Caris HPD数据库生产模式下的源数据浅析
(林芳上海海事局航海图书印制中心200090)
摘要:CARIS HPD是CARIS公司发布的一套独立而完整的航测生产数据库解决方案。CARIS HPD 数据库包括源数据库(Source Database)和产品数据库(Product Database)两部分。本文主要从源数据的构成,源数据与电子海图、纸海图之间的关系等方面来对源数据进行阐述。关键字:HPD 源数据电子海图纸海图
1.引言
随着CARIS HPD的正式投入生产之中,“源数据”这个以前很陌生的名词现在变得越来越熟悉,各种源数据的做法、规定以及标准也变得更加合理、更加完善。在一年多的源数据制作过程中,笔者也对源数据有了更深刻、更全面的认识。
2、源数据的定义、特征
源数据是利用Caris HPD制作各类海图产品时所需要的数据。在Caris HPD中所用的模块是Source Editor。源数据在数据库中存储方式是以S-57为标准的。源数据库用于管理源数据,包括空间数据和非空间数据(即属性)。CARIS HPD源数据库中的物标可以在各层之间进行关联,关联的物标属性是相同的,更改物标在任何一层的属性都会引起该物标在所有层属性的变化,但是关联的物标在各层中表现可以不一致。源数据中的物标只有经过认证后,才能用于产品生产。
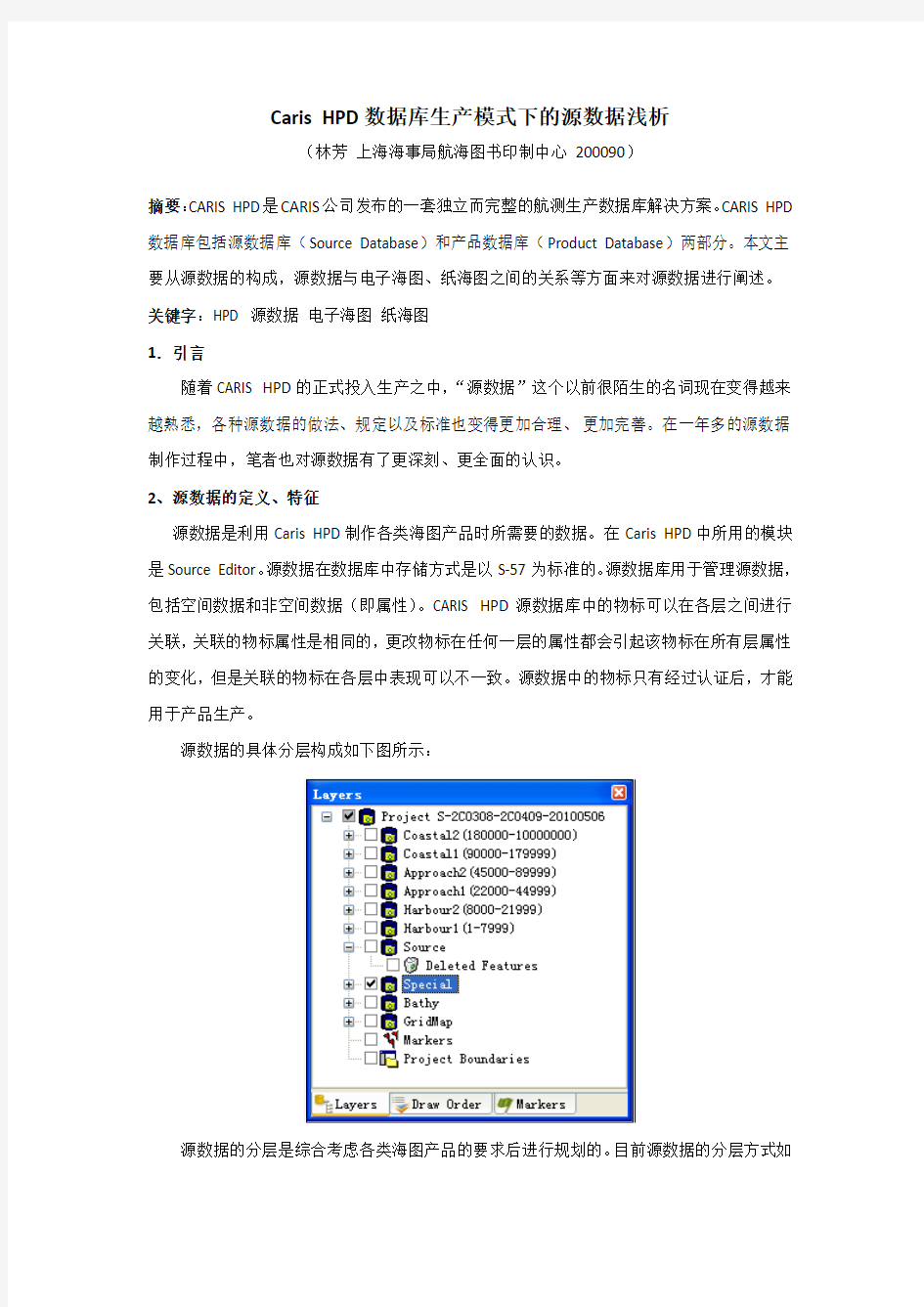
源数据的具体分层构成如下图所示:
源数据的分层是综合考虑各类海图产品的要求后进行规划的。目前源数据的分层方式如
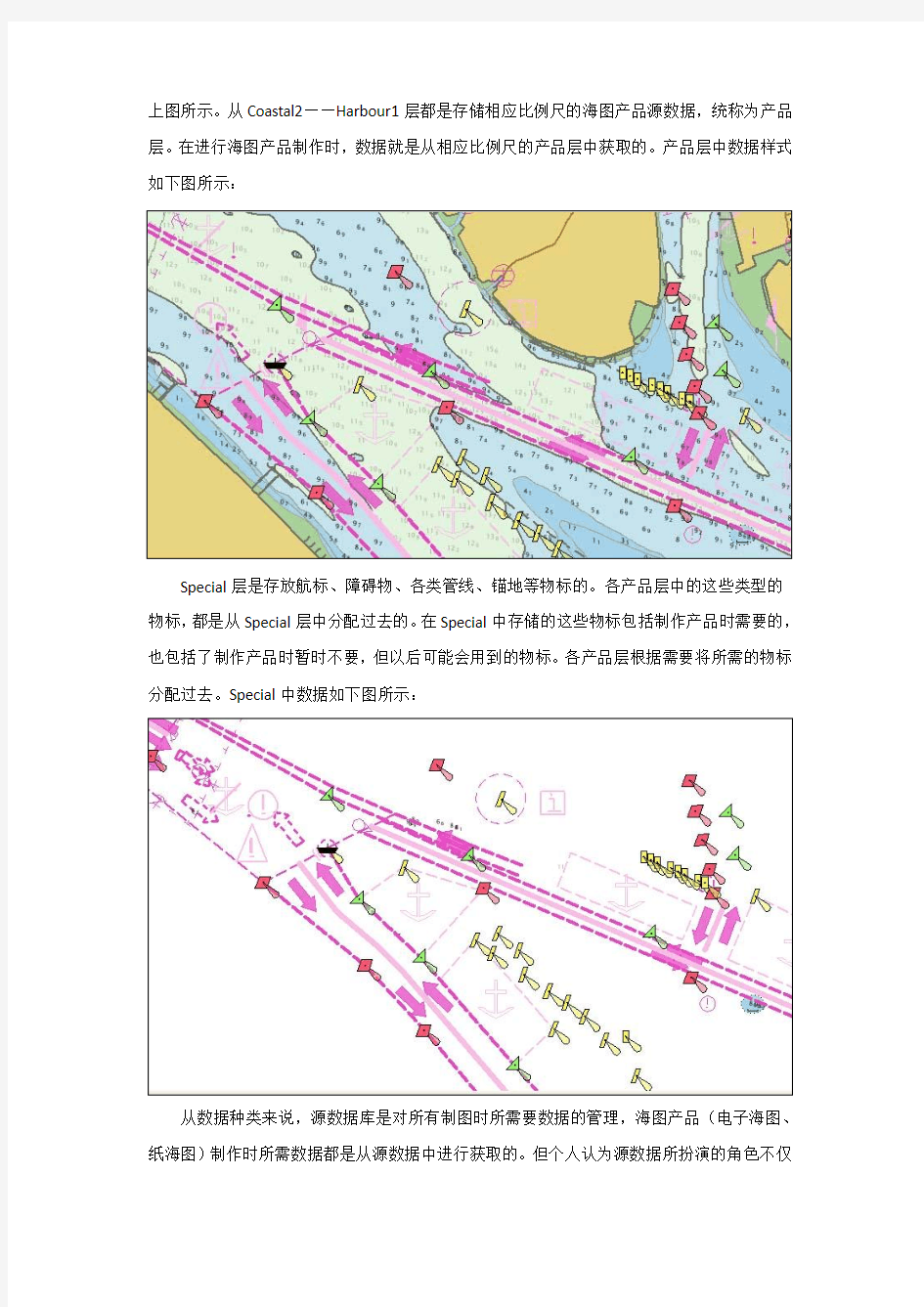
上图所示。从Coastal2——Harbour1层都是存储相应比例尺的海图产品源数据,统称为产品层。在进行海图产品制作时,数据就是从相应比例尺的产品层中获取的。产品层中数据样式如下图所示:
Special层是存放航标、障碍物、各类管线、锚地等物标的。各产品层中的这些类型的物标,都是从Special层中分配过去的。在Special中存储的这些物标包括制作产品时需要的,也包括了制作产品时暂时不要,但以后可能会用到的物标。各产品层根据需要将所需的物标分配过去。Special中数据如下图所示:
从数据种类来说,源数据库是对所有制图时所需要数据的管理,海图产品(电子海图、纸海图)制作时所需数据都是从源数据中进行获取的。但个人认为源数据所扮演的角色不仅
仅是制作纸海图、电子海图时所需数据的提供者,还是所有制图数据、小改正数据的管理者。因为有些数据从海图产品的角度上来讲暂时是不需要放到数据库中的,但是从保持制图数据的完整性上来讲,这些数据是需要保留的。例如,一些位于干出滩上的沉船在图中不需要放上,但是如果以后干出滩上的水深变深了,此处的沉船又需要放到产品中去。因此,在源数据中一些重要的物标即使本版次电子海图和纸海图上都不需要,但仍需要保存下来以供以后使用。此外,还有很多航标、管线等物标,目前在图上由于各种原因不需要反映出来,但这些物标都是很重要的信息,都需要在源数据中都存储起来。
从这个角度来说,源数据其实是整合了以前所用的多个数据库——航标信息管理系统、航标障碍物一览表等等,以及存储了物标的所有的有用信息。这样使得所有数据的来源统一、属性一致,表现一致,避免产生同一数据在不同数据库中属性不统一的情况发生。因此,源数据不仅仅可以给制图海图产品提供来源,也可以为编辑改正通告等其它相关查询工作提供很大的帮助,更是为数据的统一性提供了一个很好条件。
3、源数据与电子海图、纸海图
源数据的作业依据
a 《IHO数字化海道测量数据传输标准》IHO S-57 3.1版
b 《电子海图验证检查推荐标准》IHO S-58 4.0版
c 《ENC生产指南》IHO S-65 1.1版
d 《电子航海图编绘规范》
e 《中国海图图式》GB 12319-1998
f 《中国海图图式与源数据对照表》
纸海图的作业依据
a 《中国海图图式》
b 《中国航海图编绘规范》
c 《港口航道图编绘技术规定》
电子海图作业依据
a 《IHO数字化海道测量数据传输标准》IHO S-57 3.1版
b 《电子海图验证检查推荐标准》IHO S-58 4.0版
c 《ENC生产指南》IHO S-65 1.1版
d 《电子航海图编绘规范》
从以上源数据、纸海图、电子海图的作业依据可以看出,源数据的数据质量既需要满足
纸海图的要求又需要满足电子海图的要求。
3.1 源数据与纸海图
源数据是纸海图的基础,提供了制作纸海图时所需要的信息。空间信息是直接以物标的形状反应出来的。源数据的空间信息和纸海图的空间信息是一致的;对于S-57标准中无法表示,或者表示的空间结构与纸海图不一致的地方,则以制图物标表示。因此源数据中制图物标的绝大部分作用仅仅是补充物标形状上的缺陷。而纸海图上的注记信息则大部分来源于源数据中物标的属性里。对于航标以及部分无法通过物标类型判断符号的物标,在源数据中会赋予特征码,而这些特征码是和纸海图中符号的特征码是一致的。在赋予了特征码之后,可以按纸海图的符号显示出来。在制作纸海图时,可以根据这些属性来添加注记,或者对系统自动生成的注记进行修改以达到纸海图的要求。在进行源数据制作时,会以SH的显示方式将源数据进行显示,以此种方式进行显示时,物标的符号、优先等级和纸海图都是一样的。通过这种方式进行显示,可以检查源数据是否符合纸海图的图面要求。例如:码头与陆地相接处是否屏蔽等。下图为源数据中以SH显示方式进行显示时的数据样式。
虽然纸海图的注记是来源于源数据的属性,但一般情况下不能直接利用系统自动生成的注记,而是要从属性中经过判断后,进行提取、综合而形成纸海图的注记。
纸海图注重图面的美观。这里美观我认为包括两个方面,一方面是物标本身的空间位置是否美观,例如等深线是否圆滑、水深选取疏密程度合理等;另一方面是注记摆放的相对位置、疏密程度是否合理、是否美观。在纸海图中,空间位置的美观很大程度上是取决于源数据,因为纸海图上的等深线、水深等物标都是直接从源数据中读取的。在制作纸海图时比较少对物的标空间信息进行修改。因此,物标的空间位置美观在源数据中就应做到,以保证产
品的空间位置美观。(例如:等深线圆滑、物标的形状美观),对于纸海图中关于注记的这些内容都是储存在属性中的,源数据在此方面无要求。但要做到表达清楚、统一,以便于在产品制作时容易识别。
3.2 源数据与电子海图
