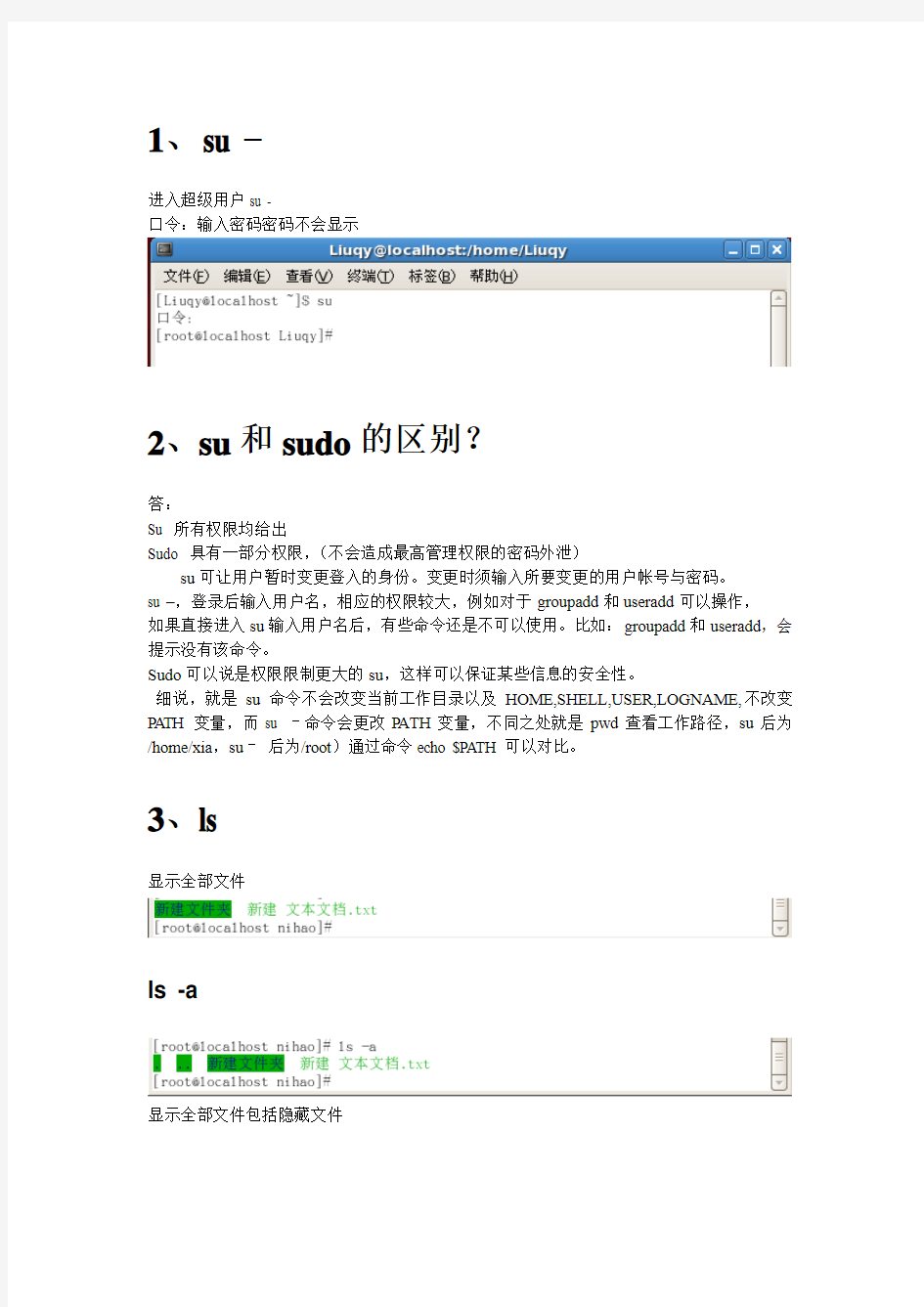

1、su –
进入超级用户su -
口令:输入密码密码不会显示
2、su和sudo的区别?
答:
Su 所有权限均给出
Sudo 具有一部分权限,(不会造成最高管理权限的密码外泄)
su可让用户暂时变更登入的身份。变更时须输入所要变更的用户帐号与密码。
su –,登录后输入用户名,相应的权限较大,例如对于groupadd和useradd可以操作,
如果直接进入su输入用户名后,有些命令还是不可以使用。比如:groupadd和useradd,会提示没有该命令。
Sudo可以说是权限限制更大的su,这样可以保证某些信息的安全性。
细说,就是su命令不会改变当前工作目录以及HOME,SHELL,USER,LOGNAME,不改变PATH变量,而su –命令会更改PA TH变量,不同之处就是pwd查看工作路径,su后为/home/xia,su–后为/root)通过命令echo $PATH可以对比。
3、ls
显示全部文件
ls -a
显示全部文件包括隐藏文件
ls –l
ll(相当于ls –l)
以长格式列出
ls -al
将全部的内容包括隐藏文件以长格式显示
r可读代表数字4 w可写代表数字2 x可执行代表数字1 —数字代表0
计算值为每一组的和的组合
例如下面的值是644(4+2+0 0+2+0 2+0+0)
rw--r-r--
第一组文件所有者的权限是可读可写,同组人的权限是可读的,其他人的权限是可读的
-rw------1 root root 281 08-13 17:24 .bash——history
(每三个为一组)第一组文件所有人都权限文件,所有人同组人的权限第三组其他人的权限数字1,表示有几个文件链接到该文件文件所有者(第一个root)组(第二个root)主要用来分配权限文件占用的磁盘空间文件创建或者修改时间文件名
文件不可以只有可执行权限,
但是文件夹如果只有可执行权限是可以将自己的文件进行删除操作
4、磁盘文件分类
cd /dev/ dev存储计算机所有的硬件
d目录文件深蓝色
l链接文件相当于快捷方式浅蓝色
c字符设备文件例如:键盘
b块设备例如:硬盘一个扇区一个扇区的记录信息
p管道设备文件
-普通文件黑色
红色的是压缩文件
绿色的问可执行文件
5、cd 切换
cd /home 表示进入根目录的home
~代表根目录进入主文件夹
cd –进入主文件夹
cd /进入根目录
cd 进入根目录
对于如果不是根目录可以不用加/
例如:
cd /dev
cd net
代表进入根目录的dev内部的文件net
6、mkdir创建文件夹
新建文件夹mkdir Test
进入新建的文件夹内
进入用户主目录下的Test cd ~/Test 或者cd Test
cd ..进入上一级文件夹
cd ~表示退回原始环境~处不管处于何处都会跳转到~目录
在原始环境下创建的目录在home文件夹内,但是有可能不会显示
cd –返回上一次所在目录(如果从主目录进入的某一文件夹则返回到主目录)
7、touch 创建文件
创建文件总计4代表的是可能的链接数字是由系统给出的
8、删除文件以及目录
1)rm
rm test.txt 删除文件的命令,无法删除目录
2)rmdir
rmdir Test(文件目录) 删除空目录
3)rm –r
rm -r Test 询问式删除目录不管有没有文件(有多少个文件进行几次确认)
4)rm –rf
rm -rf Test 不用确认式删除目录,即使有文件也可以删除(一般不使用这种方法,因为有可能误删)
9、cp
cp 文件文件路径
将某一文件放入某一文件夹内(拷贝)
10、mv
mv 文件名文件路径名
将文件剪切到123文件夹内(剪切操作)
11、可能用到的指令1)日历cal
Cal
这样只显示当前月份的日期
cal 3 2012
查看2012 年的3月份日历
Cal 2012显示某一年的全部日期
2)bc(计算器)
计算器scale=n表示做除法保留位数,如果不写明,一律保留整数,代表保留几位小数,默认的的小数位数为0
