
聚类分析
聚类分析(Cluster Analysis)是根据事物本身的特性研究个体分类的方法。
聚类分析的原则是同一类中的个体有较大的相似性,不同类的个体差异很大。
根据分类对象不同分为样品聚类和变量聚类。
样品聚类在统计学中又称为Q型聚类。用SPSS的术语来说就是对事件(cases)进行聚类,或是说对观测量进行聚类。是根据被观测的对象的各种特征,即反映被观测对象的特征的各变量值进行分类。
变量聚类在统计学中有称为R型聚类。反映事物特点的变量有很多,我们往往根据所研究的问题选择部分变量对事物的某一方面进行研究。
SPSS中进行聚类和判别分析的统计过程是由菜单Analyze---Classify导出的
选择Classify 可以显示三个过程命令:
1 K-Means Cluster进行快速聚类过程。
2 Hierarchical Cluster进行样本聚类和变量聚类过程。
3 Discriminant进行判别分析过程。
通常情况下在聚类进行之前 Proximitice 过程先根据反映各类特性的变量对原始数据
进行预处理,即利用标准化方法对原始数据进行一次转换。并进行相似性测度或距离测度。然后 Cluster 过程根据转换后的数据进行聚类分析。
在SPSS for Windows 中分层聚类各方法都包含了 Proximitice 过程对数据的处理和Cluster 过程。对数据的分析给出的统计量可以帮助用户确定最好的分类结果。
1.1 主要功能
聚类的方法有多种,最常用的是分层聚类法。根据聚类过程不同又分为凝聚法和分解法。
分解法:聚类开始把所有个体(观测量或变量)都视为属于一大类,然后根据距离和相似性逐层分解,直到参与聚类的每个个体自成一类为止。
凝聚法:聚类开始把参与聚类的每个个体(观测量或变量)视为一类,根据两类之间的距离或相似性逐步合并直到合并为一个大类为止。
无论哪种方法,其聚类原则都是近似的聚为一类,即距离最近或最相似的聚为一类。实际上以上两种方法是方向相反的两种聚类过程。
调用此过程可完成系统聚类分析。在系统聚类分析中用户事先无法确定类别数,系统将所有例数均调入内存,且可执行不同的聚类算法。系统聚类分析有两种形式,一是对研究对象本身进行分类称为Q聚类。另一种是对研究对象的观察指标进行分类称为R型聚类。
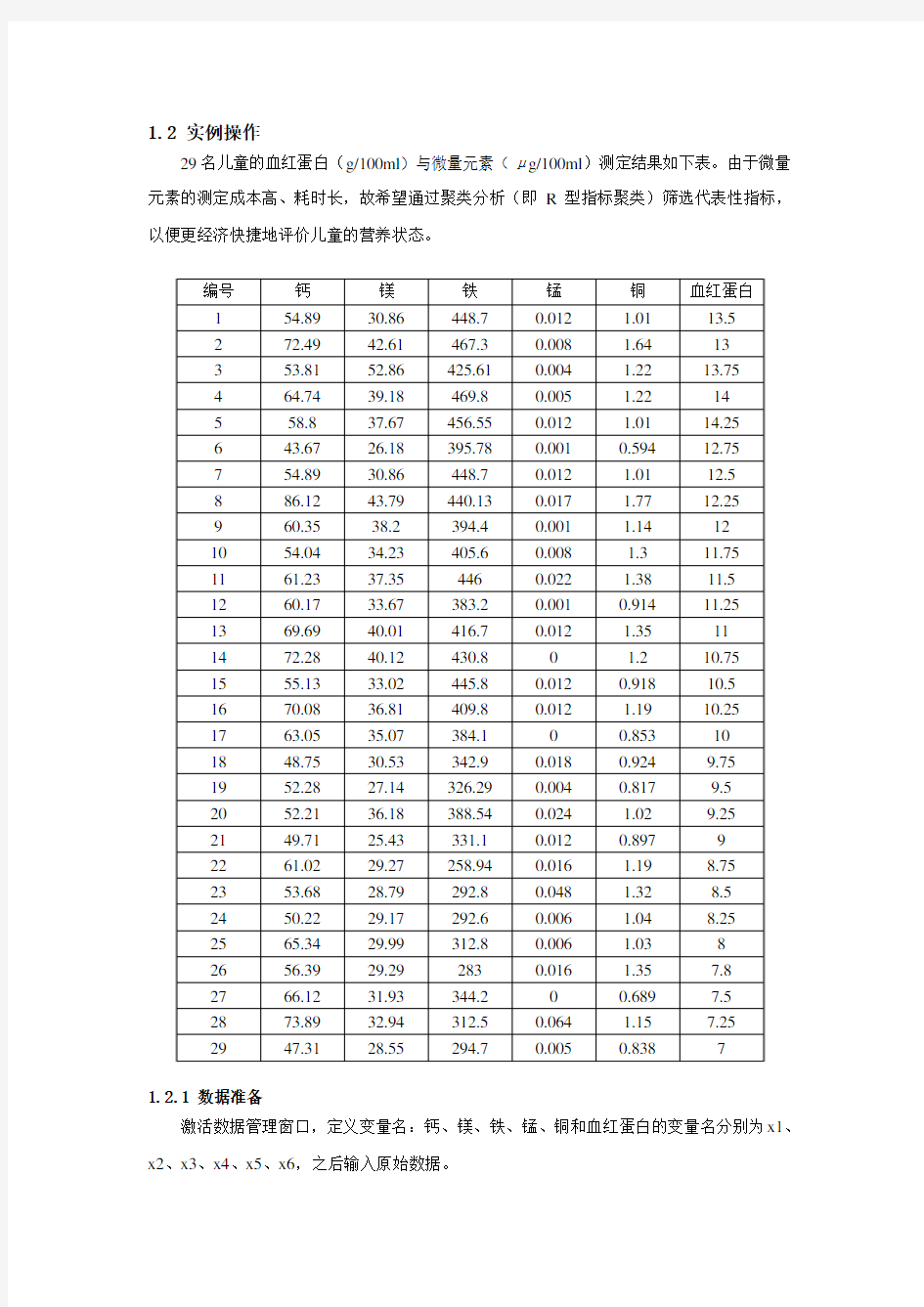
1.2 实例操作
29名儿童的血红蛋白(g/100ml)与微量元素(μg/100ml)测定结果如下表。由于微量元素的测定成本高、耗时长,故希望通过聚类分析(即R型指标聚类)筛选代表性指标,以便更经济快捷地评价儿童的营养状态。
编号钙镁铁锰铜血红蛋白
154.8930.86448.70.012 1.0113.5
272.4942.61467.30.008 1.6413
353.8152.86425.610.004 1.2213.75
464.7439.18469.80.005 1.2214
558.837.67456.550.012 1.0114.25
643.6726.18395.780.0010.59412.75
754.8930.86448.70.012 1.0112.5
886.1243.79440.130.017 1.7712.25
960.3538.2394.40.001 1.1412
1054.0434.23405.60.008 1.311.75
1161.2337.354460.022 1.3811.5
1260.1733.67383.20.0010.91411.25
1369.6940.01416.70.012 1.3511
1472.2840.12430.80 1.210.75
1555.1333.02445.80.0120.91810.5
1670.0836.81409.80.012 1.1910.25
1763.0535.07384.100.85310
1848.7530.53342.90.0180.9249.75
1952.2827.14326.290.0040.8179.5
2052.2136.18388.540.024 1.029.25
2149.7125.43331.10.0120.8979
2261.0229.27258.940.016 1.198.75
2353.6828.79292.80.048 1.328.5
2450.2229.17292.60.006 1.048.25
2565.3429.99312.80.006 1.038
2656.3929.292830.016 1.357.8
2766.1231.93344.200.6897.5
2873.8932.94312.50.064 1.157.25
2947.3128.55294.70.0050.8387
1.2.1数据准备
激活数据管理窗口,定义变量名:钙、镁、铁、锰、铜和血红蛋白的变量名分别为x1、x2、x3、x4、x5、x6,之后输入原始数据。
1.2.2 统计分析
激活Statistics菜单选 Classify 中的 Hierarchical Cluster...项,弹出 Hierarchical Cluster Analysis 对话框。从对话框左侧的变量列表中选x1、x2、x3、x4、x5、x6,点击按钮使之进入 Variable(s) 框;在 Cluster 处选择聚类类型,其中 Cases 表示观察对象聚类,Variables 表示变量聚类,本例选择 Variables。