电子海图及电子海图显示及信息系统一起为航海人员提供一个海图信息平台,使使用者能够非常直观、方便地了解所处海域的状况。同时在这个平台上集成有多种航海设备的信息(如GPS、雷达等)。S-57标准(国际海道测量组织(IHO)第57号特殊出版物——《数字海道测量数据传输标准》)是电子海图的标准之一。在S-57标准中有181个物标,其中地理物标160个、元物标13个、组合物标3个、制图物标5个。同时,电子海图还有另外一个标准:S-58(电子海图有效性检核推荐案)。S-58是对S-57数据进行数据架构及物标表示进行检核的。由于电子海图要通过S-58检查,所以在电子海图中制图物标是不允许存在的。源数据制作的依据很大一部分是制作电子海图的依据。源数据的也是以S-57标准进行数据存储的。源数据虽然以S-57标准存储,但由于要表示或者存储的信息不仅仅只有电子海图的信息,还有一些其它的信息。S-57的这些属性不满足这个要求。例如上面所提到的制图物标。为此,源数据自定义了一些属性,例如:$fcode(用于航标特征码的编码)、$hbnum(用于航标编号的编码)、$spinf(用于其它需要保存信息的编码)等属性。另外,对于一些电子海图中不需要表示而纸海图中需要表示的物标,在源数据中则以制图物标的形式表示。这些制图物标以及自定义的属性,在制作纸海图时,可以导入到纸海图产品中去;在制作电子海图时,系统会自动将这些制图物标过滤掉。也就是说制作纸海图时,可以看到源数据中的所有物标和属性,可以根据需要进行取舍。但在制作电子海图时,只能看到符合电子海图标准的物标及属性。
源数据虽然很大程度上与电子海图很相似,甚至在HPD Source Editor中可以输出000文件,但是源数据不能和电子海图完全等同。包括HPD Source Editor中输出的000文件也是不能符合电子海图的要求,只是一种数据格式而已。综上所述,电子海图与源数据的主要不同有:
1)源数据中的物标有一些自定义的属性,电子海图中没有。
2)源数据中有制图物标,而电子海图中不允许有制图物标存在。
3)源数据中部分物标是断开的,电子海图中相同属性的物标需要连接起来。
4)源数据中只有部分物标赋过最小比例尺,电子海图中则要对所有需要赋最小比例尺的物标进行赋值。
5)电子海图中有元物标,源数据中无。
4 源数据的管理
源数据是无缝存储的,没有图幅概念。理论上源数据的线、面物标是可以根据实际空间连续不断开的。但因为HPD数据库是允许多用户同时访问的,因此会常出现多个用户访问同一物标的情况,而此种情况会造成物标锁定,降低工作效率。为了尽可能解决此问题,结合网格化测量,在HPD源数据库中,物标是按照一定比例尺的网格断开的。目前,外业测量部分是按网格测量,部分是按图幅范围进行测量的。在源数据制作时,要规划好各个工程的范围,以免作业人员之间相互影响。
由于源数据库中,物标数量非常多,属性复杂。如作业人员一不小心删除物标或者更改物标的属性,可能会很难发现。这需要质检人员格外细心。同时,也需要作业人员严格按照作业指导书的方法进行操作,严格执行相关技术规定,以免丢失重要的物标和属性。目前库中的源数据相对来说还不是很完整,还需要不断的进行完善。
5 结语
源数据是制作纸海图、电子海图的基础。同时也是各类制图数据的综合管理者。源数据与电子海图、纸海图都有很大程度的相似,但又不能完全与任何一个产品等同。源数据库在给海图产品制作提供来源的同时,也对各类制图数据的管理。例如,改正通告编辑等工作所需数据都可以在该库中进行查询到。以上是本人关于源数据的一些拙见,如有不正之处,恳请指正。
参考文献
[1] 吴宇晓、张良,Caris Hpd 技术浅析,测绘科技信息交流论文集,2007,成都
1.数据库应用系统的设计步骤 按规范设计的方法可将数据库设计分为以下六个阶段 (1)需求分析; (2)概念结构设计; (3)逻辑结构设计; (4)数据库物理设计; (5)数据库实施; (6)数据库运行和维护。 2.需求分析 需求收集和分析是数据库应用系统设计的第一阶段。明确地把它作为数据库应用系统设计的第一步是十分重要的。这一阶段收集到的基础数据和一组数据流图(Data Flow Diaˉgram———DFD)是下一步设计概念结构的基础。概念结构对整个数据库设计具有深刻影响。而要设计好概念结构,就必须在需求分析阶段用系统的观点来考虑问题、收集和分析数据及其处理。如何分析和表达用户需求呢?在众多的分析方法中,结构化分析(Structured Analysis,简称SA方法)是一个简单实用的方法。SA方法用自顶向下、逐层分解的方式分析系统。用数据流图,数据字典描述系统。然后把一个处理功能的具体内容分解为若干子功能,每个子功能继续分解,直到把系统的工作过程表达清楚为止。在处理功能逐步分解的同时,它们所用的数据也逐级分解。形成若干层次的数据流图。数据流图表达了数据和处理过程的关系。处理过程的处理逻辑常常用判定表或判定树来描述。数据字典(Data Dictionary,简称DD)则是对系统中数据的详尽描述,是各类数据属性的清单。对数据库应用系统设计来讲,数据字典是进行详细的数据收集和数据分析所获得的主要结果。数据字典是各类数据描述的集合,它通常包括以下5个部分: (1)数据项,是数据最小单位。 (2)数据结构,是若干数据项有意义的集合。 (3)数据流,可以是数据项,也可以是数据结构。表示某一处理过程的输入输出。 (4)数据存储,处理过程中存取的数据。常常是手工凭证、手工文档或计算机文件。 (5)处理过程。
数据库体系结构数据库如何处理一个查询 当应用程序向PostgreSQL系统提交一个查询时,一般要经过五个阶段:
联接阶段 一旦建立起来一个联接,客户端进程就可以向后端服务器进程发送查询了。查询是通过纯文本传输的,也就是说在前端不做任何分析处理。服务器分析查询,创建执行规划,执行该规划并且通过已经建立起来的联接把检索出来的记录返回给客户端。 分析阶段 解析器的功能就其目的性来说,就是检查从应用程序(客户端)发送过来的查询,核对语法并创建一个查询分析树(querytree)。 重写阶段 重写系统是一个位于分析器阶段和规划器/优化器之间的模块。它接收分析阶段来的查询树且搜索任何应用到查询树上的规则,(规则存储在系统表里)并根据给出的规则体进行转换。 重写系统的一个应用就是实现视图。当一个查询访问一个视图时(也就是说,一个虚拟表),重写系统改写用户的查询,使之成为一个访问在视图定义里给出的基本表的查询。 优化阶段 规划器/优化器的任务是创建一个优化了的执行规划。它首先合并对出现在查询里的关系进行扫描和连接所有可能的方法。这样创建的所有路径都导致相同结果,而优化器的任务就是计算每个路径的开销并且找出开销最小的那条路径。