quit退出
3)uname 查看系统的信息
uname -a使用系统的详细信息
使用系统(Linux)主机名(localhost.localdomin)内核版本号(2.6.18) 最后面的i686是内核版本号基于什么开发的
4)Who 查看用户Linux登录时间
上面的是Linux登录日期
底下的为打开的终端时间
5)whoami 显示当前用户登录身份
6)date
查看时间
12、Tab键
补全键按一下tab
按两下tab键显示系统下的命令
空格翻页
Q退出
13、man帮助键
man ls
查某一命令的具体功能
14、用户的创建以及删除
1)添加组名以及查看
2)添加用户以及检查
Wang(用户名)501 用户ID 502 组IDcat查看用户文件内容cat /etc/passwd 第一列用户名第二列密用户ID 组ID 中间路径
用户的密码存储在/etc/shadow 内部
3)删除用户以及组
必须加-r否则以后创建个人用户均会失败
4)查看创建成功依据
最后命令解释器
用户ID>=500是用户创建的,<500是系统自己安装的,但是像65534是端口号cat etc/group
组名密码组ID
15、更改文件权限
chmod 755 abc
绿色可执行文件只要有一组人中有可以执行就是可
16、挂载光驱
cd ~
1)查找磁盘光驱
ll /dev/cd*
查看以cd开头的文件
2)创建光驱文件夹-
cd /mnt
mkdir cdrom
3)挂载光驱
mount /dev/hdc /mnt/cdrom
将dev下的hdc挂载到cdrom内部
4)解除挂载
先卸载掉原来的光驱否则以后不能看后边挂载的光驱
17、创建U盘挂载
1)在Oracal VM VirtualBox 内在运行的虚拟机环境下处右击【设置】->选中【USB设备】将原来的USB筛选器内的信息全部删除,然后添加U盘的名字
2)重新启动虚拟机
3)加载硬盘时点击安装,使USB设备活动状态处于闪动状态然后执行以下命令进行挂载操作。
4)检查将要挂载的U盘的位置
5)挂载U盘
6)解除挂载cd /mnt
umount /dev/hdc /mnt/cdrom(挂载位置)
umount
18、压缩命令
压缩
z代表调用了.gz c压缩condense v可视化visual压缩到某个文件的过程显示f文件系统
tar -zcvf scsconfig.log.tar.gz(压缩后的文件名)scsfconfig.log(压缩前的文件名)
解压缩x
解压到默认文件夹
tar -zxvf scsconfig.log.tar.gz
解压到已知目录
tar -zxvf scsconfig.log.tar.gz -C 12(压缩的文件位置)解压到某一文件夹内
19、reset和clear清屏命令行
reset
回到原来的位置
clear
20、exit退出登录
21、特殊操作命令一般不用
关机:init 0 (halt) 或者(shut down)对于关机以及重启一般采用第三种,因为可以通过参数的限制控制关机以及重启时间,适合我们的逻辑,一般不要执行此操作,移位虚拟机上的Linux可能导致虚拟机不能使用。
重启:init 6 (reboot) 或者(shut down -r)
回到图形界面:ctrl+Alt+F7
关掉图形界面: init 3
注销: exit
22、忘记root密码
进入单用户模式修改密码
1.在出现grub画面时,用上下键选中你平时启动linux的那一项,然后按e键
2. 再次用上下键选中你平时启动linux的那一项(类似于kernel/boot/vmlinuz-2.4.18-14 ro root=LABEL=/),然后按e键
3. 修改你现在见到的命令行,加入single,结果如下:
kernel /boot/vmlinuz-2.4.18-14 single ro root=LABEL=/ single1
4. 回车返回,然后按b键启动,即可直接进入linux命令行
5.用password命令修改密码
6.Init 6重启
23、是不是block越大越好?
