毛毛雨:AM 3885999
RHCS 基于 RHEL6.0 x86_64(实验教程) 实验说明:所用的RHEL 版本均为 6.0 x86_64,宿主机支持虚拟化,内存不小于4G。
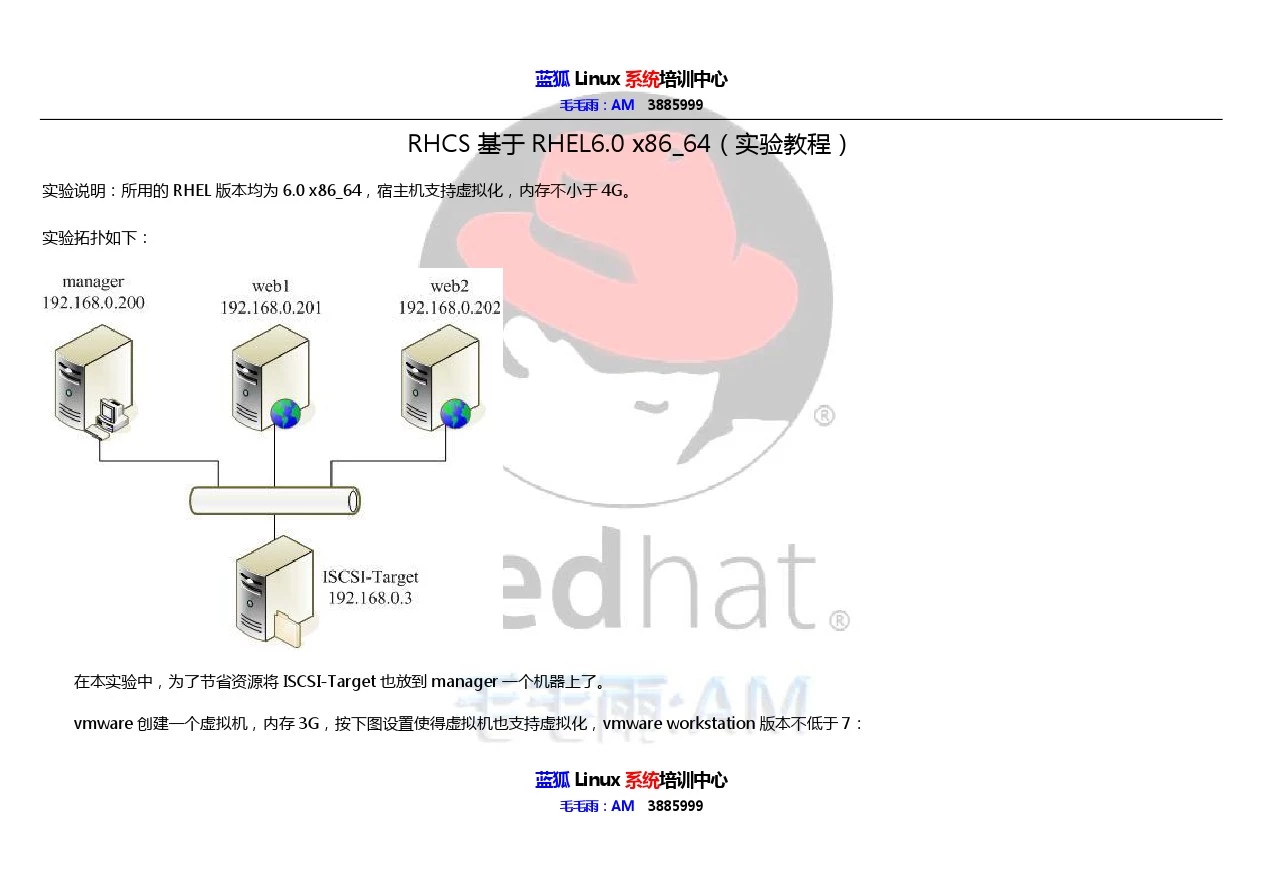
实验拓扑如下:
在本实验中,为了节省资源将 ISCSI-Target 也放到 manager 一个机器上了。
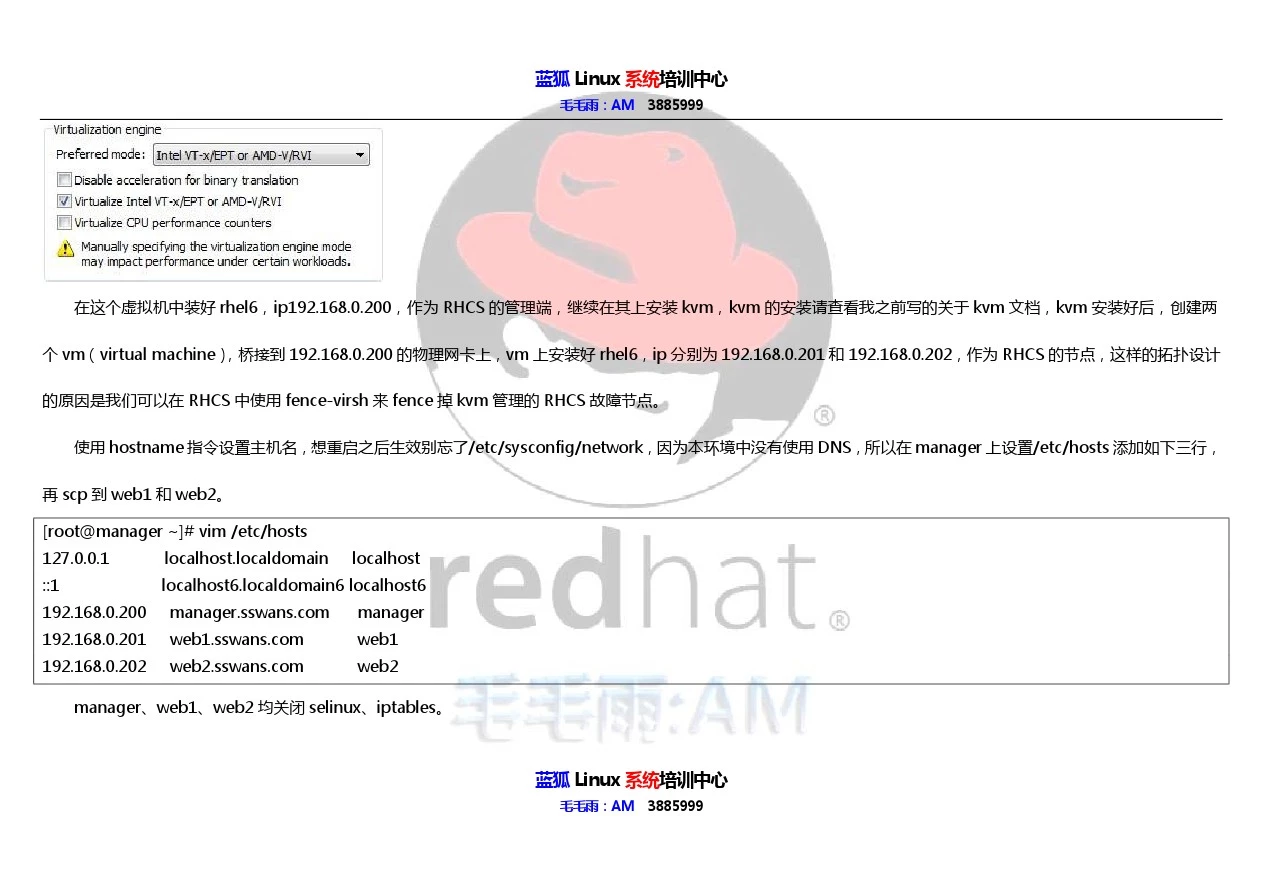
vmware 创建一个虚拟机,内存3G,按下图设置使得虚拟机也支持虚拟化,vmware workstation 版本不低于7:
蓝狐Linux系统培训中心
毛毛雨:AM 3885999
毛毛雨:AM 3885999
蓝狐Linux 系统培训中心
毛毛雨:AM 3885999
在这个虚拟机中装好 rhel6,ip192.168.0.200,作为 RHCS 的管理端,继续在其上安装 kvm,kvm 的安装请查看我之前写的关于 kvm 文档,kvm 安装好后,创建两 个 vm(virtual machine) ,桥接到 192.168.0.200 的物理网卡上,vm 上安装好 rhel6,ip 分别为192.168.0.201和 192.168.0.202,作为 RHCS 的节点,这样的拓扑设计 的原因是我们可以在 RHCS 中使用 fence-virsh 来fence 掉 kvm 管理的 RHCS 故障节点。
使用hostname 指令设置主机名,想重启之后生效别忘了/etc/sysconfig/network,因为本环境中没有使用DNS,所以在manager 上设置/etc/hosts 添加如下三行, 再 scp 到 web1 和web2。 [root@manager ~]# vim /etc/hosts
127.0.0.1
localhost.localdomain localhost ::1
localhost6.localdomain6 localhost6
192.168.0.200
https://www.doczj.com/doc/401186395.html, manager 192.168.0.201
https://www.doczj.com/doc/401186395.html, web1 192.168.0.202 https://www.doczj.com/doc/401186395.html, web2 manager、web1、web2 均关闭selinux、iptables。
毛毛雨:AM 3885999
在 manager上建 1个 target,2 个lun,用作导出 iscsi存储给节点使用。 主要步骤及指令如下:
fdisk 分出来两个分区sda5、6,大小为1G、10M,fdisk 之后使用 partx -a /dev/sda 重读分区,可以不用重启系统。
[root@manager ~]# yum install scsi-target-utils -y 安装iscsi-target 端
[root@manager ~]# chkconfig tgtd on ; /etc/init.d/tgtd start 随机启动;启动服务
[root@manager ~]# tgtadm -L iscsi -m target -o new -t 1 -T https://www.doczj.com/doc/401186395.html,.sswans:disk1 创建target
[root@manager ~]# tgtadm -L iscsi -m logicalunit -o new -t 1 -l 1 -b /dev/sda5 创建lun1,对应sda5 分区
[root@manager ~]# tgtadm -L iscsi -m logicalunit -o new -t 1 -l 2 -b /dev/sda6 创建lun2,对应sda6 分区
[root@manager ~]# tgtadm -L iscsi -m target -o bind -t 1 -I ALL 设置ACL 访问控制,ALL 为任意访问
[root@manager ~]# tgt-admin --dump > /etc/tgt/targets.conf dump 保存配置,以后每次重启都会生效 安装luci工具,RHCS 管理端,请配置好yum仓库,RHCS 相关的包在 iso 镜像中的 HighAvailability 和ResilientStroage中
[root@manager ~]# yum install luci -y
[root@manager ~]# chkconfig luci on ; /etc/init.d/luci start
Point your web browser to https://https://www.doczj.com/doc/401186395.html,:8084 to access luci 等节点安装好 ricci 后,可以使用这个 url 对节点进行管理和配置 节点web1、web2 上都执行如下动作,以web1为例:
[root@web1 ~]# yum install rgmanager -y 会自动安装 ricci、cman 等包
[root@web1 ~]# chkconfig ricci on ; /etc/init.d/ricci start
[root@web1 ~]# chkconfig NetworkManager off ; /etc/init.d/NetworkManager stop
[root@web1 ~]# chkconfig cman on ; chkconfig rgmanager on ; chkconfig modclusterd on
[root@web1 ~]# /etc/init.d/cman start ; /etc/init.d/rgmanager start;/etc/init.d/modclusterd start
使用浏览器打开luci的 url,新建一个集群,名为 sSWans,添加两个节点,一个名为web1,另一个名为 web2,因为之前在两个节点上都安装了 ricci、cman等包,
蓝狐Linux系统培训中心
毛毛雨:AM 3885999
毛毛雨:AM 3885999
所以单选 use locally installed packages,enable shared storage support 选项其实就是指的 gfs,我们在后面手动装包来实施,这里不勾选。
检查节点的服务状态,确定 cman、rgmanager、ricci、modcluster 服务处于 running 状态。如有问题,请注意查看节点的/var/log/message 日志进行排错。
点击菜单中的Failover Domains,添加一个热备切换域,名为 web_FD,勾选 no Failback,勾选web1,web2 两个节点。
点击菜单中的 Resources,添加一个 ip address 资源,ip为 192.168.0.252,这个 ip就是提供服务的虚拟 ip,再添加一个 script,名为 http,脚本路径/ etc/init.d/httpd。
点击菜单中的Services,添加一个服务,名为apache,选择刚创建的热备切换域web_FD,添加资源,把刚创建的 ip 资源和脚本资源添加进来,如果服务需要使用的 资源具有先后关系,那么需要将前提资源以子资源(add a child resource)的形式添加。
在两个节点上针对httpd写一个index.html的页面,web1上 [root@web1 ~]# echo web1 > /var/www/html/index.html ,web2的index.html内容为web2, 这样待会服务启动后,我们去访问这个 apache 服务,可以通过访问到的内容来检测集群提供的服务是由哪个节点完成的。
