
文章编号:100025404(2007)0320267203论著AR I M A模型在流行性感冒预测中的应用
漆 莉1,李 革1,李 勤2 (1重庆医科大学公共卫生学院流行病学教研室,重庆400016;2重庆市疾病预防控制中心传染病防治所,重庆400042)
提 要:目的 探讨AR I M A模型在流感预测方面的应用,建立流感发病预测模型,并证明模型的适用性。方法 利用重庆市2002年1月-2006年6月流感发病数资料,通过SPSS拟合AR I M A模型,用Q统计量法对模型适应性进行检验。结果 建立AR I M A(1,1,1)模型,模型Q统计量<χ2α(m),P>0105,证实了该模型的适用性。结论 AR I M A模型可用于流感发病的动态分析和短期预测。
关键词:AR I M A模型;时间序列;流行性感冒;预测
中图法分类号:R181.2;R183.3;R511.7文献标识码:A
Appli ca ti on s of AR I M A m odel on pred i cti ve i n c i dence of i n fluenza
Q IL i1,L I Ge1,L IQ in2(1Ep ide m i ol ogy depart m ent of Public Health School,Chongqing Medical University,Chongqing400016,2Center of D isease Contr ol of Chongqing,Chongqing400042,China)
Abstract:O b j ec ti ve T o exp l ore the app licati on of aut o regressive integrated moving average(AR I M A) and establish a p redictive model for influenza t o f orecast the dyna m ic trend in order t o devel op the p reventi on policy scientifically.M e tho d s Sa mp les which caught influenza fr om2002Jan t o2006Jun in Chongqing city were subjected.SPSS was used t o fit AR I M A model,and Q statistic was used t o verify the app licability of the model.R e su lts The model of AR I M A(1,1,1)was established.The statistic of Q was s maller thanχ2α(m), verifying the app licability of this model.Co nc l u s i o n The AR I M A model can be used t o analyze the influenza incidence and make a short2ter m p redicti on.
Key words:aut o regressive integrated moving average model;ti m e series;influenza;p redicti on
流行性感冒(简称流感)曾给人类造成严重灾难,具有周期性大流行的规律,近年来禽流感疫情形势严峻,一旦禽流感病毒与人类流感病毒重组,将会成为新的人类病毒引起流感大流行,许多专家预测下一次全球流感大流行即将来临。因此,流感的流行动态引起国际社会高度关注,探讨有效的流感预测方法,对流感大流行的预防和控制极具实用价值。本研究采用时间序列分析法中的求和自回归滑动平均模型法(aut o regressive integrated moving average,AR I M A)来建立流感发病预测模型,为我市的流感防制工作提供科学依据。
1 资料与方法
1.1 一般资料
资料来源于国家疾病报告管理系统,包括重庆市2002至
作者简介:漆 莉(1981-),女,重庆市人,硕士研究生,主要从事流行病学方面的研究。电话:138********
通讯作者:李 革,电话:(023)68485002
收稿日期:2006209207;修回日期:20062102052006年的流感按月统计发病数。由于该市人口基数大(3000多万),且相对稳定,发病数与发病率的变化趋势基本一致,因
此,本课题采用流感的月发病数建立时间序列。
1.2 AR I M A模型法
1.2.1 基本思想及模型类型[1] AR I M A模型法的基本思想是将时间序列视为一组依赖于时间(t)的随机变量,这组随机变量所具有的自相关性表征了预测对象发展的延续性,而这种自相关性一旦被相应的数学模型描述出来,就可以从时间序列的过去值及现在值预测其未来的值。
其模型类型分为自回归模型即AR(p)模型、滑动平均模型即MA(q)模型和自回归滑动平均模型即AR I M A(p、d、q)模型。基本公式为:
^y
t
=<1y
t-1
+<1y
t-2
+…+<
p
y
t-p
+e
t
-θ1e
t-1
-θ2e
t-2
-…-θq e t-q
其中p、d、q分别表示时间序列的自回归阶数、差分阶数和
滑动平均阶数,^y
t
为时间序列在t时期的预测值,y
t-1
为t-i时
期的观测值,<
i
为模型自回归系数,θ
i
为模型滑动平均系数,
e t-i为时间序列模型在t-i时期的误差或偏差。
1.2.2 预测的步骤[2]第一阶段 模型的识别。利用自相关分析、偏相关分析等方法,对时间序列的随机性、平稳性及季节
762
第29卷第3期2007年2月
第 三 军 医 大 学 学 报
ACT A AC ADE M I A E ME D I C I N AE M I L I T AR I S TERTI A E
Vol.29,No.3
Feb.2007
性进行分析,依据A I C 和B I C 准则确定模型阶数,建立AR I M A 预测模型。在不断改变模型的阶数后,A I C 与B I C 值最小的模型为最佳模型。
第二阶段:参数估计和模型检验。用SPSS 统计软件进行模型的参数估计,通过对原始时间序列与所建立AR I M A 模型之间的误差序列e t 检验来实现对模型适应性的检验,若e t 具有随机性,表示所建立的模型适合用于预测,否则提示该模型需进一步改进,应返回第一阶段重新建模。本研究中e t 随机性
用博克斯2皮尔斯Q 统计量法进行检验,若Q 统计量χ2α(m )(m 为模型中所含的最大时滞),则表明所选用的AR I M A 模型是合
适的,可以用于预测。
第三阶段:预测应用。用选定的模型对将来某个时期的数值作出预测,AR I M A 模型法短期预测精度较高,即1~3个月的预测,故本研究仅对重庆市2006年7、8、9月的流感发病数进行预测。
