
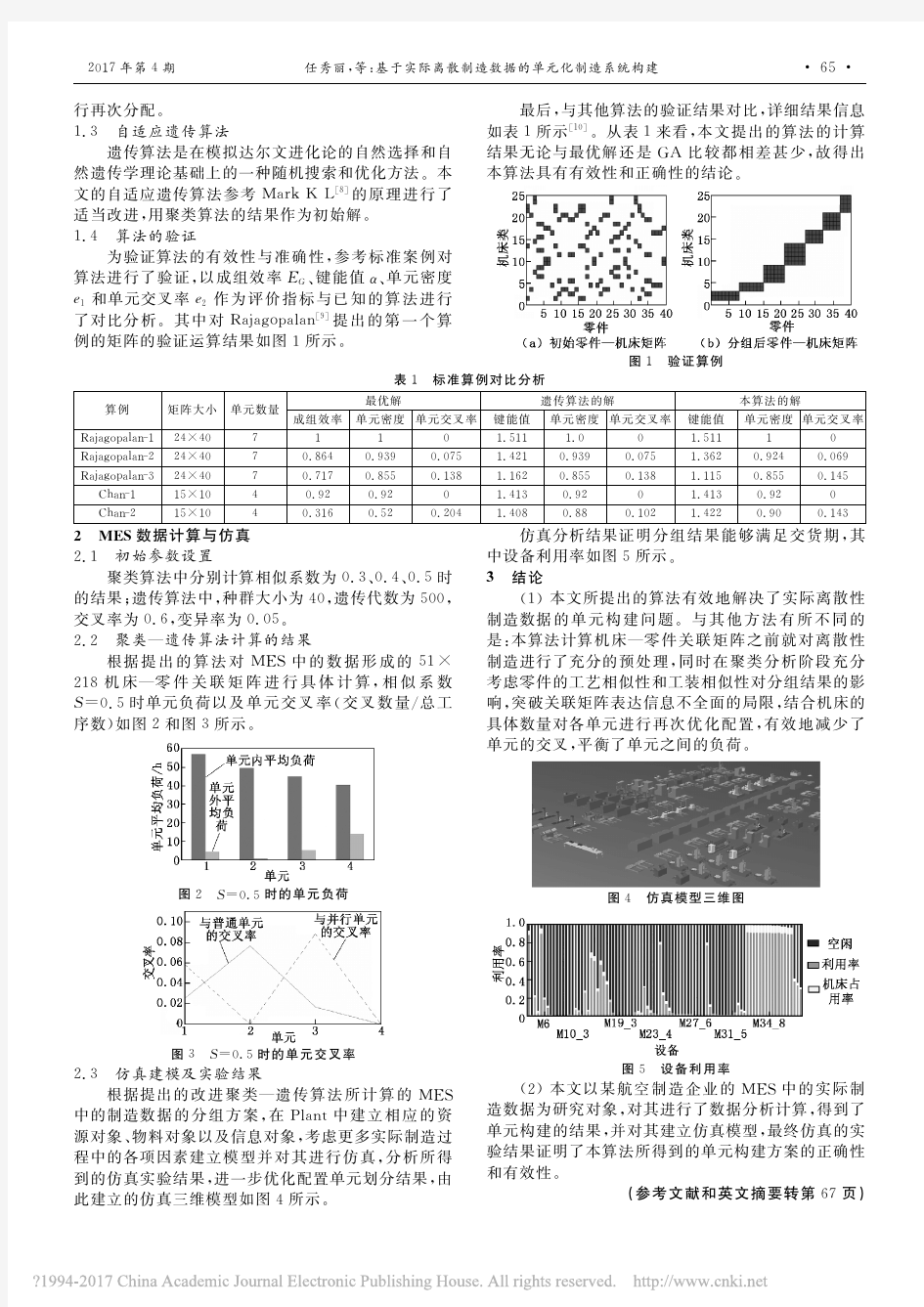
§6.4.1数据的离散程度(一) 学习目标: 1.了解刻画数据离散程度的三个量度——极差、标准差和方差,能借助计算器求出相应的数值。 2.通过实例体会用样本估计总体的思想,进一步认识“离散程度”的意义。 3.能借助计算器求出一组数据的方差、标准差,并在具体问题情景中加以运用。 活动过程: 活动一:回顾旧知 1.平均数计算公式是什么? 2.平均数反映数据的什么趋势? 活动二:新知探究 1.想一想 阅读课本149页,完成下列问题 (1)你能从图中估计出甲、乙两厂被抽取鸡腿的平均质量吗? (2)求甲、乙两厂被抽取的鸡腿的平均质量。 (3)在图中画出表示平均质量的直线(画在书上),观察图象你发现了什么? (4)从甲厂抽取的这20只鸡腿质量的最大值是多少?最小值呢?它们差几克?乙厂呢? (5)如果只考虑鸡腿规格,你认为外贸公司应购买哪个厂的鸡腿?为什么? 2.概念引入 生活中数据除了“平均水平”外还有离散程度。离散程度是指数据相对于“平均数”的 ___________程度。数据的离散程度可以用极差、方差、标准差来刻画。 极差:是指一组数据中最_____数据与最______数据的差,极差是用来刻画数据离散程度的一个统计量。
方差:各个数据与平均数之差的平方的平均数,记作s2,设有一组数据:x1, x2, x3,……,xn,其平均数为x 则()()()()[]2 23222121 x x x x n s x x x x n -++-+-+-=Λ 标准差(即方差的算术平方根) ()()()()[]2 2322211x x x x n s x x x x n -++-+-+-=Λ 3.练一练 如果丙厂也参加了竞争,从该厂抽样调查了20只鸡腿质量如下:(单位:g ) 75 74 73 78 72 76 74 76 74 75 74 72 73 72 78 76 77 77 77 79 (1)丙厂这20只鸡腿质量的平均数和极差是多少? (2)如何刻画丙厂这20只鸡腿质量与其平均数的差距?分别求出甲、丙两厂的20只鸡腿质量与对应平均数的差距。 (3)在甲、丙两厂中,你认为哪个厂鸡腿质量更符合要求?为什么? 小结: 当几组数据的平均数相等或比较接近时,我们可以用极差,方差或标准差来比较数据的离散程度.一组数据的极差、方差或标准差越小,说明数据的离散程度越_____(填“大”或“小”),数据的波动越_______,说明数据越稳定。 练习反馈“ 1.五个数1,2,4,5,a,的平均数是3,则a=__ __,这五个数的方差是______; 2.甲、乙两个小组各10名学生的某次数学测验成绩如下:(单位:分) 甲组:76,90,84,86,81,87,86,82,85,83 乙组:82,84,85,89,79,80,91,89,79,74 (1)甲组数据的众数是____________,乙组数据的中位数是_________________ (2)若甲组数据的平均数为x ,乙组数据的平均数为y ,则x 与y 的大小关系是 (3)经计算知:s 2甲=13.2, s 2乙=26.36, s 2甲______s 2乙(填>、=、<符号),这说明___________________________________________________________
机器学习处理数据为什么把连续性特征离散化 在学习机器学习中,看过挺多案例,看到很多人在处理数据的时候,经常把连续性特征离散化。为此挺好奇,为什么要这么做,什么情况下才要做呢。 一、离散化原因 数据离散化是指将连续的数据进行分段,使其变为一段段离散化的区间。分段的原则有基于等距离、等频率或优化的方法。数据离散化的原因主要有以下几点: 1、算法需要 比如决策树、朴素贝叶斯等算法,都是基于离散型的数据展开的。如果要使用该类算法,必须将离散型的数据进行。有效的离散化能减小算法的时间和空间开销,提高系统对样本的分类聚类能力和抗噪声能力。 2、离散化的特征相对于连续型特征更易理解,更接近知识层面的表达 比如工资收入,月薪2000和月薪20000,从连续型特征来看高低薪的差异还要通过数值层面才能理解,但将其转换为离散型数据(底薪、高薪),则可以更加直观的表达出了我们心中所想的高薪和底薪。 3、可以有效的克服数据中隐藏的缺陷,使模型结果更加稳定 二、离散化的优势 在工业界,很少直接将连续值作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点: 1. 离散特征的增加和减少都很容易,易于模型的快速迭代; 2. 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展; 3. 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰; 4. 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
