面不属于创建新属性的相关方法的是: (B) A.特征提取 B.特征修改 C.映射数据到新的空间 D.特征构造 13)下面哪个属于映射数据到新的空间的方法? (A) A.傅立叶变换 B.特征加权 C.渐进抽样 D.维归约 14)假设属性income的最大最小值分别是12000元和98000元。利用最大最小规范化的方 法将属性的值映射到0至1的范围内。对属性income的73600元将被转化为:(D) A.0.821 B.1.224 C.1.458 D.0.716 15)一所大学内的各年纪人数分别为:一年级200人,二年级160人,三年级130人,四年 级110人。则年级属性的众数是: (A) A.一年级 B.二年级 C.三年级 D.四年级
一、解答题(满分30分,每小题5分) 1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之 首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。 2. 时间序列数据挖掘的方法有哪些,请详细阐述之 时间序列数据挖掘的方法有: 1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。 2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。 3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
2018级硕士研究生课程考试试题 课程名称:数据、模型与决策 适用专业:2018级MBA 一、名词解释(每题5,共20分) 1.灵敏度分析 2.最大流问题 3.决策树 4.仿真 1.灵敏度分析 在根据一定数据求得最优解后,当这些数据中某一个或某几个发生变化 时,对最优解会产生什么影响。或者说,要使最优解保持不变,各个数据可以有多大的幅度的变动。这种研究线性规划模型的原始数据变化对最优解产生的影响就叫做线性规划的灵敏度分析。 2. 最大流问题 给一个有向图D=(V ,A),在V 中指定了一点,称为发点(记为v s ),和另一点,称为收点(记为v t ),其余的点叫中间点。对于每一个弧(v i ,v j )∈A,对应有一个c(v i ,v j )≥0(或简写为c ij ),称为弧的容量。通常把这样的D 叫作一个网络。记作D=(V ,A ,C)。对D 中的任一弧(v i ,v j )有流量f(v i ,v j ) (有时也简记作f ij ),称集合f={f ij }为网络D 上的一个流。满足1)容量限制条件:对每一弧(v i ,v j )∈A ,0≤f ij ≤c ij ;2)平衡条件:流出量=流入量,即对每个i(i ≠s, t)有 (,)(,)0i j j i ij ji v v A v v A f f ∈∈- =∑ ∑ 的流 f 称为可行流。最大流问题就是在网络中,寻 找流量最大的可行流,即求一个流{f ij },使其流量v(f)达到最大,且满足:0≤f ij ≤c ij (v i ,v j )∈A , ()()()()() ,ij ji v f i s f f i s t v f i t ?=?-=≠??-=? ∑∑ 。 3.决策树 决策树又称为判定树,是数据挖掘技术中的一种重要的分类方法,它是一种 以树结构(包括二叉树和多叉树)形式来表达的预测分析模型。具体方法是:通过把实例从根节点排列到某个叶子节点来分类实例;叶子节点即为实例所属的分类;树上每个节点说明了对实例的某个属性的测试,节点的每个后继分支对应于该属性的一个可能值。决策树起源于Marin 和Stone 为了研究人类概念模型而得来,于1966年提出。主要算法有:CART 算法,ID3算法,C4.5算法,SLIQ 分类方法,SPRINT 法,PUBLIC 法等等。 4.仿真 科学研究通常有三种途径;理认推导、科学实验和仿真模拟。人们在认识自然、利用自然过程中,为了更好地完成这一能动过程,需要对物质世界及非物质世界进行实验研究。然而试验分析对某些真实系统可能是不允许的。因此,在实践中出现了用模型来代替真实系统做试验的方法,以解决上述无法直接对真实系统进行试验分析的问题。仿真是通过对系统模型的试验去研究一个存在的或设计中的系统。仿真是一门建立在相似理论,控制理论,系统科学和计算机基础上的综合性和试验性学科。 二、简答题(每题10分,共30分) 1.线性规划模型由哪些部分组成?线性规划模型有哪些性质? 答:线性规划模型由决策变量、目标函数、约束条件等组成构成。线性规划模型的具体性 质包括:1)目标函数是决策变量的线性函数;2)约束条件是决策变量的线性等式或不等式。 2.什么是概率决策的期望值方法?决策树方法与期望值法有何关系? 答:决策的前提条件存在确定、不确定及风险三种情况,在不确定及存在风险情况下进行 决策,可以依据不确定事件及风险发生的概率计算相应的期望值,通过期望收益最大化或期望损失最小化进行决策,即为概率决策的期望值方法。决策树法是指借助树状图,按照客观概率的大小,计算出各个方案的期望值,并对各个方案期望值进行比较,从中选择一个最为满意方案的方法。因此,决策树法属于概率决策期望值方法的一种。 3.有些什么类型的仿真?什么是仿真的Monte Carlo 进程? 答:仿真是通过对系统模型的试验去研究一个存在的或设计中的系统。大致可分成:计算 机仿真、半物理仿真及全物理仿真。计算机仿真也被称为纯数学仿真,它是一种通过建立与
