
课程设计
课程:数据结构
题目:排序算法比较
专业班级:
姓名:
学号:
设计时间:
指导教师:
设计题目
排序算法比较
运行环境(软、硬件环境)
操作系统windows
运行环境vc6.0
算法设计的思想
大架构采用模块化编程的思想,将每个不同的功能分别写成不同的子程序,分别进行封装构成各个小的模块,最后将各个模块组合起来。在每个子程序的编写过程中特事特办面对不同的预想功能采取不同的数据结构不同的算法实现。
总体算法思想为按功能分块,依照预想功能实现顺序拼装。
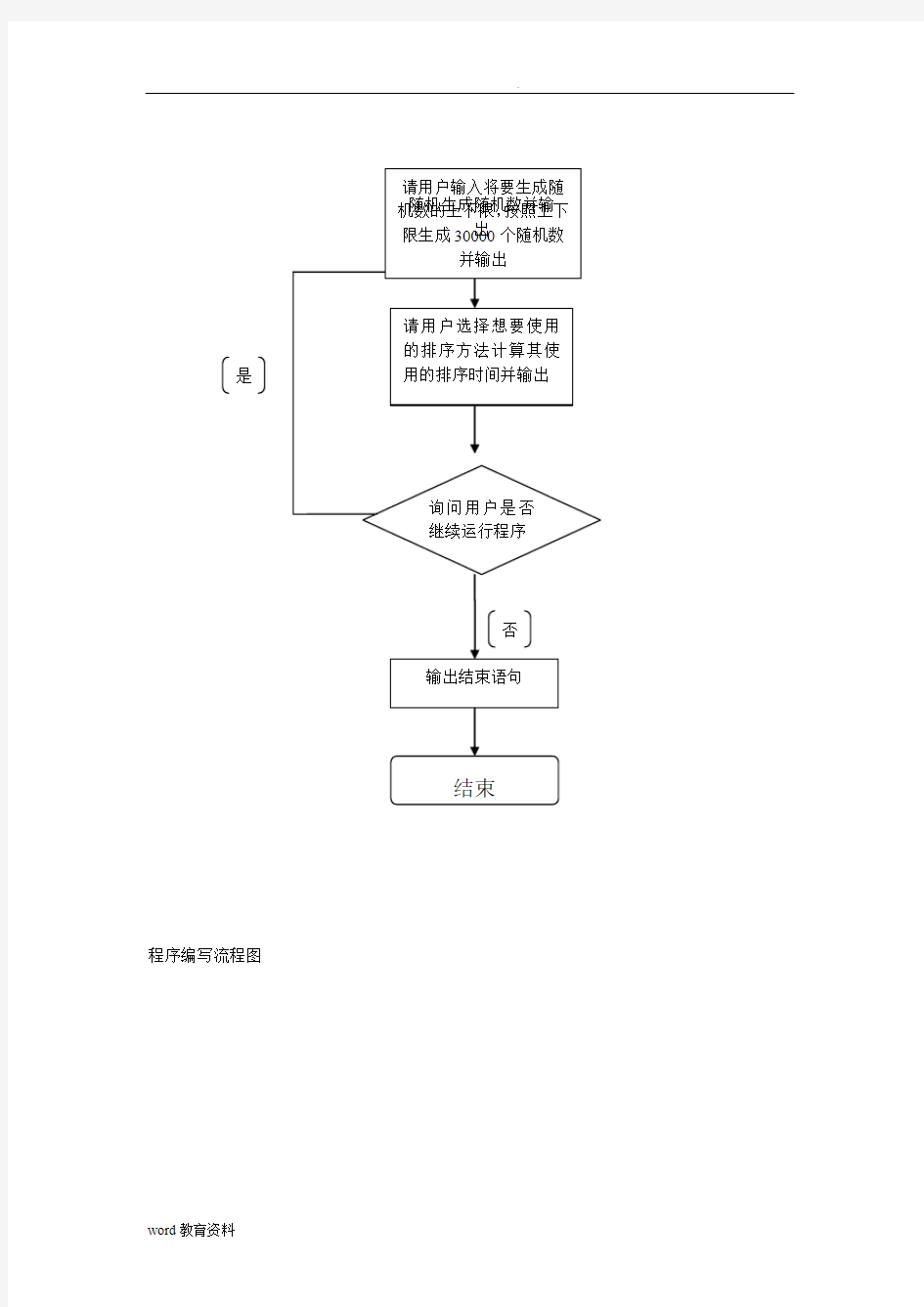
具体思想请见流程图。
流程图
功能流程图
是
程序编写流程图
算法流程图
算法设计分析
程序总体采用模块化设计,程序间通过传参和调用进行有机组合。这样的总体布局将将各个功能隔离开来,每个模块负责每个模块的功能,使得程序的布局简单明了。且子程序只有在
被调用时才会运行大大节约系统资源减少了运算时间。同时由于功能的隔离使得程序的扩展性大大提高,无论程序将要任何改动时,都会方便很多。
源代码
#include
#include
#include
int a[30000];
int choice;
int choice1;
struct xlx{
int key;
int link;
} aa[30000];
int aaa[300000];
void main1();
/*************************直接插入排序函数***********************/
void direct(int a[]){
printf("\n现在使用直接插入排序法进行排序:\n");
int i,j,w;
for(i=0;i<30000;i++)
{
for(j=i;j>=0;j--)
{
if(a[j]>=a[j+1])
{
w=a[j];
a[j]=a[j+1];
a[j+1]=w;
}
}
}
}
/*************************冒泡排序函数*************************/
void bubble_sort(int a[])
{
printf("\n下面使用冒泡排序法进行排序:");
int i,j,w;
for(i=0;i<30000;i++)
for(j=0;j<30000-i;j++)
if(a[j]>a[j+1])
{
w=a[j];
a[j]=a[j+1];
a[j+1]=w;
}
}
/*************************选择排序****************************/ void choices_sort(int a[])
{ printf("\n现在使用选择排序法进行排序:\n");
int i,j,k,t;
for(i=0;i<30000;i++)
{
k=i;
for(j=i+1;j<30000;j++)
if(a[k]>a[j])
k=j;
t=a[i];
a[i]=a[k];
a[k]=t;
}
}
/*************************快速排序****************************/ quick(int first,int end,int L[])
{
int left=first,right=end,key;
key=L[first];
while(left { while((left right--; if(left L[left++]=L[right]; while((left left++; if(left L[left]=key; return left; } void quick_sort(int L[],int first,int end) { int split; if(first { split=quick(first,end,L); quick_sort(L,first,split-1); quick_sort(L,split+1,end); } } /**************************堆排序*****************************/ void sift(int *x, int n, int s) { int t, k, j; t = *(x+s); /*暂存开始元素*/ k = s; /*开始元素下标*/ j = 2*k + 1; /*右子树元素下标*/ while (j { if (j { j++; } if (t<*(x+j)) /*调整*/ { *(x+k) = *(x+j); k = j; /*调整后,开始元素也随之调整*/ j = 2*k + 1; } else /*没有需要调整了,已经是个堆了,退出循环。*/ { break; } } *(x+k) = t; /*开始元素放到它正确位置*/ void heap_sort(int *x, int n) { int i, k, t; for (i=n/2-1; i>=0; i--) { sift(x,n,i); /*初始建堆*/ } for (k=n-1; k>=1; k--) { t = *(x+0); /*堆顶放到最后*/ *(x+0) = *(x+k); *(x+k) = t; sift(x,k,0); /*剩下的数再建堆*/ } } /*************************归并排序****************************/ int listmerge(struct xlx list[],int first,int second)/*递归传递*/ { int start=30000; while(first!=-1&&second!=-1) if(list[first].key<=list[second].key) { list[start].link=first; first=list[second].link; } else { list[start].link=second; start=second; second=list[second].link; } if (first=-1) list[start].link=second; else list[start].link=first; return list[30000].link; } int rmerge(struct xlx list[],int lower,int upper) /* 归并并返回已排序的结果数组的起始位置*/ { int middle; if(lower>=upper) return lower; else{ middle=(lower+upper); return