
Logistic 回归 Logistic 回归是多元回归分析的拓展,其因变量不是连续的变量;在logistic 分析中,因变量是分类的变量;logistic 和probit 回归皆为定性回归方程的一种;他们的特点就在于回归因变量的离散型而非连续型。Logistic 回归又分为binary 和multinominal 两类; 1、Logistic 回归原理 Logistic 回归Logistic 回归模型描述的是概率P 与协变量12,.......k x x x 之间的关系,考虑到P 的取值在0----1之间,为此要首先把Plogistic 变换为()ln( )1p f p p =-,使得它的取值在+∞-∞到之间,然后建立logistic 回归模型 P=p(Y=1) ()ln()1p f p p =-=011+......k k x x βββ++ 011011+......+......1k k k k x x x x e p e ββββββ++++?=+ Logistic 回归模型的数据结构 观察值个数 取1的观察值个数 取0的观察值个数 协变量12,.......k x x x 的值 N1 r1 n1-ri ……………………… N2 r2 n2-r2 ………………………. . . . . . . . . Nt rt nt-rt ………………………. 根据数据,得到参数0 1....k βββ的似然函数 011011011+ (1) +......+......1()()11k k i i i k k k k x x r n r t i x x x x e e e βββββββββ++-=++++∏++ 使用迭代算法可以求得0 1....k βββ的极大似然估计。 2、含名义数据的logistic 模型 婚姻状况是名义数据,分为四种情形:未婚、有配偶、丧偶、离婚;在建立logistic 模型时,定义变量M1、M2、M3,使得
1.逻辑回归模型 1.1逻辑回归模型 考虑具有p个独立变量的向量,设条件概率为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为 (1.1) 上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。 其中。如果含有名义变量,则将其变为dummy变量。一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有 (1.2) 定义不发生事件的条件概率为 (1.3) 那么,事件发生与事件不发生的概率之比为 (1.4) 这个比值称为事件的发生比(the odds of experiencing an event),简称为odds。因为0
得到的概率。在同样条件下得到的条件概率为。于是,得到一个观测值的概率为 (1.6) 因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。 (1.7) 上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估计。于是,最大似然估计的关键就是求出参数,使上式取得最大值。 对上述函数求对数 (1.8) 上式称为对数似然函数。为了估计能使取得最大的参数的值。 对此函数求导,得到p+1个似然方程。 (1.9) ,j=1,2,..,p. 上式称为似然方程。为了解上述非线性方程,应用牛顿-拉斐森(Newton-Raphson)方法进行迭代求解。 1.3牛顿-拉斐森迭代法 对求二阶偏导数,即Hessian矩阵为 (1.10) 如果写成矩阵形式,以H表示Hessian矩阵,X表示 (1.11) 令
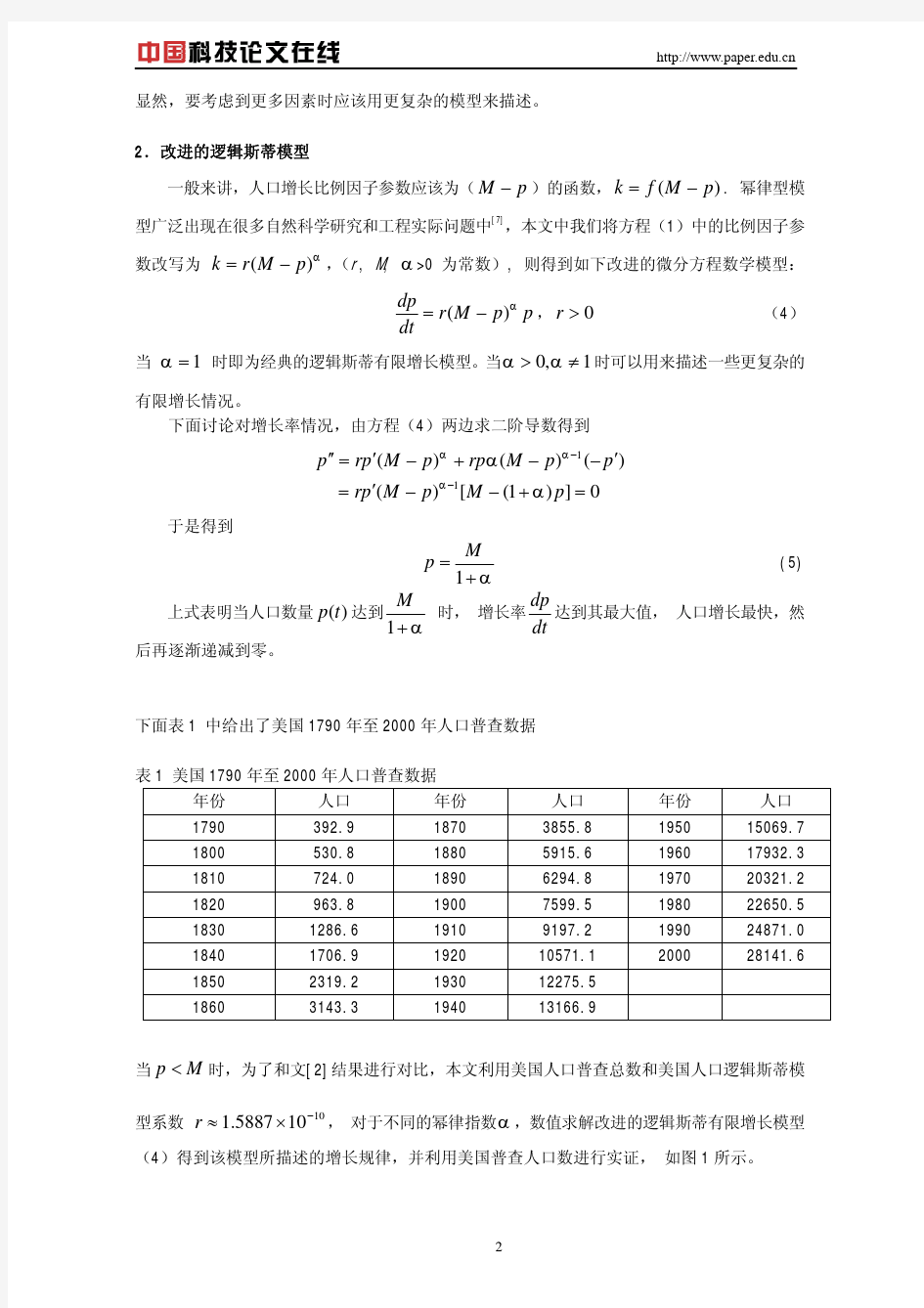
逻辑斯蒂方程及经济学应用 梁美娟,生物0801,20080205035 摘 要:逻辑斯蒂方程是一种非线性微分方程,其数学模型S 型曲线模型被广泛应用于描述事物的增长,本文系统的阐述了该方程的历史和演变,分析其生态学意义,并说明了该模型在经济学上的应用。 关键词:逻辑斯蒂方程;Lotka-V olterra 模型;前景理论;S 型曲线 一 前言 逻辑斯蒂方程广泛应用于描述客观事物的S 型变化现象。逻辑斯蒂数学模型是一条单调递增的,单参数k 为渐近线的S 型曲线。基本数量特征是当t 很小的时,呈指数增长,而当t 很大时,增长速度下降,且接近一个值(k )趋于平稳。利用它我们可以表征种群的数量动态,描述客观事物增长过程,还可以对满足该方程的现象进行预测,有助于相关政策的制定。另外,logistic 方程还可以作为其它模型如Lotka-V olterra 竞争模型的理论基础。 二.