
Websphere集群的安装
1、主节点安装DM (2)
2、websphere软件升级: (8)
3、启动DM控制台 (14)
4、创建节点1的应用服务器 (14)
5、登录DM控制台,创建节点 (16)
6、创建集群节点 (20)
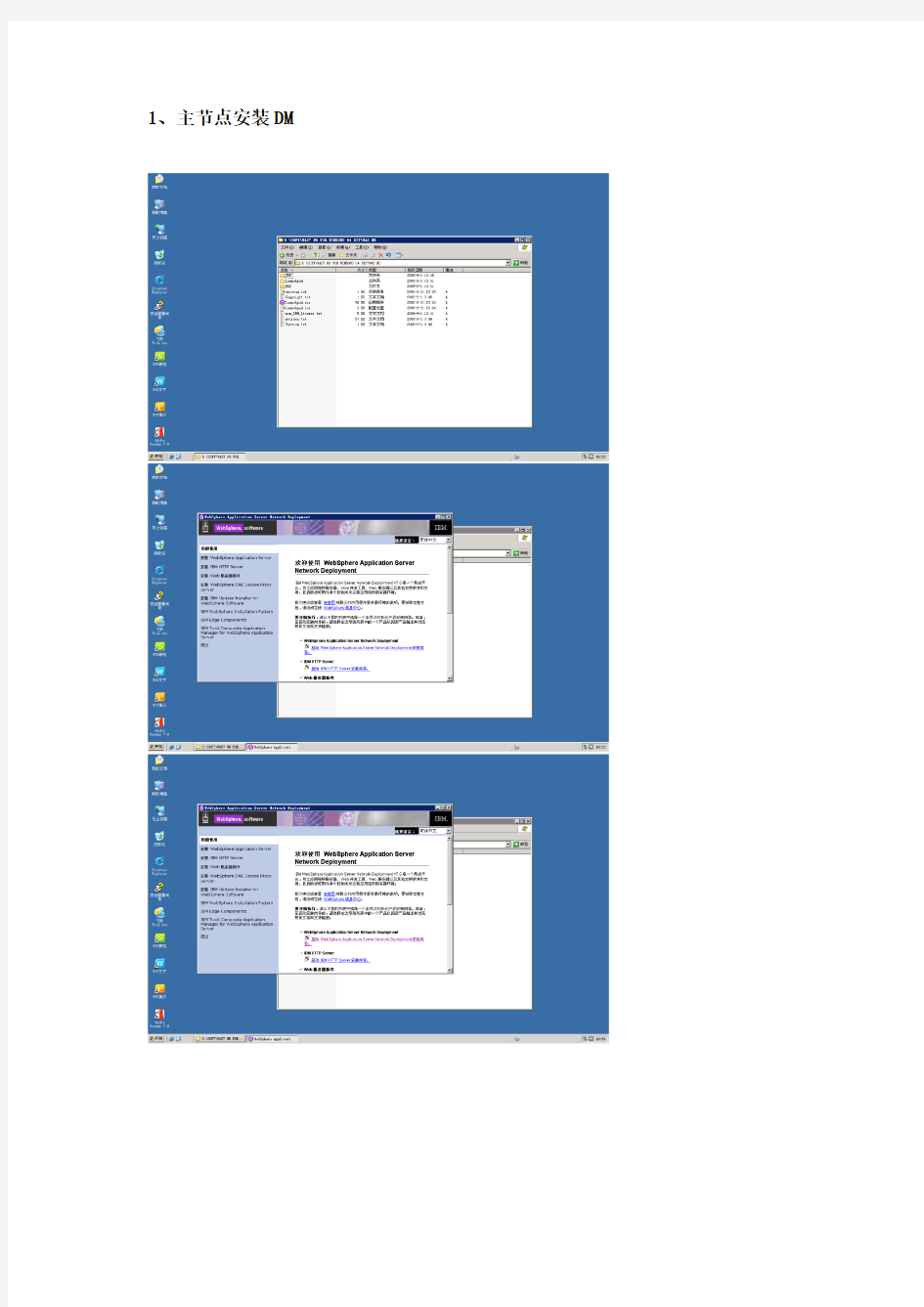
1、主节点安装DM
第二个节点选择“应用程序服务器”,其他过程和上述类似。
2、websphere软件升级:
这个是存放升级补丁的路径
3、启动DM控制台
4、创建节点1的应用服务器
websphere7.0 X64位没有图形化安装,只有通过命令行实现
manageprofiles -create -profilename node01 –adminusername websphere -adminpassword
websphere
5、登录DM控制台,创建节点
第一个节点启动情况
添加第二个节点:
6、创建集群节点
系统结构: 两台服务器集群,通过网络同时与阵列相连。其中一台为当前活动服务器,另一台热备。 服务器间通过心跳线相连,确保集群讯息传递。 目的: 为防止单点故障,集群服务通过服务器即时切换,实现任意一台服务器故障后,用户依然能对阵列上所存储的资源进行操作而不受影响,为维修或更换设备赢得时间。 整体思路: 1.在阵列上创建仲裁分驱和共享分驱 2.启动集群服务器中的一台A,查看是否识别出阵列上划分的空间。是则格式化分驱, 并启动集群服务器B,检查其是否识别已分驱的磁盘。是则关闭服务器B,然后在 服务器A上创建集群 3.选择域,输入要创建的集群名称 4.输入节点A主机名,可点击BROWSE选择服务器名称 5.等待系统执行前至配置,如无异常执行下一步 6.输入集群ip地址,此地址为虚拟集群服务器地址,并无实际设备存在
7.在域服务器上创建一个集群用户,在集群向导中输入用户名密码 8.点击QUORUM选择在阵列上创建的仲裁磁盘,结束配置 9.启动集群服务器B,启动集群管理服务,选择加入集群。 10.选择要加入集群的节点服务器B 11.等待配置完成,若无异常进行下一步 12.输入集群服务器所在域的域用户密码 13.检察配置信息,无误则结束配置 14.右键单击RESOURCE新建资源 15.输入资源名称并选择资源类型及所在组 16.将与之关联的服务器加入相关组 17.设置共享名称及路径,单击完成结束配置 18.设置共享资源完全共享权限 19.在当前管理服务器上设置共享磁盘的权限 一.环境准备条件: 1.域服务器至少一台 2.在域中创建用户,为后边集群服务器登陆使用 3.两台准备做集群的节点服务器,需配置双网卡。 4.准备心跳线一根,将两台节点服务器相连。 二。配置集群 域用户:cluster 主机A信息: 主机A名称:NASA 域名:12.CALT.CASC 公网IP:10.21.0.171 心跳IP:192.168.0.1 主机B信息: 主机B名称:NASB 域名:12.CALT.CASC 公网IP:10.21.0.172 心跳IP:192.168.0.2
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS 本教程讲述如何配置Hadoop 集群,默认读者已经掌握了Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置。 本教程由厦门大学数据库实验室出品,转载请注明。本教程适合于原生Hadoop 2,包括Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行Hadoop。另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。 为了方便新手入门,我们准备了两篇不同系统的Hadoop 伪分布式配置教程。但其他Hadoop 教程我们将不再区分,可同时适用于Ubuntu 和CentOS/RedHat 系统。例如本教程以Ubuntu 系统为主要演示环境,但对Ubuntu/CentOS 的不同配置之处、CentOS 6.x 与CentOS 7 的操作区别等都会尽量给出注明。 环境 本教程使用Ubuntu 14.04 64位作为系统环境,基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1,Hadoop 2.4.1 等。 本教程简单的使用两个节点作为集群环境: 一个作为Master 节点,局域网IP 为192.168.1.121;另一个作为Slave 节点,局域网IP 为192.168.1.122。 准备工作 Hadoop 集群的安装配置大致为如下流程: 1.选定一台机器作为Master 2.在Master 节点上配置hadoop 用户、安装SSH server、安装Java 环境 3.在Master 节点上安装Hadoop,并完成配置 4.在其他Slave 节点上配置hadoop 用户、安装SSH server、安装Java 环境 5.