listmerge(list,rmerge(list,lower,middle), rmerge(list,middle+1,upper)); } } /*************************时间计算函数************************/ void timer(int choice) { double t1,t2,t;int i; t1=(double) clock(); if(choice==1) direct(a); if(choice==2) bubble_sort(a); if(choice==3) choices_sort(a); if(choice==4) printf("\n现在使用快速排序法进行排序:\n"); quick_sort(a,0,29999); } if(choice==5) heap_sort(a,30000); if(choice==6) rmerge(aa,0,29999); t2=(double) clock(); t=difftime(t2,t1)/1000; for(i=0;i<30000;i++) printf("%d ",a[i]); printf("\n排序结束您所用排序时间为:%f秒\n",t); } /**************************菜单函数***************************/ void menu(int choice1) { int i; if (choice1==1) { for(i=0;i<=30000;i++) {a[i]=aaa[i]; aa[i].key=aaa[i];} main1(); } if (choice1==2) { printf("谢谢使用,再见!!"); } } /**************************生成随机数函数**********************/ void sjs() { int i=0,j,b,h,l; printf("请输入你所期望的将要生成随机数的取值范围:\n"); printf("最小值(不能为负数):"); scanf("%d",&l); printf("最大值(无上限):"); scanf("%d",&h); srand( (int) time(0)); for(j=0;i<30000;j++) { b=rand(); if(b>=l&&b<=h) { a[i]=b; aa[i].key=b; aaa[i]=b; i++; } } for(i=0;i<30000;i++) printf("%d ",a[i]); } void main1(){ printf("\n\n请选择你所希望使用的排序方法:\n\n1。直接插入排序\n2。冒泡排序\n3。选择排序\n4。快速排序\n5。堆排序\n6。归并排序\n"); scanf("%d",&choice); timer(choice); printf("\n\n排序完毕,请选择下一步您要完成的工作:\n\n1.返回选择另一种排序方法排序\n2.退出\n"); scanf("%d",&choice1); menu(choice1); } /*************************主函数******************************/ void main() { sjs(); main1(); } for (k=n-1; k>=1; k--) { t = *(x+0); /*堆顶放到最后*/ *(x+0) = *(x+k); *(x+k) = t; sift(x,k,0); /*剩下的数再建堆*/ } } /*************************归并排序****************************/ int listmerge(struct xlx list[],int first,int second)/*递归传递*/ { int start=30000; while(first!=-1&&second!=-1) if(list[first].key<=list[second].key) { list[start].link=first; first=list[second].link; } else { list[start].link=second; start=second; second=list[second].link; } if (first=-1) list[start].link=second; else list[start].link=first; return list[30000].link; } int rmerge(struct xlx list[],int lower,int upper) /* 归并并返回已排序的结果数组 的起始位置*/ { int middle; if(lower>=upper) return lower; else{ middle=(lower+upper); return listmerge(list,rmerge(list,lower,middle), rmerge(list,middle+1,upper)); } } /*************************时间计算函数************************/ void time(int choice){ double t1,t2,t;int i; t1=(double) clock(); if(choice==1) direct(a); if(choice==2) bubble_sort(a); if(choice==3) choices_sort(a); if(choice==4) { printf("\n现在使用快速排序法进行排序:\n"); quick_sort(a,0,29999); } if(choice==5) heap_sort(a,30000); if(choice==6) rmerge(aa,0,29999); t2=(double) clock(); t=difftime(t2,t1)/1000; for(i=0;i<30000;i++) printf("%d ",a[i]); printf("\n排序结束您所用排序时间为:%f秒\n",t); } /**************************菜单函数***************************/ void menu(int choice1) { int i; if (choice1==1) { for(i=0;i<=30000;i++) {a[i]=aaa[i]; aa[i].key=aaa[i];} main1(); } if (choice1==2) { printf("谢谢使用,再见!!"); } } void main1(){ printf("\n\n请选择你所希望使用的排序方法:\n\n1。