
操作指南
操作指南通过不同的例子向用户介绍软件的使用。您将会发现eCognition可以操作不同的数据,并可应用于不同的领域。操作指南涉及软件全部的重要特征。通过这个指南,可了解新的术语和技术。(由于eCognition现升级为4.0,故指南中可能有部分在软件4.0版使用中有出入,待4.0版的说明书正式出版后再做修正,且水平有限,给您造成的不便请谅解!)
例1: TM影像的切割(子集)
关键字:多分辨率分割,样本对象,最邻近分类,训练检测区域掩模,特征空间优化
例2:分析城区表面的不可渗透度(如水泥,沥青等路面)
关键字:训练检测区域掩模,基于分类的分割,多层分类,利用多尺度信息,精度评估,导出专题层
例3高分辨率的航空数字化
关键字:成员函数,数字表面模型,专题层,类相关特征,边界优化
例4 印度尼西亚热带雨林雷达图像
关键字:子对象线性分析分割,基于子对象的线特征
例5航空照片和丹麦的LIDAR表面模型
关键字:自定义特征,自动操作,多重窗口函数,基于分类的分割
此操作手册如果和其它eCognition的解释性章节结合起来使用,效果会更好。更有利于用户掌握eCognition的特征。
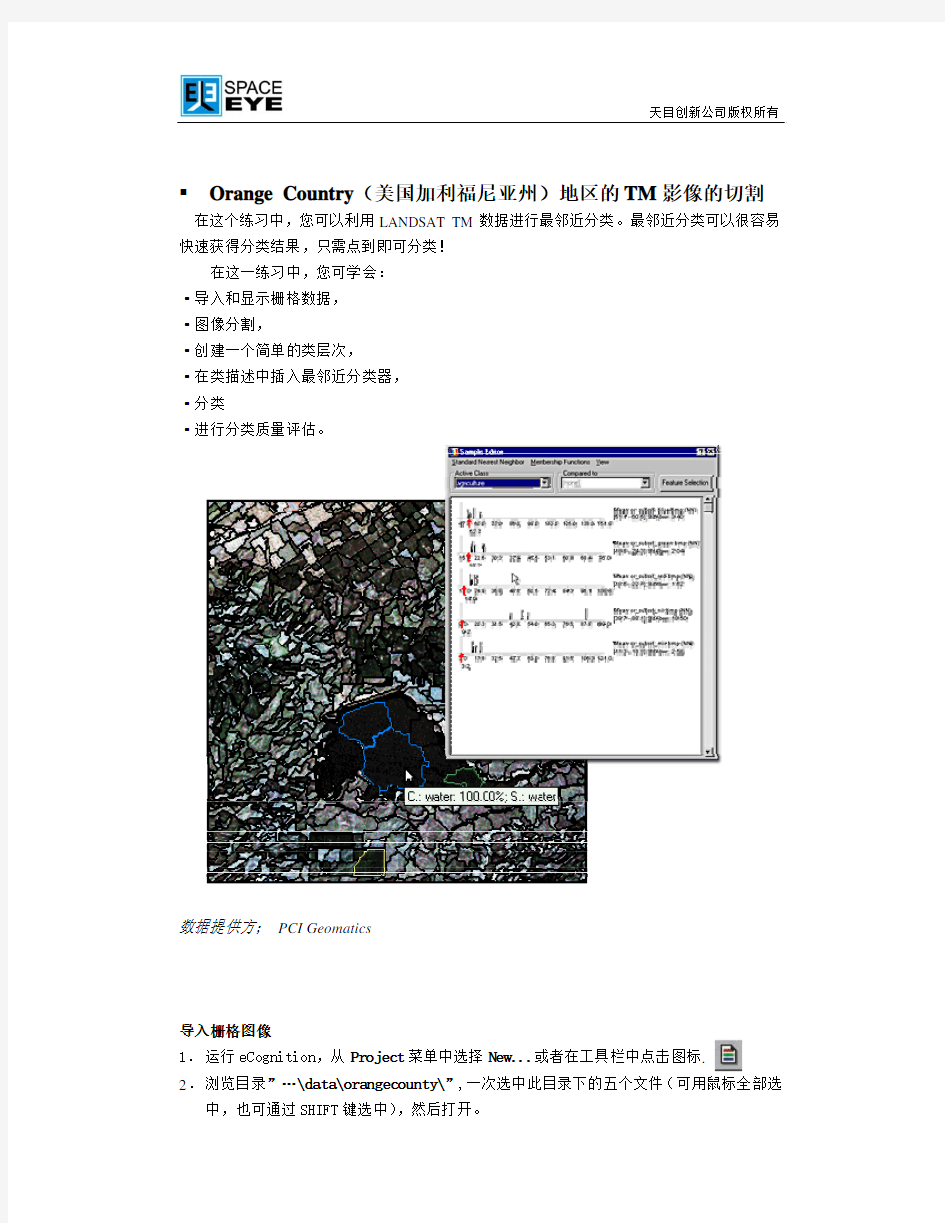
Orange Country(美国加利福尼亚州)地区的TM影像的切割在这个练习中,您可以利用LANDSAT TM数据进行最邻近分类。最邻近分类可以很容易快速获得分类结果,只需点到即可分类!