Block文件存储的最小单位
Block越小,磁盘分区的使用率越高,block 越大,相对磁盘的性能越好。
性能好是因为空间、文件分配情况的数据记录随着block 变大而变小。文件系统可以更快的定位位置并且读取。
但也有例外,因为系统在读取的时候,有两种数据读取方式,一种是基于文件读取,另外一种是基于block 读取方式。如果你的数据存储程序基于block ,那么一次需要读取的数据
就会变大,相对的,要处理的数据就会变多。就会变相影响某些效率。
所以根据实际情况,如果是大量零碎文件存储、以及大量临时文件的读写,为了增加磁盘空间效率,可以缩小block ,如果是大文件的数据存储,比如数据库应用,可以放大block 来提高磁盘数据寻址效率。
24、pwd显示当前工作目录
CAD中有哪些命令?我们可以把它们分为几类。一类是绘图类,二类是编辑类,三类是设置类,四类是其它类,包括标注、视图等。我们依次分析。 第一类,绘图类。常用的命令有: Line 直线 Xline 构造线 mline 双线 pline 多义线 rectang 矩形 arc 圆弧 circle 圆 hatch 填充 boundary 边界 block 定义块 insert 插入快 第二类,编辑类。常用的命令有: Matchprop 特性匹配 Hatchedit 填充图案编辑 Pedit 多义线编辑 Erase 擦除 Copy 拷贝 Mirror 镜像 Offset 平移 Array 阵列 Move 移动 Rotate 旋转 Scale 缩放 Stretch 拉伸 Lengthen 拉长 Trim 裁减 Extend 延伸 Break 打断 Fillet 倒圆角 Explode 炸裂 Align 对齐 Properties 属性
绘图工具栏: 直线(L):全称(line) 在屏幕上指定两点可画出一条直线。也可用相对坐标 或者在正交模式打开的情况下,直接给实际距离鼠标拖动来控制方向 构造线(XL):全称(xline) H为水平V为垂直O为偏移A为角度B为等分一个角度。 多段线(PL):全称(pline) 首先在屏幕上指定一点,然后有相应提示: 指定下一个点或[圆弧(A)/半宽(H)/长度(L)/放弃(U)/宽度(W)]。可根据需要来设置。 其中“圆弧”指定宽度可画任意角度圆弧;“半宽”指多段线的一半宽度,即如要高线宽为10,则5;“长度”给相应的值,则画出相应长度的多段线;“放弃”指放弃一次操作;“宽度”指多段线的宽度 多边形(pol):全称(polygon) 所绘制多边形为正多边形,边数可以自己设 E:根据边绘制多边形也可根据圆的半径利用外切和内接来画正多边形 矩形(REC):全称(rectang) 点击矩形工具后出现下列提示: 指定第一个角点或[倒角(C)/标高(E)/圆角(F)/厚度(T)/宽度(W)] 其中“倒角”是将90度直角的两条边割去一点。变成一个斜角。“标高”是空间上的意义可以在三视图当中展现出来,标高是相对的;“圆角”:即是将四个直角边倒成半径为X的圆角;“厚度”:空间上的意义,可在Z轴上表现出来“宽度”:平面空间的概念,指矩形四边的宽度。 圆弧(ARC或A):默认为3点画圆弧,成弧方向为逆时针,画优弧半径给负值。绘图菜单中有如下选项: 起点、圆心、端点; 起点、圆心、角度; 起点、圆心、长度; 起点、端点、角度; 起点、端点、方向; 起点、端点、半径; 圆心、起点、端点; 圆心、起点、角度; 圆心、起点、长度;
HADOOP表操作 1、hadoop简单说明 hadoop 数据库中的数据是以文件方式存存储。一个数据表即是一个数据文件。hadoop目前仅在LINUX 的环境下面运行。使用hadoop数据库的语法即hive语法。(可百度hive语法学习) 通过s_crt连接到主机。 使用SCRT连接到主机,输入hive命令,进行hadoop数据库操作。 2、使用hive 进行HADOOP数据库操作
3、hadoop数据库几个基本命令 show datebases; 查看数据库内容; 注意:hadoop用的hive语法用“;”结束,代表一个命令输入完成。 usezb_dim; show tables;
4、在hadoop数据库上面建表; a1: 了解hadoop的数据类型 int 整型; bigint 整型,与int 的区别是长度在于int; int,bigint 相当于oralce的number型,但是不带小数点。 doubble 相当于oracle的numbe型,可带小数点; string 相当于oralce的varchar2(),但是不用带长度; a2: 建表,由于hadoop的数据是以文件有形式存放,所以需要指定分隔符。 create table zb_dim.dim_bi_test_yu3(id bigint,test1 string,test2 string)
row format delimited fields terminated by '\t' stored as textfile; --这里指定'\t'为分隔符 a2.1 查看建表结构: describe A2.2 往表里面插入数据。 由于hadoop的数据是以文件存在,所以插入数据要先生成一个数据文件,然后使用SFTP将数据文件导入表中。
数据库文件及记录命令 ADD TABLE 在当前数据库中添加一个自由表 APPEND 在表的末尾添加一个或多个新记录 APPEND FROM ARRAY 由数组添加记录到表中 APPEND FROM 从一个文件中读入记录,追加到当前表的尾部 APPEND GENERAL 从文件中导入OLE对象并将其放入通用字段中 APPEND MEMO 将文本文件的内容复制到备注字段中 APPEND PROCEDURES 将文本文件中的存储过程追加到当前数据库中 A VERAGE 计算数值表达式或字段的算术平均值 BLANK 清除当前记录中所有字段的数据 BROWSE 打开浏览窗口,显示当前或选定表的记录 CALCULATE 对表中的字段或包含字段的表达式进行财务和统计操作CHANGE 显示要编辑的字段 CLOSE 关闭各种类型的文件 CLOSE MEMO 关闭一个或多个备注编辑窗口 COMPILE DATABASE 编译数据库中的存储过程 CONTINUE 继续执行先前的LOCATE命令 COPY MEMO 复制当前记录中的指定备注字段的内容到文本文件 COPY PROCEDURES 将当前数据库中’的存储过程复制到文本文件 COPY STRUCTURE 用当前选择的表结构创建一个新的空自由表 COPY STRUCTURE EXTENDED 创建新表,它的字段包含当前选定表的结构信息COPY TO ARRAY 将当前选定表中的数据复制到数组