说明:
(1) Variable(s) 栏存放分析变量栏。
(2) Label Cases 栏存放标识变量。
(3) Cluster 栏选择聚类类型。
选择 Variable(s) 项要进行变量聚类
选择 Cases 项要进行观测量聚类
点击Statistics...钮,弹出Hierarchical Cluster Analysis: Statistics对话框,选择Proximity matrix,要求显示距离矩阵,点击Continue钮返回Hierarchical Cluster Analysis对话框。
本例要求系统输出聚类结果的树状关系图,故点击 Plots... 钮弹出 Hierarchical Cluster Analysis:Plots 对话框,选择 Dendrogram (树形图)项,点击 Continue 钮返回 Hierarchical Cluster Analysis 对话框。
点击Method...钮弹出Hierarchical Cluster Analysis:Method对话框,系统提供7种聚类方法供用户选择:
Between-groups linkage:类间平均链锁法;合并两类的结果使所有的两两项对之间的平均距离最小。项对的两个成员分别属于不同的类。该方法中使用的是各对之间的距离,即非最大距离也非最小距离。
Within-groups linkage:类内平均链锁法;若当两类合并为一类后,合并后的类中的所有项之间的平均距离最小。两类间的距离即是合并后的类中所有可能的观测量对之间的距离平方。
Nearest neighbor:最近邻居法;该方法首先合并最近的或最相似的两项,用两类间最近点间的距离代表两类间的距离。
Furthest neighbor:最远邻居法;用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法。
Centroid clustering:重心法,应与欧氏距离平方法一起使用;像计算所有各项均值之间的距离那样计算两类之间的距离,该距离随聚类的进行不断减小。
Median clustering:中间距离法,应与欧氏距离平方法一起使用;
Ward's method:离差平方和法,应与欧氏距离平方法一起使用。
本例选择类间平均链锁法(系统默认方法)。
在选择距离测量技术上,系统提供8种形式供用户选择:
Euclidean distance:Euclidean距离,即两观察单位间的距离为其值差的平方和的平方根,该技术用于Q型聚类;
Squared Euclidean distance:Euclidean距离平方,即两观察单位间的距离为其值差的平方和,该技术用于Q型聚类;
Cosine:变量矢量的余弦,这是模型相似性的度量;
Pearson correlation:相关系数距离,适用于R型聚类;
Chebychev:Chebychev距离,即两观察单位间的距离为其任意变量的最大绝对差值,该技术用于Q型聚类;
Block:City-Block或Manhattan距离,即两观察单位间的距离为其值差的绝对值和,适用于Q型聚类;
Minkowski:距离是一个绝对幂的度量,即变量绝对值的第p次幂之和的平方根;p由用户指定
Customized:距离是一个绝对幂的度量,即变量绝对值的第p次幂之和的第r次根,p 与r由用户指定。
本例选用Pearson correlation,点击Continue钮返回Hierarchical Cluster Analysis对话框,再点击OK钮即完成分析。
1.2.3 结果解释
得到结果如表
①处理数据的基本信息
29例样本进入聚类分析,采用相关系数测量技术。
②欧氏不相似系数平方矩阵
先显示各变量间的相关系数,这对于后面选择典型变量是十分有用的。
③聚类的凝聚过程表
显示类间平均链锁法的合并进程,即第一步,X3与X6被合并,它们之间的相关系数最大,为0.863431;第二步,X1与X5合并,其间相关系数为0.624839;第三步,X2与第一步的合并项被合并,它们之间的相关系数为0.602099;
第四步,它们与第二步的合并项再合并,其间相关系数为0.338335;第五步,与最后一个变量X4合并,这个相关系数最小,为按类间平均链锁法,变量合并过程的冰柱图如下。先是X3与X6合并,接着X1与X5合并,然后X3、X6与X2合并,接着再与X1、X5合并,最后加上X4,六个变量全部合并。
④聚为五类的冰柱图
用更为直观的聚类树状关系图表示,即X1、X2、X3、X5、X6先聚合后与X4再聚合。这表明,在评价儿童营养状态时,可在微量元素钙、镁、铁、铜和血红蛋白5个指标中选择一个,再加上微量元素锰即可,其效果与六个指标都用是基本等价的,但更经济更迅速。
* * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * * Dendrogram using Average Linkage (Between Groups)
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25
Label Num +---------+---------+---------+---------+---------+
X3 3 ò?òòòòòòòòòòòòò?
X6 6 ò÷ùòòòòòòòòòòòòò?
X2 2 òòòòòòòòòòòòòòò÷ùòòòòòòòòòòòòòòòòòòò?