在两个节点上都监控日志tail -f /var/log/message,启动这个apache服务,查看服务启动时节点的信息,有助于更好的理解 rhcs和增加排错经验。如无意外,此时 应该可以看到apache 服务会在其中一个节点上启动,我的启动在 web1 上,在 Services 菜单可以看到,在任意节点上用指令clustat 查看更快更方便。
做到这里,我们完成了一个rhcs 的最小部署,也是一个特殊情况,也就是two_node 两节点模式,此时的集群可以提供设定的web 服务,在节点web1使用init指令关机 或重启,apache服务都能正常迁移到节点web2,但是,如果提供服务的web1节点网卡故障,我们可以使用指令模拟网卡故障 [root@web1 ~]# ifdown eth0 ,那么
蓝狐Linux系统培训中心
毛毛雨:AM 3885999
毛毛雨:AM 3885999
集群无法将 web服务迁移到 web2 节点上,从日志可以看到 web2 要fence掉 web1,但是没有fence method,此时,我们在正常节点web2 上使用指令
[root@web2 ~]# fence_ack_manual web1
About to override fencing for web1.
Improper use of this command can cause severe file system damage.
Continue [NO/absolutely]? absolutely
Done
意思是告诉正常节点 web2,已经成功fence掉故障节点 web1,web2 可以抢夺原本运行在web1 上的apache 服务了,注意看日志,这原本就是fence设计的原理。如
果你没有使用 fence_ack_manual 而将 web1 的网卡重新开启或者重启 web1,那么 web2 的 cman服务会被停止掉,留意 web2 的日志,这种情况下,web2 的 cman 服务重启不了啦,你只能选择重启系统。
因此,我们的集群是需要fence 设备的,下面开始添加 fence 设备,在节点 web1 和 web2 上做如下动作:
[root@web1 ~]# mv /usr/sbin/fence_apc{,.bak}
[root@web1 ~]# ln -s /usr/sbin/fence_virsh /usr/sbin/fence_apc
因为在 luci 的Fence Devices 菜单中,添加fence 设备,下拉菜单中并没有fence_virsh 项,所以上面的动作就是用fence_virsh 替换 fence_apc。
“偷龙转凤”之后,我们选择下拉菜单中的 fence_apc,其实这时候调用的是 fence_virsh,name填 virsh_fence,ip填 192.168.0.200,login填 root,password 填上对应的密码,这样子,我们就成功添加了一个可以fence kvm 节点的fence设备,接下来,将这个fence设备应用到节点上,web1为例,luci中点击 web1节点, 添加fence_method,名为web_fence,再添加fence instance,选择刚创建的virsh_fence,port 填web1,此处的web1不是web1的hostname,而是kvm 上的vm
名;节点web2 上 port 换成 web2,其他跟 web1 设置一样。
蓝狐Linux系统培训中心
毛毛雨:AM 3885999
毛毛雨:AM 3885999
很有必要解释一下fence工作原理, 当web1网卡故障的时候, web1是与外部网络断开连接的, 但web1会认为web2挂掉了, web1使用fence设备去fence web2, 因为web1的网卡故障,所以web1 fence web2是不会成功的,同时web2也会发现web1挂掉了,web2使用fence设备去fence web1,web2的网卡是正常的, 所以 web2 的fence 指令能正常发送到fence 设备上,fence 掉 web1,并且会把原来由 web1 提供的apache 服务及资源抢夺过来,由 web2 对外提供apache 服务。
以上 fence设置的默认 action为 reboot,如果要换成 off 关机,需修改/etc/cluster/cluster.conf 文件,添加红字部分,
配置好fence 之后,回到 services 菜单,看到 web 服务是运行在 web1上的,我们再次将 web1的网卡故障掉,你会发现web1 会自动重启,并且web2 抢夺到原本 运行在web1上的apache 服务,作为集群提供服务的节点。这个过程依然不要忘记多看日志。
接下来,我们再体验GFS,之前不是在 manager 上导出了 iscsi的存储吗,现在有用武之地了,在两个节点上使用如下动作挂载iscsi 存储:
[root@web1 ~]# yum install iscsi-initiator-utils -y 挂载 iscsi存储需要安装的包
[root@web1 ~]# chkconfig iscsi on
[root@web1 ~]# iscsiadm -m discovery -t sendtargets -p 192.168.0.200
[root@web1 ~]# /etc/init.d/iscsi start 启动 iscsi服务,发现/dev 下多了两个盘,sdb,sdc
蓝狐Linux系统培训中心
毛毛雨:AM 3885999
毛毛雨:AM 3885999
[root@web1 ~]# udevadm info -q all -n /dev/sdb 查看sdb 设备在被内核识别时候的信息,用作写 udev规则,用来固定iscsi 设备在本机的设备名称。
从上条指令结果中提取这条用作书写 udev规则的条件,ID_SCSI_SERIAL=beaf11
[root@web1 ~]# vim /etc/udev/rules.d/99-iscsi.rules
KERNEL=="sd[b-z]",ENV{ID_SCSI_SERIAL}=="beaf11",NAME="disk_gfs"
KERNEL=="sd[b-z]",ENV{ID_SCSI_SERIAL}=="beaf12",NAME="qdisk
[root@web1 ~]# udevadm trigger 触发刚写的 udev 规则,查看/dev 下,sdb,sdc已经不见了,出现了 disk_gfs 和 qdisk 两个块设备 [root@web1 ~]# yum install lvm2-cluster gfs2-utils -y 安装 gfs 需要的包
[root@web1 ~]# chkconfig clvmd on
clvm信息是自动在集群节点上同步的,所以以下动作只需在任意节点上做一次,在此之前,修改lvm2支持集群,使用指令
[root@web1 ~]# lvmconf --enable-cluster
确保各个上的 clvmd服务是启动的。
[root@web1 ~]# pvcreate /dev/disk_gfs 创建物理卷
[root@web1 ~]# vgcreate gfs /dev/disk_gfs 创建卷组
[root@web1 ~]# vgdisplay gfs | grep Cluster 可以看到 Clustered yes 表示是 clvm,在其他节点也可以看到相同信息
[root@web1 ~]# lvcreate -l 100%free -n gfslv gfs 创建名为 gfslv的逻辑卷,使用 gfs 卷组100%的剩余空间
[root@web1 ~]# mkfs.gfs2 -j 2 -t sSWans:gfslv -p lock_dlm /dev/gfs/gfslv
格式化为 gfs2,设定锁机制及 2 份journal,-t 分两部分,集群名:设备名,格式化的时间有点长,耐心等待。
[root@web1 ~]# mount -t gfs2 /dev/gfs/gfslv /var/www/html
[root@web1 ~]# echo web-service > /var/www/html/index.html 设置 index.html 页面的内容