COPY TO 用当前选定表的内容创建新文件 COUNT 统计表中记录数目 CREATE 生成一个新的VisualFoxPro表 CREATE CONNECTION 创建一个命名连接并把它存储在当前数据库中 CREATE DATABASE 创建并打开一个数据库 CREATE TRIGGER 创建表的删除、插入或更新触发器 CREATE VIEW 从VisualFoxPro环境创建视图文件 DELETE 给要删除的记录做标记 DELETE CONNECTION 从当前数据库中删除一个命名连接 DELETE DATABASE 从磁盘上删除数据库 DELETE TRIGGER 从当前数据库的表中删除“删除”、“插入”或“更新”触发器│ DELETE VIEW 从当前数据库中删除一个SQL视图 DISPLAY 在VisualFoxPro主窗口或用户自定义窗口中显示与当前表有关的信息DISPLAY CONNECTIONS 显示当前数据库中与命名连接有关的信息 DISPLAY DATABASE 显示有关当前数据库的信息,或当前数据库中的字段、命名连接、表或视图的信息 DISPLAY MEMORY 显示内存变量和数组的当前内容 DISPLAY PROCEDURES 显示当前数据库中存储过程的名称 DISPLAY STRUCTURE 显示一个表文件的结构 DISPLAY TABLES 显示包含在当前数据库中所有的表和表的信息 DISPLAY VIEWS 显示当前数据库中关于SQL视图的信息以及SQL视图是否基于本地或远程表的信息 DROP TABLE 把一个表从数据库中移出,并从磁盘中删除它 DROP VIEW 从当前数据库中删除指定的SQL视图
Oracle SQLPlus常用命令及解释 1.@ 执行位于指定脚本中的SQLPlus语句。可以从本地文件系统或Web服务器中调用脚本。可以为脚本中的变量传递值。在iSQL*Plus中只能从Web服务器中调用脚本。 2.@@ 执行位于指定脚本中的SQL*Plus语句。这个命令和@(“at”符号)命令功能差不多。在执行嵌套的命令文件时它很有用,因为它会在与调用它的命令文件相同的路径或url中查找指定的命令文件。在iSQL*Plus中只支持url形式。 3./ 执行保存在SQL缓冲区中的最近执行的SQL命令或PL/SQL块。在SQL*Plus命令行中,可在命令提示符或行号提示符使用斜线(/)。也可在iSQL*Plus的输入区中使用斜线(/)。斜线不会列出要执行的命令。 4.ACCEPT 可以修改既有变量,也可定义一个新变量并等待用户输入初始值,读取一行输入并保存到给出的用户变量中。ACCEPT在iSQL*Plus中不可用。 5.APPEND 把指定文本添加到SQL缓冲区中当前行的后面。如果text的最前面包含一个空格可在APPEND和text间输入两个空格。如果text的最后是一个分号,可在命令结尾输入两个分号(SQL*Plus会把单个的分号解释为一个命令结束符)。APPEND 在iSQL*Plus中不可用。 6.ARCHIVE LOG 查看和管理归档信息。启动或停止自动归档联机重做日志,手工(显示地)归档指定的重做日志,或者显示重做日志文件的信息。 7.ATTRIBUTE 为对象类型列的给定属性指定其显示特性,或者列出单个属性或所有属性的当前显示特性。 8.BREAK 分开重复列。指定报表中格式发生更改的位置和要执行的格式化动作(例如,在列值每次发生变化时跳过一行)。只输入BREAK而不包含任何子句可列出当前的BREAK定义。 9.BTITLE 在每个报表页的底部放置一个标题并对其格式化,或者列出当前BTITLE定义。
收集日志操作如下: HPS 1、将附件HPSRPT_Enhanced_v9.0.00r2.zip 文件copy到目标服务器,存放在c:\ 2、解压到当前文件夹后双击运行HPSRPT_Enhanced_v9.0.00r2.cmd文件 3、不要关闭DOS运行窗口大约15分钟左右会自动消失说明运行完成。 4、完成后需要到C:\WINDOWS\HPSReports\Enhanced\Report\cab 目录下查看生成文件信息 5、收集对应时间点的cab文件即可。 第一个日志:ADU报告 2、打开开始——程序——HP System Tools——HP Array Configuration Utility——HP Array Configuration Utility。
3、选择Local Applcation Mode,本地应用模式。 4、打开了HP Array Configuration Utility工具后,点中间的Diagnostics选项卡,选中左侧的
阵列卡,右侧会出现2个按钮,查看和提取日志报告,我们选择Generate Diagnostic Report。 5、提示Reprot Generation Complete日志提取完毕,这时可以选择右下角Save report按钮。
6、选择保存,弹出保存菜单,点保存。 7、可以选择保存到桌面上。
第二个报告:survey报告 打开开始——程序——HP System Tools——HP Insight Diagnostics online Edition for Windows ——HP Insight Diagnostics online Edition for Windows。 9、提示安全证书报警,选择是,继续。
日志管理与分析-日志收集及来源 【前言】 对广大IT工作者,尤其是运维和安全人员来说,“日志”是一个再熟悉不过的名词。日志从哪来?机房中的各种软件(系统、防火墙)和硬件(交换机、路由器等),都在不断地生成日志。IT安全业界的无数实践告诉我们,健全的日志记录和分析系统,是系统正常运营、优化以及安全事故响应的基础,虽然安全系统厂商为我们提供了五花八门的解决方案,但基石仍是具有充足性、可用性、安全性的日志记录系统。实际工作中,许多单位内部对日志并没有充分的认识,安全建设更多在于投入 设备,比如防火墙、IDS、IPS、防病毒软件等,被动地希望这些系统帮助我们完成一切工作,但是俗话说的好:“魔高一尺道高一丈”,以特征码和预定义规则为基础的上述设备,在防护方面永远落在攻击者后面,防微杜渐才是真正的出路。作为一名合格的安全人员,了解日志的概念,了解日志的配置和分析方法,是发现威胁、抵御攻击的重要技能,有了这方面的深刻认识,各种自动化安全解决方案才能真正地发挥效能。 1、日志数据 简单地说,日志消息就是计算机系统、设备、软件等在某种触发下反应生成的东西。确切的触发在很大程度上取决于日志消息的来源。例如,UNix操作系统会记录用户登录和注销的消息,防火墙将记录ACL 通过和拒绝的消息,磁盘存储系统在故障发生或者在某些系统认为将会发生故障的情况下会生成日志消息。 日志数据就是一条日志消息里用来告诉你为什么生成消息的信息,例如,web服务器一般会在有人访问web页面请求资源(图片、