X1 1 òòòòòòòòòòòòò?òòòòòòòòòòòòòòò÷ó
X5 5 òòòòòòòòòòòòò÷ó
X4 4 òòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòòò÷
这表明在评价儿童营养状态时可在微量元素钙、镁、铁、铜和血红蛋白5个指标中选择一个再加上微量元素锰即可。其效果与六个指标都是基本等价的,但更经济更迅速。
空间聚类的研究现状及其应用* 戴晓燕1 过仲阳1 李勤奋2 吴健平1 (1华东师范大学教育部地球信息科学实验室 上海 200062) (2上海市地质调查研究院 上海 200072) 摘 要 作为空间数据挖掘的一种重要手段,空间聚类目前已在许多领域得到了应用。文章在对已有空间聚类分析方法概括和总结的基础上,结合国家卫星气象中心高分辨率有限区域分析预报系统产品中的数值格点预报(HLAFS)值,运用K-均值法对影响青藏高原上中尺度对流系统(MCS)移动的散度场进行了研究,得到了一些有意义的结论。 关键词 空间聚类 K-均值法 散度 1 前言 随着GPS、GI S和遥感技术的应用和发展,大量的与空间有关的数据正在快速增长。然而,尽管数据库技术可以实现对空间数据的输入、编辑、统计分析以及查询处理,但是无法发现隐藏在这些大型数据库中有价值的模式和模型。而空间数据挖掘可以提取空间数据库中隐含的知识、空间关系或其他有意义的模式等[1]。这些模式的挖掘主要包括特征规则、差异规则、关联规则、分类规则及聚类规则等,特别是聚类规则,在空间数据的特征提取中起到了极其重要的作用。 空间聚类是指将数据对象集分组成为由类似的对象组成的簇,这样在同一簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大,即相异度较大。作为一种非监督学习方法,空间聚类不依赖于预先定义的类和带类标号的训练实例。由于空间数据库中包含了大量与空间有关的数据,这些数据来自不同的应用领域。例如,土地利用、居住类型的空间分布、商业区位分布等。因此,根据数据库中的数据,运用空间聚类来提取不同领域的分布特征,是空间数据挖掘的一个重要部分。 空间聚类方法通常可以分为四大类:划分法、层次法、基于密度的方法和基于网格的方法。算法的选择取决于应用目的,例如商业区位分析要求距离总和最小,通常用K-均值法或K-中心点法;而对于栅格数据分析和图像识别,基于密度的算法更合适。此外,算法的速度、聚类质量以及数据的特征,包括数据的维数、噪声的数量等因素都影响到算法的选择[2]。 本文在对已有空间聚类分析方法概括和总结的基础上,结合国家卫星气象中心高分辨率有限区域分析预报系统产品中的数值格点预报(HLAFS)值,运用K-均值法对影响青藏高原上中尺度对流系统(MCS)移动的散度场进行了研究,得到了一些有意义的结论。 2 划分法 设在d维空间中,给定n个数据对象的集合D 和参数K,运用划分法进行聚类时,首先将数据对象分成K个簇,使得每个对象对于簇中心或簇分布的偏离总和最小[2]。聚类过程中,通常用相似度函数来计算某个点的偏离。常用的划分方法有K-均值(K-means)法和K-中心(K-medoids)法,但它们仅适合中、小型数据库的情形。为了获取大型数据库中数据的聚类体,人们对上述方法进行了改进,提出了K-原型法(K-prototypes method)、期望最大法EM(Expectation Maximization)、基于随机搜索的方法(ClAR ANS)等。 K-均值法[3]根据簇中数据对象的平均值来计算 ——————————————— *基金项目:国家自然科学基金资助。(资助号: 40371080) 收稿日期:2003-7-11 第一作者简介:戴晓燕,女,1979年生,华东师范大学 地理系硕士研究生,主要从事空间数 据挖掘的研究。 · 41 · 2003年第4期 上海地质 Shanghai Geology
肤色在各颜色空间的聚类分析 摘要肤色是人体表面最显著的特征之一。对不同肤色在RGB、YCbCr颜色空间内和同一肤色在不同亮度环境下的聚类情况进行深入的分析研究,发现肤色在YCbCr空间内聚类效果更好,更适合做肤色分割。然后在此基础上对黑色肤色、黄色肤色及白色肤色在YCbCr空间内进行肤色分割,达到较好的分割效果。 关键词肤色;颜色空间;肤色分割;YCbCr空间 肤色是人体表面最显著的特征之一,由于它对姿势、旋转、表情等变化不敏感,因此将人体的肤色特征应用于人脸检测与识别、表情识别、手势识别具有很大的优势,所以肤色特征是人脸识别、表情识别、与手势识别中最为常用的分割方法。然而,若要利用肤色进行分割,我们首先应该对肤色以及肤色的聚类情况进行分析。 世界上的人种主要有三种,即尼格罗—澳大利亚人种(黑色皮肤),蒙古人种(黄色皮肤),欧罗巴人种(白色皮肤)。尽管人的肤色因人种的不同而不同,呈现出不同的颜色,但是有学者指出:排除亮度、周围环境等对肤色的影响后,皮肤的色调基本一致。本文对在不同环境下的不同肤色进行取样,然后分别在RGB、YCbCr颜色空间进行统计,从而对比分析肤色在各颜色空间聚类的情况。 1肤色在各颜色空间的聚类比较 1.1不同肤色在RGB和YCbCr颜色空间上的分布 图1—图2给出了黄色、黑色和白色肤色分别在RGB、YCbcr空间的分布情况。 由图1—图2可以得出,不同肤色在RGB、YCbCr空间的分布有如下特征: 1)不同肤色在不同颜色空间均分布在很小的范围内。 2)不同肤色在不同颜色空间内不是随机分布,而是在某固定区域呈聚类分布。 3)不同肤色在YCbCr空间内分布的聚类状态要好于在RGB空间内分布的聚类状态。 4)不同肤色在亮度上的差异远远高于在色度上的差异。 1.2肤色在不同亮度下的分布 图3—图4给出了不同亮度下的同一肤色分别在RGB、YCbCr空间的分布情况。图(a)至图(d)的肤色来源于同一人在不同亮度下的照片。
5.2酿酒葡萄的等级划分 5.2.1葡萄酒的质量分类 由问题1中我们得知,第二组评酒员的的评价结果更为可信,所以我们通过第二组评酒员对于酒的评分做出处理。我们通过excel计算出每位评酒员对每支酒的总分,然后计算出每支酒的10个分数的平均值,作为总的对于这支酒的等级评价。 通过国际酿酒工会对于葡萄酒的分级,以百分制标准评级,总共评出了六个级别(见表5)。 在问题2的计算中,我们求出了各支酒的分数,考虑到所有分数在区间[61.6,81.5]波动,以原等级表分级,结果将会很模糊,不能分得比较清晰。为此我们需要进一步细化等级。为此我们重新细化出5个等级,为了方便计算,我们还对等级进行降序数字等级(见表6)。 通过对数据的预处理,我们得到了一个新的关于葡萄酒的分级表格(见表7):