在这一练习中,您可学会:
·导入和显示栅格数据,
·图像分割,
·创建一个简单的类层次,
·在类描述中插入最邻近分类器,
·分类
·进行分类质量评估。
数据提供方; PCI Geomatics
导入栅格图像
1.运行eCognition,从Project菜单中选择New...或者在工具栏中点击图标.
2.浏览目录”…\data\orangecounty\”,一次选中此目录下的五个文件(可用鼠标全部选中,也可通过SHIFT键选中),然后打开。
3.按照波长改变tif文件顺序
4.点击Create按钮导入栅格图层到新工程中。
5.打开“Edit Layer Mixing”对话框,
(利用主菜单中“View>Layer Mixing”或者点击工具栏上的), 进行波段组合显示,三层混合显示。如下操作:
6.点击ok按钮,就显示如下视图。
7.打开”Edit Highlight Colors”对话框,可通过View菜单或者单击工具栏中的),)
来改变”Selection”和”Outlines”的颜色
8.点击Active View按钮
此时,栅格数据导入并显示。
但此时只有单个像素信息可以利用。
要生成图像对象(成组的像素),
必须通过分割这个过程。
生成图像对象
1.从Segmentation菜单中选择Multiresolution Segmentation..或者在工具栏中点击图标。
注意:切记分割图像时的一个最基本的规则是,所生成的对象要尽可能的大,同时必要的时候又要尽可能的小。
2.编辑分割参数,注意位图文件的Layer weight权重在右侧进行调整。
3.点击Start.
4.生成polygons查看图像对象的outlines(“Polygons>Create Polygons”或者点击工具栏中的),像。并且要选择好生成polygons的那个层。
5.利用”View Settings”对话框显示分割完后的图像,可以显示成原始图像,也可以用对象均值(具有光滑的outlines)显示.
6. 可利用 进行均值和像素值显示的切换,利用 进行outlines的显示和隐藏。
现在已经建立了一个简单的包括图像对象层的体系。从每一个图像对象中我们可以得到大量可用于图像分类的信息。
通过分类体系创建知识库
1.从“Classification”中选择”Open Class Hierarchy”,或者从”Toolbars&Dialogs”
选择“Class Hierarchy”,或在工具栏中点击图标。
在这一练习中,设定了四类:impervious
surface,water,agriculture和rural.首先要做的是确定
每一类的名称和颜色。
2.确定是在“Inheritance”模式下。
3.选择Classification>Edit Classes>Insert Class或
者在此窗口点击鼠标右键,选择”Insert Class”,
生成impervious surface,water,agriculture和
rura l四类。
插入分类器
eCognition提供两种不同的分类器:最邻近和成员函数。这个练习是运用最邻近分类方法。当你在类描述中插入标准最邻近表达式前,要定义特征空间,在此特征空间中的图像对象间的距离将会被计算。相比传统的的最邻近方法,此标准最邻近是在项目中的一种定义,因此可以用一个有代表性的特征空间作用到所有的类描述中。当你在任意地方改变标准最邻近的特征空间时,其它地方的也会随之改变。
1.选择菜单”Classification>Nearest Neighbor>Edit Standard NN Feature Space... 2.您可以看到在右边的窗口里五个层的平均值已经有默认值了。若此特征空间被采纳,可点击Ok.
注意:尽量使用少的特征。在一个类描述中使用太多的特征有可能会在特征空间中导致巨大的重复,使分类复杂化且会减少有意义的信息。但是如果你必须使用大量的特征,那么推荐您使用最邻近分类器。在多维特征空间中的相关处理,最邻近要比成员函数来得适宜。
3.双击impervious surface打
开”Class Description”对话框。
4.双击逻辑表达式”and(min)”
5.鼠标移动到“Standard nearest
neighbor”表达式上,点击Insert
按钮,把它插入到类描述中。
6.关闭”Insert Expression”.
