
Clementine 11 数据挖掘案例详解
SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技
术创新方面遥遥领先。
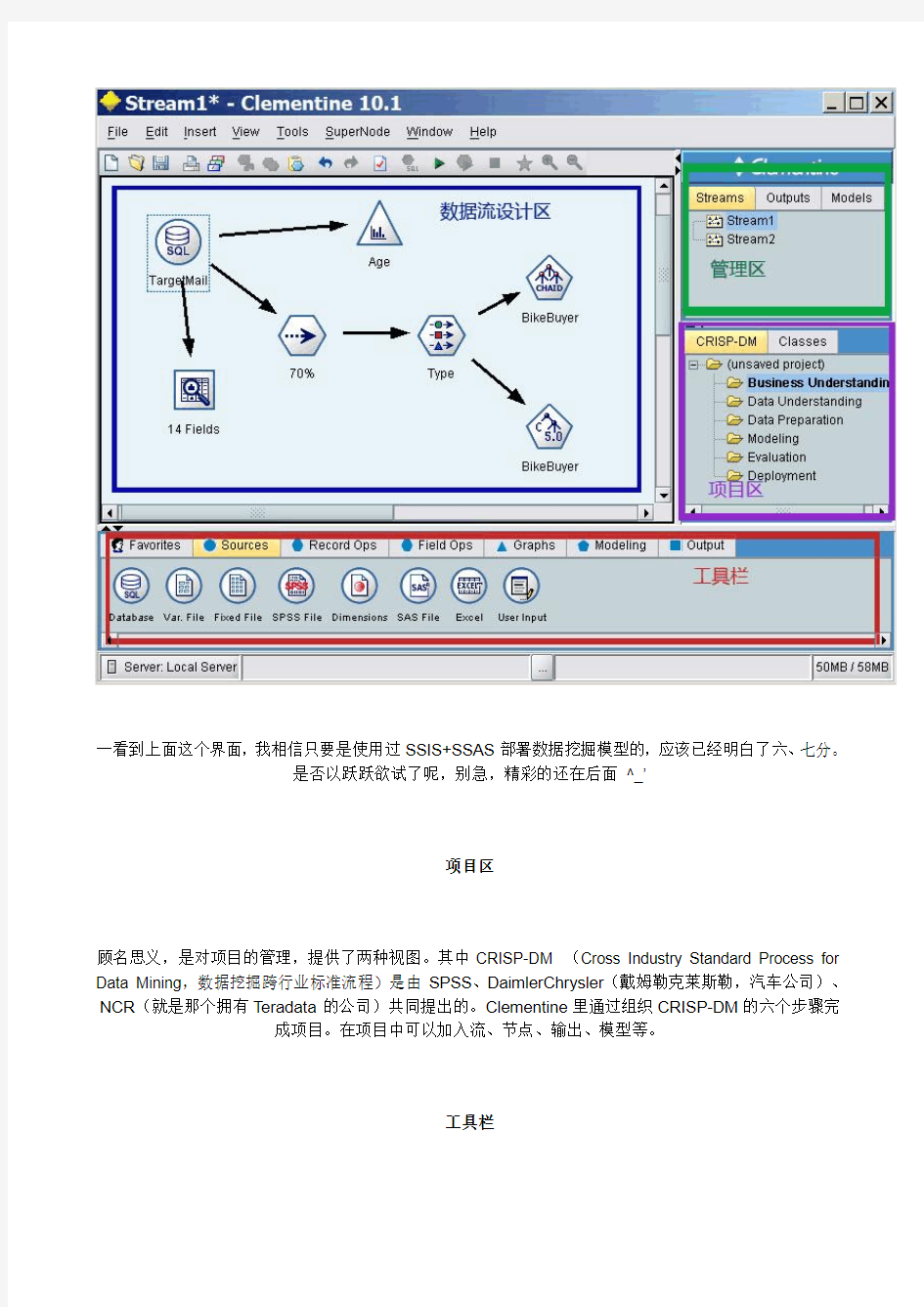
客户端基本界面
SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面^_’
项目区
顾名思义,是对项目的管理,提供了两种视图。其中CRISP-DM (Cross Industry Standard Process for Data Mining,数据挖掘跨行业标准流程)是由SPSS、DaimlerChrysler(戴姆勒克莱斯勒,汽车公司)、NCR(就是那个拥有Teradata的公司)共同提出的。Clementine里通过组织CRISP-DM的六个步骤完成项目。在项目中可以加入流、节点、输出、模型等。
工具栏
工具栏总包括了ETL、数据分析、挖掘模型工具,工具可以加入到数据流设计区中,跟SSIS中的数据流
非常相似。Clementine中有6类工具。
源工具(Sources)
相当SSIS数据流中的源组件啦,clementine支持的数据源有数据库、平面文件、Excel、维度数据、SAS
数据、用户输入等。
记录操作(Record Ops)和字段操作(Field Ops)
相当于SSIS数据流的转换组件,Record Ops是对数据行转换,Field Ops是对列转换,有些类型SSIS 的异步输出转换和同步输出转换(关于SSIS异步和同步输出的概念,详见拙作:
https://www.doczj.com/doc/4b7118397.html,/esestt/archive/2007/06/03/769411.html)。
图形(Graphs)
用于数据可视化分析。
输出(Output)
Clementine的输出不仅仅是ETL过程中的load过程,它的输出包括了对数据的统计分析报告输出。
※在ver 11,Output中的ETL数据目的工具被分到了Export的工具栏中。
模型(Model)
Clementine中包括了丰富的数据挖掘模型。
数据流设计区
这个没什么好说的,看图就知道了,有向的箭头指明了数据的流向。Clementine项目中可以有多个数据流设计区,就像在PhotoShop中可以同时开启多个设计图一样。
比如说,我这里有两个数据流:Stream1和Stream2。通过在管理区的Streams栏中点击切换不同的数量
流。
管理区
管理区包括Streams、Outputs、Models三栏。Streams上面已经说过了,是管理数据流的。
Outputs
不要跟工具栏中的输出搞混,这里的Outputs是图形、输出这类工具产生的分析结果。例如,下面的数据源连接到矩阵、数据审查、直方图工具,在执行数据流后,这个工具产生了三个输出。在管理区的Outputs
栏中双击这些输出,可看到输出的图形或报表。
Models
经过训练的模型会出现在这一栏中,这就像是真表(Truth Table)的概念那样,训练过的模型可以加入的数据流中用于预测和打分。另外,模型还可以导出为支持PMML协议的XML文件,但是PMML没有给定所有模型的规范,很多厂商都在PMML的基础上对模型内容进行了扩展,Clementine除了可以导出扩展的SPSS SmartScore,还可以导出标准的PMML 3.1。
SPSS Clementine 数据挖掘入门(2)
下面使用Adventure Works数据库中的Target Mail作例子,通过建立分类树和神经网络模型,决策树用来预测哪些人会响应促销,神经网络用来预测年收入。
Target Mail数据在SQL Server样本数据库AdventureWorksDW中的dbo.vTargetMail视图,关于Target Mail 详见:
https://www.doczj.com/doc/4b7118397.html,/zh-cn/library/ms124623.aspx#DataMining
或者我之前的随笔:https://www.doczj.com/doc/4b7118397.html,/esestt/archive/2007/06/06/773705.html
1.定义数据源
将一个Datebase源组件加入到数据流设计区,双击组件,设置数据源为dbo.vTargetMail视图。
在Types栏中点“Read Values”,会自动读取数据个字段的Type、Values等信息。
Values是字段包含的值,比如在数据集中NumberCardsOwned字段的值是从0到4的数,HouseOwnerFlag 只有1和0两种值。Type是依据Values判断字段的类型,Flag类型只包含两种值,类似于boolean;Set是指包含有限个值,类似于enumeration;Ragnge是连续性数值,类似于float。通过了解字段的类型和值,我们可以确定哪些字段能用来作为预测因子,像AddressLine、Phone、DateFirstPurchase等字段是无用的,因为这些字段的值是无序和无意义的。
Direction表明字段的用法,“In”在SQL Server中叫做“Input”,“Out”在SQL Server中叫做“PredictOnly”,“Both”在SQL Server中叫做“Predict”,“Partition”用于对数据分组。
2. 理解数据
在建模之前,我们需要了解数据集中都有哪些字段,这些字段如何分布,它们之间是否隐含着相关性等信息。只有了解这些信息后才能决定使用哪些字段,应用何种挖掘算法和算法参数。
在除了在建立数据源时Clementine能告诉我们值类型外,还能使用输出和图形组件对数据进行探索。
例如先将一个统计组件和一个条形图组件拖入数据流设计区,跟数据源组件连在一起,配置好这些组件后,点上方绿色的箭头。
等一会,然后这两个组件就会输出统计报告和条形图,这些输出会保存在管理区中(因为条形图是高级可视化组件,其输出不会出现在管理区),以后只要在管理区双击输出就可以看打开报告。
3. 准备数据
将之前的输出和图形工具从数据流涉及区中删除。
