
DFS分布式文件系统
实验目的
用户访问DFS服务器,就能够看到其他服务器上的共享文件,并进一步了解ntfs文件系统系统的权限.
实验要求
小胖公司为了公司内部共享文件方便,
单独用三台服务器存放共享文件
公司中有三个部门,
分别是财务部、销售部、技术部
现在每个部门使用一台服务器,创建一个共享文件夹,
每部门的员工只能读取自己部门的文件
各部门分别有一个部门经理,
经理对自己部门的文件夹有完全控制的权限
CEO有权查看各部门的文件
为了方便用户访问共享文件,现又购买一台服务器,
作为DFS服务器,让用户访问DFS服务器,就能够看到其他服务器上
的共享文件
实验环境
Windows sever 2003 IP: 192.168.10.100
Windows sever 2003 IP: 192.168.10.30
Windows xp IP: 192.16.10.200
实验步骤
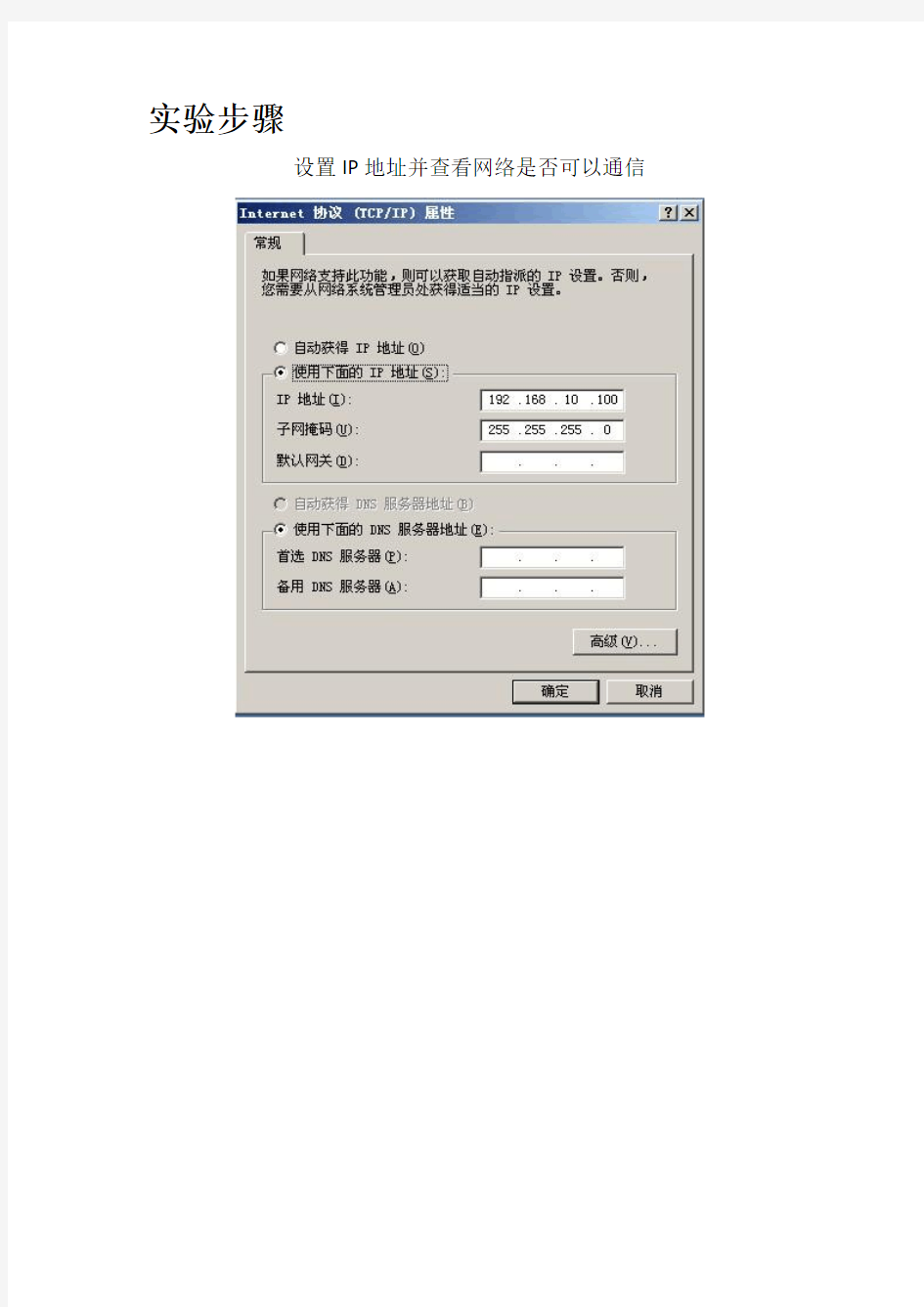
设置IP地址并查看网络是否可以通信
创建用户
在电子表格中完成下图中的数据,复制到新建的文本文档,然后将后缀名txt改为bat.
创建各部门所需的文件夹
更改用户权限
断绝继承
添加用户
用户之间用分号隔开
给添加的用户设置权限
设置共享
共享权限开最大
其他两个文件夹设置同样的NTFS权限与共享.
打开第二个windows sever 2003 起DFS服务
‘
计算机名称一定要与服务器名完全一致
建立好根目录以后,还得需要建立新的连接.
其他两个共享的连接按照同样的方法建立新的连接,连接建好了以后,DFS就搭建好了.
由于通过DFS服务器,最终到达目的文件,相当于做了两次共享,所以需要两次验证。为了方便两台windows sever 2003 上需要的用户一致,并密码也一致。
测试:用cwb01(NTFS权限:读取) 第一次输入密码
第二次输入密码
查看文件
不能够读取技术部由于销售部
不能够新建文件与重命名
测试:ceo(NTFS权限:读取)
可以读取财务部,技术部,销售部三个文件.
由于只有读取权限,不能新建与重命名
测试:CEBJL(NTFS权限:完全控制)
6苏州大学学报(工科版)第30卷 图1I-IDFS架构 2HDFS与LinuxFS比较 HDFS的节点不管是DataNode还是NameNode都运行在Linux上,HDFS的每次读/写操作都要通过LinuxFS的读/写操作来完成,从这个角度来看,LinuxPS是HDFS的底层文件系统。 2.1目录树(DirectoryTree) 两种文件系统都选择“树”来组织文件,我们称之为目录树。文件存储在“树叶”,其余的节点都是目录。但两者细节结构存在区别,如图2与图3所示。 一二 Root \ 图2ItDFS目录树围3LinuxFS目录树 2.2数据块(Block) Block是LinuxFS读/写操作的最小单元,大小相等。典型的LinuxFSBlock大小为4MB,Block与DataN-ode之间的对应关系是固定的、天然存在的,不需要系统定义。 HDFS读/写操作的最小单元也称为Block,大小可以由用户定义,默认值是64MB。Block与DataNode的对应关系是动态的,需要系统进行描述、管理。整个集群来看,每个Block存在至少三个内容一样的备份,且一定存放在不同的计算机上。 2.3索引节点(INode) LinuxFS中的每个文件及目录都由一个INode代表,INode中定义一组外存上的Block。 HDPS中INode是目录树的单元,HDFS的目录树正是在INode的集合之上生成的。INode分为两类,一类INode代表文件,指向一组Block,没有子INode,是目录树的叶节点;另一类INode代表目录,没有Block,指向一组子INode,作为索引节点。在Hadoop0.16.0之前,只有一类INode,每个INode都指向Block和子IN-ode,比现有的INode占用更多的内存空间。 2.4目录项(Dentry) Dentry是LinuxFS的核心数据结构,通过指向父Den姆和子Dentry生成目录树,同时也记录了文件名并 指向INode,事实上是建立了<FileName,INode>,目录树中同一个INode可以有多个这样的映射,这正是连
HDFS分布式文件系统具备的优点 随着互联网数据规模的不断增大,对文件存储系统提出了更高的要求,需要更大的容量、更好的性能以及更高安全性的文件存储系统,与传统分布式文件系统一样,HDFS分布式文件系统也是通过计算机网络与节点相连,但也有优于传统分布式文件系统的优点。 1. 支持超大文件 HDFS分布式文件系统具有很大的数据集,可以存储TB或PB级别的超大数据文件,能够提供比较高的数据传输带宽与数据访问吞吐量,相应的,HDFS开放了一些POSIX的必须接口,容许流式访问文件系统的数据。 2. 高容错性能 HDFS面向的是成百上千的服务器集群,每台服务器上存储着文件系统的部分数据,在集群的环境中,硬件故障是常见的问题,这就意味着总是有一部分硬件因各种原因而无法工作,因此,错误检测和快速、自动的恢复是HDFS最核心的架构目标,因此,HDFS具有高度的容错性。 3. 高数据吞吐量 HDFS采用的是“一次性写,多次读”这种简单的数据一致性模型,在HDFS 中,一个文件一旦经过创建、写入、关闭后,一般就不需要修改了,这样简单的一致性模型,有利于提高吞吐量。 4. 流式数据访问 HDFS的数据处理规模比较大,应用一次需要访问大量的数据,同时这些应用一般都是批量处理,而不是用户交互式处理,应用程序能以流的形式访问数据
集。 Hadoop已经迅速成长为首选的、适用于非结构化数据的大数据分析解决方案,HDFS分布式文件系统是Hadoop的核心组件之一,保证了大数据的可靠存储,与MapReduce配合使用,可以对结构化和复杂大数据进行快速、可靠分析,从而为企业做出更好的决策,促进收入增长,改善服务,降低成本提供有力支撑!
DFS使用方法总结(超详细) 使用分布式文件系统 (DFS),系统管理员可以使用户方便地访问和管理物理上分布在网络各处的文件。通过DFS,可以使分布在多个服务器上的文件如同位于网络上的一个位置一样显示在用户面前。 您可采用两种方式实施分布式文件系统:一种是独立的根目录分布式文件系统,另一种是域分布式文件系统。 独立的DFS根目录: 不使用 Active Directory。 至多只能有一个根目录级别的目标。 使用文件复制服务不能支持自动文件复制。 通过服务器群集支持容错。 域DFS根目录: 必须宿主在域成员服务器上。 使它的DFS名称空间自动发布到 Active Directory 中。 可以有多个根目录级别的目标。 通过 FRS 支持自动文件复制。 通过 FRS 支持容错。 分布式文件系统 (DFS) 映射由一个DFS根目录、一个或多个DFS链接以及指向一个或多个目标的引用组成。 DFS根目录所驻留的域服务器称为主服务器。通过在域中的其他服务器上创建根目标,可以复制DFS根目录。这将确保在主服务器不可用时,文件仍可使用。因为域分布式文件系统的主服务器是域中的成员服务器,所以默认情况下,DFS映射将自动发布到 Active Directory 中,从而提供了跨越主服务器的DFS拓扑同步。这反过来又对DFS根目录提供了容错性,并支持目标的可选复制。通过向DFS根目录中添加DFS链接,您可扩展DFS映射。Windows Server 2003 家族对DFS映射中分层结构的层数的唯一限制是对任何文件路径最多使用 260 个字符。新DFS链接可以引用具有或没有子文件夹的目标,或引用整个Windows Server 2003 家族卷。 创建DFS根目录 使用DFS管理工具,您可以指定某个目标,指派它为DFS根目录。除了访问该目标外,用户还可以访问该目标的任何子文件夹。使用 Windows Server 2003 Enterprise Edition 或Windows Server 2003 Datacenter Edition 时,您可在单独计算机上作为多个DFS根目录的宿主。由于DFS Active Directory 对象的大小,大型的基于域的DFS名称空间可能会显著地增加网络传输量。因此,建议您为域根使用的DFS链接的个数少于 5000。建议在运行 Windows Server 2003 的服务器上的独立的根目录的最大名称空间为 50,000 个链接。 如何创建DFS根目录: 1.打开分布式文件系统。 2.在“操作”菜单上,单击“新建根目录”。
分布式文件系统架构设计
目录 1.前言 (3) 2.HDFS1 (3) 3.HDFS2 (5) 4.HDFS3 (11) 5.结语 (15)
1.前言 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS,解决了海量数据存储的问题;实现了一个分布式计算引擎MapReduce,解决了海量数据如何计算的问题;实现了一个分布式资源调度框架YARN,解决了资源调度,任务管理的问题。而我们今天重点给大家介绍的是Hadoop里享誉世界的优秀的分布式文件系统-HDFS。 Hadoop重要的比较大的版本有:Hadoop1,Hadoop2,hadoop3。同时也相对应的有HDFS1,HDFS2,HDFS3三个大版本。后面的HDFS的版本,都是对前一个版本的架构进行了调整优化,而在这个调整优化的过程当中都是解决上一个版本的架构缺陷,然而这些低版本的架构缺陷也是我们在平时工作当中会经常遇到的问题,所以这篇文章一个重要的目的就是通过给大家介绍HDFS不同版本的架构演进,通过学习高版本是如何解决低版本的架构问题从而来提升我们的系统架构能力。 2.HDFS1
最早出来投入商业使用的的Hadoop的版本,我们称为Hadoop1,里面的HDFS就是HDFS1,当时刚出来HDFS1,大家都很兴奋,因为它解决了一个海量数据如何存储的问题。HDFS1用的是主从式架构,主节点只有一个叫:Namenode,从节点有多个叫:DataNode。 我们往HDFS上上传一个大文件,HDFS会自动把文件划分成为大小固定的数据块(HDFS1的时候,默认块的大小是64M,可以配置),然后这些数据块会分散到存储的不同的服务器上面,为了保证数据安全,HDFS1里默认每个数据块都有3个副本。Namenode是HDFS的主节点,里面维护了文件系统的目录树,存储了文件系统的元数据信息,用户上传文件,下载文件等操作都必须跟NameNode进行交互,因为它存储了元数据信息,Namenode为了能快速响应用户的操作,启动的时候就把元数据信息加载到了内存里面。DataNode是HDFS的从节点,干的活就很简单,就是存储block文件块。
第一部分CEPH 1.1 特点 Ceph最大的特点是分布式的元数据服务器通过CRUSH,一种拟算法来分配文件的locaiton,其核心是 RADOS(resilient automatic distributed object storage),一个对象集群存储,本身提供对象的高可用,错误检测和修复功能。 1.2 组成 CEPH文件系统有三个主要模块: a)Client:每个Client实例向主机或进程提供一组类似于POSIX的接口。 b)OSD簇:用于存储所有的数据和元数据。 c)元数据服务簇:协调安全性、一致性与耦合性时,管理命名空间(文件名和 目录名) 1.3 架构原理 Client:用户 I/O:输入/输出 MDS:Metadata Cluster Server 元数据簇服务器 OSD:Object Storage Device 对象存储设备
Client通过与OSD的直接通讯实现I/O操作。这一过程有两种操作方式: 1. 直接通过Client实例连接到Client; 2. 通过一个文件系统连接到Client。 当一个进行打开一个文件时,Client向MDS簇发送一个请求。MDS通过文件系统层级结构把文件名翻译成文件节点(inode),并获得节点号、模式(mode)、大小与其他文件元数据。注意文件节点号与文件意义对应。如果文件存在并可以获得操作权,则MDS通过结构体返回节点号、文件长度与其他文件信息。MDS同时赋予Client操作权(如果该Client还没有的话)。目前操作权有四种,分别通过一个bit表示:读(read)、缓冲读(cache read)、写(write)、缓冲写(buffer write)。在未来,操作权会增加安全关键字,用于client向OSD证明它们可以对数据进行读写(目前的策略是全部client 都允许)。之后,包含在文件I/O中的MDS被用于限制管理能力,以保证文件的一致性与语义的合理性。 CEPH产生一组条目来进行文件数据到一系列对象的映射。为了避免任何为文件分配元数据的需要。对象名简单的把文件节点需要与条目号对应起来。对象复制品通过CRUSH(著名的映射函数)分配给OSD。例如,如果一个或多个Client打开同一个文件进行读操作,一个MDS会赋予他们读与缓存文件内容的能力。通过文件节点号、层级与文件大小,Client可以命名或分配所有包含该文件数据的对象,并直接从OSD簇中读取。任何不存在的对象或字节序列被定义为文件洞或0。同样的,如果Client打开文件进行写操作。它获得使用缓冲写的能力。任何位置上的数据都被写到合适的OSD上的合适的对象中。Client 关闭文件时,会自动放弃这种能力,并向MDS提供新的文件大小(写入时的最大偏移)。它重新定义了那些存在的并包含文件数据的对象的集合。 CEPH的设计思想有一些创新点主要有以下两个方面: 第一,数据的定位是通过CRUSH算法来实现的。
分布式文件系统(DFS)解决方案 一“分布式文件系统(DFS)”概述 DFS并不是一种文件系统,它是Windows Server System上的一种客户/服务器模式的网络服务。它可以让把局域网中不同计算机上的不同的文件共享按照其功能组织成一个逻辑的分级目录结构。系统管理员可以利用分布式文件系统(DFS),使用户访问和管理那些物理上跨网络分布的文件更加容易。通过DFS,可以使分布在多个服务器或者不同网络位置的文件在用户面前显示时,就如同位于网络上的一个位置。用户在访问文件时不再需要知道和指定它们的实际物理位置。 例如,如果您的销售资料分散在某个域中的多个存储设备上,您可以利用DFS 使其显示时就好像所有的资料都位于同一网络共享下,这样用户就不必到网络上的多个位置去查找他们需要的信息。 二部署使用“分布式文件系统(DFS)”的原因 ●访问共享文件夹的用户分布在一个站点的多个位置或多个站点上; ●大多数用户都需要访问多个共享文件夹; ●通过重新分布共享文件夹可以改善服务器的负载平衡状况; ●用户需要对共享文件夹的不间断访问;
●您的组织中有供内部或外部使用的Web 站点; ●用户访问共享文件需要权限。 三“分布式文件系统(DFS)”类型 可以按下面两种方式中的任何一种来实施分布式文件系统: 1.作为独立的分布式文件系统。 ●不使用Active Directory。 ●至多只能有一个根目录级别的目标。 ●使用文件复制服务不能支持自动文件复制。 ●通过服务器群集支持容错。 2.作为基于域的分布式文件系统。 ●必须宿主在域成员服务器上。 ●使它的DFS 名称空间自动发布到Active Directory 中。 ●可以有多个根目录级别的目标。 ●通过FRS 支持自动文件复制。 ●通过FRS 支持容错。 四分布式文件系统特性 除了Windows Server System 中基于服务器的DFS 组件外,还有基于客户的DFS 组件。DFS 客户程序可以将对DFS 根目录或DFS 链接的引用缓存一段时间,该时间由管理员指定。此存储和读取过程对于
FastDFS (7) Fastdfs简介 (7) Fastdfs系统结构图 (7) FastDFS和mogileFS的对比 (8) MogileFS (10) Mogilefs简介 (10) Mogilefs组成部分 (10) 0)数据库(MySQL)部分 (10) 1)存储节点 (11) 2)trackers(跟踪器) (11) 3)工具 (11) 4)Client (11) Mogilefs的特点 (12) 1. 应用层——没有特殊的组件要求 (12) 2. 无单点失败 (12) 3. 自动的文件复制 (12) 4. “比RAID好多了” (12) 5. 传输中立,无特殊协议 (13) 6.简单的命名空间 (13) 7.不用共享任何东西 (13) 8.不需要RAID (13)
9.不会碰到文件系统本身的不可知情况 (13) HDFS (14) HDFS简介 (14) 特点和目标 (14) 1. 硬件故障 (14) 2. 流式的数据访问 (14) 3. 简单一致性模型 (15) 4. 通信协议 (15) 基本概念 (15) 1. 数据块(block) (15) 2. 元数据节点(Namenode)和数据节点(datanode) . 16 2.1这些结点的用途 (16) 2.2元数据节点文件夹结构 (17) 2.3文件系统命名空间映像文件及修改日志 (18) 2.4从元数据节点的目录结构 (21) 2.5数据节点的目录结构 (21) 文件读写 (22) 1.读取文件 (22) 1.1 读取文件示意图 (22) 1.2 文件读取的过程 (23) 2.写入文件 (24) 2.1 写入文件示意图 (24)
分布式文件系统概述(一) 杨栋 yangdonglee@https://www.doczj.com/doc/2c834554.html, 2006-12 摘要 文件系统是操作系统用来组织磁盘文件的方法和数据结构。传统的文件系统指各种UNIX平台的文件系统,包括UFS、FFS、EXT2、XFS等,这些文件系统都是单机文件系统,也称本地文件系统。随着网络的兴起,为了解决资源共享问题,出现了分布式文件系统。分布式文件系统是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。本文1简要回顾了本地文件系统,然后按照发展例程大致介绍了2006年之前各时期主要的分布式文件系统,最后从设计目标、体系结构及关键技术等方面比较了各个分布式文件系统的异同。目前很火的Hadoop文件系统、S3文件系统都是从NFS等早期文件系统一步步演化而来的,了解分布式文件系统的历史,有助于大家更加深刻地领会分布式文件系统的精髓。 1本文写于2006年底,借鉴了别人的大量资料,目的是为了与同学们分享分布式文件系统的发展史。笔者在硕士期间跟随中科院计算所的孟老师、熊老师和唐荣锋进行分布式文件系统的研究和开发。分布式文件系统源远流长,本文只是选择了其发展史上的部分实例进行简单描述,由于笔者水平十分有限,错误之处难免很多,各位同学发现问题之后麻烦回复邮件到yangdonglee@https://www.doczj.com/doc/2c834554.html,,我会尽全力完善,或者请各位同学自行修正。笔者目前在百度进行云计算方面的研究和开发,希望有兴趣的同学一起进行探讨。
目录 1.引言 (5) 2.本地文件系统 (5) 2.1FFS (6) 2.2LFS (6) 2.3Ext3 (7) 3.分布式文件系统 (7) 3.1 发展历程 (7) 3.2分布式文件系统分类 (8) 3.2.1 实现方法 (8) 3.2.2研究状况 (8) 3.3 NFS (9) 3.3.1概述 (9) 3.3.2 体系结构 (9) 3.3.3 通信机制 (10) 3.3.4进程 (10) 3.3.5 命名 (10) 3.3.6 同步机制 (11) 3.3.7 缓存和复制 (11) 3.3.8 容错性 (12) 3.3.9 安全性 (13) 3.4 AFS、DFS、Coda和InterMezzo (13) 3.5 SpriteFS和Zebra (14) 3.6xFS (16) 3.6.1 概述 (16) 3.6.2 体系结构 (16) 3.6.3 通信 (16) 3.6.4 进程 (17) 3.6.5 命名 (18) 3.6.6 缓存 (19)
常见的分布式文件系统有,GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等。各自适用于不同的领域。它们都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。 Google学术论文,这是众多分布式文件系统的起源 ================================== Google File System(大规模分散文件系统) MapReduce (大规模分散FrameWork) BigTable(大规模分散数据库) Chubby(分散锁服务) 一般你搜索Google_三大论文中文版(Bigtable、 GFS、 Google MapReduce)就有了。做个中文版下载源:https://www.doczj.com/doc/2c834554.html,/topics/download/38db9a29-3e17-3dce-bc93-df9286081126 做个原版地址链接: https://www.doczj.com/doc/2c834554.html,/papers/gfs.html https://www.doczj.com/doc/2c834554.html,/papers/bigtable.html https://www.doczj.com/doc/2c834554.html,/papers/mapreduce.html GFS(Google File System) -------------------------------------- Google公司为了满足本公司需求而开发的基于Linux的专有分布式文件系统。。尽管Google公布了该系统的一些技术细节,但Google并没有将该系统的软件部分作为开源软件发布。 下面分布式文件系统都是类 GFS的产品。
分布式文件系统、集群文件系统、并行文件系统,这三种概念很容易混淆,实际中大家也经常不加区分地使用。总是有人问起这三者的区别和联系,其实它们之间在概念上的确有交叉重叠的地方,但是也存在显著不同之处。分布式文件系统自然地,分布式是重点,它是相对与本地文件系统而言的。分布式文件系统通常指C/S架构或网络文件系统,用户数据没有直接连接到本地主机,而是存储在远程存储服务器上。NFS/CIFS是最为常见的分布式文件系统,这就是我们说的NAS系统。分布式文件系统中,存储服务器的节点数可能是1个(如传统NAS),也可以有多个(如集群NAS)。对于单个节点的分布式文件系统来说,存在单点故障和性能瓶颈问题。除了NAS以外,典型的分布式文件系统还有AFS,以及下面将要介绍的集群文件系统(如Lustre, GlusterFS, PVFS2等)。集群文件系统集群主要分为高性能集群HPC(High Performance Cluster)、高可用集群HAC(High Availablity Cluster)和负载均衡集群LBC(Load Balancing Cluster)。集群文件系统是指协同多个节点提供高性能、高可用或负载均衡的文件系统,它是分布式文件系统的一个子集,消除了单点故障和性能瓶问题。对于客户端来说集群是透明的,它看到是一个单一的全局命名空间,用户文件访问请求被分散到所有集群上进行处理。此外,可扩展性(包括Scale-Up和Scale-Out)、可靠性、易管理等也是集群文件系统追求的目标。在元数据管理方面,可以采用专用的服务器,也可以采用服务器集群,或者采用完全对等分布的无专用元数据服务器架构。目前典型的集群文件系统有SONAS, ISILON, IBRIX, NetAPP-GX, Lustre, PVFS2, GlusterFS, Google File System, LoongStore, CZSS等。并行文件系统这种文件系统能够支持并行应用,比如MPI。在并行文件系统环境下,所有客户端可以在同一时间并发读写同一个文件。并发读,大部分文件系统都能够实现。并发写实现起来要复杂许多,既要保证数据一致性,又要最大限度提高并行性,因此在锁机制方面需要特别设计,如细粒度的字节锁。通常SAN 共享文件系统都是并行文件系统,如GPFS、StorNext、GFS、BWFS,集群文件系统大多也是并行文件系统,如Lustre, Panasas等。如何区分?区分这三者的重点是分布式、集群、并行三个前缀关键字。简单来说,非本地直连的、通过网络连接的,这种为分布式文件系统;分布式文件系统中,服务器节点由多个组成的,这种为集群文件系统;支持并行应用(如MPI)的,这种为并行文件系统。在上面所举的例子中也可以看出,这三个概念之间具有重叠之处,比如Lustre,它既是分布式文件系统,也是集群和并行文件系统。但是,它们也有不同之处。集群文件系统是分布式文件系统,但反之则不成立,比如NAS、AFS。SAN文件系统是并行文件系统,但可能不是集群文件系统,如StorNext。GFS、HDFS之类,它们是集群文件系统,但可能不是并行文件系统。实际中,三者概念搞理清后,分析清楚文件系统的特征,应该还是容易正确地为其划分类别的。
文件系统比较 MogileFS MogileFS是一款开源的、高性能的、分布式的文件系统,用于组建分布式文件集群,跟Memcached是同门,都由LiveJournal旗下Danga Interactive公司开发。 MogileFS能干什么 最主要的功能就是:用来存取海量文件,而不用关心具体的文件存放位置、存储容量大小,以及文件损坏和丢失等问题。 MogileFS特点 1:应用层:不需要特殊的核心组件 2:无单点失败:MogileFS分布式文件存储系统安装的三个组件(存储节点、跟踪器、跟踪用的数据库),均可运行在多个机器上,因此没有单点失败。 3:自动进行文件复制:基于不同的文件“分类”,文件可以被自动的复制到多个有足够存储空间的存储节点上,这样可以满足这个“类别”的最少复制要求。 4:比RAID更好:在一个非存储区域网络的RAID中,磁盘是冗余的,但主机不是,如果你整个机器坏了,那么文件也将不能访问。MogileFS分布式文件存储系统在不同的机器之间进行文件复制,因此文件始终是可用的。 5:传输中立,无特殊协议 6:简单的命名空间:文件通过一个给定的key来确定,是一个全局的命名空间 MogileFS的适用性——擅长处理海量小文件 由于MogileFS不支持对一个文件的随机读写,因此注定了只适合做一部分 应用。比如图片服务,静态HTML服务。 FastDFS FastDFS是一个开源的分布式文件系统,她对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
分布式文件系统研究16:Global File System 分类:技术日志 前段时间比较忙,好久没发技术文章了,几天来一个,嘿嘿 Global File System 简介 GFS(Global File System)是Minnesota大学开发的基于SAN的共享存储的机群文件系统,后来Sis tina公司将GFS产品化。GFS在很长一段时间都是以源代码开放软件的形式出现的,后来由于Sistina希望通过向用户提供支持和服务的计划未能取得成功,为了要促进自己的财务收入,Sistina在2001年将GFS 变成了一种“专有软件”。Red Hat公司收购Sistina之后,在遵循GPL协议(General Public License)的条件下履行诺言公开了GFS的源代码。现在,GFS的全名被称为“红帽全球文件系统”(Red Hat Global File System ,GFS)的软件,每台服务器每年收取2200美元的费用。 可能是redhat为了更好的收取服务费的缘故,有关GFS的文档真是少之又少,我只能从网上一些零星的资料来看看GFS的概貌。 框架 GFS最初是在IRIX上开发的,后来移植到LINUX上,并开放源码。基本框架如下图所示。 图1 GFS的基本框架图 通过使用GFS,多台服务器可以共用一个文件系统来存储文件。信息既可以存储在服务器上,也可以存储在一个存储局域网络上。 GFS与GPFS结构相似,但它是全对称的机群文件系统,没有服务器,因而没有性能瓶颈和单一故障点。GFS将文件数据缓存于节点的存储设备中,而不是缓存在节点的内存中。并通过设备锁来同步不同节点对文件的访问,保持UNIX文件共享语义。GFS实现了日志,节点失效可以快速恢复。GFS使用SCSI
3种分布式文件系统
第一部分CEPH 1.1 特点 Ceph最大的特点是分布式的元数据服务器通过CRUSH,一种拟算法来分配文件的locaiton,其核心是 RADOS(resilient automatic distributed object storage),一个对象集群存储,本身提供对象的高可用,错误检测和修复功能。 1.2 组成 CEPH文件系统有三个主要模块: a)Client:每个Client实例向主机或进程提供一组类似于POSIX的接口。 b)OSD簇:用于存储所有的数据和元数据。 c)元数据服务簇:协调安全性、一致性与耦合性时,管理命名空间(文件名和 目录名) 1.3 架构原理 Client:用户 I/O:输入/输出 MDS:Metadata Cluster Server 元数据簇服务器 OSD:Object Storage Device 对象存储设备
传统的,或者通常的并行文件系统,数据的定位的信息是保存在文件的metadata 中的,也就是inode结构中,通过到metadata server上去获取数据分布的信息。而在Ceph中,是通过CRUSH 这个算法来提供数据定位的。 第二,元数据服务器可以提供集群metadata server 服务。 只要当我们了解了其结构后,感觉并没有太大的特点。元数据服务器一般就用来存储文件和目录的信息,提供统一的命名服务。在Ceph中,元数据的inode , dentry,以及日志都是在对象存储集群RADOS中存储,这就使得metadata的持久化都是在远程的RADOS中完成,metadata server 不保存状态,只是缓存最近的inode 和 dentry项,当metadata server 失效后,其所所有信息都可以从RADOS中获取,可以比较容易恢复。 CEPH最核心的,就是RADOS就是RADOS(resilient automatic distributed object storage). 其resilient 指的是可以轻松扩展,automatic 指的是其对象存储集群可以处理failover, failure recovery。RADOS 对象集群其对外提供了一个高可用的,可扩展的,对象集群,从客户端的角度看,就是一个统一命名空间的对象存储。 1.4 使用方式 (一)Ceph 的Monitor 用来监控集群中所有节点的状态信息,完成类似配置服务的功能。在Ceph 里,配置主要就是cluster map ,其保存集群所有节点信息,并和所有的节点保持心跳,来监控所有的节点状态。 其通过Paxos算法实现实现自身的高可用,也就是说,这个Ceph Monitor 是不会有单点问题的。目前流行的zookeeper 的功能,以及实现都类似。(二)对象存储 Ceph文件系统中的数据和元数据都保存在对象中。对于对象存储,通常的定义是:一个Object,由三部分组成(id,metadata,data),id是对象的标识,这个不必多说。所谓的metadata,就是key/value的键值存储,至于用来保存什么信息,由文件系统的语义定义。data就是实际存储的数据。 Ceph的对象,包括四个部分(id,metadata,attribute,data),在Ceph 里,一个Object,实际就对应本地文件系统的一个文件,一个对象的attribute,也是key/value的键值对,其保存在本地文件系统的文件的扩展属性中。对象的metadata就是key/value的键值对,目前Ceph保存在google开源的一个
windows server 2008 分布式文件系统 DFS [windows 2008 server 新技术文章] 概述 分布式文件系统(Distributed file systems) 是Windows 2008服务器中众多的功能之一,它可以把分布在许多不同服务器上的共享文件夹组合在一个逻辑名字空间中,使用户可以更方便地查找和访问网络上的共享文件夹。如公司网络上有8台员工每天都需要使用的文件服务器,如果没有Dfs 服务器,用户需要记住8台服务器的名字和所有共享文件夹的共享名,还必须映射多个驱动器。有了DFS 后,可以在公司的域控制器DC 服务器上创建一个DFS 根目录,该服务器也就成为了DFS 根目录服务器,该 DFS 根目录与其他文件服务器上的共享文件夹之间都存在连接。用户在访问DFS 根目录时,这些共享文件夹也都依赖于根目录 服务器。事实上,连接可以把用户的访问重新定向到文件服务器上的共享文件夹。DFS 可以解决一些由于存储容量限制、规划不好或在网络上添加服务器而引起的“分布共享”问题。 windows server 2008的DFS 服务还提供另一个功能,同步数据。DFS 的数据同步功能可以实现网络中两台或多台服务器文件数据内容的一致性。 安装 DFS 简介 DFS 根的概念 在windows 2008又称命名空间。在Windows 2008中可以创建两种DFS 根:独立型和基于域型的DFS 根。使用独立型的DFS 根,一旦用作DFS 根服务器的服务器当机,即使所有包含共享文件夹的服务器仍然在运行,用户也不能再访问共享文件夹。使用基于域的DFS 根,可以指定其他的服务器(称作根复制服务器)来保存DFS 的副本,从而使整个系统具有一定的容错性和负载平衡能力,也就在一定程度上解决了独 立型DFS 根带来的问题。此外,通过使用 活动目录AD 地址,一个与DFS 根服务器连接的用户也将试图连接同名的地址,减少网络上的数据流量。 通过建立根复制服务器,可以在DFS 树中创建连接,把用户提交给共享文件夹的各个副本,它不但提供了一定程度的容错能力和负载平衡能力,而且可以在共享一级上充分利用网络的拓扑结构来控制网络上的数据流量。 DFS 根的创建
大数据技术与应用 网络与交换技术国家重点实验室 交换与智能控制研究中心 程祥 2016年9月
提纲-大数据存储和管理1. 分布式文件系统 1.1 概述 1.2 典型分布式文件系统 1.3 HDFS 2. 分布式数据库 2.1 概述 2.2 NoSQL 2.3 HBase 2.4 MongoDB(略) 2.5 云数据库(略)
1.1 概述 ?定义:相对于本地文件系统,分布式文件系统是一种通过网络实现文件在多台主机上进行分布式存储的文件系统。 ?分布式文件系统一般采用C/S模式,客户端以特定的通信协议通过网络与服务器建立连接,提出文件访问请求。 ?客户端和服务器可以通过设置访问权限来限制请求方对底层数据存储块的访问。
1.2 典型的分布式文件系统 ?NFS (Network File System) 由Sun微系统公司作为TCP/IP网上的文件共享系统开发,后移植到Linux等其他平台。其接口都已经标准化。 ?AFS (Andrew File System) 由卡耐基梅隆大学信息技术中心(ITC)开发,主要用于管理分部在不同网络节点上的文件。AFS与 NFS不同,AFS提供给用户的是一个完全透明,永远唯一的逻辑路径(NFS需要物理路径访问)。
1.2 典型的分布式文件系统(续) ?GFS(Google File System) 由Google开发,是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,并提供容错功能。 ?HDFS(Hadoop Distributed File System) HDFS是Apache Hadoop项目的一个子项目,是一个高度容错的分布式文件系统,设计用于在低成本硬件上运行,适合存储大数据,GFS的开源版本。
一种分布式文件系统的设计和实现 程炜烨 (华中科技大学计算机学院湖北武汉 430074) 摘要:分布式文件系统在集群存储中起着重要的作用,。本文详细介绍了一种分布式文件系统的设计和实现,着重叙述了统一名字空间的设计和Linux下客户端文件系统的实现。该分布式文件系统的读写性能比网上邻居有明显的优势。 关键词:集群存储;统一名字空间;超级块;目录项;索引节点 The design and implement of a distribute file system CHENG Weiye (School of Computer Science, Huazhong University of Science and Technology, Wuhan 430074, China) Abstract: Distribute file system plays an important role in cluster storage. The design and implement of the distribute file system is discussed in detail, especially the design of global name space and the implement of file system in Linux. Key words: cluster storage; global name space; super block; directory entry; index node 1引言 为了满足文件存储的新的要求(大容量、高可靠性、高可用性、高性能、动态可扩展性、易维护性),设计一种好的分布式文件系统越来越成为需要。分布式文件系统使得分布在多个节点上的文件如同位于网络上的一个位置便于动态扩展和维护。由于分布式文件系统中的数据可能来自很多不同 的节点,它所管理的数据也可能存储在不同的节点上,这使得分布式文件系统中有很多设计和实现与本地文件系统存在巨大的差别。下面主要讲述分布式文件系统设计和实现中所要面对和解决的主要 问题错误!未找到引用源。。 2软件总体结构 设计一个好的分布式文件系统是集群存储的关键。我们设计的分布式文件系统通过统一名字空间管理使得分布在多个服务器上的文件如同位于网络上的一个位置便于动态扩展和维护。 我们把整个系统主要划分客户端与服务器端两部分。客户端包括MVFS文件系统,CC模块(Client Cache),CNS模块(Client Name Space),CN模块(Client Network)。服务器端包括SC模块(Server Cache),SNS模块(Server Name Space),SN模块(Server Network)。应用程序的I/O请求首先送给MVFS文件系统,MVFS文件系统根据文件句柄获得本文件系统的全局文件名并把对文件的访问转换为对CC的访问。CC 收到请求之后,如果在Cache中没有发现对应的数据,则将请求发给CNS 层,CNS层根据全局文件名获得该文件所在的服务器。最终通过CN层将命令发给服务器。服务器端SN层通过网络接待命令后,将命令传递给SNS层负责将全局文件名转化成本地的文件名,然后到SC 层去查找,如果在Cache中找不到,最终会通过本地的文件系统完成对应的I/O 请求。整个系统的总体结构如图1所示。 在服务器端还有一个全局管理程序(心跳协议程序)。通过该心跳协议程序,所有的存储节点的所共享出来的文件构成了整个文件系统的单一的全局逻辑树,从而可以让客户端见到唯一确定的全局逻辑树。
分布式基础学习
所谓分布式,在这里,很狭义的指代以 Google 的三驾马车,GFS、Map/Reduce、BigTable 为框架核心的分布 式存储和计算系统。通常如我一样初学的人,会以 Google 这几份经典的论文作为开端的。它们勾勒出了分布式存 储和计算的一个基本蓝图,已可窥见其几分风韵,但终究还是由于缺少一些实现的代码和示例,色彩有些斑驳,缺 少了点感性。幸好我们还有 Open Source,还有 Hadoop。Hadoop 是一个基于 Java 实现的,开源的,分布式 存储和计算的项目。作为这个领域最富盛名的开源项目之一,它的使用者也是大牌如云,包括了 Yahoo,Amazon, Facebook 等等(好吧,还可能有校内,不过这真的没啥分量...)。Hadoop 本身,实现的是分布式的文件系统 HDFS,和分布式的计算(Map/Reduce)框架,此外,它还不是一个人在战斗,Hadoop 包含一系列扩展项目, 包括了分布式文件数据库 HBase(对应 Google 的 BigTable),分布式协同服务 ZooKeeper(对应 Google 的 Chubby),等等。。。 如此,一个看上去不错的黄金搭档浮出水面,Google 的论文 + Hadoop 的实现,顺着论文的框架看具体的实现, 用实现来进一步理解论文的逻辑,看上去至少很美。网上有很多前辈们,做过 Hadoop 相关的源码剖析工作,我关 注最多的是这里,目前博主已经完成了 HDFS 的剖析工作,Map/Reduce 的剖析正火热进行中,更新频率之高, 剖析之详尽,都是难得一见的,所以,走过路过一定不要错过了。此外,还有很多 Hadoop 的关注者和使用者贴过 相关的文章, 比如: 这里,这里。 也可以去 Hadoop 的中文站点(不知是民间还是官方...) ,搜罗一些学习资料。 。。 我个人从上述资料中受益匪浅,而我自己要做的整理,与原始的源码剖析有些不同,不是依照实现的模块,而是基 于论文的脉络和实现这样系统的基本脉络来进行的,也算,从另一个角度给出一些东西吧。鉴于个人对于分布式系 统的理解非常的浅薄,缺少足够的实践经验,深入的问题就不班门弄斧了,仅做梳理和解析,大牛至此,可绕路而 行了。。。
一. 分布式文件系统
分布式文件系统,在整个分布式系统体系中处于最低层最基础的地位,存储嘛,没了数据,再好的计算平台,再完 善的数据库系统,都成了无水之舟了。那么,什么是分布式文件系统,顾名思义,就是分布式 文件系统 分布式+文件系统 分布式 文件系统。它包含 这两个方面的内涵,从文件系统的客户使用的角度来看,它就是一个标准的文件系统,提供了一系列 API,由此进 行文件或目录的创建、移动、删除,以及对文件的读写等操作。从内部实现来看,分布式的系统则不再和普通文件 系统一样负责管理本地磁盘, 它的文件内容和目录结构都不是存储在本地磁盘上, 而是通过网络传输到远端系统上。 并且,同一个文件存储不只是在一台机器上,而是在一簇机器上分布式存储,协同提供服务,正所谓分布式。。。 因此,考量一个分布式文件系统的实现,其实不妨可以从这两方面来分别剖析,而后合二为一。首先,看它如何去 实现文件系统所需的基本增删改查的功能。然后,看它如何考虑分布式系统的特点,提供更好的容错性,负载平衡, 等等之类的。这二者合二为一,就明白了一个分布式文件系统,整体的实现模式。。。
I. 术语对照
说任何东西,都需要统一一下语言先,不然明明说的一个意思,却容易被理解到另一个地方去。Hadoop 的分布式 文件系统 HDFS,基本是按照 Google 论文中的 GFS 的架构来实现的。但是,HDFS 为了彰显其不走寻常路的本 性,其中的大量术语,都与 GFS 截然不同。明明都是一个枝上长的土豆,它偏偏就要叫山药蛋,弄得水火不容的, 苦了我们看客。秉承老好人,谁也不得罪的方针,文中,既不采用 GFS 的叫法,也不采用 Hadoop 的称谓,而是 另辟蹊径,自立门户,搞一套自己的中文翻译,为了避免不必要的痛楚,特此先来一帖术语对照表,要不懂查一查, 包治百病。。。
文中所用翻译 主控服务器
HDFS 中的术语 NameNode
GFS 中的术语 Master
术语解释 整个文件系统的大脑,它
1
分布式文件系统概述 文件系统是操作系统的一个重要组成部分,通过对操作系统所管理的存储空间的抽象,向用户提供统一的、对象化的访问接口,屏蔽对物理设备的直接操作和资源管理。 根据计算环境和所提供功能的不同,文件系统可划分为四个层次,从低到高依次是:单处理器单用户的本地文件系统,如DOS的文件系统;多处理器单用户的本地文件系统,如OS/2的文件系统;多处理器多用户的文件系统,如Unix的本地文件系统;多处理器多用户的分布式文件系统。 本地文件系统(Local File System)是指文件系统管理的物理存储资源直接连接在本地节点上,处理器通过系统总线可以直接访问。分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。上述按照层次的分类中,高层次的文件系统都是以低层次的文件系统为基础,实现了更高级的功能。比如多处理器单用户的本地文件系统需要比单处理器单用户的本地文件系统多考虑并发控制(Concurrency Control),因为可能存在多个处理器同时访问文件系统的情况;多处理器多用户的文件系统需要比多处理器单用户的本地文件系统多考虑数据安全访问方面的设计,因为多个用户存在于同一个系统中,保证数据的授权访问是一个关键;多处理器多用户的分布式文件系统需要比多处理器多用户的文件系统多考虑分布式体系结构带来的诸多问题,比如同步访问、缓冲一致性等。 随着层次的提高,文件系统在设计和实现方面的难度也会成倍提高。但是,现在的分布式文件系统一般还是保持与最基本的本地文件系统几乎相同的访问接口和对象模型,这主要是为了向用户提供向后的兼容性,同时保持原来的简单对象模型和访问接口。但这并不说明文件系统设计和实现的难度没有增加。正是由于对用户透明地改变了结构,满足用户的需求,以掩盖分布式文件操作的复杂性,才大大增加了分布式文件系统的实现难度[12]。 一、分布式文件系统的发展历史 在计算机性能不断提升的同时,计算机部件的平均价格却在不断下降。用户可以用更低的成本,购买更好、更快、更稳定的设备。存储系统、文件系统面临的新挑战也随之而来:如何管理更多的设备,提供更好的性能,更加有效地降低管理成本等。各种新的存储技术和分布式文件技术层出不穷,以满足用户日益增长的需求。以下为分布式文件系统的发展过程中的几个阶段[12]: 1980~1990年早期的分布式文件系统一般以提供标准接口的远程文件访问为目的,更多地关注访问的性能和数据的可靠性。主要以NFS和AFS(Andrew File System)最具代表性,它们对以后的文件系统设计也具有十分重要的影响。 1990~1995年20世纪90年代初,面对广域网和大容量存储应用的需求,以及当时产生的先进的高性能对称多处理器的设计思想,加利福尼亚大学设计开发的xFS,克服了以前的分布式文件系统一般都运行在局域网(LAN)上的弱点,很好地解决了在广域网上进行缓存,以减少网络流量的难题。它所采用的多层次结构很好地利用了文件系统的局部访问的特性,无效写回(Invalidation-based Write Back)缓存一致性协议,减少了网络负载。对本地主机和本地存储空间的有效利用,使它具有较好的性能。 1995~2000年在这个阶段,计算机技术和网络技术有了突飞猛进的发展,单位存储的成本大幅降低。而数据总线带宽、磁盘速度的增长无法满足应用对数据带宽的需求,存储