
计量学习题练习(一)
小组成员:产慧贤 高媛 张文晶 陈晓申
模型一
一.参数估计
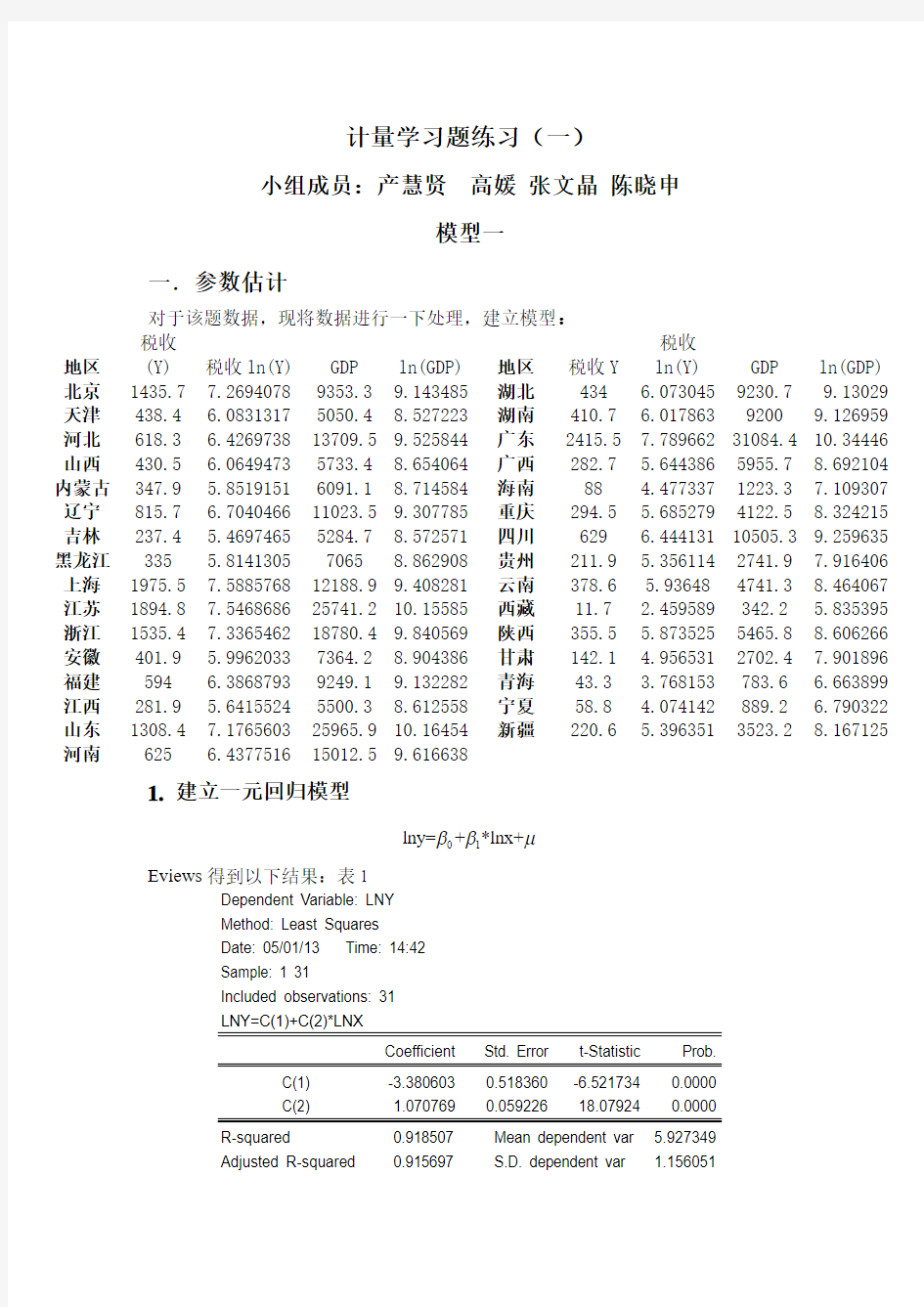
对于该题数据,现将数据进行一下处理,建立模型: 地区 税收
(Y) 税收ln(Y) GDP ln(GDP) 地区 税收Y 税收
ln(Y) GDP ln(GDP) 北京 1435.7 7.2694078 9353.3 9.143485 湖北 434 6.073045 9230.7 9.13029 天津 438.4 6.0831317 5050.4 8.527223 湖南 410.7 6.017863 9200 9.126959 河北 618.3 6.4269738 13709.5 9.525844 广东 2415.5 7.789662 31084.4 10.34446 山西 430.5 6.0649473 5733.4 8.654064 广西 282.7 5.644386 5955.7 8.692104 内蒙古 347.9 5.8519151 6091.1 8.714584 海南 88 4.477337 1223.3 7.109307 辽宁 815.7 6.7040466 11023.5 9.307785 重庆 294.5 5.685279 4122.5 8.324215 吉林 237.4 5.4697465 5284.7 8.572571 四川 629 6.444131 10505.3 9.259635 黑龙江 335 5.8141305 7065 8.862908 贵州 211.9 5.356114 2741.9 7.916406 上海 1975.5 7.5885768 12188.9 9.408281 云南 378.6 5.93648 4741.3 8.464067 江苏 1894.8 7.5468686 25741.2 10.15585 西藏 11.7 2.459589 342.2 5.835395 浙江 1535.4 7.3365462 18780.4 9.840569 陕西 355.5 5.873525 5465.8 8.606266 安徽 401.9 5.9962033 7364.2 8.904386 甘肃 142.1 4.956531 2702.4 7.901896 福建 594 6.3868793 9249.1 9.132282 青海 43.3 3.768153 783.6 6.663899 江西 281.9 5.6415524 5500.3 8.612558 宁夏 58.8 4.074142 889.2 6.790322 山东 1308.4 7.1765603 25965.9 10.16454 新疆 220.6 5.396351 3523.2 8.167125 河南 625 6.4377516 15012.5 9.616638
1. 建立一元回归模型
01lny=+*lnx+ββμ
Eviews 得到以下结果:表1
Dependent Variable: LNY Method: Least Squares Date: 05/01/13 Time: 14:42 Sample: 1 31
Included observations: 31 LNY=C(1)+C(2)*LNX
Coefficient Std. Error t-Statistic Prob. C(1) -3.380603 0.518360 -6.521734 0.0000 C(2)
1.070769
0.059226
18.07924
0.0000 R-squared
0.918507 Mean dependent var 5.927349 Adjusted R-squared
0.915697 S.D. dependent var
1.156051
S.E. of regression 0.335659 Akaike info criterion 0.716900 Sum squared resid 3.267345 Schwarz criterion 0.809415 Log likelihood -9.111948 F-statistic 326.8590 Durbin-Watson stat
1.652914 Prob(F-statistic)
0.000000
于是得到: i i lny =-3.3806+1.0707*lnx ∧
(-6.52) (18.079)
20.91857R = 326.859F = .. 1.6529DW =
2.模型检验
20.91857R =,说明在线性模型中,税收值的总离差,由gdp 的离差解释部分
为91.857%,模型拟合得比之前拟合的较好。 截距项的t 值为-6.52,大于显著性水平下自由度为n-2=29的临界值为048.2)29(025.0=t ,斜率项t 值为1.107。表明中国2007年各地区,国内生产总值gdp 每增加1亿元,税收增加0.0714047
亿元。
3.预测
2008年某地区国内生产总值为8500亿元,代入上述方程可得2008年某地区税收预测的点的估计值为:
2008ln -3.3806 1.0707*ln8500 6.307y =+=
二.模型的异方差检验
1. 图示法
(1) 生成残差列e2
(2) 画出lnx 与e2的散点图
由下图可以看出,残差平方项e2对解释变量lnx 的散点图主要分布在分布图型中的下三角部分,可以看出平方项随lnx 的变动呈现增大趋势。因而,模型很可能存在异方差,下面进行检验。
2.G-D检验
(1)对变量x取值排列
(2)构造子样本空间,建立回归模型
在本例中,样本容量n=31,删除中间n/4的观测数值,即大约7个观测值,余下部分平分得两个样本子区间:1-12和20-31,样本个数均是12个。
(3)对1-12个lnx与lny的ls拟合得到:表2
Dependent Variable: LNY
Method: Least Squares
Date: 05/01/13 Time: 15:00
Sample: 1 12
Included observations: 12
LNY=C(1)+C(2)*LNX
Coefficient Std. Error t-Statistic Prob.