执行阶段 接受规划器/优化器传过来地查询规划然后递归地处理它,抽取所需要的行集合。执行器就是对应于上面所提到的查询引擎中的执行处理客户端发来的请求(Executor),它是查询引擎的核心模块。 执行器实际上是一个需求-拉动地流水线机制。每次调用一个规划节点地时候,它都必须给出更多的一个行,或者汇报它已经完成行的传递。 针对不同的SQL查询类型,执行器会有不同的执行方案,而这些方案的选择是按照执行器机制进行的。
已知关系模式R(city, street, zip)其中city为城市编号,street为街道编号,zip为邮政编码,一个城市的一条街道只有一个邮政编码,一个邮政编码只属于一个城市。请写出R上成立的所有函数依赖及所有候选键,并说明R最高就是第几范式。 现有某个应用,涉及到两个实体集,相关的属性为: 实体集R(A1,A2,A3,A4),其中,A1为码 实体集S(B1,B2,B3),其中B1为码 从实体集R到S存在一对一的联系,联系属性就是C1与C2。 1、设计相应的关系数据模型; 2、如果将上述应用的数据库设计为一个关系模式,如下: RS(A1,A2,A3,A4,B1,B2,B3,C1,C2) 这种设计就是否合适?并说明理由。 3、上述第2题的关系模式RS满足第二范式不?为什么? 4、如果将上述应用的数据库设计为两个关系模式,如下: R1 (A1,A2,A3,A4,B1,C1,C2) R2 (B1,B2,B3) 假设存在函数依赖A2→A3,B2→B3 指出关系模式R1、R2最高满足第几范式?(在1NF~BCNF之内)。 设基商业集团数据库中有商店、商品、职工三类实体。其中商店的属性有:商店编号、商店名称、地址;商品的属性有:商品号、商品名、规格、单价;职工的属性有:职工号、姓名、性别。 每个商店可销售多种商品,每种商品也可放在多个商店销售。 每个商店聘用多名职工,每名职工只能在一个商店工作。 根据上面叙述,解答以下问题: (1)设计E—R模型,要求标注连通词,可省略属性。 (2)将E—R模型转换成关系模型,标出每一个关系的主码与外码(如果存在)。 (3)写出定义参照完整性的SQL子句,要求满足“当参照表中数据更新时,外码也自动更新”。 关系模式中R(B,C,M,T,A,G),根据语义有如下函数依赖集: F={ B-C, (M,T)-- B,(M,C)-T, (M,A)-àT ,(A,B)- G } 关系模式R的码就是( D ) A、(M,T) B、(M,C) C、(M,A) D、(A,B) R的规范化程度最高达到( B ) A、1NF B、2NF C、3NF D、4NF 描述学生的关系模式r(sno,sd,mn,cno,g),其中sno表示学号,sd表示系名,mn表示系主任姓名,cno表示课程号,g 表示学生成绩。其数据语义就是:一个系有若干学生,但一个学生只属于一个系;一个系只有一名系主任;一个学生可以选修多门课程,每门课程有若干学生选修;每个学生所学的每门课程都有一个成绩。完成如下要求: (1)给出关系模式r上的所有函数依赖;
数据库的设计理论 第一节,关系模式的设计问题 一概念: 1. 关系模型:用二维表来表示实体集,用外键来表示实体间的联系,这样的数据模型,叫做关系数据模型。 关系模型包含内涵和外延两个方面: 外延:就是关系或实例、或当前值。它与时间有关,随时间的变化而变化。(主要是由于元组的插入、删除、修改等操作引起的) 内涵:内涵是与时间独立的,它包括关系属性、以及域的一些定义和说明。还有数据的各种完整性约束。 数据的完整性约束分为静态约束和动态约束。 静态约束包括数据之间的联系(称为数据依赖),主键的设计和各种限制。 动态约束主要定义如插入、删除和修改等操作的影响。 通常我们称内涵为关系模式。 2. 关系模式:是对一个关系的描述,二维表的表头那一行称为关系模式,又称为表的框架或记录类型。 关系模式的定义包括:模式名、属性名、值域名和模式的主键。关系模式仅仅是对数据特征的描述。 关系模式的一般形式为R ( U , D , DOM , F ) R 是关系名。 U 是全部属性的集合。 D 是属性域的集合。 DOM 是U 和D 之间的映射关系,关系运算的安全限制。 F 是属性间的各种约束关系,也称为数据依赖。
关系模式可以表示为: 关系模式(属性名1,属性名2 ,……,属性名n ) 示例:学生(学号,姓名,年龄,性别,籍贯)。 当且仅当U 上的一个关系r 满足 F 时,r 就称为关系模式R(U,F)上的一个关系,R是关系的型,r 是关系的值,每个值称为R 的一个关系。 关系数据库模式: 一个数据库是由多个关系构成的。 一个关系数据库对应多个不同的关系模式,关系数据库模式是一个数据库中所有的关系模式的集合。它规定了数据库的全局逻辑结构。 关系数据库模式可以表示为: S = { Ri < Ui , Di , DOM , Fi > | i = 1,2,…, n } 3. 关系子模式 关系子模式是用户所用到的那部分数据的描述。 外模式是关系子模式的集合。 4. 存储模式 存储模式及内模式。 关系数据库理论的主要内容: (1)数据依赖。数据依赖起着核心的作用。 (2)范式。 (3)模式的设计方法。 如何设计一个合理的数据库模式: (1)与实际问题相结合。 泛关系模式:把现实问题的所有属性组成一个关系模式 泛关系:泛关系模式的实例称为泛关系。 泛关系模式中存在的问题: a 数据冗余 b 更新异常, c 插入异常 d 删除异常。
制造企业生产管理系统详细设计书 目录 第一章引言 --------------------------------------------1 第一节选题意义 --------------------------------------------------1 第二节开发的目标-------------------------------------------------1 第二章开发环境 ----------------------------------------2 第一节系统建设的平台选择-----------------------------------------2 第二节系统的开发环境---------------------------------------------2 第三章信息系统分析-------------------------------------3 第一节信息系统的可行性分析 --------------------------------------3 第二节企业现行系统的调查及用户需求分析---------------------------5 