将Master 节点上的/usr/local/hadoop 目录复制到其他Slave 节点上 6.在Master 节点上开启Hadoop 配置hadoop 用户、安装SSH server、安装Java 环境、安装Hadoop 等过程已经在Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置中有详细介绍,请前往查看,不再重复叙述。 继续下一步配置前,请先完成上述流程的前 4 个步骤。 网络配置 假设集群所用的节点都位于同一个局域网。 如果使用的是虚拟机安装的系统,那么需要更改网络连接方式为桥接(Bridge)模式,才能实现多个节点互连,例如在VirturalBox 中的设置如下图。此外,如果节点的系统是在虚拟机中直接复制的,要确保各个节点的Mac 地址不同(可以点右边的按钮随机生成MAC 地址,否则IP 会冲突):
Citrix软件问题汇总: 一、安装问题 1、在安装Citrix Presentation Server 4.0时提示Error 10001 原因分析:Citrix Presentation Server 4.0的英文版安装过程中会一直搜索机器上的NT AUT HORITY\Authenticated Users用户,一旦出现该用户组被列在不同的名称下,就会出现错误 解决方法:通过msiexec命令来执行Citrix Presentation Server 4.0的安装步骤,命令行如下: Msiexec /i “
2003服务器集群实验 一、服务器集群简介 什么是服务器群集?有何作用? 服务器群集是一组协同工作并运行Microsoft群集服务(Microsoft Cl uster Service,MSCS)的独立服务器。它为资源和应用程序提供高可用性、故障恢复、可伸缩性和可管理性。它允许客户端在出现故障和计划中的暂停时,依然能够访问应用程序和资源。如果群集中的某一台服务器由于故障或维护需要而无法使用,资源和应用程序将转移到可用的群集节点上。 服务器群集不同于NLB群集,服务器群集是有独立计算机系统(节点)构成的组,不同节点协同工作,就像单个系统一样,从而确保关键的应用程序和资源始终可由客户端使用。用于访问量较少的企业内网的服务器的冗余和可靠性。 哪些版本的操作系统支持服务器群集? 只有两个版本的windows server 2003系统支持该技术:企业版和数据中心版。 服务器群集的应用范围? 服务器群集最多可以支持8个节点,可实现DHCP、文件共享、后台打印、MS SQL server、exchange server等服务的可靠性。 二、群集专业术语 节点: 构建群集的物理计算机 群集服务: 运行群集管理器或运行群集必须启动的服务 资源: IP地址、磁盘、服务器应用程序等都可以叫做资源 共享磁盘: 群集节点之间通过光纤SCSI 电缆等共同连接的磁盘柜或存储 仲裁资源: 构建群集时,有一块磁盘会用来仲裁信息,其中包括当前的服务状态各个节点的状态以及群集转移时的一些日志 资源状态: 主要指资源目前是处于联机状态还是脱机状态 资源依赖: 资源之间的依存关系 组: 故障转移的最小单位 虚拟服务器: 提供一组服务--如数据库文件和打印共享等 故障转移: 应用从宕机的节点切换到正常联机的节点
服务器集群系统中,服务器不再分布在各处,而是集中在一起统一进行管理和维护。它保持了分布式客户机/服务器模式的开发性、可扩展性的优点,同时又具备了终端/主机模式的资源共享和集中易于管理的优点。 服务器集群系统中,服务器不再分布在各处,而是集中在一起统一进行管理和维护。它保持了分布式客户机/服务器模式的开发性、可扩展性的优点,同时又具备了终端/主机模式的资源共享和集中易于管理的优点。相对集中的集群系统,降低了系统管理的成本,而且还提供了和大型服务器系统相媲美的处理能力。 在传统的终端/主机的网络模式时代,终端功能简单,无需维护工作,在主机一端进行专门的管理与维护,具有资源共享、便于管理的特点。但是,主机造价昂贵,终端没有处理能力,限制了网络的规模化发展。之后的客户机/服务器模式推进了计算产业的标准化和开发化的发展,为系统提供了相当大的灵活性,但是随着分布系统规模的规模扩大,系统的维护和管理带来了巨大的开销。 面向Internet的服务型应用,需要高性能的硬件平台作为支持,将并行技术应用在服务器领域中,是计算机发展的必然趋势。并行处理技术在高性能计算领域中,高可用和高性能是集群服务器系统发展的两个重要方向。 集群的概念 集群英文名称是CLUSTER,是一组相互独立的、通过高速网络互联的计算机,它们构 成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。 和传统的高性能计算机技术相比,集群技术可以利用各档次的服务器作为节点,系统造价低,可以实现很高的运算速度,完成大运算量的计算,具有较高的响应能力,能够满足当今日益增长的信息服务的需求。 #P# 集群技术应用的需求 Internet用户数量呈几何级数增长和科学计算的复杂性要求计算机有更高的处理能力,而CPU的发展无法跟上不断增长的需求,于是我们面临以下问题: ●大规模计算如基因数据的分析、气象预报、石油勘探需要极高的计算性能。