[root@web1 ~]# echo "/dev/gfs/gfslv /var/www/html gfs2 defaults 0 0" >> /etc/fstab 设置启动自动挂载,两个>>,别写成>
蓝狐Linux系统培训中心
毛毛雨:AM 3885999
毛毛雨:AM 3885999
在 luci的 Resources 菜单添加一个 gfs2 资源,name 为web_data,mount point为/var/www/html,filesystem type为 gfs2。打开Services 菜单,点击apache 服务,添加一个资源,选择刚创建的web_data。
这时候已经是个完整的两节点RHCS 应用了。附上 cluster.conf
蓝狐Linux系统培训中心
毛毛雨:AM 3885999
毛毛雨:AM 3885999
蓝狐Linux系统培训中心
毛毛雨:AM 3885999
毛毛雨:AM 3885999
接下来,我们继续讨论一个问题,当节点超过两个的时候,比如说四节点,如果1、2节点通信正常,3、4节点通信正常,但是1、2和3、4之间通信不正常,那么1、 2 形成一个组,3、4形成一个组,互不相让,争夺服务和资源,形成 split-brain,这是我们不希望出现的状况,我们怎么去解决这个问题呢?答案就是使用 quorum disk 仲裁磁盘。这种机制是这样的,集群的每个节点都分配一个投票数,一般情况下票数为1,票数如果不一样通常是因为节点性能不同、电源或者网络或者存储是否有冗余等 因素,qdisk是一个共享存储,一般 10M 大小就够了,所有节点周期性地在 qdisk上进行“签到” (目前 RHCS 最多支持 16 个节点“签到” ) 。qdisk 也设置成具有一定的 票数, 签到成功的节点可以赢得qdisk的投票, 当票数超过票数总和的一半时, 集群才能启动。 那之前的两节点没有使用qdisk, 节点之间通信故障, 为什么没有形成split-brain 呢,那是因为 two-node 是一个特殊情况,所以在前面的 cluster.conf 中
还记得之前在manager上导出了一个1G和一个10M的iscsi存储吗?并且都在节点上挂载了的,挂载成/dev/disk_gfs 的做了gfs 存储,另一个挂载成什么?对了, /dev/qdisk,我们就利用它来做quorum disk。在任意节点上对共享存储分区进行qdisk格式化,标签为qdiskWeb, 完成后可以在其他节点使用mkqdisk -L来查看qdisk 信息。嗯,在做 qdisk 之前,我们先把之前two_node 模式的集群状态用指令显示出来,等下和非two_node 模式做比较用。
[root@web2 ~]# cman_tool status > status 将集群信息重定向到主目录下的status 文件,稍后做比较
[root@web2 ~]# mkqdisk -c /dev/qdisk -l qdiskWeb 格式化 qdisk
蓝狐Linux系统培训中心
毛毛雨:AM 3885999
毛毛雨:AM 3885999
然后在 luci的 Configure菜单里选择 Qdisk Configuration,设置 Interval、Votes、Minimum Score都为 1,TKO(原本为拳击术语,技术性击倒,在这可以理解 为失败次数上限)为 10,单选By device label,值为 qdiskWeb,设置 Heuristics,Path to Program 为 ping -c1 192.168.0.200,Interval 为 2,Score为 1,TKO 为 3,Heuristics 是 qdisk 的一个增强机制,试想一下,如果web1和 web2 之间的网络连接断开了,但是都和 qdisk有连接,那么 qdisk 还能起到原本该有的作用吗?显然 是不能的,所以我们可以使用 heuristics,增加一些其他的检测手段,来确定到底是哪个节点有问题应该被fence 掉。在默认情况下,expected_votes是等于total_votes 的,集群启动的条件为获得的票数>expected_votes/2,也就是说 quorum 值 = expected/2 + 1。
细心的同学应该已经发现 cluster.conf 中
配置好后,在各节点上/etc/init.d/cman start 启动 qdisk,很可能会失败,查看 messages 日志,发现需要将 token timeout 调到不低于某个值,在Configure 菜单 里有个 Network Configuration,点击show advanced properties,修改 token timeout 值,并修改 consensus timeout为token timeout+2000,再启动 cman 就可 以了。
在任意节点使用 clustat 可以看到 qdisk 开始工作了,再使用 cman_tool status 查看信息,与之前的status 文件进行比较,相信你应该可以自己得出结论了。
那么到这,RHCS 就跟大家讲完了,超过两节点的RHCS 大家自己做做吧。
蓝狐Linux系统培训中心
毛毛雨:AM 3885999
毛毛雨:AM 3885999
蓝狐Linux系统培训中心 毛毛雨:AM 3885999
服务器集群设计 服务器集群技术随着服务器硬件系统与网络操作系统的发展而产生的,在可用性、高可靠性、系统冗余等方面越来越发挥重要中用,是核心系统必不可少的。数据库保存者抄表系统的数据,是整个信息系统的关键所在。 解决系统可靠性的措施通常是备份和群集。备份不能快速恢复,主要用于安全保存,数据库和系统的快速故障恢复通常采用HA(高可用)群集模式, HA 能提供不间断的系统服务,在线系统发生故障时,离线系统能立即发现故障并立即进行接管,继续对外提供服务。HA技术可以有效防止关键业务主机宕机而造成的系统停止运行,被广泛采用。HA技术有两种模式: 具有公共存储系统的HA 数据存储在公共的存储系统上,服务器1为活动服务器,服务器2为待机服务器(备份服务器),当服务器1发生故障时(软或硬件故障),服务器2通过私有网络(心跳路径)侦测到服务器1的故障并自动接管服务器1上所有的资源(如IP地址、存储系统、数据库服务、计算机名等),继续为客户机提供数据或其他应用服务。 独立存储系统的HA数据存储在各自服务器的独占存储设备上(内置磁盘或磁盘阵列) ,没有共享存储系统,数据保存在每个服务器独占的存储设备上。通过镜像技术使每台服务器的数据保持同步,切换时间更短,可靠性比共享存储系统的方案更高,并避免了单点崩溃的可能性,增加了数据的安全性及系统的可用性。两台服务器之间的距离不受外部存储设备连接线的限制,因而可以将两台服务器放置在不同位置。
根据上述分析、系统要求、应用软件采用三层结构的优势以及艾因泰克在发电企业几十家的建设经验,方案采用独立存储系统的HA模式。 由于两套数据库服务器只有一台在线工作,方案本着最大限度节约资源的原则,充分高性能服务器的性能,在备用服务器上运行系统的WEB应用。采用双机双应用,互为备用结构。即在线数据库服务器是 WEB应用服务器的备用服务器,在线WEB应用服务器是数据库服务器的备用服务器。这种结构不但充分发挥性能服务器的优势,又保证关键服务器具有自动备用服务器。不但节约了成本,而且避免了采用共用存储设备单点故障带来的数据丢失的灾难,是最佳的选择。 数据库和应用服务器集群结构如下图: 服务器采用2台PowerEdge R900,配置7块146G磁盘,2块磁盘组成RAID 1镜像,作为操作系统盘。5块组成磁盘组成RAID 5,作为数据盘。 集群镜像软件选用RoseMirrorHA。RoseMirrorHA是一个可靠的、稳定的、高性能的应用高可用保护解决方案,实现应用程序的保护,保证了业务的持续运
为什么选择容错 Stratus容错服务器与双机热备方案比较
一、容错技术和集群的比较: 1、可靠性比较:
容错服务器的可靠性可达到99.999%以上,其设计原理是“容错原则---容忍错误发生,当出现任意单点故障时,不会对系统造成任何影响,系统仍然连续工作”。而集群方案的可靠性只能在99.9%~99.99%之间,其设计原理是“避错原则----当系统出现故障时,如何补救错误、避免错误进一步扩大”。 2、拓扑结构比较: 计算机业界对可靠性的定义 容错服务器独立服务器 阵的独立服务器 系统 消除单点心 系统结构复杂 环节过多,外部连接 故障发生点多 系统结构简单 如同单机,内部连接 故障发生点少 无单点故障的集群方案 无单点故障的容错方案
3、软硬件架构: 在系统架构中,容错服务器结构简单,且是单软件映像。 1、 工作原理比较: 硬软件结构复杂 依赖集群软件 对所有软件和硬件要求苛刻 切换机制只能覆盖部分实际应用情况 硬软件结构简单 纯硬件容错结构 对所有软件无特殊要求 时钟同步,无需切换
容错方案在出现任何单点故障的情况之下系统工作状态均不会中断,且是零切换时间,进而完整的保护了静态数据及动态数据。 2、维护管理及实施比较: 由于容错服务器的冗余全部是依靠硬件完成的,避免了对软件及人为因素的依赖,因此,其实施及维护非常简单、方便。 3、集群和容错软硬件可靠性实测比较: System Application Fault-Tolerant Cluster Conventional 容错方案的软硬件可靠性是最高的;集群方案虽然略微提高了硬件的可靠性,但却牺牲了软件本身的可靠性。
浪潮WIN2K 集群服务解决方案 集群服务的需求分析 随着Internet服务和电子商务的迅速发展,计算机系统的重要性也日益上升,对服务器可伸缩性和高可用性的要求也变得越来越高。集群技术的出现和发展则很好地解决了这两个问题。群集是由一组独立的计算机组成,这些计算机一起工作以运行一系列共同的应用程序,同时,为用户和应用程序提供单一的系统映射。群集内的计算机物理上通过电缆连接,程序上则通过群集软件连接。这些连接允许计算机使用故障应急与负载平衡功能,而故障应急与负载平衡功能在单机上是不可能实现的。 有网络负载平衡功能的Windows 2000为在分布和负载平衡的方式下建立关键且合乎要求的网站的工作提供了完整的基础结构。与组件服务的分布式应用程序特性和Internet 信息服务的增强可伸缩性相结合,网络负载平衡有助于确保服务能够灵活处理最重的通信负荷,同时,保持对服务器状态的监控,确保系统不停机。 Win2000群集技术具有以下特点: ·可伸缩性:加入更多的处理器或计算机可提高群集的计算能力,一般的桌面机每秒能够处理几千个请求,而传统的IA服务器每秒能够处理几万个请求。那么对于需要每秒处理几十万个请求的企业来说,如果不采用集群技术,唯一的选择就是购买更加高档的中、小型计算机。如果这样做,虽然系统性能提高了十倍,但其购买价格和维护费用就会上升几十倍甚至更多。 ·高度的可用性:群集具有避免单点故障发生的能力。应用程序能够跨计算机进行分配,以实现并行运算与故障恢复,并提供更高的可用性。即便某一台服务器停止运行,一个由进程调用的故障应急程序会自动将该服务器的工作负荷转移至另一台服务器,以保证提供持续不断的服务。 ·易管理性:群集以单一系统映射的形式来面向最终用户、应用程序及网络,同时,也为管理员提供单一的控制点,而这种单一控制点则可能是远程的。 随着计算机应用地位的逐渐提升,系统安全和重要性的日益增加,基于Win2000的负载均衡必将会有着极为广阔的应用前景。 Win2K集群技术 一、集群
本文由szg81贡献 doc1。 七台服务器的集群方案 在传统的终端/主机的网络模式时代,终端功能简单,无需维护工作,在主机一端进行专门的管理与维护,具有资源共享、便于 管理的特点。但是,主机造价昂贵,终端没有处理能力,限制了网络的规模化发展。之后的客户机/服务器模式推进了计算产业 的标准化和开发化的发展,为系统提供了相当大的灵活性,但是随着分布系统规模的规模扩大,系统的维护和管理带来了巨大 的开销。面向 Internet 的服务型应用,需要高性能的硬件平台作为支持,将并行技术应用在服务器领域中,是计算机发展的必然 趋势。并行处理技术在高性能计算领域中,高可用和高性能是集群服务器系统发展的两个重要方向。 集群的概念 集群英文名称是 CLUSTER,是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管 理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。和传统的高性能计算 机技术相比,集群技术可以利用各档次的服务器作为节点,系统造价低,可以实现很高的运算速度,完成大运算量的计算,具 有较高的响应能力,能够满足当今日益增长的信息服务的需求。 集群技术应用的需求 Internet 用户数量呈几何级数增长和科学计算的复杂性要求计算机有更高的处理能力,而 CPU 的发展无法跟上不断增长的需求, 于是我们面临以下问题: ●大规模计算如基因数据的分析、气象预报、石油勘探需要极高的计算性能。 ●应用规模的发展使单个服务器难以承担负载。 ●不断增长的需求需要硬件有灵活的可扩展性。 ●关键性的业务需要可靠的容错机制。 IA 集群系统(CLUSTER)的特点 ●由若干完整的计算机互联组成一个统一的计算机系统; ●可以采用现成的通用硬件设备或特殊应用的硬件设备,例如专用的通讯设备; ●需要特殊软件支持,例如支持集群技术的操作系统或数据库等等; ●可实现单一系统映像,即操作控制、IP 登录点、文件结构、存储空间、I/O 空间、作业管理系统等等的单一化; ●在集群系统中可以动态地加入新的服务器和删除需要淘汰的服务器, 从而能够最大限度地扩展系统以满足不断增长的应用的需 要; ●可用性是集群系统应用中最重要的因素,是评价和衡量系统的一个重要指标; ●能够为用户提供不间断的服务,由于系统中包括了多个结点,当一个结点出现故障的时候,整个系统仍然能够继续为用户提供 服务; ●具有极高的性能价格比,和传统的大型主机相比,具有很大的价格优势; ●资源可充分利用,集群系统的每个结点都是相对独立的机器,当这些机器不提供服务或者不需要使用的时候,仍然能够被充分 利用。而大型主机上更新下来的配件就难以被重新利用了。 实现服务器集群的硬件配置 ●网络服务器 七台 ●服务器操作系统硬盘 七块 ●ULTRA 160 LVD SCSI 磁盘阵列 一个 ●18G SCSI 硬盘 十块 ●网络服务网卡 十四块 服务器集群的实践步骤 ●在安装机群服务之前的准备: 1、 十四块 18G SCSI 硬盘组成磁盘阵列,做 RAID5。 2、 两台服务器要求都配置双网卡,分别安装 Microsoft Windows Server2008 操作系统,并配置网络。 3、 所有磁盘必须设置成基本盘,阵列磁盘分区必须大于 7 个。 4、 每台服务器都要加入域当中,成为域成员,并且在每台服务器上都要有管理员权限。 ●安装配置服务器网络要点 1、在这一部分,每个服务器需要两个网络适配器,一个连接公众网,一个连接内部网(它只包含了群集节点) 内部网适配器 。 建立点对点的通信、群集状态信号和群集管理。每个节点的公众网适配器连接该群集到公众网上,并在此驻留客户。 2、安装 Microsoft Windows 2000 Adwance Server 操作系统后,开始配置每台服务器的网络。在网络连接中我们给连接公众网的 命名为"外网",连接内部网的命名为"内网"并分别指定 IP 地址为:节点 1:内网:ip:10.10.10.11 外网 ip:192.168.0.192 子网 掩码:255.255.255.0 网关:192.168.0.191(主域控制器 ip) ;节点 2:内网:ip:10.10.10.12 外网 ip:192.168.0.193 子网掩码: 255.255.255.0 网关:192.168.0.191;节点 3:内网:ip:10.10.10.13 外网 ip:192.168.0.194 子网掩码:255.255.255.0 网关: 192.168.0.191;节点 4:内网:ip:10.10.10.14 外网 ip:192.168.0.195 子网掩码:255.255.255.0 网关:192.168.0.191;节点 5: 内
存储集群双机热备方案