C(1) -3.968776 0.602761 -6.584327 0.0001
C(2) 1.153781 0.077381 14.91044 0.0000 R-squared 0.956956 Mean dependent var 4.961365
Adjusted R-squared 0.952652 S.D. dependent var 1.081787
S.E. of regression 0.235393 Akaike info criterion 0.095892
Sum squared resid 0.554099 Schwarz criterion 0.176710
Log likelihood 1.424648 F-statistic 222.3213
Durbin-Watson stat 2.076750 Prob(F-statistic) 0.000000
(4)对20-31个lnx与lny的ls拟合得到:表3
Dependent Variable: LNY
Method: Least Squares
Date: 05/01/13 Time: 15:02
Sample: 20 31
Included observations: 12
LNY=C(1)+C(2)*LNX
Coefficient Std. Error t-Statistic Prob.
C(1) -1.425296 3.005094 -0.474293 0.6455
C(2) 0.871810 0.313192 2.783628 0.0193 R-squared 0.436575 Mean dependent var 6.931704
Adjusted R-squared 0.380232 S.D. dependent var 0.580464
S.E. of regression 0.456972 Akaike info criterion 1.422623
Sum squared resid 2.088236 Schwarz criterion 1.503441
Log likelihood -6.535740 F-statistic 7.748583
Durbin-Watson stat 2.323928 Prob(F-statistic) 0.019330
(5)F量统计值
基于上面表2和表3中残差平方和RSS的数据,即:RSS1=0.554099,RSS2=2.088236,根据G-D检验,F统计量的值为:=2/1 3.7687
F RSS RSS=
(6)判断
在自由度为5%和10%的显著性水平下,查表可得:自由度为(9,9)的F分
布的临界值分别为
0.05=3.18
F和
0.12.44
F=因为F=3.7687>
0.05=3.18
F同时
F=3.7687>
0.12.44
F=,因而在5%和10%的显著性水平下拒绝两组子样本方差相同的假设,即存在异方差。
3.White检验
由上面表1的结果,在此基础上得到以下结论:
White Heteroskedasticity Test:
F-statistic 0.317344 Probability 0.730664
Obs*R-squared 0.687116 Probability 0.709242
Test Equation:
Dependent Variable: RESID^2
Method: Least Squares
Date: 05/01/13 Time: 15:24
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C 0.176098 1.609648 0.109402 0.9137
LNX -0.047448 0.392488 -0.120891 0.9046
LNX^2 0.004462 0.023718 0.188106 0.8522
R-squared 0.022165 Mean dependent var 0.105398
Adjusted R-squared -0.047680 S.D. dependent var 0.186731
S.E. of regression 0.191131 Akaike info criterion -0.379953
Sum squared resid 1.022866 Schwarz criterion -0.241180
Log likelihood 8.889275 F-statistic 0.317344
Durbin-Watson stat 2.243240 Prob(F-statistic) 0.730664
去掉交叉项的辅助回归结果为:
22
()
e=0.176098-0.047448*lnx+0.004462*lnx
(0.1094)(-0.1208)(0.188106)
2=0.022165
R
怀特统计量2
R==,在5%的显著性水平下,不能拒绝同
n31*0.0221650.6871
方差的假设。
三.异方差的修正:加权最小二乘(WLS)
1. 生成权数
2.加权最小二乘
Dependent Variable: LNY
Method: Least Squares
Date: 05/01/13 Time: 19:17
Sample: 1 31
Included observations: 31
Weighting series: W
Variable Coefficient Std. Error t-Statistic Prob.
C -3.302263 0.007968 -414.4455 0.0000
LNX 1.061058 0.000948 1119.149 0.0000 Weighted Statistics
R-squared 0.999999 Mean dependent var 5.427339
Adjusted R-squared 0.999999 S.D. dependent var 18.47340
S.E. of regression 0.020366 Akaike info criterion -4.887589
Sum squared resid 0.012028 Schwarz criterion -4.795074
Log likelihood 77.75763 F-statistic 24684019
Durbin-Watson stat 1.887028 Prob(F-statistic) 0.000000
Unweighted Statistics
R-squared 0.918403 Mean dependent var 5.927349
Adjusted R-squared 0.915589 S.D. dependent var 1.156051
S.E. of regression 0.335874 Sum squared resid 3.271521
Durbin-Watson stat 2.000877
加权后的结果为:ln y=-3.302263+1.061058*ln x
(-414,44)(1119.29)
20.9999
R D.W=1.887 F=24684019 RSS=0.012
可以看出运用加权最小二乘消除异方差后,lnx参数的t的检验有了显著性的改进。这表明,即使在1%的显著性水平下,都不能拒绝参数影响。
3.检验加权回归模型的异方差性
进行加权回归,得到:
Dependent Variable: W*LNY
Method: Least Squares
Date: 05/01/13 Time: 19:20
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
W -3.302263 0.007968 -414.4455 0.0000
W*LNX 1.061058 0.000948 1119.149 0.0000 R-squared 0.999999 Mean dependent var 2914.437
Adjusted R-squared 0.999999 S.D. dependent var 9920.066
S.E. of regression 10.93621 Akaike info criterion 7.684377
Sum squared resid 3468.422 Schwarz criterion 7.776892
Log likelihood -117.1078 F-statistic 24684019
Durbin-Watson stat 1.887028 Prob(F-statistic) 0.000000
加权模型为:w*ln y=-3.3022*w+1.0610*w*ln x
对该模型进行怀特检验如下:
White Heteroskedasticity Test:
F-statistic 695.6980 Probability 0.000000
Obs*R-squared 30.77879 Probability 0.000010
Test Equation:
Dependent Variable: RESID^2
Method: Least Squares
Date: 05/01/13 Time: 19:21
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C -14.90832 5.280516 -2.823270 0.0092
W 0.034425 1.252183 0.027492 0.9783
W^2 0.007189 0.005241 1.371783 0.1823
W*(W*LNX) -0.001923 0.001393 -1.380520 0.1796
W*LNX 0.172442 0.135554 1.272130 0.2150
(W*LNX)^2 0.000122 8.97E-05 1.360747 0.1857 R-squared 0.992864 Mean dependent var 111.8846
Adjusted R-squared 0.991437 S.D. dependent var 256.7210
S.E. of regression 23.75590 Akaike info criterion 9.345524
Sum squared resid 14108.57 Schwarz criterion 9.623070
Log likelihood -138.8556 F-statistic 695.6980
Durbin-Watson stat 2.036856 Prob(F-statistic) 0.000000
20.9928
==大于相应的检验值,R=,怀特统计量为:2
n*R31*0.992830.7
因而不能拒绝同方差。
四.序列相关性检验
在表1 中得到:DW=1.6529,在5%的显著性水平下,样本容量为31的DW 的上限和下限临界值分别为:dl=1.36,du=1.50,因而可以判断序列无相关。
模型二
下表是中国内地2007年各地区税收Y和国内生产总值GDP的统计资料
单位:亿元地区税收Y GDP 地区税收Y GDP
北京1435.7 9353.3 湖北434 9230.7
天津438.4 5050.4 湖南410.7 9200
河北618.3 13709.5 广东2415.5 31084.4
山西430.5 5733.4 广西282.7 5955.7
内蒙古347.9 6091.1 海南88 1223.3
辽宁815.7 11023.5 重庆294.5 4122.5
吉林237.4 5284.7 四川629 10505.3
黑龙江335 7065 贵州211.9 2741.9
上海1975.5 12188.9 云南378.6 4741.3
江苏1894.8 25741.2 西藏11.7 342.2
浙江1535.4 18780.4 陕西355.5 5465.8
安徽401.9 7364.2 甘肃142.1 2702.4
福建594 9249.1 青海43.3 783.6
江西281.9 5500.3 宁夏58.8 889.2
山东1308.4 25965.9 新疆220.6 3523.2
河南625 15012.5
根据题意,作出以下分析:
一.参数估计
1.建立模型
根据题给的数据,建立税收随国内生产总值gdp 变化的一元线性回归方程。此处令:gdp 为x ,我们假设拟建立如下的一元回归模型:01y=+*x+ββμ 利用eviews 得到以下结果:表1.1
Dependent Variable: Y Method: Least Squares Date: 05/01/13 Time: 15:48 Sample: 1 31
Included observations: 31 Y=C(1)+C(2)*X
Coefficient Std. Error t-Statistic Prob. C(1) 889.7773 163.2625 5.449980 0.0000 C(2)
-0.030224
0.014051
-2.151017
0.0399 R-squared
0.137594 Mean dependent var 621.0548 Adjusted R-squared 0.107856 S.D. dependent var 619.5803 S.E. of regression 585.2143 Akaike info criterion 15.64417 Sum squared resid 9931799. Schwarz criterion 15.73669 Log likelihood -240.4847 F-statistic 4.626873 Durbin-Watson stat
1.711522 Prob(F-statistic)
0.039941
即:回归结果为:
i i y =-10.62963+0.0714047*x ∧
(86.06) (0.0047)
20.7603R = 91.9919F = .. 1.571DW =
2模型检验
20.7603R =,说明在线性模型中,税收值的总离差,由gdp 的离差解释部分
为76.03%,模型拟合得较好。 截距项的t 值为86.06,大于显著性水平下自由度为n-2=29的临界值为048.2)29(025.0=t ,斜率项t 值为0.0047。表明中国2007年各地区,国内生产总值gdp 每增加1亿元,税收增加0.0714047亿元。
3.预测
2008年某地区国内生产总值为8500亿元,代入上述方程可得2008年某地区税收预测的点的估计值为:
=+
=8500*0714047.062963.10-2008y 593.26987 预测区间:
E(X)=8891.1258 var(x)=5.782E7
所以在95%的置信度下税收收入的预测区间为
置信上限:]7
782.5*)131()1258.88918500(311[*2-312760310*
048.226987.5932
E --++ =593.26987+115.0716=593.3+115.1
置信下限:]7
782.5*)131()1258.88918500(311[*2-312760310*
048.2-26987.5932
E --+=593.3+115.1 所以95%的置信度下税收收入的预测区间为:(477.6,708.3)
二.异方差检验
1.图示法
由上图可以看出,残差平方项e22对解释变量x 的散点图主要分布在分布图
型中的下三角部分,可以看出平方项随x 的变动呈现增大趋势。因而,模型很可能存在异方差,下面进行检验。
2.G-D 检验
(1)对变量x 取值排列
(2)构造子样本空间,建立回归模型
在本例中,样本容量n=31,删除中间n/4的观测数值,即大约7个观测值,余下部分平分得两个样本子区间:1-12和20-31,样本个数均是12个。 (3)对1-12个x 与y 的ls 拟合得到:表2.1
Dependent Variable: Y
Method: Least Squares
Date: 05/01/13 Time: 15:58
Sample: 1 12
Included observations: 12
Variable Coefficient Std. Error t-Statistic Prob.
C 532.6148 365.9122 1.455581 0.1762
X 0.110525 0.102464 1.078678 0.3061 R-squared 0.104227 Mean dependent var 872.2083
Adjusted R-squared 0.014650 S.D. dependent var 650.7977
S.E. of regression 646.0130 Akaike info criterion 15.93053
Sum squared resid 4173328. Schwarz criterion 16.01135
Log likelihood -93.58317 F-statistic 1.163547
Durbin-Watson stat 1.402942 Prob(F-statistic) 0.306062 (4)对20-31个x与y的ls拟合得到:表2.2
Dependent Variable: Y
Method: Least Squares
Date: 05/01/13 Time: 15:59
Sample: 20 31
Included observations: 12
Variable Coefficient Std. Error t-Statistic Prob.