2 结果
2.1 流感发病基本情况
各月流感发病数呈现出明显波动,每年均出现发病高峰月,但发病高峰出现的时间不太一致,未发现有明显的季节性和周期性波动。2003年4月报告发病数明显增多,可能与当时“非典”疫情形势严峻,各医疗机构加大了对呼吸道病例的搜索力度有关,见图1
。
图1 重庆市2002年1月至2006年6月流感发病时序图
2.2 建立AR I M A 预测模型
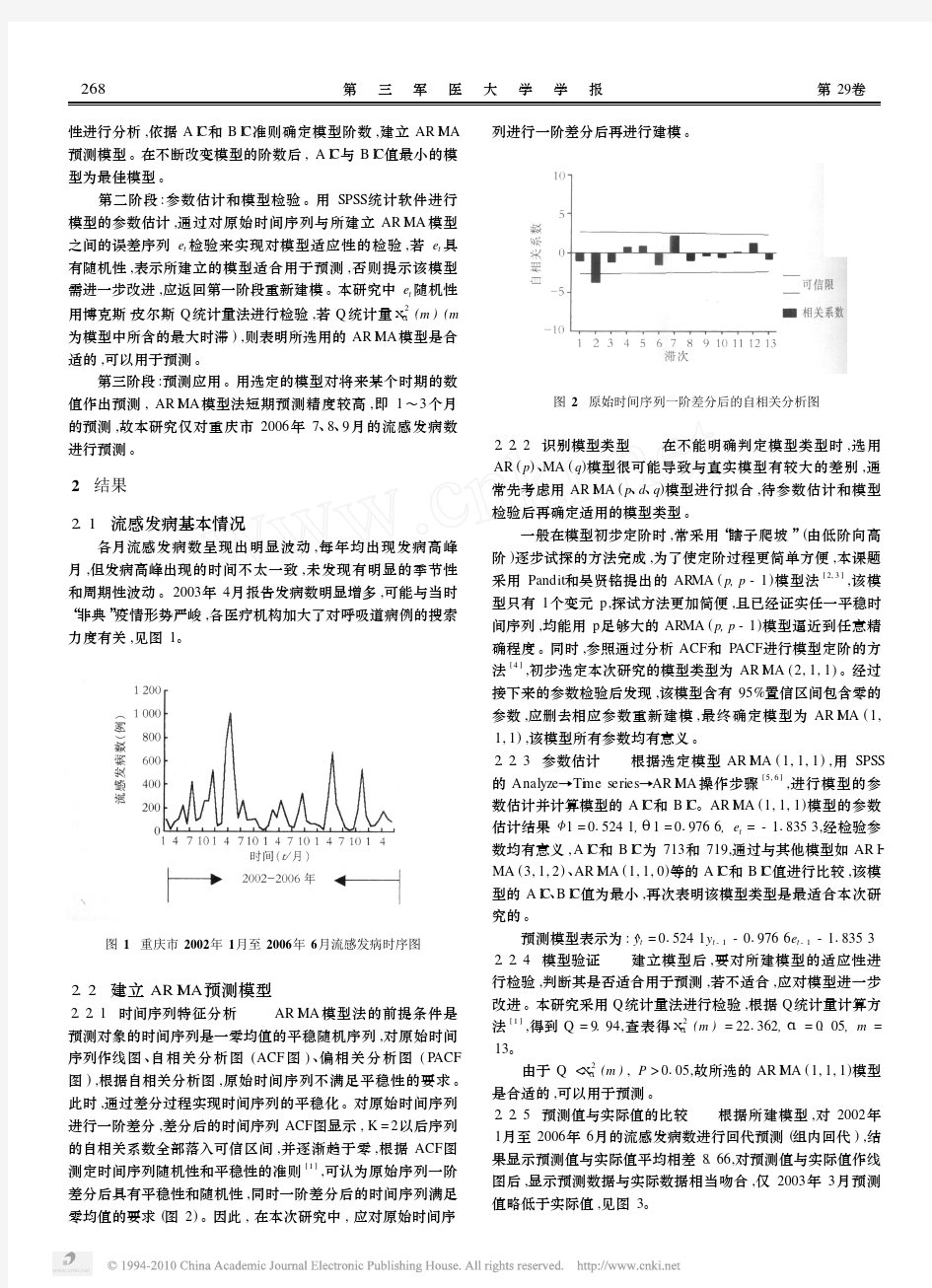
2.2.1 时间序列特征分析 AR I M A 模型法的前提条件是
预测对象的时间序列是一零均值的平稳随机序列,对原始时间
序列作线图、自相关分析图(ACF 图)、偏相关分析图(P ACF 图),根据自相关分析图,原始时间序列不满足平稳性的要求。此时,通过差分过程实现时间序列的平稳化。对原始时间序列进行一阶差分,差分后的时间序列ACF 图显示,K =2以后序列的自相关系数全部落入可信区间,并逐渐趋于零,根据ACF 图测定时间序列随机性和平稳性的准则[1],可认为原始序列一阶差分后具有平稳性和随机性,同时一阶差分后的时间序列满足零均值的要求(图2)。因此,在本次研究中,应对原始时间序
列进行一阶差分后再进行建模
。
图2 原始时间序列一阶差分后的自相关分析图
2.2.2 识别模型类型 在不能明确判定模型类型时,选用AR (p )、MA (q )模型很可能导致与真实模型有较大的差别,通
常先考虑用AR I M A (p 、d 、q )模型进行拟合,待参数估计和模型检验后再确定适用的模型类型。
一般在模型初步定阶时,常采用“瞎子爬坡”
(由低阶向高阶)逐步试探的方法完成,为了使定阶过程更简单方便,本课题
采用Pandit 和吴贤铭提出的AR MA (p,p -1)模型法[2,3],该模型只有1个变元p,探试方法更加简便,且已经证实任一平稳时间序列,均能用p 足够大的AR MA (p,p -1)模型逼近到任意精确程度。同时,参照通过分析ACF 和P ACF 进行模型定阶的方法[4],初步选定本次研究的模型类型为AR I M A (2,1,1)。经过接下来的参数检验后发现,该模型含有95%置信区间包含零的参数,应删去相应参数重新建模,最终确定模型为AR I M A (1,
1,1),该模型所有参数均有意义。
2.2.3 参数估计 根据选定模型AR I M A (1,1,1),用SPSS
的Analyze →Ti m e series →AR I M A 操作步骤[5,6],进行模型的参数估计并计算模型的A I C 和B I C 。AR I M A (1,1,1)模型的参数
估计结果<1=015241,θ1=019766,e t =-118353,经检验参数均有意义,A I C 和B I C 为713和719,通过与其他模型如AR I 2MA (3,1,2)、AR I M A (1,1,0)等的A I C 和B I C 值进行比较,该模型的A I C 、B I C 值为最小,再次表明该模型类型是最适合本次研究的。
预测模型表示为:^y t =015241y t -1-019766e t -1-118353
2.2.4 模型验证 建立模型后,要对所建模型的适应性进
行检验,判断其是否适合用于预测,若不适合,应对模型进一步改进。本研究采用Q 统计量法进行检验,根据Q 统计量计算方
法[1],得到Q =9.94,查表得χ2
α(m )=221362,α=0
.05,m =13。
由于Q <χ2α(m ),P >0105,故所选的AR I
M A (1,1,1)模型是合适的,可以用于预测。
2.2.5 预测值与实际值的比较 根据所建模型,对2002年1月至2006年6月的流感发病数进行回代预测(组内回代),结
果显示预测值与实际值平均相差8.66,对预测值与实际值作线图后,显示预测数据与实际数据相当吻合,仅2003年3月预测值略低于实际值,见图3。
862 第 三 军 医 大 学 学 报 第29卷
第3期 漆 莉,等.AR I M A模型在流行性感冒预测中的应用
图3 AR I M A(1,1,1)预测模型拟合图
2.3 预测及与真实值的比较
时间序列分析主要目的在于对未来值进行预测以评估其发展趋势,本研究对2006年7-9月的流感发病数进行短期预测,预测结果为:此3个月流感发病数分别是119、125和128。此3个月实际发病数分别为121、118和115,平均相对误差418%。
3 讨论
当影响预测对象的因素错综复杂或有关影响因素数据资料无法获得时,传统的因果回归分析法无法完成预测,时间序列分析法可以很好的克服这些难题,该方法以时间(t)综合代替这些影响因素,建立时序模型,达到预测的目的。该方法已经广泛的应用于经济学、工程学、生物学、环境卫生等领域[7,8]。近年来,有学者探讨其在医学领域的应用,认为该方法可较好的用于疾病发病或死亡的预测预报[9-11]。
AR I M A模型法是最通用的时间序列预测方法,不需要对时间序列的发展模式作先验的假设,而且可以通过反复识别修改,获得最满意的模型,其过程借助于计算机操作简单方便,是一种实用性强、精确度高的短期预测方法[12]。本研究将这种方法用于流感发病的预测,预测值与真实值相对误差小于5%,取得了较好的预测效果。
此外,除了这种预测方法,还有状态空间模型、灰色预测法、趋势外推法等,每种方法都有其一定的适应范围。状态空间法要求序列具有马尔科夫特性(即系统的将来与其过去独立);当序列波动性较大时,灰色模型很难实施;趋势外推法利用某种函数分析描述序列的发展趋势,但很难找到适宜的预测模型,导致该方法无法实施。
流感发病的影响因素很多,一般认为流感具有季节性流行特征,但本次研究对原始时间序列进行分析,并未发现其具有明显的季节性,因此,只有对流感进行长期不间断地动态观察,才能及时准确的掌握其发病的变化趋势。本研究在不考虑季节因素的影响下,对其进行建模,获得了比较满意的预测模型AR I M A(1, 1,1),经Q统计量法进行检验,模型可用于短期预测。在有条件的情况下,可以收集更多的数据进行组外回代,进一步验证模型预报的精确度。
本研究证实了AR I M A模型法能够较好的用于流感发病的预测,该模型在其他传染病发病预测中的应用也值得进一步探讨。但是,应用AR I M A模型需注意:①至少需要50个以上的历史统计数据。②单次分析建立的AR I M A模型,不能作为永久不变的预测工具,只能用于短期预测。在实际工作中,应尽可能多的收集足够的时间序列数据,对已建立的模型用新的实际值进行验证,并不断加入新的实际值,以修正或重新拟合更能反映实际情况的流感预测模型。
除了对流感的月发病数进行动态分析外,AR I M A 法还可以对流感的其他周期性的指标如周、旬、季、年发病数等进行分析预测。
(致谢:感谢重庆医科大学流行病学与卫生统计学教研室的钟朝辉、邓丹、易静、钟晓妮、周燕容老师以及研究生黄彦在课题研究中的指导!)
