
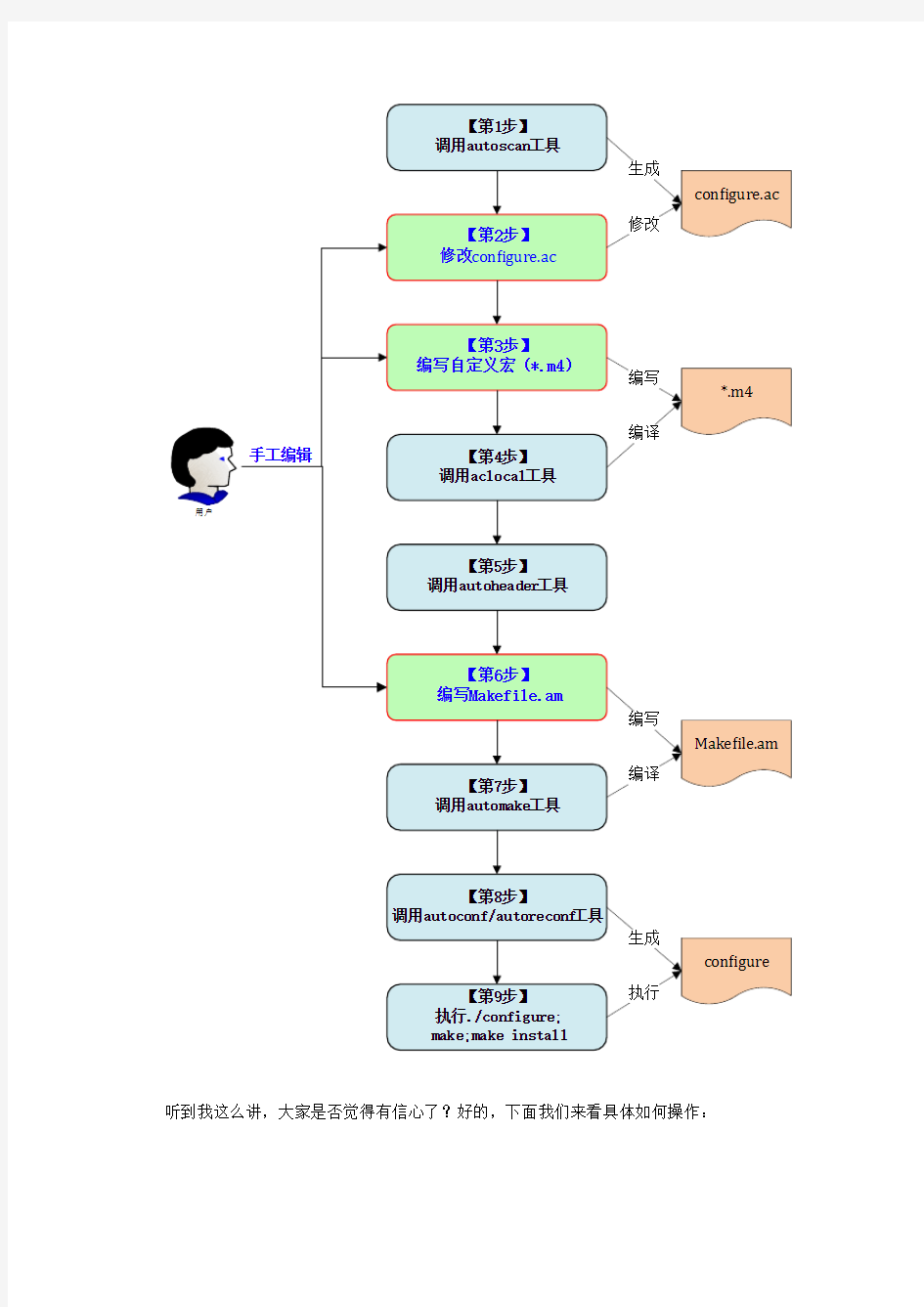
大型项目使用Automake/Autoconf完成编译配置
使用过开源C/C++项目的同学们都知道,标准的编译过程已经变成了简单的三部曲:configure/make/make install, 使用起来很方便,不像平时自己写代码,要手写一堆复杂的Makefile,而且换个编译环境,Makefile还需要修改(Eclipse也是这样)。
这么好的东东当然要拿来用了,但GNU的Autotool系列博大精深,工具数量又多,涉及的语言也多,要是自己从头看到尾,黄花菜都凉了,项目估计早就结束了;上网搜样例倒是有一大堆,但都是“hello world”的样例,离真正完成大型项目的目标还差得远。
没有办法,对照网上的样例,再找几个开源的源码,然后参考各种Autotools的手册,花了2天时间,终于完成了一个基本可用的Autotools。为了避免其他XDJM也浪费时间,因此将过程总结下来,就算是新年礼物,送给大家!!
提纲挈领:使用Autotools其实很简单
大家不要看到那么多工具,其实使用起来很简单,总结起来就是两部分:
1)按照顺序调用各个工具;
2)修改或者添加3个文件;
整个操作顺序如下图:
听到我这么讲,大家是否觉得有信心了?好的,下面我们来看具体如何操作:
1.源码根目录调用autoscan脚本,生成configure.scan文件,然后将此文件重命名为
configure.ac(或configure.in,早期使用.in后缀)
2.修改【configure.ac】,利用autoconf提供的各种M4宏,配置项目需要的各种自动
化探测项目
3.编写【自定义宏】,建议每个宏一个单独的*.m4文件;
4.调用acloca l收集configure.ac中用到的各种非Autoconf的宏,包括自定义宏;
5.调用autoheader,扫描configure.ac(configure.in)、acconfig.h(如果存在),生成
config.h.in宏定义文件,里面主要是根据configure.ac中某些特定宏(如AC_DEFINE)生成的#define和#undefine宏,configure在将根据实际的探测结果决定这些宏是否定义(具体见后面例子)。
6.按照automake规定的规则和项目的目录结构,编写一个或多个【Makefile.am】
(Makefile.am数目和存放位置和源码目录结构相关),Makefile.am主要写的就是编译的目标及其源码组成。
7.调用automake,将每个Makefile.am转化成Makefile.in,同时生成满足GNU编码
规范的一系列文件(带-a选项自动添加缺少的文件,但有几个仍需要自己添加,在执行automake前需执行touch NEWS README AUTHORS ChangeLog)。如果configure.ac配置了使用libtool(定义了AC_PROG_LIBTOOL宏(老版本)或LT_INIT宏),需要在此步骤前先在项目根目录执行libtoolize --automake --copy --force,以生成ltmain.sh,供automake和config.status调用。
8.调用autoconf,利用M4解析configure.ac,生成shell脚本configure。以上几步完
成后,开发者的工作就算完成了,后面的定制就由开源软件的用户根据需要给configure输入不同的参数来完成。
9.用户调用configure,生成Makefile,然后make && make install。
整个过程步骤有9步,但其中有6步你只需要简单的敲一个命令即可,只有剩下的三步需要你动手写一些东西,对应上面步骤中的蓝色黑体字部分,而本文的重点就是如何在大型项目中完成这三歩。
步步为营:三步完成编译配置
【第2步:修改configure.ac文件】
从上面的步骤可以看到,使用autoscan工具扫描后就会生成一个简单的configure.ac文件,这已经是一个完整的configure.ac文件框架了,但还不足以达到我们的要求,因此我们要在框架里面添加一些东西:
1.1 添加AM_INIT_AUTOMAKE宏
在AC_INIT 宏下一行添加AM_INIT_AUTOMAKE([foreign -Wall -Werror]),中括号里面的选项可以根据需要来修改,具体请看automake手册关于这个宏的说明。
1.2 如果需要,添加AC_CONFIG_HEADERS([config.h])宏
添加这个宏很简单,但关键是“如果需要”,什么情况下需要这个宏呢?