将Field Ops中的Filter组件加入数据流,在Filter中可以去除不需要的字段。
我们只需要使用MaritalStatus、Gender、YearlyIncome、TatalChildren、NumberChildrenAtHome、EnglishEducation、EnglishOccupation、HouseOwnerFlag、NumberCarsOwned、CommuteDistance、Region、Age、BikeBuyer这些字段。
加入Sample组件做随机抽样,从源数据中抽取70%的数据作为训练集,剩下30%作为检验集。
注意为种子指定一个值,学过统计和计算机的应该知道只要种子不变,计算机产生的伪随机序列是不变的。因为要使用两个挖掘模型,模型的输入和预测字段是不同的,需要加入两个Type组件,将数据分流。
决策树模型用于预测甚麽人会响应促销而购买自行车,要将BikeBuyer字段作为预测列。
神经网络用于预测年收入,需要将YearlyIncome设置为预测字段。
有时候用于预测的输入字段太多,会耗费大量训练时间,可以使用Feature Selection组件筛选对预测字段影响较大的字段。
从Modeling中将Feature Selection字段拖出来,连接到神经网络模型的组件后面,然后点击上方的Execute Selection。
Feature Selection模型训练后在管理区出现模型,右击模型,选Browse可查看模型内容。模型从12个字段中选出了11个字段,认为这11个字段对年收入的影响比较大,所以我们只要用这11个字段作为输入列即可。
将模型从管理区拖入数据流设计区,替换原来的Feature Selection组件。
4. 建模
加入Nearal Net和CHAID模型组件,在CHAID组件设置中,将Mode项设为”Launch interactive session”。然后点上方的绿色箭头执行整个数据流。
Clementine在训练CHAID树时,会开启交互式会话窗口,在交互会话中可以控制树生长和对树剪枝,避免过拟合。如果确定模型后点上方黄色的图标。
完成后,在管理区又多了两个模型。把它们拖入数据流设计区,开始评估模型。
5. 模型评估
修改抽样组件,将Mode改成“Discard Sample”,意思是抛弃之前用于训练模型的那70%数据,将剩下30%数据用于检验。注意种子不要更改。
我这里只检验CHAID决策树模型。将各种组件跟CHAID模型关联。
执行后,得到提升图、预测准确率表……
SPSS聚类分析过程 聚类的主要过程一般可分为如下四个步骤: 1.数据预处理(标准化) 2.构造关系矩阵(亲疏关系的描述) 3.聚类(根据不同方法进行分类) 4.确定最佳分类(类别数) SPSS软件聚类步骤 1. 数据预处理(标准化) →Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择从Transform Values框中点击向下箭头,此为标准化方法,将出现如下可选项,从中选一即可: 标准化方法解释:None:不进行标准化,这是系统默认值;Z Scores:标准化变换;Range –1 to 1:极差标准化变换(作用:变换后的数据均值为0,极差为1,且|x ij*|<1,消去了量纲的影响;在以后的分析计算中可以减少误差的产生。);Range 0 to 1(极差正规化变换/ 规格化变换); 2. 构造关系矩阵 在SPSS中如何选择测度(相似性统计量): →Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择常用测度(选项说明):Euclidean distance:欧氏距离(二阶Minkowski距离),用途:聚类分析中用得最广泛的距离;Squared Eucidean distance:平方欧氏距离;Cosine:夹角余弦(相似性测度;Pearson correlation:皮尔逊相关系数; 3. 选择聚类方法 SPSS中如何选择系统聚类法 常用系统聚类方法 a)Between-groups linkage 组间平均距离连接法 方法简述:合并两类的结果使所有的两两项对之间的平均距离最小。(项对的两成员分属不同类)特点:非最大距离,也非最小距离 b)Within-groups linkage 组内平均连接法 方法简述:两类合并为一类后,合并后的类中所有项之间的平均距离最小 C)Nearest neighbor 最近邻法(最短距离法) 方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法
案例一:转错电话,夫妻不和你们赔吗? 深夜一点,有一位女士来电要求转3115房间。话务员立即将电话直接转入了3115房间。第二天早晨,大堂经理接到3115房间孙小姐的投诉电话,说昨晚的来电不是找她的,她的正常休息因此受到了干扰,希望饭店对此作出解释。大堂副理经调查,了解到该电话要找的是前一位住3115房的客人,他已于昨晚9点退房离店了。孙小姐是快12点时才入住的,她刚洗完澡睡下不久,就被电话吵醒了,你说能不生气吗? 谁知一波未平,一波又起。原住3115房的刘先生紧接着也打来了投诉电话,说昨晚他太太打电话来找他,由于话务员不分青红皂白就将电话接了进去,接电话的又是一位小姐,引起了太太的误会,导致太太跟他翻脸。刘先生说此事破坏了他们的夫妻感情,如果不给他一个圆满的答复,他一定不会放过那个话务员,而且今后他公司的人都不再入住此饭店。 问题:请问这位大堂经理该怎么办? 参考做法: 方法一: 向刘先生解释,刘太太当时确实很肯定地要转3115房,而那房间也没有要求免于打扰,故将电话接进去也无可厚非。而事情偏偏那么凑巧,房间又住进去的是位小姐,从而引起了刘太太的误解。对此,饭店表示遗憾并道歉。请刘先生代为将事情的来龙去脉向刘太太解释清楚,并转达饭店对他们的歉意。 方法二: 向刘先生深表歉意。由于无意之中影响了他们夫妻间的感情,表示饭店一定会对此负责任的。征得刘先生的同意后,向刘太太解释事情的来龙去脉,以期解除其中的误会,求得刘太太的谅解。必要时,可出具证明证实刘先生在当晚9点就已离开了饭店。同时感谢刘先生及时将此事告知饭店,引起了饭店的重视,从而帮助饭店提高服务水平。 启示: 1)操作规范不能忽略一些关键细节。 