目录 一、前言 (3) 1、公司简介 (3) 2、企业构想 (3) 3、背景资料 (4) 二、需求分析 (4) 三、方案设计 (5) 1.双机容错基本架构 (5) 2、软件容错原理 (6) 3、设计原则 (7) 4、拓扑结构图 (7) 四、方案介绍 (10) 方案一1对1数据库服务器应用 (10) 方案二CLUSTER数据库服务器应用 (11) 五、设备选型 (12) 方案1:双机热备+冷机备份 (12) 方案2:群集+负载均衡+冷机备份 (13) 六、售后服务 (15) 1、技术支持与服务 (15) 2、用户培训 (15)
一、前言 1.1、公司简介 《公司名称》成立于2000年,专业从事网络安全设备营销。随着业务的迅速发展,经历了从计算机营销到综合系统集成的飞跃发展。从成立至今已完成数百个网络工程,为政府、银行、公安、交通、电信、电力等行业提供了IT相关系统集成项目项目和硬件安全产品,并取得销售思科、华为、安达通、IBM、HP、Microsoft等产品上海地区市场名列前茅的骄人业绩。 《公司名称》致力于实现网络商务模式的转型。作为国内领先的联网和安全性解决方案供应商,《公司名称》对依赖网络获得战略性收益的客户一直给予密切关注。公司的客户来自全国各行各业,包括主要的网络运营商、企业、政府机构以及研究和教育机构等。 《公司名称》推出的一系列互联网解决方案,提供所需的安全性和性能来支持国内大型、复杂、要求严格的关键网络,其中包括国内的20余家企事业和政府机关. 《公司名称》成立的唯一宗旨是--企业以诚信为本安全以创新为魂。今天,《公司名称》通过以下努力,帮助国内客户转变他们的网络经济模式,从而建立强大的竞争优势:(1)提出合理的解决方案,以抵御日益频繁复杂的攻击 (2)利用网络应用和服务来取得市场竞争优势。 (3)为客户和业务合作伙伴提供安全的定制方式来接入远程资源 1.2、企业构想 《公司名称》的构想是建立一个新型公共安全网络,将互联网广泛的连接性和专用网络有保障的性能和安全性完美地结合起来。《公司名称》正与业界顶尖的合作伙伴协作,通过先进的技术和高科产品来实施这个构想。使我们和国内各大企业可通过一个新型公共网络来获得有保障的安全性能来支持高级应用。 《公司名称》正在帮助客户改进关键网络的经济模式、安全性以及性能。凭借国际上要求最严格的网络所开发安全产品,《公司名称》正致力于使联网超越低价商品化连接性的境界。《公司名称》正推动国内各行业的网络转型,将今天的"尽力而为"网络改造成可靠、安全的高速网络,以满足今天和未来应用的需要。 1.3、背景资料 随着计算机系统的日益庞大,应用的增多,客户要求计算机网络系统具有高可靠,高
1.业务连续 1.1.共享存储集群 业务系统运营时,服务器、网络、应用等故障将导致业务系统无常对外提供业务,造成业务中断,将会给企业带来无法估量的损失。针对业务系统面临的运营风险,Rose提供了基于共享存储的高可用解决方案,当服务器、网络、应用发生故障时,Rose可以自动快速将业务系统切换到集群备机运行,保证整个业务系统的对外正常服务,为业务系统提供7x24连续运营的强大保障。 1.1.1.适用场景 基于共享磁盘阵列的高可用集群,以保障业务系统连续运营 硬件结构:2台主机、1台磁盘阵列
主机 备机心跳 磁盘阵列 局域网 1.1. 2.案例分析 某证券公司案例 客户需求分析 某证券公司在全国100多个城市和地区共设有40多个分公司、100多个营业部。经营围涵盖:证券经纪,证券投资咨询,与证券交易、证券投资活动有关的财务顾问,证券承销与保荐,证券自营,证券资产管理,融资融券,证券投资基金代销,金融产品代销,为期货公司提供中间介绍业务,证券投资基金托管,股票期权做市。 该证券公司的系统承担着企业的部沟通、关键信息的传达等重要角色,随着企业的业务发展,系统的压力越来越重。由于服务器为单机运行,如果发生意外宕机,将会给企业的日常工作带来不便,甚至
给企业带来重大损失。因此,急需对服务器实现高可用保护,保障服务器的7×24小时连续运营。 解决方案 经过实际的需求调研,结合客户实际应用环境,推荐采用共享存储的热备集群方案。部署热备集群前的单机环境:业务系统,后台数据库为MySQL,操作系统为RedHat6,数据存储于磁盘阵列。 在单机单柜的基础上,增加1台备用主机,即可构建基于共享存储的热备集群。增加1台物理服务器作为服务器的备机,并在备机部署系统,通过Rose共享存储热备集群产品,实现对应用的高可用保护。如主机上运行的系统出现异常故障导致宕机,比如应用服务异常、硬件设备故障,Rose将实时监测该故障,并自动将系统切换至备用主机,以保障系统的连续运营。
现状分析 我国公安集群无线通信系统所采用的通信体制是集群信令系统和在“集群脑系统接口性能规范”基础上制定的编号制式。 模拟集群系统是最早引入我国的集群系统。首先,系统内部没有制定互联的标准,造成各厂商之间无法互联互通,甚至在同一省市由于存在不同厂商的模拟系统,同一地市的公安部门都无法互联互通,全国公安联网更是天方夜谭,根本无法实现;其次,由于固有的技术缺陷,移动终端无法越区切换,移动终端从某一基站覆盖范围移动到另一基站覆盖范围是通信将中断,给实际工作带来诸多不便;第三,由于数据功能和数据接口没有定义,除语音调度外,系统更多功能无法实现,单纯的对讲功能已不能满足用户的需要;第四,模拟系统专网建设需要投入较高的建设成本,每年还要投入大量的人力和资金进行维护,这不是一般的用户能够承受的;第五,随着数字移动通信技术的飞速发展以及国家加强对无线频点的管制,用户很难再申请到新频点,模拟运营面临停牌,模拟集群网已趋向淘汰。 需求说明 随着社会经济的不断发展,日常公共安全管理、重大活动勤务保障和反恐处突的需求非常迫切,公安机关对无线通信的需求不断增长,现有频率资源十分紧张,频率干扰日益严重,缺乏通信安全手段,现有模拟系统无法支持大容量数据业务(大容量的
定位等),公安无线通信难以满足同一指挥、反应快速、协调有序、安全准确、运转高效、可靠地进行通信联络和信息传输。系统在满足公安需求的前提下存在以下亟待解决的问题: ◆频率资源不足 现有模拟通信频率带宽为,可用于公安集群通信的频点仅为对,难于建设更多集群基站和信道,无法增加覆盖范围和移动用户,已经严重制约了无线通信系统的发展。 ◆信号干扰日益严重 城市无线电波传输环境越来越恶劣,对现有公安无线通信带来了直接的影响。另外,由于在部分省市公安的市区采用了模拟集群同播、模拟常规等同播系统,造成重叠区同频信号干扰严重,这不但直接影响了警务活动的效率,更可能在关键时刻造成不可挽回的损失。 ◆通信保密性差 社会治安形式日益复杂,突发事件日益增多,公安反恐维稳任务日益加重,通信安全的保障是公安机关有力打击犯罪的根本举措。现在的模拟通信通过简单的频谱扫描就可以获取通信信息,这给公安机关的通信留下巨大的隐患,对重大警务活动的安全性带来危害。 ◆系统业务扩展性差 现有模拟集群系统无法支持较大容量数据业务,除语音调度外,数据功能和数据接口没有定义,使得系统功能过于单一。如:
https://www.doczj.com/doc/401186395.html,nderSoft(LVGUI-ch.DOC) Normal **项目 多机互备集群解决方案 销售:王晓强 作者:市场部 上海联鼎软件股份有限公司 https://www.doczj.com/doc/401186395.html, 版权所有 目录 第一章引言2 1.1公司介绍2 1.2背景3 1.3方案设计总原则5 第二章需求描述6 2.1需求概述6 2.2现状说明和存在问题6 2.3总体需求说明7 第三章方案设计7 3.1项目风险分析8 3.2需解决的问题8
3.3设计原则9 第四章方案描述10 4.1总体方案概述10 4.2集群系统方案概述11 4.3工作流程简单描述11 4.4L ANDER C LUSTER软件的优势:12 第五章方案优势13 第六章技术规格19 第一章引言 1.1公司介绍 联鼎软件(Landersoft)是领先的核心业务及数据安全系统解决方案供应商,致力于通过保障用户关键应用及核心电子化数据,确保企业在全球信息化持续发展进程中无间断的竞争力及信心。产品面向应用高可用性,以及全球范围内的核心系统容灾及数据保护。在中国已有超过5000个用户,9500例安装,市场占有率达到前三位,覆盖金融、电信、医疗、政府、交通、电力、教育、制造业、基础资源等行业,已被证明适用于各种应用、服务器、存储硬件和相关设备并实现互操作。 联鼎软件拥有先进的多平台测试开发系统及前瞻性的用户体验中心。公司大中华区总部设在上海,南亚总部设在新加坡,在中国大型城市设有分支机构,形成具有强大优势的销售管理体系和技术支持体系,能够更好、更及时的响应用户需求。 联鼎认为,未来十年,随着IT技术的加速发展,社会对IT环境及服务将高度依赖,保障企业