7.点击OK来关闭”Class
Description”对话框。
8.重复步骤把标准最邻近这个分类器
插入到剩余的类描述中。
或者,也可以通过选择菜
单”Classification>Nearest Neighbor>Apply
Standard NN to Classes”把它插入到类描述中
定义样本对象
eCognition中最邻近分类方法类似于传统图像分析软件中的监督分类方法,你必须首先定义训练区,它是一个类的典型代表。在eCognition中这样的训练区称为样本或者是样本对象。1.为了更容易识别图像对象,把显示模式从”Object mean”切换到”Pixel”,在“ View Settings”中激活”Outlines”。或者利用工具栏中的按钮完成。
2.按照下图改变图层显示方式。
在这个视图中,大部分的对象都可很容易识别出来,亮绿色代表农业用地,不可渗透对象显示成紫色且呈现出高纹理。水体显示成黑色,但在图像的左下角不要把它们同山区造成的阴影相混淆。其它剩下的对象代表农村地区。农村地区包含不同的光谱特征的地物。所以,农村地区是一个非均质类型。很幸运的是,eCognition的最邻近分类器可解决这种问题。
3.从Samples菜单中选择Open Sample Editer命令...或者在工具栏中点击图标。 4.从Samples菜单中选择Select Samples。
在Sample editor窗口中显示了特征值的五种曲线。此特征值是对象在每个通道的平均值。这样,在Sample editor中显示的特征空间等同于标准最邻近特征空间。左上角的Active Class选择框中可以选择要编辑的类名称。其样本特征值可以和右上角Compared to下拉框中其它的类进行比较。
5.在Active Class选择框中选择agriculture或者在Class Hierarchy中点击此类。
6.点击agriculture类的样
本对象。
单击时,将会有一个红色箭头
在每个特征上标记此对象的
值。
7.双击或者按住SHIFT单击
某一对象,即可标记此对
象为样本对象
这一样本对象的特征值就会
以直方图方式显示出来。
8.在sapmle editor中通过
上述方法再插入三个其它
的样本对象
练习人工最邻近分类时,开始对每个类选择一个或者少量的样本对象,在特征空间中覆盖此类的范围,尤其当这一类是非均质的,否则这样的非均质对象就不能够充分的被考虑到。在下几个步骤中,您可学会如何改善分类效果。
注意,在使用最邻近分类器时,每一类的分布不需要是连续的!这样,就可以总结农业地区中不同的非均质地区。
9.重复以上样本的选择,分别为water,impervious surface和rural定义样本区。每一类选择两到三个样本对象。不要忘记选择要定义样本的类作为active class.
利用最邻近分类方法,训练区是由选择的样本对象决定的。现在第一次分类就可以进行了。
对图像对象分类
在前面的步骤中,已定义了特征空间和为最邻近分类方法要用的一些初始样本。因而已经完成了分类所需的知识。下列步骤就是用来完成图像对象分类的:
1.编辑分类过程的参数。由于此练习现在只有一个对象层,所以类描述中没有类间相关特
征可以利用,可以选择无类间相关特征的分类
2.点击工具栏中的图标开始分类。
3.改变视窗显示分类后结果(点击) ),禁止outlines
由于分类结果依赖选择的样本,您做出来的效果可能会和上面的图像稍微有些不同。
以上的结果看上去非常不错,但是仍然需要进一步的改善。注意,一方面图像中有一部分对象没有指定给任何类,另外一方面,有相当多的对象被分错了,尤其是图像左下角部分中的水。此外,太多的对象被分成了不可渗透表面。
这些误分可以在迭代步骤中,通过校正典型的误分对象时进行改正。
4.转到您想处理的类上
5.改变视窗返回到样本、像素和outlines上。打开第二个窗口显示分类结果,并且和第一
个窗口相关,将会非常有益。(Window>New Window 及Window>Link all Windows)
6.通过双击,把一个或者两个未分类的图像对象样本指定到它们属于的类上。
7.把一个或者两个误分的图像样本对象指定到正确的类上。
8.重新分类,并且显示没有outlines的分类结果。
新的分类结果会比原来的图像好一些,但还有改进的余地,如果需要可继续编辑样本对象。
9.重复把未分类的对象作为样本,把错分类的对象纠正到正确的类中,再次分类,检查分
类结果。
10.重复这种指定样本和分类的循环过程,直到得到满意的分类结果。
实际上,对最邻近分类这种不断改进的迭代方法会导致多维特征空间中类分布的边界不同。先确定少数的样本,需要的时候再逐步添加样本,是一种非常有效的分类方法。这是因为最邻近分类器不依赖连续的、高斯函数分布,并且在特征空间中可以发现特别复杂的形状分布。
接下来,让客观的方法来检验分类结果精度。
分类结果评估
1.从Tools菜单中选择Accuracy Assessmnet选
项。
2.选择Best Classification Result统计类型。
在eCognition中,已分类的对象不是简单的属于
某一类或是不属于某一类。可以得到Class
Hierarchy中每个类的成员函数值的详细清单。一
类对象如果具有最高的成员函数值,且不低于最低
成员函数值,我们就能把它分为此类。这个值可以
从”Classification>Advanced Settings>Minimum
Membership V alue…”编辑。
对于分类结果的精度,有一点很重要,就是一
种图像对象的最高成员函数值绝对很高,这就表明
此对象属性非常适合于至少一类对象的描述。
使用最邻近分类方法,一个高的成员函数值意
味着同某一给定样本之间的特征距离很接近。对每
一类图像对象,用最邻近分类方法,通过增加最邻
近函数的方法可能会使分类精度提高。但是,这种
过程可能会降低分类的稳定性。
3.点击Show statistics.
