
多语言市场攻略宝典
多语言市场是为帮助供应商开拓非英语市场而建立的,且独立于阿里巴巴国际站的语种网站体系。现包括西班牙语、葡萄牙语、法语、俄语等12个主流语种,除覆盖传统欧美市场中的非英语买家群体外,南美、俄罗斯等新兴市场更是多语言市场重点的拓展区域。
那么如何通过这片蓝海市场获取更多的商机呢?一起看看小编整理的攻略一本通。
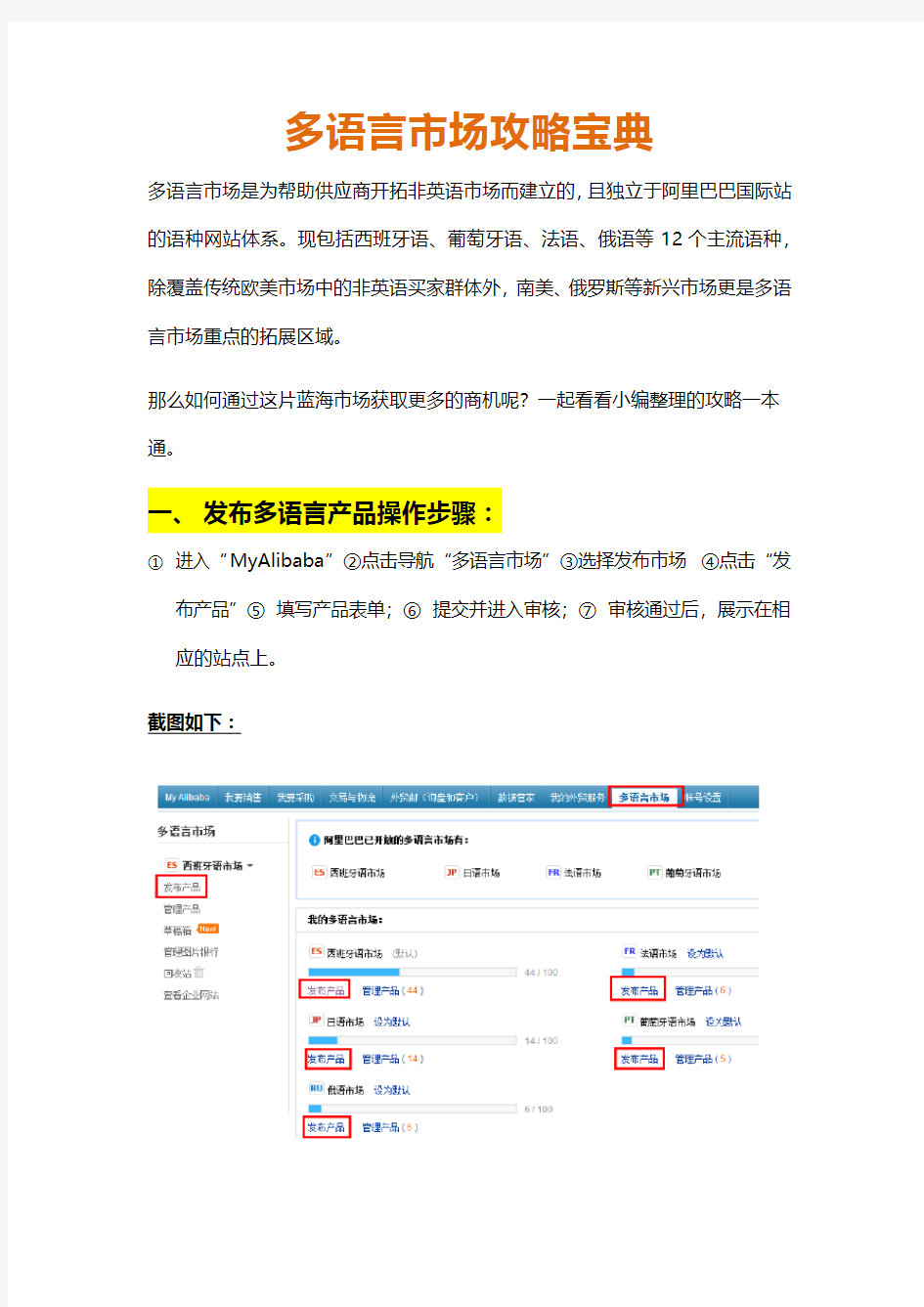
一、发布多语言产品操作步骤:
①进入“MyAlibaba”②点击导航“多语言市场”③选择发布市场④点击“发
布产品”⑤填写产品表单;⑥提交并进入审核;⑦审核通过后,展示在相应的站点上。
二、多语言产品发布技巧:
多语言产品的详细描述与英文产品的发布思路是差不多的。关键词的获取和产品图片略微不同,我们一起看下:
(一)产品关键词
对讲西语的国家而言,同样的产品,不同国家的叫法可能都不同,所以关键词的设置也就不会是完全一样的。符合产品所在国家的关键词才是最容易让客户找到你的关键词。
Tips:
?英文翻译成小语种,可能存在多个译文,此时可进行google的图片搜索,来判断各译文的准确度。
?除了使用翻译软件外,可以通过查阅国外的相关行业网站或者同行网站,然后从他们那边获取产品关键词。
?
攻略内容。
提升攻略:如何选取多语言产品关键词
(二)产品图片:
?图片的特殊性是它是没有语言障碍的限制来传递信息,因此产品图片的质量显得尤为重要,思路即图片清晰,背景以纯色/单一颜色为佳,产品突
出,像素600*600;大小<3MB;产品占图片比重80%,正方形为佳。
(三)产品详细描述:
关于产品信息的内容:建议不要太过复杂,一个原因是使用自己不太擅长的语种,内容越多,出错的概率越大;另一方面,提供最能体现产品特性的内容,更利于客户对产品的了解。
三、翻译工具使用技巧:
翻译工具可选择产品发布表单的“在线翻译”功能,也可使用站外的翻译工具:建议将中文内容转化为英文后再通过翻译工具翻译为小语种,这种方式翻译出来的准确率会更高。
提升攻略:西语产品-翻译工具小技巧
四、如何查看多语言产品的排名
(一)多语言搜索排序的基本原则:
?公平排序:所有会员公平参与排序。(搜索List与关搜产品无关,p4p 产品位占1~5位)
?活跃优先:原发产品优先排序。
?高质量优先:原发产品内排序:原发产品高信息质量优先排序。(二)如何找到自己的小语种网站?