逻辑斯蒂方程的历史和演变 最早在1798年,英国统计学家Malthus(1766-1843)的《人口原理》中提出闻名于世的Malthus 人口模型。假设:在人口自然增长过程中,相对净增长率(出生率减死亡率)为常数,即单位时间人口的增长是与人口正比例,比例系数r 。 ?????==0 )(0N N rN dt dN t (1) 该模型准确反映了1700-1964年的人口增长,表明人口以指数规律随时间无限增长。但不是适应与以后的增长。因地球上各资源只可供一定数量的人生活,人口增加,环境的限制越来越明显,r 减少。1838年,比利时数学家P.F.Verhulst 引入N m ,表示自然条件所能容纳的最大人口数,Verhulst 假设的有限环境的物种相对增长率为 ?????=-=0 )(0)1(N N N K N r dt dN t (2) 由曲线得出以下结论:不管初值为多少,人口总量最终接近于极限值K ,极限值的一半(即r/2K )前,是加速生长的时候,过了这一点以后,增长速度减少,并且迟早会达到零。 三、逻辑斯蒂方程的生态学应用 1、在种群生态学中,种群的增长是一个复杂的问题,,由于种群手到诸多因素的影响,如环境条件、营养条件、出生率、死亡率、个体基数及时代特征等。
SPSS与社会统计学课程作业二 [1]陈昱,陈银蓉,马文博. 基于Logistic模型的水库移民安置区居民土地流转意愿分析——四川、湖南、湖北移民安置区的调查[J]. 资源科学,2011,06:1178-1185. 一、变量赋值 1.被解释变量用0表示不愿意流转,1表示愿意流转,有意愿上的状态表示效果。 2.性别分别用1和2表示男女,男女不存在有没有状态的表征,所以用1、2赋值非常合适;它的预计影响方向为负,是基于学者张林秀、刘承芳等认为:由于农村男性外出打工的几率高于女性,女性更愿意在家耕种土地,这就可能导致女性不愿意转出土地的基础上设定的。 3.教育程度越高赋值越高,且预测影响为正,这个也是在文章前面定量分析的时候引用学者李实的观点说明赋值的理由。 4.职业类型中,兼业化程度越高赋值越高,且为正向。从家庭收入对农业收入的依赖性原理角度来看这个不难理解。 5.其它变量的赋值依据实际情况初步判断也不能理解其赋值的缘由。然而对于“是否为村干部”这一变量来看,预测的趋向是:是村干部则不愿意流转,前面的分析并没有说明为什么会是这样。虽然这知识一种预判,但是若能够给出预判的一丁点理由就更好了。 二、系数解读
1.标准化系数中,x1,x3,x7,x9,x11,x12系数为付,意味着性别是男、与市中心距离 越近、家庭人口和劳动力人数越少、农业收入占比越少、认为土地经营权权属则土地流转的意愿越强; 2.其中X3(与市中心距离),x9(劳动力人数)影响系数绝对值较大,分别为0.815,0.322。 在显著性检验方面,x3、x9、x11分别通过了15%、1%、5%的显著性检验。也就是说,土地不愿意流转与劳动力人数多有显著相关性,与农业收入占比高有较显著的相关,与市中心距离近相关性不显著。 3.系数为正的变量中,影响系数均不高,但能通过显著性检验的有:x2、x5(15%);x10、 x13(5%);x4(1%)。说明文化程度高对愿意流转的影响是非常显著的,而且在系数为正的变量中,x4的系数为最大,说明x4与y(1)显著相关。 三、模型检验
实验目的: 1、使学生们认识到环境资源是有限的,任何种群数量的动态变化都受到环境条 件的制约。 2、加深对逻辑斯蒂增长模型的理解与认识,深刻领会该模型中生物学特性参数 r与环境因子参数----生态学特性参数K的重要作用。 3、学会如何通过实验估计出r、K两个参数和进行曲线拟合的方法。 实验原理: 种群在资源有限环境中的数量增长不是无限的,当种群在一个资源有限的空间中增长时,随着种群密度的上升,对有限空间资源和其他生活必需条件的种内竞争也将加强,必然影响到种群的出生率和存活率,从而降低了种群的实际增长率,直至种群停止增长,甚至使种群数量下降。逻辑斯蒂增长是种群在资源有限环境下连续增长的一种最简单的形式,又称阻滞增长。 种群在有限环境中的增长曲线是S型的,它具有两个特点: 1、S型增长曲线有一个上渐近线,即S型增长曲线逐渐接近于某一特定 的最大值,但不会超过这个最大值的水平,此值即为种群生存的最大 环境容纳量,通常用K表示。当种群大小到达K值时,将不再增长。 2、S型曲线是逐渐变化的,平滑的,而不是骤然变化的。 逻辑斯蒂增长的数学模型: dN dt =rN( K?N K ) 或 dN dt =rN(1? N K ) 式中:dN dt —种群在单位时间的增长率; N—种群大小; t—时间; r—种群的瞬时增长率; K—环境容纳量; (1?N K )—“剩余空间”,即种群还可以继续利用的增长空间。逻辑斯蒂增长模型的积分式: N= K 1+e a?rt 式中:a—常数; e—常数,自然对数的底。实验器材:
恒温光照培养箱、实体显微镜、凹拨片、1000毫升烧杯、100毫升量筒、移液枪(50微升),1千瓦电炉、普通天平、干稻草、鲁哥氏固定液、50毫升锥形瓶、纱布、橡皮筋、白胶布条、封口膜、标记笔、计数器、自制的观测数据记录表格 方法与步骤: 1、准备草履虫原液 从湖泊或水渠中采集草履虫。 2、制备草履虫培养液 (1)制取干稻草5g,剪成3~4厘米长的小段。 (2)在1000毫升烧杯中加水800毫升,用纱布包裹好干稻草,放入水中煮沸10分钟,直至煎出液呈现淡黄色。 (3)将稻草煎出液置于室温下冷却后,经过过滤,即可作为草履虫培养液备用。 3、确定培养液中草履虫种群的初始密度 (1)用50微升移液枪取50微升草履虫原液于凹拨片上,当在实体显微镜下看到有游动的草履虫时,再用滴管取一小滴哥鲁氏固定液于凹玻片 上杀死草履虫,在实体显微镜下进行草履虫计数。 (2)按上述方法重复取样4次,对四次计数的草履虫数求平均值,并推算出草履虫原液中的种群密度。 (3)取冷却后的草履虫培养液50毫升,置于50毫升烧杯中。经过计算,用移液枪取适量的草履虫原液放入培养液中,使培养液中的草履虫的 个数在1-2个。此时培养液中的草履虫密度即为初始种群密度。 (4)用纱布和橡皮筋将实验用的烧杯罩好,并做好本组标记,放置在20摄氏度与30摄氏度的恒温光照培养箱中培养。 4、定期检测和记录 (1)在实验开始后10天内,每天定时对培养液中的草履虫密度进行检测。 (2)将每天的观测数据记录在表格中。 5、环境容纳量K的确定 将10天中得到的草履虫种群大小数据,标定在以时间为横坐标,草履虫种群数量为纵坐标的平面坐标系中,从得到的散点图中不仅可以看出草履虫种群大小随时间的变化规律,还可以得到此环境条件下可以容纳草履虫的最大环境容纳量K,通常从平衡点以后,选取最大的一个N,以防止在计算ln[(K-N)/N]的过程中真数出现负值。 最大环境容纳量K还可以通过三点法求得。三点法的公式为 K=2N1N2N3?N22(N1+N3) N1N3?N2 式中:N 1,N 2 ,N 3 —分别为时间间隔基本相等的三个种群数量,要求时间间隔尽量 大一些。 6、瞬时增长率r的确定 瞬时增长率r可以用回归分析的方法来确定。首先将Logistic方程的积分式变形为
1.逻辑回归模型 1.1 逻辑回归模型 考虑具有p个独立变量的向量■',设条件概率卩;上二?丨门二广为根据观测 量相对于某事件发生的概率。逻辑回归模型可表示为 :「( 1.1) 上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。 其中-" I' 1 c' ■-..【?。如果含有名义变量,则将其变为dummy 变量。一个具有k个取值的名义变量,将变为k-1个dummy 变量。这样,有 — I ( 1.2) 这个比值称为事件的发生比(the odds of experie ncing an event), 0
得到I 的概率。在同样条件下得到-- 的条件概率为丨:一"。 得到一个观测值的概率为 因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。 (1.7) 上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估 譏备心)( 」' (1.10 是, ◎ )*(1 ¥严(1.6 ) i-l 计。于是,最大似然估计的关键就是求出参数:- ,使上式取得最大值。 对上述函数求对数 — (1.8) 上式称为对数似然函数。为了估计能使亠取得最大的参数的值。 对此函数求导,得到p+1个似然方程。 Ei 片 n:—E L尹—心肿一时 (1.9 ) ^叶切迄尸,j=1,2,..,p. 上式称为似然方程。为了解上述非线性方程,应用牛顿-拉斐森 进行迭代求解。 (Newto n-Raphs on) 方法1.3 牛顿-拉斐森迭代法 对-八?求二阶偏导数,即Hessian矩阵为 如果写成矩阵形式,以H表示Hessian矩阵,X表示 (1.11 )
SPSS操作方法之五 SPSS操作方法:逻辑回归 例证8.3: 在一次关于公共交通的社会调查中,一个调查项目是“乘公交车上下班,还是骑自行车上下班”因变量Y=1表示乘车,Y=0表示骑车。自变量X1表示年龄;X2表示表示月收入;X3表示性别,取1时为男性,取0时为女性。调查对象为工薪族群体。数据见下表:试建立Y与自变量之间的Logistic回归。 逻辑回归SPSS操作方法的具体步骤: 1.选择Analyze→Regreessin→Binary Logistic,打开对话框如图1所示:
图1 主对话框Logistic回归。 2.选择因变量Y进入Dependent框内,将自变量选择进入Convariates框。也可以将不同的自变量组放在不同的块(block)中,可以分析不同的自变量组对因变量的贡献。 3.在Mothed框内选择自变量的筛选策略: Enter表示强行进入法;(本例选择) Forword和Bacword都表示逐步筛选策略;Forword 为自变量逐步进入,Bacword是自变量逐步剔出。Conditional ;LR; Wald分别表示不同的检验统计量,如Forword Wald表示自变量进入方程的依据是Wald统计量。 4.在Selection中选择一个变量作为条件变量,只有满足条件的变量数据才能参与回归分析。 5.单击Categorical打开Categorical对话框如图2所示:对定性变量的自变量选择参照类。常用的方法是Indicator,即以某个特定的类为参照类,Last表示以最大值对应的类为参照类(系统默认),First表示以最小值对应的类为参照类。选择后点击Continue按钮返回主对话框。(本例不作选择性) 图2 Categorical对话框 6.单击Option按钮,打开Option对话框如图3所示
逻辑斯蒂模型(Logistic growth model ) 1.原始逻辑斯蒂模型: 设0t 时刻的人口总数为)(0t N ,t 时刻人口总数为)(t N ,则: ?????==0 0)(N t N rN dt dN 但是这个模型有很大的局限性:只考虑出生率和死亡率,而没有考虑环境因素,实际上人类生存的环境中资源并不是无限的,因而人口的增长也不可能是无限的。此人口模型只符合人口的过去而不能用来预测未来人口总数。 2.改进逻辑斯蒂模型: 考虑自然资源和环境对人口的影响,实际上人类所生存的环境中资源并不是无限的,因而人口的增长也不可能是无限的,因此,将人口增长率为常数这一假设修改为:?????=-=0 02)(N t N KN rN dt dN 其中K r ,称为生命系数 分析如下: rt t t e r K N r K t N -∞→∞→-+=)1(1lim )(lim 0 0)1(1lim 0?-+=∞→r K N r K t = K r N KN r KN r KN r dt dN KN r dt dN KN dt dN r dt N d ))(2)(2()2(222---=-=-= 说明: (1)当∞→t 时,K r t N → )(,结论是不管其初值,人口总数最终将趋向于极限值K r /; (2)当K r N 00时,0)(2 N K r KN KN rN dt dN -=-=,说明)(t N 是时间的单调递增函数; (3)当K r N 2 时,022 dt N d ,曲线上凹,当K r N 2 时,022 dt N d ,曲线下凹。
表九用spss软件得到各观察值所对应的拟核值,残差值和标准残差 拟合值97077.7 101458.9 105412.6 108940.84 112057.91 114787.4 117159.2 残差-818.74 -2753.91 438.35 3763.15 2275.08 1035.51 11.73 标准残 -0.7505 -2.0548 0.3051 2.5699 1.5537 0.7098 0.0080 差 拟合值119206.2120962.7122462.4123737.3124817.2125729.2126497.3残差-689.28-1112.76-1341.41-1348.34-1191.28-968.25-711.37标准残 -0.4707-0.7540-0.9009-0.8985-0.7899-0.6410-0.4720差 拟合值127142.9127684.4128138.0128517.4128834.5129099.2 残差-399.93-57.47314.93709.501153.451656.76 标准残 -0.2670-0.03870.21470.49060.81010.941 差 从新数据得到F=372.3471 p值=0.001 从新数据得到相关系数R=0.9888,相关性比较强,说明这种拟合是比较贴切的,本文建立逻辑斯蒂模型:0.8840.185 =+ y e-- 130517.5/(1)x
§4 从倍周期分定走向混沌 4-1 逻辑斯谛(Logistic )映射 我们将以一个非常简单的数学模型来加以说明从倍周期分定走向混沌现象。该模型称为有限环境中无世代交替昆虫生息繁衍模型。若昆虫不加以条件控制,每年增加λ倍,我们将一年作为一代,把第几代的虫日记为,则有: i N o i i i N N N 11++==λλ (4-1) i N ,1>λ增长很快,发生“虫口爆炸”,但虫口太多则会由于争夺有限食物和生存空间, 以及由于接触传染导致疾病曼延,使虫口数目减少,它正比于,假定虫口环境允许的最大虫口为,并令2 i N o N o i i N N x = ,则该模型由一个迭代方程表示: 21i i i N N N λλ?=+ 即为: )1(1i i i x x x ?=+λ (4-2) 其中:]4,0[], 1,0[∈∈λi x 。 (4-2)式就是有名的逻辑斯谛映射。 4-2 倍周期分歧走向混沌 借助于对这一非线性迭代方程进行迭代计算,我们可以清楚地看到非线性系统通过倍周期分岔进入混沌状态的途径。 (一)迭代过程 迭代过程可以用图解来表示。图4-1中的水平轴表示,竖直轴表示,抛物线表示(4-2)式右端的迭代函数。45o线表示n x 1+n x n n x x =+1的关系。由水平轴上的初始点作竖直线,找到与抛物线的交点,A 的纵坐标就是。由点 )0,(0x R ),(10x x A 1x