这个宏的目的是输出config.h,这是一个C的头文件,里面主要是包含很多宏定义#define,说到这里其实就很明确了,输出这个文件的目的就是提供各种相关的宏,而宏在代码中的作用就是#ifdef,也就是说:如果你的代码需要用到宏开关进行控制,那么就要输出这个文件。具体的使用方法如下:
1)首先确定代码中需要使用什么宏来进行开关定制,确定宏的名称,编写和宏相关的代码,且要包含config.h的头文件;
2)在configure.ac中的各种处理(例如AC_CHECK_***,AC_ARG_***)中使用AC_DEFINE 宏定义C/C++的宏,名称和上面的相同;如果是使用AC_CHECK_HEADERS,会自动添加宏定义;
3)执行完第7歩后,Autoconf就会自动生成config .h文件
1.3添加编译链接需要的程序
编译链接需要用到的程序需要添加在# Checks for programs.注释后面。对于C/C++来说,最常见的就是gcc, g++, 静态库编译、动态库编译,对应的选项如下:
AC_PROG_CXX
AC_PROG_CC
AC_PROG_RANLIB
如果使用libtool编译,则选项如下,注意使用了libtool则需要将AC_PROG_RANLIB去掉LT_INIT
1.4 在configure.ac代码中各个部分添加自己的检测处理
这一步是我们的主要工作,需要根据自己的项目具体情况来编写,常见操作对应的宏和样例请参考本文后面的“【常见操作对应的宏】”:。至于具体添加在哪个地方,configure.ac 中的注释已经清楚的告诉你了,例如:
# Checks for libraries.
# Checks for library functions.
1.5 在AC_OUTPUT上一行添加AC_CONFIG_FILES宏
添加这个宏的目的是制定Autoconf输出哪些文件,常见的文件就是Makefile文件,config.h 在AC_CONFIG_HEADERS宏里面指定了,这里不需要再次指定。例如:
【第3步:编写自定义的Autoconf宏】
Autoconf虽然提供了很多内置的宏,但在实际项目中,这些宏不可能满足所有的要求,有的处理还是要自己完成。虽然在configure.ac文件中可以直接编写各种处理代码,但这样做有几个缺点:
1)很不美观:打开configure.ac文件,密密麻麻的一大段花花绿绿的Shell代码,看着眼花缭乱;
2)修改起来很麻烦:要找半天才能找到要修改的位置,一不小心就改错了;
就像写C/C++代码要进行封装一样,Autoconf的处理也需要进行封装,这个封装就是自定宏,定义完成后在configure.ac中调用,看起来很清爽,修改也很简单。
下面我们来看如何自定义宏:
2.1 新建一个单独的目录,用于存放自定义宏,一般定义为m4
2.2 新建自定义宏文件
建议每个宏一个文件,文件必须以.m4结尾,文件名就是宏名(当然如果你非要不这么做也可以,文件名随便取)
2.3 编写Autoconf宏
具体的编写方式请参考Autoconf的手册第10章节,最好边看手册边对照一个开源软件的样例,这样效果最好了。这里说明几个需要注意的地方:
1)m4宏不是shell,请不要直接在文件中写shell代码,而要在宏的各个部分里面写代码;最常见的就是if-else判断,如果要在代码中编写if-else判断,需要使用AS_IF宏,或者在其它宏里面写,例如AC_ARG_WITH, AC_CACHE_CHECK;
2)AC_DEFUN是定义autoconf的宏,AC_DEFINE是定义C/C++的config .h里面的宏,不要混淆了;
2.4 运行aclocal工具,生成aclocal.m4
由于自定义宏是放在我们新建的目录中的,configure.ac并没有像C/C++那样的include 语句可用,因此也就找不到这些宏,这时就需要aclocal工具了:aclocal会将自定义宏编译成configure.ac可用的宏,保存在和configure.ac同级目录下的aclocal.m4文件中,这样在configure.ac就能够直接使用了。具体的编译方法如下(m4就是你的目录):
aclocal -I m4
同时需要在根目录下的Makefile.am中添加ACLOCAL_AMFLAGS = -I m4。
还有一种方法是将所有的自定义宏都放入到一个acinclude.m4文件中,不过不推荐这种方法,原因是因为这种方法的缺点和直接将所有自定义宏放入configure.ac中没有多大差别。
【第6步:编写Makefile.am文件】
对于大型项目来说,代码一般都是分目录存放的,而不会像Hello world样例那样简单的就几个文件,因此写Makefile.am就麻烦一些,但其实主要是工作量增加了,原则都是一样的:
原则1:每个目录一个Makefile.am文件;同时在configure.ac的AC_CONFIG_FILES宏中指定输出所有的Makefile文件,例如:
AC_CONFIG_FILES([Makefile tools/Makefile common/Makefile worker/Makefile])
原则2:父目录需要包含子目录
在父目录下的Makefile.am中添加: SUBDIRS = 所有子目录,例如SUBDIRS=test tools
原则3:Makefile.am中指明当前目录如何编译
前两个原则很简单,这里就不多说了,重点说一下如何编写Makefile.am。
编写Makefile.am主要是完成3件事情:编译(make)、安装(make install)、打包(make dist),下面我们一一来进行讲解。
3.1 编译安装
编译和安装的规则是绑定在一起的,通过同一条语句同时指定了编译和安装的处理方式,具体的格式为:安装目录_编译类型=编译目标
3.1.1【安装目录】
例如:bin_PROGRAMS = hello subdir/goodbye,其中安装目录是bin,编译类型是PROGRAMS,编译目标是两个程序hello, goodbye.