2)部门应重视每一起案例,总结经验,吸取教训,将坏事变为好事。 案例二:为什么不可以签单 某天下午,一批来自某单位的客人来酒店餐厅用餐。餐后客人提出该单位在店内有两万内存,要求签单。经信用结算组查阅,发现客人所报金额与签单人姓名均与原始记录不符。为了维护签单权益,信用结算组便通知餐务中心该单位并无内存,而宾客坚持称确有内存,一定要签单。餐务中心与客人协调,提出先将本次餐费结清,由帐台出具收条,待有确切证明能够签单,再退还此款,在内存中结算餐费。客人当时表示同意。 过两天,经该单位存款当事人与酒店联系,说明上次餐费可以签单,酒店立刻退还了钱款。而此时宾客以酒店工作有疏漏为由提出投诉,并要求餐费折扣。餐务中心与信用结算组共同向客人解释了缘由,再三说明这也是维护该单位内存的安全以及保密性而执行的一项工作制度,对此事给宾客造成的不便表示歉意,餐务中心给予该单位用餐8.8折优惠,信用结算组也提出将尽快改进工作方法,避免类似的误会发生。 最终,宾客满意而归。 事后,质管办召集两部门针对此投诉进行分析。财务部态度非常积极,提出了一项改进方法,向各内存单位签单人发放临时卡片,其他客人消费时只需出示此卡同样签单有效,能够使工作做得更圆满一些。餐务中心也表示将增强两部位之间的协调与合作,促使服务产品更完美。 案例分析: 餐务中心与信用结算组均体现了积极主动的服务意识和合作精神。 第一,在事件发生过程中,信用结算组在宾客提供的资料与记录不相符时,严格执行专
1.在不同的工作现场中,目视管理的关注对象是有所区别的,一般说来,企业可将目视管理的重点放在( ) 回答:正确 1. A 办公现场的物品、作业、设备等管理中 2. B 员工的工作程序、效率 3. C 物品的流通与保管 4. D 以上都不正确 2.全面质量管理与传统的质量管理相比,具有什么特点( ) 回答:正确 1. A 以适用性为标准 2. B 以人为本 3. C 突出改进的动态性管理 4. D 以上都包括 3.企业对于不要物的处理方法应该遵循什么原则来执行( ) 回答:正确 1. A 申请部门与判定部门分开 2. B 由一个统一的部门来处理不要物 3. C A和B都正确 4. D A和B都不正确 4.下面各项对定点摄影的描述正确的是( ) 回答:正确 1. A 定点摄影简单的说就是拍照 2. B 定点摄影是6S管理推行中必不可少的重要工具 3. C 定点摄影不能督促各部门的整工作 4. D 以上都不正确 5.推行6S管理的企业在清洁时常采用的运作手法是( ) 回答:正确 1. A 红牌作战
2. B 目视管理 3. C 查检表 4. D 以上都包括 6.将物品的形状勾勒出来,将物品放置在对应的图案上,这种管理物品的方法称为( ) 回答:正确 1. A 形迹管理 2. B 形象管理 3. C 图像管理 4. D 直观管理 7.在对各部门评估考核的过程中,对某些污染最严重、实施难度最大的车间,应该( ) 回答:正确 1. A 给予特殊照顾 2. B 采用加权系数综合考评 3. C 和其他车间一视同仁 4. D 不考评 8.企业的6S管理要获得预期的效果,首先要有一个良好的、全方位的过程控制,对于部门来说要做到( ) 回答:正确 1. A 成立6S推行小组 2. B 进行部门内部的宣传教育 3. C A和B都正确 4. D A和B都不正确 9.在整理的过程中,红牌作战的目的与主要任务是( ) 回答:正确 1. A 寻找工作中的失误 2. B 寻找工作场所中可以改善之处 3. C 寻找更高效率的工作方法
基于因子分析和K均值聚类法对河南省经济发展水平研 究 一、因子分析的基本概念 1.1、引言 因子分析的概念起源于20世纪初Karl Pearson和Charles Spearmen 等人关于智力测验的统计分析。目前,因子分析已成功应用于心理学、医学、气象、地址、经济学等领域,并因此促进了理论的不断丰富和完善,它是多元统计分析中典型方法之一。 因子分析也是一种降维、简化数据的技术。它通过研究众多变量之间的内部依赖关系,探究观测数据中的基本结构,并用少数几个“抽象”的变量来表示其基本的数据结构。这几个“抽象”的变量被称作“因子”,能反映原来众多变量的主要信息。原始的变量是可观测的显在变量,而因子一般是不可观测的潜在变量。 因子分析的内容非常丰富,常用的因子分析类型是R型因子分析和Q型因子分析。R型因子分析是对变量作因子分析,Q型因子分析是对样品作因子分析。而本文侧重讨论R型因子分析。 1.2、因子分析模型 因子分析模型中,假定每个原始变量由两部分组成:公共因子和特殊因子。公共因子是各个原始变量所共有的因子,解释变量之间的相关关系。特殊因子顾名思义是每个原始变量所特有的因子,表示该变量不能被公共因子解释的部分。原始变量与因子分析时抽出的公共因子的相关关系用因子负荷表示。 常用的因子分析类型是R型因子分析和Q型因子分析。 (1). R型:从变量的相关阵出发,找出控制所有变量的几个公共因子,
用以对变量或样本进行分类。 (2). Q 型:从样本的相相似据阵出发,找出控制所有样本的几个主要因素。 (一)R 型因子分析的数学模型 R 型因子分析中的公共因子是不可以直接观测但又客观存在的共同影响因素,每一个变量都可以表示成公共因子的线性函数与特殊因子之和,即 i m im i i i F a F a F a X ε++++= 2211 ,p i ,2,1= 上式中的m F F F ,,21称为公共因子,i ε称为i X 的特殊因子。该模型可用矩阵表示为 ε+=AF X 即 这里 ),(21212222111211m pm p p m m A A A a a a a a a a a a A =??????????????= ??????????????=p X X X X 21, ?????? ??????=m F F F F 21, ??????????????=p εεεε 2 1 且满足: (1)p m ≤; (2)0),cov(=εF ,即公共因子与特殊因子是不相关的; 1111122112211222221122m m m m p p p pm m p X a F a F a F X a F a F a F X a F a F a F εεε=++++??=++++????=++ ++ ?