上述统计值以矩阵表示。如果想要以图表形式显示,可以利用”View Settings”对话框,点击“Mode”改变显示模式。图表显示方式可以表明每类对象的赋值,从红色(低值)到绿色(高值)。如果你选择的不同的样本对象,有可能你的结果会和上面的有些差异。
4.在图像对象上移动鼠标可获取最佳分类结果的信息。
如上所见,大部分对象上的最佳分类的值都是很显著的高,只有少数对象的值比较低,例如上述例子中的最小值是0.103。这个信息可以用来检验特殊的对象。每类对象的平均值和标准偏差显示只有一小部分对象的分类是用很低的成员函数值。总而言之,类分配还是很明显的。
5.如果您想以ASCII文件格式输出这些统计数据,点击Save Statistics.
检查分类的稳定性
成员函数值不是指概率,就象它们加起来不等于100%一样,所以对某一类来讲,一个高的成员函数值并不一定说明它就是属于这一类。如果在最好的成员函数值和次好的成员函数值之间仅有微小的差别,这个分类结果可能就不会很好。在同一层中,通过Accuracy Assessmen t对话框中的Classification Stability选项,所有类型中的这个差别都可以检测到。
1.打开Accuracy Assessment对话框。
2.选择Classification Stability统计方
式。
3.点击Show Statistics.
对每一类,分类结果的稳定性可通过图中所有的类别统计计算出来。
4.移动鼠标到图像对象上获取确切的分类稳定信息。
大多数对象在最好和次好的成员类评估中都有一个比较明显的差别,所以它们可以很清楚的赋值。
使用最邻近分类器时,图像上的对象有较高的成员函数通常不止一类,这就取决于最邻近函数曲线,它通过在特征空间中计算某个图像对象矢量到样本矢量的距离来计算出模糊值。很多对象的次好同最好选择很相近,是由于在特征描述中两类有重叠。原因是在特征空间中不同类别对象之间的特征的距离都很小。对这些对象来说,分类结果的稳定性就不会很高。分类结果平均的稳定性可通过拉低邻近函数曲线得到改善。
但是,最邻近函数曲线的变化只能影响成员函数的绝对值和各类之间的相关距离,但不影响依赖于成员函数值的成员函数的顺序。因此分类的稳定性对最邻近分类结果的评估不具有决定性作用。
就分类稳定性而言,可以用成员函数这个分类器得到好的结果。然而基于成员函数的分类在多维特征空间中可能体现不出最邻近分类的效果。
用预定义试验区域检查分类结果
载入试验区域
1.从菜单栏中选择Samples>Load TTA Mask…(TTA:训练和检测区域掩模)选项。
在eCognition中术语”test areas”等同于TTA Mask。
2.选择文件TTAMask_oc.txt作为转换表。
3.在弹出的对话框中选择不要创建类(类层次关系早已生成)。
4.选择文件TTAMask_oc.asc作为实际的训练和检验遮掩。
预定义的TTA Mask显示如下。
注意:如果导入TTA mask到工程中时,你不能从它那里自动生成样本。从TTA mask中声明样本必须用菜单”Samples>Create Samples from TTA Mask”才能执行。
把类同TTA Mask链接起来
1.在”Samples”菜单中选择”Edit Conversion
Table…”
2.如果在TTA mask和要链接的类中不能相对
应,那就点击unlink all按钮,随后鼠标右
击TTA Mask中的选项,把类链接进去。
3.重复这个过程,把water,agriculture,rural 和
impervious surface这几个类做完。
比较实际分类结果和试验地区
1.从Tools菜单中打开
Accuracy Assessment对
话框。
2.选择”Error Matrix based
on TTA Mask”作为统计类
型
3.点击“Show statistics”
上述误差矩阵提供了每类的
统计信息。每一类的TTA
mask象元数是给定的。如水体,它的识别率是100%。而农业区域这类,有部分对象是错分的总数6636个农业对象分到了农业类,485分到了不可渗透表面类中。当分类结果被认为是比较显著时,可以说分类精度评价的目的已经达到。当然,通过不断的定义新样本分类,还是有改善的余地。
定义优化特征空间