双机容错系统方案 1.前言 对现代企业来说,利用计算机系统来提供及时可靠的信息和服务是必不可少的,另一方面,计算机硬件和软件都不可避免地会发生故障,这些故障有可能给企业带来极大的损失,甚至整个服务的终止,网络的瘫痪。可见,对一些行业,如:金融(银行、信用合作社、证券公司)等,系统的容错性和不间断性尤其显得重要。因此,必须采取适当的措施来确保计算机系统的容错性和不间断性,以维护系统的高可用性和高安全性,提高企业形象,争取更多的客户,保证对客户的承诺,减少人工操作错误、达到系统可用性和可靠性为99.999%。 2.双机容错系统简介 根据用户提出的系统高可用性和高安全性的需求,推出基于Cluster集群技术的双机容错解决方案,包括用于对双服务器实时监控的Lifekeeper容错软件和作为数据存储设备的系列磁盘阵列柜。通过软硬件两部分的紧密配合,提供给客户一套具有单点故障容错能力,且性价比优越的用户应用系统运行平台。 3.Cluster集群技术 Cluster集群技术可如下定义:一组相互独立的服务器在网络中表现为单一的系统,并以单一系统的模式加以管理。此单一系统为客户工作站提供高可靠性的服务。 Cluster大多数模式下,集群中所有的计算机拥有一个共同的名称,集群内任一系统上运行的服务可被所有的网络客户所使用。Cluster必须可以协调管理各分离的组件的错误和失败,并可透明的向Cluster中加入组件。 一个Cluster包含多台(至少二台)拥有共享数据储存空间的服务器。任何一台服务器运行一个应用时,应用数据被存储在共享的数据空间内。每台服务器的操作系统和应用程序文件存储在其各自的本地储存空间上。 Cluster内各节点服务器通过一内部局域网相互通讯。当一台节点服务器发生故障时,这台服务器上所运行的应用程序将在另一节点服务器上被自动接管。当一个应用服务发生故障时,应用服务将被重新启动或被另一台服务器接管。当以上任一故障发生时,客户将能很快连接到新的应用服务上。 4.工作拓扑图
天一阁·月湖景区无线集群通信指挥系统 (设计方案) 浙江宝兴智慧城市建设有限公司 二○一七年七月
目录 1 项目概述 .................................................... 错误 ! 未定义书签。 通信现状 . ............................................ 错误 ! 未定义书签。 集群通信必要性 . ...................................... 错误 ! 未定义书签。 信道利用率高 . .................................... 错误 ! 未定义书签。 业务功能丰富 . .................................... 错误 ! 未定义书签。 系统建成后可实现的功能 . .............................. 错误 ! 未定义书签。 数字集群系统的先进性 . ............................ 错误 ! 未定义书签。 2 项目总体设计方案 ............................................. 错误 ! 未定义书签。 设计目标 . ............................................ 错误 ! 未定义书签。 系统组网方案 . ........................................ 错误 ! 未定义书签。 基站建设 . ........................................ 错误 ! 未定义书签。 站点容量计算 . .................................... 错误 ! 未定义书签。 站点部署示意图 . .................................. 错误 ! 未定义书签。 系统规划 . ........................................ 错误 ! 未定义书签。 系统特点及功能介绍 . .................................. 错误 ! 未定义书签。 基本业务功能 . .................................... 错误 ! 未定义书签。 移动性管理 . .............................. 错误 ! 未定义书签。 安全功能 . ................................ 错误 ! 未定义书签。 基本话音业务 . ............................ 错误 ! 未定义书签。 基本数据业务 . ............................ 错误 ! 未定义书签。 有线调度功能 . .................................... 错误 ! 未定义书签。 语音调度功能 . ............................ 错误 ! 未定义书签。 基本业务功能 ......................... 错误 ! 未定义书签。 多选呼叫 . ............................ 错误 ! 未定义书签。 用户监听 . ............................ 错误 ! 未定义书签。 强插 / 强拆 . ........................... 错误 ! 未定义书签。 遥晕 / 复活 . ........................... 错误 ! 未定义书签。 在线检测 . ............................ 错误 ! 未定义书签。 呼叫提醒 . ............................ 错误 ! 未定义书签。 会议 . ................................ 错误 ! 未定义书签。 遥毙 . ................................ 错误 ! 未定义书签。 短信管理 . ................................ 错误 ! 未定义书签。 紧急告警 . ................................ 错误 ! 未定义书签。 录音回放 . ................................ 错误 ! 未定义书签。 报表查询 . ................................ 错误 ! 未定义书签。 数字系统网管系统 . ................................ 错误 ! 未定义书签。 3 系统设备介绍 ................................................ 错误 ! 未定义书签。 单基站示意图 . ........................................ 错误 ! 未定义书签。 信道机 . .............................................. 错误 ! 未定义书签。 产品描述 . ........................................ 错误 ! 未定义书签。 技术规格 . ........................................ 错误 ! 未定义书签。 合路器 . .............................................. 错误 ! 未定义书签。 分路器 . .............................................. 错误 ! 未定义书签。 双工器 . .............................................. 错误 ! 未定义书签。 室外全向天线 . ........................................ 错误 ! 未定义书签。 手持终端 PD680 ....................................... 错误 ! 未定义书签。