参考文献:
[1]徐国祥.统计预测和决策[M].上海:上海财经大学出版社,1998:
150-177.
[2]王振龙.时间序列分析[M].北京:中国统计出版社,1999:89-
125.
[3]李先孝.时间序列分析基础[M].武汉:华中理工大学出版社,
1991:113-116.
[4]易丹辉.统计预测方法与应用[M].北京:中国人民大学出版社,
1988:212-280.
[5]张文彤.SPSS11统计分析教程(高级篇)[M].北京:北京希望电子
出版社,2002:250-285.
[6]张彦琦,黄 彦,田考聪.SPSS在医院统计预测中的应用[J].中
国医院统计,2002,9(3):131-134.
[7]Kao J J,Huang S S.Forecasts using neural net w ork versusBox2Jenkins
methodol ogy f or ambient air quality monit oring data[J].J A ir W aste Manag A ss oc,2002,50(2):219-226.
[8]Helfenstein U.Box2Jenkins modelling in medical research[J].Stat
MethodsMed Res,1996,5(1):3-22.
[9]Cardinal M,Roy R,La mber J.On the app licati on of integer2valued
ti m e series models f or the analysis of disease incidence[J].Stat Med,
1999,18(15):2025-2039.
[10]钟朝晖,刘达伟,张 燕.重庆市主城区人口死亡率的时间序列分
析[J].中国公共卫生,2003,19(7):796-799.
[11]梁桂玲,刘 颜,邓泗沐.AR I M A模型应用于月门诊量预测[J].
中国医院统计,2006,13(1):24-26.
[12]Daniels M L,Dom inici F,Samet J M,et al.Esti m ating particulate
matter2mortality dose2res ponse curves and threshold levels:an analysis
of daily ti m e2series f or the20largest US cities[J].Am J Ep ide m i ol,
2000,152(5):397-406.
(编辑 薛国文)
962
龙源期刊网 https://www.doczj.com/doc/6d16499.html, 基于ARIMA模型下的时间序列分析与预测 作者:万艳苹 来源:《金融经济·学术版》2008年第09期 摘要:大多数的时间序列存在着惯性,或者说具有迟缓性。通过对这种惯性的分析,可以由时间序列的当前值对其未来值进行估计。本文以1949年到2004年江苏省社会消费品零售总额数据为研究对象,将这些数据平稳化并做分析,发现ARIMA(1,1,2)模型能比较好的对江苏省社会消费品零售总额进行市时间序列分析和预测,。 关键词:ARIMA;江苏省消费品零售总额;时间序列分析 一、引言 江苏省是一个经济大省,经济一直保持平稳较快增长,城乡居民收入都位于全国前茅,消费品需求旺盛,人们生活水平比较高。其中社会消费品零售总额是反映人民生活水平提高的一个很好的指标。所以对社会消费品零售总额做分析就比较重要。但是影响社会消费品零售总额的因素有很多,包括收入、住房、医疗、教育以及人们的预期等很多因素,而且这些因素之间又保持着错综复杂的联系。因此运用数理经济模型来分析和预测较为困难。所以本文采用ARIMA模型对江苏省的社会消费品零售总额进行分析,得出其规律性,并预测其未来值。 二、ARIMA模型的说明和构建 ARIMA模型又称为博克斯-詹金斯模型。ARIMA模型是由三个过程组成:自回归过程(AR(p));单整(I(d));移动平均过程(MA(q))。AR(p)即自回归过程,是指一个过程的当前值是过去值的线性函数。如:如果当前观测值仅与上期(滞后一期)的观测值有显著的线性函数关系,则我们就说这是一阶自回归过程,记作AR(1)。推广之,如果当前值与滞后p期的观测值都有线性关系则称p阶自回归过程,记作AR(p)。MA(q),即移动平均过程,是指模型值可以表示为过去残差项(即过去的模型拟合值与过去观测值的差)的线性函数。如:MA(1)过程,说明时间序列受到滞后一期残差项的影响。推广之,MA(q)是指时间序列受到滞后q期残差项的
课程论文 (2016 / 2017学年第 1 学期) 课程名称应用时间序列分析 指导单位经济学院 指导教师易莹莹 学生姓名班级学号 学院(系) 经济学院专业经济统计学
实验三ARIMA 模型建模与预测实验指导 一、实验目的: 了解ARIMA 模型的特点和建模过程,了解AR ,MA 和ARIMA 模型三者之间的区别与联系,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念: 所谓ARIMA 模型,是指将非平稳时间序列转化为平稳时间序列,然后将平稳的时间序列建立ARMA 模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,我们主要用到两个工具:自相关函数ACF ,偏自相关函数PACF 以及它们各自的相关图。对于一个序列{}t X 而言,它的第j 阶自相关系数j ρ为它的j 阶自协方差除以方差,即j ρ=j 0γγ,它是关于滞后期j 的函数,因此我们也称之为自相关函数,通常记ACF(j )。偏自相关函数PACF(j )度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验任务: 1、实验内容: (1)根据时序图的形状,采用相应的方法把非平稳序列平稳化; (2)对经过平稳化后的1950年到2005年中国进出口贸易总额数据建立合适的(,,)ARIMA p d q 模型,并能够利用此模型进行进出口贸易总额的预测。 2、实验要求: (1)深刻理解非平稳时间序列的概念和ARIMA 模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA 模型;如何利用ARIMA 模型进行预测; (3)熟练掌握相关Eviews 操作,读懂模型参数估计结果。 四、实验要求: 实验过程描述(包括变量定义、分析过程、分析结果及其解释、实验过程遇到的问题及体会)。 实验题:对经过平稳化后的1950年到2005年中国进出口贸易总额数据建立合适的(,,)ARIMA p d q 模型,并能够利用此模型进行进出口贸易总额的预测。
季节ARIMA模型建模与预测实验指导
————————————————————————————————作者: ————————————————————————————————日期: ?