案例11:洗澡时没水了 住在宾馆401房间的王先生早上起来想洗个热水澡放松一下。但洗至一半时,水突然变凉。王先生非常懊恼,匆匆洗完澡后给总台打电话抱怨。接到电话的服务员正忙碌着为前来退房的客人结账,一听客人说没有热水,一边工作一边回答:“对不起,请您向客房中心查询,电话号码是58。”本来一肚子气的王先生一听就来气,嚷道:“你们
饭店怎么搞的,我洗不成澡向你们反映,你竟然让我再拨其他电话!”,说完,“啪”的一声,就把电话挂上了。 处理分析:宾馆的每一位服务员都应树立以顾客为关注焦点的服务意识,不管是谁,只要接到顾客的抱怨,都应主动地向主管部门反映,而不能让顾客再找别的部门反映。本案对客人抱怨的正确回答应该是:“对不起,先生,我马上通知工程部来检修。”然后迅速通知主管部门处理,这样王先生就不会发怒。本案没有做到“顾客沟通”的 道这是酒店的问题,而并不关心这是谁或哪个部门的问题,所以,接待投诉客人,首要的是先解决客人所反映的问题,而不是追究责任,更不能当着客人的面,推卸责任! 给客人多种选择方案 在解决客人投诉中所反映的问题时,往往有多种方案,为了表示对客人的尊重,应征求客人的意见,请客人选择,这也是处理客人投诉的艺术之一。
尽量给客人肯定的答复再就是处理客人投诉时,要不要给自己留有余地的问题。一些酒店管理人员认为,为了避免在处理客人投诉时,使自己陷入被动,一定要给自己留有余地,不能把话说死。比如,不应说:“十分钟可解决。”而应说:“我尽快帮您办”或“我尽最大努力帮您办好”。殊不知,客人,尤其是日本及欧美客人,最反感的就是不把话说死,什么事情都没有个明确的时间概念,正如一位投诉客人所言“贻误时间,欧美和日本客人尤为恼火”。因此,处理客人投诉 、 打开热水龙头,同样是凉水。于是打电话到总台,回答是:“对不起,晚上12点以后,无热水供应。”客人无言以对,心想,该酒店从收费标准到硬件设备,最少应算星级酒店,怎么能12点以后就不供应热水呢?可又一想,既然是酒店的规定,也不好再说什么,只能自认倒霉。“不过,如果您需要的话,我让楼层服务员为您烧一桶热水送到房间,好吗?”还未等客人放下电话,前台小姐又补充道。 “那好啊,多谢了!”客人对酒店能够破例为自己提供服务表示感激。
基于因子分析和聚类分析的客户偏好探究 一文献综述 二十世纪五十年代中期,美国学者温德尔史密斯提出了顾客细分理论。该理论指出,顾客由于其文化观念、收入、消费习俗等方面的不同可以分为不同的消费群体。企业在经营中应该针对不同的顾客提供针对性的服务,这样才能够利用有限资源进行有效的市场竞争。对顾客的细分从方法上讲有根据人口特征和购买历史的细分和根据顾客对企业的价值即基于顾客的消费金额、消费频率的细分。本文的细分是基于购买历史和人口特征的聚类分析。饭店作为一个古老的服务行业,在现阶段的高度竞争市场下的发展趋势最重要的方面便是服务趋于个性化,所以针对饭店的消费群体特征的聚类可以对饭店进行定位,在此基础上通过分析目标客户群体对消费质量评价的最主要影响因素可以达到其服务个性化的目标。波特把顾客的价值定义为买方感知性与购买成本的一种权衡。对顾客的个性化服务增加了买方的感知度从而加大了他们愿意为此付出的成本,于是饭店便可以增加营业额。 聚类分析是把研究对象视作多维空间中的许多点, 并合理地分成若干类,即一种根据变量域之间的相似性而逐步归群成类的方法,它能客观地反映这些变量或区域之间的内在组合关系。1故聚类算法是对顾客进行分析的一个有效方式。在聚类分析的众多算法中因子分析是研究如何以最少的信息丢失, 将众多原始变量浓缩成少数几个因子变量, 以及如何使因子变量具有较强的可解释性的一种多元统计分析方法。2而典型的k-means算法以平方误差准则较好地实现了空间聚类,对于大数据集的处理效率较高。3在对顾客细分相关文献的研究过程中,主要运用的方法有神经网络,分层聚类,因子分析等方法。比如,在关于网络青少年用户的分类中,作者用层次聚类的方法,通过对青少年年龄,性别,民族,网络可得性,父母的观点等变量等变量定义不同的上网动机,在此基础上对其进行了分类。而在研究人寿保险持有者未来购买基金支持寿险可能性的文章中,通过灰度聚类和神经网络利用消费者的基本信息,财产地位信息,风险承受程度将消费者分为了忠实客户和非忠实客户。在对客户忠诚度的聚类中,作者用RFM的商业模型用DBI确定了Kmeans的最优K值,并最终用kmeans对客户忠诚度进行了聚类。 经过综合分析,我们选择了这两种方法处理顾客数据和饭店的基本资料。即,通过 k-means对客户进行聚类后通过因子分析分析不同类别客户的评价影响因素。 为分析每类客户倾向的饭店特征,本文根据客户聚类结果对饭店数据进行筛选。由于饭店部分属性之间具有相关性,本文采用因子分析法挖掘其“根本属性”,之后对饭店数据进 1李蓉, 李宇. 基与主成分分析与聚类分析方法的我国西部区域划分问题的研究. 科技广场, 2李新蕊.主成分分析、因子分析、聚类分析的比较与应用. 山东教育学院学报. 3杨善林.kmeans 算法中的k 值优化问题研究系统工程理论与实践
SPSS软件聚类分析过程的图文解释及结果的全面分析
SPSS聚类分析过程 聚类的主要过程一般可分为如下四个步骤: 1.数据预处理(标准化) 2.构造关系矩阵(亲疏关系的描述) 3.聚类(根据不同方法进行分类) 4.确定最佳分类(类别数) SPSS软件聚类步骤 1. 数据预处理(标准化) →Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择 从Transform Values框中点击向下箭头,此为标准化方法,将出现如下可选项,从中选一即可:
标准化方法解释:None:不进行标准化,这是系统默认值;Z Scores:标准化变换;Range –1 to 1:极差标准化变换(作用:变换后的数据均值为0,极差为1,且|x ij*|<1,消去了量纲的影响;在以后的分析计算中可以减少误差的产生。);Range 0 to 1(极差正规化变换 / 规格化变换); 2. 构造关系矩阵 在SPSS中如何选择测度(相似性统计量): →Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择
常用测度(选项说明):Euclidean distance:欧氏距离(二阶Minkowski距离),用途:聚类分析中用得最广泛的距离;Squared Eucidean distance:平方欧氏距离;Cosine:夹角余弦(相似性测度;Pearson correlation:皮尔逊相关系数; 3. 选择聚类方法 SPSS中如何选择系统聚类法 常用系统聚类方法 a)Between-groups linkage 组间平均距离连接法 方法简述:合并两类的结果使所有的两两项对之