文件等等)的时候记录日志。如果用户访问的页面需要通过认证,日 志消息将会包含用户名。日志消息可以分成下面的几种通用类型: ?信息:这种类型的消息被设计成告诉用户和管理员一些没有风险的事情发生了。例如,Cisco IOS将在系统重启的时候生成消息。不过,需要注意的是,如果重启发生在非正常维护时间或是业务时间,就有发出报警的理由。 ?调试:软件系统在应用程序代码运行时发生调试信息,是为了给软件开发人员提供故障检测和定位问题的帮助。 ?警告:警告消息是在系统需要或者丢失东西,而又不影响操作系统的情况下发生的。 ?错误:错误日志消息是用来传达在计算机系统中出现的各种级别的错误。例如,操作系统在无法同步缓冲区到磁盘的时候会生成错误信息。?警报:警报表明发生了一些有趣的事,一般情况下,警报是属于安全设备和安全相关系统的,但并不是硬性规定。在计算机网络中可能会运行一个入侵防御系统IPS,检查所有入站的流量。它将根据数据包的内容判断是否允许其进行网络连接。如果IPS检测到一个恶意连接,可能会采取任何预先配置的处置。IPS会记录下检测结果以及所采取的行动。 2、日志数据的传输与收集 计算机或者其他设备都实现了日志记录子系统,能够在确定有必 要的时候生成日志消息,具体的确定方式取决于设备。另外,必须有 一个用来接收和收集日志消息的地方,这个地方一般被称为日志主 机。日志主机是一个计算机系统,一般来说可能是linux和windows服
Hadoop 集群基本操作命令 列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help (注:一般手动安装hadoop大数据平台,只需要创建一个用户即可,所有的操作命令就可以在这个用户下执行;现在是使用ambari安装的dadoop大数据平台,安装过程中会自动创建hadoop生态系统组件的用户,那么就可以到相应的用户下操作了,当然也可以在root用户下执行。下面的图就是执行的结果,只是hadoop shell 支持的所有命令,详细命令解说在下面,因为太多,我没有粘贴。) 显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name (注:可能有些命令,不知道什么意思,那么可以通过上面的命令查看该命令的详细使用信息。例子: 这里我用的是hdfs用户。) 注:上面的两个命令就可以帮助查找所有的haodoop命令和该命令的详细使用资料。
创建一个名为 /daxiong 的目录 $ bin/hadoop dfs -mkdir /daxiong 查看名为 /daxiong/myfile.txt 的文件内容$ bin/hadoop dfs -cat /hadoop dfs -cat /user/haha/part-m-00000 上图看到的是我上传上去的一张表,我只截了一部分图。 注:hadoop fs <..> 命令等同于hadoop dfs <..> 命令(hdfs fs/dfs)显示Datanode列表 $ bin/hadoop dfsadmin -report
$ bin/hadoop dfsadmin -help 命令能列出所有当前支持的命令。比如: -report:报告HDFS的基本统计信息。 注:有些信息也可以在NameNode Web服务首页看到 运行HDFS文件系统检查工具(fsck tools) 用法:hadoop fsck [GENERIC_OPTIONS]
Hadoop命令大全 Hadoop配置: Hadoop配置文件core-site.xml应增加如下配置,否则可能重启后发生Hadoop 命名节点文件丢失问题:
1、列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help 2、显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name 3、用户可使用以下命令在指定路径下查看历史日志汇总 $ bin/hadoop job -history output-dir 这条命令会显示作业的细节信息,失败和终止的任务细节。 4、关于作业的更多细节,比如成功的任务,以及对每个任务的所做的尝试次数等可以用下面的命令查看 $ bin/hadoop job -history all output-dir 5、格式化一个新的分布式文件系统: $ bin/hadoop namenode -format 6、在分配的NameNode上,运行下面的命令启动HDFS: $ bin/start-dfs.sh bin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。 7、在分配的JobTracker上,运行下面的命令启动Map/Reduce: $ bin/start-mapred.sh bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves 文件的内容,在所有列出的slave上启动TaskTracker守护进程。 8、在分配的NameNode上,执行下面的命令停止HDFS: $ bin/stop-dfs.sh bin/stop-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止DataNode守护进程。 9、在分配的JobTracker上,运行下面的命令停止Map/Reduce: $ bin/stop-mapred.sh bin/stop-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止TaskTracker守护进程。 10、启动所有 $ bin/start-all.sh 11、关闭所有 $ bin/stop-all.sh DFSShell 10、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 11、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 12、查看名为 /foodir/myfile.txt 的文件内容 $ bin/hadoop dfs -cat /foodir/myfile.txt