),(10x x A 作水平直线,求它与45o线的交点,经B 点再作竖直线,求得与抛物 线的交点,这样就得到了。仿此做法可得到所迭代点。 ),(11x x B ),(21x x 2x 从任何初始值出发迭代时,一般有个暂态过程。但我们关心的不是暂态过程,而是这所趋向的终态集。终态集的情况与控制参数λ有很大关系。增加λ值就意味着增加系统的非线性的程度。改变λ值,不仅仅改变了终态的量,而且也改变了终态的质。它所影响的不仅仅是终态所包含的定态的个数和大小,而且也影响到终态究竟会不会达到稳定。 (二)终态性质 ①当31<<γ时,迭代结果的归宿是一个确定值,趋于一个不动点,即抛物线与45o线的交点,这相当于系统处于一个稳定态,如图4-2(a)所示。此值与λ有关,且与λ值有一一对应关系。当4.2=λ时,12/711==+i x x 。迭代的结果为一个不动点的情况,其周期为1,这表示从出发,迭代一次就回到。 i x i x ②当449.33<<γ时,迭代的终态在一个正方形上循环,亦即在两个值之间往复跳跃,与一个i x λ值对应将有两个值,即其归宿轮流取两个值,如图4-2(b)所示。当i x 2.3=λ时,此值为i i x x =?+2,7995.05130.0周期为2,表示从出发,迭代二次后回到。所以,从图3-12(a)到3-12(b)中间发生了一个倍周期分岔,一个稳定态分裂成为两 i x i x 图4-2 叠代过程 种状态,而系统便在两个交替变动的值间来回振荡。 ③当544.3449.3<<λ时,最终在四个值之间循环跳跃,如图4-2(c)所示。 +4,即终态集是个四周期解,表示从出发,迭代四次后回到。所以,从图4-2(b) 到3-12(c),中间又发生了一个倍周期分岔,两种状态分裂成四种状态,而系统便在四个交 i x i i x x i x i x =
逻辑回归模型分析见解
1.逻辑回归模型 1.1逻辑回归模型 考虑具有P个独立变量的向量*=(Xl,X2,”q),设条件概率= 为根据观测量相对于某事件发生 的概率。逻辑回归模型可表示为 1 L十严 上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。 其中。如果含有名义变量,则将其变为dummy 变量。一个具有k个取值的名义变量,将变为k-1个dummy 变量。这样,有 定义不发生事件的条件概率为 (1.1) (1.2)
尸wmx 十各-占 (1.3 ) 那么,事件发生与事件不发生的概率之比为 F (H =1|幻—P “曲 = Q | x ) \-p 这个比值称为事件 的发生比 (the odds of experie ncing an eve nt), 简称为 odds 。 因为0
于是,最大似然估计的关键就是求出参数 ,使上式取得 最大值。 对上述函数求对数 山应?*的?召仙恥区;]丨门丫」訓:叩丄】 (i 8 ) 上式称为对数似然函数。为了估计能使 £(旳取得 最大的参数的值。 对此函数求导,得到p+1个似然方程。 纠片-v 相严纠# _ ]新.站卄”和丸 (i 9 ) 圣屮.『;-* 几-百工 一 f Ji' j=1 2 p 上式称为似然方程。为了解上述非线性方程,应 用牛顿一拉斐森 (Newto n-Raphso n ) 方法 进行迭代求解。 亦占二址(1-隔) 兰丝二-S 耳赳兀(1-花) 阴阴处心“ (1.10 ) 如果写成矩阵形式,以H 表示 Hessian 矩阵, X 表示 1.3 牛顿-拉斐森迭代法 对心;求二阶偏导数,即Hessian 矩阵为 护 M - i-l
如何用SPSS做logistic回归分析解读
————————————————————————————————作者:————————————————————————————————日期:
如何用spss17.0进行二元和多元logistic回归分析 一、二元logistic回归分析 二元logistic回归分析的前提为因变量是可以转化为0、1的二分变量,如:死亡或者生存,男性或者女性,有或无,Yes或No,是或否的情况。 下面以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进行二元logistic回归分析。 (一)数据准备和SPSS选项设置 第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS和NCAS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NCAS转化为1、0分类,是ICAS赋值为1,否赋值为0。年龄为数值变量,可直接输入到spss中,而性别需要转化为(1、0)分类变量输入到spss当中,假设男性为1,女性为0,但在后续分析中系统会将1,0置换(下面还会介绍),因此为方便期间我们这里先将男女赋值置换,即男性为“0”,女性为“1”。 图1-1 第二步:打开“二值Logistic 回归分析”对话框: 沿着主菜单的“分析(Analyze)→回归(Regression)→二元logistic (Binary Logistic)”的路径(图1-2)打开二值Logistic 回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素方差分析中与ICAS 显著相关的为性别、年龄、有无高血压,有无糖尿病等(P<0.05),因此我们这里选择以性别和年龄为例进行分析。
Logistic 回归模型 1 Logistic 回归模型的基本知识 1.1 Logistic 模型简介 主要应用在研究某些现象发生的概率p ,比如股票涨还是跌,公司成功或失败的概率,以及讨论概率 p 与那些因素有关。显然作为概率值,一定有10≤≤p ,因此很难用线性模型描述概率p 与自变量的关 系,另外如果p 接近两个极端值,此时一般方法难以较好地反映p 的微小变化。为此在构建p 与自变量关系的模型时,变换一下思路,不直接研究p ,而是研究p 的一个严格单调函数)(p G ,并要求)(p G 在p 接近两端值时对其微小变化很敏感。于是Logit 变换被提出来: p p p Logit -=1ln )( (1) 其中当p 从10→时,)(p Logit 从+∞→∞-,这个变化范围在模型数据处理上带来很大的方便, 解决了上述面临的难题。另外从函数的变形可得如下等价的公式: X T X T T e e p X p p p Logit βββ+= ?=-=11ln )( (2) 模型(2)的基本要求是,因变量(y )是个二元变量,仅取0或1两个值,而因变量取1的概率 )|1(X y P =就是模型要研究的对象。而T k x x x X ),,,,1(21 =,其中i x 表示影响y 的第i 个因素,它可以 是定性变量也可以是定量变量,T k ),,,(10ββββ =。为此模型(2)可以表述成: k x k x k x k x k k e e p x x p p βββββββββ+++++++=?+++=- 1101 1011011ln (3) 显然p y E =)(,故上述模型表明) (1) (ln y E y E -是k x x x ,,,21 的线性函数。此时我们称满足上面条件 的回归方程为Logistic 线性回归。 Logistic 线性回归的主要问题是不能用普通的回归方式来分析模型,一方面离散变量的误差形式服从伯努利分布而非正态分布,即没有正态性假设前提;二是二值变量方差不是常数,有异方差性。不同于多元线性回归的最小二乘估计法则(残差平方和最小),Logistic 变换的非线性特征采用极大似然估计的方法寻求最佳的回归系数。因此评价模型的拟合度的标准变为似然值而非离差平方和。 定义1 称事件发生与不发生的概率比为 优势比(比数比 odds ratio 简称OR),形式上表示为 OR= k x k x e p p βββ+++=- 1101 (4) 定义2 Logistic 回归模型是通过极大似然估计法得到的,故模型好坏的评价准则有似然值来表征,称 -2?ln ()L β 为估计值β?的拟合似然度,该值越小越好,如果模型完全拟合,则似然值?()L β为1,而拟合似然度达到最小,值为0。其中?()lnL β 表示β?的对数似然函数值。 定义3 记)?(β Var 为估计值β?的方差-协方差矩阵,2 1 )]?([)?(ββVar S =为β?的标准差矩阵,则称 k i S w ii i i ,,2,1,]?[ 2 ==β (5) 为i β?的Wald 统计量,在大样本时,i w 近似服从)1(2 χ分布,通过它实现对系数的显著性检验。