常用缺省的安装目录如下
除了常用的缺省目录外,有时候我们还需要自定义目录,例如我们希望安装完成后安装目录下有一个配置文件目录config,同时将指定的test.ini拷贝到config目录,则config目录需要通过自定义目录方式定义,然后按照缺省目录的使用方式使用。例如:
在根目录下的Makefile.am中添加如下内容:
configdir=${prefix}/config => 定义一个自定义的目录名称config,注意dir后缀是固定的config_DATA=config/test.ini => 使用自定义的目录config,必须要有这句,否则目录不会创建, =号后面如果有对应的文件,安装时会将对应的文件拷贝到config目录下。
3.1.2【编译类型】
常见编译类型如下,没有自定义编译类型
3.1.3【编译目标】
编译目标其实就是编译类型对应的具体文件,其中需要make生成的文件主要有如下几个:可执行程序_PROGRAMS,普通库文件_LIBRARIES,libtool库文件_LTLIBRARIES,其它类
型对应的编译目标不需要编译,源文件就是目标文件。
标准的编译配置
如果你熟悉gcc的编译命令写法,那么Automake的Makefile.am编译过程就很好写了。因为Automake只是将写在一行gcc命令里的各个不同部分的信息分开定义而已。我们来看具体是如何定义的:
_SOURCES:对应gcc命令中的源代码文件
_LIBADD:编译链接库时需要链接的其它库,对应gcc命令中的*.a等文件
_LDADD:编译链接程序时需要链接的其他库,对应gcc命令中的*.a等文件
_LDFLAGS:链接选项,对应gcc命令中的-L, -l, -shared, -fpic等选项
_LIBTOOLFLAGS:libtool编译时的选项
**FLAGS(例如_CFLAGS/_CXXFLAGS):编译选项,对应gcc命令中的-O2, -g, -I等选项
举例如下:
如何编译可执行程序
对于大型项目来说,代码基本上都是分目录存放的,如果是直接写makefile文件,一般都是将所有源文件首先编译成*.o的文件,再链接成最终的二进制文件。但在Automake 里面这样是行不通的,因为你只要仔细看编译类型表格就会发现,并没有一种编译类型能够编译*.o文件,无法像常规makefile那样来编写,所以就需要采取一些技巧。
其实这个技巧也很简单:将非main函数所在目录的文件编译成静态链接库,然后采用链接静态库的方式编译可执行程序。
样例如下:
=================根目录Makefile.am======================
=================tool目录Makefile.am======================
===============common目录Makefile.am======================
==============worker目录Makefile.am============================
如何编译静态库
Automake天然支持编译静态库,只需要将编译类型指定为_LIBRARIES即可。
如何编译动态库
需要注意的是:_LIBRARIES只支持静态库(即*.a文件),而不支持编译动态库(*.so)文件,要编译动态链接库,需要使用_PROGRAMS。除此之外,还需要采用自定义目录的方式避开Automake的两个隐含的限制:
1)如果使用bin_PROGRAMS, 则库文件会安装到bin目录下,这个不符合我们对动态库
的要求;
2)automake不允许用lib_ PROGRAMS
下面假设将utils编译成so,采用自定义目录的方式,修改Makefile.am如下:
如何编译libtool库
对于跨平台可移植的库来说,推荐使用libtool编译,而且Automake内置了libtool的支持,只需要将编译类型修改为_LTLIBRARIES即可。
需要注意的是:如果要使用libtool编译,需要在configure.ac中添加LT_INIT宏,同时注释掉AC_PROG_RANLIB,因为使用了LT_INIT后,AC_PROG_RANLIB就没有作用了。
3.2 打包
Automake缺省情况下会自动打包,自动打包包含如下内容:
1)所有源文件
2)所有Makefile.am/Makefile.in文件
3)configure读取的文件
4)Make file.am’s (using include) 和configure.ac’ (using m4_include)包含的文件
5)缺省的文件,例如README, ChangeLog, NEWS, AUTHORS
如果除了这些缺省的文件外,你还想将其它文件打包(一般包括静态库、头文件、配置文件、帮助文件),有如下两种方法:
(1)粗粒度方式:通过EXTRA_DIST来指定,指定文件就打包文件,指定目录就打包目录,
例如:
EXTRA_DIST=conf/config.ini test tools/initialize.sh
如果test是目录,那么会将test目录下所有的文件和目录都打包。
(2)细粒度方式:在“安装目录_编译类型=编译目标”前添加dist(表示需要打包), 或者
nodist(不需要打包),例如:
【后记】
GNU Autotool工具博大精深,我也是结合项目的实际应用来使用的,并没有完整的研究所有的工具,因此难免存在瑕疵和纰漏,如果大家发现有疑问或者问题的地方,欢迎大家指正。当然,GNU自己的手册是最权威的,如果你有疑问的话,参考手册,以手册为准。
如果想了解autotools的工作原理和流程以及更高级的技巧,请参考胡华强写的《autoconf and automake介绍与典型应用.doc》。
【常见操作对应的宏】
1)给./configure添加--with-package参数,例如:./configure --with-libmemcached AC_ARG_WITH,具体如何写请参考autoconf手册15.2章节,里面给了一个完整的样例。2)给./configure添加–enable-feature参数,例如:./configure –enable-multithread AC_ARG_ENABLE,顾名思义,这个宏的意思就是打开开关,这个开关可以是编译开关,也可以是代码功能开关,如果是编译开关,则要配合AM_CONDITIONAL宏来使用(样例请看automake手册20.1章节的AM_CONDITIONAL宏说明);如果是代码功能开关,则要配合AC_DEFINE宏来使用(请参考autoconf手册15.2章节的AC_ARG_WITH宏的样例)3)在./configure的时候检查头文件
AC_CHECK_HEADER: 检查一个头文件
AC_CHECK_HEADERS:检查一批头文件
4)在./configure时检查库文件
AC_CHECK_LIB:样例请参考autoconf手册15.2章节的AC_ARG_WITH宏的样例
5)修改make行为
如果你想修改默认的make行为,可以先使用AC_ARG_WITH或者AC_ARG_ENABLE添加./configure参数,再结合如下两个宏来完成:
AM_CONDITIONAL:在./configure.ac中增加一个automake宏,在Makefile.am中使用if-else-endif来使用宏;
AC_SUBST:在./configure.ac中直接修改automake的变量,例如AM_CXXFLAGS,AM_CFLAGS等编译链接。
【参考资料】
1. 入门材料:https://www.doczj.com/doc/5c13322892.html,/autobook/autobook/autobook_toc.html。
2. autoconf手册:https://www.doczj.com/doc/5c13322892.html,/software/autoconf/manual/autoconf.html。
3. automake手册:https://www.doczj.com/doc/5c13322892.html,/automake/automake.html。