DOS磁盘文件操作命令 一、实验目的 本章主要通过常用的DOS命令的练习,了解DOS的基本功能及其基本组成和DOS常用命令的使用方法。 二、实验条件要求 1.硬件:计算机 2.软件环境:Windows XP 三、实验基本知识点 1. DIR(Dir ectory) 功能:显示指定路径上所有文件或目录的信息 格式:dir [盘符:][路径][文件名] [参数] 参数: /w:宽屏显示,一排显示5个文件名,而不会显示修改时间,文件大小等信息;/p:分页显示,当屏幕无法将信息完全显示时,可使用其进行分页显示; /a:显示当前目录下的所有文件和文件夹; /s:显示当前目录及其子目录下所有的文件。 2. MD(M ake D irectory) 功能:创建新的子目录 格式:md <盘符:><路径名> <子目录名> 3. CD(C hange D irectory) 功能:改变当前目录 格式:cd <盘符:> <路径名> <子目录名> 注意: 根目录是驱动器的目录树状结构的顶层,要返回到根目录,在命令行输入:cd \ 如果想返回到上一层目录,在当前命令提示符下输入:cd.. 如果想进入下一层目录,在当前命令提示符下输入:cd 目录名 4. 全屏幕编辑命令:EDIT 格式:EDIT <文件名>
说明: (1)仅可编辑纯文本格式的文件 (2)指定文件存在时编辑该文件,不存在时新建该文件 5. 显示文件内容命令:TYPE 格式:TYPE <文件名> 说明: (1)可以正常显示纯文本格式文件的内容,而.COM、.EXE等显示出来是乱码。(2)一次只能显示一个文件内容,所以文件名不能使用通配符。 6. 文件复制命令:COPY 格式:COPY <源文件> [目标文件] 说明: (1)源文件指定想要复制的文件来自哪里——[盘符1:][路径1][文件名1] (2)目标文件指定文件拷贝到何方——[盘符2:][路径2][文件名2] (3)如缺省盘符则为当前盘符;路径若为当前目录可缺省路径。 (4)源文件名不能缺省,目标文件名缺省时表示拷贝后不改变文件名。 7. Tree 功能:显示指定驱动器上所有目录路径和这些目录下的所有文件名 格式:tree <盘符:> 8. 文件改名命令:REN 格式:REN <旧文件名> <新文件名> 说明: (1)改名后的文件仍在原目录中,不能对新文件名指定盘符和路径。 (2)可以使用通配符来实现批量改名。 9. 显示和修改文件属性命令:ATTRIB 格式:[盘符][路径] A TTRIB [文件名][+S/-S][+H/-H][+R/-R][+A/-A] 说明: (1)盘符和路径指出ATTRIB.EXE位置 (2)参数+S/-S:对指定文件设置或取消系统属性 (3)参数+H/-H:对指定文件设置或取消隐含属性 (4)参数+R/-R:对指定文件设置或取消只读属性 (5)参数+A/-A:对指定文件设置或取消归档属性
Hadoop测试题 一.填空题,1分(41空),2分(42空)共125分 1.(每空1分) datanode 负责HDFS数据存储。 2.(每空1分)HDFS中的block默认保存 3 份。 3.(每空1分)ResourceManager 程序通常与NameNode 在一个节点启动。 4.(每空1分)hadoop运行的模式有:单机模式、伪分布模式、完全分布式。 5.(每空1分)Hadoop集群搭建中常用的4个配置文件为:core-site.xml 、hdfs-site.xml 、mapred-site.xml 、yarn-site.xml 。 6.(每空2分)HDFS将要存储的大文件进行分割,分割后存放在既定的存储块 中,并通过预先设定的优化处理,模式对存储的数据进行预处理,从而解决了大文件储存与计算的需求。 7.(每空2分)一个HDFS集群包括两大部分,即namenode 与datanode 。一般来说,一 个集群中会有一个namenode 和多个datanode 共同工作。 8.(每空2分) namenode 是集群的主服务器,主要是用于对HDFS中所有的文件及内容 数据进行维护,并不断读取记录集群中datanode 主机情况与工作状态,并通过读取与写入镜像日志文件的方式进行存储。 9.(每空2分) datanode 在HDFS集群中担任任务具体执行角色,是集群的工作节点。文 件被分成若干个相同大小的数据块,分别存储在若干个datanode 上,datanode 会定期向集群内namenode 发送自己的运行状态与存储内容,并根据namnode 发送的指令进行工作。 10.(每空2分) namenode 负责接受客户端发送过来的信息,然后将文件存储位置信息发 送给client ,由client 直接与datanode 进行联系,从而进行部分文件的运算与操作。 11.(每空1分) block 是HDFS的基本存储单元,默认大小是128M 。 12.(每空1分)HDFS还可以对已经存储的Block进行多副本备份,将每个Block至少复制到 3 个相互独立的硬件上,这样可以快速恢复损坏的数据。 13.(每空2分)当客户端的读取操作发生错误的时候,客户端会向namenode 报告错误,并 请求namenode 排除错误的datanode 后,重新根据距离排序,从而获得一个新的的读取路径。如果所有的datanode 都报告读取失败,那么整个任务就读取失败。14.(每空2分)对于写出操作过程中出现的问题,FSDataOutputStream 并不会立即关闭。 客户端向Namenode报告错误信息,并直接向提供备份的datanode 中写入数据。备份datanode 被升级为首选datanode ,并在其余2个datanode 中备份复制数据。 NameNode对错误的DataNode进行标记以便后续对其进行处理。 15.(每空1分)格式化HDFS系统的命令为:hdfs namenode –format 。 16.(每空1分)启动hdfs的shell脚本为:start-dfs.sh 。 17.(每空1分)启动yarn的shell脚本为:start-yarn.sh 。 18.(每空1分)停止hdfs的shell脚本为:stop-dfs.sh 。 19.(每空1分)hadoop创建多级目录(如:/a/b/c)的命令为:hadoop fs –mkdir –p /a/b/c 。 20.(每空1分)hadoop显示根目录命令为:hadoop fs –lsr 。 21.(每空1分)hadoop包含的四大模块分别是:Hadoop common 、HDFS 、