考虑到葡萄酒的质量与酿酒葡萄间有比较之间的关系,我们将保留葡萄酒质量对于酿酒葡萄的影响,先单纯从酿酒葡萄的理化指标对酿酒葡萄进行分类,然后在通过葡萄酒质量对酿酒葡萄质量的优劣进一步进行划分。 5.2.2建立模型 在通过酿酒葡萄的理化指标对酿酒葡萄分类的过程,我们用到了聚类分析方法中的ward 最小方差法,又叫做离差平方和法。 聚类分析是研究分类问题的一种多元统计方法。所谓类,通俗地说,就是指相似元素的集合。为了将样品进行分类,就需要研究样品之间关系。这里的最小方差法的基本思想就是将一个样品看作P 维空间的一个点,并在空间的定义距离,距离较近的点归为一类;距离较远的点归为不同的类。面对现在的问题,我们不知道元素的分类,连要分成几类都不知道。现在我们将用SAS 系统里面的stepdisc 和cluster 过程完成判别分析和聚类分析,最终确定元素对象的分类问题。 建立数据阵,具体数学表示为: 1111...............m n nm X X X X X ????=?????? (5.2.1) 式中,行向量1(,...,)i i im X x x =表示第i 个样品; 列向量1(,...,)'j j nj X x x =’,表示第j 项指标。(i=1,2,…,n;j=1,2,…m) 接下来我们将要对数据进行变化,以便于我们比较和消除纲量。在此我们用了使用最广范的方法,ward 最小方差法。其中用到了类间距离来进行比较,定义为: 2||||/(1/1/)kl k l k l D X X n n =-+ (5.2.2) Ward 方法并类时总是使得并类导致的类内离差平方和增量最小。 系统聚类数的确定。在聚类分析中,系统聚类最终得到的一个聚类树,如何确定类的个数,这是一个十分困难但又必须解决的问题;因为分类本身就没有一定标准,人们可以从不同的角度给出不同的分类。在实际应用中常使用下面几种
刘向民物流工程 S11085240007 聚类分析方法应用举例 多元统计,是研究多个随机变量之间相互依赖关系以及内在统计规律性的一门统计学科。多元统计所包括的内容很多.但在实际统计分析中,聚类分析是应用最广泛的方法之一。聚类分析(cluste:Analysis),是研究分类问题的一种多元统计分析方法社会经济统计的分类问题,过去在传统方法上,主要是结合一定的专业知识进行定性分类处理。由于定性分类主要是靠经验完成,因而其结论难免带有较多的主观性和随意性,故不能很好地揭示客观事物内在的本质差别和联系。而聚类分析能带来定量上的分析可以解决这个问题,下面通过一些实例来描述聚类分析方法在应用上的体现; 1 基于聚类分析的安徽省物流需求研究 选取了分行业统计的年产值类指标构建物流需求指标体系(X组),具体指标包括:农业总产值(万元)(X1)、工业总产值(亿元)(X2)、建筑业总产值(万元)(X3)、社会消费零售总额(万元)(X4)、亿元商品市场成交额(万元)(X5)、进出口总额(万美元)(X6)。该指标体系通过农业、工业、建筑业、批发业、零售业及国际贸易的发生额较全面地反映了地区的物流需求情况。 2 研究方法 分类问题一般的解决法是聚类分析或者因子分析基础上的聚类分析。由于本文最终期望得安徽省地级市物流需求分类情况,无需了解各个指标体系的内在系统结构,故选择聚类分析方法更简明。进行聚类分析时,本文采用的是基于样本聚类的Q型系统聚类方法。 3研究过程和结果 3.1地区物流需求指标的聚类分析 由分析软件输出的聚类过程统计量如表1所示。可以看出,伪F统计量在归为4类及7类
时较大,说明归为4类及7类时较好;伪T2统计量在1类、2类、3类时较大,由于伪T2大说明上一次归类效果较好,所以归为4类、3类、2类效果较好。而R2的值在由4类归为3类、由3类归为2类以及由2类归为1类时都有较大的减小,说明归类为2类、3类和4类都是比较好的。半偏R2统计量的值越大,则上一步聚类效果更好,所以归为4类、3 类、2类效果都较好。综合考虑四个统计量的值,并考虑分类的实用性,本文认为归为4类比较合适。聚类图见图1。 由软件分析得的聚类过程得到每一类的各个指标的平均值如表2所示。可以看出,四类地区的区分明显,各种产值指标依次递减。依据四类地区物流需求情况可将安徽省的17个地级市分为物流需求旺盛的省会经济圈、需求较大的马铜芜地区;物流需求量小的两淮和皖南山物流需求量小的两淮和皖南山区以及物流需求较小的第三类地区。
各地区各行业工资水平的分析(2009年数据) 小组成员:张艺伟、赵月、陈媛、邹莉、朱海龙、曾磊、胡瑛、候银萍 1.研究背景及意义 1.1 研究背景 工资水平是指一定区域和一定时间内劳动者平均收入的高低程度。生产决定分配,只有经济发展才能提供更多的可分配的社会产品,因此一个地区的工资水平在一定程度上反映了其经济发展的水平。 1.2 研究意义 1. 通过多元统计分析方法,探究一个地区的工资水平与其经济发展水平之间的内在联系。 2. 将平均工资水平划分为3类,分析哪些地区、哪些行业的工资水平较高,可以为大学生就业提供宏观上的方向指引。 2.数据来源与描述 2.1 数据来源——《中国劳动统计年鉴─2010》 (URL:https://www.doczj.com/doc/4613017955.html,/Navi/YearBook.aspx?id=N2011010069&floor=1###) 主编单位:国家统计局人口和就业统计司,人力资源和社会保障部规划财务司 出版社:中国统计出版社 简介:《中国劳动统计年鉴─2010》是一部全面反映中华人民共和国劳动经济情况的资料性年刊。本刊收集了2009年全国和各省、自治区、直辖市、香港特别行政区、澳门特别行政区的有关劳动统计数据。本书资料的取得形式主要有国家和部门的报表统计、行政记录和抽样调查。 2.2 数据描述 本数据集记录了全国31个省市(港、澳、台除外)的工资状况,各省市分别记录了其23个主要行业的平均工资水平,这23个主要行业包括:企业、事业、机关、金融业、制造业、建筑业、房地产业、农林牧渔业等等,具体数据格式参见图-0。
图-0 3.分析方法及原理 3.1 通过描述统计分析方法,判断哪些行业平均工资水平较高 描述统计分析方法主要是从基本统计量(诸如均值、方差、标准差、极大/小值、偏度、峰度等)的计算和描述开始的,并辅助于SPSS提供的图形功能,能够把握数据的基本特征和整体的分布特征。 在本案例中,通过比较不同行业(诸如企业、事业、机关、建筑业、制造业……)工资的均值、极大/小值,可以从总体上判断哪些行业的平均工资水平较高,哪些行业的较低。 3.2 通过聚类分析方法,判断哪些地区平均工资水平较高 聚类分析是依据研究对象的个体特征,对其进行分类的方法,分类在经济、管理、社会学、医学等领域,都有广泛的应用。聚类分析能够将一批样本(或变量)数据根据其诸多特征,按照在性质上的亲疏程度在没有先验知识的情况下进行自动分类,产生多个分类结果。类内部个体特征之间具有相似性,不同类间个体特征的差异性较大。 在本案例中,我们将采用两种方法进行聚类分析:一种是系统聚类法,另一种是K-均值法(快速聚类法)。 3.2.1系统聚类法 系统聚类法的基本原理:首先将一定数量的样本或指标各自看成一类,然后根据样本(或指标)的亲疏程度,将亲疏程度最高的两类进行合并,然后考虑合并后的类与其他类之间的亲疏程度,再进行合并。重复这一过程,直到将所有的样本(或指标)合并为一类。 系统聚类分为Q型聚类和R型聚类两种:Q型聚类是对样本进行聚类,它使具有相似特征的样本聚集在一起,使差异性大的样本分离开来;R型聚类是对变量进行聚类,它使差异性大的变量分离开来,相似的变量聚集在一起,这样就可以在相似变量中选择少数具有代表性的变量参与其他分析,实现减少变量个数、降低变量维度的目的。 在本例中进行的是Q型聚类。 类与类之间距离的计算方法主要有以下几种: (1)最短距离法(Nearest Neighbor),是指两类之间每个个体距离的最小值; (2)最长距离法(Farthest Neighbor),是指两类之间每个个体距离的最大值; (3)组间联接法(Between-groups Linkage),是指两类之间个体之间距离的平均值;