直接插入排序\n2。冒泡排序\n3。 选择排序\n4。快速排序\n5。堆排序\n6。归并排序\n"); scanf("%d",&choice); time(choice); printf("\n\n排序完毕,请选择下一步您要完成的工作:\n\n1.返回选择另一种排序方法排序\n2.退出\n"); scanf("%d",&choice1); menu(choice1); } /*************************主函数******************************/ void main() { sjs(); main1(); } 运行结果分析 生成30000个随机数 选择使用排序算法 直接排序排序所用时间 冒泡排序所用时间 选择排序所用时间 快速排序所用时间 堆排序所用时间 各排序排序时间分别为: 直接排序:3.448秒 冒泡排序:3.76秒 选择排序:1.575秒 快速排序:0.00秒 堆排序:0.016秒 归并排序:7.487秒 (注:此处快速排序并非排序时间为0,而是时间很短在表示范围外,当实验数据扩大到一定数值后会有相应时间显示) 通过数据不难看出6种排序方法处理一组相同数据时,快速排序处理速度最快堆排序次之,归并排序最慢。 六.课设心得 整个程序前前后后整整用了一个星期,每天只要有空闲时间就在翻书本,画流程图,写代码,反反复复一点一点。一个星期的编写让我进步不少,心得也不少,但是说实话让我认识最深的是四点,刻骨铭心: 对于编程来说看书很重要,但实实在在的动手去编才是王道! 任何程序想要写起来不被自己搞晕,就一定要画流程图,省时省事! 编程一定养成良好的编程习惯,无论命名还是结构! 任何程序算法是灵魂,程序的好坏很大部分取决于算法,只是一组数的排序差别就如此之大,跟别说一个比排序负责多倍的排序! 排序算法汇总 第1节排序及其基本概念 一、基本概念 1.什么是排序 排序是数据处理中经常使用的一种重要运算。 设文件由n个记录{R1,R2,……,Rn}组成,n个记录对应的关键字集合为{K1,K2,……,Kn}。所谓排序就是将这n个记录按关键字大小递增或递减重新排列。b5E2RGbCAP 2.稳定性 当待排序记录的关键字均不相同时,排序结果是惟一的,否则排序结果不唯一。 如果文件中关键字相同的记录经过某种排序方法进行排序之后,仍能保持它们在排序之前的相对次序,则称这种排序方法是稳定的;否则,称这种排序方法是不稳定的。p1EanqFDPw 3.排序的方式 由于文件大小不同使排序过程中涉及的存储器不同,可将排序分成内部排序和外部排序两类。整个排序过程都在内存进行的排序,称为内部排序;反之,若排序过程中要进行数据的内、外存交换,则称之为外部排序。DXDiTa9E3d 内排序适用于记录个数不是很多的小文件,而外排序则适用于记录个数太多,不能一次性放人内存的大文件。 内排序是排序的基础,本讲主要介绍各种内部排序的方法。 按策略划分内部排序方法可以分为五类:插入排序、选择排序、交换排序、归并排序和分配排序。 二、排序算法分析 1.排序算法的基本操作 几乎所有的排序都有两个基本的操作: <1)关键字大小的比较。 <2)改变记录的位置。具体处理方式依赖于记录的存储形式,对于顺序型记录,一般移动记录本身,而链式存储的记录则通过改变指向记录的指针实现重定位。RTCrpUDGiT 为了简化描述,在下面的讲解中,我们只考虑记录的关键字,则其存储结构也简化为数组或链表。并约定排序结果为递增。5PCzVD7HxA 2.排序算法性能评价 排序的算法很多,不同的算法有不同的优缺点,没有哪种算法在任何情况下都是最好的。评价一种排序算法好坏的标准主要有两条:jLBHrnAILg <1)执行时间和所需的辅助空间,即时间复杂度和空间复杂度; <2)算法本身的复杂程度,比如算法是否易读、是否易于实现。 第2节插入排序 插入排序的基本思想是:每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的记录集中,使记录依然有序,直到所有待排序记录全部插入完成。xHAQX74J0X 一、直接插入排序 1.直接插入排序的思想 排序算法 一、插入排序(Insertion Sort) 1. 基本思想: 每次将一个待排序的数据元素,插入到前面已经排好序的数列中的适当位置,使数列依然有序;直到待排序数据元素全部插入完为止。 2. 排序过程: 【示例】: [初始关键字] [49] 38 65 97 76 13 27 49 J=2(38) [38 49] 65 97 76 13 27 49 J=3(65) [38 49 65] 97 76 13 27 49 J=4(97) [38 49 65 97] 76 13 27 49 J=5(76) [38 49 65 76 97] 13 27 49 J=6(13) [13 38 49 65 76 97] 27 49 J=7(27) [13 27 38 49 65 76 97] 49 J=8(49) [13 27 38 49 49 65 76 97] Procedure InsertSort(Var R : FileType); //对R[1..N]按递增序进行插入排序, R[0]是监视哨// Begin for I := 2 To N Do //依次插入R[2],...,R[n]// begin R[0] := R[I]; J := I - 1; While R[0] < R[J] Do //查找R[I]的插入位置// begin R[J+1] := R[J]; //将大于R[I]的元素后移// J := J - 1 end R[J + 1] := R[0] ; //插入R[I] // end End; //InsertSort // 二、选择排序 1. 基本思想: 每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。 2. 排序过程: 【示例】: 初始关键字[49 38 65 97 76 13 27 49] 第一趟排序后13 [38 65 97 76 49 27 49] 第二趟排序后13 27 [65 97 76 49 38 49] 第三趟排序后13 27 38 [97 76 49 65 49] 第四趟排序后13 27 38 49 [49 97 65 76] 第五趟排序后13 27 38 49 49 [97 97 76] 1.一元稀疏多项式计算器 [问题描述] 设计一个一元稀疏多项式简单计算器。 [基本要求] 输入并建立多项式; 输出多项式,输出形式为整数序列:n, c1, e1, c2, e2,……, cn, en ,其中n是多项式的项数,ci, ei分别是第i项的系数和指数,序列按指数降序排序; 多项式a和b相加,建立多项式a+b; 多项式a和b相减,建立多项式a-b; [测试数据] (2x+5x8-3.1x11)+(7-5x8+11x9)=(-3.1x11+11x9+2x+7) (6x-3-x+4.4x2-1.2x9)-(-6x-3+5.4x2-x2+7.8x15)=(-7.8x15-1.2x9-x+12x-3) (1+x+x2+x3+x4+x5)+(-x3-x4)=(x5+x2+x+1) (x+x3)+(-x-x3)=0 (x+x2+x3)+0=(x3+x2+x) [实现提示] 用带头结点的单链表存储多项式,多项式的项数存放在头结点中。 2.背包问题的求解 [问题描述] 假设有一个能装入总体积为T的背包和n件体积分别为w1, w2, …,wn的物品,能否从n件物品中挑选若干件恰好装满背包,即使w1+w2+…+wn=T,要求找出所有满足上述条件的解。例如:当T=10,各件物品的体积为{1,8,4,3,5,2}时,可找到下列4组解:(1,4,3,2)、(1,4,5)、(8,2)、(3,5,2) [实现提示] 可利用回溯法的设计思想来解决背包问题。首先,将物品排成一列,然后顺序选取物品转入背包,假设已选取了前i件物品之后背包还没有装满,则继续选取第i+1件物品,若该件物品“太大”不能装入,则弃之而继续选取下一件,直至背包装满为止。但如果在剩余的物品中找不到合适的物品以填满背包,则说明“刚刚”装入背包的那件物品“不合适”,应将它取出“弃之一边”,继续再从“它之后”的物品中选取,如此重复,直至求得满足条件的解,或者无解。 由于回溯求解的规则是“后进先出”因此自然要用到栈。 3.完全二叉树判断 用一个二叉链表存储的二叉树,判断其是否是完全二叉树。 4.最小生成树求解(1人) 任意创建一个图,利用克鲁斯卡尔算法,求出该图的最小生成树。 5.最小生成树求解(1人) 任意创建一个图,利用普里姆算法,求出该图的最小生成树。 6.树状显示二叉树 编写函数displaytree(二叉树的根指针,数据值宽度,屏幕的宽度)输出树的直观示意图。输出的二叉树是垂直打印的,同层的节点在同一行上。 [问题描述] 假设数据宽度datawidth=2,而屏幕宽度screenwidth为64=26,假设节点的输出位置用 (层号,须打印的空格数)来界定。 第0层:根在(0,32)处输出; 《数据结构I》三级项目报告 大连东软信息学院 电子工程系 ××××年××月 三级项目报告注意事项 1. 按照项目要求书写项目报告,条理清晰,数据准确; 2. 项目报告严禁抄袭,如发现抄袭的情况,则抄袭者与被抄袭者均 以0分计; 3. 课程结束后报告上交教师,并进行考核与存档。 三级项目报告格式规范 1. 正文:宋体,小四号,首行缩进2字符,1.5倍行距,段前段后 各0行; 2. 图表:居中,图名用五号字,中文用宋体,英文用“Times New Roman”,位于图表下方,须全文统一。 目录 一项目设计方案 (3) 二项目设计分析 (4) 三项目设计成果 (4) 四项目创新创业 (5) 五项目展望 (6) 附录一:项目成员 (6) 附录二:相关代码、电路图等 (6) 一项目设计方案 1、项目名称: 垃圾回收 2、项目要求及系统基本功能: 1)利用数据结构的知识独立完成一个应用系统设计 2)程序正常运行,能够实现基本的数据增加、删除、修改、查询等功能3)体现程序实现算法复杂度优化 4)体现程序的健壮性 二项目设计分析 1、系统预期实现基本功能: (结合本系统预期具体实现,描述出对应基本要求(增、删、改、查等)的具体功能) 1. 2. 3. 4. 5. 6. 7. 2、项目模块功能描述 (基本分为组织实施组织、程序功能模块编写、系统说明撰写等。其中程序功能子模块实现) 模块一: 主要任务:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX 模块二: 主要任务:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX 模块n: 主要任务:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX 一、冒泡排序 冒泡排序(BubbleSort)的基本概念是:依次比较相邻的两个数,将小数放在前面,大数放在后面。即在第一趟:首先比较第1个和第2个数,将小数放前,大数放后。然后比较第2个数和第3个数,将小数放前,大数放后,如此继续,直至比较最后两个数,将小数放前,大数放后。至此第一趟结束,将最大的数放到了最后。在第二趟:仍从第一对数开始比较(因为可能由于第2个数和第3个数的交换,使得第1个数不再小于第2个数),将小数放前,大数放后,一直比较到倒数第二个数(倒数第一的位置上已经是最大的),第二趟结束,在倒数第二的位置上得到一个新的最大数(其实在整个数列中是第二大的数)。如此下去,重复以上过程,直至最终完成排序。 代码实现如下: 二、插入排序 插入排序的基本思想是每步将一个待排序的记录按其排序码值的大小,插到前面已经排好的文件中的适当位置,直到全部插入完为止。插入排序方法主要有直接插入排序和希尔排序。 直接插入排序具体算法描述如下: 1. 从第一个元素开始,该元素可以认为已经被排序 2. 取出下一个元素,在已经排序的元素序列中从后向前扫描 3. 如果该元素(已排序)大于新元素,将该元素移到下一位置 4. 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置 5. 将新元素插入到下一位置中 6. 重复步骤2 伪码描述如下: 代码实现如下: 三、归并排序 归并排序是将两个或两个以上的有序子表合并成一个新的有序表。初始时,把含有n个结点的待排序序列看作由n个长度都为1的有序子表组成,将它们依次两两归并得到长度为2的若干有序子表,再对它们两两合并。直到得到长度为n的有序表,排序结束。 归并操作的工作原理如下: 1、申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列 2、设定两个指针,最初位置分别为两个已经排序序列的起始位置 3、比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置 4、重复步骤3直到某一指针达到序列尾 5、将另一序列剩下的所有元素直接复制到合并序列尾 代码实现如下: HUNAN UNIVERSITY 课程实习报告 题目:排序算法的时间性能学生姓名 学生学号 专业班级 指导老师李晓鸿 完成日期 设计一组实验来比较下列排序算法的时间性能 快速排序、堆排序、希尔排序、冒泡排序、归并排序(其他排序也可以作为比较的对象) 要求 (1)时间性能包括平均时间性能、最好情况下的时间性能、最差情况下的时间性能等。 (2)实验数据应具有说服力,包括:数据要有一定的规模(如元素个数从100到10000);数据的初始特性类型要多,因而需要具有随机性;实验数据的组数要多,即同一规模的数组要多选几种不同类型的数据来实验。实验结果要能以清晰的形式给出,如图、表等。 (3)算法所用时间必须是机器时间,也可以包括比较和交换元素的次数。 (4)实验分析及其结果要能以清晰的方式来描述,如数学公式或图表等。 (5)要给出实验的方案及其分析。 说明 本题重点在以下几个方面: 理解和掌握以实验方式比较算法性能的方法;掌握测试实验方案的设计;理解并实现测试数据的产生方法;掌握实验数据的分析和结论提炼;实验结果汇报等。 一、需求分析 (1) 输入的形式和输入值的范围:本程序要求实现各种算法的时间性能的比 较,由于需要比较的数目较大,不能手动输入,于是采用系统生成随机数。 用户输入随机数的个数n,然后调用随机事件函数产生n个随机数,对这些随机数进行排序。于是数据为整数 (2) 输出的形式:输出在各种数目的随机数下,各种排序算法所用的时间和 比较次数。 (3) 程序所能达到的功能:该程序可以根据用户的输入而产生相应的随机 数,然后对随机数进行各种排序,根据排序进行时间和次数的比较。 (4)测试数据:略 二、概要设计 数据结构课程设计 课程名称:内部排序算法比较 年级/院系:11级计算机科学与技术学院 姓名/学号: 指导老师: 第一章问题描述 排序是数据结构中重要的一个部分,也是在实际开发中易遇到的问题,所以研究各种排算法的时间消耗对于在实际应用当中很有必要通过分析实际结合算法的特性进行选择和使用哪种算法可以使实际问题得到更好更充分的解决!该系统通过对各种内部排序算法如直接插入排序,冒泡排序,简单选择排序,快速排序,希尔排序,堆排序、二路归并排序等,以关键码的比较次数和移动次数分析其特点,并进行比较,估算每种算法的时间消耗,从而比较各种算法的优劣和使用情况!排序表的数据是多种不同的情况,如随机产生数据、极端的数据如已是正序或逆序数据。比较的结果用一个直方图表示。 第二章系统分析 界面的设计如图所示: |******************************| |-------欢迎使用---------| |-----(1)随机取数-------| |-----(2)自行输入-------| |-----(0)退出使用-------| |******************************| 请选择操作方式: 如上图所示该系统的功能有: (1):选择1 时系统由客户输入要进行测试的元素个数由电脑随机选取数字进行各种排序结果得到准确的比较和移动次数并 打印出结果。 (2)选择2 时系统由客户自己输入要进行测试的元素进行各种排序结果得到准确的比较和移动次数并打印出结果。 (3)选择0 打印“谢谢使用!!”退出系统的使用!! 第三章系统设计 (I)友好的人机界面设计:(如图3.1所示) |******************************| |-------欢迎使用---------| |-----(1)随机取数-------| |-----(2)自行输入-------| |-----(0)退出使用-------| 《数据结构与算法》课程设计报告 学号: 班级序号: 姓名: 指导教师: 成绩: 中国地质大学信息工程学院地理信息系统系 2011年12 月 1.需求规格说明 【问题描述】 利用哈夫曼编码进行对已有文件进行重新编码可以大大提高减小文件大小,减少存储空间。但是,这要求在首先对一个现有文件进行编码行成新的文件,也就是压缩。在文件使用时,再对压缩文件进行解压缩,也就是译码,复原原有文件。试为完成此功能,写一个压缩/解压缩软件。 【基本要求】 一个完整的系统应具有以下功能: (1)压缩准备。读取指定被压缩文件,对文件进行分析,建立哈夫曼树,并给出分析结果(包括数据集大小,每个数据的权值,压缩前后文件的大小),在屏幕上输出。 (2)压缩。利用已建好的哈夫曼树,对文件进行编码,并将哈夫曼编码及文件编码后的数据一起写入文件中,形成压缩文件(*.Haf)。 (3)解压缩。打开已有压缩文件(*.Haf),读取其中的哈夫曼编码,构建哈夫曼树,读取其中的数据,进行译码后,写入文件,完成解压缩。 (4)程序使用命令行方式运行 压缩命令:SZip A Test.Haf 1.doc 解压缩命令:SZip X Test.Haf 2.doc或SZip X Test.Haf 用户输入的命令不正确时,给出提示。 (5)使用面向对象的思想编程,压缩/解压缩、哈夫曼构建功能分别构建类实现。 2.总体分析与设计 (1)设计思想: 1、压缩准备:1> 读文件,逐个读取字符,统计频率 2> 建立哈夫曼树 3> 获得哈弗曼编码 2、压缩过程: 1> 建立一个新文件,将储存权值和字符的对象数组取存储在文件头 一、设计思想 插入排序:首先,我们定义我们需要排序的数组,得到数组的长度。如果数组只有一个数字,那么我们直接认为它已经是排好序的,就不需要再进行调整,直接就得到了我们的结果。否则,我们从数组中的第二个元素开始遍历。然后,启动主索引,我们用curr当做我们遍历的主索引,每次主索引的开始,我们都使得要插入的位置(insertIndex)等于-1,即我们认为主索引之前的元素没有比主索引指向的元素值大的元素,那么自然主索引位置的元素不需要挪动位置。然后,开始副索引,副索引遍历所有主索引之前的排好的元素,当发现主索引之前的某个元素比主索引指向的元素的值大时,我们就将要插入的位置(insertIndex)记为第一个比主索引指向元素的位置,跳出副索引;否则,等待副索引自然完成。副索引遍历结束后,我们判断当前要插入的位置(insertIndex)是否等于-1,如果等于-1,说明主索引之前元素的值没有一个比主索引指向的元素的值大,那么主索引位置的元素不要挪动位置,回到主索引,主索引向后走一位,进行下一次主索引的遍历;否则,说明主索引之前insertIndex位置元素的值比主索引指向的元素的值大,那么,我们记录当前主索引指向的元素的值,然后将主索引之前从insertIndex位置开始的所有元素依次向后挪一位,这里注意,要从后向前一位一位挪,否则,会使得数组成为一串相同的数字。最后,将记录下的当前索引指向的元素的值放在要插入的位置(insertIndex)处,进行下一次主索引的遍历。继续上面的工作,最终我们就可以得到我们的排序结果。插入排序的特点在于,我们每次遍历,主索引之前的元素都是已经排好序的,我们找到比主索引指向元素的值大的第一个元素的位置,然后将主索引指向位置的元素插入到该位置,将该位置之后一直到主索引位置的元素依次向后挪动。这样的方法,使得挪动的次数相对较多,如果对于排序数据量较大,挪动成本较高的情况时,这种排序算法显然成本较高,时间复杂度相对较差,是初等通用排序算法中的一种。 选择排序:选择排序相对插入排序,是插入排序的一个优化,优化的前提是我们认为数据是比较大的,挪动数据的代价比数据比较的代价大很多,所以我们选择排序是追求少挪动,以比较次数换取挪动次数。首先,我们定义我们需要排序的数组,得到数组的长度,定义一个结果数组,用来存放排好序的数组,定义一个最小值,定义一个最小值的位置。然后,进入我们的遍历,每次进入遍历的时候我们都使得当前的最小值为9999,即认为每次最小值都是最大的数,用来进行和其他元素比较得到最小值,每次认为最小值的位置都是0,用来重新记录最小值的位置。然后,进入第二层循环,进行数值的比较,如果数组中的某个元素的值比最小值小,那么将当前的最小值设为元素的值,然后记录下来元素的位置,这样,当跳出循环体的时候,我们会得到要排序数组中的最小值,然后将最小值位置的数值设置为9999,即我们得到了最小值之后,就让数组中的这个数成为最大值,然后将结果数组result[]第主索引值位置上的元素赋值为最小值,进行下一次外层循环重复上面的工作。最终我们就得到了排好序的结果数组result[]。选择排序的优势在于,我们挪动元素的次数很少,只是每次对要排序的数组进行整体遍历,找到其中的最小的元素,然后将改元素的值放到一个新的结果数组中去,这样大大减少了挪动的次序,即我们要排序的数组有多少元素,我们就挪动多少次,而因为每次都要对数组的所有元素进行遍历,那么比较的次数就比较多,达到了n2次,所以,我们使用选择排序的前提是,认为挪动元素要比比较元素的成本高出很多的时候。他相对与插入排序,他的比较次数大于插入排序的次数,而挪动次数就很少,元素有多少个,挪动次数就是多少个。 希尔排序:首先,我们定义一个要排序的数组,然后定义一个步长的数组,该步长数组是由一组特定的数字组成的,步长数组具体得到过程我们不去考虑,是由科学家经过很长时间计算得到的,已经根据时间复杂度的要求,得到了最适合希尔排序的一组步长值以及计算 各种排序算法的总结和比较 1 快速排序(QuickSort) 快速排序是一个就地排序,分而治之,大规模递归的算法。从本质上来说,它是归并排序的就地版本。快速排序可以由下面四步组成。 (1)如果不多于1个数据,直接返回。 (2)一般选择序列最左边的值作为支点数据。(3)将序列分成2部分,一部分都大于支点数据,另外一部分都小于支点数据。 (4)对两边利用递归排序数列。 快速排序比大部分排序算法都要快。尽管我们可以在某些特殊的情况下写出比快速排序快的算法,但是就通常情况而言,没有比它更快的了。快速排序是递归的,对于内存非常有限的机器来说,它不是一个好的选择。 2 归并排序(MergeSort) 归并排序先分解要排序的序列,从1分成2,2分成4,依次分解,当分解到只有1个一组的时候,就可以排序这些分组,然后依次合并回原来的序列中,这样就可以排序所有数据。合并排序比堆排序稍微快一点,但是需要比堆排序多一倍的内存空间,因为它需要一个额外的数组。 3 堆排序(HeapSort) 堆排序适合于数据量非常大的场合(百万数据)。 堆排序不需要大量的递归或者多维的暂存数组。这对于数据量非常巨大的序列是合适的。比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。 堆排序会将所有的数据建成一个堆,最大的数据在堆顶,然后将堆顶数据和序列的最后一个数据交换。接下来再次重建堆,交换数据,依次下去,就可以排序所有的数据。 Shell排序通过将数据分成不同的组,先对每一组进行排序,然后再对所有的元素进行一次插入排序,以减少数据交换和移动的次数。平均效率是O(nlogn)。其中分组的合理性会对算法产生重要的影响。现在多用D.E.Knuth的分组方法。 Shell排序比冒泡排序快5倍,比插入排序大致快2倍。Shell排序比起QuickSort,MergeSort,HeapSort慢很多。但是它相对比较简单,它适合于数据量在5000以下并且速度并不是特别重要的场合。它对于数据量较小的数列重复排序是非常好的。 5 插入排序(InsertSort) 插入排序通过把序列中的值插入一个已经排序好的序列中,直到该序列的结束。插入排序是对冒泡排序的改进。它比冒泡排序快2倍。一般不用在数据大于1000的场合下使用插入排序,或者重复排序超过200数据项的序列。 一、问题描述 1、排序问题描述 排序是计算机程序设计的一种重要操作,他的功能是将一组任意顺序数据元素(记录),根据某一个(或几个)关键字按一定的顺序重新排列成为有序的序列。简单地说,就是将一组“无序”的记录序列调整为“有序”的记录序列的一种操作。 本次课程设计主要涉及几种常用的排序方法,分析了排序的实质,排序的应用,排序的分类,同时进行各排序方法的效率比较,包括比较次数和交换次数。我们利用java语言来实现本排序综合系统,该系统包含了:插入排序、交换排序、选择排序、归并排序。其中包括: (1)插入排序的有关算法:不带监视哨的直接插入排序的实现; (2)交换排序有关算法:冒泡排序、快速排序的实现; (3)选择排序的有关算法:直接选择排序、堆排序的实现; (4)归并排序的有关算法:2-路归并排序的实现。 2、界面设计模块问题描述 设计一个菜单式界面,让用户可以选择要解决的问题,同时可以退出程序。界面要求简洁明了,大方得体,便于用户的使用,同时,对于用户的错误选择可以进行有效的处理。 二、问题分析 本人设计的是交换排序,它的基本思想是两两比较带排序记录的关键字,若两个记录的次序相反则交换这两个记录,直到没有反序的记录为止。应用交换排序基本思想的主要排序方法有冒泡排序和快速排序。 冒泡排序的基本思想是:将待排序的数组看作从上到下排列,把关键字值较小的记录看作“较轻的”,关键字值较大的纪录看作“较重的”,较小关键字值的记录好像水中的气泡一样,向上浮;较大关键字值的纪录如水中的石块向下沉,当所有的气泡都浮到了相应的位置,并且所有的石块都沉到了水中,排序就结束了。 冒泡排序的步骤: 1)置初值i=1; 2)在无序序列{r[0],r[1],…,r[n-i]}中,从头至尾依次比较相邻的两个记录r[j] 与r[j+1](0<=j<=n-i-1),若r[j].key>r[j+1].key,则交换位置; 3)i=i+1; 4)重复步骤2)和3),直到步骤2)中未发生记录交换或i=n-1为止; 要实现上述步骤,需要引入一个布尔变量flag,用来标记相邻记录是否发生交换。 快速排序的基本思想是:通过一趟排序将要排序的记录分割成独立的两个部分,其中一部分的所有记录的关键字值都比另外一部分的所有记录关键字值小,然后再按此方法对这两部分记录分别进行快速排序,整个排序过程可以递归进行,以此达到整个记录序列变成有序。 快速排序步骤: 1)设置两个变量i、j,初值分别为low和high,分别表示待排序序列的起始下 课程设计说明书 课程名称:数据结构 专业:班级: 姓名:学号: 指导教师:成绩: 完成日期:年月日 任务书 题目:黑白棋系统 设计内容及要求: 1.课程设计任务内容 通过玩家与电脑双方的交替下棋,在一个8行8列的方格中,进行棋子的相互交替翻转。反复循环下棋,最后让双方的棋子填满整个方格。再根据循环遍历方格程序,判断玩家与电脑双方的棋子数。进行大小判断,最红给出胜负的一方。并根据y/n选项,判断是否要进行下一局的游戏。 2.课程设计要求 实现黑白两色棋子的对峙 开发环境:vc++6.0 实现目标: (1)熟悉的运用c语言程序编写代码。 (2)能够理清整个程序的运行过程并绘画流程图 (3)了解如何定义局部变量和整体变量; (4)学会上机调试程序,发现问题,并解决 (5)学习使用C++程序来了解游戏原理。 (6)学习用文档书写程序说明 摘要 本文的研究工作在于利用计算机模拟人脑进行下黑白棋,计算机下棋是人工智能领域中的一个研究热点,多年以来,随着计算机技术和人工智能技术的不断发展,计算机下棋的水平得到了长足的进步 该程序的最终胜负是由棋盘上岗双方的棋子的个数来判断的,多的一方为胜,少的一方为负。所以该程序主要运用的战术有削弱对手行动战术、四角优先战术、在游戏开局和中局时,程序采用削弱对手行动力战术,即尽量减少对手能够落子的位置;在游戏终局时则采用最大贪吃战术,即尽可能多的吃掉对手的棋子;而四角优先战术则是贯穿游戏的始终,棋盘的四角围稳定角,不会被对手吃掉,所以这里是兵家的必争之地,在阻止对手进角的同时,自己却又要努力的进角。 关键词:黑白棋;编程;设计 冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。 #include 常见内部排序算法比较 排序算法是数据结构学科经典的内容,其中内部排序现有的算法有很多种,究竟各有什么特点呢?本文力图设计实现常用内部排序算法并进行比较。分别为起泡排序,直接插入排序,简单选择排序,快速排序,堆排序,针对关键字的比较次数和移动次数进行测试比较。 问题分析和总体设计 ADT OrderableList { 数据对象:D={ai| ai∈IntegerSet,i=1,2,…,n,n≥0} 数据关系:R1={〈ai-1,ai〉|ai-1, ai∈D, i=1,2,…,n} 基本操作: InitList(n) 操作结果:构造一个长度为n,元素值依次为1,2,…,n的有序表。Randomizel(d,isInverseOrser) 操作结果:随机打乱 BubbleSort( ) 操作结果:进行起泡排序 InserSort( ) 操作结果:进行插入排序 SelectSort( ) 操作结果:进行选择排序 QuickSort( ) 操作结果:进行快速排序 HeapSort( ) 操作结果:进行堆排序 ListTraverse(visit( )) 操作结果:依次对L种的每个元素调用函数visit( ) }ADT OrderableList 待排序表的元素的关键字为整数.用正序,逆序和不同乱序程度的不同数据做测试比较,对关键字的比较次数和移动次数(关键字交换计为3次移动)进行测试比较.要求显示提示信息,用户由键盘输入待排序表的表长(100-1000)和不同测试数据的组数(8-18).每次测试完毕,要求列表现是比较结果. 要求对结果进行分析. 详细设计 1、起泡排序 算法:核心思想是扫描数据清单,寻找出现乱序的两个相邻的项目。当找到这两个项目后,交换项目的位置然后继续扫描。重复上面的操作直到所有的项目都按顺序排好。 bubblesort(struct rec r[],int n) { int i,j; struct rec w; unsigned long int compare=0,move=0; for(i=1;i<=n-1;i++) for(j=n;j>=i+1;j--) { if(r[j].key 数据结构各种排序算法总结 2009-08-19 11:09 计算机排序与人进行排序的不同:计算机程序不能象人一样通览所有的数据,只能根据计算机的"比较"原理,在同一时间内对两个队员进行比较,这是算法的一种"短视"。 1. 冒泡排序 BubbleSort 最简单的一个 public void bubbleSort() { int out, in; for(out=nElems-1; out>0; out--) // outer loop (backward) for(in=0; in swap(out, min); // swap them } // end for(out) } // end selectionSort() 效率:O(N2) 3. 插入排序 insertSort 在插入排序中,一组数据在某个时刻实局部有序的,为在冒泡和选择排序中实完全有序的。 public void insertionSort() { int in, out; for(out=1; out 《数据结构》课程设计报告 专业 班级 姓名 学号 指导教师 起止时间 课程设计:排序综合 一、任务描述 利用随机函数产生n个随机整数(20000以上),对这些数进行多种方法进行排序。(1)至少采用三种方法实现上述问题求解(提示,可采用的方法有插入排序、希尔排序、起泡排序、快速排序、选择排序、堆排序、归并排序)。并把排序后的结果保存在不同的文件中。 (2)统计每一种排序方法的性能(以上机运行程序所花费的时间为准进行对比),找出其中两种较快的方法。 要求:根据以上任务说明,设计程序完成功能。 二、问题分析 1、功能分析 分析设计课题的要求,要求编程实现以下功能: (1)随机生成N个整数,存放到线性表中; (2)起泡排序并计算所需时间; (3)简单选择排序并计算时间; (4)希尔排序并计算时间; (5)直接插入排序并计算所需时间; (6)时间效率比较。 2、数据对象分析 存储数据的线性表应为顺序存储。 三、数据结构设计 使用顺序表实现,有关定义如下: typedef int Status; typedef int KeyType ; //设排序码为整型量 typedef int InfoType; typedef struct { //定义被排序记录结构类型 KeyType key ; //排序码 I nfoType otherinfo; //其它数据项 } RedType ; typedef struct { RedType * r; //存储带排序记录的顺序表 //r[0]作哨兵或缓冲区 int length ; //顺序表的长度 } SqList ; //定义顺序表类型 四、功能设计 (一)主控菜单设计 编号 课程设计 题目 1、一元稀疏多项式计算器 2、模拟浏览器操作程序 3、背包问题的求解 4、八皇后问题 二级学院计算机科学与工程学院 专业计算机科学与技术 班级 2011级 37-3班 学生姓名 XX 学号 XXXXXXXXXX 指导教师 XXXXX 评阅教师 时间 1、一元稀疏多项式计算器 【实验内容】 一元稀疏多项式计算器。 【问题描述】 设计一个一元稀疏多项式简单计算器。 【需求分析】 其基本功能包括: (1)输入并建立多项式; (2)输出多项式,输出形式为整数序列为:n,c1,e1,c2,e2,……,cn,en,其中n 是多项式的项数,ci,ei分别是第i项的系数和指数,序列按指数降序排序;(3)多项式a和b相减,建立多项a+b; (4)多项式a和b相减,建立多项式a-b; (5)计算多项式在x处的值; (6)计算器的仿真界面(选做); 【概要设计】 -=ADT=- { void input(Jd *ha,Jd *hb); void sort(dnode *h) dnode *operate(dnode *a,dnode *b) float qiuzhi(int x,dnode *h) f",sum); printf("\n"); } 【运行结果及分析】 (1)输入多项式: (2)输出多项式(多项式格式为:c1x^e1+c2x^e2+…+cnx^en): (3)实现多项式a和b相加: (4)实现多项式a和b相减: (5)计算多项式在x处的值: 2、模拟浏览器操作程序 【实验内容】 模拟浏览器操作程序 【问题描述】 标准Web浏览器具有在最近访问的网页间后退和前进的功能。实现这些功能的一个方法是:使用两个栈,追踪可以后退和前进而能够到达的网页。在本题中,要求模拟实现这一功能。 【需求分析】 需要支持以下指令: BACK:将当前页推到“前进栈”的顶部。取出“后退栈”中顶端的页面,使它成为当前页。若“后退栈”是空的,忽略该命令。 FORWARD:将当前页推到“后退栈”的顶部。取出“前进栈”中顶部的页面,使它成为当前页。如果“前进栈”是空的,忽略该命令。 VISIT 排序算法题目及其代码 1、明明的随机数(Noip2006) 【问题描述】 明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性,他先用计算机生成了N个1到1000之间的随机整数(N≤100),对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着不同的学生的学号。然后再把这些数从小到大排序,按照排好的顺序去找同学做调查。请你协助明明完成“去重”与“排序”的工作。 【输入文件】 输入文件random.in 有2行, 第1行为1个正整数,表示所生成的随机数的个数:N 第2行有N个用空格隔开的正整数,为所产生的随机数。 【输出文件】 输出文件random.out 也是2行,第1行为1个正整数M,表示不相同的随机数的个数。第2行为M个用空格隔开的正整数,为从小到大排好序的不相同的随机数。 【输入样例】 10 20 40 32 67 40 20 89 300 400 15 【输出样例】 8 15 20 32 40 67 89 300 400 【参考程序】 var n,s:byte; i,min,max,x:word; b:array[1..1000]of boolean; begin assign(input,'random.in');reset(input); assign(output,'random.out');rewrite(output); readln(n); fillchar(b,sizeof(b),false); min:=1000;max:=0;s:=0; for i:=1 to n do begin read(x); b[x]:=true; if x 排序算法: (1) 直接插入排序 (2) 折半插入排序(3) 冒泡排序 (4) 简单选择排序 (5) 快速排序(6) 堆排序 (7) 归并排序 【算法分析】 (1)直接插入排序;它是一种最简单的排序方法,它的基本操作是将一个记录插入到已排好的序的有序表中,从而得到一个新的、记录数增加1的有序表。 (2)折半插入排序:插入排序的基本操作是在一个有序表中进行查找和插入,我们知道这个查找操作可以利用折半查找来实现,由此进行的插入排序称之为折半插入排序。折半插入排序所需附加存储空间和直接插入相同,从时间上比较,折半插入排序仅减少了关键字间的比较次数,而记录的移动次数不变。 (3)冒泡排序:比较相邻关键字,若为逆序(非递增),则交换,最终将最大的记录放到最后一个记录的位置上,此为第一趟冒泡排序;对前n-1记录重复上操作,确定倒数第二个位置记录;……以此类推,直至的到一个递增的表。 (4)简单选择排序:通过n-i次关键字间的比较,从n-i+1个记录中选出关键字最小的记录,并和第i(1<=i<=n)个记录交换之。 (5)快速排序:它是对冒泡排序的一种改进,基本思想是,通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。 (6)堆排序: 使记录序列按关键字非递减有序排列,在堆排序的算法中先建一个“大顶堆”,即先选得一个关键字为最大的记录并与序列中最后一个记录交换,然后对序列中前n-1记录进行筛选,重新将它调整为一个“大顶堆”,如此反复直至排序结束。 (7)归并排序:归并的含义是将两个或两个以上的有序表组合成一个新的有序表。假设初始序列含有n个记录,则可看成是n个有序的子序列,每个子序列的长度为1,然后两两归并,得到n/2个长度为2或1的有序子序列;再两两归并,……,如此重复,直至得到一个长度为n的有序序列为止,这种排序称为2-路归并排序。 【算法实现】 (1)直接插入排序: void InsertSort(SqList &L){ for(i=2;i<=L.length ;i++) if(L.elem[i]排序算法汇总(图解加程序代码)
各种排序算法比较
数据结构课程设计
数据结构课程设计报告模板
排序算法
数据结构各种排序算法的时间性能
数据结构课程设计(内部排序算法比较_C语言)
数据结构课程设计报告
几种排序算法的分析与比较--C语言
各种排序算法的总结和比较
数据结构课程设计-排序
数据结构课程设计报告模板
c语言排序算法总结(主要是代码实现)
几种常见内部排序算法比较
数据结构 各种排序算法
数据结构课程设计排序实验报告
数据结构课程设计报告
排序算法题目及其代码
数据结构课程设计排序算法总结
相关主题
文本预览