C 376.8659 117.6779 3.202522 0.0095
X -0.009412 0.006695 -1.405937 0.1900 R-squared 0.165043 Mean dependent var 226.3917
Adjusted R-squared 0.081547 S.D. dependent var 176.8261
S.E. of regression 169.4630 Akaike info criterion 13.25416
Sum squared resid 287177.0 Schwarz criterion 13.33498
Log likelihood -77.52495 F-statistic 1.976659
Durbin-Watson stat 2.541685 Prob(F-statistic) 0.190046
(5)F量统计值
基于上面表2和表3中残差平方和RSS的数据,即:RSS1=4173328,RSS2=287177,根据G-D检验,F统计量的值为:=2/10.00688124
F RSS RSS=
(6)判断
在自由度为5%和10%的显著性水平下,查表可得:自由度为(9,9)的F分布的
临界值分别为
0.05=3.18
F和
0.12.44
F=因为F=0.00688<
0.05=3.18
F
同时F=3.7687<
0.12.44
F=,因而在5%和10%的显著性水平下都不能拒绝两组子样本方差相同的假设,即不存在异方差。
3.White检验
由上面表1的结果,在此基础上得到以下结论:
White Heteroskedasticity Test:
F-statistic 0.474884 Probability 0.626875
Obs*R-squared 1.017031 Probability 0.601388
Test Equation:
Dependent Variable: RESID^2
Method: Least Squares
Date: 05/01/13 Time: 16:04
Sample: 1 31
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C 303323.0 279580.9 1.084920 0.2872
X 17.83990 52.81626 0.337773 0.7381
X^2 -0.001049 0.001759 -0.596199 0.5558 R-squared 0.032807 Mean dependent var 320380.6
Adjusted R-squared -0.036278 S.D. dependent var 647578.9
S.E. of regression 659220.6 Akaike info criterion 29.72727
Sum squared resid 1.22E+13 Schwarz criterion 29.86604
Log likelihood -457.7727 F-statistic 0.474884
Durbin-Watson stat 1.912779 Prob(F-statistic) 0.626875
去掉交叉项的辅助回归结果为:
22
e=303323+17.8399*x-0.001049*x
(1.0849)(0.337773)(-0.596199)
2=0.032807
R
怀特统计量2
R==,在5%的显著性水平下,不能拒绝同方
n31*0.032807 1.017017
差的假设。
综上:不存在同方差。
四.序列相关性检验
在表1.1中,DW=1.7115,在5%的显著性水平下,样本容量为31的DW 的上限和下限临界值分别为:dl=1.36,du=1.50,因而可以判断序列无相关。
读书破万卷下笔如有神 山东轻工业学院08/09学年第二学期《计量经济学》期末考试试卷 (B卷)(本试卷共7 页) 适用班级:经管学院07级所有学生 20 分)共(本题共一、单项选择题10 小题,每小题2 分, 得分请将其代码填写在每小题列出的四个备选项中只有一个 1. 在多元回归中,调整后的判定系数与判定系数的关系有() A. < B. > C. D.关系不能确定 2R=1时有()根据判定系数2. 与F统计量的关系可知,当 A.F=-1 B.F=0 C.F=1 D. F=∞ 3.DW检验法适用于检验() A.异方差性 B.序列相关 C.多重共线性 D.设定误差 2=0.98,X1的t值=如果一个二元回归模型的 4. OLS结果为R0.00001,X2的t 值=0.0000008,则可能存在()问题。 A. 异方差 B. 自相关 C. 多重共线 D. 随机解释变量 读书破万卷下笔如有神
5. 在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近1,则表明模型中存在() A.异方差性 B.序列相关 C.多重共线性 D.拟合优度低 6.容易产生自相关的数据是() A.横截面数据 B.时间序列数据 C.年度数据 D.混合数据 ????中,模型:检验7. 线性回归??????x?ux?x?y i20ik1i12kii?时,所用的统计量为:()),2,(,?0?k?,1H:0? i ?i0????????ii1k?1?t?nt??ttn?k.. B A ?????? ??VV ????ii1??n?tFnk?1,?k?1ktF?.. D C?????? ii22???? ??VV ii2????,8. 对于线性回归模型:检验随机误差项是否u?xxy????????x tkt221ttt0k1存在自相关的统计 量是:() ???2ee?d61?tti2t?1t??d B. A.??1r nn2? ??n1nn???2e t1?t??2n?r i?t.. D C?t?? ?V2r1?i9. 若回归模型中的随机误差项存在一阶自回归形式的序列相关,则估计模型参数应采用() A.普通最小二乘法 B.加权最小二乘法 C.广义差分法 D.工具变量法 d和d,在给定显著水平下,若DW统计量的下和上临界值分别为则当10. ul d DW d 时,可认为随机误差项()ul
第一章绪论 一、填空题: 1.计量经济学是以揭示经济活动中客观存在的__________为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为__________、__________、__________三者的结合。 2.数理经济模型揭示经济活动中各个因素之间的__________关系,用__________性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间__________的关系,用__________性的数学方程加以描述。 3.经济数学模型是用__________描述经济活动。 4.计量经济学根据研究对象和内容侧重面不同,可以分为__________计量经济学和__________计量经济学。 5.计量经济学模型包括__________和__________两大类。 6.建模过程中理论模型的设计主要包括三部分工作,即__________、____________________、____________________。 7.确定理论模型中所包含的变量,主要指确定__________。 8.可以作为解释变量的几类变量有__________变量、__________变量、__________变量和__________变量。 9.选择模型数学形式的主要依据是__________。 10.研究经济问题时,一般要处理三种类型的数据:__________数据、__________数据和__________数据。 11.样本数据的质量包括四个方面__________、__________、__________、__________。 12.模型参数的估计包括__________、__________和软件的应用等内容。 13.计量经济学模型用于预测前必须通过的检验分别是__________检验、__________检验、__________检验和__________检验。
计量经济学大作业――影响居民消费水平的主要因素分析 学号:0120231 姓名:孙馥琳 专业:122税务 修课时间:2014—2015学年第二学期 任课教师:万建香老师 成绩: 评语:
影响居民消费水平的主要因素分析 摘要 就我国近阶段消费方面出现的一些情况,利用1993年至2008年的相关数据对我国消费的影响因素进行实证分析。目的在于让我们更加了解我国消费的因素。先通过相关的背景理论提出问题;搜集了相关的数据,利用EVIEWS软件对计量模型进行了参数估计和检验,并加以修正。本文主要是通过对影响居民消费水平的主要因素分析揭示中国居民消费水平的现状及问题,并依此提出部分政策 关键词:居民消费水平国内生产总值收入 Abstract Abstractthe recent phase of consumption in China is in some cases, using the related data from 1993 to 2008, the empirical analysis on the influence factors of consumption in our country. Purpose is to let us know more about China's consumption factors. To pass the relevant background theory questions; Collected the relevant data, using EVIEWS software measurement model for the parameter estimation and test, and modified. This article mainly through the analysis of the main factors influencing the residents' consumption level to reveal current situation and problems of Chinese residents' consumption level, and accordingly puts forward some policies. Keywords: residents' consumption level Gross domestic product (GDP)