实验六季节ARIMA模型建模与预测实验指导 学号:20131363038 姓名:阙丹凤班级:金融工程1班 一、实验目的 学会识别时间序列的季节变动,能看出其季节波动趋势。学会剔除季节因素的方法,了解ARIMA模型的特点和建模过程,掌握利用最小二乘法等方法对ARIMA模型进行估计,利用信息准则对估计的ARIMA模型进行诊断,以及如何利用ARIMA模型进行预测。掌握在实证研究如何运用Eviews软件进行ARIMA模型的识别、诊断、估计和预测。 二、实验内容及要求 1、实验内容: 根据美国国家安全委员会统计的1973-1978年美国月度事故死亡率数据,请选择适当模型拟合该序列的发展。 2、实验要求: (1)深刻理解季节非平稳时间序列的概念和季节ARIMA模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA模型;如何利用ARIMA模型进行预测; (3)熟练掌握相关Eviews操作。 三、实验步骤 第一步:导入数据 第二步:画出时序图
6,000 7,000 8,000 9,000 10,000 11,000 12,000 510152025303540455055 606570 SIWANGRENSHU 由时序图可知,死亡人数虽然没有上升或者下降趋势,但由季节变动因素影响。 第三步:季节差分法消除季节变动 由时序图可知,波动的周期大约为12,所以对原序列作12步差分,得到新序列如下图所示。
股票预测模型【运用ARIMA模型预测股票价格】 [摘要]ARIMA模型是时间序列中十分常见和常用的一种模型,应用与经济的各个领域。本文基于ARIMA模型,采用了莱宝高科近67个交易日的数据,对历史数据进行分析,并且在此基础上做出一定的预测,试图为现实的投资提供一些参考信息。[关键字]ARIMA模型;股价预测;莱宝高科一、引言时间序列分析是从一段时间上的一组属性值数据中发现模式并预测未来值的过程。ARIMA模型是目前最常用的用于拟合非平稳序列的模型,对于满足有限参数线形模型的平稳时间序列的分析,ARIMA在理论上已趋成熟,它用有限参数线形模型描述时间序列的自相关结构,便于进行统计分析与数学处理。有限参数线形模型能描述的随机现象相当广泛,模型拟合的精度能达到实际工程的要求,而且由有限参数的线形模型结构可推导出适用的线形预报理论。利用ARIMA 模型描述的时间序列预报问题在金融,股票等领域具有重要的理论意义。本文将利用ARIMA模型结合莱宝高科的数据建立模型,并运用该模型对莱宝的股票日收盘价进行预测。二、ARIMA模型的建立 2.1ARIMA模型简介ARIMA是自回归移动平均结合模型的简写形式,用于平稳序列或通过差分而平稳的序列分析,简记为ARIMA(p,d,q)用公式表示为:△dZt=Xt=ψ1Xt-1+ψ2Xt-2+?+ψpXt-p+at-θ1at-1-θ2at-2-?-θqat-q 其中,p、d、q分别是自回归阶数、差分阶数和滑动平均阶数;Zt是时间序列;Xt是经过d阶差分后的时间序列值;at-q是时间为t-q的随机扰动项;ψp、θq分别是对应项前的系数。 2.2模型建立流程(1)平稳性检验以2010-3-4到2010-6-10的“莱宝高科”(002106)股票的收盘价作为模型的数据进行建立时间序列模型:做出折线图观察数据的特征:进行单位根检验,判别序列是否为平稳序列;若一阶差分后的数据为平稳序列,可以建立时间序列模型。说明原数据为一阶单整。(2)模型的选择和参数的估计根据数据的平稳性特征,初步确定建立ARIMA模型。观察一阶差分以后的序列的自相关函数和偏自相关
R 语言环境下使用ARIMA模型做时间序列预测 1.序列平稳性检验 通过趋势线、自相关(ACF)与偏自相关(PACF)图、假设检验和因素分解等方法确定序列平稳性,识别周期性,从而为选择适当的模型提供依据。 1.1绘制趋势线 图1 序列趋势线图 从图1很难判断出序列的平稳性。 1.2绘制自相关和偏自相关图
图2 序列的自相关和偏自相关图
从图2可以看出,ACF拖尾,PACF1步截尾(p=1),说明该现金流时间序列可能是平稳性时间序列。 1.3 ADF、PP和KPSS 检验平稳性 图3 ADF、PP和KPSS检验结果 通过ADF检验,说明该现金流时间序列是平稳性时间序列(p-value for ADF test <0.02,拒绝零假设).pp test和kpss test 结果中的警告信息说明这两种检验在这里不可用。但是这些检验没有充分考虑趋势、周期和季节性等因素。下面对该序列进行趋势、季节性和不确定性因素分解来进一步确认序列的平稳性。 1.4 趋势、季节性和不确定性因素分解 R 提供了两种方法来分解时间序列中的趋势、季节性和不确定性因素。第一种是使用简单的对称过滤法,把相应时期内经趋势调整后的观察值进行平均,通过decompose()函数实现,如图4。第二种方法更为精确,它通过平滑增大规模后的观察值来寻找趋势、季节和不确定因素,利用stl()函数实现。如图5。
图4 decompose()函数分解法 图5 stl()函数分解法 两种方法得到的结果非常相似。从上图可以看出,该现金流时间序列没有很明显的长期趋势。但是有明显的季节性或周期性趋势,经分解后的不确定因素明显减少。
BOX-JENKINS 预测法 1 适用于平稳时序的三种基本模型 (1)()AR p 模型(Auto regression Model )——自回归模型 p 阶自回归模型: 式中,为时间序列第时刻的观察值,即为因变量或称被解释变量;, 为时序的滞后序列,这里作为自变量或称为解释变量;是随机误 差项;,,,为待估的自回归参数。 (2)()MA q 模型(Moving Average Model )——移动平均模型 q 阶移动平均模型: 式中,μ为时间序列的平均数,但当{}t y 序列在0上下变动时,显然μ=0,可删除此项;t e ,1t e -,2t e -,…,t q e -为模型在第t 期,第1t -期,…,第t q -期 的误差;1θ,2θ,…,q θ为待估的移动平均参数。 (3)(,)ARMA p q 模型——自回归移动平均模型(Auto regression Moving Average Model ) 模型的形式为: 显然,(,)ARMA p q 模型为自回归模型和移动平均模型的混合模型。当q =0,时,退化为纯自回归模型()AR p ;当p =0时,退化为移动平均模型()MA q 。 2 改进的ARMA 模型 (1)(,,)ARIMA p d q 模型 这里的d 是对原时序进行逐期差分的阶数,差分的目的是为了让某些非平稳(具有一定趋势的)序列变换为平稳的,通常来说d 的取值一般为0,1,2。 对于具有趋势性非平稳时序,不能直接建立ARMA 模型,只能对经过平稳化处理,而后对新的平稳时序建立(,)ARMA p q 模型。这里的平文化处理可以是差分处理,也可以是对数变换,也可以是两者相结合,先对数变换再进行差分处理。 (2)(,,)(,,)s ARIMA p d q P D Q 模型 对于具有季节性的非平稳时序(如冰箱的销售量,羽绒服的销售量),也同样需要进行季节差分,从而得到平稳时序。这里的D 即为进行季节差分的阶数; ,P Q 分别是季节性自回归阶数和季节性移动平均阶数;S 为季节周期的长度, 如时序为月度数据,则S =12,时序为季度数据,则S =4。 在SPSS19.0中的操作如下
实验指导书ARIMA 模型建模与预测