hadoop:建立一个单节点集群伪分布式操作 安装路径为:/opt/hadoop-2.7.2.tar.gz 解压hadoop: tar -zxvf hadoop-2.7.2.tar.gz 配置文件 1. etc/hadoop/hadoop-env.sh export JAVA_HOME=/opt/jdk1.8 2. etc/hadoop/core-site.xml
服务器集群设计 服务器集群技术随着服务器硬件系统与网络操作系统的发展而产生的,在可用性、高可靠性、系统冗余等方面越来越发挥重要中用,是核心系统必不可少的。数据库保存者抄表系统的数据,是整个信息系统的关键所在。 解决系统可靠性的措施通常是备份和群集。备份不能快速恢复,主要用于安全保存,数据库和系统的快速故障恢复通常采用HA(高可用)群集模式, HA 能提供不间断的系统服务,在线系统发生故障时,离线系统能立即发现故障并立即进行接管,继续对外提供服务。HA技术可以有效防止关键业务主机宕机而造成的系统停止运行,被广泛采用。HA技术有两种模式: 具有公共存储系统的HA 数据存储在公共的存储系统上,服务器1为活动服务器,服务器2为待机服务器(备份服务器),当服务器1发生故障时(软或硬件故障),服务器2通过私有网络(心跳路径)侦测到服务器1的故障并自动接管服务器1上所有的资源(如IP地址、存储系统、数据库服务、计算机名等),继续为客户机提供数据或其他应用服务。 独立存储系统的HA数据存储在各自服务器的独占存储设备上(内置磁盘或磁盘阵列) ,没有共享存储系统,数据保存在每个服务器独占的存储设备上。通过镜像技术使每台服务器的数据保持同步,切换时间更短,可靠性比共享存储系统的方案更高,并避免了单点崩溃的可能性,增加了数据的安全性及系统的可用性。两台服务器之间的距离不受外部存储设备连接线的限制,因而可以将两台服务器放置在不同位置。
根据上述分析、系统要求、应用软件采用三层结构的优势以及艾因泰克在发电企业几十家的建设经验,方案采用独立存储系统的HA模式。 由于两套数据库服务器只有一台在线工作,方案本着最大限度节约资源的原则,充分高性能服务器的性能,在备用服务器上运行系统的WEB应用。采用双机双应用,互为备用结构。即在线数据库服务器是 WEB应用服务器的备用服务器,在线WEB应用服务器是数据库服务器的备用服务器。这种结构不但充分发挥性能服务器的优势,又保证关键服务器具有自动备用服务器。不但节约了成本,而且避免了采用共用存储设备单点故障带来的数据丢失的灾难,是最佳的选择。 数据库和应用服务器集群结构如下图: 服务器采用2台PowerEdge R900,配置7块146G磁盘,2块磁盘组成RAID 1镜像,作为操作系统盘。5块组成磁盘组成RAID 5,作为数据盘。 集群镜像软件选用RoseMirrorHA。RoseMirrorHA是一个可靠的、稳定的、高性能的应用高可用保护解决方案,实现应用程序的保护,保证了业务的持续运
搭建一个服务器集群 包含负载均衡,HA高可用,MySQL主从复制,备份服务器,和监控服务器,服务用discuz 论坛演示 服务器配置如下 服务器名服务器ip服务器作用 backup192.168.199.180备份+zabbix监控+NFS Nginx1192.168.199.142主Director Nginx2192.168.199.145从Director Apache1192.168.199.200Apache1 Apache2192.168.199.210Apache2 Apache3192.168.199.233Apache3 Mysql1192.168.199.126主mysql Mysql2192.168.199.131从mysql Mysql3192.168.199.197从mysql VIP192.168.199.3Apache负载均衡VIP 在所有服务器上操作 #关闭selinux sed-i's/SELINUX=enforcing/SELINUX=disabled/'/etc/selinux/config&&setenforce0; #清空iptables iptables-F&&service iptables save; #安装nfs服务 yum install-y nfs-utils epel-release 配置backup服务器 mkdir-p/data/discuz#建立discuz应用目录 mkdir/opt/backup#建立backup目录 #设置目录的属主和属组 chown-R shared:shared/data/discuz chown-R shared:shared/opt/backup vi/etc/exports#设置共享目录 /data/discuz/192.168.199.0/24(rw,sync,all_squash,anonuid=500,anongid=500) /opt/backup/192.168.199.0/24(rw,sync,all_squash,anonuid=500,anongid=500) /etc/init.d/rpcbind start;/etc/init.d/nfs start#启动NFS服务 配置mysql服务器 #挂载NFS服务器backup目录 mount-t nfs-onolock192.168.199.180:/opt/backup/opt vi/etc/fstab 192.168.199.180:/opt/backup/opt nfs nolock00 安装MySQL #在3台mysql服务器上下载mysql5.7的二进制安装文件
前言 本篇主要介绍在大数据应用中比较常用的一款软件Mysql,我相信这款软件不紧紧在大数据分析的时候会用到,现在作为开源系统中的比较优秀的一款关系型开源数据库已经被很多互联网公司所使用,而且现在正慢慢的壮大中。 在大数据分析的系统中作为离线分析计算中比较普遍的两种处理思路就是:1、写程序利用 mapper-Reducer的算法平台进行分析;2、利用Hive组件进行书写Hive SQL进行分析。 第二种方法用到的Hive组件存储元数据最常用的关系型数据库最常用的就是开源的MySQL了,这也是本篇最主要讲解的。 技术准备 VMware虚拟机、CentOS 6.8 64 bit、SecureCRT、VSFTP、Notepad++ 软件下载 我们需要从Mysql官网上选择相应版本的安装介质,官网地址如下: MySQL下载地址:https://www.doczj.com/doc/3011853040.html,/downloads/
默认进入的页面是企业版,这个是要收费的,这里一般建议选择社区开源版本,土豪公司除外。
然后选择相应的版本,这里我们选择通用的Server版本,点击Download下载按钮,将安装包下载到本地。 下载完成,上传至我们要安装的系统目录。 这里,需要提示下,一般在Linux系统中大型公用的软件安装在/opt目录中,比如上图我已经安装了Sql Server On linux,默认就安装在这个目录中,这里我手动创建了mysql目录。 将我们下载的MySQL安装介质,上传至该目录下。
安装流程 1、首先解压当前压缩包,进入目录 cd /opt/mysql/ tar -xf mysql-5.7.16-1.el7.x86_64.rpm-bundle.tar 这样,我们就完成了这个安装包的解压。 2、创建MySql超级管理用户 这里我们需要单独创建一个mySQL的用户,作为MySQL的超级管理员用户,这里也方便我们以后的管理。 groupaddmysql 添加用户组 useradd -g mysqlmysql 添加用户 id mysql 查看用户信息。
本文由szg81贡献 doc1。 七台服务器的集群方案 在传统的终端/主机的网络模式时代,终端功能简单,无需维护工作,在主机一端进行专门的管理与维护,具有资源共享、便于 管理的特点。但是,主机造价昂贵,终端没有处理能力,限制了网络的规模化发展。之后的客户机/服务器模式推进了计算产业 的标准化和开发化的发展,为系统提供了相当大的灵活性,但是随着分布系统规模的规模扩大,系统的维护和管理带来了巨大 的开销。面向 Internet 的服务型应用,需要高性能的硬件平台作为支持,将并行技术应用在服务器领域中,是计算机发展的必然 趋势。并行处理技术在高性能计算领域中,高可用和高性能是集群服务器系统发展的两个重要方向。 集群的概念 集群英文名称是 CLUSTER,是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管 理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。和传统的高性能计算 机技术相比,集群技术可以利用各档次的服务器作为节点,系统造价低,可以实现很高的运算速度,完成大运算量的计算,具 有较高的响应能力,能够满足当今日益增长的信息服务的需求。 集群技术应用的需求 Internet 用户数量呈几何级数增长和科学计算的复杂性要求计算机有更高的处理能力,而 CPU 的发展无法跟上不断增长的需求, 于是我们面临以下问题: ●大规模计算如基因数据的分析、气象预报、石油勘探需要极高的计算性能。 ●应用规模的发展使单个服务器难以承担负载。 ●不断增长的需求需要硬件有灵活的可扩展性。 ●关键性的业务需要可靠的容错机制。 