计量经济学第三章作业 经济131 王晨莹 13013121 15.(1)① 打开材料数据表3-5,获得如图3-5-1所示: 3-5-1 ② 根据题目确定被解释变量为税收收入(T )、解释变量为工业(GY )、进出口总额(IE )、金融业(JR )、交通运输业(JT)、建筑业(JY )。 ③ 建模: t t JY JT JR IE GY T μββββββ++++++=543210 ④ 建立变量组: 在主菜单上Eviews 命令框中直接输入命令“Data T GY IE JR JT JY ”,将直接出现已定义变量名称的数据编辑窗口。如图3-5-2所示:
图3-5-2 ⑤估计模型参数: 在主菜单上依次单击“Quick→Estimate Equation”,弹出对话框,在“Specification”选项卡中输入模型中被解释变量(T)、常数项(C)、解释变量(GY、IE、JR、JT、JY)序列,并选择估计方法及样本区间(1985-2009)。如图3-5-3所示,其结果如图3-5-4所示: 图3-5-3
图3-5-4 ⑥ 参数估计结果分析: 经参数估计后,回归模型为 ∧T = 117.5 - 0.772 GY + 0.232 IE + 1.82 JR + 1.895 JT + 2.853 JY (0.2168) (-3.068) (5.552) (3.184) (2.261) (3.047) 995.02=R ,F=798 , d=0.674 ⑦ 模型中参数表明,在工业、建筑业、进出口、金融业、交通运输业中,建筑业对税收的影响最大,工业(GY )每增加1亿元,税收收入(T )将减少3.068亿元(但不符合经济意义);进出口总额(IE )每增加1亿元,税收收入(T )将增加5.552亿元;金融业(JR )每增加1亿元,税收收入(T )将增加3.184亿元;交通运输业(JT)每增加1亿元,税收收入(T )将增加2.261亿元;建筑业(JY )每增加1亿元,税收收入(T )将增加3.047亿元。抛出这5类因素对税收的影响,政府从其他部门和产业所征收数额为117.48。 (2)多重共线性检验:存在多重共线性 由上图可知,工业的结构参数为负,不符经济意义,故去掉工业得到新的模型:
1、已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X (45.2)(1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题: (1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 答:(1)系数的符号是正确的,政府债券的价格与利率是负相关关系,利率的上升会引起政府债券价格的下降。 (2)i Y 代表的是样本值,而i ?Y 代表的是给定i X 的条件下i Y 的期望值,即?(/)i i i Y E Y X =。此模型是根据样本数据得出的回归结果,左边应当是i Y 的期望值,因此是i ?Y 而不是i Y 。 (3)没有遗漏,因为这是根据样本做出的回归结果,并不是理论模型。 (4)截距项101.4表示在X 取0时Y 的水平,本例中它没有实际意义;斜率项-4.78表明利率X 每上升一个百分点,引起政府债券价格Y 降低478美元。 2、有10户家庭的收入(X ,元)和消费(Y ,百元)数据如下表: 10户家庭的收入(X )与消费(Y )的资料 X 20 30 33 40 15 13 26 38 35 43 Y 7 9 8 11 5 4 8 10 9 10 若建立的消费Y 对收入X 的回归直线的Eviews 输出结果如下: Dependent Variable: Y var Adjusted R-squared 0.892292 F-statistic 75.55898 (1)说明回归直线的代表性及解释能力。 (2)在95%的置信度下检验参数的显着性。(0.025(10) 2.2281t =,0.05(10) 1.8125t =,0.025(8) 2.3060t =,0.05(8) 1.8595t =) (3)在95%的置信度下,预测当X =45(百元)时,消费(Y )的置信区间。(其
学院:__________金融学院_____________ 上课学期: ___ 2011-2012第一学期_________ 课程名称: _______ 金融计量学_____________ 指导教师:_______ _ ______________ 实验主题:_ GDP增长与三大产业关系模型____ 小组成员: 二零一一年十一月二十四日 目录
摘要 (3) 1.引言 (3) 2.提出问题 (3) 3.建立模型 (4) 4.制作散点图 (4) 5.模型参数估计 (8) 6.模型的检验 (9) 6.1.计量经济学检验 (9) 6.1.1.多重共线性检验 (9) 6.1.1.1.简单回归系数检验 (10) 6.1.1.2.找出最简单的回归形式 (10) 6.1.1.3.逐步回归法检验 (14) 6.1.2.异方差性检验 (15) 6.1.2.1.图示检验法 (16) 6.1.2.2.White检验 (16) 6.1.2.3.异方差的修正 (17) 6.1.3.随即扰动项序列相关检验 (18) 6.1.3.1.D.W.检验 (18) 6.1.3.2.拉格朗日乘数(LM)检验 (19) 6.1.3.3.序列相关性修正 (19) 6.2.经济意义检验 (20) 6.3.统计检验 (21) 6.3.1.拟合优度检验 (21) 6.3.2.方程显著性检验——F检验 (21) 6.3.3.参数显著性检验——t检验 (21) 7.结论 (22) 8.对策与建议 (23) 9.参考文献: (23)
摘要 经济发展是以GDP增长为前提的,而GDP增长与产业结构变动又有着密不可分的关系。本文采用1981年至2010年的统计数据,通过建立多元线性回归模型,运用最小二乘法,研究三大产业增长对我国GDP增长的贡献,从而得出调整产业结构对转变经济发展方式,促进我国经济可持续发展的重要性。 关键字:GDP增长;三大产业;产业结构 1.引言 GDP增长通常是指在一个较长的时间跨度上,一个国家人均产出(或人均收入)水平的持续增加。GDP增长率的高低体现了一个国家或地区在一定时期内经济总量的增长速度,也是衡量一个国家或地区总体经济实力增长速度的标志。它构成了经济发展的物质基础,而产业结构的调整与优化升级对于GDP增长乃至经济发展至关重要。 一个国家产业结构的状态及优化升级能力,是GDP发展的重要动力。十六大报告提出,推进产业结构优化升级,形成以高新技术产业为先导、基础产业和制造业为支撑、服务业全面发展的产业格局。十七大报告明确指出,推动产业结构优化升级,这是关系国民经济全局紧迫而重大的战略任务。《十二五规划纲要》又将经济结构战略性调整作为主攻方向和核心任务。产业结构优化升级对于促进我国经济全面协调可持续发展具有重要作用。 2.提出问题 我国把各种产业划分为第一产业,第二产业和第三产业。他们在整个国民经济中各自发挥着不同程度的作用。近几十年来来我国的经济已经发生了天翻地覆的变化。各大产业在整个国民经济中所占的地位和作用也在发生着相应的变化和调整。对于这种变化是否符合我国的经济发展趋势,对我国的经济影响作用是否
下表列出了某年中国部分省市城镇居民每个家庭平均全年可支配收入X与消费性支出Y 的统计数据。 地区可支配收入 (X)消费性支出 (Y) 地区可支配收入 (X) 消费性支出 (Y) 北京10349.69 8493.49 浙江9279.16 7020.22 天津8140.50 6121.04 山东6489.97 5022.00 河北5661.16 4348.47 河南4766.26 3830.71 山西4724.11 3941.87 湖北5524.54 4644.5 内蒙古5129.05 3927.75 湖南6218.73 5218.79 辽宁5357.79 4356.06 广东9761.57 8016.91 吉林4810.00 4020.87 陕西5124.24 4276.67 黑龙江4912.88 3824.44 甘肃4916.25 4126.47 上海11718.01 8868.19 青海5169.96 4185.73 江苏6800.23 5323.18 新疆5644.86 4422.93 (1)试用普通最小二乘法建立居民人均消费支出与可支配收入的线性模型; (2)检验模型是否存在异方差性; (3)如果存在异方差性,试采用适当的方法估计模型参数。 解: (1)a.建立对象,录入可支配收入X与消费性支出Y,如下图: b. 设定一元线性回归模型为: 点击主界面菜单Quick\Estimate Equation,在弹出的对话框中输入Y、C、X,操作