实验指导书(ARIMA模型建模与预测) 例:中国1952- 的进出口总额数据建模及预测 1、模型识别和定阶 (1)数据录入 打开Eviews软件,选择“File”菜单中的“New--Workfile”选项,在“Workfile structure type”栏选择“Dated –regular frequency”,在“Date specification”栏中分别选择“Annual”(年数据) ,分别在起始年输入1952,终止年输入,文件名输入“im_ex”,点击ok,见下图,这样就建立了一个工作文件。 在workfile中新建序列im_ex,并录入数据(点击File/Import/Read Text-Lotus-Excel…, 找到相应的Excel数据集,打开数据集,出现如下图的窗口,
在“Data order”选项中选择“By observation-series in columns”即按照观察值顺序录入,第一个数据是从B15开始的,因此在“Upper-left data cell”中输入B15,本例只有一列数据,在“Names for series or number if named in file”中输入序列的名字im_ex,点击ok,则录入了数据): (2)时序图判断平稳性 双击序列im_ex,点击view/Graph/line,得到下列对话框:
得到如下该序列的时序图,由图形能够看出该序列呈指数上升趋势,直观来看,显著非平稳。 IM_EX 240,000 200,000 160,000 120,000 80,000 40,000 556065707580859095000510 (3 因为数据有指数上升趋势,为了减小波动,对其对数化,在Eviews命令框中输入相应的命令“series y=log(im_ex)”就得到对数序列,其时序图见下图,对数化后的序列远没有原始序列波动剧烈:
实验指导书(ARIMA 模型建模与预测) 例:我国1952-2011年的进出口总额数据建模及预测 1、模型识别和定阶 (1)数据录入 打开 Eviews 软件,选择"File ”菜单中的"New--Workfile ”选项,在"Workfile structure type ”栏选择"Dated -regular frequency ”,在"Date specification ”栏中 分别选择“ Annual ” (年数据),分别在起始年输入 1952,终止年输入 2011,文件名输入 “im_ex ”,点击ok ,见下图,这样就建立了一个工作文件。 在 workfile 中新建序列im_ex , 并录入数据 (点击 File/Import/Read Text-Lotus-Excel …, File | Edit Object View 卩 iroc Quick Options Window Help New ? □pen i Save Fetch from DB... T5D Fi le Im port-. DRI Bask Economics Database... Read Text-Lctu s-Excel... 找到相应的Excel 数据集,打开数据集,出现如下图的窗口,在“ Data order ”选项中 选择“ By observation-series in columns ”即按照观察值顺序录入,第一个数据是从 B15 开始的,所以在“ Upper-left data cell ”中输入B15,本例只有一列数据,在“ Namesfor series or number if named in file ”中输入序列的名字 im_ex ,点击ok ,则录入了数据): import Ex port Print PtFrtl Setup-.,.
实验二 ARIMA 模型的建立 一、实验目的 熟悉ARIMA 模型,掌握利用ARIMA 模型建模过程,学会利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及学会利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念 ARIMA 模型,即将非平稳时间序列转化为平稳时间序列,然后将平稳的时间序列建立ARMA 模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,主要用到两个工具:自相关函数ACF ,偏自相关函数PACF 以及它们各自的相关图。对于一个序列{}t X 而言,它的第j 阶自相关系数j ρ为它的j 阶自协方差除以方差,即j ρ=j 0γγ ,它是关于滞后期j 的函数,因此我们也称之为自相关函数,通常记ACF(j )。偏自相关函数PACF(j )度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验内容 (1)根据时序图的形状,采用相应的方法把非平稳序列平稳化; (2)对经过平稳化后的2000年1月到2011年10月美国的失业率数据建立ARIMA (,,p d q )模型,并利用此模型进行失业率的预测。 四、实验要求: 了解ARIMA 模型的特点和建模过程,了解AR ,MA 和ARIMA 模型三者之间的区别与联系,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。 五、实验步骤 (1) 输入原始数据 打开Eviews 软件,选择“File ”菜单中的“New--Workfile ”选项,在“Workfile structure type ”栏中选择“Dated-regular frequency ”,在“Frequency ”栏中选择“Monthly ”,分别在起始月输入1991.01,终止月输入2010.12,点击ok ,见图1。再建立一个New object ,将选取的x 的月度数据复制进去 。
基于ARIMA模型对河南省2010年GDP预 测 摘要:ARIMA模型是对ARMA模型的差分得到的平稳时间序列模型,具有序列相关性,本文收集了1978-2009年河南省GDP数据,根据ARIMA模型的性质、利用统计软件对河南省2010年GDP进行预测。 关键字:平稳性、ARMA模型、ARIMA模型 由于2008年金融海啸的全面性的爆发,我国的整体经济水平难免呈现不良的发展趋势,4万亿的救市计划,终于达到2009年的保八目标。在这个时候如果对我国GDP进行预测,难免有些偏差,因此本文选择受金融危机影响较小、地处中原、经济持续平稳增长的河南省为例,收集改革开放30年来的数据对2010年的GDP进行预测。GDP时间序列具有明显的增长趋势,因此ARMA模型显然的不稳定的,基于ARMA模型进行差分,发现二次差分的结果不仅稳定,而且表示出良好的序列相关性,所以能用ARMIMA模型对为例GDP 进行预测。比较原始值GDP和预测值GDPF,两曲线吻合的比较好。 一、ARIMA模型的建立 时间序列模型有四种:自回归模型AR、移动平均模型MA、自回归移动平均模型ARMA、自回归差分移动平均模型ARIMA,可以
说前三种都是ARIMA 模型的特殊形式。 1. 自回归模型AR(p) p 阶自回归模型记作AR(p),满足下面的方程: t p t p t t t y y y c y εφφφ+++++=--- 2211 其中:参数 c 为常数;1,2 ,…,p 是自回归模型系数;p 为自回归模型阶数;t ε是均值为0方差为 2σ 的白噪声序列。 2. 移动平均模型MA(q) q 阶移动平均模型记作MA(q) ,满足下面的方程: q t q t t t y ---+++=εθεθεθμ 2211 其中:参数μ为常数;q θθθ,,,21 是 q 阶移动平均模型的系数; t ε是均值为0,方差为2σ 的白噪声序列。 3. ARMA(p,q)模型 q t q t t p t p t t y y c y ----++++++=εθεθεφφ 1111 显然此模型是模型AR(p)与MA(q)的组合形式,称为混合模型,常记作ARMA(p,q)。当 p=0 时,ARMA(0, q) = MA(q);当q = 0时,ARMA(p, 0) = AR(p)。 4. ARIMA (p,d,q )模型 对于非平稳序列,经过几次差分后,如果能得到平稳的时间序列,就称这样的序列为单整序列。设t y 是 d 阶单整序列,记作:t y ~ I(d),则 t d t d t y L y w )1(-=?= t w 为平稳序列,即t w ~ I(0) ,于是可以对t w 建立ARMA(p,q) 模