CentOS 丛书目录 — 系统管理 — 网络服务 — 应用部署 文件与目录操作命令 内容提要 1. 掌握常用的文件操作命令 2. 掌握常用的目录操作命令 目录操作命令 ls 功能说明: 显示文件和目录列表 命令格式: ls [参数] [<文件或目录> …] 常用参数: -a : 不隐藏任何以 . 字符开始的条目 -b : 用八进制形式显示非打印字符 -R : 递归列出所有子目录 -d : 当遇到目录时列出目录本身而非目录内的文件,并且不跟随符号链接 -F : 在条目后加上文件类型的指示符号 (*/=@| 其中一个) -l : 使用较长格式列出信息 -L : 当显示符号链接的文件信息时,显示符号链接所指示的对象而并非符号链接本身的信息-x : 逐行列出项目而不是逐栏列出 -1 : 每行只列出一个文件 -r : 依相反次序排列 -S : 根据文件大小排序 -X : 根据扩展名排序 -c : 根据状态改变时间(ctim e)排序 -t : 根据最后修改时间(m tim e)排序 -u : 根据最后访问时间(atim e)排序 使用举例: $ ls $ ls -a $ ls -F $ ls -l $ ls -R $ ls -Sl $ ls -rl $ ls -cl $ ls -tl $ ls -ul $ ls some/dir/file $ ls some/dir/ $ ls -d some/dir/
tree 功能说明: 显示文件和目录树 命令格式: tree [参数] [<目录>] 常用参数: -a : 不隐藏任何以 . 字符开始的条目 -d : 只显示目录不显示文件 -f : 每个文件都显示路径 -F : 在条目后加上文件类型的指示符号 (*/=@| 其中一个) -r : 依相反次序排列 -t : 根据最后修改时间(m tim e)排序 -L n : 只显示 n 层目录(n为数字) ––dirsfirst : 目录显示在前文件显示在后 使用举例: $ tree $ tree -d $ tree -F $ tree -L 3 $ tree /some/dir/ pwd 功能说明: 显示当前工作目录 命令格式: pwd [参数] 常用参数: -P : 若目录是一个符号链接,显示的是物理路径而不是符号链接使用举例: $ pwd $ pwd -P cd 功能说明: 切换目录 命令格式: cd [参数] [<目录>] 常用参数: -P : 若目录是一个符号链接,显示的是物理路径而不是符号链接使用举例: $ cd /some/dir/ $ cd -P Examples $ cd $ cd ~
Cad常用命令及使用方法 一、绘图命令 直线:L 用法:输入命令L/回车/鼠标指定第一点/输入数值(也就是指定第二点)/回车(这时直线就画出来了)/回车(结束命令) 射线:RAY 用法:输入命令RAY/回车/鼠标指定射线起点/指定通过点/回车(结束命令) 构造线:XL 用法:输入命令XL/回车/鼠标指定构造线起点/指定通过点/回车(结束命令) 多段线:PL 用法1:同直线命令 用法2:输入命令PL/回车/指定起点/输入W(绘制带有宽度的线)/回车/指定线起点宽度/回车/指定线结束点宽度/回车/输入数值(线的长度值)/回车(结束命令) 正多边形:POL 用法:输入命令POL/回车/指定边数/回车/鼠标指定正多边形的中心点/输入选项(C外切于圆;I内接于圆)/回车/输入半径/回车(结束命令) 矩形:REC 用法1:输入命令REC/回车/鼠标指定第一角点/指定第二角点 用法2:输入命令REC/回车/输入C(绘制带有倒角的矩形)/回车/输入第一倒角值/回车/输入第二倒角值/回车/鼠标指定第一角点/指定第二角点 用法3:输入命令REC/回车/输入F(绘制带有圆角的矩形)/回车/输入圆角半径/回车/指定第一角点/指定第二角点 圆弧:A 用法:输入命令A/回车/指定圆弧起点/指定圆弧中点/指定圆弧结束点 (绘制圆弧的方法有11种,可参考绘图菜单---圆弧选项) 圆:C 用法:输入命令C/回车/鼠标指定圆心/输入半径值/回车(命令结束) (绘制圆的方法有6种,可参考绘图菜单---圆选项) 样条曲线:SPL 用法:输入命令SPL/回车/鼠标指定要绘制的范围即可/需要三下回车结束命令 椭圆:EL
Hadoop面试题目及答案(附目录) 选择题 1.下面哪个程序负责HDFS 数据存储。 a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker 答案C datanode 2. HDfS 中的block 默认保存几份? a)3 份b)2 份c)1 份d)不确定 答案A 默认3 份 3.下列哪个程序通常与NameNode 在一个节点启动? a)SecondaryNameNode b)DataNode c)TaskTracker d)Jobtracker 答案D 分析:hadoop 的集群是基于master/slave 模式,namenode 和jobtracker 属于master,datanode 和tasktracker 属于slave,master 只有一个,而slave 有多个SecondaryNameNode 内存需求和NameNode 在一个数量级上,所以通常secondaryNameNode(运行在单独的物理机器上)和NameNode 运行在不同的机器上。 JobTracker 和TaskTracker JobTracker 对应于NameNode,TaskTracker 对应于DataNode,DataNode 和NameNode 是针对数据存放来而言的,JobTracker 和TaskTracker 是对于MapReduce 执行而言的。mapreduce 中几个主要概念,mapreduce 整体上可以分为这么几条执行线索:jobclient,JobTracker 与TaskTracker。 1、JobClient 会在用户端通过JobClient 类将应用已经配置参数打包成jar 文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker 创建每一个Task(即MapTask 和ReduceTask)并将它们分发到各个TaskTracker 服务中去执行。 2、JobTracker 是一个master 服务,软件启动之后JobTracker 接收Job,负责调度Job 的每一个子任务task 运行于TaskTracker 上,并监控它们,如果发现有失败的task 就重新运行它。一般情况应该把JobTracker 部署在单独的机器上。 3、TaskTracker 是运行在多个节点上的slaver 服务。TaskTracker 主动与JobTracker 通信,接收作业,并负责直接执行每一个任务。TaskTracker 都需要运行在HDFS 的DataNode 上。 4. Hadoop 作者 a)Martin Fowler b)Kent Beck c)Doug cutting 答案C Doug cutting 5. HDFS 默认Block Size a)32MB b)64MB c)128MB 答案:B 6. 下列哪项通常是集群的最主要瓶颈 a)CPU b)网络c)磁盘IO d)内存 答案:C 磁盘 首先集群的目的是为了节省成本,用廉价的pc 机,取代小型机及大型机。小型机和大型机