如何衡量数据的离散程 度精编版 MQS system office room 【MQS16H-TTMS2A-MQSS8Q8-MQSH16898】
如何衡量数据的离散程度 我们通常使用均值、中位数、众数等统计量来反映数据的集中趋势,但这些统计量无法完全反应数据的特征,即使均值相等的数据集也存在无限种分布的可能,所以需要结合数据的离散程度。常用的可以反映数据离散程度的统计量如下: 极差(Range) 极差也叫全距,指数据集中的最大值与最小值之差: 极差计算比较简单,能从一定程度上反映的数据集的离散情况,但因为最大值和最小值都取的是极端,而没有考虑中间其他数据项,因此往往会受异常点的影响不能真实反映数据的离散情况。 四分位距(interquartilerange,IQR) 我们通常使用箱形图来表现一个数据集的分布特征: 一般中间矩形箱的上下两边分别为数据集的上四分位数(75%,Q3)和下四分位数(25%,Q1),中间的横线代表数据集的中位数(50%,Media,Q2),四分位距是使用Q3减去Q1计算得到: 如果将数据集升序排列,即处于数据集3/4位置的数值减去1/4位置的数值。四分位距规避了数据集中存在异常大或者异常小的数值影响极差对离散程度的判断,但四分位距还是单纯的两个数值相减,并没有考虑其他数值的情况,所以也无法比较完整地表现数据集的整体离散情况。 方差(Variance) 方差使用均值作为参照系,考虑了数据集中所有数值相对均值的偏离情况,并使用平方的方式进行求和取平均,避免正负数的相互抵消: 方差是最常用的衡量数据离散情况的统计量。 标准差(StandardDeviation) 方差得到的数值偏差均值取平方后的算术平均数,为了能够得到一个跟数据集中的数值同样数量级的统计量,于是就有了标准差,标准差就是对方差取开方后得到的: 基于均值和标准差就可以大致明确数据集的中心及数值在中心周围的波动情况,也可以计算正态总体的置信区间等统计量。
第7章离散控制系统的分析与综合 7.3 离散系统的能控性和能观性 1、离散系统的能控性和能观性判据 ◆能控性和能观性定义: 对有限个采样周期,若能找到控制信号序列,能使任意一个初始状态转移到零状态,则系统是状态完全能控的;若根据有限个采样周期的输出序列,能唯一地确定任意初始状态,则系统是状态完全能观的。 ◆能控性和能观性判据: A B C状态完全能控的充要条件 n阶线性定常离散系统(,,) 是
1 rank rank[,,,]n c Q B AB A B n -== 状态完全能观的充要条件是 1rank rank o n C CA Q n CA -轾犏犏犏==犏犏犏臌 2、连续系统离散化后的能控性与能观性 设具有零阶保持器的n 阶连续系统以采样周期T 离散为离散系统。 定理:若连续系统不能控(不能观),则其离散系统必不能控(不能观)。若连续系统能控(能观),其互异特征值(含 重特征值)为μλλλ,, , 21,若对一切 μλλ,,2,1,,0][ ==-j i R j i e
的互异特征值满足 ,2,1,2][±±=≠-k T k I j i m πλλ 则其离散系统必保持能控(能观)性。 7.4 离散系统的稳定性 1、离散系统稳定的充要条件 1)赛尔维斯特展开定理 设n 阶系数矩阵A 具有互异特征值n λλλ,,, 21,)(A f 是A 函数,则有 i i n i A f A f )()(1λ∑== 其中 j i i n i j j i I A A λλλ--= ∏≠=,1
2)离散系统稳定的充要条件 线性定常离散系统齐次状态方程 的解为 ()(0)k x k A x = 由系统的特征方程 0zI A -= 可解得系统的特征值。 设A 的特征值n λλλ,,, 21两两互异,则由赛尔维斯特展开定理得 1n k k i i i A λA ==?
6.4 数据的离散程度 第一环节:情境引入 内容:为了提高农副产品的国际竞争力,一些行业协会对农副产品的规格进行了划分,某外贸公司要出口一批规格为75g的鸡腿.现有2个厂家提供货源,它们的价格相同,鸡腿的品质也相近。 质检员分别从甲、乙两厂的产品中抽样调查了20只鸡腿,它们的质量(单位:g)如下: 甲厂:75 74 74 76 73 76 75 77 77 74 74 75 75 76 73 76 73 78 77 72 乙厂:75 78 72 77 74 75 73 79 72 75 80 71 76 77 73 78 71 76 73 75 把这些数据表示成下图: 质量/g 甲厂乙厂 (1)你能从图中估计出甲、乙两厂被抽取鸡腿的平均质量是多少? (2)求甲、乙两厂被抽取鸡腿的平均质量,并在图中画出表示平均质量的直线。 (3)从甲厂抽取的这20只鸡腿质量的最大值是多少?最小值又是多少?它们相差几克?从乙厂抽取的这20只鸡腿质量的最大值又是多少?最小值呢?它们相差几克? (4)如果只考虑鸡腿的规格,你认为外贸公司应购买哪家公司的鸡腿?说明你的理由。 在学生讨论交流的的基础上,教师结合实例给出极差的概念:
极差是指一组数据中最大数据与最小数据的差。它是刻画数据离散程度的一个统计量。 目的:通过一个实际问题情境,让学生感受仅有平均水平是很难对所有事物进行分析,从而顺利引入研究数据的其它量度:极差。 注意事项:当一组数据的平均数与中位数相近时,学生在原有的知识与遇到问题情境产生知识碰撞时,才能较好地理解概念。 第二环节:合作探究 内容1: 如果丙厂也参与了竞争,从该厂抽样调查了20只鸡腿,它们的质量数据如下图: 78 质量/g (1)丙厂这20只鸡腿质量的平均数和极差分别是多少? (2)如何刻画丙厂这20只鸡腿的质量与其平均数的差距?分别求出甲、丙两厂的20只鸡腿质量与其相应平均数的差距。 (3)在甲、丙两厂中,你认为哪个厂的鸡腿质量更符合要求?为什么? 数学上,数据的离散程度还可以用方差或标准差刻画。 方差是各个数据与平均数之差的平方的平均数,即: ()()()[] 222212...1x x x x x x n s n -++-+-= 注:x 是这一组数据x 1,x 2,…,x n 的平均数,s 2是方差,而标准差就是方差的算术平方根。一般说来,一组数据的极差、方差、标准差越小,这组数据就越稳定。 说明:标准差的单位与已知数据的单位相同,使用时应当标明单位;方差的单位是已知单位的平方,使用时可以不标明单位。 目的:通过对丙厂与甲、乙两厂的对比发现,仅有极差还不能准确刻画一组
电商仓配一体化管理 系统 解决方案 1 项目介绍 项目背景 在我国,专业的仓储物流服务正以一股热浪趋势发展,一方面客户对仓储物流服务质量要求越来越高,另一方面市场竞争日益激烈,物流企业是否具有现代仓储物流管理理念和核心竞争优势就显得格外重要,只有理念创新,才能步步领先,倡导将先进的信息网络技术和现代仓储物流技术结合,建立现代仓储物流管理综合服务。随着我过经济的蓬勃发展,尤其是IT技术的突飞猛进更是让物流也得发展如虎添翼,它帮助企业节约了物流成本,提高了物流效率。 目前的第三方仓储物流服务普遍存在以下问题,设备系统落后:一般第三方仅使用了货架、简单输送线、纸质拣货单等设备进行作业,往往作业效率不高同时错误率还维持在一个较高水平。作业方式落后:大部分企业还处在以人工作业为主的原始管理状态,分拣效率低下,人工成本持高不下。信息管理落后:很多企业目前还没有自己的仓储管理系统,或者有
仓储管理系统却是一座信息孤岛,没有与客户的系统和快递系统等对接,没有集成仓库设备, 从而不能起到优化业务流程、提高出入库效率等功能。 针对以上情况紫鉞科技凭借多年的硬件基础及丰富的仓储管理系统经验,为客户打造电 商仓配一体化管理信息系统解决方案。系统引入带有条码扫描或RFID扫描的智能终端随时 随地进行入库、出库、盘点等操作,实现仓库全程无纸化管理。系统可以实现对企业仓储管 理各个环节的全程实时业务管理,直到业务流程处理完毕,提高了效率,减少了错误,使管 理人员可以及时地了解每一个环节的状况和问题,及时应对处理。系统上游与客户管理系统 对接,下游与各快递管理系统对接,实现物流产业链的无缝集成,简化繁琐的系统操作,降 低漏操作、错误操作,提高业务流程效率。 项目目标 针对电商仓配一体化管理信息系统建设,我们提出如下建设目标: 1、用计算机信息系统最大限度的支持仓配管理信息的处理,充分发挥人机协同的功效,降低企业对员工技能、经验的依赖。 2、既可实现对单一客户仓库的精细化管理,也可实现分布在各地的多客户多库房管理。 3、对货物入库、库位分配、存储、波次分析、订单拣货、快递发货、库存盘点等进行动态管理,仓库作业全程电子化操作。 4、优化订单拣货流程,按波次统一拣货,智能分单,提高订单出库效率。 5、提供货品信息、货位、库存量、盘点、订单跟踪、物流跟踪、客户结算、快递结算等报表。 6、实现与上游多家网店管理系统的对接,使客户系统数据与订单状态与本系统保持一致; 7、实现和下游快递系统对接,自动申请电子面单;自动查询获取订单发货情况,无需再派专人上各快递公司网站查单。 8、系统功能可扩展性强,能根据企业发展中不断变化的业务管理,增加新功能。 9、在满足所有需求的前提下,选择合理的系统架构和设备,使系统具有较好的性能和价格优势,充分保护贵单位的投资,降低系统的运营和使用成本。 2系统总体设计 系统网络架构
实验利用MATLAB进行离散控制系统模拟本试验的目的主要是让学生初步掌握MATLAB软件在离散控制系统分析和设计中的应用。 1.连续系统的离散化。 在MATLAB软件中,对连续系统的离散化主要是利用函数c2dm( )函数来实现的,c2dm( )函数的一般格式为 C2dm( num, den, T, method),可以通过MATLAB的帮助文件进行查询。其中: Num:传递函数分子多项式系数; Den:传递函数分母多项式系数; T:采样周期; Method:转换方法; 允许用户采用的转换方法有:零阶保持器(ZOH)等五种。
2.求离散系统的相应: 在MATLAB中,求采样系统的响应可运用dstep( ),dimpulse( ),dlsim( )来实现的。分别用于求取采样系统的阶跃,脉冲,零输入及任意输入时的响应,其中dstep( )的一般格式如下: dstep( num, den, n),可以通过MATLAB的帮助文件进行查询。其中: Num:传递函数分子多项式系数; Den:传递函数分母多项式系数; N:采样点数; 3.此外,离散控制系统也可以用simulink工具箱进行仿真,仿真界面
如下图(采样周期可以在对应模块中进行设定)。 1.编制程序实现上面三个仿真程序。 2.把得到的图形和结果拷贝在试验报告上。 3.在第1个例子中,改变采样周期为0.25,重新运行程序,把结果和原来结果进行比较,并说明为什么? 4.在第2个例子中,改变采样点数为70,重新运行程序,把结果和原来结果进行比较,并说明为什么?同样,改变采样周期T,观察不同周 期下系统阶跃响应的动态性能,分析采样周期对系统动态性能的影响。 1. 1) num=10; den=[1,7,10]; t=0.1 [numz,denz]=c2dm(num,den,t,'zoh'); printsys(numz,denz,'z') 得出结果: t = 0.1000 num/den = 0.039803 z + 0.031521 ------------------------ z^2 - 1.4253 z + 0.49659 若t改为0.25: num=10;
数据的离散程度 一、选择 1、国家统计局发布的统计公报显示:2001到2005年,我国GDP 增长率分别为8.3%,9.1%,10.0%,10.1%,9.9%。经济学家评论说:这五年的年度GDP 增长率之间相当平稳。从统计学的角度看,“增长率之间相当平稳”说明这组数据的( )较小。 A 、标准差 B 、中位数 C 、平均数 D 、众数 2、刘翔为了备战2008年奥运会,刻苦进行110米跨栏训练,为判断他的成绩是否温度,教练对他10次训练的成绩进行统计分析,则教练需了解刘翔这10次成绩的( ) A 、众数 B 、方差 C 、平均数 D 、频数 3、若一组数据1、2、3、x 的极差是6,则x 的值为( ) A 、7 B 、8 C 、9 D 、7或-3 4、下列说法中,错误的有 ( ) ①一组数据的标准差是它的差的平方;②数据8,9,10,11,1l 的众数是2;③如果数据x 1,x 2,…,x n 的平均数为x ,那么(x 1-x )+(x 2-x )+…(x n -x )=0;④数据0,-1,l ,-2,1的中位数是l . A 、4个 B 、3个 C 、2个 D 、l 个 二、填空 5、数据:1、3、4、7、2的极差是 。 6、对某校同龄的70名女学生的身高进行测量,其中最高的是169㎝,最矮的是146㎝,对这组数据进行整理时,可得极差为 。 7、甲、乙、丙三台包装机同时分装质量为400 克的茶叶.从它们各自分装的茶叶中分别随机 抽取了10盒,测得它们的实际质量的方差如下表所示: 根据表中数据,可以认为三台包装机中, 包装机包装的茶叶质量最稳定。 8、小明和小兵两人参加学校组织的理化实验操作测试,近期的5次测试成绩如右图所示,则小明5次成绩的方差S 12与小兵5次成绩的方差S 22之间的大小关系为S 12 S 22.(填“>”、“<”、“=”) 9、一组数据的方差 ])10()10()10[(15 1 222212-++-+-= n x x x s ,则这组数据的平均数是 ,n x 中下标 n= 。 10、已知一组数据x1,x2,…,xn 的方差是a 。则数据x1-4,x2-4,…,xn -4的方差是 ;数据 3x1,3x2,…,3xn 的方差是 。 三、解答 11、在某旅游景区上山的一条小路上,有一些断断续续的台阶。如图是其中的甲、乙段台阶路的示意图。请你用所学过的有关统计知识(平均数、中位数、方差和极差)回答下列问题: 16 14 14 16 15 15 甲路段 17 19 10 18 15 11 乙路段
智慧出行大数据一体化 管理平台 建 设 方 案 1
目录 第1章前言 (11) 第2章总体设计 (12) 2.1、系统概述 (12) 2.2、系统设计原则 (14) 2.3、系统框架 (16) 第3章出行大数据采集子系统 (20) 3.1、前端采集技术 (20) 3.2、数据共享和交换平台 (22) 3.3、框架支撑平台 (23) 3.3.1、基础网络服务平台 (23) 3.3.2、架构 (24) 3.3.3、服务端/NetServer (25) 3.3.4、NetBusiness (25) 3.3.5、NetClient (26) 3.3.6、核心技术 (26) EPOLL多路复用I/O模型 (26) 3.3.7、共享内存数据库 (29) 2
3.3.8、概述 (29) 3.3.9、设计思路 (30) MEMORYCACHE的通道 (30) 3.3.10、消息组件 (40) 3.3.11、日志管理 (44) 3.3.12、系统预警及系统告警与状态管理 (45) 3.3.13、一致性哈希分发 (46) 第4章大数据资源整合存储子系统 (58) 4.1、基础出行数据 (58) 4.1.1、城市路网数据 (59) 4.1.2、公交线路数据 (106) 4.1.3、公交车辆数据 (109) 4.1.4、长途客运车数据 (110) 4.1.5、出租车数据 (113) 4.1.6、危化品车数据 (114) 4.1.7、共享单车数据 (115) 4.1.8、火车客运数据 (116) 4.1.9、民航客运数据 (119) 3
4.1.10、出行资产数据 (121) 4.1.11、出行需求数据 (122) 4.1.12、公路费用数据 (127) 4.1.13、气象数据 (127) 4.1.14、监控设备数据 (128) 4.1.15、追逃车辆数据 (129) 4.2、实时采集数据 (129) 4.3、实时计算数据 (129) 4.3.1、城市出行运行数据 (130) 4.3.2、公交车实时位置数据 (133) 4.3.3、公交(地铁)卡刷卡数据 (134) 4.3.4、长途客车实时数据 (135) 4.3.5、出租车实时数据 (136) 4.3.6、危化品车实时数据 (137) 4.3.7、共享单车实时数据 (138) 4.3.8、路口通行量 (139) 4.3.9、套牌嫌疑车数据 (139) 4.3.10、基于车辆识别的OD分析数据 (140) 4
标准差 标准差(Standard Deviation),也称(mean square error),是各数据偏离的距离的平均数,它是离均差平方和平均后的方根,用σ表示。标准差是方差的。标准差能反映一个数据集的离散程度。平均数相同的,标准差未必相同。 标准差(Standard Deviation),在统计中最常使用作为程度(statistical dispersion)上的。标准差定义为的,反映组内个体间的离散程度。测量到分布程度的结果,原则上具有两种性质: 为非负数值,与测量资料具有相同单位。一个总量的标准差或一个的标准差,及一个子集合样品数的标准差之间,有所差别。 标准计算公式 假设有一组数值X1,X2,X3,......Xn(皆为),其平均值为μ,公式如图1. 图1 标准差也被称为,或者实验标准差,公式如图2。 图2 简单来说,标准差是一组数据分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。 例如,两组数的集合{0, 5, 9, 14} 和{5, 6, 8, 9} 其平均值都是7,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量。例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。 标准差应用于投资上,可作为量度回报稳定性的。标准差数值越大,代表回报远离过去值,回报较不稳定故风险越高。相反,标准差数值越细,代表回报较为稳定,风险亦较小。 例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。这两组的平均数都是70,但A组的标准差为17.078分,B组的标准差为2.16分(此数据是在R统计软件中运行获得),说明A组学生之间的差距要比B组学生之间的差距大得多。 如是总体,根号内N=n,如是,标准差公式根号内N=(n-1),因为我们大量接触的是样本,所以普遍使用根号内除以(n-1)。 公式意义 所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一,即变异数),再把所得值开根号,所得之数就是这组数据的标准差。 深蓝区域是距平均值小于一个标准差之内的数值范围。在中,此范围所占比率为全部数值之68%。根据正态分布,两个标准差之内(深蓝,蓝)的
一体化数据管理平台DATRIX 产品介绍 因“虚”而实,数据管理创新
需求篇 IDC数字宇宙研究《从混沌中提取价值》指出,全球的数据量每18个月就要翻一番,目前每年产生的数据量已经高达40EB(1EB=10000PB),未来十年全球的大数据将增加50倍。数据飞速的甚至是爆炸式的增长方式,每个信息用户都深有体会,从上世纪早期数据容量大多以MB为单位,到上世纪末过渡到以GB为单位,再到当前TB已是标准单位,甚至PB级别的数据量在很多系统中也不再是一个偶然现象,种种迹象表明,大数据的时代已真正到来。 大数据这个词汇越来越多地被提及,从大数据的定义来说,大数据具备三个V的显著特性: 1、Volume:数据量巨大,起码是TB级别以上的数据量才称之为大数据,对于大数据来说,数据量的巨大导致访问、处理、传输各个方面开销显著增加,也就有必要使用更好的处理方式来应对。 2、Variety:数据类型繁多,结构化数据、非结构化数据和半结构化数据各自均包含多种数据类型。结构化数据中主要为数据库数据(ORACLE、DB2、SQL等);非结构化数据类型更为丰富(办公文档、文本、图片、XML、HTML、各类报表、视频、音频等);半结构化数据是一种新型的定义方式,相对于结构化数据的先有结构再有数据,半结构化数据则是先有数据再有结构。多种数据类型并存导致整个数据处理难度加大,无法用统一的手段来解决全数据问题。 3、Velocity:数据增长非常快速,这种增长速度之前是难以想象的,随着更多的业务发展(社交媒体、云计算、物联网等),各种先进数据格式的出现(高清、3D、富媒体等),导致了数据是爆炸式的增长速度。这种爆炸式的数据增长主要是由数据的属性所多样化带来的,数据首先具备时间属性,历史数据、当前数据和未来数据均需要保持和考虑,需要保留多个历史副本;其次数据具备多格式的特性,一份数据会因应用系统的不同而带来不同格式的访问需求;最后数据还要有多位置的属性,在个人、家庭、单位及云环境下会有多个副本,用于多个场景。 非结构化数据管理难题 非结构化数据在大数据中时代的地位无疑是最为重要的,根据Gartner统计,在当前的环境中,企业有20%的数据是结构化数据,80%的数据是非结构
6.4 数据的离散程度 1.了解极差的意义,掌握极差的计算方法; 2.理解方差、标准差的意义,会用样本方差、标准差估计总体的方差、标准差.(重点、难点) 一、情境导入 从图中我们可以算出甲、乙两人射中的环数都是70环,但教练还是选择乙运动员参赛. 问题1:从数学角度,你知道为什么教练员选乙运动员参赛吗? 问题2:你在现实生活中遇到过类似情况吗? 二、合作探究 探究点一:极差 欢欢写了一组数据:9.5,9,8.5,8,7.5,这组数据的极差是( ) A .0.5 B .8.5 C .2.5 D .2 解析:这组数据的最大值是9.5,最小值是7.5,因此这组数据的极差是:9.5-7.5= 2.故选D. 方法总结:要计算一组数据的极差,找出最大值与最小值是关键. 探究点二:方差、标准差 【类型一】 方差和标准差的计算 求数据7,6,8,8,5,9,7,7,6,7的方差和标准差. 解析:一组数据的方差计算有两个常用的简化公式:(1)s 2=1n [(x 21+x 22+…+x 2n )-nx 2];(2)s 2=1n [(x 1′2+x 2′2+…+x n ′2)-nx ′2],其中x 1′=x 1-a ,x 2′=x 2-a ,…,x n ′=x n -a ,a 是
接近原数据平均数的一个常数,x′是x1′,x2′,…,x n′的平均数. 解:方法一:因为x=1 10(7×4+6×2+8×2+5+9)=7,所以s2= 1 10 [(7-7)2+(6-7)2 +(8-7)2+(8-7)2+(5-7)2+(9-7)2+(7-7)2+(7-7)2+(6-7)2+(7-7)2]=1.2. 所以标准差s=30 5 . 方法二:同方法一,所以s2=1 10 [(72+62+82+82+52+92+72+72+62+72)-10×72]= 1.2,标准差s=30 5 . 方法三:将各数据减7,得新数据:0,-1,1,1,-2,2,0,0,-1,0.而x′=0, 所以s2=1 10 [02+(-1)2+12+12+(-2)2+22+02+02+(-1)2+02-10×02]=1.2.所以标准 差s=30 5 . 方法总结:计算一组数据的方差和标准差的步骤:先计算该组数据的平均数(或需加减的数值),然后按方差(或标准差)的计算公式计算. 【类型二】方差和标准差的应用 在一次女子排球比赛中,甲、乙两队参赛选手的年龄(单位:岁)如下: 甲队:26,25,28,28,24,28,26,28,27,29; 乙队:28,27,25,28,27,26,28,27,27,26. (1)两队参赛选手的平均年龄分别是多少? (2)利用标准差比较说明两队参赛选手年龄波动的情况. 解析:先求出两队参赛选手年龄的平均值,再由标准差的定义求出s甲与s乙,最后比较大小并作出判断. 解:(1)x甲=1 10 ×(26+25+28+28+24+28+26+28+27+29)=26.9(岁), x乙=1 10 ×(28+27+25+28+27+26+28+27+27+26)=26.9(岁). (2)s2甲= 1 10 ×[(26-26.9)2+(25-26.9)2+…+(29-26.9)2]=2.29, s2乙=1 10 ×[(28-26.9)2+(27-26.9)2+…+(26-26.9)2]=0.89. 所以s甲= 2.29≈1.51, s乙=0.89≈0.94, 因为s甲>s乙, 所以甲队参赛选手年龄波动比乙队大. 方法总结:求标准差时,应先求出方差,然后取其算术平方根.标准差越大(小)其数据
东南大学自动化学院 实验报告 课程名称:计算机控制技术 第 2 次实验 实验名称:实验三离散化方法研究 院(系):自动化学院专业:自动化 姓名:学号: 实验室:416 实验组别: 同组人员:实验时间:2014年4月10日评定成绩:审阅教师:
一、实验目的 1.学习并掌握数字控制器的设计方法(按模拟系统设计方法与按离散设计方法); 2.熟悉将模拟控制器D(S)离散为数字控制器的原理与方法(按模拟系统设计方法); 3.通过数模混合实验,对D(S)的多种离散化方法作比较研究,并对D(S)离散化前后闭环系统的性能进行比较,以加深对计算机控制系统的理解。 二、实验设备 1.THBDC-1型 控制理论·计算机控制技术实验平台 2.PCI-1711数据采集卡一块 3.PC 机1台(安装软件“VC++”及“THJK_Server ”) 三、实验原理 由于计算机的发展,计算机及其相应的信号变换装置(A/D 和D/A )取代了常规的模拟控制。在对原有的连续控制系统进行改造时,最方便的办法是将原来的模拟控制器离散化。在介绍设计方法之前,首先应该分析计算机控制系统的特点。图3-1为计算机控制系统的原理框图。 图3-1 计算机控制系统原理框图 由图3-1可见,从虚线I 向左看,数字计算机的作用是一个数字控制器,其输入量和输出量都是离散的数字量,所以,这一系统具有离散系统的特性,分析的工具是z 变换。由虚线II 向右看,被控对象的输入和输出都是模拟量,所以该系统是连续变化的模拟系统,可以用拉氏变换进行分析。通过上面的分析可知,计算机控制系统实际上是一个混合系统,既可以在一定条件下近似地把它看成模拟系统,用连续变化的模拟系统的分析工具进行动态分析和设计,再将设计结果转变成数字计算机的控制算法。也可以把计算机控制系统经过适当变换,变成纯粹的离散系统,用z 变化等工具进行分析设计,直接设计出控制算法。 按模拟系统设计方法进行设计的基本思想是,当采样系统的采样频率足够高时,采样系统的特性接近于连续变化的模拟系统,此时忽略采样开关和保持器,将整个系统看成是连续变化的模拟系统,用s 域的方法设计校正装置D(s),再用s 域到z 域的离散化方法求得离散传递函数D(z)。为了校验计算结果是否满足系统要求,求得D(z)后可把整个系统闭合而成离散的闭环系统。用z 域分析法对系统的动态特性进行最终的检验,离散后的D(z)对D(s)的逼真度既取决于采样频率,也取决于所用的离散化方法。离散化方法虽然有许多,但各种离散化方法有一共同的特点:采样速率低,D(z)的精度和逼真度越低,系统的动态特性与预 数 字 计算机 D/A A/D 模 拟 控制对象 R Y I II
数据离散化和概念分层产生 通过将属性值域划分为区间,数据离散化技术可以用来减少给定连续属性值的个数。区间的标记可以替代实际的数据值。用少数区间标记替换连续属性的数值,从而减少和简化了原来的数据。这导致挖掘结果的简洁、易于使用的、知识层面的表示。离散化技术可以根据如何进行离散化加以分类,如根据是否使用类信息或根据进行方向(即自顶向下或自底向上)分类。如果离散化过程使用类信息,则称它为监督离散化(supervised iscretization);否则是非监督的(unsupervised)。如果首先找出一点或几个点(称作分裂点或割点)来划分整个属性区间,然后在结果区间上递归地重复这一过程,则称它为自顶向下离散化或分裂。自底向上离散化或合并正好相反,首先将所有的连续值看作可能的分裂点,通过合并相邻域的值形成区间,然后递归地应用这一过程于结果区间。可以对一个属性递归地进行离散化,产生属性值的分层或多分辨率划分,称作概念分层。概念分层对于多个抽象层的挖掘是有用的。 对于给定的数值属性,概念分层定义了该属性的一个离散化。通过收集较高层的概念(如青年、中年或老年)并用它们替换较低层的概念(如年龄的数值),概念分层可以用来归约数据。通过这种数据泛化,尽管细节丢失了,但是泛化后的数据更有意义、更容易解释。 这有助于通常需要的多种挖掘任务的数据挖掘结果的一致表示。此外,与对大型未泛化的数据集挖掘相比,对归约的数据进行挖掘所需的I/O操作更少,并且更有效。正因为如此,离散化技术和概念分层作为预处理步骤,在数据挖掘之前而不是在挖掘过程进行。属性price的概念分层例子在图2-22给出。对于同一个属性可以定义多个概念分层,以适合不同用户的需要。 图1 属性price的一个概念分层,其中区间($X.$Y]表示从$X(不包括)到$Y (包括)的区间对于用户或领域专家,人工地定义概念分层可能是一项令人乏味、耗时的任务。幸而,可以使用一些离散化方法来自动地产生或动态地提炼数值属性的概念分层。此外,许多分类属性的分层结构蕴涵在数据库模式中,可以在模式定义级自动地定义。 我们来看看数值和分类数据的概念分层的产生。
智慧环保大数据一体化管理平台 建 设 方 案 I
目录 第1章前言 (13) 1.1、建设背景 (14) 1.1.1、相关政策 (14) 1.1.2、政策引导:三个说得清 (15) 1.2、环境面临问题 (15) 1.2.1、全球十大环境问题 (15) 1.2.2、国内面临环境问题 (16) 1.3、智慧环保发展需求 (16) 1.4、建设目标 (17) 1.4.1、业务协同化 (17) 1.4.2、监控一体化 (18) 1.4.3、资源共享化 (18) 1.4.4、决策智能化 (18) 1.4.5、信息透明化 (19) 第2章设计原则和设计依据 (20) 2.1、设计原则 (20) 2.1.1、以标准化为纲,促进系统建设规范化 (20) 2.1.2、以数据流为轴,提高信息资源共享的水平和能力 (21) 2.1.3、以顶层设计为本,破解业务系统建设偏失 (22) 2.1.4、以流程规范为重,通过整合与重构推进业务协同 (22) I
2.1.5、以数据挖掘和模型技术为径,提升综合决策能力 (23) 2.2、设计依据 (23) 第3章智慧环保大数据平台总体规划 (1) 3.1、建设目标 (1) 3.1.1、广泛感知、一体化管理。 (2) 3.1.2、海量聚集、智能处理。 (2) 3.1.3、面向决策、面向管理 (2) 3.1.4、应急决策、及时响应。 (2) 3.2、建设原则 (3) 3.2.1、统筹规划、分步实施。 (3) 3.2.2、需求导向驱动、界面友好 (3) 3.2.3、保护既往投资、整合现有资源 (3) 3.2.4、充分发挥各领域专业厂商的优势、做到强强联合 (3) 3.2.5、统一标准规范、保障安全 (4) 3.3、总体框架 (4) 3.3.1、一个中心:环境数据中心 (4) 3.3.2、两大门户:内网办公门户和外网公众服务门户 (5) 3.3.3、三个平台 (5) 3.3.3.1、环境地理信息平台 (5) 3.3.3.2、综合办公一体化平台 (5) 3.3.3.3、数据交换平台 (6) II
Using the Weka Discretize Filter 1.Start Weka – you get the Weka GUI chooser window. 2.Click on the Explorer button and you get the Weka Knowledge Explorer window. 3.Click on the “Open File..” button and open an ARFF file (try it first with an example supplied in Weka-3-4/data, e.g. weather.arff). You get the following:
the area right of the Choose button. You get the following:
You see here the default parameters of this filter. Click on More to get more information about these parameters. 5.Click on the Apply button to do the discretization. Then select one of the original numeric attributes (e.g. temperature) and see how it is discretized in the Selected attribute window.
如何衡量数据的离散程度 我们通常使用均值、中位数、众数等统计量来反映数据的集中趋势,但这些统计量无法完全反应数据的特征,即使均值相等的数据集也存在无限种分布的可能,所以需要结合数据的离散程度。常用的可以反映数据离散程度的统计量如下: 极差(Range) 极差也叫全距,指数据集中的最大值与最小值之差: 极差计算比较简单,能从一定程度上反映的数据集的离散情况,但因为最大值和最小值都取的是极端,而没有考虑中间其他数据项,因此往往会受异常点的影响不能真实反映数据的离散情况。 四分位距(interquartile range,IQR) 我们通常使用箱形图来表现一个数据集的分布特征: 一般中间矩形箱的上下两边分别为数据集的上四分位数(75%,Q3)和下四分位数(25%,Q1),中间的横线代表数据集的中位数(50%,Media,Q2),四分位距是使用Q3减去Q1计算得到:
如果将数据集升序排列,即处于数据集3/4位置的数值减去1/4位置的数值。四分位距规避了数据集中存在异常大或者异常小的数值影响极差对离散程度的判断,但四分位距还是单纯的两个数值相减,并没有考虑其他数值的情况,所以也无法比较完整地表现数据集的整体离散情况。 方差(Variance) 方差使用均值作为参照系,考虑了数据集中所有数值相对均值的偏离情况,并使用平方的方式进行求和取平均,避免正负数的相互抵消: 方差是最常用的衡量数据离散情况的统计量。 标准差(Standard Deviation) 方差得到的数值偏差均值取平方后的算术平均数,为了能够得到一个跟数据集中的数值同样数量级的统计量,于是就有了标准差,标准差就是对方差取开方后得到的: 基于均值和标准差就可以大致明确数据集的中心及数值在中心周围的波动情况,也可以计算正态总体的置信区间等统计量。 平均差(Mean Deviation) 方差用取平方的方式消除数值偏差的正负,平均差用绝对值的方式消除偏差的正负性。平均差可以用均值作为参考系,也可以用中位数,这里使用均值: 平均差相对标准差而言,更不易受极端值的影响,因为标准差是通过方差的平方计算而来的,但是平均差用的是绝对值,其实是一个逻辑判断的过程而并非直接计算的过程,所以标准差的计算过程更加简单直接。 变异系数(Coefficient of Variation,CV) 上面介绍的方差、标准差和平均差等都是数值的绝对量,无法规避数值度量单位的
东南大学自动化学院 实验报告课程名称:计算机控制技术 第二次实验 实验名称:离散化方法的研究 院(系):自动化专业:自动化 姓名:学号: 实验室:实验组别: 同组人员:实验时间:2012 年3月26日 评定成绩:审阅教师:
一、实验目的 1.学习并掌握数字控制器的设计方法(按模拟系统设计方法与按离散设计方法); 2.熟悉将模拟控制器D(S)离散为数字控制器的原理与方法(按模拟系统设计方法); 3.通过数模混合实验,对D(S)的多种离散化方法作比较研究,并对D(S)离散化前后闭环系统的性能进行比较,以加深对计算机控制系统的理解。 二、实验设备 1.THBDC-1型控制理论·计算机控制技术实验平台 2.PCI-1711数据采集卡一块 3.PC机1台(安装软件“VC++”及“THJK_Server”) 三、实验原理 由于计算机的发展,计算机及其相应的信号变换装置(A/D和D/A)取代了常规的模拟控制。在对原有的连续控制系统进行改造时,最方便的办法是将原来的模拟控制器离散化。在介绍设计方法之前,首先应该分析计算机控制系统的特点。图3-1为计算机控制系统的原理框图。 图3-1 计算机控制系统原理框图 由图3-1可见,从虚线I向左看,数字计算机的作用是一个数字控制器,其输入量和输出量都是离散的数字量,所以,这一系统具有离散系统的特性,分析的工具是z变换。由虚线II向右看,被控对象的输入和输出都是模拟量,所以该系统是连续变化的模拟系统,可以用拉氏变换进行分析。通过上面的分析可知,计算机控制系统实际上是一个混合系统,既可以在一定条件下近似地把它看成模拟系统,用连续变化的模拟系统的分析工具进行动态分析和设计,再将设计结果转变成数字计算机的控制算法。也可以把计算机控制系统经过适当变换,变成纯粹的离散系统,用z变化等工具进行分析设计,直接设计出控制算法。 按模拟系统设计方法进行设计的基本思想是,当采样系统的采样频率足够高时,采样系统的特性接近于连续变化的模拟系统,此时忽略采样开关和保持器,将整个系统看成是连续变化的模拟系统,用s域的方法设计校正装置D(s),再用s域到z域的离散化方法求得离散传递函数D(z)。为了校验计算结果是否满足系统要求,求得D(z)后可把整个系统闭合而成离散的闭环系统。用z域分析法对系统的动态特性进行最终的检验,离散后的D(z)对D(s)的逼真度既取决于采样频率,也取决于所用的离散化方法。离散化方法虽然有许多,但各种离散化方法有一共同的特点:采样速率低,D(z)的精度和逼真度越低,系统的动态特性与预定的要求相差就越大。由于在离散化的过程中动态特性总要变坏,人们将先设计D(s)再进行离散化的方法称为“近似方法”。