IA 集群系统(CLUSTER)的特点 ●由若干完整的计算机互联组成一个统一的计算机系统; ●可以采用现成的通用硬件设备或特殊应用的硬件设备,例如专用的通讯设备; ●需要特殊软件支持,例如支持集群技术的操作系统或数据库等等; ●可实现单一系统映像,即操作控制、IP 登录点、文件结构、存储空间、I/O 空间、作业管理系统等等的单一化; ●在集群系统中可以动态地加入新的服务器和删除需要淘汰的服务器, 从而能够最大限度地扩展系统以满足不断增长的应用的需 要; ●可用性是集群系统应用中最重要的因素,是评价和衡量系统的一个重要指标; ●能够为用户提供不间断的服务,由于系统中包括了多个结点,当一个结点出现故障的时候,整个系统仍然能够继续为用户提供 服务; ●具有极高的性能价格比,和传统的大型主机相比,具有很大的价格优势; ●资源可充分利用,集群系统的每个结点都是相对独立的机器,当这些机器不提供服务或者不需要使用的时候,仍然能够被充分 利用。而大型主机上更新下来的配件就难以被重新利用了。 实现服务器集群的硬件配置 ●网络服务器 七台 ●服务器操作系统硬盘 七块 ●ULTRA 160 LVD SCSI 磁盘阵列 一个 ●18G SCSI 硬盘 十块 ●网络服务网卡 十四块 服务器集群的实践步骤 ●在安装机群服务之前的准备: 1、 十四块 18G SCSI 硬盘组成磁盘阵列,做 RAID5。 2、 两台服务器要求都配置双网卡,分别安装 Microsoft Windows Server2008 操作系统,并配置网络。 3、 所有磁盘必须设置成基本盘,阵列磁盘分区必须大于 7 个。 4、 每台服务器都要加入域当中,成为域成员,并且在每台服务器上都要有管理员权限。 ●安装配置服务器网络要点 1、在这一部分,每个服务器需要两个网络适配器,一个连接公众网,一个连接内部网(它只包含了群集节点) 内部网适配器 。 建立点对点的通信、群集状态信号和群集管理。每个节点的公众网适配器连接该群集到公众网上,并在此驻留客户。 2、安装 Microsoft Windows 2000 Adwance Server 操作系统后,开始配置每台服务器的网络。在网络连接中我们给连接公众网的 命名为"外网",连接内部网的命名为"内网"并分别指定 IP 地址为:节点 1:内网:ip:10.10.10.11 外网 ip:192.168.0.192 子网 掩码:255.255.255.0 网关:192.168.0.191(主域控制器 ip) ;节点 2:内网:ip:10.10.10.12 外网 ip:192.168.0.193 子网掩码: 255.255.255.0 网关:192.168.0.191;节点 3:内网:ip:10.10.10.13 外网 ip:192.168.0.194 子网掩码:255.255.255.0 网关: 192.168.0.191;节点 4:内网:ip:10.10.10.14 外网 ip:192.168.0.195 子网掩码:255.255.255.0 网关:192.168.0.191;节点 5: 内
l i n u x服务器集群的详细 配置 This model paper was revised by the Standardization Office on December 10, 2020
linux服务器集群的详细配置 一、计算机集群简介 计算机集群简称集群是一种计算机系统,它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作。在某种意义上,他们可以被看作是一台计算机。集群系统中的单个计算机通常称为节点,通常通过局域网连接,但也有其它的可能连接方式。集群计算机通常用来改进单个计算机的计算速度和/或可靠性。一般情况下集群计算机比单个计算机,比如工作站或超级计算机性能价格比要高得多。 二、集群的分类 群分为同构与异构两种,它们的区别在于:组成集群系统的计算机之间的体系结构是否相同。集群计算机按功能和结构可以分成以下几类: 高可用性集群 High-availability (HA) clusters 负载均衡集群 Load balancing clusters 高性能计算集群 High-performance (HPC) clusters 网格计算 Grid computing 高可用性集群 一般是指当集群中有某个节点失效的情况下,其上的任务会自动转移到其他正常的节点上。还指可以将集群中的某节点进行离线维护再上线,该过程并不影响整个集群的运行。 负载均衡集群
负载均衡集群运行时一般通过一个或者多个前端负载均衡器将工作负载分发到后端的一组服务器上,从而达到整个系统的高性能和高可用性。这样的计算机集群有时也被称为服务器群(Server Farm)。一般高可用性集群和负载均衡集群会使用类似的技术,或同时具有高可用性与负载均衡的特点。 Linux虚拟服务器(LVS)项目在Linux操作系统上提供了最常用的负载均衡软件。 高性能计算集群 高性能计算集群采用将计算任务分配到集群的不同计算节点而提高计算能力,因而主要应用在科学计算领域。比较流行的HPC采用Linux操作系统和其它一些免费软件来完成并行运算。这一集群配置通常被称为Beowulf集群。这类集群通常运行特定的程序以发挥HPC cluster的并行能力。这类程序一般应用特定的运行库, 比如专为科学计算设计的MPI库 集群特别适合于在计算中各计算节点之间发生大量数据通讯的计算作业,比如一个节点的中间结果或影响到其它节点计算结果的情况。 网格计算 网格计算或网格集群是一种与集群计算非常相关的技术。网格与传统集群的主要差别是网格是连接一组相关并不信任的计算机,它的运作更像一个计算公共设施而不是一个独立的计算机。还有,网格通常比集群支持更多不同类型的计算机集合。 网格计算是针对有许多独立作业的工作任务作优化,在计算过程中作业间无需共享数据。网格主要服务于管理在独立执行工作的计算机间的作业分配。资源如存储可以被所有结点共享,但作业的中间结果不会影响在其他网格结点上作业的进展。