1.原发市场在MA后台通过“查看企业网站”进入自己的小语种网站
2.非原发市场在对应的语种网站上,通过supplier搜索自己公司名称来定位属于自己的小语种网站。
伏魔战记3.9详细攻略 首先,伏魔战记这张图,有3个出生点,4个技能塔,3个专属配件爆点。 3个出生点,4个技能塔,我想没啥可介绍的了。 箱子一共有4种 1、木箱:爆天字套、各类衣服配件1,偶然出衣服配件2 2、铁箱:爆各类衣服配件2,偶然出衣服配件3 3、铜像:爆各类衣服配件3,偶然出武器配件任意1个 4、宝箱:爆各类衣服配件3和武器配件任意1个,正常情况是什么职业打的出什么职业的武器配件,也有时候不出或者出其他职业的武器配件,但是那几率很小。 3个专属配件爆点。 1、雪山:爆法师和弓手的武器配件衣服配件(风神、雷神、水神、冥神衣服配件和武器配件) 2、火山:爆战士职业武器配件衣服配件(火神、土神衣服配件和武器配件) 3、墓地:爆战士职业武器配件衣服配件(战神、死神衣服配件和武器配件) 下面介绍下攻略吧,难4~5的攻略,以3.9I版为准的。 队员配置:基本职业一般为3力1敏3弓,敏只要1个就够了,多了没用;2力是最起码的了,少了不行,拆塔的主力呢。 通关职业配置基本要求:金钱2W、战神1套、死神2~3套、风神2~3套。 堕落天使之翼(魔器): 堕落天使之翼=天使之翼+黑暗之心(打野怪BOSS刷出几率高) 天使之翼: 天使之翼=天使手镯+魔源结晶 天使手镯=活力之戒+生命之戒+幸运之戒 魔源结晶=魔力护符+魔法挂坠+魔力球
魔器
火神套装: 火神套装=火神战铠+火神战刃 火神战铠=沙拉曼德的精神+沙拉曼德的灵魂 沙拉曼德的精神=流光刺刀+火焰护身符+炎之结晶 沙拉曼德的灵魂=暮光指环+火龙臂盾+地狱火炬 火神战刃=魔法剑+赤龙牙+阵法宝石(看人品有时候会合到别的剑例如:死神战
8086汇编指令手册 一、数据传输指令 它们在存贮器和寄存器、寄存器和输入输出端口之间传送数据. 1. 通用数据传送指令. MOV 传送字或字节. MOVSX 先符号扩展,再传送. MOVZX 先零扩展,再传送. PUSH 把字压入堆栈. POP 把字弹出堆栈. PUSHA 把AX,CX,DX,BX,SP,BP,SI,DI依次压入堆栈. POPA 把DI,SI,BP,SP,BX,DX,CX,AX依次弹出堆栈. PUSHAD 把EAX,ECX,EDX,EBX,ESP,EBP,ESI,EDI依次压入堆栈. POPAD 把EDI,ESI,EBP,ESP,EBX,EDX,ECX,EAX依次弹出堆栈. BSWAP 交换32位寄存器里字节的顺序 XCHG 交换字或字节.( 至少有一个操作数为寄存器,段寄存器不可作为操作数) CMPXCHG 比较并交换操作数.( 第二个操作数必须为累加器AL/AX/EAX ) XADD 先交换再累加.( 结果在第一个操作数里) XLAT 字节查表转换. —— BX 指向一张256 字节的表的起点, AL 为表的索引值(0-255,即 0-FFH); 返回AL 为查表结果. ( [BX+AL]->AL ) 2. 输入输出端口传送指令. IN I/O端口输入. ( 语法: IN 累加器, {端口号│DX} ) OUT I/O端口输出. ( 语法: OUT {端口号│DX},累加器) 输入输出端口由立即方式指定时, 其范围是0-255; 由寄存器DX 指定时, 其范围是0-65535. 3. 目的地址传送指令. LEA 装入有效地址. 例: LEA DX,string ;把偏移地址存到DX. LDS 传送目标指针,把指针内容装入DS. 例: LDS SI,string ;把段地址:偏移地址存到DS:SI. LES 传送目标指针,把指针内容装入ES. 例: LES DI,string ;把段地址:偏移地址存到ES:DI. LFS 传送目标指针,把指针内容装入FS. 例: LFS DI,string ;把段地址:偏移地址存到FS:DI. LGS 传送目标指针,把指针内容装入GS. 例: LGS DI,string ;把段地址:偏移地址存到GS:DI. LSS 传送目标指针,把指针内容装入SS. 例: LSS DI,string ;把段地址:偏移地址存到SS:DI. 4. 标志传送指令. LAHF 标志寄存器传送,把标志装入AH. SAHF 标志寄存器传送,把AH内容装入标志寄存器.