摘要:为了对航材的需求进行预测,本文根据时间序列乘积季节模型,利用统计软件spss,对收集到的航材需求的历史数据进行了建模、参数估计、检验、预测,经检验预测效果较好。该方法简便实用,利于实际推广和使用。 abstract: in order to predict the uncertain demand for aircraft spareparts,a multiple arima model is used to solve this problem by time series forecasting system in spss. the prediction result and its applications are discussed. this method is simple, practical and convenient for spreading. 关键词:时间序列;需求预测;参数估计;白噪声序列 中图分类号:td176 文献标识码:a 文章编号:1006-4311(2016)24-0250-02 0 引言 随着航空兵部队的换装和飞机的更新换代,航空器材的种类越来越多,价值越来越昂贵,如何根据消耗器材的历史数据,准确预测未来器材的需求,这不仅提高了航材保障的精细化程度,减少了库存,避免了因器材具有时效性而产生的浪费,而且增加了航材保障的可预见性,为完成各种飞行任务奠定基础。某种型号的航材需求量,可随着时间的推移,形成一个序列,成为航材需求的时间序列。对某种型号的航材来说,需求量在一定的时间内,是不确定的,它受到飞机训练强度、环境气候、季节性等因素的影响。因此时间序列可能随着时间的推移,呈现一定的趋势性,也可能受季节因素的影响,呈现一定的季节性,如雨季训练强度减少,对器材的消耗就少,需求就相应的减少。而目前对航材需求量的预测,大多采用回归法,滑动平均法,而这些方法的处理和预测,缺少对季节性的考量,而利用时间序列arima (p,d,q)(p,d,q)s模型,可对影响航材需求的各种因素综合考虑,对于短期预测效果较好。 1 arima(p,d,q)(p,d,q)s模型 如果时间序列(yt)是平稳的,可以利用自回归移动平均模型arma(p,q)实现建模和预测,但如果时间序列具有趋势性的非平稳时序,不能直接建立arma(p,q)模型,只能对其经过平稳化处理。这里平稳化处理一般用差分处理,差分处理后的模型记为arima(p,d,q),d是差分的阶数,记bk为k阶滞后算子,即bkyt=yt-k,若k=1,则byt=yt-1。差分形式用(1-b)d表示,如果d=1,(1-b)yt=yt-yt-1,就是一阶差分。有些序列的值和季节变动有关,往往还要进行剔除季节性的影响,这样还要进行季节差分,可表示成(1-bs)d,表示d阶季节差分,若d=1,则(1-bs)yt=yt-yt-s就是一阶季节差分,如果是月度季节差分,s=12,如果是季度季节差分,s=4。为了考虑各种情况,考虑如下的模型形式:?准(b)u(b)(1-b)d(1-bs)dyt=θ(b)v(b)εt 该模型就是模型arima(p,d,q)(p,d,q)s,是自回归移动平均模型的推广。 其中,?准(b)=1-?准1b-?准2b2-…-?准pbp是p阶自回归算子,θ(b)=1-θ1b-θ2b2-…-θpbq,是q阶移动平均算子,(1-b)d是d阶差分算子,u(b)=1-u1bs-u2b2s-…-upbps是p阶季节自回归移动算子,v(b)=1-v1bs-v2b2s-…-vqbqs是q阶季节移动平均算子,(1-bs)d是d阶季节差分算子,其中?准1,?准2,…,?准p,θ1,θ2,…,θq,u1,u2,…,up,v1,v2,…,vq,都是待估参数。 2 利用arima(p,d,q)(p,d,q)s模型预测的步骤 第一步:转化成平稳序列。严格的判定序列的平稳性比较困难,可借助图像,如果图像无趋势性,无周期性,可大致认为序列平稳,也可利用自相关函数acf,若自相关函数acf 随滞后期增大,而迅速趋于0,则认为该序列是平稳的。非平稳性序列,如果具有较强的趋势性,可以通过逐期差分,逐期差分的次数,决定模型中d的取值,如果序列周期性比较明显,可以通过季节差分来实现平稳性,季节差分的阶数,就是模型中的d。
5 ARIMA 模型预测 5.1 模型选取 目前,学术界较为成熟的预测方法很多,各种不同的预测方法有其所面向的 特定对象,不存在一种普遍“最好”的预测方法。GM (1,1)模型预测是以灰色 系统理论为基础,通过原始数据的分析处理和建立灰色模型,对系统未来状态作 出科学的定量预测的一种方法。我们采用GM (1,1)模型是基于以下两方面的考 虑:第一,GM (1,1)模型对数据要求较低,而其他多数预测方法以数理统计为 基础,对样本量有较高要求。我们用来做预测的数据时序只有14年,预测使用 GM (1,1)模型较好;第二,GM (1,1)模型的计算量相对较小,计算方法相对简 单,适用性较好。 5.2 模型假设前提 1、假设未来重庆地区经济发展基本态势不变; 2、假设未来中央政府对重庆实施的政策方向基本不变; 3、假设未来不会出现战争、瘟疫及其它不可抗拒的自然或社会因素。 5.3 预测数据来源 预测样本为1997—2008年的重庆市农资价格指数、化学肥料价格指数、饲 料价格指数。具体预测样本数据如下: 表5.1 1997—2008年重庆部分农资价格指数 单位:% 为提高数据预测的科学性,我们以1996年(直辖前)的农资价格为基期, 假设1996年农资产品价格为100元,则以后第i 年的农资产品价格计算公式如下: i i Z Z G ???=∏ 1997100 经此换算,得到1997—2008年的预测样本。其中,NZJG 表示换算后的农资, HXFL 表示换算后的化肥,SL 表示换算后的饲料。具体见下表:
表5.2 1997—2008年转换后的预测样本 单位:元 5.4 GM (1,1)模型建立与检验 5.4.1 序列的建立 设由n 个原始数据组成的原始序列为x (0)(k)={x (0)(1),x (0)(2),…,x (0)(n)}。那么可以得到四个样本原始序列: NZJG x (0)(k)= {105.9,95.7,…,120.3}; HXFL x (0)(k)= {93.6,81.8,…,89.9}; SL x (0)(k)= {96.6,87.9,…,118.7}。 5.4.2 级比检验 级别检验是GM (1,1)建模的数据检验,经计算可得: NZJG 级比序列={ 0.904,0.932 ,…, 1.198}; HXFL 地区序列={ 0.874, 0.965,…, 1.200 }; SL 地区序列={ 0.910, 0.919,…, 1.170}; 都落在界区(0.7515,1.3307)内。这表明,以上三个样本序列均可以进行GM (1,1)模型建模。 5.4.3 模型的方程 通过一次累加生成新序列:x (1)(k)={x (1)(1),x (1)(2),…,x (1)(n)},则GM(1,1) 模型相应的微分方程为:μ=+)()(11ax dt dx 其中,a 称为发展灰度,μ为内生控制灰度,它们是方程中重要的参数。通过求解微分方程,即可得到预测模型。由于GM (1,1)预测模型种类较多,我们选取其中较常用的一种如下: a e a x x ak k μμ+????? ?-=-+.1)1( 1^ ),2,1,0(n k , =