SPSS软件操作实例——某移动公司客户细分模型 数据准备:数据来源于telco.sav,如图1所示,Customer_ID表示客户编号,Peak_mins表示工作日上班时期电话时长,OffPeak_mins表示工作日下班时期电话时长等。 图1 telco.sav数据 分析目的:对移动手机用户进行细分,了解不同用户群体的消费习惯,以更好的对其进行定制性的业务推销,所以需要运用聚类分析。 操作步骤: 1,从菜单中选择【文件】——【打开】——【数据】,在打开数据窗口中选择数据位置以及文件类型,将数据telco.sav导入SPSS软件中,如图2所示。 图2 打开数据菜单选项 2,从菜单中选择【分析】——【描述统计】——【描述】,然后在描述性窗口中,将需要标准化的变量选到右边的“变量列表”,勾选“将标准化得分另存为变量”,点确定,如图3所示。
图3 数据标准化 3,从菜单中选择【分析】——【分类】——【K-均值聚类】,在K-均值聚类分析窗口中将标准化之后的结果选入右边“变量列表”,客户编号选入“个案标记依据”,聚类数改为5。点击迭代按钮,在迭代窗口将最大迭代次数改为100,点击继续。点击保存按钮,在保存窗口勾选“聚类成员”、“与聚类中心的距离”,点击继续。点击选项按钮,在选项窗口勾选“ANOV A表”、“每个个案的聚类信息”,点击继续。点击确定按钮,运行聚类分析,如图4所示。 图4 聚类分析操作
由最终聚类中心表可得最终分成的5个类它们各自的均值。 第一类:依据总通话时间长,上班通话时间长,国际通话时间长等特征,将第一类命名为高端商用客户。 第二类:依据其在各项指标中均较低,将第二类命名为不常使用客户。 第三类:依据总通话和上班通话时间居中等特征,将第三类命名为中端商用客户。第四类:依据下班通话时间最长等特征,将第四类命名为日常客户。 第五类:依据平均每次通话时间最长等特征,将第五类命名为长聊客户。 由ANOVA表可根据F值大小近似得到哪些变量对聚类有贡献,本例题中重要程度排序为:总通话时长>工作日上班时期电话时长>工作日下班时期电话时
空间聚类概念 空间聚类作为聚类分析的一个研究方向,是指将空间数据集中的对象分成由相似对象组成的类。同类中的对象间具有较高的相似度,而不同类中的对象间差异较大。作为一种无监督的学习方法,空间聚类不需要任何先验知识,比如预先定义的类或带类的标号等。由于空间聚类方法能根据空间对象的属性对空间对象进行分类划分,其已经被广泛应用在城市规划、环境监测、地震预报等领域,发挥着较大的作用。同时,空间聚类也一直都是空间数据挖掘研究领域中的一个重要研究分支。目前,己有许多文献资料提出了针对不同数据类型的多种空间聚类算法,一些著名的软件,如WEAK、SPSS、SAS等软件中已经集成了各种聚类分析软件包。 1 空间数据的复杂性 空间聚类分析的对象是空间数据。由于空间数据具有空间实体的位置、大小、形状、方位及几何拓扑关系等信息,使得空间数据的存储结构和表现形式比传统事务型数据更为复杂,空间数据的复杂特性表现: (1)空间属性间的非线性关系。由于空问数据中蕴含着复杂的拓扑关系,因此,空间属性间呈现出一种非线性关系。这种非线性关系不仅是空间数据挖掘中需要进一步研究的问题,也是空问聚类所面临的难点之一。 (2)空间数据的尺度特征。空间数据的尺度特征足指在不同的层次上,空间数据所表现出来的特征和规律都不尽相同。虽然在空间信息的概化和细化过程中可以利用此特征发现整体和局部的不同特点,但对空间聚类任务来说,实际上是增加了空间聚类的难度。 (3) 间信息的模糊性。空间信息的模糊性足指各种类型的窄问信息中,包含大量的模糊信息,如空问位置、间关系的模糊性,这种特性最终会导致空间聚类结果的不确定性。 (4)空间数据的高维度。空问数据的高维度性是指空间数据的属性(包括空间属性和非空间属性)个数迅速增加,比如在遥感领域,获取的空间数据的维度已经快速增加到几十甚至上百个,这会给空间聚类的研究增加很大的困难。 2 空间聚类算法 目前,研究人员已经对空间聚类问题进行了较为深入的研究,提出了多种算法。根据空间聚类采用的不同思想,空间聚类算法主要可归纳为以下几种:基于划分的聚类算法、基于层次的聚类算法、基于密度的聚类算法、基于网格的聚类算法、基于模型的聚类算法以及其它形式的聚类算法,如图l所示。 (1)基于划分的聚类 基于划分的聚类方法是最早出现并被经常使用的经典聚类算法。其基本思想是:在给定的数据集随机抽取n个元组作为n个聚类的初始中心点,然后通过不断计算其它数据与这几个中心点的距离(比如欧几里得距离),将每个元组划分到其距离最近的分组中,从而完成聚类的划分。由于基于划分的聚类方法比较容易理解,且易实现,目前其已被广泛的弓l入到空间聚类中,用于空间数据的分类。其中最为常用的几种算法是:k一平均(k-means)算法、kl中心点(k—medoids)算法和EM(expectation maximization)算法。k一平均算法’使
姓名:于一发学号:XXXX105XXXX2 班级:07信息聚类分析在现实中的应用 随着生产技术和科学的发展,人类的认识不断加深,分类越来越细,要求也越来越高,光凭经验和专业知识是不能确切分类的,往往需要定量和定性的分析结合起来去分类,于是工具逐渐被引进分类学中,形成了数值分类学。后来随着多元分析的引进,聚类分析逐渐从数值分类学中脱离出来形成一个相对独立的分支。 一、聚类分析的定义: 聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。聚类分析的目标就是在相似的基础上收集数据来分类。聚类源于很多领域,包括数学,计算机科学,统计学,生物学和经济学。在不同的应用领域,很多聚类技术都得到了发展,这些技术方法被用作描述数据,衡量不同数据源间的相似性,以及把数据源分类到不同的簇中。 从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS 等。 从机器学习的角度讲,簇相当于隐藏模式。聚类是搜索簇的无监督学习过程。与分类不同,无监督学习不依赖预先定义的类或带类标记的训练实例,需要由聚类学习算法自动确定标记,而分类学习的实例或数据对象有类别标记。聚类是观察式学习,而不是示例式的学习。 二、聚类分析的应用: 聚类分析师数据挖掘中一种常用的技术,在实践中可以多角度应用于市场分析,为市场营销战略和策略的制定提供科学合理的参考。主要介绍其在市场分析中的应用,并且我们从客户细分、实验市场选择、抽样方案设计、销售篇区确定、市场机会研究五个方面探讨聚类分析在市场分析中的具体应用。 (1)在客户细分中的应用: 消费同一种类的商品或服务时,不同的客户有不同的消费特点,通过研究这些特点,企业可以制定出不同的营销组合,从而获取最大的消费者剩余,这就是客户细分的主要目的。常用的客户分类方法主要有三类:经验描述法,由决策者根据经验对客户进行类别划分;传统统计法,根据客户属性特征的简单统计来划分客户类别;非传统统计方法,即基于人工智能技术的非数值方法。聚类分析法兼有后两类方法的特点,能够有效完成客户细分的过程。 例如,客户的购买动机一般由需要、认知、学习等内因和文化、社会、家庭、小群体、参考群体等外因共同决定。要按购买动机的不同来划分客户时,可以把前述因素作为分析变量,并将所有目标客户每一个分析变量的指标值量化出来,再运用聚类分析法进行分类。在指标值量化时如果遇到一些定性的指标值,可以用一些定性数据定量化的方法加以转化,如模糊评价法等。除此之外,可以将客户满意度水平和重复购买机会大小作为属性进行分类;还可以在区分客户之间差异性的问题上纳入一套新的分类法,将客户的差异性变量划分为五类:产品利益、