eyBuild 中文手册 版本状态文件标识:eyBuild Group 当前版本:0.3.0 作 者:newzy 文件状态: [ ] 草稿 [√] 正式发布 [ ] 正在修改 完成日期: 2006-3-28 修订日志版本 日期 变更位置 变更内容 变更者 0.1.0 2006-1-22 新建 newzy 0.2.0 2006-2-6 全部 完成初版 newzy 0.2.1 2006-2-9 CSP 注释符 修改CSP 注释符 newzy 0.2.2 2006-2-13 头部 CSP 的解释、联系信息等 newzy 2006-3-25 0.3.0 2006-3-28 全文 为eybuild-0.8更新 newzy 更多信息: 请访问eyBuild 的网站 https://www.doczj.com/doc/473983083.html, 或发送email 到: newzy@https://www.doczj.com/doc/473983083.html, , xxt@https://www.doczj.com/doc/473983083.html,
目录 第1章序言 (3) 第2章什么是eyBuild (5) 2.1 CSP与CGI (5) 2.2 为什么要选择eyBuild开发Web站点 (6) 第3章 CSP的语法 (8) 3.1 CSP的语句 (8) 3.2 语句格式 (8) 3.3 CSP的语句行宏定义前缀符 (8) 3.4 CSP的注释前缀符(//) (10) 3.5 CSP的指令前缀符(@) (10) 3.6 CSP的require指令 (11) 3.7 CSP的内建函数前缀符($) (13) 3.8 CSP的字符串输出前缀符(=,=$ 和 =%) (13) 3.9 在CSP中输出总结 (14) 3.10 在CSP中获取输入 (14) 3.11 CGI前缀和ROM前缀 (18) 第4章 eyBuild开发环境简介 (20) 4.1 安装eyBuild (20) 4.2 eyBuild目录结构 (20) 4.3 project 的目录结构 (23) 4.4 什么是虚目录 (23) 4.5 MAP文件 (23) 4.6 WEB2BIN (25) 4.7 CSP2BIN (26) 4.8 DONEMAP (26) 4.9 脚本的入口cgimain() (28) 4.10 CSP 页面内置对象 (29) 第5章建立工程并生成CGI可执行文件 (30) 5.1 建立工程的一般步骤 (30) 5.2 示例 (30) 5.2.1 环境准备: (30) 5.2.2 创建源文件 (30) 5.2.3 配置翻译器 (31) 5.2.4 翻译CSP文件和ROM文件 (32) 5.2.5 创建项目编译环境 (33) 5.2.6 运行结果 (34) 第6章调试 (35) 6.1 用ebSetDebug()调试 (35) 6.2 异常中断调试 (35)
MOV指令为双操作数指令,两个操作数中必须有一个是寄存器. MOV DST , SRC // Byte / Word 执行操作: dst = src 1.目的数可以是通用寄存器, 存储单元和段寄存器(但不允许用CS段寄存器). 2.立即数不能直接送段寄存器 3.不允许在两个存储单元直接传送数据 4.不允许在两个段寄存器间直接传送信息 PUSH入栈指令及POP出栈指令: 堆栈操作是以“后进先出”的方式进行数据操作. PUSH SRC //Word 入栈的操作数除不允许用立即数外,可以为通用寄存器,段寄存器(全部)和存储器. 入栈时高位字节先入栈,低位字节后入栈. POP DST //Word 出栈操作数除不允许用立即数和CS段寄存器外, 可以为通用寄存器,段寄存器和存储器. 执行POP SS指令后,堆栈区在存储区的位置要改变. 执行POP SP 指令后,栈顶的位置要改变. XCHG(eXCHanG)交换指令: 将两操作数值交换. XCHG OPR1, OPR2 //Byte/Word 执行操作: Tmp=OPR1 OPR1=OPR2 OPR2=Tmp 1.必须有一个操作数是在寄存器中 2.不能与段寄存器交换数据 3.存储器与存储器之间不能交换数据. XLAT(TRANSLATE)换码指令: 把一种代码转换为另一种代码. XLAT (OPR 可选) //Byte 执行操作: AL=(BX+AL) 指令执行时只使用预先已存入BX中的表格首地址,执行后,AL中内容则是所要转换的代码. LEA(Load Effective Address) 有效地址传送寄存器指令 LEA REG , SRC //指令把源操作数SRC的有效地址送到指定的寄存器中. 执行操作: REG = EAsrc 注: SRC只能是各种寻址方式的存储器操作数,REG只能是16位寄存器 MOV BX , OFFSET OPER_ONE 等价于LEA BX , OPER_ONE MOV SP , [BX] //将BX间接寻址的相继的二个存储单元的内容送入SP中 LEA SP , [BX] //将BX的内容作为存储器有效地址送入SP中 LDS(Load DS with pointer)指针送寄存器和DS指令 LDS REG , SRC //常指定SI寄存器。 执行操作: REG=(SRC), DS=(SRC+2) //将SRC指出的前二个存储单元的内容送入指令中指定的寄存器中,后二个存储单元送入DS段寄存器中。
GCC中文手册 GCC Section: GNU Tools (1) Updated: 2003/12/05 Index Return to Main Contents NAME gcc,g++-GNU工程的C和C++编译器(egcs-1.1.2) 总览(SYNOPSIS) gcc[option|filename]... g++[option|filename]... 警告(WARNING) 本手册页内容摘自GNU C编译器的完整文档,仅限于解释选项的含义. 除非有人自愿维护,否则本手册页不再更新.如果发现手册页和软件之间有所矛盾,请查对Info文件, Info 文件是权威文档. 如果我们发觉本手册页的内容由于过时而导致明显的混乱和抱怨时,我们就停止发布它.不可能有其他选择,象更新Info文件同时更新man手册,因为其他维护GNU CC的工作没有留给我们时间做这个. GNU工程认为man手册是过时产物,应该把时间用到别的地方. 如果需要完整和最新的文档,请查阅Info文件`gcc'或Using and Porting GNU CC (for version 2. 0) (使用和移植GNU CC 2.0) 手册.二者均来自Texinfo原文件gcc.texinfo. 描述(DESCRIPTION)
C和C++编译器是集成的.他们都要用四个步骤中的一个或多个处理输入文件: 预处理(preprocessing),编译(compilation),汇编(assembly)和连接(linking).源文件后缀名标识源文件的语言,但是对编译器来说,后缀名控制着缺省设定: gcc 认为预处理后的文件(.i)是C文件,并且设定C形式的连接. g++ 认为预处理后的文件(.i)是C++文件,并且设定C++形式的连接. 源文件后缀名指出语言种类以及后期的操作: .c C源程序;预处理,编译,汇编 .C C++源程序;预处理,编译,汇编 .cc C++源程序;预处理,编译,汇编 .cxx C++源程序;预处理,编译,汇编 .m Objective-C源程序;预处理,编译,汇编 .i预处理后的C文件;编译,汇编 .ii预处理后的C++文件;编译,汇编 .s汇编语言源程序;汇编 .S汇编语言源程序;预处理,汇编 .h预处理器文件;通常不出现在命令行上 其他后缀名的文件被传递给连接器(linker).通常包括: .o目标文件(Object file) .a归档库文件(Archive file) 除非使用了-c, -S,或-E选项(或者编译错误阻止了完整的过程),否则连接总是最后的步骤.在连接阶段中,所有对应于源程序的.o文件, -l库文件,无法识别的文件名(包括指定的.o目标文件和.a库文件)按命令行中的顺序传递给连接器.