基于因子分析和Logistic回归分析的 儿童心理发展状况及其对策研究 摘要:目前,在儿童心理健康研究中,归纳方法已经比较成熟了,而对数据进行数学分析的方法还不够完善,本文主要运用因子分析、主成分分析和Logistics分析等多元统计学中的分析方法,对儿童心理健康状况做了一定的科学分析。通过分析,得到了影响孩子心理健康的因素,并提出针对性的解决方案,提出了一些行之有效的解决措施。通过归纳法与数据分析法的比较,数据分析比归纳法更具有科学依据也更为准确。 关键词:因子分析;主成分分析;Logistics回归分析;心理健康;儿童 Abstract:At present, in the study of children's mental health, the method of induction has become more mature, and the method of mathematical analysis of data is still not perfect. This article mainly uses multivariate analysis methods such as factor analysis, principal component analysis, and logistic analysis. The children's mental health status has done some scientific analysis. Through analysis, the factors that affect the children's mental health are obtained, and specific solutions are proposed, and some effective solutions are proposed. By comparing the induction method with the data analysis method, the data analysis is more scientific and accurate than the induction method. Key word: Factor analysis; Principal component analysis; Logistics analysis ; Mental health; Children
对线性回归、逻辑回归、各种回归的概念学习回归问题的条件/前提: 1)收集的数据 2)假设的模型,即一个函数,这个函数里含有未知的参数,通过学习,可以估计出参数。然后利用这个模型去预测/分类新的数据。 1. 线性回归 假设特征和结果都满足线性。即不大于一次方。这个是针对收集的数据而言。 收集的数据中,每一个分量,就可以看做一个特征数据。每个特征至少对应一个未知的参数。这样就形成了一个线性模型函数,向量表示形式: 这个就是一个组合问题,已知一些数据,如何求里面的未知参数,给出一个最优解。一个线性矩阵方程,直接求解,很可能无法直接求解。有唯一解的数据集,微乎其微。 基本上都是解不存在的超定方程组。因此,需要退一步,将参数求解问题,转化为求最小误差问题,求出一个最接近的解,这就是一个松弛求解。 求一个最接近解,直观上,就能想到,误差最小的表达形式。仍然是一个含未知参数的线性模型,一堆观测数据,其模型与数据的误差最小的形式,模型与数据差的平方和最小: 这就是损失函数的来源。接下来,就是求解这个函数的方法,有最小二乘法,梯度下降法。 https://www.doczj.com/doc/5112402656.html,/wiki/%E7%BA%BF%E6%80%A7%E6%96%B9%E7%A8%8B%E7%BB%84 最小二乘法 是一个直接的数学求解公式,不过它要求X是列满秩的, 梯度下降法 分别有梯度下降法,批梯度下降法,增量梯度下降。本质上,都是偏导数,步长/最佳学习率,更新,收敛的
问题。这个算法只是最优化原理中的一个普通的方法,可以结合最优化原理来学,就容易理解了。 2. 逻辑回归 逻辑回归与线性回归的联系、异同? 逻辑回归的模型是一个非线性模型,sigmoid函数,又称逻辑回归函数。但是它本质上又是一个线性回归模型,因为除去sigmoid映射函数关系,其他的步骤,算法都是线性回归的。可以说,逻辑回归,都是以线性回归为理论支持的。只不过,线性模型,无法做到sigmoid的非线性形式,sigmoid可以轻松处理0/1分类问题。 另外它的推导含义:仍然与线性回归的最大似然估计推导相同,最大似然函数连续积(这里的分布,可以使伯努利分布,或泊松分布等其他分布形式),求导,得损失函数。 逻辑回归函数 表现了0,1分类的形式。 应用举例: 是否垃圾分类? 是否肿瘤、癌症诊断? 是否金融欺诈? 3. 一般线性回归 线性回归是以高斯分布为误差分析模型;逻辑回归采用的是伯努利分布分析误差。 而高斯分布、伯努利分布、贝塔分布、迪特里特分布,都属于指数分布。 而一般线性回归,在x条件下,y的概率分布p(y|x) 就是指指数分布.