4. libtool手册:https://www.doczj.com/doc/5c13322892.html,/software/libtool/manual/libtool.html
5. tutorial:http://www.lrde.epita.fr/~adl/dl/autotools.pdf。
gcc编译器使用简明指南 gcc对文件的处理需要经过预处理->编译->汇编->链接的步骤,从而产生一个可执行文件,各部分对应不同的文件类型,具体如下: file.c c程序源文件 file.i c程序预处理后文件 file.cxx c++程序源文件,也可以是https://www.doczj.com/doc/5c13322892.html, / file.cpp / file.c++ file.ii c++程序预处理后文件 file.h c/c++头文件 file.s 汇编程序文件 file.o 目标代码文件 gcc [选项]文件列表 -ansi 强制完全ANSI一致 -c 仅编译或汇编,生成目标代码文件,将.c、.i、.s等文件生成.o文件,其余文件被忽略 -S 仅编译,不进行汇编和链接,将.c、.i等文件生成.s文件,其余文件被忽略 -E 仅预处理,并发送预处理后的.i文件到标准输出,其余文件被忽略 -o file 创建可执行文件并保存在file中,而不是默认文件a.out -g 产生用于调试和排错的扩展符号表,用于GDB调试,切记-g和-O通常不能一起使用 -w 取消所有警告 -W 给出更详细的警告 -O [num]优化,可以指定0-3作为优化级别,级别0表示没有优化 -x language 默认为-x none,即依靠后缀名确定文件类型,加上-x lan确定后面所有文件类型,直到下一个-x出现为止 -D macro[=]类似于源程序里的#define,在-D macro中的macro可被源程序识别,例如gcc -D NUM -D FILE=\"bbs.txt\" hello.c -o hello,第一个-D选项定义宏NUM,在程序中可以使用#ifdef来检查是否被设置,第二个-D定义宏FILE,在源程序中可用 -U macro 类似于源程序开头定义#undef macro,也就是取消源程序中的某个宏定义
<PL0编译器-PCompiler> 软件需求说明书 作者:刁诗云、麻汉华、潘彦荃、周津、李程完成日期:2009年6月7日 签收人: 签收日期: 修改情况记录:
目录 软件需求说明书 (1) 1 引言 (1) 1.1 编写目的 (1) 1.2 项目背景 (1) 2 项目概述 (2) 2.1 产品描述 (2) 2.2 产品功能 (2) 2.3 用户特点 (2) 3 具体需求 (3) 3.1 EBNF定义的PL/0文法 (3) 3.2 语法图 (4) 3.3 功能需求 (6) 3.4 系统概要设计 (15)
1 引言 1.1 编写目的 为了清楚表达客户提出的需求,便于用户理解和确认项目所包含的具体功能需求、性能需求以及非公能性需求,因此以文件化的形式,把系统整体及其部分的业务流程、系统功能进行了详细的说明。同时,此文也对开发人员起到引导的作用,请认真阅读。 1.2 项目背景 PL/0是由世界著名计算机科学家、PASCAL语言的创始人N.Wirth教授选择提供的。在选择PL/0语言的过程中,Wirth很费了一番脑筋。一方面他希望借助这个语言,能尽可能把程序设计语言和编译技术一些最重要的内容都讲到;但另一方面又不希望内容太多,太杂,而希望尽可能简单一些,以便与有限的课时和课程范围相适应。于是他精心选择提供了这个PL/0语言。事实证明,它非常适合于编译技术的教学,目前已被国内越来越多的编译教材所采用。 PL/0语言的语句类型比较丰富,能适应各种可能的程序结构。最进本的是赋值语句。组合结构语句有语句串、条件语句和循环语句。还有重要的子程序概念,是通过过程说明和过程调用两部分实现的。至于数据类型和数据结构,PL/0则特别简单,只有整数类型一种,没有数据结构,因此只允许有整常数和整数变量的说明以及相应的算术运算表达式。PL/0允许在一个过程范围内说明常数、变量和过程。这些常数、变量和过程只在它们被说明的过程范围内有效。PL/0语言也允许递归调用,既可以间接递归,也可以直接递归。
linux下gcc编译器的使用 1、文件后缀名 .c C 源程序 .C C++ 源程序 .cc C++ 源程序 .cxx C++ 源程序 .m Objective –C源程序 .i 预处理过的c源程序 .ii 预处理过的C++源程序 .s 组合语言源程序 .S 组合语言源程序 .h 头文件 .o 目标文件 .a 存档文件 2、GCC常用选项 -c 通知GCC取消链接步骤,即编译源码并在最后生成目标文件; -Dmacro定义指定的宏,使它能够通过源码中的#ifdef进行检验 #define -static 指定程序编译时采用静态编译的方法; -E 不经过编译预处理程序的输出而输送至标准输出; -g获得有关调试程序的详细信息,它不能与-o选项联合使用; -Idirectory在包含文件搜索路径的起点处添加指定目录; -llibrary提示链接程序在创建最终可执行文件时包含指定的库; -O、-O2、-O3将优化状态打开,该选项不能与-g选项联合使用; -S要求编译程序生成来自源代码的汇编程序输出; -v启动所有警报; -Wall发生警报时取消编译操作,即将警报看作是错误; -Werror在发生警报时取消编译操作,即把报警当作是错误; -w 禁止所有的报警。 目前Linux下最常用的C语言编译器是GCC(GNU Compiler Collection),它是GNU项目中符合ANSI C标准的编译系统,能够编译用C、C++和Object C等语言编写的程序。GCC不仅功能非常强大,结构也异常灵活。最值得称道的一点就是它可以通过不同的前端模块来支持各种语言,如Java、 Fortran、Pascal、Modula-3和Ada等。开放、自由和灵活是Linux的魅力所在,而这一点在GCC上的体现就是程序员通过它能够更好地控制整个编译过程。
《编译原理》课程设计大纲 课程编号: 课程名称:编译原理/Compiler Principles 周数/学分:1周/1学分 先修课程:高级程序设计语言、汇编语言、离散数学、数据结构 适用专业:计算机科学与技术专业、软件工程专业 开课学院,系或教研室:计算机科学与技术学院 一、课程设计的目的 课程设计是对学生的一种全面综合训练,是与课堂听讲、自学和练习相辅相成的必不可少的一个教学环节。通常,设计题中的问题比平时的练习题要复杂,也更接近实际。编译原理这门课程安排的课程设计的目的是旨在要求学生进一步巩固课堂上所学的理论知识,深化理解和灵活掌握教学内容,选择合适的数据逻辑结构表示问题,然后编制算法和程序完成设计要求,从而进一步培养学生独立思考问题、分析问题、解决实际问题的动手能力。 要求学生在上机前应认真做好各种准备工作,熟悉机器的操作系统和语言的集成环境,独立完成算法编制和程序代码的编写。 设计时间: 开发工具: (1) DOS环境下使用Turbo C; (2) Windows环境下使用Visual C++ 。 (3) 其它熟悉语言。 二、课程设计的内容和要求 设计题一:算术表达式的语法分析及语义分析程序设计。 1.目的
通过设计、编制、调试一个算术表达式的语法及语义分析程序,加深对语法及语义分析原理的理解,并实现词法分析程序对单词序列的词 法检查和分析。 2.设计内容及要求: 算术表达式的文法: 〈无符号整数〉∷= 〈数字〉{〈数字〉} 〈标志符〉∷= 〈字母〉{〈字母〉|〈数字〉} 〈表达式〉∷= [+|-]〈项〉{〈加法运算符〉〈项〉} 〈项〉∷= 〈因子〉{〈乘法运算符〉〈因子〉} 〈因子〉∷= 〈标志符〉|〈无符号整数〉|‘(’〈表达式〉‘)’ 〈加法运算符〉∷= +|- 〈乘法运算符〉∷= *|/ (1) 分别选择递归下降法、算符优先分析法(或简单优 先法)完成以上任务,中间代码选用逆波兰式。 (2) 分别选择LL(1)、LR法完成以上任务,中间代码选 用四元式。 (3) 写出算术表达式的符合分析方法要求的文法,给出 分析方法的思想,完成分析程序设计。 (4) 编制好分析程序后,设计若干用例,上机测试并通 过所设计的分析程序。 设计题二:简单计算器的设计 1.目的 通过设计、编制、调试一个简单计算器程序,加深对语法及语 义分析原理的理解,并实现词法分析程序对单词序列的词法检 查和分析。 2.设计内容及要求 算术表达式的文法:
一、编译时的常见错误 1. 数据类型错误。此类错误是初学者编程时的常见现象, 下面是一些要引起注意的错误: (1) 所有变量和常量必须要加以说明。 (2) 变量只能赋给相同类型的数据。 (3) 对scanf()语句, 用户可能输入错误类型的数据项, 这将导致运行时出错, 并报出错信息。为避免这样的错误出现, 你就提示用户输入正确类型的数据。 (4) 在执行算术运算时要注意: a. 根据语法规则书写双精度数字。要写0.5, 而不是写.5; 要写1.0, 而不是1。尽管C语言会自动地把整型转换成双精度型, 但书写双精度型是个好习惯。让C语言为你做强行转换这是一种效率不高的程序设计风格。这有可能导致转换产生错误。 b. 不要用0除。这是一个灾难性的错误, 它会导致程序失败, 不管C 语言的什么版本, 都是如此, 执行除法运算要特别小心。 c. 确保所有的双精度数(包括那些程序输入用的双精度数) 是在实数范围之内。 d. 所有整数必须在整数允许的范围内。这适用于所有计算结果, 包括中间结果。 2. 将函数后面的";"忘掉。此时错误提示色棒将停在该语句下的一行, 并显示: Statement missing ; in function <函数名> 3. 给宏指令如#include, #define等语句尾加了";"号。 4. "{"和"}"、"("和")"、"/*"和"*/"不匹配。引时色棒将位于错误所在的行, 并提示出有关丢掉括号的信息。 5. 没有用#include指令说明头文件, 错误信息提示有关该函数所使用的参数未定义。 6. 使用了Turbo C保留关键字作为标识符, 此时将提示定义了太多数据类型。 7. 将定义变量语句放在了执行语句后面。此时会提示语法错误。 8. 使用了未定义的变量, 此时屏幕显示: Undefined symbol '<变量名>' in function <函数名> 9. 警告错误太多。忽略这些警告错误并不影响程序的执行和结果。编译时当警告错误数目大于某一规定值时(缺省为100)便退出编译器, 这时应改变集成开发环境Options/Compiler/Errors中的有关警告错误检查开关为off。 10. 将关系符"=="误用作赋值号"="。此时屏幕显示: Lvalue required in function <函数名> 二、连接时的常见错误 1. 将Turbo C库函数名写错。这种情况下在连接时将会认为此函数是用户自定义函数。此时屏幕显示: Undefined symbol '<函数名>' in <程序名> 2. 多个文件连接时, 没有在"Project/Project name中指定项目文件(.PRJ文件), 此时出现找不到函数的错误。 3. 子函数在说明和定义时类型不一致。 4. 程序调用的子函数没有定义。 三、运行时的常见错误 1. 路径名错误。在MS-DOS中, 斜杠(\)表示一个目录名; 而在Turbo C 中斜杠是个某个字符串的一个转义字符, 这样, 在用Turbo C 字符串给出一个路径名时应考虑"\"的转义的作用。例如, 有这样一条语句: file=fopen("c:\new\tbc.dat", "rb"); 目的是打开C盘中NEW目录中的TBC.DAT文件, 但做不到。这里"\"后面紧接的分别是"n"及"t", "\n"及"\t"将被分别编译为换行及tab字符, DOS将认为它是不正确的文件名而拒绝接受, 因为文件名中不能和换行或tab字符。正确的写法应为: file=fopen("c:\\new\\tbc.dat", "rb"); 2. 格式化输入输出时, 规定的类型与变量本身的类型不一致。例如: float l;
实验三vi编辑器及GCC编译器的使用 【实验目的】 一、掌握文本编辑器vi的使用方法 二、了解GNU gcc编译器 三、掌握使用GCC编译C语言程序的方法 【实验内容】 一、vi的三种工作模式: 1、命令模式: 执行相关文本编辑命令 2、输入模式: 输入文本 3、末行模式: 实现查找、替换、保存、多文件操作等等功能 二、进入vi,直接在Shell提示符下键入vi [文件名称],如果该文件在当前目录不存在,则vi创建之。 三、退出vi 1、在命令模式下输入“: wq”,保存文件并退出vi 2、若不需要保存文件,输入“: q” 3、若文件已修改,但不保存,输入“:
q!”强制退出vi 4、其它一些不常用的方法在此省略。 四、命令模式下的常用编辑命令 1、启动vi后,进入的是vi的命令模式 2、按i键,进入输入模式,可以进行文本的编辑,在输入模式下,按esc 键,可切换回命令模式 i: 光标位置不变,可在光标左侧插入正文 a: 光标位置向后退一格,可在光标左侧插入正文 o: 在光标所在行的下一行增添新行 O: 在光标所在行的上一行增添新行 I: 光标跳到当前行的开头 A: 光标跳到当前行的末尾 3、光标的移动 k、j、h、l分别等同于上、下、左、右箭头键 Ctrl+b,向上翻一页
Ctrl+f,向下翻一页 nH,将光标移到屏幕的第n行 nL,将光标移到屏幕的倒数第n行 4、删除文本 nX,删除光标所指向的后n个字符 D,删除光标右侧的所有字符(包括光标所指向的字符)db,删除光标左侧的全部字符 ndd,删除当前行和当前行以后的n行内容 5、粘贴和复制 p,将缓冲区的内容粘贴到当前字符的右侧 P,将缓冲区的内容粘贴到当前字符的左侧 yy,复制当前行到内存缓冲区 nyy,复制n行内容到内存缓冲区 6、搜索字符串 /str1,正向搜索字符串str1 n,继续搜索 ?str2,反向搜索字符串str2 7、撤销和重复 u,撤销前一条命令的执行结果 .,重复最后一条命令
编译原理程序设计报告 一个简单文法的编译器的设计与实现专业班级:计算机1406班 组长姓名:宋世波 组长学号: 20143753 指导教师:肖桐 2016年12月
设计分工 组长学号及姓名:宋世波20143753 分工:文法及数据结构设计 词法分析 语法分析(LL1) 基于DAG的中间代码优化 部分目标代码生成 组员1学号及姓名:黄润华20143740 分工:中间代码生成(LR0) 部分目标代码生成 组员2学号及姓名:孙何奇20143754 分工:符号表组织 部分目标代码生成
摘要 编译器是将便于人编写,阅读,维护的高级计算机语言翻译为计算机能解读、运行的低阶机器语言的程序。编译是从源代码(通常为高阶语言)到能直接被计算机或虚拟机执行的目标代码(通常为低阶语言或机器语言)的翻译过程。 一.编译器的概述 1.编译器的概念 编译器是将便于人编写,阅读,维护的高级计算机语言翻译为计算机能解读、运行的低阶机器语言的程序。编译器将原始程序作为输入,翻译产生使用目标语言的等价程序。源代码一般为高阶语言如Pascal、C++、Java 等,而目标语言则是汇编语言或目标机器的目标代码,有时也称作机器代码。 2.编译器的种类 编译器可以生成用来在与编译器本身所在的计算机和操作系统(平台)相同的环境下运行的目标代码,这种编译器又叫做“本地”编译器。另外,编译器也可以生成用来在其它平台上运行的目标代码,这种编译器又叫做交叉编译器。交叉编译器在生成新的硬件平台时非常有用。“源码到源码编译器”是指用一种高阶语言作为输入,输出也是高阶语言的编译器。例如: 自动并行化编译器经常采用一种高阶语言作为输入,转换其中的代码,并用并行代码注释对它进行注释(如OpenMP)或者用语