1、采用一台机器开两个虚拟机的方式构成两台电脑的环境,用root登录。 分别查看其IP地址:输入# ifconfig,可得主机IP:192.168.1.99;分机为:192.168.1.100。 2、在两台机器上的/etc/hosts均添加相应的主机名和IP地址: 这里主机名命名为shenghao,分机名命名为slave: 保存后重启网络: 3、两台机器上均创立hadoop用户(注意是用root登陆) # useradd hadoop # passwd hadoop 输入111111做为密码 登录hadoop用户: 注意,登录用户名为hadoop,而不是自己命名的shenghao。 4、ssh的配置 进入centos的“系统→管理→服务器设置→服务,查看sshd服务是否运行。 在所有的机器上生成密码对: # ssh-keygen -t rsa 这时hadoop目录下生成一个.ssh的文件夹, 可以通过# ls .ssh/来查看里面产生的私钥和公钥:id_rsa和id_rsa.pub。 更改.ssh的读写权限: # chmod 755 .ssh 在namenode上(即主机上)
进入.ssh,将id_rsa.pub直接复制为authorized_keys(namenode的公钥): # cp id_rsa.pub authorized_keys 更改authorized_keys的读写权限: # chmod 644 authorized_keys 【这个不必须,但保险起见,推荐使用】 然后上传到datanode上(即分机上): # scp authorized_keys hadoop@slave:/home/hadoop/.ssh # cd .. 退出.ssh文件夹 这样shenghao就可以免密码登录slave了: 然后输入exit就可以退出去。 然后在datanode上(即分机上): 将datanode上之前产生的公钥id_rsa.pub复制到namenode上的.ssh目录中,并重命名为slave.id_rsa.pub,这是为了区分从各个datanode上传过来的公钥,这里就一个datanode,简单标记下就可。 # scp -r id_rsa.pub hadoop@shenghao:/home/hadoop/.ssh/slave.id_rsa.pub 复制完毕,此时,由于namenode中已经存在authorized_keys文件,所以这里是追加,不是复制。在namenode上执行以下命令,将每个datanode的公钥信息追加: # cat slave.id_rsa.pub >> authorized_keys 这样,namenode和datanode之间便可以相互ssh上并不需要密码: 然后输入exit就可以退出去。 5、hadoop的集群部署 配置hadoop前一定要配置JDK,请参考相关资料,这里就不赘述了。 将下载好的hadoop-0.19.0.tar.gz文件上传到namenode的/home/hadoop/hadoopinstall 解压文件: # tar zxvf hadoop-0.19.0.tar.gz 在/erc/profile的最后添加hadoop的路径: # set hadoop path export HADOOP_HOME=/home/hadoop/hadoopinstall/hadoop-0.20.2 export PATH=$HADOOP_HOME/bin:$PATH 之后配置hadoop/conf中的4个文件:
(售后服务)集群服务器安 装
WIN2Kadvanceserver集群服务器安装 壹:安装要求 1.软件要求 于群集里的所有计算机上,均安装了MicrosoftWindows2000AdvancedServer或 Windows2000DataCenterServer。 2.硬件要求 群集服务节点的硬件,必须满足Windows2000AdvancedServer或Windows2000DataCenterServer的硬件要求。这些要求可于产品兼容性查找页面找到。 群集硬件必须是于群集服务硬件兼容性列表里的(HCL)。到Windows硬件兼容性列 表中,查询群集,就能够找到最新的群集服务HCL。 俩台满足HCL的计算机,分别具有如下配置: 有所安装的Windows2000AdvancedServer或 Windows2000DataCenterServer的启动盘。