基于SPSS logistic回归分析探究不同月均收入的男女比例 一一一 华北科技学院基础部北京东燕郊 065201 摘要:在计划经济时代,由于中国政府推行男女性别平等的就业制度和工资分配制度,因而城市劳动力性别工资差异并不明显。经济改革以来,伴随着由计划经济向市场经济的转型,工资分配机制发生了根本改变,性别工资差异越来越明显。性别分割是我国劳动力市场上一直存在的一种现象,性别收入差距总体趋势在扩大;个体特征差异能够在一定程度上解释性别收入差异,现阶段性别收入差异在很大程度上是由于劳动者本身的人力资本水平引起的,是正常合理的范围;歧视仍然是造成性别收入差距的一个原因,女性在获得教育的机会上还是比男性要低,而且女性很难进入到高收入行业和职业,使得在教育方面女性仍然处于不利地位。本文将运用SPSS二元回归分析探究不同月均收入对应的男女比例并得出结论,旨在对分析结果提出一些有建设性的建议。 关键词:logistic回归分析;SPSS软件;人均收入;性别比例 Based on SPSS logistic regression analysis to explore the sex ratio of different monthly income NIU Xiaoyu (North China institute of science and technology,Beijing,065201,China) Abstract: In the era of planned economy, as a result of the Chinese government to implement gender equality employment system and salary distribution system, and urban labor gender wage gap is not obvious. Since the economic reform, with the transition from planned economy to market economy, fundamental changes have taken place in wage distribution mechanism, the gender wage gap is more and more obvious. Gender segmentation is China's labor market has been a phenomenon of gender overall trend in the expanding income gap; Individual characteristics can partly explain the gender income differences, gender differences at present stage is largely caused by the human capital level of laborer itself, is a normal reasonable range; Discrimination is still a cause of the gender pay gap, women in the opportunity to gain education or lower than men,
一、逻辑斯蒂方程建立的过程及背景 在自然界和社会上存在大量的 s型变化的现象, 逻辑斯蒂Logistic模型几乎是描述 s型增长的唯一数学模型.这是一条连 续的、单调递增的、以参数 k为上渐近线的 s型曲线, 其变化 速度一开始增长较慢, 中间段增长速度加快, 以后增长速度下 降并且趋于稳定. 利用它可以表征种群的数量动态, 描述某一 研究对象的增长过程, 也可作为其它复杂模型的理论基础如 Lotka- Volterra两种群竞争模型. 可以看出逻辑斯蒂方程不管 在自然科学领域还是在社会科学中都具有非常广泛的用途. 1逻辑斯蒂模型的产生与发展 在提出逻辑斯蒂模型之前, 最早给出种群生态学经典数学模型 是 M althus模型, 由英国统计学家 M althus( 1766- 1834)在 1798年人口原理!一书中, 提出了闻名于世的 M althus人口模 型. 设 t0时刻的人口总数为 N ( t0), t时刻人口总数为 N( t), 则: dN/dt=rN N(t0)=N0 但是这个模型有很大的局限性: 只考虑出生率和死亡率, 而没 有考虑环境因素. 实际上人类所生存的环境中资源并不是无限 的, 因而人口的增长也不可能是无限的, 实践证明 M althus人 口模型只符合人口的过去而不能用来预测未来人口总数. 比利 时数学家Verhulst对Malthus模型中关于人口增长率为常数这一 假设修改为 dNdt=rN-KN^2 N(t0)=N0 其中 r,K称为生命系数(VitalCoefficients). (2)式就 是最早的逻辑斯蒂模型. 解之得: N(t) =1/(K/r+(1/N0-K/r)exp(-rt) 二、逻辑斯蒂方程在MATLAB中的实现 function f = curvefun1(x,t) syms x t; k=9000;
基于R 软件的Logistic 回归实证分析 应用统计 章程 1220120484 摘要:Logisic 回归模型是研究响应变量为非连续变量时的一种重要分析方法,但它的计算依赖于统计软件。本文通过实证对使用R 软件处理Logistic 模型做出简要分析。 引言:线性回归模型是定量分析和数据挖掘中最常用的统计分析方法之一,但线性回归分析一般要求响应变量是连续变量、数据分布为正态分布等条件。在实际分析研究中,经常遇到的是非连续的响应变量,即分类响应变量,如经济学研究中所涉及的是否购买某种商品、流行病学中研究的某些条件下是否会患病等。在研究二分变量与诸多自变量之间的相互关系时,通常选用Logistic 回归模型。 1、Logistic 回归 Logistic 模型是由比利时生物学家Verhulst 于1838年提出,最早是为了研究人口问题而对Malthus 方程做出的改进,起初并没有引起重视,后来美国人口学家Pear 在研究美国人口问题时再次提出这个方程才使其开始流行,故现代文献中常称之为Verhulst-pearl 阻碍方程。该模型之所以称为Logistic 模型,是因为其有某种推理的含义。 一般的Logistic 模型形式如下: () ()() 12n 011n 011n P Y=1|x ,x ,exp x x 1exp x x ββββββ+++=++++n n …,x …… 对上式做logit 变换,Logistic 回归模型可以写成: 011n p logit(p)=ln()=x x 1-p βββ+++n … 由于Logistic 回归模型涉及较复杂的数学理论,数据统计分析的计算往往较为复杂,一般无法用手工计算,只能在计算机上实现。在统计软件方面,常用的有SAS 、SPSS 、S-PLUS 等,但这些软件大多是商业性的,需要支付昂贵的购买费用。而R 软件是一款免费的统计软件,它提供了有弹性的、互动的环境来分析、展示数据,且提供若干统计程序包以及一些集成统计计算工具和函数,使得用户可以灵活机动地进行数据分析,简化了数据分析过程。它可以完成大多数模型的统计计算,并帮助用户分析计算结果。本文将结合实例,展示如何在R 软件中实现对Logistic 模型的统计分析。 2、Logistic 模型的拟合 回归模型的拟合主要是求模型中的参数估计值,Logistic 模型的参数估计通常采用极大似然法(maximum likelihood ,ML )。极大似然法的基本思想是先建立似然函数与对数似然函数,再通过使对数似然函数最大来求解相应的参数值,所得到的估计值称为参数的极大似然估计值。极大似然估计具有一致性、有效性和正态性等很好的统计性质,样本数据越大时,其估计值就越精确。 鉴于Logistic 模型时基于二项分布族的广义线性模型,因此在R 软件中可通过glm 语句建立回归关系,再用summary 语句得到其详细结果。在得到模型拟合结果后,还可用