《6S管理实战》课前自评 1. SO 9000是一个品质管理体系,拥有三级文字化的资料,分别是( ) 错误 C正确 ? A .定点照片、质量手册、红牌记录 ? B .质量手册、红牌记录、改进标准 ? C .质量手册、标准程序、记录 ? D .定点照片、记录、程序 2.在不同的工作现场中,目视管理的关注对象是有所区别的,一般说来,企业可将目视管理的重点放在( ) 正确 ? A .办公现场的物品、作业、设备等管理中 ? B .员工的工作程序、效率 ? C .物品的流通与保管 ? D .以上都不正确 3.推行6S管理的企业在清洁时常采用的运作手法是( ) 正确 ? A .红牌作战 ? B .目视管理 ? C .查检表 ? D .D以上都包括 4.6S管理要求及时进行清扫,清扫的目的是( ) 错误 D正确 ? A .培养全员讲卫生的习惯 ? B .创造干净、清爽的工作环境 ? C .使人心情舒畅 ? D .以上都包括 5.将物品的形状勾勒出来,将物品放置在对应的图案上,这种管理物品的方法称为( ) 错误 A正确 ? A .形迹管理 ? B .形象管理 ? C .图像管理 ? D .直观管理
第1讲 6S管理的定位(一) 【本讲重点】 6s管理概述 品质文化及现场管理提升的基础(上) 6S管理概论 6S的基本含义 所谓6S,是指对生产现场各生产要素(主要是物的要素)所处状态不断进行整理、整顿、清洁、清扫、提高素养及安全的活动。如表1-1所示,由于整理(Seiri)、整顿(Seiton)、清扫(Seiso)、清洁(Seiketsu)、素养(Shitsuke)和安全(Safety)这六个词在日语中罗马拼音或英语中的第一个字母是“S”,所以简称6S。 表1-1 6S的含义 中文日文英文典型例子 整理SEIRI Organization 定期处置不用的物品 整顿SEITON Neatness 金牌标准:30秒内就可找到所需物品 清扫SEISO Cleaning 自己的区域自己负责清扫 清洁SEIKETSU Standardization 明确每天的6S时间 素养SHITSUKE Discipline and Training 严守规定、团队精神、文明礼仪 安全SAFETY Safety 严格按照规章、流程作业 6S的其他说法 6S有很多种说法,最基本的内容是5S。西方国家一般将5S定义为分类、定位、刷洗、制度化和标准化,这五个英语单词的首个字母也都是S,如表1-2所示。5S加上安全(Safety)就变成6S,加上节约(Saving)就变成7S,加上服务(Service)就变成8S,再加上顾客满意(Satisfaction)就变成了9S。不管是在哪个国家,5S或6S的说法虽然存在差异,但是内涵都是一致的。 表1-2 西方国家的5S说法 中文英文内容 分类Sort 区分要与不要之物,并将不需要之物清除掉 定位Straighten 将需要的物品合理放置,以利使用 刷洗Scrub 清除垃圾、污物 制度化Systematize 使日常活动及检查工作成为制度
聚类分析原理及步骤——将未知数据按相似程度分类到不同的类或簇的过程 1》传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS等。 典型使用 1》动植物分类和对基因进行分类 2》在网上进行文档归类来修复信息 3》帮助电子商务的用户了解自己的客户,向客户提供更合适的服务 主要步骤 1》数据预处理——选择数量,类型和特征的标度((依据特征选择和抽取)特征选择选择重要的特征,特征抽取把输入的特征转化 为一个新的显著特征,它们经常被用来获取一个合适的特征集来为避免“维数 灾”进行聚类)和将孤立点移出数据(孤立点是不依附于一般数 据行为或模型的数据) 2》为衡量数据点间的相似度定义一个距离函数——既然相类似性是定义一个类的基础,那么不同数据之间在同一个特 征空间相似度的衡量对于聚类步骤是很重要的,由于特征类型和特 征标度的多样性,距离度量必须谨慎,它经常依赖于使用,例如, 通常通过定义在特征空间的距离度量来评估不同对象的相异性,很 多距离度都使用在一些不同的领域一个简单的距离度量,如 Euclidean距离,经常被用作反映不同数据间的相异性,一些有关相
似性的度量,例如PMC和SMC,能够被用来特征化不同数据的概 念相似性,在图像聚类上,子图图像的误差更正能够被用来衡量两 个图形的相似性 3》聚类或分组——将数据对象分到不同的类中【划分方法 (划分方法一般从初始划分和最优化一个聚类标准开始,Cris p Clustering和Fuzzy Clusterin是划分方法的两个主要技术,Crisp Clustering,它的每一个数据都属于单独的类;Fuzzy Clustering,它的 每个数据可能在任何一个类中)和层次方法(基于某个标准产生一 个嵌套的划分系列,它可以度量不同类之间的相似性或一个类的可分 离性用来合并和分裂类)是聚类分析的两个主要方法,另外还有基于 密度的聚类,基于模型的聚类,基于网格的聚类】 4》评估输出——评估聚类结果的质量(它是通过一个类有效索引来 评价,,一般来说,几何性质,包括类间的分离和类内部的耦合,一般 都用来评价聚类结果的质量,类有效索引在决定类的数目时经常扮演 了一个重要角色,类有效索引的最佳值被期望从真实的类数目中获取, 一个通常的决定类数目的方法是选择一个特定的类有效索引的最佳 值,这个索引能否真实的得出类的数目是判断该索引是否有效的标准, 很多已经存在的标准对于相互分离的类数据集合都能得出很好的结 果,但是对于复杂的数据集,却通常行不通,例如,对于交叠类的集 合。) 聚类分析的主要计算方法原理及步骤划分法 1》将数据集分割成K个组(每个组至少包 含一个数据且每一个数据纪录属于且 仅属于一个分组),每个组成为一类2》通过反复迭代的方法改变分组,使得每 一次改进之后的分组方案都较前一次 好(标准就是:同一分组中的记录越近 越好,而不同分组中的纪录越远越好, 使用这个基本思想的算法有:
第4讲 6s管理实战内容(一) 【本讲重点】 整理 整顿概述 整顿—形迹管理(上) 整理 整理的含义与流程 1.整理的含义 整理是指区分需要与不需要的事、物,再对不需要的事、物加以处理。在现场工作环境中,区分需要的和不需要的工具及文件等物品对于提高工作效率是很有必要的。 整理是改善生产现场的第一步。首先应对生产现场摆放和停置的各种物品进行分类,然后对于现场不需要的物品,诸如用剩的材料、多余的半成品、切下的料头、切屑、垃圾、废品、用完的工具、报废的设备、个人生活用品等,应坚决清理出现场。 2.整理的流程 如图3-1所示,整理的流程大致可分为分类、归类、制定基准、判断要与不要、处理以及现场的改善6个步骤。对于6S管理来说,整理的流程中最为重要的步骤就是制定“要不要”、“留不留”的判断基准。如果判断基准没有可操作性,那么整理就无从下手。 图3-1 整理的流程 整理的要点 整理的实施要点就是对生产现场中摆放和停置的物品进行分类,然后按照判断基准区分出物品的使用等级。可见,整理的关键在于制定合理的判断基准。在整理中有三个非常重要的基准:第一、“要与不要”的基准;第二、“场所”的基准;第三、废弃处理的原则。 1.“要与不要”的判断基准 “要与不要”的判断基准应当非常的明确。例如,办公桌的玻璃板下面不允许放置私人照片。表3-1中列出了实施6S管理后办公桌上允许及不允许摆放的物品,通过目视管理,进行有效的标识,就能找出差距,这样才能有利于改正。 表3-1 办公桌上允许及不允许放置的物品