linux系统下C编译器— gcc 入门 <一>gcc简介 Linux系统下的gcc(GNU C Compiler)是GNU推出的功能强大、性能优越的多平台编译器,是GNU的代表作品之一。gcc是可以在多种硬体平台上编译出可执行程序的超级编译器,其执行效率与一般的编译器相比平均效率要高20%~30%。gcc编译器能将C、C++语言源程序、汇程式化序和目标程序编译、连接成可执行文件,如果没有给出可执行文件的名字,gcc将生成一个名为 a.out的文件。在Linux系统中,可执行文件没有统一的后缀,系统从文件的属性来区分可执行文件和不可执行文件。而gcc则通过后缀来区别输入文件的类别,下面我们来介绍gcc所遵循的部分约定规则。 .c为后缀的文件,C语言源代码文件; .a为后缀的文件,是由目标文件构成的档案库文件; .C,.cc或.cxx 为后缀的文件,是C++源代码文件; .h为后缀的文件,是程序所包含的头文件; .i 为后缀的文件,是已经预处理过的C源代码文件; .ii为后缀的文件,是已经预处理过的C++源代码文件; .m为后缀的文件,是Objective-C源代码文件; .o为后缀的文件,是编译后的目标文件; .s为后缀的文件,是汇编语言源代码文件; .S为后缀的文件,是经过预编译的汇编语言源代码文件。 <二>gcc的执行过程 虽然我们称gcc是C语言的编译器,但使用gcc由C语言源代码文件生成可执行文件的过程不仅仅是编译的过程,而是要经历四个相互关联的步骤∶预处理(也称预编译,Preprocessing)、编译(Compilation)、汇编(Assembly)和连接(Linking)。命令gcc首先调用cpp进行预处理,在预处理过程中,对源代码文件中的文件包含(include)、预编译语句(如宏定义define等)进行分析。接着调用cc1进行编译,这个阶段根据输入文件生成以.o为后缀的目标文件。汇编过程是针对汇编语言的步骤,调用as进行工作,一般来讲,. S为后缀的汇编语言源代码文件和汇编,.s为后缀的汇编语言文件经过预编译和汇编之后都生成以.o为后缀的目标文件。当所有的目标文件都生成之后,gcc就调用ld来完成最后的关键性工作,这个阶段就是连接。在连接阶段,所有的目标文件被安排在可执行程序中的恰当的位置,同时,该程序所调用到的库函数也从各自所在的档案库中连到合适的地方。 <三>gcc的基本用法和选项 在使用gcc编译器的时候,我们必须给出一系列必要的调用参数和文件名称。g cc编译器的调用参数大约有100多个,其中多数参数我们可能根本就用不到,这里只介绍其中最基本、最常用的参数。
编译原理课程设计报告 实验名称编译原理课程设计 班级 学号 姓名 指导教师 实验成绩 2013 年06月
一、实验目的 通过设计、编写和调试,将正规式转换为不确定的有穷自动机,再将不确定的有穷自动机转换为与之等价的确定的有穷自动机,最后再将确定有穷自动机进行简化。 通过设计、编写和调试构造LR(0)项目集规范簇和LR分析表、对给定的符号串进行LR分析的程序,了解构造LR(0)分析表的步骤,对文法的要求,能够从文法G出发生成LR(0)分析表,并对给定的符号串进行分析。 二、实验内容 正规式——>NFA——>DFA——>MFA 1.正规式转化为不确定的有穷自动机 (1)目的与要求 通过设计、编写和调试将正规式转换为不确定的有穷自动机的程序,使学生了解Thompson算法,掌握转换过程中的相关概念和方法,NFA的表现形式可以是表格或图形。 (2)问题描述 任意给定一个正规式r(包括连接、或、闭包运算),根据Thompson算法设计一个程序,生成与该正规式等价的NFA N。 (3)算法描述 对于Σ上的每个正规式R,可以构造一个Σ上的NFA M,使得L(M)=L(R)。 步骤1:首先构造基本符号的有穷自动机。 步骤2:其次构造连接、或和闭包运算的有穷自动机。
(4)基本要求 算法实现的基本要求是: (1) 输入一个正规式r; (2) 输出与正规式r等价的NFA。(5)测试数据 输入正规式:(a|b)*(aa|bb)(a|b)* 得到与之等价的NFA N
(6)输出结果 2.不确定的有穷自动机的确定化 (1)目的与要求 通过设计、编写和调试将不确定的有穷自动机转换为与之等价的确定的有穷自动机的程序,使学生了解子集法,掌握转换过程中的相关概念和方法。DFA的表现形式可以是表格或图形。(2)问题描述 任意给定一个不确定的有穷自动机N,根据算法设计一个程序,将该NFA N变换为与之等价的DFA D。 (3)算法描述 用子集法将NFA转换成接受同样语言的DFA。 步骤一:对状态图进行改造 (1) 增加状态X,Y,使之成为新的唯一的初态和终态。从X引ε弧到原初态结点, 从原终态结 点引ε弧到Y结点。 (2) 对状态图进一步进行如下形式的改变
一、选择 1.将编译程序分成若干个“遍”是为了_使程序的结构更加清晰__。 2.正规式 MI 和 M2 等价是指__.M1 和 M2 所识别的语言集相等_。 3.中间代码生成时所依据的是 _语义规则_。 4.后缀式 ab+cd+/可用表达式__(a+b)/(c+d)_来表示。 6.一个编译程序中,不仅包含词法分析,_语法分析 ____,中间代码生成,代码优化,目标代码生成等五个部分。 7.词法分析器用于识别__单词___。 8.语法分析器则可以发现源程序中的___语法错误__。 9.下面关于解释程序的描述正确的是__解释程序的特点是处理程序时不产生目标代码 ___。 10.解释程序处理语言时 , 大多数采用的是__先将源程序转化为中间代码 , 再解释执行___方法。 11.编译过程中 , 语法分析器的任务就是__(2)(3)(4)___。 (1) 分析单词是怎样构成的 (2) 分析单词串是如何构成语句和说明的 (3) 分析语句和说明是如何构成程序的 (4) 分析程序的结构 12.编译程序是一种__解释程序__。 13.文法 G 所描述的语言是_由文法的开始符号推出的所有终极符串___的集合。 14.文法分为四种类型,即 0 型、1 型、2 型、3 型。其中 3 型文法是___正则文法__。 15.一个上下文无关文法 G 包括四个组成部分,它们是:一组非终结符号,一组终结符号,一个开始符号,以及一组 _产生式__。 16.通常一个编译程序中,不仅包含词法分析,语法分析,中间代码生成,代码优化,目标代码生成等五个部分,还应包括_表格处理和出错处理__。 17.文法 G[N]= ( {b} , {N , B} , N , {N→b│ bB , B→bN} ),该文法所描述的语言是L(G[N])={b2i+1│ i ≥0} 18.一个句型中的最左_简单短语___称为该句型的句柄。 19.设 G 是一个给定的文法,S 是文法的开始符号,如果 S->x( 其中 x∈V*), 则称 x 是 文法 G 的一个__句型__。 21.若一个文法是递归的,则它所产生的语言的句子_是无穷多个___。 22.词法分析器用于识别_单词_。 23.在语法分析处理中, FIRST 集合、 FOLLOW 集合、 SELECT 集合均是_终极符集 ___。 24.在自底向上的语法分析方法中,分析的关键是_寻找句柄 ___。 25.在 LR 分析法中,分析栈中存放的状态是识别规范句型__活前缀__的 DFA 状态。 26.文法 G 产生的__句子___的全体是该文法描述的语言。 27.若文法 G 定义的语言是无限集,则文法必然是 __递归的_ 28.四种形式语言文法中,1 型文法又称为 _短语结构文法__文法。 29.一个文法所描述的语言是_唯一的__。 30. _中间代码生成___和代码优化部分不是每个编译程序都必需的。 31._解释程序和编译程序___是两类程序语言处理程序。 32.数组的内情向量中肯定不含有数组的_维数___的信息。 33. 一个上下文无关文法 G 包括四个组成部分,它们是:一组非终结符号,一组终结符号,一个开始符号,以及一组__D___。 34.文法分为四种类型,即 0 型、1 型、2 型、3 型。其中 2 型文法是__上下文无关文法__。 35.一个上下文无关文法 G 包括四个组成部分,它们是:一组非终结符号,一组终结符号,一个开始符号,以及一组 __产生式___。 36.__ BASIC ___是一种典型的解释型语言。 37.与编译系统相比,解释系统___比较简单 , 可移植性好 , 执行速度慢__。 38.用高级语言编写的程序经编译后产生的程序叫__目标程序___。 39.编写一个计算机高级语言的源程序后 , 到正式上机运行之前,一般要经过__(1)(2)(3)__这几步: (1) 编辑 (2) 编译 (3) 连接 (4) 运行 40.把汇编语言程序翻译成机器可执行的目标程序的工作是由__编译器__完成的。 41.词法分析器的输出结果是__单词的种别编码和自身值__。 42.文法 G :S→xSx|y 所识别的语言是_ xnyxn(n≥0)___。 43.如果文法 G 是无二义的,则它的任何句子α__最左推导和最右推导对应的语法树必定相同_。 44.构造编译程序应掌握___源程序目标语言编译方法___。 45.四元式之间的联系是通过__临时变量___实现的。 46.表达式( ┐ A ∨B)∧(C∨D)的逆波兰表示为___ A ┐ B∨CD∨∧__。 47. 优化可生成__运行时间短且占用存储空间小___的目标代码。 48.下列__删除多余运算 ____优化方法不是针对循环优化进行的。 49.编译程序使用__说明标识符的过程或函数的静态层次___区别标识符的作用域。 50.编译程序绝大多数时间花在___表格管理__ 上。 51.编译程序是对__高级语言的翻译___。