XX科研院所 服务器虚拟集群系统 技术方案
目录 1前言 (1) 2项目建设必要性分析 (1) 3方案设计 (3) 3.1总体拓扑 (3) 3.2方案概述 (3) 3.3VM WARE 服务器虚拟化方案 (5) 3.3.1服务器虚拟化方案概述 (5) 3.3.2方案架构及描述 (7) 3.3.3方案优势 (15) 3.4C ITRIX X EN DE SKTOP桌面虚拟化方案 (16) 3.4.1桌面虚拟化概述 (16) 3.4.2方案架构及描述 (29) 3.4.3Citrix产品及功能描述 (36) 3.5V F OGLIGHT虚拟环境监控方案 (40) 3.5.1虚拟环境监控方案概述 (40) 3.5.2方案介绍 (44) 3.6接入网络解决方案 (54) 3.6.1方案描述 (54) 3.6.2物理布局设计 (58) 3.6.3方案优势 (59) 3.6.4业务服务器区接入层设计的创新发展 (60) 3.6.5基于Nexus产品的创新设计总结 (64) 4配置方案 (65)
1前言 广泛采用的IT 平台在应用范围和复杂性方面急速发展,服务器数量、网络复杂程度和存储容量也随着一波波的技术变革而激增。由此导致的诸多问题目前仍在困扰着各信息化部门。如:服务器利用率低下、多应用并存导致系统不稳定、整机备份还原困难、计划内或计划外的停机导致服务中断等。 服务器虚拟化技术,经过数十年的发展,成功的解决了这些问题,为基础资源整合提供了理想的解决方案。通过部署服务器虚拟集群,将多个服务器、网络存储设备、备份系统等作为一个资源池,从资源池中灵活的分配适当的资源给相应的应用,使得上述问题迎刃而解。今天,服务器虚拟化技术已经被广泛应用在各个领域,作为绿色数据中心的核心技术手段,发挥着重大的作用。 2项目建设必要性分析 随着信息化工作的不断推进,XX科研院所已建立若干重要应用系统等。这些系统的正常运行切实保障了XX科研院所的科研生产顺利开展,大大提高了工作效率和科研能力。这些应用无不需要良好的服务器环境作为支撑,而且随着应用数量及性能要求的不断提高,对服务器环境资源的要求也将越来越高。同时,随着科研生产对信息化的依赖性增强,保障数据中心稳定、不间断的运行显得越来越重要。 数据中心现有多台服务器,每台服务器都运行多个应用服务。目前主要存在以下几个问题: 1.服务器资源使用率不均匀平均使用率低于40%。 2.计划外或计划内停机维护,影响应用服务的不间断运行。 3.部署新应用的成本较高。 这些问题越来越严重的影响着数据中心安全稳定的运行,解决这些问题迫在眉睫。
被误读的NEC容错服务器 误读一:容错很好很昂贵 由于容错服务器采用的是硬件全冗余的技术,而且在两套硬件之间还通过独立芯片和软件保证故障时零时间切换,因而其价格要比同规格的PC服务器高出许多。 更为典型的一个用户反馈是:NEC容错服务器产品很好,可用性很高,但是不是像IBM的z系列和HP的NonStop系列动辄都是百万美元? 从上述两种态度可以看出中国用户对容错的应用定位尚属模糊。根据IDC 数据,广义概念上的容错市场约占整个服务器市场的4%,包括IBM的System z、HP的NonStop和NEC的Santa Clara、Express 5800/ft以及Stratus的ftServer 6200,前三者为传统大型主机,后二者为容错服务器。显而易见,这一市场面对的是属于中高端的窄众用户。 而了解上述用户特征后自然明白,容错所谓的昂贵其实纯属误读:如果只需要进行基础IT建设的成长型企业,完全可以采用普通的塔式和机架式服务器,而不必使用容错产品;如果是需要高可用性的中高端用户,那么容错服务器相对大型主机而言,其实相当便宜。以NEC的容错服务器Express 5800/ft为例,目前最低配置的成本甚至已经与同规格的双机热备方案相当。 误读二:虚拟化取代容错 随着用户对计算资源利用率、灵活调度的高度渴求,导致近几年来虚拟技术在PC服务器上快速增长,VMware、Citrix等技术供应商也迅速走红,由此也产生了这样一种观念:虚拟万能,即通过虚拟就能实现计算资源的灵活配置、调度并保证故障时的自动迁移。 虚拟化真是万灵丹吗?显然不是。从硬件架构的层次上看,虚拟层位于底层硬件之上,只能解决虚拟机及其应用的故障迁移。如果是底层硬件故障,诸如主板故障、电源故障、CPU损坏等,虚拟技术是无能为力的。 随着虚拟化技术的普及,容错服务器会变得越来越重要。因为当物理机宕掉的时候,它会影响运行在其上的虚拟机,所以越是依赖虚拟技术的用户越需要保证底层硬件的高可用。 误读三:容错使用很复杂 对于使用过大型主机和双机热备等高可用方案的用户来说,配置及管理系统绝对是一个技术上的考验。这也使得一些用户产生了“高可用等于高复杂”的观点。
服务器集群技术方案 集群(Cluster )技术是发展高性能计算机的一项技术。它是一组相互独立的计算机,利用高速通信网络组成一个单一的计算机系统,并以单一系统的模式加以管理。其出发点是提供高可靠性、可扩充性和抗灾难性。一个集群包含多台拥有共享数据存储空间的服务器,各服务器通过内部局域网相互通信。当一台服务器发生故障时,它所运行的应用程序将由其它服务器自动接管。在大多数模式 下,集群中所有的计算机拥有一个共同的名称,集群内的任一系统上运行的服务 都可被所有的网络客户使用。采用集群系统通常是为了提高系统的稳定性和网络中心的数据处理能力及服务能力。 当前主流的集群方式包括以下几种: 1. 服务器主备集群方式 服务器主-备方式由一台服务器在正常运行状态提供对外服务,其它集群节点作为备份机,备份机在正常状态下不接受外部的应用请求,实时对生产机进行检测,当生产机停机时才会接管应用服务,因此设备利用率最高可达50%主备 方式集群如下图所示,节点2为正常提供服务的服务器,运行多个应用 (pkgA,pkgB..),节点1平时只监控节点2的状态,不对外提供服务,当节点2 出现故障时,节点1将把两个应用接管过来,并对外提供服务。 图表错误!文档中没有指定样式的文字。-1主备方式集群 2. 服务器互备份集群方式 多台服务器组成集群,每台服务器运行独立的应用,同时作为其它服务器的 备份机,当主应用中断,服务将被其它集群节点所接管,接管服务的节点将运行自身应用和
故障服务器的应用,这种方式各集群节点的硬件资源均可被应用于对外服务。互备方式集群如下图所示,节点1和节点2分别运行1个或多个不同的应用,但只对外提供本地的主应用,两个节点之间互相进行监控,集群中任何一个节点出现故障后,另一个节点把故障节点的主应用接管过来,所有应用服务由一台服务器完成。 图表错误!文档中没有指定样式的文字。-2互备份方式集群 这种方式的主要缺点在于: 由于需要重新启动数据库核心进程,无法保证数据库系统连续不间断地运行 在系统切换的过程中,客户端与服务器之间的数据库连接会中断,需要重新进行数 据库的连接和登录工作 由于数据库系统只能在一台服务器上运行,另一台服务器无法分担系统的负载,实 际上造成了客户投资的浪费。在有些系统中,为了解决双机负载分担的问题,将应 用系统人为分割为两个数据库系统,分别在两台服务器上运行。这种方式在一定程 度上解决了负载分担的问题,但给系统管理、统计分析等业务处理带来了很多额外 的复杂性 3. 服务器并行集群方式 集群有多台服务器构成,同时提供相同的应用,可以实现多台服务器之间的负载均衡, 提供大访问量的应用需求,如Web访问及数据库等应用,服务器并行集群方式一般由应用系 统自身(如OracleRAC中间件负载均衡等)或外部专用服务器负载均衡设备实现。 jL# R?i uat Hiti.iEMXff DLM珀心XM4子耳 vVLH Ctid TW