《伏魔战记》力战攻略心得 《伏魔战记》是一款魔兽多人RPG防守地图,最多能支持7人同时作战,在这款地图中比较有意思的是它的坐骑系统和游戏的随机性。下面给大家介绍一下伏魔战记中的力战攻略: 1、技能:开局必须有加血,2技能可选辅助攻击防御任意一个,后期技能必须有神圣之光5,分身5,闪避5,重生,天神下凡。有人问硬化皮肤和天神下凡那个好,我觉得吧,如果是难5,你根本没经验去升级硬化皮肤不说,到第二幕,硬化皮肤5级才减少伤害40点最小伤害点4点,有毛用啊,还不如1级得天神呢。 2、开局后的各个步骤: (1)开局以后怎么说呢,就是打打就跑,拆一个箱子跑大半圈,而且开局后所有的天字套的装备都要贡献出来,给敏战,给弓手,开局时候你要这些东西一点用没有,敏战走以后你想你拿个天使或者拿个手镯开铜宝,你让弓手怎么办?本来就不好出武器。所以力战只可能是最后一个拿到天使的,而且40分钟之前你的绝大多数时间只能开木箱和铁箱,提供附件。40后如果啥都不差了,非主拆的开始升级,到10级后去火山,在火山拉墓地武器配件合成武器卖钱,先提供钱给敏战,给2500左右其他的给主拆,给主拆4000左右你自己留的差不多够升级了出去升级。主拆力战40后杀黑、赤龙,杀2、3、4、5BOSS,然后开始无限升级。 (2)第二幕力战主要就是拆塔,拆塔顺序一般都是从上路开始,一直从上路拆掉1个兵营后拆神庙,再去下路拆兵营,最后老家。如果多套战神,也可以直接走中路跳到神庙那里拆了神庙,其他俩兵营也是跳进去拆了后拆老家。 还有保险点的打法,就是到上或者下路刷兵那里呆着,放出分身后分身停那里,然后你狂A分身,出黑线了,你就让1个分身跟着黑线跑,你还在那里A分身,如此几次后你再进去,收拾收拾就是一片塔没了。难度3的时候你可以一直这样卡黑线,能把老家卡到剩一半血。如果你直接过去拆塔,那要狂摁S或者H,出黑线技能,要不你那点攻击不够干啥的。再就是带个传送,快死了传送回来,不然BOSS升级后打你很疼。 参考自:3d小游戏https://www.doczj.com/doc/473983083.html,
8086/8088指令系统记忆表 数据寄存器分为: AH&AL=AX(accumulator):累加寄存器,常用于运算;在乘除等指令中指定用来存放操作数,另外,所有的I/O指令都使用这一寄存器与外界设备传送数据. BH&BL=BX(base):基址寄存器,常用于地址索引; CH&CL=CX(count):计数寄存器,常用于计数;常用于保存计算值,如在移位指令,循环(loop)和串处理指令中用作隐含的计数器. DH&DL=DX(data):数据寄存器,常用于数据传递。他们的特点是,这4个16位的寄存器可以分为高8位: AH, BH, CH, DH.以及低八位:AL,BL,CL,DL。这2组8位寄存器可以分别寻址,并单独使用。 另一组是指针寄存器和变址寄存器,包括: SP(Stack Pointer):堆栈指针,与SS配合使用,可指向目前的堆栈位置; BP(Base Pointer):基址指针寄存器,可用作SS的一个相对基址位置; SI(Source Index):源变址寄存器可用来存放相对于DS段之源变址指针; DI(Destination Index):目的变址寄存器,可用来存放相对于ES 段之目的变址指针。 指令指针IP(Instruction Pointer) 标志寄存器FR(Flag Register) OF(overflow flag) DF(direction flag) CF(carrier flag) PF(parity flag) AF(auxiliary flag) ZF(zero flag) SF(sign flag) IF(interrupt flag) TF(trap flag) 段寄存器(Segment Register) 为了运用所有的内存空间,8086设定了四个段寄存器,专门用来保存段地址: CS(Code Segment):代码段寄存器; DS(Data Segment):数据段寄存器; SS(Stack Segment):堆栈段寄存器;
第4章初始化与清除 第2章利用了一些分散的典型C语言库的构件,并把它们封装在一个s t r u c t中,从而在库的应用方面做了有意义的改进。(从现在起,这个抽象数据类型称为类)。 这样不仅为库构件提供了单一一致的入口指针,也用类名隐藏了类内部的函数名。在第3章中,我们介绍了存取控制(隐藏实现),这就为类的设计者提供了一种设立界线的途径,通过界线的设立来决定哪些是用户可以处理的,哪些是禁止的。这意味着数据类型的内部机制对设计者来说是可控的和能自行处理的。这样让用户也清楚哪些成员是他们能够使用并加以注意的。 封装和实现的隐藏大大地改善了库的使用。它们提供的新的数据类型的概念在某些方面比从C中继承的嵌入式数据类型要好。现在C ++编译器可以为这种新的数据类型提供类型检查,这样在使用这种数据类型时就确保了一定的安全性。 当然,说到安全性,C ++的编译器能比C编译器提供更多的功能。在本章及以后的章节中,我们将看到许多C ++的另外一些性能。它们可以让我们程序中的错误暴露无遗,有时甚至在我们编译这个程序之前,帮我们查出错误,但通常是编译器的警告和出错信息。所以我们不久就会习惯:在第一次编译时总听不到编译器那意味着正确的提示音。 安全性包括初始化和清除两个方面。在C语言中,如果程序员忘记了初始化或清除一个变量,就会导致一大段程序错误。这在一个库中尤其如此,特别是当用户不知如何对一个s t r u c t 初始化,甚至不知道必须要初始化时。