arm-linux-gcc常用参数讲解gcc编译器使用方法 我们需要编译出运行在ARM平台上的代码,所使用的交叉编译器为arm-linux-gcc。下面将arm-linux-gcc编译工具的一些常用命令参数介绍给大家。 在此之前首先介绍下编译器的工作过程,在使用GCC编译程序时,编译过程分为四个阶段: 1. 预处理(Pre-Processing) 2. 编译(Compiling) 3. 汇编(Assembling) 4. 链接(Linking) Linux程序员可以根据自己的需要让GCC在编译的任何阶段结束,以便检查或使用编译器在该阶段的输出信息,或者对最后生成的二进制文件进行控制,以便通过加入不同数量和种类的调试代码来为今后的调试做好准备。和其它常用的编译器一样,GCC也提供了灵活而强大的代码优化功能,利用它可以生成执行效率更高的代码。 以文件example.c为例说明它的用法 0. arm-linux-gcc -o example example.c 不加-c、-S、-E参数,编译器将执行预处理、编译、汇编、连接操作直接生成可执行代码。 -o参数用于指定输出的文件,输出文件名为example,如果不指定输出文件,则默认输出 a.out 1. arm-linux-gcc -c -o example.oexample.c -c参数将对源程序example.c进行预处理、编译、汇编操作,生成example.0文件 去掉指定输出选项"-o example.o"自动输出为example.o,所以说在这里-o加不加都可以 2.arm-linux-gcc -S -o example.sexample.c -S参数将对源程序example.c进行预处理、编译,生成example.s文件 -o选项同上 3.arm-linux-gcc -E -o example.iexample.c -E参数将对源程序example.c进行预处理,生成example.i文件(不同版本不一样,有的将预处理后的内容打印到屏幕上) 就是将#include,#define等进行文件插入及宏扩展等操作。 4.arm-linux-gcc -v -o example example.c 加上-v参数,显示编译时的详细信息,编译器的版本,编译过程等。 5.arm-linux-gcc -g -o example example.c -g选项,加入GDB能够使用的调试信息,使用GDB调试时比较方便。 6.arm-linux-gcc -Wall -o example example.c -Wall选项打开了所有需要注意的警告信息,像在声明之前就使用的函数,声明后却没有使用的变量等。 7.arm-linux-gcc -Ox -o example example.c -Ox使用优化选项,X的值为空、0、1、2、3 0为不优化,优化的目的是减少代码空间和提高执行效率等,但相应的编译过程时间将较长并占用较大的内存空间。 8.arm-linux-gcc -I /home/include -o example example.c -Idirname: 将dirname所指出的目录加入到程序头文件目录列表中。如果在预设系统及当前目录中没有找到需要的文件,就到指定的dirname目录中去寻找。 9.arm-linux-gcc -L /home/lib -o example example.c
2011-2012学年第二学期 《编译原理》课程设计报告 学院:计算机科学与工程学院 班级: 学生姓名:学号: 成绩: 指导教师: 时间:2012年5 月
目录 一、课程设计的目的 ---------------------------------------------------------------- - 1 - 二、课堂实验及课程设计的内容 -------------------------------------------------- - 1 - 2.1、课堂实验内容-------------------------------------------------------------- - 1 - 2.2、课程设计内容-------------------------------------------------------------- - 1 - 三、visual studio 2008 简介------------------------------------------------------- - 2 - 四、问题分析及相关原理介绍 ----------------------------------------------------- - 3 - 4.1、实验部分问题分析及相关原理介绍 ---------------------------------- - 3 - 4.1.1、词法分析功能介绍及分析------------------------------------- - 3 - 4.1.2、语法分析功能介绍及分析------------------------------------- - 3 - 4.1.3、语义分析功能介绍及分析------------------------------------- - 4 - 4.2、课程设计部分问题分析及相关原理介绍 ---------------------------- - 5 - 4.2.1、编译程序介绍 ----------------------------------------------------- - 5 - 4.2.2、对所写编译程序的源语言的描述(C语言) -------------- - 6 - 4.2.3、各部分的功能介绍及分析 -------------------------------------- - 7 - 4.3、关键算法:单词的识别-------------------------------------------------- - 8 - 4.3.1、算法思想介绍 ----------------------------------------------------- - 8 - 4.3.2、算法功能及分析 -------------------------------------------------- - 8 - 五、设计思路及关键问题的解决方法 ------------------------------------------ - 10 - 5.1、编译系统------------------------------------------------------------------ - 10 - 5.1.1、设计思路 --------------------------------------------------------- - 10 - 5.2、词法分析器总控算法--------------------------------------------------- - 12 - 5.2.1、设计思路 --------------------------------------------------------- - 12 - 5.2.2、关键问题及其解决方法 --------------------------------------- - 13 - 六、结果及测试分析-------------------------------------------------------------- - 14 - 6.1、软件运行环境及限制--------------------------------------------------- - 14 - 6.2、测试数据说明------------------------------------------------------------ - 14 - 6.3、运行结果及功能说明--------------------------------------------------- - 16 - 6.4、测试及分析说明--------------------------------------------------------- - 16 - 七、总结及心得体会 --------------------------------------------------------------- - 17 - 7.1、设计过程------------------------------------------------------------------ - 17 - 7.2、困难与收获 ------------------------------------------------------------- - 17 - 八、参考文献 ------------------------------------------------------------------------ - 18 -