一、企业现行系统的调查--------------------------------------------5 二、用户需求分析--------------------------------------------------6 第三节新系统逻辑模型的提出 --------------------------------------6 一、生产管理信息系统关联图--------------------------------------6 二、生产管理信息系统顶层图--------------------------------------7 三、生产管理信息系统数据流图--------------------------------------7 第四章信息系统设计-------------------------------------8 第一节信息系统的概要设计-----------------------------------------8 一、系统总体流程设计----------------------------------------------8 二、系统功能模块设计----------------------------------------------9 第二节信息系统的详细设计-----------------------------------------10 一、数据库设计----------------------------------------------------10 二、用户界面及功能的具体实现--------------------------------------15 第五章测试报告 ----------------------------------------24 第六章系统开发总结-------------------------------------24 附录:参考文献-----------------------------------------25
北邮数据库实验四数据 库模式的设计 Revised by Chen Zhen in 2021
北京邮电大学 实验报告 课程名称数据库 实验名称数据库模式的设计班级 姓名 学号 指导老师 成绩_________ 实验
.1.实验目的 1.了解E-R图的基本概念和根据数据需求描述抽象出E-R图并将其转换为数据库逻辑模式进而实现数据库中的表和视图。 2.通过进行数据库表的建立操作,熟悉并掌握Power designer数据库表的建立方法,理解关系数据库表的结构,巩固SQL标准中关于数据库表的建立语句。 3.通过对Power designer中建立、维护视图的实验,熟悉Power designe中对视图的操作方法和途径,理解和掌握视图的概念。 .2.实验内容 1 针对以下需求信息,尽可能全面地给出各个实体的属性和实体之间的系。 在线考试系统需求信息如下: 在线考试系统是关于一门课程的授课教师安排自己的学生在线参加各种考试的应 用,如果阶段性考试,期中考试和期末考试等。在线考试系统要求有用户的登录和登出。在线考试系统主要包括用户管理、试题管理、试卷管理和考试管理功能。需要实现教师输入试题,从试题生成试卷;学生参加考试获取试卷,提交答案和给出考试成绩等主要逻辑功能。 系统的用户包括教师、学生角色,一个用户有且只有一种角色。 鉴于在线考试的客观条件限制,试题完全采用单项选择形式。试题有所属知识点、内容、分值、备选答案和唯一正确答案等属性组成。课程的知识点是确定的,可以扩展,一道试题只能考察一个知识点。
教师录入各种试题构成题库,并根据考察的知识点不同生成试卷,相同知识点的试题只能在一张试卷中出现一次,试卷由试卷标题和一定数量(即知识点的数量)的试题组成。试卷生成后,教师指定某次考试使用的试卷,学生参加考试使用统一的试卷,考试信息还包含考试标题、任教老师、考试时间。 学生登录后,可以参加考试并在提交答案后立刻得到自己的考试成绩,也可以查看自己的考试历史记录。教师登录后可以查看学生的成绩。 ?2将E-R图输入Power Designer形成概念模型 ? 3 使用Power Designe将输入的E-R图转换成数据库物理模型 ? 4 使用Power Designe将输入的数据库物理模型转化为生成数据库中的表和视图的脚 本 ? 5 执行SQl脚本,生成表和视图 ? 6 成功后,查看生成的表和视图的情况 .3.实验环境 普通PC、Windows系列操作系统、IBM DB2 数据库管理系统 .4.实验步骤、结果与分析 1)五个实体: 用户: 用户ID( UserID )、用户名(UserName)、角色(Role)、密码(Password). 试题库(ItemBank): 题目代码(ItemID)、题目内容(Icontent)、分数(Iscore)、选项(Ioption)、正确答案(Ianswer)、知识点代码(PointID)(froeign). 知识点(KonwledgePoint): 知识点代码(PointID)、知识点内容(Pcontent)、知识点学科(Psubject). 试卷(Paper):
数据库基础 ( 视频讲解:25分钟) 本章主要介绍数据库的相关概念,包括数据库系统的简介、数据库的体系结构、数据模型、常见关系数据库。通过本章的学习,读者应该掌握数据库系统、数据模型、数据库三级模式结构以及数据库规范化等概念,掌握常见的关系数据库。 通过阅读本章,您可以: 了解数据库技术的发展 掌握数据库系统的组成 掌握数据库的体系结构 熟悉数据模型 掌握常见的关系数据库 1 第 章
1.1 数据库系统简介 视频讲解:光盘\TM\lx\1\数据库系统简介.exe 数据库系统(DataBase System,DBS)是由数据库及其管理软件组成的系统,人们常把与数据库有关的硬件和软件系统称为数据库系统。 1.1.1 数据库技术的发展 数据库技术是应数据管理任务的需求而产生的,随着计算机技术的发展,对数据管理技术也不断地提出更高的要求,其先后经历了人工管理、文件系统、数据库系统等3个阶段,这3个阶段的特点分别如下所述。 (1)人工管理阶段 20世纪50年代中期以前,计算机主要用于科学计算。当时硬件和软件设备都很落后,数据基本依赖于人工管理,人工管理数据具有如下特点: ?数据不保存。 ?使用应用程序管理数据。 ?数据不共享。 ?数据不具有独立性。 (2)文件系统阶段 20世纪50年代后期到60年代中期,硬件和软件技术都有了进一步发展,出现了磁盘等存储设备和专门的数据管理软件即文件系统,文件系统具有如下特点: ?数据可以长期保存。 ?由文件系统管理数据。 ?共享性差,数据冗余大。 ?数据独立性差。 (3)数据库系统阶段 20世纪60年代后期以来,计算机应用于管理系统,而且规模越来越大,应用越来越广泛,数据量急剧增长,对共享功能的要求越来越强烈。这样使用文件系统管理数据已经不能满足要求,于是为了解决一系列问题,出现了数据库系统来统一管理数据。数据库系统满足了多用户、多应用共享数据的需求,它比文件系统具有明显的优点,标志着管理技术的飞跃。 1.1.2 数据库系统的组成 数据库系统是采用数据库技术的计算机系统,是由数据库(数据)、数据库管理系统(软件)、数
生产管理系统设计与实现 摘要:计算机语言是互联网发展的重要基础语言,在计算机编程语言里也分不同的方向,比如Java、Android、PHP等各种不同的语言,而在我的系统中主要用到的语言,就是Java。Java作为一款目前十分火爆的编程语言,因其简单性,面向对象、分布性、编译和解释性、稳健性、安全性、可移植性、高性能、多线索性、动态性等等特性受到大量程序员的青睐。而本次我要介绍的系统主要是以Eclipse为开发工具,Java的框架现在最常用的有五种Mybatis、Spring、Hibernate、Struts2、SpringMVC,各个框架之间可以集成,我主要使用的框架有Spring、SpringMVC、Hibernate而前端我的界面我采用的是HTML、CSS、JavaScript (Jquery)等页面技术,前端框架框架使用Jquery和Bootstrap。 关键词:后台开发;Java;Bootstrap;Spring;Hibernate Abstract:Computer language is the important basis for the development of the Internet, in the computer programming language also points in different directions, such as Java, android, a variety of different languages such as PHP, and mainly used in language in my system, it is Java.Java as a very popular programming languages at present, because of itssimplicity,object-oriented,distributed, compile and explanatory, robustness, security, portability, high performance, multiplewirealtogether, dynamic, and so on characteristics favored by a lot of programmers.And this I want to introduce the system is mainly based on the eclipse development tools, Java framework is now the most commonly used there are five mybatis, spring, hibernate, struts 2, for springmvc, between each frame can be integrated, I mainly use the spring framework, for springmvc, hibernate and front-end interface I use HTML, CSS, JavaScript, jquery) page, such as technology,The front-end frame framework USES Jquery and Bootstrap. Key words:The background and development; Java; Bootstrap; Spring; Hibernate
一、选择题 1.同一个关系模型的任意两个元组值(A )。 A. 不能全同 B. 可全同 C. 必须全同 D. 以上都不是2.关系模式R中的属性全部是主属性,则R的最高范式必定是(B )。 A. 2NF B. 3NF C. BCNF D. 4NF 3.下列哪个不是数据库系统必须提供的数据控制功能(B )。 A. 安全性 B. 可移植性 C. 完整性 D. 并发控制 4.若关系R的候选码都是由单属性构成的,则R的最高范式必定是(B )。 A. 1NF B. 2NF C. 3NF D.无法确定 5.下列哪些运算是关系代数的基本运算(D )。 A. 交、并、差 B. 投影、选取、除、联结 C. 联结、自然联结、笛卡尔乘积 D. 投影、选取、笛卡尔乘积、差运算6.SQL语句的一次查询结果是(D )。 A. 数据项 B. 记录 C. 元组 D. 表 7.在关系R(R#, RN, S#)和S(S#,SN, SD)中,R的主码是R#, S的主码是S#,则S#在R中称为(A )。 A. 外码候选码 C. 主码 D. 超码 8.在DBS中,DBMS和OS之间关系是(D )。 A. 并发运行 B. 相互调用 C. OS调用DBMS DBMS调用OS 9.层次模型、网状模型和关系模型的划分根据是(D )。 A. 记录长度 B. 文件的大小 C. 联系的复杂程度 D. 数据之间的联系 10.下列哪个是单目运算(C )。 A. 差 B. 并 C. 投影 D. 除法 11.采用SQL查询语言对关系进行查询操作,若要求查询结果中不能出现重复元组,可在SELECT子句后增加保留字( A )。 A. DISTINCT B. UNIQUE C. NOT NULL D. SINGLE 12.下列SQL语句中,能够实现“给用户teacher授予查询SC的权限”这一功能的是(A )。 A. GRANT SELECT on SC to teacher B. REVOKE SELECT on SC to teacher C. GRANT SELECT on TABLE to teacher D. REVOKE SELECT on TABLE to teacher 13.设有关系S (SNO,SNAME,DNAME,DADDR),将其规范化到第三范式正确的答案是( B )。 A. S1(SNO,SNAME)S2(DNAME,DADDR) B. S1 (SNO,SNAME,DNAME)DEPT(DNAME,DADDR) C. S1(SNO,SNAME,DADDR)S2(SNO,SNAME)
生产管理系统解决方案、生产管理系统解决方案框
生产管理系统是针对制造型企业的生产运营而开发的管理系统。生产管理系 统主要包括订单管理、生产计划管理、成本管理、物料需求计划、采购管理、库 * 希燮孜测 设计中心 <产品、工艺) 生产计划 贬会管逵 * 采嗚计划 〔采购 计划 资金菁求 计划 能力需求 计划 牝源零求 计対 主产线 {隨工 生产作业 计划 更量管逢 亘定资A 人员工资 圭龙成本 寿户誉至
存管理、付款管理、质量管理、生产绩效等核心管理系统,实施生产管理系统能 够提高了各组织部分管理的准确性,指导原材料定购,及时掌控各方数据信息, 优化资金的合理使用,提高生产的效率和节省生产成本。 、生产管理系统解决方案需求分析 社会的信息化的深入发展,各企业都在加快建设特信息网络平台的步伐。 企业在处理 采购、生产、成本管理、质量管理等重要环节方面,正在逐步加强对 利用信息化网络平台和计算机的利用。 在企业生产管理中,对可视化信息的需求 十分迫切。比如,在安全防卫方面,企业需要再厂区、厂房、仓库以及各交界处 实施全天候视频监控及预警、录像系统;监管人员需要及时掌握各厂房车间的流 水线的生产情况;领导层也有了解各生产环节实时生产情况, 现场语音交流指导 和处理突发状况的需求。 此外,制造行业的人力成本不断上升,而且人工处理缓慢,出错率高, 因此企业对于 生产管理 软件开发提出了更高的要求,企业通过实施生产管理系统 解决方案,不仅促进企业生产社会化自动化要求, 也是企业发展、减少成本需要。 另一方面,我国正处在粗放式经济增长方式向集约型转变的道路上, 利用生产管 订单管理 作业指示 车间離 储区管理 设备管理 8$订单昨 xan 制HI 际 WKSttSSB AVI 壕冲删齟 iSfigffVESS? 的删整 工作胴般 柞1?标单豹8 自榊£1$ ma 砸时计 <4-HA l-W JW MB] gsat^H 脚T 草酣 低业计鵬产 SETH aas^it#) 作业拒示 生产 设备管 车间监控
已知关系模式R(city, street, zip)其中city为城市编号,street为街道编号,zip为邮政编码,一个城市的一条街道只有一个邮政编码,一个邮政编码只属于一个城市。请写出R上成立的所有函数依赖及所有候选键,并说明R最高是第几范式。 现有某个应用,涉及到两个实体集,相关的属性为: 实体集R(A1,A2,A3,A4),其中,A1为码 实体集S(B1,B2,B3),其中B1为码 从实体集R到S存在一对一的联系,联系属性是C1和C2。 1.设计相应的关系数据模型; 2.如果将上述应用的数据库设计为一个关系模式,如下: RS(A1,A2,A3,A4,B1,B2,B3,C1,C2) 这种设计是否合适并说明理由。 3.上述第2题的关系模式RS满足第二范式吗为什么 4.如果将上述应用的数据库设计为两个关系模式,如下: R1 (A1,A2,A3,A4,B1,C1,C2) R2 (B1,B2,B3) 假设存在函数依赖A2→A3,B2→B3 指出关系模式R1、R2最高满足第几范式(在1NF~BCNF之内)。 设基商业集团数据库中有商店、商品、职工三类实体。其中商店的属性有:商店编号、商店名称、地址;商品的属性有:商品号、商品名、规格、单价;职工的属性有:职工号、姓名、性别。 每个商店可销售多种商品,每种商品也可放在多个商店销售。 每个商店聘用多名职工,每名职工只能在一个商店工作。 根据上面叙述,解答以下问题: (1)设计E—R模型,要求标注连通词,可省略属性。 (2)将E—R模型转换成关系模型,标出每一个关系的主码和外码(如果存在)。 (3)写出定义参照完整性的SQL子句,要求满足“当参照表中数据更新时,外码也自动更新”。 关系模式中R(B,C,M,T,A,G),根据语义有如下函数依赖集: F={ B-C, (M,T)-- B,(M,C)-T, (M,A)-àT ,(A,B)- G } 关系模式R的码是( D ) A. (M,T) B. (M,C) C. (M,A) D.(A,B) R的规范化程度最高达到(B ) A. 1NF B. 2NF C. 3NF D. 4NF 描述学生的关系模式r(sno,sd,mn,cno,g),其中sno表示学号,sd表示系名,mn表示系主任姓名,cno
关系数据库的模式设计 本章的理论性较强,学习时有无从下手的感觉,在学习时应多加思考,从概念出发去理解理论,前后的理论有较强的联系,因此要逐个理解,但对于理论的证明等内容则不必深究,本章重点是函数依赖,无损联接、保持依赖和范式的概念。 一、关系模式的设计问题(识记) 关系数据库是以关系模型为基础的数据库,它利用关系来描述现实世界。一个关系既可以用来描述一个实体及其属性,也可以用来描述实体间的联系。关系实质上就是一张二维表,表的行称为元组,列称为属性 . 关系模式是用来定义关系的,这里的关系模式我们可以简单地理解为一个表的结构,一个关系数据库包含一组关系,也就是包含一组二维表,这些二维表结构体的集合就构成数据库的模式(也可以理解为数据库的结构)。 关系数据库设计理论包括三个方面内容:数据依赖、范式、模式设计方法。核心内容是数据依赖。 泛关系模式:把现实问题的所有属性组成一个关系模式R(U),这个关系模式就称为泛关系模式。 数据库模式:把泛关系模式用一组关系模式的集合ρ来表示时,这个ρ就是数据库模式。 下面我们总结一下关系模式的相关内容从“大”到“小”的排列 泛关系模式→数据库模式→关系数据库→表结构→关系模式实例(表)→记录(行、列。) 关系模式的存储异常:数据冗余、更新异常、插入异常和删除异常 二、函数依赖(FD) 1、函数依赖的定义(领会):设有关系模式R(A1,A2,……An)或简记为R(U),X,Y是U的子集,r是R的任一具体关系,如果对r的任意两个元组t1,t2,由t1[X]=t2[X]导致t1[Y]=t2[Y],则称X函数决定Y,或Y函数依赖于X,记为X→Y.X→Y为模式R的一个函数依赖。 这个定义可以这样理解:有一张设计好的二维表,X,Y是表的某些列(可以是一列,也可以是多列),若在表中的第t1行,和第t2行上的X值相等,那么必有t1行和t2行上的Y值也相等,这就是说Y函数依赖于X. 2、函数依赖的逻辑蕴涵(识记) 设F是关系模式R的一个函数依赖集,X,Y是R的属性子集,如果从F中的函数依赖能够推出X→Y,则称F逻辑蕴涵X→Y,记为F|=X→Y.
数据库系统原理自测题(2) 一、单项选择题 1.数据库物理存储方式的描述称为【B】 A.外模式B.内模式 C.概念模式D.逻辑模式 2.在下面给出的内容中,不属于DBA职责的是【A】A.定义概念模式B.修改模式结构 C.编写应用程序D.编写完整行规则 3.用户涉及的逻辑结构用描述【C】 A.模式B.存储模式 C.概念模型D.逻辑模式 4.数据库在磁盘上的基本组织形式是【B】A.DB B.文件 C.二维表 D.系统目录 5.在DBS中,最接近于物理存储设备一级的结构,称为【D】A.外模式B.概念模式C.用户模式D.内模式 6.从模块结构考察,DBMS由两大部分组成:【B】A.查询处理器和文件管理器B.查询处理器和存储管理器 C.数据库编译器和存储管理器D.数据库编译器和缓冲区管理器 7.设W=RS,且W、R、S的属性个数分别为w、r和s,那么三者之间应满足 【A】 A.w≤r+s B.w<r+s C.w≥r+s D.w>r+s 8.数据库系统的体系结构是数据库系统的总体框架,一般来说数据库系统应具有三级模式体系结构,它们是【A】 A.外模式、逻辑模式和内模式B.内模式、用户模式和外模式 C.内模式、子模式和概念模式D.子模式、模式和概念模式 9.ER图是表示概念模型的有效工具之一,在ER图中的菱形框表示【A】A.联系B.实体 C.实体的属性D.联系的属性 10.数据库管理系统中数据操纵语言DML所事项的操作一般包括【A】 A.查询、插入、修改、删除B.排序、授权、删除 C.建立、插入、修改、排序D.建立、授权、修改
11.设有关系R(A,B,C)和关系S(B,C,D),那么与RS等价的关系代数表达式是【C】 A.π1,2,3,4(σ2=1∧3=2(R×S))B.π1,2,3,6(σ2=1∧3=2(R×S)) C.π1,2,3,6(σ2=4∧3=5(R×S))D.π1,2,3,4(σ2=4∧3=5(R×S))12.在关系模式R中,函数依赖X→Y的语义是【B】A.在R的某一关系中,若两个元组的X值相等,则Y值也相等 B.在R的每一关系中,若两个元组的X值相等,则Y值也相等 C.在R的某一关系中,Y值应与X值相等 D.在R的每一关系中,Y值应与X值相等 13.设有关系模式R(A,B,C,D),R上成立的FD集F={A→C,B→C},则属性集BD 的闭包(BD)+为【B】A.BD B.BCD C.ABD D.ABCD 14.有10个实体类型,并且它们之间存在着10个不同的二元联系,其中2个是1:1联系类型,3个是1:N联系类型,5个是M:N联系类型,那么根据转换规则,这个ER结构转换成的关系模式有【B】 A.13个B.15个C.18个D.20个 15.关系模式R分解成数据库模式ρ的一个优点是【D】A.数据分散存储在多个关系中B.数据容易恢复 C.提高了查询速度D.存储悬挂元组 16.事务并发执行时,每个事务不必关心其他事务,如同在单用户环境下执行一样,这个性质称为事务的【D】A.持久性B.一致性C.孤立性D.隔离性 17.用户或应用程序使用数据库的方式称为【B】A.封锁B.权限C.口令D.事务 18. 常用的关系运算是关系代数和。【C 】 A .集合代数 B .逻辑演算 C .关系演算 D .集合演算 19.在关系代数表达式优化策略中,应尽可能早执行操作【C】A.投影B.连接 C.选择D.笛卡儿积 20.当关系R和S自然连接时,能够把R和S原核舍弃的元组放到结果关系中的操作是 【D】A.左外连接B.右外连接 C.外部并D.外连接 规范化为BCNF 【C 】A.消除非主属性对码的部分函数依赖B .消除非主属性对码的传递函数依赖 C.消除主属性对码的部分和传递函数依赖D .消除非平凡且非函数依赖的多值依赖23.对用户而言,ODBC技术屏蔽掉了【B】A.不同服务器的差异B.不同DBS的差异
生产管理系统解决方案一、生产管理系统解决方案框
二、 生产管理系统是针对制造型企业的生产运营而开发的管理系统。生产管理系
统主要包括订单管理、生产计划管理、成本管理、物料需求计划、采购管理、库存管理、付款管理、质量管理、生产绩效等核心管理系统,实施生产管理系统能够提高了各组织部分管理的准确性,指导原材料定购,及时掌控各方数据信息,优化资金的合理使用,提高生产的效率和节省生产成本。
二、生产管理系统解决方案需求分析 社会的信息化的深入发展,各企业都在加快建设特信息网络平台的步伐。企业在处理采购、生产、成本管理、质量管理等重要环节方面,正在逐步加强对利用信息化网络平台和计算机的利用。在企业生产管理中,对可视化信息的需求十分迫切。比如,在安全防卫方面,企业需要再厂区、厂房、仓库以及各交界处实施全天候视频监控及预警、录像系统;监管人员需要及时掌握各厂房车间的流水线的生产情况;领导层也有了解各生产环节实时生产情况,现场语音交流指导和处理突发状况的需求。 此外,制造行业的人力成本不断上升,而且人工处理缓慢,出错率高,因此企业对于生产管理软件开发提出了更高的要求,企业通过实施生产管理系统解决方案,不仅促进企业生产社会化自动化要求,也是企业发展、减少成本需要。另一方面,我国正处在粗放式经济增长方式向集约型转变的道路上,利用生产管理软件来实现车间生产管理的信息化和生产管理的信息化,用生产管理软件的精确管理控制代替手工的粗放式管理,更好的节约物料资源,降低产品的成本,创造出最大的经济效益,不断地增强企业的核心竞争力。
三、生产管理系统解决方案 生产流程越来越复杂,使得企业越来越难以控制生产过程,对流程的管理也随之缺乏灵活性;同时,社会分工越来越细化,生产工人对所从事的生产的全过程也缺乏了解,因此也缺乏改变已有条件的积极主动性。 现在,企业生产有一种趋势向小型化、自治化的制造和装配单元发展,生产管理系统的生产计划和控制可以只对制造或者其他部门规定某个时间段应该完成的粗略生产计划;具体的生产调度,如技术、分配、质量管理等功能都分开控制完成,企业可以采用生产控制方法可以减轻负荷。 生产管理系统解决方案——工厂结构体系图
大型共享数据库的数据关系模型 E.F.Codd IBM Research Laboratory,SanJose,California 未来的数据库使用者一定是和数据在机器中的存储(即数据库的内部模式)相隔离的。而通过提示服务来提供信息是一个不太令人满意的解决方法。当数据的内部模式表示发生改变,甚至数据内部表示的多个方面发生改变时,终端用户和大多数应用程序的活动都不会受到影响。因此,查询、更新和报告存储信息类型的自然增长和变动都需要在数据表示中表现出来。 现存的不可推断的、格式化的数据系统给用户提供了树结构的文件或者更一般的网格模式的数据。本文在第一部分讨论这些模式的不足之处。并且会介绍一种基于n元组关系的模式,一种数据库关系的正式形式和通用数据子句的概念。第二部分将讨论一些关系的操作(不是逻辑层面的),并且把这些操作应用于用户模式上解决冗余和一致性问题。 1关系模式和一般模式 1.1简介 这篇文章是关于系统的基本关系原理的应用,这个原理提供了共享大型格式化数据库的方法。除了Childs[1]的文章有介绍外,用于数据库系统的关系的主要应用 还表现在演绎推理型的问-答系统中。Levein和Maron[2]提供了大量关于这个领域的参考资料。 