(2)a.生成残差序列。在工作文件中点击Object\Generate Series…,在弹出的窗口中,在主窗口键入命令如下“e1=resid^2”得到残差平方和序列e1。如下图: (3)a. 设定一元线性回归模型为:
一、判断正误(20分) 1. 随机误差项i u 和残差项i e 是一回事。( F ) 2. 给定显著性水平a 及自由度,若计算得到的t 值超过临界的t 值,我们将接受零 假设( F ) 3. 利用OLS 法求得的样本回归直线t t X b b Y 21? +=通过样本均值点),(Y X 。( T ) 4. 判定系数ESS TSS R =2 。( F ) 5. 整个多元回归模型在统计上是显著的意味着模型中任何一个单独的变量均是统计显著的。( F ) 6. 双对数模型的2 R 值可以与对数线性模型的相比较,但不能与线性对数模型的相比较。( T ) 7. 为了避免陷入虚拟变量陷阱,如果一个定性变量有m 类,则要引入m 个虚拟变量。( F ) 8. 在存在异方差情况下,常用的OLS 法总是高估了估计量的标准差。( T ) 9. 识别的阶条件仅仅是判别模型是否可识别的必要条件而不是充分条件。( T ) 10. 如果零假设H 0:B 2=0,在显著性水平5%下不被拒绝,则认为B 2一定是0。 ( F ) 六、什么是自相关杜宾—瓦尔森检验的前提条件和步骤是什么(15分) 解:自相关,在时间(如时间序列数据)或者空间(如在截面数据中)上按顺序排列的序列的各成员之间存在着相关关系。在计量经济学中指回归模型中随机扰动项之间存在相关关系。用符号表示: ()j i u u E u u j i j i ≠≠=0 ),cov( 杜宾—瓦尔森检验的前提条件为: (1)回归模型包括截距项。 (2)变量X 是非随机变量。 (3)扰动项t u 的产生机制是 表示自相关系数),11(1≤≤-+=-ρρt t t v u u 上述这个描述机制我们称为一阶自回归模型,通常记为AR(1)。 (4)在回归方程的解释变量中,不包括把因变量的滞后变量。即检验对于自回归模型是不使用的。 杜宾—瓦尔森检验的步骤为: (1)进行OLS 的回归并获得e t 。 (2)计算d 值。 (3)给定样本容量n 和解释变量k 的个数,从临界值表中查得d L 和d U 。
以往计量经济学作业答案 第一次作业: 1-2. 计量经济学的研究的对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征? 答:计量经济学的研究对象是经济现象,是研究经济现象中的具体数量规律(或者说,计量经济学是利用数学方法,根据统计测定的经济数据,对反映经济现象本质的经济数量关系进行研究)。计量经济学的内容大致包括两个方面:一是方法论,即计量经济学方法或理论计量经济学;二是应用,即应用计量经济学;无论是理论计量经济学还是应用计量经济学,都包括理论、方法和数据三种要素。 计量经济学模型研究的经济关系有两个基本特征:一是随机关系;二是因果关系。 1-4.建立与应用计量经济学模型的主要步骤有哪些? 答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和一致性;(3)估计模型参数;(4)模型检验,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。 1-6.模型的检验包括几个方面?其具体含义是什么? 答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型预测检验。在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 第二次作业: 2-1 答:P27 6条 2-3 线性回归模型有哪些基本假设?违背基本假设的计量经济学模
计量经济学大作业 ――税收影响因素的研究学号: 姓名: 专业:
税收影响因素的研究 摘要 本文研究的是税收影响因素模型,通过对1991-2010年税收规模资料的分析,以了解税收的结构、规模及演变的新特点,并探讨影响税收的各因素,运用Eviews软件对1991—2010的历史数据进行分析,并通过我国实际经济发展状况和政策导向运用此关系对以后情况进行预测。 关键词:税收财政支出 OLS 1 问题的提出 从进入21世纪以来,我国的经济发展面临着巨大的挑战与机遇,在新的经济背景下,基于知识和信息的产业发展迅速,全球一体化日渐深入,中国已是WTO的一员。新形势的经济发展是经济稳定和协调增长的结果,由于税收具有敛财与调控的重要功能,因而他在现实的经济发展中至始至终都发挥着非常重要的作用,所以研究影响我国税收收入的主要原因具有非常重要的作用。改革开放以来,中国经济高涨,对税收影响最大的当属财政支出。另外各种消费价格指数也是重要影响因素,而前人有对国内生产总值是否具有影响进行过实证分析。经济发展水平是制约税制结构的生产力要素,两者之间的相关程度较高。这种相关性主要表现为经济发展水平规定着税收参与社会产品分配的比例,决定着税制结构的选择。经济发展水平的差异通常以人均国内生产总值的高低来衡量。在人均国内生产总值不同的国家里,税收规模即税收占国内生产总值的比重是不一样的。以世界银行公布的1980年的调查材料为例,在人均国内生产总值260美元的低收入国家里,国内生产总值税收率为13.2%;人均国内生产总值为2000美元的中等收入国家,这一比率为23.3%;而在人均国内生产总值为1万美元的高收入国家,这一比例是28.1%。显然,一国国内生产总值税收率愈高,税负承受能力愈强,因而也为税制结构的调整提供了物质基础。本文站在前人的基础上,引用计量的方法,将三者综合起来对税收进行探讨,作者认为,在我国经济飞速发展的过程中,国内生产总值有了很大的增长,因而本文将国内生产总值引入该项目的实证研究分析。
1、家庭消费支出(Y )、可支配收入(1X )、个人个财富(2X )设定模型下: i i i i X X Y μβββ+++=22110 回归分析结果为: LS 18/4/02 Error T-Statistic Prob. C ________ 2X - ________ 2X R-squared ________ Mean dependent var Adjusted R-squared . dependent var . of regression ________ Akaike info criterion Sum squared resid Schwartz criterion Log likelihood - 31.8585 F-statistic Durbin-Watson stat Prob(F-statistic) 补齐表中划线部分的数据(保留四位小数);并写出回归分析报告。 由表可知,9504.02=R 故 9614.01 10310) 9504.01(12=----=R 回归分析报告如下: 由以上结果整理得: t= 9614.02=R n=10 从回归结果来看,9614.02=R ,9504.02=R ,3339.87=F ,不够大,则模型的拟合优度不是很好. 模型说明当可支配收入每增加1元,平均说来家庭消费支出将减少元,当个人财富每增加1元,平均来说家庭消费支出将增加元。 参数检验:
在显着性水平上检验1β,2β的显着性。 365.2)310(7108.0025.01=-<-=t t Θ 故接受原假设,即认为01=β。 365.2)310(7969.1025.02=-<=t t Θ 故接受原假设,即认为02=β。 即模型中,可支配收入与个人财富不是影响家庭消费支出的显着因素。 2、为了解释牙买加对进口的需求 ,根据19年的数据得到下面的回归结果: se = R 2= 2 R = 其中:Y=进口量(百万美元),X 1=个人消费支出(美元/年),X 2=进口价格/国内价格。 (1) 解释截距项,及X 1和X 2系数的意义; 答:截距项为,在此没有什么意义。1X 的系数表明在其它条件不变时,个人年消费量增加1美元,牙买加对进口的需求平均增加万美元。2X 的系数表明在其它条件不变时,进口商品与国内商品的比价增加1美元,牙买加对进口的需求平均减少万美元。 (2)Y 的总离差中被回归方程解释的部分,未被回归方程解释的部分; 答:由题目可得,可决系数96.02=R ,总离差中被回归方程解释的部分为96%,未被回归方程解释的部分为4%。 (3)对回归方程进行显着性检验,并解释检验结果; 原假设:0:210==ββH 计算F 统计量 16 04.0296.01=--=k n RSS k ESS F =192 63.3)16,2(19205.0=>=F F Θ 故拒绝原假设,即回归方程显着成立。 (4)对参数进行显着性检验,并解释检验结果。 对21ββ进行显着性检验 96.174.210092.002.0) ?(?05.011`11=>=-=-=t SE t βββ 故拒绝原假设,即1β显着。 96.12.1084.001.0) ?(?05.02222=<=-=-=t SE t βββ 故接受原假设,即2β不显着。 4.根据某地1961—1999年共39年的总产出Y 、劳动投入L 和资本投入K 的年度 数据,运用普通最小二乘法估计得出了下列回归方程: ,DW= 式下括号中的数字为相应估计量的标准误。 (1)解释回归系数的经济含义; (2)系数的符号符合你的预期吗为什么