该启动盘不能位于下面 所描述的共享存储总线上。 共享的磁盘有独立的PCI存储适配器(SCSI或光纤)。启动盘适配器 除外。 群集里的每台计算机有俩块PCI网络适配器。 有HCL兼容的外部存储单元,它跟所有的计算机相连。它被作为群 集磁盘使用。建议使用独立磁盘冗余阵列(RAID)。 用存储线缆,将共享设备连接到所有的计算机。可参考制造商的指南, 配置存储设备。 3.网络要求 唯壹的NetBIOS群集名。 五个独立的、静态的IP地址:俩个用于内部网的网络适配器(192.0.0.1、192.0.0.2), 俩个用于外接公众网的网络适配器(10.10.100.1、10.10.100.2),壹个用于群集本身 (10.10.100.3)。
两台服务器集群巧搭建 服务器集群系统中,服务器不再分布在各处,而是集中在一起统一进行管理和维护。它保持了分布式客户机/服务器模式的开发性、可扩展性的优点,同时又具备了终端/主机模式的资源共享和集中易于管理的优点。 服务器集群系统中,服务器不再分布在各处,而是集中在一起统一进行管理和维护。它保持了分布式客户机/服务器模式的开发性、可扩展性的优点,同时又具备了终端/主机模式的资源共享和集中易于管理的优点。相对集中的集群系统,降低了系统管理的成本,而且还提供了和大型服务器系统相媲美的处理能力。 在传统的终端/主机的网络模式时代,终端功能简单,无需维护工作,在主机一端进行专门的管理与维护,具有资源共享、便于管理的特点。但是,主机造价昂贵,终端没有处理能力,限制了网络的规模化发展。之后的客户机/服务器模式推进了计算产业的标准化和开发化的发展,为系统提供了相当大的灵活性,但是随着分布系统规模的规模扩大,系统的维护和管理带来了巨大的开销。 面向Internet的服务型应用,需要高性能的硬件平台作为支持,将并行技术应用在服务器领域中,是计算机发展的必然趋势。并行处理技术在高性能计算领域中,高可用和高性能是集群服务器系统发展的两个重要方向。 集群的概念 集群英文名称是CLUSTER,是一组相互独立的、通过高速网络互联的计算机,它们构 成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。 和传统的高性能计算机技术相比,集群技术可以利用各档次的服务器作为节点,系统造价低,可以实现很高的运算速度,完成大运算量的计算,具有较高的响应能力,能够满足当今日益增长的信息服务的需求。 #P# 集群技术应用的需求 Internet用户数量呈几何级数增长和科学计算的复杂性要求计算机有更高的处理能力,而CPU的发展无法跟上不断增长的需求,于是我们面临以下问题: ●大规模计算如基因数据的分析、气象预报、石油勘探需要极高的计算性能。 ●应用规模的发展使单个服务器难以承担负载。 ●不断增长的需求需要硬件有灵活的可扩展性。 ●关键性的业务需要可靠的容错机制。 #P# IA集群系统(CLUSTER)的特点 ●由若干完整的计算机互联组成一个统一的计算机系统; ●可以采用现成的通用硬件设备或特殊应用的硬件设备,例如专用的通讯设备;
Hadoop集群搭建(二)HDFS HDFS只是Hadoop最基本的一个服务,很多其他服务,都是基于HDFS 展开的。所以部署一个HDFS集群,是很核心的一个动作,也是大数据平台的开始。 安装Hadoop集群,首先需要有Zookeeper才可以完成安装。如果没有Zookeeper,请先部署一套Zookeeper。另外,JDK以及物理主机的一些设置等。都请参考下文: Hadoop集群搭建(一) Zookeeper 下面开始HDFS的安装 HDFS主机分配 1.19 2.168.67.101 c6701 --Namenode+datanode 2.192.168.67.102 c6702 --datanode 3.192.168.67.103 c6703 --datanode 1. 安装HDFS,解压hadoop- 2.6.0-EDH-0u2.tar.gz 我同时下载2.6和2.7版本的软件,先安装2.6,然后在执行2.6到2.7的升级步骤 https://www.doczj.com/doc/3011853040.html,eradd hdfs 2.echo "hdfs:hdfs"| chpasswd 3.su - hdfs