2006年 8月第42卷 第4期北京师范大学学报(自然科学版) Jour nal of Beijing N ormal U niver sity (N atural Science )A ug.2006 V ol.42 N o.4 应用空间聚类进行点数据分布研究* 林冬云1) 刘慧平1,2,3)? (1)北京师范大学地理学与遥感科学学院;2)北京师范大学遥感科学国家重点实验室; 3)北京师范大学环境遥感与数字城市北京市重点实验室:100875,北京) 摘要 空间数据挖掘是寻找大数据量空间分布的重要方法,应用地理信息系统(G IS )进行空间数据挖掘是目前进行海量数据分析的重要手段之一.应用空间聚类方法对北京市海淀区54325个企业点数据进行量化分析研究,通过空间位置聚类,进行属性指标量化,从而进行属性指标分层聚类,得到企业空间分布特征.研究表明,空间聚类方法是进行点数据空间分布研究的有效方法. 关键词 空间聚类;企业分布;地理信息系统;量化 *国家自然科学基金资助项目(40271035);国家“十五”科技攻关课题资助项目(2003BA808A16-6) ?通讯作者 收稿日期:2005-11-23 随着数据获取和处理技术的迅速发展及数据库管 理系统的广泛应用,人们积累的数据越来越多,但在激增的数据背后隐藏着许多重要的信息,由于缺乏有效的方法,导致了一种“数据爆炸但知识贫乏”的现象[1],面对这一挑战,数据挖掘(data mining ,DM )和知识发现(know ledge discovery in database s ,KDD )技术应运而生并得到迅速发展,它的出现为自动和智能地把海量的数据转化成为有用的信息和知识提供了手段. 作为DM 技术一个新的分支,空间DM 也称基于空间数据库的数据挖掘和知识发现(spatial data mining and know ledge disco very ),是指从空间数据库中提取隐含的、用户感兴趣的空间和非空间的模式、普遍特征、规则和知识的过程[2]. 空间聚类方法是空间数据挖掘中的主要方法之一,是在一个比较大的多维数据集中根据距离的度量找出簇或稠密区域.聚类算法无需背景知识,能直接从空间数据库中发现有意义的空间聚类结构[3].在无先验知识的情况下,聚类分析技术是进行数据挖掘时的首选[4],因而运用空间数据聚类方法来处理海量数据,对于提取大型空间数据库中有用的信息和知识具有十分重要的现实意义. 目前,对于空间聚类的研究主要集中在算法研究和应用研究上,存在2种偏向,一是从事GIS 理论方法和技术工具研究的工作者大多根据空间对象的地理坐标进行聚类,即只考虑对象的空间邻近性,而不考虑对象属性特征的相似性[2,5];另一种是从事GIS 应用和地学研究的工作者,直接套用传统聚类分析方法,根据属性特征集进行分析,忽视了对象的空间邻近性[6]. 而空间对象本质上具有地理位置和属性特征双重含 义,二者结合才能完整地描述空间特征和空间差异.将地理位置和属性特征纳入统一的空间距离测度和空间聚类分析系统,将会改善空间分析和空间DM 的信息 质量[7-9] . 本文主要应用GIS 分析技术,采用空间DM 中的空间聚类方法,通过将空间位置与属性相结合的聚类方法,对北京市海淀区5万多个企事业单位的点分布数据进行分析,探讨对于属性是定性描述的点分布数据的量化方法. 1 研究区和数据来源 海淀区是北京市重要近郊区,占地面积大,人口众多,交通发达,存在着大量的居民和村民混居现象,是中心城市自上而下的扩散能力最强、城乡一体化程度最高、城乡联系最密切的地区,也是大都市空间扩展的主要地区[10]. 研究使用的数据来源是2001年北京市企业数据的统计表,经数字化处理生成企业单位点位分布图,按照数据文件中企业注册地址信息,结合参考北京市电子地图、北京市街道胡同地图集、北京市地图、网上北京市地图以及有关企事业单位的网站,将海淀区共计54325条记录生成5万多个企业的点分布图. 2 研究方法 应用GIS 提取企事业单位分布空间坐标,进行按位置距离聚类分析,获得位置聚类小区,然后进行属性指标的量化,应用聚类分析进行属性聚类,分析企事业
一个用R语言进行聚类分析的例子 2013 年4 月21 日 By student 在网上(https://www.doczj.com/doc/4613017955.html,/ )找到了一个用R语言进行聚类分析的例子, 在整个例子中做了一些中文解释说明. 数据集用的是iris 第一步:对数据集进行初步统计分析 #检查数据的维度 > dim(iris) [1] 150 5 #显示数据集中的列名 > names(iris) [1] “Sepal.Length” “Sepal.Width” “Petal.Length” “Petal.Width” “Species” #显示数据集的内部结构 > str(iris) …data.frame?: 150 obs. of 5 variables: $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 … $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 … $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 … $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 … $ Species : Factor w/ 3 levels “setosa”,”versicolor”,..: 1 1 1 1 1 1 1 1 1 1 … #显示数据集的属性 > attributes(iris) $names –就是数据集的列名 [1] “Sepal.Length” “Sepal.Width” “Petal.Length” “Petal.Width” “Species” $https://www.doczj.com/doc/4613017955.html,s –个人理解就是每行数据的标号 [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [21] 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 [41] 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 [61] 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 [81] 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 [101] 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 [121] 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 [141] 141 142 143 144 145 146 147 148 149 150 $class –表示类别 [1] “data.frame”