(库中通常不包含初始化函数,所以用户不得不手工初始化s t r u c t)。清除是一个特殊问题,因为C程序员一旦用过了一个变量后就把它忘记了,所以对一个库的s t r u c t来说,必要的清除工作往往被遗忘了。 在C ++中,初始化和清除的概念是简化类库使用的关键所在,并可以减少那些由于用户忘记这些操作而引起的许多细微错误。本章就来讨论C ++的这些特征。 4.1 用构造函数确保初始化 在s t a s h和s t a c k类中都曾调用i n i t i a l i z e()函数,这暗示无论用什么方法使用这些类的对象,在使用之前都应当调用这一函数。很不幸的是,这要求用户必须正确地初始化。而用户在专注于用那令人惊奇的库来解决他们的问题的时候,往往忽视了这些细节。在C ++中,初始化实在太重要了,所以不能留给用户来完成。类的设计者可以通过提供一个叫做构造函数的特殊函数来保证每个对象都正确的初始化。如果一个类有构造函数,编译器在创建对象时就自动调用这一函数,这一切在用户使用他们的对象之前就已经完成了。对用户来说,是否调用构造函数并不是可选的,它是由编译器在对象定义时完成的。 接下来的问题是这个函数叫什么名字。这必须考虑两点,首先这个名字不能与类的其他成员函数冲突,其次,因为该函数是由编译器调用的,所以编译器必须总能知道调用哪个函数。S t r o u s t r u p的方法似乎是最容易也是最符合逻辑的:构造函数的名字与类的名字一样。这使得这样的函数在初始化时自动被调用。 下面是一个带构造函数的类的简单例子:
C语言库函数参考手册 转载说明:可能有些函数已经过时,但从学习的角度来看,还是有一定的参考价值。 分类函数,所在函数库为ctype.h int isalpha(int ch) 若ch是字母('A'-'Z','a'-'z')返回非0值,否则返回0 int isalnum(int ch) 若ch是字母('A'-'Z','a'-'z')或数字('0'-'9') 返回非0值,否则返回0 int isascii(int ch) 若ch是字符(ASCII码中的0-127)返回非0值,否则返回0 int iscntrl(int ch) 若ch是作废字符(0x7F)或普通控制字符(0x00-0x1F) 返回非0值,否则返回0 int isdigit(int ch) 若ch是数字('0'-'9')返回非0值,否则返回0 int isgraph(int ch) 若ch是可打印字符(不含空格)(0x21-0x7E)返回非0值,否则返回0 int islower(int ch) 若ch是小写字母('a'-'z')返回非0值,否则返回0 int isprint(int ch) 若ch是可打印字符(含空格)(0x20-0x7E)返回非0值,否则返回0 int ispunct(int ch) 若ch是标点字符(0x00-0x1F)返回非0值,否则返回0 int isspace(int ch) 若ch是空格(' '),水平制表符('\t'),回车符('\r'), 走纸换行('\f'),垂直制表符('\v'),换行符('\n') 返回非0值,否则返回0 int isupper(int ch) 若ch是大写字母('A'-'Z')返回非0值,否则返回0 int isxdigit(int ch) 若ch是16进制数('0'-'9','A'-'F','a'-'f')返回非0值, 否则返回0 int tolower(int ch) 若ch是大写字母('A'-'Z')返回相应的小写字母('a'-'z') int toupper(int ch) 若ch是小写字母('a'-'z')返回相应的大写字母('A'-'Z') 数学函数,所在函数库为math.h、stdlib.h、string.h、float.h int abs(int i) 返回整型参数i的绝对值 double cabs(struct complex znum) 返回复数znum的绝对值 double fabs(double x) 返回双精度参数x的绝对值 long labs(long n) 返回长整型参数n的绝对值 double exp(double x) 返回指数函数ex的值 double frexp(double value,int *eptr) 返回value=x*2n中x的值,n存贮在eptr中double ldexp(double value,int exp); 返回value*2exp的值 double log(double x) 返回logex的值 double log10(double x) 返回log10x的值 double pow(double x,double y) 返回xy的值 double pow10(int p) 返回10p的值 double sqrt(double x) 返回+√x的值 double acos(double x) 返回x的反余弦cos-1(x)值,x为弧度double asin(double x) 返回x的反正弦sin-1(x)值,x为弧度double atan(double x) 返回x的反正切tan-1(x)值,x为弧度double atan2(double y,double x) 返回y/x的反正切tan-1(x)值,y的x为弧度