ARIMA模型预测 一、模型选择 预测就是重要得统计技术,对于领导层进行科学决策具有不可替代得支撑作用。 常用得预测方法包括定性预测法、传统时间序列预测(如移动平均预测、指数平滑预测)、现代时间序列预测(如ARIMA模型)、灰色预测(GM)、线性回归预测、非线性曲线预测、马尔可夫预测等方法。 综合考量方法简捷性、科学性原则,我选择ARIMA模型预测、GM(1,1)模型预测两种方法进行预测,并将结果相互比对,权衡取舍,从而选择最佳得预测结果。 二ARIMA模型预测 (一)预测软件选择--—-R软件 ARIMA模型预测,可实现得软件较多,如SPSS、SAS、Eviews、R等。使用R软件建模预测得优点就是:第一,R就是世最强大、最有前景得软件,已经成为美国得主流。第二,R就是免费软件、而SPSS、SAS、Eviews正版软件极为昂贵,盗版存在侵权问题,可以引起法律纠纷。第三、R软件可以将程序保存为一个程序文件,略加修改便可用于其它数据得建模预测,便于方法得推广。 (二)指标与数据 指标就是销售量(x),样本区间就是1964-2013年,保存文本文件data。txt中。 (三)预测得具体步骤 1、准备工作 (1)下载安装R软件 目前最新版本就是R3.1。2,发布日期就是2014-10—31,下载地址就是。我使用得就是R3。1。1。 (2)把数据文件data、txt文件复制“我得文档”①。 (3)把data、txt文件读入R软件,并起个名字。具体操作就是:打开R软件,①我的文档是默认的工作目录,也可以修改自定义工作目录。
输入(输入每一行后,回车): data=read。table("data、txt",header=T) data #查瞧数据① 回车表示执行。完成上面操作后,R窗口会显示: (4)把销售额(x)转化为时间序列格式 x=ts(x,start=1964) x 结果: 2、对x进行平稳性检验 ARMA模型得一个前提条件就是,要求数列就是平稳时间序列。所以,要先对数列x进行平稳性检验。 先做时间序列图: 从时间序列图可以瞧出,销售量x不具有上升得趋势,也不具有起降得趋势,初步判断,销售量x就是平稳时间序列。但观察时间序列图就是不精确得,更严格得办法就是进行单位根检验。 单位根检验就是通行得检验数列平稳性得工具,常用得有ADF单位根检验、PP单位根检验与KPSS单位根检验三种方法。 单位根检验得准备工作就是,安装tseries程序包。安装方法:在联网状态下,点菜单“Packages-Install packages”,在弹出得对话框中,选择一个镜像,如China(Beijing1),确定。然后弹出附加包列表,选择tseries,确定即可。 安装完附加包后,执行下面操作: ①#后的提示语句是给自己看的,并不影响R运行
摘要:在经济快速发展的今天,对gdp的分析预测显得尤为重要。本文就1978-2014年的国内生产总值进行了分析,建立了arima模型。通过数据平稳性检验、模型的参数识别、模型诊断等综合分析,确立了arima(3,1,3)为最优模型。该模型具有简单实用、预测精度高的特点,能恰当描述中国gdp的状况,可以用来进行短期预测,为政府部门制定经济计划提供依据和参考。 关键词:gdp;arima模型;预测 一、引言 gdp是指一定时期内,一个国家或地区在经济中所生产的全部最终产品和劳务的市场价值总和。我们常常用它来反映经济的发展状况以及价格的变化情况,并且以此为政府制定相应的政策提供参考。在经济快速发展,竞争日益激烈的当今社会,谁能准确把握经济的未来走势,合理的判断经济的景气情况,谁就能立于不败之地,因此需要对国家gdp的预测进行分析,这也是本文研究的意义所在。 二、文献综述 对经济发展的研究,一直以来受到广大学术界和政府部门的青睐,被学者研究至今,而gdp作为衡量经济发展的重要方向。从理论到实证都有很多,由于越来越多的因素的影响,绝大部分的经济时间序列数据呈现出非平稳性[1]。一般的模型都只能对平稳时间序列进行分析,或者将非平稳的转化为平稳的,而arima模型在处理非平稳序列方面有其独特的优势,因此很多学者都用它来建模。如胡永红等的将arima应用于区域水生态足迹研究[2];池启水等的arima应用于预测煤炭消费量[3]。 随着科学的发展,技术的进步,在arima建模过程中,对于如何判定滞后阶数,不同的学者给出了不同的建议和决策,例如龚国勇和刘明鼎在做文章时,通过直接观察相关图来判断,并未考虑aic准则或sc准则,如此得出的滞后阶数并不一定为最优的[3-4]。 综合以上参考文献的阅读研究,本文在用arima模型进行gdp预测时,对于最优参数的选取,通过多次检验和尝试来确定,以保证该模型为最理想的模型。 三、模型简介 (一)arima模型概述 又称为自回归移动平均模型,由ar(p)、ma(q)、arma(p,q)逐渐拓展而来,因为后三种模型只能针对平稳时间序列建模,arima模型打破了这个限制,可以直接对非平稳学建模,它由自回归项、移动平均项和转化为平稳序列所需要的差分次数所构成。 (二)arima模型建模的一般步骤 1、对数据进行平稳化处理和检验 在进行模型拟合之前,要先对时间序列的平稳性进行判断,判断方法可以通过观察其图形进行初步判断,然后通过单位根检验作进一步判断。没通过检验的序列说明是不平稳的,则要先进行平稳化,如差分变换或者对数差分变换,直到通过检验,变为平稳序列为止。 2、arma(p,q)模型拟合 由于前边的平稳化处理可以得到之后阶数d,而对p,q的确定则通过自相关和偏自相关系数,结合aic和sc准则综合判断来确定。 3、参数估计与检验 以上的模型拟合完以后,就要估计未知参数,并对估计出来的参数的显著性和合理性进行检验。 4、对整个模型进行诊断 对整个模型的有效性进行诊断,以判断信息的提取是否充分合理,否则需要对模型进行重新拟合。
案例五、季节ARIMA模型建模与预测实验指导 一、实验目的 学会识别时间序列的季节变动,能看出其季节波动趋势。学会剔除季节因素的方法,了解ARIMA模型的特点和建模过程,掌握利用最小二乘法等方法对ARIMA模型进行估计,利用信息准则对估计的ARIMA模型进行诊断,以及如何利用ARIMA模型进行预测。掌握在实证研究如何运用Eviews软件进行ARIMA模型的识别、诊断、估计和预测。 二、基本概念 季节变动:客观社会经济现象受季节影响,在一年内有规律的季节更替现象,其周期为一年四个季度或12个月份。 季节ARIMA模型是指将受季节影响的非平稳时间序列通过消除季节影响转化为平稳时间序列,然后将平稳时间序列建立ARMA模型。ARIMA模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA)、自回归过程(AR)、自回归移动平均过程(ARMA)以及ARIMA过程。 三、实验内容及要求 1、实验内容: (1)根据时序图的形状,采用相应的方法把周期性的非平稳序列平稳化; (2)对经过平稳化后的桂林市1999年到2006的季度旅游总收入序列运用经典B-J方法论 p d q)模型,并能够利用此模型进行未来旅游总收入的短期预测。建立合适的ARIMA(,, 2、实验要求: (1)深刻理解季节非平稳时间序列的概念和季节ARIMA模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA模型;如何利用ARIMA模型进行预测; (3)熟练掌握相关Eviews操作。 四、实验指导 1、模型识别 (1)数据录入 打开Eviews软件,选择“File”菜单中的“New--Workfile”选项,在“Workfile structure type”栏选择“Dated –regular frequency”,在“Date specification”栏中分别选择“Quarterly”(季度数据) ,分别在起始年输入1999,终止年输入2006,点击ok,见图5-1,这样就建立了一个季度数据的工作文件。点击File/Import,找到相应的Excel数据集,导入即可。