C语言文件操作函数大全 clearerr(清除文件流的错误旗标) 相关函数 feof 表头文件 #include
视图模式介绍: 普通视图 router> 特权视图 router# /在普通模式下输入enable 全局视图 router(config)# /在特权模式下输入config t 接口视图 router(config-if)# /在全局模式下输入int 接口名称例如int s0或int e0 路由协议视图 router(config-route)# /在全局模式下输入router 动态路由协议名称 1、基本配置: router>enable /进入特权模式 router#conf t /进入全局配置模式 router(config)# hostname xxx /设置设备名称就好像给我们的计算机起个名字 router(config)#enable password /设置特权口令 router(config)#no ip domain lookup /不允许路由器缺省使用DNS解析命令 router(config)# Service password-encrypt /对所有在路由器上输入的口令进行暗文加密router(config)#line vty 0 4 /进入设置telnet服务模式 router(config-line)#password xxx /设置telnet的密码 router(config-line)#login /使能可以登陆 router(config)#line con 0 /进入控制口的服务模式 router(config-line)#password xxx /要设置console的密码 router(config-line)#login /使能可以登陆 2、接口配置: router(config)#int s0 /进入接口配置模式 serial 0 端口配置(如果是模块化的路由器前面加上槽位编号,例如serial0/0 代表这个路由器的0槽位上的第一个接口) router(config-if)#ip add xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx /添加ip 地址和掩码router(config-if)#enca hdlc/ppp 捆绑链路协议 hdlc 或者 ppp 思科缺省串口封装的链路层协议是HDLC所以在show run配置的时候接口上的配置没有,如果要封装为别的链路层协议例如PPP/FR/X25就是看到接口下的enca ppp或者enca fr router(config)#int loopback /建立环回口(逻辑接口)模拟不同的本机网段 router(config-if)#ip add xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx /添加ip 地址和掩码给环回口 在物理接口上配置了ip地址后用no shut启用这个物理接口反之可以用shutdown管理性的关闭接口 3、路由配置: (1)静态路由 router(config)#ip route xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx 下一条或自己的接口router(config)#ip route 0.0.0.0 0.0.0.0 s 0 添加缺省路由 (2)动态路由 rip协议 router(config)#router rip /启动rip协议 router(config-router)#network xxx.xxx.xxx.xxx /宣告自己的网段 router(config-router)#version 2 转换为rip 2版本 router(config-router)#no auto-summary /关闭自动汇总功能,rip V2才有作用 router(config-router)# passive-int 接口名 /启动本路由器的那个接口为被动接口
收集日志的方法(V5.5及以下版本) 刘奇liuqi@https://www.doczj.com/doc/4211044201.html,2010-9-14 说明:本文档非本人编写,为深圳同事总结。 举例说明,怎样把程序出错时,或者程序运行慢的前台界面现象截图,前台详细日志,后台详细日志收集和提交。 1. 某客户查询凭证时,前台报错。 2.下面介绍怎样把日志收集完整给开发, 在打开这个出错节点之前,我们先打开前台日志,在程序的右上角上一个日志按钮, 并把log level设置为debug, 按clear 按钮清除之前的日志,让收集的日志更为准确 3.在服务器端运行wassysconfig.bat—log- 日志配置http://localhost:88 –读取(中间件必须在启动状态),下图中88为nc的web访问端口,如果是80端口访问nc,请在此输入80. 把anonymous和nclog 级别设置为debug,滚动策略中最大字节设置为10m,最大文件数设置为20,并按保存。如下图,这个时候,所在访问nc服务器的88端口的操作,将会有debug输出到指定目录的指定文件。(ncv5产品是可以动态打开和关闭日志,不需要重新启动中间件才生效)
4.在服务器端打开日志目录D:\ufida\ufsoft\nclogs\server1,按日期排序日志文件,记下nc-log 和anony-log当前正在输出的文件(可能有很多nc-log和anony-log文件,要记住正在输出的最新的日志文件),如下图nc-log[0].log和anony-log[0].log是正在输入的日志文件 1.准备工作都完成了,我们需要把问题重现一次。以便生成日志并提交给开发。如下图, 我们操作凭证查询,界面报错,我们可以使用键盘上的prtscreen键直接截图到word文件,把前台直接看到的错误保存下来。 2.问题重现后,我们立即去把后台日志的级别设置为error,并保存。防止其他用户操作nc 产生大量的日志输出,不便查找我们所要的信息,如下图