1、Linux集群主要分成三大类( 高可用集群,负载均衡集群,科学计算集群)(下面只介绍负载均衡集群) 负载均衡集群(Load Balance Cluster) 负载均衡系统:集群中所有的节点都处于活动状态,它们分摊系统的工作负载。一般Web服务器集群、数据库集群和应用服务器集群都属于这种类型。 负载均衡集群一般用于相应网络请求的网页服务器,数据库服务器。这种集群可以在接到请求时,检查接受请求较少,不繁忙的服务器,并把请求转到这些服务器上。从检查其他服务器状态这一点上看,负载均衡和容错集群很接近,不同之处是数量上更多。 2、负载均衡系统:负载均衡又有DNS负载均衡(比较常用)、IP负载均衡、反向代理负载均衡等,也就是在集群中有服务器A、B、C,它们都是互不影响,互不相干的,任何一台的机器宕了,都不会影响其他机器的运行,当用户来一个请求,有负载均衡器的算法决定由哪台机器来处理,假如你的算法是采用round算法,有用户a、b、c,那么分别由服务器A、B、C来处理; 3、分布式是指将不同的业务分布在不同的地方。 而集群指的是将几台服务器集中在一起,实现同一业务。 分布式中的每一个节点,都可以做集群。 而集群并不一定就是分布式的。 举例:就比如新浪网,访问的人多了,他可以做一个群集,前面放一个响应服务器,后面几台服务器完成同一业务,如果有业务访问的时候,响应服务器看哪台服务器的负载不是很重,就将给哪一台去完成。 而分布式,从窄意上理解,也跟集群差不多,但是它的组织比较松散,不像集群,有一个组织性,一台服务器垮了,其它的服务器可以顶上来。 分布式的每一个节点,都完成不同的业务,一个节点垮了,哪这个业务就不可访问了。
双节点数据库负载均衡解决方案 问题的提出? 在SQL Server数据库平台上,企业的数据库系统存在的形式主要有单机模式和集群模式(为了保证数据库的可用性或实现备份)如:失败转移集群(MSCS)、镜像(Mirror)、第三方的高可用(HA)集群或备份软件等。伴随着企业的发展,企业的数据量和访问量也会迅猛增加,此时数据库就会面临很大的负载和压力,意味着数据库会成为整个信息系统的瓶颈。这些“集群”技术能解决这类问题吗?SQL Server数据库上传统的集群技术 Microsoft Cluster Server(MSCS) 相对于单点来说Microsoft Cluster Server(MSCS)是一个可以提升可用性的技术,属于高可用集群,Microsoft称之为失败转移集群。 MSCS 从硬件连接上看,很像Oracle的RAC,两个节点,通过网络连接,共享磁盘;事实上SQL Server 数据库只运行在一个节点上,当出现故障时,另一个节点只是作为这个节点的备份; 因为始终只有一个节点在运行,在性能上也得不到提升,系统也就不具备扩展的能力。当现有的服务器不能满足应用的负载时只能更换更高配置的服务器。 Mirror 镜像是SQL Server 2005中的一个主要特点,目的是为了提高可用性,和MSCS相比,用户实现数据库的高可用更容易了,不需要共享磁盘柜,也不受地域的限制。共设了三个服务器,第一是工作数据库(Principal Datebase),第二个是镜像数据库(Mirror),第三个是监视服务器(Witness Server,在可用性方面有了一些保证,但仍然是单服务器工作;在扩展和性能的提升上依旧没有什么帮助。
双机热备方案 双机热备针对的是服务器的临时故障所做的一种备份技术,通过双机热备,来避免长时间的服务中断,保证系统长期、可靠的服务。 1.集群技术 在了解双机热备之前,我们先了解什么是集群技术。 集群(Cluster)技术是指一组相互独立的计算机,利用高速通信网络组成一个计算机系统,每个群集节点(即集群中的每台计算机)都是运行其自己进程的一个独立服务器。这些进程可以彼此通信,对网络客户机来说就像是形成了一个单一系统,协同起来向用户提供应用程序、系统资源和数据,并以单一系统的模式加以管理。一个客户端(Client)与集群相互作用时,集群像是一个独立的服务器。计算机集群技术的出发点是为了提供更高的可用性、可管理性、可伸缩性的计算机系统。一个集群包含多台拥有共享数据存储空间的服务器,各服务器通过内部局域网相互通信。当一个节点发生故障时,它所运行的应用程序将由其他节点自动接管。 其中,只有两个节点的高可用集群又称为双机热备,即使用两台服务器互相备份。当一台服务器出现故障时,可由另一台服务器承担服务任务,从而在不需要人工干预的情况下,自动保证系统能持续对外提供服务。可见,双机热备是集群技术中最简单的一种。 2. 双机热备适用对象 一般邮件服务器是要长年累月工作的,且为了工作上需要,其邮件备份工作就绝对少不了。有些企业为了避免服务器故障产生数据丢失等现象,都会采用RAID 技术和数据备份技术。但是数据备份只能解决系统出现问题后的恢复;而RAID
技术,又只能解决硬盘的问题。我们知道,无论是硬件还是软件问题,都会造成邮件服务的中断,而RAID及数据备份技术恰恰就不能解决避免服务中断的问题。 要恢复服务器,再轻微的问题或者强悍的技术支持,服务器都要中断一段时间,对于一些需要随时实时在线的用户而言,丢失邮件就等于丢失金钱,损失可大可小,这类用户是很难忍受服务中断的。因此,就需要通过双机热备,来避免长时间的服务中断,保证系统长期、可靠的服务。 3. 实现方案 双机热备有两种实现模式,一种是基于共享的存储设备的方式,另一种是没有共享的存储设备的方式,一般称为纯软件方式。 1)基于共享的存储设备的方式 基于存储共享的双机热备是双机热备的最标准方案。对于这种方式,采用两台服务器(邮件系统同时运行在两台服务器上),使用共享的存储设备磁盘阵列(邮件系统的数据都存放在该磁盘阵列中)。两台服务器可以采用互备、主从、并行等不同的方式。在工作过程中,两台服务器将以一个虚拟的IP地址对外提供服务,依工作方式的不同,将服务请求发送给其中一台服务器承担。同时,服务器
美国stratus公司:容错服务器的简单理 【IT168 资讯】美国stratus容错公司出品的容错服务器是一种可以实现零时间停机的服务器,在一些关键性领域里应用非常广泛,例如:电信、机场、银行、冶金行业、安全、医院的HIS系统、电视台、公安、电力行业、大的零售业,等一切要求高可用性的行业, 这类用户以前在没有办法的情况下选用的是高可用性集群,英文原文为High Availability Cluster, 简称双机HA Cluster,是指以减少服务中断(宕机)时间为目的的服务器集群技术,简称双机,这种方式实现起来非常复杂,后期维护成本也很高,对技术人员的依赖也非常严重,而且因为cluster不能实现0时间停机(消除单点故障的集群可用性是99.99%),所以他的设计目标是减少停机时间而不是避免停机时间,而容错服务器设计上就是避免停机,高可用性的时间是99.9998%,如果2个方案价格相当,您选择减少停机还是选择避免停机的服务器呢? 容错的优势 容错服务器的几点优势简单说说!(主要是和双机的区别说一下) 1:国际著名检测组织IDC公布:容错服务器的高可用性是99.9998%,而消除单点故障的集群是99.99%,IBM的大型机为99.995% 2:设计上容错的目标是避免停机,而集群是减少停机(当我们有避免停机的方案,我们为什么还要选择减少停机的方案呢?) 3:容错能有效的保护动态数据不丢失,而双机只能保证写入硬盘的数据; 4:容错能支持热插拔任意的硬件,包括主板,CPU等关键性硬件, 5:布置非常简单,只需要装单套系统,数据库也只需要一套,免去双机软件和研发代码的麻烦,从而大大的减少工程师的工作量,也大大的减少了软件成本. 6:速度比同配置的双机要快20%以上. 7:后期维护成本几乎为零,而双机的话需要工程师的支持,或许由于系统补丁的升级需要额外的研发双机代码来保证系统的切换成功; 8:容错是没有切换时间的,而双机由于硬件宕机后会发生停顿的情况,还有就是双机切换工作是有可能不成功的. 9.容错的windows系统因为有容错揪错芯片,所以容错的windows系统比传统的windows系统稳定,也许您用很多年都不需要重起windows,因为它永远和刚开机一样快,容错因此承诺容错的windows比IBM的AIX还稳定.因为您用上了容错就不知道什么叫停机. 上面说了很多与双机对比的优势,下面我们通过案例来实际了解容错到底有多好: