
光盘cda转mp3格式方法
cda是光盘文件,如果大家把它复制到电脑会发现播放不出来,听不到音乐。无论你用什么格式的播放器。其实是因为你复制的cda文件只是一个快捷方式而已,大家看它的大小只有几KB或者44KB就知道了。正确的转换方法是光盘在光驱里的时候用转换工具转换,转换cda的软件有说用兔子尾巴的,有说用windows 自带的windows media player,但是操作都有点繁琐,其实用千千静听就可以了,还方便。我就给大家说说光盘cda转mp3格式步骤吧
1.光盘放进光驱
2.载入千千静听播放器
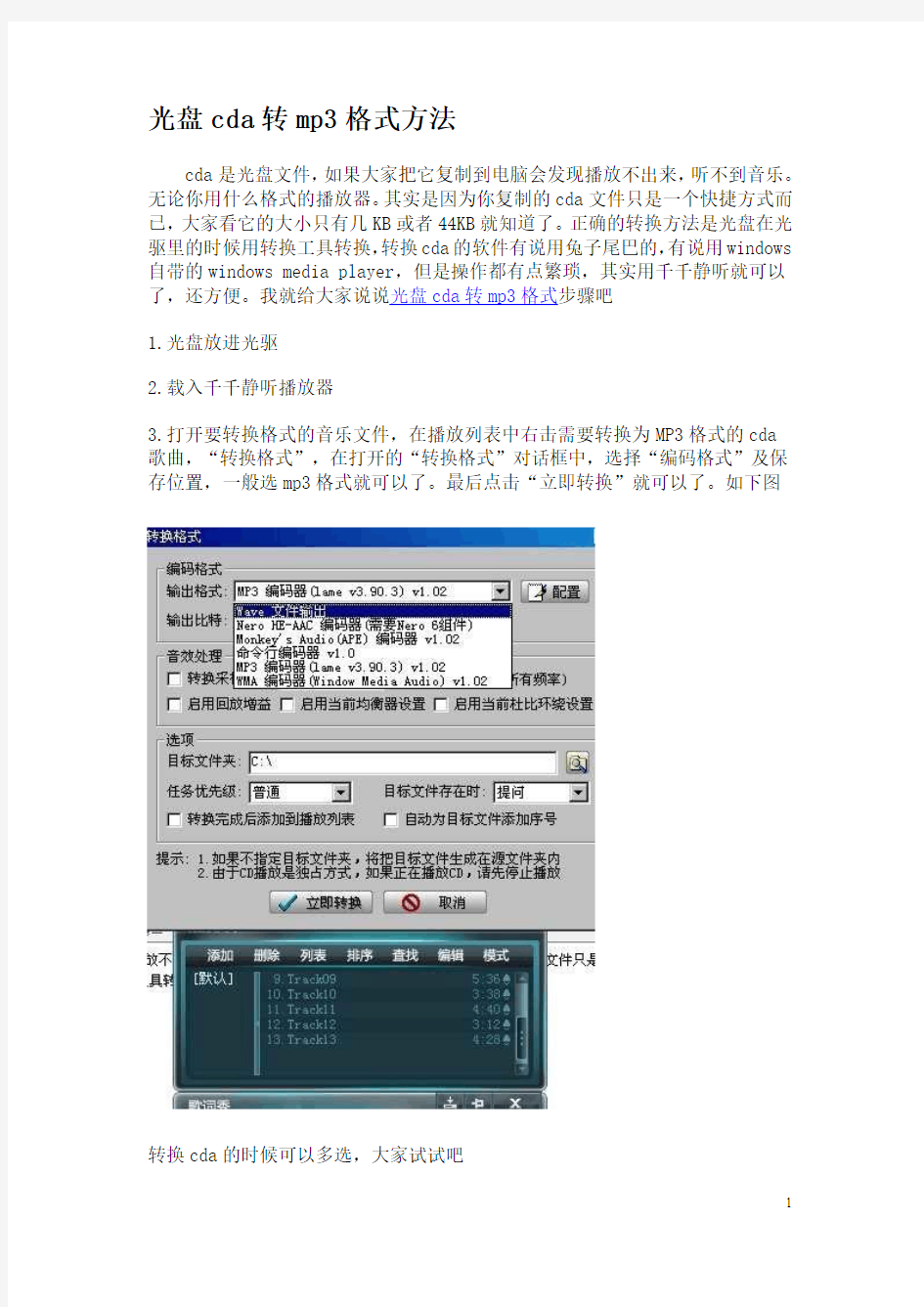
3.打开要转换格式的音乐文件,在播放列表中右击需要转换为MP3格式的cda
歌曲,“转换格式”,在打开的“转换格式”对话框中,选择“编码格式”及保存位置,一般选mp3格式就可以了。最后点击“立即转换”就可以了。如下图
转换cda的时候可以多选,大家试试吧
详细介绍:
酷爱音乐的朋友,都拥有大量的CD光碟。CD的音质无与伦比,但携带起来太不方便。如何把歌曲压缩成MP3格式,再连同歌词一起装进小巧的数字MP3里呢?使用千千静听,就可以完美的实现这个过程!
一、打开CD的音轨文件
把CD光碟插入光驱中。启动千千静听,在播放列表中选择“添加文件夹”命令。如下图所示:
选择光碟所在光驱的路径,确定之后,千千静听就会自动把该张光盘上所有的音轨文件都添加到播放列表中了。如果你只想选择CD上的一部分歌曲进行,可以选择播放列表菜单中的“添加文件”命令,按住键盘的Ctrl键,同时用鼠标点选你想要的歌曲就可以了。
二、编辑信息
现在,就可以用千千静听来欣赏这些CD文件了。
不过看到列表里面一堆字母与数字的组合,是不是有点郁闷呢?别急,我们来为这些歌曲正名!如果你听的是欧美的正版CD,那么就可以借助千千的FreeDB功能来获取音乐信息了,右键单击歌曲文件,选择“freedb 查询”。
FreeDB是一家免费提供CD音轨标签信息的外国机构,大多是针对欧美发行的CD,而且需要正版信息。如果你不幸没有在freedb上查到音轨的信息,也不用气馁,我们自己来编辑!这里需要一些技巧来简化你的操作。通常来讲,同一张CD上的歌曲有着同样的歌手名,专辑,年代等等信息,所以我们用批量操作来添加这些信息。首先选择全部歌曲,在右键菜单中选择“批量文件属性”。在文件属性对话框内填入这些歌曲共同的信息:艺术家,专辑,年代,等等。这里注意:音轨一项其实不必填,因为千千静听会自动填写好的。然后选择“保存到文件”。
接下来我们可以为不同的歌曲编辑不同的名字了。右键单击你想要编辑的歌曲,选择“文件属性”命令,编辑对话框和上面是一样的,这次我们只要在“标题”一栏填入正确的歌曲名称就好了。全部编辑完成后,就像下面的样子:
三、格式转换
下面,我们就要把这些CD音轨转换成MP3格式了。全选列表中的歌曲,在右键菜单中选择“转换格式命令”,我们就能够看到格式转换对话框了。在编码格式中选择“MP3编码器”,默认使用当前的配置参数和音效处理设置,最后在“目标文件夹”中选择你要把MP3文件存放的路径就可以了。
如果你不需要采用特殊设置,此刻单击“立即转换”就可以了。否则,还可以通过单击“配置”
按钮来进行一些高级设置。
、
码率越高,音质越好,同时文件也会越大。如果想要在两者之间选择一个均衡点,可以选择用变长码率。但通常来讲,我们采用默认设置就好。转换速度视歌曲的长度和你所设定的参数而定,一般来说,转换一首歌只需要不到半分钟的时间。
四、修改文件名
转换完成之后,可以看到目标文件夹里存放着以音轨序号命名的MP3文件名。把它们添加到千千静听的播放列表里,能够看到它们的歌手名和歌曲名信息,这是因为千千在转换的过程中,替我们保留了这些信息。既然这样,我们何不用“歌手名—歌曲名”这样的格式来命名这些MP3文件呢?其实这非常简单,只需要全选列表文件,在右键菜单中选择“重命名文件”即可。
这里我们选择“歌手—歌曲名.扩展名”的格式,这样命名以后,歌曲文件就是“孙燕姿- 逆光.mp3”这样的格式。你也可以选择其它格式或者自定义格式。
五、下载歌词
很多的数字MP3都支持LRC歌词同步播放了,到哪里去找歌词呢?这可一直都是千千静听的强项,用千千来播放我们刚才转换过的MP3,在播放过程中,歌词就自动下载到自己的电脑中了。
六、发送MP3文件及歌词到数字MP3播放器
现在我们只剩下最后一个步骤了。事实上,这个步骤也是异常的简单。先把数字MP3连接到电脑上。然后在列表中选择你要挪移的歌曲条目,在右键菜单中选择“发送到”,然后再选择MP3驱动器的盘符就可以了。
在发送歌曲之后,千千会问我们是否需要同时发送相应的歌词文件。还等什么?当然是啦!
OK!大功告成!我们可以发现,千千已经为我们把歌词文件改成和MP3文件相同的文件名了。这样在数字MP3播放的时候就能够自动识别这些歌词文件了,是不是很酷啊!
数据挖掘综述
数据挖掘综述 摘要:数据挖掘是一项较新的数据库技术,它基于由日常积累的大量数据所构成的数据库,从中发现潜在的、有价值的信息——称为知识,用于支持决策。数据挖掘是一项数据库应用技术,本文首先对数据挖掘进行概述,阐明数据挖掘产生的背景,数据挖掘的步骤和基本技术是什么,然后介绍数据挖掘的算法和主要应用领域、国内外发展现状以及发展趋势。 关键词:数据挖掘,算法,数据库 ABSTRACT:Data mining is a relatively new database technology, it is based on database, which is constituted by a large number of data coming from daily accumulation, and find potential, valuable information - called knowledge from it, used to support decision-making. Data mining is a database application technology, this article first outlines, expounds the background of data mining , the steps and basic technology, then data mining algorithm and main application fields, the domestic and foreign development status and development trend. KEY WORDS: data mining ,algorithm, database 数据挖掘产生的背景 上世纪九十年代.随着数据库系统的广泛应用和网络技术的高速发展,数据库技术也进入一个全新的阶段,即从过去仅管理一些简单数据发展到管理由各种计算机所产生的图形、图像、音频、视频、电子档案、Web页面等多种类型的复杂数据,并且数据量也越来越大。在给我们提供丰富信息的同时,也体现出明显的海量信息特征。信息爆炸时代.海量信息给人们带来许多负面影响,最主要的就是有效信息难以提炼。过多无用的信息必然会产生信息距离(the Distance of Information-state Transition,信息状态转移距离,是对一个事物信息状态转移所遇到障碍的测度。简称DIST或DIT)和有用知识的丢失。这也就是约翰·内斯伯特(John Nalsbert)称为的“信息丰富而知识贫乏”窘境。因此,人们迫切希望能对海量数据进行深入分析,发现并提取隐藏在其中的信息.以更好地利用这些数据。但仅以数据库系统的录入、查询、统计等功能,无法发现数据中存在的关系和规则,无法根据现有的数据预测未来的发展趋势。更缺乏挖掘数据背后隐藏知识的手段。正是在这样的条件下,数据挖掘技术应运而生。 数据挖掘的步骤 在实施数据挖掘之前,先制定采取什么样的步骤,每一步都做什么,达到什么样的目标是必要的,有了好的计划才能保证数据挖掘有条不紊的实施并取得成功。很多软件供应商和数据挖掘顾问公司投提供了一些数据挖掘过程模型,来指导他们的用户一步步的进行数据挖掘工作。比如SPSS公司的5A和SAS公司的SEMMA。 数据挖掘过程模型步骤主要包括:1定义商业问题;2建立数据挖掘模型;3分析数据;4准备数据;5建立模型;6评价模型;7实施。 1定义商业问题。在开始知识发现之前最先的同时也是最重要的要求就是了
数据挖掘常用的方法 在大数据时代,数据挖掘是最关键的工作。大数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的大型数据库中发现隐含在其中有价值的、潜在有用的信息和知识的过程,也是一种决策支持过程。其主要基于人工智能,机器学习,模式学习,统计学等。通过对大数据高度自动化地分析,做出归纳性的推理,从中挖掘出潜在的模式,可以帮助企业、商家、用户调整市场政策、减少风险、理性面对市场,并做出正确的决策。目前,在很多领域尤其是在商业领域如银行、电信、电商等,数据挖掘可以解决很多问题,包括市场营销策略制定、背景分析、企业管理危机等。大数据的挖掘常用的方法有分类、回归分析、聚类、关联规则、神经网络方法、Web 数据挖掘等。这些方法从不同的角度对数据进行挖掘。 (1)分类。分类是找出数据库中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到摸个给定的类别中。可以应用到涉及到应用分类、趋势预测中,如淘宝商铺将用户在一段时间内的购买情况划分成不同的类,根据情况向用户推荐关联类的商品,从而增加商铺的销售量。 (2)回归分析。回归分析反映了数据库中数据的属性值的特性,通过函数表达数据映射的关系来发现属性值之间的依赖关系。它可以应用到对数据序列的预测及相关关系的研究中去。在市场营销中,回归分析可以被应用到各个方面。如通过对本季度销售的回归分析,对下一季度的销售趋势作出预测并做出针对性的营销改变。
(3)聚类。聚类类似于分类,但与分类的目的不同,是针对数据的相似性和差异性将一组数据分为几个类别。属于同一类别的数据间的相似性很大,但不同类别之间数据的相似性很小,跨类的数据关联性很低。 (4)关联规则。关联规则是隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现。关联规则的挖掘过程主要包括两个阶段:第一阶段为从海量原始数据中找出所有的高频项目组;第二极端为从这些高频项目组产生关联规则。关联规则挖掘技术已经被广泛应用于金融行业企业中用以预测客户的需求,各银行在自己的ATM 机上通过捆绑客户可能感兴趣的信息供用户了解并获取相应信息来改善自身的营销。 (5)神经网络方法。神经网络作为一种先进的人工智能技术,因其自身自行处理、分布存储和高度容错等特性非常适合处理非线性的以及那些以模糊、不完整、不严密的知识或数据为特征的处理问题,它的这一特点十分适合解决数据挖掘的问题。典型的神经网络模型主要分为三大类:第一类是以用于分类预测和模式识别的前馈式神经网络模型,其主要代表为函数型网络、感知机;第二类是用于联想记忆和优化算法的反馈式神经网络模型,以Hopfield 的离散模型和连续模型为代表。第三类是用于聚类的自组织映射方法,以ART 模型为代表。虽然神经网络有多种模型及算法,但在特定领域的数据挖掘中使用何种模型及算法并没有统一的规则,而且人们很难理解网络的学习及决策过程。 (6)Web数据挖掘。Web数据挖掘是一项综合性技术,指Web 从文档结构和使用的集合C 中发现隐含的模式P,如果将C看做是输入,P 看做是输出,那么Web 挖掘过程就可以看做是从输入到输出的一个映射过程。
数据挖掘的方法有哪些? 时间:2012-11-1111:24来源:百度空间作者:温馨小筑围观:1436次 利用数据挖掘进行数据分析常用的方法主要有分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘等,它们分别从不同的角度对数据进行挖掘。 1、分类 分类是找出数据库中一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到某个给定的类别。它可以应用到客户的分类、客户的属性和特征分析、客户满意度分析、客户的购买趋势预测等,如一个汽车零售商将客户按照对汽车的喜好划分成不同的类,这样营销人员就可以将新型汽车的广告手册直接邮寄到有这种喜好的客户手中,从而大大增加了商业机会。 2、回归分析 回归分析方法反映的是事务数据库中属性值在时间上的特征,产生一个将数据项映射到一个实值预测变量的函数,发现变量或属性间的依赖关系,其主要研究问题包括数据序列的趋势特征、数据序列的预测以及数据间的相关关系等。它可以应用到市场营销的各个方面,如客户寻求、保持和预防客户流失活动、产品生命周期分析、销售趋势预测及有针对性的促销活动等。 3、聚类 聚类分析是把一组数据按照相似性和差异性分为几个类别,其目的是使得属于同一类别的数据间的相似性尽可能大,不同类别中的数据间的相似性尽可能小。它可以应用到客户群体的分类、客户背景分析、客户购买趋势预测、市场的细分等。 4、关联规则 关联规则是描述数据库中数据项之间所存在的关系的规则,即根据一个事务中某些项的出现可导出另一些项在同一事务中也出现,即隐藏在数据间的关联或相互关系。在客户关系管理中,通过对企业的客户数据库里的大量数据进行挖掘,可以从大量的记录中发现有趣的关联关系,找出影响市场营销效果的关键因素,为产品定位、定价与定制客户群,客户寻求、细分与保持,市场营销与推销,营销风险评估和诈骗预测等决策支持提供参考依据。 5、特征 特征分析是从数据库中的一组数据中提取出关于这些数据的特征式,这些特征式表达了该数据集的总体特征。如营销人员通过对客户流失因素的特征提取,可以得到导致客户流失的一系列原因和主要特征,利用这些特征可以有效地预防客户的流失。
数据挖掘领域的十大经典算法原理及应用 国际权威的学术组织the IEEE International Conference on Data Mining (ICDM) 2006年12月评选出了数据挖掘领域的十大经典算法:C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, and CART. 不仅仅是选中的十大算法,其实参加评选的18种算法,实际上随便拿出一种来都可以称得上是经典算法,它们在数据挖掘领域都产生了极为深远的影响。 1.C4.5 C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法.C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进: 1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足; 2) 在树构造过程中进行剪枝; 3) 能够完成对连续属性的离散化处理; 4) 能够对不完整数据进行处理。
C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。 2. The k-means algorithm即K-Means算法 k-means algorithm算法是一个聚类算法,把n的对象根据他们的属性分为k个分割,k < n。它与处理混合正态分布的最大期望算法很相似,因为他们都试图找到数据中自然聚类的中心。它假设对象属性来自于空间向量,并且目标是使各个群组内部的均方误差总和最小。 3. Support vector machines 支持向量机,英文为Support Vector Machine,简称SV 机(论文中一般简称SVM)。它是一种監督式學習的方法,它广泛的应用于统计分类以及回归分析中。支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。分隔超平面使两个平行超平面的距离最大化。假定平行超平面
《海量数据挖掘技术及工程实践》题目 一、单选题(共80题) 1)( D )的目的缩小数据的取值范围,使其更适合于数据挖掘算法的需要,并且能够得到 和原始数据相同的分析结果。 A.数据清洗 B.数据集成 C.数据变换 D.数据归约 2)某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖 掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 3)以下两种描述分别对应哪两种对分类算法的评价标准? (A) (a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (b)描述有多少比例的小偷给警察抓了的标准。 A. Precision,Recall B. Recall,Precision A. Precision,ROC D. Recall,ROC 4)将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 5)当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数 据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 6)建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的 哪一类任务?(C) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 7)下面哪种不属于数据预处理的方法? (D) A.变量代换 B.离散化
C.聚集 D.估计遗漏值 8)假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内? (B) A.第一个 B.第二个 C.第三个 D.第四个 9)下面哪个不属于数据的属性类型:(D) A.标称 B.序数 C.区间 D.相异 10)只有非零值才重要的二元属性被称作:( C ) A.计数属性 B.离散属性 C.非对称的二元属性 D.对称属性 11)以下哪种方法不属于特征选择的标准方法: (D) A.嵌入 B.过滤 C.包装 D.抽样 12)下面不属于创建新属性的相关方法的是: (B) A.特征提取 B.特征修改 C.映射数据到新的空间 D.特征构造 13)下面哪个属于映射数据到新的空间的方法? (A) A.傅立叶变换 B.特征加权 C.渐进抽样 D.维归约 14)假设属性income的最大最小值分别是12000元和98000元。利用最大最小规范化的方 法将属性的值映射到0至1的范围内。对属性income的73600元将被转化为:(D) A.0.821 B.1.224 C.1.458 D.0.716 15)一所大学内的各年纪人数分别为:一年级200人,二年级160人,三年级130人,四年 级110人。则年级属性的众数是: (A) A.一年级 B.二年级 C.三年级 D.四年级
怎么把OGG音乐转换成MP3格式
ogg全称应该是OGG Vorbis,是一种新的音频压缩格式,类似于MP3等的音乐格式。但有一点不同的是,它是完全免费、开放和没有专利限制的。OGG Vorbis有一个特点是支持多声道,随着它的流行,以后用随身听来听DTS编码的多声道作品将不会是梦想。ogg设计格式是非常先进的。创建的OGG文件可以在未来的任何播放器上播放,因此,这种文件格式可以不断地进行大小和音质的改良,而不影响旧有的编码器或播放器。 当然ogg设计格式先进归先进,但是当下大部分手机、移动音频播放器等还是不支持播放*.ogg格式的,想要将ogg格式的音乐放到平常手机上播放,还得ogg转换成mp3格式,那么现在就让小编给大家说说怎么将ogg转mp3格式吧。这是一个很简单的操作过程。首先,下载ogg转mp3格式转换器,安装打开软件,点击添加视频或者直接双击空白处可以添加视频以及音频文件。
点击下方预制方案最右边的小三角形下拉框,进入输出音频格式选择面板,此软件给大伙提供了当下流行的众多音视频格式转换: - 视频:rm、rmvb、3gp、mp4、avi、flv、f4v、mpg、vob、dat、wmv、asf、mkv、dv、mov、ts、mts、webm等。 - 音频:aac、ac3、aiff、amr、m4a、mp2、mp3、ogg、ra、au、wav、wma、mka、flac(无损)、wav(无损)等。
是不是感觉很炫目牛叉的感觉,支持那么多格式转换,OK ,言归正传,我们是要将ogg转mp3格式,所以这里选择输出音频格式为mp3格式 输出音频选为mp3格式后,点击一下回到主界面,在其下方还有一个参数选择面板,上面提供了音频质量输出挑选及路径的更改,再往右边一点,那里有一个【合并成一个文件】的选框,勾选它的意思是如果你要进行多个音频转换的