2.“场所”的基准 所谓场所的基准,指的是到底在什么地方要与不要的判断。可以根据物品的使用次数、使用频率来判定物品应该放在什么地方才合适,如表3-2所示。明确场所的标准,不应当按照个人的经验来判断,否则无法体现出6S管理的科学性。 3.“废弃处理”的原则 工作失误、市场变化等因素,是企业或个人无法控制的。因此,不要物是永远存在的。对于不要物的处理方法,通常要按照两个原则来执行:第一、区分申请部门与判定部门;第二,由一个统一的部门来处理不要物。 例如,质检科负责不用物料的档案管理和判定;设备科负责不用设备、工具、仪表、计量器具的档案管理和判定;工厂办公室负责不用物品的审核、判定、申报;采运部、销售部负责不要物的处置;财务部负责不要物处置资金的管理。 “整理”强调使用价值,而不是原购买价值 在6S管理活动的整理过程中,需要强调的重要意识之一就是:我们看重的是物品的使用价值,而不是原来的购买价值。物品的原购买价格再高,如果企业在相当长的时间没有使用该物品的需要,那么这件物品的使用价值就不高,应该处理的就要及时处理掉。 很多企业认为有些物品几年以后可能还会用到,舍不得处理掉,结果导致无用品过多的堆积,既不利于现场的规范、整洁和高效率,又需要付出不菲的存储费用,最为重要的是妨碍了管理人员科学管理意识的树立。因此,现场管理者一定要认识到,规范的现场管理带来的效益远远大于物品的残值处理可能造成的损失。
第28卷 第4期2010年4月科 学 学 研 究 S t u d i e s i nS c i e n c e o f S c i e n c e V o l .28N o .4 A p r .2010 文章编号:1003-2053(2010)04-0508-07 基于聚类-因子分析的科技评价指标体系构建 顾雪松,迟国泰,程 鹤 (大连理工大学管理学院,辽宁大连116024) 摘 要:根据“坚持以人为本,树立全面、协调、可持续的发展观,促进经济社会和人的全面发展”的科学发展观的内涵,从科技投入、科技产出、科技对经济与社会的影响三个方面海选科学技术评价指标,利用R 聚类与因子分析相结合的方法定量筛选指标,构建了科学技术综合评价指标体系。本文的创新与特色:一是通过R 聚类将同一准则层内的指标分类,使不同的类代表科技评价的不同方面。二是通过因子分析筛选出各个类中因子载荷最大的指标、并剔除其他指标,既保证了筛选出的指标在所在类别中对评价结果影响最显著、又避免了同一类指标的信息重复。三是研究结果表明,最终建立的指标体系用18%的指标反映了98%的原始信息。四是通过科技进步贡献率、万元G D P 综合能耗等指标反映了全面、协调与可持续发展的科学发展内涵。五是在国际权威机构典型观点高频指标基础上进行客观数据筛选的指标体系,兼具专家知识和客观实际的双重信息。 关键词:科技评价体系;科技评价指标;科学发展;指标体系中图分类号:N 945.16;F 204 文献标识码:A 收稿日期:2009-06-11;修回日期:2009-10-19 基金项目:国家社会科学基金重大项目(06&Z D 039);大连理工大学人文社会科学研究基金重大项目(D U T H S 2007101) 作者简介:顾雪松(1984-),男,辽宁抚顺人,硕士研究生,研究方向为复杂系统评价。 迟国泰(1955-),男,黑龙江海伦人,教授、博士生导师,博士,研究方向为复杂系统评价。 程 鹤(1983-),女,吉林松原人,博士研究生,研究方向为复杂系统评价。 科学技术评价指标体系的构建是根据“坚持以人为本,树立全面、协调、可持续的发展观,促进经济社会和人的全面发展”的科学发展观的内涵,筛选出对科学技术评价有重要影响的代表性指标。建立合理的指标体系是科学技术评价的关键。如果指标体系不合理,则无论采用什么评价方法,评价结果都不会有任何意义。 (1)科学技术评价指标体系的研究现状一是国外权威机构的评价指标体系。代表性的有经济合作与发展组织(O E C D )[1] 、瑞士洛桑国际管理研究院(I M D )[2] 、世界银行(W o r l dB a n k )[3] 等建立的科学技术评价指标体系。 二是国内权威机构的科技评价指标体系。代表性的有中国科学技术部建立的科技发展评价指标体系 [4] 。 以上两类指标体系虽然权威性强,但是偏向于 宏观层面各个国家科学技术综合竞争力的评价,不适合不同一国之内不同地区微观层面的评价。 三是学术文献整理得出的评价体系。代表性的 有唐炎钊建立的区域科技创新评价指标体系[5] 。 吴强等用文献聚合分析建立的科技评价指标体 系 [6] 。T i s d e l l C l e m 等针对中国的科技体制改革建 立的科技评价指标体系[7] 。S h i n i c h i K o b a y a s h i 等在 日本建立的科技评价指标体系[8] 。H a r i o l f G r u p p 等 建立的评价国家科技政策的指标体系[9] 。 这类指标体系存在反映同一科技信息的多个重复指标,指标体系庞杂。 (2)科学技术评价指标筛选方法的研究现状一是基于专家经验的主观筛选方法。孙兰学从科学技术评价的内涵出发对科技创新评价指标进行筛选 [10] 。专家主观筛选法存在的问题是单纯依靠 指标的含义和个人经验,主观随意性强。 二是客观的评价指标筛选方法。范柏乃等对城市技术创新能力评价指标进行筛选[11] 。郭冰洋筛 选农业科技现代化评价指标 [12] 。赵金楼等建立了 科技创新型企业评价指标阶段式综合筛选方法[13] 。 客观筛选法存在的问题是过度依赖于指标数据,忽 略了指标的实际含义。 DOI :10.16192/j .cn ki .1003-2053.2010.04.021
客户投诉实战案例分析 【内容提要】 结合实际,列举、分析客户服务中的某些案例,以增长实战经验 极端客户投诉处理的实战练习案例 客户:我已经排了二十分钟的队了!你们究竟在做什么?!这么一点事情需要那么长的时间吗?! 【点评分析】 极端客户有些可能是难缠的客户,是很严重的挑战。 根据我们讲到的投诉处理的正确方法和步骤: 第一步,要受理投诉,首先要道歉。 第二步,对事情做出合理的解释,说明原因。 第三步,需要对由此给顾客带来的不便表示同情和理解。 第四步,迅速告知顾客问题的解决方案,并付诸行动。 第五步,再次向顾客表示歉意,表明我们要改进服务的诚意和决心。 第六步,要谢谢客户对企业的惠顾。 这六步做下来就是一个标准的投诉的有效处理。 客户:你们又把我的电话费算错了!我自己算的这个月的电话费最多200元,可你们的电话单上竟然有500元,你们是不是抢钱啊!我一定要你们给我解释清楚不可。不然我就上消协告你们去! 【点评分析】 第一步是立即受理,真诚道歉,缓和气氛,让顾客感到受重视。 第二步对由此给客户带来的不便表示同情和理解。