计量经济学期末考试简答题 1.简述计量经济学与经济学、统计学、数理统计学学科间的关系。 2.计量经济模型有哪些应用? 3.简述建立与应用计量经济模型的主要步骤。 4.对计量经济模型的检验应从几个方面入手? 5.计量经济学应用的数据是怎样进行分类的? 6.在计量经济模型中,为什么会存在随机误差项? 7.古典线性回归模型的基本假定是什么? 8.总体回归模型与样本回归模型的区别与联系。 9.试述回归分析与相关分析的联系和区别。 10.在满足古典假定条件下,一元线性回归模型的普通最小二乘估计量有哪些统计性质?11.简述BLUE的含义。 12.对于多元线性回归模型,为什么在进行了总体显著性F检验之后,还要对每个回归系数进行是否为0的t检验? 13.给定二元回归模型:,请叙述模型的古典假定。 14.在多元线性回归分析中,为什么用修正的决定系数衡量估计模型对样本观测值的拟合优度? 15.修正的决定系数及其作用。 16.常见的非线性回归模型有几种情况? 17. 18观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。 19.什么是异方差性?试举例说明经济现象中的异方差性。 20.产生异方差性的原因及异方差性对模型的OLS估计有何影响。 21.检验异方差性的方法有哪些? 22.异方差性的解决方法有哪些? 23.什么是加权最小二乘法?它的基本思想是什么? 24.样本分段法(即戈德菲尔特——匡特检验)检验异方差性的基本原理及其使用条件。25.简述DW检验的局限性。 26.序列相关性的后果。 27.简述序列相关性的几种检验方法。 28.广义最小二乘法(GLS)的基本思想是什么? 29.解决序列相关性的问题主要有哪几种方法? 30.差分法的基本思想是什么? 31.差分法和广义差分法主要区别是什么? 32.请简述什么是虚假序列相关。 33.序列相关和自相关的概念和范畴是否是一个意思? 34.DW值与一阶自相关系数的关系是什么? 35.什么是多重共线性?产生多重共线性的原因是什么? 36.什么是完全多重共线性?什么是不完全多重共线性? 37.完全多重共线性对OLS估计量的影响有哪些? 38.不完全多重共线性对OLS估计量的影响有哪些? 39.从哪些症状中可以判断可能存在多重共线性? 40.什么是方差膨胀因子检验法? 41.模型中引入虚拟变量的作用是什么? 42.虚拟变量引入的原则是什么? 43.虚拟变量引入的方式及每种方式的作用是什么? 44.判断计量经济模型优劣的基本原则是什么? 45.模型设定误差的类型有那些? 46.工具变量选择必须满足的条件是什么? 47.设定误差产生的主要原因是什么? 48.在建立计量经济学模型时,什么时候,为什么要引入虚拟变量? 49.估计有限分布滞后模型会遇到哪些困难 50.什么是滞后现像?产生滞后现像的原因主要有哪些? 51.简述koyck模型的特点。 52.简述联立方程的类型有哪几种 53.简述联立方程的变量有哪几种类型
计量经济学(第四版)习题参考答案 潘省初
第一章 绪论 试列出计量经济分析的主要步骤。 一般说来,计量经济分析按照以下步骤进行: (1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项? 为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。 什么是时间序列和横截面数据? 试举例说明二者的区别。 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。 横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。 估计量和估计值有何区别? 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。在一项应用中,依据估计量算出的一个具体的数值,称为估计值。如Y 就是一个估计量,1 n i i Y Y n == ∑。现有一样本,共4个数,100,104,96,130,则 根据这个样本的数据运用均值估计量得出的均值估计值为 5.1074 130 96104100=+++。 第二章 计量经济分析的统计学基础 略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间 N S S x = = 4 5= 用 =,N-1=15个自由度查表得005.0t =,故99%置信限为 x S t X 005.0± =174±×=174± 也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。 25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体? 原假设 120:0=μH 备择假设 120:1≠μH 检验统计量 () 10/2510/25 X X μσ-Z == == 查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。 某月对零售商店的调查结果表明,市郊食品店的月平均销售额为2500元,在下一个月份中,取出16个这种食品店的一个样本,其月平均销售额为2600元,销售额的标准差为480元。试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化? 原假设 : 2500:0=μH 备择假设 : 2500:1≠μH ()100/1200.83?480/16 X X t μσ-= === 查表得 131.2)116(025.0=-t 因为t = < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。
2010-2011第二学期 计量经济学大作业 大作业名称:2008年12月我国税收多因素分析 组长: 学号:00 姓名:专业:财政学 成员: 学号:00 姓名:专业:财政学 学号:00 姓名:专业:财政学 选课班级:A01 任课教师:徐晔成绩: 评语:__________________________________________________ 教师签名:批阅日期:
计量经济大作业要求如下: 目的要求: 1.熟练掌握计量经济学的主要理论与方法; 2.能够理论联系实际; 3.能够运用计量经济学软件Eviews进行计算和分析; 4.要求:word文档格式,内容四千字左右,并附数据。 内容: 1.确立问题: 选择一个经济预测问题或经济分析问题,根据一定的经济理论和实际经验分析所涉及的经济领域或经济系统中某一经济变量与其它一些(至少二个)经济变量之间的因果关系。 2.建立模型: 初步建立其多元线性回归模型,利用软件求解回归方程;进行经济意义检验、统计与经济计量检验,解决可能出现的违反基本假设的问题,最后确定回归方程。 3.提供图表: 给出说明该回归方程建立效果较好的必要的图表,如通过被解释变量的观察值曲线与拟合值曲线来比较其拟合效果。 4.实证分析: 利用回归方程的结果进行一定的经济预测或经济分析。 江西财经大学信息管理学院 计量经济学课程组 2011/2/19
2008年12月 我国税收多因素分析 【摘要】:本文主要分析税收收入与国民生产总值及进出口的关系,通过数据拟合模型,将几者之间的关系量化。 一、研究背景 税收是国家为了实现其职能,按照法定标准,无偿取得财政收入的一种手段,是国家凭借政治权力参与国民收入分配和再分配而形成的一种特定分配关系。是我们国财政收入的基本因素,也影响着我国经济的发展。税收收入的影响因素是来自于多方面的,如居民消费水平、城乡储蓄存款年末余额、财政支出总量以及国内生产总值等等。近年来,我国的税收增长远远快于GDP的增长速度,通过对税收增长的两个影响因素进行分析,从中找出对我国的税收增长影响最大的影响因素。 二、研究目的 税收是国家为了实现其职能,凭借政治权利,参与一部分社会产品或国民收入分配与再分配所进行的一系列经济活动。税收的课税权主体是国家,具体包括各级政府及其财税部门。税收活动的目的是为国家实现其职能服务的,这是所有国家爱税收的共性。 税收分配的对象是一部分社会产品或国民收入,可以是实物或货币,这反映出税收分配由实物形式向货币形式发展演变的过程。税收既是财政收入的支柱,又是宏观调控的杠杆。在国家的宏观调控体系中,税收是集经济、法律、行政手段于一身的重要工具,具有不可替代的作用,是国家职能实现不可缺少的手段。因此,分析税收收入,有助于正确把握宏观经济规律,有助于合理制定国家财政政策,从而起到维护国家、分配收入、配置资源、稳定经济的重要作用。 本文主要通过对国内生产总值和国内进出口总额两个因素进行多因素分析,并根据相关数据,建立模型,对此进行数量分析。在得到我国税收收入与各主要因素间的线性关系后,针对此模型分别对违背基本假设的三种情况进行假设检验和计量经济学检验,并对模型的估计结果进行分析。 我们建立税收收入模型的目的有以下三点: (1)结果分析,即对宏观经济变量之间的关系作定性的分析; (2)预测未来,即预测未来税收收入的总量及规模; (3)政策评价,利用模型对各种政策方案进行分析和比较。 在实际经济系统税收收入的实现过程中,税收收入受到经济增长、GDP总量及结构、进出口总额以及税收政策与制度等因素的影响。而由经济增长转换为税收的增长还要经过政策性和实施性两次漏出,如下图: GDP分解: GDP(C+V+M) →可征税GDP(V+M) →应税GDP →税收 ↓↓↓税收漏出:不可征税GDP(C)政策性漏出实施性漏出 ↓↓税收政策及制度:税制不完善税收征管不力税收经济生活受制于国家政策,国家政策会因税收经济现状而处于部分调整中,这种调整主要是指税收经济的动荡对整体宏观经济造成的消极影响会促使国家为稳定经济采取相应措施。