4.cd /tmp/software 5.tar -zxvf hadoop-2. 6.0-EDH-0u2.tar.gz -C /home/hdfs/ 6.mkdir -p /data/hadoop/temp 7.mkdir -p /data/hadoop/journal 8.mkdir -p /data/hadoop/hdfs/name 9.mkdir -p /data/hadoop/hdfs/data 10.chown -R hdfs:hdfs /data/hadoop 11.chown -R hdfs:hdfs /data/hadoop/temp 12.chown -R hdfs:hdfs /data/hadoop/journal 13.chown -R hdfs:hdfs /data/hadoop/hdfs/name 14.chown -R hdfs:hdfs /data/hadoop/hdfs/data 15.$ pwd 16./home/hdfs/hadoop-2.6.0-EDH-0u2/etc/hadoop 2. 修改core-site.xml对应的参数 1.$ cat core-site.xml 2.<configuration> 3.<!--指定hdfs的nameservice为ns --> 4.<property> 5.<name>fs.defaultFS</name> 6.<value>hdfs://ns</value> 7.</property> 8.<!--指定hadoop数据临时存放目录-->
W A S集群部署方案及安装 配置手册 Prepared on 24 November 2020
1. 部署方案参考 如上图所示,中间件平台主要包括两大部分: ●负载分发层 ?包括两台服务器,通过Heartbeat实现HA,提供浮动IP给客户 端,保证了系统不存在单点故障问题 ?负载分发软件采用IBM HTTP Server实现 ?通过IBM HTTP Server配置虚拟主机,实现对不同应用的请求进行 分发到不同的后台WAS中间件集群。 ●WAS中间件集群 ?包括两台4CPU(每CPU 4Core)服务,每个服务器上通过水平扩展可 以启动多个WAS服务器。 ?基于应用部署要求,为每个应用建立一个集群,逻辑上实现应用之 间的隔离。 ?每个集群可以根据应用的负载,动态分配WAS服务器实例数。如 HR应用访问量较大则分配4个WAS实例。
?但最小要保证一个集群至少包括2个WAS实现,并且这两个实例 分别在不同的物理服务器上,这样才能保证不出现单点故障。 ?部署管理器,部署在WAS Server1上。 2. WebSphere 7安装及配置 此安装配置说明仅供参考,还需要根据现场实现情况进行调整。 2.1.WAS安装 一、四台服务器拓朴结构 四台机器IP地址,名称与安装内容 主机名IP 安装软件(组件)
其中DM控制台管理用户admin,口令 两个web服务器的管理用户也是admin,口令 二、安装后验收 可打开应用服务器主机的控制管理台,管理用户admin,口令****** 服务器->集群下建有应用集群 服务器->应用服务器下建有两个WEB服务 节点共有五个,分别是一个控制节点(一个dmgr节点),两个受控节点(两个app 节点),两个非受控节点(两个web节点) 集群下各受控节点已同步,并启动服务;两个WEB服务已生成插件、传播插件并启动。 在DMGR控制管理台可直接控制两个WEB的启动与停止。 三、安装前系统检查 ?群集安装时,确认所有机子的日期要一致 ?确认磁盘空间足够 两个应用服务器的安装文件放在/was_install 两个WEB服务器的安装文件放在/http_install 安装目录都是安装于默认的/opt目录下
7 步10 分钟服务器集群已构建完毕 1、前言 每当服务器要报废,或者有新业务上线的时候,运维人总是会比较辛苦,要上线新的服 务器以支撑业务,这通常意味着一系列的工作,上架服务器、分配网络、安装对应的操作系 统、安装业务应用,这些仅仅是第一步而已,但这已经耗费了大量的时间。可能运维兄弟的 另一半永远不会担心为什么下班了还没有回家,那肯定是在加班!对于物理环境而言,上线 一台服务器跟上线一个服务器集群,也许都是重复工作,但却需要大量的时间。如果我告诉 你,上线一个服务器集群,只需要10 分钟,你信吗? 其实没什么信不信的,因为这就是事实!这不是什么高级的人工智能,而是得益于云计算技术的成熟发展,人均运维几千台服务器已经不是什么难事,大幅缩减简单重复的工作,几分钟构建一套应用集群,已经真实可用了,下面就介绍如何在10 分钟内构建一套完整的服务器集群。 2、第一分钟,构建网络 使用公有云服务的话,就省去了服务器上架等流程,直接从接通网络开始。在使用公有 云时,我们通常做的第一件事情是构建网络,相对于物理环境下的复杂网络配置,在公有云 上构建网络只需要简单两步,整个过程不到1 分钟: 第一步创建路由器 图1
在网络界面选择“路由器”,然后点击“创建”,选择你希望构建服务器集群的数据中心,如图1 中的“华北、华南、华东、香港”,这是公有云数据中心所在的位置。然后输入你希望创建的路由器的名称,比如创建一个名为“Testlab”的路由器。 第二步创建子网 图2 在网络界面选择“子网”,然后点击“创建”,在弹窗内输入子网名称和CIDR,并选择需要连接的路由器,如图2 所示,创建同名的子网和路由器,这是出于便于管理的目的,然后CIDR 中选择希望使用的网段,这个可根据实际需求进行选择。图2 中选择了“192.168.2.0/24” 网段,这主要是为了与之前的网络进行隔离。点击“确定”按钮之后,等待页面刷新,不到5 秒钟,网络就创建好了,然后就可以进入服务器创建过程了。