寄存器与存储器 1. 寄存器功能 . 寄存器的一般用途和专用用途 . CS:IP 控制程序执行流程 . SS:SP 提供堆栈栈顶单元地址 . DS:BX(SI,DI) 提供数据段内单元地址 . SS:BP 提供堆栈内单元地址 . ES:BX(SI,DI) 提供附加段内单元地址 .AX,CX,BX和CX寄存器多用于运算和暂存中间计算结果,但又专用于某些指令(查阅指令表)。 PSW程序状态字寄存器只能通过专用指令( LAHF,SAHF和堆栈(PUSHF,POPF进行存取。 2. 存储器分段管理 . 解决了16 位寄存器构成20 位地址的问题 . 便于程序重定位 . 20 位物理地址= 段地址* 16 + 偏移地址 . 程序分段组织: 一般由代码段,堆栈段,数据段和附加段组成,不设置堆栈段时则使用系统内部的堆栈。 3. 堆栈 . 堆栈是一种先进后出的数据结构, 数据的存取在栈顶进行, 数据入栈使堆栈向地址减小的方向扩展。 . 堆栈常用于保存子程序调用和中断响应时的断点以及暂存数据或中间计算结果。 .堆栈总是以字为单位存取 指令系统与寻址方式 1. 指令系统 . 计算机提供给用户使用的机器指令集称为指令系统,大多数指令为双操作数指令。执行指令后,一般源操作数不变,目的操作数被计算结果替代。 .机器指令由CPU执行,完成某种运算或操作,8086/8088指令系统中的指令分为6类:数据 传送,算术运算,逻辑运算,串操作,控制转移和处理机控制。 2. 寻址方式 . 寻址方式确定执行指令时获得操作数地址的方法 . 分为与数据有关的寻址方式(7 种)和与转移地址有关的寻址方式(4)种。 . 与数据有关的寻址方式的一般用途: (1) 立即数寻址方式--将常量赋给寄存器或存储单元 (2) 直接寻址方式--存取单个变量 (3) 寄存器寻址方式--访问寄存器的速度快于访问存储单元的速度 (4) 寄存器间接寻址方式--访问数组元素 (5) 变址寻址方式 (6) 基址变址寻址方式 (7) 相对基址变址寻址方式(5),(6),(7)都便于处理数组元素 .与数据有关的寻址方式中,提供地址的寄存器只能是BX,SI,DI或BP . 与转移地址有关的寻址方式的一般用途: (1) 段内直接寻址--段内直接转移或子程序调用 (2)段内间接寻址--段内间接转移或子程序调用 (3)段间直接寻址--段间直接转移或子程序调用 (4)段间间接寻址--段间间接转移或子程序调用
版权说明: 本资料内容摘录自《C程序设计语言(第二版)》K&R著 徐宝文 李志译 尤晋元审校 机械工业出版社出版 一书。版权属原作者和出版社所有。制作本资料为了我本人学习和参考,非商业用途。 建议读者阅读原书学习比较好,它更详细。 目录: A.12 预处理 主要介绍预处理器的功能和预处理的过程。 A.12.1三字符序列 主要介绍 ??=, ??(, ??<等三字符序列。 A.12.2 行连接 主要介绍反斜杠\结束的指令行处理过程。 A.12.3 宏定义和扩展 主要介绍#define 标识符 记号序列,#define 标识符(标识符表opt) 记号序列,#undef 标识符,还有#和##等一些东西,有一些例子。 A.12.4 文件包含 主要介绍#include <文件名>和#include “文件名”指令。 A.12.5 条件编译 介绍#if 常量表达式/#ifdef 标识符/#ifndef 标识符,#elif 常量表达式,#else, #endif语句。 A.12.6 行控制 介绍#line指令。 A.12.7 错误信息生成 介绍#error指令。 A.12.8 pragma 介绍#pragma。 A.12.9 空指令 介绍空指令#。 A.12.10 预定义名字 介绍__LINE__, __FILE__, __DATE__, __TIME__, __STDC__等。
A.12 预处理 返回目录 预处理器执行宏替换,条件编译以及包含指定的文件。以#开头的命令行(“#”前可以有空格)就是预处理器处理的对象。这些命令行的语法独立于语言的其它部分,他们可以出现在任何地方,其作用可以延续到所在编译单元的末尾(与作用域无关)。行边界是有实际意义的;每一行都将单独进行分析(有关如何将行连接起来的详细信息参考A.12.2节)。对预处理器而言,记号可以是任何语言记号,也可以是类似于#include指令(参见A.12.4节)中表示文件名的字符序列。此外,所有未进行其它定义的字符都将被认为是记号。但是,在预处理器指令行中,除空格,横向制表符外的其它空白字符的作用是没有定义的。 预处理过程在逻辑上可以划分为几个连续的阶段(在某些特殊的实现中可以缩减)。 1) 首先,将A.12.1节所述的三字符序列替换为等价字符。如果操作系统环境需要,还要在原文件的各行 之间插入换行符。 2) 将指令行中位于换行符前的反斜杠符\删掉,以把各指令行连接起来(参见A.12.2节)。 3) 程序分成用空白符分割的记号。注释将被替换为一个空白符。接着执行预处理指令,并且进行宏扩展 (参见A.12.3节~A.12.10节)。 4) 将字符常量和字符串字面值中的转义字符序列替换为等价字符,然后把相邻的字符串字面值连接起来。 5) 收集必要的程序和数据,并将外部函数和对象的引用与其定义连接,翻译经过以上处理的结果,然后与 其它程序和库连接起来。 A.12.1 三字符序列 返回目录 C语言源程序的字符集是7位ASCII码的子集,但它是ISO 646-1983不变代码集的超集。为了将程序通过这种缩减的字符集表示出来,下列所示的所有三字符序列都要用相应的单个字符替换,这种替换在进行所有其它处理之前进行。 ??= # ??( [ ??< { ??/ \ ??) ] ??> } ??’ ^ ??! | ??- ~ 除此之外不进行其它替换。 说明:三字符序列是ANSI标准新引入的特征。 A.12.2 行连接 通过将以反斜杠\结束的指令行末尾的反斜杠和其后的换行符删除掉,可以将若干指令行合并一行。这种处理要在分隔记号之前进行。 A.12.3 宏定义和扩展 返回目录 类似于下列形式的控制指令: #define 标识符 记号序列 将使得预处理器把该标识符后续出现的各个实例用给定的记号序列替换。记号序列前后的空白符将被丢弃掉。第二次用#define指令定义同一个标识符是错误的,除非第二次定义的标记序列与第一次相同(所有的空白分隔符将被认为是相同的)。 类似于下列形式的指令行: #define 标识符(标识符表opt) 记号序列 是一个带有形式参数(由标识符表指定)的宏定义,其中第一个标识符与圆括号(之间没有空格。同第一种形式一样,记号序列前后的空白符都将被丢掉。如果要对宏进行重新定义,则必须保证其形式参数个数、拼写及记号序列都必须与前面的定义相同。 类似于下列的控制指令: #undef 标识符