实验指导书(ARIMA模型建模与预测) 例:我国1952-2011年的进出口总额数据建模及预测 1、模型识别和定阶 (1)数据录入 打开Eviews软件,选择“File”菜单中的“New--Workfile”选项,在“Workfile structure type”栏选择“Dated –regular frequency”,在“Date specification”栏中分别选择“Annual”(年数据) ,分别在起始年输入1952,终止年输入2011,文件名输入“im_ex”,点击ok,见下图,这样就建立了一个工作文件。 在workfile中新建序列im_ex,并录入数据(点击File/Import/Read Text-Lotus-Excel…, 找到相应的Excel数据集,打开数据集,出现如下图的窗口,在“Data order”选项中选择“By observation-series in columns”即按照观察值顺序录入,第一个数据是从B15开始的,所以在“Upper-left data cell”中输入B15,本例只有一列数据,在“Names for series or number if named in file”中输入序列的名字im_ex,点击ok,则录入了数据):
(2)时序图判断平稳性 双击序列im_ex,点击view/Graph/line,得到下列对话框: 显著非平稳。 因为数据有指数上升趋势,为了减小波动,对其对数化,在Eviews命令框中输入相应
的命令“series y=log(im_ex)”就得到对数序列,其时序图见下图,对数化后的序列远没有原始序列波动剧烈: 从自相关系数可以看出,呈周期衰减到零的速度非常缓慢,所以断定y 序列非平稳。为了证实这个结论,进一步对其做ADF检验。双击序列y,点击view/unit root test,出现下图的对话框,
实验五 ARIMA 模型的概念和构造 一、实验目的 了解AR ,MA 以及ARIMA 模型的特点,了解三者之间的区别联系,以及AR 与MA 的转换,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念 所谓ARIMA 模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,我们主要用到两个工具:自相关函数(简称ACF ),偏自相关函数(简称PACF)以及它们各自的相关图(即ACF 、PACF 相对于滞后长度描图)。对于一个序列 来说,它的第j 阶自相关系数(记作 )定义为它的j 阶自协方差除以它的方差,即 j ρ= j 0γ ,它是关于j 的函数,因此我们也称之为自相关函数,通常记ACF(j)。偏自相关函数PACF(j)度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验内容及要求 1、实验内容: 根据1991年1月~2005年1月我国货币供应量(广义货币M2)的月度时间数据来说明在Eviews3.1 软件中如何利用B-J 方法论建立合适的ARIMA (p,d,q )模型,并利用此模型进行数据的预测。 2、实验要求: (1)深刻理解上述基本概念; (2)思考:如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA 模型;如何利用ARIMA 模型进行预测; (3)熟练掌握相关Eviews 操作。 四、实验指导 1、ARIMA 模型的识别 (1)导入数据 打开Eviews 软件,选择“File”菜单中的“New --Workfile”选项,出现“Workfile Range”对话框,在“Workfile frequency”框中选择“Monthly ”,在“Start date”和“End date”框中分别输入“1991:01”和“2005:01”,然后单击“OK”,选择“File”菜单中的“Import --Read Text-Lotus-Excel”选项,找到要导入的名为EX6.2.xls 的Excel 文档,单击“打开”出现“Excel Spreadsheet Import”对话框并在其中输入相关数据名称(M2),再单击“OK”完成数据导入。 (2)模型的识别 首先利用ADF 检验,确定d 值,判断M2序列为2阶非平稳过程(由于具体操作方法我们在第五章中予以说明,此处略),即d 的值为2,将两次差分后得到的平稳序列命名为W2;下面我们来看W2的自相关、偏自相关函数图。 打开W2序列,点击{}t Y j ρ
第5讲ARIMA模型预测案例 【例1】(1120070693)中国公路客运量ARIMA模型(缺中间项的自回归模型)中国公路客运量数据(1950 2005)序列与差分序列见图。 序列存在异方差。应该用对数差分序列建立模型。 Lny序列DLny序列 建立AR(5)模型
Q(15)=17.3。相应概率0.19。样本内预测评价:
【例2】(1120070642)美元与欧元汇率(rate )变动分析 自1973年布雷顿森林体系崩溃以来,各国和地区货币汇率趋于浮动,各主要国家间的汇率波动成为世界金融市场最显著的特征之一。自1999年1月欧元作为帐面货币问世、2002年元旦欧元纸币与铸币正式投入流通以来,欧元对美元的汇率曾几度大起大落。 1973年以来美元/欧元的变动趋势。从图中美元-欧元(1999年前的德国马克)汇率的变动趋势图可以看出,30多年来美元汇率大涨大跌,大体上经历五个时期: 第1时期,从20世纪70年代初到1979年的美元贬值期。至1971年8月,美元的黄金储备从1949年的245.6亿美元减少到102亿美元,而外国对美国的短期债权已达520亿美元;黄金官价从每盎司35美元涨到1978年下半年的每盎司200多美元,美国政府被迫宣布美元贬值,停止以美元兑换黄金。自1973年2月起的14个月里,美元对欧洲国家货币平均汇率下跌了23.6%。从1978年起美国财政部宣布对美元汇率进行干预。通过这一次美元贬值和美元与黄金脱钩,美国摆脱了外国央行用美元向美国兑换黄金的沉重包袱。但是,这次美元走弱却是造成发达国家通货膨胀加剧和陷入经济衰退的一个重要原因。 第2时期,从1980年到1985年的美元升值期。从1980年7月到1985年2月初,美元对其他10种主要货币的比价上升了73%。在美国经济结构正处在大调整的时期,美元升值对美国吸引外资起了重要作用。但是,随着美元升值,美国外贸逆差急剧增加。据美国商务部统计,从1980年到1985年,美国对外贸易逆差从322.24亿美元增加到1697.77亿美元。 第3时期,从1985年到1995年初的美元贬值期。1985年9月22日,美国、联邦德国、法国、英国和日本5国财长在纽约广场饭店举行会议并达成协议,即“广场协议”,决定5国联合行动,有秩序地使主要货币对美元升值,以矫正美元估值过高的局面。按年平均汇率比较,1988年与1985年相比,联邦德国马克对美元汇率上升70.5%。