第三步迅速对事件作出合理的解释,说明原因,争取客户的理解。 第四步告知顾客解决方案,并付诸行动。 第五步再次向顾客表示歉意和今后改进服务的诚意和决心,最后感谢顾客对企业的惠顾。 客户:你们的服务太差劲了!你们在三个星期前就说很快能修好,可是到现在还没有任何消息!你们到底有没有信用啊?我不管!我今天一定要取到机子,否则你们就赔偿我的全部损失! 【点评分析】 (1)受理,道歉,缓和气氛,让对方受到重视。 (2)对由此给顾客带来的不便表示同情和理解,这是很重要的。 (3)马上告诉客户解决方案。 (4)最后再次表示歉意,感谢他的惠顾。 客户:这件事完全是你的责任,我觉得你非常不称职!我现在要见你们经理,把你开除掉! 【点评分析】 步骤、原则和前面大致相同。不同的地方是,需要向客户陈述自己的原因,争取顾客对自己工作的同情和理解—— (1)不是去理解和同情客户了,因为他要求把你开除掉。这时候,需要争取他对你的同情和理解。比如你可以说:“非常抱歉,我刚刚做这项工作时间不长,经验不足,希望您能理解我。确实是因为我的工作给您带来了损失,我再次向您表示歉意。”然后,告诉他解决方案。 (2)再次表达歉意和改进服务的决心:“我以后一定努力改进我的工作,谢谢
聚类分析原理及步骤 ——将未知数据按相似程度分类到不同的类或簇的过程 1》传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚 类法、有序样品聚类、有重叠聚类和模糊聚类等。采用k-均值、k-中 心点等算法的聚类分析工具已被加入到许多着名的统计分析软件包 中,如SPSS、SAS等。 典型应用 1》动植物分类和对基因进行分类 2》在网上进行文档归类来修复信息 3》帮助电子商务的用户了解自己的客户,向客户提供更合适 的服务 主要步骤 1》数据预处理——选择数量,类型和特征的标度((依据特征 选择和抽取)特征选择选择重要的特征,特征抽取把输入的特征转化 为一个新的显着特征,它们经常被用来获取一个合适的特征集来为避 免“维数灾”进行聚类)和将孤立点移出数据(孤立点是不依附 于一般数据行为或模型的数据) 2》为衡量数据点间的相似度定义一个距离函数——既然相类似性是定义一个类的基础,那么不同数据之间在同一个特征空间相似度的衡 量对于聚类步骤是很重要的,由于特征类型和特征标度的多样性,距离度量 必须谨慎,它经常依赖于应用,例如,通常通过定义在特征空间的距离度量
来评估不同对象的相异性,很多距离度都应用在一些不同的领域一个简单的 距离度量,如Euclidean距离,经常被用作反映不同数据间的相异性,一些 有关相似性的度量,例如PMC和SMC,能够被用来特征化不同数据的概念相 似性,在图像聚类上,子图图像的误差更正能够被用来衡量两个图形的相似 性 3》聚类或分组——将数据对象分到不同的类中【划分方法(划分 方法一般从初始划分和最优化一个聚类标准开始,Cris p Clustering和Fuzzy Clusterin是划分方法的两个主要技术,Crisp Clustering,它的每一个数据 都属于单独的类;Fuzzy Clustering,它的每个数据可能在任何一个类中)和 层次方法(基于某个标准产生一个嵌套的划分系列,它可以度量不同类之间 的相似性或一个类的可分离性用来合并和分裂类)是聚类分析的两个主要方法, 另外还有基于密度的聚类,基于模型的聚类,基于网格的聚类】4》评估输出——评估聚类结果的质量(它是通过一个类有效索引来评价,, 一般来说,几何性质,包括类间的分离和类内部的耦合,一般都用来评价聚类 结果的质量,类有效索引在决定类的数目时经常扮演了一个重要角色,类有效 索引的最佳值被期望从真实的类数目中获取,一个通常的决定类数目的方法是 选择一个特定的类有效索引的最佳值,这个索引能否真实的得出类的数目是判 断该索引是否有效的标准,很多已经存在的标准对于相互分离的类数据集合都 能得出很好的结果,但是对于复杂的数据集,却通常行不通,例如,对于交叠 类的集合。) 聚类分析的主要计算方法原理及步骤 划分法 1》将数据集分割成K个组(每个组至少包含一 个数据且每一个数据纪录属于且仅属于一个 分组),每个组成为一类 2》通过反复迭代的方法改变分组,使得每一次 改进之后的分组方案都较前一次好(标准就 是:同一分组中的记录越近越好,而不同分 组中的纪录越远越好,使用这个基本思想的 算法有:K-MEANS算法、K-MEDOIDS算法、
A.《酒店投诉处理案例和方法》1 案例1:重复卖房之后 1 案例2:客人抱怨你的工作 1 案例3:遇到刁难客人 2 案例4:做卫生时不小心损坏了客人的东西 2 案例5:做的蛋糕被别人取走 2 案例6:喝咖啡时结账时间太长 2 案例7:对客人的问话不再理睬 2 案例8:一顾客投诉按摩员工作不够认真 2 案例9:总机叫早不到位 3 案例10:服务员查房报错 3 案例11:洗澡时没水了 3 B.在面对投诉问题时,我们应该怎么办3 C.推荐程序3 D.推荐方法4 E.酒店投诉处理五字诀4 F.处理客人投诉的程序和方法4 G.在接待和处理客人投诉时,要注意以下几点:5 H.、处理投诉时的常用客套话7 I.婉转回决客人的不合理要求7 J.七步有效处理客人投诉. 第一步:表达尊重;例句:8 A.前言:酒店会接待各种各样的客人,因此很有可能会面对各种的投诉。员工在对待客人的投诉时要有正确的心态,客人只是想解决他们的问题,并非刻意为难你。所以尽你的全力帮他们解决困难就好,他们会十分感谢你的。如果确实是客人无理取闹,也要委婉应答。灵活运用语言技巧,把“对”让给客人的同时也要维护酒店和自己的利益。
实例分析: 案例1:重复卖房之后 处理分析:1.接到报告后,应迅速赶到楼层,向客人表示歉意; 2.通知总台重新安排房间,房间尽量安排在本楼层,离原来的房间不要太远,为了方便,房间的格调,大小,方向尽量与原来的相同或略优(不涉及价格规格); 3.房间安排好后,让行李员将房间钥匙和重新写好的欢迎卡送上楼层,带客人到新的房间; 4.真诚地向客人致歉,并酌情赠送鲜花、果品;查找出重复卖房的原因,将其记录在案。 案例2:客人抱怨你的工作 客人发脾气抱怨你的工作时如何处理处理分析:服务员接待客人,是自己的责任,即使挨了客人的骂,也就同样做好接待工作;当客人发脾气时,要保持冷静,待客人平静后再做婉言解释与道歉,绝对不能与客人争吵或谩骂;如果客人的气尚未平息,应及时向领导汇报。 案例3:遇到刁难客人 遇到刁难的客人,你应该以什么样的方法和态度来面对处理分析:由于客人的性情、修养、阶层、年龄、性别等各有不同,客人不时会遇到不如意的事情,心情不愉快,有时就会对我们的服务工作有所挑剔;服务员应在日常的服务工作中的揣摩客人的心理,掌握客人的性格和生活特点,热情、有礼、主动、周到的为客服务,力求将服务工作做在客人开口之前;遇客人刁难,要通过详细了解、细心观察,分析客人刁难的原因,针对性地做好服务工作,注意保持冷静的态度,以礼相待,严于责己,表示歉意,如问题未解决,应向上级反映,做好情况记录。 案例4:做卫生时不小心损坏了客人的东西 做卫生时不小心损坏了客人的东西,怎么办处理分析:做客房卫生时我们应该小心谨慎,特别对客人放在台面上的东西一般都不应该动,有必要移动时也要轻拿轻放,卫生做完要放回原处;如万一不小心损坏客人的物品,应如实向上级反映,并主动向客人道歉(如果物品贵重,应有主管或经理陪同),承认自己的过失;征求客人的意见,客人要求赔偿时,酌情处理 案例5:做的蛋糕被别人取走