除了层平均值外,eCognition在定义类和特征空间时还能提供更多其它的特征。除了利用最邻近分类器,现在还能利用特征空间优化工具(通过点击 )来更好帮助类别的分离。确定已经用“Sample Editor”中的“Active class”为每个类都选择了样本,您可以查看每个类的样本。然后调出”Feature Optimization”对话框。
点击”Select Features”按钮创建特征空
间,降低优化维护。从弹出的对话框中
选择所有层的均值,除了“brightness
和Max.Diff”,所有层的标准偏差和所有
的对比率。
可以看到,初始的特征空间有15维。
考虑所有的特征,进入编辑控
制”Maximum dimension”,值为15,点
击”Calculate”.比较旧的用层平均值描述的特征空间和新的特征空间:选中“Features”窗口中的所有平均值,点击”Show Distance Matrix”。这个矩阵将会显示特征空间中的所有类样本间的特征距离。
从上可看出,一些类如果光靠平均值很难区分开。点击”Advanced”按钮可以获得更多优化特征空间的信息。
缺省的最好的分类特征如右。点击”Show
Distance matrix”检查在特征空间中的样本间
距离。比较这个距离矩阵和层平均值的矩阵。
可以发现,特征空间中的最邻近样本之间的距
离比层平均值特征距离要大。这表明优化的特
征空间要比纯层平均值特征空间更适宜于区
分类。
可以点击”Apply to Std.NN”更新标准最邻近的特征空间。检查”Classify Project”,用新的标准最邻近方法去自动分类。可以注意到,有部分对象没有被分类,但是同时分类的稳定性提高了。如果分类结果还是不令人满意,那么再添加/除去样本,优化后再分类。
总结
在这个练习中,可以学会
·向项目中导入栅格数据。
·进行图像分割
·创建分类体系,插入标准最邻近作为分类器。
·声明最邻近分类的样本对象和特征空间优化。
·进行最邻近分类:点击即分类。
·使用不同的方法检验分类的精度。
·创建最优的分离特征空间
如果对这些工具运用比较熟练,就可转到下一个练习。如果感觉不能把握,,重复上述过程加强理解
分析城区表面的不可渗透度(如水泥,沥青等路面)
此练习的重点是在不同分辨率的多图像对象层中提取多尺度的信息。目的就是生成一幅能够反映德国德绍城的城区不可渗透表面的图像。
在这个练习中,可学到:
·进行基于分类的对象融合。
·创建一个包括多不同分辨率的图像对象体系结构。
·为最终的分类准备小尺度和大尺度的信息。
·运用不同尺度的信息进行图像分类。
·使用eCognition的统计工具。
·输入对象成专题层。
德国萨克森环境所提供图像
此练习将从”Take the Plunge”(是整个说明书中的一个练习章节中的例子)的分类结果的调整开始。类结构体系和样本是产生相同的分类结果的必要条件,所以其分类等级将同样本一起导入。
导入删格图层
1.启动eCognition,选择“Project>New…”或者在工具栏中点击 图标。
2.打开并显示删格图层。
生成图像对象
1.选择“Multiresolution
Segmentation”或者在工具
栏中点击相应的命令。
2.如图编辑分割的各种参
数。
导入类结构体系
1.点击图标,或者从”Classification”菜单中选择”Open Class Hieerarchy”或者从“Toolbars&Dialogs”菜单中选择”Class Hierarchy”,打开类结构体系窗口。
2.从“Classification”菜单中选择”Load Class Hierarchy…”,或者右键点击“Class Hierarchy”对话框,选择”Load Class Hierarchy”。
3.选择”…\data\impervious\plunge.dkb”作为类结构体系文件,打开。
图像进行分类
编辑分类参数,(选中class-related features,five classification cycles),点击
下图就是我们的分类结果,可以通过点击左右箭头 来浏览语义群体系。
我们的主要兴趣集中在城市地区。城市地区的不可渗透度需要做预计。同前一个例子不同,这里我们不仅要生成一幅专题地图,而且这幅专题地图要能够显示城市的不可渗透度。这时,我们要利用不同分割层次上的所有信息。第一步,要创建一个合理的对象等级体系,