伏魔战记单通秘籍 说真的不开秘籍想完成单通是非常困难的,大家可以尝试,我在试验的过程中是开了秘籍的。 主要用到两个秘籍,一个是whosyourdaddy,也就是无敌秘籍。 一个是thedudeabides即快速刷新技能的秘籍。 注:这个秘籍在使用的过程中必须不断的输入,输入一次启用秘籍,输入第二次取消秘籍,在输入一次,这时所有的技能会刷新,为什么要用到这个技能,因为这涉及到单通所必须的一个环节,即自己招兵。 讲了上面的,就说道为什么要用这个秘籍,没错,稍微熟悉战记的人都知道,有个boss会掉落一本书(好像是第一幕的第三个boss),这本书在你学习了心灵之火和烈焰风暴(必须是满级5级),然后点这本书,就会学习到一个新的技能,召唤火人。 然后,想要单通必须选择法系英雄,因为第二幕的护送任务,所有的人都知道一个人是完不成的,所以,如果你选了法系英雄并且出道了精灵王套装,你就回召唤一个树人,而这个树人就是你单通的关键。 最后讲一下我个人单通时的一些技巧,第一幕的时候必须快速的刷出天使之翼和精灵王套装,如果一直无法刷出灵木法杖,那最好重来,如果时间充沛可以选择抓个龙坐骑。在完成这些后找到一个方尖碑刷怪大钱,学习和升级技能光环,一定要合成火人,如果钱实在不够的话可以考虑用秘籍keysersoze 1000000(迅速得到1000000元) 进入第二幕后,前面好守,在进入第八波的时候,召唤一个树人m住大将军,然后英雄往池塘走,在大贤者即即将走的道路上把怪堵住,这个过程中一直召唤火人回去守家,这是实现单通最关键的一个环节,英雄一定要一直走在大贤者的前面替大贤者开道,然后在到达传送阵的时候,英雄m住大贤者,专心ob到树人和大将军,操从树人保护大将军,英雄可以不管。 至于英雄技能方面,最好在火人的基础上学习两个治疗技能(做好是群加血技能和瞬间加血技能,如果不是就删掉重学)两个攻击技能(我个人偏向飓风和霜风,方便为大贤者开道和加血) 最后,一次你未必会实现成功,所以在进入第二幕第7波怪的时候,最好保存一下游戏,方便自己重来。以上就是所有的单通技巧,祝你单通成功。嘿嘿。
数据传输指令 ───────────────────────────────────────它们在存贮器和寄存器、寄存器和输入输出端口之间传送数据. 1. 通用数据传送指令. MOV 传送字或字节. MOVSX 先符号扩展,再传送. MOVZX 先零扩展,再传送. PUSH 把字压入堆栈. POP 把字弹出堆栈. PUSHA 把AX,CX,DX,BX,SP,BP,SI,DI依次压入堆栈. POPA 把DI,SI,BP,SP,BX,DX,CX,AX依次弹出堆栈. PUSHAD 把EAX,ECX,EDX,EBX,ESP,EBP,ESI,EDI依次压入堆栈. POPAD 把EDI,ESI,EBP,ESP,EBX,EDX,ECX,EAX依次弹出堆栈. BSWAP 交换32位寄存器里字节的顺序 XCHG 交换字或字节.( 至少有一个操作数为寄存器,段寄存器不可作为操作数) CMPXCHG 比较并交换操作数.( 第二个操作数必须为累加器AL/AX/EAX ) XADD 先交换再累加.( 结果在第一个操作数里 ) XLAT 字节查表转换. ── BX 指向一张 256 字节的表的起点, AL 为表的索引值 (0-255,即 0-FFH); 返回 AL 为查表结果. ( [BX+AL]->AL ) 2. 输入输出端口传送指令. IN I/O端口输入. ( 语法: IN 累加器, {端口号│DX} ) OUT I/O端口输出. ( 语法: OUT {端口号│DX},累加器 ) 输入输出端口由立即方式指定时, 其范围是 0-255; 由寄存器 DX 指定时, 其范围是 0-65535. 3. 目的地址传送指令. LEA 装入有效地址. 例: LEA DX,string ;把偏移地址存到DX. LDS 传送目标指针,把指针内容装入DS. 例: LDS SI,string ;把段地址:偏移地址存到DS:SI. LES 传送目标指针,把指针内容装入ES. 例: LES DI,string ;把段地址:偏移地址存到ES:DI. LFS 传送目标指针,把指针内容装入FS. 例: LFS DI,string ;把段地址:偏移地址存到FS:DI. LGS 传送目标指针,把指针内容装入GS. 例: LGS DI,string ;把段地址:偏移地址存到GS:DI. LSS 传送目标指针,把指针内容装入SS. 例: LSS DI,string ;把段地址:偏移地址存到SS:DI. 4. 标志传送指令. LAHF 标志寄存器传送,把标志装入AH. SAHF 标志寄存器传送,把AH内容装入标志寄存器. PUSHF 标志入栈. POPF 标志出栈. PUSHD 32位标志入栈.