大数据时代的数据挖掘 大数据是2012的时髦词汇,正受到越来越多人的关注和谈论。大数据之所以受到人们的关注和谈论,是因为隐藏在大数据后面超千亿美元的市场机会。 大数据时代,数据挖掘是最关键的工作。以下内容供个人学习用,感兴趣的朋友可以看一下。 智库百科是这样描述数据挖掘的“数据挖掘又称数据库中的知识发现,是目前人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术等,高度自动化地分析企业的数据,做出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整市场策略,减少风险,做出正确的决策。 数据挖掘的定义 技术上的定义及含义 数据挖掘(Data Mining )就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。这个定义包括好几层含义:数据源必须是真实的、大量的、含噪声的;发现的是用户感兴趣的知识;发现的知识要可接受、可理解、可运用;并不要求发现放之四海皆准的知识,仅支持特定的发现问题。 与数据挖掘相近的同义词有数据融合、人工智能、商务智能、模式识别、机器学习、知识发现、数据分析和决策支持等。 ----何为知识从广义上理解,数据、信息也是知识的表现形式,但是人们更把概念、规则、模式、规律和约束等看作知识。人们把数据看作是形成知识的源泉,好像从矿石中采矿或淘金一样。原始数据可以是结构化的,如关系数据库中的数据;也可以是半结构化的,如文本、图形和图像数据;甚至是分布在网络上的异构型数据。发现知识的方法可以是数学的,也可以是非数学的;可以是演绎的,也可以是归纳的。发现的知识可以被用于信息管理,查询优化,决策支持和过程控制等,还可以用于数据自身的维护。因此,数据挖掘是一门交叉学科,它把人们对数据的应用从低层次的简单查询,提升到从数据中挖掘知识,提供决策支持。在这种需求牵引下,汇聚了不同领域的研究者,尤其是数据库技术、人工智能技术、数理统计、可视化技术、并行计算等方面的学者和工程技术人员,投身到数据挖掘这一新兴的研究领域,形成新的技术热点。 这里所说的知识发现,不是要求发现放之四海而皆准的真理,也不是要去发现崭新的自然科学定理和纯数学公式,更不是什么机器定理证明。实际上,所有发现的知识都是相对的,是有特定前提和约束条件,面向特定领域的,同时还要能够易于被用户理解。最好能用自然语言表达所发现的结果。n x _s u x i a n g n i n g
学习18大经典数据挖掘算法 本文所有涉及到的数据挖掘代码的都放在了github上了。 地址链接: https://https://www.doczj.com/doc/366648710.html,/linyiqun/DataMiningAlgorithm 大概花了将近2个月的时间,自己把18大数据挖掘的经典算法进行了学习并且进行了代码实现,涉及到了决策分类,聚类,链接挖掘,关联挖掘,模式挖掘等等方面。也算是对数据挖掘领域的小小入门了吧。下面就做个小小的总结,后面都是我自己相应算法的博文链接,希望能够帮助大家学习。 1.C4.5算法。C4.5算法与ID3算法一样,都是数学分类算法,C4.5算法是ID3算法的一个改进。ID3算法采用信息增益进行决策判断,而C4.5采用的是增益率。 详细介绍链接:https://www.doczj.com/doc/366648710.html,/androidlushangderen/article/details/42395865 2.CART算法。CART算法的全称是分类回归树算法,他是一个二元分类,采用的是类似于熵的基尼指数作为分类决策,形成决策树后之后还要进行剪枝,我自己在实现整个算法的时候采用的是代价复杂度算法, 详细介绍链接:https://www.doczj.com/doc/366648710.html,/androidlushangderen/article/details/42558235 3.KNN(K最近邻)算法。给定一些已经训练好的数据,输入一个新的测试数据点,计算包含于此测试数据点的最近的点的分类情况,哪个分类的类型占多数,则此测试点的分类与此相同,所以在这里,有的时候可以复制不同的分类点不同的权重。近的点的权重大点,远的点自然就小点。 详细介绍链接:https://www.doczj.com/doc/366648710.html,/androidlushangderen/article/details/42613011 4.Naive Bayes(朴素贝叶斯)算法。朴素贝叶斯算法是贝叶斯算法里面一种比较简单的分类算法,用到了一个比较重要的贝叶斯定理,用一句简单的话概括就是条件概率的相互转换推导。 详细介绍链接:https://www.doczj.com/doc/366648710.html,/androidlushangderen/article/details/42680161 5.SVM(支持向量机)算法。支持向量机算法是一种对线性和非线性数据进行分类的方法,非线性数据进行分类的时候可以通过核函数转为线性的情况再处理。其中的一个关键的步骤是搜索最大边缘超平面。 详细介绍链接:https://www.doczj.com/doc/366648710.html,/androidlushangderen/article/details/42780439 6.EM(期望最大化)算法。期望最大化算法,可以拆分为2个算法,1个E-Step期望化步骤,和1个M-Step最大化步骤。他是一种算法框架,在每次计算结果之后,逼近统计模型参数的最大似然或最大后验估计。
:号学 题目-一 - -二 二 三四五六七八九十总成绩复核得分 阅卷教师 :名姓班 级 业专 院 学院学学科息信与学数 题试试考末期期学季春年学一320数据挖掘试卷 课程代码:C0204413课程:数据挖掘A卷 一、判断题(每题1分,10分) 1. 从点作为个体簇开始,每一步合并两个最接近的簇,这是一种分裂的层次聚类方法。() 2. 数据挖掘的目标不在于数据采集策略,而在于对已经存在的数据进行模式的发掘。() 3. 在聚类分析当中,簇内的相似性越大,簇间的差别越大,聚类的效果就越差。() 4. 当两个点之间的邻近度取它们之间距离的平方时,Ward方法与组平均非常相似。() 5. DBSCAN是相对抗噪声的,并且能够处理任意形状和大小的簇。() 6. 属性的性质不必与用来度量他的值的性质相同。() 7. 全链对噪声点和离群点很敏感。() 8. 对于非对称的属性,只有非零值才是重要的。() 9. K均值可以很好的处理不同密度的数据。() 10. 单链技术擅长处理椭圆形状的簇。() 二、选择题(每题2分,30分) 1. 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分 离?() A. 分类 B.聚类 C.关联分析 D.主成分分析 2. ()将两个簇的邻近度定义为不同簇的所有点对邻近度的平均值,它是一种凝聚层次聚类技术。 A. MIN(单链) B.MAX(全链) C.组平均 D.Ward方法 3. 数据挖掘的经典案例“啤酒与尿布试验”最 主要是应用了()数据挖掘方法。 A分类B预测C关联规则分析D聚类 4. 关于K均值和DBSCAN的比较,以下说法不正确的是() A. K均值丢弃被它识别为噪声的对象,而DBSCAN —般聚类所有对 象。 B. K均值使用簇的基于原型的概念,DBSCAN使用基于密度的概念。 