Lab 6 聚类分析 一、分析背景 Chrysler公司为了赢得市场竞争地位,决定推出新产品Viper,该种产品的目标客户是雅皮士阶层。为了进一步了解这种人群的心理特征,定位自己的产品,吸引目标客户,Chrysler公司进行了一次市场调研。研究者使用九点量表测量400名被试者对30项陈述的态度,从而了解这些目标客户的心理特征。调研还询问被试者对Dodge Viper型汽车的态度来测量标准变量,标准变量的测量通过九点量表来测试消费者对“我愿意购买Chrysler公司生产的Dodge Viper型汽车”的态度。 本次分析的目的是:通过聚类分析,将原始变量分别聚成三类和四类,比较两种方法的效果。同时,比较使用原始变量得到的聚类结果和使用因子得分得到的聚类结果,看哪一种方法能更好地解释数据。 二、分析结果 1、根据原始变量进行的聚类分析 首先根据原始变量进行聚类分析,由于样本数较大,采用迭代聚类法,分别将样本聚为三类和四类,下面是聚类分析的结果比较。 表 1 聚为三类后的组重心表 2 聚为四类后的组重心 表 3 聚为三类的每组样本数表 聚为四类的每组样本数
表5 聚为三类后组重心之间的距离 表 6 聚为四类后组重心之间的距离 由方差分析的结果(结果略)可知,在聚为三类和四类的分析中,V8,V9,V18,V19,V20和V27的组间差异均大于0.05,结果不显著。 2、 根据因子得分进行的聚类分析 以下是根据因子得分,采用迭代法将样本聚为三类和四类的结果: 表7 聚为三类后的组重心 -.45298 .16364 .29950 .36038 -.22794 -.15239 .28739 -.32881 .00765 .25444 .70915 -.87203 .52946 -.29355 -.26021 .18363 .11953 -.28471 .00228 .20936 -.18616 .56772 -.64844 .01414 消费因子 时尚因子 社会因子 爱国因子 期望因子 偏好因子 个性因子 家庭因子 1 2 3 Cluster 表 8 聚为三类时的样本数 137.000 123.000 140.000 400.000 .000 1 2 3 Cluster Valid Missing
k-means聚类”——数据分析、数据挖掘 一、概要 分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应。但就是很多时候上述条件得不到满足,尤其就是在处理海量数据的时候,如果通过预处理使得数据满足分类算法的要求,则代价非常大,这时候可以考虑使用聚类算法。聚类属于无监督学习,相比于分类,聚类不依赖预定义的类与类标号的训练实例。本文介绍一种常见的聚类算法——k 均值与k 中心点聚类,最后会举一个实例:应用聚类方法试图解决一个在体育界大家颇具争议的问题——中国男足近几年在亚洲到底处于几流水平。 二、聚类问题 所谓聚类问题,就就是给定一个元素集合D,其中每个元素具有n 个可观察属性,使用某种算法将D 划分成k 个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。其中每个子集叫做一个簇。 与分类不同,分类就是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类就是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,就是无监督学习的一种。目前聚类广泛应用于统计学、生物学、数据库技术与市场营销等领域,相应的算法也非常的多。本文仅介绍一种最简单的聚类算法——k 均值(k-means)算法。 三、概念介绍 区分两个概念: hard clustering:一个文档要么属于类w,要么不属于类w,即文档对确定的类w就是二值的1或0。 soft clustering:一个文档可以属于类w1,同时也可以属于w2,而且文档属于一个类的值不就是0或1,可以就是0、3这样的小数。 K-Means就就是一种hard clustering,所谓K-means里的K就就是我们要事先指定分类的个数,即K个。 k-means算法的流程如下: 1)从N个文档随机选取K个文档作为初始质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类
一篇文章透彻解读聚类分析及案例实操 【数盟致力于成为最卓越的数据科学社区,聚焦于大数据、分析挖掘、数据可视化领域,业务范围:线下活动、在线课程、猎头服务、项目对接】【限时优惠福利】数据定义未来,2016 年 5 月12 日-14 日DTCC2016 中国数据库技术大会登陆北京!大会云集了国内外数据行业顶尖专家,设定2 个主会场,24 个分会场,将吸引共3000 多名IT 人士参会!马上领取数盟专属购票优惠88 折上折,猛戳文末“阅读原文” 抢先购票!摘要:本文主要是介绍一下SAS 的聚类案例,希望大家都动手做一遍,很多问题只有在亲自动手的过程中才会有发现有收获有心得。这里重点拿常见的工具SAS+R语言+Python 介绍! 1 聚类分析介绍1.1 基本概念聚类就是一种寻找数据之间一种内在结构的技术。聚类把全体数据实例组织成一些相似组,而这些相似组被称作聚类。处于相同聚类中的数据实例彼此相同,处于不同聚类中的实例彼此不同。聚类技术通常又被称为无监督学习,因为与监督学习不同,在聚类中那些表示数据类别的分类或者分组信息是没有的。通过上述表述,我们可以把聚类定义为将数据集中在某些方面具有相似性的数据成员进行分类组织的过程。因此,聚类就是一些数据实例的集合,这个集合中的元素彼此相似,但是它们都与其他聚类中的元素不同。在聚类的相关文献中,一个数据实例有时又被称为对象,因为现实世界中的一个对象可以用数据实例来描述。同时,它有时也被称作数据点(Data Point) ,因为我们可以用r 维空间的一个点来表示数据实例,其中r 表示数据的属性个数。下图显示了一个二维数据集聚类过程,从该图中可以清楚
例题1:下表是我国16个地区农民在1982年支出情况的抽样调查数据的汇总资料,每个地区都调查了反映每人平均生活消费支出情况的六个指标。试利用调查资料对16个地区进行分类。 地区食品衣着燃料住房 生活用品及其 他文化生活服务支出 北京: 天津{ 河北 山西? 内蒙古? 辽宁 ^ 吉林 黑龙江】 上海?江苏 浙江! 5安徽@ 福建 江西、 山东— 河南 ]
下面用统计学软件SAS(Statistical Analysis System) data dfdf; input city $ x1 x2 x3 x4 x5 x6;cards; beijing tianjing hebei shanxi neimenggu liaoning … jilin heilongjiang shanghai jiangsu zhejiang anhui fujian jiangxi shandong henan ;run; ^ proc cluster data=dfdf std outtree=tree method=ave pesudo rsq;id city;run; /*ward离差平方和法war; 类平均法ave; 重心法cen;最长