讲座8 6S管理的实际内容(5) [本讲座的重点] 实施6S管理的11个步骤 全面和计划的控制 红牌战 现场摄影 实施6S管理的11个步骤 了解6S管理的内容和要领是6S管理的基础。但是,仅仅知道6S的内容还远远不够。取得显著成果的关键是加强6S管理的过程控制。一般而言,实施6S管理包括以下11个步骤: 1.建立执行机构 实施6S管理的第一步是建立实施组织。仅给车间主任配备一些教科书,并给每个干部和员工一些课程,对6S的管理工作就做得不好。 6S管理本身是一种企业行为,因此,实施6S管理必须基于企业。 如图5-1所示,从组织成立之初,公司的董事将是执行委员会的董事,而副董事的职位可以在下面设置。在6S推广委员会中,推广办公室是一个非常重要的职能部门。它负责控制整个6S促销过程,并负责制定相应的标准,系统,竞争方法,奖惩措施。 图5-1推进委员会组织结构图 【案件】 公司制造部门的6S促进委员会的组织结构分为主席,委员会成员,官员和检查员,如下图所示(图
中的人员姓名均为虚构)。其中,委员会成员的主要职责包括:评估审核项目,仲裁6S审核投诉,研究和讨论6S可行解决方案的实施,处理审核过程中的异常问题,及时检查6S的执行情况,制定6S评分表以及各种奖励和处罚规定,并监督6S评估的公平性。 官员的职责包括参加6S审核,保持公平,有权对计分标准提出异议,对实施6S活动提出建议,在所有计分中保持公平,否则会受到严厉惩罚。审核员的权力和职责主要包括:审核制造部门的6S实施,保持公平,在6S实施中积极提出问题和建议,每个审核项目必须由监督员签名,以及拒绝审核的人员。拒绝必须提交给委员会进行处理,每月审核四次,每次审核之间至少间隔三天。 2.制定实施政策和目标 实施6S管理的第二步是制定6S管理的实施政策和最终目标。一些知名公司’6S的实施政策包括:“告别昨天,挑战自我,创造美丽的新形象”,“规范场景和真实物体,提高人们的素质”,“更换设备,改变人员,改变环境,并最终实现企业“质素的根本创新”。 关于实施目标,每个实施部门可以考虑为自己设定一些分阶段的目标,并切实实现这些目标,从而实现企业的整体目标。例如,您可以询问“第四个月每个部门的评估超过90分”,“在一分钟内找到所需文件”。 3.制定实施计划和时间表 实施6S管理的第三步是制定实施计划和相应的时间表,并发布计划,以便每个人都知道实施细节。制定时间表和计划,如表5-1所示,以便相关部门的负责人和整个公司的员工知道应在什么时间内完成哪些工作,例如:何时进入模型区域的选择和何时进行模型区域6S实施以及何时举行模型区域分阶段交流会议。 项目项目 实施6S管理议程 一月二月游行四月可能六月...月 1个促进组织的建立 2 初步准备 3 宣传教育 4 样品区选择
使用SPSS软件进行因子分析和聚类分析的方法 一、方法原理 1.因子分析(FactorAnalysis ) 因子分析是从多个变量指标中选择出少数几个综合变量指标的一种降维的多元统计方法。 我们在多元分析中处理的是多指标的问题,观察指标的增加是为了使研究过程趋于完整,但由于指标太多,使得分析的复杂性增加;同时在实际工作中,指标间经常具备一定的相关性,使得观测数据所放映的信息有重叠,故人们希望用较少的指标代替原来较多的指标,但依然能放映原有的全部信息,于是就产生了因子分析方法。 2.聚类分析(ClusterAnlysis ) 聚类分析是根据事物本身特性来研究个体分类的统计方法,是按照物以类聚的原则来研究的事物分类。 3.市场细分方法的流程图
1理■業2凳| 1因子A 因孑A 1園不&A 1…因€ i zld W余五头冒卓巨云奈蓉跻门彳耳字
、实证分析
总人口d生产总值 〔亿J 消费忌霰 〔亿) 人均年工資 (千) 年度总储番 额丿忑亿 年屢阳政 总收入/亿 1启东币U4 33 153 63 50.27io. as ⑵551O.02 2江郡币10S. 69139. ZB 43.3610. &4119.4211用3丹阳币80. 2E 174 T546. 0113.50 95 81 16.62 4如皋市143 S7 他.7& 37.3611.M33 18gm 5Xft市154. 99103. 29 26.00 10.3T 76.61 7.K 6东台市116. 24135 03 36.02 101.60 35.39 3.30 7 如东县109. 36 102. 57 36.8011.&£33.68 3.37 fi沐阳县174. 54 87. 05 21.35 9.15 空⑷ 3 81 Q邳州市158 0492. 6323.798.664J0.24S.70 10海妄县95. 5493 54 26.4411.5S111.7& 8.51 11油县119. 5086. 60IB. 53 8.8453.51 5. W IL姜堰市90. TO36. 33 31.51 10.96 76.40 3.S2 13 射阳县104. TO96. 15 25.509.60 46.43 5 90 14105. 0073. 50 1^.70g.2S40.61 3 85 15丈丰市73. 3T go. so 21芒一9.8€53 33& 31 1&91. gg S7. 8&20.35 9.7S 47.39 4.83 17建湖县79. L2ei. az 23.269.5146.£1 5.82 10 东海县114. 35 5S 2816.24 a.24S8.O4 3.00 10高邯市03 06 TO. SI 20.95 10.2051.53 5 5C 20107.筍SI. 73 19.29 9.5627.4T 3 0E 21丰县LOQ. 0054 2016.80 8.2S28.8& 2 53 22103. DO56. 70 14 60 9 3927 19 3.00 23琵都县35. 0090. 6022.009,7S12.75 5.01 24枚征市50. 35724Q29.0014.56S2 35 11 2S £5m洪103. 00sa go 12.30T.9E22.0& 3 ZE新沂市S5. GO54 £01T.S0 3 31 Z6 15 3 33 2T谨水县103. 0052. 60 14. TO S.D3 1^.41 2.51 2?谨云县107. 23 10. 02 14.51 7.95 1^.65 1 97 29杼中币27 2480. Id i甘.1813.坨51.22 8.31 ?0肝胎县T3. 2256. 6513^810.00 le.^r 3.06 31踝水县40. E3&】,E5 19.71 13. 9T Z2.23 6. H 芳曜南72. T1 瓯470S6 T .95 11.53 2 W 33响水县57. 00瓯47 a. 9T 3.94 15.3& 2.04 34金湖县36. 0431. 4510.409.3517.5& 2.7^