C. K均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的簇 D. K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇 5. 下列关于 Ward 'Method说法错误的是:() A. 对噪声点和离群点敏感度比较小 B. 擅长处理球状的簇 C. 对于Ward方法,两个簇的邻近度定义为两个簇合并时导致的平方误差 D. 当两个点之间的邻近度取它们之间距离的平方时,Ward方法与组平均非常相似 6. 下列关于层次聚类存在的问题说法正确的是:() A. 具有全局优化目标函数 B. Group Average擅长处理球状的簇 C. 可以处理不同大小簇的能力 D. Max对噪声点和离群点很敏感 7. 下列关于凝聚层次聚类的说法中,说法错误的事: () A. 一旦两个簇合并,该操作就不能撤销 B. 算法的终止条件是仅剩下一个簇 2 C. 空间复杂度为O m D. 具有全局优化目标函数 8规则{牛奶,尿布}T{啤酒}的支持度和置信度分别为:()
数据挖掘入门读物: 深入浅出数据分析这书挺简单的,基本的内容都涉及了,说得也比较清楚,最后谈到了R是大加分。难易程度:非常易。 啤酒与尿布通过案例来说事情,而且是最经典的例子。难易程度:非常易。 数据之美一本介绍性的书籍,每章都解决一个具体的问题,甚至还有代码,对理解数据分析的应用领域和做法非常有帮助。难易程度:易。 数学之美这本书非常棒啦,入门读起来很不错! 数据分析: SciPy and NumPy 这本书可以归类为数据分析书吧,因为numpy和scipy真的是非常强大啊。Python for Data Analysis 作者是Pandas这个包的作者,看过他在Scipy会议上的演讲,实例非常强!Bad Data Handbook 很好玩的书,作者的角度很不同。 数据挖掘适合入门的教程: 集体智慧编程学习数据分析、数据挖掘、机器学习人员应该仔细阅读的第一本书。作者通过实际例子介绍了机器学习和数据挖掘中的算法,浅显易懂,还有可执行的Python代码。难易程度:中。 Machine Learning in Action 用人话把复杂难懂的机器学习算法解释清楚了,其中有零星的数学公式,但是是以解释清楚为目的的。而且有Python代码,大赞!目前中科院的王斌老师(微博:王斌_ICTIR)已经翻译这本书了机器学习实战(豆瓣)。这本书本身质量就很高,王老师的翻译质量也很高。难易程度:中。我带的研究生入门必看数目之一! Building Machine Learning Systems with Python 虽然是英文的,但是由于写得很简单,比较理解,又有Python 代码跟着,辅助理解。 数据挖掘导论最近几年数据挖掘教材中比较好的一本书,被美国诸多大学的数据挖掘课作为教材,没有推荐Jiawei Han老师的那本书,因为个人觉得那本书对于初学者来说不太容易读懂。难易程度:中上。Machine Learning for Hackers 也是通过实例讲解机器学习算法,用R实现的,可以一边学习机器学习一边学习R。 数据挖掘稍微专业些的: Introduction to Semi-Supervised Learning 半监督学习必读必看的书。 Learning to Rank for Information Retrieval 微软亚院刘铁岩老师关于LTR的著作,啥都不说了,推荐!Learning to Rank for Information Retrieval and Natural Language Processing 李航老师关于LTR的书,也是当时他在微软亚院时候的书,可见微软亚院对LTR的研究之深,贡献之大。 推荐系统实践这本书不用说了,研究推荐系统必须要读的书,而且是第一本要读的书。 Graphical Models, Exponential Families, and Variational Inference 这个是Jordan老爷子和他的得意门徒Martin J Wainwright 在Foundation of Machine Learning Research上的创刊号,可以免费下载,比较难懂,但是一旦读通了,graphical model的相关内容就可以踏平了。 Natural Language Processing with Python NLP 经典,其实主要是讲NLTK 这个包,但是啊,NLTK 这个包几乎涵盖了NLP 的很多内容了啊! 数据挖掘机器学习教材: The Elements of Statistical Learning 这本书有对应的中文版:统计学习基础(豆瓣)。书中配有R包,非常赞!可以参照着代码学习算法。 统计学习方法李航老师的扛鼎之作,强烈推荐。难易程度:难。 Machine Learning 去年出版的新书,作者Kevin Murrphy教授是机器学习领域中年少有为的代表。这书是他的集大成之作,写完之后,就去Google了,产学研结合,没有比这个更好的了。
大数据常用的算法(分类、回归分析、聚类、关联规则) 在大数据时代,数据挖掘是最关键的工作。大数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的大型数据库中发现隐含在其中有价值的、潜在有用的信息和知识的过程,也是一种决策支持过程。其主要基于人工智能,机器学习,模式学习,统计学等。通过对大数据高度自动化地分析,做出归纳性的推理,从中挖掘出潜在的模式,可以帮助企业、商家、用户调整市场政策、减少风险、理性面对市场,并做出正确的决策。目前,在很多领域尤其是在商业领域如银行、电信、电商等,数据挖掘可以解决很多问题,包括市场营销策略制定、背景分析、企业管理危机等。大数据的挖掘常用的方法有分类、回归分析、聚类、关联规则、神经网络方法、Web 数据挖掘等。这些方法从不同的角度对数据进行挖掘。 (1)分类。分类是找出数据库中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到摸个给定的类别中。可以应用到涉及到应用分类、趋势预测中,如淘宝商铺将用户在一段时间内的购买情况划分成不同的类,根据情况向用户推荐关联类的商品,从而增加商铺的销售量。 (2)回归分析。回归分析反映了数据库中数据的属性值的特性,通过函数表达数据映射的关系来发现属性值之间的依赖关系。它可以应用到对数据序列的预测及相关关系的研究中去。在市场营销中,回归分析可以被应用到各个方面。如通过对本季度销售的回归分析,对下一季度的销售趋势作出预测并做出针对性的营销改变。 (3)聚类。聚类类似于分类,但与分类的目的不同,是针对数据的相似性和差异性将一组数据分为几个类别。属于同一类别的数据间的相似性很大,但不同类别之间数据的相似性很小,跨类的数据关联性很低。 (4)关联规则。关联规则是隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现。关联规则的挖掘过程主要包括两个阶段:第一阶段为从海量原始数据中找出所有的高频项目组;第二极端为从这些高频项目组产生关联规则。关联规则挖掘技术已经被广泛应用于金融行业企业中用以预测客户的需求,各银行在自己的ATM 机上通过捆绑客户可能感兴趣的信息供用户了解并获取相应信息来改善自身的营销。 (5)神经网络方法。神经网络作为一种先进的人工智能技术,因其自身自行处理、分布存储和高度容错等特性非常适合处理非线性的以及那些以模糊、不完整、不严密的知识或数据为特征的处理问题,它的这一特点十分适合解决数据挖掘的问题。典型的神经网络模型主要分为三大类:第一类是以用于分类预测和模式识别的前馈式神经网络模型,其主要代表为函数型网络、感知机;第二类是用于联想记忆和优化算法的反馈式神经网络模型,以Hopfield 的离散模型和连续模型为代表。第三类是用于聚类的自组织映射方法,以ART 模型为代表。虽然神经网络有多种模型及算法,但在特定领域的数据挖掘中使用何种模型及算法并没有统一的规则,而且人们很难理解网络的学习及决策过程。 (6)Web数据挖掘。Web数据挖掘是一项综合性技术,指Web 从文档结构和使用的集合C 中发现隐含的模式P,如果将C看做是输入,P 看做是输出,那么Web 挖掘过程就可以看做是从输入到输出的一个映射过程。 当前越来越多的Web 数据都是以数据流的形式出现的,因此对Web 数据流挖掘就具有很重要的意义。目前常用的Web数据挖掘算法有:PageRank算法,HITS算法以及LOGSOM 算法。这三种算法提到的用户都是笼统的用户,并没有区分用户的个体。目前Web 数据挖掘面临着一些问题,包括:用户的分类问题、网站内容时效性问题,用户在页面停留时间问题,页面的链入与链出数问题等。在Web 技术高速发展的今天,
网易云音乐ncm格式怎么转换成mp3格式各位读友大家好,此文档由网络收集而来,欢迎您下载,谢谢 网易云音乐ncm格式怎么转换成mp3格式 方法一:借助360安全浏览器或者qq浏览器 1.电脑版网易云音乐选择要下载播放的会员曲目,右键复制链接, 2.在360浏览器或者qq浏览器中打开链接,把鼠标移到播放键,点击右键,选择审查元素,点击network,f5刷新一下 3.点击播放,type那栏找到media(或者audio),或者直接在size那栏寻找最大一个文件 4.复制mp3文件链接,新建下载,就能下载到你想要的mp3格式文件了。 方法二:格式工厂转换: 1、首先,下载安装格式工厂,打开格式工厂软件。
2、打开格式工厂窗口后,选择音频选项 3、在音频选项窗口中,选择MP3按钮。 4、MP3窗口中,选择添加文件选项。 5、打开ncm格式音乐所在的目录后,选择文件名后的文件格式为All Files。 6、我们要转换的文件,就显示在窗口中了,点击选中后单击打开。 7、回到MP3窗口后,单击确定按钮。 8、单击开始按钮,音乐格式就开始转换了。 9、打开转换文件保存的目录,ncm格式音乐文件已转换为Mp3格式了。 方法三:BesLyric: 1、选择ncm 文件 点击“选择”弹出对话框后,可以看到可以选择ncm文件 2、点击匹配ID 播放ncm文件前,需要先匹配该文件对应的网易云音乐中的音乐ID。因为ncm文件是网易云独家加密的,所以这里需要间接的获得可以播放的文件,这里需要的是,网易云里对应的音乐ID。
3、匹配ncm 文件对应在网易云音乐的ID 这里匹配ID有2种可用的选择,一种是使用软件的“ID搜索”功能,另一种是自己“自己动手”去网易云复制歌曲分享链接,得到ID a) 软件搜索ID 搜索后“选用”一个ID,然后点击“确定匹配” 即可完成匹配。但有多个搜索结果时,可以点击“查看”、“试听”,根据此进一步确认ID。 值得注意的是,如果无法“试听”,意味着网易云音乐可能已经没有该歌曲的版权,将无法匹配该ID。 b) 自己动手 另一种方法是:“自己动手”去网易云复制歌曲分享链接,得到ID可以参照软件的提示页面获得即可,得到ID后,点击“确定匹配”
数据挖掘主要工具软件简介 Dataminning指一种透过数理模式来分析企业内储存的大量资料,以找出不同的客户或市场划分,分析出消费者喜好和行为的方法。前面介绍了报表软件选购指南,本篇介绍数据挖掘常用工具。 市场上的数据挖掘工具一般分为三个组成部分: a、通用型工具; b、综合/DSS/OLAP数据挖掘工具; c、快速发展的面向特定应用的工具。 通用型工具占有最大和最成熟的那部分市场。通用的数据挖掘工具不区分具体数据的含义,采用通用的挖掘算法,处理常见的数据类型,其中包括的主要工具有IBM 公司Almaden 研究中心开发的QUEST 系统,SGI 公司开发的MineSet 系统,加拿大Simon Fraser 大学开发的DBMiner 系统、SAS Enterprise Miner、IBM Intelligent Miner、Oracle Darwin、SPSS Clementine、Unica PRW等软件。通用的数据挖掘工具可以做多种模式的挖掘,挖掘什么、用什么来挖掘都由用户根据自己的应用来选择。 综合数据挖掘工具这一部分市场反映了商业对具有多功能的决策支持工具的真实和迫切的需求。商业要求该工具能提供管理报告、在线分析处理和普通结构中的数据挖掘能力。这些综合工具包括Cognos Scenario和Business Objects等。 面向特定应用工具这一部分工具正在快速发展,在这一领域的厂商设法通过提供商业方案而不是寻求方案的一种技术来区分自己和别的领域的厂商。这些工
具是纵向的、贯穿这一领域的方方面面,其常用工具有重点应用在零售业的KD1、主要应用在保险业的Option&Choices和针对欺诈行为探查开发的HNC软件。 下面简单介绍几种常用的数据挖掘工具: 1. QUEST QUEST 是IBM 公司Almaden 研究中心开发的一个多任务数据挖掘系统,目的是为新一代决策支持系统的应用开发提供高效的数据开采基本构件。系统具有如下特点: (1)提供了专门在大型数据库上进行各种开采的功能:关联规则发现、序列模式发现、时间序列聚类、决策树分类、递增式主动开采等。 (2)各种开采算法具有近似线性(O(n))计算复杂度,可适用于任意大小的数据库。 (3)算法具有找全性,即能将所有满足指定类型的模式全部寻找出来。 (4)为各种发现功能设计了相应的并行算法。 2. MineSet MineSet 是由SGI 公司和美国Standford 大学联合开发的多任务数据挖掘系统。MineSet 集成多种数据挖掘算法和可视化工具,帮助用户直观地、实时地发掘、理解大量数据背后的知识。MineSet 2.6 有如下特点: (1)MineSet 以先进的可视化显示方法闻名于世。MineSet 2.6 中使用了6 种可视化工具来表现数据和知识。对同一个挖掘结果可以用不同的可视化工具以各种形式表示,用户也可以按照个人的喜好调整最终效果, 以便更好地理解。MineSet 2.6 中的可视化工具有Splat Visualize、Scatter Visualize、Map