相比之下,这里要解决的问题是一些数据独立性的问题——应用程序和终端活动之于数据类型增长和数据表示变动的独立性,而数据一致性问题即使在非演绎推 理型系统中也是很棘手的。 在目前流行的非推论性系统中,第一部分要介绍的数据的关系视图(或叫做模式)在一些方面似乎优于图模式和网格模式[3,4]。这种模式提供了一种根据数据的自然结构来描述描述数据的方式——也就是说,不用为了数据的机器表示而添加其 他的将结构。因此,这种模式为高水准的数据语言提供了基础,而这种数据语言机 制一方面可以达到最大化程序之间的独立性,另一方面也可以最大化数据的机器表 示和组织之间的独立性。 关系模式更高一级的优势在于它构成了关系处理可导性、冗余性和一致性的坚固基础——这些将在第二部分讨论。另一方面,网络模型产生了一些混淆,尤其是 把连接的源误作为关系的源(见第二部分“连接陷阱”) 最后,关系视图允许对目前格式化数据系统的范围和逻辑限制的更清晰的估算,并且有在单独的系统内竞争数据表示方式的优点(从逻辑的观点)。更清楚的这个观点的示例会在本文中的不同部分中被阐释。但是支持关系模式的系统实现不会讨论。 1.2目前系统的数据相关性 最近发展的信息系统中数据描述表的提供是向数据独立性目标[5,6,7]靠近的重要提高。这些表可以使改变数据库中数据表示的某些特征变得更容易些。但是,许 多数据表示特征可以在不逻辑地削弱一些应用程序的情况下被改变的功能仍受到相 当的限制。更进一步,与用户交互的数据模式仍然有一些散乱的代表性特征,特别
数据库设计的基本步骤 一、数据库设计的生存期 按照规范设计的方法,考虑到数据库及其应用系统开发的全过程,将数据库设计分为六个阶段。如下图。 ①需求分析 需求收集和分析,得到用数据字典描述的数据需求,用数据流图描述的处理需求。 ②概念结构设计 对需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型(用E-R图表示)。 ③逻辑结构设计 将概念结构转换为某个DBMS所支持的数据模型(例如关系模型),并对其 进行优化。 ④物理结构设计 为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构和存取方法)。 ⑤数据库实施
运用DBMS提供的数据语言(例如SQL)及其宿主语言(例如C),根据逻 辑设计和物理设计的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行。 ⑥数据库运行和维护 数据库应用系统经过试运行后即可投入正式运行。在数据库系统运行过程中必须不断地对其进行评价、调整与修改。 说明:设计一个完善的数据库应用系统是不可能一蹴而就的,它往往是上述六个阶段的不断反复。 二、数据库设计阶段的内容 设计步骤既是数据库设计的过程,也包括了数据库应用系统的设计过程。下面针对各阶段的设计内容给出各阶段的设计描述。如下图。 三、数据库设计阶段的模式 数据库结构设计的不同阶段形成数据库的各级模式,如下图。 需求分析阶段:综合各个用户的应用需求;
概念设计阶段:形成独立于机器特点,独立于各个DBMS产品的概念模式,即E-R图; 逻辑设计阶段:将E-R图转换成具体的数据库产品支持的数据模型,如关 系模型,形成数据库逻辑模式;然后根据用户处理的要求、安全性的考虑,在基本表的基础上再建立必要的视图,形成数据的外模式; 物理设计阶段:根据DBMS特点和处理的需要,进行物理存储安排,建立索引,形成数据库内模式。
制造企业生产管理系统详细设计书第一章引言 中小企业是我国国民经济中,数量最多,解决就业最多的经济实体.在我国乡镇及乡(镇)以上的工业企业中,中小企业在我国加入“WTO”之后,这些企业面临者国外两大市场的竞争压力,由于这些企业自身大多经济技术实力较为薄弱.生产制造和开发设计能力落后,对市场的承受能力较低,在把握稍纵即逝的市场机遇方面。显得力不从心,需与其它企业各种方式加强合作发挥各自特长,集体面对市场的考验,风险共担,利润同享[24]。 制造企业生产管理信息系统(Production Management Information system for Manufacturing Enterprises.PMISME)是用于解决企业核心企业和各成员之间生产任务的分发、生产进度的控制、产品运输和库存管理等工作的协调和管理系统。本系统是以生产计划为主,涉及到采购与库存的信息管理系统。 第一节选题意义 随着信息的迅速发展,给各个大中小企业的发展带来了不可否认的巨大变化,公司开始关注信息社会。在社会的推动下,信息管理风靡整个。在制造企业中,生产信息数据量大,处理条件复杂,人工处理困难。生产管理信息系统借助计算机强大的处理能力以及大大的降低管理人员的工作量,利用系统做好决策,准确性也得到充分的提高。 在这一背景下,生产管理系统就成为一个非常好的课题。我这次的毕业设计主要针对中小企业,做一个适合中小企业使用的系统。 第二节开发的目标 在互联网上查阅资料后,再根据中小型企业的特点:信息的处理缺乏规、中小企业由于发展时间短、计算机和网络技术的普及应用率低、管理观念和管理模式比较传统、中小企业规模相对较小等,本着实用、够用,不盲目求全求大的原则,设计开发简单易用,符合人们使用习惯和技术能力的生产管理信息系统,总结出需要解决的问题大致有以下二点:
1概述 1.1目的 软件研发数据库设计规范作为数据库设计的操作规范,详细描述了数据库设计过程及结果,用于指导系统设计人员正确理解和开展数据库设计。 1.2适用范围 1.3术语定义 DBMS:数据库管理系统,常用的商业DBMS有Oracle, SQL Server, DB2等。 数据库设计:数据库设计是在给定的应用场景下,构造适用的数据库模式,建立数据库及其应用系统,有效存储数据,满足用户信息要求和处理要求。 概念数据模型:概念数据模型以实体-关系 (Entity-RelationShip,简称E-R)理论为基础,并对这一理论进行了扩充。它从用户的观点出发对信息进行建模,主要用于数据库概念级别的设计,独立于机器和各DBMS产品。可以用Sybase PowerDesigner工具来建立概念数据模型(CDM)。 逻辑数据模型:将概念数据模型转换成具体的数据库产品支持的数据模型,如关系模型,形成数据库逻辑模式。可
以用Sybase PowerDesigner工具直接建立逻辑数据模型(LDM),或者通过CDM转换得到。 物理数据模型:在逻辑数据模型基础上,根据DBMS特点和处理的需要,进行物理存储安排,设计索引,形成数据库内模式。可以用Sybase PowerDesigner工具直接建立物理数据模型(PDM),或者通过CDM / LDM转换得到。 2数据库设计原则 按阶段实施并形成该阶段的成果物 一般符合3NF范式要求;兼顾规范与效率 使用公司规定的数据库设计软件工具 命名符合公司标准和项目标准 3数据库设计目标 规范性:一般符合3NF范式要求,减少冗余数据。 高效率:兼顾规范与效率,适当进行反范式化,满足应用系统的性能要求。 紧凑性:例如能用char(10)的就不要用char(20),提高存储的利用率和系统性能,但同时也要兼顾扩展性和可移植性。 易用性:数据库设计清晰易用,用户和开发人员均能容