《数据模型与决策》练习题及答案1 《管理统计学》习题解答 (2010年秋MBA周末二班,邢广杰,学号: ) 第3章描述性统计量 (一) P53 第1题 抽查某系30个教工,年龄如下所示: 61,54,57,53,56,40,38,33,33,45,28,22,23,23,24,22,21,45,42, 36,36,35,28,25,37,35,42,35,63,21 (i)求样本均值、样本方差、样本中位数、极差、众数; (ii)把样本分为7组,且组距相同。作出列表数据和直方图; (iii)根据分组数据求样本均值、样本方差、样本中位数和众数。解: n1(i)样本均值=37.1岁 x,x,in,i1 nn211222样本方差=189.33448 s,(X,X),(X,nX),,iin-1n-1,,i1i1 把样本按大小顺序排列:21,21,22,22,23,23,24,25,28,28,33,33,35,35, 35,36,36,37,38,40,42,42,45,45,53,54,56,57,61,63 1样本中位数=(35+36)/2=35.5岁 m,(X,X)nn()(,1)222 R,X,X,极差63-21=42岁 (n)(1) m,众数35岁 0 (ii)样本分为7组、且组距相同的列表数据、直方图如下所示 累计频教工分组教工年龄组中值 数教职工岁数分组频数图f频数() 分组(岁) (x) i (16,23] 6 19.5 6 10
8(23,30] 4 26.5 10 6(30,37] 8 33.5 18 频数频数4(37,44] 4 40.5 22 2(44,51] 2 47.5 24 0 (51,58] 4 54.5 28 23303744515865 教职工岁数(58,65] 2 61.5 30 (iii)根据分组数据求样本均值、样本方差、样本中位数和众数。 k1样本均值=36.3岁 X,Xif,in,i1 1 kk211222样本方差=174.3724 s,(X,X)f,(Xf,nX),,iiiin-1n-1,,i1i1 n30,F,1022样本中位数=34.375岁 m,I,i,30,7f8 ff,84,mm-1众数33.5岁 mIi307,,,,,02fff2844,,,,,mm-1m,1 (二) P53 第2题 某单位统计了不同级别的员工的月工资水平资料如下: 月工资(元) 800 1000 1200 1500 1900 2000 2400 员工数(人) 5 8 25 36 24 16 6 累计频数 5 13 38 74 98 114 120 求样本均值、样本标准差、样本中位数和众数。 解: k1样本均值=1566.667元 X,Xif,in,i1 kk21122样本标准差=398.1751元 s,(X,X)f,(Xf,nX),,iiiin-1n-1,,i1i1 样本中位数在累计74人的那一组,m=1500元; m,1500众数元。 0 第7章参数统计推断
经济与管理学院 MBA Economics and Management School of Wuhan University ×××级×××班《数据、模型与决策》试题 出题人:刘伟考试形式:闭卷考试时间:2007年7月×日120分钟 姓名_______学号_______ 记分_______ 一、名词解释及简答题(各题5分) 1、众数 2、直方图 3、变异系数 4、相关系数 5、虚拟变量 6、置信区间 7、最小二乘(平方)法 8、线性回归模型 9、多重共线性10、完全多重共线性11、不完全多重共线性 12、虚拟变量模型 13、总体回归函数 14、何为虚变量回归模型?为什么将虚变量值设为取0、1 ? 15、回归方程的显著性检验与回归系数的显著性检验什么区别与联系? 16、在回归方程的最小二乘法估计中,对回归模型有哪些基本假设? 17、回归方程的显著性检验与回归系数的显著性检验什么区别与联系? 18、为什么从计量经济学模型得到的预测值不是一个确定的值?预测值的置信区间和置 信度的含义是什么?在相同的置信度下如何才能缩小置信区间? 19、影子价格20、对偶规划21、模型22、约束条件23、目标函数 24、决策变量25、协方差26、拟合优度检验 二、计算题(各题10分) 1、500家美国公司1993年底的平均资产为11270(单位:百万美元),标准差为2780(百万美元)。这些公司的平均价格收益比为31,标准差为8。请问哪一个指标的差异大? 2、有一种电子元件,要求其使用寿命不得低于1000小时,现抽25件,测 得其均值950小时,方差为900小时。已知该种元件寿命服从正态分布, .; (1)写出该种电子元件使用寿命的置信区间,取α=005 (2)若已知使用寿命的标准差σ=100,写出该种电子元件使用寿命的 .;在 置信区间,取α=005 α=005 .下,且已知σ=100这批元件合格否? 3、某商店的日销售额服从正态分布,据统计去年的日均销售额是2.74万元,
《数据模型与决策》复习(附参考答案) 2018.9 一、填空题(五题共15分) 1. 已知成年男子的身高服从正态分布N(167.48,6.092),随机调查100位成年男子的身高,那么,这100位男子身高的平均数服从的分布是 ① 。 解:N(167.48,0.609) 考查知识点:已知总体服从正态分布,求样本均值的分布。 2. 某高校想了解大学生每个月的消费情况,随机抽取了100名大学生,算得平均月消费额为1488元,标准差是2240元。根据正态分布的“68-95-99”法则,该高校大学生每个月的消费额的95%估计区间为 ② 。 解:[1040,1936] 考查知识点:区间估计的求法。正态总体均值的区间估计是[n s Z X α --1,n s Z X α-+1] 其中X 是样本平均数,s 是样本的标准差,n 是样本数。 详解:直接带公式得:区间估计是 [n s Z X α --1,n s Z X α-+1]= [100224021488-,100224021488+] =[1040,1936] 3. 从遗传规律看,一个产妇生男生女的概率是一样的,都是50%,但也有个人的特殊情况。假设某人前一胎是女孩,那么她的下一胎也是女孩的概率为0.55;如果某人前一胎是男孩,那么她的下一胎还是男孩的概率为0.48。已知小李第一胎是女孩,那么她的第三胎生男孩的概率是 ③ 。 解 p=0.4653 考查知识点:离散概率计算方法。 详解:假设B1=第1胎生男孩,B2=第2胎生男孩,B3=第3胎生男孩 G1=第1胎生女孩,G2=第2胎生女孩,G3=第3胎生女孩 P (B3)=P (B3B2)+P (B3G2)(直观解释是:第二胎生男孩的情况下第三胎生男孩,第二胎生女孩的情况下第三胎生男孩,两个概率之和为P (B3))