在大数据时代,数据挖掘是最关键的工作。大数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的大型数据库中发现隐含在其中有价值的、潜在有用的信息和知识的过程,也是一种决策支持过程。其主要基于人工智能,机器学习,模式学习,统计学等。通过对大数据高度自动化地分析,做出归纳性的推理,从中挖掘出潜在的模式,可以帮助企业、商家、用户调整市场政策、减少风险、理性面对市场,并做出正确的决策。目前,在很多领域尤其是在商业领域如银行、电信、电商等,数据挖掘可以解决很多问题,包括市场营销策略制定、背景分析、企业管理危机等。大数据的挖掘常用的方法有分类、回归分析、聚类、关联规则、神经网络方法、Web 数据挖掘等。这些方法从不同的角度对数据进行挖掘。 1.分类 分类是找出数据库中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到摸个给定的类别中。可以应用到涉及到应用分类、趋势预测中,如淘宝商铺将用户在一段时间内的购买情况划分成不同的类,根据情况向用户推荐关联类的商品,从而增加商铺的销售量。 它可以应用到客户的分类、客户的属性和特征分析、客户满意度分析、客户的购买趋势预测等,如一个汽车零售商将客户按照对汽车的喜好划分成不同的类,这样营销人员就可以将新型汽车的广告手册直接邮寄到有这种喜好的客户手中,从而大大增加了商业机会。 分类的方法有:决策树、贝叶斯、人工神经网络。 1.1决策树 决策树是用于分类和预测的主要技术之一,决策树学习是以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的实例中推理出以决策树表示的分类规则。构造决策树的目的是找出属性和类别间的关系,用它来预测将来未知类别的记录的类别。它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性值判断从该节点向下的分支,在决策树的叶节点得到结论。 1.2贝叶斯 贝叶斯(Bayes)分类算法是一类利用概率统计知识进行分类的算法,如朴素贝叶斯
全面解析数据挖掘的分类及各种分析方法 1.数据挖掘能做以下六种不同事情(分析方法): ?分类(Classification) ?估值(Estimation) ?预言(Prediction) ?相关性分组或关联规则(Affinitygroupingorassociationrules) ?聚集(Clustering) ?描述和可视化(DescriptionandVisualization) ?复杂数据类型挖掘(Text,Web,图形图像,视频,音频等) 2.数据挖掘分类 以上六种数据挖掘的分析方法可以分为两类:直接数据挖掘;间接数据挖掘?直接数据挖掘 目标是利用可用的数据建立一个模型,这个模型对剩余的数据,对一个特定的变量(可以理解成数据库中表的属性,即列)进行描述。 ?间接数据挖掘 目标中没有选出某一具体的变量,用模型进行描述;而是在所有的变量中建立起某种关系。 ?分类、估值、预言属于直接数据挖掘;后三种属于间接数据挖掘 3.各种分析方法的简介 ?分类(Classification) 首先从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类。 例子: a.信用卡申请者,分类为低、中、高风险 b.分配客户到预先定义的客户分片 注意:类的个数是确定的,预先定义好的 ?估值(Estimation) 估值与分类类似,不同之处在于,分类描述的是离散型变量的输出,而估值处理连续值的输出;分类的类别是确定数目的,估值的量是不确定的。 例子: a.根据购买模式,估计一个家庭的孩子个数 b.根据购买模式,估计一个家庭的收入 c.估计realestate的价值
在看电视的时候,听到一些好听的歌曲,大家都是迫不及待的去会音乐播放器上搜索这首歌曲,但是发现同一首歌曲居然有多种格式,这个时候大家可以试试将它转换成同种MP3格式,其实转换MP3音频格式并不是很难,找对了简单的方法,对你们来说是很简单的,别急,下面这篇文章已经介绍的很清楚了,你们如果想要学习的话可以往下看下去哦!希望可以有效的帮助到你们。 关于工具: 迅捷音频转换器它是一款多功能的音频编辑处理软件,软件具有音频剪切、音频提取、音频合并和音频转换这四个功能,这款工具操作简单,功能强大可以多种分割方式进行音频剪切,操作简单特点,支持而且软件不仅支持单个文件操作,还支持文件批量操作!是个不错的选择。
打开工具 我们在下载安装完一款工具的时候,这个时候这需要在电脑桌面双击打开这款软件就可以准备转换了。 添加音频文件 打开之后,界面会出现不同的四种功能。今天我们是要将音频格式转换,所以只需要点击音频转换就可以了,然后依次添加文件或是添加文件夹。
选择输出格式 这个时候,在回到界面,在界面右上角有个选择输出格式,里面有多种格式,大家点击MP3就可以了,然后在设置音频的质量以及声道问题。 文件保存位置
基本的设置完成之后,接着及就要设置文件的保存路劲了,那么这个时候我们只需要单击文件输出目录,在窗口中进行选择即可,然后开始转换。 格式转换成功 耐心等待一会,当你们看到100%的时候,就已经转换成功了,这时候点击打开按钮,弹出的窗口中就会看见转换的音频了。
以上就是怎么转换MP3格式的全部内容啦,你们学会了吗?感谢你们的阅读。 When you are old and grey and full of sleep, And nodding by the fire, take down this book, And slowly read, and dream of the soft look Your eyes had once, and of their shadows deep; How many loved your moments of glad grace, And loved your beauty with love false or true, But one man loved the pilgrim soul in you, And loved the sorrows of your changing face; And bending down beside the glowing bars, Murmur, a little sadly, how love fled