集美大学计算机工程学院实验报告 课程名称:编译原理班级: 指导教师:: 实验项目编号:实验一学号: 实验项目名称:词法分析器的设计实验成绩: 一、实验目的 通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。 二、实验容 编写一个词法分析器,从输入的源程序(编写的语言为C语言的一个子集)中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的部编码及单词符号自身值。(遇到错误时可显示“Error”,然后跳过错误部分继续显示) 三、实验要求 1、词法分析器的功能和输出格式 词法分析器的功能是输入源程序,输出单词符号。词法分析器的单词符 2 别单词的类型,将标识符和常量分别插入到相应的符号表中,增加错误处理等。 3、编程语言不限。
四、实验设计方案 1、数据字典 本实验用到的数据字典如下表所示:
3、实验程序 #include
初学者初用ICCAVR编程的时候,经常会出现一些错误,现在将常见的错误报告整理如下。这里的一些错误是为了展示说明而故意制造的,欢迎你提供你遇到的错误和解决方法。 一、正常编译通过 CODE: C:\icc\bin\imakew -f main.mak iccavr -c -IC:\icc\include\ -e -DA TMEGA -DA TMega16 -l -g -Mavr_enhanced D:\桌面\实验教程\LED应用\霓虹灯\main.c iccavr -o main -LC:\icc\lib\ -g -ucrtatmega.o -bfunc_lit:0x54.0x4000 -dram_end:0x45f -bdata:0x60.0x45f -dhwstk_size:16 -beeprom:1.512 -fihx_coff -S2 @main.lk -lcatmega Device 1% full. Done. [url="][/url] 这是我们最想看到的了,万事大吉。 二、工程中未加入.C文件 CODE: C:\icc\bin\imakew -f main.mak iccavr -o main -LC:\icc\lib\ -g -ucrtatmega.o -bfunc_lit:0x54.0x4000 -dram_end:0x45f -bdata:0x60.0x45f -dhwstk_size:16 -beeprom:1.512 -fihx_coff -S2 @main.lk -lcatmega unknown file type @main.lk, passed to linker !ERROR unknown file type '@main.lk' C:\icc\bin\imakew.exe: Error code 1 Done: there are error(s). Exit code: 1 解决办法:将你的程序加入工程中,可以右键程序区>>ADD to project 三、程序没有后缀名,或者后缀名不正确。 CODE: C:\icc\bin\imakew -f main.mak C:\icc\bin\imakew.exe: 'main' is up to date Done. 这是一个很难理解的错误,它是由工程中的程序文件没有后缀名造成的。 解决办法:将原有文件移出工程,将文件的后缀名改为.C,然后再加入工程中。 四、没有main函数
gcc编译器 CFLAGS 标志参数说明2012-11-14 15:10:28 分类:LINUX CFLAGS = -g -O2 -Wall -Werror -Wno-unused 编译出现警告性错误unused-but-set-variable,变量定义但没有使用,解决方法: 增加CFLAGS 或CPPFLAGS参数如下: CPPFLAGS=" -Werror -Wno-unused-but-set-variable" || exit 1 Gcc总体选项列表 后缀名所对应的语言 -S只是编译不汇编,生成汇编代码 -E只进行预编译,不做其他处理 -g在可执行程序中包含标准调试信息 -o file把输出文件输出到file里 -v打印出编译器内部编译各过程的命令行信息和编译器的版本 -I dir在头文件的搜索路径列表中添加dir目录 -L dir在库文件的搜索路径列表中添加dir目录 -static链接静态库 -llibrary连接名为library的库文件 ·“-I dir” 正如上表中所述,“-I dir”选项可以在头文件的搜索路径列表中添加dir目录。由于Linux 中头文件都默认放到了“/usr/include/”目录下,因此,当用户希望添加放置在其他位置的头文件时,就可以通过“-I dir”选项来指定,这样,Gcc就会到相应的位置查找对应的目录。 比如在“/root/workplace/Gcc”下有两个文件: #include int main() { printf(“Hello!!\n”); return 0; } #include
这样,就可在Gcc命令行中加入“-I”选项: [root@localhost Gcc] Gcc hello1.c –I /root/workplace/Gcc/ -o hello1 这样,Gcc就能够执行出正确结果。 小知识 在include语句中,“<>”表示在标准路径中搜索头文件,““”” 表示在本目录中搜索。故在上例中,可把hello1.c的“#include” 改为“#include “my.h””,就不需要加上“-I”选项了。 ·“-L dir” 选项“-L dir”的功能与“-I dir”类似,能够在库文件的搜索路径列表中添加dir目录。 例如有程序hello_sq.c需要用到目录“/root/workplace/Gcc/lib”下的一个动态库 libsunq.so,则只需键入如下命令即可: [root@localhost Gcc] Gcc hello_sq.c –L /root/workplace/Gcc/lib –lsunq –o hello_sq 需要注意的是,“-I dir”和“-L dir”都只是指定了路径,而没有指定文件,因此不能在 路径中包含文件名。 另外值得详细解释一下的是“-l”选项,它指示Gcc去连接库文件libsunq.so。由于在Linux 下的库文件命名时有一个规定:必须以lib三个字母开头。因此在用-l选项指定链接的库 文件名时可以省去lib三个字母。也就是说Gcc在对”-lsunq”进行处理时,会自动去链接 名为 libsunq.so的文件。 (2)告警和出错选项 Gcc的告警和出错选项如表3.8所示。 Gcc总体选项列表 选项含义 -ansi 支持符合ANSI标准的C程序 -pedantic 允许发出ANSI C标准所列的全部警告信息 -pedantic-error 允许发出ANSI C标准所列的全部错误信息 -w 关闭所有告警 -Wall 允许发出Gcc提供的所有有用的报警信息 -werror 把所有的告警信息转化为错误信息,并在告警发生时终止编译过程 下面结合实例对这几个告警和出错选项进行简单的讲解。 如有以下程序段: #include void main() { long long tmp = 1; printf(“This is a bad code!\n”);