C h a p t e r1I n t r o d u c t i o n 1.1W h a t i s l i n g u i s t i c s? 1.1.1D e f i n i t i o n ★Linguistics is generally defined as the scientific study of language. 1.1.2T h e s c o p e o f l i n g u i s t i c s语言学范畴 Phonetics语音学/Phonology音系学/Morphology形态学/Syntax句法学/Semantics 语义学/Pragmatics语用学 Macrolinguistics宏观语言学: sociolinguistics社会语言学/Psycholinguistics心理语言学/Applied linguistics应用语言学 1.1.3I m p o r t a n t d i s t i n c t i o n s i n l i n g u i s t i c s语言学中重要区别 1) prescriptive vs. descriptive 规定性与描述性 2) synchronic vs. diachronic 共时性与历时性Saussure 3) speech & writing 口语和书面语 4) langue & parole 语言(抽象)和言语(具体) Saussure 5) competence & performance 能力和运用Chomsky 6) traditional grammar & modern linguistics 传统语法和现代语言学 ★索绪尔——现代语言学之父 1.2W h a t i s l a n g u a g e? 1.2.1D e f i n i t i o n o f l a n g u a g e ★Language is a system of arbitrary vocal symbols used for human communication. 1.2.2D e s i g n f e a t u r e s o f l a n g u a g e语言的区别性特征H o c k e t t (1) Arbitrariness任意性:符号的音与义之间没有逻辑联系。比如说,不同的语言使用不同的音指相同的事物。
X86汇编语言学习手记 X86汇编语言学习手记(1) 1. 编译环境 OS: Solaris 9 X86 Compiler: gcc 3.3.2 Linker: Solaris Link Editors 5.x Debug Tool: mdb Editor: vi 注:关于编译环境的安装和设置,可以参考文章:Solaris 上的开发环境安装及设置。 mdb是Solaris提供的kernel debug工具,这里用它做反汇编和汇编语言调试工具。 如果在Linux平台可以用gdb进行反汇编和调试。 2. 最简C代码分析 为简化问题,来分析一下最简的c代码生成的汇编代码: # vi test1.c int main() { return 0; } 编译该程序,产生二进制文件: # gcc test1.c -o test1 # file test1 test1: ELF 32-bit LSB executable 80386 Version 1, dynamically linked, not stripped test1是一个ELF格式32位小端(Little Endian)的可执行文件,动态链接并且符号表没有去除。 这正是Unix/Linux平台典型的可执行文件格式。 用mdb反汇编可以观察生成的汇编代码: # mdb test1 Loading modules: [ libc.so.1 ]
> main::dis ; 反汇编main函数,mdb的命令一般格式为<地址>::dis main: pushl %ebp ; ebp寄存器内容压栈,即保存main函数的上级调用函数的栈基地址 main+1: movl %esp,%ebp ; esp值赋给ebp,设置main函数的栈基址main+3: subl $8,%esp main+6: andl $0xf0,%esp main+9: movl $0,%eax main+0xe: subl %eax,%esp main+0x10: movl $0,%eax ; 设置函数返回值0 main+0x15: leave ; 将ebp值赋给esp,pop先前栈内的上级函数栈的基地址给ebp,恢复原栈基址 main+0x16: ret ; main函数返回,回到上级调用 > 注:这里得到的汇编语言语法格式与Intel的手册有很大不同,Unix/Linux采用AT&T 汇编格式作为汇编语言的语法格式 如果想了解AT&T汇编可以参考文章:Linux AT&T 汇编语言开发指南问题:谁调用了main函数? 在C语言的层面来看,main函数是一个程序的起始入口点,而实际上,ELF可执行文件的入口点并不是main而是_start。 mdb也可以反汇编_start: > _start::dis ;从_start 的地址开始反汇编 _start: pushl $0 _start+2: pushl $0 _start+4: movl %esp,%ebp _start+6: pushl %edx _start+7: movl $0x80504b0,%eax _start+0xc: testl %eax,%eax _start+0xe: je +0xf <_start+0x1d> _start+0x10: pushl $0x80504b0 _start+0x15: call -0x75
汇编语言指令以及伪指令速查手册 它们在存贮器和寄存器、寄存器和输入输出端口之间传送数据. 1.通用数据传送指令. MOV传送字或字节. MOVSX先符号扩展,再传送. MOVZX先零扩展,再传送. PUSH把字压入堆栈. POP把字弹出堆栈. PUSHA把AX,CX,DX,BX,SP,BP,SI,DI依次压入堆栈. POPA把DI,SI,BP,SP,BX,DX,CX,AX依次弹出堆栈. PUSHAD把EAX,ECX,EDX,EBX,ESP,EBP,ESI,EDI依次压入堆栈. POPAD把EDI,ESI,EBP,ESP,EBX,EDX,ECX,EAX依次弹出堆栈. BSWAP交换32位寄存器里字节的顺序 XCHG交换字或字节.(至少有一个操作数为寄存器,段寄存器不可作为操作数) CMPXCHG比较并交换操作数.(第二个操作数必须为累加器AL/AX/EAX) XADD先交换再累加.(结果在第一个操作数里) XLAT字节查表转换. ──BX指向一张256字节的表的起点,AL为表的索引值(0-255,即 0-FFH);返回AL为查表结果.([BX+AL]->AL) 2.输入输出端口传送指令. IN I/O端口输入.(语法:IN累加器,{端口号│DX}) OUT I/O端口输出.(语法:OUT{端口号│DX},累加器) 输入输出端口由立即方式指定时,其范围是0-255;由寄存器DX指定时, 其范围是0-65535. 3.目的地址传送指令. LEA装入有效地址. 例:LEA DX,string;把偏移地址存到DX. LDS传送目标指针,把指针内容装入DS. 例:LDS SI,string;把段地址:偏移地址存到DS:SI. LES传送目标指针,把指针内容装入ES. 例:LES DI,string;把段地址:偏移地址存到ES:DI. LFS传送目标指针,把指针内容装入FS. 例:LFS DI,string;把段地址:偏移地址存到FS:DI. LGS传送目标指针,把指针内容装入GS. 例:LGS DI,string;把段地址:偏移地址存到GS:DI. LSS传送目标指针,把指针内容装入SS. 例:LSS DI,string;把段地址:偏移地址存到SS:DI. 4.标志传送指令. LAHF标志寄存器传送,把标志装入AH. SAHF标志寄存器传送,把AH内容装入标志寄存器. PUSHF标志入栈. POPF标志出栈.