距离法com;中间距离法med; 最短距离法sin;密度估计法den;极 大似然法eml; 可变类平均fle;相似分析法mcq; 两阶段密度估计 two; */ proc tree data=tree out=new graphics horizontal; id city;run; Cluster History、 ] Norm RMS @ NCL Clusters Joined---FREQ SPRSQ RSQ PSF PST2Dist 15 , anhui fujian2. 14hebei ; henan 2. 13CL14shanxi !3 12CL15jiangxi3(4 11jiangsu zhejiang2》. 10CL13neimengg4) 9tianjing shandong2! . 8CL9CL114《7liaoning jilin2. |heilongj CL124
多元统计分析中的降维方法在四川省社会福利中的应用 由于计算机的发展和日益广泛的使用,多元分析方法也很快地应用到社会学、农业、医学、经济学、地质、气象等各个领域。在国外,从自然科学到社会科学的许多方面,都已证实了多元分析方法是一种很有用的数据处理方法;在我国,多元分析对于农业、气象、国家标准和误差分析等许多方面的研究工作都取得了很大的成绩,引起了广泛的注意。在许多领域的研究中,为了全面系统地分析问题,对研究对象进行综合评价,我们常常需要考虑衡量问题的多个指标(即变量),由于变量之间可能存在着相关性,如果采用一元统计方法,把多个变量分开,一次分析一个变量,就会丢失大量的信息,研究结果也会偏差很大。因此需要采用多元统计分析的方法,同时对所有变量的观测数据进行分析。多元统计分析就是一种同时研究多个变量之间的相互关系,经过对变量的综合处理,充分提取变量之间的信息,进行综合分析和评价的统计方法。多元统计分析法主要包括降维、分类、回归及其他统计思想。 一.多元统计分析方法中降维的方法 1.概述 多元统计分析方法是同时对多个变量的观察数据做综合处理和分析。在不损失有价值信息的情况下,简化观测数据或数据结构,尽可能简单地将被研究对象描述出来,使得对复杂现象的解释变得更容易些。同时,采用多元统计分析中的聚类分析或判别分析可以对变量或样品进行分类与分组。根据所测量的特征和分类规则将一些“类似的”对象或变量分组。多元统计分析也可以研究变量间依赖性。即对变量间关系的本质进行研究。是否所有的变量都相互独立?还是一个变量或多个变量依赖于其他变量?它们又是怎样依赖的?通过观测变量数据的散点图,我们可以建立多元回归统计模型,确定出变量之间具体的依赖关系,进而可以根据某些变量的观测值预测另一个或另一些变量的值对事物现象的发展作预测。最后我们需要构造假设,并对所建立的以多元总体参数形式陈述的多种特殊统计假设进行检验。 在多元统计分析方法中数据简化或结构简化,实质上就是数学中的降维方法。多元统计分析中的降维方法主要包括聚类分析、判别分析、主成分分析、因子分析、对应分析和典型相关分析等几种方法。其中主成分分析和因子分析是在作综合评价方面应用最广泛、较为有效的方法。本文主要介绍这两种多元统计分析方法的应用。 2 主成分分析 2.1主成分分析的基本思想 在大部分实际问题中,需要考察的变量多,变量之间是有一定的相关性的,主成分分析就是以损失很少部分信息为代价,保留绝大部分信息的前提下, 将原来众多具有一定线性相关性的p个指标压缩成少数几个互不相关的综合指 标(主成分),并通过原来变量的少数几个的线性组合来给出各个主成分的具有实际背景和意义的解释。由于主成分分析浓缩了众多指标的信息,降低了指标的
《应用多元统计分析》 ——报告 班级: 学号: 姓名: 指导教师:
聚类分析的案例分析 摘要 本文主要用SPSS软件对实验数据运用系统聚类法和K均值聚类法进行聚类分析,从而实现聚类分析及其运用。利用聚类分析研究某化工厂周围的几个地区的 气体浓度的情况,从而判断出这几个地区的污染程度。 经过聚类分析可以得到,样本6这一地区的气体浓度值最高,污染程度是最严重的,样本3和样本4气体浓度较高,污染程度也比较严重,因此要给予及时的控制和改善。 关键词:SPSS软件聚类分析学生成绩
一、数学模型 聚类分析的基本思想是认为各个样本与所选择的指标之间存在着不同程度的相似性。可以根据这些相似性把相似程度较高的归为一类,从而对其总体进行分析和总结,判断其之间的差距。 系统聚类法的基本思想是在这几个样本之间定义其之间的距离,在多个变量之间定义其相似系数,距离或者相似系数代表着样本或者变量之间的相似程度。根据相似程度的不同大小,将样本进行归类,将关系较为密切的归为一类,关系较为疏远的后归为一类,用不同的方法将所有的样本都聚到合适的类中,这里我们用的是最近距离法,形成一个聚类树形图,可据此清楚的看出样本的分类情况。 K均值法是将每个样品分配给最近中心的类中,只产生指定类数的聚类结果。 二、数据来源 《应用多元统计分析》第一版164页第6题 我国山区有一某大型化工厂,在该厂区的邻近地区中挑选其中最具有代表性的8个大气取样点,在固定的时间点每日4次抽取6种大气样本,测定其中包含的8个取样点中每种气体的平均浓度,数据如下表。试用聚类分析方法对取样点及大气污染气体进行分类。
三、建立数学模型 一、运行过程 (一)系统聚类分析 在SPSS界面对上述数据进行系统聚类分析如图1和图2所示,进行最近距离分类。 图1
六、聚类分析 (一)概述 1.聚类分析的目的 根据已知数据,计算样本或者变量之间亲疏关系的统计量(距离或相关系数)。根据某种准则(最短距离法、最长距离法、中间距离法、重心法),使同一类内的差别较小,而类与类之间的差别较大,最初达到的就是将样本或变量分成若干类。 2.聚类分析的分类 3.距离与相似性 为了对样本或者变量进行分类,就需要研究样本之间的关系,最常用的方法有两个。
(二)系统聚类 1.系统聚类的步骤 距离的具体定义及计算方式 计算n各样本两两之间的距离 将距离接近的数据依次合并为一类,再计算,再合并 画聚类图,解释类与类之间的关系 2.亲疏程度度量方法 3.系统聚类的分类
4.SPSS操作及实例 SPSS采用的是凝聚法。 案例:根据30个省的23个主要行业的平均工资情况,通过聚类分析来判断哪些地区平均工资水平高。 SPSS操作及结果: 打开SPSS上方菜单栏中的分析->分类->系统聚类 选择变量->勾选统计量->在绘制里选择树状图和冰柱图 勾选方法(通常使用组间联接)->度量区间->选择标准化方式(全距从0到
1) 下图为近似矩阵表,标注了相关系数,数值越大,距离越接近 下图为聚类分析结果表,第一类表示这是聚类分析的第几步,第二三列表示该步中那几个样本或者小类聚成一类,第四列表示距离,第五六列表示本步骤中参与的是个体还是小类(0表示样本,非0表示第n步生成的小类),第七列表示本步骤的聚类结果将在以下第几步中用到。
下面是冰柱图和树状图的结果,根据树状图可以看出,如果分为三类的话,第一类包括北京上海,第二类包括天津、广东、浙江、江苏、西藏,剩下的归为一类。 (三)快速聚类(适合大样本聚类) 1.快速聚类的步骤 指定聚类数目K 确定K个初始类的中心(自定义或者根据数据中心初步确定) 根据距离最近的原则进行分类 根据新的中心位置,重新计算每一记录距离新的类别中心的的距离,并重新分类 重复步骤4,直到达到标准