《计量经济学》期末考试复习资料 第一章绪论 参考重点: 计量经济学的一般建模过程 第一章课后题(1.4.6) 1.什么是计量经济学计量经济学方法与一般经济数学方法有什么区别 答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科,是由经济学、统计学和数学三者结合而成的交叉学科。 计量经济学方法揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。 4.建立与应用计量经济学模型的主要步骤有哪些 答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和—致性;(3)估计模型参数;(4)检验模型,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。 6.模型的检验包括几个方面其具体含义是什么 答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型的预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 第二章经典单方程计量经济学模型:一元线性回归模型参考重点: 1.相关分析与回归分析的概念、联系以及区别 2.总体随机项与样本随机项的区别与联系
计量经济学大作业――普通高等学校在校学生总数变动的多因素分析学号:0090863 0090817 0090832 姓名:组长:邱碧涛组员:杨意钟丹兰 专业:财政学 修课时间:2011-2012第一学期 任课教师:朱永军 成绩: 评语:本文通过对中国普通高等学校在校学生总数的变动进行多因素分析,采用中国1985年到2009年的数据,建立以在校大学生总数为应变量,以其它可量化影响因素为自变量的多元线性回归模型,并利用模型对在校大学生总数进行数量化分析,得出各因素与在校大学生总数成正相关关系的结论。从大作业的完成情况来看,说明本小组成员对计量经济学有一定程度的理解,并能使用Eviews软件进行实证分析。 Email:275474458@https://www.doczj.com/doc/4e72541.html,
普通高等学校在校学生总数变动的多因素分析 摘要 本文主要通过对中国普通高等学校在校学生总数的变动进行多因素分析,建立以在校大学生总数为应变量,以其它可量化影响因素为自变量的多元线性回归模型,并利用模型对在校大学生总数进行数量化分析,观察各因素是如何分别影响在校大学生总数的。 关键词:在校大学生总数多因素分析模型计量经济学检验 Abstract This text uses the total number of students in Chinese colleges and universities to do multivariate analysis, and it establishes a multiple linear regression model, which uses the total number of college students to be the dependent variable and other factors to be the independent variable .What's more, it uses the model to do quantitative analysis of the total number of college students, and observe how various factors affect the total number of college students respectively. Key words: The total number of college students, Multivariate analysis, Model, Econometric, Test
《计量经济学》期末总复习 一、单项选择题 1.在双对数线性模型lnY i =ln β0+β1lnX i +u i 中,β1的含义是( D ) A .Y 关于X 的增长量 B .Y 关于X 的发展速度 C .Y 关于X 的边际倾向 D .Y 关于X 的弹性 2.在二元线性回归模型:i i 22i 110i u X X Y +β+β+β=中,1β表示( A ) A .当X 2不变、X 1变动一个单位时,Y 的平均变动 B .当X 1不变、X 2变动一个单位时,Y 的平均变动 C .当X 1和X 2都保持不变时, Y 的平均变动 D .当X 1和X 2都变动一个单位时, Y 的平均变动 3.如果线性回归模型的随机误差项存在异方差,则参数的普通最小二乘估计量是(D ) A .无偏的,但方差不是最小的 B .有偏的,且方差不是最小的 C .无偏的,且方差最小 D .有偏的,但方差仍为最小 4.DW 检验法适用于检验( B ) A .异方差 B .序列相关 C .多重共线性 D .设定误差 5.如果X 为随机解释变量,X i 与随机误差项u i 相关,即有Cov(X i ,u i )≠0,则普通最小二乘估计β ?是( B ) A .有偏的、一致的 B .有偏的、非一致的 C .无偏的、一致的 D .无偏的、非一致的 6.设某商品需求模型为Y t =β0+β1X t + u t ,其中Y 是商品的需求量,X 是商品价格,为了考虑全年4个季节变动的影响,假设模型中引入了4个虚拟变量,则会产生的问题为( ) A .异方差性 B .序列相关 C .不完全的多重共线性 D .完全的多重共线性 7.当截距和斜率同时变动模型Y i =α0+α1D+β1X i +β2 (DX i )+u i 退化为截距变动模型时,能
2015-2016年第2学期 计量经济学大作业 论文名称:中国货币流通量、货款额 和居民消费水平指数分析 学号:姓名:专业: 学号:姓名:专业: 学号:姓名:专业: 选课班级:A05任课老师:陶长琪评语: 教师签名:批阅日期:
一、摘要 经济与货币流通量是相辅相成密不可分的,经济的发展必然会带来货币流通量的增加,进而也会带来消费的增加。而一个国家贷款额的多少和居民消费水平指数的大小往往能够在某种程度上反映该国家经济的发展水平。因此,经济将货币流通量、贷款额和居民消费水平指数紧密地联系起来。 计量经济学可以帮助我们通过建立多元线性模型来反应货币流通量、贷款额和居民消费水平指数三者之间的关系。我们可以通过进行拟合优度检验,F检验,显著性检验,异方差检验,相关性检验和多重共线性检验等多种检验方法最终确定模型,使得建立的模型达到最优的结果。 最后通过对模型的进一步分析,我们可以得出货币流通量、货款额和居民消费水平指数三者之间的关系,即贷款额与居民消费水平指数的增加均会导致货币流通量的增加。 关键字:货币流通量,贷款额,居民消费水平指数,多元线性模型
Abstract Economic and monetary circulation is complementary to close, the development of economy will inevitably bring about the increase of monetary circulation, and also can bring consumption increase. A national loan amount how many and dweller consumption level index size tend to a certain extent reflects the development level of national economy.Thus, the economy will the amount of money in circulation, the loan amount and dweller consumption level index closely linked. Econometrics can help us through the establishment of multiple linear models to response the amount of money in circulation, the loan amount and dweller consumption level index of the relationship between the three.We can through the goodness-of-fit testing ,and F inspection, significant inspection, heteroscedastic inspection , the inspection and multiple linear correlation of inspection to determine the final model, makes the establishment of the model to achieve the optimal result. Based on further analysis of the model, we can conclude that the amount of money in circulation, the amount of goods and dweller consumption level index of the relationship between the three, namely, the loan amount and consumption level of exponential increase will lead to the increase of the amount of money in circulation. Key words: The amount of money in circulation, the loan amount dweller consumption level index, multivariate linear model